Алгоритмы обучения нейронной сети: наиболее распространенные варианты
На сегодняшний день используются различные алгоритмы обучения нейронных сетей. Каждый из них имеет свои достоинства и недостатки. Но конечная цель – самостоятельное извлечение знаний интеллектуальной системой – так или иначе достигается.
Принцип работы искусственной нейронной сети схож с принципом работы человеческого мозга, но это вовсе не значит, что методы обучения НС будут аналогичными. Тут все же требуются несколько иные подходы к проблеме, о которых мы сегодня и поговорим.
Нейронная сеть и возможность ее обучения
Принцип работы нейронной сети (НС) и ее структура взяты из нейробиологии. Сама идея заключалась в том, чтобы получить математическую модель и ее программное воплощение, которые бы имитировали деятельность человеческого мозга. Разработками в этой области ученые занимаются уже с середины прошлого века. Однако лишь в последние годы развитие нейросетей смогло достичь впечатляющих результатов.
Почему работа в этом направлении так важна? Дело в том, что ни одна вычислительная система не в состоянии воплотить аналитические способности человеческого мозга. Между тем, именно эти качества необходимы программам для решения ряда сложных задач.
В настоящее время нейронные сети используют в следующих направлениях:
- Классификационный анализ — разделение вводных данных по каким-либо признакам. Например, в медицине нейросеть облегчает задачи по диагностике: возраст пациента и его пол, жалобы на здоровье, результаты анализа, записи из анамнеза, реакция на препараты и т.д. – все это позволяет распределить больных по степени тяжести состояния.
- Прогнозирование — с учетом показателей можно спрогнозировать последующие события. Например, каршеринг использует нейросети для выявления агрессивных водителей, чтобы в дальнейшем ограничить им доступ к авто.
- Распознавание образов — это наиболее популярная область для использования нейросетей: идентификация символов на бумаге и банковских картах; распознавание лиц для решения вопросов государственной безопасности; поиск по картинке в Google и прочее.
В основе функционирования искусственного интеллекта лежит машинное обучение. Оно позволяет совершенствовать производительность ИИ без перепрограммирования системы. Говоря простым языком, этот процесс похож на обучение ребенка – он учится классифицировать и распознавать объекты, определять взаимосвязь между ними, и день за днем у него это получается все лучше.
Машинное обучение неразрывно связано с НС и представляет собой работу, при которой смоделированная среда имитирует процессы наработки опыта человеком, постепенно повышая точность результатов.
Узнай, какие ИТ — профессии
входят в ТОП-30 с доходом
от 210 000 ₽/мес
Павел Симонов
Исполнительный директор Geekbrains
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Павел Симонов
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Получить подборку бесплатно
Уже скачали 23672
2 типа обучения нейронных сетей
Существуют разные алгоритмы обучения нейронных сетей. Однако все они подчиняются двум основным принципам: с учителем и без него. Если проводить аналогию с обучением человека, то он также способен приобретать опыт или с наставником, который будет направлять и указывать верный ответ, или без него, ориентируясь лишь на собственные наблюдения. Разница между этими двумя подходами заключается в том, что для одних «уроков» учитель необходим, а для других достаточно самостоятельного усвоения материала.
Процесс обучение с учителем
При таком процессе нейросети предлагают выборку обучающих примеров. Данные подают на «вход» сети, ожидая получить правильный «выход», т.е. ответ, который даст НС после обработки внутри своей структуры. Результат сравнивают с эталонным, т.е. правильным ответом. Если НС выдает неверное решение, то необходимо откорректировать весовые коэффициенты связи и запустить процесс заново, тем самым добиваясь снижения процента ошибочных ответов.
Обучающие примеры поступают в НС в определенной последовательности. Для каждого ответа происходит расчет ошибки и подстройка весов. Все это происходит до тех пор, пока неверные ответы по всему объему обучающего материала не примут значение допустимых показателей.
