Введение в GitOps для OpenShift
Сегодня мы расскажем о принципах и моделях GitOps, а также о том, как эти модели реализуются на платформе OpenShift. Интерактивное руководство на эту тему доступно по ссылке.

Если вкратце, то GitOps – это набор практических методов использования pull-запросов Git для управления конфигурациями инфраструктуры и приложений. Git-репозиторий в рамках GitOps рассматривается как один единственный источник сведений о состоянии системы, причем любые изменения этого состояния полностью отслеживаются и поддаются аудиту.
Идея с отслеживаемостью изменений в GitOps отнюдь не нова, такой подход уже давно и практически повсеместно применяется при работе с исходным кодом приложений. GitOps просто реализует аналогичные функции (review-проверки, pull-запросы, теги и т. д.) при управлении конфигурациями инфраструктуры и приложений и дает аналогичные преимущества, как в случае управления исходным кодом.
Для GitOps нет какого-то академического определения или утвержденного свода правил, лишь свод принципов, на которых строится эта практика:
- Декларативное описание системы хранится в репозитории Git (конфиги, мониторинг и т. д).
- Изменения состояния выполняются через pull-запросы.
- Состояние работающих систем приводится в соответствие с данными в репозитории с помощью push-запросов Git.
Принципы GitOps
- Определения систем описываются как исходный код
- Желаемое состояние и конфигурация систем задаются и версионируются в Git
- Изменения в конфигурациях могут автоматически применяться с помощью pull-запросов
И при этом не нужно раздавать админские полномочия направо и налево. Чтобы выполнить commit изменений в конфигурации, пользователи достаточно соответствующих полномочий в репозитории Git, где хранятся эти конфигурации.
- Устранение проблемы неконтролируемого дрифта конфигураций
Модели GitOps для OpenShift
On-Cluster Resource Reconciller
Согласно этой модели в кластере есть контроллер, который отвечает за сравнение Kubernetes-ресурсов (файлов YAML) в Git-репозитории с реальными ресурсами кластера. При выявлении расхождений контроллер рассылает уведомления и, возможно, принимает меры для устранения несоответствий. Эта модель GitOps используется в Anthos Config Management и Weaveworks Flux.

External Resource Reconciler (Push)
Эту модель можно рассматривать как разновидность предыдущей, когда у нас есть один или несколько контроллеров, отвечающих за синхронизацию ресурсов в парах «репозиторий Git – кластер Kubernetes». Отличие же здесь в том, что в каждом управляемом кластере необязательно должен быть свой отдельный контроллер. Пары «Git – кластер k8s» часто определяются как CRD-описания (custom resources definition), в которых можно описать, как контроллер должен выполнять синхронизацию. В рамках этой модели контроллеры сравнивают Git-репозиторий, заданный в CRD, с ресурсами кластера Kubernetes, которые тоже заданы в CRD, и выполняют соответствующие действия по результатам сравнения. В частности, такая модель GitOpsиспользуется в ArgoCD.

GitOps на платформе OpenShift
Администрирование мультикластерной Kubernetes-инфраструктуры
С распространением Kubernetes и ростом популярности мультиоблачных стратегий и периферийных вычислений (edge computing) увеличивается и среднее количество кластеров OpenShift в расчете на одного заказчика.
Например, при использовании периферийных вычислений кластеры одного заказчика могут развертываться сотнями и даже тысячами. В результате он вынужден управлять несколькими независимыми или согласованными кластерами OpenShift в публичном облаке и on-premise.
При этом приходится решать массу проблем, в частности:
- Контролировать, что кластеры находятся в идентичном состоянии (конфиги, мониторинг, хранилища и т. д.)
- Повторно создавать (или восстанавливать) кластеры по известному состоянию.
- Создавать новые кластеры по известному состоянию.
- Накатывать изменения на нескольких кластерах OpenShift.
- Откатывать изменений на нескольких кластерах OpenShift.
- Увязывать шаблонизированные конфигураций с различными средами.
Конфигурации приложения
В ходе своего жизненного цикла приложения часто проходят через цепочку кластеров (dev, stage и т. д.), прежде чем попасть в продакшн-кластер. Кроме того, из-за требований доступности и масштабируемости заказчики часто развертывают приложения сразу на нескольких кластерах on-premise или в нескольких регионах публичной облачной платформы.
- Обеспечивать движение приложений (бинарники, конфиги и т. д) между кластерам (dev, stage и т. д.).
- Накатывать изменения в приложениях (бинарники, конфиги и т. д) в нескольких кластерах OpenShift.
- Откатывать изменения в приложениях до уровня предыдущей известного состояния.
Сценарии использования OpenShift GitOps
1. Применение изменений из Git-репозитория
Администратор кластера может хранить конфигурации кластера OpenShift в Git-репозитории и автоматически применять их, чтобы без лишних усилий создавать новые кластеры и приводить их в состояние, идентичное известному состоянию, которое хранится в Git-репозитории.
2. Синхронизация с Secret Manager
Админу также пригодится возможность синхронизировать secret-объекты OpenShift с соответствующим ПО наподобие Vault, чтобы управлять ими с помощью специально созданных для этого инструментов.
3. Контроль дрифта конфигураций
Админ будет только за, если OpenShift GitOps будет сам выявлять и предупреждать о расхождениях между реальными конфигурациями и теми, что заданы в репозитории, чтобы можно было оперативно реагировать на дрифт.
4. Уведомления о дрифте конфигураций
Пригодятся в том случае, когда админ хочет оперативно узнавать о случаях дрифта конфигураций, чтобы быстро принимать соответствующие меры самостоятельно.
5. Ручная синхронизация конфигураций при дрифте
Позволяет админу синхронизировать кластер OpenShift с репозиторием Git в случае дрифта конфигураций, чтобы быстро вернуть кластер к предыдущему известному состоянию.
6.Автосихронизация конфигураций при дрифте
Админ также может настроить кластер OpenShift на автоматическую синхронизацию с репозиторием при обнаружении дрифта, чтобы конфигурация кластера всегда соответствовала конфигами в Git’е.
7. Несколько кластеров – один репозиторий
Админ может хранить в одном репозитории Git конфигурации сразу нескольких различных кластеров OpenShift и выборочно применять их по мере надобности.
8. Иерархия кластерных конфигураций (наследование)
Админ может задать иерархию кластерных конфигураций в репозитории (stage, prod, app portfolio и т. д с наследованием). Иначе говоря, он может определять, как должны применяться конфигурации – к одному или к нескольким кластерам.
Например, если админ задает в Git репозитории иерархию «Продакшн кластеры (prod) → Кластеры системы X → Продакшн кластеры системы X», то к продакшн-кластерам системы X применяется объединение следующих конфигов:
- Конфиги, общие для всех продакшн-кластеров.
- Конфиги для кластера системы X.
- Конфиги для продакшн-кластера системы X.
9. Шаблоны и переопределение конфигураций
Админ может переопределить набор унаследованных конфигов и их значений, например, чтобы тоньше настроить конфигурацию для определенных кластеров, к котором они будут применяться.
10. Избирательные include’ы и exclude’ы для конфигураций, конфигурации приложений
Админ может задать условия применения или неприменения тех или иных конфигураций к кластерам с определенными характеристиками.
11. Поддержка шаблонов
Разработчикам пригодится возможность выбирать, как будут определяться ресурсы приложения (Helm Chart, чистый Kubernetes’овский yaml и т. д), чтобы использовать наиболее подходящий формат для каждого конкретного приложения.
Инструменты GitOps на платфомре OpenShift
ArgoCD
ArgoCD реализует модель External Resource Reconcile и предлагает централизованный UI для оркестрации отношений между кластерами и Git-репозиториями по схеме «один ко многим». К недостаткам этой программы можно отнести невозможность управлять приложениями при неработающем ArgoCD.
Flux
Flux реализует модель On-Cluster Resource Reconcile, и, как следствие, здесь нет централизованного управления репозиторием определений, что является слабым местом. С другой стороны, именно из-за отсутствия централизации возможность управлять приложениями сохраняется и при выходе из строя одного кластера.
Установка ArgoCD на OpenShift
ArgoCD предлагает отличный интерфейс командной строки и веб-консоль, поэтому здесь мы не будем рассматривать Flux и другие альтернативы.
Чтобы развернуть ArgoCD на платформе OpenShift 4, выполните следующие шаги в качестве администратора кластера:
Развертывание компонентов ArgoCD на платформе OpenShift
# Create a new namespace for ArgoCD components oc create namespace argocd # Apply the ArgoCD Install Manifest oc -n argocd apply -f https://raw.githubusercontent.com/argoproj/argo-cd/v1.2.2/manifests/install.yaml # Get the ArgoCD Server password ARGOCD_SERVER_PASSWORD=$(oc -n argocd get pod -l "app.kubernetes.io/name=argocd-server" -o jsonpath='')Доработка ArgoCD Server, чтобы его видел OpenShift Route
# Patch ArgoCD Server so no TLS is configured on the server (--insecure) PATCH='],"containers":[<"command":["argocd-server","--insecure","--staticassets","/shared/app"],"name":"argocd-server">]>>>>' oc -n argocd patch deployment argocd-server -p $PATCH # Expose the ArgoCD Server using an Edge OpenShift Route so TLS is used for incoming connections oc -n argocd create route edge argocd-server --service=argocd-server --port=http --insecure-policy=RedirectРазвертывание ArgoCD Cli Tool
# Download the argocd binary, place it under /usr/local/bin and give it execution permissions curl -L https://github.com/argoproj/argo-cd/releases/download/v1.2.2/argocd-linux-amd64 -o /usr/local/bin/argocd chmod +x /usr/local/bin/argocdСмена админского пароля ArgoCD Server
# Get ArgoCD Server Route Hostname ARGOCD_ROUTE=$(oc -n argocd get route argocd-server -o jsonpath='') # Login with the current admin password argocd --insecure --grpc-web login $:443 --username admin --password $ # Update admin's password argocd --insecure --grpc-web --server $:443 account update-password --current-password $ --new-passwordПосле выполнения этих шагов с ArgoCD Server можно работать через веб-консоль ArgoCD WebUI или инструментарий командной строки ArgoCD Cli.
https://blog.openshift.com/is-it-too-late-to-integrate-gitops/
GitOps – никогда не поздно
«Поезд ушел» – так говорят о ситуации, когда возможность что-то сделать упущена. В случае с OpenShift желание тут же начать использовать эту новую классную платформу часто создает именно такую ситуацию с управлением и обслуживанием маршрутов, deployment’ов и других объектов OpenShift. Но всегда ли шанс окончательно упущен?
Продолжая серию статей о GitOps, сегодня мы покажем, как преобразовать созданное вручную приложение и его ресурсы в некий процесс, где всем управляет инструментарий GitOps. Для этого мы сначала руками развернем приложение httpd. На скрине ниже показано, как мы создаем пространство имен, deployment и сервис, а потом делаем expose для этого сервиса, чтобы создать маршрут.
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/namespace.yaml oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/deployment.yaml oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/service.yaml oc expose svc/httpd -n simple-appИтак, у нас есть созданное вручную приложение. Теперь его надо перевести под управление GitOps без потери доступности. Вкратце, это делает так:
- Создаем Git-репозиторий для кода.
- Экспортируем наши текущие объекты и загружаем их в репозиторий Git.
- Выбираем и развертываем инструментарий GitOps.
- Добавляем в этот инструментарий наш репозиторий.
- Определяем приложение в нашем инструментарии GitOps.
- Выполняем пробный запуск приложения, используя инструментарий GitOps.
- Синхронизируем объекты с помощью инструментария GitOps.
- Включаем очистку (pruning) и автосинхронизацию объектов.
В нашем примере мы создадим новый публичный репозиторий на GitHub. Назвать его можно как угодно, мы используем имя blogpost.
Если YAML-файлы объектов не хранились локально или в Git’е, то придется воспользоваться бинарниками oc или kubectl. На скрине ниже мы запрашиваем YAML для нашего пространства имен, deployment’а, сервиса и маршрута. Перед этим мы клонировали только что созданный репозиторий и перешли в него командой cd.
oc get namespace simple-app -o yaml --export > namespace.yaml oc get deployment httpd -o yaml -n simple-app --export > deployment.yaml oc get service httpd -o yaml -n simple-app --export > service.yaml oc get route httpd -o yaml -n simple-app --export > route.yamlТеперь поправим файл deployment.yaml, чтобы удалить из него поле, которое Argo CD не может синхронизировать.
sed -i '/\sgeneration: .*/d' deployment.yamlКроме того, надо изменить маршрут. Сначала мы зададим многострочную переменную, а затем заменим ingress: null на содержимое этой переменной.
export ROUTE=" ingress:\\ - conditions:\\ - status: 'True'\\ type: Admitted" sed -i "s/ ingress: null/$ROUTE/g" route.yamlТак, с файлами разобрались, осталось сохранить их в Git-репозиторий. После чего этот репозиторий становится одним-единственным источником сведений, и любые ручные изменения объектов должны быть строго запрещены.
git commit -am ‘initial commit of objects’ git push origin masterДалее мы исходим из того, что ArgoCD у вас уже развернут (как это сделать – см. предыдущий пост). Поэтому добавим в Argo CD созданный нами репозиторий, содержащий код приложения из нашего примера. Только убедитесь, что указываете именно тот репозиторий, который создали ранее.
argocd repo add https://github.com/cooktheryan/blogpostТеперь создаем приложение. Приложение задает значения, чтобы инструментарий GitOps понимал, какой репозиторий и пути использовать, какой OpenShift необходим для управления объектами, а также какая конкретная ветвь репозитория нужна, и должна ли выполняться автосихронизация ресурсов.
argocd app create --project default \ --name simple-app --repo https://github.com/cooktheryan/blogpost.git \ --path . --dest-server https://kubernetes.default.svc \ --dest-namespace simple-app --revision master --sync-policy noneПосле того, как приложение задано в Argo CD, этот инструментарий начинает проверять уже развернутые объекты на соответствие определениям в репозитории. В нашем примере автосинхронизация и очистка отключены, поэтому элементы пока не меняются. Обратите внимание, что в интерфейсе Argo CD наше приложение будет иметь статус «Out of Sync» (Не синхронизировано), поскольку нет label-метки, которую проставляет ArgoCD.
Именно поэтому, когда мы чуть позднее запустим синхронизацию, повторное развертывание объектов выполняться не будет.
Теперь выполним пробный запуск, чтобы убедиться, что в наших файлах нет ошибок.
argocd app sync simple-app --dry-runЕсли ошибок нет, то можно переходить к синхронизации.
argocd app sync simple-appПосле выполнения команды argocd get над нашим приложением, мы должны увидеть, что статус приложения изменился на Healthy (Исправно) или Synced (Синхронизировано). Это будет означать, что все ресурсы в репозитории Git теперь соответствует тем ресурсам, что уже развернуты.
argocd app get simple-app Name: simple-app Project: default Server: https://kubernetes.default.svc Namespace: simple-app URL: https://argocd-server-route-argocd.apps.example.com/applications/simple-app Repo: https://github.com/cooktheryan/blogpost.git Target: master Path: . Sync Policy: Sync Status: Synced to master (60e1678) Health Status: Healthy . А вот теперь уже можно включать автосинхронизацию и очистку, чтобы гарантировать, что ничего не будет создаваться вручную и что каждый раз, когда объект создается или обновляется в репозиторий, будет выполняться развертывание.
argocd app set simple-app --sync-policy automated --auto-pruneИтак, мы успешно перевели под управление GitOps приложение, которое изначально никак не использовало GitOps.
OpenShift – Обзор
OpenShift – это Платформа облачной разработки как услуга (PaaS), размещенная в Red Hat. Это удобная облачная платформа с открытым исходным кодом, используемая для создания, тестирования и запуска приложений и, наконец, их развертывания в облаке.
OpenShift способен управлять приложениями, написанными на разных языках, таких как Node.js, Ruby, Python, Perl и Java. Одной из ключевых особенностей OpenShift является его расширяемость, которая помогает пользователям поддерживать приложение, написанное на других языках.
OpenShift поставляется с различными концепциями виртуализации в качестве уровня абстракции. Основная концепция OpenShift основана на виртуализации.
Виртуализация
В общем, виртуализация может быть определена как создание виртуальной системы, а не физической или фактической версии чего-либо, начиная с системы, хранилища или операционной системы. Основная цель виртуализации – сделать ИТ-инфраструктуру более масштабируемой и надежной. Концепция виртуализации существует уже несколько десятилетий, и с развитием ИТ-индустрии сегодня она может быть применена к широкому кругу уровней, начиная с системного уровня, аппаратного уровня и заканчивая виртуализацией на уровне сервера.
Как это устроено
Это может быть описано как технология, в которой любое приложение или операционная система отделены от своего фактического физического уровня. Одним из ключевых применений технологии виртуализации является виртуализация серверов, в которой используется программное обеспечение, называемое гипервизором, для отделения уровня от базового оборудования. Производительность операционной системы, работающей на виртуализации, такая же, как и на физическом оборудовании. Однако концепция виртуализации популярна, так как большинство работающих систем и приложений не требуют использования базового оборудования.
Физическая и виртуальная архитектура
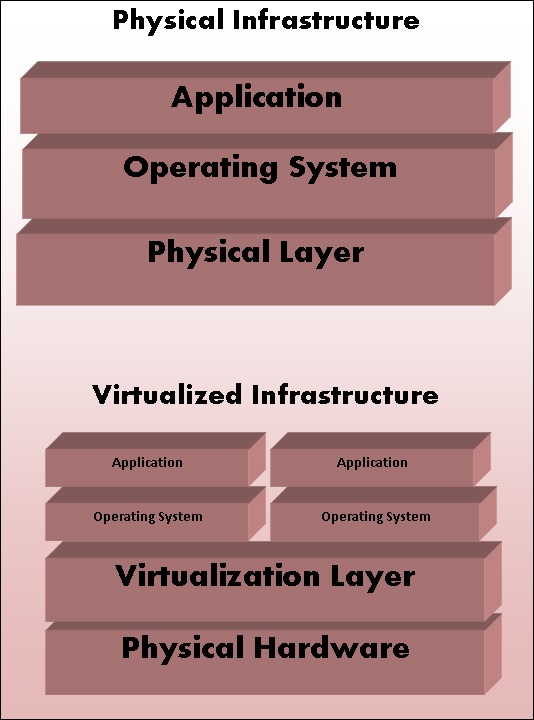
Типы виртуализации
- Виртуализация приложений – в этом методе приложение абстрагируется от базовой операционной системы. Этот метод очень полезен, в котором приложение может быть запущено изолированно, без зависимости от операционной системы.
- Виртуализация рабочего стола. Этот метод используется для уменьшения нагрузки на рабочую станцию, на которой можно получить удаленный доступ к рабочему столу с помощью тонкого клиента на рабочем столе. В этом методе рабочие столы в основном работают в центре обработки данных. Классическим примером может служить образ виртуального рабочего стола (VDI), который используется в большинстве организаций.
- Виртуализация данных – это метод абстрагирования и отход от традиционного метода управления данными и данными.
- Виртуализация сервера. В этом методе виртуализируются ресурсы, относящиеся к серверу, которые включают физический сервер, процесс и операционную систему. Программное обеспечение, обеспечивающее эту абстракцию, часто называют гипервизором.
- Виртуализация хранилища – это процесс объединения нескольких устройств хранения в одно устройство хранения, управляемое из единой центральной консоли.
- Виртуализация сети – это метод, при котором все доступные сетевые ресурсы объединяются путем разделения доступной полосы пропускания и каналов, каждый из которых не зависит друг от друга.
Виртуализация приложений – в этом методе приложение абстрагируется от базовой операционной системы. Этот метод очень полезен, в котором приложение может быть запущено изолированно, без зависимости от операционной системы.
Виртуализация рабочего стола. Этот метод используется для уменьшения нагрузки на рабочую станцию, на которой можно получить удаленный доступ к рабочему столу с помощью тонкого клиента на рабочем столе. В этом методе рабочие столы в основном работают в центре обработки данных. Классическим примером может служить образ виртуального рабочего стола (VDI), который используется в большинстве организаций.
Виртуализация данных – это метод абстрагирования и отход от традиционного метода управления данными и данными.
Виртуализация сервера. В этом методе виртуализируются ресурсы, относящиеся к серверу, которые включают физический сервер, процесс и операционную систему. Программное обеспечение, обеспечивающее эту абстракцию, часто называют гипервизором.
Виртуализация хранилища – это процесс объединения нескольких устройств хранения в одно устройство хранения, управляемое из единой центральной консоли.
Виртуализация сети – это метод, при котором все доступные сетевые ресурсы объединяются путем разделения доступной полосы пропускания и каналов, каждый из которых не зависит друг от друга.
OpenShift
OpenShift – это облачная платформа приложений как услуга (PaaS). Это технология с открытым исходным кодом, которая помогает организациям перевести свою традиционную инфраструктуру приложений и платформу из физических, виртуальных сред в облако.
OpenShift поддерживает очень широкий спектр приложений, которые могут быть легко разработаны и развернуты на облачной платформе OpenShift. OpenShift в основном поддерживает три вида платформ для разработчиков и пользователей.
Инфраструктура как услуга (IaaS)
В этом формате поставщик услуг предоставляет виртуальным машинам аппаратного уровня некоторую предопределенную конфигурацию виртуального оборудования. В этом пространстве есть несколько конкурентов, начиная с облачного сервиса AWS Google, Rackspace и многих других.
Основной недостаток IaaS после длительной процедуры настройки и инвестиций заключается в том, что каждый по-прежнему отвечает за установку и обслуживание операционной системы и пакетов серверов, управление сетью инфраструктуры и заботу о базовом системном администрировании.
Программное обеспечение как услуга (SaaS)
С SaaS меньше всего беспокоятся о базовой инфраструктуре. Это так же просто, как подключи и играй, где пользователь просто должен подписаться на услуги и начать использовать его. Основным недостатком этой настройки является то, что можно выполнить только минимальную настройку, которая разрешена поставщиком услуг. Одним из наиболее распространенных примеров SaaS является Gmail, где пользователю просто нужно войти в систему и начать его использовать. Пользователь также может внести небольшие изменения в свой аккаунт. Однако это не очень полезно с точки зрения разработчика.
Платформа как услуга (PaaS)
Это можно рассматривать как промежуточный слой между SaaS и IaaS. Основная цель оценки PaaS – для разработчиков, в которых среду разработки можно раскрутить с помощью нескольких команд. Эти среды спроектированы таким образом, чтобы они могли удовлетворить все потребности разработки, прямо от наличия сервера веб-приложений с базой данных. Для этого вам просто требуется одна команда, и поставщик услуг сделает все за вас.
Зачем использовать OpenShift?
OpenShift предоставляет корпоративным подразделениям общую платформу для размещения своих приложений в облаке, не беспокоясь о базовой операционной системе. Это упрощает использование, разработку и развертывание приложений в облаке. Одной из ключевых особенностей является то, что он предоставляет управляемое оборудование и сетевые ресурсы для всех видов разработки и тестирования. С помощью OpenShift разработчик PaaS может свободно разрабатывать необходимую среду со спецификациями.
OpenShift предоставляет различные виды соглашений об уровне обслуживания, когда речь идет о планах обслуживания.
Бесплатно – этот план ограничен тремя передачами с 1 ГБ места для каждого.
Бронза – этот план включает в себя 3 передачи и расширяется до 16 передач с 1 ГБ пространства на передачу.
Щепка – это бронзовый 16-ступенчатый план, однако он имеет емкость 6 ГБ без дополнительных затрат.
Помимо вышеупомянутых функций, OpenShift также предлагает локальную версию, известную как OpenShift Enterprise. В OpenShift разработчики имеют возможность разрабатывать масштабируемые и немасштабируемые приложения, и эти проекты реализуются с использованием серверов HAproxy.
Характеристики
OpenShift поддерживает несколько функций. Немногие из них –
- Поддержка нескольких языков
- Поддержка нескольких баз данных
- Система расширяемых картриджей
- Управление версиями исходного кода
- Развертывание в один клик
- Поддержка нескольких сред
- Стандартизированный рабочий процесс разработчиков
- Зависимость и управление сборкой
- Автоматическое масштабирование приложения
- Отзывчивая веб-консоль
- Богатый набор инструментов для командной строки
- Удаленный SSH вход в приложения
- Поддержка Rest API
- Стек приложений самообслуживания по требованию
- Встроенные службы баз данных
- Непрерывная интеграция и управление релизами
- Интеграция с IDE
- Удаленная отладка приложений
OpenShift – Типы
OpenShift возникла из его базы под названием OpenShift V2, которая в основном основывалась на концепции шестерен и картриджей, где каждый компонент имеет свои спецификации, начиная от создания машины до развертывания приложения, от сборки до развертывания приложения.
Картриджи – они были центром создания нового приложения, начиная с того типа приложения, который требуется среде для их запуска, и всех зависимостей, удовлетворяющих требованиям этого раздела.
Шестерня – Его можно определить как медвежий металл или сервер с определенными характеристиками, касающимися ресурсов, памяти и процессора. Они считались фундаментальной единицей для запуска приложения.
Приложение. Это просто относится к приложению или любому приложению интеграции, которое будет развернуто и запущено в среде OpenShift.
По мере того как мы углубимся в этот раздел, мы обсудим различные форматы и предложения OpenShift. В прежние времена у OpenShift было три основных версии.
OpenShift Origin – это было дополнение сообщества или версия OpenShift с открытым исходным кодом. Он также был известен как основной проект для двух других версий.
OpenShift Online – это публичный PaaS как сервис, размещенный на AWS.
OpenShift Enterprise – это усиленная версия OpenShift с лицензиями независимых поставщиков и поставщиков.
OpenShift Online
OpenShift online – это предложение сообщества OpenShift, с помощью которого можно быстро создавать, развертывать и масштабировать контейнерные приложения в общедоступном облаке. Это платформа для разработки и хостинга приложений в общедоступном облаке Red Hat, которая позволяет автоматизировать предоставление, управление и масштабирование приложений, что помогает разработчику сосредоточиться на написании логики приложения.
Настройка учетной записи в Red Hat OpenShift Online
Шаг 1 – зайдите в браузер и посетите сайт https://manage.openshift.com/
Шаг 3 – Если у вас нет учетной записи Red Hat, зарегистрируйтесь в онлайн-сервисе OpenShift, используя следующую ссылку.
После входа вы увидите следующую страницу.
После того, как у вас все будет на месте, Red Hat покажет некоторые базовые данные учетной записи, как показано на следующем снимке экрана.
Наконец, когда вы вошли в систему, вы увидите следующую страницу.
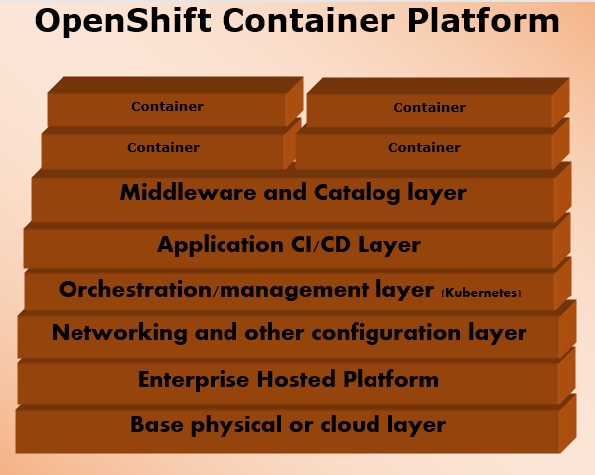
Контейнерная платформа OpenShift
Контейнерная платформа OpenShift – это корпоративная платформа, которая помогает нескольким группам, таким как команда разработчиков и ИТ-специалистов, создавать и развертывать контейнерную инфраструктуру. Все контейнеры, встроенные в OpenShift, используют очень надежную технологию контейнеризации Docker, которая может быть развернута в любом центре обработки данных публично размещенных облачных платформ.
Контейнерная платформа OpenShift была формально известна как OpenShift Enterprises. Это локальная частная платформа Red Hat как услуга, построенная на основе базовой концепции контейнеров приложений на основе Docker, в которой управление оркестровкой и администрированием осуществляет Kubernetes.
