Нейронные сети — математический аппарат
В наши дни возрастает необходимость в системах, которые способны не только выполнять однажды запрограммированную последовательность действий над заранее определенными данными, но и способны сами анализировать вновь поступающую информацию, находить в ней закономерности, производить прогнозирование и т.д. В этой области приложений самым лучшим образом зарекомендовали себя так называемые нейронные сети – самообучающиеся системы, имитирующие деятельность человеческого мозга. Рассмотрим подробнее структуру искусственных нейронных сетей (НС) и их применение в конкретных задачах.
Искусственный нейрон
Несмотря на большое разнообразие вариантов нейронных сетей, все они имеют общие черты. Так, все они, так же, как и мозг человека, состоят из большого числа связанных между собой однотипных элементов – нейронов, которые имитируют нейроны головного мозга. На рис. 1 показана схема нейрона.
Из рисунка видно, что искусственный нейрон, так же, как и живой, состоит из синапсов, связывающих входы нейрона с ядром; ядра нейрона, которое осуществляет обработку входных сигналов и аксона, который связывает нейрон с нейронами следующего слоя. Каждый синапс имеет вес, который определяет, насколько соответствующий вход нейрона влияет на его состояние. Состояние нейрона определяется по формуле
$S =\sum \limits_^ \,x_iw_i$, (1)
n – число входов нейрона
xi – значение i-го входа нейрона
wi – вес i-го синапса.
Затем определяется значение аксона нейрона по формуле
Где f – некоторая функция, которая называется активационной. Наиболее часто в качестве активационной функции используется так называемый сигмоид, который имеет следующий вид:
Основное достоинство этой функции в том, что она дифференцируема на всей оси абсцисс и имеет очень простую производную:
При уменьшении параметра a сигмоид становится более пологим, вырождаясь в горизонтальную линию на уровне 0,5 при a=0. При увеличении a сигмоид все больше приближается к функции единичного скачка.
Нейронные сети обратного распространения
Нейронные сети обратного распространения – это мощнейший инструмент поиска закономерностей, прогнозирования, качественного анализа. Такое название – сети обратного распространения (back propagation) они получили из-за используемого алгоритма обучения, в котором ошибка распространяется от выходного слоя к входному, т. е. в направлении, противоположном направлению распространения сигнала при нормальном функционировании сети.
Нейронная сеть обратного распространения состоит из нескольких слоев нейронов, причем каждый нейрон слоя i связан с каждым нейроном слоя i+1, т. е. речь идет о полносвязной НС.
В общем случае задача обучения НС сводится к нахождению некой функциональной зависимости Y=F(X) где X – входной, а Y – выходной векторы. В общем случае такая задача, при ограниченном наборе входных данных, имеет бесконечное множество решений. Для ограничения пространства поиска при обучении ставится задача минимизации целевой функции ошибки НС, которая находится по методу наименьших квадратов:
yj – значение j-го выхода нейросети,
dj – целевое значение j-го выхода,
p – число нейронов в выходном слое.
Обучение нейросети производится методом градиентного спуска, т. е. на каждой итерации изменение веса производится по формуле:
где h – параметр, определяющий скорость обучения.
yj – значение выхода j-го нейрона,
Sj – взвешенная сумма входных сигналов, определяемая по формуле (1).
При этом множитель
Далее рассмотрим определение первого множителя формулы (7).
k – число нейронов в слое n+1.
Введем вспомогательную переменную
Тогда мы сможем определить рекурсивную формулу для определения n-ного слоя, если нам известно следующего (n+1)-го слоя.
Нахождение же для последнего слоя НС не представляет трудности, так как нам известен целевой вектор, т. е. вектор тех значений, которые должна выдавать НС при данном наборе входных значений.
И наконец запишем формулу (6) в раскрытом виде
Рассмотрим теперь полный алгоритм обучения нейросети:
- подать на вход НС один из требуемых образов и определить значения выходов нейронов нейросети
- рассчитать для выходного слоя НС по формуле (12) и рассчитать изменения весов выходного слоя N по формуле (13)
- Рассчитать по формулам (11) и (13) соответственно и $\Delta w_^$ для остальных слоев НС,
- Скорректировать все веса НС $w_^\,(t) = w_^\,(t\,-\,1) \,+\,\Delta w_^\,(t)$, (14)
- Если ошибка существенна, то перейти на шаг 1
На этапе 2 сети поочередно в случайном порядке предъявляются вектора из обучающей последовательности.
Повышение эффективности обучения НС обратного распространения
Простейший метод градиентного спуска, рассмотренный выше, очень неэффективен в случае, когда производные по различным весам сильно отличаются. Это соответствует ситуации, когда значение функции S для некоторых нейронов близка по модулю к 1 или когда модуль некоторых весов много больше 1. В этом случае для плавного уменьшения ошибки надо выбирать очень маленькую скорость обучения, но при этом обучение может занять непозволительно много времени.
Простейшим методом усовершенствования градиентного спуска является введение момента m, когда влияние градиента на изменение весов изменяется со временем. Тогда формула (13) примет вид
Дополнительным преимуществом от введения момента является способность алгоритма преодолевать мелкие локальные минимумы.
Представление входных данных
Основное отличие НС в том, что в них все входные и выходные параметры представлены в виде чисел с плавающей точкой обычно в диапазоне [0..1]. В то же время данные предметной области часто имеют другое кодирование. Так, это могут быть числа в произвольном диапазоне, даты, символьные строки. Таким образом данные о проблеме могут быть как количественными, так и качественными. Рассмотрим сначала преобразование качественных данных в числовые, а затем рассмотрим способ преобразования входных данных в требуемый диапазон.
Качественные данные мы можем разделить на две группы: упорядоченные (ординальные) и неупорядоченные. Для рассмотрения способов кодирования этих данных мы рассмотрим задачу о прогнозировании успешности лечения какого-либо заболевания. Примером упорядоченных данных могут, например, являться данные, например, о дополнительных факторах риска при данном заболевании.
ожирение
курение
гипертония
А также возможным примером может быть, например, возраст больного:
60 и старше
Опасность каждого фактора возрастает в таблицах при движении слева направо.
В первом случае мы видим, что у больного может быть несколько факторов риска одновременно. В таком случае нам необходимо использовать такое кодирование, при котором отсутствует ситуация, когда разным комбинациям факторов соответствует одно и то же значение. Наиболее распространен способ кодирования, когда каждому фактору ставится в соответствие разряд двоичного числа. 1 в этом разряде говорит о наличии фактора, а 0 о его отсутствии. Параметру нет можно поставить в соответствии число 0. Таким образом для представления всех факторов достаточно 4-х разрядного двоичного числа. Таким образом число 10102 = 1010 означает наличие у больного гипертонии и употребления алкоголя, а числу 00002 соответствует отсутствие у больного факторов риска. Таким образом факторы риска будут представлены числами в диапазоне [0..15].
Во втором случае мы также можем кодировать все значения двоичными весами, но это будет нецелесообразно, т.к. набор возможных значений будет слишком неравномерным. В этом случае более правильным будет установка в соответствие каждому значению своего веса, отличающегося на 1 от веса соседнего значения. Так, число 3 будет соответствовать возрасту 50-59 лет. Таким образом возраст будет закодирован числами в диапазоне [0..4].
В принципе аналогично можно поступать и для неупорядоченных данных, поставив в соответствие каждому значению какое-либо число. Однако это вводит нежелательную упорядоченность, которая может исказить данные, и сильно затруднить процесс обучения. В качестве одного из способов решения этой проблемы можно предложить поставить в соответствие каждому значению одного из входов НС. В этом случае при наличии этого значения соответствующий ему вход устанавливается в 1 или в 0 при противном случае. К сожалению, данный способ не является панацеей, ибо при большом количестве вариантов входного значения число входов НС разрастается до огромного количества. Это резко увеличит затраты времени на обучение. В качестве варианта обхода этой проблемы можно использовать несколько другое решение. В соответствие каждому значению входного параметра ставится бинарный вектор, каждый разряд которого соответствует отдельному входу НС.
Литература
- Dirk Emma Baestaens, Willem Max Van Den Bergh, Douglas Wood, «Neural Network Solution for Trading in Financial Markets», Pitman publishing
- R. M. Hristev, «Artifical Neural Networks»
- С. Короткий, «Нейронные сети: Алгоритм обратного распространения»
- С. Короткий, «Нейронные сети: Основные положения»
«Искусственный интеллект: что могут нейронные сети и как они изменят нашу жизнь?»
19 декабря в рамках лекционного проекта Фонда Егора Гайдара состоялось выступление кандидата физико-математических наук, руководителя проекта iPavlov и заведующего лабораторией нейронных систем и глубокого обучения Московского физико-технического института (МФТИ) Михаила Бурцева, в рамках которого он рассказал о перспективах построения искусственного интеллекта, работающего по образцу человеческого мозга. Модератором мероприятия выступил экономический обозреватель Борис Грозовский. Подробности лекции эксперта — в видео “Ъ” и стенограмме доклада.

Фонд Егора Гайдара при информационной поддержке “Ъ” запустил курс лекционного проекта «Экономический факультет» «Экономика наступившего будущего». В курс вошли четыре лекции, посвященные высоким технологиям,— криптовалютам, блокчейну, искусственному интеллекту и нейронным сетям, большим данным.
Первая лекция цикла «Экономика наступившего будущего», посвященная криптовалютам, состоялась 21 ноября. Подробнее — в материале “Ъ” «Криптовалюты: новая экономика или новая пирамида?» .
Вторая лекция состоялась 5 декабря и была посвящена перспективам внедрения искусственного интеллекта. Подробнее — в материале “Ъ” «Человек и машина — выгодный союз или жесткая конкуренция?» .
Стенограмма лекции
Когда меня пригласили прочитать лекцию, мне очень понравилось название цикла — «Экономика наступившего будущего». Я занимаюсь нейросетями больше десяти лет, но последние два-три года часто возникает ощущение, что будущее неотвратимо наступает. В этом плане название цикла как нельзя лучше отражает то, о чем я хотел бы рассказать и что мы могли бы пообсуждать после лекции. Соответственно, я планирую рассказать вам о том, что собой представляют нейронные сети и как они используются сегодня для создания интеллектуальных систем. Было также заявлено «как они изменят нашу жизнь», но об этом мы как раз сможем поговорить в более интерактивной форме, потому что тут, я думаю, вопрос открытый. Мне самому интересно, какие вы видите возможности, которых не вижу я.
Давайте начнем с того, что же такое искусственный интеллект. Попробуем определить предмет, про который мы говорим. Классическое определение искусственного интеллекта — это построение некоторых машин, которые будут обладать интеллектом, сопоставимым с интеллектом человека. Но возникает вопрос: зачем мы этим занимаемся? Зачем общество этим занимается? Здесь, мне кажется, есть две грани. Первая грань — это прикладная цель, которая в первую очередь приходит в голову, когда мы слышим об искусственном интеллекте. Мы хотим получить помощника, который, скажем так, дополнит наш естественный интеллект, позволив нам решать какие-то задачи. Как калькулятор сильно упростил нам жизнь, позволив сделать то, что еще сто лет назад считалось сильно интеллектуальным,— умножение, сложение, деление больших чисел. Это предок искусственного интеллекта. Вторая грань — если мы посмотрим на искусственный интеллект как на фундаментальную программу исследования, то на самом деле, так как мы хотим построить машину, сопоставимую по интеллекту с человеком, то мы неизбежно задаемся вопросом: что же представляет собой интеллект человека? Как говорил Ричард Фейнман: «Чтобы что-то понять, мне нужно знать, как это построить». Так и здесь. Строя искусственный интеллект, мы в каком-то смысле лучше разбираемся, как устроен естественный интеллект. И в этом смысле мы проникаем в область философии, то есть мы разбираемся с природой человека. Как устроен человек, какие у него мотивы, почему он ведет себя тем или иным образом. То есть это очень интересно именно с исследовательской точки зрения. Это, как мне кажется, основные причины, почему мы занимаемся искусственным интеллектом.
Давайте вкратце рассмотрим, как вообще мы можем строить искусственный интеллект. Представьте, что вы стали организатором проекта по созданию искусственного интеллекта. С чего вы начнете? Какие есть варианты? Первое — взломать голову. Мы исследуем, как состоящий из нейронов мозг решает какую-то задачу, и потом, понимая принципы, как эти составные части взаимодействуют, строим работающий алгоритм. То есть мы будем строить модель мозга из нейронов, и, соответственно, у нас получится искусственная нейронная сеть. Второй путь — разобраться, что такое интеллект. Мы можем взять людей, которые решают интеллектуальные задачи, и сверить процесс. Как они это делают, какие приемы используют, в какой момент у них возникает, например, доказательство математической теоремы. Потом мы попытаемся построить некую модель решения интеллектуальных задач, формализуем ее и будем пытаться запустить на компьютере, чтобы она порождала такие же интеллектуальные результаты. Это два основных подхода к тому, как вообще люди делают искусственный интеллект: один основан на моделировании биологической системы мозга, а второй — на рассуждении человека. Это то, что называется «символьный искусственный интеллект», а до недавнего времени называлось «традиционный искусственный интеллект» или «искусственный интеллект», но сегодня происходит переход с понятия «символьного искусственного интеллекта» на понятие «нейросетевой».
Вкратце история — как вообще появилось такое направление исследований, как искусственный интеллект. В середине прошлого века Норберт Винер придумал науку, которая называлась кибернетикой. Это наука, которая попыталась формализовать и построить модель организации, при этом отделив саму модель организации от субстрата, на которой эта организация может разворачиваться. То есть это может быть организация клеток в организме, может быть организация людей в обществе или организация каких-то механических артефактов, которые образует искусственный интеллект. Соответственно, зарождение искусственного интеллекта началось с кибернетики, с построения робототехнических машин, которые могли решать какие-то задачи. Они могли ехать на свет или, наоборот, прятаться от света, объезжать препятствия. Когда появились компьютеры, это открыло возможность для появления искусственного интеллекта именно в том виде, в котором мы его наблюдаем сегодня — как некоторой программы, которая управляет компьютером и может, например, давать осмысленные ответы. Бурная попытка применить алгоритм искусственного интеллекта к решению практических задач показала, что какие-то простые задачи мы можем решить достаточно быстро даже на тех примитивных компьютерах, которые появились в середине 1950-х — начале 1960-х годов. Одно из известных достижений того времени — программа «Логик-теоретик», которая на основании аксиомы смогла доказать все теоремы школьной геометрии.
У людей были очень высокие ожидания. Можно сказать, что был такой хайп искусственного интеллекта. Военные и правительства вкладывали кучу денег, и это вылилось в то, что мы называем «золотые годы искусственного интеллекта». Параллельно в тени развивался наш нейросетевой искусственный интеллект. При этом если мы почитаем, какие прогнозы давали ведущие исследователи в то время, то увидим, что в 1960-е годы они говорили, что через десять лет компьютер сможет выполнять работу среднестатистического человека. Такие заявления делались на регулярной основе всеми, и понятно, почему им давалось так много денег. Кто откажется от того, чтобы у него был робот, который через десять лет будет делать все, что делает человек? В связи с этим так же понятно, почему исследования искусственного интеллекта были заморожены. Когда те люди, которые давали деньги, через десять лет не увидели того, что им обещали, они решили, что все это пустое, и прикрыли финансирование.
Несмотря на это было наработано достаточно большое количество алгоритмов и подходов к решению задач. И они оказались применимы в некоторых узких областях. Оказалось, что можно построить экспертные системы на основании некоторых входных данных и описывающих ее состояние фактов и, например, диагностировать какие-то заболевания. В результате к искусственному интеллекту на некоторое время вернулись, но при этом сами системы не получили широкого распространения. То есть удалось закрыть несколько предметных областей, а дальше развитие уперлось в потолок. Одновременно возродился интерес к искусственным нейронным сетям, возникли всякие модели параллельных распределенных вычислений и так далее. И здесь удалось получить различные результаты по кластеризации и нейросетевой памяти. Но эти исследования так и остались в основном в рамках исследовательских лабораторий.
Начиная с конца 1990-х годов и до последнего времени в течение двадцати лет, мы наблюдали такую вялотекущую ситуацию, когда слово «искусственный интеллект» вышло из употребления нормальными учеными. Считалось, что если кто-то говорит, что он занимается искусственным интеллектом, это, наверное, не профессиональный ученый, а такой увлекающийся мыслитель-любитель, который пытается что-то сочинить. То есть человек не мог признаться, даже если он занимался искусственным интеллектом, что он занимается искусственным интеллектом. Поэтому это стали называть машинным обучением. Что значит машинное обучение? Это такой прагматический подход. Допустим, у нас есть набор методов — математическая статистика, методы оптимизации и так далее. Мы будем их использовать для решения практических задач и все это назовем машинным обучением. При этом удалось решить много интересных прикладных задач, и так продолжалось до 2012 года. А в 2012 году появился замечательный термин — «глубокое обучение».
Оказалось, что начиная с середины 2000-х годов нейросети снова стали набирать эффективность и показывать в лабораториях хорошие результаты. Есть задача категоризации изображений, когда имеется несколько миллионов изображений и тысяча категорий, и вам нужно по изображению определить, к какой категории оно относится. Соответственно, в 2010 году самый лучший алгоритм такой классификации давал ошибку около 27%. Но между 2010 и 2012 годом произошло очень сильное падение этой ошибки. То есть алгоритмы стали качественно лучше решать эту задачу. И если человек неправильно классифицирует изображения в конкретном наборе в 5% случаев, то алгоритм тогда делал 4,5% ошибок, а сейчас — уже 3%. Такой быстрый прогресс в данной области был связан с тем, что как раз здесь были впервые применены нейросетевые методы. А затем уже каждое решение, которое улучшало результат предыдущего года, было основано на нейросетях. Почему они называются глубокими, мы узнаем позже.
Так что же такое искусственные нейронные сети? Давайте попробуем разобраться. Начнем с того, что посмотрим, как устроены естественные нейронные сети. Обычно для этого изучается мозг лабораторных мышей С57black6 — такая линейка черных мышей. Одна из областей мозга называется гиппокамп. Чем она интересна? Тем, что это область, от которой очень сильно зависит эпизодическая память. В гиппокампе есть подобласть, которая называется «зубчатая фасция». Она позволяет распознавать очень близко лежащие друг к другу контексты, и, что самое интересное, в этой области происходит нейрогенез. То есть там на протяжении всей жизни у взрослого животного рождаются нейроны. Утверждение, что нейроны не восстанавливаются, на самом деле ошибочно — в мозге человека и других животных нейроны делятся и растут.
Что собой представляют отдельные нейроны гранулярного слоя зубчатой фасции? Нейрон состоит из трех частей: продолговатое тело клетки, дендритное дерево, которое принимает сигналы от других клеток, и тонкий отросток, так называемый аксон, который позволяет передавать информацию другим клеткам. Как это происходит? На дендритном дереве есть отростки, которые называются шипиками. На концах этих шипиков — синапсы. Из аксонов выбрасывается некоторое химическое вещество, которое называется нейромедиатором. Везикулы, которые наполнены нейромедиаторами, соединяются с мембраной и выбрасываются в межклеточное пространство. Чтобы почувствовать этот сигнал, нам нужно, чтобы другая клетка получила эти химические молекулы и каким-то образом почувствовала их. Для этого между клетками устанавливается так называемый синапс — такое уплотнение, в котором молекулы, специальные клеточные адгезии, связывают мембраны двух клеток. Также сюда вставляются рецепторы — это молекулы, которые позволяют определить, что присутствуют какие-то химические вещества. Таким образом, в синаптическую щель между двумя мембранами выбрасывается некоторое химическое вещество, молекулы, которые находятся на мембране постсинаптического нейрона, чувствуют это вещество, и сигнал передается внутрь клетки. Сигналы с разных частей нашего дендритного дерева собираются на теле, и клетка может, например, в какой-то момент решить, что она должна послать сигнал другим клеткам, которые находятся в мозге.