Такой тип обучения имеет отличительную черту – уровень ошибочных ответов, который выясняют путем сравнения планируемых показателей с реальными. С помощью многократного повторения процесса происходит выявление стоимостной функции, т.е. разницы между ожидаемыми и текущими результатами.
Обучение с учителем подходит для решения вопросов, в которых известен требуемый результат. Например, для классификации изображений, распознавания звуков или голоса, прогнозирования, функции аппроксимации.
Процесс обучение без учителя
Он предполагает наличие лишь вводных данных. Алгоритмы обучения нейронных сетей без учителя корректируют весовые коэффициенты таким образом, чтобы НС могла из схожих по некоему принципу данных на «входе» выдать результат, обнаруживающий другие взаимосвязи и закономерности между этими данными. В процессе обучения происходит выделение параметров, характерных для моделей обучающего материала, и дальнейшее объединение этих моделей в группировки по схожим признакам.
Данные, которые поступают на «вход», после обработки нейросетью сложатся в тот или иной ответ. Однако до обучения нельзя предугадать, в какой форме этот ответ поступит. Соответственно, сам процесс обучения должен обуславливать трансформацию результата в понятную форму. Это не представляет сложностей. Как правило, можно легко отследить, какую взаимосвязь задала данным нейросеть в процессе их обработки.
Алгоритмы обучения нейросетей без учителя используют данные без классификации или меток. НС сама выстраивает логическую цепочку и усваивает понимание этих действий, ориентируясь лишь на вводные данные. По сути, это повторяет человеческое самообучение: индивид, предпринимая какие-либо действия, делает выводы о правильности либо ошибочности решения, ориентируясь на последствия.
Обучение без учителя применяют для кластеризации, языковых моделей, обнаружения аномалий, статистических моделей.
3 наиболее распространенных алгоритма обучения нейронных сетей
Выделяют три основных вида алгоритмов обучения нейронных сетей.
Метод обратного распространения
Этот метод также называют Backpropagation. Он является одним из основных способов обучения и содержит в своей основе алгоритм вычисления градиентного спуска. Другими словами, двигаясь вдоль градиента, происходит расчет локального максимума и минимума функции.
Для вас подарок! В свободном доступе до 05.11 —>
Скачайте ТОП-10
бесплатных нейросетей
для программирования
Помогут писать код быстрее на 25%
Чтобы получить подарок, заполните информацию в открывшемся окне
Для лучшего понимания процесса необходимо перевести функцию в график, который будет отображать зависимость значений ошибки от веса синапса. На полученной кривой нужно определить точку с наименьшим и наибольшим показателем. В то же время необходимо графически отобразить все веса, и рассчитать для каждого из них глобальный минимум.
Значение градиента будет иметь векторную величину, которая даст представление о направлении и крутизне склона. Поиск значения градиента осуществляется путем вычисления производной от функции в требуемой точке. Такая точка будет иметь значение веса, распределенное случайным образом. В ней следует проводить расчет градиента и определять направленность движения спуска. Вычисления необходимо производить последовательно во всех точках, пока не будет достигнут локальный минимум, останавливающий дальнейший спуск.
Чтобы преодолеть этот затруднительный этап, нужно задать такое значение для момента, которое разрешит пройти участок графика и оказаться в требуемой точке. В случае недостаточного значения преодолеть выпуклость не удастся, а если значение будет слишком большим, то высока вероятность «проскока» глобального минимума.
На общую скорость обучения нейросети влияет не только момент ускорения, но и еще одно значение, являющееся гиперпараметром и определяющееся методом подбора.
Наиболее благоприятное сочетание значений невозможно знать предварительно. Оно выявляется в ходе нескольких обучений и корректировок в нужную сторону.
Сам метод обучения представляет собой процесс, при котором поступающие данные распространяются между нейронами с помощью синапсов. Передача осуществляется до тех пор, пока данные не достигнут слоя «выхода», трансформировавшись в ответ. Эта операция носит название «передача вперед».
