Как сравнить две таблицы sql
Для работы с данными из нескольких таблиц можете попробовать следующие варианты.
Оператор JOIN используется для объединения двух таблиц по определенному условию, например, по ключевому полю. Следующий запрос объединяет две таблицы table1 и table2 по столбцу id и выбирает все строки, где значения в столбцах column1 и column2 совпадают:
Оператор EXCEPT используется для вычитания одной таблицы из другой. Следующий запрос выбирает все строки из таблицы table1 , которых нет в таблице table2 :
Еще есть оператор UNION для объединения строк из двух таблиц, но это не сравнение таблиц, а скорее склейка данных из них.
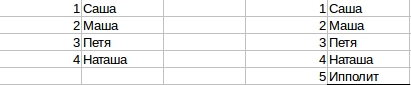
Сравнение двух таблиц по содержимому в SQL
Как сравнить две одинаковые по структуре но различающиеся по содержимому таблицы.
SELECT *
FROM base1 a
LEFT JOIN base2 b ON a.id = b.id
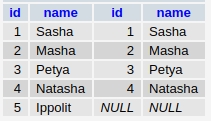
В этом примере вместо отсутствующих значений получим NULL.
Запрос с использованием функции EXCEPT
SELECT * FROM test1
SELECT * FROM test2
вернет тот же результат что и запрос
SELECT * FROM test2
WHERE id NOT IN (SELECT id FROM test1)

В данном случае будут отображены только те строки. которые не совпадают.
SQL-Ex blog

Недавно мы рассматривали сравнение схем с помощью Azure Data Studio. Что если нам потребуется сравнение таблиц с помощью запроса? В этой статье мы сравним использование EXCEPT, NOT IN, и NOT EXISTS для нахождения различий в двух таблицах.
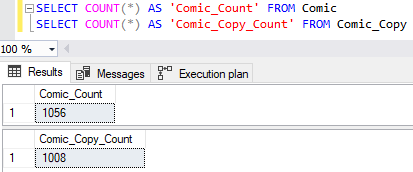
Мы будем сравнивать две таблицы Comic и Comic_Copy. В Comic содержится на 48 строк больше, чем в Comic_Copy. Давайте найдем отличие.
EXCEPT
Давайте начнем сравнение с EXCEPT. При использовании EXCEPT мы захотим иметь одинаковое число и порядок столбцов, а также одинаковые типы данных. Мы удовлетворяем этим критериям в нашем примере, поэтому давайте выполним наш запрос и посмотрим на результаты:
SELECT Id,Title
FROM Comic
EXCEPT
SELECT Id,Title
FROM Comic_Copy;
GO
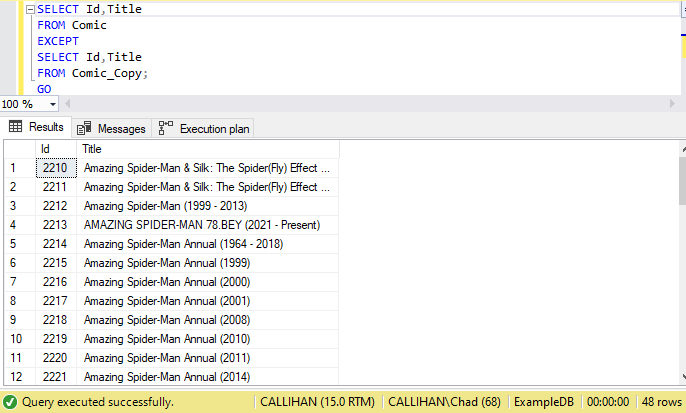
Мы видим 48 строк, что правдоподобно, исходя из подсчетов, которые мы рассматривали ранее.
NOT IN
Теперь мы будем использовать NOT IN для сравнения таблиц. Выберем Id из таблицы Comic, и будем использовать подзапрос, чтобы получить идентификаторы в Comic_Copy:
SELECT Id, Title
FROM Comic
WHERE Id NOT IN (
SELECT Id
FROM Comic_Copy
);
GO

