LIFO и FIFO
Терминология, пришедшая в IT из бухучета. Так называют подходы к организации данных.
FIFO (First In, First Out, «первый пришел – первый ушел») – поведение как в очереди в магазине. Ему соответствует структура данных очередь. У такого хранилища две операции: enqueue – добавить элемент в конец, и dequeue – забрать из начала.
LIFO (Last In, First Out, «последний пришел – первый ушел» – наоборот, первый пришедший ждет всех остальных, подобно стопке тарелок. Соответственно, его реализует структура данных стек. Операция push кладет новый элемент наверх стопки, pop забирает сверху же.
Термины применяются не только к способу доступа к данным, но и к порядку разрешения конфликтов. Так, например, по принципу LIFO или FIFO может определяться порядок исполнения параллельно пришедших сигналов какой-либо системы: доступа к диску, планировки задач ОС, и прочих.
Какая структура данных организована по принципу последним пришел первым ушел подробнее
Как называл свою книгу Н.Вирт, «Алгоритмы + структуры данных = программы».
Наиболее популярные структуры данных: массив, очередь, стек, дек, список, дерево, граф.
Стек — это структура данных, организованная по принципу «первый пришел, первый ушел», по английски First In First Out, сокращенно FIFO. В бытовом смысле это обычная очередь.
Список предписаний структуры «Очередь элементов типа E »:
1. Начать работу
2. Сделать очередь пустой
3. Очередь пуста: да/нет
4. Добавить элемент < вх: E>в конец очереди
5. Взять элемент из начала очереди в
6. Начало очереди: E
7. Удалить начало очереди
8. Кончить работу
Стек — это структура данных, организованная по принципу «последний пришел, первый ушел», по английски Last In First Out, сокращенно LIFO. В бытовом смысле это просто стопка, из которой можно брать и в которую можно класть только сверху.
Список предписаний структуры «Стек элементов типа E »:
1. Начать работу
2. Кончить работу
3. Сделать стек пустым
4. Стек пуст: да/нет
5. Добавить элемент < вх: E>в стек
6. Взять элемент из стека в
7. Вершина стека: E
8. Удалить вершину стека
Дек похож на стек, но операции положить/вытолкнуть можно производить не только сверху, но и снизу дека.
Список предписаний структуры «Дек элементов типа E »:
1. Начать работу
2. Сделать пустым
4. Добавить элемент в начало/конец дека
5 . Взять элемент из начала/конца дека в
6 . Начало/конец дека: E
7. Удалить начало/конец дека
8. Кончить работу
Список предписаний структуры «Множество элементов типа E »:
1. Начать работу
2. Сделать множество пустым
3. Множество пусто: да/нет
4. Добавить элемент < вх: E>в множество
5. Удалить элемент < вх: E>из множества
6. Элемент < вх: E>принадлежит множеству: да/нет
7. Взять какой-нибудь элемент множества в
8. Кончить работу
Список предписаний структуры «Последовательность элементов типа E »:
1. Начать работу
2. Сделать последовательность пустой
3. Последовательность пуста: да/нет
4. Добавить элемент < вх: E>в конец последовательности
5. Встать в начало последовательности
6. Есть/нет непрочитанные элементы
7. Прочесть очередной элемент последовательности в
8. Очередной элемент последовательности: E
9. Пропустить очередной элемент последовательности
10. Кончить работу
Список предписаний структуры «Л2-список элементов типа E »:
1. Начать работу
2. Сделать список пустым
3. Список пуст: да/нет
4. Установить указатель в начало/конец списка
5. Указатель в начале/конце списка: да/нет
6. Передвинуть указатель списка вперед/назад
7. Добавить элемент < вх: E>до указателя/за указателем списка
8. Взять элемент списка до указателя/за указателем в
9. Элемент списка до указателя/за указателем: E
10. Удалить элемент списка до указателя/за указателем
11. Кончить работу
Название списка «линейный двунаправленный» означает, что элементы списка упорядочены линейно, а указатель можно двигать вперед/назад.
В линейном однонаправленном списке элемены упорядочены тоже линейно, но указатель можно двигать только вперед:
Список предписаний структуры «Л1-список элементов типа E »:
1. Начать работу
2. Сделать список пустым
3. Список пуст: да/нет
4. Установить указатель в начало списка
5. Указатель в конце списка: да/нет
6. Передвинуть указатель списка вперед
7. Добавить элемент < вх: E>за указателем списка
8. Взять элемент списка за указателем в
9. Элемент списка за указателем: E
10. Удалить элемент списка за указателем
11. Кончить работу
Список предписаний структуры «Вектор элементов типа E с индексом типа И»:
1. Начать работу
2. Элемент вектора с индексом < вх: И >: E
3. Кончить работу
Реализация одних структур на базе других
1. Реализация последовательности на базе двух очередей.
Последовательность будем хранить в левой (ЛО) и правой (ПО) очередях. Левая часть будет соответствовать прочитанной части последовательности, а правая — непрочитанной.
Предписание Начать работу
ЛО. Начать работу
ПО. Начать работу
Предписание Сделать последовательность пустой
ЛО.Сделать очередь пустой
ПО. Сделать очередь пустой
Предписание Последовательность пуста: да/нет
Ответ : = ЛО.пуста и ПО.пуста
Предписание Добавить элемент < вх: E>в конец последовательности
ПО.Добавить элемент < вх: E>в конец очереди
Предписание Встать в начало последовательности
// Перекладываем все элементы из правой очереди в левую
Цикл Пока ПО.Очередь не пуста выполнять
ПО.Взять элемент из начала очередь в
ЛО.Добавить элемент < вх: E>в конец очереди
Утверждение: ПО.Очередь пуста
// Перекладываем все элементы из левой очереди в правую
Цикл Пока ЛО.Очередь не пуста выполнять
ЛО.Взять элемент из начала очередь в
ПО.Добавить элемент < вх: E>в конец очереди
Утверждение: ЛО.Очередь пуста
Предписание Есть непрочитанные элементы
Ответ: ПО.очередь не пуста
Предписание Прочесть очередной элемент в
ПО.Взять элемент из начала очереди в
ЛО.Добавить элемент < вх: E>в конец очереди
Предписание Очередной элемент последовательности: E
Ответ : = ПО.Начало очереди
Предписание Пропустить очередной элемент последовательности: E
ПО.Взять элемент из начала очереди в
ЛО.Добавить элемент < вх: E>в конец очереди
Предписание Кончить работу
2. Задачи на реализацию одних структур на базе других:
1) Реализовать стек на базе L1- списка
2 ) Реализовать очередь на базе L1- списка
3 ) Дек на базе L2- списка
Реализация стека на базе вектора на языке C++
Реализация стека вещественных чисел на базе вектора, class RealStack (Борисенко В.В.):
Пример использования класса RealStack для разработки стекового калькулятора на языке C++ ( Борисенко В.В.) :
Литература
1. Кушниренко А.Г., Лебедев Г.В. Программирование для математиков: Учеб. пособие для вузов — М.: Наука. Гл.ред.физ.-мат.лит., 1988
Стратегии отбора товаров на складе: какие бывают и как выбрать

Отлаженная складская логистика — важное конкурентное преимущество для бизнеса, который занимается производством или реализацией продукции. От того, как товары движутся через склад, как организован учет, какой метод учета используется, зависит эффективность складских процессов. Цифровизация логистики привела к изменениям в работе складов и логистических центров. Сейчас для учета товаров используют системы управления складом (Warehouse Management System, сокращенно WMS), которые позволяют вести точный учет товаров, контролировать сроки хранения, содержат информацию об их расположении, оптимизируют использование складского пространства. Больше информации о том, что такое WMS, вы можете узнать в другой нашей статье.
Однако упорядоченной структуры на складе недостаточно. Чтобы эффективно работать с системами управления складом, необходимо определиться с принципами обработки товара. Для этого в складской логистике используют 3 стратегии — FIFO, FEFO и LIFO. В этой статье вы узнаете, что это за методы отбора, для каких групп товаров используют каждый из них, и как выбрать подходящий для конкретного склада.
Принципы FIFO и FEFO в складской логистике
Самые распространенные подходы к отбору товара — FIFO и FEFO. Это акронимы от англоязычных понятий. FIFO расшифровывается как “First In, First Out” (“первым пришел — первым ушел”), а FEFO — “First Expire, First Out” (“первый истекает — первый выходит”).