Дарим скидку от 60%
на обучение «Искусственный интеллект с нуля» до 05 ноября
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
Как только ответ получен, происходит расчет ошибки, и в соответствии с ней выполняется обратная передача. Цель такого действия – приведение синаптических весов к оптимальным значениям при движении от выходного слоя к входному.
Для такого алгоритма обучения нейронных сетей необходимо использовать дифференцируемые функции активации. Это связано с тем, что распространение в обратном направлении определяется разностью между ответами, а также произведением между ним и производной функцией от входного значения.
Для успешного обучения требуется передать ошибку на все веса НС. При расчете ошибки можно высчитать и дельту на выходном слое. Она будет методично переходить от нейрона к нейрону.
Далее нужно рассчитать градиент для всех исходящих связей. После этого, с учетом полученных данных, требуется провести обновление весов и вычислить величину изменения с помощью функции МОР. Вместе с тем следует помнить о скорости обучения и моменте.
Метод упругого распространения
Этот метод называют также Resilient propagation (сокращенно Rprop). Он был предложен как альтернатива предыдущему способу обучения, который требует слишком много времени и становится неудобным, если результаты нужно получить в короткие сроки. Для увеличения скорости операций было разработано много вспомогательных алгоритмов, в том числе и методика упругого распространения.
Этот метод является основным при обучении по принципу epoch (один полный проход датасета через НС). Для подгонки весовых коэффициентов он использует лишь знаки производных частного случая. При этом обязательно выдерживать правило, позволяющее определить значение коррекции коэффициента веса.
Только до 2.11
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:

ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы зарегистрироваться на бесплатный интенсив и получить в подарок подборку файлов от GeekBrains, заполните информацию в открывшемся окне
Если на этой стадии вычислений производная меняет свой знак на противоположный, то это говорит о чересчур большом изменении и об упущении локального минимума. Следовательно, нужно возвратить весу предыдущее значение и уменьшить величину изменения. Если же знак остался прежним, то следует поднять величину изменения веса для максимальной сходимости.
Если закрепить ключевые показатели подстройки весов, то можно не настраивать глобальные параметры – это является дополнительным плюсом использования метода. Причем существуют готовые значения таких показателей. Их применение рекомендовано, но жестких рамок по выбору значений нет.
Чтобы величина веса не была чрезмерно большой или, наоборот, маленькой, следует оперировать значением коррекции с установленными пределами. При расчете этого значения необходимо придерживаться правила.
Если в определенной точке производная меняет свой знак с «+» на «−», то это говорит о росте ошибки. Поэтому вес требуется изменить в меньшую сторону. В противоположной ситуации – вес нужно увеличить.
В этом случае порядок операций будет таковым:
- определение значения коррекции;
- расчет частных производных;
- расчет новой величины коррекции весовых значений;
- корректировка весов.
Если условие остановки алгоритма не исполняется, то происходит возврат к расчету производных, и цикл запускается по новому кругу.
Благодаря методу упругого распространения сходимость НС добивается в сроки, значительно меньшие, чем при предыдущем алгоритме.
Генетический алгоритм обучения
Еще один распространенный подход – это обучение нейронной сети генетическим алгоритмом (Genetic Algorithm). По своему принципу он схож с эволюционными процессами природы, которые основываются на комбинировании (скрещивании) результатов.
Откройте для себя захватывающий мир IT! Обучайтесь со скидкой до 61% и получайте современную профессию с гарантией трудоустройства. Первый месяц – бесплатно. Выбирайте программу прямо сейчас и станьте востребованным специалистом.
Другими словами, происходит естественный отбор, где новое поколение является продуктом комбинации результатов с самыми лучшими свойствами. Если итог такого скрещивания не подходит по каким-то критериям, то отбор совершается вновь, пока продукт не станет совершенным.
Завершение алгоритма происходит в тот момент, когда заканчиваются отведенные ему попытки или время на мутацию. При этом результат может остаться недостигнутым. Данный метод используется для улучшения показателей весов НС при условии, что структура задана по умолчанию. Вес при этом должен быть прописан двоичным кодом, а полный набор веса сформирует итоговый результат. Расчет ошибки на выходе обуславливает оценку эффективности.