Теперь представьте, что в вашем мозге 80 млрд клеток шлют друг другу химические сигналы, и вы ощущаете, например, удовольствие от того, что придумали стихотворение, или вы наслаждаетесь какой-то прекрасной мелодией, или вы влюбились в кого-то. Все это определяется взаимодействием между этими клетками. А когда вы изучаете что-то новое, ваша память об этом новом и то знание, которое вы приобретаете, сохраняется в контактах. То есть клетки усиливают контакты друг с другом, как-то их модифицируют, и за счет этого мы можем обучаться, что-то помнить, чувствовать и управлять нашим поведением.
Теперь давайте попробуем смоделировать наш мозг. Как будет выглядеть простейшая, самая примитивная модель нервной клетки. Сверху у нас есть дендритное дерево, там же входы некоторого нашего алгоритма. На вход подаются значения Х1, Х2 Х3, Х4 и Х5. Число пропорционально тому объему нейромедиатора, который на нас выбросила другая клетка. Понятно, что какие-то клетки в момент времени могут этого вещества выбросить больше, какие-то — меньше. Соответственно, каждый раз эти Х1, Х2 Х3, Х4 и Х5 могут быть разными. Но чтобы почувствовать эти молекулы, нам нужен рецептор с другой стороны. Потому что если рецепторов ноль, то сколько бы на нас ни выбрасывали этого химического вещества, наша клетка ничего не почувствует. Чтобы смоделировать нашу чувствительность к этому веществу, мы ее описываем при помощи некоторого коэффициента W. Это называется — вес связи. Соответственно, если значение большое и вес большой, то мы их перемножаем и получаем большое влияние данного входа на нашу активность. Если же химический сигнал, который нам послали, нулевой, несмотря на то, что в другом месте может быть хороший синапс, то этот вход никак не повлияет на нашу активность. С другой стороны, при одинаковом объеме нейромедиатора тот вход, который имеет больший вес, сильнее повлияет на активность нашего нейрона.
То есть что мы делаем? Мы считаем, насколько каждый вход повлиял на нашу активность — просто берем, суммируем, перемножаем каждое значение на вес и подсчитываем их сумму. Затем мы должны определить Y. Обычно в машинном обучении то, что у нас поступает на вход нашей программы, называется Х, а то, что мы получаем на выходе — Y. Чтобы посчитать наш Y, делаем некоторое преобразование и рассчитываем функцию от суммы воздействия для того, чтобы смоделировать пороговое действие нейрона. То есть пока у нас порог воздействия не преодолен, наш нейрон не активен. Когда эта суммарная активность превышает порог, то в зависимости от функции — она называется функцией активации — мы можем регулировать порог, например, смещением, которое обычно называется W. При этом мы можем посчитать, какой выход будет у нашего нейрона. Обычно если у нас порог, про который я говорил, превышен, то значение Y будет большим, ну или стремиться к единице, а если маленьким, то будет либо минус единица, либо ноль, либо уходить в минус бесконечность, в зависимости от того, какую активационную функцию мы выберем.
Хорошо, мы поняли, что представляет собой отдельный нейрон. Но мозг состоит не из одного нейрона — у нас 80 миллиардов, а у мыши несколько сот миллионов. Теперь мы должны объединить эти нейроны в сеть. Что у нас происходит? Когда мы погружены в окружающий мир, то если мы посмотрим на зрительную систему, то у нас есть палочки, колбочки, фотоактивируемые клетки, которые в зависимости от того, сколько на них попало света, моделируют свою активность. Естественно, затем эти сигналы передаются по цепочке все глубже в мозг, и мозг пытается восстановить картину мира, который нас окружает. Соответственно, у нас есть входной слой нашей сети и есть некоторый скрытый слой. То есть вы идете по улице, переходите улицу, обернулись и вдруг увидели, что на вас мчится машина. У вас сигнал поступил, перешел в скрытый слой, ваша модель мира сработала и предсказала, что машина может в вас врезаться, если вы не ускорите шаг или не отскочите назад. И есть выходные элементы. Это мотонейроны, которые управляют вашим движением. Они приводят к изменению поведения — вы не идете спокойно, а пытаетесь отскочить в сторону или как-то грозите кулаком водителю, то есть предпринимаете какие-то действия. Таким образом, мы строим из наших нейронов многослойную нейронную сеть. Чем больше у нее слоев, тем она глубже. Поэтому глубокие сети — это те сети, в которых больше пяти, может быть, сотни слоев и очень много нейронов. Так мы принимаем решения.
Давайте немного упростим задачу, скажем, на примере классификации изображений. Как мы ее рассматриваем? У нас есть изображение. Что мы будем подавать на вход нашей нейросети? Мы будем подавать описание пикселей. То есть если у нас есть изображение 10х10, то там 100 пикселей. Предположим, у нас есть красный, зеленый и синий — соответственно, у нас есть 300 значений: Х1, Х2 — и до Х300. Предположим, мы решаем задачу: у нас есть много изображений, и нам для нашего бизнеса необходимо отличать кошек от Незнайки. Кошку мы пропускаем, а Незнайку не пропускаем. Потому что кошка должна ловить в подвале мышей, а Незнайка может сломать водопровод. Мы строим систему видеонаблюдения, где на вход подаем изображение, и есть два выхода — система должна выдать 1, если Незнайка, и 0, если кошка.
Чем задается правильность функционирования сети? Функция активации обычно фиксирована, соответственно, у нас есть пороги и W — вот эти веса. Вначале, когда у нас есть фотографии, мы не знаем, какие веса соответствуют в этой сети правильному решению. Нам нужно подобрать эти веса таким образом, чтобы ошибка по отличению Незнайки от кошки была минимальной. Здесь мы видим, чем нейросеть отличается от стандартного программирования. Потому что если программирование стандартное, мы подойдем к этой задаче как ИТ-программист: «Ага, я должен придумать, по каким признакам кошка отличается от Незнайки. Потом я напишу программу, которая в изображениях будет искать эти признаки кошки или Незнайки и при помощи условий — вот это кошка, вот это Незнайка — вычислять эту функцию». Мы же говорим, что мы не хотим знать, чем кошка отличается от Незнайки, нам плевать. Мы сделаем специальный алгоритм обучения, который сам построит такую функцию, которая будет решать нашу задачу. То есть мы не пишем программу руками, а мы как бы обучаем программу получать тот функционал, который нам необходим.
Как мы это будем делать? У нас есть некоторый набор примеров, это называется обучающая выборка, чем больше примеров, тем лучше. Например, у нас есть 10 тыс. изображений Незнайки и 10 тыс. изображений кошки, которых мы уже сфотографировали и для которых мы уже заранее знаем, где кошка, а где Незнайка. Теперь мы хотим на основе этих изображений подобрать веса таким образом, чтобы, когда у нас появятся новые изображения кошки и Незнайки, которых мы никогда не видели, система все равно могла их различить. Мы это делаем так. Сначала мы эти веса задаем случайным образом и начинаем подавать на вход изображения. Как вы думает, что будет на выходе, если мы зададим веса случайным образом? Можно назвать это бардаком. Система будет случайно называть ответ. И тут мы переходим к самой интересной части нейронных сетей — к так называемому алгоритму обратного распространения ошибки.
Как мы можем изменять веса? Мы их можем изменять следующим образом. Мы подали картинку, рассчитали все активности всех нейронов сначала в одном слое, потом в другом, и так во всех промежуточных слоях, пока не дойдем до выхода. На выходе мы имеем некоторый ответ, где Незнайка, а где кошка. Мы сравниваем тот ответ, который дала нейронная сеть, с тем ответом, который является у нас истинным. Потому что мы уже знаем все ответы для всех картинок в обучающей выборке. И рассчитываем ошибку. Если, например, у нас на выходе было 0,5, а нужно, чтобы была единица, следовательно, у нас ошибка минус 0,5. То есть мы как бы говорим о том, что нам не хватает минус 0,5 для того, чтобы дать правильный ответ по данному выходу. Или, наоборот, если у нас был слишком маленький выход, а мы его хотим увеличить, то у нас будет положительная ошибка. Затем нам нужно как-то учесть вклад весов в эту ошибку. Теперь нам надо узнать, как эти два нейрона и два веса повлияли на вклад в ошибку. Какие допущения мы можем сделать, чтобы посчитать разницу, насколько нам нужно каждый из весов изменить? На самом деле, мы видим, во-первых, активность этих нейронов, во-вторых, вес, и можем посчитать, какой из нейронов какой вклад в эту ошибку внес. Например, если этот нейрон не был активен, он был равен нулю, то он никакого вклада в эту ошибку не внес. С другой стороны, чем более активен нейрон, тем больший вклад он внес. Но если они были одинаково активны, то больший вклад в ошибку внес тот, у кого вес больше. Соответственно, изменение веса должно быть пропорционально ему самому, плюс пропорционально активности нейрона с предыдущего слоя и пропорционально производной нашей функции активации. Почему важна производная? Потому что мы можем вес как увеличить, так и уменьшить. И чтобы сместиться в правильную сторону, нам нужно учесть производную.
Значит, раньше у нас была ошибка только на выходе. Теперь мы посчитали ошибку для первого слоя нашей нейросети. Теперь вопрос в том, как мы посчитаем ошибку для следующего слоя? Мы применяем тот же самый метод, пока не дойдем до самых первых весов. Таким образом, у нас ошибка как бы растекается по нашей нейросети и веса корректируются. Этот алгоритм получил название метода обратного распространения ошибки, потому что ошибка распространяется как бы от выхода к началу. И это очень мощный алгоритм (метод обратного распространения ошибки.— “Ъ”), потому что его придумали в начале 1970-х годов, и с тех пор все нейросети только этим алгоритмом тренируются. То есть все, что я буду сегодня рассказывать, натренировано алгоритмом, который принципиально работает по такому же принципу. Как я говорил, нейросети возникли еще в 1950-х годах, но для того, чтобы изобрести этот алгоритм, потребовалось двадцать лет. А после понадобилось еще двадцать-тридцать лет, чтобы возникло глубокое обучение. Там были собственные проблемы. Все те архитектуры, которые вы сегодня увидите, очень сложные. Они все натренированы алгоритмом обратного распространения ошибки. Самые сложные пытаются даже смоделировать машину Тьюринга, то есть сделать универсальный компьютер на нейросетях.
Почему нейросети вдруг стали настолько эффективны? Оказалось, что нейросетевые методы проигрывают классическим методам статистики, если данных мало. Если у вас есть десять картинок Незнайки и десять картинок кошки, то нейросети применять бессмысленно. Вы не сможете их натренировать и не сможете получить хорошее качество работы. Однако если у вас есть 10 тыс. Незнаек и 10 тыс. кошек, то здесь нейросети побьют любые алгоритмы, построенные на классических методах. Пятнадцать лет назад ни у кого не было достаточных вычислительных мощностей, чтобы строить и обрабатывать большие нейронные сети, да и больших объемов данных, на которых можно было бы обучаться, не было. Только поэтому никто не знал, что если сделать сеть поглубже и дать побольше данных, то можно получить такие впечатляющие результаты. Но появились графические ускорители для расчета игр в реальном времени, и оказалось, что их можно использовать для того, чтобы тренировать нейронные сети, потому что там в матрице перемножаются такие операции, которые на этих ускорителях очень хорошо распараллеливаются. И это привело к той революции нейронных сетей, про которую мы сейчас узнаем.
Существуют три основных направления в области глубокого обучения. Это направление, связанное с компьютерным зрением, где нейронные сети пытаются что-то увидеть во внешнем мире, направление, связанное с предсказанием последовательности, где нейросети пытаются понять, что происходит в окружающем мире, и так называемое обучение с подкреплением, где нейросети учатся чем-то управлять. Рассмотрим каждое из них.
В компьютерном зрении основным алгоритмом является так называемая сверточная нейросеть. Что представляет собой эта модификация нейросети? У вас есть две функции — f и g. Функция свертки этих двух функций заключается в том, что вы эти две функции просто сдвигаете относительно друг друга на определенную величину, перемножаете все значения и складываете их. Соответственно, если у вас есть ступенька и треугольник и они друг с другом не совпадают, то функция свертки будет равна нулю, потому что эти функции вне этой области равны нулю. Но есть некоторая область значений сдвигов, для которой у вас, когда они максимально совпадают, значение функции свертки будет максимальным. Отсюда понятно, как мы можем это использовать для анализа изображений. У вас есть картинка и есть некоторый паттерн, который вы хотите найти в этой картинке, то есть у вас есть, например, Незнайка или кошка и вы хотите найти, где у этой кошки глаз. Вы можете закодировать некоторый паттерн яркости, который похож на глаз, и потом этим паттерном просканировать все изображение. Фактически вы вычисляете свертку изображения с паттерном глаза. Соответственно, в том участке изображения, который будет наиболее похожим на тот паттерн, который вы ищете, у вас функция свертки будет максимальной. Там вы сможете построить карту изображения, на которой максимальное значение будет в тех областях, в которых как раз ваш паттерн и находится.
А теперь представьте, что вы хотите распознавать сложные изображения, которые состоят из многих признаков. Что вы делаете? Фактически это у вас как один нейрон. У нейрона есть девять входов, выход, веса. Ваш паттерн — это веса. Вход — это фактически ваше значение яркостей. Вы перемножаете веса на вход этого нейрона, складываете их и получаете некое значение. Это значение — выход вашего нейрона, то значение свертки, которое вы хотите получить. Соответственно, вы делаете много нейронов, случайно задаете им веса. То есть изначально, когда вы решаете задачу, вы не знаете, какие признаки позволят вам отличить кошку от Незнайки. В принципе вы знаете, что у кошки есть полоски, а у Незнайки — шляпа. Для какой-то другой задачи будут другие признаки. И вы хотите универсальный алгоритм, который будет находить те признаки, которые будут наиболее информативны для разделения двух категорий. Соответственно, вы строите такую сеть, в которой на вход подается задача распознавания, соответственно, у вас есть некоторое число входных сверточных нейронов. Каждый из них строит свою карту признаков. Затем происходит определенная операция сжатия этих карт признаков, а потом эти карты признаков подаются на другие сверточные нейроны, и они ищут признаки уже в этих картах признаков. И так мы эту операцию можем проводить несколько раз, постепенно выискивая признаки все более и более высоко уровня абстракции. А затем эти карты признаков подаются на нашу полносвязную сеть прямого распространения, в которой наш сигнал передается от входных к выходным нейронам, и в конце у нас стоит классификатор. Вот так, очень просто, устроены сверточные нейронные сети.
Что сегодня мы можем сделать при помощи самых интересных сверточных сетей? Во-первых, мы можем локализовать объекты. То есть нейросеть может определить, что находится в некоторой рамке. Во-вторых, можем разметить и сегментировать изображение. В-третьих, алгоритм может определить пол и возраст человека. То есть если у нас было много примеров людей разного пола и возраста и мы натренировали нашу нейросеть предсказывать возраст и пол людей, то она нам будет предсказывать возраст и пол людей по изображению. В-четвертых, она может определять эмоции человека, если у нас был размеченный набор обучающих данных, в котором мы знали, с какими эмоциями присутствовал человек. Вот такие классные приложения. Сейчас любой разработчик может подписаться на сервис «Облачный Microsoft», загрузить свои фотки, и сервис через две минуты выдаст вам все эмоции или возраст с полом. То есть это, фактически, технологии, которые сейчас любой человек может использовать в своих продуктах.
Можно делать другие интересные вещи. Наверняка вы все слышали о приложении Prisma. Что мы можем сделать с его помощью? Мы можем перенести стиль одного изображения на содержание другого. Это как раз позволяют сделать наши сверточные слои. Мы можем найти, как признаки скоррелированы друг с другом в одном изображении, а потом перенести эту корреляцию признаков на содержание другого изображения. Ну и есть примеры того, как мы можем Храм Василия Блаженного раскрасить под хохлому. Такой быстрый инструмент, при помощи которого дизайнеры, например, могут совмещать какие-то две разные идеи. Мы можем научить нейросеть читать по губам. Если у нас есть субтитры и видео с человеком, который говорит, то мы можем отобразить его речь в тексте и построить такую нейросеть, которая предсказывает текст. Если у вас есть видео без звука, но видно, как человек говорит, то вы можете восстановить текст автоматически.
Но, оказывается, можно сделать и более сумасшедшие вещи. Есть такой подход — генеративные соревновательные сети (generative adversarial network — GAN). Это такой тип нейросетей, который использует автоэнкодеры — когда мы сначала кодируем изображение, а потом его восстанавливаем. Мы можем их использовать для того, чтобы натренировать хитрые генераторы изображений. То есть мы сначала преобразуем изображение в некое скрытое представление из нашего внутреннего скрытого слоя — это называется энкодер-часть, а потом подаем наше скрытое представление на вход декодера, и оно выдает картинку. Мы можем взять три картинки с изображением лица мужчины в очках, для каждого из них у нас будет скрытое изображение внутри нашей нейросети. Это будет некий вектор в некоем пространстве изображений. Теперь мы сложим эти три вектора и усредним. Получится некое усредненное изображение мужчины в очках. Потом мы возьмем три изображения мужчин без очков, подадим их скрытые представления на вход нашей нейросети, усредним векторы — и получим усредненное изображение мужчины без очков. То же самое мы можем проделать для женщины без очков. Итого у нас получилось три вектора. Теперь мы можем взять вектор мужчины в очках, вычесть из него вектор мужчины без очков и прибавить вектор женщины без очков. Тот вектор, который у нас получился, мы подадим на декодер, и наша сеть сама сгенерирует изображение женщины в очках, хотя она этой картинки никогда не видела. Могут быть варианты — очки с разной яркостью, женщина слегка не та, что мы прибавляли, но в целом эффект может получаться очень интересный.
Буквально пару недель назад на конференции NIPS компания InVideo представляла развитие этой технологии, в рамках которой вы можете на основе взятых черт знаменитостей сгенерировать усредненное изображение этих знаменитостей и даже синтезировать видео с этими людьми. Фактически вы можете создавать некие синтетические личности, которые будут присутствовать в ваших сериалах или фильмах. Так вы можете сэкономить кучу денег, потому что вам не нужно будет платить настоящим актерам.
Следующая задача — рекуррентные нейронные сети. Они могут предсказывать последовательности. Чтобы предсказать последовательность, нам нужно знать некую историю. В стандартных нейросетях у нас есть Х на входе, есть некоторый слой нашей нейросети, есть выход, и информация распространяется все время прямо. Если же мы возьмем другой отсчет времени, то наша нейросеть забудет о том, что она знала в предыдущем отсчете. Но для того, чтобы иметь возможность предсказывать, нам как раз нужно, чтобы нейросеть помнила о многих отсчетах времени. Как это сделать? Обычно это решается так: мы берем выход нашей нейросети за предыдущий момент времени и подаем эти значения ей же на вход, на слой нейросети. Что-то пришло в момент времени T, но пришло не только то, что передал ей предыдущий момент Т, но и то, что она сама выдавала в момент времени Т-1. Таким образом, мы сразу подаем параллельно два вектора. И на основании этого вычисляем значение выхода для момента времени Т. Получается, что нейросеть может сама себе передавать то, что она «думала» в предыдущий момент времени. Это позволяет сохранить информацию о предыдущих входах. Такой тип нейросетей и называется рекуррентным, потому что они имеют рекуррентные связи. Если мы подойдем в лоб к решению этой задачи, то рекуррентные нейросети работают не очень хорошо, потому что когда мы разворачиваем эту обратную петлю, то фактически наращиваем слои нашей нейронной сети. От момента времени 0 наша нейросеть будет погружаться все глубже и глубже — в момент времени 100 нейросеть наша тоже будет глубиной 100. Поскольку ошибка в обратную сторону распространяется, она постоянно растекается по нашей сети и затухает. Поэтому наша нейросеть очень плохо учится, так как каждый раз происходит умножение на некоторые коэффициенты и наши ошибки затухают.