Принцип FIFO на складе подразумевает отгрузку в первую очередь товара, который поступил на склад раньше всего, затем грузов, которые поступили на хранение вторыми и т.д. Например, на склад поступили две партии консерв. Одна — в первых числах месяца, вторая — в последних. Согласно принципу FIFO, когда поступит заказ, первыми будут отгружать консервы, которые поступили на склад в первых числах месяца.
При использовании правила FEFO, фактором при выборе приоритетности отгрузки является не время прибытия груза на склад, а срок годности. Т.е. товар, чей срок годности истекает первым, отгружают первым. Например, на склад поступили две партии товаров. Первая — поступила в первых числах месяца со сроком годности 30 дней. Вторая — в последних числах месяца со сроком годности 15 дней. Когда на складе используют подход FEFO, первой отгрузят партию со сроком годности 15 дней, несмотря на то, что она поступила на склад второй.
Эти методы похожи по своему принципу приоритетности, ведь в большинстве случаев товар, который только поступил на склад, имеет больший срок годности, чем тот, который находится там уже длительное время.
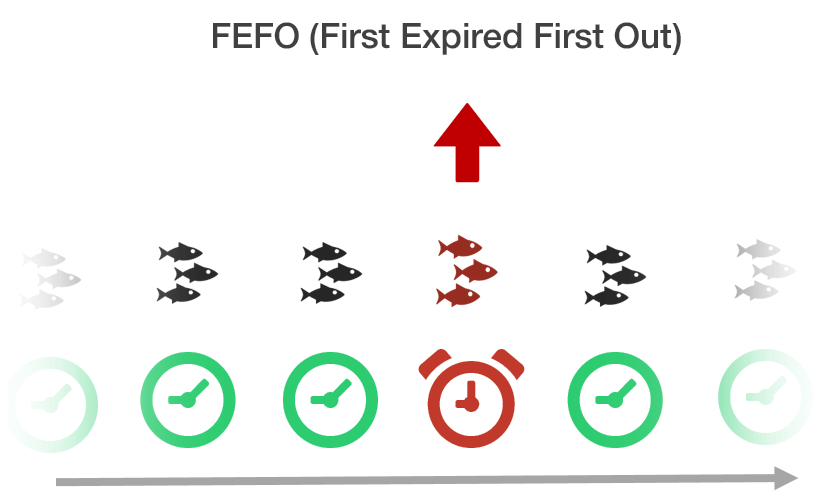
Эти подходы используют для тех групп товаров, которые нельзя долго хранить. Это продукты питания, лекарства, товары повседневного спроса и другая продукция, которую нужно реализовать в короткие сроки. В эту категорию также относят сезонные товары, fashion-сегмент и электронику, поскольку чем дольше они лежат на складе, тем выше вероятность того, что они потеряют свою актуальность и не будут реализованы.
Главные преимущества стратегий ФЕФО и ФИФО
- Сокращение устаревших запасов. Если продукт устаревает и теряет свою привлекательность для потребителей, бизнес может понести серьезные убытки. Подходы FEFO и FIFO снижают вероятность того, что товар не будет продан до истечения срока годности и потери актуальности на рынке.
- Снижение затрат на складскую логистику. Если товар не будет долго находиться на складе, стоимость его хранения будет соответственно ниже.
- Повышение уровня удовлетворенности клиентов. Поскольку оборачиваемость запасов на складе высокая, клиенты с меньшей вероятностью получат просроченную или некачественную продукцию. Это повышает уровень доверия потребителей.
- Снижение влияния инфляции на бизнес. Инфляция — постоянный процесс. Стоимость производства растет, а отправка запасов, которые были произведены раньше и чья себестоимость ниже, способствует повышению прибыльности бизнеса.
Недостатки FIFO и FEFO: что нужно учесть
- Необходим точный учет товаров. Внедрение FIFO и FEFO означает целенаправленное отслеживание складских запасов. Нужна грамотная система отслеживания всех товаров которые поступают и отгружаются со склада.
- Необходимо правильно организовать складское пространство. Чтобы эффективно реализовать стратегии FIFO и FEFO, склад должен быть тщательно организован. Продукцию, которая давно поступила на склад, необходимо размещать рядом с зоной отгрузки. Для этого нужно иметь достаточно складских площадей и специализированное погрузочно-разгрузочное и стеллажное оборудование.
- Сложно масштабировать бизнес. Когда бизнес начинает расширяться, ему нужно больше складских помещений. Вносить большое количество информации о товарах и контролировать их сроки годности на разных складах, может быть сложно.
- Более высокие налоги. Поскольку использование FIFO и FEFO минимизирует инфляцию, то это влияет на рост прибыли, и соответственно на увеличение налогов.
Принцип LIFO: что это и для каких товаров он подходит
Подход LIFO (от англ. Last In, First Out — “последним пришёл — первым вышел”) противоположен принципам FIFO и FEFO. В этом случае товары, которые поступили на склад последними, должны быть обработаны и отгружены в первую очередь. Принцип метода схож с принципом стопки тарелок, когда можно взять тарелку из середины стопки, только сняв те, которые лежат сверху.

Такой подход широко используется для хрупкой продукции, которую нежелательно лишний раз перемещать по складу, и для однородных товаров, например, сыпучих стройматериалов. У них длительный срок хранения, и они не подвержены устареванию. Это позволяет рационально использовать все пространство склада (особенно, если оно ограничено) и экономит время на погрузочно-разгрузочных работах.
В чем выгода использования метода ЛИФО
- Оптимизация складского пространства. При подходе LIFO, новая партия товаров размещается поверх уже имеющихся запасов на складе. Таким образом, нужно меньше складского пространства, поскольку ротация запасов не требуется.
- Сравнение затрат и доходов. LIFO позволяет легко сопоставить расходы и доходы за последнее время. Когда растут расходы на производство и, следовательно, увеличивается себестоимость товара. Так, у бизнеса есть четкое понимание о своих доходах.
- Сокращение налогов. Благодаря более точной оценке актуальной прибыли, ниже вероятность того, что компания будет переоценивать свои доходы и недооценивать себестоимость товаров. Поэтому сумма доходов будет соответствовать действительности, и налоги на прибыль будут меньше.
- Меньше списаний. Если рыночная стоимость продукции колеблется, то при падении цен выгоднее продавать товары, которые были произведены ранее. Таким образом, убытки сокращаются.
Недостатки принципа LIFO
- Складские запасы остаются. Есть вероятность, что устаревшие запасы никогда не будут реализованы. Поэтому этот метод рекомендуется только для товаров с длительным сроком годности.
- Снижение доходов в период инфляции. Во время инфляции, компания, которая использует метод LIFO, уменьшает заявленную в отчетах прибыль. Это может снизить привлекательность компании в глазах инвесторов.
- Занижение реального количества запасов. Количество запасов в отчетах обычно занижается, поскольку оно основано на более старых расходах. Из-за этого состояние оборотного капитала компании может казаться хуже, чем оно есть на самом деле.
- Сложности при выходе на международный рынок. Хотя сейчас LIFO — распространенная практика, не во всех странах она является разрешенной. Поэтому компаниям, которые стремятся к масштабированию в международных масштабах, стоит использовать метод ФИФО.
Как организовать работу склада с помощью разных стратегий
Прежде всего необходимо правильно разместить товар на складе. FIFO предполагает размещения грузов, которые поступили на склад раньше остальных, рядом с зоной отгрузки. Используя метод FEFO, компании ставят вперед товары с истекающим сроком годности, а грузы с длительным сроком хранения размещают в глубине склада. Все это требует больших складских пространств и грамотной их организации. При LIFO стратегия размещения продукции, которая только что прибыла, значительно проще — ее помещают поверх старых запасов. Таким образом, зоны погрузки и отгрузки находятся рядом.

Чтобы складские процессы осуществлялись эффективно, бизнесу необходимо приобрести специальное оборудование. Для методов FEFO и FIFO используют стеллажи гравитационного типа. Под действием силы тяжести грузы перемещают от места разгрузки до места выгрузки. Это позволяет оптимизировать использование грузоподъемной техники. При подходе LIFO подходят шаттловые стеллажи, которые позволяют максимально использовать пространство склада и необходимы при работе с большими объемами товаров.