В условиях высоких темпов цифровизации общества нейросети являются весьма перспективной областью для развития. Они способны обучиться тем процессам, которые человеческий мозг производит неосознанно, то есть не понимая принципа алгоритма.
Несмотря на то, что нейронные сети в чем-то повторяют разум человека, нужно понимать, что это лишь искусственное его подобие, но не полноценный эквивалент.
Способы сохранения и загрузки моделей в Keras
Часто спроектированную и обученную модель требуется сохранять для последующего ее использования в прикладных задачах. Либо, еще в процессе обучения создавать контрольные точки на случай возникновения какого-либо сбоя. Могут быть и другие причины, требующие запись данных на носитель и последующего восстановления модели. На этом занятии мы с вами рассмотрим такой базовый функционал пакета Keras.
Для простоты положим, что у нас простая задача классификации изображений цифр последовательной полносвязной сетью:
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers from tensorflow.keras.datasets import mnist tf.random.set_seed(1) (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(-1, 784) / 255.0 x_test = x_test.reshape(-1, 784) / 255.0 y_train = keras.utils.to_categorical(y_train, 10) y_test = keras.utils.to_categorical(y_test, 10) model = keras.Sequential([ layers.Dense(128, activation='relu'), layers.Dense(10, activation='softmax') ]) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc']) model.fit(x_train, y_train, epochs=5)
- model.save() или tf.keras.models.save_model() – для записи модели на носитель;
- keras.models.load_model() – для загрузки модели по указанному пути.
model.save('16_model') model_loaded = keras.models.load_model('16_model')
И, затем, прогнать тестовую выборку через загруженную модель:
model_loaded.evaluate(x_test, y_test)
- архитектура модели;
- значения весовых коэффициентов модели;
- информация о начальной настройки метода compile() (вид оптимизатора, функции потерь и метрик);
- состояние оптимизатора в момент сохранения модели (для возможности продолжения обучения из текущего состояния).
model.save('16_model_2.h5') model.save('16_model_3', save_format='h5') model_loaded = keras.models.load_model('16_model_2.h5')
Разумеется, рекомендуется использовать новый формат данных при сохранении моделей.
Методы get_config() и from_config()
Остается вопрос, как более детально происходит сохранение и загрузка архитектуры модели? Что конкретно хранится на диске? Согласно документации: https://www.tensorflow.org/guide/keras/save_and_serialize формат SavedModel хранит имя класса, реализацию функцииcall(), потери, веса и значение конфигурации (если в модели реализован метод get_config). Так вот, при отсутствии явного описания конфигурации, реализация функции call() используется для воссоздания работы модели или слоя (если реконструируется отдельный слой). Чтобы все это было понятнее, давайте рассмотрим пример сохранения и загрузки пользовательского класса модели с полносвязными слоями:
class NeuralNetwork(tf.keras.Model): def __init__(self, units): super().__init__() self.units = units self.model_layers = [layers.Dense(n, activation='relu') for n in self.units] def call(self, inputs): x = inputs for layer in self.model_layers: x = layer(x) return x
Мы здесь в конструкторе формируем список полносвязных слоев с функцией активации ReLU, а затем, в методе call() пропускаем входной сигнал последовательно через эти слои. Далее, мы должны воспользоваться этой моделью, чтобы сформировались весовые коэффициенты:
model = NeuralNetwork([128, 10]) y = model.predict(tf.expand_dims(x_test[0], axis=0)) print(y)
И, если теперь выполнить сохранение этой модели:
model.save('16_model')
то в файле saved_model.pb будет храниться реализация метода call(), которая и будет определять структуру модели. Тоесть, послееезагрузки:
model_loaded = keras.models.load_model('16_model')
будет воссоздан класс NeuralNetwork вместе с конкретной реализацией метода call() и теми же самыми весовыми коэффициентами. Именно поэтому, при пропускании того же самого входного сигнала, мы получим абсолютно такие же результаты:
