Стратегия инкрементального наполнения витрин: необходимость, реализация, подводные камни

- Обработка этих данных требует значительного времени (и затрат ��)
- Исторические данные не меняются (или не должны меняться) — как правило, это свершившиеся факты
- Если Вам удается не делать повторную обработку исторических данных — Вы экономите время и затраты
В самом деле, давайте просто хранить одну большую таблицу, в которую будем добавлять новые данные по мере необходимости. Остается только разобраться:
- Что значит новые данные и как их выделить?
- Что значит добавлять?
- Как не потерять строки и не остаться с копиями строк?
Если нам удастся найти ответы на эти вопросы — мы сумеем строить Хранилище более оптимальным способом!

Необходимость инкрементального расчета на реальном примере
Предлагаю попробовать найти решение на примере, приближенном к реальности. Рассмотрим сферу транспорта и передвижения по городу:

- Имеем координаты начала и окончания маршрута (широта / долгота — lat / lon)
- Справочник ГЕО-зон, включающий улицы, районы города, вокзалы, аэропорты, Points of interest (музеи, торговые центры и т.д.)
- Возможность выполнить Spatial Join в СУБД, то есть найти привязку точки на карте конкретной ГЕО-зоне (или нескольким)
Учитывая тот факт, что Spatial Join является довольно затратной (CPU-intensive) операцией, а также то, что маршрут поездки, как правило, не может меняться после её окончания, мне представляется очень удобным накапливать эти данные инкрементальным образом. Исходный запрос выглядит следующим образом:
select -- IDs orders.request_id , orders.city_id -- PICKUP , pickup.kind as pickup_kind , pickup.zone_name as pickup_zone , coalesce(pickup.is_airport, false) as pickup_is_airport -- DROPOFF , dropoff.kind as dropoff_kind , dropoff.zone_name as dropoff_zone , coalesce(dropoff.is_airport, false) as dropoff_is_airport -- METADATA , orders.__metadata_timestamp from > as orders left join > as pickup on ST_Intersects( ST_Point(orders.pickup_position_lon, orders.pickup_position_lat), pickup.geometry) left join > as dropoff on ST_Intersects( ST_Point(orders.dropoff_position_lon, orders.dropoff_position_lat), dropoff.geometry)Эволюционно, этот запрос мог проделать следующий путь:
- Создадим VIEW для получения всех результатов на момент запроса
- Как только запросы станут слишком долгими, материализуем результаты в виде TABLE
- Когда расчет таблицы станет слишком долгим и дорогостоящим — рассмотрим применение стратегию INCREMENTAL
Как реализовать инкрементальную стратегию наполнения на уровне DDL/DML команд?
- Первый запуск – полный пересчет из исходных данных
Здесь всё понятно. Пока у нас не сформирована витрина ни в каком виде, придется переварить весь набор данных из исходных таблиц.
- Для любого последующего запуска – идентифицировать новые записи (дельта / delta)
В этом может помочь либо монотонно возрастащий ключ (sequence), либо временная метка (timestamp) создания или обновления записи.
Наша задача — взять те записи, которые уже есть в таблице-источнике, но которых еще нет в уже существующей версии витрины.
create temp table int_requests_zones_tmp as ( select -- IDs orders.request_id , orders.city_id -- PICKUP , pickup.kind as pickup_kind , pickup.zone_name as pickup_zone , coalesce(pickup.is_airport, false) as pickup_is_airport -- DROPOFF , dropoff.kind as dropoff_kind , dropoff.zone_name as dropoff_zone , coalesce(dropoff.is_airport, false) as dropoff_is_airport -- METADATA , orders.__metadata_timestamp from > as orders left join > as pickup on ST_Intersects( ST_Point(orders.pickup_position_lon, orders.pickup_position_lat), pickup.geometry) left join > as dropoff on ST_Intersects( ST_Point(orders.dropoff_position_lon, orders.dropoff_position_lat), dropoff.geometry) -- GET DELTA ROWS ONLY where orders.__metadata_timestamp >= (select max(__metadata_timestamp) as high_watermark from "intermediate"."int_requests_zones_tmp") )- Записать дельту в основную таблицу
После создания таблицы с дельта-строками, нам потребуется записать их в существующую витрину.
Сделать это можно несколькими способами, в зависимости от того, что поддерживает используемая Вами СУБД:
- DELETE + INSERT (удалить старые версии строк и вставить новые целиком)
- Операция MERGE (UPSERT) — оптимизированная версия UPDATE + INSERT
- INSERT OVERWRITE (замена целых партиций)
delete from "intermediate"."int_requests_zones_tmp" where request_id in (select request_id from int_requests_zones_tmp) ; insert into "intermediate"."int_requests_zones_tmp" select * from int_requests_zones_tmp ; Схематично инкрементальную стратегию можно изобразить следующим образом:

dbt упрощает использование материализации incremental
dbt умеет строить инкрементальные модели из коробки. Компилируемый код уже адаптирован под возможности конкретной СУБД, будь то Redshift, Snowflake, BigQuery или даже Clickhouse! Делается это при помощи ряда конфигураций и Jinja-шаблонов:
- Выбор типа материализации incremental :
- Формулируем правило нахождения дельты
Ранее мы использовали конструкцию:
-- GET DELTA ROWS ONLY where orders.__metadata_timestamp >= (select max(__metadata_timestamp) as high_watermark from >) Однако это должен быть фильтр, который применяется только для инкрементального запуска и игнорируется для полного пересчета:
where true and orders.__metadata_timestamp >= (select max(__metadata_timestamp) as high_watermark from >)
Обратите внимание на специальные переменные Jinja:
> обозначает существующий объект в СУБД, который однозначно соответствует данной модели dbt (в которой эта консутркция используется).
is_incremental() принимает значение True при соблюдении следующих условий:
- В СУБД уже существует таблица, соответствующая модели dbt
- Модель сконфигурирована на материализацию incremental (см. пункт 1)
- Запуск осуществляется без флага —full-refresh (в противном случае будет полный пересчет витрины)
Обратная сторона и ограничения инкрементальных моделей
Однако как и почти везде, у инкрементального подхода тоже есть ряд ограничений, недостатков и сложностей. В основном, они связаны со спецификой использования и характером поступления исходных данных:
- Late arriving data — данные, которые приходят не в порядке возникновения событий
- Сложности с расчетом оконных функций (window functions), требующих наличия всей выборки строк для корректных расчетов
В случае данных, которые приходят в DWH позже есть опасность просто потерять записи. Отловить такие кейсы могут помочь тесты данных:

Каким образом можно попробовать решить эту проблему? Увеличить интервал фильтр на look-back period! Например, на 3 часа назад:
where true and orders.__metadata_timestamp >= (select max(__metadata_timestamp) as high_watermark from >) - interval '3 hours'
Этот вариант уже означает, что я с меньшей вероятностью пропущу какие-либо строки, однако я 100% буду обрабатывать некоторый объем записей повторно, а значит мне придется выполнить ряд операций DELETE / INSERT / MERGE , чтобы избежать формирования дублирующих записей, что, конечно, в свою очередь скажется на производительности.
Чувствуете trade-off? Что-то приобретаем, что-то платим.
В свою очередь и look-back period не гарантирует 100% соответствия. Я сталкивался с ситуациями ошибок, пауз, отключений в пайплайнах Extract & Load, что look-back period в 3 часа было уже недостаточно. Можно, конечно, увеличивать интервал до 12, 24 или даже 48 часов, однако можно подумать и над альтернативным подходом.
Что если мы попробуем выполнить так называемый Anti-join?
left join > on orders.request_id = >.request_id and orders.__metadata_timestamp = >.__metadata_timestamp where >.request_id is null
По сути это означает:
- взять либо совершенно новые записи ( request_id отсутствует в > )
- либо взять те request_id которые уже есть в > но имеют более свежий __metadata_timestamp (запись была модифицирована с полсднего расчета)
Здесь стоит обратить внимание на план запроса, ведь наша основная задача – выполнять расчеты только с дельтой. Если этот фильтр будет применен после обработки всего массива строк — всяческий смысл в инкрементальном подходе пропадает.
Посмотрите на пример неудовлетворительного плана запроса – фильтрация происходит после выполнения 2-х GEO-spatial joins:
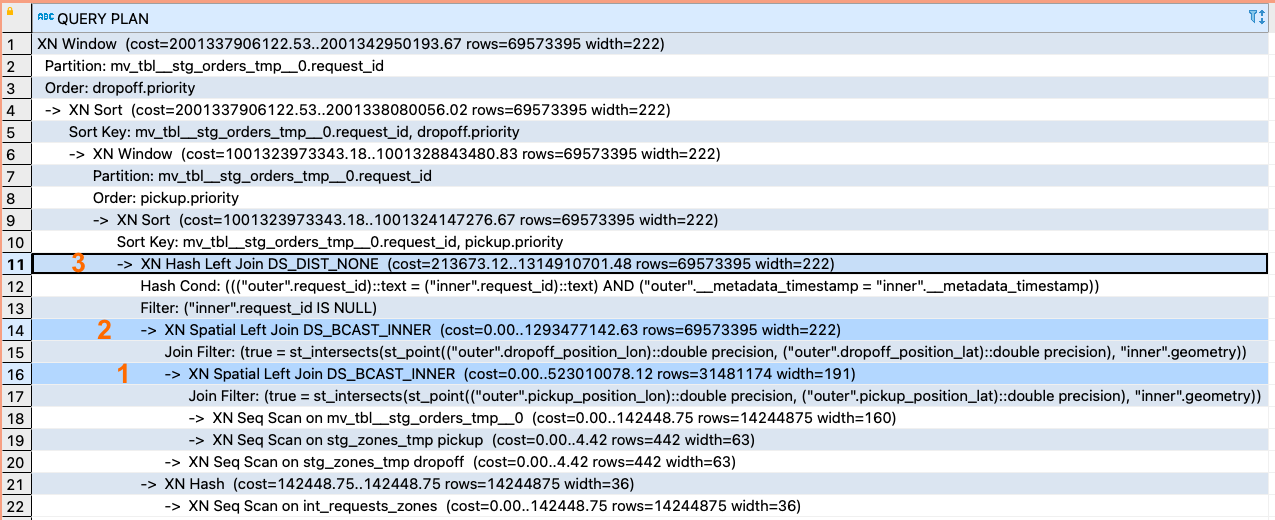
И теперь пример желаемого плана запроса – сначала фильтруем строки, потом обрабатываем:

Инкрементальная стратегия — отличный паттерн, но не панацея
Инкрементальные модели предполагают некий tradeoff:
- Большинство таких моделей не гарантируют 100% точность
- Подразумевается дополнительная сложность в виде кода по обработке дельта-строк
- В погоне за точностью результатов можно потерять всяческие преимущества инкрементальности
Для применения этого паттерна однозначно есть хорошие кандидаты:
- Immutable event streams – append-only поток событий, которые не меняются
- Наличие в таблице надежной временной метки изменения записи updated_at
В свою очередь, не очень хорошие кандидаты на применение паттерна:
- Относительно небольшие таблицы
- Частые изменения в данных: новые колонки, названия атрибутов и т.д.
- Строки могут быть модифицированы в непредсказуемом порядке
- Логика расчета требует наличия всего массива строк (оконные функции)
Умение упрощать и оптимизировать хотят видеть нанимающие менеджеры
Инженеры, обладающие широким набором паттернов, практик, подходов, а главное, умением применять их к решению конкретных задач, ценятся необычайно высоко.
На live-сессиях я и мои коллеги делимся своим опытом и реальными кейсами:
- Продвинутое моделирование и Data Vault
- dbt + подготовка собственных модулей к нему
- Data Testing + Slim Continous Integration
- Materialized Views
- И многое другое
Реальные специалисты отрасли, практические знания, проекты с использованием ресурсов Яндекс.Облака. Если Вам стало интересно, изучите программы и приходите на вебинары DWH Analyst.
Также своими наблюдениями, опытом и практиками я делюсь в ТГ-канале Technology Enthusiast.
Напишите в комментарий, если сталкивались с необходимостью строить инкрементальные модели, и каким образом решали эту задачу?
Как построить современное аналитическое хранилище данных на базе Cloudera Hadoop
В конце прошлого года GlowByte и Газпромбанк сделали большой совместный доклад на конференции Big Data Days, посвященный созданию современного аналитического хранилища данных на базе экосистемы Cloudera Hadoop. В статье мы рассказали об опыте построения системы, сложностях и вызовах, с которыми пришлось столкнуться и преодолеть, чтобы достичь успеха в проекте.

Появление технологии Hadoop десятилетние назад вызвало на рынке интеграции данных небывалый ажиотаж и оптимизм. Индустрия задалась вопросом — «а готова ли технология вытеснить традиционные системы обработки данных?». За прошедшую декаду было сломано немало копий в этой битве. Кто-то успел разочароваться, кто-то добился локальных успехов, а тем временем сама экосистема прошла короткий, но стремительный эволюционный путь, который позволяет уверенно сказать, что в настоящий момент не существует задачи и вызова в области обработки и интеграции данных, которую не способен решить Hadoop.
В этой статье мы попытаемся дать ответ на главный вопрос — как создать современное аналитическое хранилище данных на базе экосистемы Cloudera на примере проекта, реализованного нами в “Газпромбанк” АО. Попутно расскажем как мы справились с основными вызовами при решении задачи.
“Газпромбанк” АО — один их ведущих системообразующих финансовых институтов РФ. Он входит в топ-3 банков по активам России и всей Восточной Европы и имеет разветвленную сеть дочерних филиалов.
Банк традиционно на рынке финансовых услуг был консервативным и ориентировался на корпоративный сектор, но в 2017 году принял стратегию “Цифровой трансформации” с целью развития направления розничного бизнеса.
Розничный банковский сектор является высококонкурентным в РФ и для реализации стратегии Газпромбанку потребовалось создание новой технологической платформы, которая должна удовлетворять современным требованиям, так как основой интенсивного роста на конкурентном рынке могут быть только data driven процессы.
На тот момент в Банке уже было несколько платформ интеграции данных. Основная платформа КХД занята классическими, но критичными с точки зрения бизнеса задачами: управленческой, финансовой и регуляторной отчетности. Внесение изменения в текущую архитектуру КХД несло серьезные риски и финансовые затраты. Поэтому было принято решение разделить задачи и создавать аналитическую платформу с нуля.
Верхнеуровнево задачи ставились следующие:
- Создание озера данных (как единой среды, в которой располагаются все необходимые для анализа данные);
- Консолидации данных из озера в единую модель;
- Создание аналитический инфраструктуры;
- Интеграция с бизнес-приложениями;
- Создание витрин данных;
- Внедрение Self-service инструментов;
- Создание Data Science окружения.
Этап проработки архитектуры важно начинать после консолидации и уточнения всех ключевых требований к системе. Требования мы разделили на два больших блока:
- Обеспечение данными бизнес-приложений: аналитический CRM, Real Time Offer, Next Best Offer, розничный кредитный конвейер;
- Возможность работы с сырыми данными из систем-источников as is (функция Data Lake);
- Среда статистического моделирования;
- Быстрое подключение новых систем источников к ландшафту;
- Возможность обработки данных за всю историю хранения;
- Единая модель консолидированных данных (аналитическое ядро);
- Графовая аналитика;
- Текстовая аналитика;
- Обеспечение качества данных.
- Высокая производительность при дешевом горизонтальном масштабировании;
- Отказоустойчивость и высокая доступность;
- Разделяемая нагрузка и гарантированный SLA;
- ELT обработка и трансформация данных;
- Совместимость с имеющимися Enterprise решениями (например, SAP Business Objects, SAS);
- Ролевая модель доступа и полное обеспечение требований информационной безопасности.
Кроме этого, система должна быть линейно масштабируемой, основываться на open source технологиях, и самое главное — соотношение стоимость\производительность должно быть самым конкурентным из всех предложений на рынке.
Для создания единой аналитической платформы розничного бизнеса мы выбрали стек Hadoop на базе дистрибутива Cloudera Data Hub
Архитектура решения
Рассмотрим архитектуру решения.

