Бинарные поисковые деревья
Деревом (англ. tree) называется связный граф без циклов. На практике часто приходится иметь дело со специальными видами деревьев. Наиболее распространенным среди них являются корневые деревья.
Корневое дерево (или ориентированное дерево с корнем, англ. directed rooted tree) — это ориентированный граф, который удовлетворяет следующим условиям:
- имеется в точности одна вершина, в которую не входит ни одна дуга и которая называется корнем;
- в каждую вершину, кроме корня, входит ровно одна дуга;
- из корня имеется путь к каждой вершине.
Если в корневом дереве существует путь из [math]v[/math] в [math]w[/math] , то [math]v[/math] называют предком вершины [math]w[/math] , а [math]w[/math] — потомком вершины [math]v[/math] . Стоит отметить, что любая вершина является своим собственным потомком. Если вершина не имеет других потомков, то её называют висячей вершиной (англ. pendant vertex) или листом (мн. листьями, англ. leaf / leaves). Вершины, отличные от корня и листьев, называют внутренними.
Если [math](v, w)[/math] — дуга корневого дерева, то [math]v[/math] называется отцом (также родителем или непосредственным предком) вершины [math]w[/math] , а [math]w[/math] называется сыном (или непосредственным потомком) вершины [math]v[/math] . Подграф, порождённый всеми потомками вершины [math]v[/math] (включая вершину [math]v[/math] ) корневого дерева [math]T[/math] , называется поддеревом (англ. subtree) корневого дерева [math]T[/math] с корнем в вершине [math]v[/math] .
Глубиной (англ. depth) вершины [math]v[/math] в корневом дереве называется длина (в дугах) единственного пути из корня в эту вершину.
Высотой (англ. height) вершины [math]v[/math] в корневом дереве называется длина (в дугах) наибольшего пути из вершины [math]v[/math] до одного из его потомков. Высота корневого дерева — высота корня.
Уровнем (англ. level) вершины [math]v[/math] называется разность высоты дерева и глубины вершины [math]v[/math] .
Упорядоченное корневое дерево — это корневое дерево, у которого дуги, выходящие из каждой вершины, упорядочены (в дальнейшем будем считать, что они упорядочены слева направо).
Бинарное дерево (англ. binary tree) — это упорядоченное корневое дерево, у каждой вершины которого имеется не более двух сыновей. В бинарном дереве каждый сын произвольной вершины определяется как левый или правый. Поддерево (если оно существует), корнем которого является левый сын вершины [math]v[/math] , называется левым поддеревом вершины [math]v[/math] . Аналогичным образом определяется правое поддерево для вершины [math]v[/math] .
Представление в памяти
Существует несколько способов представления бинарных деревьев (предполагаем, что вершины дерева занумерованы целыми числами от 1 до n).
- Представление в виде двух массивов — Left и Right :
- если вершина j является левым (правым) сыном вершины i, то Left[i] = j ( Right[i] = j );
- если у вершины i нет левого (правого) сына, то Left[i] = 0 ( Right[i] = 0 ).
- Представление в виде списковой структуры, когда каждый элемент списка содержит помимо информационной части (ключ вершины, дополнительные метки и т. п. ), ссылку на левого и правого ее сыновей и, возможно, ссылку на отца:
type tree_ptr = ^tree vertex; tree_vertex = record element: element_type; left: tree_ptr; right: tree_ptr; end;
Бинарное дерево поиска
Бинарное поисковое дерево высоты 3 с 9 вершинами, корнем 8 и листьями 1, 4, 7 и 13, средней по значению среди вершин дерева является вершина 7
Предположим, что каждой вершине бинарного дерева соответствует некоторое ключевое значение (например целое число). Бинарное дерево называется деревом поиска (бинарным поисковым деревом), если для каждой вершины [math]v[/math] ключи всех вершин в левом поддереве вершины [math]v[/math] меньше ключа вершины [math]v[/math] , а ключи всех вершин в правом поддереве — больше. В поисковом дереве нет двух вершин с одинаковыми ключевыми значениями, если не оговорено иное. Минимальный (максимальный) элемент бинарного поискового дерева соответствует ключевому значению самой левой (правой) вершины дерева.
Во многих задачах требуется найти среднюю по значению из вершин дерева. Средней по значению является та из вершин дерева, которой соответствует ключевое значение [math]x[/math] , для которого число вершин дерева, имеющих ключевое значение строго меньшее [math]x[/math] , равно числу вершин дерева, имеющих ключевые значения строго большие [math]x[/math] . Если число вершин в дереве чётно, то будем считать, что средней по значению вершины не существует. Если же дерево состоит из единственной вершины, то будем полагать, что эта вершина является средней по значению.