y = model_loaded.predict(tf.expand_dims(x_test[0], axis=0)) print(y)
На первый взгляд эта информация может показаться избыточной. Какая нам разница, как все это в деталях работает, главное, что мы можем сохранять и загружать модели?Однако, существуют ситуации, когда это имеет важное значение. И одну из них я сейчас продемонстрирую. Предположим, что мы бы хотели загрузить модель, но с некоторыми изменениями. Например, вместо функции активации ReLU использовать другую – linear. По идее, для этого можно описать еще один похожий класс модели NeuralNetworkLinear с измененной активационной функцией:
class NeuralNetworkLinear(tf.keras.Model): def __init__(self, units): super().__init__() self.units = units self.model_layers = [layers.Dense(n, activation='linear') for n in self.units] def call(self, inputs): x = inputs for layer in self.model_layers: x = layer(x) return x
А при загрузке указать, чтобы вместо прежнего класса NeuralNetwork был подставлен новый:
model_loaded = keras.models.load_model('16_model', custom_objects={"NeuralNetwork": NeuralNetworkLinear})
Однако, при запуске программы, мы увидим прежний результат, так как через метод call() будут восстановлены исходные полносвязные слоии конструктор класса вызван не будет. Чтобы полноценно использовать новую модель класса NeuralNetworkLinear при загрузке данных, в файл необходимо сохранять конфигурацию модели, а затем, реконструировать ее по этой конфигурации. Для этого в оба класса добавим два специальных метода:
def get_config(self): return {'units': self.units} @classmethod def from_config(cls, config): return cls(**config)
- Sequential.from_config(config);
- Model.from_config(config).
config = model.get_config()
- json_config = model.to_json() – конфигурация архитектуры в формате JSON;
- new_model = keras.models.model_from_json(json_config) – загрузкаархитектуры модели из JSON-формата.
Методы get_weights(), set_weights() и save_weights(), load_weights()
- get_weights() – получение коэффициентов модели / слоя;
- set_weights() – установка коэффициентов модели / слоя;
- save_weights() – запись коэффициентов модели / слоя на носитель;
- set_weights() – загрузка коэффициентов модели / слоя с носителя.
model = NeuralNetwork([128, 10]) model2 = NeuralNetwork([128, 10])
Затем, пропустить через них входной сигнал (для формирования весовых коэффициентов в слоях):
y = model.predict(tf.expand_dims(x_test[0], axis=0)) print(y) y = model2.predict(tf.expand_dims(x_test[0], axis=0)) print(y)
А потом скопировать веса, допустим, из первой модели во вторую:
# считываем и записываем веса только после пропускания через модели входного сигнала # иначе возникнет ошибка из-за отсутствия начальной инициализации весов weights = model.get_weights() model2.set_weights(weights) y = model2.predict(tf.expand_dims(x_test[0], axis=0)) print(y)
Как видим, последний вывод для y совпадает по значениям с первой моделью. Это показывает корректность копирования данных. Похожие действия можно выполнять и на уровне отдельных слоев, так как они поддерживают те же самые методы get_weights() и set_weights(). Вторая пара методов save_weights() и load_weights() позволяет сохранять веса на диск, а затем, считывать их обратно в модель. Делается это очень простопутем вызова этих методов для модели или слоя:
model.save_weights('model_weights') model2.load_weights('model_weights')
- model_weights.data-00000-of-00001 – значения весовых коэффициентов;
- model_weights.index – индексный вспомогательный файл.
model.save_weights('model_weights.h5') model2.load_weights('model_weights.h5')
Настройка нейронной сети для детекции необходимых объектов

Нейронные сети – сложные математические алгоритмы, которые помогают решать большой круг задач. Перед использованием их необходимо настроить и обучить. Обучение нейронной сети достаточно долгий по времени и затратный по вычислительным ресурсам процесс. Однако существуют инструменты, благодаря которым мы можем упростить эти проблемы. Сегодня мы рассмотрим процесс переобучения нейронной сети по детекции определенного объекта на изображении.