Другими словами, OpenShift объединяет Docker и Kubernetes на уровне предприятия. Это программное обеспечение контейнерной платформы для корпоративных подразделений, позволяющее развертывать и управлять заявителями в инфраструктуре по своему выбору. Например, размещение экземпляров OpenShift на экземплярах AWS.
Контейнерная платформа OpenShift доступна в двух уровнях пакета .
OpenShift Container Local – это для тех разработчиков, которые хотят развертывать и тестировать приложения на локальном компьютере. Этот пакет в основном используется командами разработчиков для разработки и тестирования приложений.
OpenShift Container Lab – предназначена для расширенной оценки приложения, начиная с разработки и заканчивая развертыванием в среде pre-prod.
OpenShift, посвященный
Это еще одно предложение, добавленное к портфелю OpenShift, в котором клиент может выбрать размещение контейнерной платформы в любом общедоступном облаке по своему выбору. Это дает конечному пользователю истинное представление о мульти-облачных предложениях, где они могут использовать OpenShift в любом облаке, которое удовлетворяет их потребностям.
Это одно из новейших предложений Red Hat, в котором конечный пользователь может использовать OpenShift для создания тестового развертывания и запуска своего приложения в OpenShift, размещенном в облаке.
Особенности OpenShift Dedicated
OpenShift предлагает специализированную платформу приложений решений в общедоступном облаке, и она унаследована от технологии OpenShift 3.
- Расширяемый и открытый. Он основан на открытой концепции Docker и развернут в облаке, благодаря чему он может расходовать средства по мере необходимости.
- Портативность. Поскольку приложение построено с использованием Docker, приложения, работающие на Docker, могут быть легко отправлены из одного места в другое, где поддерживается Docker.
- Оркестровка – В OpenShift 3 одна из ключевых функций оркестровки контейнеров и управления кластерами поддерживается с помощью Kubernetes, который появился в OpenShift версии 3.
- Автоматизация – эта версия OpenShift включена с возможностью управления исходным кодом, автоматизации сборки и автоматизации развертывания, что делает ее очень популярной на рынке в качестве платформы как поставщика услуг.
Расширяемый и открытый. Он основан на открытой концепции Docker и развернут в облаке, благодаря чему он может расходовать средства по мере необходимости.
Портативность. Поскольку приложение построено с использованием Docker, приложения, работающие на Docker, могут быть легко отправлены из одного места в другое, где поддерживается Docker.
Оркестровка – В OpenShift 3 одна из ключевых функций оркестровки контейнеров и управления кластерами поддерживается с помощью Kubernetes, который появился в OpenShift версии 3.
Автоматизация – эта версия OpenShift включена с возможностью управления исходным кодом, автоматизации сборки и автоматизации развертывания, что делает ее очень популярной на рынке в качестве платформы как поставщика услуг.
Конкуренты OpenShift
Google App Engine – это бесплатная платформа Google для разработки и размещения веб-приложений. Механизм приложений Google предлагает платформу для быстрой разработки и развертывания.
Microsoft Azure – Облако Azure размещается Microsoft в своих центрах обработки данных.
Amazon Elastic Cloud Compute – это встроенные сервисы, предоставляемые Amazon, которые помогают в разработке и размещении масштабируемых веб-приложений в облаке.
Cloud Foundry – это платформа PaaS с открытым исходным кодом для приложений Java, Ruby, Python и Node.js.
CloudStack – Apache CloudStack – это проект, разработанный Citrix и призванный стать прямым конкурентом OpenShift и OpenStack.
OpenStack – еще одна облачная технология, предоставляемая Red Hat для облачных вычислений.
Kubernetes – это технология прямого управления и кластерного управления, созданная для управления контейнером Docker.
OpenShift – Архитектура
OpenShift – это многоуровневая система, в которой каждый слой тесно связан с другим уровнем с использованием кластера Kubernetes и Docker. Архитектура OpenShift разработана таким образом, что она может поддерживать и управлять контейнерами Docker, которые размещаются поверх всех слоев с использованием Kubernetes. В отличие от более ранней версии OpenShift V2, новая версия OpenShift V3 поддерживает контейнерную инфраструктуру. В этой модели Docker помогает создавать легкие контейнеры на основе Linux, а Kubernetes поддерживает задачу организации и управления контейнерами на нескольких хостах.
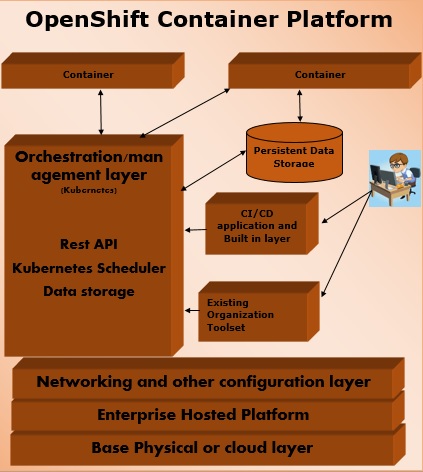
Компоненты OpenShift
Одним из ключевых компонентов архитектуры OpenShift является управление контейнерной инфраструктурой в Kubernetes. Kubernetes отвечает за развертывание и управление инфраструктурой. В любом кластере Kubernetes мы можем иметь более одного главного и несколько узлов, что гарантирует отсутствие сбоя в настройке.
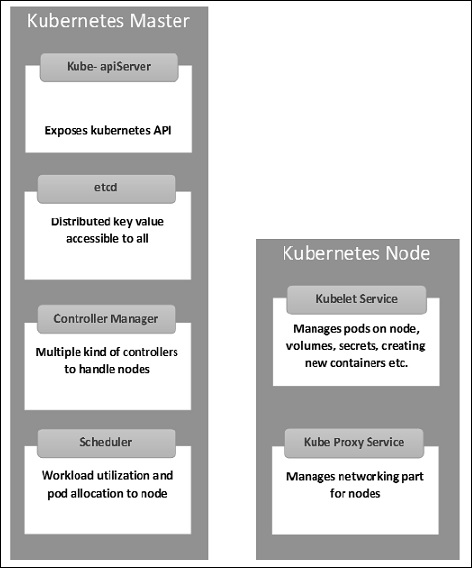
Kubernetes Master Machine Компоненты
Etcd – хранит информацию о конфигурации, которая может использоваться каждым из узлов в кластере. Это хранилище значений ключей высокой доступности, которое может быть распределено по нескольким узлам. Он должен быть доступен только серверу API Kubernetes, поскольку он может содержать конфиденциальную информацию. Это распределенное ключевое значение Store, которое доступно всем.
Сервер API – Kubernetes – это сервер API, который обеспечивает все операции в кластере с использованием API. Сервер API реализует интерфейс, который означает, что различные инструменты и библиотеки могут легко взаимодействовать с ним. Kubeconfig – это пакет вместе с инструментами на стороне сервера, которые можно использовать для связи. Это разоблачает API Kubernetes ».
Диспетчер контроллеров. Этот компонент отвечает за большинство сборщиков, которые регулируют состояние кластера и выполняют задачу. Его можно рассматривать как демон, который работает в бесконечном цикле и отвечает за сбор и отправку информации на сервер API. Он работает для получения общего состояния кластера, а затем вносит изменения, чтобы привести текущее состояние сервера в желаемое состояние. Ключевыми контроллерами являются контроллер репликации, контроллер конечной точки, контроллер пространства имен и контроллер учетной записи службы. Диспетчер контроллеров запускает контроллеры различного типа для обработки узлов, конечных точек и т. Д.
Планировщик – это ключевой компонент мастера Kubernetes. Это служба в мастере, которая отвечает за распределение рабочей нагрузки. Он отвечает за отслеживание использования рабочей нагрузки на узлах кластера, а затем за размещение рабочей нагрузки, на которой доступны ресурсы, и за принятие рабочей нагрузки. Другими словами, это механизм, отвечающий за распределение модулей доступным узлам. Планировщик отвечает за использование рабочей нагрузки и выделение модуля новому узлу.
Узлы Kubernetes
Ниже приведены ключевые компоненты сервера Node, которые необходимы для связи с мастером Kubernetes.
Docker . Первым требованием каждого узла является Docker, который помогает запускать контейнеры инкапсулированных приложений в относительно изолированной, но облегченной операционной среде.
Служба Kubelet – это небольшая служба в каждом узле, которая отвечает за передачу информации в службу уровня управления и обратно. Он взаимодействует с хранилищем etcd для чтения деталей конфигурации и значений Wright. Это связывается с главным компонентом для получения команд и работы. Затем процесс kubelet берет на себя ответственность за поддержание рабочего состояния и сервера узла. Он управляет сетевыми правилами, переадресацией портов и т. Д.
Прокси-сервис Kubernetes – это прокси-сервис, который работает на каждом узле и помогает сделать сервисы доступными для внешнего хоста. Помогает в пересылке запроса на исправление контейнеров. Прокси-сервис Kubernetes способен выполнять примитивную балансировку нагрузки. Это гарантирует, что сетевая среда предсказуема и доступна, но в то же время она также изолирована. Он управляет модулями на узлах, томами, секретами, проверкой работоспособности новых контейнеров и т. Д.
Интегрированный Реестр Контейнеров OpenShift
Реестр контейнеров OpenShift – это встроенное хранилище Red Hat, которое используется для хранения образов Docker. В последней интегрированной версии OpenShift появился пользовательский интерфейс для просмотра изображений во внутреннем хранилище OpenShift. Эти реестры могут содержать изображения с указанными тегами, которые впоследствии используются для создания из него контейнеров.
Часто используемые термины
Изображение – изображения Kubernetes (Docker) являются ключевыми строительными блоками контейнерной инфраструктуры. На данный момент Kubernetes поддерживает только изображения Docker. Внутри каждого контейнера в модуле находится изображение Docker. При настройке модуля свойство изображения в файле конфигурации имеет тот же синтаксис, что и команда Docker.
Проект – их можно определить как переименованную версию домена, которая присутствовала в более ранней версии OpenShift V2.
Контейнер – это те, которые создаются после развертывания образа на узле кластера Kubernetes.
Узел . Узел – это рабочая машина в кластере Kubernetes, которая также называется minion для master. Это рабочие единицы, которые могут быть физическими, виртуальными или облачными.
Pod – Модуль – это набор контейнеров и его хранилище внутри узла кластера Kubernetes. Можно создать контейнер с несколькими контейнерами внутри. Например, хранение контейнера базы данных и контейнера веб-сервера внутри модуля.
OpenShift – настройка среды
В этой главе мы узнаем о настройке среды OpenShift.
Системные требования
Чтобы настроить корпоративный OpenShift, необходимо иметь активную учетную запись Red Hat. Поскольку OpenShift работает на архитектуре мастера и узла Kubernetes, нам необходимо установить их на отдельных машинах, где одна машина работает как мастер, а другая работает на узле. Для того, чтобы настроить оба, существуют минимальные системные требования.
Конфигурация главной машины
Ниже приведены минимальные системные требования для конфигурации главной машины.
- Базовая машина, размещенная в физической, виртуальной или любой облачной среде.
- По крайней мере, Linux 7 с необходимыми пакетами на этом экземпляре.
- 2 ядра процессора.
- Не менее 8 ГБ ОЗУ.
- 30 ГБ встроенной памяти на жестком диске.
Базовая машина, размещенная в физической, виртуальной или любой облачной среде.
По крайней мере, Linux 7 с необходимыми пакетами на этом экземпляре.
2 ядра процессора.
Не менее 8 ГБ ОЗУ.
30 ГБ встроенной памяти на жестком диске.
Конфигурация узла машины
- Физический или виртуальный базовый образ, указанный для главной машины.
- По крайней мере, Linux 7 на машине.
- Докер установлен с версией не ниже 1.6.
- 1 ядро процессора.
- 8 ГБ ОЗУ.
- 15 ГБ жесткий диск для размещения изображений и 15 ГБ для хранения изображений.
Пошаговое руководство по настройке OpenShift
В следующем описании мы собираемся настроить лабораторную среду OpenShift, которая впоследствии может быть расширена до более крупного кластера. Поскольку OpenShift требует настройки мастера и узла, нам потребуется как минимум две машины, размещенные на облачной, физической или виртуальной машине.
Шаг 1 – Сначала установите Linux на обе машины, где Linux 7 должна быть наименьшей версией. Это можно сделать с помощью следующих команд, если у вас есть активная подписка Red Hat.
# subscription-manager repos --disable = "*"
# subscription-manager repos --enable = "rhel-7-server-rpms"
# subscription-manager repos --enable = "rhel-7-server-extras-rpms"
# subscription-manager repos --enable = "rhel-7-server-optional-rpms"
# subscription-manager repos --enable = "rhel-7-server-ose-3.0-rpms"
# yum install wget git net-tools bind-utils iptables-services bridge-utils
# yum install wget git net-tools bind-utils iptables-services bridge-utils
# yum install python-virtualenv
# yum install gcc
# yum install httpd-tools
# yum install docker
# yum update
После того как у нас будут установлены все вышеперечисленные базовые пакеты, следующим шагом будет настройка Docker на соответствующих машинах.
Шаг 2. Настройте Docker таким образом, чтобы он разрешал небезопасную связь только в локальной сети. Для этого отредактируйте файл Docker внутри / etc / sysconfig. Если файл отсутствует, вам нужно создать его вручную.
# vi /etc/sysconfig/docker OPTIONS = --selinux-enabled --insecure-registry 192.168.122.0/24
После настройки Docker на главном компьютере нам нужно установить беспарольную связь между обеими машинами. Для этого мы будем использовать аутентификацию с открытым и закрытым ключом.
Шаг 3 – Сгенерируйте ключи на главном компьютере, а затем скопируйте ключ id_rsa.pub в файл авторизованного ключа узлового компьютера, что можно сделать с помощью следующей команды.
# ssh-keygen
# ssh-copy-id -i .ssh/id_rsa.pub root@ose3-node.test.com
После того, как вы выполнили все вышеперечисленные настройки, далее следует настроить OpenShift версии 3 на главном компьютере.
Шаг 4 – На главном компьютере выполните следующую команду curl.
Приведенная выше команда установит установку для OSV3. Следующим шагом будет настройка OpenShift V3 на машине.
Если вы не можете загрузить из Интернета напрямую, его можно загрузить с https://install.openshift.com/portable/oo-install-ose.tgz в виде пакета tar, из которого установщик может работать на локальном главном компьютере.
Как только у нас будет готовая настройка, нам нужно начать с фактической конфигурации OSV3 на машинах. Эта настройка очень специфична для тестирования среды на фактическое производство, у нас есть LDAP и другие компоненты.
Шаг 5 – На главном компьютере настройте следующий код, расположенный в /etc/openshift/master/master-config.yaml
# vi /etc/openshift/master/master-config.yaml identityProviders: - name: my_htpasswd_provider challenge: true login: true provider: apiVersion: v1 kind: HTPasswdPasswordIdentityProvider file: /root/users.htpasswd routingConfig: subdomain: testing.com
Затем создайте стандартного пользователя для администрирования по умолчанию.
# htpasswd -c /root/users.htpasswd admin
Шаг 6 – Поскольку OpenShift использует реестр Docker для настройки изображений, нам нужно настроить реестр Docker. Это используется для создания и хранения образов Docker после сборки.
Создайте каталог на компьютере узла OpenShift с помощью следующей команды.
# mkdir /images
Затем войдите в систему на главном компьютере, используя учетные данные администратора по умолчанию, которые создаются при настройке реестра.
# oc login Username: system:admin
Переключитесь на созданный по умолчанию проект.
# oc project default
Шаг 7 – Создайте реестр Docker.
#echo '>' | oc create -f -
Изменить пользовательские привилегии.
#oc edit scc privileged users: - system:serviceaccount:openshift-infra:build-controller - system:serviceaccount:default:registry
Создайте и отредактируйте реестр изображений.
#oadm registry --service-account = registry -- config = /etc/openshift/master/admin.kubeconfig -- credentials = /etc/openshift/master/openshift-registry.kubeconfig -- images = 'registry.access.redhat.com/openshift3/ose-$:$' -- mount-host = /images
Шаг 8 – Создайте маршрутизацию по умолчанию.
По умолчанию OpenShift использует OpenVswitch в качестве программной сети. Используйте следующую команду для создания маршрутизации по умолчанию. Это используется для балансировки нагрузки и прокси-маршрутизации. Маршрутизатор похож на реестр Docker, а также работает в реестре.
# echo '>' | oc create -f -
Далее отредактируйте привилегии пользователя.
#oc edit scc privileged users: - system:serviceaccount:openshift-infra:build-controller - system:serviceaccount:default:registry - system:serviceaccount:default:router #oadm router router-1 --replicas = 1 -- credentials = '/etc/openshift/master/openshift-router.kubeconfig' -- images = 'registry.access.redhat.com/openshift3/ose-$:$'
Шаг 9 – Настройте DNS.
Для обработки URL-запроса OpenShift нужна рабочая среда DNS. Эта конфигурация DNS необходима для создания подстановочного знака, который необходим для создания подстановочного знака DNS, указывающего на маршрутизатор.
# yum install bind-utils bind
# systemctl start named
# systemctl enable named
vi /etc/named.conf options ; forwarders < 10.38.55.13; ; >; zone "lab.com" IN < type master; file "/var/named/dynamic/test.com.zone"; allow-update < none; >; >;
Шаг 10 – Последний шаг – настроить github-сервер на главном компьютере OpenShift V3, что необязательно. Это можно легко сделать с помощью следующей последовательности команд.
#yum install curl openssh-server
#systemctl enable sshd
# systemctl start sshd
# firewall-cmd --permanent --add-service = http
# systemctl reload firewalld
#curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-
#yum install gitlab-ce
# gitlab-ctl reconfigure
После завершения вышеуказанной настройки вы можете проверить и развернуть приложения, о которых мы узнаем больше в следующих главах.
OpenShift – базовая концепция
Прежде чем начать с фактической настройки и развертывания приложений, нам необходимо понять некоторые основные термины и понятия, используемые в OpenShift V3.
Контейнеры и изображения
Изображений
Это основные строительные блоки OpenShift, которые формируются из образов Docker. В каждом модуле OpenShift кластер имеет свои собственные изображения, работающие внутри него. Когда мы настраиваем модуль, у нас есть поле, которое будет объединено в реестр. Этот файл конфигурации извлечет образ и развернет его на узле кластера.
apiVersion: v1 kind: pod metadata: name: Tesing_for_Image_pull -----------> Name of Pod spec: containers: - name: neo4j-server ------------------------> Name of the image image: ----------> Image to be pulled imagePullPolicy: Always ------------->Image pull policy command: [“echo”, “SUCCESS”] -------------------> Massage after image pull
Чтобы вытащить и создать из него образ, выполните следующую команду. OC – это клиент для связи со средой OpenShift после входа в систему.
$ oc create –f Tesing_for_Image_pull
Контейнер
Это создается, когда образ Docker развертывается в кластере OpenShift. При определении любой конфигурации мы определяем секцию контейнера в файле конфигурации. Внутри одного контейнера может быть несколько образов, и все контейнеры, работающие на узле кластера, управляются OpenShift Kubernetes.
spec: containers: - name: py ------------------------> Name of the container image: python----------> Image going to get deployed on container command: [“python”, “SUCCESS”] restartPocliy: Never --------> Restart policy of container
Ниже приведены спецификации для определения контейнера, в котором работает несколько изображений.
apiVersion: v1 kind: Pod metadata: name: Tomcat spec: containers: - name: Tomcat image: tomcat: 8.0 ports: - containerPort: 7500 imagePullPolicy: Always -name: Database Image: mongoDB Ports: - containerPort: 7501 imagePullPolicy: Always
В приведенной выше конфигурации мы определили многоконтейнерный модуль с двумя образами Tomcat и MongoDB внутри.
Стручки и Услуги
Бобы
Pod можно определить как коллекцию контейнера и его хранилище внутри узла кластера OpenShift (Kubernetes). В общем, у нас есть два типа контейнеров, начиная с одного контейнера и заканчивая несколькими контейнерами.
Single Container Pod – Они могут быть легко созданы с помощью команды OC или файла базовой конфигурации yml.
$ oc run —image =
Создайте его с помощью простого файла yaml следующим образом.
apiVersion: v1 kind: Pod metadata: name: apache spec: containers: - name: apache image: apache: 8.0 ports: - containerPort: 7500 imagePullPolicy: Always
Как только вышеуказанный файл будет создан, он сгенерирует модуль с помощью следующей команды.
$ oc create –f apache.yml
Multi-Container Pod – это несколько контейнеров, в которых у нас работает более одного контейнера. Они создаются с использованием файлов yaml следующим образом.
apiVersion: v1 kind: Pod metadata: name: Tomcat spec: containers: - name: Tomcat image: tomcat: 8.0 ports: - containerPort: 7500 imagePullPolicy: Always -name: Database Image: mongoDB Ports: - containerPort: 7501 imagePullPolicy: Always
После создания этих файлов мы можем просто использовать тот же метод, что и выше, для создания контейнера.
Сервис – Поскольку у нас есть набор контейнеров, работающих внутри модуля, таким же образом у нас есть сервис, который можно определить как логический набор модулей. Это абстрактный слой поверх модуля, который предоставляет одно имя IP и DNS, через которое можно получить доступ к модулям. Сервис помогает управлять конфигурацией балансировки нагрузки и очень легко масштабировать модуль. В OpenShift сервис – это объект REST, обожествление которого можно опубликовать в apiService на главном сервере OpenShift для создания нового экземпляра.
apiVersion: v1 kind: Service metadata: name: Tutorial_point_service spec: ports: - port: 8080 targetPort: 31999
Строит и Потоки
Строит
В OpenShift сборка – это процесс преобразования изображений в контейнеры. Это обработка, которая преобразует исходный код в изображение. Этот процесс сборки работает по заранее определенной стратегии построения исходного кода для изображения.
Сборка обрабатывает несколько стратегий и источников.
Стратегии сборки
- Source to Image – это в основном инструмент, который помогает в создании воспроизводимых изображений. Эти образы всегда находятся в состоянии готовности к запуску с помощью команды запуска Docker.
- Сборка Docker – это процесс, в котором изображения создаются с использованием файла Docker с помощью простой команды сборки Docker.
- Custom Build – это сборки, которые используются для создания базовых образов Docker.
Source to Image – это в основном инструмент, который помогает в создании воспроизводимых изображений. Эти образы всегда находятся в состоянии готовности к запуску с помощью команды запуска Docker.
Сборка Docker – это процесс, в котором изображения создаются с использованием файла Docker с помощью простой команды сборки Docker.
Custom Build – это сборки, которые используются для создания базовых образов Docker.
Источники сборки
Git – Этот источник используется, когда Git-репозиторий используется для построения изображений. Dockerfile не является обязательным. Конфигурации из исходного кода выглядят следующим образом.
source: type: "Git" git: uri: "https://github.com/vipin/testing.git" ref: "master" contextDir: "app/dir" dockerfile: "FROM openshift/ruby-22-centos7\nUSER example"
Dockerfile – Dockerfile используется в качестве входных данных в файле конфигурации.
source: type: "Dockerfile" dockerfile: "FROM ubuntu: latest RUN yum install -y httpd"
Потоки изображений – Потоки изображений создаются после вытягивания изображений. Преимущество потока изображений заключается в том, что он ищет обновления для новой версии изображения. Это используется для сравнения любого количества изображений контейнера в формате Docker, идентифицированных тегами.
Потоки изображений могут автоматически выполнять действие при создании нового изображения. Все сборки и развертывания могут отслеживать действия с изображениями и выполнять соответствующие действия. Ниже описано, как мы определяем построение потока.
apiVersion: v1 kind: ImageStream metadata: annotations: openshift.io/generated-by: OpenShiftNewApp generation: 1 labels: app: ruby-sample-build selflink: /oapi/v1/namespaces/test/imagestreams/origin-ruby-sample uid: ee2b9405-c68c-11e5-8a99-525400f25e34 spec: <> status: dockerImageRepository: 172.30.56.218:5000/test/origin-ruby-sample tags: - items: - created: 2016-01-29T13:40:11Z dockerImageReference: 172.30.56.218:5000/test/origin-apache-sample generation: 1 image: vklnld908.int.clsa.com/vipin/test tag: latest
Маршруты и шаблоны
Маршруты
В OpenShift маршрутизация – это метод представления сервиса внешнему миру путем создания и настройки внешнего хоста, доступного для доступа. Маршруты и конечные точки используются для предоставления сервиса внешнему миру, откуда пользователь может использовать имя подключения (DNS) для доступа к определенному приложению.
В OpenShift маршруты создаются с использованием маршрутизаторов, которые развертываются администратором OpenShift в кластере. Маршрутизаторы используются для привязки портов HTTP (80) и https (443) к внешним приложениям.
Ниже приведены различные виды протоколов, поддерживаемых маршрутами.
При настройке службы селекторы используются для настройки службы и поиска конечной точки с использованием этой службы. Ниже приведен пример того, как мы создаем сервис и маршрутизацию для этого сервиса, используя соответствующий протокол.
"kind": "Service", "apiVersion": "v1", "metadata": "name": "Openshift-Rservice">, "spec": "selector": "name":"RService-openshift">, "ports": [ "protocol": "TCP", "port": 8888, "targetPort": 8080 > ] > >
Затем выполните следующую команду, и служба будет создана.
$ oc create -f ~/training/content/Openshift-Rservice.json
Так выглядит сервис после создания.
$ oc describe service Openshift-Rservice Name: Openshift-Rservice Labels: Selector: name = RService-openshift Type: ClusterIP IP: 172.30.42.80 Port: 8080/TCP Endpoints: Session Affinity: None No events.
Создайте маршрутизацию для сервиса, используя следующий код.
"kind": "Route", "apiVersion": "v1", "metadata": "name": "Openshift-service-route">, "spec": "host": "hello-openshift.cloudapps.example.com", "to": "kind": "Service", "name": "OpenShift-route-service" >, "tls": "termination": "edge"> > >
Когда команда OC используется для создания маршрута, создается новый экземпляр ресурса маршрута.
Шаблоны
Шаблоны определяются как стандартный объект в OpenShift, который можно использовать несколько раз. Он параметризован списком заполнителей, которые используются для создания нескольких объектов. Это может быть использовано для создания чего угодно, начиная от модуля и заканчивая сетью, для которого пользователи имеют право создавать. Список объектов может быть создан, если шаблон из интерфейса CLI или GUI в образе загружен в каталог проекта.
apiVersion: v1 kind: Template metadata: name: annotations: description: iconClass: «icon-redis» tags: objects: — apiVersion: v1 kind: Pod metadata: name: spec: containers: image: name: master ports: — containerPort: protocol: labels: redis:
Аутентификация и Авторизация
Аутентификация
В OpenShift при настройке главной и клиентской структуры мастер предлагает встроенную функцию сервера OAuth. OAuth-сервер используется для генерации токенов, который используется для аутентификации в API. Так как OAuth является настройкой по умолчанию для master, у нас по умолчанию используется провайдер идентификации Allow All. Присутствуют разные провайдеры идентификации, которые можно настроить по адресу /etc/openshift/master/master-config.yaml .
В OAuth есть разные типы провайдеров идентификации.
- Позволять все
- Запретить все
- Htpasswd
- LDAP
- Базовая аутентификация
Позволять все
apiVersion: v1 kind: Pod metadata: name: redis-master spec: containers: image: dockerfile/redis name: master ports: - containerPort: 6379 protocol: TCP oauthConfig: identityProviders: - name: my_allow_provider challenge: true login: true provider: apiVersion: v1 kind: AllowAllPasswordIdentityProvider
Запретить все
apiVersion: v1 kind: Pod metadata: name: redis-master spec: containers: image: dockerfile/redis name: master ports: - containerPort: 6379 protocol: TCP oauthConfig: identityProviders: - name: my_allow_provider challenge: true login: true provider: apiVersion: v1 kind: DenyAllPasswordIdentityProvider
Htpasswd
Чтобы использовать HTPasswd, нам нужно сначала настроить Httpd-tools на главном компьютере, а затем настроить его так же, как мы это делали для других.
identityProviders: - name: my_htpasswd_provider challenge: true login: true provider: apiVersion: v1 kind: HTPasswdPasswordIdentityProvider
авторизация
Авторизация – это функция мастера OpenShift, которая используется для валидации пользователя. Это означает, что он проверяет пользователя, который пытается выполнить действие, чтобы определить, авторизован ли пользователь для выполнения этого действия в данном проекте. Это помогает администратору контролировать доступ к проектам.
