Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
pip install lxml pip install requests pip install beautifulsoup4Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
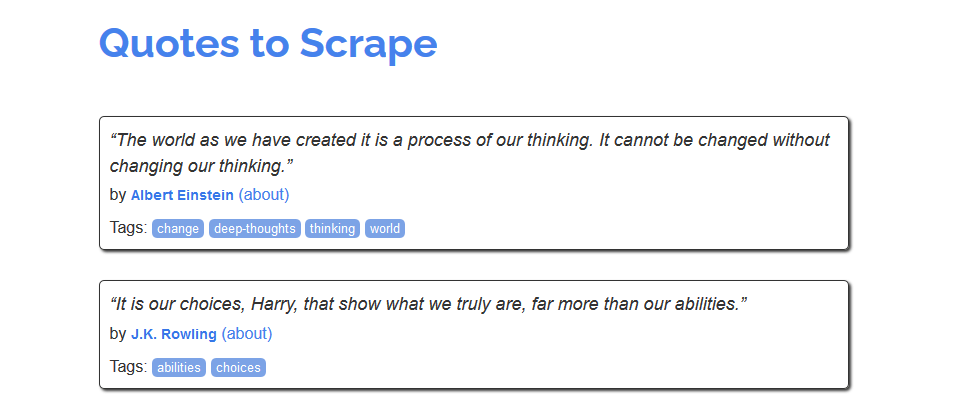
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
На этом примере можно увидеть, что разметка включает массу на первый взгляд перемешенных данных. Задача веб-скрапинга — получение доступа к тем частям страницы, которые нужны. Многие разработчики используют регулярные выражения для этого, но библиотека Beautiful Soup в Python — более дружелюбный способ извлечения необходимой информации.
Создание скрипта скрапинга
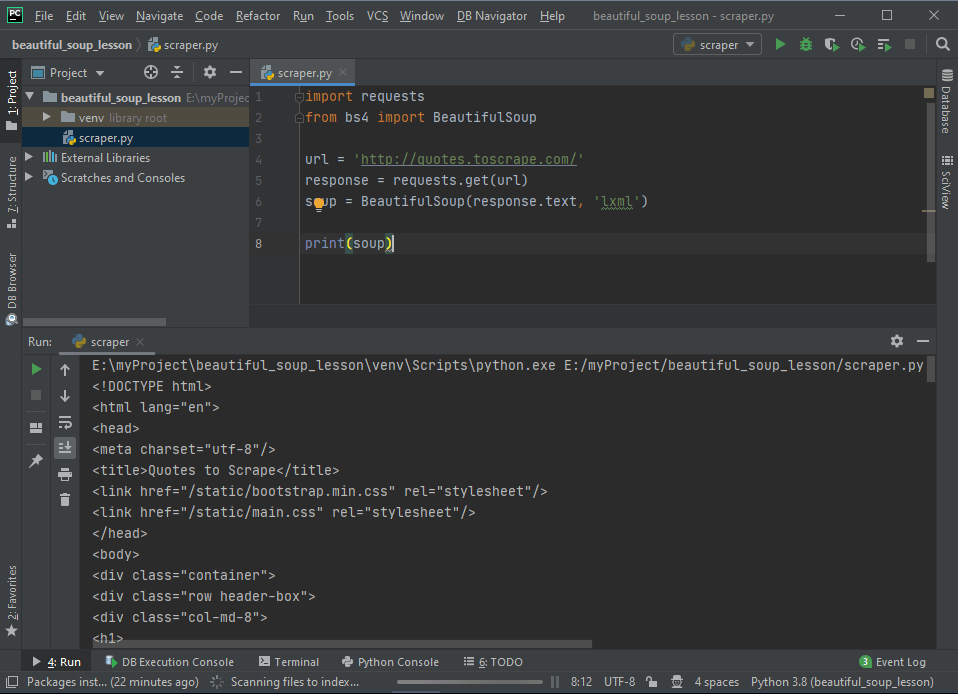
В PyCharm (или другой IDE) добавим новый файл для кода, который будет отвечать за парсинг.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
print(soup)Отрывок выше — это лишь начало кода. В первую очередь в верхней части файла выполняется импорт библиотек requests и Beautiful Soup. Затем в переменной url сохраняется адрес страницы, с которой будет поступать информация. Эта переменная затем передается функции requests.get() . Результат присваивается переменной response . Дальше используем конструктор BeautifulSoup() , чтобы поместить текст ответа в переменную soup . В качестве формата выберем lxml . Наконец, выведем переменную. Результат должен выглядеть приблизительно вот так.
