Blob
ArrayBuffer и бинарные массивы являются частью ECMA-стандарта и, соответственно, частью JavaScript.
Кроме того, в браузере имеются дополнительные высокоуровневые объекты, описанные в File API.
Объект Blob состоит из необязательной строки type (обычно MIME-тип) и blobParts – последовательности других объектов Blob , строк и BufferSource .
Благодаря type мы можем загружать и скачивать Blob-объекты, где type естественно становится Content-Type в сетевых запросах.
Конструктор имеет следующий синтаксис:
new Blob(blobParts, options);- blobParts – массив значений Blob / BufferSource / String .
- options – необязательный объект с дополнительными настройками:
- type – тип объекта, обычно MIME-тип, например. image/png ,
- endings – если указан, то окончания строк создаваемого Blob будут изменены в соответствии с текущей операционной системой ( \r\n или \n ). По умолчанию «transparent» (ничего не делать), но также может быть «native» (изменять).
// создадим Blob из строки let blob = new Blob(["…"], ); // обратите внимание: первый аргумент должен быть массивом [. ]// создадим Blob из типизированного массива и строк let hello = new Uint8Array([72, 101, 108, 108, 111]); // "hello" в бинарной форме let blob = new Blob([hello, ' ', 'world'], );Мы можем получить срез Blob, используя:
blob.slice([byteStart], [byteEnd], [contentType]);- byteStart – стартовая позиция байта, по умолчанию 0.
- byteEnd – последний байт, по умолчанию до конца.
- contentType – тип type создаваемого Blob-объекта, по умолчанию такой же, как и исходный.
Аргументы – как в array.slice , отрицательные числа также разрешены.
Blob не изменяем (immutable)
Мы не можем изменять данные напрямую в Blob, но мы можем делать срезы и создавать новый Blob на их основе, объединять несколько объектов в новый и так далее.
Это поведение аналогично JavaScript-строке: мы не можем изменить символы в строке, но мы можем создать новую исправленную строку на базе имеющейся.
Blob как URL
Давайте начнём с простого примера. При клике на ссылку мы загружаем динамически генерируемый Blob с hello world содержимым как файл:
); link.href = URL.createObjectURL(blob);Мы также можем создать ссылку динамически, используя только JavaScript, и эмулировать на ней клик, используя link.click() , тогда загрузка начнётся автоматически.
Далее простой пример создания «на лету» и загрузки Blob-объекта, без использования HTML:
let link = document.createElement('a'); link.download = 'hello.txt'; let blob = new Blob(['Hello, world!'], ); link.href = URL.createObjectURL(blob); link.click(); URL.revokeObjectURL(link.href);URL.createObjectURL берёт Blob и создаёт уникальный URL для него в формате blob:/ .
Вот как выглядит сгенерированный URL:
blob:https://javascript.info/1e67e00e-860d-40a5-89ae-6ab0cbee6273Браузер для каждого URL, сгенерированного через URL.createObjectURL , сохраняет внутреннее соответствие URL → Blob . Таким образом, такие URL короткие, но дают доступ к большому объекту Blob .
Сгенерированный url действителен, только пока текущий документ открыт. Это позволяет ссылаться на сгенерированный в нём Blob в
, или в любом другом объекте, где ожидается url в качестве одного из параметров.
В данном случае возможен побочный эффект. Пока в карте соответствия существует ссылка на Blob, он находится в памяти. Браузер не может освободить память, занятую Blob-объектом.
Ссылка в карте соответствия автоматически удаляется при выгрузке документа, после этого также освобождается память. Но если приложение имеет длительный жизненный цикл, это может произойти не скоро. Таким образом, если мы создадим URL для Blob, он будет висеть в памяти, даже если в нём нет больше необходимости.
URL.revokeObjectURL(url) удаляет внутреннюю ссылку на объект, что позволяет удалить его (если нет другой ссылки) сборщику мусора, и память будет освобождена.
В последнем примере мы использовали Blob только единожды, для мгновенной загрузки, после мы сразу же вызвали URL.revokeObjectURL(link.href) .
В предыдущем примере с кликабельной HTML-ссылкой мы не вызывали URL.revokeObjectURL(link.href) , потому что это сделало бы ссылку недействительной. После удаления внутренней ссылки на Blob , URL больше не будет работать.
Blob to base64
Альтернатива URL.createObjectURL – конвертация Blob-объекта в строку с кодировкой base64.
Эта кодировка представляет двоичные данные в виде строки с безопасными для чтения символами в ASCII-кодах от 0 до 64. И что более важно – мы можем использовать эту кодировку для «data-urls».
data url имеет форму data:[][;base64], . Мы можем использовать такой url где угодно наряду с «обычным» url.
Браузер декодирует строку и показывает смайлик:
Для трансформации Blob в base64 мы будем использовать встроенный в браузер объект типа FileReader . Он может читать данные из Blob в множестве форматов. В следующей главе мы рассмотрим это более глубоко.
Вот пример загрузки Blob при помощи base64:
let link = document.createElement('a'); link.download = 'hello.txt'; let blob = new Blob(['Hello, world!'], ); let reader = new FileReader(); reader.readAsDataURL(blob); // конвертирует Blob в base64 и вызывает onload reader.onload = function() < link.href = reader.result; // url с данными link.click(); >;Оба варианта могут быть использованы для создания URL с Blob. Но обычно URL.createObjectURL(blob) является более быстрым и безопасным.
URL.createObjectURL(blob)
- Нужно отзывать объект для освобождения памяти.
- Прямой доступ к Blob, без «кодирования/декодирования».
Blob to data url
- Нет необходимости что-либо отзывать.
- Потеря производительности и памяти при декодировании больших Blob-объектов.
Изображение в Blob
Мы можем создать Blob для изображения, части изображения или даже создать скриншот страницы. Что удобно для последующей загрузки куда-либо.
Операции с изображениями выполняются через элемент :
- Для отрисовки изображения (или его части) на холсте (canvas) используется canvas.drawImage.
- Вызов canvas-метода .toBlob(callback, format, quality) создаёт Blob и вызывает функцию callback при завершении.
В примере ниже изображение просто копируется, но мы можем взять его часть или трансформировать его на canvas перед созданием Blob:
// берём любое изображение let img = document.querySelector('img'); // создаём того же размера let canvas = document.createElement('canvas'); canvas.width = img.clientWidth; canvas.height = img.clientHeight; let context = canvas.getContext('2d'); // копируем изображение в canvas (метод позволяет вырезать часть изображения) context.drawImage(img, 0, 0); // мы можем вращать изображение при помощи context.rotate() и делать множество других преобразований // toBlob является асинхронной операцией, для которой callback-функция вызывается при завершении canvas.toBlob(function(blob) < // после того, как Blob создан, загружаем его let link = document.createElement('a'); link.download = 'example.png'; link.href = URL.createObjectURL(blob); link.click(); // удаляем внутреннюю ссылку на Blob, что позволит браузеру очистить память URL.revokeObjectURL(link.href); >, 'image/png');Или если вы предпочитаете async/await вместо колбэка:
let blob = await new Promise(resolve => canvasElem.toBlob(resolve, 'image/png'));Для создания скриншота страницы мы можем использовать такую библиотеку, как https://github.com/niklasvh/html2canvas. Всё, что она делает, это просто проходит страницу и отрисовывает её в . После этого мы может получить Blob одним из вышеуказанных способов.