Чтобы избавиться от этого затухания градиентов, в 1997 году исследователь Юрген Шмидхубер предложил заменить один нейрон на подсеть из пяти нейронов. То есть теперь слой нейросети состоит из «юнитов». Смоделируем ячейку памяти. У нас есть некоторые значения, которые хранятся в этой ячейке. Есть нейроны, которые могут управлять тем, что мы можем что-то в эту ячейку памяти записать, что-то из нее считать и вывести наружу. При этом управление ячейкой осуществляется индивидуально своим набором нейронов. Веса этих нейронов тоже обучаются — и в этом вся красота полученной архитектуры. Когда мы из этих ячеек построим большую нейросеть, они все будут обучаться с помощью алгоритма обратного распространения ошибки. То есть алгоритм у нас остается тот же самый, даже несмотря на то, что сеть у нас значительно усложнилась.
Это позволило, например, создать систему машинного перевода. Буквально год назад Google заменил свою старую систему машинного перевода на нейросетевую — значительно лучшего качества. По сравнению со старой версией машинного перевода Google 2015 года человеческий перевод получал гораздо больше оценок. Но по сравнению с новым нейросетевым алгоритмом Google, который используется сегодня, оценки человеческого перевода сопоставимы. На самом деле переводом вы пользуетесь каждый день — когда забиваете что-то в поиске, то второй и третий по значимости сигнал по тому, какой ресурс вы получите в выдаче на первой странице, тоже определяется нейросетями. Представители Google все время показывают график, в котором с каждым годом все больше и больше внутренних проектов используют нейросети и глубокое обучение. Если в 2012 году это были один-два проекта, то сегодня — около 5 тыс. Фактически нейросети — это та технология, которой вы пользуетесь каждый день, хотя, быть может, даже этого не подозреваете. Некоторые люди, которые этим занимаются, провозгласили, что нейросети и искусственный интеллект — это новое электричество. В том смысле, что это та технология, которой мы пользуемся, не замечая, но она плотно вошла в нашу жизнь.
Какого же эффекта мы можем достичь с помощью этих рекуррентных нейросетей? Я покажу вам результаты, которые поразили меня до глубины души. Если бы мне кто-то сказал за месяц до этого, что такое возможно, а это было летом 2015 года, я бы ответил, мол, ребята, я занимаюсь нейронными сетями десять лет, не надо мне рассказывать сказки. Но когда мы сами взяли нейросеть, провели ее обучение и увидели результат, который она выдает, то убедились, что это на самом деле так. Мы решали задачу моделирования языка. Формально это задача предсказания следующего символа. Например, у нас есть куча текстов Достоевского. Мы подаем на вход нашей нейросети 100 символов (букв, включая пробелы и знаки препинания) из произведений Достоевского, и ее задача — предсказать следующий символ. Этот символ мы можем снова подать на вход и предсказать следующий — и так далее. Но нам не хотелось экспериментировать на Достоевском, поэтому мы взяли субтитры к сериалу — примерно 10 млн слов из «Хроник вампиров» и еще чего-то. На этом материале сеть училась предсказывать следующие символы.
Итак, задача: есть 100 символов, нужно предсказать 101-й. Мы выложили в интернет интерфейс, где можно было забить какую-то начальную фразу, а нейросеть пыталась ее продолжить. Я отобрал наиболее интересные результаты. Человек пишет: «Ты глупый». То есть на вход нейросети подаются все эти буквы, пробел между «ы» и «г», а также перевод строки. И она предсказывает следующий символ: «К» большое. Мы подаем эту «К» ей на вход, она предсказывает следующий символ «а», подаем на вход «а» и т. д. — в результате получаем сгенерированную фразу: «Как насчет “привет”». Когда мы анализирует этот ответ, он выглядит абсолютно логично. Причем у него есть особенности: почему нейросеть сказала про привет? Если это начало диалога, то логично, что с фразы «ты глупый» не начинают. Поэтому нейросеть говорит: «Как насчет “привет”», причем слово «привет» закавычивает, давая понять, что это слово относится не к ней самой. Так что пусть у нашей нейросети и нет научной степени по филологии, но уж знания русского языка у нее глубокие.
Другой пример. Я попытался задать более сложный контекст, чтобы нейросети было непросто ответить. Вопрос: «Какой чудный вечер. Не правда ли?» Это довольно длинная последовательность символов, два предложения, много пробелов, знак вопроса. Вот ее ответ: «Ты действительно думаешь, что я буду помнить об этом?» Здесь ничего про вечер не сказано, ответ вопросом на вопрос. Но если мы попытаемся проинтерпретировать, то это вполне осмысленно. То есть если вечер чудесный, то подразумевается, что тот, кому про это сказали, захочет это запомнить. Отсюда такой ответ нейросети. И отдельно обратите внимание, что она (нейросеть.— “Ъ”) еще и знаки препинания правильно расставляет, и ошибок в словах не делает. И это при том, что мы в нее не закладывали правил русского языка, словаря слов, никаких грамматических основ — мы дали нейросети только последовательность символов. Мне кажется, что в таких условиях выдача подобных ответов — просто поразительный феномен. Я до сих пор удивляюсь: как она может это генерировать?
Еще один пример. Здесь вообще получился очень жизненный диалог. Человек: «Ты дура». Машина: «Так почему тебе не все равно?» Человек: «Потому что мне с тобой жить!» Машина: «Ты совсем не такой!» Человек: «Ты обиделась?» Машина: «Угу». Покажу еще пример ее работы. Человек: «Забавно, но ты всего лишь программа и никогда не сможешь мыслить». Машина: «Конечно, дело в том, что сейчас не лучшее время». Все логично, да? Но это ваша интерпретация, нам не известно, что на самом деле нейросеть имела в виду, это же все из сериалов.
А теперь — про разнообразие, которое порождала нейросеть. В принципе эта нейросеть является вероятностной моделью текста, она выдает вероятность следующего символа, но не точно, какой будет следующий символ. И мы можем пропорционально этой вероятности выбирать. Таким образом, мы можем генерировать разные последовательности. В одном случае на один и тот же вход мы выберем одну букву, в другом случае — другую . Мы подаем на вход предложение: «Алиса теперь счастлива». И просим нейросеть продолжить. Предсказать, как бы эта последовательность продолжалась. Везде продолжение начинается со слова «она». То есть нейросеть как бы улавливает, что здесь было про Алису и «счастлива», пол того субъекта, про который идет речь. В некоторых ответах есть нечто, что коррелирует с тем, что она счастлива. Например: «Она выглядит прекрасно». Или она была на концерте, поэтому она счастлива. Или она великолепна или влюблена, поэтому она счастлива. Или вот: «Она в опасности». Видимо, счастливые люди с большей вероятностью попадают в опасные ситуации, чем несчастливые. Можно сделать такой вывод. Или например: «Алиса попала в беду». Здесь мы видим, что тональность уже сменилась: «А она не знает кто ты», или «А она изменила свою жизнь», или «Она не собирается никого убивать». Раз она попала в беду, в ответах появляется что-то уже тревожное. А откуда появились эти нотки, мы не знаем. То есть нейросеть зачем-то вставила эти нотки. Из субтитров. Там были знаки ноток.
Но, видимо, в субтитрах все-таки больше про женщин, потому что на женские затравки она отвечает более осмысленно, а на мужские, наверное, не хватает статистики. «Джон теперь счастлив». — «Да, на дворе 800 фунтов на каждом месте», «Преступление в тысячу тысяч градусов по матче», «В самом деле собирался позволить себе просто бросить все на свои места». То есть осмысленность ответов сильно пострадала, хотя предложения изначально схожие. А вот «Джон попал в беду» — совсем тяжело: «Свиньи собираются в Старлинк-сити», «И когда он вернулся, я выбросил его в офис», «Он был не таким как был в прошлом году», «Сверхъестественное, ваша честь, это был не мы».
Я не знаю, насколько это вас впечатлило, меня это впечатлило очень сильно. Мой прогноз был бы такой, что, возможно, нейросеть сможет выучить некоторые слова из пяти букв и воспроизводить их в некотором случайном порядке. Но под прогнозом, что она сможет без ошибок генерировать такие длинные фразы, которые можно осмысленно интерпретировать, я бы, честно говоря, никогда не подписался.
Давайте я еще быстренько расскажу о том, о чем все волнуются в последнее время. Нейросетевое обучение с подкреплением. Это такой подход, который необходим для того, чтобы выучить некоторые действия у агента. Каждые действия агента как-то при этом меняют среду. В предыдущих задачах мы прогнозировали, но не влияли на саму задачу. Мы не влияли никак на изображения, которые классифицируем, не влияли никак на последовательность, которую мы генерируем. А здесь наша задача ставится так: мы хотим повлиять на тот вход, который у нас есть, чтобы привести в то целевое состояние, которое нам необходимо. Агент — это некоторый субъект, который может воздействовать на окружающую среду. Мы не знаем, как решать эту задачу по обучению агента. Но мы знаем, что такое хорошо и что такое плохо. Поэтому мы можем в те моменты, когда агент достигает той цели, которую мы перед ним поставили, давать ему некую величину, которую мы называем наградой или подкреплением. Таким образом, нам необходимо получить алгоритм, который будет по последовательности и по наградам выучивать такие действия, которые в данной ситуации будут максимизировать награду.
В 2016 году в журнале Nature вышла статья, где был описан достаточно универсальный алгоритм, который научили играть в игры Atari. И он попал на обложку журнала Nature. Если вы знаете, журнал Nature — это один из наиболее авторитетных и престижных еженедельников в мире науки, где публикуются действительно научные статьи. Если ты напечатал статью в Nature, то твой авторитет среди ученых очень сильно возрастает. Бывают, конечно, исключения, но в основном там действительно публикуются очень важные с точки зрения науки работы. Как ставится задача? У нас есть 49 игр Atari, мы подаем на вход нашей нейросети картинки из этих игр, но никак не объясняем правила. Мы будем одну и ту же нейросеть учить на разных играх и хотим, чтобы она на всех играх училась хорошо. Но нейросеть одна, и под конкретную игру она подстраивается только в процессе обучения. Заранее мы ничего не закладываем.
Соответственно, у нас есть картинки, которые попадают на вход нашей нейросети, но вы все знаете, что такое сверточные сети — я рассказывал полчаса назад. Сверточные нейросети преобразуют картинки, выделяют признаки, и на выходе нейросети она выдает действие, которое управляет джойстиком. Соответственно, команды от джойстика передаются в симулятор игры, и он управляет поведением игры. Когда вы набираете очки, ваш агент получает подкрепление, и задача агента — увеличить эти очки. То есть здесь мы не говорим ему напрямую, какие действия выбирать, а просто в тот момент, когда он увеличил очки, говорим, что это хорошо. И задача — обучить этот алгоритм. Например, нейросеть управляет подводной лодкой. Задача: рыб — уничтожать, водолазов — подбирать и время от времени, когда кислород заканчивается, всплывать и заряжаться кислородом. Нейросети это удается не всегда, иногда она погибает. Но оказывается, что этот результат нашел не только научное признание и попал на обложку журнала Nature, а был получен некоторым стартапом, и за пару месяцев до того, как это было опубликовано, этот стартап купила компания Google. При этом из результатов у этого стартапа были только те, которые они публиковали в журнале Nature. Как вы думаете, за сколько компания Google купила этот стартап? За 600 миллионов.
Следующий вопрос. Что связывает Гарри Каспарова и Ли Седоль, чемпиона по го (игра.— “Ъ” )? Правильно. Их обоих победил искусственный интеллект. В 1997 году DeepBlue обыграл Каспарова, а чемпиона го обыграли в прошлом году. Почему так? До последнего времени считалось, что го — очень сложная игра. Это связано с количеством вариантов, которые нужно перебрать, чтобы рассчитать все возможные исходы игры, и описывается так называемым коэффициентом ветвления. То есть во сколько возможных состояний игры мы можем перейти из текущего состояния игры, совершая разрешенные в игре действия. Для шахмат средний коэффициент ветвления — около 35. А в го этот коэффициент ветвления — 250. Соответственно, вы понимаете, что когда мы идем вглубь, то каждый раз мы умножаем на это число. И понятно, что для го мы очень быстро получаем такое количество вариантов, которое превышает число частиц в наблюдаемой вселенной, и перебрать их не представляется возможным. Нужен какой-то другой вариант решения этой задачи. Если в шахматах мы можем в лоб рассчитать варианты для очень большого числа позиций и тупо знать те ходы, которые нужно сделать, чтобы выиграть или не проиграть, то в го это гораздо сложнее. Многие люди говорили, чтобы распознавать все ситуации, нужна интуиция.
Тот же самый стартап, который купили за 600 миллионов, через год снова появился на обложке журнала Nature. Теперь он предложил алгоритм, который, глядя на доску, мог выдавать оценку того, насколько эта позиция хороша, то есть достаточно быстро предсказывать. Вы можете скомбинировать это предсказание с алгоритмом поиска по дереву и при помощи нейросети оценивать позиции и раскрывать только те, которые являются наиболее выигрышными. Таким образом, вы делаете не полный перебор, а только под дерево, которое является наиболее перспективным в данный момент. Этот алгоритм — версия AlphaGo (в статья была опубликована версия AlphaGo Fan) — и обыграл Ли Седоля в Го. Тогда программы в го играли на уровне хорошего любителя, но не профессионала. Чтобы обучить эту версию, нужно было 176 графических процессоров на распределенном кластере. И она выиграла у чемпиона Европы со счетом 5:0.
Затем появилась адаптированная версия программы — AlphaGoLee. Она использовала 48 Tensor Processing Unit — это типа TPU, но специально адаптированных под нейросети. У Ли Седоля она выиграла со счетом 4:1. Потом была AlphaGoMaster на 4 TPU, которая выигрывала у профессиональных игроков со счетом 60:0. Буквально месяц назад появилась программа AlphaGoZero, которая на 4 TPU на одном компьютере (уже не на кластере) обыграла со счетом 100:0 ту версию программы, которая обыграла Ли Седоля, и со счетом 89:11 — версию AlphaGoMaster. Следующую версию опубликовали несколько дней назад — AlphaZero. Она, опять же, на четырех TPU со счетом 60:40 сыграла против AlphaGoZero. Первая версия программы AlphaGoLee сначала тренировалась на реальных играх. То есть была взята база данных игр, и на ней программа училась играть, как человек. А вот программы AlphaGoZero и AlphaZero — почему Zero? Потому что они вообще не использовали никакой информации от человека. Как они училась? Просто играли сами с собой и обучались на своих играх. И вот так хорошо обучились.
Теперь вопрос. Зачем компания Google купила эту штуку? Она взяла этот алгоритм, который использовался для игр, и приложили к задаче управления охлаждением дата-центра. Теперь в момент, когда включается нейросетевое управление, потребление падает, когда выключается — возвращается к старому уровню. В среднем экономия около 40%. Google поддерживает огромное количество дата-центров, чтобы обеспечить качество сервиса, и для них экономить по 40% на электроэнергии, а для дата-центров электроэнергия — вообще основная затратная статья, это очень существенно. Не знаю, окупилось ли, но, по крайней мере, существенную часть, возможно, возместило.
За свою историю искусственный интеллект переживал взлеты и падения, и сегодня мы находимся на самой вершине нового ажиотажа вокруг искусственного интеллекта , где все считают, что искусственный интеллект — «новое электричество» и так далее. Возможно, скоро этот ажиотаж спадет, но сейчас самый пик. Почему здесь в зале так много людей, большинство из которых не знают, что такое глубокое обучение, и все равно пришли. Видимо, тема добирается из других сфер жизни и привлекает сюда людей. Пик интереса связан с тем, что давно известные нейросетевые алгоритмы за счет больших данных и больших вычислительных возможностей стали решать те задачи, которые раньше не могли быть решены, и давать очень интересные результаты, которые могут быть внедрены в очень многих областях экономики.
Соответственно, что делаем мы в этой области? В нашей лаборатории мы реализуем проект, поддержанный Национальной технологической инициативой — это инициатива нашего президента, связанная с попыткой переставить какие-то части нашей экономики с сырьевых рельсов на высокотехнологичные. Инициатива связана, с одной стороны, с поддержкой инновационных бизнесов, а с другой — с инфраструктурой для этих инновационных бизнесов. Соответственно, в рамках этой национальной технологической инициативы Физтех при софинансировании Сбербанка выполняет проект. И цели проекта — это разработка алгоритмов глубокого машинного обучения и машинного интеллекта в виде некоторой технологической платформы для автоматизации ведения целенаправленного диалога с пользователем.
Сегодня у нас возникает целая область экономики, связанная с текстовой коммуникацией. Люди пользуются мобильными устройствами, и число пользователей мессенджеров на мобильных платформах уже превысило число пользователей соцсетей. Это значит, что огромное количество коммуникаций люди осуществляют в текстовом формате. Но при этом нет хороших инструментов для компаний, чтобы общаться в этом мире с пользователями. Есть большой запрос на решения, когда компании могли бы достучаться до вас, как-то вам помочь или решить какую-то вашу проблему через чат. С другой стороны, те решения на создание диалоговых систем, которые до последнего времени существовали, не очень эффективны, потому что они основаны на некоторых закодированных сценариях, заданных программистом, и эти сценарии, как оказалось, не очень хорошо масштабируются и не могут описать все многообразие нашей разговорной жизни. Разные люди по-разному выражают свои мысли, бывают разные ситуации, и все это очень сложно воспринять и заранее предусмотреть. Но, как мы видели, нейросети очень хорошо справляются с такой неопределенностью. Они могут генерировать ответы, похожие на ответы человека. Они могут делать машинный перевод. И поэтому есть надежда, что мы сможем использовать нейросетевые технологии для того, чтобы решить хотя бы часть проблем в создании разговорных интерфейсов.
Таким образом, цель этого проекта — как раз создать такую открытую платформу, которая могла бы быть использована компаниями для создания продуктов в этой области. То есть мы создаем технологию, отдаем ее компаниям и говорим: «Мы вас будем поддерживать, мы будем вам помогать эту технологию внедрять, а вы, пожалуйста, делайте свои бизнесы и вносите свой вклад в экономику». Каковы стейкхолдеры нашего проекта? С точки зрения NTI, это компании на высокотехнологичных рынках. Например, Сбербанк, который хочет, имея эту технологию в качестве основы, создать решения для автоматизации каких-то сервисов, например, колл-центров или служб поддержки. Это Физтех, которому интересно развивать внутри себя компетенцию по искусственному интеллекту. Это исследователи и разработчики, которым нужны инструменты для того, чтобы быстро создавать таких интеллектуальных диалоговых агентов.