Система разделена на два кластера Cloudera Data Hub. Кластер регламентных процессов и Лаборатория данных
1. Кластер регламентных процессов
Все регламентные источники данных подключаются к данному кластеру. Все регламентные ETL расчеты также работают на этом контуре. Все системы потребители данных “запитываются” из регламентного кластера. Таким образом выполняется жесткая изоляция непредсказуемой пользовательской нагрузки от критичных бизнес процессов.
В настоящий момент к Hadoop подключено свыше 40-ка систем-источников с регламентом от t-1 день до t-15 минут для batch загрузки, а также real-time интеграция с процессинговым центром. Регламентный контур поставляет данные во все системы розничного бизнеса:
- Аналитический CRM;
- Розничный кредитный конвейер;
- Антифрод система;
- Система принятия решений;
- Collection;
- MDM;
- Система графовой аналитики;
- Система текстовой аналитики;
- BI отчетность
2. Кластер пользовательских экспериментов “Лаборатория данных”
В то же время, все данные, которые загружаются на регламентный контур в режиме онлайн, реплицируются на контур пользовательских экспериментов. Задержка по времени минимальная и зависит только от пропускной способности сетевого канала тк контур лаборатории данных находится в другом ЦОДе. Те пользовательский контур одновременно выполняет роль Disaster Recovery плеча в случае выхода из строя основного ЦОДа.
Дата инженеры и дата science специалисты получают все необходимые данные для проведения своих исследований и проверки гипотез без задержки и без ожидания днями и неделями, когда нужные им данные для расчетов или тренировки моделей, куда-то выгрузят. Они доступны все в одном месте и всегда свежие. Дополнительно на кластере лаборатории данных создаются пользовательские песочницы, где можно создавать и свои объекты. Также ресурсы кластера распределены именно для высококонкурентной пользовательской нагрузки. На регламентный кластер у пользовательского доступа нет.
После проверки гипотез, подготовки требований для регламентных расчетов либо тренировки моделей, результаты передаются для постановки на регламентный контур и сопровождения.
Дополнительно на контуре лаборатории создано окружение управления жизненным циклом моделей, окружение пользовательских аналитических приложений с управлением, ресурсами на K8S, подключены два специализированных узла с GPU ускорением для обучения моделей.
Система мониторинга и управления кластерами, загрузками, ETL, реализована на дополнительных виртуальных машинах, не включенных напрямую в кластера Cloudera.
Сейчас версия дистрибутива CDH 5.16.1. В архитектурный подход закладывалась ситуация выхода из строя двух любых узлов без последующей остановки системы.
Характеристики Data узлов следующие: CPU 2×22 Cores 768Gb RAM SAS HDD 12x4Tb. Все собрано в HPE DL380 в соответствии с рекомендациями Cloudera Enterprise Reference Architecture for Bare Metal Deployments. Такой “необычный”, как кому-то может показаться, сайзинг связан с выбором подхода по ETL и процессингового движка для работы с данными. Об этом немного ниже. Необычность его в том, что вместо “100500” маленьких узлов, мы выбираем меньше узлов, но сами узлы “жирнее”.
Основные технические вызовы
В процессе проработки и внедрения мы столкнулись с рядом технических вызовов, которые необходимо было решить, для того чтобы система удовлетворяла выше заявленным высоким требованиям.
- Выбор основного процессингового движка в Hadoop;
- Подход по трансформации данных (ETL);
- Репликация данных «Система-источник –> Hadoop» и «Hadoop –> Hadoop»;
- Изоляция изменений и консистентность данных;
- Управление конкурентной нагрузкой;
- Обеспечение требований информационной безопасности
Далее рассмотрим каждый из этих пунктов детально.
Выбор основного процессингового движка
Горький опыт первых попыток некоторых игроков реализовать ХД в Hadoop 1.0 показал, что нельзя построить систему обработки данных руками java программистов, не имеющих опыта построения классических ХД за плечами, не понимающих базовых понятий жизненного цикла данных, не способных «отличить дебет от кредита» или «рассчитать просрочку». Следовательно, для успеха нам надо сформировать команду специалистов по данным, понимающих нашу предметную область и использовать язык структурированных запросов SQL.
В целом, базовый принцип работы, с данными которого стоит придерживаться – если задачу можно решить на SQL то ее нужно решать только на SQL. А большинство задач с данными решаются именно с помощью языка структурированных запросов. Да и нанять и подготовить команду SQL-щиков для проектной работы быстрее и дешевле чем «специалистов по данным, окончивших курсы на диване из рекламы в инстаграм».
Для нас это означало что необходимо выбрать «правильный» SQL движок для работы с данными в Hadoop. Остановили свой выбор на движке Impala так как он имеет ряд конкурентных преимуществ. Ну и собственно ориентация на Impala во многом и предопределила выбор в пользу Cloudera как дистрибутива Hadoop для построения аналитического хранилища.
Чем же Impala так хороша?
Impala – движок распределенных вычислений, работающий напрямую с данными HDFS, а не транслирующий команды в другой фреймворк вроде MapReduce, TEZ или SPARK.
Impala – движок который большинство всех операций выполняет в памяти.
Impala читает только те блоки Parquet, которые удовлетворяют условиям выборки и соединений (bloom фильтрация, динамическая фильтрация), а не поднимает для обработки весь массив данных. Поэтому в большинстве аналитических задач на практике Impala быстрее, чем другие традиционные MPP движки вроде Teradata или GreenPlum.
Impala имеет хинты, позволяющие очень легко управлять планом запроса, что весьма важный критерий при разработке и оптимизации сложных ETL преобразований без переписывания запроса.
Движок не разделяет общие ресурсы Hadoop с другими сервисами так как не использует YARN и имеет свой ресурсный менеджмент. Это обеспечивает предсказуемую высоко конкурентную нагрузку.
Синтаксис SQL настолько близок к традиционным движкам, что на подготовку разработчика или аналитика, имеющего опыт другой SQL системы, уходит не больше 3-4х часов.
Вот как работа с Hadoop выглядит глазами аналитика:

Это работа в веб-ноутбуке Hue, который идет вместе с Cloudera. Не обделены и те пользователи, кто предпочитает работать с классическими толстыми SQL клиентами или сводными таблицами Excel.

Многие кто читал рекомендации Cloudera, могут задаться вопросом – а почему Impala не рекомендована как ETL движок, а только как движок пользовательского ad-hoc или BI доступа? Ответ на самом деле прост — Impala не имеет гарантии исполнения запроса «чтобы не стало» в отличие от Hive. Eсли падает запрос или узел, то запрос автоматически не перезапустится и поднимать его надо вручную.
Это проблема легко решаема – ETL поток или запрос в приложении должны уметь перезапускаться в таких ситуациях.
ETL потоки в нашем решении перезапускаются без вмешательства администратора автоматически:
- При падении запроса происходит автоматический анализ причины;
- При необходимости автоматически подбираются параметры конкретного запроса или параметры сессии чтобы повторный перезапуск отработал без ошибок;
- Выполняется сбор статистической информации по ошибкам для дальнейшего анализа и настройки потока чтобы в будущем по данному запросу или job’у таких ситуаций не возникало.
У нас на проекте сложилась парадоксальная ситуация — команда аналитиков и инженеров по данным, работающих над проектом, знала про Hadoop только то, что на логотипе есть желтый слоник. Для них Hadoop — это привычный SQL. Уже после “уборки урожая” (завершения разработки аналитического слоя, о котором речь пойдет ниже), ребята попросили провести для них обучение по Hadoop чтобы быть “в теме”.
Подход по трансформации данных
В разработке трансформации данных важно не только выбрать правильный движок, но и принять правильные стандарты разработки. У нас давно сформировался подход к таким задачам как metadata driven E-L-T при котором трансформация данных отрисовывается в диаграмме ETL инструмента, который в свою очередь генерирует SQL и запускает его в среде исполнения. При этом SQL должен быть максимально оптимальным с точки зрения конкретной среды исполнения. На рынке не так много ETL инструментов, позволяющих управлять генерацией SQL. В данном внедрении использовался инструмент SAS Data Integration.
Весь регламентный ETL выполнен в подходе metadata driven ELT. Никаких ручных скриптов с планировкой на airflow!
Такой подход позволяет
- Автоматизировать процессы управления метаданными;
- Автоматизировать процесс построения lineage данных как средствами самого ETL инструмента, так и средствами доступа к API;
- Повысить качество процессов внесения изменений и управления данными т.к. вся информация о зависимостях всех объектов и всех job’в хранится в метаданных ETL инструмента.
- Использовать CI/CD процессы в разработке


SAS DI позволяет визуализировать граф зависимостей в штатном функционале или можно выгрузить метаданные через API и использовать их для анализа в других средах.

Репликация данных
Загрузка данных в систему – ключевая отправная точка реализации функциональных бизнес требований системы.
Для этой функции был разработан специализированный инструмент – Data Replicator. Инструмент позволяет в очень короткие сроки подключать системы источники и настраивать загрузку данных в Hadoop.
- Синхронизация метаданных с источника;
- Встроенные механизмы контроля качества загруженных данных;
- Загрузка в различных режимах работы в т.ч. полная копия, извлечение и загрузка инкремента (по любой скалярной детерминированной функции), архивация данных источника и т.д.
Решение имеет гибкие настройки позволяющие приоритизировать задания загрузки, балансировку, контроль многопоточности. Это позволяет бережно относится к источнику при извлечении данных, но в то же время гарантировать SLA доступности данных в Hadoop.
Другая очень важная функция Data Replicator’а — автоматическая репликация данных с регламентного кластера Hadoop на DR кластер. Данные, загружаемые из систем-источников реплицируются автоматически, для деривативных данных существует API. Все регламентные ETL процессы, при обновлении целевой таблицы вызывают API которое запускает процесс мгновенного копирования изменений на резервный контур. Таким образом, DR кластер, который так же выполняет роль пользовательской песочницы, всегда имеет «свежие» данные.
Нами реализовано множество конфигураций для различных СУБД используемых как источники в ГПБ, также для других процессинговых движков Hadoop (для случаев когда другой кластер Hadoop является источником данных для системы) и есть возможность обрабатывать данные, загруженные в систему другими инструментами, например kafka, flume, или промышленный ETL tool.
Изоляция изменений и консистентность
Любой кто работал в Hadoop сталкивался с проблемой конкурентного доступа к данным. Когда пользователь читает таблицу, а другая сессия пытается туда записать данные, то происходит блокировка таблицы (в случае Hive) либо пользовательский запрос падает (в случае Impala).
Самое распространенное решение на практике – выделение регламентных окон на загрузку во время которых не допускается работа пользователей, либо каждая новая порция загрузки записывается в новую партицию. Для нас первый подход неприемлем тк мы должны гарантировать доступность данных 24х7 как по загрузке так и по доступу. Второй подход не применим т.к. он предполагает секционирование данных только по дате\порции загрузке, что неприемлемо если требуется отличное секционирование (по первичному ключу, по системе источнику и т.д.). Так же второй метод приводит к избыточному хранению данных.