Политики авторизации контролируются с помощью –
Оценка авторизации производится с использованием –
- тождественность
- действие
- Наручники
- Кластерная политика
- Местная политика
OpenShift – Начало работы
OpenShift состоит из двух типов медиан для создания и развертывания приложений с помощью графического интерфейса или интерфейса командной строки. В этой главе мы будем использовать CLI для создания нового приложения. Мы будем использовать клиент OC для связи со средой OpenShift.
Создание нового приложения
В OpenShift есть три способа создания нового приложения.
- Из исходного кода
- Из изображения
- Из шаблона
Из исходного кода
Когда мы пытаемся создать приложение из исходного кода, OpenShift ищет файл Docker, который должен присутствовать в репозитории, который определяет процесс сборки приложения. Мы будем использовать oc new-app для создания приложения.
Первое, что следует иметь в виду при использовании репо, это то, что он должен указывать на источник в репо, откуда OpenShift будет извлекать код и собирать его.
Если репозиторий клонирован на компьютере Docker, на котором установлен клиент OC, и пользователь находится в том же каталоге, его можно создать с помощью следующей команды.
$ oc new-app .
Ниже приведен пример попытки построить из удаленного репо для определенной ветви.
$ oc new-app https://github.com/openshift/Testing-deployment.git#test1
Здесь test1 – это ветка, из которой мы пытаемся создать новое приложение в OpenShift.
При указании файла Docker в хранилище мы должны определить стратегию сборки, как показано ниже.
$ oc new-app OpenShift/OpenShift-test~https://github.com/openshift/Testingdeployment.git
Из изображения
При создании приложения с использованием изображений изображения присутствуют на локальном сервере Docker, во внутреннем хранилище Docker или в концентраторе Docker. Единственное, в чем пользователь должен убедиться, это то, что он может без проблем извлекать изображения из концентратора.
OpenShift имеет возможность определять используемый источник, будь то образ Docker или поток источника. Однако, если пользователь желает, он может явно определить, является ли это потоком изображения или изображением Docker.
$ oc new-app - - docker-image tomcat
Использование потока изображений –
$ oc new-app tomcat:v1
Из шаблона
Шаблоны могут быть использованы для создания нового приложения. Это может быть уже существующий шаблон или создание нового шаблона.
Следующий файл yaml представляет собой шаблон, который можно использовать для развертывания.
apiVersion: v1 kind: Template metadata: name: annotations: description: iconClass: «icon-redis» tags: objects: — apiVersion: v1 kind: Pod metadata: name: spec: containers: image: name: master ports: — containerPort: protocol: labels: redis:
Разработка и развертывание веб-приложения
Разработка нового приложения в OpenShift
Чтобы создать новое приложение в OpenShift, мы должны написать новый код приложения и собрать его, используя команды сборки OpenShift OC. Как уже говорилось, у нас есть несколько способов создания нового изображения. Здесь мы будем использовать шаблон для сборки приложения. Этот шаблон создаст новое приложение при запуске с помощью команды oc new-app.
Будет создан следующий шаблон: два интерфейсных приложения и одна база данных. Наряду с этим, он создаст два новых сервиса, и эти приложения будут развернуты в кластере OpenShift. При создании и развертывании приложения сначала необходимо создать пространство имен в OpenShift и развернуть приложение в этом пространстве имен.
Создать новое пространство имен
$ oc new-project openshift-test --display-name = "OpenShift 3 Sample" -- description = "This is an example project to demonstrate OpenShift v3"
шаблон
"kind": "Template", "apiVersion": "v1", "metadata": "name": "openshift-helloworld-sample", "creationTimestamp": null, "annotations": "description": "This example shows how to create a simple openshift application in openshift origin v3", "iconClass": "icon-openshift", "tags": "instant-app,openshift,mysql" > > >,
Определения объектов
Секретное определение в шаблоне
"objects": [ "kind": "Secret", "apiVersion": "v1", "metadata": "name": "dbsecret">, "stringData" : "mysql-user" : "$", "mysql-password" : "$" > >,
Определение сервиса в шаблоне
"kind": "Service", "apiVersion": "v1", "metadata": "name": "frontend", "creationTimestamp": null >, "spec": "ports": [ "name": "web", "protocol": "TCP", "port": 5432, "targetPort": 8080, "nodePort": 0 > ], "selector": "name": "frontend">, "type": "ClusterIP", "sessionAffinity": "None" >, "status": "loadBalancer": <> > >,
Определение маршрута в шаблоне
"kind": "Route", "apiVersion": "v1", "metadata": "name": "route-edge", "creationTimestamp": null, "annotations": "template.openshift.io/expose-uri": "http://" > >, "spec": "host": "www.example.com", "to": "kind": "Service", "name": "frontend" >, "tls": "termination": "edge" > >, "status": <> >, "kind": "ImageStream", "apiVersion": "v1", "metadata": "name": "origin-openshift-sample", "creationTimestamp": null >, "spec": <>, "status": "dockerImageRepository": "" > >, "kind": "ImageStream", "apiVersion": "v1", "metadata": "name": "openshift-22-ubuntu7", "creationTimestamp": null >, "spec": "dockerImageRepository": "ubuntu/openshift-22-ubuntu7" >, "status": "dockerImageRepository": "" > >,
Создать определение конфигурации в шаблоне
"kind": "BuildConfig", "apiVersion": "v1", "metadata": "name": "openshift-sample-build", "creationTimestamp": null, "labels": name": "openshift-sample-build"> >, "spec": < "triggers": [ < "type": "GitHub", "github": < "secret": "secret101" > >, < "type": "Generic", "generic": < "secret": "secret101", "allowEnv": true > >, < "type": "ImageChange", "imageChange": <> >, < "type": "ConfigChange”> ], "source": "type": "Git", "git": "uri": https://github.com/openshift/openshift-hello-world.git > >, "strategy": "type": "Docker", "dockerStrategy": "from": "kind": "ImageStreamTag", "name": "openshift-22-ubuntu7:latest” >, "env": [ < "name": "EXAMPLE", "value": "sample-app" > ] > >, "output": < "to": < "kind": "ImageStreamTag", "name": "origin-openshift-sample:latest" > >, "postCommit": < "args": ["bundle", "exec", "rake", "test"] >, "status": < "lastVersion": 0 > > >,
Конфигурация развертывания в шаблоне
"status": "lastVersion": 0 > "kind": "DeploymentConfig", "apiVersion": "v1", "metadata": "name": "frontend", "creationTimestamp": null > >, "spec": "strategy": "type": "Rolling", "rollingParams": "updatePeriodSeconds": 1, "intervalSeconds": 1, "timeoutSeconds": 120, "pre": "failurePolicy": "Abort", "execNewPod": "command": [ "/bin/true" ], "env": [ "name": "CUSTOM_VAR1", "value": "custom_value1" > ] > > > > > "triggers": [ "type": "ImageChange", "imageChangeParams": "automatic": true, "containerNames": [ "openshift-helloworld" ], "from": "kind": "ImageStreamTag", "name": "origin-openshift-sample:latest" > > >, "type": "ConfigChange" > ], "replicas": 2, "selector": "name": "frontend" >, "template": "metadata": "creationTimestamp": null, "labels": "name": "frontend" > >, "spec": "containers": [ "name": "openshift-helloworld", "image": "origin-openshift-sample", "ports": [ "containerPort": 8080, "protocol": "TCP” > ], "env": [ < "name": "MYSQL_USER", "valueFrom": < "secretKeyRef" : < "name" : "dbsecret", "key" : "mysql-user" > > >, < "name": "MYSQL_PASSWORD", "valueFrom": < "secretKeyRef" : < "name" : "dbsecret", "key" : "mysql-password" > > >, < "name": "MYSQL_DATABASE", "value": "$MYSQL_DATABASE>" > ], "resources": <>, "terminationMessagePath": "/dev/termination-log", "imagePullPolicy": "IfNotPresent", "securityContext": < "capabilities": <>, "privileged": false > > ], "restartPolicy": "Always", "dnsPolicy": "ClusterFirst" >, "status": <> >,
Определение сервиса в шаблоне
"kind": "Service", "apiVersion": "v1", "metadata": "name": "database", "creationTimestamp": null >, "spec": "ports": [ "name": "db", "protocol": "TCP", "port": 5434, "targetPort": 3306, "nodePort": 0 > ], "selector": "name": "database >, "type": "ClusterIP", "sessionAffinity": "None" >, "status": < "loadBalancer": <> > >,
Определение конфигурации развертывания в шаблоне
"kind": "DeploymentConfig", "apiVersion": "v1", "metadata": "name": "database", "creationTimestamp": null >, "spec": "strategy": "type": "Recreate", "resources": <> >, "triggers": [ "type": "ConfigChange" > ], "replicas": 1, "selector": "name": "database">, "template": "metadata": "creationTimestamp": null, "labels": "name": "database"> >, "template": "metadata": "creationTimestamp": null, "labels": "name": "database" > >, "spec": "containers": [ "name": "openshift-helloworld-database", "image": "ubuntu/mysql-57-ubuntu7:latest", "ports": [ "containerPort": 3306, "protocol": "TCP" > ], "env": [ "name": "MYSQL_USER", "valueFrom": "secretKeyRef" : "name" : "dbsecret", "key" : "mysql-user" > > >, "name": "MYSQL_PASSWORD", "valueFrom": "secretKeyRef" : "name" : "dbsecret", "key" : "mysql-password" > > >, "name": "MYSQL_DATABASE", "value": "$" > ], "resources": <>, "volumeMounts": [ "name": "openshift-helloworld-data", "mountPath": "/var/lib/mysql/data" > ], "terminationMessagePath": "/dev/termination-log", "imagePullPolicy": "Always", "securityContext": "capabilities": <>, "privileged": false > > ], "volumes": [ "name": "openshift-helloworld-data", "emptyDir": "medium": ""> > ], "restartPolicy": "Always", "dnsPolicy": "ClusterFirst” > > >, "status": <> >, "parameters": [ < "name": "MYSQL_USER", "description": "database username", "generate": "expression", "from": "user[A-Z0-9]3>", "required": true >, < "name": "MYSQL_PASSWORD", "description": "database password", "generate": "expression", "from": "[a-zA-Z0-9]8>", "required": true >, < "name": "MYSQL_DATABASE", "description": "database name", "value": "root", "required": true > ], "labels": < "template": "application-template-dockerbuild" > >
Приведенный выше файл шаблона необходимо скомпилировать сразу. Нам нужно сначала скопировать весь контент в один файл и назвать его как файл yaml после того, как он будет сделан.
Нам нужно выполнить следующую команду, чтобы создать приложение.
$ oc new-app application-template-stibuild.json --> Deploying template openshift-helloworld-sample for "application-template-stibuild.json" openshift-helloworld-sample --------- This example shows how to create a simple ruby application in openshift origin v3 * With parameters: * MYSQL_USER = userPJJ # generated * MYSQL_PASSWORD = cJHNK3se # generated * MYSQL_DATABASE = root --> Creating resources with label app = ruby-helloworld-sample . service "frontend" created route "route-edge" created imagestream "origin-ruby-sample" created imagestream "ruby-22-centos7" created buildconfig "ruby-sample-build" created deploymentconfig "frontend" created service "database" created deploymentconfig "database" created --> Success Build scheduled, use 'oc logs -f bc/ruby-sample-build' to track its progress. Run 'oc status' to view your app.
Если мы хотим отслеживать сборку, это можно сделать с помощью –
$ oc get builds NAME TYPE FROM STATUS STARTED DURATION openshift-sample-build-1 Source Git@bd94cbb Running 7 seconds ago 7s
Мы можем проверить развернутые приложения в OpenShift, используя –
$ oc get pods NAME READY STATUS RESTARTS AGE database-1-le4wx 1/1 Running 0 1m frontend-1-e572n 1/1 Running 0 27s frontend-1-votq4 1/1 Running 0 31s opeshift-sample-build-1-build 0/1 Completed 0 1m
Мы можем проверить, созданы ли сервисы приложений согласно определению сервиса, используя
$ oc get services NAME CLUSTER-IP EXTERNAL-IP PORT(S) SELECTOR AGE database 172.30.80.39 5434/TCP name=database 1m frontend 172.30.17.4 5432/TCP name=frontend 1m
OpenShift – автоматизация сборки
В OpenShift у нас есть несколько методов автоматизации конвейера сборки. Для этого нам нужно создать ресурс BuildConfig для описания процесса сборки. Поток в BuildConfig можно сравнить с определением задания в определении задания Дженкинса. При создании потока сборки мы должны выбрать стратегию сборки.
Файл BuildConfig
В OpenShift BuildConfig – это объект отдыха, используемый для подключения к API, а затем для создания нового экземпляра.
kind: "BuildConfig" apiVersion: "v1" metadata: name: "" spec: runPolicy: "Serial" triggers: - type: "GitHub" github: secret: "" - type: "Generic" generic: secret: "secret101" - type: "ImageChange" source: type: "" git: uri: "https://github.com/openshift/openshift-hello-world" dockerfile: "FROM openshift/openshift-22-centos7\nUSER example" strategy: type: "Source" sourceStrategy: from: kind: "ImageStreamTag" name: "openshift-20-centos7:latest" output: to: kind: "ImageStreamTag" name: "origin-openshift-sample:latest" postCommit: script: "bundle exec rake test"
В OpenShift есть четыре типа стратегий сборки.
- Стратегия исходного изображения
- Стратегия докера
- Индивидуальная стратегия
- Трубопроводная стратегия
Стратегия исходного изображения
Позволяет создавать изображения контейнеров, начиная с исходного кода. В этом потоке фактический код сначала загружается в контейнер, а затем компилируется внутри него. Скомпилированный код развертывается в том же контейнере, а изображение создается из этого кода.
strategy: type: "Source" sourceStrategy: from: kind: "ImageStreamTag" name: "builder-image:latest" forcePull: true
Есть несколько стратегий стратегии.
- Forcepull
- Инкрементные сборки
- Внешние сборки
Докерская стратегия
В этом потоке OpenShift использует Dockerfile для создания образа, а затем загружает созданные изображения в реестр Docker.
strategy: type: Docker dockerStrategy: from: kind: "ImageStreamTag" name: "ubuntu:latest"
Опцию Docker file можно использовать в нескольких местах, начиная с пути к файлу, без кэширования и принудительного извлечения.
- Из изображения
- Путь к Dockerfile
- Нет кеша
- Сила тяги
Индивидуальная стратегия
Это один из различных видов стратегии сборки, в котором нет такого принуждения, что результатом сборки будет изображение. Это можно сравнить со свободной работой Дженкинса. С этим мы можем создать Jar, RPM и другие пакеты.
strategy: type: "Custom" customStrategy: from: kind: "DockerImage" name: "openshift/sti-image-builder"
Он состоит из нескольких стратегий сборки.
- Разоблачить сокет Docker
- Секреты
- Сила тяги
Трубопроводная стратегия
Конвейерная стратегия используется для создания пользовательских конвейеров сборки. Это в основном используется для реализации рабочего процесса в конвейере. Этот поток сборки использует пользовательский поток конвейера сборки с использованием языка Groovy DSL. OpenShift создаст конвейерное задание в Jenkins и выполнит его. Этот трубопроводный поток также можно использовать в Jenkins. В этой стратегии мы используем Jenkinsfile и добавляем это в определение buildconfig.
Strategy: type: "JenkinsPipeline" jenkinsPipelineStrategy: jenkinsfile: "node('agent') "
Использование сборки конвейера
kind: «BuildConfig» apiVersion: «v1» metadata: name: «test-pipeline» spec: source: type: «Git» git: uri: «https://github.com/openshift/openshift-hello-world» strategy: type: «JenkinsPipeline» jenkinsPipelineStrategy: jenkinsfilePath:
OpenShift – CLI
OpenShift CLI используется для управления приложениями OpenShift из командной строки. OpenShift CLI имеет возможность управлять сквозным жизненным циклом приложения. В общем, мы будем использовать OC, который является клиентом OpenShift, для связи с OpenShift.
Настройка OpenShift CLI
Чтобы настроить клиент OC в другой операционной системе, нам нужно выполнить другую последовательность шагов.
OC Client для Windows
Шаг 2 – Распакуйте пакет по целевому пути на машине.
Шаг 3 – Отредактируйте переменную окружения пути системы.
C:\Users\xxxxxxxx\xxxxxxxx>echo %PATH% C:\oraclexe\app\oracle\product\10.2.0\server\bin;C:\Program Files (x86)\Intel\iCLS Client\;C:\Program Files\Intel\iCLS Client\;C:\Program Files (x86)\AMD APP\bin\x86_64;C:\Program Files (x86)\AMD APP\bin\x86; C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\ v1.0\;C:\Program Files (x86)\Windows Live\Shared;C:\Program Files (x86)\ATI Technologies\ATI.ACE\C ore-Static;C:\Program Files\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files (x86)\Intel\Intel(R) Management Engine Components\DAL;
Шаг 4 – Проверьте настройку OC в Windows.
C:\openshift-origin-client-tools-v3.6.0-alpha.2-3c221d5-windows>oc version oc v3.6.0-alpha.2+3c221d5 kubernetes v1.6.1+5115d708d7 features: Basic-Auth
Клиент OC для Mac OS X
Мы можем загрузить двоичные файлы установки Mac OS для того же места, что и для Windows, а затем распаковать его в папку и указать путь к исполняемому файлу в переменной среды PATH.
альтернативно
Мы можем использовать Home brew и настроить его с помощью следующей команды.
$ brew install openshift-cli
OC Client для Linux
На этой же странице у нас есть tar-файл для установки Linux, который можно использовать для установки. Позже, переменная пути может быть установлена, указывая на это конкретное исполняемое местоположение.
Распакуйте файл tar, используя следующую команду.
$ tar –xf
Выполните следующую команду, чтобы проверить аутентификацию.
C:\openshift-origin-client-tools-v3.6.0-alpha.2-3c221d5-windows>oc login Server [https://localhost:8443]:
Конфигурационные файлы CLI
Файл конфигурации OC CLI используется для управления несколькими серверами OpenShift и механизмом аутентификации. Этот файл конфигурации также используется для хранения и управления несколькими профилями и для переключения между ними. Обычный файл конфигурации выглядит следующим образом.
$ oc config view apiVersion: v1 clusters: - cluster: server: https://vklnld908.int.example.com name: openshift contexts: - context: cluster: openshift namespace: testproject user: alice name: alice current-context: alice kind: Config preferences: <> users: - name: vipin user: token: ZCJKML2365jhdfafsdj797GkjgjGKJKJGjkg232
Настройка клиента CLI
Для настройки учетных данных пользователя
$ oc config set-credentials [--client-certificate = ] [--client-key=] [--token = ] [--username = ] [--password = ]
Для настройки кластера
$ oc config set-cluster [--server = ] [--certificate-authority = ] [--api-version = ] [--insecure-skip-tls-verify = true]
пример
$ oc config set-credentials vipin --token = ZCJKML2365jhdfafsdj797GkjgjGKJKJGjkg232
Для настройки контекста
$ oc config set-context [--cluster = ] [--user = ] [--namespace = ]
Профили CLI
В одном файле конфигурации CLI у нас может быть несколько профилей, каждый из которых имеет свою конфигурацию сервера OpenShift, которую впоследствии можно использовать для переключения между различными профилями CLI.
apiVersion: v1 clusters: --→ 1 - cluster: insecure-skip-tls-verify: true server: https://vklnld908.int.example.com:8443 name: vklnld908.int.example.com:8443 - cluster: insecure-skip-tls-verify: true server: https://vklnld1446.int.example.com:8443 name: vklnld1446.int.example.com:8443 contexts: ---→ 2 - context: cluster: vklnld908.int.example.com:8443 namespace: openshift-project user: vipin/vklnld908.int.example.com:8443 name: openshift-project/vklnld908.int.example.com:8443/vipin - context: cluster: vklnld908.int.example.com:8443 namespace: testing-project user: alim/vklnld908.int.example.com:8443 name: testproject-project/openshift1/alim current-context: testing-project/vklnld908.int.example.com:8443/vipin - 3 kind: Config preferences: <> users: - name: vipin/vklnld908.int.example.com:8443 user: ---→ 4 token: ZCJKML2365jhdfafsdj797GkjgjGKJKJGjkg232
В приведенной выше конфигурации мы видим, что она разделена на четыре основных раздела, начиная с кластера, который определяет два экземпляра главных машин OpenShift. Второй контекстный раздел определяет два контекста с именами vipin и alim. Текущий контекст определяет, какой контекст используется в данный момент. Он может быть изменен на другой контекст или профиль, если мы изменим определение здесь. Наконец, определяется пользовательское определение и его токен аутентификации, который в нашем случае является vipin.
Если мы хотим проверить текущий профиль в использовании, это можно сделать с помощью –
$ oc status oc status In project testing Project (testing-project) $ oc project Using project "testing-project" from context named "testing- project/vklnld908.int.example.com:8443/vipin" on server "https://vklnld908.int.example.com:8443".
Если мы хотим переключиться на другой интерфейс командной строки, это можно сделать из командной строки, используя следующую команду.
$ oc project openshift-project Now using project "Openshift-project" on server " https://vklnld908.int.example.com:8443".
Используя приведенную выше команду, мы можем переключаться между профилями. В любой момент времени, если мы хотим просмотреть конфигурацию, мы можем использовать команду $ oc config view.
OpenShift – Операции CLI
OpenShift CLI способен выполнять все основные и расширенные настройки, управления, добавления и развертывания приложений.
Мы можем выполнять различные виды операций, используя команды OC. Этот клиент помогает вам разрабатывать, создавать, развертывать и запускать приложения на любой платформе, совместимой с OpenShift или Kubernetes. Сюда также входят административные команды для управления кластером подкомандой adm.
Основные команды
В следующей таблице перечислены основные команды OC.
Введение в понятия и тип
Авторизоваться
Войти на сервер
новый проект
Запросить новый проект
новое приложение
Создать новое приложение
Показать обзор текущего проекта
Переключиться на другой проект
Показать существующие проекты
Запустить и остановить кластер OpenShift
Введение в понятия и тип
Авторизоваться
Войти на сервер
новый проект
Запросить новый проект
новое приложение
Создать новое приложение
Показать обзор текущего проекта
Переключиться на другой проект
Показать существующие проекты
Запустить и остановить кластер OpenShift
Авторизоваться
Войдите на свой сервер и сохраните логин для последующего использования. Пользователи, впервые работающие с клиентом, должны выполнить эту команду, чтобы подключиться к серверу, установить сеанс с проверкой подлинности и сохранить подключение в файле конфигурации. Конфигурация по умолчанию будет сохранена в вашем домашнем каталоге в .kube / config.
Информация, необходимая для входа в систему, такая как имя пользователя и пароль, токен сеанса или сведения о сервере, может быть предоставлена с помощью флагов. Если не указано, команда будет запрашивать ввод пользователя по мере необходимости.
использование
oc login [URL] [options]
# Log in interactively oc login # Log in to the given server with the given certificate authority file oc login localhost:8443 --certificate-authority = /path/to/cert.crt # Log in to the given server with the given credentials (will not prompt interactively) oc login localhost:8443 --username = myuser --password=mypass
-p, –password = “ – Пароль, предложит, если не указан
-u, –username = “ – Имя пользователя , подскажет , если не указано
–certificate-authority = “ – Путь к файлу сертификата для центра сертификации.
–insecure-skip-tls-verify = false – если установлено значение true, сертификат сервера не будет проверен на достоверность. Это сделает ваши HTTPS-соединения небезопасными
–token = “ – токен на предъявителя для аутентификации на сервере API
Чтобы получить полную информацию о любой команде, используйте команду oc –help .
Команды сборки и развертывания
В следующей таблице перечислены команды построения и развертывания.
Посадочная дистанция
Управление развертыванием в Kubernetes или OpenShift
развертывание
Просмотреть, запустить, отменить или повторить развертывание
Вернуть часть приложения обратно в предыдущее состояние
новое строительство
Создать новую конфигурацию сборки
запуск сборки
Начать новую сборку
отменить-сборка
Отменить запущенные, ожидающие или новые сборки
импорт-изображение
Импортирует изображения из реестра Docker
Помечать существующие изображения в потоки изображений
Посадочная дистанция
Управление развертыванием в Kubernetes или OpenShift
развертывание
Просмотреть, запустить, отменить или повторить развертывание
Вернуть часть приложения обратно в предыдущее состояние
новое строительство
Создать новую конфигурацию сборки
запуск сборки
Начать новую сборку
отменить-сборка
Отменить запущенные, ожидающие или новые сборки
импорт-изображение
Импортирует изображения из реестра Docker
Помечать существующие изображения в потоки изображений
Команды управления приложениями
В следующей таблице перечислены команды управления приложениями.
Показать один или несколько ресурсов
Показать детали конкретного ресурса или группы ресурсов
редактировать
Редактировать ресурс на сервере
Команды, которые помогают установить определенные функции на объектах
Обновите метки на ресурсе
аннотировать
Обновите аннотации на ресурсе
разоблачать
Предоставить реплицированное приложение в качестве службы или маршрута.
Удалить один или несколько ресурсов
Измените количество модулей в развертывании
Автоматическое масштабирование конфигурации развертывания, развертывания, репликации, контроллера или набора реплик
Serviceaccounts
Управление учетными записями в вашем проекте
Показать один или несколько ресурсов
Показать детали конкретного ресурса или группы ресурсов
редактировать
Редактировать ресурс на сервере
Команды, которые помогают установить определенные функции на объектах
Обновите метки на ресурсе
аннотировать
Обновите аннотации на ресурсе
разоблачать
Предоставить реплицированное приложение в качестве службы или маршрута.
Удалить один или несколько ресурсов
Измените количество модулей в развертывании
Автоматическое масштабирование конфигурации развертывания, развертывания, репликации, контроллера или набора реплик
Serviceaccounts
Управление учетными записями в вашем проекте
Команды для устранения неполадок и отладки
В следующей таблице перечислены команды устранения неполадок и отладки.
Распечатать журналы для ресурса
Начать сессию оболочки в модуле
Копировать файлы между локальной файловой системой и модулем
Порт вперед
Переадресация одного или нескольких локальных портов на модуль
Запустить новый экземпляр модуля для отладки.
Выполнить команду в контейнере
Запустите прокси на сервере API Kubernetes
Прикреплять
Присоединить к работающему контейнеру
Запустить определенное изображение в кластере
Копировать файлы и каталоги в и из контейнеров
Распечатать журналы для ресурса
Начать сессию оболочки в модуле
Копировать файлы между локальной файловой системой и модулем
Порт вперед
Переадресация одного или нескольких локальных портов на модуль
Запустить новый экземпляр модуля для отладки.
Выполнить команду в контейнере
Запустите прокси на сервере API Kubernetes
Прикреплять
Присоединить к работающему контейнеру
Запустить определенное изображение в кластере
Копировать файлы и каталоги в и из контейнеров
Расширенные команды
В следующей таблице перечислены дополнительные команды.
Инструменты для управления кластером
Создать ресурс по имени файла или стандартному вводу
Заменить ресурс по имени файла или стандартному вводу
Применить конфигурацию к ресурсу по имени файла или стандартному вводу
Обновите поле (я) ресурса, используя стратегическое исправление слияния
Обработать шаблон в список ресурсов
Экспортируйте ресурсы, чтобы их можно было использовать в другом месте.
Извлекать секреты или конфиг карты на диск
Неактивные масштабируемые ресурсы
Наблюдайте за изменениями в ресурсах и реагируйте на них (экспериментально)
Управление политикой авторизации
перерабатывать
Конвертировать конфигурационные файлы между разными версиями API
Импортировать
Команды, которые импортируют приложения
Инструменты для управления кластером
Создать ресурс по имени файла или стандартному вводу
Заменить ресурс по имени файла или стандартному вводу
Применить конфигурацию к ресурсу по имени файла или стандартному вводу
Обновите поле (я) ресурса, используя стратегическое исправление слияния
Обработать шаблон в список ресурсов
Экспортируйте ресурсы, чтобы их можно было использовать в другом месте.