Из Blob в ArrayBuffer
Конструктор Blob позволяет создать Blob-объект практически из чего угодно, включая BufferSource .
Но если нам нужна производительная низкоуровневая обработка, мы можем использовать ArrayBuffer из FileReader :
// получаем arrayBuffer из Blob let fileReader = new FileReader(); fileReader.readAsArrayBuffer(blob); fileReader.onload = function(event) < let arrayBuffer = fileReader.result; >;Итого
В то время как ArrayBuffer , Uint8Array и другие BufferSource являются «бинарными данными», Blob представляет собой «бинарные данные с типом».
Это делает Blob удобным для операций загрузки/выгрузки данных, которые так часто используются в браузере.
Методы, которые выполняют сетевые запросы, такие как XMLHttpRequest, fetch и подобные, могут изначально работать с Blob так же, как и с другими объектами, представляющими двоичные данные.
Мы можем легко конвертировать Blob в низкоуровневые бинарные типы данных и обратно:
- Мы можем создать Blob из типизированного массива, используя конструктор new Blob(. ) .
- Мы можем обратно создать ArrayBuffer из Blob, используя FileReader , а затем создать его представление для низкоуровневых операций.
Установка BLOB-адаптера
BLOB-адаптер — это программный модуль Витрины данных, предназначенный для получения доступа из Витрины данных к BLOB-объектам ведомства. Подробнее о том, как он используется в СМЭВ4 можно узнать в статье Использование Blob Адаптера для обмена blob объектами.
Хранилище BLOB-объектов располагается на стороне ведомства и не является частью Витрины данных. Хранилище BLOB-объектов должно поддерживать регламентированный Витриной данных интерфейс доступа к BLOB-объектам по запросу.
Перед развёртыванием BLOB-адаптера необходимо ознакомится с требованиями к серверу и к самому хранилищу BLOB-адаптера, которые нужно учитывать перед развёртыванием BLOB-адаптера.
Требования к серверу BLOB-адаптера
Следующие файлы и папки файловой системы сервера, должны быть доступны процессу установки для создания и модификации, и не должны контролироваться системой управления конфигурации (при её наличии):
- /etc/hosts
- /etc/selinux/config
- /etc/sysctl.conf
- файлы директории /usr/lib/systemd/system/
- /etc/sysconfig/iptables*
- /etc/firewalld/*
- /etc/docker/*
Снаружи сервер должен быть доступен по следующим портам:
Требования к Хранилищу BLOB-объектов
Для корректной работы с хранилищем BLOB-объектов, необходимо предоставить:
- доступ к таблицам с метаданными по документам, хранилища ведомства;
- доступ к ссылкам на BLOB-объекты (изображения, архивы, pdf-файлы и т.д.) в хранилище ведомства, соответствующие метаданным;
- связь между ссылками и метаданными, если они разнесены по разным хранилищам.
Важно! Все обновления ссылок на документы происходят только через ETL, т.е. от Поставщика данных (ведомства) к Витрине. Обновление самих BLOB-объектов через витрину с последующей проливкой в ведомства не предусмотрено.
Установка модуля
Модуль BLOB-адаптер поставляется в виде jar-файла. В поставку также входит файл настроек конфигурации модуля BLOB-адаптер ( application.yml ).
Рисунок 1 – Состав jar файла BLOB-адаптера
Общий процесс установки состоит из следующих действий:
- Настроить конфигурацию модуля.
- Создать на сервере директорию для загрузки файлов модуля.
- Загрузить файлы модуля в созданную директорию.
- Запустить jar-файл модуля.
- Проверить установку модуля.
Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла application.yml . Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. раздел Конфигурация BLOB-адаптер (application.yml).
Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/blob-adapter. В случае, если ранее была установлена старая версия модуля BLOB-адаптер, сделайте его резервную копию.
Загрузка файлов на сервер
- jar-файл модуля;
- файл настроек конфигурации модуля BLOB-адаптер ( application.yml ).
Конфигурация BLOB-адаптера (application.yml)
Файл application.yml – основной конфигурационный файл BLOB-адаптер, в котором задана логика и порядок работы адаптера: получение входящих запросов, их обработка, а также настройка подключения к СМЭВ3-адаптер, к PODD-адаптер и другие настройки необходимые для корректной работы адаптера.
server :
enabled : $
port : $
metrics :
port : $
executor :
reader-pool-size : $
chunk :
size : $
kafka :
enabled : $
consumer :
blob-request : $blob.rq
property :
bootstrap.servers : *kafkaUrl
group.id : $blob-consumer
auto.offset.reset : earliest
enable.auto.commit : true
producer :
blob-result : $blob.rs
blob-error : $blob.err
property :
bootstrap.servers : *kafkaUrl
blob-storage :
protocol : $
host : $
port : $
path-prefix : $
path-postfix : $
auth :
type : $
user : $
password : $
token : $
# params:
# name1: value1
# name2: value2Параметры конфигурации
Настройка конфигурации BLOB-адаптера осуществляется путем редактирования параметров настроек в файле application.yml .
В файле конфигурации BLOB-адаптер могут быть настроены следующие секции:
- vertx — настройки параметров фреймворка Vert.x (подробнее на сайте разработчиков: https://vertx.io/docs/);
- client — настройка работы с BLOB-объектами через PODD-адаптер;
- chunk — настройка фиксированного размера блока данных для отправки через Kafka;
- blob-storage — настройка подключения к Хранилищу BLOB-объектов;
- logging — настройка сохранения лог-файла.
URL для доступа к Kafka PODD-агент.
Секция vertx
Секция vertx предназначена для настройки параметров фреймворка Vert.x (подробнее на сайте разработчиков: https://vertx.io/docs/).
vertx :
clustered : false
Секция client
Секция client определяет настройки взаимодействия с PODD-адаптер для получения входящих и исходящих запросов.
- enabled — включение/отключение работы с шиной данных Kafka через PODD-адаптер. Если значение true — взаимодействие с BLOB-объектами осуществляется через PODD-адаптер, если значение false — через СМЭВ3-адаптер.
- kafka — настройка интеграции с шиной данных Kafka (при активном (true) значении enabled).
- zookeeperHosts — подключение к Zookeeper ПОДД-агента.
- consumer — получатель данных.
- rqTopicName — формат запроса (см. раздел Спецификация модуля «BLOB-адаптер» ).
- rsTopicName — формат запроса к серверу Kafka на считывание BLOB-объекта по ссылке — blob.rs (см. раздел Спецификация модуля «BLOB-адаптер» ).
- errTopicName — формат ответа Kafka в случае ошибки — blob.err (см. раздел Спецификация модуля «BLOB-адаптер» ).
- bootstrap.servers — путь к серверу Kafka.
- bootstrap.servers — путь к серверу Kafka.
client :
enabled : $
kafka :
cluster :
zookeeperHosts : $
rootPath : $
blob :
consumer :
rqTopicName : blob.rq
property :
bootstrap.servers : *kafkaUrl
group.id : blob.consumer
auto.offset.reset : earliest
enable.auto.commit : true
producer :
rsTopicName : blob.rs
errTopicName : blob.err
base-producer-property :
bootstrap.servers : *kafkaUrl
base-consumer-property :
bootstrap.servers : *kafkaUrlСекция chunk
Секция chunk определяет настройки размера фрагмента (в байтах), на которые дробятся сообщения, содержащее тело BLOB-объекта. Размер одного chunk для каждого сообщения Kafka не должен превышать 1мб.