Вот что происходит: ПО заходит на сайт, считывает данные, получает исходный код — все по аналогии с ручным подходом. Единственное отличие в том, что в этот раз достаточно лишь одного клика.
Прохождение по структуре HTML
HTML — это HyperText Markup Language («язык гипертекстовой разметки»), который работает за счет распространения элементов документа со специальными тегами. В HTML есть много разнообразных тегов, но стандартный шаблон включает три основных: html , head и body . Они организовывают весь документ. В случае со скрапингом интерес представляет только тег body .
Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.
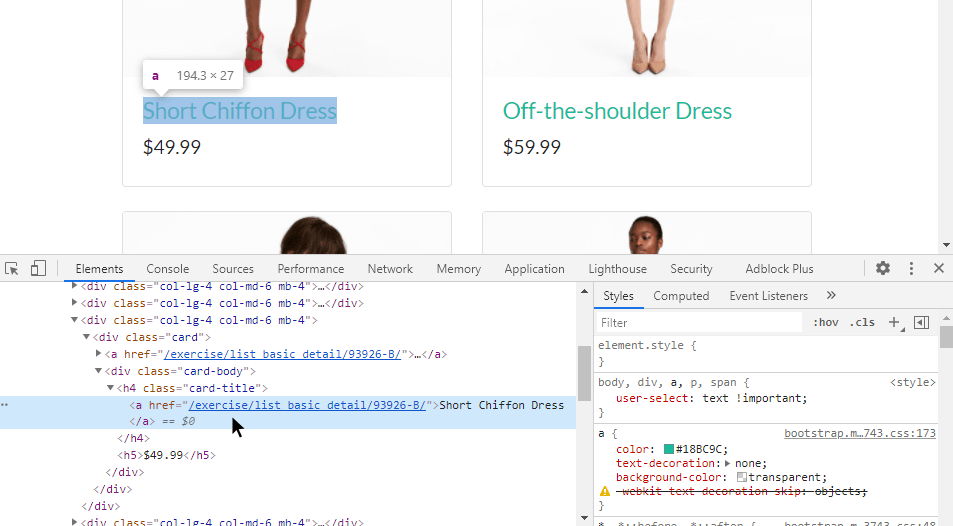
Если в браузере воспользоваться инструментом «Inspect» (CTRL+SHIFT+I), то можно достаточно просто увидеть, какая из частей разметки отвечает за тот или иной элемент страницы. Достаточно навести мышью на определенный тег span , как он подсветит соответствующую информацию на странице. Можно увидеть, что каждая цитата относится к тегу span с классом text .
Таким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это все, что нужно знать об HTML для скрапинга.
Парсинг HTML-разметки
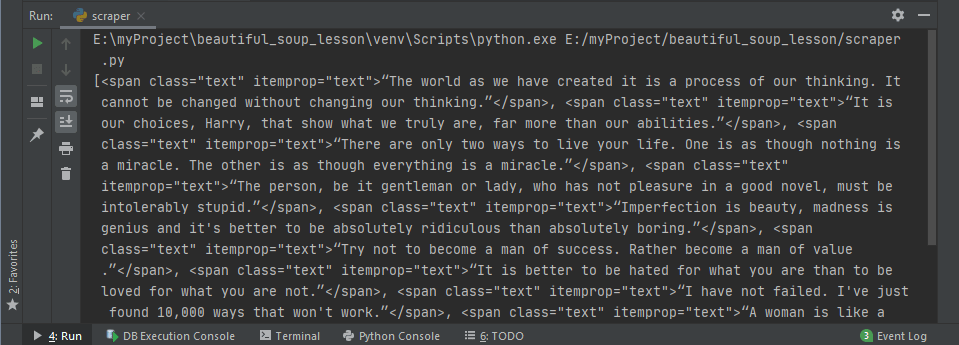
В HTML-документе хранится много информации, но благодаря Beautiful Soup проще находить нужные данные. Порой для этого требуется всего одна строка кода. Пойдем дальше и попробуем найти все теги span с классом text . Это, в свою очередь, вернет все теги. Когда нужно найти несколько одинаковых тегов, стоит использовать функцию find_all() .