Этот проект мы начали летом этого года и назвали его iPavlov в честь Ивана Петровича Павлова, знаменитого русского нейрофизиолога, который занимался исследованием условных рефлексов. То есть мозгом. Соответственно, два основных результата нашей деятельности с точки зрения технологии — это открытая библиотека, которую мы назвали DeepPavlov, и это как раз набор инструментов для создания диалоговых систем, а также набор сервисов Сбербанка, который они будут встраивать в свои продукты, например, каких-то финансовых помощников. У нас есть исследования, есть разработка нашей библиотеки, есть приложения этой библиотеки для каких-то конкретных бизнес-кейсов. Что мы хотим сделать? Мы хотим сделать набор некоторых нейросетевых блоков, из которых мы можем собрать разных агентов под разные задачи. Например, агентов, которые могут решать конкретные задачи типа бронирования билетов, или агентов, которые могут отвечать на вопросы по какой-то тематике, или агентов, которые могут просто поддерживать беседу. И потом эти агенты могут комбинироваться для каждой конкретной области, чтобы оптимально решать поставленную задачу. Это то, как мы планируем реализовывать архитектуру с точки зрения ее нейросетевого и исследовательского содержания. И, с одной стороны, наша библиотека состоит из компонентов для создания этих ботов. С другой стороны, у нас есть некоторый инструмент Bildert, при помощи которого мы можем собирать из этих ботов разговорных агентов, есть коннекторы, которые соединяют нас с мессенджерами, и есть данные, на которых мы тренируем. То есть это некоторый набор инструментов, при помощи которых можно разрабатывать и внедрять такие решения.
Наверное, на этом можно закончить. Спасибо всем.
- Евгения Чернышева подписаться отписаться
- Hi-Tech. Интервью подписаться отписаться
Внимание — все, что вам нужно: как работает attention в нейросетях
«Системный Блокъ» добрался до самых горячих технологий в мире современного глубокого обучения. Сегодня рассказываем о механизме внимания, на котором работают в 2020 году все действительно крутые нейросети. Почему внимание стало killer-фичей диплернинга, что под капотом у attention mechanism, как нейросеть понимает, какие признаки текста или картинки важнее других

Мы продолжаем серию постов об устройстве нейронных сетей. В прошлом материале «Системный Блокъ» рассказывал о том, зачем нужны рекуррентные нейросети, что такое рекуррентность и как добавить нейросети долгосрочной памяти. Сегодня мы пойдем дальше: разберем, что такое механизм внимания, для чего он нужен и как работает.
Что мы рассказывали в прошлый раз
Рекуррентный — значит возвращающийся. RNN угадывает следующие слова в тексте или ноты в мелодии, возвращаясь к своим прошлым догадкам. Прошлые догадки нейросеть хранит как вектор активации нейронов и передает с шага на шаг. Так кодируется прошлый контекст в тексте, музыке, речи.
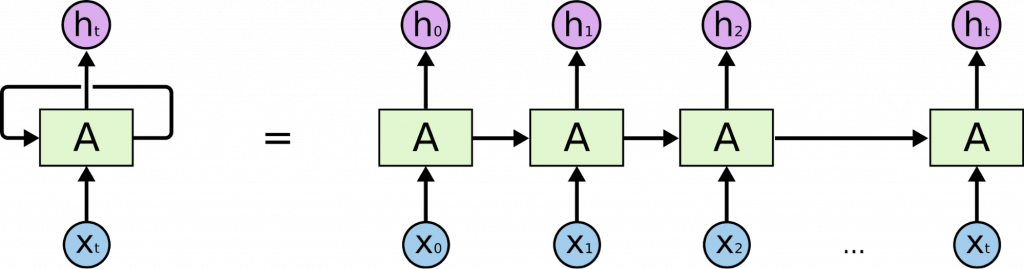
Развитие идеи RNN — нейросеть LSTM: она не передает контекст целиком, а решает, какую часть использовать, а какую — забыть. LSTM по-разному модифицировали, чтобы лучше отличать важный контекст от неважного. Даже придумали новую архитектуру GRU (Gated Recurrent Unit). В GRU тоже есть функции, определяющие, какую часть кодированного контекста передавать по цепочке дальше.
Проблема 1: RNN работает недостаточно эффективно
У всех нейросетей, что передают данные с шага на шаг, есть фундаментальные проблемы. Первая — если данные передаются по цепочке, значит, следующие вычисления не начнутся, пока не закончатся прошлые. Причина — следующий шаг принимает результат предыдущего как переменную.
Ждать, пока закончится старая операция, чтобы начать новую — долго. Компьютерное «железо», особенно графические процессоры, хорошо разбивает крупные счетные задачи на мелкие параллельные, и выполняет их вместе быстрее, чем по очереди. Иными словами, рекуррентность не дает загрузить компьютер на полную мощность.
В 2017 проблему решили исследователи из Google Brain и Google Research. В статье «Attention is all you need» («Внимание — все, что вам нужно»), они описали новый тип нейросетей — «трансформер».Трансформер — не рекуррентная нейросеть. Он не передает весь контекст по цепочке и не выбирает из него нужные части. Зато при каждом новом предсказании трансформер фокусирует внимание только на тех на словах, которые считает важными.
Спойлер: внимание вкратце — это умножение вектора слова на числа. Если слово важное — множители будут большими и вектор слова «выделится» среди соседей.
Трансформер — сложная архитектура. Лучше начать с механизма внимания рекуррентных нейросетей, которые все-таки передают информацию с шага на шаг. Так можно сделать, поскольку «внимание» нейросетей изобрели не авторы трансформеров: механизм использовался и раньше, но не был основным.
Итак, основная тема поста — механизм внимания.
Проблема 2: RNN учитывает только прошлый контекст
RNN работает медленно, но есть и вторая проблема — модели, которые мы описали, умеют смотреть только на прошлый контекст. Этого иногда мало. Вот два предложения: «He said Teddy Roosevelt was a great president» (он сказал, что Тед Рузвельт — отличный президент) и «He said Teddy bear is expensive» (он сказал, что плюшевый мишка — дорогой). Нейросеть угадывает, где в предложении стоят имена собственные и присваивает словам значения: 1 каждому имени собственному, 0 каждому другому слову.
Нейросеть дошла до слова Teddy. Ей нужно решить, означает ли Teddy имя Рузвельта или слово «плюшевый». У RNN есть только вектор Teddy и «след» прошлых слов (вектор контекста): в нем закодировано, что раньше было написано «He said», «он сказал». Надо заглянуть вперед, за нынешнее слово: тогда станет ясно, что в одном случае Teddy — Roosevelt, а в другом — мишка.
Чтобы смотреть на все предложение, а не только на прошлую часть, программисты придумали Bidirectional RNN (двунаправленную RNN или BRNN). Она обрабатывает предложение один раз слева направо, другой раз — справа налево, и только потом начинает предсказывать. В этом посте мы сначала по шагам разберем работу BRNN, потом на ее примере расскажем про механизм внимания.
Двунаправленная RNN считает контекстом все предложение целиком (или N слов слева и справа). Когда контекст — все предложение, яснее видно, что на каких-то словах нужно фокусироваться сильнее, чем на других. BRNN поможет проиллюстрировать, почему механизм внимания нужен и полезен.
Проблема 3: в RNN контекст размывается со временем
Посмотрите, сколько шагов нужно пройти вектору слова X0, чтобы попасть в предсказание слова h3. Путь получается таким длинным из-за того, что слова предсказываются последовательно.
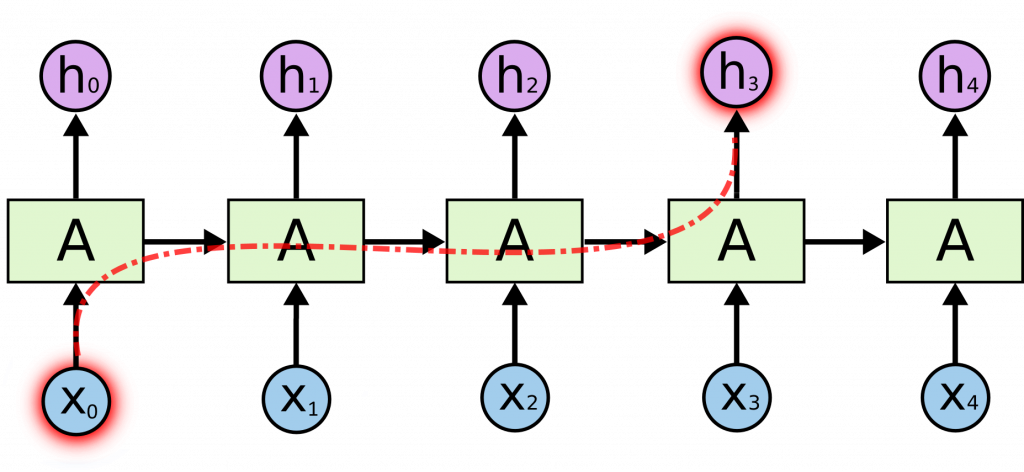
Чем длиннее путь слова, тем сильнее оно «размывается» в рекуррентной сети, даже если передавать по цепочке не весь контекст, а только важные части (как в LSTM). А отдаленные слова бывают важны. Вот предложение: «Кошка съела рыбу, котлету, сосиску и два блинчика, но все еще была голодна». Чтобы правильно угадать слово «была» (а не «был»), нужно помнить, что в контексте стоит вектор слова «кошка», а не «кот». В нейросети без внимания к вектору «кошки» примешивается вектор «котлеты», «сосиски» и «блинчиков», и к концу предложения уже трудно разобрать, что там стояло в начале.
Технические детали: на каждом шаге элементы вектора контекста возводятся в степень или умножаются, и через несколько шагов их производные либо «взрываются» (стремятся к бесконечности) либо «стираются» (стремятся к нулю). Это называется проблемой затухающих и взрывных градиентов. «Сотрутся» они или «взорвутся», отчасти зависит от того, было ли изначальное значение элемента больше или меньше единицы (если возвести 0,9 в квадрат, получится число меньше изначального, а если 1,1 — больше). Поэтому к концу преобразований всё сильно запутано.

Когда слово долго хранится в контексте, оно «портится» и слабее влияет на следующие предсказания. Это значит, что на догадку нейросети о новом слове больше всего влияют прошлое слово (и следующее, если RNN — двунаправленная). Даже в случае с умной LSTM.
Механизм внимания решает проблему. Его цель — заставить нейросеть сильнее сосредоточиться на важном слове в дальнем конце предложения. Контекст — это сумма векторов всех слов в предложении. «Подсветить» важное слово в контексте — значит умножить его вектор на большое число («вес внимания»). Чтобы понять, какое слово сейчас важно, потребуется еще одна нейросеть (внутри нейросети).

Типы рекуррентных архитектур
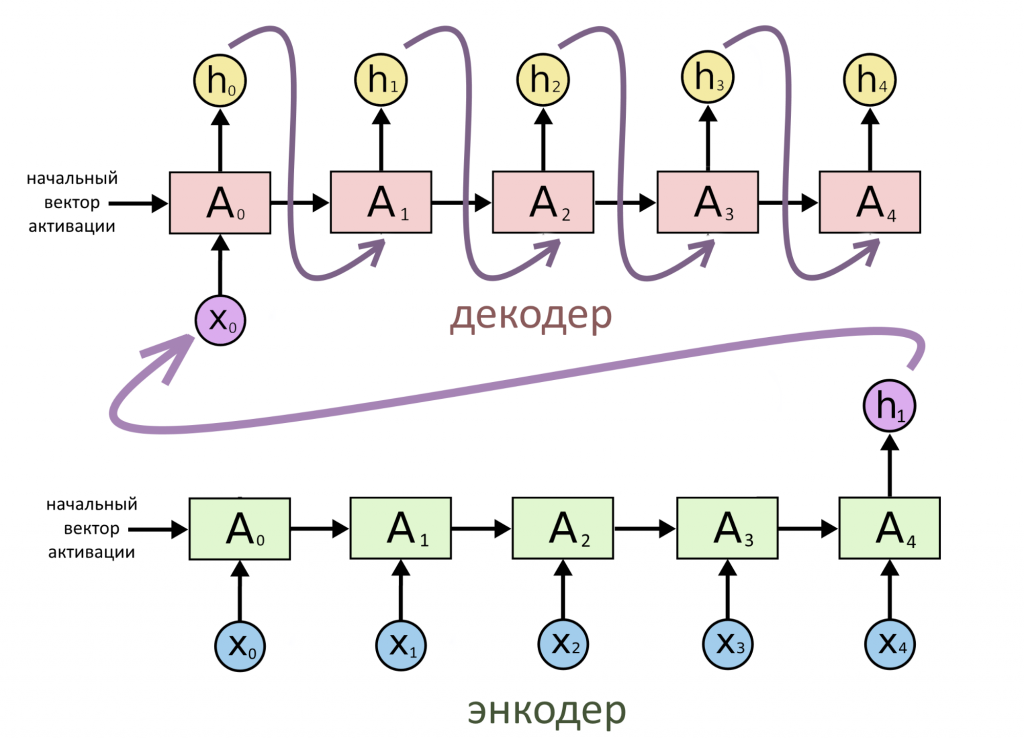
Что такое энкодер-декодер и зачем он нужен
Чтобы объяснить нейросетевое внимание на примере, мы выбрали известную научную статью 2014 года про применение нейросетей в машинном переводе (у статьи сейчас почти 13 тыс цитирований на Google Scholar). Статья — о том, как перевести текст, если у вас есть двунаправленная RNN с механизмом внимания. Нейросеть из примера состоит из двух частей: энкодера и декодера. В этом разделе объясняем, что это за части и зачем они нужны.
Вкратце: энокдер зашифрует последовательность в виде вектора (превратит входной текст в набор абстрактных чисел, которые условно кодируют смысл), а потом декодер расшифрует этот вектор в другую последовательность (например, на другом языке).
Архитектура «вектор → вектор»
В примерах раньше на входе и на выходе нейросети были последовательности. Их длины были равны.
Количество входных слов совпадает с количеством выходных. Так бывает, если пословно дополнять текст. Тогда старые предсказания h становятся новыми входными словами X. Еще так бывает, когда каждому входному слову нужно присвоить какую-то метку, например, 1 — если слово — имя собственное, 0 — если нет. Не всегда длина входной и выходной последовательности совпадают. Вот разные случаи.
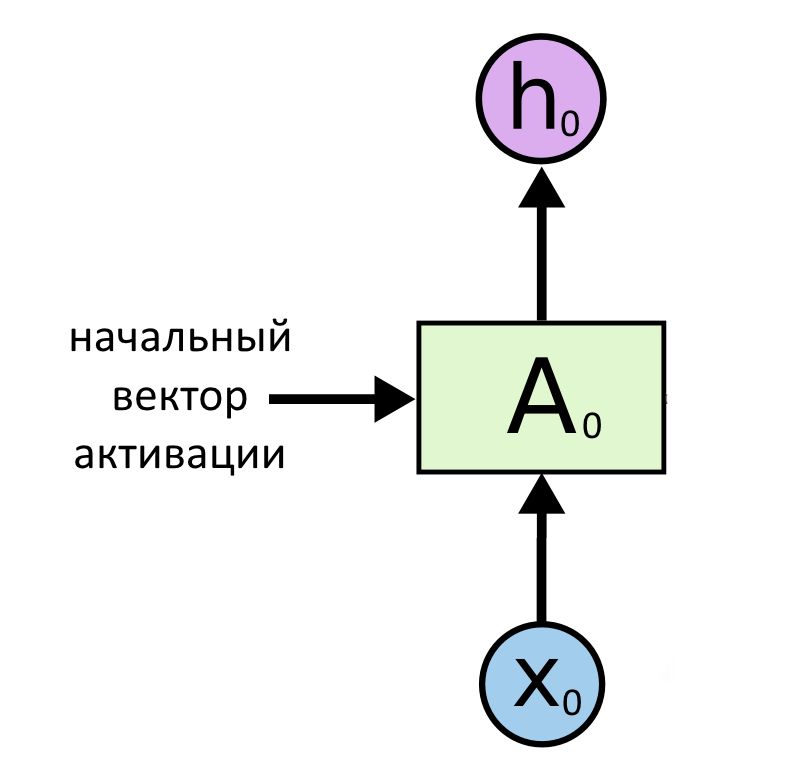
Самая простая архитектура превращает один вектор в другой вектор, пользуясь начальной активацией нейронов a(0). Здесь вообще нет последовательности генерируемых векторов. По сути, это даже не рекуррентная нейросеть, ведь она не передает свое значение никуда дальше. Но ее можно представить как частный случай рекуррентности: пример показывает, что как на входе, так и на выходе нейросети может быть не последовательность, а единственный вектор.
Это была модель «вектор → вектор».
Архитектура «вектор → последовательность»
Дополним прошлый пример, получится следующая архитектура.
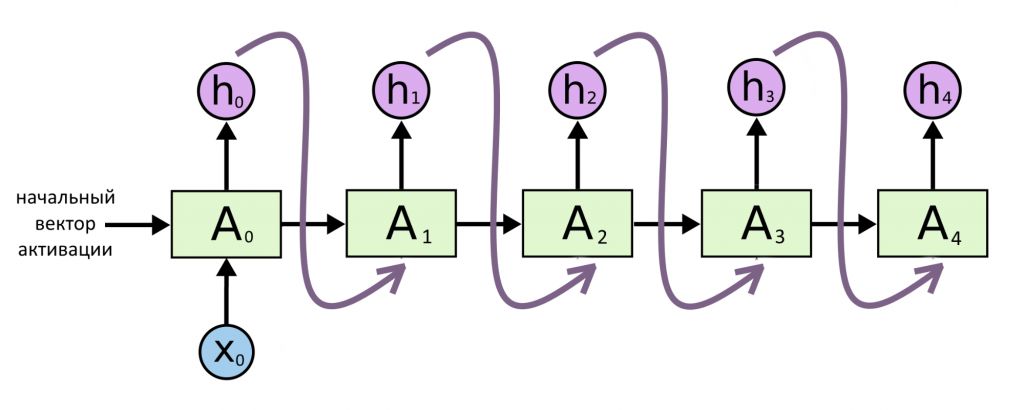
Бывает, что нужно из одного вектора сделать несколько. Пример — генерация музыки: на входе нейросети может быть только число, означающее жанр, или какое-то случайное «зерно» X. «Зерно» закодируется в вектор и превратится в ряд векторов, каждый из которых станет одной нотой. Такая модель на каждом шаге, кроме первого, принимает на вход только результат своей предыдущей работы.
Это была модель «вектор → последовательность». Иногда ее называют «генератор».
Архитектура «последовательность → вектор»
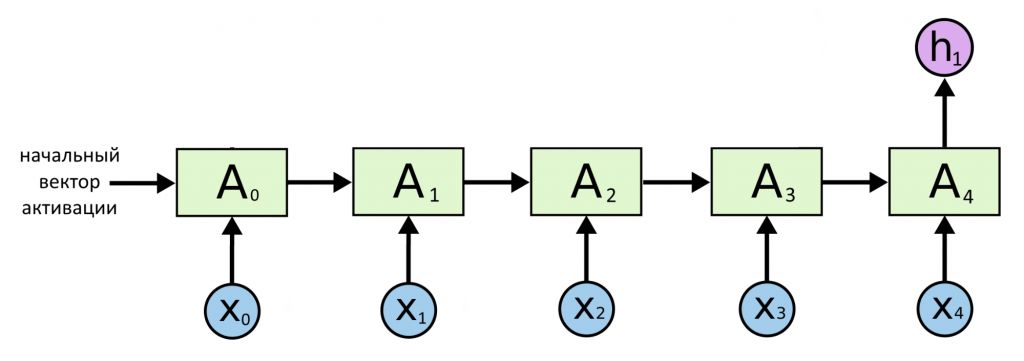
Иногда нужно череду значений переписать в виде одного значения. Например, чтобы понять тональность текста: на входе — последовательность векторов слов X, а на выходе — единый вектор Y. Его элементы показывают вероятности, что тональность текста — радость, печаль, агрессия, скука. В такой архитектуре из всех предсказанных значений сохраняется только самое последнее.