Секция blob-storage
Секция blob-storage предназначена для настройки пути к Хранилищу BLOB-объектов (GET-запрос).Формат записи имеет следующий вид:
- protocol — одно из значений http или https;
- name — ip или FQDN http-сервера, содержащего ссылку на BLOB-объекты;
- port — номер tcp-порта, если отсутствует, то следует использовать следующие порты 80 для http, 443 для https);
- path — постоянная часть пути до Хранилища BLOB-объектов (содержимого BLOB-объекта).
Секция logging
Секция logging предназначена для настройки параметров логирования:
level :
ru.itone.datamart : DEBUGЗапуск модуля
Перед запуском модуля необходимо убедиться, что на сервере с ОС Centos установлена Java. Если Java отсутствует на сервере, то запустить модуль BLOB-адаптера не получится. Чтобы установить Java на сервер необходимо воспользоваться командой:
$ sudo yum install java-11-openjdk-devel Для того, чтобы проверить наличие на сервере установленное ПО Java, а также узнать версию Java, необходимо воспользоваться командой:
$ java -version 
Рисунок 2 – Результат проверки версии установленного ПО Java.
Для ручного запуска модуля необходимо подключиться по ssh на сервер, перейти в директорию расположения jar-файла, например:
$ cd /opt/blob-adapter И запустить модуль командой:
$ java -jar blob-adapter.jar -migrate application.yaml В результате выполнения указанных выше команд запустится загрузчик модулей.
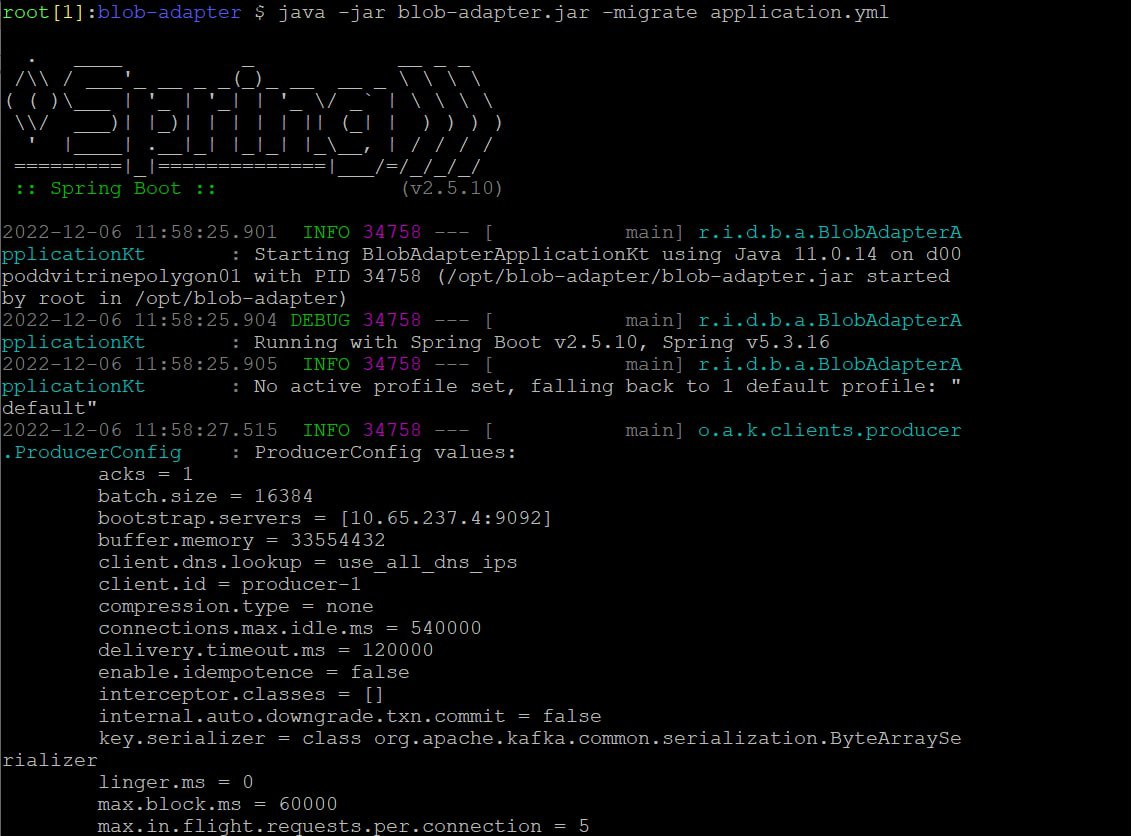
Рисунок 3 – Запуск загрузчика модулей.
Необходимо дождаться завершения установки.
Проверка модуля
Для проверки модуля BLOB-адаптер необходимо выполнить запрос к сервису.
curl -s IP:Port/metrics | grep ‘^liveness ‘ - IP — адрес сервера.
- Port — адрес сервера.
- liveness — параметр проверки работоспособности модуля.
curl -s http://172.16.10.67:9837/metrics | grep ‘^liveness ‘ Пример успешного ответа:
liveness 1.0 Ответ «1» означает, что модуль работает.
Остановка модуля
Для ручной остановки необходимо подключиться по ssh на сервер, найти процесс, который содержит jar-файл и остановить его.
ps aux | grep blob-adapter «kill» «номер процесса»
Спецификация модуля «BLOB-адаптер»
Запрос на считывание BLOB
Настоящая спецификация определяет формат обмена электронными сообщениями через BLOB-адаптер. Описывает возможность запроса на считывание BLOB-объект по полученной ссылке, получения успешного ответа на чтение содержимого BLOB или ошибки, в случае невозможности считывания, с описанием причины ошибки.
Запросы на считывание BLOB’а по ссылке.
Содержимое BLOB’а (ответ на запрос).
Сообщения об ошибке считывания.
Для строковых параметров используется кодировка UTF-8.
Настоящая спецификация определяет формат обмена электронными сообщениями через BLOB-адаптер.
Топик blob.rq — определяет запрос на считывание BLOB-объект. Одно сообщение — один запрос. Один запрос — один BLOB-объект.
текст, содержит requestId, не используется.
Сериализация: в Avro (см. схему ниже.)
«type» : «record» ,
«name» : «BlobRequest» ,
«namespace» : «datamart.blob» ,
«fields» : [
«name» : «requestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «queryRequestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «reference» ,
«type» : «type» : «record» ,
«name» : «BinaryReference» ,
«namespace» : «query.result» ,
«fields» : [
«name» : «subRequestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «path» ,
«type» : «string»
>
]
>
>
]
>- requestId — UUID базового запроса;
- queryRequestId — UUID исходного запроса, в рамках которого была получена ссылка;
- reference — объект ссылки:
- subRequestId — UUID подзапроса, в рамках которого сформирована ссылка
- path — ссылка на тело BLOB’а (получена ранее запросом данных из Витрины).
Если размер BLOB’а в хранилище 0 Байтов, то мы ответ отправляем в BLOB.RS и при этом в сообщении Value будет пустым.
Настоящая спецификация определяет формат обмена электронными сообщениями через BLOB-адаптер.