Мы опять получаем наши 48 строк.
NOT EXISTS
Наконец, давайте проверим NOT EXISTS.
SELECT Id, Title
FROM Comic AS c
WHERE NOT EXISTS (
SELECT 1
FROM Comic_Copy AS cc
WHERE cc.Id = c.Id
);
GO

Что работает лучше?
Если мы выполним все три запроса вместе, какой покажет себя лучше остальных?
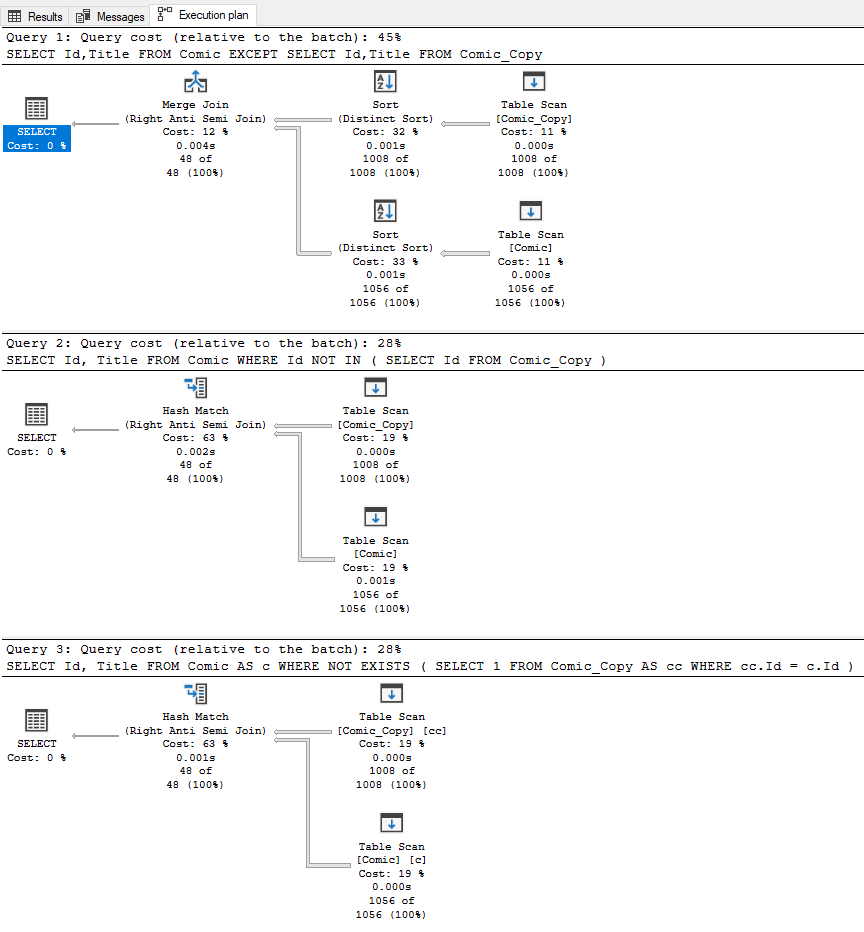
EXCEPT не кажется лучшим вариантом, в то время как два других варианта демонстрируют одинаковый план. Мы работаем с относительно небольшим набором данных, поэтому выполнение каждого запроса занимает менее секунды с одним и тем же числом логических чтений.
Хотя NOT IN и NOT EXISTS работают по-разному. Для NULL-значений NOT IN не вернет записей, поскольку NULL-значения не трактуются как сравниваемые. При использовании NOT EXISTS NULL также будут возвращаться.
Если мы изменим одно из значений title на NULL:
UPDATE Comic
SET Title = NULL
WHERE /> GO
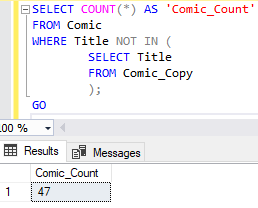
и выполним запросы на сравнение по Title, то получим разные результаты. NOT IN даст нам 47 строк:
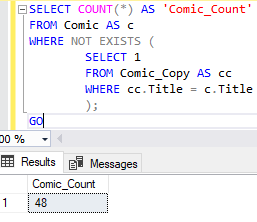
А NOT EXISTS по-прежнему дает 48:
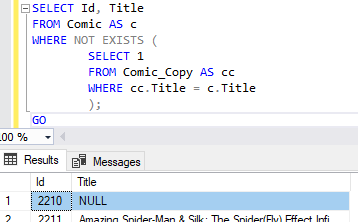
Переходим на NOT EXISTS
Мы рассмотрели три разных метода нахождения различий между таблицами. Все три варианта с использованием EXCEPT, NOT IN и NOT EXISTS могут выполнить работу, но разными способами. NOT EXISTS был бы моим «выбором» для оптимального поиска различий, но имейте в виду наличие NULL при сравнении с помощью NOT IN.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Как сравнивать две произвольные таблицы?
Добрый день!
Есть две таблицы. Известно, что большая часть данных в них пересекается. Но могут быть и совсем разные данные или измененные данные в одной из таблиц. Необходимо написать алгоритм по которому бы программа находила общие записи в таблицах и отображала. Как бы для начала подойти к этой задаче?
- Вопрос задан более трёх лет назад
- 13408 просмотров
Комментировать
Решения вопроса 0
Ответы на вопрос 4

