1.3 Введение — Что такое Git?
Что же такое Git, если говорить коротко? Очень важно понять эту часть материала, потому что если вы поймёте, что такое Git и основы того, как он работает, тогда, возможно, вам будет гораздо проще его использовать. Пока вы изучаете Git, попробуйте забыть всё, что вы знаете о других системах контроля версий, таких как Subversion и Perforce. Это позволит вам избежать определённых проблем при использовании инструмента. Git хранит и использует информацию совсем иначе по сравнению с другими системами, даже несмотря на то, что интерфейс пользователя достаточно похож, и понимание этих различий поможет вам избежать путаницы во время использования.
Снимки, а не различия
Основное отличие Git от любой другой системы контроля версий (включая Subversion и её собратьев) — это подход к работе со своими данными. Концептуально, большинство других систем хранят информацию в виде списка изменений в файлах. Эти системы (CVS, Subversion, Perforce, Bazaar и т. д.) представляют хранимую информацию в виде набора файлов и изменений, сделанных в каждом файле, по времени (обычно это называют контролем версий, основанным на различиях).
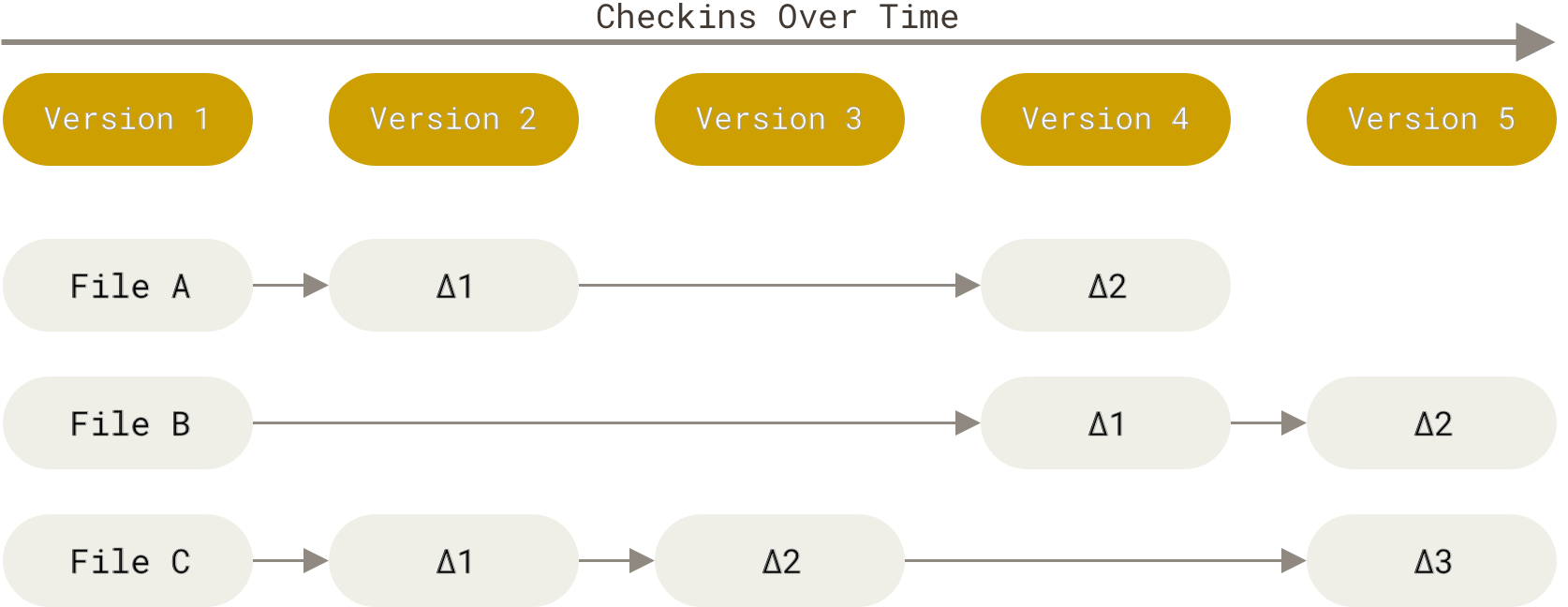
Рисунок 4. Хранение данных как набора изменений относительно первоначальной версии каждого из файлов
Git не хранит и не обрабатывает данные таким способом. Вместо этого, подход Git к хранению данных больше похож на набор снимков миниатюрной файловой системы. Каждый раз, когда вы делаете коммит, то есть сохраняете состояние своего проекта в Git, система запоминает, как выглядит каждый файл в этот момент, и сохраняет ссылку на этот снимок. Для увеличения эффективности, если файлы не были изменены, Git не запоминает эти файлы вновь, а только создаёт ссылку на предыдущую версию идентичного файла, который уже сохранён. Git представляет свои данные как, скажем, поток снимков.
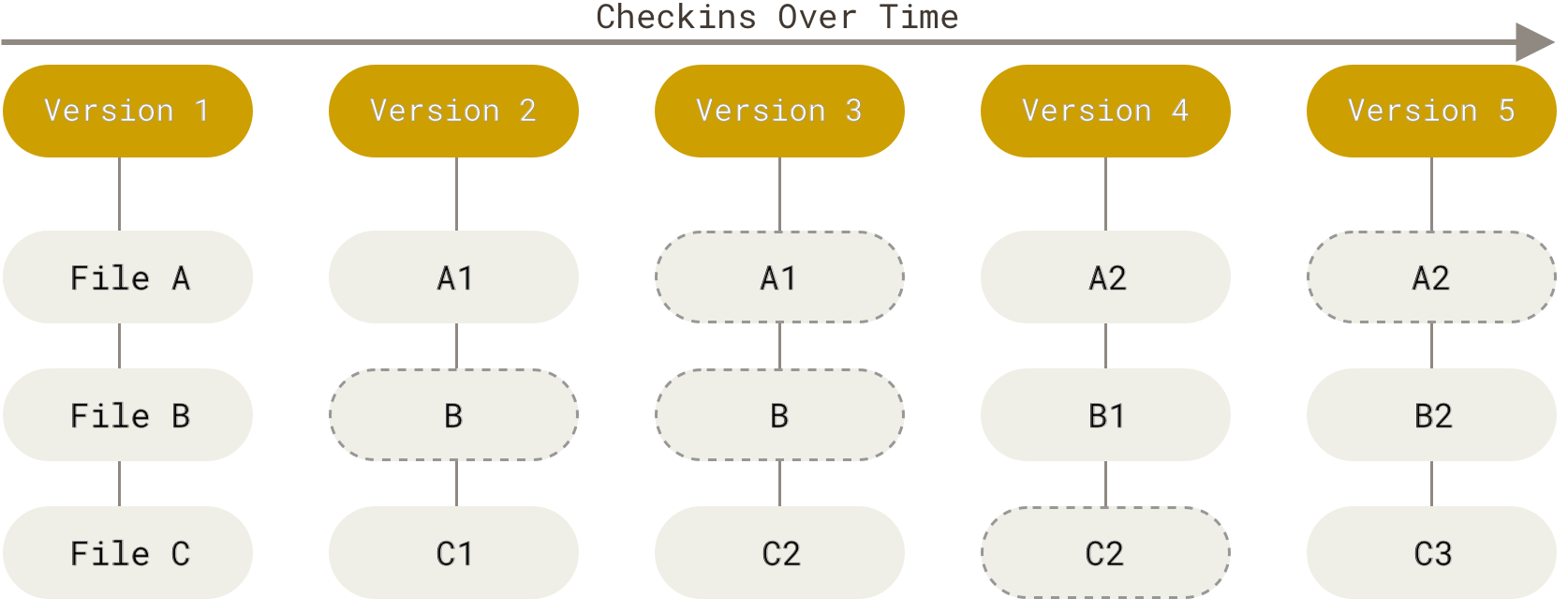
Рисунок 5. Хранение данных как снимков проекта во времени
Это очень важное различие между Git и почти любой другой системой контроля версий. Git переосмысливает практически все аспекты контроля версий, которые были скопированы из предыдущего поколения большинством других систем. Это делает Git больше похожим на миниатюрную файловую систему с удивительно мощными утилитами, надстроенными над ней, нежели просто на VCS. Когда мы будем рассматривать управление ветками в главе Ветвление в Git, мы увидим, какие преимущества вносит такой подход к работе с данными в Git.