Извлекать секреты или конфиг карты на диск
Неактивные масштабируемые ресурсы
Наблюдайте за изменениями в ресурсах и реагируйте на них (экспериментально)
Управление политикой авторизации
перерабатывать
Конвертировать конфигурационные файлы между разными версиями API
Импортировать
Команды, которые импортируют приложения
Настройка команд
В следующей таблице перечислены команды настройки.
Завершить текущий сеанс сервера
Изменить файлы конфигурации для клиента
Вернуть информацию о текущей сессии
Выходной код завершения оболочки для указанной оболочки (bash или zsh)
Завершить текущий сеанс сервера
Изменить файлы конфигурации для клиента
Вернуть информацию о текущей сессии
Выходной код завершения оболочки для указанной оболочки (bash или zsh)
OpenShift – Кластеры
OpenShift использует два метода установки для настройки кластера OpenShift.
- Метод быстрой установки
- Расширенный метод настройки
Настройка кластера
Метод быстрой установки
Этот метод используется для запуска быстрой настройки конфигурации незавершенного кластера. Чтобы использовать этот метод, нам нужно сначала установить установщик. Это можно сделать, выполнив следующую команду.
Интерактивный метод
$ atomic-openshift-installer install
Это полезно, когда вы хотите запустить интерактивную установку.
Метод автоматической установки
Этот метод используется, когда требуется установить метод автоматической установки, при котором пользователь может определить файл конфигурации yaml и поместить его в ~ / .config / openshift / с именем installer.cfg.yml. Затем можно выполнить следующую команду для установки тега –u .
$ atomic-openshift-installer –u install
По умолчанию он использует файл конфигурации, расположенный в ~ / .config / openshift / . Ansible, с другой стороны, используется в качестве резервной копии установки.
version: v2 variant: openshift-enterprise variant_version: 3.1 ansible_log_path: /tmp/ansible.log deployment: ansible_ssh_user: root hosts: - ip: 172.10.10.1 hostname: vklnld908.int.example.com public_ip: 24.222.0.1 public_hostname: master.example.com roles: - master - node containerized: true connect_to: 24.222.0.1 - ip: 172.10.10.2 hostname: vklnld1446.int.example.com public_ip: 24.222.0.2 public_hostname: node1.example.com roles: - node connect_to: 10.0.0.2 - ip: 172.10.10.3 hostname: vklnld1447.int.example.com public_ip: 10..22.2.3 public_hostname: node2.example.com roles: - node connect_to: 10.0.0.3 roles: master: : "" : "" node: : ""
Здесь у нас есть ролевая переменная, которую можно определить, если вы хотите установить какую-то конкретную переменную.
После этого мы можем проверить установку с помощью следующей команды.
$ oc get nodes NAME STATUS AGE master.example.com Ready 10d node1.example.com Ready 10d node2.example.com Ready 10d
Расширенная установка
Расширенная установка полностью основана на конфигурации Ansible, в которой присутствует полная конфигурация хоста и определение переменных, относящихся к конфигурации мастера и узла. Это содержит все детали, касающиеся конфигурации.
Как только у нас есть настройки и книга воспроизведения готова, мы можем просто запустить следующую команду для настройки кластера.
$ ansible-playbook -i inventry/hosts ~/openshift-ansible/playbooks/byo/config.yml
Добавление хостов в кластер
Мы можем добавить хост в кластер, используя –
- Инструмент быстрой установки
- Расширенный метод настройки
Инструмент быстрой установки работает как в интерактивном, так и в неинтерактивном режиме. Используйте следующую команду.
$ atomic-openshift-installer -u -c scaleup
Формат масштабирования внешнего вида конфигурационного файла приложения можно использовать для добавления как главного, так и узла.
Расширенный метод настройки
В этом методе мы обновляем файл хоста Ansible, а затем добавляем новый узел или сведения о сервере в этот файл. Файл конфигурации выглядит следующим образом.
[OSEv3:children] masters nodes new_nodes new_master
В том же файле Ansible hosts добавьте переменные детали относительно нового узла, как показано ниже.
[new_nodes] vklnld1448.int.example.com openshift_node_labels = ""
Наконец, используя обновленный файл хоста, запустите новую конфигурацию и вызовите файл конфигурации, чтобы выполнить настройку, используя следующую команду.
$ ansible-playbook -i /inventory/hosts /usr/share/ansible/openshift-ansible/playbooks/test/openshift-node/scaleup.yml
Управление кластерными журналами
Журнал кластера OpenShift – это не что иное, как журналы, генерируемые с главного и узлового компьютеров кластера. Они могут управлять любым видом журнала, начиная с журнала сервера, главного журнала, журнала контейнера, журнала модуля и т. Д. Для управления журналом контейнера имеется несколько технологий и приложений.
Немногие из перечисленных инструментов доступны для управления журналами.
Стек ELK – этот стек полезен при попытке собрать журналы со всех узлов и представить их в систематическом формате. Стек ELK в основном делится на три основные категории.
ElasticSearch – в основном ответственный за сбор информации из всех контейнеров и размещение ее в центральном месте.
Fluentd – Используется для подачи собранных бревен в двигатель контейнера поиска эластичного материала.
Kibana – графический интерфейс, используемый для представления собранных данных в виде полезной информации в графическом интерфейсе.
Следует отметить один ключевой момент: когда эта система развернута в кластере, она начинает собирать журналы со всех узлов.
Лог Диагностика
OpenShift имеет встроенную команду oc adm dignostics с OC, которую можно использовать для анализа множественных ошибок. Этот инструмент можно использовать от мастера в качестве администратора кластера. Эта утилита очень полезна для устранения неполадок и выявления известных проблем. Это работает на главном клиенте и узлах.
При запуске без каких-либо агентов или флагов, он будет искать файлы конфигурации клиента, сервера и узлов и использовать их для диагностики. Диагностику можно запустить индивидуально, передав следующие аргументы:
- AggregatedLogging
- AnalyzeLogs
- ClusterRegistry
- ClusterRoleBindings
- ClusterRoles
- ClusterRouter
- ConfigContexts
- DiagnosticPod
- MasterConfigCheck
- MasterNode
- MetricsApiProxy
- NetworkCheck
- NodeConfigCheck
- NodeDefinitions
- ServiceExternalIPs
- UnitStatus
Можно просто запустить их с помощью следующей команды.
$ oc adm diagnostics
Обновление кластера
Обновление кластера включает в себя обновление нескольких компонентов внутри кластера и получение кластера, обновленного новыми компонентами и обновлениями. Это включает в себя –
- Обновление основных компонентов
- Обновление узловых компонентов
- Обновление политик
- Модернизация маршрутов
- Обновление потока изображений
Для того, чтобы выполнить все эти обновления, нам нужно сначала получить быстрые установщики или утилиты на месте. Для этого нам нужно обновить следующие утилиты –
- атомно-OpenShift-Utils
- атомно-OpenShift-Excluder
- атомно-OpenShift-докер-Excluder
- пакет etcd
Перед началом обновления нам нужно сделать резервную копию etcd на главном компьютере, что можно сделать с помощью следующих команд.
$ ETCD_DATA_DIR = /var/lib/origin/openshift.local.etcd $ etcdctl backup \ —data-dir $ETCD_DATA_DIR \ —backup-dir $ETCD_DATA_DIR.bak.
Обновление основных компонентов
В OpenShift master мы запускаем обновление, обновляя файл etcd, а затем переходим к Docker. Наконец, мы запускаем автоматический исполнитель, чтобы получить кластер в нужном положении. Однако перед началом обновления нам нужно сначала активировать атомарные пакеты openshift на каждом из мастеров. Это можно сделать с помощью следующих команд.
Шаг 1 – Удалить пакеты atomic-openshift
$ atomic-openshift-excluder unexclude
Шаг 2 – Обновите etcd на всех мастерах.
$ yum update etcd
Шаг 3 – Перезапустите службу etcd и проверьте, успешно ли она началась.
$ systemctl restart etcd $ journalctl -r -u etcd
Шаг 4 – Обновите пакет Docker.
$ yum update docker
Шаг 5 – Перезапустите сервис Docker и проверьте, правильно ли он работает.
$ systemctl restart docker $ journalctl -r -u docker
Шаг 6 – После завершения перезагрузите систему с помощью следующих команд.
$ systemctl reboot $ journalctl -r -u docker
Шаг 7. Наконец, запустите atomic-execute, чтобы вернуть пакеты в список исключений yum.
$ atomic-openshift-excluder exclude
Нет такого принуждения для обновления политики, его нужно обновить, только если рекомендуется, что можно проверить с помощью следующей команды.
$ oadm policy reconcile-cluster-roles
В большинстве случаев нам не нужно обновлять определение политики.
Обновление узловых компонентов
После завершения основного обновления мы можем приступить к обновлению узлов. Следует иметь в виду, что период обновления должен быть коротким, чтобы избежать каких-либо проблем в кластере.
Шаг 1 – Удалите все атомарные пакеты OpenShift со всех узлов, на которых вы хотите выполнить обновление.
$ atomic-openshift-excluder unexclude
Шаг 2 – Затем отключите планирование узлов перед обновлением.
$ oadm manage-node --schedulable = false
Шаг 3 – Реплицируйте все узлы с текущего хоста на другой хост.
$ oadm drain --force --delete-local-data --ignore-daemonsets
Шаг 4 – Обновите настройку Docker на хосте.
$ yum update docker
Шаг 5 – Перезапустите службу Docker, а затем запустите узел службы Docker.
$systemctl restart docker $ systemctl restart atomic-openshift-node
Шаг 6 – Проверьте, правильно ли они запущены.
$ journalctl -r -u atomic-openshift-node
Шаг 7 – После завершения обновления перезагрузите узел компьютера.
$ systemctl reboot $ journalctl -r -u docker
Шаг 8 – Снова включите планирование на узлах.
$ oadm manage-node --schedulable.
Шаг 9 – Запустите исполнитель atomic-openshift, чтобы вернуть пакет OpenShift на узел.
$ atomic-openshift-excluder exclude
Шаг 10 – Наконец, проверьте, все ли узлы доступны.
$ oc get nodes NAME STATUS AGE master.example.com Ready 12d node1.example.com Ready 12d node2.example.com Ready 12d
OpenShift – масштабирование приложения
Автоматическое масштабирование – это функция в OpenShift, где развертываемые приложения могут масштабироваться и уменьшаться в зависимости от требований в соответствии с определенными спецификациями. В приложении OpenShift автоматическое масштабирование также называется автоматическим масштабированием. Существует два типа масштабирования приложения следующим образом.
Вертикальное масштабирование
Вертикальное масштабирование – это все больше и больше энергии на одной машине, что означает добавление процессора и жесткого диска. Это старый метод OpenShift, который сейчас не поддерживается в выпусках OpenShift.
Горизонтальное масштабирование
Этот тип масштабирования полезен, когда необходимо обработать больше запросов, увеличив число машин.
В OpenShift есть два способа включить функцию масштабирования .
- Использование файла конфигурации развертывания
- Во время запуска изображения
Использование файла конфигурации развертывания
В этом методе функция масштабирования включается через файл yaml конфигурации deploymant. Для этого используется команда OC autoscale с минимальным и максимальным количеством реплик, которые необходимо запустить в любой момент времени в кластере. Нам нужно определение объекта для создания автомасштабатора. Ниже приведен пример файла определения pod autoscaler.
apiVersion: extensions/v1beta1 kind: HorizontalPodAutoscaler metadata: name: database spec: scaleRef: kind: DeploymentConfig name: database apiVersion: v1 subresource: scale minReplicas: 1 maxReplicas: 10 cpuUtilization: targetPercentage: 80
Как только у нас будет файл, нам нужно сохранить его в формате yaml и выполнить следующую команду для развертывания.
$ oc create –f .yaml
Во время запуска изображения
Можно также автоматически масштабировать без файла yaml, используя следующую команду oc autoscale в командной строке oc.
$ oc autoscale dc/database --min 1 --max 5 --cpu-percent = 75 deploymentconfig "database" autoscaled
Эта команда также создаст файл аналогичного типа, который впоследствии можно будет использовать для справки.
Стратегии развертывания в OpenShift
Стратегия развертывания в OpenShift определяет поток развертывания с различными доступными методами. В OpenShift ниже перечислены важные типы стратегий развертывания .
- Роллинг стратегия
- Воссоздать стратегию
- Индивидуальная стратегия
Ниже приведен пример файла конфигурации развертывания, который используется в основном для развертывания на узлах OpenShift.
kind: "DeploymentConfig" apiVersion: "v1" metadata: name: "database" spec: template: metadata: labels: name: "Database1" spec: containers: - name: "vipinopenshifttest" image: "openshift/mongoDB" ports: - containerPort: 8080 protocol: "TCP" replicas: 5 selector: name: "database" triggers: - type: "ConfigChange" - type: "ImageChange" imageChangeParams: automatic: true containerNames: - "vipinopenshifttest" from: kind: "ImageStreamTag" name: "mongoDB:latest" strategy: type: "Rolling"
В приведенном выше файле Deploymentconfig у нас есть стратегия Rolling.
Мы можем использовать следующую команду OC для развертывания.
$ oc deploy --latest
Скользящая стратегия
Скользящая стратегия используется для непрерывного обновления или развертывания. Этот процесс также поддерживает хуки жизненного цикла, которые используются для внедрения кода в любой процесс развертывания.
strategy: type: Rolling rollingParams: timeoutSeconds: maxSurge: "" maxUnavailable: "" pre: <> post: <>
Воссоздать Стратегию
Эта стратегия развертывания имеет некоторые основные функции стратегии развертывания и поддерживает ловушку жизненного цикла.
strategy: type: Recreate recreateParams: pre: <> mid: <> post: <>
Индивидуальная стратегия
Это очень полезно, когда кто-то хочет предоставить свой собственный процесс или процесс развертывания. Все настройки могут быть сделаны согласно требованию.
strategy: type: Custom customParams: image: organization/mongoDB command: [ "ls -l", "$HOME" ] environment: - name: VipinOpenshiftteat value: Dev1
OpenShift – Администрирование
В этой главе мы рассмотрим такие темы, как управление узлом, настройка учетной записи службы и т. Д.
Конфигурация мастера и узла
В OpenShift нам нужно использовать команду start вместе с OC для загрузки нового сервера. При запуске нового мастера нам нужно использовать мастер вместе с командой запуска, тогда как при запуске нового узла нам нужно использовать узел вместе с командой запуска. Чтобы сделать это, нам нужно создать файлы конфигурации для мастера, а также для узлов. Мы можем создать базовый файл конфигурации для мастера и узла, используя следующую команду.
Для главного файла конфигурации
$ openshift start master --write-config = /openshift.local.config/master
Для файла конфигурации узла
$ oadm create-node-config —node-dir = /openshift.local.config/node- —node = —hostnames = ,
Выполнив следующие команды, мы получим базовые файлы конфигурации, которые можно использовать в качестве отправной точки для конфигурации. Позже мы можем иметь тот же файл для загрузки новых серверов.
apiLevels: - v1beta3 - v1 apiVersion: v1 assetConfig: logoutURL: "" masterPublicURL: https://172.10.12.1:7449 publicURL: https://172.10.2.2:7449/console/ servingInfo: bindAddress: 0.0.0.0:7449 certFile: master.server.crt clientCA: "" keyFile: master.server.key maxRequestsInFlight: 0 requestTimeoutSeconds: 0 controllers: '*' corsAllowedOrigins: - 172.10.2.2:7449 - 127.0.0.1 - localhost dnsConfig: bindAddress: 0.0.0.0:53 etcdClientInfo: ca: ca.crt certFile: master.etcd-client.crt keyFile: master.etcd-client.key urls: - https://10.0.2.15:4001 etcdConfig: address: 10.0.2.15:4001 peerAddress: 10.0.2.15:7001 peerServingInfo: bindAddress: 0.0.0.0:7001 certFile: etcd.server.crt clientCA: ca.crt keyFile: etcd.server.key servingInfo: bindAddress: 0.0.0.0:4001 certFile: etcd.server.crt clientCA: ca.crt keyFile: etcd.server.key storageDirectory: /root/openshift.local.etcd etcdStorageConfig: kubernetesStoragePrefix: kubernetes.io kubernetesStorageVersion: v1 openShiftStoragePrefix: openshift.io openShiftStorageVersion: v1 imageConfig: format: openshift/origin-$:$ latest: false kind: MasterConfig kubeletClientInfo: ca: ca.crt certFile: master.kubelet-client.crt keyFile: master.kubelet-client.key port: 10250 kubernetesMasterConfig: apiLevels: - v1beta3 - v1 apiServerArguments: null controllerArguments: null masterCount: 1 masterIP: 10.0.2.15 podEvictionTimeout: 5m schedulerConfigFile: "" servicesNodePortRange: 30000-32767 servicesSubnet: 172.30.0.0/16 staticNodeNames: [] masterClients: externalKubernetesKubeConfig: "" openshiftLoopbackKubeConfig: openshift-master.kubeconfig masterPublicURL: https://172.10.2.2:7449 networkConfig: clusterNetworkCIDR: 10.1.0.0/16 hostSubnetLength: 8 networkPluginName: "" serviceNetworkCIDR: 172.30.0.0/16 oauthConfig: assetPublicURL: https://172.10.2.2:7449/console/ grantConfig: method: auto identityProviders: - challenge: true login: true name: anypassword provider: apiVersion: v1 kind: AllowAllPasswordIdentityProvider masterPublicURL: https://172.10.2.2:7449/ masterURL: https://172.10.2.2:7449/ sessionConfig: sessionMaxAgeSeconds: 300 sessionName: ssn sessionSecretsFile: "" tokenConfig: accessTokenMaxAgeSeconds: 86400 authorizeTokenMaxAgeSeconds: 300 policyConfig: bootstrapPolicyFile: policy.json openshiftInfrastructureNamespace: openshift-infra openshiftSharedResourcesNamespace: openshift projectConfig: defaultNodeSelector: "" projectRequestMessage: "" projectRequestTemplate: "" securityAllocator: mcsAllocatorRange: s0:/2 mcsLabelsPerProject: 5 uidAllocatorRange: 1000000000-1999999999/10000 routingConfig: subdomain: router.default.svc.cluster.local serviceAccountConfig: managedNames: - default - builder - deployer masterCA: ca.crt privateKeyFile: serviceaccounts.private.key privateKeyFile: serviceaccounts.private.key publicKeyFiles: - serviceaccounts.public.key servingInfo: bindAddress: 0.0.0.0:8443 certFile: master.server.crt clientCA: ca.crt keyFile: master.server.key maxRequestsInFlight: 0 requestTimeoutSeconds: 3600
Файлы конфигурации узла
allowDisabledDocker: true apiVersion: v1 dnsDomain: cluster.local dnsIP: 172.10.2.2 dockerConfig: execHandlerName: native imageConfig: format: openshift/origin-$:$ latest: false kind: NodeConfig masterKubeConfig: node.kubeconfig networkConfig: mtu: 1450 networkPluginName: "" nodeIP: "" nodeName: node1.example.com podManifestConfig: path: "/path/to/pod-manifest-file" fileCheckIntervalSeconds: 30 servingInfo: bindAddress: 0.0.0.0:10250 certFile: server.crt clientCA: node-client-ca.crt keyFile: server.key volumeDirectory: /root/openshift.local.volumes
Вот так выглядят файлы конфигурации узла. Как только у нас есть эти файлы конфигурации, мы можем запустить следующую команду для создания главного сервера и сервера узлов.
$ openshift start --master-config = /openshift.local.config/master/master- config.yaml --node-config = /openshift.local.config/node-/node- config.yaml
Управляющие узлы
В OpenShift у нас есть утилита командной строки OC, которая в основном используется для выполнения всех операций в OpenShift. Мы можем использовать следующие команды для управления узлами.
Для перечисления узла
$ oc get nodes NAME LABELS node1.example.com kubernetes.io/hostname = vklnld1446.int.example.com node2.example.com kubernetes.io/hostname = vklnld1447.int.example.com
Описание деталей об узле
$ oc describe node
Удаление узла
$ oc delete node
Список модулей на узле
$ oadm manage-node --list-pods [--pod-selector=] [-o json|yaml]
Оценка стручков на узле
$ oadm manage-node --evacuate --dry-run [--pod-selector=]
Аутентификация конфигурации
В мастере OpenShift есть встроенный сервер OAuth, который можно использовать для управления аутентификацией. Все пользователи OpenShift получают токен с этого сервера, который помогает им общаться с OpenShift API.
В OpenShift есть разные уровни аутентификации, которые можно настроить вместе с основным файлом конфигурации.
- Позволять все
- Запретить все
- Htpasswd
- LDAP
- Базовая аутентификация
- Заголовок запроса
Определяя основную конфигурацию, мы можем определить политику идентификации, где мы можем определить тип политики, которую мы хотим использовать.
Позволять все
oauthConfig: . identityProviders: - name: Allow_Authontication challenge: true login: true provider: apiVersion: v1 kind: AllowAllPasswordIdentityProvider
Запретить все
Это запретит доступ ко всем именам пользователей и паролям.
oauthConfig: . identityProviders: - name: deny_Authontication challenge: true login: true provider: apiVersion: v1 kind: DenyAllPasswordIdentityProvider
Htpasswd
HTPasswd используется для проверки имени пользователя и пароля по отношению к зашифрованному файлу пароля.
Для создания зашифрованного файла, следующая команда.
$ htpasswd
Использование зашифрованного файла.
oauthConfig: . identityProviders: - name: htpasswd_authontication challenge: true login: true provider: apiVersion: v1 kind: HTPasswdPasswordIdentityProvider file: /path/to/users.htpasswd
Поставщик удостоверений LDAP
Это используется для аутентификации LDAP, где сервер LDAP играет ключевую роль в аутентификации.
oauthConfig: . identityProviders: - name: "ldap_authontication" challenge: true login: true provider: apiVersion: v1 kind: LDAPPasswordIdentityProvider attributes: id: - dn email: - mail name: - cn preferredUsername: - uid bindDN: "" bindPassword: "" ca: my-ldap-ca-bundle.crt insecure: false url: "ldap://ldap.example.com/ou=users,dc=acme,dc=com?uid"
Базовая аутентификация
Это используется, когда проверка имени пользователя и пароля выполняется на основе межсерверной аутентификации. Аутентификация защищена в базовом URL и представлена в формате JSON.
oauthConfig: . identityProviders: - name: my_remote_basic_auth_provider challenge: true login: true provider: apiVersion: v1 kind: BasicAuthPasswordIdentityProvider url: https://www.vklnld908.int.example.com/remote-idp ca: /path/to/ca.file certFile: /path/to/client.crt keyFile: /path/to/client.key
Настройка учетной записи службы
Учетные записи служб предоставляют гибкий способ доступа к API OpenShift, предоставляя имя пользователя и пароль для аутентификации.
Включение учетной записи службы
Сервисная учетная запись использует пару ключей открытого и закрытого ключей для аутентификации. Аутентификация в API выполняется с использованием закрытого ключа и проверки его по открытому ключу.
ServiceAccountConfig: . masterCA: ca.crt privateKeyFile: serviceaccounts.private.key publicKeyFiles: - serviceaccounts.public.key - .
Создание учетной записи службы
Используйте следующую команду для создания учетной записи службы
$ Openshift cli create service account
Работа с HTTP прокси
В большинстве производственных сред прямой доступ к Интернету ограничен. Они либо не подключены к Интернету, либо через HTTP или HTTPS-прокси. В среде OpenShift это определение прокси-машины устанавливается как переменная среды.
Это можно сделать, добавив определение прокси-сервера в файлы master и node, расположенные в / etc / sysconfig . Это похоже на то, что мы делаем для любого другого приложения.
Мастер Машина
/ И т.д. / sysconfig / OpenShift-мастер
HTTP_PROXY=http://USERNAME:PASSWORD@172.10.10.1:8080/ HTTPS_PROXY=https://USERNAME:PASSWORD@172.10.10.1:8080/ NO_PROXY=master.vklnld908.int.example.com
Узел Машина
/ И т.д. / sysconfig / OpenShift-узел
HTTP_PROXY=http://USERNAME:PASSWORD@172.10.10.1:8080/ HTTPS_PROXY=https://USERNAME:PASSWORD@172.10.10.1:8080/ NO_PROXY=master.vklnld908.int.example.com
После этого нам нужно перезапустить главный и узловой компьютеры.
Для Docker Pull
/ И т.д. / sysconfig / Докер
HTTP_PROXY = http://USERNAME:PASSWORD@172.10.10.1:8080/ HTTPS_PROXY = https://USERNAME:PASSWORD@172.10.10.1:8080/ NO_PROXY = master.vklnld1446.int.example.com
Чтобы запустить модуль в прокси-среде, это можно сделать с помощью –
containers: - env: - name: "HTTP_PROXY" value: "http://USER:PASSWORD@:10.0.1.1:8080"
Команда среды OC может использоваться для обновления существующего окружения.
OpenShift Storage с NFS
В OpenShift концепция постоянных томов и утверждений о постоянных томах образует постоянное хранилище. Это одна из ключевых концепций, при которой сначала создается постоянный том, а затем утверждается тот же том. Для этого нам необходимо иметь достаточно емкости и дискового пространства на базовом оборудовании.
apiVersion: v1 kind: PersistentVolume metadata: name: storage-unit1 spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce nfs: path: /opt server: 10.12.2.2 persistentVolumeReclaimPolicy: Recycle
Далее с помощью команды OC create создайте постоянный том.
$ oc create -f storage-unit1.yaml persistentvolume " storage-unit1 " created
Утверждение созданного объема.
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: Storage-clame1 spec: accessModes: - ReadWriteOnce resources: requests: storage: 5Gi
$ oc create -f Storage-claim1.yaml persistentvolume " Storage-clame1 " created
Управление пользователями и ролями
Администрирование пользователей и ролей используется для управления пользователями, их доступом и контроля над различными проектами.
Создание пользователя
Предопределенные шаблоны могут использоваться для создания новых пользователей в OpenShift.
kind: "Template" apiVersion: "v1" parameters: - name: vipin required: true objects: - kind: "User" apiVersion: "v1" metadata: name: "$" - kind: "Identity" apiVersion: "v1" metadata: name: "vipin:$" providerName: "SAML" providerUserName: "$" - kind: "UserIdentityMapping" apiVersion: "v1" identity: name: "vipin:$" user: name: "$"
Используйте oc create –f для создания пользователей.
$ oc create –f vipin.yaml
Используйте следующую команду, чтобы удалить пользователя в OpenShift.
$ oc delete user
Ограничение доступа пользователя
ResourceQuotas и LimitRanges используются для ограничения уровней доступа пользователей. Они используются для ограничения стручков и контейнеров в кластере.
apiVersion: v1 kind: ResourceQuota metadata: name: resources-utilization spec: hard: pods: "10"
Создание цитаты с использованием вышеуказанной конфигурации
$ oc create -f resource-quota.yaml –n –Openshift-sample
Описание ресурса цитата
$ oc describe quota resource-quota -n Openshift-sample Name: resource-quota Namespace: Openshift-sample Resource Used Hard -------- ---- ---- pods 3 10
Определение ограничений контейнера может использоваться для ограничения ресурсов, которые будут использоваться развернутыми контейнерами. Они используются для определения максимальных и минимальных ограничений определенных объектов.
Пользовательские ограничения проекта
Это в основном используется для количества проектов, которые пользователь может иметь в любой момент времени. Они в основном сделаны путем определения пользовательских уровней в категориях бронза, серебро и золото.
Сначала нам нужно определить объект, который содержит значение того, сколько проектов может иметь бронзовая, серебряная и золотая категории. Это нужно сделать в файле master-confif.yaml.
admissionConfig: pluginConfig: ProjectRequestLimit: configuration: apiVersion: v1 kind: ProjectRequestLimitConfig limits: - selector: level: platinum - selector: level: gold maxProjects: 15 - selector: level: silver maxProjects: 10 - selector: level: bronze maxProjects: 5
Перезагрузите главный сервер.