Это была модель «последовательность → вектор»
Архитектура «последовательность → последовательность» (энкодер — декодер)
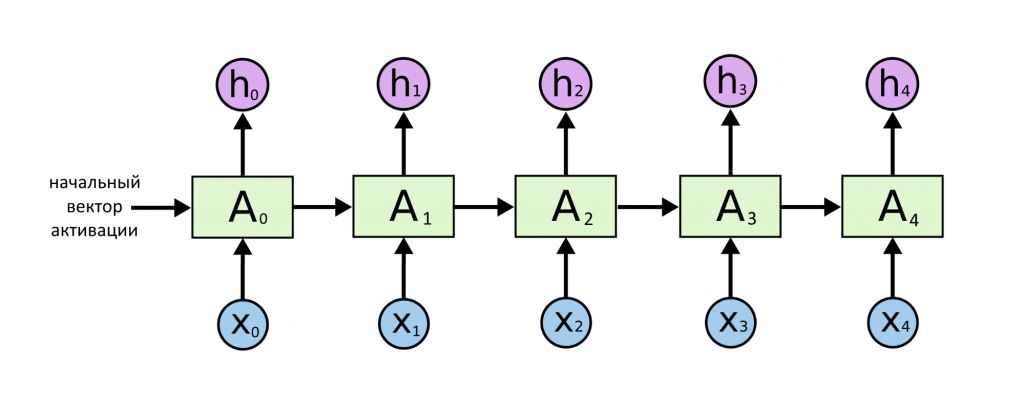
А вот случай, про который уже писали раньше. Ряд векторов — на входе и на выходе, и длины рядов равны. Одинаковость входов и выходов прочно «вшита» в архитектуру: один выходной вектор получается, если нейросеть видит на входе один входной. Все примеры из прошлой статьи — про эту архитектуру.
Это была модель «последовательность → последовательность»
Последняя модель называется «энкодер-декодер». Ей пользуются, если нужно работать по типу «последовательность → последовательность», но непонятно, как связаны длины входа и выхода (т.е. на входе 5 слов, то на выходе может быть 2, а может быть 10, и мы не можем это заранее угадать).
Что это значит на практике?
Чем хороша архитектура «энкодер — декодер» для машинного перевода
При переводе на иностранный язык число слов в оригинале и в переводе почти никогда не совпадает. Одно слово может переводиться двумя-тремя, а может вообще каким-нибудь устойчивым выражением.
Ага, думает разработчик, на входе — предложение, это последовательность слов. Если взять архитектуру «последовательность → вектор», то можно закодировать (encode) предложение единым вектором.
А раз получился единый вектор, который нужно превратить в перевод, значит, можно взять архитектуру «вектор → последовательность». Эта часть декодирует (decode) исходное предложение.
«Даже великий и ужасный трансформер состоит из кодирующей части и декодирующей»
Две части нейросети, «слепленные» таким образом вместе, образуют мощную архитектуру «энкодер-декодер». Именно она обычно используется в задачах машинного перевода. Позже мы покажем, что даже великий и ужасный трансформер состоит из кодирующей части и декодирующей.
«Энкодер-декодер» универсален. Внутри на рекуррентных слоях могут «лежать» любые архитектуры, GRU, LSTM или другие, если речь идет об обработке текста. Но самое крутое, что не обязательно сводить все именно к тексту!
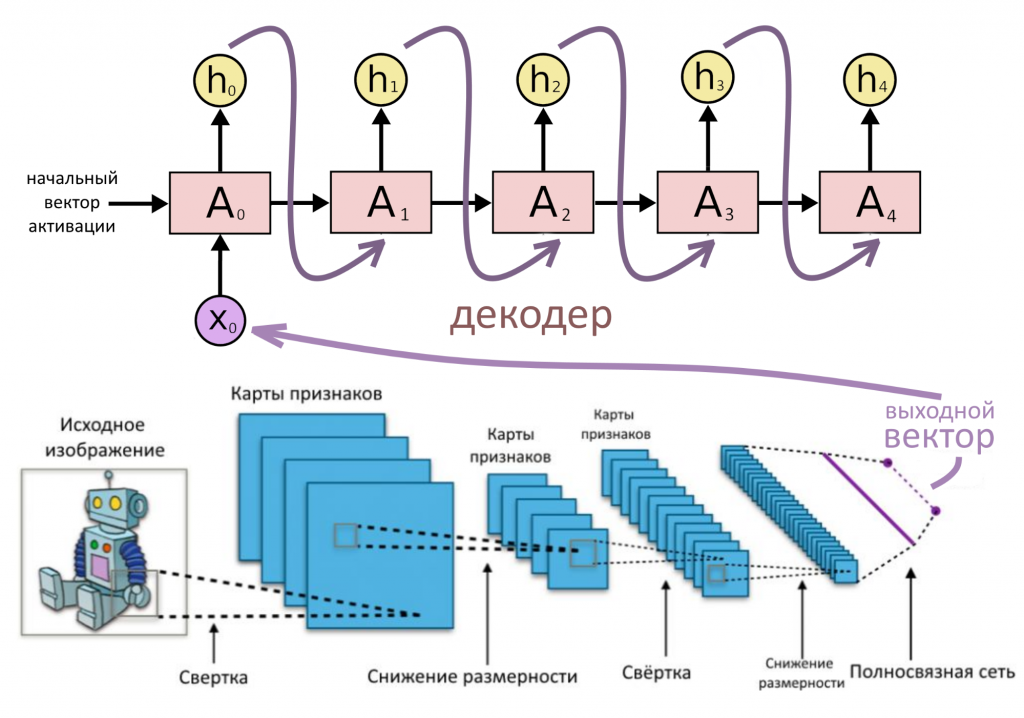
Если кодирующую часть составить из сверточных слоев, представляющих картинку в виде вектора, а декодирующую — в виде рекуррентного «генератора», можно сделать автоматическую подпись субтитров к изображениям или видео — были бы только данные для обучения. А можно — распознавать пешеходов на улице, если вы — инженер Tesla.
Ну а тот самый механизм внимания — отличный метод взаимодействия между кодирующей и декодирующей частями нейросети. Иногда его называют «интерфейсом» между двумя этими частями. Мы почти готовы разбираться с вниманием, только для этого надо еще раз вспомнить о двунаправленных RNN.
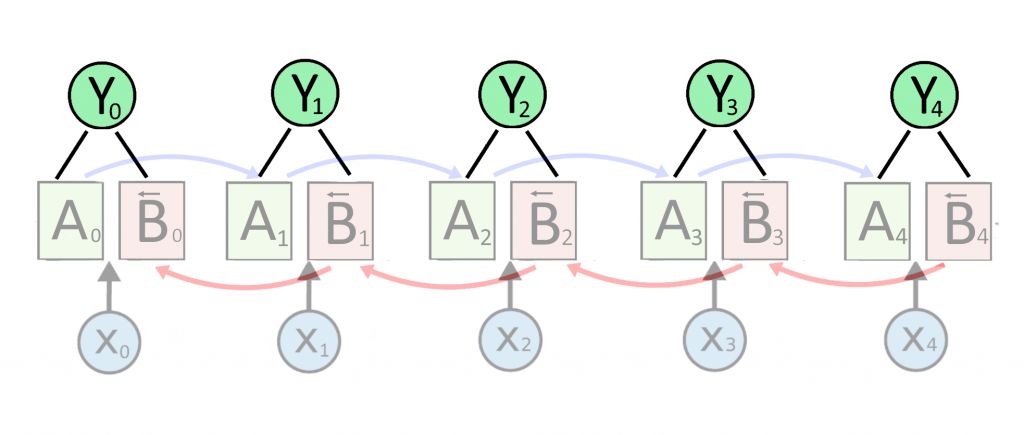
Как работает двунаправленная RNN
BRNN нужны, чтобы смотреть не только на прошлые слова, а на всю фразу
Работа начинается так: нейросети подают на вход несколько векторов слов: X1, X2, X3, X4.
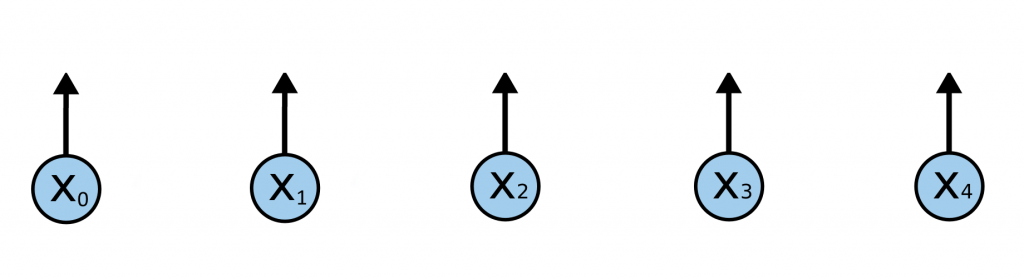
Нейросеть подает первое слово на слой A1, оттуда картину активации нейронов — на A2, и так далее слева направо. Каждый слой выдает предсказание h, это «зашифрованное» входное слово. Пока модель ведет себя как обычная RNN архитектуры «последовательность → последовательность». Только стрелки немного сместились.
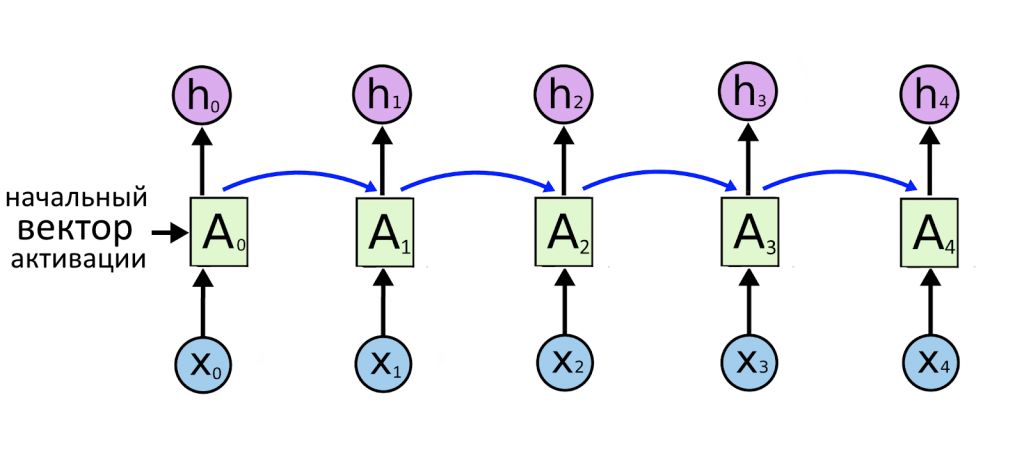
Теперь добавляем еще один слой нейронов для каждого входного слова, эти слои назовем B.
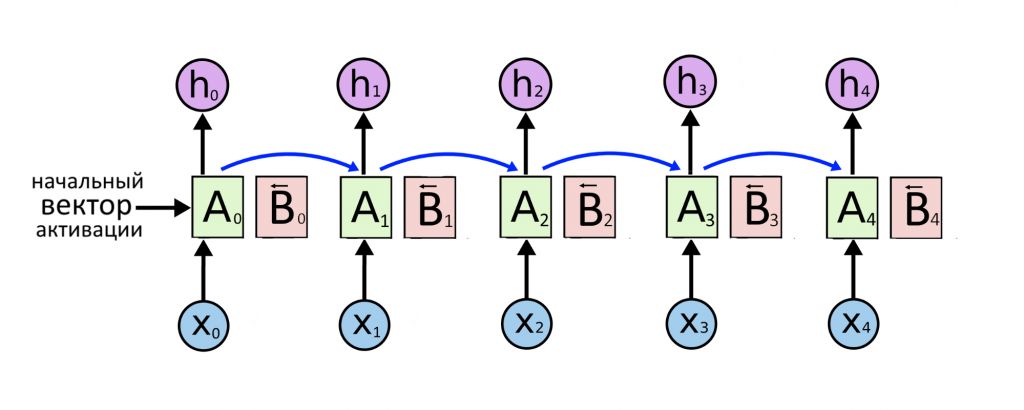
Слои B тоже выдают предсказания, но передают контекст справа налево: B4 → B3 → B2 → B1. Каждый слой B работает со своим словом: B2 получает X2, B3 получает X3. В целом — та же самая RNN, но справа налево. Ее слои начинают работу сразу, как закончит считать последний салатовый слой A (слева направо).
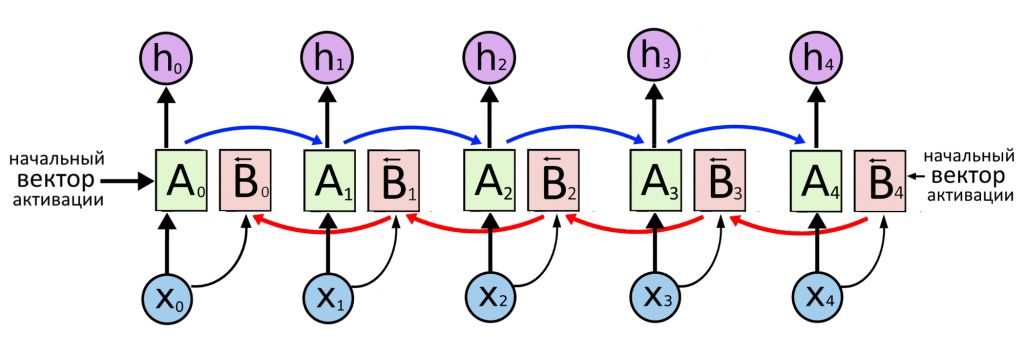
Предсказания слоев B обозначим как h(B). Выпишем каждое предсказание h и h(B) подряд и «склеим» их (конкатенируем). Результат назовем Y с нужным индексом. Вектор Y станет нейросетевой «идеей» о слове X, причем в учет этой идеи берется не только контекст до слова, но и контекст после него.
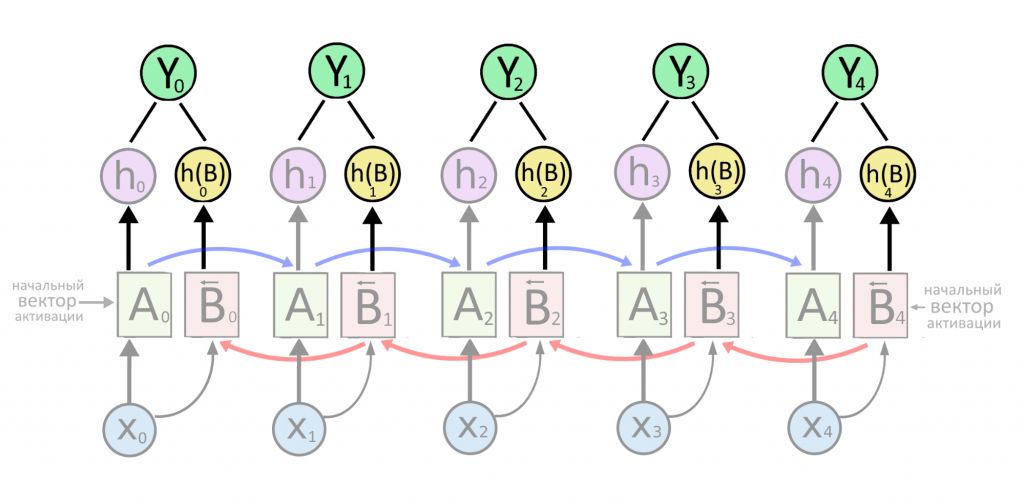
Проблем у BRNN две. Первая — на слово сильнее всего влияют ближайшие соседи (но это проблема всех рекуррентных нейросетей). Вторая — не всегда можно получить последовательность целиком. С текстом это не сложно, но если вы распознаете речь в реальном времени, придется дождаться, пока человек договорит.
И тут на сцену наконец выходит внимание.
Идея механизма внимания
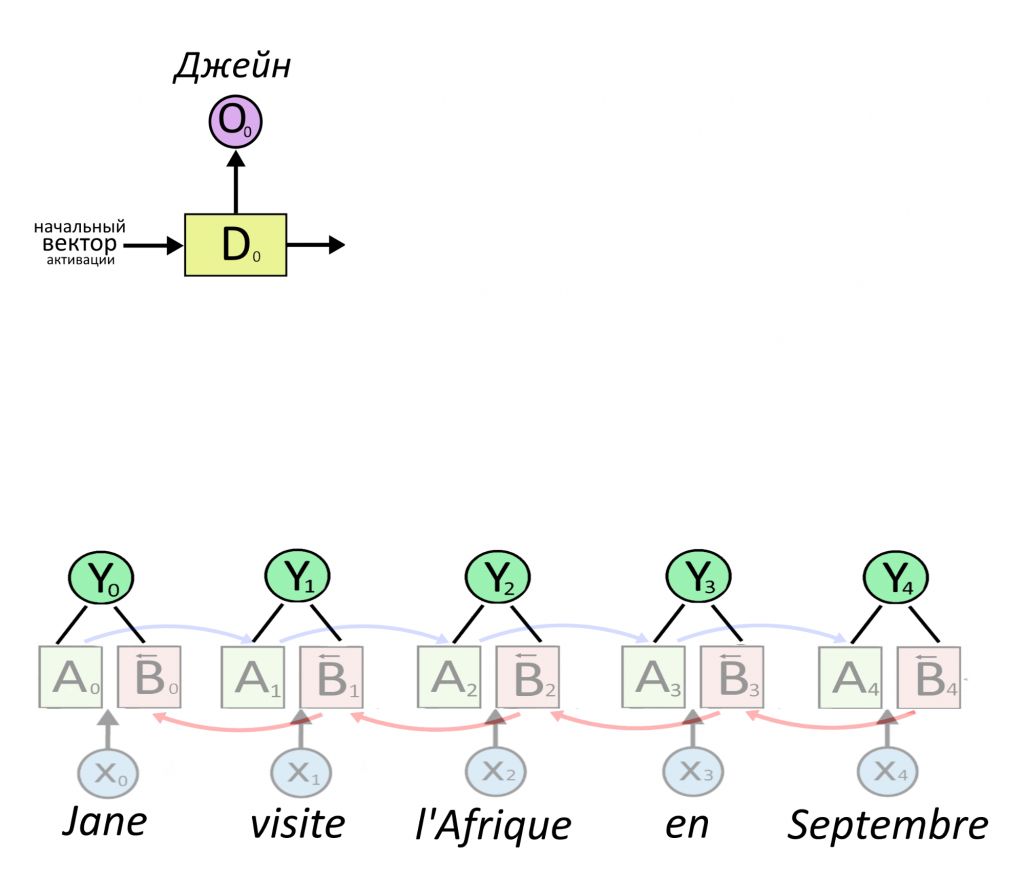
Стоит задача — перевести предложение с французского на русский при помощи модных нейросетей. Предложение — это цепочка слов, и длины цепочек в оригинале и в переводе не связаны. Значит, нужна RNN типа «энкодер-декодер». Энкодер будет двунаправленной RNN, чтобы учитывать слова не только слева, но и справа.
Энкодер зашифрует все предложение в единый вектор-контекст. Вектор-контекст — сумма векторов отдельных слов. Перед тем, как складывать слова, вектора важных слов умножим на большие числа. Таким образом мы искусственно повысим значимость важных слов на последующих шагах работы алгоритма. Это умножение — и есть механизм внимания. После кодирования декодер-RNN расшифрует вектор-контекст и сделает из него перевод. И этот перевод будет лучше, чем если бы внимания не было.
Само слово «внимание» — метафора: алгоритм заставляет нейросеть «сконцентрироваться» на отдельных элементах рабочего предложения. Так же поступает и человек: когда переводчик работает с текстом, он больше всего сосредоточен на переводе текущего слова, учитывает ближайший контекст до и после него, а если нужно, посматривает на дальние слова, сильно меняющие смысл. Всю последовательность переводчику запоминать не обязательно.
Как сделан механизм внимания в энкодере
Начнем с двунаправленной RNN. Она уже вычислила векторные представления Y для каждого слова X. Можно говорить «выучила признаки» слова. Y — это склеенные вектора активаций слоев A и B (передают контекст слева направо и справа налево).
