Пережевывая Матрицу Несоответствий — Confusion Matrix
Матрица Несоответствий довольно широко освещённый термин в науке о данных, про него без труда можно найти публикации в сети. В данной статье дано как само описание и принципы построения Матрицы Несоответствий (другие названия — Confusion matrix или Матрица Ошибок), так и основанные на этом понятии принципы работы различных метрик в задачах классификации в Машинном обучении. Несмотря на то, что само понятие Confusion Matrix является довольно простым в объяснении, начинающим Data Scientist-специалистам бывает порой нелегко разобраться в отношениях True Positive (TP), False Positive (FP), True Negative (TN), False Negative (FN) — кирпичиками, составляющими данную матрицу. Цель этой статьи познакомить читателя с альтернативным представлением Матрицы Ошибок. Данный способ, по мнению автора, является наиболее наивным методом восприятия самой Матрицы Несоответствий, что в свою очередь позволит легко ориентироваться в выводах, основанных на комбинации ее элементов, глубже понять проблему дисбаланса классов в задачах классификации.
План данной статьи:
- приведем ряд сокращений с пояснениями, которые будут использоваться в статье;
- повторим классическое описание МатрицыОшибок и ее основных составляющих;
- представим альтернативный способ запоминания МатрицыНесоответствий, в основе которого лежит графическое отношение комбинации ее элементов;
- разберем понятия Precision, Recall, TPR, FPR;
- рассмотрим понятия ROC-AUC, F1-меры метрик задач классификации;
- рассмотрим проблему дисбаланса классов в задачах классификации.
Сокращения, термины-синонимы, используемые в статье:
- ConfusionMatrix — МатрицаНесоответствий, МатрицаОшибок
- ML — Машинное обучение
- Модель (в данной статье) — алгоритм классификации
- TP — истинно-положительные объекты ( TruePositive )
- FP — ложно-положительные объекты ( FalsePasitive )
- TN — истинно-отрицательные объекты ( TrueNegative )
- FN — ложно-отрицательные объекты ( FalseNegative )
- TPR — TruePositiveRate
- FPR — FalsePositiveRate
- ROC — Receiver Operating Characteristic curve
- AUC — Area Under Curve
Автор предполагает, что читатель знаком с задачей классификации объектов в Машинном обучении, и поэтому в статье данный вопрос будет затронут поверхностно. Для простоты разберем бинарную классификацию, где истинные метки объектов принадлежат пространству.
0 — объекты относятся к нулевому классу,
1 — объекты относятся к классу 1.
Алгоритм машинного обучения выдает свой прогноз по этим меткам
здесь 0 — метки объектов, которые алгоритм классифицирует как объекты класса 0, и 1 — метки объектов, которые алгоритм считает за объекты класса 1.
Приведем модельный пример: допустим, у нас есть альбом с фотографиями животных и людей. Все фото, где присутствуют животные, пометим как объекты класса 1, а где их нет, как объекты класса 0. Сформулируем задачу: написать, алгоритм, способный понять, присутствует ли изображение животного на снимке или отсутствует. Сложность ситуации в том, что созданный классификатор не знает истинное значение, какой объект к какому классу принадлежит в реальности, и поэтому может ошибаться в своих ответах.
Для описания комбинаций, которые могут получаться при сопоставлении ответов алгоритма и истинных меток объекта в Машинном обучении, используются следующие понятия:
- TP — истинно-положительные объекты ( TruePositive) — объект представляет собой класс 1 и алгоритм его идентифицирует как класс 1
- FP — ложно-положительные объекты ( FalsePositive) — объект представляет собой класс 0, алгоритм его идентифицирует как класс 1 (ошибается)
- TN — истинно-отрицательные объекты ( TrueNegative) — объект представляет собой класс 0 и алгоритм его идентифицирует как класс 0
- FN — ложно-отрицательные объекты ( FalseNegative) — объект представляет собой класс 1, алгоритм его идентифицирует как класс 0.
Данные элементы являются составными частями Матрицы Несоответствий, построенной в координатах истинные ответы и ответы классификатора.