Пути и полупути
Путём (англ. path) в орграфе называется чередующаяся последовательность [math]v_0, (v_0, v_1), v_1, (v_1, v_2), v_2, \ldots, v_n[/math] вершин и дуг. При этом дуги в пути не могут повторяться. Первая и последняя вершины пути называются крайними, а все остальные — внутренними. Под длиной пути будем понимать число дуг в нём. Так, на приведённом рисунке последовательность [math]8, (8, 3), 3, (3, 6), 6[/math] является путём длины 2.
Определим центральную вершину некоторого пути как вершину [math]v[/math] , для которой число вершин в этом пути до неё равно числу вершин в этом пути после неё (если число вершин в пути чётно, то будем говорить, что центральной вершины для заданного пути не существует). Так, на приведённом рисунке для пути [math]8, (8, 3), 3, (3, 6), 6[/math] центральной вершиной является вершина 3.
Определим среднюю вершину некоторого пути как вершину [math]v[/math] , для которой в этом пути число вершин с меньшим, чем у вершины [math]v[/math] , ключом равно числу вершин с большим, чем у вершины [math]v[/math] , ключом (если число вершин в пути чётно, то будем говорить, что средней вершины для заданного пути не существует). Так, на приведённом рисунке для пути [math]8, (8, 3), 3, (3, 6), 6[/math] средней вершиной является вершина 6.
Для полупути (англ. semipath) снимается ограничение на направление дуг. Например, последовательность [math]3, (8, 3), 8, (8, 10), 10[/math] является полупутём длины 2, но не является путём. В полупути, как и в пути, дуги не могут повторяться.
Корнем полупути будем называть ту из вершин этого полупути, которая находится на наибольшей высоте (если выписать дуги полупути, то из коня этого полупути дуги только выходят). Центральная и средняя вершины полупути определяются аналогично, как и для пути. Для полупути [math]3, (8, 3), 8, (8, 10), 10[/math] вершина 8 является и центральной, и средней, и корнем этого полупути.
Наибольшим полупутём (англ. maximum semipath) в дереве будем называть полупуть наибольшей длины (не стоит путать наибольший полупуть с максимальным полупутём (англ. maximal semipath) — полупутём, который нельзя продолжить; наибольший полупуть всегда является максимальным, а вот обратное не всегда верно). Следует отметить, что наибольший полупуть в дереве не обязательно соединяет некоторые два листа этого дерева. Так, например, если у корня дерева только одно поддерево, то наибольший полупуть может соединять корень дерева и один из листьев. Заметим, что в дереве может быть несколько корней полупутей наибольшей длины, а через один и тот же корень может проходить несколько различных полупутей наибольшей длины. Так, в дереве, приведённом на рисунке, есть два наибольших полупути: один соединяет вершину 4 и вершину 13, другой — вершину 7 и вершину 13. Оба эти полупути имеют длину 6 и имеют общий корень — вершину 8.
Обходы дерева
Бинарное поисковое дерево. Прямой левый обход: 8, 3, 1, 6, 4, 7, 10, 14, 13; обратный левый обход: 1, 4, 7, 6, 3, 13, 14, 10, 8; внутренний левый обход: 1, 3, 4, 6, 7, 8, 10, 13, 14
Многие алгоритмы, работая с бинарными корневыми деревьями, посещают один раз в определенном порядке каждую вершину дерева. Cуществуют три наиболее распространенных способа обхода вершин бинарного дерева (предполагаем, что бинарное дерево задано списковой структурой): прямой, обратный и внутренний.
Прямой обход
Прямой порядок обхода (сверху вниз) заключается в том, что корень некоторого дерева посещается раньше, чем его поддеревья. Если после корня посещается его левое (правое) поддерево, то обход называется прямым левым (правым) обходом.
Приведем процедуру прямого левого обхода.
procedure order1(v: tree_ptr); begin if v <> nil then begin solve(v); order1(v^.left); order1(v^.right); end; end;
Обратный обход
Обратный порядок обхода (снизу вверх) заключается в том, что корень дерева посещается после его поддеревьев. Если сначала посещается левое (правое) поддерево корня, то обход называется обратным левым (правым) обходом.
Приведем процедуру обратного левого обхода.
procedure order2(v: tree_ptr); begin if v <> nil then begin order2(v^.left); order2(v^.right); solve(v); end; end;
Внутренний обход
Внутренний порядок обхода (слева направо или справа налево) заключается в том, что корень посещается после посещения одного из его поддеревьев. Если корень посещается после посещения его левого (правого) поддерева, то обход называется внутренним левым (правым) обходом. Заметим, что внутренний левый (правый) обход посещает вершины дерева в порядке возрастания (убывания) ключей вершин.