В топике blob.rs передается содержимое BLOB-объекта. Запрос на считывание BLOB-объекта определяется в топике blob.rq. Успешный ответ на запрос передается только в случае успешного выполнения считывания содержимого BLOB-объекта. Один запрос — один ответ. Один ответ — несколько сообщений. Одно сообщение — один chunk.
Если размер BLOB’а в хранилище 0 Байтов, то ответ отправляется в BLOB.RS и при этом в сообщении Value будет пустым.
В случае ошибки считывания возвращается ошибка (топик blob.err).
- REQUEST_ID (содержание значения запроса)
- AGENT_CONSUMER_ID (содержит значение из запроса)
Сериализация: в Avro (см. схему ниже.)
массив байтов, являющихся фрагментом (с номером chunkNumber) запрошенного тела BLOB’а. Не сериализуется.
«type» : «record» ,
«name» : «BlobChunk» ,
«namespace» : «datamart.blob» ,
«fields» : [
«name» : «requestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «queryRequestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «chunkNum» ,
«type» : «int»
>,
«name» : «isLast» ,
«type» : «boolean»
>
]
>- requestId — значение копируется из соответствующего параметра запроса, на который дается этот ответ;
- queryRequestId — значение копируется из соответствующего параметра запроса, на который дается этот ответ;
- chunkNumber — номер фрагмента (начинается с 1);
- isLastChunk — признак последнего фрагмента.
Настоящая спецификация определяет формат обмена электронными сообщениями через BLOB-адаптер.
Топик blob.err используется в случае ошибки считывания BLOB-объекта. Негативный ответ на запрос — описание причины ошибки, передается только в случае неудачного выполнения считывания. Один запрос — один ответ. Один ответ — одно сообщение.
- REQUEST_ID (содержание значения запроса)
- AGENT_CONSUMER_ID (содержит значение из запроса)
строка, содержит значение параметра requestId из запроса.
Сериализация: в Avro (см. схему ниже.)
«type» : «record» ,
«name» : «BlobError» ,
«namespace» : «datamart.blob» ,
«fields» : [
«name» : «requestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «queryRequestId» ,
«type» : «type» : «string» ,
«logicalType» : «uuid»
>
>,
«name» : «errorCode» ,
«type» : «string»
>,
«name» : «errorMessage» ,
«type» : «string»
>
]
>- requestId — значение копируется из соответствующего параметра запроса, на который дается этот ответ.
- queryRequestId — значение копируется из соответствующего параметра запроса, на который дается этот ответ;
- errorCode — код ошибки (формат DATAMART-ddddd, где ddddd — десятичные цифры кода ошибки);
- message — сообщение об ошибке.
Если http-запрос к хранилищу BLOB’ов вернул ошибку (код ответа не равен 200), то возвращенный код логируется (как ошибка), а в Kafka передается ( errorCode =DATAMART-17001, errorMessage= «Внутренняя ошибка» ). Если запрос вернул 200 , то ошибки нет и передаем ровно столько байтов, сколько вернул запрос (ноль байтов (пустой файл) не считается ошибкой).
Blob
Объект Blob представляет из себя подобный файлу объект с неизменяемыми, необработанными данными; они могут читаться как текст или двоичные данные, либо могут быть преобразованы в ReadableStream (en-US), таким образом, его методы могут быть использованы для обработки данных.
Blob-ы могут представлять данные, которые не обязательно должны быть в родном для JavaScript формате. Интерфейс File основан на Blob , наследует функциональность Blob и расширяет его для поддержки файлов на стороне пользователя.
Использование Blob
Для создания Blob не из объектов и данных blob, используйте конструктор Blob() . Чтобы создать blob из подмножества данных из другого blob, используйте метод slice() . Чтобы получить объект Blob для файла на файловой системе пользователя, смотрите документацию на File .
API, принимающие объекты Blob , также перечислены в документации на File .
Примечание: Метод slice() имеет изначально задаваемую длину как второй аргумент, что используется для указания числа байт копируемых в новый Blob. Если указать такие параметры start + length , которые превышают размер исходного Blob , то возвращаемый Blob будет содержать данные от начального индекса (start index) до конца исходного Blob.
Примечание: Следует помнить ,что метод slice() имеет сторонние префиксы в некоторых браузерах: blob.mozSlice() для Firefox 12 и ранее, так же blob.webkitSlice() в Safari. Старая версия метода slice() , без сторонних приставок, имеет другой алгоритм и устарела. Поддержка blob.mozSlice() была убрана в Firefox 30.
Конструктор
Возвращает создаваемый объект Blob, который содержит соединение всех данных в массиве, переданном в конструктор.
Свойства
Blob.isClosed Только для чтения Экспериментальная возможность
Логическое значение, показывающее, вызывался ли метод Blob.close() у blob. Закрытый blob не может быть прочитан.
Размер данных, содержащихся в объекте Blob , в байтах.
Строка с MIME-типом данных, содержащихся в Blob . Если тип неизвестен, строка пуста.
Методы
Blob.close() Экспериментальная возможность
Закрывает Blob объект, по возможности освобождая занятые им ресурсы.
Возвращает новый Blob объект, содержащий данные в указанном диапазоне байтов исходного Blob .
Возвращает ReadableStream (en-US), который может использоваться для чтения содержимого Blob .
Возвращает promise, который исполняется с USVString , содержащей всё содержимое Blob , интерпретируемое как текст UTF-8.
Примеры
Создание Blob
Конструктор Blob() constructor может создавать объекты blob из других объектов. Например, чтобы сконструировать blob из строки JSON:
const obj = hello: "world" >; const blob = new Blob([JSON.stringify(obj, null, 2)], type: "application/json", >);
Предупреждение: До того как конструктор Blob стал доступен, это могло быть выполнено через устаревший API BlobBuilder (en-US):
var builder = new BlobBuilder(); var fileParts = ['hey!']; builder.append(fileParts[0]); var myBlob = builder.getBlob("text/xml");
Создание URL для содержимого типизированного массива
Следующий код создаёт типизированный массив JavaScript и создаёт новый Blob , содержащий данные типизированного массива. Затем вызывается URL.createObjectURL() для преобразования blob в URL.
HTML
p> This example creates a typed array containing the ASCII codes for the space character through the letter Z, then converts it to an object URL. A link to open that object URL is created. Click the link to see the decoded object URL. p>
JavaScript
Основной частью этого кода для примера является функция typedArrayToURL() , которая создаёт Blob из переданного типизированного массива и возвращает объект URL для него. Преобразовав данные в URL объекта, их можно использовать несколькими способами, в том числе, в качестве значения атрибута src элементов (конечно, при условии, что данные содержат изображение).
function typedArrayToURL(typedArray, mimeType) return URL.createObjectURL(new Blob([typedArray.buffer], type: mimeType >)); > const bytes = new Uint8Array(59); for (let i = 0; i 59; i++) bytes[i] = 32 + i; > const url = typedArrayToURL(bytes, "text/plain"); const link = document.createElement("a"); link.href = url; link.innerText = "Open the array URL"; document.body.appendChild(link);
Другой пример
var typedArray = GetTheTypedArraySomehow(); var blob = new Blob([typedArray], type: "application/octet-binary" >); // pass a useful mime type here var url = URL.createObjectURL(blob); // url will be something like: blob:d3958f5c-0777-0845-9dcf-2cb28783acaf // now you can use the url in any context that regular URLs can be used in, for example img.src, etc.