Для LIFO подходят набивные стеллажи, когда паллетные грузы размещают в глубину конструкции. Однако, стоит учитывать, что при отгрузке продукция может повредиться, поэтому это решение подходит не для всех групп товаров. Push Back конструкции, которые совмещают в себе принципы въездных и гравитационных стеллажей, как правило, используются при подходе LIFO, но они, как и набивное оборудование, могут применяться и при использовании стратегий FIFO и FEFO.
Сравнительная таблица методов FEFO, FIFO и LIFO в складской логистике
В предыдущих разделах мы описали как работают FEFO, FIFO и LIFO на практике, какие плюсы и минусы каждого принципа и для каких товаров лучше выбрать тот или иной метод. Далее вы можете ознакомиться со сравнительной таблицей, где представлена расшифровка и суть понятий, а также в каких случаях их стоит использовать.
| Название | FEFO | FIFO | LIFO |
| Расшифровка названия | First Expire, First Out — “первый истекает — первый выходит” | First In, First Out — “первым пришел — первым ушел” | Last In, First Out — “последним пришёл — первым ушёл” |
| Суть метода | Сначала производят отгрузку товаров, чей срок годности подходит к концу. | В приоритете отгрузка товара, который поступил на склад первым. | В первую очередь осуществляется отгрузка того товара, который поступил на склад последним. |
| Когда используется | Метод подходит для обработки скоропортящихся товаров разных партий. | Применяется в случаях, когда товар подвержен устареванию, сезонности, имеет ограниченный срок хранения. | Принцип используется при работе с однородным товаром, чаще всего речь идет о больших партиях грузов. |
| Для какой товарной группы подходит | Продукты питания, медикаменты, косметика, любая продукция с ограниченным сроком годности. | Та же, что и для FEFO, + электроника, сезонные товары, fashion-сегмент; любая продукция, которая быстро устаревает/теряет актуальность. | Стройматериалы, химикаты, сыпучие материалы, сырье; продукция с неограниченным или длительным сроком хранения. |
Если ваша компания еще не определилась, какой подход к отбору товара на складе ей подходит, ей стоит передать эти задачи на аутсорсинг. Логистические провайдеры профессионально решают вопросы, связанные с хранением и обработкой грузов. WareTeka сотрудничает с 30+ поставщиками логистических услуг по всей Украине. Мы подберем для вашей компании провайдера, который работает с нужным товарным сегментом, имеет налаженную логистику и организует эффективную обработку грузов с учетом их специфики, товарного соседства и задач бизнеса.
Часто задаваемые вопросы по стратегиям отбора товаров
�� Какая из стратегий дает более эффективную оценку складских запасов?
FIFO и FEFO показывают более точную оценку своих запасов, поскольку при таких методах реализуют в первую очередь товары, которые были приобретены раньше. Запасы, которые только поступили на склад, закуплены по актуальным ценам на рынке. Это дает четкое понимание о прибыли компании. При подходе LIFO, это сложнее сделать из-за того, что продукция, которая была закуплена давно, была приобретена по цене ниже актуальной на рынке.
�� Почему метод LIFO не подходит для компаний, которые выходят на международный уровень?
Метод LIFO запрещен Международными стандартами финансовой отчетности (МСФО), поскольку он искажает данные о реальном состоянии доходности компании. Поэтому страны, которые приняли стандарты МСФО, могут отказаться от сотрудничества с компаниями, которые используют этот подход.
�� Какие методы ротации товаров на складе еще используют?
Кроме вышеперечисленных методов, используют также подходы BBD (“Best Before Day” — “первым истекает рекомендуемый срок — первым выходит”) и FPFO (“First Product, First Out” — “первый произведен — первый выходит”). Как и предыдущие стратегии, использование подобных решений подходит для работы с определенными группами товаров.
Выводы: FEFO, FIFO или LIFO — какую стратегию отбора товара выбрать
Не существует универсального решения для управления складом. Однако есть факторы, на которые нужно обратить внимание при выборе стратегии. Один из самых важных — тип товара. Для товаров, у которых ограниченный срок годности и которые нужно быстро реализовать, подойдут стратегии FEFO и FIFO. Иначе порчи товаров и убытков не избежать. Для продукции, у которой длительный срок хранения, как правило, оптимален подход LIFO. Кроме того, нужно проанализировать потребительский спрос и ситуацию на рынке. Методы FEFO и FIFO используют при обработке товаров, стоимость и спрос на которые относительно стабильны, а LIFO — для продукции, цена которых изменчива и новые единицы которых раскупают быстрее.

Чтобы применение любой из стратегий было максимально эффективным, у бизнеса должна быть налаженная складская логистика. Это ресурсозатратная часть деятельности, а потому логистический аутсорсинг — оптимальное решение как для небольших предприятий, так и для компаний, которые расширяются. Таким образом, бизнес получает закрытый вопрос хранения и обработки своей продукции, и может сосредоточиться на более приоритетных задачах.
Понятие структурированных данных. Определение и назначение базы данных. Общее понятие структуры данных
Первоначально процесс программирования предусматривал запись программистом всех алгоритмов непосредственно на машинном языке. Такой подход усугублял и без того трудную задачу разработки алгоритмов и слишком часто приводил к ошибкам, которые необходимо было обнаружить и исправить [процесс, известный как отладка] до того, как работу можно было считать законченной.
Первым шагом на пути к облегчению задачи программирования был отказ от использования цифр для записи команд и операндов непосредственно в той форме, в которой они используются в машине. С этой целью при разработке программ стали широко применять мнемоническую запись различных команд вместо их шестнадцатеричного представления. Например, вместо цифрового кода команды загрузки регистра программист мог теперь написать LOD, а вместо кода команды копирования содержимого регистра в память мог использовать мнемоническое обозначение STO. Для записи операндов были разработаны правила, в соответствии с которыми программист мог присваивать некоторым областям памяти описательные имена [их часто называют идентификаторами] и использовать их при записи команд программы вместо адресов соответствующих ячеек памяти. Такие идентификаторы обычно называют переменными. Это подчеркивает, что, изменяя значение, размещенное в данном участке памяти, мы изменяем значение, связанное с идентификатором, присвоенным этому участку по ходу выполнения программы.
При объявлении в программе переменной обычно одновременно определяют и их тип. Тип данных определяет как интерпретацию конкретных данных, так и операции, которые можно с ними выполнять. К типам данных относятся Integer [целый], Real [действительный], Character [символьный] и Boolean [логический].
Тип Integer используется для обозначения числовых данных, являющихся целыми числами. В памяти они чаще всего представляются в двоичном дополнительном коде. С данными типа Integer можно выполнять обычные арифметические операции и операции сравнения.
Тип Real предназначен для представления числовых данных, которые могут содержать нецелые величины. В памяти они обычно хранятся как двоичные числа с плавающей точкой. Операции, которые можно выполнять с данными Real, аналогичны операциям, выполняемым с данными типа Integer. Однако, что манипуляции, которые следует выполнить, чтобы сложить два элемента данных типа Real, отличаются от манипуляций, необходимых для выполнения действий с переменными типа Integer.
Тип Character используется для данных, состоящих из символов, которые хранятся в памяти в виде кодов ASCII или UNICODE. Данные этого типа можно сравнивать друг с другом [определять, какой из двух символов предшествует другому в алфавитном порядке]; проверять, является ли одна строка символов другой, а также объединять две строки в одну, более длинную строку, дописывая одну из них после другой [операция конкатенации].
Boolean относится к данным, которые могут принимать только два значения True [истина] и False [ложь]. Примером таких данных может служить результат операции сравнения двух чисел. Операции с данными типа Boolean включает проверку, является ли текущее значение переменной True или False.
Основная память машины организована в виде отдельных ячеек с последовательно увеличивающимися адресами. Однако часто эти ячейки используются как основа для реализации иных способов размещения данных. Например, текст обычно рассматривается как длинная строка символов, тогда как информация о продажах может рассматриваться как прямоугольная таблица с числовыми значениями, каждое из которых представляет число сделок, заключенных определенным работником в определенный день. Задача состоит в том, чтобы предоставить пользователю средства, позволяющие оперировать подобными абстрактными структурами, вместо того чтобы вникать в детали истинной организации данных в основной памяти машины. Для правильного использования компьютера необходимо хорошо знать структурные взаимосвязи между данными, основные методы представления структур внутри компьютера, а также методы работы с ними. Для связей между данными в компьютере используются следующие информационные структуры: массив, запись, список, дерево, стек, очередь.