Для оценки качества работы алгоритма в Машинном обучении применяются различные метрики, часть которых основана на применении отношений комбинаций элементов Матрицы Несоответствий.
Так, например, понятия , и
используются в таких метриках, как F1-мера, Accuracy, Balanced Accuracy, Precision-Recall
curve и др. В метрике ROC-AUC применяется , и
При этом ни Precision, Recall, ни FPR, TPR не являются самостоятельными мерами оценки качества работы алгоритма, а используются в соответствующих метриках в различных парных комбинациях.
Значительное количества метрик, формул, плюс проблема дисбаланса классов (непропорциональное отношение количества объектов класса 0 к классу 1) — все это во время работы с данными предполагает постоянное обращение к классическому представлению Матрицы Несоответствий. В этой статье для более легкого интуитивного усвоения описанных понятий предлагается отойти от «сухого» табличного формата, попытаться понять изложенную информацию через ее визуализацию.
Для этого представим, что мы пришли в тир пострелять по мишени.
Здесь следует напомнить, что все многообразие мира бинарная классификация делит на объекты, принадлежащие классу 1 и классу 0. Это и будет наша мишень. Изобразим это на рисунке.

Возвращаясь к нашей задаче поиска животных на фотоснимках в альбоме, объекты класса 1 — это те фотографии, на которых имеются изображения животных, объекты класса 0 — снимки, которые их не содержат в реальности.
Теперь разберемся с понятием Precision. В переводе с английский этот термин обозначает “точность”, в Машинном Обучении под Precision подразумевается насколько наш алгоритм способен правильно классифицировать класс 1 из всех объектов, которые он распознал как единички или доля тех фотографий, где есть на самом деле животные из всего объема фотографий, в которых алгоритм указал, что на них имеется целевое изображение. На данном этапе предлагаю не заучивать данное объяснение, тем более что мы интуитивно выведем его сами на примере.
Возвращаемся в импровизированный тир, тогда “точность” — это будет выстрел нашего алгоритма, который пытается найти объекты класса 1, стреляя в центр мишени.
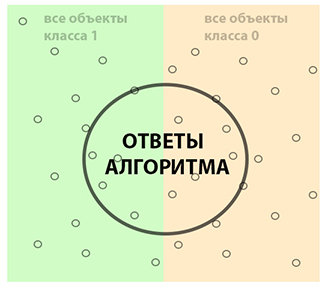
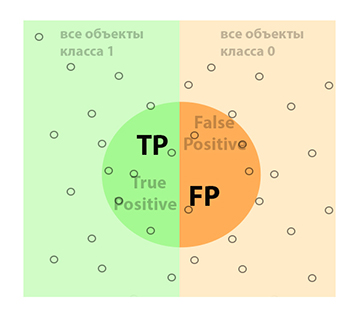
Все объекты, заключенные в контуре круга, для нашего алгоритма будут иметь метку 1, то есть интерпретированы как фотографии с животными. При этом мы видим, что алгоритм может ошибаться, так как в центр мишени вошли как фотографии с животными (объекты класса 1), так и изображения без животных (класса 0). Область, где наш алгоритм справился со своей задачей и правильно угадал класс 1, будет соответствовать True Positive (истинно положительные ответы, животные есть на снимках на самом деле), а где ошибся False Positive (ложно положительные ответы, здесь классификатор предполагает, что на фото животные есть, но на самом деле их нет).
Зона, где наш объект правильно идентифицирует объекты класса 0 и не ошибается на них, соответствует понятию True Negative — истинно негативные объекты, то есть те фотографии, где животных в реальности нет, и алгоритм с этим согласен. На рисунке 05 данный участок отмечен как TN.
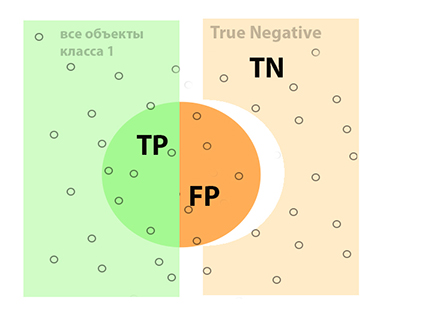
Соответственно, одна непромаркерованная область будет соответствовать как по смыслу, так и по методу исключения понятию False Negative или FN (ложно отрицательные, то есть наш алгоритм не смог эти объекты правильно классифицировать как объекты класса 1, например, спящую собаку в углу какого-то снимка распознал как камень или что-либо другое).