Приведем процедуру левого внутреннего обхода.
procedure order3(v: tree_ptr); begin if v <> nil then begin order3(v^.left); solve(v); order3(v^.right); end; end;
Для решения многих задач, предложенных в системе InsightRunner, может потребоваться вычисление для каждой вершины v некоторых меток, например, высоты, глубины, количества вершин в дереве с корнем в вершине v и др. Для выполнения этих действий можно использовать соответствующие процедуры обхода вершин дерева, а вычисления нужных меток выполнять в процедуре solve(v) .
Удаление вершины
В некоторых задачах требуется выполнить удаление заданной вершины v из дерева (предположим, что f — отец удаляемой вершины).
Задача удаления достаточно проста и выполняется за константное время, если у удаляемой вершины v не более одного поддерева (предположим, что если поддерево у вершины v существует, то w — его корень). В этом случае можно выполнить непосредственное удаление вершины v, после чего выполняются следующие действия:
- если v — корень дерева, то корнем дерева станет вершина w (если у вершины v сыновей не было, то дерево перестанет существовать);
- если v — лист, то ссылка у вершины f, указывающая на вершину v, станет пустой;
- если v не лист и не корень дерева, то ссылка у f, указывающая на v, будет указывать на w.

Случай удаления вершины v, у которой два поддерева, можно свести к предыдущему. При этом непосредственного удаления вершины v из дерева не происходит, а ключ вершины v заменяется на значение минимального (максимального) ключа среди вершин правого (левого) поддерева вершины v — такое удаление называют правым (левым).
Рассмотрим более подробно правое удаление. Предположим, что минимальный ключ в правом поддереве вершины v имела вершина z. Запишем ключ вершины z в вершину v, что приведёт к тому, что в дереве появятся две вершины v и z с одинаковыми ключевыми значениями, а это недопустимо для бинарного поискового дерева.

Поэтому, удаляем вершину z из дерева. Это сделать проще, так как вершина z не имеет левого поддерева (возможно, является листом) и завершаем процедуру удаления.
При реализации удаления нужно учитывать, что все внешние итераторы (указатели) для исходной вершины z с ключом d должны по-прежнему оставаться актуальными, поскольку вершина с ключом d продолжает существовать. В этом отношении имеет смысл, структурно удаляя из дерева вершину z, «физически» удалять всё равно вершину v, позволяя вершине z занять её место в дереве.
2-3 дерево
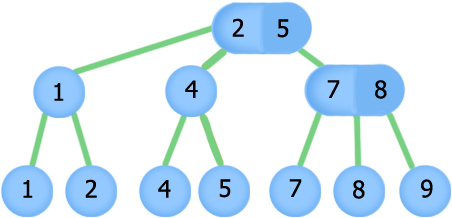
2-3 дерево (англ. 2-3 tree) — структура данных, представляющая собой сбалансированное дерево поиска, такое что из каждого узла может выходить две или три ветви и глубина всех листьев одинакова. Является частным случаем B+ дерева.
Свойства
2-3 дерево — сбалансированное дерево поиска, обладающее следующими свойствами:
- нелистовые вершины имеют либо [math]2[/math] , либо [math]3[/math] сына,
- нелистовая вершина, имеющая двух сыновей, хранит максимум левого поддерева. Нелистовая вершина, имеющая трех сыновей, хранит два значения. Первое значение хранит максимум левого поддерева, второе максимум центрального поддерева,
- сыновья упорядочены по значению максимума поддерева сына,
- все листья лежат на одной глубине,
- высота 2-3 дерева [math]O(\log)[/math] , где [math] n [/math] — количество элементов в дереве.
Операции
Введем следующие обозначения:
- [math]\mathtt[/math] — корень 2-3 дерева.
Каждый узел дерева обладает полями:
- [math]\mathtt[/math] — родитель узла,
- [math]\mathtt[/math] — сыновья узла,
- [math]\mathtt[/math] — ключи узла,
- [math]\mathtt[/math] — количество сыновей.
Поиск
- [math]x[/math] — искомое значение,
- [math]t[/math] — текущая вершина в дереве.
Изначально [math]t = \mathtt[/math] . Будем просматривать ключи в узлах, пока узел не является листом. Рассмотрим два случая:
- у текущей вершины два сына. Если её значение меньше [math]x[/math] , то [math]t = \mathtt[/math] , иначе [math]t = \mathtt[/math] .