В качестве примера для детекции объектов будем использовать алгоритм YOLOv3. Дополнительные материалы по статье вы сможете найти на github странице. Пример установки и настройки осуществляется на ОС Windows 10.
В первую очередь нам необходимо скачать или клонировать необходимые материалы для переобучения нейронной сети под определенный тип объекта с данной github страницы. Для того чтобы не возникало проблем с доступом или разрешениями, материалы лучше разместить в директории своей учетной записи, например: C:\Users\user_name\Documents\NN\.
1. Переходим в папку yolov3-master, вызываем терминал (командную строку) и выполняем команду pip install -U -r requirements.txt. При запуске команды некоторые из пакетов не установились, т.к в репозитории pip для windows, пакетов с таким названием не существует. Чтобы установка прошла успешно, в requirements.txt мы должны закомментировать несколько пакетов («torch >= 1.5» и «pycocotools»). Затем установить pytorch с помощью следующей команды:
pip install torch==1.5.0 torchvision==0.6.0 -f https://download.pytorch.org/whl/torch_stable.htmlПакет pycocotools в нашем случае не понадобится. Также необходимо скачать и установить CUDA tools, для того чтобы ваши вычисления проходили на видеокарте, что в разы увеличивает скорость переобучения.
2. После успешного завершения установки можем приступать к подготовке данных. Для лучшей работы алгоритма фотографии для обучения необходимо брать с материалов, на которых будет производится обработка. Например, необходимо обработать видеоматериалы с камер видеонаблюдения, которые установлены в помещении, где объекты располагаются под большим углом. В такой ситуации будет очень сложно обучить алгоритм для детекции объектов, которые сильно отличаются от картинок в интернете, на которых была обучена нейронная сеть. Таким образом, обучающая выборка составляется либо из скрин-снимков по видеоматериалам, либо с помощью ручной съемки фотоаппаратом. Размер обучающей выборки может сильно варьироваться, все зависит от характера задачи. В данном примере набор данных состоит из 46 картинок, на которых изображены три типа объектов (ручка, карандаш, маркер). Фотосъемка производилась на фоне стола и листа А4.
3. Следующий этап состоит в разметке объектов на изображении. Однако, перед тем как приступить к разметке, необходимо увеличить обучающую выборку с помощью нескольких методов аугментации. Это важно для улучшения способностей нейронной сети к распознаванию объектов в различных вариациях. Несколько примеров аугментации можно найти в данной тетрадке. По завершении аугментации объединяем оригинальные изображения с результатом аугментации в одну папку (важно, изображения должны располагаться в корне папки yolov3_master, например: C:\Users\user_name\Documents\NN\ yolov3_master\images\). Далее с помощью программы labelImg проводим разметку объектов, последовательно выполняя следующие шаги:

- выбираем папку с изображениями (…\yolov3_master\images\);
- выбираем папку для сохранения меток. Необходимо создать новую папку с названием labels, в той же директории где изображения (….\yolov3_master\labels\);
- меняем тип меток c PascalVOC на YOLO;
- нажимаем на инструмент выделения объектов;
- полностью выделяем все объекты, для которых хотим обучить алгоритм;
- задаем название для каждого из типов объектов (Pen, Pencil, Marker), после первого ввода эти названия буду доступны в списке для следующих изображений;
- подтверждаем;
- сохраняем метку;
- переходим к следующему изображению и повторяем пункты 4 – 8.

4. Далее нам необходимо разделить подготовленную выборку на обучающую и тестовую. В данном случае необходимо создать 2 текстовых документа (train_112.txt и test_24.txt), в которых будут указаны полный путь расположения для каждого изображения. Пример создания документов можно найти в тетрадке.