Теперь дополним наш рисунок новой информацией и сравним с табличной формой Матрицы Ошибок.

Объекты, отвечающие за расчет Precision (точность), сконцентрированы внутри центрального контура. Глядя на картинку, попробуйте сами сформулировать термин Precision.
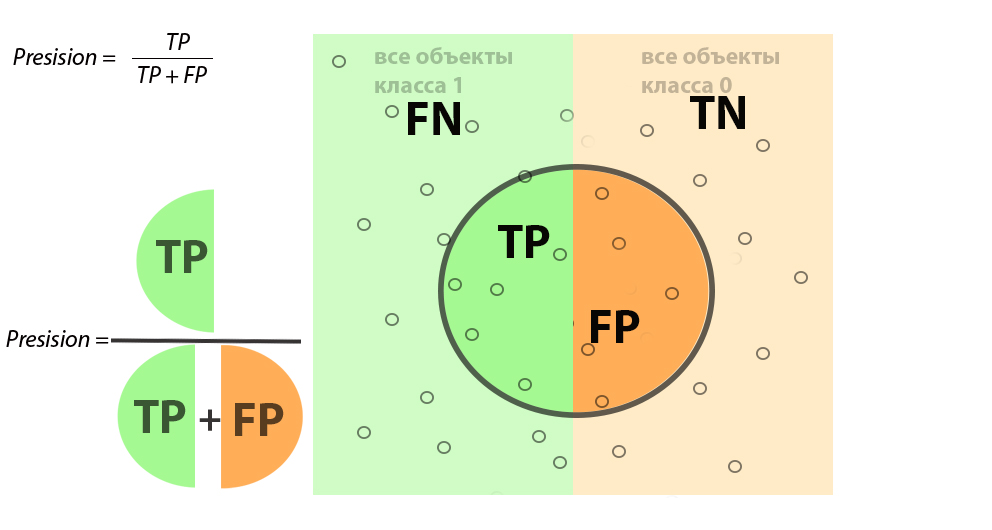
Сравните с правильным ответом: Precision — доля объектов, предсказанных алгоритмом как класс 1 и являющиеся на самом деле классом 1. В нашей задаче по определению есть ли животное на фото, это будет звучать как доля фотографий, где алгоритм распознал наличие животного, и оно на самом деле там присутствует.
Термин Recall имеет тоже довольно простую интерпретацию: способность нашего алгоритма определять класс 1.
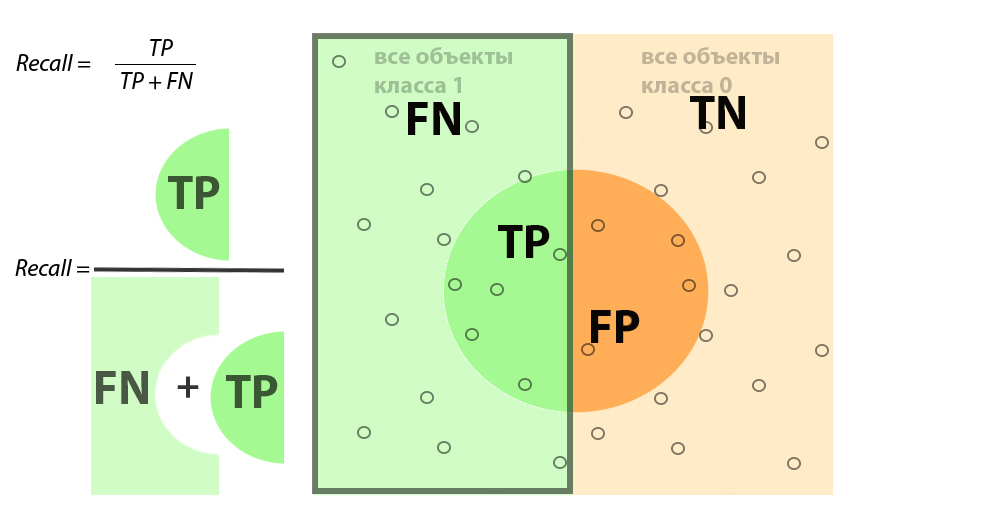
В применении к нашей задаче поиска определенных фотографий термин Полнота или Recall будет трактоваться как способность нашего алгоритма находить фото с животным из всех снимков, которые в реальности их содержат.