Массивы
Массив — это структура, содержащая в себе несколько однотипных элементов. Для упорядочивания элементов массива используются индексы. Индексы записываются в скобках после имени массива. Массив с одним индексом называется одномерным, с двумя — двумерным и т.д.
Запись
Запись — это структура, состоящая из элементов не обязательно одного типа. Отдельные элементы записи называют полями. Поле в свою очередь тоже может быть записью.
record Student (
FirstName,
LastName,
Group
)
Списки
Список — это множество записей, каждая из которых содержит специальное поле — указатель . Указатель связывает запись с какой-либо другой записью или содержит значений Null, которое говорит о том, что значение указателя не определено.
Записи в односвязном списке имеют по одному указателю, при этом они связанны в цепочку:
Стрелка на рисунке говорит о содержимом указателя, а слово Data обозначает совокупностей полей, в которых хранятся данные. Список можно организовать с помощью двумерного массива, все элементы которого с первым индексом, равным 0, предназначены для хранения данных, а элементы с первым индексом, равным 1, являются указателями.
В данном списке записи, содержащие буквы английского алфавита, выстроены в алфавитном порядке. Первая запись в списке содержит символ «A», вторая — «B» и т.д.
Для работы со списком нужно уметь выполнять три основных операции:
Pass() — обход или перемещение вдоль списка;
Add() — добавление новой записи в список;
Delete() — удаление записи из списка.
Кроме операций для работы со списком нужны еще две переменные:
переменная Head, в которой хранится информация о первой записи в списке
переменная Current, которая указывает на текущую запись в списке
В таблице сведены описания некоторых операций над списком, пример реализации которого приведен выше.
function Pass(Current) <
if (M Null) then Current:=M;
return (Current);
>
function Add(Current, New) <
M:= M;
M:=New;
return;
>
function Delete(Current) <
if (M Null) then
M:= M];
return;
>
Записи в двусвязном списке связаны между собой в цепочку, но при этом имеют два поля-указателя. Одно из них указывает на предыдущий элемент в списке, другое — на следующий элемент. Такая структура позволяет перемещаться по списку в двух направлениях: вперед и назад.
Кольцевым называется список, последняя запись которого указывает на первую. В этих списках отсутствует запись с пустым указателем.
Дерево — это разветвленный список, каждая запись которого может содержать несколько указателей. Записи, входящие в дерево, называются узлами. Узлы, у которых все указатели пустые, называются листьями. Верхний начальный узел дерева называется корневым узлом. Во многих задачах достаточно использовать двоичные [бинарные] деревья, узлы которых имеют не более двух указателей.
Пример. Требуется вычислить математическое выражение (3+7)*(2/(3-1)). Представим это выражение в виде дерева:
Каждый узел этого дерева представляет собой запись следующего вида:
record Node (
Operation
Number
LeftPointer
RightPointer
)
Листья дерева содержат числа, остальные узлы — символы операций.
Реализовав описанное дерево на двумерном массиве, мы получим следующую картину:
Для вычисления значения дерева нужно вычислить значения правого и левого поддеревьев, а потом над ними выполнить результирующую операцию. Псевдокод алгоритма решающего поставленную задачу будет иметь вид:
function Calculate (Current) <
if (M=Null) then
Result:= M;
else <
R1:=Calculate(M);
R2:=Calculate(M);
Result:=R1(M)R2;
>
return (Result);
>
Стек — это структура данных, организованная по принципу «последним пришел — первым ушел» . Доступ к данным, хранящимся в стеке, осуществляется через вершину. Данные помещаются в стек последовательно Элемент, помещенный в стек самым первым, оказывается на дне и для того чтобы его извлечь из стека, необходимо сначала извлечь все данные, которые были помещены в стек позже.
При работе со стеком возможны две аварийные ситуации: попытка прочитать данные из пустого стека; попытка занести в стек элемент, когда количество элементов в стеке достигло максимально допустимого количества.
Очередь — это структура данных, организованная по принципу «первым пришел — первым ушел» . В очереди переменное количество данных. При постановке в очередь данные добавляются в хвост, при извлечении берутся из головы.
Хеш-таблица
Хеширование — это метод, обеспечивающий прямой доступ к записям без использования каких-либо дополнительных структур. Процесс можно кратко описать следующим образом. Пространство, где хранятся данные, делится на несколько сегментов. Записи распределяются по этим сегментам согласно некоторому алгоритму, называемому алгоритмом хеширования, преобразующему значение поля ключа в номер сегмента. Каждая запись хранится в сегменте, определяемом этим процессом. Следовательно, запись можно извлечь, применив алгоритм хеширования к значению ее поля ключа и считав записи соответствующего сегмента. Структура данных, сконструированная таким способом, называется хеш-таблицей.
Например, если необходимо организовать хеш-таблицу для хранения прописных букв английского алфавита, то в качестве ключей можно выбрать ASCII-коды символов, а алгоритм хеширования будет отрезать младшие пять битов и формировать на их основе индекс элемента массива для хранения символа:
В общем случае, алгоритм хеширования должен по значению ключа производить значение индекса в границах массива и равномерно распределять ключи по элементам массива. Невыполнение последнего требования приводит к возникновению ситуаций, когда несколько записей попадает в один и тот же сегмент. Данные ситуации называются коллизиями.
Данные, хранящиеся в памяти ЭВМ, представляют собой совокупность нулей и единиц (битов). Биты объединяются в последовательности: байты, слова и т.д. Каждому участку оперативной памяти, который может вместить один байт или слово, присваивается порядковый номер (адрес).
Какой смысл заключен в данных, какими символами они выражены — буквенными или цифровыми, что означает то или иное число — все это определяется программой обработки. Все данные, необходимые для решения практических задач, подразделяются на несколько различных типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки .
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
Данные простого типа это — символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных.
· Массив (функция с конечной областью определения) — простая совокупность элементов данных одного типа, средство оперирования группой данных одного типа. Отдельный элемент массива задается индексом. Массив может быть одномерным, двумерным и т.д. Разновидностями одномерных массивов переменной длины являются структуры типа кольцо, стек, очередь и двухсторонняя очередь .
· Запись (декартово произведение) — совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называют полями . Совокупность записей одинаковой структуры называется файлом . (Файлом называют также набор данных во внешней памяти, например, на магнитном диске). Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом .
Такие структуры данных как массив или запись занимают в памяти ЭВМ постоянный объем, поэтому их называют статическими структурами. К статическим структурам относится также множество .
Имеется ряд структур, которые могут изменять свою длину — так называемые динамические структуры . К ним относятся дерево, список, ссылка.
Важной структурой, для размещения элементов, которой требуется нелинейное адресное пространство, является дерево . Существует большое количество структур данных, которые могут быть представлены как деревья. Это, например, классификационные, иерархические, рекурсивные и др. структуры. Более подробно о деревьях рассказано в параграфе 1.2.1.
Рис. 1.1. Классификация типов данных
1.1.2.Обобщенные структуры или модели данных.
Выше мы рассмотрели несколько типов структур, являющихся совокупностями элементов данных: массив, дерево, запись. Более сложный тип данных может включать эти структуры в качестве элементов. Например, элементами записи может быть массив, стек, дерево и т.д.
Существует большое разнообразие сложных типов данных, но исследования, проведенные на большом практическом материале, показали, что среди них можно выделить несколько наиболее общих. Обобщенные структуры называют также моделями данных , т.к. они отражают представление пользователя о данных реального мира.
Любая модель данных должна содержать три компоненты:
1. структура данных — описывает точку зрения пользователя на представление данных.
2. набор допустимых операций , выполняемых на структуре данных. Модель данных предполагает, как минимум, наличие языка определения данных (ЯОД), описывающего структуру их хранения, и языка манипулирования данными (ЯМД), включающего операции извлечения и модификации данных.
3. ограничения целостности — механизм поддержания соответствия данных предметной области на основе формально описанных правил.