Почти все операции выполняются локально
Для работы большинства операций в Git достаточно локальных файлов и ресурсов — в основном, системе не нужна никакая информация с других компьютеров в вашей сети. Если вы привыкли к централизованным системам контроля версий, где большинство операций страдают от задержек из-за работы с сетью, то этот аспект Git заставит вас думать, что боги скорости наделили Git несказанной мощью. Так как вся история проекта хранится прямо на вашем локальном диске, большинство операций кажутся чуть ли не мгновенными.
Для примера, чтобы посмотреть историю проекта, Git не нужно соединяться с сервером для её получения и отображения — система просто считывает данные напрямую из локальной базы данных. Это означает, что вы увидите историю проекта практически моментально. Если вам необходимо посмотреть изменения, сделанные между текущей версией файла и версией, созданной месяц назад, Git может найти файл месячной давности и локально вычислить изменения, вместо того, чтобы запрашивать удалённый сервер выполнить эту операцию, либо вместо получения старой версии файла с сервера и выполнения операции локально.
Это также означает, что есть лишь небольшое количество действий, которые вы не сможете выполнить, если вы находитесь оффлайн или не имеете доступа к VPN в данный момент. Если вы в самолёте или в поезде и хотите немного поработать, вы сможете создавать коммиты без каких-либо проблем (в вашу локальную копию, помните?): когда будет возможность подключиться к сети, все изменения можно будет синхронизировать. Если вы ушли домой и не можете подключиться через VPN, вы всё равно сможете работать. Добиться такого же поведения во многих других системах либо очень сложно, либо вовсе невозможно. В Perforce, для примера, если вы не подключены к серверу, вам не удастся сделать многого; в Subversion и CVS вы можете редактировать файлы, но вы не сможете сохранить изменения в базу данных (потому что вы не подключены к БД). Всё это может показаться не таким уж и значимым, но вы удивитесь, какое большое значение это может иметь.
Целостность Git
В Git для всего вычисляется хеш-сумма, и только потом происходит сохранение. В дальнейшем обращение к сохранённым объектам происходит по этой хеш-сумме. Это значит, что невозможно изменить содержимое файла или каталога так, чтобы Git не узнал об этом. Данная функциональность встроена в Git на низком уровне и является неотъемлемой частью его философии. Вы не потеряете информацию во время её передачи и не получите повреждённый файл без ведома Git.
Механизм, которым пользуется Git при вычислении хеш-сумм, называется SHA-1 хеш. Это строка длиной в 40 шестнадцатеричных символов (0-9 и a-f), она вычисляется на основе содержимого файла или структуры каталога. SHA-1 хеш выглядит примерно так:
24b9da6552252987aa493b52f8696cd6d3b00373Вы будете постоянно встречать хеши в Git, потому что он использует их повсеместно. На самом деле, Git сохраняет все объекты в свою базу данных не по имени, а по хеш-сумме содержимого объекта.
Git обычно только добавляет данные
Когда вы производите какие-либо действия в Git, практически все из них только добавляют новые данные в базу Git. Очень сложно заставить систему удалить данные либо сделать что-то, что нельзя впоследствии отменить. Как и в любой другой системе контроля версий, вы можете потерять или испортить свои изменения, пока они не зафиксированы, но после того, как вы зафиксируете снимок в Git, будет очень сложно что-либо потерять, особенно, если вы регулярно синхронизируете свою базу с другим репозиторием.
Всё это превращает использование Git в одно удовольствие, потому что мы знаем, что можем экспериментировать, не боясь серьёзных проблем. Для более глубокого понимания того, как Git хранит свои данные и как вы можете восстановить данные, которые кажутся утерянными, см. Операции отмены.
Три состояния
Теперь слушайте внимательно. Это самая важная вещь, которую нужно запомнить о Git, если вы хотите, чтобы остаток процесса обучения прошёл гладко. У Git есть три основных состояния, в которых могут находиться ваши файлы: изменён (modified), индексирован (staged) и зафиксирован (committed):
- К изменённым относятся файлы, которые поменялись, но ещё не были зафиксированы.
- Индексированный — это изменённый файл в его текущей версии, отмеченный для включения в следующий коммит.
- Зафиксированный значит, что файл уже сохранён в вашей локальной базе.
Мы подошли к трём основным секциям проекта Git: рабочая копия (working tree), область индексирования (staging area) и каталог Git (Git directory).

Рисунок 6. Рабочая копия, область индексирования и каталог Git
Рабочая копия является снимком одной версии проекта. Эти файлы извлекаются из сжатой базы данных в каталоге Git и помещаются на диск, для того чтобы их можно было использовать или редактировать.
Область индексирования — это файл, обычно находящийся в каталоге Git, в нём содержится информация о том, что попадёт в следующий коммит. Её техническое название на языке Git — «индекс», но фраза «область индексирования» также работает.
Каталог Git — это то место, где Git хранит метаданные и базу объектов вашего проекта. Это самая важная часть Git и это та часть, которая копируется при клонировании репозитория с другого компьютера.
Базовый подход в работе с Git выглядит так:
- Изменяете файлы вашей рабочей копии.
- Выборочно добавляете в индекс только те изменения, которые должны попасть в следующий коммит, добавляя тем самым снимки только этих изменений в индекс.
- Когда вы делаете коммит, используются файлы из индекса как есть, и этот снимок сохраняется в ваш каталог Git.
Если определённая версия файла есть в каталоге Git, эта версия считается зафиксированной (committed). Если файл был изменён и добавлен в индекс, значит, он индексирован (staged). И если файл был изменён с момента последнего распаковывания из репозитория, но не был добавлен в индекс, он считается изменённым (modified). В главе Основы Git вы узнаете больше об этих состояниях и какую пользу вы можете извлечь из них или как полностью пропустить часть с индексом.