Назначение пользователя определенному уровню.
$ oc label user vipin level = gold
Перемещение пользователя из метки, если требуется.
$ oc label user level-
Добавление ролей пользователю.
$ oadm policy add-role-to-user
Удаление роли от пользователя.
$ oadm policy remove-role-from-user
Добавление роли кластера для пользователя.
$ oadm policy add-cluster-role-to-user
Удаление роли кластера от пользователя.
$ oadm policy remove-cluster-role-from-user
Добавление роли в группу.
$ oadm policy add-role-to-user
Удаление роли из группы.
$ oadm policy remove-cluster-role-from-user
Добавление роли кластера в группу.
$ oadm policy add-cluster-role-to-group
Удаление роли кластера из группы.
$ oadm policy remove-cluster-role-from-group
Пользователь для администрирования кластера
Это одна из самых мощных ролей, где пользователь имеет возможность управлять целым кластером, начиная с создания и до удаления кластера.
$ oadm policy add-role-to-user admin -n
Пользователь с максимальной силой
$ oadm policy add-cluster-role-to-user cluster-admin
OpenShift – Докер и Кубернетес
OpenShift построен поверх Docker и Kubernetes. Все контейнеры построены поверх кластера Docker, который в основном представляет собой сервис Kubernetes поверх машин Linux, с использованием функции оркестровок Kubernetes.
В этом процессе мы создаем мастер Kubernetes, который контролирует все узлы и развертывает контейнеры на всех узлах. Основной функцией Kubernetes является управление кластером OpenShift и потоком развертывания с использованием файла конфигурации другого типа. Как и в Kubernetes, мы используем kubctl так же, как мы используем утилиту командной строки OC для создания и развертывания контейнеров на узлах кластера.
Ниже приведены различные типы конфигурационных файлов, используемых для создания различных типов объектов в кластере.
- Изображений
- POD
- обслуживание
- Контроллер репликации
- Набор реплик
- развертывание
Изображений
Изображения Kubernetes (Docker) являются ключевыми строительными блоками контейнерной инфраструктуры. На данный момент Kubernetes поддерживает только образы Docker . Внутри каждого контейнера в модуле находится изображение Docker.
apiVersion: v1 kind: pod metadata: name: Tesing_for_Image_pull -----------> 1 spec: containers: - name: neo4j-server ------------------------> 2 image: ----------> 3 imagePullPolicy: Always ------------->4 command: [“echo”, “SUCCESS”] -------------------> 5
POD
Модуль – это набор контейнеров и его хранилище внутри узла кластера Kubernetes. Можно создать контейнер с несколькими контейнерами внутри. Ниже приведен пример хранения контейнера базы данных и контейнера веб-интерфейса в одном модуле.
apiVersion: v1 kind: Pod metadata: name: Tomcat spec: containers: - name: Tomcat image: tomcat: 8.0 ports: - containerPort: 7500 imagePullPolicy: Always
обслуживание
Служба может быть определена как логический набор модулей. Его можно определить как абстракцию над модулем, которая предоставляет один IP-адрес и имя DNS, по которым можно получить доступ к модулям. С Service очень легко управлять конфигурацией балансировки нагрузки. Это помогает очень легко масштабировать POD.
apiVersion: v1 kind: Service metadata: name: Tutorial_point_service spec: ports: - port: 8080 targetPort: 31999
Контроллер репликации
Контроллер репликации является одной из ключевых функций Kubernetes, которая отвечает за управление жизненным циклом модуля. Он отвечает за то, чтобы убедиться, что указанное количество реплик pod работает в любой момент времени.
apiVersion: v1 kind: ReplicationController metadata: name: Tomcat-ReplicationController spec: replicas: 3 template: metadata: name: Tomcat-ReplicationController labels: app: App component: neo4j spec: containers: - name: Tomcat image: tomcat: 8.0 ports: - containerPort: 7474
Набор реплик
Набор реплик гарантирует, сколько реплик модуля pod должно быть запущено. Это можно рассматривать как замену контроллера репликации.
apiVersion: extensions/v1beta1 kind: ReplicaSet metadata: name: Tomcat-ReplicaSet spec: replicas: 3 selector: matchLables: tier: Backend matchExpression: - < key: tier, operation: In, values: [Backend]>app: App component: neo4j spec: containers: - name: Tomcat- image: tomcat: 8.0 ports: containerPort: 7474
развертывание
Развертывания – это обновленные и более поздние версии контроллера репликации. Они управляют развертыванием наборов реплик, которые также являются обновленной версией контроллера репликации. У них есть возможность обновить набор реплик, и они также могут откатиться к предыдущей версии.
apiVersion: extensions/v1beta1 --------------------->1 kind: Deployment --------------------------> 2 metadata: name: Tomcat-ReplicaSet spec: replicas: 3 template: metadata: lables: app: Tomcat-ReplicaSet tier: Backend spec: containers: name: Tomcat- image: tomcat: 8.0 ports: - containerPort: 7474
Все файлы конфигурации могут быть использованы для создания соответствующих им объектов Kubernetes.
$ Kubectl create –f .yaml
Следующие команды могут быть использованы, чтобы узнать подробности и описание объектов Kubernetes.
$ Kubectl get pod $ kubectl delete pod $ kubectl describe pod
Для контроллера репликации
$ Kubectl get rc $ kubectl delete rc $ kubectl describe rc
Для обслуживания
$ Kubectl get svc $ kubectl delete svc $ kubectl describe svc
Для получения более подробной информации о том, как работать с Docker и Kubernetes, пожалуйста, посетите наш учебник Kubernetes, используя следующую ссылку kubernetes .
OpenShift – Безопасность
Безопасность OpenShift – это в основном комбинация двух компонентов, которая в основном обрабатывает ограничения безопасности.
- Ограничения контекста безопасности (SCC)
- Сервисный аккаунт
Ограничения контекста безопасности (SCC)
Он в основном используется для ограничения модуля, что означает, что он определяет ограничения для модуля, а также то, какие действия он может выполнять и какие вещи он может получить в кластере.
OpenShift предоставляет набор предопределенных SCC, которые могут быть использованы, изменены и расширены администратором.
$ oc get scc NAME PRIV CAPS HOSTDIR SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY anyuid false [] false MustRunAs RunAsAny RunAsAny RunAsAny 10 hostaccess false [] true MustRunAs MustRunAsRange RunAsAny RunAsAny hostmount-anyuid false [] true MustRunAs RunAsAny RunAsAny RunAsAny nonroot false [] false MustRunAs MustRunAsNonRoot RunAsAny RunAsAny privileged true [] true RunAsAny RunAsAny RunAsAny RunAsAny restricted false [] false MustRunAs MustRunAsRange RunAsAny RunAsAny
Если кто-то хочет использовать какой-либо заранее заданный scc, это можно сделать, просто добавив пользователя или группу в scc группу.
$ oadm policy add-user-to-scc $ oadm policy add-group-to-scc
Сервисный аккаунт
Сервисные учетные записи в основном используются для управления доступом к главному API OpenShift, который вызывается при запуске команды или запроса с любого из главного или узлового компьютера.
Каждый раз, когда приложению или процессу требуется возможность, которая не предоставляется ограниченным SCC, вам нужно будет создать определенную учетную запись службы и добавить учетную запись в соответствующий SCC. Однако, если SCC не соответствует вашим требованиям, лучше создать новый SCC, соответствующий вашим требованиям, а не использовать тот, который лучше всего подходит. В конце установите его для конфигурации развертывания.
$ oc create serviceaccount Cadmin $ oc adm policy add-scc-to-user vipin -z Cadmin
Контейнерная безопасность
В OpenShift безопасность контейнеров основана на том, насколько безопасна платформа контейнеров и где работают контейнеры. Когда мы говорим о безопасности контейнеров и о том, что нужно позаботиться о них, возникает множество вещей.
Image Provenance – внедрена защищенная система маркировки, которая точно и неопровержимо определяет, откуда пришли контейнеры, работающие в производственной среде.
Сканирование безопасности – сканер изображений автоматически проверяет все изображения на наличие известных уязвимостей.
Аудит . Производственная среда регулярно проверяется, чтобы убедиться, что все контейнеры основаны на современных контейнерах, а хосты и контейнеры настроены надежно.
Изоляция и минимальные привилегии. Контейнеры работают с минимальными ресурсами и привилегиями, необходимыми для эффективного функционирования. Они не могут чрезмерно мешать хосту или другим контейнерам.
Обнаружение угроз во время выполнения – возможность обнаруживать активные угрозы для контейнерного приложения во время выполнения и автоматически реагировать на него.
Контроль доступа – модули безопасности Linux, такие как AppArmor или SELinux, используются для обеспечения контроля доступа.
Существует несколько ключевых методов архивирования безопасности контейнера.
- Управление доступом через oAuth
- Через веб-консоль самообслуживания
- По сертификатам платформы
Управление доступом через OAuth
В этом методе аутентификация для доступа к управлению API архивируется с получением защищенного токена для аутентификации через серверы OAuth, который встроен в главный компьютер OpenShift. Как администратор, вы можете изменять конфигурацию конфигурации сервера OAuth.
Подробнее о настройке сервера OAuth см. В главе 5 этого руководства.
Через веб-консоль самообслуживания
Эта функция безопасности веб-консоли встроена в веб-консоль OpenShift. Эта консоль гарантирует, что все команды, работающие вместе, не имеют доступа к другим средам без аутентификации. Мастер multi-telnet в OpenShift имеет следующие функции безопасности:
- Уровень TCL включен
- Использует сертификат x.509 для аутентификации
- Защищает конфигурацию etcd на главном компьютере
По сертификатам платформы
В этом методе сертификаты для каждого хоста настраиваются во время установки через Ansible. Поскольку он использует протокол связи HTTPS через Rest API, нам необходимо защищенное соединение TCL с различными компонентами и объектами. Это предопределенные сертификаты, однако для доступа можно даже установить собственный сертификат в кластере мастера. Во время первоначальной настройки мастера пользовательские сертификаты могут быть настроены путем переопределения существующих сертификатов с помощью параметра openshift_master_overwrite_named_certificates .
openshift_master_named_certificates = []
Для получения более подробной информации о том, как создавать пользовательские сертификаты, перейдите по следующей ссылке –
Сетевая безопасность
В OpenShift для связи используется программно-определяемая сеть (SDN). Сетевое пространство имен используется для каждого модуля в кластере, причем каждый модуль получает свой собственный IP и диапазон портов для получения сетевого трафика на нем. С помощью этого метода можно изолировать модули, из-за которых они не могут взаимодействовать с модулями в другом проекте.
Изоляция проекта
Это может сделать администратор кластера с помощью следующей команды oadm из CLI.
$ oadm pod-network isolate-projects
Это означает, что определенные выше проекты не могут взаимодействовать с другими проектами в кластере.
Объем безопасности
Под защитой томов подразумевается защита PV и PVC проектов в кластере OpenShift. В основном в OpenShift есть четыре раздела для управления доступом к томам.
- Дополнительные группы
- fsGroup
- RunAsUser
- seLinuxOptions
Дополнительные группы – Дополнительные группы – это обычные группы Linux. Когда процесс выполняется в системе, он запускается с идентификатором пользователя и идентификатором группы. Эти группы используются для управления доступом к общему хранилищу.
Проверьте монтирование NFS с помощью следующей команды.
# showmount -e Export list for f21-nfs.vm: /opt/nfs *
Проверьте сведения о NFS на сервере монтирования, используя следующую команду.
# cat /etc/exports /opt/nfs *(rw,sync,no_root_squash) . # ls -lZ /opt/nfs -d drwxrws---. nfsnobody 2325 unconfined_u:object_r:usr_t:s0 /opt/nfs # id nfsnobody uid = 65534(nfsnobody) gid = 454265(nfsnobody) groups = 454265(nfsnobody)
/ Opt / nfs / export доступен по UID 454265 и группе 2325 .
apiVersion: v1 kind: Pod . spec: containers: - name: . volumeMounts: - name: nfs mountPath: /usr/share/. securityContext: supplementalGroups: [2325] volumes: - name: nfs nfs: server: path: /opt/nfs
fsGroup обозначает группу файловой системы, которая используется для добавления дополнительных групп контейнера. Идентификатор группы дополнений используется для общего хранилища, а fsGroup – для блочного хранилища.
kind: Pod spec: containers: - name: . securityContext: fsGroup: 2325
runAsUser использует идентификатор пользователя для связи. Это используется при определении изображения контейнера в определении модуля. Один идентификатор пользователя может быть использован во всех контейнерах, если требуется.
При запуске контейнера указанный идентификатор сопоставляется с идентификатором владельца при экспорте. Если указанный идентификатор определен снаружи, он становится глобальным для всех контейнеров в модуле. Если это определено с определенным модулем, то это становится определенным для единственного контейнера.
Контейнеризация понятным языком: хранение данных и безопасность в Kubernetes, зачем нужен Ansible. Часть 2

В чём проблема с базами данных и как позаботиться о безопасности в Kubernetes? Как врубиться в Ansible? Ответы на эти и другие вопросы читайте в продолжении интервью Лекса АйТиБороды со старшим инженером Southbridge Николаем Месропяном и СТО «Слёрма» Марселем Ибраевым.
На вопросы отвечает Марсель Ибраев
В чём проблема с базами данных в Kubernetes? Для меня как для разработчика проблем нет: зафигачил базу в Docker-контейнер и работаешь.
Проблемы нет для половины, наверное, комьюнити. Это вообще холиварный вопрос. В чатике kubernetes_ru (официальном чате русскоязычного сообщества Kubernetes) постоянно эти вопросы поднимаются.
А может, Docker не нужен? Зачем мне Docker для базы?
И это тоже. Были даже такие разговоры, что если база данных удовлетворяет 12 факторам, то это обычное приложение, запускайте и всё, 2020 год на дворе. Зачем вы её выносите отдельно, туда-сюда.
Но «12 факторов» — это не совсем про базу данных, там больше про stateless говорится. У нас все-таки stateful приложение, то есть приложение, которое должно сохранять статус и результат работы. После перезапуска оно этот результат терять не должно, в отличие от stateless.
И вот именно здесь краеугольный камень. Чтобы научить Kubernetes сохранять статус приложения (базы данных, таблички — вот это всё), нужно присыпать ещё несколько абстракций сверху: PersistentVolume, PersistentVolumeClaim, StorageClass — не буду сильно углубляться. То есть просто нужно иметь в виду, что повышается планка работы с Kubernetes.
Нужен человек, который умеет настраивать кластер этой базы данных. Потому что Kubernetes не важно, что запускается в поде (Pod): stateless приложение или stateful приложение — он с ними работает одинаково. Он не соберёт магическим образом кластер баз данных и не будет за ним следить. Вы напишете манифест с тремя инстансами базы данных, Kubernetes его запустит, и это будет три отдельных инстанса базы данных, которые будут не в кластере.
Но с приложениями он умеет это делать?
Тоже нет. По факту это как бы отдельные инстансы, отдельные реплики приложения. Они по идее самостоятельные.
То есть на уровне записи и чтения данных всё равно нужно будет абстракцию какую-то свою клепать, Kubernetes ни при чём?
Да, и поэтому здесь нужны компетенции какого-то DBA, который на монолитах это уже 1000 раз настраивал, и скажет: «Да, без проблем! Настроим!».
Следующий вопрос возникает с запуском базы данных, когда нам нужно выставить request/limit. Request/limit — это инструмент, который позволяет работать с ресурсами.
Request — это запрос на ресурсы. Например, мы знаем, что этому приложению минимально нужно 200 МБ ОЗУ. Если будет меньше, оно просто крашнется и не запустится. Мы выставляем request 200.
limit — максимальная планка. Мы говорим, что 512 максимум, а если выше, то оно явно потекло и надо с ним что-то делать.
А вот как это сделать для базы данных — хрен его поймёшь! В понедельник мы работаем на типовой нагрузке, в пятницу пришла баба Люда из бухгалтерии и запустила выгрузку из 1С миллиона строк, и нагрузка в потолок.
На моей истории было дважды, когда приложение (не база данных, для базы данных это будет суперкритично) начало утилизировать очень много ресурсов, и на сервере ресурсов не хватило — всё померло. Kubernetes умный, он всё понял: взял и перетащил это приложение на другой сервер, но потреблять много ресурсов оно не перестало. Новый сервер упал, и как домино всё сложилось. Может повезти, что это всё в цикл замкнётся и будет переезжать, но ничего хорошего всё равно не будет. А с базой данных это критично, потому что вам нужно сохранять свои данные.
Есть 4 способа, как это сделать:
- очень стабильно, но дорого,
- не очень производительно, но дёшево,
- более или менее по производительности, но без гарантии,
- и дёшево, и круто.
Не очень производительно, но дёшево — это использование облачных сервисов, которые предоставляют диски. Но здесь нужно понимать, что у многих есть в инструкции (в том числе и в документации баз данных) такая сноска: «Ребята, если вы будете использовать какие-нибудь диски Google или Digital Ocean, например, то поставьте галочку “using local SSD”, чтобы использовать локальные диски, а не какие-то там через сеть, и вот тогда всё с базой данных будет OK».
Более-менее по производительности, но без гарантии (этот вариант нативно поддерживает Kubernetes) — это когда мы просто берём, грубо говоря, прокидываем диск сервера в контейнер. Мапим папочку прям. У нас на сервере могут быть SSD, и мы SSD внутрь контейнера и получаем. Минус в том, что мы тем самым прибиваем базу данных к этому серверу. Спрашивается, зачем мы запускаем её в Kubernetes, если что случись, она там и сдохнет. Ну и лежала бы на своём монолитовском сервере.
И дёшево, и круто — это собственная СХД, которую построил и поддерживает какой-то бородатый админ. При этом он ещё должен вывести уровень производительности этой СХД на такой уровень, чтобы она сравнялась как-то с SSD. Первое, что приходит в голову, — это Ceph. Но пока мы делали курс по Ceph, пообщались с теми, кто много с этой технологией работает, они сказали: «Не, чувак, там столько костылей, что это всё равно придётся закрывать мощностями оборудования». То есть такого нет.
Вот такие варианты: даже не 2 стула, а 4 — выбирай, куда садиться. Если у вас возникает вопрос: «Могу ли я запустить базу данных в Kubernetes?», значит, конкретно вы не можете пока.
В Kubernetes есть чарты (charts) и хельм (Helm), что это такое?
Сначала расскажу, как возникла потребность в их создании. Вот у нас есть кластер, всё хорошо, но мы его поднимали не просто так, а чтобы запустить приложение.
Приложение может состоять из множества микросервисов, которые надо как-то деплоить в кластер. Конечно, мы можем каждый раз править манифесты руками. Но одно приложение может содержать от пяти и до бесконечности манифестов.
Манифесты — это yaml-файлики, которые отвечают за самые разные абстракции. В том числе сам под (Pod), хотя это будет не под, а абстракция, которая называется либо Deployment (именно в ней запускают приложение), либо StatefulSet (если это stateful-приложение), либо DaemonSet, ну неважно. К нему добавляется абстракция типа Service — внутренний кубернетский балансировщик. К нему же добавится абстракция Ingress — внешний балансировщик. Там же ещё могут быть PV/PVC — короче, много всего.
Когда мы приложение разрабатываем, нам надо сделать какой-то релиз. Что-то поменялось в приложении, что-то поменяться могло в манифестах. Например, версия image была 2, стала 3. Нам придётся каждый раз ходить в репы и менять руками 2 на 3. Таких реп может быть сотни, и осталось только не забыть везде нужное поменять. В этот момент типичный админ задумывается об инструментах, которые позволяют менять все файлы внутри папки с одного паттерна на другой. И в принципе, это будет работать.
Только проблема в том, что это решение kubectl based, то есть всё равно весь вот этот вывод, который мы в папке перелопатили, мы через пайп отправляем в kubectl. Говорим: «kubectl, вот теперь всё, что у нас есть новое в папке, отправляй в кластер». И это тоже будет работать. Но если что-то пойдёт не так (циферку не ту поставили или приложение просто не поднялось), нативного способа откатиться через kubectl нет. Там есть команда kubectl rollout undo, но она работает только с deployment, а у нас могут быть и другие абстракции, с которыми она не работает. И тут возникает вопрос, а как откатываться? Потому что шаблонизация вроде более-менее понятна, да и шаблонизаторов много всяких (и Kustomize, и json.net), но как откатываться — большой вопрос.
Явный ответ на это дает Helm, потому что у него из коробки есть возможность cделать rollout, то есть откат, в случае, если какие-то есть проблемы. Работает он достаточно просто. Он все манифесты из папки, что мы нагенирировали, сохраняет в артефакт. Например, в config какой-то. Прям вот как оно есть, так и сохраняет подряд. Назвал его «артефакт версия 1», сохранил в кластер. Потом мы выпустили новый релиз. Он — ага, «артефакт версия 2». И вот так они копятся. Потом мы выкатили новый релиз, какой-нибудь версии 9, и поняли, что это не то. Он говорит: «Ок, у меня есть версия 8», достает все манифесты оттуда и фигачит в кластер.
Возвращаясь к вопросу, как вменять всё, когда этих манифестов становится за сотню и просто невозможно в голове удержать, что где поменять. Тогда на помощь приходят шаблонизаторы, темплейтирование и Helm это тоже умеет. Набор темплейтированных манифестов называется Chart.
Ты уже не раз говорил про stateful и stateless приложения. Разработчикам эти термины знакомы. И понятно, что со stateless просто: развернул и не паришься. Есть какие-то особенности разворачивания stateful приложений? И что для этого используется внутри Kubernetes? Какие-то может быть особенные штуки для хранения состояния приложения? Как оно хранится? Где оно хранится?
Сам по себе Kubernetes никакого решения не предоставляет. Нет внутренней системы хранения данных. В любом случае нужно использовать стороннее решение. Сейчас появился CSI Driver, и стало проще.
CSI Driver — это ещё один интерфейс, который позволяет унифицировать подключение внешних инструментов. Как есть Container Runtime Interface, который не только Docker может подключить, но всё, что CRI поддерживает, так и CSI может подключить всё, что его поддерживает. Технология не так давно вышла в прод, развивается и допиливается, но в целом это хороший шаг. Остаётся подключить, например, Ceph как систему хранения данных и через абстракции Kubernetes запрашивать диски или файловые системы в этой СХД и подключать себе. То есть по сути приложение будет работать с этой СХД, а Kubernetes будет в роли посредника.
А до появления этого механизма в Kubernetes нельзя было разворачивать stateful приложения?
Можно было. Есть такая штука, как storage class. Это ещё одна абстракция, и там это всё настраивается. Скажем так, объём тех решений, которые можно применять в Kubernetes, будет расти. Уже есть всякие облачные хранилища, которые можно подключать, и множество всего другого.
Как построен механизм безопасности всего процесса поднятия, слежения за твоими приложениями? Общение наверняка ведётся по https, но есть ли ещё что-нибудь? Что, например, будет, если API Kubernetes завладеет злоумышленник? Как этого избежать?
Не открывать API наружу! Достаточно просто.
А как не открывать? Выстраивать приватную сеть?
Ну да, VPN, двухфакторная авторизация — что-нибудь такое. API нужно закрывать очень хорошо, потому что каждый год находят уязвимости. В 2018 году, например, обнаружили критическую уязвимость с индексом 9,8, если я не путаю. Она позволяла поднять привилегии в API, и всё — делай, что хочешь. Были уязвимости в 2019 году. Мне запомнилась возможность подменять файлы на хосте через контейнер.
И всё это можно сделать, если авторизоваться в API. Естественно, API не дураки писали, и там есть аутентификация, тот же самый TLS, просто так ничего не сделаешь. Но уязвимости бывают, поэтому API надо всеми возможными способами закрывать.
Вопрос безопасности Kubernetes достаточно широкий, потому что на него можно взглянуть под разными углами и рассмотреть множество аспектов безопасности.
Например?
Глобально можно посмотреть в первую очередь как раз с точки зрения уязвимостей, получения прав и так далее. Решение — закрытие API. Если Kubernetes развёрнут не в облаках, а на своих виртуалках, то надо регулярно обновлять свои сервера. Про iptables и SSH наружу, я думаю, говорить не надо. Это общие и достаточно банальные требования, но их надо выполнять. Kubernetes не панацея, это дополнительный слой абстракции. Сверху намазали, и за этим теперь тоже надо как-то следить.
Второй аспект безопасности — это уровень привилегий пользователей. В Kubernetes это хорошо сделано. Есть так называемый Role Based Access Control или RBAC сокращенно. Мы можем разграничить пользователей по тому, какие действия им доступны: ты можешь работать только здесь, а ты — только здесь. Но там есть достаточно простые хаки, которые позволяют это всё очень легко обойти.
Например, в Kubernetes есть namespace — пространство имен. Условно, у нас есть Kubernetes, есть два namespace: стейджинг и продакшн. В стейджинг мы пускаем разработчиков, они там работают, но мы им не даем что-то править на проде. В прод ходит только CI/CD. Но просто имея возможность запускать свои приложения хоть где и ничего больше, я могу за 2 минуты стать админом кластера. Я запущу под (Pod), которого отправлю на запуск на master, где у нас находятся все доступы и креды, и подмонтирую их себе в контейнер. Потом я посмотрю токены, скопирую себе на компьютер и стану админом.
Это такая штука, о которой не все задумываются. Но эту штуку тоже уже прикрыли. Есть инструмент Pod security policy, который позволяет чётко сказать, какие поды и где и как могут запускаться, какие порты могут использовать.
Ещё один аспект безопасности касается работы нескольких команд в Kubernetes. Особенно, если есть на аутсорсе команды, которые пишут свою часть приложения. По умолчанию, любой человек с доступом в namespace может постучаться во все эндпоинты (endpoints), которые есть. Прикрыть это позволяет Network policies. Это своего рода firewall внутри кластера. Когда мы внешнюю команду к себе зовём, мы спрашиваем, к каким эндпоинтам она должна иметь доступ, чтобы взаимодействовать с приложением, и только эту часть открываем. В основной кластер они зайти не могут.
Если говорить про безопасность, то в Kubernetes есть ещё одна интересная штука — защита от человеческого фактора. Известно много громких факапов, произошедших по вине человека (история с GitLab, когда они положили пол своего продакшена, с Yandex.Cloud и другими компаниями). Прод базу данных снёс и оказалось, что в шести местах бэкапов нет или они неконсистентные, и случайным образом где-то там дампик лежал несколько часовой давности и типа: «Ух! (перекрестился) Слава Богу! Восстановили!»
Чтобы этого избежать, в Kubernetes тоже есть инструменты. Например, limit ranges, resource quotas. Они позволяют держать в узде тех, кто работает с Kubernetes. Например, не дают заскейлить свое приложение в какое-то очень большое количество. А такое один раз было. Коллега рассказывал: админ хотел поставить единицу. Клавиша залипла, интернет лагнул, вместо одного раза он нажал несколько — и всё. Правда, это было не на Kubernetes, а на Nomad. Но факт такой, что он: «Вам надо 111 млн приложений? Хорошо. Сейчас будет!» И всё начало лагать, естественно. Чтобы этого избежать, мы можем сказать: «Здесь максимум 10 реплик, и всё».
Ты упомянул Nomad. Какие ещё есть аналоги Kubernetes?
Самый яркий аналог, про который все говорят, — это Docker Swarm. Docker Swarm — это разработка от Docker, их нативное решение. Не требует никакой дополнительной установки: переходим в swarm-режим, и у нас появляется возможность Docker Swarm.
Docker Swarm — это тоже оркестратор, поэтому многие сравнивают его с Kubernetes. Но если говорить глобально, то Kubernetes — это более мощный комбайн, в нём больше возможностей. В Docker Swarm их чуть поменьше, но я бы сказал так: если у вас супертребований нет, то можно пользоваться и Docker Swarm. Но в отличие от него, Kubernetes, например, хорошо умеет автоскейлить. Причем, как ноды автоскейлить, заказывать, так и поды, то есть реплики приложений. В облаках это работает вообще шикарно. Пришла нагрузка с рекламной кампании — мы не сидим, не заказываем руками, а он сам сходил и заказал. Когда нагрузка ушла, он обратно их схлопнул до нужного количества.