Если убрать с картинки лишние детали, получится так
Теперь сверху появляется первый слой рекуррентного декодера D, который будет принимать на вход что-то и выдавать перевод первого слова. Перевод выдается в виде вектора O, сокращенно от output — результат. Что подавать на вход декодеру?
Декодеру можно подать представление какого-то одного слова — обычно последнего в предложении, ведь в нем собрался весь прошлый контекст. Но есть вариант круче: подадим декодеру сумму сразу всех представлений, но перед этим умножим каждое из них на свой «вес». Вес — это тоже вектор, назовем его V. Чем больше вес, тем сильнее нейросеть обращает внимание на слово.
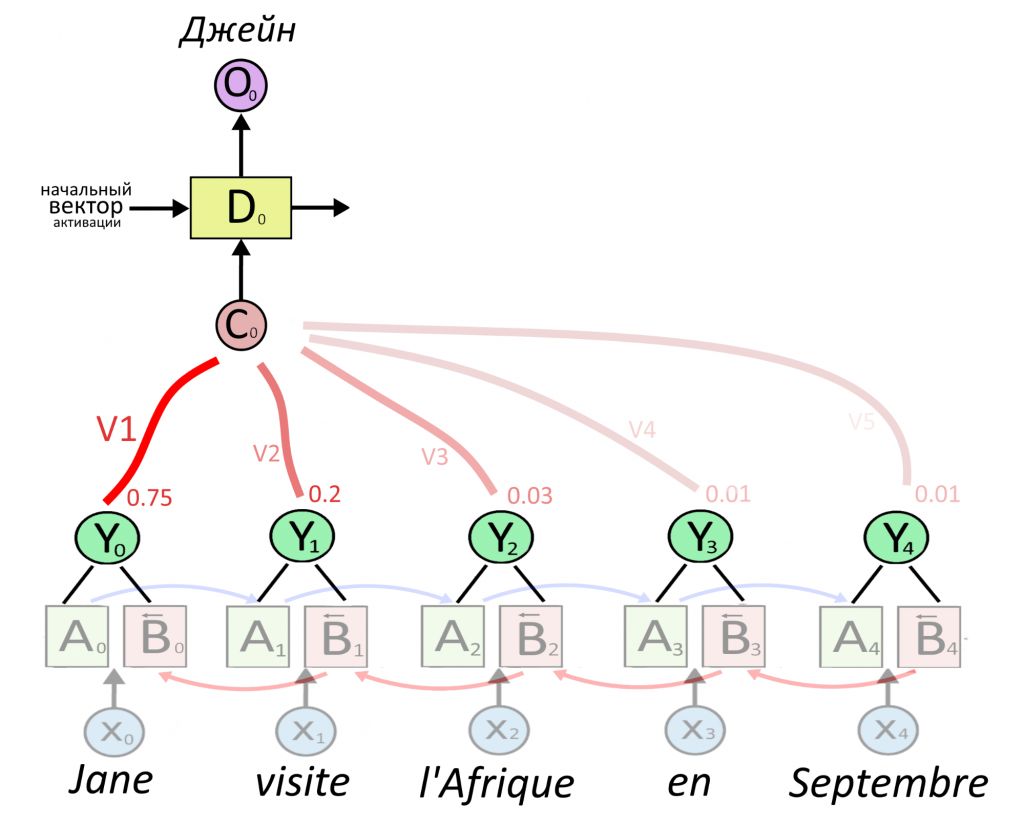
Как определить вес внимания и важность слова — ниже. Сейчас важно, что из суммы «взвешенных» (умноженных на вес) векторных представлений Y получается вектор-контекст C (от английского context). Именно вектор C, где «зашиты» не только представления каждого слова, но и степень их важности, послужит «топливом» для декодера.
Еще раз: C = V1Y1 + V2Y2 + V3Y3 + …. + VnYn.
Как сделан механизм внимания в декодере
Декодер здесь — однонаправленная RNN. Это значит, что на каждом шаге он смотрит на свою прошлую работу и на текущий вектор-контекст C, который пришел от энкодера. На первом слое декодера вектор C0 активирует какие-то нейроны, и картина их активации идет на следующий слой декодера.
На втором шаге декодирования все повторяется. Как-то (как, пока не знаем) рассчитываются новые веса внимания V для каждого слова. Взвешенная сумма векторов слов становится вектором-контекстом С1. На вход декодеру приходит его прошлая работа D0 и новый контекст C1.
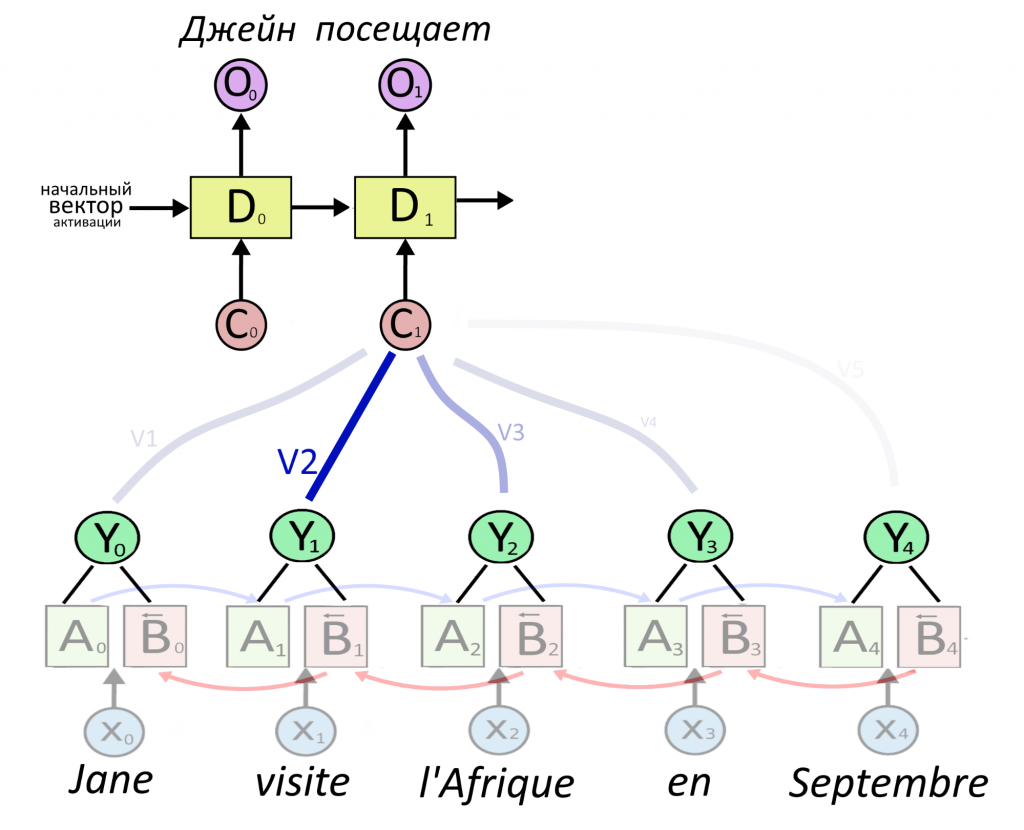
Дальше — все то же самое. Новое слово перевода получится из нового вектора-контекста и прошлой работы декодера. Так декодер будет генерировать слова одно за другим, пока не сгенерирует метку конца предложения.
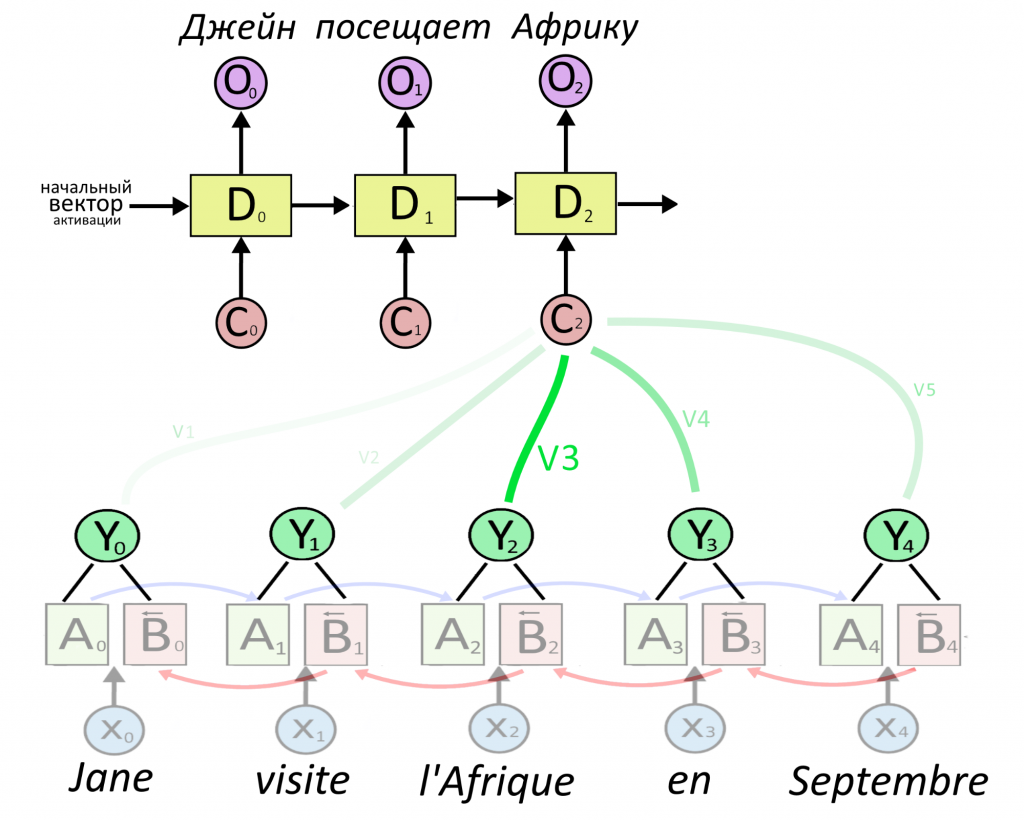
Как получить вес внимания и понять, что на самом деле важно «запомнить»?
Пускай вес предсказывает однослойная нейросеть
Важность конкретного слова зависит от реакции на него энкодера и последней активации декодера (так решили разработчики). Последняя активация декодера называется D(t-1). Нынешней активации D(t) пока нет, ее надо вычислить.
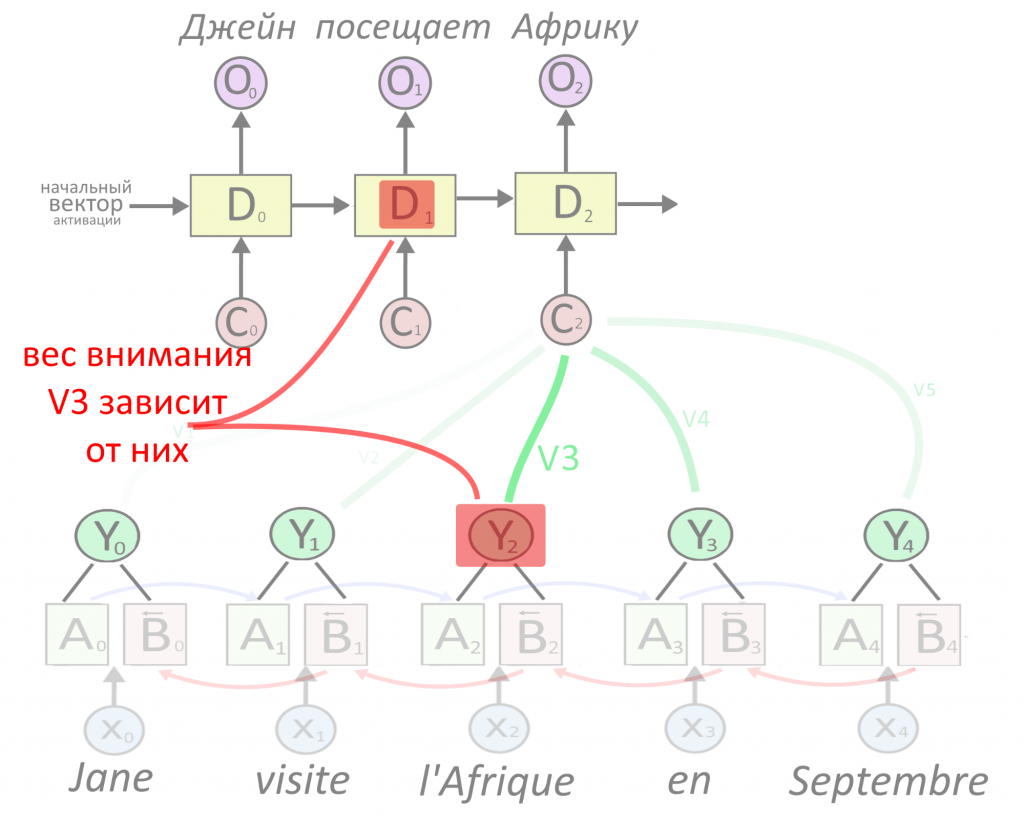
Вес внимания как-то зависит от двух переменных, но как — непонятно. Если есть зависимость — есть функция. Она принимает переменные и выдает вес внимания, и эту функцию никто точно не знает. Нейросети как раз нужны для того, чтобы моделировать неизвестные функции.
Пусть нейросеть угадывает, как из активации энкодера и декодер получить вес внимания! Но только очень маленькая, однослойная нейросеть, потому что угадывать придется много и часто.
Когда декодируется «Африка», веса внимания зависят от D1 и всех Y по очереди
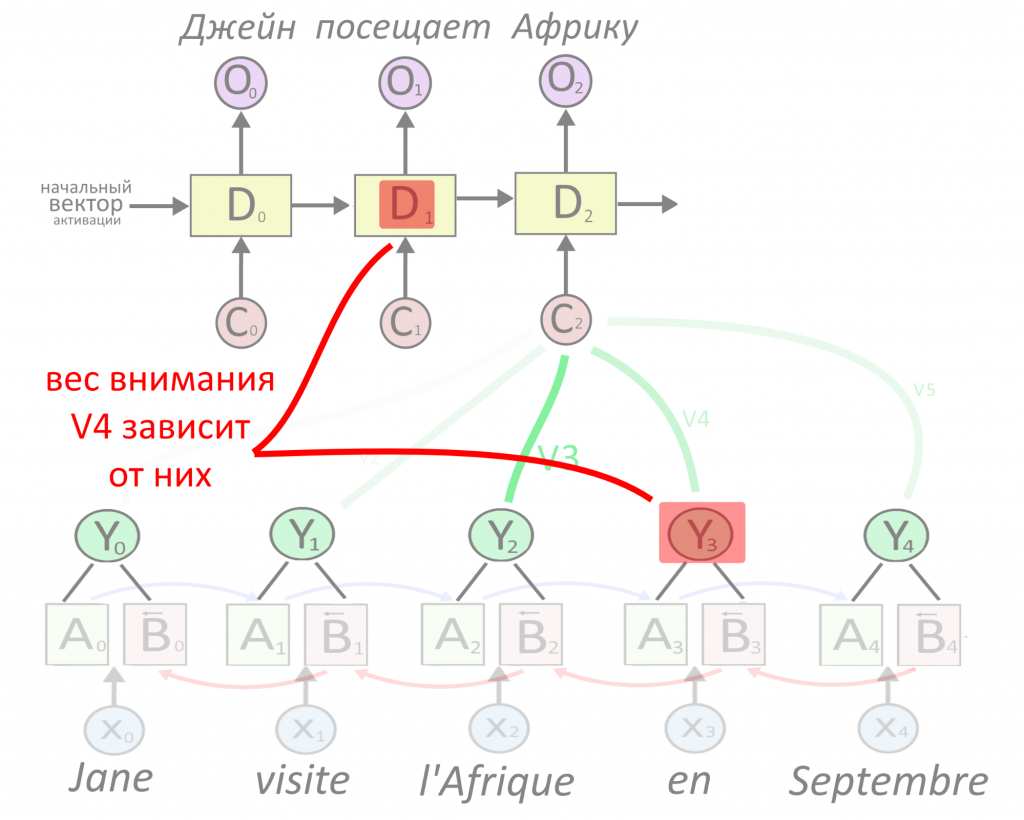
Маленькая нейросеть, о которой идет речь, — это матрица весов внимания, которая «выучивается» при обучении, плюс функция активации. То, что нейросеть «однослойная», значит, что такая матрица только одна, а то, что маленькая — значит, у матрицы буквально малая размерность.
Чтобы получить вес внимания, берем работу энкодера Y, свежую активацию декодера D(t-1), склеиваем, умножаем на матрицу. Получается вектор L. Пропускаем L через активационную функцию Softmax, получаем V, вес внимания. Сейчас расшифруем!
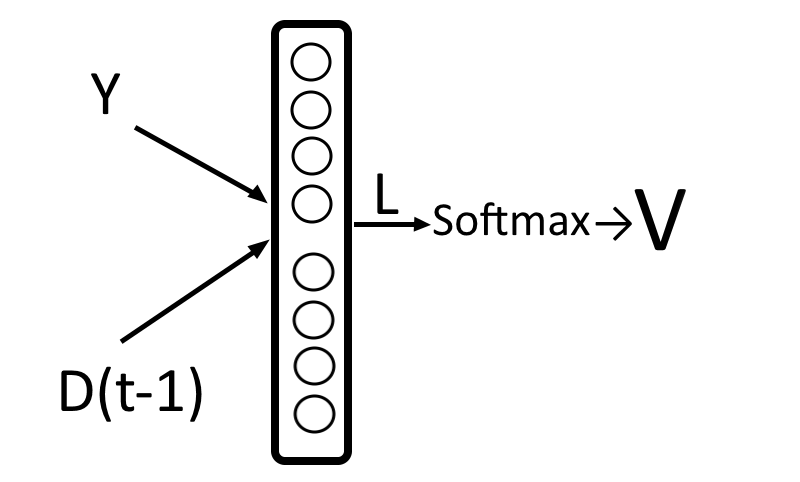
Сперва «склеиваем» вектора Y и D(t-1), эта операция называется конкатенацией. Просто записываем два вектора подряд и получаем один: [1, 2] + [3, 4] = [1, 2, 3, 4]. Теперь предсказываем L.
«Предсказать вектор L» — значит умножить входной «склеенный» вектор на матрицу весов внимания.
Предсказание пропускают через Softmax, функцию, которая превратит «сырой» вектор L, где может быть что попало, в распределение неотрицательных весов, которые в сумме дают 1.
У каждого входного слова несколько матриц внимания: по одной на каждый слой декодера. Каждую матрицу нужно выучить и где-то хранить. Поэтому авторы отмечают, что «окно внимания» их нейросети — примерно от 15 до 40 слов. Дальше становится трудно запоминать контекст. Когда нужно перевести большой текст, «окно внимания» передвигают по нему «внахлест»: так, чтобы в новое окно поместилось немного из старого. То есть в окно попадают сначала первые 40 слов, потом слова с 20 по 60-е, потом с 40 по 80, потом с 60 по 100 и т.д.
Как работает функция активации Softmax
Возводит в степень группу чисел, и каждую степень делит на сумму всех степеней
Softmax возводит натуральный логарифм e (число Эйлера) в степени всех элементов вектора. Например, дан вектор L = [929, 375, 32, 215, 657, 1464]. e^L (е в степени L) будет вектором [e^929, e^375, e^32, e^215, e^657, e^1464]. Это сделает большие числа гораздо больше и усилит разницу между ними. Все элементы вектора e^L точно положительны, так как e — положительное число, около 2,718.
Итак, первый шаг Softmax — вычислить e^L для всех элементов вектора L.