Извлечение данных из Blob
Один из способов прочесть содержимое Blob – это использовать FileReader . Следующий код читает содержимое Blob как типизированный массив.
var reader = new FileReader(); reader.addEventListener("loadend", function () // reader.result contains the contents of blob as a typed array >); reader.readAsArrayBuffer(blob);
Другой способ прочитать содержимое из Blob – это использовать Response . Следующий код читает содержимое Blob как текст:
const text = await new Response(blob).text();
const text = await blob.text();
Используя другие методы FileReader , возможно прочесть содержимое объекта Blob как строку или как URL.
Спецификации
Specification File API
# blob-sectionСовместимость с браузерами
BCD tables only load in the browser
Смотрите также
- BlobBuilder (en-US)
- FileReader
- File
- URL.createObjectURL
- Components.utils.importGlobalProperties
- Использование файлов в веб-приложениях
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 3 авг. 2023 г. by MDN contributors.
Your blueprint for a better internet.
MDN
Support
- Product help
- Report an issue
Our communities
Developers
- Web Technologies
- Learn Web Development
- MDN Plus
- Hacks Blog
- Website Privacy Notice
- Cookies
- Legal
- Community Participation Guidelines
Visit Mozilla Corporation’s not-for-profit parent, the Mozilla Foundation.
Portions of this content are ©1998– 2023 by individual mozilla.org contributors. Content available under a Creative Commons license.Операции над BLOB данными
Interbase поддерживает следующие операции над BLOB данными:
- Чтение из BLOB.
- Вставка новой строки включающей BLOB данные
- Замена данных ссылающихся на BLOB столбец.
- Обновление данных ссылающихся на BLOB столбец.
- Удаление BLOB.
API Функции динамического SQL (DSQL) и структура данных XSQLD A необходимы, чтобы выполнить SELECT, INSERT, и инструкции UPDATE, требующиеся, чтобы выбирать, вставлять, или модифицировать уместные данные Blob.
6.1.Чтение данных из BLOB.
Эти шесть шагов требуются для чтения данных из существующего BLOB:
1. Создается обычная инструкция SELECT для выбора строки содержащей BLOB столбец.
2. Подготавливается структура для вывода данных XSQLDA.
3. Подготавливается SELECT инструкция.
4. Выполняется инструкция.
5. Выбираем строки одну задругой
6. Читаем и обрабатываем BLOB данные для каждой строки.
Опишем все это подробнее, для непонимающих.
6.2.Создание SELECT инструкции
«SELECT PROJ_NAME, PROJ_DESC, PRODUCT FROM PROJECT WHERE \
PRODUCT IN («software», «hardware»,»other») ORDER BY PROJ_NAME»;
Подготовка структуры вывода XSQLDA
1. Объявляем переменную содержащую XSQLDA
2. Выделяем память
out_sqlda = (XSQLDA *)malloc(XSQLDA_LENGTH(3));
3.Ставим версию и число выходных параметров
Подготовка SELECT инструкции для выполнения
После создания XSQLDA для содержания данных столбцов каждой выбранной строки,
Строку инструкции нужно подготовить к выполнению.
1. Объявляем и инициализируем дескриптор SQL инструкции,
с помощью известной нам функции isc_dsql_allocate_statement():
isc_stmt_handle stmt; /*Объявление дескриптора инструкции */
stmt = NULL; /* Установка дескриптора в NULL перед выполнением */
3. Подготавливаем строку для выполнения с помощью isc_dsql_prepare(),которая проверяет строку(str) на синтаксические ошибки, переводит строку в формат для эффективного выполнения, и устанавливает в дескриптор инструкции (stmt) ссылку на этот созданный формат (blr что ли). Дескриптор инструкции используется позднее в функции isc_dsql_execute().
Если isc_dsql_prepare()передан указатель на XSQLDA вывода, как в следующем примере, она будет заполнять большинство полей в XSQLDA и всех подструктур XSQLVAR информацией о типа данных, длине, и имени столбца в инструкции.
Пример вызова isc_dsql_prepare():
&trans, /* Устанавливается предварительным вызовом isc_start_transaction()*/
&stmt, /*Дескриптор инструкции устанавливается в вызове этой функции. */
0, /* Определяет что инструкция- строка заканчивается 0*/
str, /* Инструкция — строка */
SQLDA_VERSION1,/* Номер версии XSQLDA */
out_sqlda /* XSQLDA для хранения данных столбцов после выполнения инструкции */
3. Устанавливаем XSQLVAR структуру для каждого столбца:
— Определяем тип столбца ( если он не был установлен isc_dsql_prepare())
— Связываем указатель структуры XSQLVAR sqldata с соответствующей локальной переменной.
Для столбцов чьи типы неизвестных этому моменту:
Приводим элементы типа данных(необязательно), к примеру, из SQL_VARYING к SQL_TEXT.
Динамически выделяем место для хранения данных на которые указывает sqldata
— Определяем число байт данных передаваемых в sqldata
— Предоставляем значение NULL индикатора для параметров
Выбранные данные для Blob (и массивов)столбцов отличаются от других типов столбцов, так что поля XSQLVAR должны быть установлены по-другому. Для не -BLOB (и не массивов) столбцов, isc_dsql_prepare () устанавливают для каждый sqltype к соответствующему типу поля, и выбранные данные помещаются в область памяти на которую указывают соответствующие sqldata, при каждой операции fetch. Для столбцов Blob, тип должен быть установлен в SQL _Blob (или SQL _Blob + 1, если нужен индикатор NULL). InterBase сохраняет внутренний идентификатор Blob (BlobID), а не данные Blob, в памяти на которую кажет sqldata, когда строки данных выбраны, так что sqldata должна указывать на память с размером нужным для хранения BlobID.
Следующий пример кода иллюстрирует назначения для Blob и столбцов не-Blob, чей тип известен ко времени компиляции.
#define PROJLEN 20
#define TYPELEN 12
char proj_name[PROJLEN + 1];
char prod_type[TYPELEN + 1];
short flag0, flag1, flag2;
out_sqlda->sqlvar[0].sqltype = SQL_TEXT + 1;
out_sqlda->sqlvar[1].sqltype = SQL_Blob + 1;
out_sqlda->sqlvar[2].sqltype = SQL_TEXT + 1;
Выполнение инструкции
После того как инструкция подготовлена можно ее выполнить.
&trans, /* Устанавливается предварительным вызовом isc_start_transaction()*/
&stmt, /* выделяется isc_dsql_allocate_statement() */
1, /* XSQLDA version number */
NULL/* NULL так как нет входных параметров */
Эта инструкция создает список выбора, это строки возвращаемые после выполнения инструкции.
6.2.Извлечение выбранных строк
Конструкция цикла извлечения используется, чтобы извлечь(в XSQLDA вывода) данные столбцов для отдельной строки из списка выбора и обработать каждую строку прежде, чем следующая строка будет выбрана. Каждое выполнение isc_dsql_fetch () выбирает данные столбцов соответствующие подструктуры XSQLVAR структуры out_sqlda. Для столбца Blob, выбирается BlobID не являющийся фактическими данными, а просто указатель на них.
isc_dsql_fetch(status_vector, &stmt,1, out_sqlda))
printf(«\nPROJECT: %–20s TYPE:%–15s\n\n»,
/* Read and process the Blob data (seenext section) */
if (fetch_stat != 100L)
/* isc_dsql_fetch returns 100 if no morerows remain to be
Чтение и обработка BLOB данных
Для чтения и обработки BLOB данных
Объявите и инициализируйте BLOB дескриптор
isc_blob_handle blob_handle; /* Объявление BLOB дескриптора. */
blob_handle= NULL; /* Уставите его в NULL перед использованием*/
Создайте буфер для хранения каждого прочитанного BLOB сегмента. Его размер должен быть максимальным размером сегмента в вашей программе используемой для чтения BLOB.