На каких операционных системах обычно запускается Kubernetes?
Ну обычно на Linux: CentOS, Debian.
А на винде умеет?
Они делают сейчас движение в сторону Windows. В принципе, стало лучше, но я бы сказал, что не надо пока этого делать.
Какими навыками нужно обладать, чтобы успешно работать с Kubernetes? Программирование, может, какое-то нужно? YAML, понятно.
Знание YAML, некоторое понимание, как работает контейнеризация… Я не знаком лично, но слышал о таких людях, которые не имеют базового бэкграунда, но с Kubernetes работать умеют. Они могут налажать с сетью, например, но при этом с Kubernetes работают.
Я бы добавил, что нужны базовые знания по сетям, по Linux (если Kubernetes будет запускаться на Linux-машинах, их надо будет тюнить) и умение читать документацию.
В каких случаях Kubernetes вообще не стоит использовать?
Не стоит использовать, если рассчитываете, что поставите его, и все вопросы решатся. К внедрению надо подходить системно, и ставить Kubernetes только тогда, когда есть реальная необходимость.
Есть ещё ситуация «Kubernetes ради зарплаты». Это когда технический специалист зашёл на Хедхантер, посмотрел на зарплаты, и пошёл пропихивать это решение в компании, чтобы потом попросить повышение: «Я же теперь специалист по Kubernetes, платите мне больше». Это вряд ли к чему-то хорошему приведёт.
С технической точки зрения Kubernetes не нужно применять для приложений, которые не удовлетворяют «12 факторам». Для приложений, которые неправильно работают на уровне микросервисов, которые не допилены до конца. В одном из проектов мы пилили и переносили, пилили и переносили, и это было сложно, потому что часть проекта работала в Kubernetes, а часть продолжала работать на монолите и надо было выстраивать взаимосвязь.
В идеальном мире, конечно, Kubernetes ставится сразу же… Сначала приложение готовится, потом уже туда. Но чаще всего нет.
Переходя к следующему блоку, спрошу: в чём различие Kubernetes и Ansible?
Ansible — это, в первую очередь, система управления конфигурацией. Kubernetes — это оркестратор контейнеров.
Знание Ansible не будет лишним, когда вы начнёте работать с Kubernetes, и наоборот. Потому что Kubernetes нужно как-то управлять, и Ansible для этого хорошо подходит.
Если мы говорим, что Kubernetes — это Infrastructure as code (IaC), то вот этим IaC нужно как-то управлять. Руками туда лезть? В идеальном мире не лезут, всё прогоняют через пайплайны: надо что-то сделать в Kubernetes — запускаешь плейбук — он пошёл сам сделал. Поэтому знание Ansible и Kubernetes, наверное, важны в равной степени.
Далее отвечает Николай Месропян
Что такое Ansible и для чего он нужен?
Это средство управления конфигурациями. Для чего нужно? Когда у вас один сервер, им можно управлять руками: просто ходить на него, набирать команды или тыкать мышкой, что-то руками править, настраивать. Если их 2, 10 — это ещё реально. Но в конце концов серверов может стать и 20, и 100, и 1000. Вот тогда возникает необходимость управлять ими более автоматизированно и централизованно.

Мы говорим про управление конфигурациями операционной системы или вообще любыми? Я задеплоил 25 приложений разных на хост, и я хочу…
Обычно я начинаю рассказ про Ansible и свой курс с концепции, которая называются питомцы и стадо — «Pets vs Cattle». Pets — это питомцы. Ты за ними ухаживаешь, лечишь, даёшь им уникальные имена. Cattle — это стадо. Если кто-то заболевает, ты его забиваешь и создаешь вместо него новый сервер. У тебя их очень много, и ты их в лицо не знаешь, а знаешь только по номерам. Питомцы превращаются в стадо, когда их становится много.
Но когда они заболевать начинают!
Когда они заболевают, это жесть, я согласен. И чтобы с этим стадом управляться, создана система управления конфигурациями. Да, разумеется, она используется и для деплоев приложений, но начинаем мы обычно с системы управления конфигурациями, операционной системой на наливке каких-то приложений, конфигурирования их в том или ином порядке — оркестрацией как бы.
Jenkins вроде как тоже кроме того, что поддерживает пайплайны, умеет конфигурировать приложения. Это в чём-то похоже на Ansible?
Нет, это совершенно разные вещи. Ansible похож на Chef, Puppet, SaltStack. Jenkins больше похож на GitLab CI и TeamCity. Это совершенно разные классы программного обеспечения для разных целей, но они могут работать вместе.
Я встречался с решениями, когда через пайплайн на GitLab CI производился деплой приложений посредством приложения, использующего внутри себя Chef.
Сам я писал пайплайны для GitLab CI на Ansible. То есть они вместе работать могут. Иногда и просто должны.
Из чего состоит Ansible, и как он вообще работает? Это какое-то приложение над приложениями или отдельный сервер, что это вообще?
Cначала расскажу про ПО для управления конфигурациями. Расскажу, чем они друг от друга отличаются, и потом перейдём конкретно к Ansible.
ПО для управления конфигурациями можно разделить на два основных класса: pull и push.
Когда работает система принципа pull, на клиентских хостах, то есть на управляемых хостах, выполняется некий daemon (сервис), который подтягивает конфигурацию с центрального репозитория и на месте уже её раскатывает.
push — это когда управляющий процесс выполняется на одном центральном сервере, а на конечные ноды доезжают только конечные изменения (по сети). То есть конфигурирование производится не на месте, а по сети.
По сети — SSH, FTP?
Как правило, SSH. Вот Ansible относится именно к push. На центральном сервере выполняется процесс, который использует конфигурацию, чаще всего хранящуюся в репозитории.
Зачем вообще нужен pull, если push выглядит достаточно красиво и ненапряжно?
В случае с pull процесс работает на клиентской ноде, стягивает конфигурацию в виде файликов, а потом уже на месте, через местные вызовы API очень быстро создаёт или поддерживает нужную конфигурацию.
При модели push центральный процесс каждый раз идёт к ноде по SSH, что-то там делает, возвращает результат, здесь он оценивается, и всё это повторяется.
Тогда чем push лучше pull?
На конечных нодах не хранится никакой конфигурации, что называется нулевой footprint (след).
Бывает важно, чтобы на клиентских машинах никто не мог понять, как и что конфигурируется. Расскажу про нашу компанию, Southbridge. У нас аутсорсинг, множество клиентов, и информация под клиентов хранится в репозитории. Потому что мы не хотим, чтобы клиент мог своими руками что-то подкрутить и сломать. Он может сделать это без злого умысла, просто: «Программист сказал, что можно сделать так, давай-ка сделаем!» А потом раз — продакшн снесся, и он приходит к нам: «У вас все плохо работает!»
В действительности таких случаев у нас не было, когда мы использовали pull-системы. Но тем не менее. К тому же лучше подстраховаться, чтобы конфигурация одних клиентов не попала каким-то другим. Именно поэтому мы используем push.
Плюс нам понравилась сама парадигма, что всё лежит в одном месте. Сами клиентские процессы иногда написаны на тяжёлых языках (Ruby, например) и тоже подъедают системные ресурсы: и память, и процессор. Поэтому это в каких-то случаях может быть нежелательным.
А клиентские ПО, клиентские ресурсы, которые в push работают, они пишутся руками или есть готовые какие-то решения?
Вот теперь я могу рассказать, из чего Ansible состоит (без слайдов и доски сложно, но попробую объяснить на пальцах).
Для Ansible мы пишем конфигурацию, состоящую из сущности под названием плейбуки (playbook), ролей и инвентаря. Плейбуки и роли — это определение конфигурации. Инвентарь — это параметризация.
Плейбук — это файл, состоящий из набора так называемых плеев (play).
Сразу скажу, что вся конфигурация пишется на YAML. Ansible написан на Python, поэтому для него родной язык разметки YAML.
Ansible, если что, лучше всего ставить в virtualenv, чтобы быть независимым от мейнтейнера…
А, да, начнём с того, где Ansible работает: управляющие хосты поддерживаются только Linux.
А если это виртуалка?
Всё равно. Всё-таки используются системные вызовы, и чтобы не адаптироваться, в качестве управляющего хоста поддерживается только Linux. Управлять можем Linux-системами, Windows-системами и Mac OS. Но для Mac, насколько я знаю, оно пока в зачаточном состоянии.
Android, мобильные платформы?
Наверняка что-то есть, но пока оно большого распространения не получило.
У нас выполняется центральный процесс, который этот плейбук читает.
Плейбук — это набор плеев. Каждый плей состоит из двух элементов: описание хостов, на которых выполняется данный участок кода, и tasks — задачи, то есть именно что делать.
Если совсем примитивно, с помощью Ansible можно сделать на хостах всё то же, что мы делаем руками, только автоматизировано, массово, детерминировано и т. д. Поэтому элементарный task или элементарная задача — это выполнение какой-нибудь команды, например. Но чаще всего используются специализированные модули: для шаблонизации файлов, для запуска сервисо
А команды — это просто команды консоли или…?
Да, есть такой модуль command, который просто выполняет консольную команду.
Он на клиенте?
А почему нельзя просто через SSH напрямую в терминал фигачить?
Модуль command — это последний шанс, если у тебя нет специализированного модуля для выполнения определённой задачи.
Чтобы запустить сервис, мы не делаем command systemctl start engine, мы используем модуль service или модуль systemd, который приводит систему, в данном случае сервис, в заданное состояние. То есть он запущен и включён либо остановлен и выключен.
Вообще, управление конфигурациями задумывалось как декларативное. То есть мы описываем желаемое состояние системы, потом эта самая управлялка приводит систему в заданное состояние. Если система уже находится в нужном состоянии, то не производится никаких действий. Это свойство называется идемпотентность.
Понятно, в не зависимости от того, сколько раз ты запускаешь…
Результат всегда один и тот же.
Это прям как в REST API, разработчикам должно быть понятно.
Поэтому мы описываем в задачах желаемую конфигурацию и Ansible приводит (если это грамотно написано) систему в заданное состояние. Если система уже в заданном состоянии, то действие не производится. Потом мы в выводе команды всё это видим.
Что такое роли? Роли можно уподобить подключаемым библиотекам. То есть мы пишем роль, которая, допустим, настраивает веб-сервер nginx, и потом из разных плейбуков для разных хостов с разными параметрами мы эту роль подключаем.
Роли могут храниться как на диске вместе с плейбуками конфигурации, так и во внешних репозиториях. Есть такая штука, называется Ansible Galaxy — это что-то вроде центрального хранилища ролей. Туда можно свою роль подать на рассмотрение. Это не то чтобы пакетный менеджер, а как GitHub, допустим. Только специализированный, исключительно для Ansible.
То есть роли — это готовые куски конфигураций, которые ты можешь у себя встраивать и переиспользовать?
Это описание конфигурации, которому ты можешь сам задавать разные параметры из инвентаря.
Отлично. И тут включается механизм параметризации?
Да. При запуске команды ansible-playbook, которая и делает нужные изменения на хостах, мы задаём ей параметром так называемый инвентарь — откуда брать параметры. В инвентаре у нас чаще всего список хостов, объединенных в группы (чтобы Ansible знал, на каких хостах выполнять те или иные задачи), и набор переменных для них, которые подставляются в роль и меняют поведение в нужную сторону.
Jinja2 это из этой темы?
Jinja2 — это весьма мощный язык шаблонизации. Jinja2 используется в ролях.
Это параметризация, как я понимаю, нет?
Это шаблон. А параметры — это то, что ты уже в этот шаблон вставляешь. Вообще, это очень мощная вещь, с помощью этого языка шаблонов можно описывать конфиги практически любой сложности и при выполнении уже непосредственно роли из своего инвентаря подставляются нужные переменные и тебе формируется нужный конфиг.
Как гарантировать, что твой конфиг работоспособный, что он не устарел, не сломался — вдруг на сервере что-то поменялось, и у тебя команда ansible-play не сработала. Это как-то тестируется?
Да, разумеется, это тестируется.
В правильно построенной инфраструктуре мимо Ansible и вообще любого средства управления конфигурациями ничего меняться не должно. То есть никто не должен ходить руками и там что-то делать и настраивать. Если он это делает, то за это нужно по рукам бить. Потому что правильный подход — это вносить нужные изменения в инвентарь. Если в используемых ролях нет нужных действий, ты дописываешь.
Это подход «инфраструктура как код» (Infrastructure-as-Code, IaC). Код в каком смысле? Код должен проходить ревью, то есть твои коллеги должны видеть, что ты написал и подтвердить, что это вменяемо.
Речь про конфигурации?
Да. То есть точно также весь инфраструктурный код хранится в репозитории GitLab, GitHub — чем вы там пользуетесь.
Рядом с продуктовым кодом? Или это отдельная репа?
Разумеется, отдельная. Это много реп чаще всего. И потом перед тем как что-то изменить, ты делаешь merge request с изменениями (в зависимости от того, какая схема у вас в компании принята). В простейшем случае пишешь в телегу коллеге: «Вот, я написал, посмотри» и кидаешь ссылку. Он говорит: «Всё нормально, идём на тестирование».
Раз инфраструктура как код, у нас код проходит пайплайн. Всегда самый первый или второй job — это lint. Команда ansible-lint просматривает код на синтаксические ошибки и дает дельные советы. Если ты ставишь пакет, вызывая его как command «yum» или «apt-get» install, то тебе линтер напишет: «Используй специализированный модуль yum или apt». То есть тут не только синтаксические ошибки, но и семантика.
Разумеется, кроме проверки синтаксиса, есть инструмент полного тестирования. Потому что синтаксический анализатор не знает общего замысла твоего плейбука и не может знать, что будет в конце, идемпотентна данная конфигурация или нет. Есть такой инструмент, называется Molecule. Она запускает виртуальную машину.
Главный вопрос: не на проде же ты это будешь делать?
Да, разумеется, запускается виртуалка, в ней согласно описанной для Molecule конфигурации запускается Ansible плейбук.
А где гарантия, что виртуалка похожа на прод?
Надо самому следить.
Продакшн у нас же изначально чистый, как я понимаю?
Продакшн у нас изначально чистый. То есть с момента рождения он у нас сделан с помощью Ansible. Поэтому тестовая виртуалка обязана быть похожа на прод. Если нужно, туда можно и приложения вкатить отдельным job’ом.
А по ресурсам она тоже должна быть такая же, как прод, или необязательно?
Это зависит от конкретного случая. Если после запуска Molecule ты тестируешь ещё что-то с помощью каких-то внешних инструментов… Условно говоря, выкатываешь сайт, тестируешь Selenium (такое тоже бывает), то, естественно, ресурсов должно быть больше. Если он у тебя просто проходит набор ролей, то ресурсов нужно ровно столько, чтобы этот Python в память влез.
Тебе как человеку, который работает с Ansible, нужно программирование? Ты говорил, язык разметки YAML, написан на Python, нужно ли дописывать какие-то модули, ещё что-то. Просто, чтобы понимали девелоперы: нужно ли владеть языком при работе с Ansible?
Можно не владеть. Но лучше владеть.
Каким и для чего?
Python. Потому что, если под конкретную задачу нет нужного модуля, конечно, можно написать это всё в виде скрипта и дёргать его из task, но это плохой тон, это называется «bashsible» в комьюнити, связанных с Ansible. И это прям фу-фу.
Чаще советуют написать специализированный модуль под свою задачу. Его можно написать на Shell, да и вообще на любом языке, потому что там просто система вызовов, но лучше всего писать на нативном для этого дела.
Нативном для Ansible, да?
Потому что можно на C попробовать это сделать.
Ну, если затраченные усилия будут оправданы, почему бы и нет.
Какие есть более или менее популярные аналоги Ansible? Или это монополист на рынке?
Нет, это, конечно, не монополист. Значительно более старые решения (в смысле прошедшие более длинный путь развития) — это Chef и CFEngine. Последний сейчас уже мало используется.
Они все работают примерно одинаково?
Они работают в основном как pull: на настраиваемой ноде выполняется сервис, который тянет конфигурацию.
Ansible — единственный, кто делает push из крупных?
Ansible умеет pull, но это не основной его режим работы. SaltStack тоже умеет push, но это не его основной режим работы. Ansible, можно сказать, в этом плане единственный. Ну и видимо, народу нравится, потому что я смотрю время от времени Google Trends по запросам, относящимся к Chef, к Ansible, и вижу, что Ansible набирает всё большую популярность. Более старых решения на пятилетнем промежутке её чуть-чуть теряют. Хотя есть энтузиасты, которые за них топят и их поддерживают.
Может, есть какие-то книги, что можно почитать, чтобы базово познакомиться с Ansible?
Знакомство с Ansible лучше всего начать с документации. На docs.ansible.com расписаны и самые основы, и примеры простых плейбуков, и вообще всё что нужно.
Я еще скажу про книгу Ansible: Up and Running. Книга неплохая, но Ansible достаточно быстро развивается и поэтому многие вещи в ней уже устарели. Поэтому лучше всего начинать именно с документации на сайте, она там всегда актуальна.
Вопросы задавал Лекс АйТиБорода @ iamitbeard
Принципы безопасности
Мы считаем, что все команды способны на великие свершения. Наша миссия — раскрыть потенциал каждой команды, независимо от размера и отрасли, и помочь человечеству перейти на новый этап развития, используя возможности программного обеспечения.
Мы понимаем, что миссия вашей компании значит для вас ничуть не меньше, чем для нас наша собственная. Мы также понимаем, что информация лежит в основе всего нашего бизнеса и жизни в целом. Поэтому доверие клиентов — наша главная цель, а обеспечение безопасности всегда остается первоочередной задачей. Наша программа обеспечения безопасности полностью открыта, чтобы вы могли понять принцип ее работы и уверенно применять наши продукты и сервисы.
Ознакомьтесь подробнее с нашим подходом к обеспечению безопасности и узнайте, каким образом клиенты могут внести в эту область свой вклад.
Если не указано иное, информация на этой странице касается продуктов Atlassian Cloud — Jira, Confluence и Bitbucket.
Наш подход к обеспечению безопасности
Этот раздел посвящен подходу компании Atlassian к обеспечению безопасности. В нем рассмотрены основные действия и методы в ряде доменов безопасности для защиты наших собственных сред (включая облачные платформы) и процессов, предназначенных для создания максимально безопасных продуктов для наших клиентов и пользователей.
Наши основные принципы обеспечения безопасности
В основе нашего подхода к обеспечению безопасности лежит несколько тезисов.
- Мы хотим стать примером для наших коллег в вопросах безопасности облака и продуктов.
- Мы стремимся отвечать всем требованиям клиентов к безопасности облака и превосходить требования отраслевых стандартов и сертификаций безопасности.
- Мы открыто делимся информацией о своих программах, процессах и показателях и стремимся к их прозрачности. Это означает, что мы рассказываем о своем развитии и ждем того же от других поставщиков облачных услуг, а также устанавливаем новые стандарты для клиентов.
Основное внимание в этом разделе уделяется ряду мер и инициатив. С их помощью мы воплотили в жизнь основные принципы обеспечения безопасности, заключенные в этих главных тезисах.
Мы также гордимся тем, что многие из наших главных продуктов лежат в основе повседневных операций и рабочих процессов в компании Atlassian и являются их ключевой составляющей. Например, приложения Jira и Confluence составляют основу нашего подхода к управлению инцидентами и программ управления уязвимостями. Это означает, что мы заинтересованы в обеспечении безопасности наших продуктов. Дело не только в том, что одна из наших ключевых ценностей звучит как «Проявляйте заботу о клиентах», но и в том, что мы сами используем эти продукты.
Наша команда
Уверены, что большинство компаний готовы сказать то же самое, — но мы бесконечно гордимся нашей командой по обеспечению безопасности. Мы считаем, что сформировали и вырастили команду самых лучших и талантливых специалистов в отрасли. Наша команда по обеспечению безопасности насчитывает более 100 сотрудников из офисов в Сиднее, Амстердаме, Бангалоре, Остине, Маунтин-Вью, Сан-Франциско и Нью-Йорке (плюс несколько участников, которые работают дистанционно); возглавляет команду генеральный директор по информационной безопасности в Сан-Франциско. Эта команда постоянно развивается, тем самым подтверждая, что безопасность является сферой особого внимания для Atlassian. У нас есть множество вспомогательных команд, в том числе:
- команда по обеспечению безопасности продуктов — отвечает за безопасность наших продуктов и платформ;
- команда по обеспечению безопасности экосистемы — отвечает за безопасность нашего магазина Marketplace и аддонов;
- команда по сбору и анализу данных безопасности — отвечает за выявление инцидентов безопасности и реагирование на них;
- «красная команда» — отвечает за моделирование атак и (или) угроз и тренировку команды по сбору и анализу данных безопасности;
- команда по разработке архитектуры безопасности — отвечает за определение требований к безопасности наших продуктов и платформ;
- команда по обеспечению корпоративной безопасности — отвечает за обеспечение безопасности внутри компании в аспектах, касающихся собственной сети и приложений;
- команда по формированию доверия пользователей — отвечает за отслеживание ожиданий клиентов и реагирование на них, а также обеспечивает прозрачность наших процессов и методов работы;
- команда по разработке приложений и обеспечению надежности — отвечает за создание и эксплуатацию инструментов для команды по обеспечению безопасности;
- команда по повышению грамотности и подготовке — отвечает за обучение наших сотрудников и партнеров принципам безопасной работы.
Пока наша команда по обеспечению безопасности продолжает расширяться, каждый сотрудник Atlassian играет свою роль в нашей миссии по повышению уровня безопасности. Мы не устаем напоминать им об этом с первого до последнего дня работы в компании. Мы хотим стать примером для других компаний в вопросах облачной безопасности, соответствовать всем требованиям клиентов к облачной безопасности, превосходить требования всех отраслевых стандартов и сертификаций безопасности и с гордостью публиковать сведения о защите данных наших клиентов. Наши цели и видение транслируются каждому сотруднику с первого до последнего дня работы в компании Atlassian.
Дополнительные программы, которые помогают нам поддерживать безопасность на должном уровне
Наше внимание сосредоточено на основах безопасности. При этом мы реализовываем ряд программ, которые помогают следить и за тем, чтобы наш подход к обеспечению безопасности оставался как можно более разносторонним, позволяя работать на опережение. Вот некоторые из наших программ.
Программа «Чемпионы безопасности»
В каждой нашей команде по продукту и сервисной команде назначен руководитель по безопасности, который следит за тем, чтобы его коллеги всегда выполняли требования основных инициатив безопасности и сохранялся открытый диалог с нашей центральной командой по обеспечению безопасности. Таким образом, безопасность остается в центре внимания всех сотрудников нашей организации.
Программа поддержки безопасности
Эта программа служит дополнением процессов реагирования на инциденты в Atlassian. Мы встроили в стандартный процесс управления инцидентами отдельную программу, чтобы заблаговременно выявлять инциденты и создавать для них соответствующие предупреждения. Учитываются не только известные нам и актуальные типы инцидентов, но и угрозы, с которыми мы столкнемся в будущем.
Программа вознаграждения за найденные ошибки
Наша программа вознаграждения за найденные ошибки неизменно признается одной из лучших в отрасли и позволяет нам прибегать к помощи авторитетного сообщества, состоящего из десятков тысяч исследователей, которые постоянно тестируют наши продукты и отчитываются о любых обнаруженных уязвимостях.
Постоянное совершенствование нашей программы безопасности
Мы стремимся к тому, чтобы наша программа безопасности оставалась актуальной и служила примером для других компаний отрасли. Мы понимаем, что для этого нам необходимо постоянно оценивать наш текущий подход к обеспечению безопасности (а также сравнивать его с подходами наших коллег по цеху) и выявлять возможности для улучшения.
С этой целью мы провели (и продолжаем проводить) многочисленные оценки зрелости нашей программы безопасности, к участию в которых приглашаются независимые консалтинговые компании в сфере безопасности. В 2020 году мы также провели независимую оценку всей нашей программы «Надежность и безопасность». Мы учитываем данные, полученные в результате всей этой работы, в том числе основные рекомендации, чтобы заполнить любые пробелы и воспользоваться каждой возможностью стать лучше.
Мы также учредили несколько программ для разных команд, занимающихся обеспечением безопасности, таких как команда по безопасности продуктов и команда по сбору и анализу данных безопасности, чтобы направлять внутренние процессы оптимизации. Мы разработали показатели для поддержки каждой из этих программ, которые отслеживаются силами нашей команды по управлению безопасностью. С помощью этих показателей мы выявляем области для улучшения в каждой из наших основных компетенций и сосредотачиваем на них усилия.
Дополнительная информация
Этот документ дает общее представление о нашем подходе к обеспечению безопасности. Подробная информация о нашей программе безопасности доступна на странице Atlassian Trust Center. Там вы также найдете ряд специальных веб-страниц и технических документов, посвященных различным аспектам нашей программы безопасности, включая следующие.
- Подход компании Atlassian к управлению данными клиентов
- Наш подход к внешнему тестированию безопасности
- Наш подход к управлению инцидентами безопасности
- Наш подход к управлению уязвимостями
- Общая ответственность за обеспечение облачной безопасности
- Наша система Atlassian Trust Management System
- Политики Atlassian в сфере безопасности и технологий
Защита нашей внутренней среды
Отправной точкой эффективного подхода к обеспечению безопасности является наведение порядка в собственном хозяйстве. Для этого, в частности, нужно обеспечить безопасность наших внутренних сред. Для этого применяется ряд мер.
Встраивание средств обеспечения безопасности в архитектуру наших сетей
Компания Atlassian практикует многоуровневый подход к обеспечению безопасности сетей. Мы внедряем методы защиты на каждом уровне облачных сред, разделяя существующую инфраструктуру на зоны, среды и сервисы. Мы ввели ограничения по зонам, которые включают в себя введение лимита сетевого трафика на уровне офиса/сотрудников, данных клиентов, CI/CD и DMZ. У нас также предусмотрена изоляция сред, чтобы контролировать подключения между рабочими и нерабочими средами. Данные рабочей среды не реплицируются за пределами рабочих сред. Доступ к рабочим сетям и сервисам возможен только из тех же сетей, то есть доступ к рабочему сервису может получить только другой рабочий сервис.
Для коммуникации между сервисами требуется явная авторизация с использованием списка разрешенных сервисов. Доступ к конфиденциальным сетям регулируется с помощью маршрутизации виртуальных частных облаков (VPC), а также использования программно конфигурируемых сетей и правил для брандмауэров. Все подключения в этих сетях зашифрованы. Мы также внедрили систему обнаружения вторжений как в офисных, так и в производственных сетях, чтобы выявлять возможные угрозы.
Обеспечение безопасного доступа к нашим сетям при помощи модели «нулевого доверия»
Компания Atlassian использует концепцию «нулевого доверия» для обеспечения безопасного доступа к своей корпоративной сети, внутренним приложениям и облачным средам. Простыми словами основной постулат этой концепции можно сформулировать так: «Никогда не доверяйте, всегда проверяйте».
Концепция «нулевого доверия» отличается от традиционных подходов к обеспечению сетевой безопасности, в рамках которых правомочность доступа пользователя к ресурсам в сети определяется только посредством аутентификации. Такие подходы сопряжены с риском использования недоверенного или небезопасного устройства, что может поставить безопасность под угрозу. По этой причине многие организации начали переход к модели, в рамках которой доступ к сети могут получать только доверенные устройства. Для этого они используют технологии управления мобильными устройствами или разрешают доступ на уровне сети ограниченному кругу известных устройств, внесенных в специальный список.
Эти подходы позволяют добиться нужных результатов, но им недостает детализации. Подход компании Atlassian, в основе которого лежит концепция «нулевого доверия», гарантирует, что решение о предоставлении пользователям доступа к ресурсам и сервисам в наших сетях выносится не только на основании их учетных данных, предоставленных для аутентификации, но и с учетом динамической политики. Таким образом решение о предоставлении доступа к тому или иному ресурсу или об отказе в нем выносится с учетом ряда факторов и на основе состояния безопасности пользовательского устройства (независимо от его местоположения).