Забегая вперед хочется отметить, что в настоящее время в HIVE 3 проблемы решена путем добавления поддержки ACID транзакционности, но, в нашей версии дистрибутива у нас далеко не третий Hive (да еще и на Map Reduce), а хотим получить высокую производительность и конкурентную нагрузку и поэтому нам пришлось реализовать ACID для Impala в Hadoop самостоятельно.
В нашем решении изоляция выполнена с применением подхода HDFS snapshot и разделения слоя хранения и доступа к данным через VIEW.
Когда данные записываются в HDFS, сразу, мгновенно создается снапшот на который переключается VIEW.
Пользователь читает данные с VIEW, а не напрямую с таблицы, поэтому следующая сессия записи никак не влияет на его текущий запрос.
Все что остается делать – это переключать VIEW на новые HDFS снапшоты, число которых определяется максимальной длительностью пользовательских запросов и частотой обновления данных в Hadoop. Те в сухом остатке мы получаем аналог UNDO в Oracle, retention период которого зависит от количества снапшотов и регламента загрузки данных.
Основной секрет в том, что как только процессинговый движок определил какие данные из HDFS он должен прочитать, после этого DDL VIEW или таблицы может быть изменен т.к. оптимизатор больше не будет обращаться к словарю metastore. Т.е. можно выполнить переключение VIEW на другую директорию.
Функционал HDFS Snapshot настолько легковесный и быстрый что позволяет создавать сотни снапшотов в минуту и никак не влияет на производительность системы.
Изоляции изменений в нашем решении также является функцией DataReplictor’а. Все загружаемые данные изолируются автоматически, причем на обеих контурах системы, а производные ETL данные изолируются через вызов API. Каждое изменение целевого объекта, которое происходит в рамках ETL процесса завершается вызовом API по созданию снапшота и переключению VIEW.
Благодаря такому решению, все загрузки и все данные доступны в режиме 24х7 без регламентных окон. HDFS снапшоты не приводят к большому избыточному хранению данных в HDFS. Наш опыт показал, что для часто меняющихся регламентных данных хранение снапшотов за трое суток приводит к увеличению размера максимум на 25%.
Управление конкурентной нагрузкой
Следующий большой блок требований – управление конкурентной нагрузкой.
На практике это означает что нужно обеспечить

- Предсказуемую работу регламентных процессов;
- Приоритизация пользователей в зависимости от принадлежности к ресурсной группе;
- Отсутствие, минимизация или управление отказами в обслуживании;
Как это обеспечено на практике
- Настроено разделение ресурсов между сервисами Hadoop на уровне ОС через cgroups;
- Правильное распределение памяти между нуждами ОС и Hadoop;
- Правильное распределение памяти внутри кластера между служебными сервисами Hadoop, YARN приложениями и Impala;
- Выделение ресурсных пулов Impala отдельным пользовательским группам – для гарантии обслуживания и приоритизации запросов.
Результат – предсказуемая высококонкурентная нагрузка десятков пользователей одновременно и десятков тысяч ETL запросов в сутки без влияния на другие составляющие экосистемы Cloudera.

Ри. Количество SQL запросов, завершающихся каждую секунду.
В настоящий момент на кластере регламентных расчетов в сутки регистрируется и успешно выполняется в среднем 900 тыс SQL запросов по трансформации и загрузке данных. В дни массовых загрузок и расчетов эта цифра поднимается до полутора миллионов.

При этом мы видим, что остается внушительный запас по производительности с тз возможностей повышения конкурентной работы. Есть понимание что это может быть и 1,5 млн и 2 млн запросов. Это означает что выбранный подход оказался верным и пропускная способность системы как и ее предсказуемость под нагрузкой показывает выдающиеся результаты.
Информационная безопасность
В финансовом секторе традиционно вопросы информационной безопасности являются одними из самых ключевых тк приходится работать с данными, которые не только подлежат защите с тз федерального законодательства, но и с требованиями, которые периодически ужесточаются госрегулятором. При выборе дистрибутива Hadoop стоит особое внимание уделять этим требованиям, так как большинство не вендорских сборок, либо сборок, спроектированных на базе популярных open source дистрибутивов (например Apache Big Top) не позволяют закрывать часть требований и при выводе системы в промышленную эксплуатацию можно столкнуться с неприятными сюрпризами недопуска системы от службы ИБ.
В кластере Cloudera нами были реализованные следующие требования:
- Ролевая модель доступа к данным
- Все пользователи включены в группы Active Directory (AD) каталога;
- Группы AD зарегистрированы в Sentry;
- В Sentry выполнено разграничение доступа для баз Impala и директорий HDFS;
- Каждый Target слой данных имеет ролевые слои VIEW с ограничениями на чувствительные данные в соответствии с ролевой моделью доступа;
- Пользовательские запросы;
- Запросы ETL;
- Точки интеграции Hadoop с другими системами;
Единый аналитический слой данных
Наличие общего слоя консолидированных данных – основное требование аналитического ХД.
Без этого Hadoop (как и любое другое ХД) – озеро данных, которое пользователи начинают превращать со временем в неуправляемое болото. Поэтому важно иметь общую версию правды над этим озером чтобы все задачи решались в единой системе координат.
Был разработан единый аналитический слой консолидированных данных. Источником для него является копия детального слой КХД, которая регулярно реплицируется в среду Hadoop, а также дополнительные источники, подключаемые напрямую, минуя КХД.
Модель ориентирована на пользовательский ad-hoc доступ и проектировалась с учетом требований типовых задач клиентской аналитики, риск моделей, скоринга.
Реализованы все области данных, необходимые для решения задач розничного бизнеса и моделирования такие как:
- Аккредитивы;
- Депозиты;
- Залоги;
- Заявки;
- Карты;
- Контрагенты;
- MDM;
- Кредиты;
- Сегмент клиента;
- Рейтинги;
- Агрегаты;
- Справочники;
- Счета;
- Эквайринг;
- Векселя;
- РЕПО;
- Резервы.
В настоящий момент, слой состоит из 177 целевых объектов и порядка 2350 бизнес-атрибутов. В snappy сжатии объем данных порядка 20 Тб (не менее 100 Тб в RAW).
В модель загружена история с 2010 года. Ведь точность моделей зависит от глубины истории данных, на которых она обучается. Более того, история очищалась аналитическими алгоритмами. В банке разветвленная филиальная сеть и часть филиалов мигрировали друг в друга, клиенты переходили из одного филиала в другой, производили пролонгацию сделок и тд. Все это составляет определенные сложности для анализа данных. Но в конечном целевом слое вся история отношений с каждым клиентом, все сделки, имеют непрерывную историю в рамках одного суррогатного ключа без пересекающихся интервалов историчности.
Реализованный единый слой — источник данных для производных прикладных витрин под бизнес-приложения, отчетность и модели. Сейчас у нас около 40 производных регламентных витрин, состоящих из 550 целевых таблиц и примерно 13200 атрибутов.
Надежность
Часто приходится слушать о ненадежности решений, спроектированных на Hadoop. За два года эксплуатации Cloudera Data Hub у нас практически не было каких-либо проблем, связанных с простоем системы. Случилось буквально пара инцидентов, повлиявших не регламентные процессы.
Один раз у нас забилось место, выделенное под БД metastore (недостатки мониторинга).
В другой раз была попытка выгрузить несколько сотен миллионов транзакций через Impala. В результате “прилег” координатор и другие пользователи и процессы не могли подключиться на этот координатор. Как результат выработали правило – каждый отдельный вид процессов (загрузка данных, ETL, пользователи, приложения) подключается к своему координатору, который еще имеет дублера для балансировки. Ну и конечно большие выгрузки данных в системы потребители лучше делать через sqoop export. Ну и в последних релизах Impala уже без проблем может отдавать десятки миллионов записей на подключение.
Да, случаются выходы из строя дисков, приходится иногда делать decommission узлов для их замены, но все это проходит прозрачно для пользователей без остановки работы, ведь наш архитектурный подход сразу подразумевал устойчивость к выходу из строя как минимум двух любых узлов.
Итоги
В настоящий момент система является фабрикой данных всех розничных процессов Банка и аналитических приложений. Платформой ежедневно пользуется 36 департаментов и примерно 500 пользователей для самостоятельного решения задач по аналитике и моделированию.