Второй шаг — поделить каждый отдельный элемент e^L на сумму всех элементов e^L. Это даст «нормализованное», то есть относительное представление каждого элемента с учетом всех остальных элементов вектора. Такое представление мы и назовем вектором V, весом внимания.
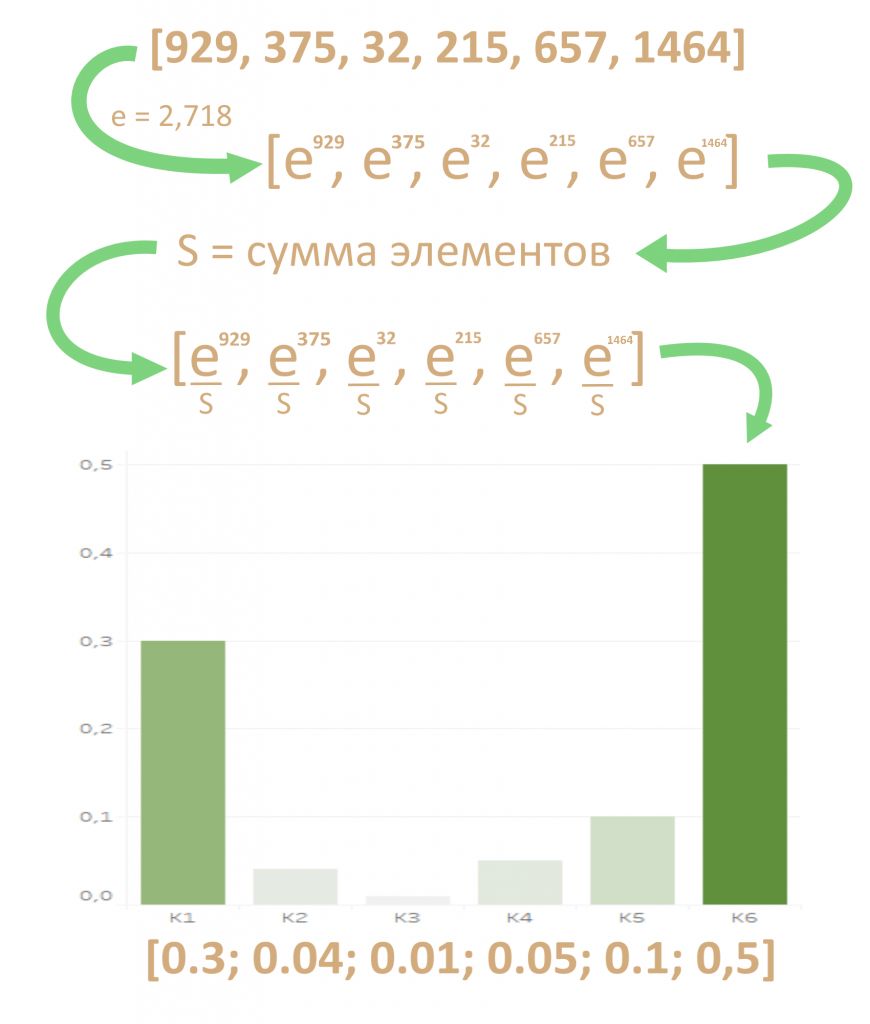
Резюме: что в сухом остатке
Выпишем самое важное, что есть в нейросети:
- вектора Y — слова, закодированные с учетом контекста слева и справа от них
- вектор D — прошлое состояние декодера
- вектор V — вес внимания, предсказан с учетом Y и D
- вектор-контекст C — сумма всех слов Y, умноженных каждое на свой вес внимания V
- вектор O — перевод следующего слова, предсказан с учетом прошлого состояния декодера D и вектора-контекста C
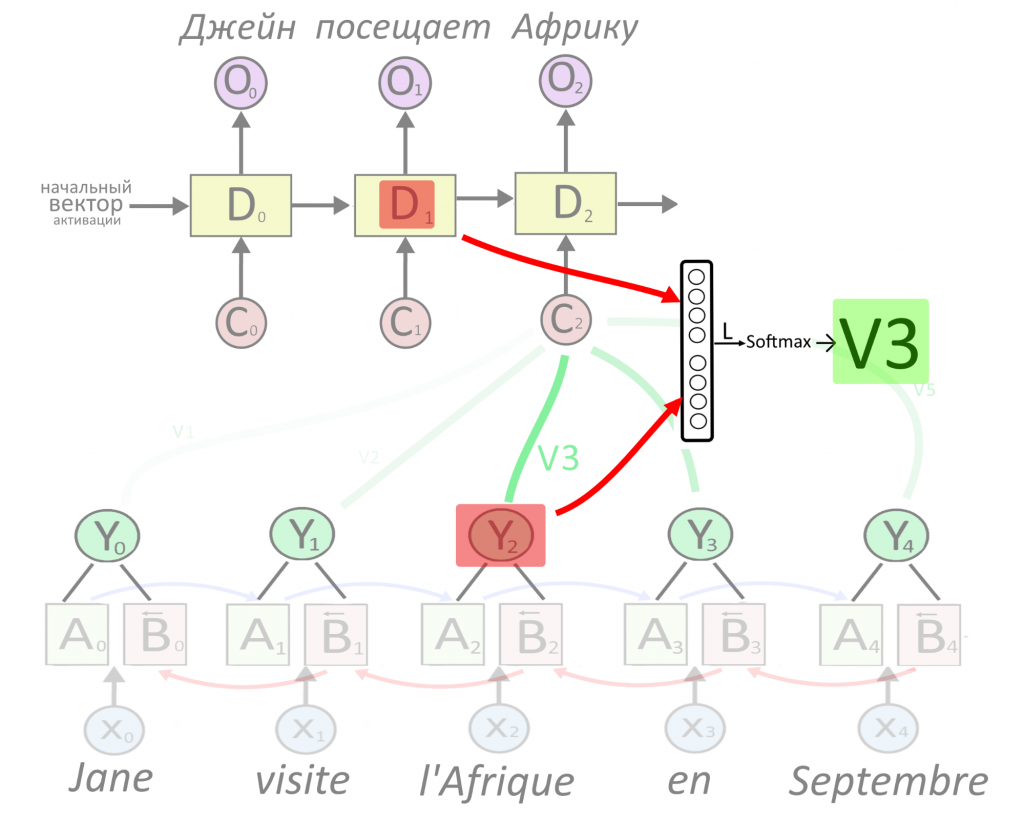
В общем, если пересказывать в двух словах, внимание нейросети — это всего лишь умножение векторов. Зато теперь вы знаете, каких именно.
Зачем это нужно
Внимание в нейросетях — очень влиятельная идея. Сейчас все самые крутые архитектуры в обработке языка, начиная с GPT-2 от OpenAI и BERT до самых современных, полагаются на механизм внимания. Внимание можно применять не только в обработке текста: если «прикрутить» механизм к сверточным нейросетям, можно визуализировать, на какие части картинки смотрела нейросеть, когда решила, что на ней изобразили собаку.
В следующих текстах «Системный Блокъ» расскажет о трансформерах — нейросетевых архитектурах, которые не передают информацию с шага на шаг, как это делают RNN, но справляются с задачами обработки последовательностей (типа машинного перевода) не хуже. Основа их работы — именно механизм внимания. Только там внимание устроено еще хитрее, чем описано выше.
Многие базовые концепции из этого текста (архитектура «энкодер-декодер», двунаправленная RNN) встретятся вам еще не раз, если вы захотите узнать больше о современных технологиях обработки языка. Например, о нейросетевых архитектурах ELMo и BERT, которые просто доминируют на современном компьютерно-лингвистическом «танцполе» ��
Оставайтесь с нами и не пропустите самое интересное из мира автоматической обработки естественного языка!
Источники
- Курс Sequence Models на Coursera от deeplearning.ai — основа данного текста
- [1409.0473] Neural Machine Translation by Jointly Learning to Align and Translate — академическая статья, где описана архитектура, использованная в качестве примера
- Пример применения CNN-энкодера с механизмом внимания (Computerphile)
- Механизм внимания в картинках
Свёрточные нейронные сети — надежда и опора генеративного ИИ
![]()
Искусственный интеллект корректнее было бы называть искусственной интуицией: машина ведь не мыслит в человеческом понимании этого термина — она буквально по наитию ставит в соответствие набору входных параметров определённый результат. Другое дело, что наитие это вполне поддаётся математическому описанию
⇣ Содержание
- Отбрасывая несущественное
- Только не в трубочку!
- Что здесь?
Согласно определению из «Философского словаря», интеллект есть способность мыслить, т. е. совокупность тех умственных функций — включая сравнение, порождение абстракций, формирование понятий, суждений, умозаключений и проч., — что превращают восприятие (иными словами, неизбирательную фиксацию потока входящей информации) в знание (обладающее потенциалом практического действия структурированное понимание подноготной объекта, процесса, явления). В этом смысле генеративный ИИ — да и в целом модели машинного обучения — никаким интеллектом, ясное дело, не обладает. Наученная распознавать изображения кошечек с точностью 99,999% машина не способна сформулировать, что есть «кошечка» в её представлении, т. е. свести выработанные ею критерии этого самого распознавания к виду, заведомо постижимому биологическим оператором. А значит, прямого знания она ему не передаст, — лишь продемонстрирует результат работы своей интуиции.
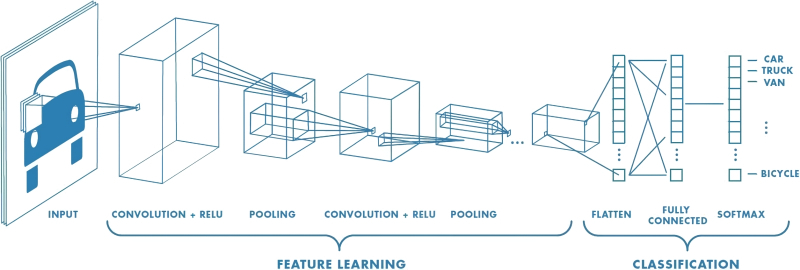
Общая схема работы нейросети, распознающей (классифицирующей) объекты на изображениях: feature learning — участок со свёрточными подсетями (источник: Saturn Cloud)
Зато интуиция, согласно тому же словарю, — это переживание или вдохновенное постижение, приобретённое непосредственно. То бишь реализованное не путём интроспективного размышления (рефлексии), без которого непредставима работа интеллекта, а через подспудное, неосознаваемое в явном виде, неинтерпретируемое ухватывание (кто сказал: «Извлечение из латентного пространства»?) некой сути. Вот же она, корректная расшифровка второй литеры в акрониме «ИИ», — «интуиция»! Хорошо натренированная система просто берёт и ставит в соответствие одной оцифрованной сущности другую. Запросу «напиши за меня курсовую» — адекватно отвечающий определению «курсовой» убедительно складный текст; подсказке «заброшенный замок на мрачной скале» — проникнутую ожидаемым настроением картинку и т. д. Притом ни чуточки не рефлексируя в процессе выдачи над тем, в какой мере соответствуют действительности сделанные в тексте выводы или к какой исторической эпохе либо фэнтезийной вселенной могла бы относиться (если это не указано явно в подсказке) воспроизводимая в изображении структура. Интуиция в чистом виде.
Роднит с человеческой интуицией (да и с животной, кстати, тоже — в отличие от развитого интеллекта это вовсе не видовая особенность Homo sapiens) работу генеративного ИИ и сам принцип действия цифровой нейросети. По многослойной плотной связке искусственных нейронов (перцептронов) проходят сигналы, формируя не поддающиеся адекватной интерпретации человеком промежуточные результаты, — но в итоге получается текст, или картинка, или иная выдача, вполне доступная для постижения тем же самым человеком. Более того, в ряде случаев ИИ справляется с задачами распознавания определённых объектов (на снимках из космоса, например) лучше занимавшихся этим годами живых операторов — просто потому, что не подвержен усталости, минутной рассеянности и иным влияющим на человека факторам. Ключевую же роль в процессе формирования искусственной интуиции — выявления в наборе входных данных закономерностей, не поддающихся чёткой фиксации, зато прекрасно работающих, — играют свёрточные нейронные сети.
⇡#Отбрасывая несущественное
В первом приближении устройство и принцип действия компьютерных нейросетей мы уже описывали: будем надеяться, представление о перцептроне и о многослойной плотной нейронной сети унитарной размерности (с одним и тем же числом перцептронов в каждом слое) у внимательного и памятливого читателя уже имеется. И оно придётся, именно как основа, весьма кстати для понимания того, о чём мы собираемся говорить далее, — поскольку свёрточная нейронная сеть (convolutional neural network, CNN) отличается переменной размерностью: не все её слои равновелики. Именно за счёт этого она способна, как станет вскоре понятно, более эффективно — в сравнении с унитарной — решать поставленные перед нею практические задачи. Чаще всего — распознавание образов на статичных изображениях и видео, а также обработку определённых данных внутри более крупных генеративных моделей машинного обучения.
Различные слои и клетки коры головного мозга (источник: Kenhub)
Откуда вообще взялась идея усложнить конструкцию нейросети, дифференцировав различные её слои? Начнём с того, что такая эталонная природная нейросетевая структура, как кора головного мозга человека, существенным образом неоднородна. Даже не говоря уже о том, что в ней выделяются зоны, выполняющие различные задачи (распознавание речи, восприятие тактильных ощущений и т. п.), сама кора в целом многослойна, причём различные участки её слоёв устроены по-разному и содержат разные же — и по габаритам, и по числу образуемых связей — нервные клетки. Более того: даже в пределах одного уровня одного и того же слоя активность разных нейронов может значительным образом различаться.
В частности, зрительная кора, благодаря которой в сознании формируется визуальная картина окружающего мира, составлена из весьма неоднородных клеток. У каждого из зрительных нейронов имеется своё рецептивное поле — участок с рецепторами, реагирующими на те или иные стимулы. Например, для ганглиозной клетки сетчатки глаза рецепторами служат знакомые по школьному курсу физиологии человека палочки и колбочки — клетки, реагирующие на силу воспринимаемого света и/или его спектральный состав. В свою очередь, определённая совокупность ганглиозных клеток работает в качестве рецептивного поля для нейрона, расположенного уже в зрительной коре головного мозга — в затылочной его части, довольно далеко от сетчатки. И критерии срабатывания этих нейронов довольно избирательны: к примеру, часть нейронов в зрительной зоне V1 возбуждается исключительно в ответ на появление в поле зрения вертикальных структур (сплошных линий — либо выстроенных по вертикали точек, штрихов и т. п.), а другая часть — только горизонтальных.
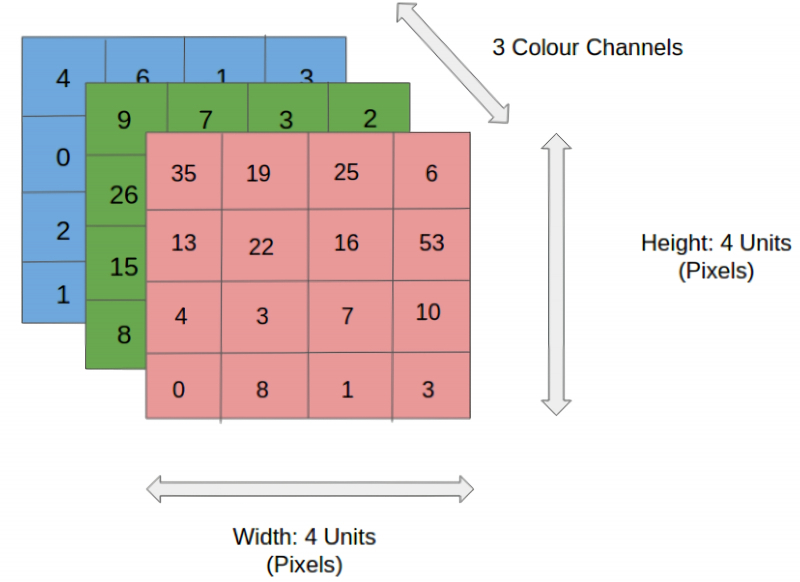
Кодирование цветного изображения 4 × 4 × 3 — с разбиением на квадрат 4х4 пискела и заданием трёх каналов цветности (источник: Saturn Cloud)
Помимо очевидного соображения «раз эволюция выбирает для обработки визуальных данных нейросети с понижением размерности в последующих слоях, это может оказаться наиболее эффективно», для предпочтения CNN машинным сетям унитарной размерности есть и другое обоснование, не менее убедительное: технико-экономическое. Допустим, некая квадратная цветная картинка в первом грубом приближении может быть закодирована всего 16 пикселами, — в сетке 4 × 4 (схожую задачу, только в обратную сторону, решают системы преобразования текстовых подсказок в изображения, вроде рассматривавшейся нами ранее Stable Diffusion: они мозаику из разноцветных крупных пятен преобразуют, постепенно добавляя в нужных местах нужного «шума», в идентифицируемое человеком изображение). Кстати, не стоит забывать, что для сохранения информации о цвете потребуется сформировать уже три матрицы 4 × 4 — для красного, зелёного и синего каналов. Таким образом, запись данных даже о столь грубо закодированной картинке будет представлена не 16, а 48 числами (кодировка 4 × 4 × 3, где первые два значения соответствуют размерности изображения, а последнее указывает на число цветовых каналов: если выбрать кодировку CMYK, последних станет уже 4).
Да, технически совсем не сложно преобразовать эти 48 чисел из матричного формата в векторный (из нескольких таблиц — в единый столбец) и подать получившуюся последовательность данных на вход унитарной полносвязной нейросети с обратным распространением ошибок — пусть выискивает там закономерности. Но с ростом габаритов исходной картинки задача становится всё менее подъёмной. Для кодирования обоев «Рабочего стола» в Full HD понадобится 1920 × 1080 × 3 ≈ 6,22 млн чисел — вот почему, кстати, формат BMP (картинки в котором примерно схожим неэкономным образом и сохранялись) к настоящему времени практически вышел из употребления: слишком уж непрактично тяжёлыми становятся представленные в таком виде файлы. Понятно теперь, что и нейросеть для обработки изображений в высоком разрешении — будь то классификация объектов на них или же, напротив, создание картинок по текстовым подсказкам — нуждается в понижении размерности; из соображений хотя бы разумной достаточности затрачиваемых на её функционирование вычислительных мощностей. Но каким именно образом производить это понижение?
⇡#Только не в трубочку!
Собственно, «свёрточная» в названии CNN как раз и указывает на способ, применяемый для понижения размерности слоёв нейросети и именуемый попросту свёрткой. Интуитивно ясно, что «свернуть» в приложении к данным значит не просто «сократить» (тогда логичнее было бы сказать «обрезать» или «округлить»), а «компактифицировать с сохранением наиболее важной информации». И вот каким образом это делают CNN.
Последовательное применение операции свёртки к одному из слоёв исходного оцифрованного изображения (источник: Saturn Cloud)
Пусть имеется исходная матрица значений — допустим, пикселы какого-то изображения — высокой размерности. В нашем примере — 5 × 5 (точнее, 5 × 5 × 1, — не будем забывать, что каждой позиции может соответствовать не просто число, но вектор, кодирующий некую дополнительную информацию). Для операции свёртки применяется так называемое ядро или фильтр (kernel/filter) — небольшая матрица весов, представленных обычно целыми числами. Точно так же, как веса на входах перцептронов, составляющие ядро весовые компоненты могут (и должны, в общем случае!) корректироваться в процессе работы нейросети методом обратного распространения ошибки, но пока для определённости примем, что ядро — фиксированная матрица 3 × 3 следующего вида:
Собственно свёртка заключается в:
- наложении ядра последовательно на исходную матрицу, начиная с верхнего левого угла,
- перемножении чисел в соответствующих ячейках, суммировании полученных результатов —
- и записи суммы в ячейку выходной матрицы, которая будет уже обладать заведомо меньшей размерностью, чем изначальная.