В процессе исторического развития в СУБД использовалось следующие модели данных:
В последнее время все большее значение приобретает объектно-ориентированный подход к представлению данных.
1.2.Методы доступа к данным
Вопросы представления данных тесно связаны с операциями, при помощи которых эти данные обрабатываются. К числу таких операций относятся: выборка, изменение, включение и исключение данных. В основе всех перечисленных операций лежит операция доступа , которую нельзя рассматривать независимо от способа представления.
В задачах поиска предполагается, что все данные хранятся в памяти с определенной идентификацией и, говоря о доступе, имеют в виду, прежде всего, доступ к данным (называемым ключами), однозначно идентифицирующим связанные с ними совокупности данных.
Пусть нам необходимо организовать доступ к файлу, содержащему набор одинаковых записей, каждая из которых имеет уникальное значение ключевого поля. Самый простой способ поиска — последовательно просматривать каждую запись в файле до тех пор, пока не будет найдена та, значение ключа которой удовлетворяет критерию поиска. Очевидно, этот способ весьма неэффективен, поскольку записи в файле не упорядочены по значению ключевого поля. Сортировка записей в файле также неприменима, поскольку требует еще больших затрат времени и должна выполняться после каждого добавления записи. Поэтому, поступают следующим образом — ключи вместе с указателями на соответствующие записи в файле копируют в другую структуру, которая позволяет быстро выполнять операции сортировки и поиска. При доступе к данным вначале в этой структуре находят соответствующее значение ключа, а затем по хранящемуся вместе с ним указателю получают запись из фала.
Существуют два класса методов, реализующих доступ к данным по ключу:
· методы поиска по дереву,
1.2.1.Методы поиска по дереву
Определение: Деревом называется конечное множество, состоящее из одного или более элементов, называемых узлами, таких, что:
1. между узлами имеет место отношение типа «исходный — порожденный»;
2. есть только один узел, не имеющий исходного узла. Он называется корнем;
3. все узлы за исключением корня имеют только один исходный; каждый узел может иметь несколько порожденных узлов;
4. отношение «исходный — порожденный» действует только в одном направлении, т.е. ни один потомок некоторого узла не может стать для него предком.
Число порожденных отдельного узла (число поддеревьев данного корня) называется его степенью . Узел с нулевой степенью называют листом или концевым узлом. Максимальное значение степени всех узлов данного дерева называется степенью дерева .
Если в дереве между порожденными узлами, имеющими общий исходный, считается существенным их порядок, то дерево называется упорядоченным . В задачах поиска почти всегда рассматриваются упорядоченные деревья.
Упорядоченное дерево, степень которого не больше 2 называется бинарным деревом. Бинарное дерево особенно часто используется при поиске в оперативной памяти. Алгоритм поиска: вначале аргумент поиска сравнивается с ключом, находящимся в корне. Если аргумент совпадает с ключом, поиск закончен, если же не совпадает, то в случае, когда аргумент оказывается меньше ключа, поиск продолжается в левом поддереве, а в случае, когда больше ключа — в правом поддереве. Увеличив уровень на 1, повторяют сравнение, считая текущий узел корнем.
Пример: Пусть дан список студентов, содержащий их фамилии и средний бал успеваемости (см. таблицу 1.1). В качестве ключа используется фамилия студента. Предположим, что все записи имеют фиксированную длину, тогда в качестве указателя можно использовать номер записи. Смещение записи в файле в этом случае будет вычисляться как ([номер_записи ] -1) * [длина_записи ] . Пусть аргумент поиска «Петров». На рисунке 1.2 показано одно из возможных для этого набора данных бинарное дерево поиска и путь поиска.

Рис. 1.2. Поиск по бинарному дереву
Заметим, что здесь используется следующее правило сравнения строковых переменных: считается, что значение символа соответствует его порядковому номеру в алфавите. Поэтому «И» меньше «К», а «К» меньше «С». Если текущие символы в сравниваемых строках совпадают, то сравниваются символы в следующих позициях.
Бинарные деревья особенно эффективны в случае, когда множество ключей заранее неизвестно, либо когда это множество интенсивно изменяется. Очевидно, что при переменном множестве ключей лучше иметь сбалансированное дерево .
Определение: Бинарное дерево называют сбалансированным (balanced ), если высота левого поддерева каждого узла отличается от высоты правого поддерева не более чем на 1.
При поиске данных во внешней памяти очень важной является проблема сокращения числа перемещений данных из ВЗУ в оперативную память. Поэтому, в данном случае по сравнению с бинарными деревьями более выгодными окажутся сильно ветвящиеся деревья — т.к. их высота меньше, то при поиске потребуется меньше обращений к внешней памяти. Наибольшее применение в этом случае получили В-деревья (В — balanced )
Определение: В-деревом порядка n называется сильно ветвящееся дерево степени 2n+1, обладающее следующими свойствами:
- Каждый узел, за исключением корня, содержит не менее n и не более 2n ключей.
- Корень содержит не менее одного и не более 2n ключей.
- Все листья расположены на одном уровне.
- Каждый промежуточный узел содержит два списка: упорядоченный по возрастанию значений список ключей и соответствующий ему список указателей (для листовых узлов список указателей отсутствует).
Для такого дерева:
· сравнительно просто может быть организован последовательный доступ, т.к. все листья расположены на одном уровне;
· при добавлении и изменении ключей все изменения ограничиваются, как правило, одним узлом.

Рис. 1.3.Сбалансированное дерево
В -дерево, в котором истинные значения содержатся только в листьях (концевых узлах), называется В + — деревом . Во внутренних узлах такого дерева содержатся ключи-разделители, задающие диапазон изменения ключей для поддеревьев.
Подробнее о различных видах сбалансированных деревьев, а также методах их реализации можно прочитать в литературе, список которой приведен в конце страницы. Следует отметить, что B — деревья наилучшим образом подходят только для организации доступа к достаточно простым (одномерным) структурам данных. Для доступа к более сложным структурам, таким, например, как пространственные (многомерные) данные в последнее время все чаще используют R -деревья.
R -дерево (R -Tree ) это индексная структура для доступа к пространственным данным, предложенная А. Гуттманом (Калифорнийский университет, Беркли). R-дерево допускает произвольное выполнение операций добавления, удаления и поиска данных без периодической переиндексации.
Для представления данных используются записи, каждая из которых имеет уникальный идентификатор (tuple-identifier ). В каждом концевом узле (листе) дерева содержится запись вида ( I,tuple-identifier ) , где I — n -мерный параллелепипед, содержащий указатели на пространственные данные (его также называют minimal bounding rectangle , MBR), а каждый элемент в tuple-identifier содержит верхнюю и нижнюю границу параллелепипеда в соответствующем измерении.
Неконцевые узлы содержат записи вида (I, childnode-pointer ) , где I минимальный ограничивающий параллелепипед для MBR всех узлов, производных по отношению к данному. Childnode-pointer — это указатель на производные узлы.
Пусть M и m R-Tree является сильно сбалансированным деревом, т.е. все листья находятся на одном уровне.
· Корневой узел имеет, как минимум, двух потомков.
· Для каждого элемента (I, childnode-pointer ) в неконцевом узле I является наименьшим возможным параллелепипедом, т.е. содержит все параллелепипеды производных узлов.
· Каждый концевой узел (лист) содержит от m до M индексных записей.
· Для каждой индексной записи (I, tuple-identifier ) в концевом узле I является параллелепипедом, который содержит n -мерный объект данных, на который указывает tuple-identifier .
1.2.2.Хеширование
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского слова «to hash » — резать, измельчать). Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае, ключевые данные, используемые для определения адреса записи, организуются в виде таблицы, называемой хеш-таблицей.
Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов.
Аннотация: Дается общее понятие структуры данных как исполнителя, который организует работу с данными: хранение, добавление и удаление, поиск и т.п. Рассматриваются реализации одних структур на базе других, в частности, реализации на базе массива. Приводятся наиболее важные из простейших структур данных: очередь и стек, а также их непрерывные реализации на базе массива. Даются многочисленные примеры использования стека в программировании. Рассматривается обратная польская запись формулы (знак операции после аргументов) и способ ее вычисления на стековой машине. В качестве примера использования обратной польской записи рассматривается графический язык PostScript. Материал иллюстрируется проектом «Cтековый калькулятор», реализованным на языке Си.