Проще говоря, мы выделили три уровня ресурсов (в зависимости от степени их относительной критичности и ценности) в нашей сети, вокруг которых выстроена модель «нулевого доверия».
- Открытый уровень. Доступ к сервисам этого уровня может получить любой корпоративный пользователь, который успешно пройдет аутентификацию в нашей сети.
- Нижний уровень. Доступ к этим ресурсам предоставляется прошедшему аутентификацию корпоративному пользователю, только если он обращается к нашей сети с доверенного корпоративного устройства (такого, которое принадлежит компании Atlassian и которым она управляет) или управляемого личного устройства (собственного устройства пользователя, зарегистрированного в программе управления мобильными устройствами (MDM) Atlassian).
- Верхний уровень. Доступ к этим ресурсам можно получить только прошедшему аутентификацию корпоративному пользователю с корпоративного устройства, выданного компанией Atlassian. Получить доступ к рабочим сервисам из нашей корпоративной сети можно только с помощью устройства верхнего уровня, пройдя аутентификацию на базе SAML.

Реализация модели нулевого доверия компанией Atlassian происходит за счет ряда автоматизированных процессов, сервисов и компонентов. Вот как она работает на верхнем уровне.
- Прошедшим аутентификацию пользователям с корпоративными или управляемыми личными устройствами наш сервис Trust Engine предоставляет сертификат. В сертификате содержатся метаданные, указывающие, для какого устройства он выдан: личного или корпоративного. Сертификат помещается на устройства при помощи наших решений по управлению конечными точками и регулярно обновляется (или отзывается).
- Когда пользователь проходит аутентификацию, его сертификат запрашивается для изучения нашей инфраструктурой. Информация из сертификата позволяет определить правомочность аккаунта пользователя и тип используемого устройства. На основании этой информации пользователю предоставляется доступ либо к сети нижнего уровня, где его возможности работы с сетью и приложениями ограничены, либо к верхнему уровню. Устройства, подключенные к сети Atlassian, опрашиваются каждый час, и наши решения по управлению конечными точками создают перекрестные ссылки на них, чтобы получить информацию о владельце, безопасности и состоянии устройства. При этом устройства также подвергаются проверке на соответствие минимальным требованиям. В ходе нее проверяются наличие средств защиты от вредоносного ПО, шифрование, версии ОС и т. д.
- Информация о соответствии устройств пользователей требованиям поступает в центральную базу данных. На ее основании принимается решение о предоставлении пользователям доступа к ресурсам в нашей сети или об отказе в нем. Устройства, помеченные как не отвечающие требованиям, будут отключены от нашей сети.
Компания Atlassian подготовила документ, в котором описываются принципы и реализация архитектуры «нулевого доверия».
Защищенное управление доступом к нашим системам и сервисам
В компании Atlassian детально прописан процесс управления доступом (его предоставления или отзыва) пользователя для всех систем и служб. У нас существует установленный рабочий процесс (с синхронизацией каждые 8 часов), посредством которого соединены наша система управления кадровыми ресурсами и система управления доступом. Контроль доступа осуществляется на основе ролей с помощью предопределенных профилей пользователей. Благодаря этому сотрудникам предоставляется ровно столько прав доступа, сколько необходимо для исполнения должностных обязанностей. Все аккаунты пользователей должны быть утверждены руководством, прежде чем они получат доступ к данным, приложениям, инфраструктуре или сетевым компонентам.
Поддерживая нашу архитектуру «нулевого доверия», мы контролируем доступ к собственным корпоративным приложениям посредством платформы единого входа. Чтобы получить доступ к любому из наших приложений, сотрудники должны пройти аутентификацию посредством этой платформы, которая запрашивает аутентификационные данные двух разных типов. Пользователям необходимо пройти аутентификацию с помощью ключей U2F либо с помощью мобильного приложения, предназначенного для проверки подлинности (предоставляется компанией Atlassian). Мы отказались от менее надежных методов аутентификации, таких как использование одноразовых паролей, рассылаемых по SMS или сообщаемых по телефону. Компания Atlassian приняла этот подход, чтобы сделать процесс аутентификации устойчивым к фишингу и атакам через посредника. Любую систему, которая рассылает коды в текстовых сообщениях, может взломать опытный злоумышленник.
Защита наших конечных точек
Компания Atlassian использует несколько решений по управлению конечными точками, чтобы развертывать обновления и патчи для операционных систем и ключевых приложений на всем комплексе наших конечных точек. Мы также внедрили множество решений по защите конечных точек, чтобы устранить такие угрозы, как вредоносное ПО.
Наша модель, основанная на принципе «нулевого доверия», предполагает, что для доступа к большинству наших сервисов с личного мобильного устройства сотрудники компании Atlassian должны регистрироваться в нашей программе управления мобильными устройствами (MDM). Благодаря этому мы можем гарантировать, что все мобильные устройства, подключающиеся к нашей сети, соответствуют минимальным требованиям к безопасности, в том числе в таких аспектах, как шифрование, блокировка устройства, наличие средств защиты от вредоносного ПО и актуальность версий ОС.
Все отвечающие критериям сотрудники, которые регистрируются и постоянно выполняют требования нашей программы MDM, получают от компании Atlassian ежемесячное вознаграждение за участие.
Если какое-либо устройство определяется как не отвечающее требованиям, сотрудник получит по электронной почте соответствующее уведомление. Сотруднику дается 24 часа на исправление нарушения, прежде чем доступ для этого устройства будет прекращен.
Безопасность в нашей повседневной работе
Мы прилагаем множество усилий, чтобы безопасность стала неотъемлемой частью всех аспектов наших повседневных операционных процессов. Мы стремимся к тому, чтобы безопасность всегда учитывалась в наших методах работы и нам как можно реже приходилось совершенствовать или доводить до ума систему безопасности постфактум.
Отслеживание наших информационных ресурсов
Наши рабочие системы размещены в инфраструктуре, предоставленной поставщиками облачных услуг. Из-за характера этих услуг системы не отслеживаются на аппаратном уровне. Базовые микросервисы, на основе которых работают наши продукты, отслеживаются в специально созданной сервисной базе данных. Эта база данных автоматически обновляется при развертывании какого-либо сервиса.
Наша команда по технологиям рабочего места проводит инвентаризацию всех конечных точек с помощью нашего собственного программного обеспечения Jira для целей отслеживания.
Управление изменениями в нашей среде
Наш процесс управления изменениями немного отличается от традиционного. Традиционные процессы опираются на иерархию в виде пирамиды. В этом случае запросы на изменение обрабатываются специальной группой, которая одобряет или отклоняет их.
Мы сделали выбор в пользу открытого подхода, который мы называем «Проверка коллегами, зеленая сборка» (PRGB). В отличие от традиционного процесса управления изменениями подход PRGB требует, чтобы каждое изменение — будь то изменение кода или инфраструктуры — проверялось одним или несколькими коллегами на предмет проблем, которые могли возникнуть в результате изменения. Чем критичнее изменение или системы, которые оно затронет, тем больше привлекается проверяющих. Наши специалисты выявляют и помечают проблемы, прежде чем изменение будет реализовано. Этот процесс зарекомендовал себя как гибкий и адаптируемый подход к управлению изменениями в нашей среде. Под «зеленой сборкой» подразумевается, что наш конвейер CI/CD должен произвести успешную или «чистую» сборку, включающую новые изменения. Если какие-либо составляющие изменения не проходят интеграционное тестирование, функциональное тестирование, модульное тестирование или тестирование безопасности, сборка отклоняется и возвращается на стадию исходного запроса на изменение для устранения всех неполадок.
Управление конфигурациями в наших системах
В нашей компании лишь ограниченному числу специалистов и архитекторов разрешено устанавливать программное обеспечение в рабочей среде. В большинстве случаев установка ПО невозможна. Для управления конфигурациями и изменениями на серверах в наших рабочих средах используются инструменты управления конфигурациями. Предполагается, что для непосредственного внесения изменений в эти системы утвержденная конфигурация передается посредством инструментов управления конфигурацией. Благодаря этому обеспечивается согласованность. Мы полагаемся на стандартные образы машин Amazon (Amazon Machine Image, AMI). Все изменения в наших AMI или операционных системах должны совершаться посредством нашего стандартного процесса управления изменениями. Мы отслеживаем конфигурации-исключения и сообщаем о них. Кроме того, у нас реализована изоляция ресурсов, чтобы проблемы с каким-либо сервисом не повлияли на работу других сервисов. Мы также используем процесс «Проверка коллегами, зеленая сборка» (PRGB). В ходе этого процесса множество проверяющих утверждают изменения конфигурации, переданные через инструменты управления конфигурациями. Все сборки снабжаются криптографической подписью. В нашей рабочей среде можно запускать только сборки такого типа.
Использование журналов
С помощью платформы управления информацией о безопасности и событиями безопасности (SIEM) мы собираем журналы из различных источников, устанавливаем правила мониторинга для этих собранных журналов и затем помечаем все подозрительные действия. Оценка таких оповещений, а также их дальнейшее расследование и надлежащая эскалация определяются внутренними процессами компании. Ключевые системные журналы передаются из каждой системы, причем журналы доступны только для чтения. Команда по обеспечению безопасности Atlassian создает оповещения на нашей платформе аналитики безопасности и отслеживает признаки угрозы. Наши команды по обеспечению надежности используют эту платформу, чтобы отслеживать проблемы, влияющие на доступность или производительность. Журналы хранятся в течение 30 дней в архивах «горячего» резервирования и в течение 365 дней в архивах «холодного» резервирования.
Основные системные журналы объединяются как во внутреннюю систему анализа журналов, так и в систему обнаружения вторжений.
Журналы играют важнейшую роль в нашей глобальной стратегии обнаружения вторжений и реагирования на них. Подробнее об этом написано в разделе «Наш подход к выявлению угроз безопасности, их предупреждению и реагированию на них».
Обеспечение непрерывности бизнеса и аварийного восстановления
Нам очень важно, чтобы наши продукты были отказоустойчивыми — во многом по той причине, что команда Atlassian сама полагается на эти продукты. Мы понимаем, что иногда могут случаться перебои в работе. Поэтому мы стремимся внедрить процессы на случай перебоев, чтобы их воздействие на наших клиентов было минимальным. В наших программах по обеспечению непрерывности бизнеса (BC) и аварийного восстановления (DR) предусмотрены различные меры, которые помогают достичь соответствующих целей.
Руководство компании вовлечено в планирование непрерывности бизнеса и аварийного восстановления. Такой контроль необходим, чтобы все команды чувствовали на себе личную ответственность за обеспечение устойчивости. В ходе мероприятий по планированию BC и DR мы стремимся найти подходящий баланс между затратами, выгодами и рисками. Для этого мы проводим анализ целевых сроков восстановления (RTO) и целевых точек восстановления (RPO) сервисов. В результате этого анализа мы создали простую систему из 4 уровней. С помощью нее можно поделить сервисы на группы в зависимости от того, какие требования выдвигаются к их восстановлению. Подробнее об этом подходе см. на странице «Подход компании Atlassian к управлению данными клиентов».
Наши программы BC и DR предполагают следующие мероприятия.
1. Встраивание средств обеспечения резервирования для удовлетворения требований к отказоустойчивости
2. Тестирование и проверка мер обеспечения избыточности
3. Использование результатов тестирования для непрерывного улучшения мер обеспечения BC и DR
Наши продукты создаются с расчетом на эффективное использование возможностей избыточности, таких как зоны доступности и регионы, предоставляемых поставщиками облачных услуг.
Мы непрерывно отслеживаем широкий спектр показателей, чтобы как можно раньше обнаружить потенциальные проблемы. Эти показатели используются для настройки оповещений для инженеров по обеспечению надежности сайта (SRE) или соответствующих команд по проектированию продукта. При превышении порогового значения показателей незамедлительно принимаются меры согласно процедуре реагирования на инциденты. Кроме того, команда SRE играет ведущую роль в выявлении недостатков программы DR, а также устраняет их совместно с командой по управлению рисками и обеспечению соответствия требованиям. Каждая из наших команд включает чемпиона по DR, который помогает ее участникам в управлении аварийным восстановлением в рамках их функциональных обязанностей, а также контролирует этот процесс.
Тестирование DR охватывает такие аспекты, как процессы и технологии, в том числе документирование нужных процессов. Тестирование проводится регулярно и с учетом уровня важности сервиса. Например, процессы резервного копирования и восстановления данных основных систем, предназначенных для клиентов, тестируются ежеквартально. Мы проводим ручное и целенаправленное тестирование аварийного переключения систем. Такое тестирование может быть относительно простым (обсуждение моделируемой ситуации) или же более сложным, с проверкой аварийного переключения в зонах доступности и регионах. Результаты тестирования тщательно фиксируются и документируются независимо от сложности. Проводится их анализ и выявляются недостатки и возможности для улучшения, которые затем обрабатываются в виде заявок Jira. Благодаря этому весь процесс непрерывно совершенствуется.
Мы проводим ежегодную оценку последствий для бизнеса (BIA) с целью определить риски критически важных сервисов. Результаты оценки используются для определения стратегии по обеспечению DR и BC. Благодаря этому возможна разработка эффективных планов по DR и BC для критически важных сервисов.
Доступность сервисов
Помимо вышеупомянутых мер, мы также публикуем для клиентов сведения о статусе доступности сервисов в режиме реального времени в собственном продукте Statuspage. В случае проблем с сервисом клиенты узнают об этом сразу после нас.
Резервное копирование
Компания Atlassian реализует комплексную программу резервного копирования. Она включает внутренние системы компании, средства резервного копирования которых соответствуют требованиям к восстановлению работоспособности систем. Кроме того, в отношении предложений Atlassian Cloud (особенно клиентских данных и данных приложений) применяются расширенные средства резервного копирования. Для ежедневного автоматического резервного копирования каждого экземпляра RDS в Atlassian используют возможности Amazon RDS (сервиса реляционных баз данных) по созданию снимков состояния.
Снимки состояния Amazon RDS хранятся в течение 30 дней. Они позволяют восстановить экземпляр до состояния на определенный момент времени и зашифрованы по стандарту AES-256. Резервные копии данных не хранятся удаленно, а реплицируются в несколько ЦОД в определенном регионе AWS. Кроме того, мы проводим ежеквартальное тестирование своих резервных копий.
Данные Bitbucket копируются в другой регион AWS. Кроме того, для каждого региона ежедневно создаются независимые резервные копии.
Эти резервные копии не используются для устранения негативных последствий от операций, инициированных клиентами (таких как перезапись отдельных полей в ходе работы скриптов, удаление задач, проектов или сайтов). Чтобы избежать потери данных, рекомендуется выполнять регулярное резервное копирование. Подробнее о создании резервных копий см. в документации по поддержке конкретного продукта.
Физическая безопасность
Методы обеспечения физической безопасности в офисах Atlassian регулируются политикой обеспечения физической безопасности и безопасности среды, благодаря которой локальная и облачная среды компании надежно защищены физически. Политика описывает такие меры и средства, как безопасные рабочие места, защита ИТ-оборудования (независимо от его местонахождения), доступ в здания и офисы только для соответствующего персонала, а также мониторинг физических точек входа и выхода. Компания придерживается таких принципов физической безопасности, как организация приема посетителей в рабочие часы с обязательной регистрацией, доступ по опознавательным знакам во все места внутреннего пользования, а также регулирование доступа через точки входа и выхода (включая главные входы и зоны погрузки) в нерабочее время и ведение видеонаблюдения в этих точках при содействии управления офисного здания.
ЦОД, с которыми сотрудничает компания Atlassian, соответствуют по меньшей мере требованиям SOC 2. Эта сертификация гарантирует наличие ряда методов защиты, в том числе физической безопасности и безопасности среды. Доступ к ЦОД осуществляется только уполномоченным персоналом после биометрической аутентификации. Меры обеспечения физической безопасности включают охрану на местах, видеонаблюдение, кабины-ловушки и дополнительные меры защиты от вторжений.
Защита данных
Мы используем ряд мер для обеспечения защиты и доступности данных клиентов, при этом предоставляя клиентам максимальный контроль над своими данными.
ЦОД
Продукты и данные Atlassian размещаются у ведущего поставщика услуг облачного хостинга — Amazon Web Services (AWS). AWS обеспечивает оптимальную производительность для клиентов по всему миру, предоставляя возможности избыточности и аварийного переключения ресурсов. Мы используем несколько регионов AWS, удаленных друг от друга географически (в восточной и западной частях США, на территории Европейского союза и в странах Азиатско-Тихоокеанского региона), а также несколько зон доступности в каждом из этих регионов. Таким образом, отказ отдельного ЦОД не ухудшает доступность продуктов или клиентских данных. Подробнее см. в документе, посвященном управлению клиентскими данными в Atlassian, и на странице облачной инфраструктуры размещения.
Физический доступ к ЦОД, где размещаются данные клиентов, осуществляется только уполномоченным персоналом, при этом право доступа проверяется с использованием биометрии. Меры обеспечения физической безопасности для ЦОД включают охрану на местах, видеонаблюдение, кабины-ловушки и дополнительные меры защиты от вторжений.
Шифрование данных
Все данные клиентов, хранящиеся в облачных продуктах Atlassian, шифруются при передаче по общедоступным сетям с помощью протокола TLS 1.2+ с полной безопасностью пересылки (PFS) для защиты от несанкционированного раскрытия или изменения. Наша реализация TLS обеспечивает использование криптостойких шифров и ключей нужной длины, если это поддерживается браузером.
Данные клиентов и вложения в Jira Software Cloud, Jira Service Management Cloud, Jira Work Management, Bitbucket Cloud, Confluence Cloud, Statuspage, Opsgenie и Trello, хранящиеся на жестких дисках наших серверов, защищены с помощью отраслевого стандарта полного шифрования диска — AES-256. Актуальные сведения об обновлениях платформы см. на дорожной карте Atlassian Trust.
Управление ключами
Для управления ключами компания Atlassian использует AWS Key Management Service (KMS). Процесс шифрования, дешифрования и управления ключами регулярно проверяется и контролируется AWS в рамках существующих внутренних процессов утверждения. Для каждого ключа назначается владелец, который отвечает за применение для него методов защиты соответствующего уровня.
Разделение держателей
Клиенты Atlassian пользуются продуктами в общей облачной ИТ-инфраструктуре, однако при этом их данные логически разделены. Таким образом, действия одного клиента не могут поставить под угрозу конфиденциальность данных или работоспособность сервиса другого клиента.
В компании Atlassian для каждого приложения используется свой подход. В случае с сервисами Jira и Confluence Cloud для логической изоляции клиентов используется концепция под названием «контекст держателей» (Tenant Context). Она реализована в коде приложения и управляется посредством созданного нами «сервиса контекста держателей» (Tenant Context Service, TCS). Согласно этой концепции:
- данные каждого клиента при хранении логически обособлены от данных других держателей;
- все запросы к данным обрабатываются Jira или Confluence в контексте определенного держателя, исключая воздействие на других держателей.
В общих чертах, TCS хранит «контекст» для каждого отдельного держателя. К контексту каждого держателя привязан уникальный идентификатор, который хранится централизованно в TCS и включает набор метаданных, связанных с этим держателем (например, в нем указаны базы данных, в которых хранятся записи о держателе, лицензии держателя, доступные ему возможности и прочая информация, относящаяся к конфигурации). Когда клиент обращается к Jira или Confluence Cloud, сервис TCS с помощью идентификатора держателя отбирает соответствующие метаданные и связывает их со всеми операциями, совершаемыми держателем в приложении в ходе сеанса.
Контекст, предоставляемый сервисом TCS, играет роль «призмы», через которую происходит взаимодействие с данными клиента и которая сфокусирована на одном конкретном держателе. Таким образом, держатель не может получить доступ к данным другого держателя и не может своими действиями повлиять на работоспособность сервиса другого держателя.
Дополнительные сведения о нашей облачной архитектуре см. в ресурсах, посвященных поддержке облачных продуктов.
Общая ответственность при управлении данными клиентов
Компания Atlassian принимает на себя ответственность за обеспечение безопасности, доступности и надлежащей производительности предоставляемых приложений, а также систем, в которых они работают, и сред размещения этих систем. Несмотря на это, безопасность является предметом солидарной ответственности Atlassian и клиентов компании. Можно выделить четыре направления по обеспечению безопасности.
Политика и соответствие требованиям
Обеспечение соответствия системы потребностям бизнеса и ее функционирования согласно требованиям отраслевых стандартов, нормативных правовых актов и иных регламентирующих документов.
Пользователи
Создание пользовательских аккаунтов и управление ими.
Информация
Содержимое, которое клиенты хранят в Confluence Cloud, Jira Cloud, Trello или Bitbucket Cloud.
Приложения Marketplace
Сторонние сервисы, которые можно интегрировать с продуктами Atlassian.
Компания Atlassian принимает все необходимые меры для защиты безопасности клиентских данных. Однако значительное влияние на безопасность оказывают и решения клиентов по настройке продуктов. При использовании продуктов следует обращать внимание на следующие важные действия.
- Подтверждение домена и централизованное управление пользовательскими аккаунтами. Администраторы в организациях клиентов могут подтвердить права организации на один или несколько доменов. После подтверждения домена у администратора появляется возможность централизованно управлять всеми аккаунтами Atlassian сотрудников и применять политики аутентификации, в том числе требования к паролям и SAML. Настоятельно рекомендуется выполнить эти действия, чтобы защитить доступ к аккаунтам и данным, которые можно получить в случае входа.
- Права доступа. Наши продукты предназначены для совместной работы, однако клиентам следует с осторожностью предоставлять пользователям права доступа к данным в организации. В некоторых случаях возможно предоставление общего доступа к данным. Компания Atlassian не может повлиять на это решение, и в этом случае данные могут быть скопированы или переданы в чужие руки.
- Централизованный доступ. Клиентам настоятельно рекомендуется использовать Atlassian Access — инструмент для централизованного администрирования и обеспечения повышенной безопасности продуктов Atlassian, используемых в организации. (Средства обеспечения безопасности включают принудительную двухфакторную аутентификацию (2FA) и систему единого входа.)
Управление доступом к данным клиентов
Все данные клиентов считаются в равной степени конфиденциальными, поэтому мы внедрили строгие методы защиты этих данных. Чтобы подготовить сотрудников и подрядчиков к работе с данными клиентов, а также дать соответствующие рекомендации, мы проводим обучение для повышения осведомленности в этой области в период адаптации.
В Atlassian данные клиентов, хранящиеся в наших приложениях, доступны только уполномоченным сотрудникам. Аутентификация выполняется с помощью индивидуальных открытых ключей, защищенных парольной фразой, а серверы принимают входящие SSH-соединения только из Atlassian и внутренних ЦОД. Доступ к любым данным предоставляется группам привилегированных пользователей и может быть предоставлен другим пользователям только после запроса и проверки. Кроме того, требуется дополнительная двухфакторная аутентификация (2FA).
Благодаря строгим методам защиты при аутентификации и авторизации наша международная команда поддержки может обеспечивать техническое обслуживание и поддержку продуктов. Доступ к размещенным приложениям и данным возможен с целью мониторинга работы приложений и выполнения технического обслуживания систем или приложений, а также по запросу клиента через нашу систему поддержки. Кроме того, клиенты могут предоставить доступ к данным определенным специалистам службы поддержки. Это можно сделать с помощью средства проверки согласия на предоставление доступа.
Несанкционированный или ненадлежащий доступ к данным клиентов рассматривается как инцидент безопасности и обрабатывается с помощью процесса управления инцидентами. Этот процесс включает инструкции по уведомлению затронутых клиентов в том случае, если было обнаружено нарушение политики.
Сохранение и удаление данных
Компания Atlassian имеет возможность удалять персональные данные по запросу пользователей, а также помогает удалять персональные данные конечным пользователям с аккаунтами Atlassian. Кроме того, Atlassian предоставляет инструменты импорта и экспорта, с помощью которых клиенты могут получать доступ к своим данным, а также импортировать и экспортировать их.
Сайты клиентов деактивируются через 15 дней после окончания срока действия подписки. Atlassian хранит данные неактивных сайтов в течение 15 дней (для сайтов пробной версии) или 60 дней (для сайтов с платной подпиской) после окончания срока действия подписки. Обратите внимание, что в случае подписки на продукты Jira данные будут удалены только после отмены подписки на все такие продукты.
Защита сотрудников
Компания Atlassian стремится к тому, чтобы все ее сотрудники умели работать безопасно, и создает соответствующие условия. Важнейшее место в культуре компании занимает установка на безопасность, благодаря которой повышается общий уровень устойчивости к потенциальным кибератакам.
Обучение мерам и правилам безопасности
Все сотрудники Atlassian проходят обучение по мерам и правилам безопасности в период адаптации и в дальнейшем на постоянной основе. Таким образом, безопасность остается важнейшим принципом компании. Мы понимаем, что многие угрозы безопасности касаются не только нашей компании, поэтому проводим обучение для команд наших подрядчиков и партнеров. В программе обучения освещаются такие темы, как современные угрозы безопасности и способы мошенничества, принципы безопасной работы, поведение, несущее потенциальную угрозу безопасности, а также вопросы соответствия нормативным и иным требованиям.
Помимо обучения по общим мерам и правилам безопасности, наши разработчики могут пройти специальное обучение по безопасному программированию. Кроме того, команды разработчиков получают поддержку от чемпионов безопасности или принимают в свой состав инженера по безопасности для выполнения соответствующих рабочих задач.
В Atlassian также поддерживаются открытые каналы коммуникации, такие как мгновенные сообщения, записи в блогах, разделы часто задаваемых вопросов и т. д., благодаря которым команда по обеспечению безопасности максимально доступна для сотрудников компании.
В октябре команда по обеспечению безопасности Atlassian проводит мероприятие под названием «Месяц осведомленности о безопасности», куда приглашаются все сотрудники и партнеры компании. В это время мы празднуем успехи каждого, кто принимал участие в обеспечении безопасности Atlassian, а также закрепляем результаты обучения, еще раз освещая важнейшие вопросы безопасности на играх и внутренних лекциях.
Программа «Чемпионы безопасности»
Программа «Чемпионы безопасности» включает назначенного руководителя по безопасности в каждой сервисной команде и команде по продукту. Этот выделенный специалист отвечает за распространение ключевых практик безопасности среди других участников команды, а также решает соответствующие задачи совместно с основной командой по обеспечению безопасности для улучшения обмена информацией.
Чемпионы проходят углубленное обучение, чтобы эффективнее выявлять уязвимости безопасности в приложениях, а также освоить принципы безопасной разработки и написания безопасного кода.
Чемпионы безопасности Atlassian регулярно встречаются, чтобы поделиться инструментами и знаниями о последних проблемах и задачах в области безопасности, с которыми они столкнулись, что полезно для всех наших команд. Эта программа позволила еще сильнее укрепить такой важный принцип культуры Atlassian, как безопасность.
Проверка биографии
Нам нужны люди, которые способствовали бы развитию культуры безопасности, созданной в Atlassian. Для этого мы проверяем в соответствии с местным законодательством биографию каждого нового сотрудника. В зависимости от должности подобная проверка может включать проверку судимостей, образования, занятости и кредитоспособности.
Безопасность продуктов
Компания Atlassian уделяет особое внимание тому, чтобы принципы безопасности внедрялись на всех этапах жизненного цикла продукта. Для этого применяется ряд методов.
Система оценки безопасности
Мы уделяем особое внимание тому, чтобы принцип безопасности лежал в основе всех наших продуктов. Для этого в компании внедрена система оценки безопасности продуктов, которая обеспечивает прозрачный мониторинг и оценку состояния безопасности всех продуктов Atlassian. В рамках этой автоматизированной процедуры используется широкий спектр критериев (текущие уязвимости, доля обученных сотрудников, недавние инциденты безопасности и укомплектованность команд чемпионами безопасности), которые позволяют сформировать всестороннюю оценку безопасности отдельного продукта.