10.2 Git изнутри — Объекты Git
Git — контентно-адресуемая файловая система. Здорово. Что это означает? А означает это, по сути, что Git — простое хранилище ключ-значение. Можно добавить туда любые данные, в ответ будет выдан ключ по которому их можно извлечь обратно.
В качестве примера, воспользуемся служебной командой git hash-object , которая берёт некоторые данные, сохраняет их в виде объекта в каталоге .git/objects (база данных объектов) и возвращает уникальный ключ, который является ссылкой на созданный объект.
Для начала создадим новый Git-репозиторий и убедимся, что каталог objects пуст:
$ git init test Initialized empty Git repository in /tmp/test/.git/ $ cd test $ find .git/objects .git/objects .git/objects/info .git/objects/pack $ find .git/objects -type fGit проинициализировал каталог objects и создал в нём пустые подкаталоги pack и info . Теперь с помощью git hash-object создадим объект и вручную добавим его в базу Git:
$ echo 'test content' | git hash-object -w --stdin d670460b4b4aece5915caf5c68d12f560a9fe3e4В простейшем случае git hash-object берёт переданный контент и возвращает уникальный ключ, который будет использоваться для хранения данных в базе Git. Параметр -w указывает команде git hash-object не просто вернуть ключ, а ещё и сохранить объект в базе данных. Последний параметр —stdin указывает, что git hash-object должна использовать данные, переданные на стандартный потока ввода; в противном случае команда ожидает путь к файлу в качестве аргумента.
Результат выполнения команды — 40-символьная контрольная сумма. Это SHA-1 хеш — контрольная сумма содержимого и заголовка, который будет рассмотрен позднее. Теперь можно посмотреть как Git хранит ваши данные:
$ find .git/objects -type f .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Мы видим новый файл в каталоге objects . Это и есть начальное внутреннее представление данных в Git — один файл на единицу хранения с именем, являющимся контрольной суммой содержимого и заголовка. Первые два символа SHA-1 определяют подкаталог файла внутри objects , остальные 38 — его имя.
Извлечь содержимое объекта можно при помощи команды cat-file . Она подобна швейцарскому ножу для анализа объектов Git. Ключ -p указывает команде cat-file автоматически определять тип объекта и выводить результат в соответствующем виде:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4 test contentТеперь вы умеете добавлять данные в Git и извлекать их обратно. То же самое можно делать и с файлами. Например, можно проверсионировать один файл. Для начала, создадим новый файл и сохраним его в базе данных Git:
$ echo 'version 1' > test.txt $ git hash-object -w test.txt 83baae61804e65cc73a7201a7252750c76066a30Теперь изменим файл и сохраним его в базе ещё раз:
$ echo 'version 2' > test.txt $ git hash-object -w test.txt 1f7a7a472abf3dd9643fd615f6da379c4acb3e3aТеперь в базе содержатся две версии файла, а также самый первый сохранённый объект:
$ find .git/objects -type f .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Теперь можно откатить файл к его первой версии:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt $ cat test.txt version 1$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt $ cat test.txt version 2Однако запоминать хеш для каждой версии неудобно, к тому же теряется имя файла, сохраняется лишь содержимое. Объекты такого типа называют блобами (англ. blob — binary large object). Имея SHA-1 объекта, можно попросить Git показать нам его тип с помощью команды cat-file -t :
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blobДеревья
Следующий тип объектов, который мы рассмотрим, — деревья — решают проблему хранения имён файлов, а также позволяют хранить группы файлов вместе. Git хранит данные сходным с файловыми системами UNIX способом, но в немного упрощённом виде. Содержимое хранится в деревьях и блобах, где дерево соответствует каталогу на файловой системе, а блоб более или менее соответствует индексу узла (inode) или содержимому файла. Дерево может содержать одну или более записей, содержащих SHA-1 хеш, соответствующий блобу или поддереву, права доступа к файлу, тип и имя файла. Например, дерево последнего коммита в проекте может выглядеть следующим образом:
$ git cat-file -p master^ 100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README 100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile 040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libЗапись master^ указывает на дерево, соответствующее последнему коммиту ветки master . Обратите внимание, что подкаталог lib — не блоб, а указатель на другое дерево:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rbПримечание
Вы можете столкнуться с различными ошибками при использовании синтаксиса master^ в зависимости от того, какую оболочку используете.
В Windows CMD символ ^ используется для экранирования, поэтому для исключения ошибок следует использовать двойной символ: git cat-file -p master^^ . В PowerShell параметры, использующие символы <>, должны быть заключены в кавычки: git cat-file -p ‘master^’ .
В ZSH символ ^ используется для подстановки, поэтому выражение следует помещать в кавычки: git cat-file -p «master^» .
Концептуально, данные хранятся в Git примерно так:
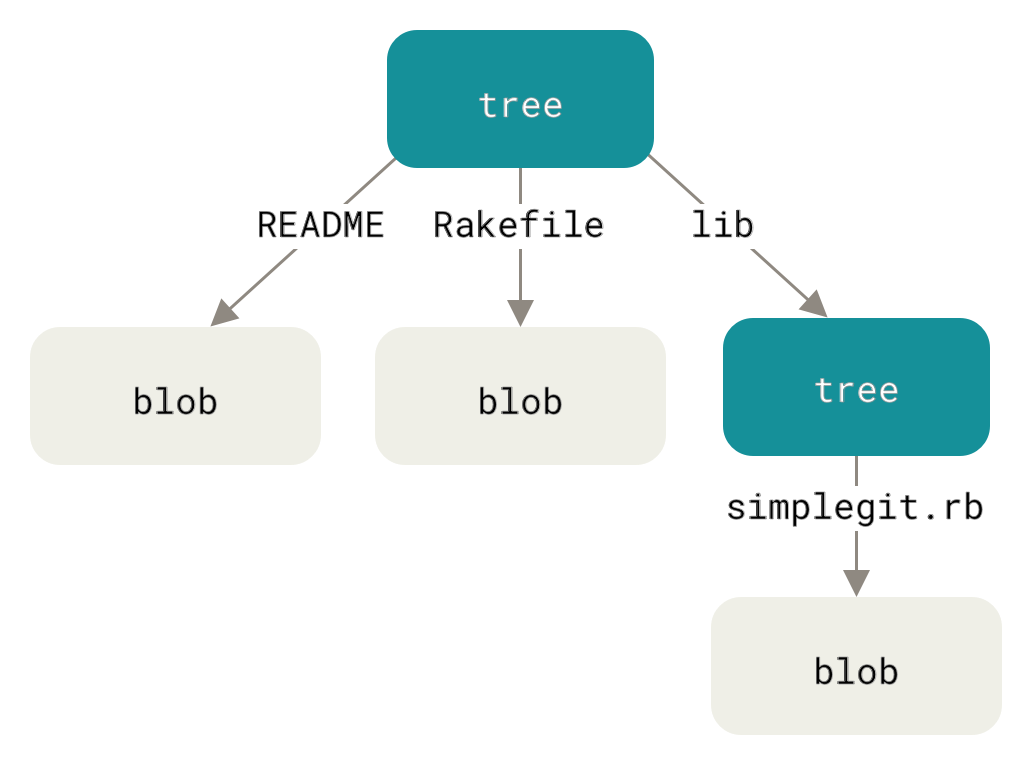
Рисунок 147. Упрощённая модель данных Git
Можно создать дерево самому. Обычно, Git создаёт дерево путём создания набора объектов из состояния области подготовленных файлов или индекса. Поэтому для создания дерева необходимо проиндексировать какие-нибудь файлы. Для создания индекса из одной записи — первой версии файла test.txt — воспользуемся низкоуровневой командой git update-index . Данная команда может искусственно добавить более раннюю версию test.txt в новый индекс. Необходимо передать опции —add , так как файл ещё не существует в индексе (да и самого индекса ещё нет), и —cacheinfo , так как добавляемого файла нет в рабочем каталоге, но он есть в базе данных. Также необходимо передать права доступа, хеш и имя файла:
$ git update-index --add --cacheinfo 100644 \ 83baae61804e65cc73a7201a7252750c76066a30 test.txtВ данном случае права доступа 100644 — означают обычный файл. Другие возможные варианты: 100755 — исполняемый файл, 120000 — символическая ссылка. Права доступа в Git сделаны по аналогии с правами доступа в UNIX, но они гораздо менее гибки: указанные три режима — единственные доступные для файлов (блобов) в Git (хотя существуют и другие режимы, используемые для каталогов и подмодулей).