Квадрат 3 × 3 допускает перемещение по матрице 5 × 5 со сдвигом на одну позицию (без выхода за её пределы) ровно три раза и по горизонтали, и по вертикали — потому в рассматриваемом примере выходная матрица будет иметь размерность 3 × 3. Если бы при том же ядре (3 × 3) исходная матрица была 7 × 7, выходная получила бы уже размерность 5 × 5.
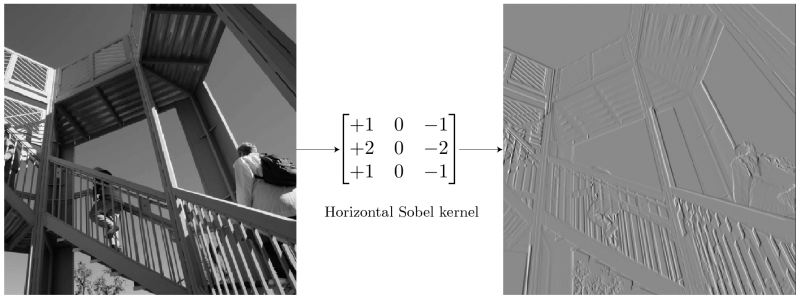
Классический фильтр Собеля производит свёртку исходного изображения по одному из измерений, явственно выделяя края вытянутых в этом же измерении структур (источник: TowardsDataScience)
Сегодня практически у каждого под рукой, а именно в предустановленном почти на любой смартфон простеньком фоторедакторе, имеется аналоговый свёрточный фильтр Собеля — средство для усиления границ объектов на изображении. В частности, горизонтальный фильтр Собеля представляет собой матрицу
при умножении исходного изображения (в оцифрованном виде, конечно) на которую пропадают малоконтрастные детали, а резкие границы ещё более усиливаются. Причина в том, что в ходе такой операции соседние пикселы — ячейки исходной матрицы — с примерно равными величинами (в данном случае яркости) после свёртки с матрицей-фильтром дают на выходе близкие к нулю значения, а если соседние значения в ячейках сильно разнились, то в результате эта разница окажется существенно усиленной.
Собственно, в этом и состоит цель свёртки: не просто понизить размерность изначальной матрицы в целях снижения вычислительной нагрузки на аппаратную часть системы, — но выявить в исходном массиве данных некие закономерности, причём в различных каналах (т. е. на каждом этапе свёртка производится не с одним, а с несколькими фильтрами, и далее эти потоки данных — каналы — обрабатываются раздельно). Очередная операция свёртки преобразует входной массив данных в очищенный линейный блок (rectified linear unit, ReLU), что представляет собой карту усиленных (за счёт отбрасывания всего малозначимого; отсюда термин «очищенный») отличительных особенностей этого массива, в которой с каждой итерацией всё более и более явно проступают нелинейные связи между её компонентами.
Если исходное изображение оцифровано трёхканальной матрицей M × N × 3, для корректной свёртки могут потребоваться разные фильтры для каждого из цветокодирующих каналов (источник: Saturn Cloud)
Однако не следует забывать, что интерпретировать сколько-нибудь явным (постижимым для человеческого сознания) образом результаты свёртки имеет смысл лишь в том случае, когда эта операция применяется к самой первой матрице данных — в рассматриваемом примере к оцифрованному и разбитому на пикселы изображению. Современные же нейросети существенно многослойны, и, когда операция свёртки выполняется для одного из глубинных (скрытых) слоёв модели, да ещё и с применением фильтра со скорректированными в процессе обратного распространения ошибки весами, уже по сути невозможно зафиксировать смысловое наполнение получаемых в итоге этой операции величин. На этом, собственно, и основано предложение сопоставлять работу ИИ с интуицией и наитием, а не со строго логичными операциями естественного интеллекта.
Помимо свёртки с понижением размерности и единичным сдвигом фильтра по исходной матрице применяются и другие операции, такие как сдвиг с перескоком ядра на 2 ячейки (в этом случае может потребоваться дополнение исходной матрицы строками и/или столбцами с нулевыми значениями, чтобы соблюсти размерность) и даже «раздувание» — своего рода обратная свёртка, на выходе которой получается матрица большей размерности. Свёрточная арифметика — существенно важная для области глубокого машинного обучения дисциплина, но углубляться в неё в рамках обзорной статьи было бы излишним.
Если исходное изображение оцифровано трёхканальной матрицей M × N × 3, для корректной свёртки могут потребоваться разные фильтры для каждого из цветокодирующих каналов (источник: Saturn Cloud)
Поскольку сами свёрточные слои располагаются один за другим последовательно (переложенные слоями группировки, речь о которых пойдёт чуть ниже), это позволяет выявлять в исходном массиве данных скрытые закономерности всё более высокого уровня — от обнаружения пары горизонтальных и пары вертикальных отрезков переходить к отождествлению изображённого на картинке квадрата, например. Грубо говоря, схожий принцип лежит в основе процесса устойчивого размывания (stable diffusion), благодаря которому нейросеть сперва обучают ставить в соответствие термину «квадрат» (точнее, кодирующему его набору токенов) вполне определённые веса на свёрточных матрицах, а затем инвертируют процесс — так что из исходной мешанины разноцветных пятен по соответствующей подсказке за несколько итераций проступает вполне геометрически правильная фигура.
После свёртки отдельные слои в ИИ-модели подвергаются несколько иной, хотя во многом и схожей операции — объединению, или группировке (pooling). Вместо того чтобы — как в случае свёртки — поэлементно перемножать фрагмент исходной матрицы на весовые коэффициенты фильтра и затем суммировать полученное, при группировке производится вычисление некой статистической функции для фрагмента исходной матрицы, покрытого фильтром-ядром. Эта функция чаще всего оказывается простым «максимальным значением»: если выборка 3 × 3 выделила такой вот фрагмент матрицы —
— то «максимальным значением» для взятых таким образом элементов в данном случае окажется «3» (а если бы хотя бы в одной ячейке оказалась четвёрка — тогда было бы «4»). Можно применять и более ресурсоёмкую функцию — вычисление среднего. Суть процедуры группировки заключается, во-первых, в понижении размерности матрицы (что опять-таки облегчает нагрузку на аппаратную часть ИИ-системы), а во-вторых — в более эффективном, чем у свёртки, выявлении инвариантных признаков представленного исходной матрицей объекта. Грубо говоря, если прямоугольное окно показано на оцифрованной картинке в перспективе, да ещё и снято под углом (dutch angle shot), для отождествления такого объекта нейросетью именно как окна одних свёрточных слоёв потребуется в общем случае больше, чем если комбинировать их с группировочными. Объединение в целом оптимизировано для обнаружения обобщённых и высокоуровневых признаков, не сводимых к простым геометрическим закономерностям, — с последним как раз лучше справляется свёртка.
Операция группировки с выборкой максимального значения в каждом из фрагментов исходной матрицы, покрываемом на очередном шаге фильтром (источник: Saturn Cloud)
Обыкновенно в системах машинного обучения, ориентированных на распознавание образов, свёрточные и группировочные слои в каждом канале располагаются парами, причём число таких пар может быть весьма велико. В результате на каждом уровне обработки исходной матрицы (разбитого на пикселы изображения) исходная картинка порождает абстракции всё более высокого уровня, отбрасывая несущественные детали — включая шум, незначительные цветовые градиенты и даже частичное затенение/перекрытие. Скажем, античная колонна, видимая сквозь ветви деревьев, будет в итоге классифицирована благодаря свёрткам — и в особенности группировкам — именно как единый цельный объект заднего плана. Однако чтобы разглядеть «образ античной колонны» в ячейках соответствующей матрицы в глубине свёрточной нейросети, представленный в виде целого ряда заполненных числами таблиц, любопытствующему энтузиасту понадобятся сверхспособности — вроде тех, которыми обладали «натуральные» (рождённые вне Матрицы) операторы из культовой киносаги братьев Вачовски.
⇡#Что здесь?
В приведённом примере с нейросетью, ориентированной на распознавание визуальных образов, структура самой этой сети разделена на два крупных блока: «выявление особенностей» (feature learning) и собственно «категоризация» (classification). Причём если над выявлением особенностей трудится многослойная подсеть из пар свёрточных и группировочных слоёв, то классификацией занимается тоже многослойная, но уже унитарная полносвязная подсеть, в которой каждый слой образован одним и тем же числом перцептронов. «Полносвязная» в данном случае означает, что выходы каждого из перцептронов предыдущего слоя передают сигналы на входы каждого из искусственных нейронов последующего.
Принципиальная схема CNN, применяемой для распознавания рукописных цифр: после двукратного повторения операций свёртки и выборки во множестве каналов выдача «уплощается» из матрицы в вектор и передаётся на вход полносвязной плотной нейросети (источник: Saturn Cloud)
Строго говоря, такая полносвязная сеть и сама в состоянии заниматься уверенным распознаванием образов, — в предыдущем материале на эту тему мы для примера рассматривали устройство именно такой сети с обратным распространением ошибок, занятой идентификацией рукописной тройки. Другое дело, что для крупных, высокодетализированных изображений распознавание через полносвязную унитарную сеть обойдётся слишком дорого — и по времени, и по затраченным аппаратным ресурсам, и по расходу электроэнергии. Блок выявления особенностей, производящий раз за разом операции свёртки и группировки, нужен именно для того, чтобы самым существенным образом понизить размерность исходного массива данных, сохранив притом всю содержавшуюся в нём ключевую информацию (в закодированном, многократно преобразованном виде, конечно).
И вот уже этот высокорафинированный (многократно ректифицированный, если вспомнить о ReLU) набор данных подаётся на вход полносвязной нейросети, отлично справляющейся с задачей классификации по существенно разнородным признакам, — как и было продемонстрировано нами ранее. Причём здесь не имеет значения, каких размеров был исходный массив: полносвязная нейросеть в любом случае будет работать с одномерным и сравнительно недлинным вектором данных. Получается он крайне незамысловато: допустим, исходное изображение обрабатывалось в блоке выявления особенностей по 50 каналам, каждый из которых на выходе серии операций свёртки и группировки выдал по одной матрице 3 × 3. Эти матрицы преобразуются в векторы (первая ячейка в первой строке становится первым элементов вектора, последняя — третьим, первая во второй строке — четвёртым и т. д.), а затем векторы точно так же прямолинейно выстраиваются в один общий — размерностью в данном случае 450 × 1. Дальнейший процесс классификации на полносвязной нейросети с обратным распространением ошибок должен уже быть в общих чертах знаком нашим читателям.
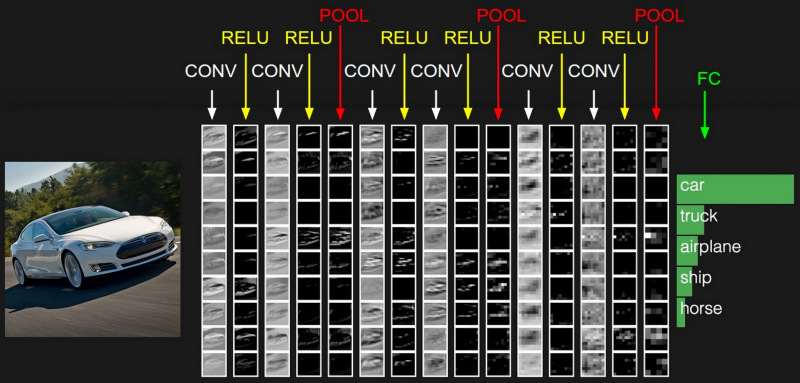
Попытка постичь, какие именно закономерности выявляет нейросеть в исходной картинке, за счёт визуализации (превращения матриц в изображения по пикселам) на каждом шаге работы CNN: свёртка (CONV), очистка (RELU), группировка (POOL) — и на выходе классификация полносвязной (fully connected, FC) подсетью (источник: Stanford University)
Свёрточные сети в течение многих лет исправно служили делу машинного зрения, поскольку ранее для выявления важнейших особенностей изображений применялись статичные инструменты, вроде упомянутого ранее фильтра Собеля. CNN же с обратным распространением ошибок для тонкой настройки фильтров в процессе обучения дали возможность, в частности, автоматизировать выявление определённых объектов на фото/видео, — причём делать это на сравнительно скромной аппаратной базе, включая интегрированные чипы не самых дорогостоящих веб-камер. Однако в последнее время у них появилось ещё более впечатляющее (по крайней мере, для заметной части интернет-аудитории) приложение: работа в составе генеративно-состязательных сетей (generative adversarial networks, GAN). Тех самых, что после обучения на обширном массиве аннотированных визуальных данных становятся способны сами создавать изображения объектов реального либо фантастического мира — с человеческой точки зрения вполне достоверные. Ну или абстрактные/сюрреалистичные, но ровно в той степени, в какой этого ожидает составивший соответствующую текстовую подсказку оператор.
Наиболее общим образом генеративное моделирование — кстати, не так уж и важно, чего именно: изображений, видеоряда, звуков или текстов — определяется как результат автоматизированного (т. е. реализуемого в ходе машинного обучения в отсутствие учителя, unsupervised learning) выявления неких закономерностей в большом массиве входных данных с последующим применением полученной модели для порождения настолько правдоподобных с точки зрения человека-оператора объектов аналогичной природы, что они могли бы быть включены им в исходный массив тренировочной информации. Звучит несколько уроборосно, но по сути так оно и есть: цель генеративного моделирования — машинное порождение таких сущностей (для определённости — картинок), которые, на взгляд человека, оказались бы неотличимы от созданных другими людьми.
Действительно, генеративный ИИ, однажды натренированный с получением фиксированной модели (определённого набора весов на входах всех своих перцептронов, — того, что в ИИ-рисовании принято называть чекпойнтом), прекрасно справляется с самостоятельным — в отсутствие дополнительного стороннего надзора — рисованием картинок по текстовым подсказкам: в этом читатели соответствующих «Мастерских» могли убедиться на собственном опыте. Но вот чтобы такой чекпойнт натренировать, необходимо уже обучение с учителем (supervised learning) в рамках упомянутой чуть выше генеративно-состязательной сети. Оно подразумевает деятельную совместную — да вдобавок ещё и состязательную! — работу двух ИИ-моделей, выступающих соответственно в ролях творца (generator) и критика (discriminator).
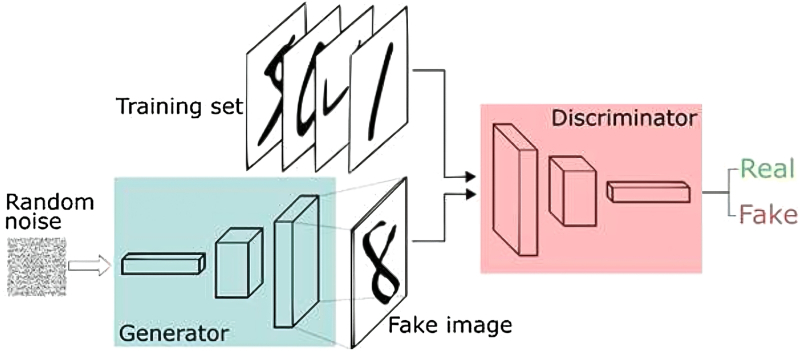
Структура типичной GAN: на вход предварительно натренированного генератора подаётся белый шум, на основе которого создаётся «поддельный» (не входивший в тренировочный набор данных) образ, — а дискриминатор, анализируя тот же исходный набор (но не прямым перебором, а тоже как нейросеть), решает, фейковую ему предложили картинку или нет (источник: Journal of Real-Time Image Processing)
Генератор натренировывается на создание новых образов на основе переработки исходного массива данных; дискриминатор же пытается распознать, принадлежит очередное полученное генератором изображение к обучающему пулу — или разительно отличается от него. Окончанием обучения обычно считается момент, когда критик начинает принимать за априори входящие в исходный массив картинки более половины из тех, что создаёт творец. То бишь в данном случае «обучение с учителем» подразумевает участие не живого оператора, а ещё одной ИИ-модели, задача которой — проверять, успешен ли генератор в создании обманчиво правдоподобных изображений. Или синтезированных под человеческий голос фраз, или притворяющихся авторскими текстов, — словом, всего, что поддаётся оцифровке для формирования первичного (тренировочного) пула данных. Важно, что обе модели в составе GAN обучаются одновременно: как генератор со временем становится успешнее в создании походящих на исходные сущностей, так и дискриминатор — в выявлении недостоверных.
Так вот, одним из наиболее распространённых подходов при построении GAN стала архитектура глубоких свёрточных генеративно-состязательных сетей (deep convolutional generative adversarial networks, DCGAN). Достоинство её в том, что DCGAN ощутимо снижает вероятность обрушения режима (коллапса режима, mode collapse) в ситуации, когда разброс вариативности выдач генератора оказывается значительно ýже, чем широта исходного набора данных по некоторому параметру. Это своего рода аналог перетренировки перцептронной модели, о которой шла речь в одном из прежних наших материалов: если в ответ на текстовую подсказку «собака» чекпойнт, которому добросовестно скармливали в процессе обучения множество изображений самых разных пород, с вероятностью 0,6 рисует шарпеев, а с вероятностью 0,4 — колли, это прямое свидетельство обрушения режима. Загвоздка здесь в том, что, поскольку тренировка генератора производится в отсутствие человеческого присмотра, а машина на данном этапе технологической эволюции всё-таки не мыслит, mode collapse автоматически крайне сложно отловить: дискриминатор ведь исправно подтверждает, что получаемые им для проверки изображения шарпеев и колли вполне адекватны имеющимся в тренировочной базе.
Архитектура генератора DCGAN напоминает запущенную в обратную сторону CNN для распознавания образов (источник: GeeksForGeeks)
Суть архитектуры DCGAN заключается в том, что на вход дискриминатора образцы для контроля подаются не поодиночке, а небольшими группами, а структура этой нейронной сети организована таким образом, что на каждом шаге свёртки размерность обрабатываемых матриц увеличивается, а число каналов параллельной обработки сокращается. В целом дизайн дискриминатора напоминает устройство самой обычной свёрточной нейросети — с рядом специфических особенностей вроде того, что шаг сдвига фильтра (convolutional stride) вместо типичной для сетей распознавания образов единицы обычно принимается равным двум, что позволяет эффективнее отбрасывать незначительные детали и выявлять более общие закономерности в исследуемом изображении.
Работа нейронной сети, порождающей некие воспринимаемые человеком сущности, в первом приближении сводится к двум операциям — кодированию и декодированию; сжатию информации и развёртыванию полученной компактной формы до итогового изображения, текста, набора звуков и пр. Но, в отличие от алгоритмической архивации (когда исходный массив данных без потерь информации уменьшается в объёме, а затем восстанавливается), в процессе отсечения нейросетью всего лишнего порождается латентное (скрытое) пространство сущностей, в котором сохраняется лишь наиболее существенная информация — и полностью игнорируется любой шум.

Затравочное изображение, проходя через генеративную ИИзобразительную нейросеть, постепенно словно бы освобождается от излишнего шума — в соответствии с текстовым описанием (источник: ИИ-генерация на основе модели SDXL 1.0)
Сохраняется, например, понятие о «собаке в общем» — точнее, интуитивное понимание сути этого термина, сформированное у модели в процессе обучения, — а в конкретное изображение пса той или иной породы в том или ином ракурсе и антураже оно преобразуется уже псевдослучайным образом в процессе декодирования — восстановления с применением, в частности, свёрточной нейросети.
Так что если бы не эти сети — кто знает, могли бы мы сегодня с такой же лёгкостью извлекать из латентного пространства всё то, чему имеем возможность удивляться, радоваться и даже чем можем возмущаться сейчас?