5. Для того чтобы искомые объекты были именованными необходимо создать файл с расширением .names, например objects.names, в котором указаны имена в том же порядке, как указано в classes.txt в папке labels. Выглядит примерно так:

Далее необходимо создать файл с расширением .data, например conf.data, в котором указано количество классов (в данном примере 3), файлы с именами объектов, а также файлы с расположением изображений для обучающей и тестовой выборки:

Файлы objects.names, conf.data и последующие файлы необходимо поместить в следующую директорию: yolov3_master\data\, заранее удалив с неё все файлы.
6. Для переобучения необходимо настроить конфигурационный файл, для этого с папки (…\yolov3_master\cfg) копируем файл yolov3-spp.cfg в папку (…\yolov3_master\data). Далее необходимо отредактировать строки (636,643 — 722,729 — 809,816) для каждого из трех слоев:
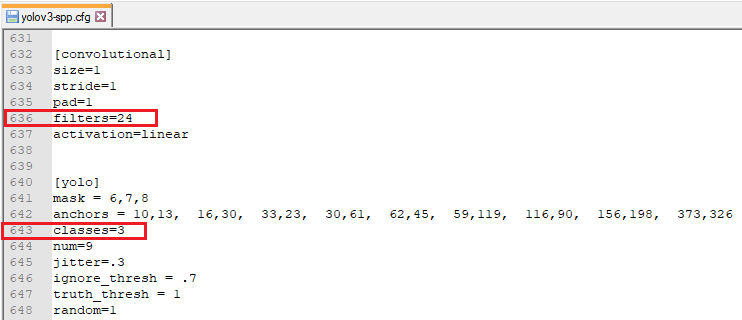
Где, filters = (5 + n) * 3 и classes = n. n – количество классов (в данном примере 3).
7. Далее необходимо скачать веса для настроенного конфигурационного файла. Для этого со страницы скачиваем файл yolov3-spp.pt и помещаем его в (…\yolov3_master\data). Для примера используется алгоритм yolov3-spp. Однако существует еще несколько вариаций алгоритма, например, yolov3-tiny, что является облегченной версией yolov3-spp. Облегченная версия менее точна, но при это скорость обработки материалов значительно выше.
8. Переходим непосредственно к переобучению алгоритма под свой тип объекта. Для этого в папке …\yolov3_master\ запускаем командную строку и вводим следующую команду:
python train.py --cfg data/yolov3-spp.cfg --data data/conf.data --weights data/yolov3-spp.pt --nosaveПосле запуска команды может возникнуть ошибка следующего характера:

Для решения данной проблемы необходимо закомментировать строки в файле utils.py в папке utils:

В теле функции check_git_status закомментируем все строки кроме print, в который передадим любую строку, например, «ss».
Также может появиться ошибка следующего вида:
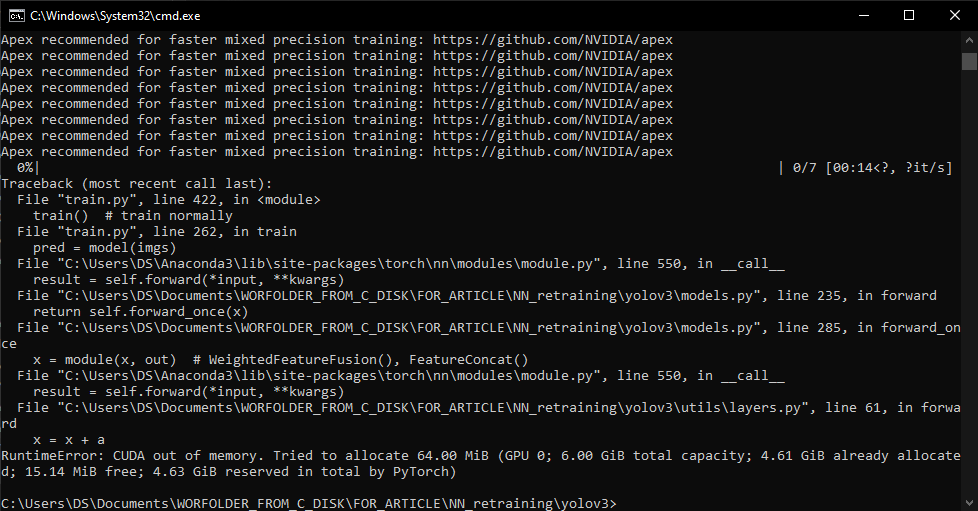