Теперь можно воспользоваться командой git write-tree для сохранения индекса в объект дерева. Здесь опция -w не требуется — команда автоматически создаст дерево из индекса, если такого дерева ещё не существует:
$ git write-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 $ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtИспользуя ту же команду git cat-file , можно проверить, что созданный объект действительно является деревом:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579 treeДавайте создадим новое дерево со второй версией файла test.txt и ещё одним файлом:
$ echo 'new file' > new.txt $ git update-index --add --cacheinfo 100644 \ 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt $ git update-index --add new.txtТеперь в области подготовленных файлов содержится новая версия файла test.txt и новый файл new.txt . Зафиксируем изменения, сохранив состояние индекса в новое дерево, и посмотрим, что из этого вышло:
$ git write-tree 0155eb4229851634a0f03eb265b69f5a2d56f341 $ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtОбратите внимание, что в данном дереве находятся записи для обоих файлов, а также, что хеш файла test.txt это хеш «второй версии» этого файла ( 1f7a7a ). Для интереса, добавим первое дерево как подкаталог текущего. Добавлять деревья в область подготовленных файлов можно с помощью команды git read-tree . В нашем случае, чтобы включить уже существующее дерево в индекс и сделать его поддеревом, необходимо использовать опцию —prefix :
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579 $ git write-tree 3c4e9cd789d88d8d89c1073707c3585e41b0e614 $ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614 040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtЕсли бы вы сейчас добавили только что сохранённое дерево в рабочий каталог, вы бы увидели два файла в его корне и подкаталог bak с первой версией файла test.txt . В таком случае хранимые структуры данных можно представить следующим образом:
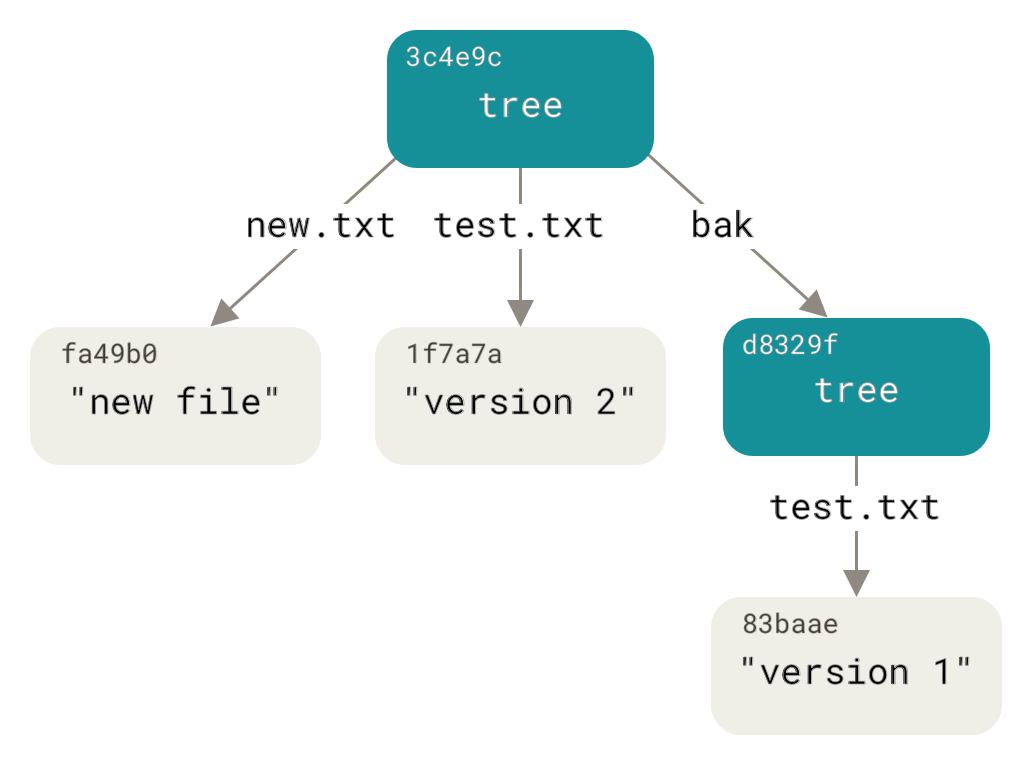
Рисунок 148. Структура данных Git для текущего состояния
Объекты коммитов
У вас есть три дерева, соответствующих разным состояниям проекта, но предыдущая проблема с необходимостью запоминать все три значения SHA-1, чтобы иметь возможность восстановить какое-либо из этих состояний, ещё не решена. К тому же у нас нет никакой информации о том, кто, когда и почему сохранил их. Такие данные — основная информация, хранимая в объекте коммита.
Для создания коммита необходимо вызвать команду commit-tree и задать SHA-1 нужного дерева и, если необходимо, родительские коммиты. Начнём с создания коммита для самого первого дерева:
$ echo 'First commit' | git commit-tree d8329f fdf4fc3344e67ab068f836878b6c4951e3b15f3dПолученный вами хеш будет отличаться, так как отличается дата создания и информация об авторе. Далее в этой главе используйте собственные хеши коммитов и тегов. Просмотреть созданный объект коммита можно командой cat-file :
$ git cat-file -p fdf4fc3 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 author Scott Chacon 1243040974 -0700 committer Scott Chacon 1243040974 -0700 First commitФормат объекта коммита прост: в нём указано дерево верхнего уровня, соответствующее состоянию проекта на некоторый момент; родительские коммиты, если существуют (в примере выше объект коммита не имеет родителей); имена автора и коммиттера (берутся из полей конфигурации user.name и user.email ) с указанием временной метки; пустая строка и сообщение коммита.