Реализованный нами проект стал финалистом номинации Cloudera Data Impact 2020 в категории Data For Enterprise AI.
Выводы
После двух лет промышленной эксплуатации нашей Системы мы сегодня с уверенностью можем сказать, то экосистема Hadoop полностью позволяет реализовать все современные требования к аналитической платформе при использовании дистрибутива Cloudera и при правильных архитектурных подходах. Система может полностью вытеснить все традиционные аналитические СУБД без какого-либо ущерба к накопленному опыту разработчиков и аналитиков. Нужно всего лишь принять правильные решения и сделать “прыжок веры”. Традиционно консервативный Газпромбанк сделал с нами этот “прыжок веры” и смог построить современную аналитическую платформу, ввязавшись в гонку на розничном рынке в кратчайшие сроки.
Об успехах в цифрах можно посмотреть в записи нашего совместно доклада.
Для проектирования современной аналитической системы не требуется гетерогенная архитектура слоеного пирога с пропитками из “гринпламов”, “тарантулов”, “игнайтов” и так далее. Все данные и сервисы работы с данными должны находится под управлением одной целостной системы. Такой подход снижает наличие дополнительных точек интеграции, а следовательно, и потенциальные отказы. Не требуются дополнительные работы и длительные сроки по интеграции и «пропитке» этих слоев данными.
Наш архитектурный подход позволяет ускорить внедрение нового функционала и как следствие улучшить time to market новых продуктов, основанных на data driven процессах.
В современных аналитических задачах не существует понятий горячих и холодных данных. Ситуация “прилета” пачки проводок, за диапазон t — 3-5 лет — это каждодневная регламентная ситуация. И для такого случая вы должны пересчитать остатки, обороты, просрочки и предоставить данные для модели или определения сегмента клиента в аналитическом CRM. Как я уже писал выше, чем глубже в истории данные, тем точнее ваши модели. Такие задачи можно решить только если все данные в одном месте и в одной системе. Наш принцип — все данные горячие!
Для успешной реализации проектной команде недостаточно опыта знания технологии Hadoop. Hadoop это всего лишь инструмент. Необходимо применять подходы проектирования классического ХД на базе SQL MPP, иначе ваша система навсегда останется “помойкой” под архивные данные, нарисованной внизу слоеного пирога как “хранилище неструктурированных и холодных данных” на архитектурной картинке.
Наши ближайшие планы
В настоящий момент мы находимся в завершающей стадии миграции на новую платформу Cloudera Data Platform 7.1. Вполне вероятно, что на момент публикации мы уже на CDP и в ближайшее время тут будут опубликованы результаты. Пока, можно с уверенностью сказать, что после проведенных тестов, мы ожидаем ряд оптимизационных улучшений, связанных с Impala 3.4, появлением страничных индексов в parquet, наличием Zstd компрессии. Новые сервисы вроде Atlas и Cloudera Data Flow позволят закрывать функции управления данными и потоковой аналитики «из коробки». В ближашее время мы также планируем пилотировать родной для Cloudera BI инструмент — Cloudera Data Visualization.
Что еще мы сделали в нашем ландшафте Hadoop:
- Real-time интеграция системы с процессинговым центром с использованием Kudu (real-time клиентские данные, доступные для работы с минимальной задержкой наступления события). Горячие данные в Kudu, холодные в Parquet, общий «склеивающий» интерфейс доступа для пользователей через SQL Impala. Результат — данные в реальном времени о состоянии карточных транзакций и остатков по карточному счету открывают для бизнеса новые возможности.
- Историзируемый слой ODS
Построение слоя ODS с использованием Oracle Golden Gate с сохранением истории изменения источника с возможностью задания гранулярности истории по каждому объекту репликации, а также архивированием в Hadoop с возможностью «схлопывания» интервалов «холодных» данных.
- Графовая аналитика
- Построение витрины property графа в Hadoop;
- Загрузка в графовую БД Arango;
- Интерфейс работы с графом для андерайтеров над Arango;
- Графовые модели (анализ окружения клиента при скоринге);
- Работа моделей по распознаванию первичных документов клиента и поиска в них аномалий (контроль фронта, антифрод, автоматизация работы с заявкой);
- Анализ новостных лент, тематических форумов
- Анализ удаленности и проходимости офисов от основных пешеходных маршрутов, автомобильных проездов и парковок;
- Оптимизация курьерских маршрутов
Каждый пункт из этого списка достоин отдельной развернутой статьи, которые обязательно появятся в будущем. Следите за обновлениями, задавайте ваши вопросы и делитесь своим опытом.
Авторы:
Евгений Вилков, ГлоуБайт.
Колесникова Елена, Газпромбанк (АО).
Data Quality: чем занимаются инженеры по качеству данных и почему их не заменить машинами
Большие данные – это не только большие возможности, но и большие заботы об их качестве. По сути, в IT появилась новая профессия: инженер по качеству данных, Data Quality Engineer. Спрос на таких специалистов велик, но как попасть в их число? Что в этой профессии самое важное? И есть ли там что-то, помимо рутинных операций? Вопросов много, попробуем в них разобраться вместе с руководителем стрима качества данных Управления подготовки данных в Департаменте анализа данных и моделирования Алексеем Ерюковым. А еще подробно расскажем про метрики и подходы, которые используются для управления качеством данных.
Говоря о больших данных и больших моделях, многие представляют потрясающие возможности детализации в описании людей, объектов и ситуаций. Эти массивы информации позволяют компаниям принимать точные взвешенные решения в отношении конкретных клиентов и обстоятельств.
Сложность в том, что когда информации много, возможные неточности в отдельных параметрах на первый взгляд кажутся несущественными и теряются на общем фоне. На самом деле цена даже небольшой ошибки может быть высока. Ведь только «чистые» данные повышают уровень принимаемых решений, и только для них справедливо правило: больше данных — лучше процессы — лучше результаты бизнеса.
Откуда берутся ошибки и чем внешние источники данных отличаются от внутренних
Чем больше данных, тем больше проблем, связанных с их качеством, причем к ошибкам может привести огромное количество причин.
Некоторые — банальные. Например, оператор при вводе персональных данных неправильно перепечатал ФИО из паспорта.
Есть ошибки в проектировании систем. Скажем, разработчики проигнорировали требование к длине поля ввода данных. Например, поле «Паспорт выдан» ограничили 35 символами. Понятно, что нужно больше, но в системе сохраняются только первые 35 введенных символов: «ФМС Тверского района по городу Моск».
Бывает, не учли, что какие-то данные вообще надо сохранять, а они потом потребовались. Например, пол клиента.
Могут возникнуть сложности, связанные с потерей части данных при передаче информации из системы в систему в ходе ETL/ELT-процессов.
При этом стоит разделять проблемы с качеством внутренних данных, которые находятся во внутрикорпоративных системах, и внешних, поступающих из сторонних источников.
В «Газпромбанке» отлажены процессы по улучшению качества данных (КД), поэтому оно постоянно растет и стабильно выше, чем КД из внешних источников.
Качество данных из внешних источников: что может пойти не так
Яркий пример — бюро кредитных историй, которые агрегируют данные из разных компаний и предоставляют их другим организациям. Некоторые требования к качеству этих данных можно описать: заполнены критические поля, есть логические проверки, например, возраст клиента от 18 до 70 лет, и так далее. Но некоторую информацию невозможно проверить физически, — скажем, срок и сумму кредита. Здесь возможны только косвенные проверки на логику событий, поэтому возрастает вероятность ошибок.
Или есть рассинхронизация данных: по информации одного бюро у клиента два кредита, а по данным другого — три. Такое возможно, например, когда один кредит погашен, но информация поступила не во все бюро кредитных историй. Или наоборот, клиент успел взять новый кредит, и его еще тоже учли не везде.
Может сказаться чисто технический момент. Например, бюро кредитных историй предоставляют информацию по клиентам и их кредитам в конкретном машинно-читаемом формате, скажем, XML-файле с четкой структурой данных. Время от времени Банк России модернизирует эти форматы, и тогда у бюро могут возникать проблемы. Ведь потребителей данных бюро кредитных историй много: одни уже переехали на обновленный формат обмена данным, а другие еще не успели. И самому бюро нужно изловчиться и обеспечить как прямую, так и обратную совместимость по данным, то есть новый формат не должен испортить процесс выгрузки для тех, кто еще не перешел на него. А тем, кто перешел, тоже нужно время на доработку процессов.
Отдельные риски ухудшения КД возникают при интеграции внешней информации во внутренние структуры данных. Например, в системах банка используются идентификаторы, позволяющие точно определять, о каком именно клиенте или заявке идет речь в данном случае. У внешних данных таких различителей нет, и тогда реального заемщика можно спутать с посторонним человеком с таким же именем и датой рождения (подобные «двойники» действительно встречаются).
Конечно, в договоре с поставщиком внешних данных прописаны требования по качеству, но на практике ошибки все равно случаются.
Еще более сложная ситуация — с параметрами, характеризующими внешнюю среду, они обычно используются в маркетинговых моделях и моделях потребителей. Тут изменения в параметрах невозможно отследить в реальном времени. Как в ковидную пандемию, когда данные, скажем, по посещаемости и среднему чеку кафе рядом с бизнес-центром обнулились, зато выручка интернет-магазинов и служб доставки подскочила кратно. Или, например, банк регулярно получал данные от партнеров, но в какой-то момент они прекратили деятельность, и поток этих данных иссяк. Или банк ввел комиссию на снятие наличных в банкомате, и клиенты-студенты из ближайшего вуза массово перешли в другой банк. Для моделей это значимые изменения популяции.
То есть во многих случаях причиной изменения вектора входящего потока данных становится некий внешний фактор.
Для разных задач нужен свой уровень качества данных
«Вишенка на торте» при перечислении проблем с КД — большая вариативность допустимого уровня качества. Он сильно зависит от специфики конкретных задач. Так, при оперативной оценке продаж кредитов в банке можно условно сказать, что за день выдали 100 млн рублей (плюс-минус один миллион). А в бухгалтерской отчетности даже плюс-минус одна копейка — недопустимая ошибка.