3. Объявите беззнаковую short переменную в которую IB будет хранить фактическую длину каждого прочитанного сегмента:
unsigned short actual_seg_len;
4. Открываем BLOB c извлеченным ранее blob_id
&blob_handle,/*Устанавливается этой функцией для ссылки на BLOB */
&blob_id,/* Blob ID полученный из out_sqlda которую заполнил isc_dsql_fetch() */
0,/* BPB length = 0; фильтр не будем использовать */
NULL/* NULL BPB, фильтр не будем использовать */
5.Читаем все BLOB данные вызывая повторно isc_get_segment(), берущую каждый Blob сегмент и его длину. Обрабатываем каждый прочитаны сегмент.
&blob_handle, /* Устанавливается isc_open_blob2()*/
&actual_seg_len,/* Длина прочитанного сегмента */
sizeof(blob_segment),/* Длина буфера сегмента */
blob_segment/* буфер сегмента */
while (blob_stat == 0 ||status_vector[1] == isc_segment)
/*isc_get_segment возвращает 0 если сегмент был полностью прочитан.
/*status_vector[1] устанавливается в isc_segment только часть */
/*сегмента была прочитана из-за буфера (blob_segment) не являющегося */
/*достаточно большим. В этом случае придется делать дополнительные вызовы */
/*isc_get_segment() для дочитывания. */
printf(«%*.*s»,actual_seg_len, actual_seg_len, blob_segment);
blob_stat =isc_get_segment(status_vector, &blob_handle,
6. Закрываем BLOB
6.2.Запись данных в BLOB
Перед тем как создать новый BLOB и записать туда данные вы должны сделать следующее.
Включить BLOB данные в строку вставляемую в таблицу
Заменить данные ссылающиеся на BLOB столбец строки
Обновить данные ссылающиеся на BLOB столбец строки
Вносимый в столбец Blob фактически не содержит данных Blob. Он содержит BlobID ссылающийся на данные, которые сохранены в другом месте. Так, чтобы установить или изменить столбец Blob, Вы должны установить (или сбросить) BlobID, сохраненный в нем. Если столбец Blob содержит BlobID, и Вы изменяете столбцы относящиеся к различным Blob (или содержащим NULL), Blob на который ссылается предварительно сохраненный BlobID будет удален в течение следующей сборки «мусора».(. )
Все эти операции требуют следующих шагов:
1. Подготовьте соответствующую инструкцию DSQL. Это будет инструкция INSERT, если Вы вставляете новую строку в таблицу, или инструкция UPDATE для изменения строки. Каждая из этих инструкций будет нуждаться в соответствующей структуре ввода XSQLDA для передачи параметров инструкции во время выполнения. BlobID нового Blob будет одним переданных значений
2. Создайте новый BLOB, и запишите в него данные.
3. Свяжите BLOB ID нового BLOB со столбцом таблицы строк над которой вы будете выполнять INSERT и UPDATE.
Примечание: вы не можете непосредственно обновлять BLOB данные. Если вы желаете модифицировать BLOB данные, вы должны:
Создать новый BLOB
Прочитать данные из старого BLOBA в буфер где вы сможете отредактировать и модифицировать их.
Записать измененные данные в новый BLOB.
Подготовить и выполнить инструкцию UPDATE которая модифицирует BLOB столбец содержащий BLOBID нового BLOB, заменяющий старый BLOB ID.
Секция ниже описывает шаги требуемые для вставки, обновления, и замены BLOB данных.
Подготовка UPDATE или INSERT инструкции.
1. Создаем саму строку для обновления
«UPDATE PROJECT SET PROJ_DESC = ? WHERE PROJ_ID = ?»;
или для вставки
char *in_str = «INSERT INTO PROJECT(PROJ_NAME, PROJ_DESC, PRODUCT,
2. Объявляем переменную содержащую структуру входных параметров
3. in_sqlda = (XSQLDA*)malloc(XSQLDA_LENGTH(2));
4. in_sqlda->version = SQLDA_VERSION1;
5.Установить XSQLVAR структуру в XSQLDA для каждого передаваемого параметра.
Определяем типы данных элементов
Для параметров типы которых известны во время компиляции: указатель sqldata связываем с локальной переменной содержащей передаваемый данные.
Для параметров типы которых неизвестны во время выполнения: выделяем память для хранения данных на которые указывает sqldata
Определяем число байт данных(размер)
Следующий код иллюстрирует все это для столбца BLOB и одного столбца тип данных которого известен во время компиляции.
#define PROJLEN 5
char proj_id[PROJLEN + 1];
in_sqlda->sqlvar[0].sqltype =SQL_Blob + 1;
Proj_id должна быть инициализирована во время выполнения (если значение не известно во времени компиляции). Blob_id должна быть установлена, чтобы обращаться к недавно созданному Blob, как описано в следующих секциях
Создание нового BLOB и хранения данных
1. Объявление и инициализация BLOB дескриптора:
isc_blob_handle blob_handle; /* Объявления BLOB дескриптора */
blob_handle= NULL; /* Устанавливаем дескриптор в NULL перед использованием*/
2. Объявление и инициализация BLOB ID:
ISC_QUAD blob_id; /* Объявление Blob ID. */
blob_id= NULL; /* Установка его в NULL перед использованием*/
3. Создание нового BLOB вызовомisc_create_blob2():
&blob_handle,/* устанавливается этой функцией ссылка на новый Blob */
&blob_id,/* Blob ID устанавливается этой функцией*/
0, /* Blob Parameter Buffer length = 0;no filter will be used*/
NULL /* NULL Blob Parameter Buffer, since no filter will be used*/
Эта функция создает новый BLOB открывает его для записи, и устанавливает blob_handle к указателю на новый BLOB
isc_create_blob2() также связывает BLOB с BLOBID, и устанавливает blob_id к указателю на BLOBID.
4. Записываем все данные, которые будут записаны в Blob, делая ряд вызовов isc_put_segment (). Следующий пример читает строки данных, и связывает каждый Blob с упомянутым blob_handle. (Get_line () читает следующую строку данных, которые будут написаны.)
unsigned short len;
&blob_handle,/* set by previousisc_create_blob2() */
len,/* длина буфера содержащего данные для записи */
line/* буфер содержащий данные для записи в BLOB*/
if (status_vector[0] == 1 &&status_vector[1])
5. Закрываем BLOB
Связывание нового BLOB с BLOB столбцом
Выполнение инструкции UPDATE связывает новый BLOB с BLOB столбцом в строке выбранной инструкции.
6.3.Удаление BLOB
существуют четыре способа удаления BLOB.
Удаляем строку содержащую BLOB. Вы можете использовать DSQL для выполнения DELETE инструкции.