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
print(quotes)Этот код сработает, а переменной quotes будет присвоен список элементов span с классом text из HTML-документа. Вывод этой переменной даст следующий результат.
Свойство text библиотеки Beautiful Soup
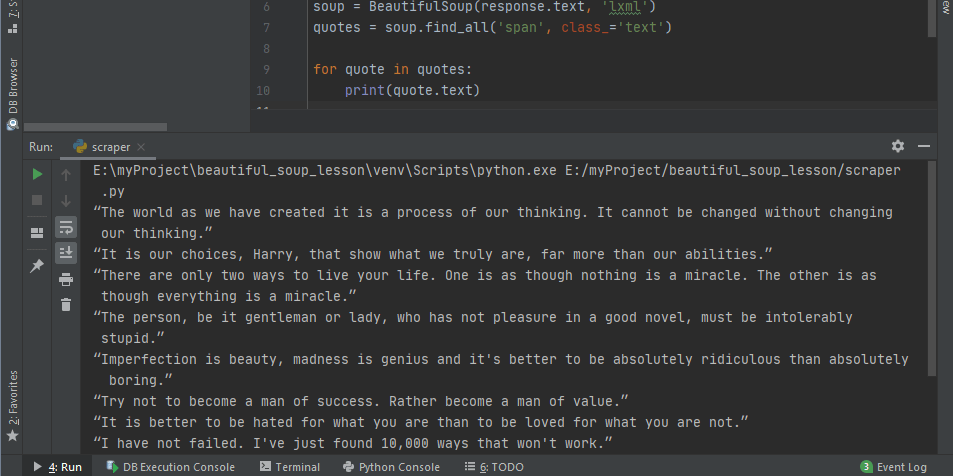
Возвращаемая разметка — это не совсем то, что нужно. Для получения только данных — цитат в этом случае — можно использовать свойство .text из библиотеки Beautiful Soup. Обратите внимание на код, где происходит перебор всех полученных данных с выводом только нужного содержимого.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
for quote in quotes:
print(quote.text)Это и дает вывод, который требовался с самого начала.
Для поиска и вывода всех авторов можно использовать следующий код. Работаем по тому же принципу — сперва нужно вручную изучить страницу. Можно обратить внимание на то, что каждый автор заключен в тег с классом author . Дальше используем функцию find_all() и сохраняем результат в переменной authors . Также стоит поменять цикл, чтобы перебирать сразу и цитаты, и авторов.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
for quote in quotes:
print(quote.text)Таким образом теперь есть и цитаты, и их авторы.
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” --Albert Einstein “It is our choices, Harry, that show what we truly are, far more than our abilities.” --J.K. Rowling “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” --Albert Einstein .Наконец, добавим код получения всех тегов для каждой цитаты. Здесь уже немного сложнее, потому что сперва нужно получить каждый внешний блок каждой коллекции тегов. Если этот первый шаг не выполнить, то теги можно будет получить, но ассоциировать их с конкретной цитатой — нет.
Когда блок получен, можно опускаться ниже с помощью функции find_all для полученного подмножества. А уже дальше потребуется добавить внутренний цикл для завершения процесса.
# scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
tags = soup.find_all('div', class_='tags')
for i in range(0, len(quotes)):
print(quotes[i].text)
print('--' + authors[i].text)
tagsforquote = tags[i].find_all('a', class_='tag')
for tagforquote in tagsforquote:
print(tagforquote.text)
print('\n')Этот код даст такой результат. Круто, не так ли?
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” --Albert Einstein change deep-thoughts thinking world “It is our choices, Harry, that show what we truly are, far more than our abilities.” --J.K. Rowling abilities choices .Практика парсинга с Beautiful Soup
Еще один хороший ресурс для изучения скрапинга — scrapingclub.com. Там есть множество руководств по использованию инструмента Scrapy. Также имеется несколько страниц, на которых можно попрактиковаться. Начнем с этой https://scrapingclub.com/exercise/list_basic/?page=1.