В процессе оценки каждая из команд по продукту может получить объективное представление о том, каким вопросам безопасности следует уделить внимание, а также выявить существующие недостатки и определить действия по их устранению. Кроме того, эта процедура системной оценки позволяет команде по обеспечению безопасности Atlassian без труда отслеживать изменения безопасности продуктов во времени, в частности по мере их масштабирования.
Партнеры по обеспечению безопасности
Наша команда по безопасности продукта реализует партнерскую программу по внедрению соответствующих мер, в рамках которой проводятся консультации для команд по продукту и осуществляется контроль за включением процессов обеспечения безопасности в цикл разработки. Поддержка продуктов, безопасность которых критически важна, осуществляется выделенными партнерами по обеспечению безопасности либо посредством ротации доступных специалистов в командах. Партнеры проводят консультации по вопросам безопасности и помогают командам отслеживать, понимать и оперативно реагировать на результаты, полученные при оценке безопасности продукта.
Адресный контроль безопасности
Команда по безопасности продукта также управляет процессами контроля безопасности проектов по разработке ПО. Процедура оценки рисков используется для расстановки приоритетов в областях, требующих контроля, а также для определения действий, необходимых для снижения рисков проекта. В зависимости от установленного уровня риска, контроль может сочетать в себе нижеперечисленные меры.
- Моделирование угроз
- Оценка проекта
- Проверка кода (вручную или с помощью инструментов)
- Тестирование безопасности
- Осуществление независимого контроля сторонними компетентными исследователями или консультантами
В этом документе вы также найдете описание ведущей в отрасли программы вознаграждения за найденные ошибки, в рамках которой проверенная группа исследователей по вопросам безопасности, созданная по принципу краудсорсинга, осуществляет непрерывный контроль безопасности.
Моделирование угроз: безопасность на этапе проектирования
На этапах планирования и проектирования продуктов моделирование угроз позволяет лучше понять, каковы потенциальные риски проекта в случае возникновения множественных угроз безопасности или разработки возможностей, безопасность которых критически важна. Моделирование проводится в форме обычного обсуждения или мозгового штурма среди технических специалистов, инженеров по безопасности, разработчиков архитектуры и менеджеров по продукту. По итогам беседы выявляются значимые угрозы безопасности и определяются их приоритеты. Эти выводы используются на этапе проектирования и позволяют внедрить необходимые методы защиты. Кроме того, они пригодятся для адресных проверок и тестирования на конечных этапах разработки.
Анализ кода
Автоматический анализ кода осуществляется на платформе под названием Security Assistant («Ассистент по безопасности»), которая поддерживает все репозитории кода в Atlassian. Платформа включает различные инструменты статического анализа, обеспечивающие полную безопасность кода. Мы непрерывно улучшаем их и добавляем новые. В ответ на новый запрос pull в репозитории платформа выполняет следующие действия.
- Поиск и выявление устаревших зависимостей кода, которые могут создавать уязвимости (подробнее об этом см. в разделе о нашем подходе к управлению уязвимостями).
- Выявление любого случайного или ненамеренного раскрытия секретной информации, содержащейся в репозиториях кода (например, токены аутентификации или криптографические ключи).
- Анализ с целью выявления проблемных шаблонов проектирования, которые могут создавать уязвимости в коде.
База знаний в области безопасности
Для того чтобы создавать продукты с высочайшим уровнем безопасности, мы обеспечиваем своих разработчиков информационной поддержкой, ресурсы которой постоянно пополняются сведениями о значимых проблемах и угрозах безопасности. Таким источником информации служит внутренняя база знаний в области безопасности приложений, которая в любое время доступна разработчикам. База знаний пополняется при поддержке программы «Чемпионы безопасности». В частности, наши команды по разработке могут посмотреть презентации о характерных проблемах и закономерностях, которые были выявлены в ходе наблюдения и несут потенциальную угрозу безопасности.
Наш подход к выявлению угроз безопасности, их предупреждению и реагированию на них
Тестирование безопасности
Подход Atlassian к тестированию безопасности основан на понятии непрерывного контроля. Мы не только проводим адресное тестирование на проникновение по состоянию на заданный момент времени — мы также используем постоянно действующую модель тестирования, которая основана на программе вознаграждения за найденные ошибки по принципу краудсорсинга. В Atlassian уверены, что такой разноплановый подход повышает шансы на обнаружение уязвимостей и помогает нам поставлять клиентам продукты с высочайшим уровнем безопасности. Подробнее см. в документе, посвященном нашему подходу к внешнему тестированию безопасности. Ниже кратко описаны меры по тестированию в Atlassian.
- Проверки безопасности в Atlassian. Как упоминалось ранее, наша команда по безопасности продукта реализует программу проверки безопасности. Регулярное тестирование безопасности является частью этой программы. Оно включает в себя проверку кода и тесты безопасности приложений, которые направлены на потенциально уязвимые области, обозначенные по итогам оценки рисков.
- Тестирование безопасности третьими сторонами. Мы сотрудничаем со специализированными консалтинговыми фирмами в области безопасности для проведения тестирования на проникновение методом белого ящика с использованием кода. Эти тесты ориентированы на угрозы и проводятся в отношении продуктов и инфраструктуры, подверженных высокому уровню риска. (Объектом тестирования могут стать наши облачные среды, новый продукт или серьезные изменения в архитектуре.)
- «Красная команда» Atlassian. В компании есть внутренняя «красная команда», которая имитирует действия злоумышленников. Ее участники пытаются выявить и использовать в своих целях уязвимости, существующие в наших системах, процессах и средах. Таким образом, мы находим и устраняем подобные угрозы в максимально короткие сроки.
- Вознаграждение за найденные ошибки. Для реализации нашей признанной программы вознаграждения за найденные ошибки привлекаются участники сообщества Bugcrowd — проверенные исследователи в области безопасности. Благодаря им непрерывно выявляются уязвимости в наших продуктах, так что обнаружить их и использовать в недобросовестных и корыстных целях становится все более ресурсоемкой задачей. Программа вознаграждения за найденные ошибки была неоднократно признана лучшей в отрасли. Она охватывает более 25 продуктов и сред компании, в том числе продукты Server, мобильные приложения и продукты Cloud.
Все уязвимости в защите, описанные в приведенных ниже отчетах, отслеживаются нашей внутренней системой Jira по мере их регистрации в программе вознаграждения за найденные ошибки. Все найденные таким образом проблемы сортируются по приоритету и отслеживаются в соответствии с нашим соглашением SLO по устранению уязвимостей в защите.
- Загрузить последний отчет о программе вознаграждения за найденные ошибки (Bug Bounty) для Atlassian (октябрь 2023 г.)
- Загрузить последний отчет о программе вознаграждения за найденные ошибки (Bug Bounty) для Halp (октябрь 2023 г.)
- Загрузить последний отчет о программе вознаграждения за найденные ошибки (Bug Bounty) для Jira Align (октябрь 2023 г.)
- Загрузить последний отчет о программе вознаграждения за найденные ошибки (Bug Bounty) для Opsgenie (октябрь 2023 г.)
- Загрузить последний отчет о программе вознаграждения за найденные ошибки (Bug Bounty) для Statuspage (октябрь 2023 г.)
- Загрузить последний отчет о программе вознаграждения за найденные ошибки (Bug Bounty) для Trello (октябрь 2023 г.)
Управление уязвимостями
Компания Atlassian постоянно работает над тем, чтобы снизить опасность и частоту появления уязвимостей в своих продуктах, сервисах и инфраструктуре, а также как можно быстрее исправлять выявленные уязвимости. С этой целью был внедрен разноплановый подход к управлению уязвимостями, который сочетает в себе автоматические и ручные процессы выявления, отслеживания и устранения уязвимостей. Мы применяем его к приложениям и инфраструктуре и непрерывно совершенствуем.
Для выявления уязвимостей в защите используются данные из различных источников, таких как автоматические сканеры, внутренние проверки системы безопасности, отчеты клиентов, а также наша публичная программа вознаграждения за найденные ошибки. На основе выявленной уязвимости немедленно создается заявка, которая регистрируется в специальном общекорпоративном проекте Jira для отслеживания уязвимостей. Данная заявка назначается ответственному владельцу системы или команде разработчиков. Благодаря централизованному подходу мы эффективно используем автоматизацию для заблаговременной рассылки уведомлений, выполнения автоматических эскалаций, а также формирования общекорпоративной отчетности, что позволяет своевременно устранять уязвимости.
Инфраструктура
Мы используем целый ряд инструментов выявления уязвимостей, которые регулярно применяем к своей инфраструктуре для автоматического поиска и обнаружения уязвимостей. Инструменты выполняют следующие функции.
- Сканирование сети позволяет определять активные сервисы, открытые порты и запущенные приложения в среде и выявлять любые уязвимости на уровне сети.
- Непрерывный поиск и выявление ресурсов по внешнему периметру сети сопровождается анализом безопасности. Кроме того, мы применяем собственный механизм поиска, выявления и учета ресурсов.
- Мониторинг конфигураций AWS помогает контролировать соответствие конфигураций наших сред AWS установленным стандартам.
Мы постоянно следим за появлением на рынке новых инструментов и пополняем свой арсенал новыми средствами, если считаем, что они расширят наши возможности по выявлению уязвимостей.
Продукты
В процессе разработки, помимо упомянутой программы Bug Bounty, мы полагаемся на ряд инструментов для выявления и предотвращения максимального числа уязвимостей и ошибок в продуктах, прежде чем к ним получат доступ клиенты. Развертывание этих инструментов в репозиториях кода обеспечивается платформой. Некоторые инструменты перечислены ниже.
- Развертывание большинства сервисов Atlassian выполняется при помощи образов контейнеров Docker. Эти образы предоставляют упакованную изолированную среду, состоящую из соответствующих системных библиотек, инструментов, настроек конфигурации и других зависимостей, которые необходимы для обеспечения работы продуктов независимо от параметров конфигурации отдельного компьютера. Мы интегрировали процесс полного сканирования безопасности контейнеров в конвейер CI/CD для всех контейнеров, развернутых в нашей среде разработки, разделе проиндексированных файлов или рабочей среде.
- Наши продукты работают на базе многочисленных библиотек с открытым исходным кодом. Для поиска и обнаружения зависимостей, а также их сличения с базой известных уязвимостей безопасности применяется сочетание инструментов различного происхождения (собственная разработка, инструменты с открытым исходным кодом, покупка инструментов других производителей).
Помимо этого, мы всегда незамедлительно реагируем на любые уведомления от наших пользователей, когда они обнаруживают уязвимости в продукте при стандартном использовании. Мы держим отправителя в курсе происходящего по мере исследования и реагирования на проблему.
Как было сказано ранее, мы используем процесс под названием «Проверка коллегами, зеленая сборка» (PRGB). Это означает, что любое изменение в коде продукта проверяется одним специалистом или группой коллег в целях предотвращения потенциальных негативных последствий.
В Atlassian применяется задокументированная политика исправления ошибок, в которой определены сроки решения задач безопасности, связанных с продуктами, в зависимости от уровня опасности ошибки.
Подробнее о политике исправления ошибок см. здесь. Информацию о недавно исправленных ошибках продуктов, а также ошибках, над которыми ведется работа, см. в общедоступной системе отслеживания ошибок Atlassian.
Реагирование на инциденты
В нашей компании применяют комплексный подход к обработке инцидентов безопасности. Любой случай негативного воздействия на конфиденциальность, целостность или доступность данных клиентов либо данных или сервисов Atlassian рассматривается нами как инцидент безопасности.
В Atlassian разработана четкая внутренняя схема, включающая задокументированные инструкции для разных типов инцидентов. В ней определены действия на каждом этапе реагирования на инцидент, что делает процессы согласованными, воспроизводимыми и эффективными. Эти действия включают обнаружение и анализ инцидентов, выделение их категорий, а также сдерживание последствий инцидентов, их устранение и восстановление систем. Кроме того, согласованность процессов достигается благодаря нашим собственным продуктам, таким как Confluence, Jira и Bitbucket, которые мы используем при реагировании на инциденты.
- Confluence служит единой базой для создания, документирования и обновления процессов реагирования на инциденты.
- В Jira удобно отслеживать процесс реагирования на потенциальные или существующие инциденты безопасности, от инициации до завершения, с помощью заявок.
- Bitbucket используется в экземплярах при разработке основанных на коде решений для уникальных проблем, возникающих в критических случаях в определенных типах инцидентов.
Централизованное ведение комплекса журналов и мониторинг продуктов и инфраструктуры позволяют быстро выявлять потенциальные инциденты, на которые наша опытная команда квалифицированных дежурных менеджеров инцидентов реагирует согласованно и эффективно. Кроме того, мы привлекаем внешних экспертов для повышения эффективности в исследовании инцидентов и реагировании на них.
Мы используем процессы уведомления клиентов, чтобы сообщить о том, что их данные были затронуты в подтвержденном инциденте, и надежные процессы анализа по результатам реагирования на инцидент, чтобы учиться на ошибках, совершенствовать используемые методы и таким образом осложнять работу злоумышленникам. Подробнее см. в документе Atlassian Trust Center, посвященном нашему подходу к управлению инцидентами безопасности.
Программа поддержки безопасности
Программа поддержки безопасности была разработана в рамках реализации нашего подхода к управлению инцидентами на фоне картины угроз, которая усложняется со временем. Для выявления инцидентов выполняется заблаговременный поиск вредоносной активности, которая угрожает Atlassian и клиентам компании. Эти операции выполняются по установленному графику на базе платформы для управления инцидентами и событиями безопасности.
Наша команда по выявлению угроз и обеспечению безопасности регулярно создает новые механизмы поиска, настраивает и улучшает существующие, а также автоматизирует операции по реагированию на инциденты. Команда подходит к своей работе с различных сторон: с точки зрения продуктов, типов атак и источников регистрации данных. Таким образом обеспечивается максимальная эффективность и высокий охват в ходе выявления инцидентов.
В рамках программы предполагается не только защититься от угроз сегодняшнего дня, но и предвидеть будущие опасности, а также подготовиться к ним. Наша команда по выявлению угроз и обеспечению безопасности также создала инструмент для стандартизации собственных механизмов поиска, чтобы обеспечить высокий уровень их согласованности и качества, который, как мы считаем, остается непревзойденным образцом в отрасли.
Подробнее о нашей Программе поддержки безопасности можно узнать на этой странице.
Программа «Red Team»
Миссия «красной команды» Atlassian заключается в непрерывном повышении устойчивости Atlassian к сложным атакам. Участники команды действуют с точки зрения злоумышленника и выявляют технические, физические и социальные уязвимости, чтобы проверить способность наших команд реагировать в реальных условиях. Такой подход позволяет нам разрабатывать и поддерживать эффективные улучшения безопасности для Atlassian. Наш подход помогает Atlassian оценивать угрозы, защищать активы и правильно реагировать на настоящие атаки.
Atlassian Red Team специализируется на полномасштабном моделировании атак и угроз. Мы действуем как злоумышленники, которые вероятнее всего станут атаковать компанию, и делаем все возможное, чтобы проникнуть в критически важные системы и подвергнуть их риску. После этого мы уведомляем всех участников и работаем вместе над внедрением долгосрочных устойчивых решений для устранения обнаруженных уязвимостей в защите.
- Измерение и повышение эффективности программы сбора и анализа данных безопасности
- Создание значительных положительных изменений в состоянии и возможностях безопасности Atlassian
- Улучшение осведомленности об уязвимости и способности реагировать на настоящие атаки
Обеспечение безопасности экосистемы и партнеров в цепочке поставок
Управление риском, связанным с поставщиками
При сотрудничестве со сторонними поставщиками (в том числе подрядчиками и поставщиками облачных услуг) компания Atlassian делает все, чтобы оградить от риска своих клиентов и их данные. Юридическая команда и команда по закупкам контролируют все взаимодействия со сторонними поставщиками. Взаимодействия с высоким или критическим уровнем риска проходят дополнительную проверку с привлечением команды по оценке рисков и обеспечению соответствия требованиям. Непрерывный и тщательный контроль обеспечивается последующими проверками при каждом продлении договора или на ежегодной основе, если того требует уровень риска конкретного взаимодействия.
Привлекая поставщиков к сотрудничеству, компания Atlassian неизменно требует от них соответствия минимальным критериям безопасности. Эти требования вносятся в положения договоров и в зависимости от уровня риска взаимодействия могут включать следующее.
- Интеграция с платформой системы единого входа Atlassian посредством SAML.
- Шифрование данных при передаче и хранении при помощи рекомендованных алгоритмов.
- Надлежащие механизмы регистрации для получения актуальной информации о потенциальных инцидентах безопасности.
Atlassian Marketplace
На платформе Atlassian Marketplace клиенты могут приобрести приложения, чтобы расширить функциональные возможности наших продуктов или интегрировать продукты со сторонними инструментами. Несмотря на то что ассортимент Marketplace в основном представлен приложениями сторонних разработчиков, в Atlassian заботятся о том, чтобы безопасность оставалась основообразующим принципом для этой экосистемы. В связи с этим предприняты следующие меры.
Программа вознаграждения за найденные ошибки — Atlassian имеет лучшую в своем классе программу вознаграждения за найденные ошибки, которая призвана повысить уровень надежности и доверия для всех приложений Marketplace. Партнеры Marketplace могут превентивно бороться с рисками нарушения безопасности, поощряя исследователей в этой области за работу по поиску уязвимостей. Чтобы получить значок Cloud Fortified или Cloud Security Participant, приложения должны участвовать в этой программе. Подробнее
Ecoscanner — платформа Ecoscanner компании Atlassian выполняет регулярную проверку безопасности для всех облачных приложений Marketplace. С ее помощью компания непрерывно отслеживает все облачные приложения Marketplace, проверяет наличие распространенных уязвимостей в защите и тем самым обеспечивает безопасность экосистемы Atlassian. Подробнее
Программа раскрытия уязвимостей предоставляет клиентам и исследователям в области безопасности дополнительный канал, через который можно сообщать компании Atlassian и партнерам Marketplace об уязвимостях в облачных приложениях. Atlassian проводит данную программу и определяет параметры, чтобы все облачные приложения могли снизить риски безопасности. Подробнее
Требования к безопасности облачных приложений — компания Atlassian установила набор минимальных требований, которым должны соответствовать все приложения Marketplace. Эти требования обязательны к исполнению и призваны обеспечить соблюдение рекомендаций по безопасности во всех приложениях. Подробнее
Политика исправления ошибок, связанных с безопасностью. Для обеспечения безопасности всех приложений в экосистеме Atlassian все партнеры Marketplace обязаны соблюдать соглашения об уровне обслуживания (SLA) в отношении исправления ошибок, связанных с безопасностью, во всех приложениях Atlassian Marketplace. При обнаружении уязвимости партнеры обязаны своевременно устранить ее. Подробнее
Программа самооценки уровня безопасности в Marketplace подразумевает сотрудничество между компанией Atlassian и партнерами, поставляющими приложения. Она призвана совершенствовать методы обеспечения безопасности для облачных приложений. Участники программы проходят ежегодную оценку безопасности, которую контролирует и подтверждает Atlassian. Чтобы получить значок Cloud Fortified, приложения должны участвовать в этой программе. Подробнее
Подробнее о нашем подходе к безопасности Marketplace см. на странице Atlassian Marketplace Trust Center.
Соответствие требованиям и управление рисками
Наши программы управления политиками и рисками
Atlassian Trust Management Program (TMP). Эта программа управления доверием основана на стандарте ISO 27001 для систем управления информационной безопасностью. В программе описан уникальный комплекс требований к безопасности компании Atlassian. При этом учтены требования, предъявляемые нашими клиентами, и методы защиты согласно ряду международных стандартов безопасности.
Мы рассматриваем эти методы защиты в контексте конкретной среды или компании и решаем, стоит ли их применять. В случае положительного решения мы находим наилучший способ их применения. Программа TMP состоит из нескольких компонентов.
- Программа управления политиками (PMP) лежит в основе TMP. Программа содержит несколько политик безопасности, охватывающих стандарт ISO 27001 и использование матрицы методов защиты облачных вычислений (CCM) Альянса безопасности облачных вычислений. Политики безопасности доступны всем нашим командам и задают для них высокую планку в вопросах обеспечения безопасности. Политики обновляются каждый год, а также всякий раз, когда мы считаем нужным скорректировать подход к безопасности ввиду новых угроз и рисков. Выдержки из политик в сфере технологий см. здесь.
- Программа управления рисками (RMP). Компания Atlassian проводит непрерывную оценку рисков для сред и продуктов, чтобы определить текущие риски и противопоставить им эффективные методы защиты и управления. Характер проведения таких оценок зависит от конкретной среды или продукта. Так, например, в отношении продуктов обычно проводится оценка технического риска и проверка кода. Кроме того, мы стремимся выявлять и учитывать бизнес-риски более высокого уровня. Мы проводим ежегодную оценку рисков в рамках программы управления корпоративными рисками и внедряем проекты по профилактике выявленных рисков не реже раза в квартал. Подробнее о нашем подходе к управлению корпоративными рисками см. на странице Atlassian Trust Center.
В программу TMP также входят еженедельные проверки работы системы соответствия требованиям и другие собрания, которые обеспечивают эффективность программы. Мы документируем эти проверки для внутреннего пользования.
Соответствие требованиям законодательства, стандартов и иных регламентирующих документов
Программа обеспечения безопасности Atlassian разработана и реализуется согласно требованиям ряда известных отраслевых стандартов. В рамках нашего подхода к безопасности мы считаем необходимым обеспечивать это соответствие, поскольку оно является для наших клиентов независимым подтверждением того, что программа Atlassian содержит все основные методы защиты безопасности.
Ниже перечислены основные стандарты, которым соответствует компания Atlassian.
ISO 27001
Стандарт ISO 27001 посвящен разработке и внедрению системы управления информационной безопасностью (ISMS). В приложении A стандарта описаны методики внедрения и управления комплексом методов защиты в рамках системы.
ISO/IEC 27018 содержит свод дополнительных практических правил по внедрению применимых методов защиты данных согласно ISO/IEC 27002. Объектом защиты выступают данные, позволяющие установить личность пользователя (PII), в облачных средах.
PCI-DSS
Используя банковскую карту для оплаты продуктов и услуг Atlassian, вы можете быть уверены в том, что совершаете безопасную транзакцию. Компания Atlassian соответствует стандартам PCI DSS.
CSA CCM / STAR
Реестр безопасности, доверия и достоверности (STAR) Альянса безопасности облачных вычислений (CSA) — это бесплатный общедоступный реестр, содержащий задокументированные методы защиты безопасности, которые используются в различных платформах облачных вычислений. Опросник CSA STAR уровня 1 для компании Atlassian можно загрузить на веб-сайте реестра CSA STAR.
Отчеты SOC2 и SOC3
Из этих отчетов наши клиенты и их аудиторы могут понять, какие средства применяются Atlassian для поддержания операций и соответствия требованиям. Многие продукты Atlassian прошли сертификацию SOC2.
Мы понимаем важность требований, которые предъявляет к нашим клиентам Общий регламент по защите данных (GDPR) и на соблюдение которых напрямую влияет использование продуктов и сервисов Atlassian. Поэтому мы выделили значительные ресурсы, чтобы помочь клиентам в выполнении этих требований.
Подробнее о нашем подходе к соблюдению требований GDPR см. на странице соответствия требованиям GDPR в Atlassian.
Федеральная программа по управлению рисками и авторизацией (FedRAMP) — это федеральная государственная программа США, которая обеспечивает стандартизированный подход к оценке безопасности, авторизации и непрерывному мониторингу облачных продуктов и сервисов.
Ознакомьтесь с индивидуальным статусом следующих продуктов Atlassian на FedRAMP Marketplace:
Полный список отраслевых стандартов, которым соответствует компания Atlassian, см. на странице программы соответствия требованиям.
Конфиденциальность в Atlassian
Atlassian реализует комплексную программу конфиденциальности, которая гарантирует соответствие компании самым высоким стандартам защиты конфиденциальности данных по всему миру. Наши инструменты и процессы управления данными помогут вам выполнить свои обязательства по обеспечению конфиденциальности. В Центре безопасности и Политике конфиденциальности мы делимся информацией о мерах, которые предпринимаем для соблюдения законов о конфиденциальности, применимых в разных регионах мира (в том числе в Европе и Калифорнии), и кратко описываем, как помогаем вам выполнить требования законов о конфиденциальности. Приведем несколько примеров:
- Конфиденциальность по умолчанию: мы по умолчанию интегрируем конфиденциальность в свои продукты (см. страницу Принципы конфиденциальности)
- Подробный анализ: мы обязуемся проводить оценку воздействия на защиту данных, чтобы обеспечить их надлежащую обработку, при необходимости консультируясь с контрольными органами
- Управление доступом и обучение: сотрудники Atlassian, имеющие доступ к персональным данным клиентов компании и обрабатывающие их, проходят обучение по обращению с такими данными и дают обязательство обеспечивать их конфиденциальность и защиту
- Профиль пользователя и инструменты обеспечения конфиденциальности: пользователи могут настраивать параметры своего профиля (см. страницу конфиденциальности для пользователей)
- Инструменты администратора для обеспечения конфиденциальности: мы информируем клиентов о том, как мы работаем с данными клиентов, а также ведем страницу конфиденциальности для администраторов с описанием важных параметров и настраиваемых возможностей
- Новости и обновления: мы сообщаем об изменениях в законодательстве о конфиденциальности, применимом в разных странах мира, на странице приложения об обработке данных (вы можете подписаться на наш RSS-канал, чтобы быть в курсе любых изменений)
Внутренний и внешний аудит
Не реже раза в год мы проводим комплексный аудит на соответствие требованиям (например, SOX, SOC2) с привлечением независимых аудиторских компаний. Мы также проводим дополнительный внутренний аудит областей с высоким уровнем риска, в том числе в сфере безопасности, и сообщаем результаты аудиторскому комитету совета директоров. Полученные данные используются в непрерывном цикле совершенствования, который помогает нам улучшать общую программу по обеспечению безопасности.
Запросы данных от правоохранительных органов и правительственных учреждений
В стремлении заслужить и сохранить доверие клиентов мы публикуем ежегодный Отчет Atlassian о прозрачности. В нем содержится информация о запросах данных, направленных правительственными учреждениями (запросы на предоставление данных пользователей, запросы на удаление содержимого или приостановку аккаунтов пользователей). Компания Atlassian тщательно изучает каждый запрос на предмет правомерности и в случае его законности раскрывает данные лишь в том объеме, который необходим для ответа.
В основе нашего подхода к ответу на запросы правоохранительных органов касательно данных клиентов лежат ценности Atlassian. Чтобы защитить конфиденциальность и права клиентов, мы предоставляем информацию о них правоохранительным органам, только если обязаны сделать это по закону, и только после обстоятельной юридической экспертизы. Для получения информации о клиенте от компании Atlassian сотрудники правоохранительных органов должны следовать юридической процедуре в соответствии с типом запрашиваемой информации, например предъявить повестку в суд, судебное распоряжение или ордер. Подробные инструкции по обработке запросов правоохранительных органов см. в Руководстве Atlassian по запросам правоохранительных органов.
Дополнительные вопросы
Обеспечение безопасности — это обширная и сложная область деятельности, поэтому невозможно детально рассказать о всей работе Atlassian в этом направлении в рамках настоящего документа. Однако изложенные здесь принципы безопасности дают общее представление о нашем подходе к ее обеспечению.
Дополнительные сведения по этой теме см. на странице Atlassian Trust Center. Кроме того, вы можете связаться с командой безопасности Atlassian на клиентском портале, если у вас возникли вопросы о безопасности в Atlassian, или задать эти вопросы нашему сообществу по надежности и безопасности Atlassian Trust.
Хотите узнать больше?
На этой странице мы упомянули еще несколько документов и ресурсов. Если вы хотите глубже понять наш подход к обеспечению безопасности и надежности, рекомендуем подробнее ознакомиться с ними.
- Запись об Atlassian в реестре CSA STAR
- Общая схема контроля безопасности
- Наше Соглашение с клиентом
- Правила исправления ошибок, связанных с безопасностью
- Правила публикации советов по обеспечению безопасности
- Отчет о прозрачности
- Руководство по соблюдению законодательства