Заменяем различные BLOB. Если Blob столбец содержит BlobID, и вы модифицируете столбец ссылающийся на разные BLOB, ранее сохраненный BLOB будет удален следующей сборкой “мусора”.
Сбрасываем в NULL столбец ссылающийся на BLOB, к примеру, используя DSQL инструкцию как следующую:
UPDATE PROJECT SET PROJ_DESC = NULLWHERE PROJ_ID = «VBASE»
Blob на который указывал удаленный blob_id будет удален следующей сборкой «мусора»
— Отказываемся от BLOB, после того как он был создан но, не был связан еще с определенным столбцом в таблице, используя isc_cancel_blob() функцию.
Запрос информации об открытом BLOB
После того, как приложение открывает Blob, оно может получить информацию о Blob.
Isc_blob_info () позволяет приложению сделать запрос для информации о Blob типа общего количества
числа сегментов в Blob, или о длине, в байтах, самого длинного сегмента. В дополнение к указателю на вектор состояния ошибки и дескриптор Blob, isc_blob_info () требует двух предоставляемых приложением буферов, буфера списков элементов, где приложение определяет информацию, которая требуется, и буфер результатов, куда InterBase возвращает требуемую информацию. Приложение заполняет буфер списков элементов с информационными запросами для isc_blob_info(), и передает ему указатель на буфер списков элементов, а также размер, в байтах, этого буфера.
Приложение должно также создать буфер результата, достаточно большой, чтобы хранить информацию, возвращенную InterBase. Оно передает указатель на буфер результата, и размер, в байтах, этого буфера в isc_blob_info(). Если InterBase пытается поместить, больше информации чем может вместить буфер результатов, она помещает значение, isc_info_truncated, определенное в ibase.h, в последний байт буфера результатов.
Буфер списка элементов запрашиваемой информации и буфер результатов.
Буфер списка элементов это char массив содержащий запрашиваемые байты значений. Каждый байт есть пункт определяющий тип желаемой информации.
Соответствующие константны определены в ibase.h
#define isc_info_blob_num_segments 4
#define isc_info_blob_max_segment 5
#define isc_info_blob_total_length 6
#define isc_info_blob_type 7
Буфер результатов содержит серию кластеров информации по каждому запрошенному элементу. Каждый кластер содержит три части.
Первый байт определяет тип возвращенной информации.
Второй байт – число определяющее число байт до конца кластера (длина инфо)
Значение хранимое в переменном числе байт, которое интерпретируется в зависимости от типа первого байта кластера
Следующая таблица показывает элементы информацию о которых можно получить
Элемент Возвращаемое значение
Запрашиваемый и возвращаемый элемент
Возвращаемое значение
Полное число сегментов
Длина самого длинного сегмента
Полный размер в байтах BLOB
Тип BLOB(0:сегментированный, 1:поток)
В дополнение к этой информации IB возвращенной ответ на запрос, IB может также возвратить один или несколько сообщений состояния в буфер результата. Каждое сообщение состояния есть беззнаковый байт в длине
Результирующий буфер слишком маленький для хранения запрашиваемой информации
Запрашиваемая информация неопеределена. Проверьте status_vector и сообщения.
6.4.Пример вызова isc_blob_info( )
Следующий код запрашивает число сегментов и максимальный размер сегмента для BLOB после открытия, получаемая информация помещается в буфер результатов
char res_buffer[20], *p, item;
SLONG max_size = 0L, num_segments = 0L;
&db_handle, /* database handle, setby isc_attach_database() */
&tr_handle, /* transaction handle, setby isc_start_transaction()
&blob_handle, /* set by thisfunction to refer to the Blob */
&blob_id, /* Blob ID of the Blob toopen */
0, /* BPB length = 0; no filter will beused */
NULL /* NULL BPB, since no filter willbe used */
if (status_vector[0] == 1 &&status_vector[1])
&blob_handle, /* Set inisc_open_blob2() call above. */
sizeof(blob_items),/* Length ofitem-list buffer. */
blob_items, /* Item-list buffer. */
sizeof(res_buffer),/* Length of resultbuffer. */
res_buffer /* Result buffer */
if (status_vector[0] == 1 &&status_vector[1])
/* An error occurred. */
/* Extract the values returned in theresult buffer. */
for (p = res_buffer; *p != isc_info_end;)
length = (short)isc_vax_integer(p, 2);
max_size = isc_vax_integer(p, length);
6.5.Blob дескрипторы
Blob дескриптор используется для предоставления динамического доступа к BLOB информации. К примеру, он может быть использован для хранения информации о BLOB данных для фильтрации, еще как кодовая страница для текстовых BLOB данных и информации о подтипе текстовых данных и не текстовых данных.
Два дескриптора Blob необходимы всякий раз, когда фильтр используется при записи или чтении Blob: один описывать данные источника фильтра, и другой цель.
BLOB дескриптор это структура определенная в заголовочном файле ibase.h как следующая:
short blob_desc_subtype; /* type of Blobdata */
short blob_desc_charset; /* characterset */
short blob_desc_segment_size; /* segmentsize */
unsigned char blob_desc_field_name [32];/* Blob column name */
unsigned char blob_desc_relation_name[32]; /* table name */
Размер сегмента BLOB есть максимальное число байт в приложении
Размер сегмента Blob -максимальное число байтов, которые приложение, как ожидается, запишет или будет читать из Blob. Вы можете использовать этот размер, чтобы выделить ваши собственные буфера. Blob_desc_relation_name и blob_desc_field_name поля содержащие строки с нулевым символом в конце.
Заполнение blob дескриптора
Есть четыре варианта для заполнения blob дескриптора
Вызываем isc_blob_default_desc(). И заполняем ей поля дескриптора значениями по умолчанию. Подтип по умолчанию есть 1 (TEXT), сегмент размером 80 байт, кодовая страница по умолчанию есть страница установленная для вашего процесса.
Вызываем isc_blob_lookup_desc(). Она обращается к системным таблицам и берет оттуда информацию о BLOB и заполняет ею поля дескриптора.
Вызываем isc_blob_set_desc(). Она инициализирует дескриптор из параметров вызова, быстрее нежели получать доступ к метаданным.
Устанавливаем поля дескриптора напрямую.
Следующий пример вызывает isc_blob_lookup_desc () чтобы узнать текущий подтип и информацию о наборе символов для столбца Blob по имени PROJ_DESC в таблице PROJECT. Функция сохраняет информацию в исходном описателе from_desс.
&db_handle; /* Set by previousisc_attach_database() call. */
&tr_handle, /* Set by previousisc_start_transaction() call. */
«PROJECT», /* имя таблицы */
«PROJ_DESC»,/* название столбца */
&from_desc,/* Blob дескриптор заполняется этой функцией. */
&global/* глобальное название колонки возвращаемое этой функцией */
Фильтрация BLOB данных
Фильтр Blob это подпрограмма, которая транслирует данные Blob из одного подтипа в другой.
InterBase включает набор специальных внутренних фильтров Blob, которые преобразовывают подтип 0
( Неструктурные данные) в подтип1 (ТЕКСТ), и из подтипа 1 к подтипу 0.