Структуры данных
«Алгоритмы + структуры данных = программы». Это — название книги Никлауса Вирта, знаменитого швейцарского специалиста по программированию, автора языков Паскаль , Модула-2, Оберон. С именем Вирта связано развитие структурного подхода к программированию. Н.Вирт известен также как блестящий педагог и автор классических учебников.
Обе составляющие программы, выделенные Н.Виртом, в равной степени важны. Не только несовершенный алгоритм , но и неудачная организация работы с данными может привести к замедлению работы программы в десятки, а иногда и в миллионы раз. С другой стороны, владение теорией программирования и умение систематически применять ее на практике позволяет быстро разрабатывать эффективные и в то же время эстетически красивые программы.
Общее понятие структуры данных
Структура данных — это исполнитель , который организует работу с данными, включая их хранение, добавление и удаление, модификацию, поиск и т.д. Структура данных поддерживает определенный порядок доступа к ним. Структуру данных можно рассматривать как своего рода склад или библиотеку. При описании структуры данных нужно перечислить набор действий, которые возможны для нее, и четко описать результат каждого действия. Будем называть такие действия предписаниями . С программной точки зрения, системе предписаний структуры данных соответствует набор функций, которые работают над общими переменными.
Структуры данных удобнее всего реализовывать в объектно-ориентированных языках. В них структуре данных соответствует класс , сами данные хранятся в переменных-членах класса (или доступ к данным осуществляется через переменные-члены), системе предписаний соответствует набор методов класса. Как правило, в объектно-ориентированных языках структуры данных реализуются в виде библиотеки стандартных классов: это так называемые контейнерные классы языка C++, входящие в стандартную библиотеку классов STL , или классы, реализующие различные структуры данных из библиотеки Java Developer Kit языка Java .
Тем не менее, структуры данных столь же успешно можно реализовывать и в традиционных языках программирования, таких как Фортран или Си . При этом следует придерживаться объектно-ориентированного стиля программирования: четко выделить набор функций, которые осуществляют работу со структурой данных, и ограничить доступ к данным только этим набором функций. Сами данные реализуются как статические (не глобальные) переменные. При программировании на языке Си структуре данных соответствуют два файла с исходными текстами:
- заголовочный, или h-файл, который описывает интерфейс структуры данных, т.е. набор прототипов функций, соответствующий системе предписаний структуры данных;
- файл реализации, или Си-файл, в котором определяются статические переменные, осуществляющие хранение и доступ к данным, а также реализуются функции, соответствующие системе предписаний структуры данных
Структура данных обычно реализуется на основе более простой базовой структуры , ранее уже реализованной, или на основе массива и набора простых переменных. Следует четко различать описание структуры данных с логической точки зрения и описание ее реализации. Различных реализаций может быть много, с логической же точки зрения (т.е. с точки зрения внешнего пользователя) все они эквивалентны и различаются, возможно, лишь скоростью выполнения предписаний.
Структуры и типы данных. Массивы, деревья, списки, графы. Операции над данными.
Данные, хранящиеся в памяти ЭВМ представляют собой совокупность нулей и единиц (битов). Биты объединяются в последовательности: байты, слова и т.д. Каждому участку оперативной памяти, который может вместить один байт или слово, присваивается порядковый номер (адрес).
Какой смысл заключен в данных, какими символами они выражены — буквенными или цифровыми, что означает то или иное число — все это определяется программой обработки. Все данные необходимые для решения практических задач подразделяются на несколько типов, причем понятие тип связывается не только с представлением данных в адресном пространстве, но и со способом их обработки.
Любые данные могут быть отнесены к одному из двух типов: основному (простому), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач.
Данные простого типа это — символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из элементарных данных формируются структуры (сложные типы) данных.
Массив (функция с конечной областью определения) — простая совокупность элементов данных одного типа, средство оперирования группой данных одного типа. Отдельный элемент массива задается индексом. Массив может быть одномерным, двумерным и т.д. Разновидностями одномерных массивов переменной длины являются структуры типа кольцо, стек, очередь и двухсторонняя очередь.
Если массив всегда занимает непрерывный участок памяти, то список являет¬ся простейшим примером, так называемой динамической структуры данных. В динамических структурах данных объект содержится в различных участках памяти, количество и состав которых может меняться в процессе работы. Единство такого объекта поддерживается за счет объединения его частей в описании класса.
Простейший линейный список представляет собой линейную последователь¬ность элементов. Для каждого из них, кроме последнего, имеется следующий элемент, и для каждого, кроме первого — предыдущий. Список традиционно изображают в виде последовательности элементов, каждый из которых со¬держит ссылку (указатель) на следующий и/или предыдущий элемент, однако заметим, что физически в представлении элементов списка может и не быть никаких ссылок.
Типичный набор операций над списком будет включать добавление, удале¬ние и поиск его элементов, вычисление длины списка, последовательную об¬работку элементов (итерацию) списка.
Как и в случае массивов, многие библиотеки классов включают в себя возможность описания и работы со списками (например, CList библиотеки клас¬сов MFC). Несмотря на это, часто возникает необходимость описания своих собственных структур данных в виде, списков, содержащих более подходя¬щие для решаемой задачи операции, более простые (и, следовательно, более эффективные), чем стандартные, или обладающие специфическими особенностями (например, упорядоченные списки).
Как правило, при описании списка представление каждого элемента списка описывается в виде отдельного класса. В этом классе в качестве его атрибута имеется ссылка на следующий и/или предыдущий элемент.
Запись (декартово произведение) — совокупность элементов данных разного типа. В простейшем случае запись содержит постоянное количество элементов, которые называют полями. Совокупность записей одинаковой структуры называется файлом. (Файлом называют также набор данных во внешней памяти, например, на магнитном диске). Для того, чтобы иметь возможность извлекать из файла отдельные записи, каждой записи присваивают уникальное имя или номер, которое служит ее идентификатором и располагается в отдельном поле. Этот идентификатор называют ключом.
Такие структуры данных как массив или запись занимают в памяти ЭВМ постоянный объем, поэтому их называют статическими структурами. К статическим структурам относится также множество.
Имеется ряд структур, которые могут изменять свою длину — так называемые динамические структуры. К ним относятся дерево, список, ссылка.
Важной структурой, для размещения элементов которой требуется нелинейное адресное пространство является дерево. Существует большое количество структур данных, которые могут быть представлены как деревья. Это, например, классификационные, иерархические, рекурсивные и др. структуры.
Обобщенные структуры или модели данных.
Выше мы рассмотрели несколько типов структур, являющихся совокупностями элементов данных: массив, дерево, запись. Более сложный тип данных может включать эти структуры в качестве элементов. Например, элементами записи может быть массив, стек, дерево и т.д.
Существует большое разнообразие сложных типов данных, но исследования, проведенные на большом практическом материале, показали, что среди них можно выделить несколько наиболее общих. Обобщенные структуры называют также моделями данных, т.к. они отражают представление пользователя о данных реального мира.
Любая модель данных должна содержать три компоненты:
Структура данных — описывает точку зрения пользователя на представление данных.
Набор допустимых операций, выполняемых на структуре данных. Модель данных предполагает, как минимум, наличие языка определения данных (ЯОД), описывающего структуру их хранения, и языка манипулирования данными (ЯМД), включающего операции извлечения и модификации данных.
Ограничения целостности — механизм поддержания соответствия данных предметной области на основе формально описанных правил.
В процессе исторического развития в СУБД использовалось следующие модели данных:
Иерархическая — В этой модели имеется один главный объект и остальные — подчиненные — объекты, находящиеся на разных уровнях иерархии. Взаимосвязи объектов образуют иерархическое дерево с одним корневым объектом.
Сетевая — Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
В сетевой модели данных любой объект может быть одновременно и главным, и подчиненным, и может участвовать в образовании любого числа взаимосвязей с другими объектами.
Реляционная — В реляционной модели данные разбиваются на наборы, которые составляют табличную структуру. Эта структура таблиц состоит из индивидуальных элементов данных, называемых полями. Одиночный набор или группа полей известна как запись.
Методы доступа к данным.