Настало время дать оценку насколько хорошо работает модель Машинного обучения. Для этого используют различные метрики, особенность их состоит в том, что такие метрики, как F1-мера, Accuracy, Balanced Accuracy, применяют различные комбинации разобранных нами методов Precision и Recall. Как эти понятия взаимодействуют между собой, очень хорошо можно понять через визуальное представление Матрицы Ошибок.
Разберем это на примере F1-мера, которая является частным случаем среднегармонической F-меры:
F1-мера является довольно стабильной метрикой при равном балансе классов (в примере с фотографиями животных, когда количество снимков, где присутствуют животные, примерно равно количеству снимков без животных). На практике большинство задач имеют перекос в балансе классов. Посмотрим, что будет происходит с описанными понятиями в этом случае.
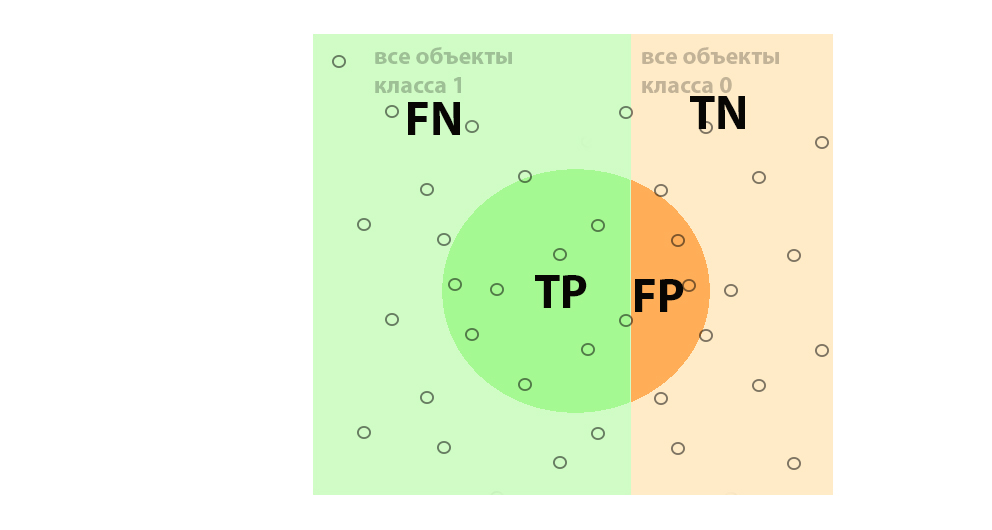
Как видно из рисунка выше, Recall пропорционально изменяется вместе с балансом классов, в то время как Precision сильно меняет значения. Для нивелирования перекоса предполагается использование некоторого β коэффициента — это и будет среднегармоническая F-мера. Хотя в отличие от нашего примера, в Машинном обучении при дисбалансе классов принято более редкий класс обозначать через 1, а наибольший через 0, но это не меняет идеи того, что изменения F-меры обусловлены нестабильным в таком случае параметром Precision. Подбор β коэффициента напрямую влияет на качество оценки работы модели. Обоснование и поиск данного коэффициента выходит за рамки данной статьи.
Теперь рассмотрим метрику ROC-AUC (Area Under Curve). Данная оценка работы алгоритма классификации рассчитывается как площадь под ROC кривой, которая строится в координатах TPR и FPR. Указанная метрика более устойчива к дисбалансу классов ввиду того, что в отличие от F1-меры здесь задействованы все элементы матрицы. Отметим, что термин TPR (True Positive Rate) равен рассмотренному ранее Recall.