Далее, создадим ещё два объекта коммита, каждый из которых будет ссылаться на предыдущий:
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3 cac0cab538b970a37ea1e769cbbde608743bc96d $ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab 1a410efbd13591db07496601ebc7a059dd55cfe9Каждый из созданных объектов коммитов указывает на одно из созданных ранее деревьев состояния проекта. Вы не поверите, но теперь у нас есть полноценная Git история, которую можно посмотреть командой git log , указав хеш последнего коммита:
$ git log --stat 1a410e commit 1a410efbd13591db07496601ebc7a059dd55cfe9 Author: Scott Chacon Date: Fri May 22 18:15:24 2009 -0700 Third commit bak/test.txt | 1 + 1 file changed, 1 insertion(+) commit cac0cab538b970a37ea1e769cbbde608743bc96d Author: Scott Chacon Date: Fri May 22 18:14:29 2009 -0700 Second commit new.txt | 1 + test.txt | 2 +- 2 files changed, 2 insertions(+), 1 deletion(-) commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d Author: Scott Chacon Date: Fri May 22 18:09:34 2009 -0700 First commit test.txt | 1 + 1 file changed, 1 insertion(+)Здорово, правда? Мы только что выполнили несколько низкоуровневых операций и получили Git репозиторий с историей без единой высокоуровневой команды. Именно так и работает Git, когда выполняются команды git add и git commit — сохраняет блобы для изменённых файлов, обновляет индекс, создаёт деревья и фиксирует изменения в объекте коммита, ссылающемся на дерево верхнего уровня и предшествующие коммиты. Эти три основных вида объектов Git — блоб, дерево и коммит — сохраняются в виде отдельных файлов в каталоге .git/objects . Вот как сейчас выглядит список объектов в этом каталоге, в комментарии указано чему соответствует каждый из них:
$ find .git/objects -type f .git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2 .git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2 .git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1 .git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content' .git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt .git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Если пройти по всем внутренним ссылкам, получится граф объектов, представленный на рисунке:
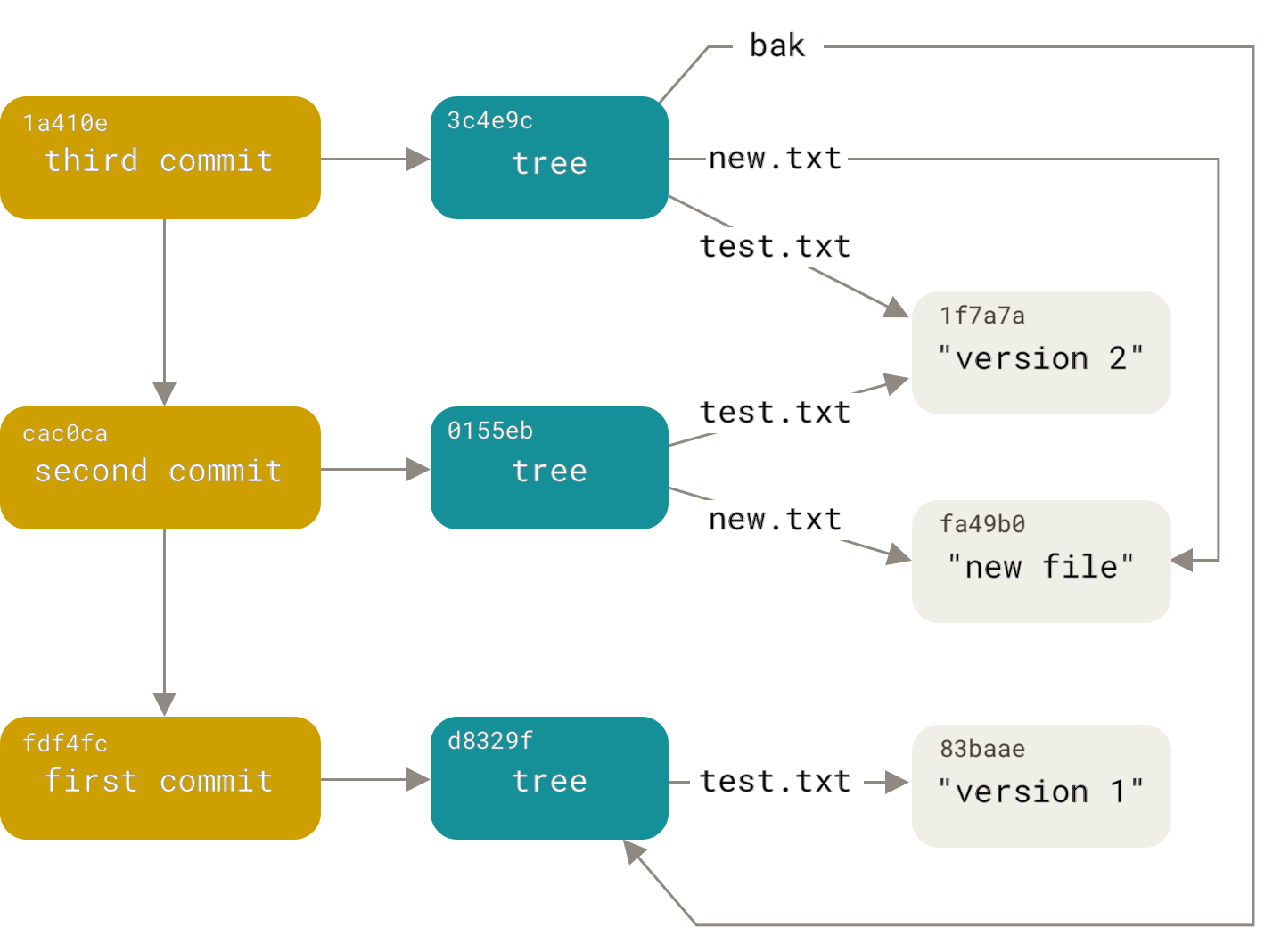
Рисунок 149. Все объекты в каталоге Git
Хранение объектов
Ранее мы упоминали, что вместе с содержимым объекта сохраняется дополнительный заголовок. Давайте посмотрим, как Git хранит объекты на диске. Мы рассмотрим как происходит сохранение блоб объекта — в данном случае это будет строка «what is up, doc?» — в интерактивном режиме на языке Ruby.
Для запуска интерактивного интерпретатора воспользуйтесь командой irb :
$ irb >> content = "what is up, doc?" => "what is up, doc?"Git создаёт заголовок, начинающийся с типа объекта, в данном случае это блоб. Далее идут пробел, размер содержимого в байтах и в конце нулевой байт:
>> header = "blob #\0" => "blob 16\u0000"Git объединяет заголовок и оригинальный контент, а затем вычисляет SHA-1 сумму от полученного результата. В Ruby значение SHA-1 для строки можно получить, подключив соответствующую библиотеку командой require и затем вызвав Digest::SHA1.hexdigest() :
>> store = header + content => "blob 16\u0000what is up, doc?" >> require 'digest/sha1' => true >> sha1 = Digest::SHA1.hexdigest(store) => "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Давайте сравним полученный результат с выводом команды git hash-object . Здесь используется echo -n для предотвращения автоматического добавления переноса строки.