Oleg Agapov @oleg_agapov
Data analyst, Business Intelligence
Всё-таки Java или SQL? 🙂
Если таки SQL. Подразумеваю, что используется Оракл.
Во-первых, если таблицы не большие, то не должно быть проблем с обычным джойном или декартовым произведением
SELECT t1.*, t2.* FROM table1 t1, table2 t2 WHERE t1.fields = t2.fieldsЕсли таблицы большие, тут нужно быть аккуратнее, чтоб не пошел фулл скан таблиц и все не зависло к чертям. Убедитесь, что в таблице есть индексы. Вам повезло, если индексы совпадают с теми полями, по которым нужно сравнивать.
Далее, я бы «откусывал» небольшие куски одной из таблиц и джойнил бы другую либо как в первом примере, либо вложенным подзапросом в SELECT. Если не критично для быстродействия, понемногу добавлял бы бОльшие куски первоначальной таблицы. Опять же, если не тормозит — то ок. В противном случае — писал бы процедуру для разбиения на куски и последующего джойна.
Ответ написан более трёх лет назад
Нравится 1 4 комментария
Если Оракл и если таблицы большие, то индексы не нужны — все равно нужно сравнить между собой ПОЛНОСТЬЮ всё. Лучше в этом случае распараллелить запрос на 4-32 потока, смотря — сколько ресурсов у сервера есть и сколько из них можно утилизировать.
Oleg Agapov @oleg_agapov
Борис: Совершенно верно, но я знаком с Map Reduce только в теории. Поэтому бы и использовал индекс, чтобы разбивать на куски (по сути — потоки) и прогонял бы по очереди. А искать известную часть одной таблицы все-таки лучше по индексу второй.
Oleg Agapov: ну опять-таки неоднозначно =) если, например, нужен кусок 100-миллионный кусок таблицы на 1 млрд записей («жалкие» 10%), то индексы лучше не использовать, т.к. время запроса, скорее всего, увеличится по сравнению с фуллсканом. Что касается разбиения на куски и дальнейшей параллельной обработки, то идея хорошая. Я примерно о том же и говорил: Oracle позволяет запустить запрос в несколько потоков (сессий).
Если выполнятся следующие условия:
1) нужен фул-скан;
2) таблицы огромные а ресурсы сервера слабые относительно объема таблиц;
3) таблицы разбиты на партиции (например по дате);
То можно запустить сверку в цикле по дате с загрузкой результата каждой итерации во временную таблицу, или выводом данныx в dbms_output (Oracle). Таким образом не будет эффекта зависшей БД, и не нужно будет гадать отработает ли вообще когда нибудь данный запрос и «рубить или не рубить» . Работа будет делаться маленькими порциями-партициями и даже в случае сбоя можно будет продолжить с «места разъединения».