В дополнение к использованию этих стандартных фильтров, Вы можете создавать ваши собственные внешние фильтры, чтобы обеспечивать специальное конвертирование данных. Например, Вы могли бы разрабатывать фильтр, чтобы преобразовывать один формат изображения к другому, например отображать то же самое изображение на мониторах с различными разрешающими способностями. Или Вы могли бы конвертировать двоичный Blob к простому тексту , чтобы легко файл переносить от одной системы к другой. Если Вы определяете фильтры, Вы можете назначать их идентификаторы подтипа от -32,768 до -1. Следующие разделы дают краткий обзор того, как писать фильтры Blob, и сопровождаются подробностями , как написать приложение, которое требует фильтрации.
Обратите внимание, что фильтры Blob доступны для баз данных, находящихся на всех платформах сервера InterBase кроме Системы Netware, где фильтры Blob не могут быть созданы.
6.6.Использование ваших собственных фильтров
В отличие от стандарта фильтров InterBase, которые конвертируют подтипом 0 в подтип 1 и наоборот, внешний фильтр Blob — вообще часть библиотеки подпрограмм, которые Вы создаете и связываете с приложением. Вы можете писать, Blob на C или Паскаль (или любой язык, который может называться из C).Чтобы использовать ваши собственные фильтры, следуйте по этим шагами:
1. Решите, какой фильтр Вы, должны написать.
2. Напишите фильтры в базовом языке.
3. Сформируйте общедоступную библиотеку фильтров.
4. Сделайте библиотеку фильтров доступной.
5. Определить фильтры для базы данных.
6. Напишите приложение, которое требует фильтрацию.
Шаги 2, 5 и 6 будут лучшеописаны в следующих разделах.
6.7.Объявление внешнего фильтра BLOB для БД
Для объявления внешнего фильтра для БД, используйте инструкции DECLARE FILTER. К примеру, следующая инструкция объявляет фильтр, SAMPLE:
DECLARE FILTER SAMPLE
INPUT TYPE –1 OUTPUT_TYPE –2
ENTRY POINT «FilterFunction»
В примере, входной подтип фильтра определен как -1 и его выходной подтип как -2. Если подтип -1определяет текст нижнего регистра, а подтип -2 текст верхнего регистра, то цель фильтра SAMPLE состояла бы в том, чтобы перевести данные Blob из текста нижнего регистра в текст верхнего регистра.
Параметры ENTRY_POINT И MODULE_NAME определяют внешнюю подпрограмму, которую вызывает, когда вызывается фильтр. Параметр MODULE_NAME определяет filter.dll, динамически загружаемую библиотеку, содержащую выполнимый код фильтра. Параметр ENTRY_POINT определяет точку входа в DLL. Хотя пример показывает только простое имя файла, это — хорошая практика для определения полного квалифицированного пути, начиная с пользователей вашего приложения желающих загрузить файл.
6.8.Создание внешних Blob фильтров
Если Вы хотите создавать ваши собственные фильтры, Вы должны иметь детальное понимание типов данных , которые Вы планируете конвертировать. InterBase не делает строгой проверки типа данных на данные Blob; это — ваша ответственность.
Определений функций фильтров
При написании фильтра, Вы должны включить точку входа, известной функции фильтра, в секции объявления программы. InterBase вызывает функцию фильтра, когда приложение выполняет операции на Blob, определенные для использования фильтра. Вся связь между InterBase и фильтром происходит через функцию фильтра. Функция самого фильтра может вызывать другие функции, которые включает исполняемая программу фильтра.
Вы объявляете имя функции фильтра и имя выполняемой программы — фильтра с параметрами ENTRY_POINT И MODULE_NAME в инструкции DECLAREFILTER.
Функция фильтрадолжна иметь следующее объявление, вызывающее последовательность:
filter_function_name(short action, isc_blob_ctl control);
Параметр, action, является одним из восьми возможных макроопределений действия, и параметр, control- элемент isc_blob_ctl, управляющей структуры Blob, определенной в файле заголовка InterBase, ibase.h. Эти параметры обсуждаются позже в этой главе.
Следующий листинг скелетного фильтра описывает функцию фильтра, jpeg_filter:
#define SUCCESS 0
#define FAILURE 1
ISC_STATUS jpeg_filter(short action, isc_blob_ctl control)
ISC_STATUS status = SUCCESS;
InterBase передает одно из восьми возможных действий к функции фильтра, jpeg_filter, посредством параметра action, и также передает экземпляр управляющей структуры Blob, isc_blob_ctl, посредством параметра, control. ellipses (…) в предыдущем листинге представляют код, который выполняет некоторые операции, для каждого действии, или случая, который перечислен в инструкции case.
6.9.Определение управляющей структуры BLOB
Управляющая структура BLOB предоставляет основные методы обмена данными между фильтром и Interbase.
Управляющая структура BLOB определена при помощи typedef, isc_blob_ctl. в ibase.h вот так:
typedef struct isc_blob_ctl
/* Указатель на внутреннюю InterBase Blob подпрограмму доступа.(функтор) */
struct isc_blob_ctl *ctl_source_handle;
/* Экземпляр ofisc_blob_ctl передаваемый во внутреннюю подпрограмму доступа IB*/
short ctl_to_sub_type;/* Целевой подтип */
short ctl_from_sub_type;/* Исходный подтип */
unsigned short ctl_buffer_length; /* Длина ctl_buffer. */
unsigned short ctl_segment_length; /* Длина текущего сегмента */
unsigned short ctl_bpb_length; /* Длина буфера параметров BLOB. */
char *ctl_bpb; /* Указатель на буфер параметров BLOB */
unsigned char*ctl_buffer; /* Указатель на сегментный буфер */
ISC_LONGctl_max_segment; /* Длина самого длинного BLOB сегмента */
ISC_LONGctl_number_segments; /* Полное число сегментов */
ISC_LONGctl_total_length; /* Полная длина BLOB*/
ISC_STATUS*ctl_status;/* Указатель на статус вектор */
long ctl_data[8];/* Данные определяемые приложением */
Семантика некоторых isc_blob_ctl полей зависит от выполняемого действия.
Например, когда приложение вызывает isc_put_segment () функцию API, InterBase передает isc_blob_filter_put_segment — действие функции фильтра. Буфер, указатель на буфер, ctl_buffer — поле управляющей структуры, передаваемый функции фильтра, содержит сегмент данных, которые будут записано, как определено приложением в его запросе к isc_put_segment (). Поскольку буфер содержит информацию, передаваемую в функцию фильтра, это называется полем IN. Функция фильтра должна включить инструкции в инструкцию case под isc_blob_filter_put_segment для выполнения фильтрации и затем передачи данных для записи в базу данных. Это может быть сделано, вызовом *ctl_source подпрограммы доступной внутри Interbase подпрограммы. Для подробной информации относительно ctl_source, см. Руководство Программиста.
С другой стороны, когда приложение вызывает isc_get_segment () функцию API, и буфер, на него указывает ctl_buffer в управляющей структуре переданной функции фильтра, пуст. В этом случае, InterBase передает isc_blob_filter_get_segment действие- функции фильтра. Обработка действия- функции isc_blob_filter_get_segment фильтра должна включить команды для заполнения ctl_buffer сегментом данных из базы данных, чтобы возвратить его приложению. Это может быть сделано, вызовом *ctl_source подпрограммы доступной внутри IB. В этом случае, буфер используется для вывода информации функцией фильтра, и называется полем OUT.
Следующая таблица описывает каждое из полей в isc_blob_ctl управляющей структуре Blob, используются ли они для ввода функции фильтра (IN), или вывода (OUT).