$ echo -n "what is up, doc?" | git hash-object --stdin bd9dbf5aae1a3862dd1526723246b20206e5fc37Git сжимает новые данные при помощи zlib, в Ruby это можно сделать с помощью одноимённой библиотеки. Сперва необходимо подключить её, а затем вызвать Zlib::Deflate.deflate() :
>> require 'zlib' => true >> zlib_content = Zlib::Deflate.deflate(store) => "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"После этого сохраним сжатую строку в объект на диске. Определим путь к файлу, который будет записан (первые два символа хеша используются в качестве названия каталога, оставшиеся 38 — в качестве имени файла в ней). В Ruby для безопасного создания нескольких вложенных каталогов можно использовать функцию FileUtils.mkdir_p() . Далее, откроем файл вызовом File.open() и запишем сжатые данные вызовом write() для полученного файлового дескриптора:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38] => ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37" >> require 'fileutils' => true >> FileUtils.mkdir_p(File.dirname(path)) => ".git/objects/bd" >> File.open(path, 'w') < |f| f.write zlib_content >=> 32Теперь проверим содержимое объекта с помощью git cat-file :
--- $ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37 what is up, doc? ---Вот и всё, мы создали корректный блоб объект для Git.
Все другие объекты создаются аналогичным образом, меняется лишь запись о типе в заголовке: «blob», «commit» либо «tree». Стоит добавить, что блоб может иметь практически любое содержимое, однако содержимое объектов деревьев и коммитов записывается в очень строгом формате.
Три состояния

Теперь читайте особенно внимательно. Это самая важная вещь, которую нужно запомнить о Git’е, если вы хотите, чтобы оставшееся обучение прошло гладко. Git имеет три основных состояния, в которых могут находиться ваши файлы: изменённые, индексированные и зафиксированные.
- означает, что вы изменили файл, но ещё не зафиксировали его в своем локальном репозитории.
- — это изменённый файл, текущую версию которого вы отметили для включения в следующий коммит (для фиксации в своём локальном репозитории).
- означает, что файл уже сохранён в вашем локальном репозитории.
Таким образом, мы подошли к трём основным секциям проекта Git: рабочий каталог, индекс и репозиторий.
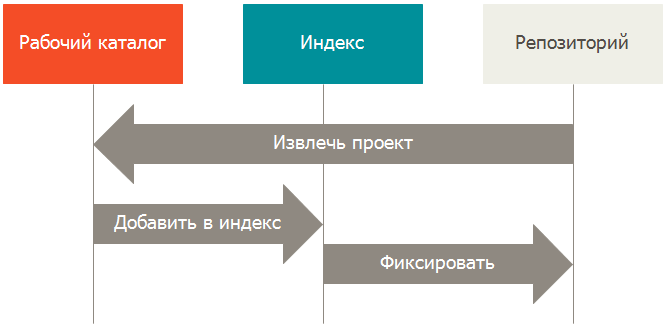
содержит одну версию проекта. Файлы этой версии извлекаются из сжатой базы данных в репозитории и располагаются на диске, для того чтобы их можно было изменять и использовать.
— это файл, располагающийся в репозитории. В нём содержится информация о том, какие изменения попадут в следующий коммит. Эту область ещё называют staging area.
— это место, в котором Git хранит метаданные и базу объектов вашего проекта. База объектов — самая важная часть Git’а, и это та часть, которая копируется при клонировании репозитория с другого компьютера.
Базовый подход в работе с Git’ом выглядит так:
- Вы изменяете файлы в вашем рабочем каталоге.
- Вы выборочно добавляете в индекс только те изменения, которые вы хотите зафиксировать следующим коммитом.
- Вы фиксируете изменения. При этом файлы в том состоянии, в котором они находятся в индексе, сохраняются в вашем репозитории навсегда в виде снимка.
Если определённая версия файла находится в репозитории, значит, она зафиксирована. Если файл был изменён и добавлен в индекс, значит, он был проиндексирован. И если файл был изменён с того момента, когда он был извлечён из репозитория, но не был добавлен в индекс, он считается изменённым. В главе Основы Git’а вы узнаете больше об этих состояниях и о том, какую пользу вы можете извлечь из их существования или как полностью пропустить этап индексирования.
Введение в Git: настройка и основные команды
Как установить и настроить Git в различных ОС, создать новые и клонировать существующие репозитории, а также базовые концепции ведения веток.
Эта инструкция — часть курса «Введение в Git».
Смотреть весь курс
Введение
Git — один из видов систем контроля версий (или СКВ). Такие системы записывают изменения в набор файлов, а позже позволяют вернуться к определенной версии.
Вам может пригодиться СКВ, если вы, например, программист, системный администратор, дизайнер (или в целом работаете с массивом изменяющихся файлов) и хотите сохранить каждую версию проекта. Вы сможете вернуться к любому из сохраненных состояний, просмотреть изменения и увидеть их авторов. Так гораздо проще исправлять возникающие проблемы.
В целом СКВ можно разделить таким образом:
- Локальные — все файлы хранятся только в вашей операционной системе, например, разложены по папкам с версиями.
- Централизованные — проект хранится на сервере, а ваша рабочая версия включает только текущий набор файлов.
- Распределенные — копии проекта (и вся информация о версиях) располагаются не только на сервере, но и на нескольких клиентских машинах, чтобы обеспечить устойчивость к отказу сервера.
Очевидно, что Git — не единственная система контроля версий, однако по многим параметрам самая удобная и популярная на сегодняшний день. Благодаря распределенной структуре репозитории Git хранятся на всех клиентских компьютерах, что защищает от потерь данных и позволяет полноценно управлять версиями проекта оффлайн.
Главная отличительная черта Git состоит в подходе к обработке данных. Каждый раз при сохранении данных проекта (коммите) система фиксирует состояние файла (делает снимок) и создает ссылку на этот снимок. Последующие изменения отражаются через ссылки на более ранние версии файла. Нет необходимости снова сохранять файл целиком. К тому же, основываясь на контрольных hash-суммах, система снимков обеспечивает целостность всей истории изменений. На практике это означает, что невозможно (либо крайне трудно) полностью удалить данные из рабочего каталога и утратить к ним любой доступ. В большинстве случаев данные можно восстановить из ранней версии проекта.
Таким образом, систему контроля версий в Git проще всего представлять как поток снимков (сохраненных состояний проекта).
Принципы работы с Git
У проектных файлов в Git есть 3 базовых состояния
- Измененные (modified) — файлы в процессе рабочего редактирования.
- Индексированные (staged) — та часть измененных файлов, которая уже подготовлена к фиксации после редактирования.
- Зафиксированные (committed) — файлы, уже сохраненные в локальном репозитории.
У Git есть рабочий каталог, где хранятся метаданные и локальная база рабочего проекта. Именно эта часть копируется, когда вы клонируете проект (репозиторий) с сервера.
Чаще всего работа с Git устроена примерно так:
- Вы вносите правки в файлы рабочей копии проекта.
- Индексируете их, подготавливая к коммиту (здесь Git создает снимки новых правок).
- Делаете коммит, и индексированные правки наконец сохраняются в вашем каталоге Git.