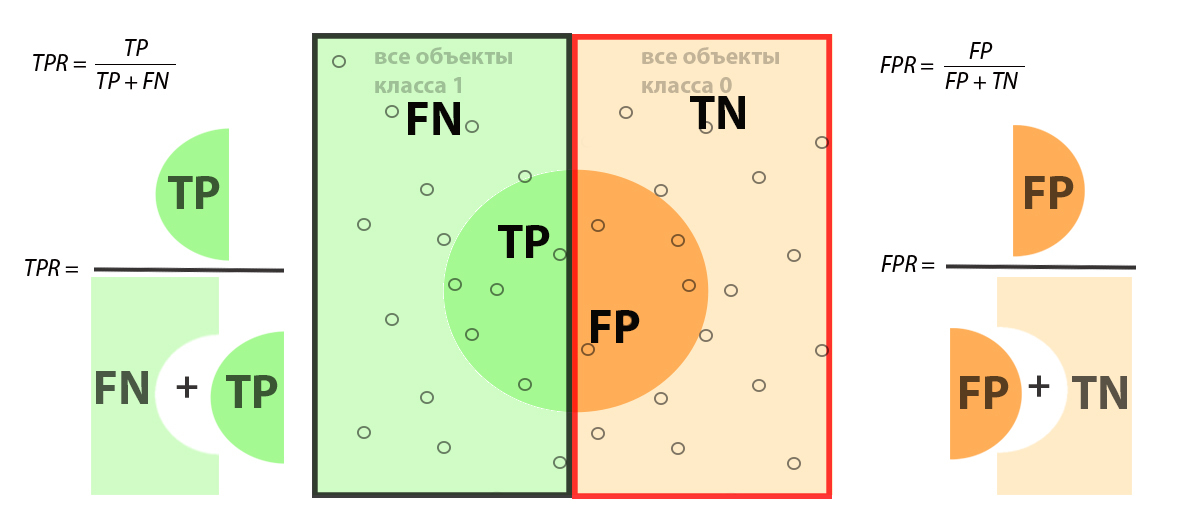
Из рисунка понятно причина стабильности метрики ROC-AUC при дисбалансе классов: при увеличении, например, количества объектов класса 0 все элементы входящие в FPR будут также пропорционально увеличиваться, а элементы, составляющие TPR наоборот уменьшаться. Но при этом итоговое значение FPR и TPR будут примерно соотноситься к тем значениям, когда дисбаланса класса нет.
Из рисунка понятно причина стабильности метрики ROC-AUC при дисбалансе классов: при увеличении, например, количества объектов класса 0 все элементы входящие в FPR будут также пропорционально увеличиваться, а элементы, составляющие TPR наоборот уменьшаться. Но при этом итоговое значение FPR и TPR будут примерно соотноситься к тем значениям, когда дисбаланса класса нет.
Заключение
В машинном обучении в задачах классификации для оценки насколько хорошо работает построенная модель и сравнения ее с другими алгоритмами применяются специальные агрегированные метрики. Для наилучшего освоения основ применения данных метрик специалисту по данным необходимо хорошо понимать концепцию их описания в терминах ошибок классификации — Матрице Ошибок или Матрице Несоответствий. В данной статье, предложен способ визуализировать Confusion Matrix в более легкий формат для восприятия в сравнении с классическим табличным видом. Через это представление рассмотрены часть метрик классификации и их элементов, разобрано поведение этих метрик при сбалансированных выборках и дисбалансе классов.
- Confusion Matrix
- Матрица Ошибок
- Матрица Несоответствий
- Дисбаланс классов
- машинное обучение
- классификация
- метрики классификации
- roc-auc
- F1-мера
- Машинное обучение
- Статистика в IT
- Интервью
Gazolin Production / Blog
Что такое матрица ошибок и зачем она нужна: пример расчета стоимости ошибки прогнозирования

Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений.
Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений. Прогнозируемые значения описываются как положительные и отрицательные, а фактические – как истинные и ложные [6]. Вообще матрица ошибок используется для оценки точности моделей в задачах классификации. Но прогнозирование и распознавание образов можно рассматривать как частный случай этой проблемы, поэтому confusion matrix актуальна и для измерения точности предсказаний. Важно, что матрица ошибок позволяет оценить эффективность прогноза не только в качественном, но и в количественном выражении, т.е. измерить стоимость ошибки в деньгах. Например, каковы будут расходы на удержание пользователя, если машинное обучение предсказало, что он перестанет приносить компании пользу [7]? Аналогичный вопрос по предсказанию оттока (Churn Rate) актуален и в HR-сфере для удержания ключевых сотрудников, мотивация которых снижается. Впрочем, матрица ошибок может использоваться не только в рамках применения Machine Learning. По сути, этот метод оценки стоимости прогноза является универсальным аналитическим инструментом.
| Реальность | ||
| Прогноз | + | — |
| + | True Positive (истинно-положительное решение): прогноз совпал с реальностью, результат положительный произошел, как и было предсказано ML-моделью | False Positive (ложноположительное решение): ошибка 1-го рода, ML-модель предсказала положительный результат, а на самом деле он отрицательный |
| — | False Negative (ложноотрицательное решение): ошибка 2-го рода – ML-модель предсказала отрицательный результат, но на самом деле он положительный | True Negative (истинно-отрицательное решение): результат отрицательный, ML-прогноз совпал с реальностью |

С математической точки зрения оценить точность ML-модели можно с помощью следующих метрик [8]:
- Точность – сколько всего результатов было предсказано верно;
- Доля ошибок;
- Полнота – сколько истинных результатов было предсказано верно;
- F-мера, которая позволяет сравнить 2 модели, одновременно оценив полноту и точность. Здесь используется среднее гармоническое вместо среднего арифметического, сглаживая расчеты за счет исключения экстремальных значений.
В количественном выражении это будет выглядеть так:

Метрики оценки качества прогноза: полнота, точность, F-мера
Рассмотрим матрицу ошибок на практическом примере для задачи прогнозирования спроса на скоропортящуюся продукцию, которая должна быть продана конечному пользователю в течение суток. Например, букеты цветов, продающиеся по цене k рублей при закупочной стоимости в p рублей. Предположим, с помощью Machine Learning было предложена 2 варианта:
- Положительный прогноз (+), что по цене kбудут полностью раскуплены все цветы в количестве n букетов.
- Отрицательный прогноз (+), что по цене kбудут полностью раскуплены не все цветы, останется m не проданных букетов.
Соответственно, матрица ошибок для этого случая будет выглядеть следующим образом:
| Прогноз | Реальность | |
| Проданы все букеты цветов | Остались не проданные m букетов | |
| +: Проданы все n букетов по k рублей c ценой закупки p | True Positive: прогноз совпал с реальностью, все закупленные n букетов проданы Выручка = n*kЗатраты = n*pПрибыль = n*(k-p)Стоимость ошибки = 0 | False Positive: ошибка 1-го рода, ML-модель предсказала, что будет n продаж, а на самом деле их было (n-m), осталось m не проданных букетов, которые пропали и не вернули затраты на их покупку Выручка = (n-m)*kЗатраты = n*pПрибыль = n*(k-p) – m*kСтоимость ошибки = m*p |
| —: Остались не проданные m букетов c ценой закупки p | False Negative: ошибка 2-го рода – ML-модель предсказала, что n букетов не будет продано, поэтому закупили (n-m) букетов, но спрос был на n букетов. Эффект недополученной прибыли Выручка = (n-m)*kЗатраты = (n-m)*pПрибыль = (n-m)*(k-p)Стоимость ошибки = m*k | True Negative: ML-прогноз совпал с реальностью, было раскуплено (n-m) букетов по цене k, сколько и было изначально закуплено по цене p Выручка = (n-m)*kЗатраты = (n-m)*pПрибыль = (n-m)*(k-p)Стоимость ошибки = 0 |
Таким образом, с помощью confusion matrix можно измерить эффективность прогноза в денежном выражении, что весьма актуально для практического бизнес-приложения Machine Learning. Впрочем, отметим еще раз, что данный метод предварительной оценки будущих сценариев можно использовать и вне сферы Data Science, оценивая риски и перспективы в рамках классического бизнес-анализа.