Нужно просто извлечь название элемента и его цену, отобразив данные в виде списка. Шаг первый — изучить исходный код для определения HTML. Судя по всему, здесь использовался Bootstrap.
После этого должен получиться следующий код.
# shop_scraper.py
import requests
from bs4 import BeautifulSoup
url = 'https://scrapingclub.com/exercise/list_basic/?page=1'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=1):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f': за ')1: $24.99 за Short Dress 2: $29.99 за Patterned Slacks 3: $49.99 за Short Chiffon Dress 4: $59.99 за Off-the-shoulder Dress .Скрапинг с учетом пагинации
Ссылка выше ведет на одну страницу коллекции, включающей на самом деле несколько страниц. На это указывает page=1 в адресе. Скрипт Beautiful Soup можно настроить и так, чтобы скрапинг происходил на нескольких страницах. Вот код, который будет извлекать данные со всех связанных страниц. Когда все URL захвачены, скрипт может выполнять запросы к каждой из них и парсить результаты.
# shop_scraper.py
# версия для понимания процессов
import requests
from bs4 import BeautifulSoup
url = 'https://scrapingclub.com/exercise/list_basic/?page=1'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=1):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f': за ')
pages = soup.find('ul', class_='pagination')
urls = []
links = pages.find_all('a', class_='page-link')
for link in links:
pageNum = int(link.text) if link.text.isdigit() else None
if pageNum != None:
hrefval = link.get('href')
urls.append(hrefval)
for slug in urls:
newUrl = url.replace('?page=1', slug)
response = requests.get(newUrl)
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('div', class_='col-lg-4 col-md-6 mb-4')
for n, i in enumerate(items, start=n):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f': за ')Результат будет выглядеть следующим образом.
1: $24.99 за Short Dress 2: $29.99 за Patterned Slacks 3: $49.99 за Short Chiffon Dress . 52: $6.99 за T-shirt 53: $6.99 за T-shirt 54: $49.99 за BlazerЭтот код можно оптимизировать для более продвинутых читателей:
import requests
from bs4 import BeautifulSoup
url = 'https://scrapingclub.com/exercise/list_basic/'
params =
# задаем число больше номера первой страницы, для старта цикла
pages = 2
n = 1
while params['page'] for n, i in enumerate(items, start=n):
itemName = i.find('h4', class_='card-title').text.strip()
itemPrice = i.find('h5').text
print(f': за ')
# [-2] предпоследнее значение, потому что последнее "Next"
last_page_num = int(soup.find_all('a', class_='page-link')[-2].text)
pages = last_page_num if pages < last_page_num else pages
params['page'] += 1Выводы
Beautiful Soup — одна из немногих библиотек для скрапинга в Python. С ней очень просто начать работать. Скрипты можно использовать для сбора и компиляции данных из интернета, а результат — как для анализа данных, так и для других сценариев.
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python
Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.


- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests from bs4 import BeautifulSoup as bs import pandas as pd И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" r = requests.get(URL_TEMPLATE) print(r.status_code) Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text) Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
Комірник
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') for name in vacancies_names: print(name.a['title']) Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Some information about vacancy.
Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: print('https://www.work.ua'+name.a['href']) for info in vacancies_info: print(info.text) И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests from bs4 import BeautifulSoup as bs import pandas as pd URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2" FILE_NAME = "test.csv" def parse(url = URL_TEMPLATE): result_list = r = requests.get(url) soup = bs(r.text, "html.parser") vacancies_names = soup.find_all('h2', class_='add-bottom-sm') vacancies_info = soup.find_all('p', class_='overflow') for name in vacancies_names: result_list['href'].append('https://www.work.ua'+name.a['href']) result_list['title'].append(name.a['title']) for info in vacancies_info: result_list['about'].append(info.text) return result_list df = pd.DataFrame(data=parse()) df.to_csv(FILE_NAME) После запуска появится файл test.csv — с результатами поиска.
Узнайте, как использовать Beautiful Soup для парсинга страниц с помощью Python за 3 минуты
Ищете краткое руководство, чтобы начать парсинг веб-страниц с помощью Python’s Beautiful Soup? Вы пришли по адресу – читайте статью и начните работу.