Данная ошибка говорит о том, что не хватает памяти видеокарты для построения вычислительного графа. Одним из способов решения данной проблемы является уменьшение размера батча при обучении. Для этого в файле (…\yolov3_master\train.py) необходимо изменить параметр batch_size, по умолчанию установлено 16, изменим на меньшее значение (8 или 4) кратное 4:
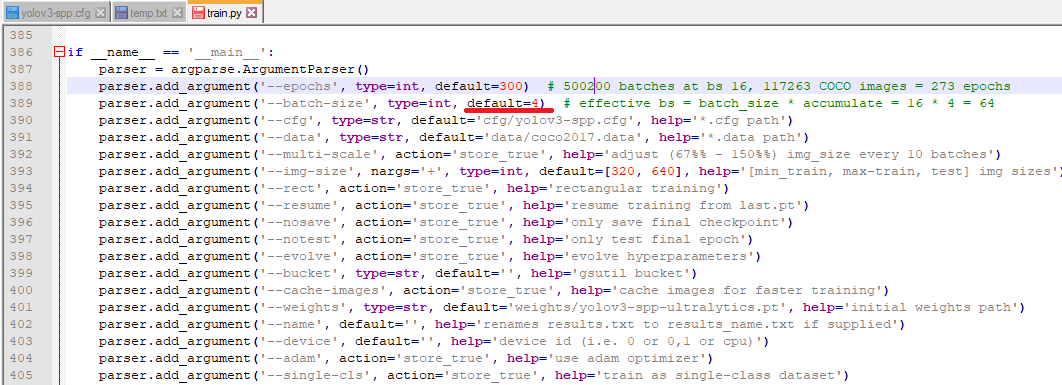
Также данное значение можно передать явно, используя значение параметра при инициализации:
python train.py --cfg data/yolov3-spp.cfg --data data/conf.data --weights data/yolov3-spp.pt --batch-size 4 --nosaveВ примере выше мы указали конфигурационный файл, файл с информацией об обучающей выборке, веса и параметр сохранения.
Параметр —nosave указывает на то что будет сохранен только финальный файл с весами. Также можно настроить в файле train.py режим сохранения, например, если вы хотите сохранять веса каждые 400 epoch:

Также важно указать параметр —epochs, количество эпох зависит от типа объектов, объема обучающей выборки и других факторов. В данном примере изначально было 46 изображений, с помощью методов аугментации набор данных увеличился до 136, из них 112 – обучающая выборка, 24 – тестовая выборка. Вычисления проводились на видеокарте GTX 1060 6 GB. Первая попытка проводилась для 300 эпох, обучение заняло порядка 2.5 часов. Выявилась очень плохая точность алгоритма. Вторая попытка проводилась для 1200 эпох, обучение заняло ~ 12 часов. По окончании обучения в папку (…\yolov3_master\weights\) сохранятся веса — файл last.pt. Для того чтобы проверить работоспособность алгоритма необходимо запустить следующую команду:
python detect.py --weights weights/last.pt --cfg data/yolov3-spp.cfg --names data/objects.namesПеред запуском команды необходимо поместить изображения для обработки алгоритмом в папку (…\yolov3_master\data\samples\). Результат появится в папке (…\yolov3_master\output\).

Таким образом, проведено переобучение готовой нейронной сети, которая была способна определять 80 классов объектов, под новые 3 типа объекта, не вошедших в этот список. Для объекта «маркер» алгоритм не совсем точен, уверенность составляет меньше 0.5. Одной из причин может быть малый размер обучающей выборки, т.к. в данном примере изображений с маркерами было 26 %, остальное ручки и карандаши.
- нейронные сети
- машинное обучение