Simple guide to confusion matrix terminology
A confusion matrix is a table that is often used to describe the performance of a classification model (or «classifier») on a set of test data for which the true values are known. The confusion matrix itself is relatively simple to understand, but the related terminology can be confusing.
I wanted to create a «quick reference guide» for confusion matrix terminology because I couldn’t find an existing resource that suited my requirements: compact in presentation, using numbers instead of arbitrary variables, and explained both in terms of formulas and sentences.
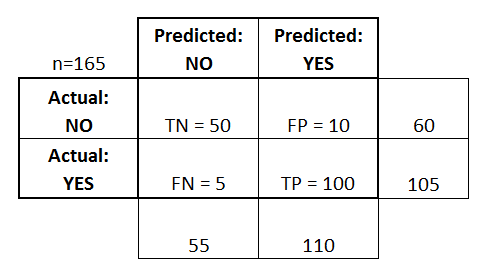
Let’s start with an example confusion matrix for a binary classifier (though it can easily be extended to the case of more than two classes):

What can we learn from this matrix?
- There are two possible predicted classes: «yes» and «no». If we were predicting the presence of a disease, for example, «yes» would mean they have the disease, and «no» would mean they don’t have the disease.
- The classifier made a total of 165 predictions (e.g., 165 patients were being tested for the presence of that disease).
- Out of those 165 cases, the classifier predicted «yes» 110 times, and «no» 55 times.
- In reality, 105 patients in the sample have the disease, and 60 patients do not.
Let’s now define the most basic terms, which are whole numbers (not rates):
- true positives (TP): These are cases in which we predicted yes (they have the disease), and they do have the disease.
- true negatives (TN): We predicted no, and they don’t have the disease.
- false positives (FP): We predicted yes, but they don’t actually have the disease. (Also known as a «Type I error.»)
- false negatives (FN): We predicted no, but they actually do have the disease. (Also known as a «Type II error.»)
I’ve added these terms to the confusion matrix, and also added the row and column totals:
This is a list of rates that are often computed from a confusion matrix for a binary classifier:
- Accuracy: Overall, how often is the classifier correct?
- (TP+TN)/total = (100+50)/165 = 0.91
- (FP+FN)/total = (10+5)/165 = 0.09
- equivalent to 1 minus Accuracy
- also known as «Error Rate»
- TP/actual yes = 100/105 = 0.95
- also known as «Sensitivity» or «Recall»
- FP/actual no = 10/60 = 0.17
- TN/actual no = 50/60 = 0.83
- equivalent to 1 minus False Positive Rate
- also known as «Specificity»
- TP/predicted yes = 100/110 = 0.91
- actual yes/total = 105/165 = 0.64
A couple other terms are also worth mentioning:
- Null Error Rate: This is how often you would be wrong if you always predicted the majority class. (In our example, the null error rate would be 60/165=0.36 because if you always predicted yes, you would only be wrong for the 60 «no» cases.) This can be a useful baseline metric to compare your classifier against. However, the best classifier for a particular application will sometimes have a higher error rate than the null error rate, as demonstrated by the Accuracy Paradox.
- Cohen’s Kappa: This is essentially a measure of how well the classifier performed as compared to how well it would have performed simply by chance. In other words, a model will have a high Kappa score if there is a big difference between the accuracy and the null error rate. (More details about Cohen’s Kappa.)
- F Score: This is a weighted average of the true positive rate (recall) and precision. (More details about the F Score.)
- ROC Curve: This is a commonly used graph that summarizes the performance of a classifier over all possible thresholds. It is generated by plotting the True Positive Rate (y-axis) against the False Positive Rate (x-axis) as you vary the threshold for assigning observations to a given class. (More details about ROC Curves.)