1 min read
Rafael Levi
Senior Business Manager
В этой статье мы обсудим:
- Как работает веб-скрапинг?
- Что такое Beautiful Soup?
- Как установить Requests и Beautiful Soup
- Шаги для парсинга на Python с Requests и Beautiful Soup
Как работает веб-скрапинг?
Веб-скрапинг – это способ получения определенных данных с целевой веб-страницы. Когда вы исследуете страницу, написанный код отправляет запрос на сервер, где она находится. Код загружает ее, извлекая элементы, указанные в задании сканирования.
Допустим, нам нужны целевые данные в тегах заголовка H3. Мы напишем код для парсера, который будет искать именно эту информацию. Он будет работать в три этапа:
Этап 1: Отправка запроса на сервер для загрузки содержимого сайта.
Шаг 2: Изучение HTML страниц для поиска нужных тегов H3.
Шаг 3: Копирование текста внутри целевых тегов, создание выходных данных в формате, указанном ранее в коде.
Задачи веб-скрапинга можно выполнять на многих языках программирования с помощью различных библиотек, но именно библиотека Beautiful Soup в Python – наиболее востребованный и эффективный метод. Ниже мы рассмотрим основы парсинга на Python с Beautiful Soup.
Что такое Beautiful Soup?
Beautiful Soup является библиотекой Python, которая анализирует документы HTML и XML. Она создает дерево разбора для проанализированных страниц, которое позволяет извлекать данные из HTML. Кроме того, автоматически преобразует документ в Юникод. Поэтому вам не придется думать о кодировках. Этот инструмент помогает не только парсить, но и очищать данные. Beautiful Soup поддерживает парсер HTML библиотеки Python и несколько сторонних: lxml или hml5lib.
Подробнее о возможностях читайте здесь: Документация по Beautiful Soup.
Как установить Requests и Beautiful Soup
Вам нужен pip или другой установщик Python. По желанию можете использовать свою лабораторию jupyter. В этой статье мы используем pip, так как он более удобный. Откройте терминал или Jupyter Lab и напишите:
Давайте распечатаем таблицу, чтобы получить лучшее представление о том, что у нас есть, и воспользуемся .prettify().
Ваш вывод должен выглядеть примерно так:
Теперь ищем нужные вам данные. Для данного примера нам нужна только цитата и имя автора. Как видите, все эти данные находятся по адресу
Давайте пройдемся по всем экземплярам класса и получим цитаты в нашей таблице.
Теперь вам должны быть доступны только
в каждом экземпляре цикла. Вы можете проверить это, выполнив print(row) в цикле.
Мы ищем информацию под ключом “img alt”, поэтому давайте создадим переменную quote и присвоим ей эти данные.
Как вы видите, я завернул его в оператор ‘try’. В этом случае, если в одной из строк не будет искомых данных, вы не получите ошибку, и цикл будет продолжен. Я также разделил результаты на ‘-‘. Как вы видели ранее, текст и имя автора разделяются с помощью знака ‘-‘ Давайте используем его, чтобы разделить эти два знака.
Вот и все, вы закончили. Вот как теперь должна выглядеть ваша цитата:
В конце этого процесса вы можете сохранить свои данные в файл, и ваш код должен выглядеть примерно так:
Парсер лучших за сутки статей habr(а) на Python. Очень подробно и просто
Всем привет, сегодня я вам покажу и расскажу, как можно легко написать парсер для сбора лучших статей дня в виде json файла, в формате, "Название статьи": "ссылка". Кто не понял о каких лучших статьях дня я говорю, вот ссылка "https://habr.com/ru/top/daily/".