Установка Git
Создать свой проект и начать пользоваться Git в нем достаточно просто. Мы будем рассматривать работу в командной строке терминала, потому что там реализован полный набор команд. Вероятно, в будущем вам будет проще воспользоваться встроенными инструментами в крупном приложении (например, в Visual Studio, если вы программист).
Однако командная строка все равно удобна для тонкой настройки и «нестандартных» действий, поэтому полезно представлять себе, как управлять проектом через нее.
Сначала потребуется установить Git на свой компьютер.
Установка в Linux
Для дистрибутивов, похожих на Fedora, RHEL или CentOS, выполните команду dnf:
> sudo dnf install git-all На Ubuntu и других Debian-подобных систем введите apt:
> sudo apt install git Более подробные сведения можно получить по ссылке: https://git-scm.com/download/linux.
Установка на Mac
Один из способов установки — воспользоваться Xcode Command Line Tools. В терминале нужно ввести:
> git --version И следовать дальнейшим инструкциям.
Если вы пользуетесь Homebrew, запустите команду:
$ brew install git Установка в Windows
Новейшая сборка доступна на официальном сайте Git по ссылке: https://git-scm.com/download/win (загрузка запустится автоматически).
Настройка Git
Настроить рабочую среду нужно только один раз — после обновлений параметры не сбросятся. Если понадобится, в любое время можно изменить ваши настройки.
Самый удобный способ изменения конфигурации — встроенная утилита git config. Настройки Git имеют три уровня:
- Параметры из файла [path]/etc/gitconfig (системные) могут работать для всех пользователей системы и репозиториев. Они редактируются командой git config —system.
- Параметры из файла ~/.gitconfig или ~/.config/git/config (глобальные) применяются к одному пользователю, если запустить команду git config —global.
- Локальные параметры из файла config в рабочем каталоге .git/config сохраняют только для выбранного репозитория. Ему соответствует команда git config —local.
Если запускать git config без параметров, будет использоваться локальный уровень, никакие из более глобальных настроек не изменятся.
Всю используемую конфигурацию можно просмотреть так:
> git config --list --show-origin Представимся Git, чтобы в рабочих коммитах сохранялось ваше авторство:
> git config --global user.name "Danil Z" > git config --global user.email danilz@danilz.com Также можно выбрать и текстовый редактор, введя команду git config —global core.editor. Например, чтобы выбрать Emacs, выполните:
> git config --global core.editor emacs В Windows нужно указывать полный путь к файлу. К примеру, для установки Notepad++ нужно запустить подобную команду:
> git config --global core.editor "'C:/Program Files/Notepad++/notepad++.exe' -multiInst -notabbar -nosession -noPlugin" Стоит отметить, что на практике текстовый редактор в Git может и не пригодиться, особенно если вы активно используете стороннее ПО — например, в Visual Studio все текстовые заметки для Git можно писать в отдельном окне. Текстовые редакторы в командной строке отличаются своеобразным управлением, которое потребует от вас отдельного изучения.
Общий список текущих настроек просматривается с помощью команды git config —list. Проверить, что записано в любой из доступных настроек, можно командой с ключом git config :
> git config user.email Выбор ветки по умолчанию
Итак, наконец можно создать репозиторий в выбранном каталоге командой git init. Основная ветка автоматически будет названа master. Изменить это (в нашем случае задав ветку main) можно так:
> git config --global init.defaultBranch main Работа в репозитории
Как правило, есть два варианта начать работу с репозиторием Git:
- Можно выбрать локальный каталог и создать новый репозиторий в нем.
- Можно клонировать существующий репозиторий с локального компьютера или сервера. Обычно проекты клонируются именно с сервера.
Если у вас на компьютере уже есть рабочий проект, но еще не назначен контроль версий, то нужно сначала перейти в каталог проекта.
> cd /home/user/SomeConsoleApp > cd /Users/user/SomeConsoleApp > cd C:/Users/user/SomeConsoleApp > git init Команда создаст каталог с именем .git, в котором будут храниться структурные файлы репозитория.
И, наконец, нужно добавить под контроль версий все существующие файлы командой git add . (точка в конце важна!). Можно добавлять и по одному файлу, с помощью git add .
Заодно создадим начальный коммит командой git commit:
> git add readme.md > git commit -m 'Initial project version' Команду git add можно гибко настраивать с помощью дополнительных параметров (флагов), которые подробно описаны в официальной документации: https://git-scm.com/docs/git-add. К примеру, команда git add —force добавит даже игнорируемые файлы, а git add —update позволит обновить отслеживаемые файлы.
В этом репозитории вы можете продолжать работать и дальше, со временем обновляя его и отправляя рабочие версии на сервер.
Клонирование существующего репозитория
Когда вы работаете в команде, разрабатываемые проекты часто размещают на сервере. Это один из самых распространенных сценариев. Вам нужно получить копию проекта последней версии на свой компьютер, чтобы далее вносить в него свой вклад.
В качестве примера мы будем рассматривать проект, который создадим на ресурсе https://github.com/ . После регистрации на сайте и подтверждения по e-mail нужно создать новый репозиторий, как показано на скриншотах.
Видно, что можно выбрать тип репозитория:
- публичный (public) – доступ открыт для любого пользователя, однако права на редактирование выдает владелец проекта;
- приватный/скрытый (private) — проект виден только владельцу, другие участники добавляются вручную.
Для нашего примера создадим приватный репозиторий под названием SomeConsoleApp и будем работать с ним далее.
Самые удобные способы клонирования проекта — через протоколы HTTP и SSH, прочесть обо всех более развёрнуто можно по ссылке: https://git-scm.com/book/en/v2/Git-on-the-Server-The-Protocols.
Для наших целей воспользуемся протоколом https и следующей командой:
> git clone https://github.com/DanZDev2/SomeConsoleApp SomeConsoleApp На вашем компьютере в каталоге, куда вы перешли в командной строке, должен появиться каталог SomeConsoleApp, внутри него — каталог .git и все скачанные файлы репозитория последней версии.
После получения проекта обычно начинается более рутинный рабочий процесс — правки, добавление функционала и т. д. Далее в какой-то момент вы захотите сохранить прогресс в новой версии проекта.
Правила и периодичность обновления могут быть почти любыми, но хорошим тоном обычно считается сохранять рабочую (или промежуточно завершенную) версию. Важное требование для команд разработчиков — возможность сборки проекта, иначе другие участники команды будут вынуждены тратить время на борьбу с ошибками компиляции.
Сохранение снимков и просмотр статуса проекта
Как упоминалось ранее, часть файлов в рабочем каталоге может и не находиться под контролем версий. За отслеживаемыми файлами «наблюдает» Git, они были как минимум в прошлом снимке состояния проекта. Неотслеживаемыми могут быть, например, вспомогательные файлы в рабочем проекте, если они не зафиксированы в прошлой версии проекта и не готовы к коммиту. Их можно выделить в отдельную категорию для Git, о чем будет рассказано далее.
Сразу после клонирования все файлы проекта будут отслеживаемыми. Отредактировав их и привнеся что-то новое, вы индексируете (stage) и фиксируете (commit) правки, и так для каждой версии проекта.