And finally, for those of you from the world of Bayesian statistics, here’s a quick summary of these terms from Applied Predictive Modeling:
In relation to Bayesian statistics, the sensitivity and specificity are the conditional probabilities, the prevalence is the prior, and the positive/negative predicted values are the posterior probabilities.
Want to learn more?
In my new 35-minute video, Making sense of the confusion matrix, I explain these concepts in more depth and cover more advanced topics:
- How to calculate precision and recall for multi-class problems
- How to analyze a 10-class confusion matrix
- How to choose the right evaluation metric for your problem
- Why accuracy is often a misleading metric
Let me know if you have any questions!
Как оценить стоимость прогноза Machine Learning и не только: строим confusion matrix

Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по оценке моделей. Читайте в нашей статье, что такое матрица ошибок (confusion matrix) и как она помогает измерить эффективность используемых ML-алгоритмов и других инструментов бизнес-аналитики, оценив потенциальные убытки и выгоды от возможных сценариев будущего в задаче прогнозирования спроса.
От ритейла до банка: 5 примеров применения Big Data и Machine Learning в задачах прогнозирования спроса и предложения
Вообще сегодня задача прогнозирования спроса стала довольно обыденным приложением методов Machine Learning (ML) в реальном бизнесе. В частности, в декабре 2019 года сервис объявлений «Юла» ускорил публикацию объявлений по продаже товаров с помощью функции их распознавания по фотографии. Помимо собственно распознавания того, что сфотографировано, нейросетевые модели предлагают пользователю уточнить характеристики продукта и оценивают его стоимость в среднем по рынку. При этом пользователю выдается прогноз, насколько быстро он продаст товар при различных ценах [1].
Другой пример, московский сервис приготовления и доставки еды навынос «Кухня на районе» с помощью нейросетей и ежедневной статистики продаж рассчитывает, сколько продуктов нужно привезти на каждую точку, чтобы минимизировать количество остатков. Анализируя данные по проданным позициям в разных локациях, нейросеть из 3 500 вариантов отбирает сотню блюд, которые будут максимально востребованы, чтобы готовить именно их на районных кухнях в течение следующей недели [2].
Подобным образом, на основе постоянного анализа продаж, машинное обучение позволяет эффективно решить задачу ценообразования, установив наиболее оптимальную стоимость на отдельные продукты и целые товарные категории. Например, именно это было сделано в отечественном интернет-магазине детских игрушек Babadu.ru, когда методы Machine Learning помогли разработать несколько маркетинговых стратегий, наиболее выгодных для ритейлера [3]. Аналогично строятся ML-модели эластичного спроса в другом российском гиганте интернет-торговли, Ozon.ru. Разработанный алгоритм анализирует значения более 150 признаков в истории продаж, чтобы на выходе предоставить точный прогноз по будущим заказам. При этом в модели заложена функция минимизации денежных потерь на покупку и хранение лишних товаров на складе или отток клиента (Churn Rate) из-за отсутствия нужного продукта [4].
Похожая задача прогнозирования спроса актуальна и для банков, которые стремятся оптимизировать процессы работы с наличными деньгами в своих банкоматах. Финансовые корпорации хотят, с одной стороны, чтобы средства не лежали в банкоматах «без дела»: гораздо выгоднее, например, разместить их на краткосрочном депозите. Но, клиенты будут недовольны, когда столкнутся с отказом из-за недостаточного количества денег в банкомате. Это грозит репутационными потерями, поэтому банк стремится решить данную проблему с помощью точного предсказания спроса на наличность в каждой точке расположения банкоматов. При этом нужно учитывать, что спрос на наличные зависит от множества параметров: макроэкономические факторы, политические новости, социальные события, расположение банкомата, прогноз погоды, время года, день недели и т.д. Чтобы предсказать завтрашнюю потребность в наличных для конкретного банкомата, Сбербанк, например, с 2016 года использует адаптивные алгоритмы машинного обучения вместе с классическими методами анализа временных рядов. Такие модели обеспечивают динамическое перестроение всех анализируемых параметров, предоставляя на выходе эффективный план оптимального распределения и перемещения наличных между банкоматами [5].