Вопросы представления данных тесно связаны с операциями, при помощи которых эти данные обрабатываются. К числу таких операций относятся: выборка, изменение, включение и исключение данных. В основе всех перечисленных операций лежит операция доступа, которую нельзя рассматривать независимо от способа представления.
В задачах поиска предполагается, что все данные хранятся в памяти с определенной идентификацией и, говоря о доступе, имеют в виду прежде всего доступ к данным (называемым ключами), однозначно идентифицирующим связанные с ними совокупности данных.
Пусть нам необходимо организовать доступ к файлу, содержащему набор одинаковых записей, каждая из которых имеет уникальное значение ключевого поля. Самый простой способ поиска — последовательно просматривать каждую запись в файле до тех пор, пока не будет найдена та, значение ключа которой удовлетворяет критерию поиска. Очевидно, этот способ весьма неэффективен, поскольку записи в файле не упорядочены по значению ключевого поля. Сортировка записей в файле также неприменима, поскольку требует еще больших затрат времени и должна выполняться после каждого добавления записи. Поэтому, поступают следующим образом — ключи вместе с указателями на соответствующие записи в файле копируют в другую структуру, которая позволяет быстро выполнять операции сортировки и поиска. При доступе к данным вначале в этой структуре находят соответствующее значение ключа, а затем по хранящемуся вместе с ним указателю получают запись из фала.
Существуют два класса методов, реализующих доступ к данным по ключу:
Методы поиска по дереву,
Теория графов является важной частью вычислительной математики. С помощью этой теории решаются большое количество задач из различных областей. Граф состоит из множества вершин и множества ребер, которые соединяют между собой вершины. С точки зрения теории графов не имеет значения, какой смысл вкладывается в вершины и ребра. Вершинами могут быть населенными пункты, а ребрами дороги, соединяющие их, или вершинами являться подпрограммы, соединенные вершин ребрами означает взаимодействие подпрограмм. Часто имеет значение направления дуги в графе. Если ребро имеет направление, оно называется дугой, а граф с ориентированными ребрами называется орграфом.
Дадим теперь более формально основное определение теории графов. Граф G есть упорядоченная пара (V,E), где V — непустое множество вершин, E — множество пар элементов множества V, пара элементов из V называется ребром. Упорядоченная пара элементов из V называется дугой. Если все пары в Е — упорядочены, то граф называется ориентированным.
Путь — это любая последовательность вершин орграфа такая, что в этой последовательности вершина b может следовать за вершиной a, только если существует дуга, следующая из а в b. Аналогично можно определить путь, состоящий из дуг. Путь начинающийся в одной вершине и заканчивающийся в одной вершине называется циклом. Граф в котором отсутствуют циклы, называется ациклическим.
Важным частным случаем графа является дерево.
Определение: Деревом называется конечное множество, состоящее из одного или более элементов, называемых узлами, таких, что:
Между узлами имеет место отношение типа «исходный-порожденный»;
Есть только один узел, не имеющий исходного. Он называется корнем;
Все узлы за исключением корня имеют только один исходный; каждый узел может иметь несколько порожденных;
Отношение «исходный-порожденный» действует только в одном направлении, т.е. ни один потомок некоторого узла не может стать для него предком.
Число порожденных отдельного узла (число поддеревьев данного корня) называется его степенью. Узел с нулевой степенью называют листом или концевым узлом. Максимальное значение степени всех узлов данного дерева называется степенью дерева.
Если в дереве между порожденными узлами, имеющими общий исходный, считается существенным их порядок, то дерево называется упорядоченным. В задачах поиска почти всегда рассматриваются упорядоченные деревья.
Упорядоченное дерево, степень которого не больше 2 называется бинарным деревом. Бинарное дерево особенно часто используется при поиске в оперативной памяти. Алгоритм поиска: вначале аргумент поиска сравнивается с ключом, находящимся в корне. Если аргумент совпадает с ключом, поиск закончен, если же не совпадает, то в случае, когда аргумент оказывается меньше ключа, поиск продолжается в левом поддереве, а в случае когда больше ключа — в правом поддереве. Увеличив уровень на 1 повторяют сравнение, считая текущий узел корнем.
Бинарные деревья особенно эффективны в случае когда множество ключей заранее неизвестно, либо когда это множество интенсивно изменяется. Очевидно, что при переменном множестве ключей лучше иметь сбалансированное дерево.
Определение: Бинарное дерево называют сбалансированным (balanced), если высота левого поддерева каждого узла отличается от высоты правого поддерева не более чем на 1.
Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией (от английского «to hash» — резать, измельчать). Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи организуются в виде таблицы, называемой хеш-таблицей.
Если множество ключей заранее неизвестно или очень велико, то от идеи однозначного вычисления адреса записи по ее ключу отказываются, а хеш-функцию рассматривают просто как функцию, рассеивающую множество ключей во множество адресов.
Структура данных — программная единица, позволяющая сберегать и обрабатывать массу однотипных или же логически связанных сведений в вычислительных устройствах. Если требуется добавить, найти, изменить или удалить сведения, структура предоставит определенный пакет опций, что составляет ее интерфейс.
Что включает в себя понятие структуры данных?
Этот термин может иметь несколько близких, но все же отличительных значений. Это:
- абстрактный тип;
- реализация абстрактного вида информации;
- экземпляр типа данных, к примеру, определенный список.
Если говорить о структуре данных в контексте функционального программирования, то это особенная единица, что сберегается при изменениях. О ней неформально можно сказать как о единой структуре, несмотря на то что могут иметься различные версии.
Что формирует структуру?
Формируется с помощью ссылок и операций над ними в определенном языке программирования. Стоит сказать, что разные виды структур подходят для осуществления разных приложений, некоторые, к примеру, обладают совершенно узкой специализацией и подходят только для производства установленных задач.
Если взять B-деревья, то они обычно подходят для формирования баз данных и только для них. В этот же час хеш-таблички применяются еще повсеместно на практике для создания различных словарей, к примеру, для демонстрации доменных наименований в интернет-адресах ПК, а не только для формирования баз.
Во время разработки того или иного программного обеспечения сложность реализации и качество функциональности программ напрямую зависят от правильного применения структур данных. Такое понимание вещей дало толчок к разработке формальных методик разработки и языков программирования, где структуры, а не алгоритмы ставятся на лидирующие позиции в архитектуре программы.
Стоит отметить, что многие языки программирования обладают установленным типом модульности, что позволяет структурам с данными безопасно использоваться в различных приложениях. Яркими примерами являются языки Java, C# и C++. Сейчас классическая структура используемых данных представлена в стандартных библиотеках языков программирования или непосредственно она встроена уже в сам язык. К примеру, хэш-таблицы встроена в Lua, Python, Perl, Ruby, Tcl и другие. Широко применяется стандартная библиотека шаблонов в C++.
Сравниваем структуру в функциональном и императивном программировании

Стоит сразу оговорится, что проектировать структуры для функциональных языков сложнее, чем для императивных, как минимум на это есть две причины:
- Фактически все структуры часто применяют на практике присваивание, которое в чисто функциональном стиле не используется.
- Функциональные структуры — это гибкие системы. В императивном программировании старые версии просто заменяются на новые, а в функциональном все работает, как работало. Иными словами, в императивном программировании структуры являются эфемерными, а в функциональном они постоянные.
Что включает в себя структура?
Часто данные, с которыми работают программы, сберегаются во встроенных в применяемом языке программирования массивах, константе или в переменной длине. Массив — это простейшая структура со сведениями, однако для решения некоторых задач требуется большая эффективность некоторых операций, потому применяются иные структуры (сложнее).
Простейший массив подходит для частого обращения к установленным компонентам по индексам и их изменению, а удаление элементов из средины функционирует за принципом O(N)O(N). Если вам требуется удалить элементы, чтобы разрешить определенные задачи, то придется воспользоваться иной структурой. К примеру, бинарное дерево (std::set) позволяет делать это по O(logN)O(logN), однако оно не поддерживает работу с индексами, выполняется исключительно поочередный обход элементов и их поиск по значению. Таким образом, можно сказать, что структура отличается операциями, что она способна выполнять, а также скоростью их проделывания. Для примера стоит рассмотреть простейшие структуры, что не дают выгоды в эффективности, но имеют точно установленный набор поддерживаемых операций.