При этом нужно внимательно следить, чтобы вспомогательные файлы, особенно объемные, оставались вне контроля версий. Если по недосмотру добавить их в коммит и отправить на сервер — вероятнее всего, ваши правки придется частично откатывать.
Проверить состояние файлов в рабочем каталоге можно командой git status. После клонирования консоль выведет примерно такую информацию:
On branch master Your branch is up to date with ‘origin/master’. nothing to commit, working tree clean Теперь отредактируем файлы (в этом примере было консольное демо-приложение, созданное с помощью Visual Studio) и сравним статус:
>git status On branch master Your branch is up to date with ‘origin/master’. Untracked files: (use “git add . ” to include in what will be committed) Program.cs SomeConsoleApp.csproj SomeConsoleApp.sln nothing added to commit but untracked files present (use “git add” to track) Теперь зафиксируем изменения. В коммит войдут только те файлы, которые вы изменили и добавили командой git add. Остальные будут лишь дополнительными файлами в каталоге проекта.
Стандартный способ — команда git commit, которую мы уже видели раньше. Без дополнительных аргументов она откроет встроенный текстовый редактор, поэтому для простоты рекомендуется добавить аргумент -m и вписать комментарий в кавычках:
> git commit -m "Task 2: basic project template added" Для удаления ненужных файлов из репозитория можно использовать команду git rm . Файл также пропадет из рабочего каталога. Выполнить коммит необходимо и в этом случае; до тех пор структура проекта не изменится.
Файл .gitignore
Как упоминалось ранее, в рабочий каталог могут попадать файлы, которые вам бы не хотелось отправлять на сервер. Это и документы с вашими экспериментами или образцами, и автоматически генерируемые части проекта, актуальные только на вашем компьютере. Git может полностью игнорировать их, если создать в рабочем каталоге файл с названием .gitignore и внести в него все имена ненужных файлов и папок.
Открывать файл можно в любом текстовом редакторе. Обычно удобнее не перечислять абсолютно все имена (которые к тому же всегда известны), а воспользоваться подобными инструкциями:
/bin /obj *.pdb *.exe Если прописать такое содержимое файла .gitignore, то репозиторий git будет полностью игнорировать папки /bin и /obj, а также любые файлы с расширениями .pdb и .exe, хранящиеся в вашем рабочем каталоге.
Рекомендуется создавать .gitignore до первой отправки вашего проекта в удаленный репозиторий, чтобы на сервер не попало никаких лишних файлов и каталогов. Разумеется, важно проверить, чтобы в .gitignore не были упомянуты критичные для проекта файлы, иначе у других участников команды возникнут проблемы после следующего обновления.
Управление удаленными репозиториями
Просмотреть список текущих онлайн-репозиториев можно командой git remote. Добавить другие — с помощью команды git remote add , например:
>git remote add myDemo https://github.com/DanZDev2/DemoApp >git remote myDemo origin Отправка изменений в удаленный репозиторий (Push)
На вашем компьютере есть проект со внесенными изменениями, но вы хотите поделиться новой версией со всей командой.
Команда для отправки изменений на сервер такова: git push . Если ваша ветка называется master, то команда для отправки коммитов станет такой:
> git push origin master Она сработает, если у вас есть права на запись на том сервере, откуда вы клонировали проект. Также предполагается, что другие участники команды за это время не обновляли репозиторий.
Следует к тому же помнить, что в разработке для промежуточных правок часто используется не главная ветка (master), а одна из параллельных (например, Dev). Работая в команде, этому обязательно нужно уделять пристальное внимание.
Получение изменений из репозитория (Pull)
Самый простой и быстрый способ получить изменения с сервера — выполнить команду git pull, которая извлечет (fetch) данные с сервера и попытается встроить/объединить (merge) их с вашей локальной версией проекта.
На этом этапе могут возникать конфликты версий, когда несколько человек поработали над одними и теми же файлами в проекте и сохранили свои изменения. Избежать этого можно, если изолировать части проекта, поручив работу над одной частью только одному человеку. Разумеется, на практике это не всегда выполнимо, поэтому в Git есть инструменты для разрешения конфликтов версий. Они будут рассмотрены далее.
Создание веток и переключение между ними
Создадим две дополнительные ветки Dev и Test (например, одна может пригодиться для процесса разработки, а другая — для запуска в тестирование). Введем команду git branch дважды с разными аргументами:
>git branch Dev >git branch Test Ветки созданы, но мы по-прежнему работаем в master. Для переключения на другую нужно выполнить git checkout :
>git checkout Dev Switched to branch ‘Dev’ Your branch is up to date with ‘origin/Dev’. Внесем некоторые изменения в файл README.md и зафиксируем их, чтобы они отразились в ветке Dev:
>git add . >git commit -m “dev readme changed” [Dev #####] dev readme changed 1 file changed, 2 insertions(+) Если теперь отправить их на сервер, то можно убедиться в появившемся отличии веток:
Для переключения обратно на ветку master нужно снова ввести команду git checkout master. Она не изменялась, а значит, после редактирования проекта ветки разойдутся. Это нормальная ситуация для проектов в Git. Важно только понимать, для каких целей используется каждая из веток, и не забывать вовремя переключаться между ними.
Слияние веток (merge)
Работа над проектами часто ведется в несколько этапов, им могут соответствовать ветки (в нашем примере Dev → Test → master). Отдельные ветки могут создаваться для срочного исправления багов, быстрого добавления временных функций, для делегирования части работы другому отделу и т. д. Предположим, что нужно применить изменения из ветки Dev, внеся их в master. Перейдем в master и выполним команду git merge :
>git merge Dev Updating #####..##### Fast-forward README.md | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) Изменения успешно перенесены. В наших упрощенных условиях команда завершилась без ошибок, не найдя конфликтов в файлах. Если же над общими участками какого-либо файла успели поработать несколько человек, с этим нужно разбираться вручную. При возникновении ошибок Git помечает общие части файлов из разных веток и сообщает о конфликте.
Для разрешения конфликтов есть консольная утилита git mergetool. Однако если файл проекта объемный, а общих частей много, пользоваться ей не слишком удобно. Общая рекомендация для таких случаев — пользоваться сторонними инструментами, как и в случае с текстовым редактором для Git.
Когда спорные участки всех файлов приведены к итоговому состоянию, нужно повторить стандартную процедуру: создать коммит и отправить их командой push в нужную ветку в репозитории.
Дальнейшая работа с проектом из репозитория Git, как правило, повторяется по алгоритму:
- pull (забрать изменения с сервера);
- внести правки, добавить что-то важное в проекте;
add (добавить изменённые файлы к коммиту); - commit (сохранить состояние проекта с комментариями);
- push (отправить изменения на сервер).
- merge (при необходимости внедрить изменения из другой ветки проекта).
Заключение
Мы рассмотрели, как устанавливать и настраивать Git в различных ОС, создавать новые и клонировать существующие репозитории, получать и отправлять новые версии проекта, а также ознакомились с базовыми концепциями ведения веток.
Этой информации обычно хватает для повседневных задач, связанных с хранением рабочих проектов.