Итак, библиотеки, которые будут нам нужны (вставляем в командную строку, либо в терминале или куда вам удобно):
pip install beautifulsoup4 pip install requests pip install fake-useragent pip install lxmlИнициализируем модули в наш заранее созданный проект, т.е. файл с расширением py.
from bs4 import BeautifulSoup import random import json import requests import datetime from fake_useragent import UserAgentСоздаем переменную с модулем fake_useragent, чтобы мы могли потом использовать для генерации user-agent:
ua = UserAgent()Определяем заголовки (для того чтобы сервер сайта мог понять, как он должен отправить ответ, а также помогает серверу определить отправителя запроса)
headers = < 'accept': 'application/json, text/plain, */*', 'user-Agent': ua.google, >Создаем словарь, где будут храниться название и ссылка на каждую статью:
article_dict = <>Указываем url c форматирование кода, где i - номер страницы, которое вставляться при каждом проходе цикла.
url = f'https://habr.com/ru/top/daily/'Отправляем get запрос на сайт, указывая в первом аргументе - переменную с url сайта, во-втором заголовки. Атрибут text, нужен чтобы получить текстовое содержанием html страницы.
req = requests.get(url, headers=headers).textТеперь с помощью BeautifulSoup соберем весь html код страницы.
soup = BeautifulSoup(req, 'lxml')Если попробовать вывести такой код с помощью print(soup), выведется весь html код страницы.
Далее, используя наш "soup" созданный в прошлом шаге, с помощью метода find_all собираем все ссылки с помощью тега "a" в первом аргументе, во-втором, с помощью F12, ищем класс у всех ссылок наших статей, как мы видим это - tm-article-snippet__title-link.

all_hrefs_articles = soup.find_all('a', class_='tm-title__link')Класс указывается с нижним подчеркиванием, т.к. это ключевое (зарезервированное) слово в Python.
Создаем еще один цикл, где мы будем проходиться по всем статьям собранных в переменной all_hrefs_articles.
for article in all_hrefs_articles:В теге "a" с классом "tm-article-snippet__title-link" находится еще один тег "span" c нашими именами ссылок, получим его с помощью метода find.
article_name = article.find('span').text # собираем названия статейТеперь получим ссылку на статью, указываем что это f строка, и с помощью get запроса в скобочках получаем атрибут "href" - основной атрибут тега "a".
article_link = f'https://habr.com'Получается ссылка, например: "https://habr.com/ru/company/tinkoff/blog/715604/"
Теперь указываем пару ключ - значение для названия и ссылку на статью (для нашего словаря):
article_dict[article_name] = article_linkВыходим из обоих циклов. С помощью конструкции "with open" создаем файл articles_ + дата и время создания файла с помощью модуля datetime, который мы импортировали, файл создаем с расширением .json (ну мне так удобнее), следующее мы указываем 'w', что означает, что нужно создать файл с таким-то названием и вписать следующий код, который мы укажем внутри файла, также указываем кодировку " encoding ='utf-8' ", чтобы файл мог отобразить русские символы.
with open(f"articles_.json", "w", encoding='utf-8') as f: Создаем конструкцию try, except (если нет ошибок при парсинге, выводится try, если выводится ошибка при парсинге => except)
try: except: В try, мы "говорим", чтобы в json файл отправлялись данные, 1 - словарь с нашими статьями , 2 - имя файла, куда отправлять данные (в открытии файла мы указали в конце его как f, чтобы с ним можно было работать), 3 - отступы (я сделал 4 для удобства чтения, можно указать свое), 4 - экранирование ASCII символов, и следующей строкой вывод, что статьи успешно были получены.
print('Статьи были успешно получены')В except, мы выводим, что статьи не удалось получить и нужно искать проблемы в коде.
print('Статьи не удалось получить')В конечном итоге, должно получиться что-то похожее:
from bs4 import BeautifulSoup import random import json import requests import datetime from fake_useragent import UserAgent ua = UserAgent() headers = < 'accept': 'application/json, text/plain, */*', 'user-Agent': ua.google, >article_dict = <> url = f'https://habr.com/ru/top/daily/' req = requests.get(url, headers=headers).text soup = BeautifulSoup(req, 'lxml') all_hrefs_articles = soup.find_all('a', class_='tm-title__link') # получаем статьи for article in all_hrefs_articles: # проходимся по статьям article_name = article.find('span').text # собираем названия статей article_link = f'https://habr.com' # ссылки на статьи article_dict[article_name] = article_link with open(f"articles_.json", "w", encoding='utf-8') as f: try: json.dump(article_dict, f, indent=4, ensure_ascii=False) print('Статьи были успешно получены') except: print('Статьи не удалось получить')