- у текущей вершины три сына. Если второе значение меньше [math]x[/math] , то [math]t = \mathtt[/math] . Если первое значение меньше [math]x[/math] , то [math]t = \mathtt[/math] , иначе [math]t = \mathtt[/math] .
T search(T x): Node t = root while (t не является листом) if (t.length == 2) if (t.keys[0] < x) t = t.sons[1] else t = t.sons[0] else if (t.keys[1] < x) t = t.sons[2] else if (t.keys[0] < x) t = t.sons[1] else t = t.sons[0] return t.keys[0]
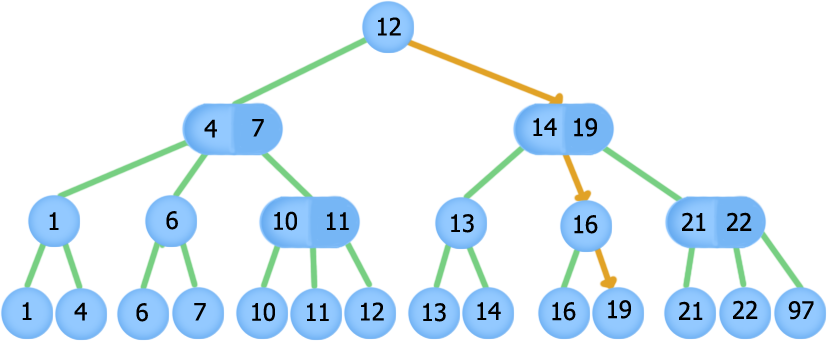
Поиск элемента 19, оранжевые стрелки обозначают путь по дереву при поиске
Вставка элемента
- [math]x[/math] — добавляемое значение,
- [math]t[/math] — текущая вершина в дереве. Изначально [math]t = \mathtt[/math] .
Если корня не существует — дерево пустое, то новый элемент и будет корнем (одновременно и листом). Иначе поступим следующим образом:
Найдем сперва, где бы находился элемент, применив [math]\mathtt[/math] . Далее проверим есть ли у этого узла родитель, если его нет, то в дереве всего один элемент — лист. Возьмем этот лист и новый узел, и создадим для них родителя, лист и новый узел расположим в порядке возрастания.
Если родитель существует, то подвесим к нему ещё одного сына. Если сыновей стало [math]4[/math] , то разделим родителя на два узла, и повторим разделение теперь для его родителя, ведь у него тоже могло быть уже [math]3[/math] сына, а мы разделили и у него стало на [math]1[/math] сына больше. (перед разделением обновим ключи).
function splitParent(Node t): if (t.length > 3) Node a = Node(sons = , keys = , parent = t.parent, length = 2) t.sons[2].parent = a t.sons[3].parent = a t.length = 2 t.sons[2] = null t.sons[3] = null if (t.parent != null) t.parent[t.length] = a t.length++ сортируем сыновей у t.parent splitParent(t.parent) else // мы расщепили корень, надо подвесить его к общему родителю, который будет новым корнем Node t = root root.sons[0] = t root.sons[1] = a t.parent = root a.parent = root root.length = 2 сортируем сыновей у root
Если сыновей стало [math]3[/math] , то ничего не делаем. Далее необходимо восстановить ключи на пути от новой вершины до корня:
function updateKeys(Node t): Node a = t.parent while (a != null) for i = 0 .. a.length - 1 a.keys[i] = max(a.sons[i]) // max — возвращает максимальное значение в поддереве. a = a.parent // Примечание: max легко находить, если хранить максимум // правого поддерева в каждом узле — это значение и будет max(a.sons[i])
[math]\mathtt[/math] необходимо запускать от нового узла. Добавление элемента:
function insert(T x): Node n = Node(x) if (root == null) root = n return Node a = searchNode(x) if (a.parent == null) Node t = root root.sons[0] = t root.sons[1] = n t.parent = root n.parent = root root.length = 2 сортируем сыновей у root else Node p = a.parent p.sons[p.length] = n p.length++ n.parent = p сортируем сыновей у p updateKeys(n) split(n) updateKeys(n)
Так как мы спускаемся один раз, и поднимаемся вверх при расщеплении родителей не более одного раза, то [math]\mathtt[/math] работает за [math]O(\log)[/math] .