Все зависит от того, какие данные считаются качественными в конкретной ситуации. А это зависит от того, можно ли с их помощью решить поставленную задачу. Для одних задач количество ошибок на уровне 20% считается нормой, а для других даже 1% ошибочных данных — недопустимо много (при том, что абсолютного нуля не бывает).
На практике выбор приемлемого уровня качества — это результат договоренности с заказчиком. Личный опыт говорит, что уровень отклонений в 3% достаточен для решения почти любой задачи, но окончательное решение всегда остается за заказчиком.
Итак, проблем с КД для моделей — огромное количество. Для их устранения нет простых и гарантированных решений. Что делать?
В игру вступает команда спасателей данных
Управлять качеством данных компаниям помогают отдельные команды, которые занимаются исключительно Data Quality. И не всякий человек из IT, умеющий писать программы, может стать инженером по качеству данных. Программисты, которые привыкли работать строго по бизнес-требованиям, вряд ли подойдут: здесь нужно не столько умение описывать обработку данных, сколько аналитические способности. Скорее карьера КД-специалиста подойдет программисту с аналитическим складом ума или бизнес-аналитику со знанием основ работы с данными в информационных системах.
В «Газпромбанке» есть полноценное подразделение Data Quality — служба управления качеством данных, которая отвечает за улучшение КД во всем банке. Кроме того, в департаменте анализа данных и моделирования создан отдельный стрим по вопросам КД для моделей. Сейчас в этом стриме работает шесть человек, каждый из которых в среднем может поддерживать параллельно три витрины данных. Витрины обычно обновляются в одно и то же время, чаще всего раз в месяц.
Наш подход — сплошной контроль качества данных
Чтобы контролировать КД на всех этапах работы бизнес-приложений, в «Газпромбанке» практикуют сплошной контроль качества внешних данных, которые используются в моделях.
Теоретическое обоснование такого подхода дает концепция Data Governance.
Также есть стандарт DMBOK (Data Management Body of Knowledge), в котором прописаны все этапы взаимодействия с данными от момента их появления до утилизации. В 2009 году эксперты Международной ассоциации управления данными DAMA выпустили «Руководство DAMA к своду знаний по управлению данными (DMBOK)». Книга фактически заложила фундамент для развития новых профессий, относящихся к управлению данными. Позже вышло второе издание — DAMA-DMBOK2, есть перевод на русский язык. DAMA-DMBOK2 можно назвать сводом знаний — это полное и актуальное введение в дисциплину управления данными с обзором лучших практик. Рекомендую прочитать книгу всем, кто хочет профессионально заниматься задачами качества данных и другими вопросами из области управления данными.
Например, для практических шагов в Data Quality удобно использовать «пирамиду DMBOK2». Она включает все области знаний об управлении данными из DAMA DMBOK2 и помогает понять: на каком этапе компания находится сейчас и как двигаться дальше, чтобы выстроить надежные процессы управления данными.
Пирамида DMBOK2.
Источник: https://dataliteracy.ru- Мониторинг качества данных ключевых витрин в части моделирования.
- Разработка новых промышленных правил контроля качества данных (ККД).
- Анализ инцидентов и оценка их влияния на бизнес.
- Участие в приемке доработок витрин (в части моделей).
- Контроль статусов инцидентов корпоративного хранилища данных (КХД) и взаимодействия с офисом директора по цифровым технологиям (CDO, Chief Digital Officer).
- Проверка данных на предмет аномалий.
Данные для моделей — в чем главный подвох? В теории и на практике
Теоретически задача взять под контроль качество внешних данных вполне решаемая. И понятно, как: сравнивать текущее качество данных с неким эталоном. Процесс можно автоматизировать, а человека подключать только в том случае, когда выявлены отклонения и нужно проанализировать их причины. Но есть нюансы. Вот как это работает в Газпромбанке.
Данные для моделирования — не сырые: это агрегированные данные из витрин, каждая из которых строится на десяти и более источниках, как внешних, так и внутренних, и хранит 1000 и более столбцов. При этом в каждой витрине обычно более 10 млн строк, а поддержка истории данных составляет от четырех лет, и чем глубже, тем лучше.
Доверительный интервал отклонений в сравнении с предыдущим срезом по ключевым метрикам установлен по умолчанию на уровне 10%. Есть три рабочих дня — время на анализ инцидентов для ежемесячных моделей. То есть в течение трех дней надо проанализировать все эти тысячу с лишним столбцов в витрине на предмет расхождений с эталоном.
Подвох в том, что при таких условиях прямая сверка данных с эталонными невозможна. Опять вопрос: что делать?
Сила контроля — в метриках качества
Мы решили использовать оценочные метрики. И сверку производим по этим оценочным метрикам. За условный эталон берем витрину с качественными данными в том виде, какой она имела сразу после разработки. Следующий срез проверяем на уровень качества также в сравнении с эталоном.
Всего мы используем около двух десятков метрик для контроля КД входного вектора моделей. В том числе, для числовых переменных: минимальное, максимальное, медианное и среднее значения, суммарное значение переменной за текущий срез, а для таблицы — количество пустых и заполненных значений по переменной в абсолютном и относительном выражении, а также отклонение. Порог допустимых отклонений мы приняли на уровне 10%. Иными словами, если отклонение в количестве построенных строк по сравнению с предыдущим срезом превышает 10%, это уже инцидент с КД, который требует дополнительного исследования.
Иногда коллеги задают вопрос: как можно достичь максимальной «объективности» в оценках метрик качества разных типов данных? Ответ простой: личный опыт работы с этими типами данных и аналитическое чутье — вот лучшие помощники в деле контроля качества данных.
Отдельно отмечу интересную метрику — индекс стабильности популяции (Population Stability Index, PSI). Он полезен для анализа изменений входных данных для розничных моделей. Скажем, при разработке модели популяцию клиентов составляли мужчины и женщины: 60% и 40% соответственно, при этом возраст половины клиентов составлял 30–45 лет, 30% — старше 50 лет и 20% — молодая аудитория в возрасте 20–30 лет. Если на очередном срезе мы увидим существенные изменения в наполнении переменных, например, выросла доля молодежи или женщин, значит, произошло изменение популяции клиентов (а на уровне данных — дрейф данных, data drift), и текущая модель для нее работает плохо.
Так что метрика PSI — прозрачная и легко интерпретируемая, поскольку дает конкретное значение. Если значение PSI < 0,1, изменений в выборке нет. Если PSI находится в интервале от 0,1 до 0,2, в выборке есть изменения и нужно разбираться. Значение PSI >0,2 говорит о таких значительных изменениях в выборке, при которых использовать модель нельзя.
Коллеги говорят, что бывали ситуации, когда значение PSI превышало 0,2 и модель приходилось перестраивать. Однако за время моей работы в департаменте анализа данных и моделирования, а это уже больше года, такого не случалось.
Процессы и инциденты контроля качества данных: ближе к реальному времени
Сейчас мы сконцентрированы на ежемесячных моделях, для которых установлен регламент — три рабочих дня на анализ инцидентов. Но уже в работе витрина данных заявок из РКК (розничного кредитного конвейера), которая обновляется ежедневно, и одна из наших текущих задач — согласовать с заказчиком регламент анализа инцидентов.
Вообще, обработка инцидентов с качеством данных (ИКД) — захватывающее занятие. С одной стороны, все просто: мы видим, что конкретное поле или ряд полей витрины (а может и вся витрина) заполнены не верно. С другой стороны, оценка влияния такого инцидента на бизнес — сложный процесс, и именно здесь открывается простор для творческих аналитических упражнений.
Например, сейчас в Газпромбанке проходит исследовательский проект по оценке влияния ИКД на модель. Если коротко, мы искусственно искажаем данные по нескольким полям, и прогоняем модель по этим данным. То же самое делаем с качественными данными. Затем сравниваем результаты работы модели и пытаемся оцифровать расхождение в разных показателях: например, не выдали Х кредитов на сумму Y рублей. Детали раскрыть не могу, потому что сама методология обработки ИКД развивается вместе с этим проектом.
Процессы обеспечения качества данных имеют специфический характер и требуют для формализации специфических инструментов. Для управления подготовкой данных мы используем известный подход — матрица RACI, которую мы расширили пунктами, относящимися к процессу контроля КД.
Напомню, что матрица RACI (или матрица ответственности) — инструмент для управления отношениями в команде. Это таблица, с помощью которой по всем задачам проекта распределяются роли исполнителей, их полномочия и ответственность. Собственно, основные роли и составляют название метода: Responsible (ответственный сотрудник), Accountable — исполнитель, Consult — консультант, Iinformed — тот, кого нужно проинформировать после произведенного действия.
В нашей матрице RACI появились два новых пункта:
· Первичная оценка качества данных витрины. После того, как разработан прототип витрины, и еще до передачи ее заказчику на изучение мы оцениваем качество данных по ключевым метрикам. То есть за короткий отрезок времени можно увидеть состояние данных в витрине, их качество, имеющиеся отклонения.
· Проверка качества данных после после обновления витрины в промышленной эксплуатации.
На оценку качества данных витрины уходит неполный рабочий день, а для промышленной оценки КД нужно 3 часа на запуск проверок. Выявленные аномалии разбирают инженеры по качеству данных.
Главное для нас при работе с витринами для моделирования — проверка данных на предмет аномалий. Поскольку поля витрины — это некие агрегаты, а не сырые данные, не всегда можно проверить их как-то иначе на полноту, логику и другие параметры. Хорошо то, что здесь есть возможность использовать готовые программные инструменты, например, библиотеки на языке Python или решения, позволяющие оценивать дрейф данных. Правда, мы оказались очень взыскательными пользователями и отбросили многие инструменты: одни не поддерживали нужные нам объемы данных, у других был неудобный интерфейс.
В итоге мы активно используем метод Isolation Forest, который показывает очень хорошие результаты в выявлении аномалий в данных. Впрочем, для этого также потребуется аналитическое чутье, поскольку допустимый уровень отклонения в изолирующем лесе устанавливается на основе экспертного мнения.