Стек
Это один из типов структур данных, представленный в виде ограниченного простейшего массива. Классический стек поддерживает всего лишь три опции:
- Внести элемент в стек (Сложность: O(1)O(1)).
- Извлечение элемента из стека (Сложность: O(1)O(1)).
- Проверка, пустой ли стек или нет (Сложность: O(1)O(1)).
Чтобы пояснить принцип работы стека, можно применить на практике аналогию с банкой печенья. Представьте, что на дне посудины лежит несколько печенюшек. Наверх вы можете положить еще пару кусочков или же вы можете, наоборот, взять одну печеньку сверху. Остальные печеньки будут закрыты верхними, и вы про них ничего не будете знать. Вот так дела обстоят и со стеком. Для описания понятия применяется аббревиатура LIFO (Last In, First Out), которая подчеркивает, что компонент, попавший внутрь стека последним, будет первым же и извлечен из него.
Очередь

Это еще один тип структуры данных, что поддерживает тот же набор опций, что и стек, однако у него противоположная семантика. Для описания очереди применяется аббревиатура FIFO (First In, First Out), потому как вначале извлекается элемент, что добавлен был раньше всех. Название структуры говорит за себя — принцип работы полностью совпадает с очередями, что можно увидеть в магазине, супермаркете.
Дек
Это еще один вид структуры данных, который еще называют очередью с двумя концами. Опция поддерживает следующий набор операций:
- Внести элемент в начало (Сложность: O(1)O(1)).
- Извлечь компонент из начала (Сложность: O(1)O(1)).
- Внесение элемента в конец (Сложность: O(1)O(1)).
- Извлечение элемента из конца (Сложность: O(1)O(1)).
- Проверка, пустой ли дек (Сложность: O(1)O(1)).
Списки

Данная структура данных определяет последовательность линейно связанных компонентов, для которых разрешены операции добавления компонентов в любое место списка и его удаление. Линейный список задается указателем на начало списка. Типичные операции над списками: обход, поиск конкретного компонента, вставка элемента, удаление компонента, объединение двух списков в единое целое, разбивка списка на пару и так далее. Стоит оговориться, что в линейном списке, помимо первого, имеется предыдущий компонент для каждого элемента, не включая последний. Это означает, что компоненты списка находятся в упорядоченном состоянии. Да, обработка такого списка не всегда удобна, ведь нет возможности продвижения в противоположную сторону — от конца списка к началу. Однако в линейном списке можно поэтапно пройтись по всем составляющим.
Еще существуют кольцевые списки. Это такая же структура, что и линейный список, однако она имеет дополнительную связь между первым и последним компонентами. Другими словами, следующим за последним элементом является первый компонент.
В этом списке элементы равноправны. Выделение первого и последнего — это условность.
Деревья

Это совокупность компонентов, что именуются узлами, в котором есть главный (один) компонент в виде корня, а все остальные разбиты на множество непересекающихся элементов. Каждое множество является деревом, а корень каждого древа — потомком корня дерева. Другими словами, все компоненты соединены между собой отношениями предок-потомок. Как результат можно наблюдать иерархическую структуру узлов. Если узлы не имеют потомка, то они называются листьями. Над деревом определены такие операции, как: добавление компонента и его удаление, обход, поиск компонента. Особую роль в информатике играют бинарные деревья. Что это такое? Это частный случай дерева, где каждый узел может иметь не больше пары потомков, являющихся корнями левого и правого поддерева. Если дополнительно для узлов дерева выполняется еще условие, что все значения компонентов левого поддерева меньше значений корня, а значения компонентов правого поддерева больше корня, то такое дерево именуется деревом бинарного поиска, и предназначается оно для быстрого нахождения элементов. Как же работает алгоритм поиска в таком случае? Искомое значение сравнивается со значением корня, и в зависимости от результата поиск либо завершается, либо продолжается, но исключительно в левом или правом поддереве. Общее число операций сравнения не станет превосходить высоту дерева (это наибольшее число компонентов на пути от корня до одного из листьев).
Графы

Графы — это совокупность компонентов, что именуются вершинами вместе с комплексом отношений между данными вершинами, которые называются ребрами. Графическая интерпретация данной структуры представлена в виде множества точек, что отвечают за вершины, а некоторые пары соединены линиями или стрелками, что соответствует ребрам. Последний случай говорит о том, что граф нужно называть ориентированным.
Графами можно описывать объекты какой угодно структуры, они являются главным средством для описания сложных структур и функционирования всех систем.
Детальней об абстрактной структуре

Для построения алгоритма требуется провести формализацию данных или, иными словами, необходимо привести данные к определенной информационной модели, что уже исследована и написана. Как только модель будет найдена, то можно утверждать, что установлена абстрактная структура.
Это основная структура данных, демонстрирующая признаки, качества объекта, взаимосвязь между компонентами объекта и операции, что возможно осуществить над ним. Основная задача — поиск и отображение форм представления сведений, комфортных для компьютерной корректировки. Стоит оговориться сразу, что информатика как точная наука действует с формальными объектами.
Анализ структур данных производится следующими объектами:
- Целые и вещественные числа.
- Логические значения.
- Символы.
Для обработки на компьютере всех элементов существуют соответствующие алгоритмы и структуры данных. Типичные объекты можно объединить в сложные структуры. Можно добавить операции над ними, правила к определенным компонентам этой структуры.
Структура организации данных включает в себя:
- Векторы.
- Динамические структуры.
- Таблицы.
- Многомерные массивы.
- Графы.
Если все элементы выбраны удачно, то это будет залогом формирования эффективных алгоритмов и структур данных. Если применять на практике аналогию структур и реальных объектов, то можно эффективно разрешать существующие задачи.
Стоит заметить, что все структуры организации данных существуют и по отдельности в программировании. Над ними много трудились еще в восемнадцатых и девятнадцатых веках, когда еще и в помине не было вычислительной машины.
Возможно разрабатывать алгоритм в понятиях абстрактной структуры, однако для реализации алгоритма на определенном языке программирования потребуется отыскать методику для ее представления в типах данных, операторах, что поддерживаются конкретным языком программирования. Для создания структур, таких как вектор, табличка, строка, последовательность, во многих языках программирования имеются классические типы данных: одномерный или двухмерный массив, строка, файл.
Мы разобрались с характеристиками структур данных, теперь стоит уделить больше внимания пониманию понятия структуры. При решении абсолютно любой задачи требуется работать с какими-то данными, чтобы произвести операции над информацией. У каждой задачи есть свой набор операций, однако некоторый набор применяется на практике чаще для решения разнообразных заданий. В таком случае полезно придумать определенный способ организации информации, что позволит выполнять эти операции как можно эффективнее. Как только такой способ появился, можно считать, что у вас появился «черный ящик», в котором будут сберегаться данные определенного рода и который станет выполнять те или иные операции с данными. Это позволит отвлечься от деталей и полностью сконцентрироваться на характерных особенностях задачи. Данный «черный ящик» может быть реализован любым образом, при этом необходимо стремиться к как можно более продуктивной реализации.
Кому это необходимо знать?
Ознакомится с информацией стоит начинающим программистам, которые желают отыскать свое место в этой сфере, но не знают, куда податься. Это основы в каждом языке программирования, потому будет не лишним узнать сразу же о структурах данных, а после работать с ними на конкретных примерах и с определенным языком. Не следует забывать, что каждую структуру возможно охарактеризовать логическими и физическими представлениями, а также совокупностью операций над этими представлениями.
Не забывайте: если говорите о той или иной структуре, то имейте в виду ее логическое представление, ведь физическое представление полностью сокрыто от «внешнего наблюдателя».
Кроме того, имейте в виду, что логическое представление совершенно не зависит от языка программирования и от вычислительной машины, а физическое, наоборот, зависит от трансляторов и вычислительной техники. К примеру, двумерный массив в «Фортране» и «Паскале» можно представить идентичным образом, а физическое представление в одной и той же вычислительной машине на этих языках будет отличаться.
Не спешите начинать учить конкретные структуры, лучше всего понять их классификацию, ознакомиться со всеми в теории и желательно на практике. Стоит помнить, что изменчивость — это важный признак структуры, и он указывает на статическое, динамическое или же полустатическое положение. Изучайте основы, прежде чем приступить к более глобальным вещам, это вам поможет в дальнейшем развитии.