В дополнение к библиотеке Isolation Forest применяем Apache Superset для визуализации результатов. Процесс автоматизирован: запустить его и получить результаты может любой аналитик с минимальными знаниями программирования.
Обеспечение качества данных: промышленный подход
Сфера качества данных для моделей хайповая и молодая, в России ей нет и 10 лет. Большинство компаний уже поняли, что для эффективной работы качественных моделей нужны качественные данные. Сегодня идет переход на новый уровень постижения проблематики Data Quality — осознание того, что управление качеством данных не может быть разовой операцией или небольшим IT-проектом, реализуемым однажды.
Ведь даже при работе с внутренними данными регулярно происходят инциденты качества данных. Типичный пример: IT-специалисты обновили систему, но не учли, что это повлияет на какой-то процесс. Или одно из полей обнулилось. Или выносили обновления, и витрина-источник не собралась вовремя, новые данные не поступили. Продолжать можно бесконечно. Мораль: данных с «вечным» качеством не бывает, работать над улучшением нужно постоянно. И заниматься этим должна специализированная команда профессионалов, пусть даже небольшая.
Заменить специалистов по качеству данных каким-нибудь программным роботом (RPA) невозможно, потому что ежедневное управление качеством данных — далеко не рутинные процедуры «нажимания кнопок». Специалист в области Data Quality должен точно понимать процессы, особенности данных, разбираться в предметной области. Иными словами, разбирая инциденты КД, инженер глубоко погружается в специфику бизнес-процесса и основное время при разборе тратит на понимание глубинных причин проблем с данными. Для этого требуются аналитические способности, которые есть только у человеческого ума.
Подход к организации электронного взаимодействия посредством витрин данных Текст научной статьи по специальности «Компьютерные и информационные науки»
СИСТЕМА МЕЖВЕДОМСТВЕННОГО ЭЛЕКТРОННОГО ВЗАИМОДЕЙСТВИЯ / «ЭЛЕКТРОННАЯ РОССИЯ» / ПОРТАЛЬНЫЕ РЕШЕНИЯ / «ЭЛЕКТРОННЫЕ СЕРВИСЫ» / ХРАНИЛИЩЕ ДАННЫХ / OLAP-ТЕХНОЛОГИЯ / СУБД / ВИТРИНЫ ДАННЫХ / «ELECTRONIC RUSSIA» / INTERAGENCY ELECTRONIC INTERACTION SYSTEM / PORTAL DECISION / WEB SYSTEM / DATA WAREHOUSE / OLAP TECHNOLOGY / DBMS / DATA MART
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Горбачев Д. В., Кононова М. В.
Рассматривается необходимость решения организации обмена данными в системе межведомственного электронного взаимодействия , которое строится на основе витрин данных , позволяющих решить основную задачу в межведомственных коммуникациях.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Горбачев Д. В., Кононова М. В.
Создание региональных систем межведомственного электронного взаимодействия
Способы организации межведомственного информационного взаимодействия органов и организаций, исполняющих государственные функции
Система межведомственного электронного взаимодействия как механизм работы электронного правительства
Региональная система межведомственного электронного взаимодействия как основа предоставления государственных и муниципальных услуг
Технологическая интеграция сети многофункциональных центров предоставления государственных и муниципальных услуг в систему межведомственного электронного взаимодействия
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.ON ELECTRONIC INTERACTION USING DATE MART
The article considers the issue of data exchange in interagency electronic interaction system on the basis of data mart that enables to solve the main task of interagency communication.
Текст научной работы на тему «Подход к организации электронного взаимодействия посредством витрин данных»
Д. В. Горбачев, кандидат технических наук, доцент, доцент кафедры инноватики и информационных технологий, ФГБОУ ВПО «Оренбургский государственный институт менеджмента» e-mail: gordi47@mail.ru
М. В. Кононова, старший преподаватель кафедры инноватики и информационных технологий ФГБОУ ВПО «Оренбургский государственный институт менеджмента» e-mail:Klumar@mail.ru
ПОДХОД К ОРГАНИЗАЦИИ ЭЛЕКТРОННОГО ВЗАИМОДЕЙСТВИЯ ПОСРЕДСТВОМ ВИТРИН ДАННЫХ
Рассматривается необходимость решения организации обмена данными в системе межведомственного электронного взаимодействия, которое строится на основе витрин данных, позволяющих решить основную задачу в межведомственных коммуникациях.
Ключевые слова: система межведомственного электронного взаимодействия, «электронная Россия», портальные решения, «электронные сервисы», хранилище данных, OLAP-технология, СУБД, витрины данных.
Несмотря на активно развивающееся техническое и организационное оснащение межведомственного электронного взаимодействия, не полностью решенной остается задача консолидации информационных массивов. В связи с этим обоснование применения информационной технологии, позволяющей объединять в цельные системы большие объемы разнородной информации, является актуальным.
В последнее время правительственные сайты в сети Интернет становятся все более популярными, активное развитие Сети заставляет властные органы большинства стран развивать электронную составляющую своей деятельности.
Согласно данным исследования, люди, прежде всего, обращаются к правительственным ресурсам для получения информации. В то же время увеличивается процент населения, использующий их для заключения сделок, получения персонифицированных услуг.
Наиболее популярны сайты электронного правительства в Швеции — 57% населения считают их очень полезными, а также в Норвегии (56%), Сингапуре и Дании (53%), Англия и Япония в этом отношении имеют самые низкие показатели (13%), Россия (2%) (рис. 1).
В России для реализации проекта по внедрению электронного правительства разработана и принята федеральная целевая программа «Электронная Россия (2002-2010 годы)».
Рис. 1. Показатели популярности сайтов электронного правительства
До сих пор правительство составляло рейтинги готовности регионов к электронному взаимодействию на основании данных, которые предоставляли сами чиновники субъектов. Подсчет числа обращений через СМЭВ показал, что лидером по интенсивности работы с федеральными сервисами является Челябинская область. На ее долю пришлось более 725 тыс. запросов, то есть почти пятая часть всех обращений. Всего более 100 тыс. обращений насчитывается у восьми субъектов. Интересно, что суммарно на их долю приходится более 89% таких взаимодействий.
Если же в число лидеров включить регионы, перешагнувшие барьер в 10 тыс. обращений к СМЭВ, то число таких субъектов достигнет 16, а суммарная доля их запросов превышает 98%.
В целом готовность всех органов власти по работе с СМЭВ оценивается в 60%, отметил глава Минкомсвязи. Так, к СМЭВ подключены 100% федеральных органов исполнительной власти. На региональном уровне к системе подключено 87% (1 тыс. 427) органов исполнительной власти. В то же время к системе подключено только 47% (10 тыс. 925) муниципальных органов. При этом
Н. Никифоров подчеркнул, что на 100% региональных и муниципальных органов власти подключены к СМЭВ в Алтайском крае и Татарстане.
По показателям проектирования СМЭВ Самарская область — наш ближайший сосед по территориальному расположению субъектов РФ, согласно данным правительственной комиссии по внедрению информационных технологий в деятельность органов власти, вошла в пятерку регионов-лидеров по России. В то время как Оренбургская область не отмечена никакими достижениями [13].
Система межведомственного электронного взаимодействия представляет собой федеральную государственную информационную систему, включающую информационные базы данных, в том числе содержащие сведения об используемых органами и организациями программных и технических средствах, обеспечивающих возможность доступа через систему взаимодействия к их информационным системам (далее — «электронные сервисы»), сведения об истории движения в системе взаимодействия электронных сообщений при предоставлении государственных и
Государство Гражданское общество
Законодательная Исполнительная Судебная
власть власть власть
Информационное общество — взаимодействие на основе ИКТ
— органов власти внутри себя ■ органов власти между собой
■ органов власти с гражданами и организациями
— граждан между сабой
— организаций между собой ■ граждан и организаций
Электронный Электронное Электронное Электронные Электронный Электронный
парламент правительство правосудие выборы гражданин бизнес и коммерция
Электронное государство — взаимодействие на основе ИКТ с N \
— органов власти внутри себя — органов власти между собой — органов власти с гражданами и организациями
Органы исполнительной Органы местного _ _
власти самоуправления ГРажданв Организации
Электронное Правительство — взаимодействие на основе ИКТ
Органов исполнительной власти и органов местного самоуправления Органов исполнительной власти и органов местного самоуправления
между собой при осуществлении полномочий: между собой и гражданским обществом при осуществлении полномочий:
— Формирование и реализация единой государственной и муниципальной политики
НС Граждане^ ^ Бизнес сообщество
Осуществление контрольнонадзорной деятельности
Рис. 2. Место и роль электронного правительства в решении задачи формирования
информационного общества в РФ
муниципальных услуг, исполнении государственных и муниципальных функций в электронной форме, а также программные и технические средства, обеспечивающие взаимодействие информационных систем органов и организаций через СМЭВ.
В качестве технологического решения организации взаимодействия применимого в СМЭВ, Законом определяется портальное решение.
Порталы подразделяются на федеральные власти и власти субъектов РФ. Основными порталом государственных и муниципальных услуг является «Единый портал государственных и муниципальных услуг» www.gosuslugi.ru.
Основным электронным документом, идентифицирующим пользователя СМЭВ, является универсальная электронная карта, представляющая собой материальный носитель, содержащий зафиксированную на нем в визуальной (графической) и электронной (машиносчитываемой) формах информацию о пользователе картой и обеспечивающий доступ к информации о пользователе картой, используемой для удостоверения прав пользователя картой на получение государственных и муниципальных услуг, а также иных услуг, оказание которых осуществляется с учетом положений о предоставлении госуслуг, в том числе для совершения в случаях, предусмотренных законодательством Российской Федерации, юридически значимых действий в электронной форме. Пользователем универсальной электронной картой может быть гражданин Российской Федерации, а также в случаях, предусмотренных федеральными законами, иностранный гражданин либо лицо без гражданства (далее, если не указано иное, — гражданин).
Таким образом, на законодательном уровне точно устанавливаются общие требования к организации и технологиям межведомственного взаимодействия.
Системный проект инфраструктуры электронного правительства разработан Министерством связи и массовых коммуникаций Российской Федерации в 2010 году с целью определения основных мероприятий по формированию инфраструктуры электронного правительства.
Основным системнополагающим элементом Системного проекта является модель, устанавливающая роль и место электронного правительства в системе государственного и муниципального управления (рис. 2).
Рис. 3. Взаимосвязь компонентов «электронного правительства»
Одним из способов автоматизации функций, единообразно выполняемых федеральными и региональными органами власти, органами местного самоуправления, является создание новых или доработка существующих решений до уровня типовых программных решений (типовых ИС). Согласно положений Системного проекта разработка и создание типовых ИС производится как на федеральном, так и региональном уровнях.
Технологическое обеспечение предоставления государственных услуг в электронном виде. функционирование инфраструктурных компонентов электронного правительства осуществляется с помощью федерального и региональных сегментов инфраструктуры, изображено на рисунке
Из рисунка 4 видно, что центральным интеграционным элементов инфраструктуры электронного правительства является СМЭВ. Межведомственное электронное взаимодействие осуществляется через территориально распределенную телекоммуникационную инфраструктуру электронного правительства путем использования потребителями электронных сервисов, предоставляемых единой информационной системой межведомственного электронного взаимодействия.
Таким образом, на концептуальном уровне, СМЭВ, выступая в роли интеграционной шины и/ или интеграционного брокера, не отвергает концепции автоматизации деловых процессов (для государственных органов, работающих преимущественно с документом — создания систем документооборота), а является дополнительной к ней. Система электронного документооборота реализует сквозной процесс предоставления государственной услуги, система межведомственного электронного взаимодействия обеспечивает участие в этом процессе ранее несвязанных ресурсов, предоставляя транспортную и логическую среду для обмена стандартизованными сообщениями между системой документооборота (системой исполнения деловых процессов) и внешними информационными ресурсами.
Витрина Данных (ВД) — это упрощенный вариант ХД, содержащий только тематически объединенные данные (рис. 5).
Рис. 4. Ключевые компоненты инфраструктуры электронного правительства в составе федерального и регионального сегментов
ВД содержит данные, ориентированные на конкретного пользователя, существенно меньше по объему, и для ее реализации требуется меньше затрат. ВД могут строиться как самостоятельно, так и вместе с ХД. ВД внедряются гораздо быстрее и быстрее виден эффект от их использования.
Достоинствами решения на основе витрин данных являются простота создания и наполнения ВД, поскольку наполнение происходит из единого стандартизированного источника очищенных данных — из ХД, простота расширения за счет добавления новых ВД, а также снижение нагрузки на основное ХД.
Недостатки заключаются в избыточности, так как данные хранятся и в ХД, и в ВД, а также в дополнительных затратах на разработку СППР с ХД и ВД.
Информационно-технологическим обеспечением функционирования витрин данных является OLAP-технология. OLAP-системы построены на двух базовых принципах:
— все данные предварительно агрегируются на всех соответствующих уровнях и организуются так, чтобы обеспечить максимально быстрый доступ к ним;
Рис. 5. Структура системы с ХД и ВД
— язык манипулирования данными основан на использовании понятий предметной области.
В основе OLAP лежит понятие гиперкуба, или многомерного куба данных, в ячейках которого хранятся анализируемые (числовые) данные. Поэтому данные из хранилища сначала помещаются в специальную многомерную базу (MultidimensionalDataBase, MDB), а затем эффективно обрабатываются OLAP-сервером. Технология использования OLAP для проектирования и работы витрин данных показана на рисунке 6.
Таким образом, приведенный пример показывает высокую эффективность использования технологии витрин данных для организации консолидированного доступа к большим объемам информации. Применение витрин данных для решения проблемных вопросов СМЭВ позволит уменьшить нагрузки на инфокоммуникационную инфраструктуру системы, а также облегчить работу персонала при обработке запросов и формировании итоговых документов оказания государственных и муниципальных услуг.
Внедрение в систему МЭДО витрины данных имеет целью систематизации и автоматизации процессов передачи запросов и получения результатов при реализации государственных и муниципальных услуг.
Витрины данных, как правило, характеризуются наличием явной размерности время. При этом структура данной размерности может меняться в зависимости от моделируемой предметной области и требований, предъявляемых пользователями к представлению времени.
Состояние витрины данных всегда будет актуализировано. Пользователи обращаются с запросами только к витрине данных и получают из нее необходимую информацию (рис. 7).
Однако в данном процессе могут возникнуть сложности, связанные со стыковкой форматов данных. В связи с тем что большинство государственных, федеральных и муниципальных учреждений и организаций в настоящее время уже имеют собственные базы и хранилища данных, сопровождаемые различными СУБД, ситуация с различиями и нестыковками форматов является достаточно актуальной. Решением данной проблемы может являться универсальный программный шлюз, который будет преобразовывать запрос от исполнителя услуги к витрине данных источника сведений в соответствующий формат. В принципе эта задача в некоторых случаях может быть решена с помощью стандартных средств операционных систем и/или СУБД. Например, в семействе ОС MS Windows имеется встроенная поддержка набора драйверов доступа к базам данных различных форматов посредством службы ODBC.
Централизованное хранилище данных
Таким образом, основная проблема применения витрин данных — различие форматов исходных данных — может быть решена достаточно простыми способами. А применение витрин данных позволит принципиально изменить информационные потоки, циркулирующие в системе МЭДО.
Концептуальный подход к модификации потоков движения запросов и ответов на них показан на рисунке 8.
Согласно изображенной на рисунке схеме общая витрина данных формируется всеми участниками выполнения некоторой гипотетической государственной услуги. Сама витрина в данной ситуации может размещаться на серверах Правительства региона или сервере ведомства, ответственного за исполнение услуги.
Изменение информационных процессов, связанные с применением витрин данных, позволяют исключить циклы и блокировки. Структура витрины данных является предопределенной, а содержательное наполнение может варьироваться в зависимости от потребностей организаторов-исполнителей, осуществляющих запросы к ним.
Запросы могут поступать в смежные организации традиционным путем — с помощью сообщений, передаваемых по электронной почте. Затем оператор смежной организации формирует запрос-обращение к собственной базе данных и, далее, полученные результаты помещаются в витрину данных. Затем оператор-исполнитель документа обращается к витрине и выбирает из нее нужную информацию. Заключительным этапом является формирование итогового документа.
Таким образом, можно сделать следующие выводы:
1. Принципиальным технологическим решением, позволяющим значительно минимизировать циклы информационных потоков, является применение витрин данных в качестве информационных баз, к которым могут подключаться абоненты по мере необходимости, то есть для поиска и сбора требуемой информации.
2. Каждую такую витрину данных формирует и сопровождает объект-источник: учреждение. организация, ведущая основной учет сведений.
3. Проведенный анализ показывает высокую эффективность использования технологии витрин данных для организации консолидированного доступа к большим объемам информации.
4. Применение витрин данных для решения проблемных вопросов СМЭВ, позволит уменьшить нагрузки на инфокоммуникационную инфраструктуру системы, а также облегчить работу персонала при обработке запросов и формировании итоговых документов оказания государственных и муниципальных услуг.
Решение организации обмена данными в системе межведомственного электронного взаимодействия строится на основе витрин данных, позволяющих решить основную задачу в межведомственных коммуникациях. В данной статье не рассматривались вопросы защиты витрин данных и каналов доступа к ним, поскольку эти задачи представляют собой отдельную большую и очень значимую проблему.
1. Кренке, Д. Теория и практика построения баз данных : [пер. с англ.] / Д. Кренке. — 9-е изд. -СПб. : Питер, 2005. — 858 с.
2. Ларичев, О. Н. Теория и методы принятия решений / О. Н. Ларичев. — М. : Логос, 2002. -1226 с.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
3. Лоза, А. Важные аспекты эффективного внедрения систем автоматизированного проектирования / А. Лоза // САПР и графика. — 2009. — № 9 (155). — С. 50-53.
4. Мартин, Дж. Организация баз данных в вычислительных системах / Дж. Мартин. — М. : Мир, 2008. — 161 с.
5. Никольский, С. Н. Метаонтологии и обобщенная задача реализации / С. Н. Никольский // Автоматизация и современные технологии. — 2008. — № 9. — С. 24-29.
6. Орлов, С. А. Технология разработки программного обеспечения / С. А. Орлов. — СПб. : Питер, 2002 — 464 с.
7. Осовецкий, Л. Г. К вопросу иммунологии сложных информационных систем / Л. Г. Осо-вецкий, Г. Ф. Нестерук, В. М. Бормотов // Известия вузов. Приборостроение. — 2007. — Т. 46.
8. Павлов, А. С. Обеспечение взаимодействия информационных систем с помощью универсальных форматов данных // Известия вузов. Строительство. — 2010. — № 7. — С.134-138.
9. Петров, В. Н. Информационные системы / В. Н. Петров. — СПб. : Питер, 2002. — 344 с.
10. Программное и информационное обеспечение учебного назначения. Высшее профессиональное образование. Информационные системы (в образовании) : № 3911 ВНТИЦ N 50200401186 Наименование разработки: Информатика, как основообразующая дисциплина формирования ин-формсреды образования // Компьютерные учебные программы и инновации. — 2009. — № 7.
11. Создание базы данных для ведения «Ведомственного реестра» Минобразования России / Литвиненко М. В.; Моск. гос. унив. геод. и картогр. — Москва, 2000. — 9 с. — Библиогр. 5 назв. -Рус. — Деп. в ОНИПР ЦНИИГАиК 10.10.2000 г. № 729-гд 2000Деп.