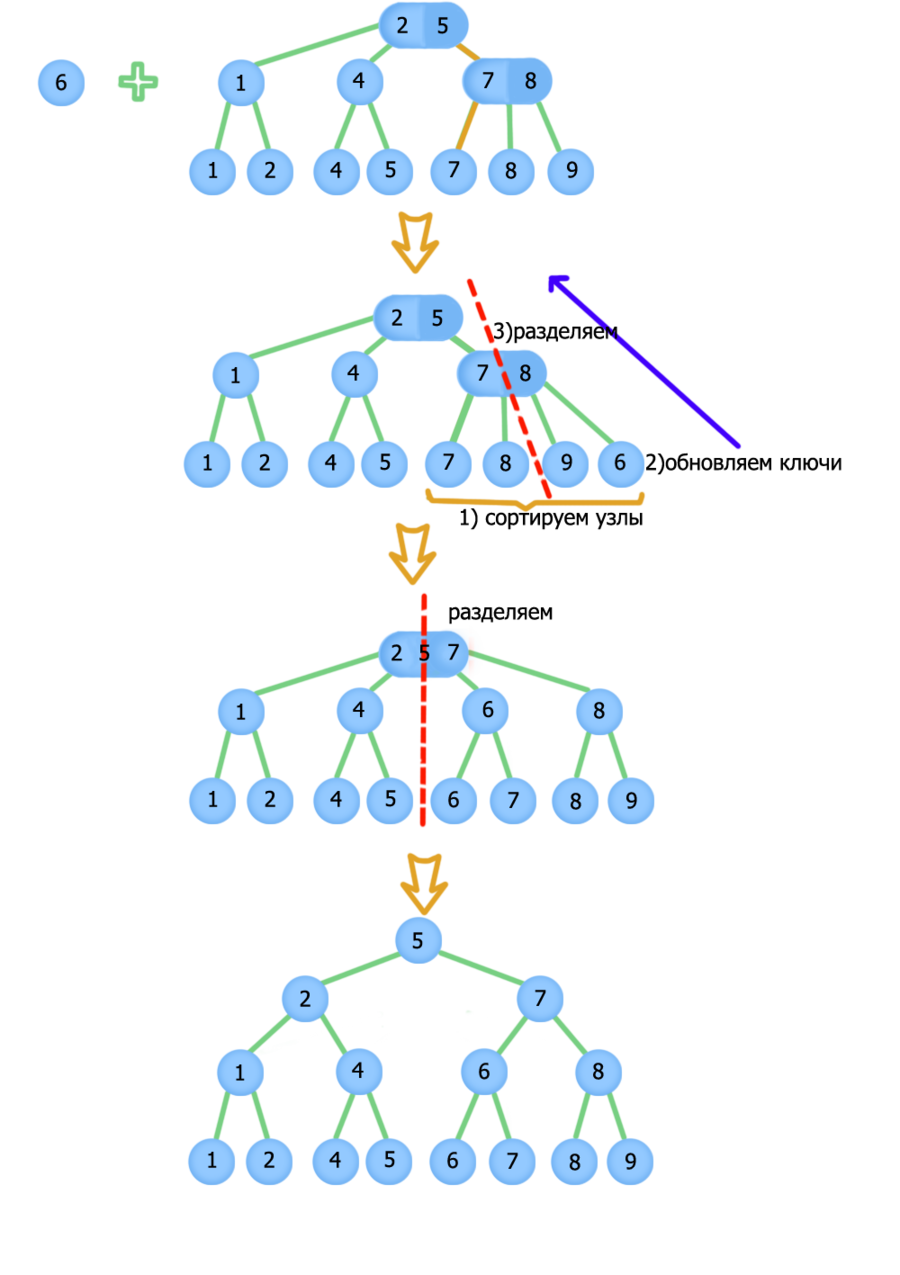
Добавление элемента с ключом 6
Удаление элемента
- [math]x[/math] — значение удаляемого узла,
- [math]t[/math] — текущий узел,
- [math]b[/math] — брат [math]t[/math] ,
- [math]p[/math] — отец [math]t[/math] ,
- [math]np[/math] — соседний брат [math]p[/math] ,
- [math]gp[/math] — отец [math]p[/math] .
Пусть изначально [math]t = \mathtt[/math] — узел, где находится [math]x[/math] .
Если у [math]t[/math] не существует родителя, то это корень (одновременно и единственный элемент в дереве). Удалим его.
Если [math]p[/math] существует, и у него строго больше [math]2[/math] сыновей, то просто удалим [math]t[/math] , а у [math]p[/math] уменьшим количество детей.
Если у родителя [math]t[/math] два сына, рассмотрим возможные случаи (сперва везде удаляем [math]t[/math] ):
- [math]np[/math] не существует, тогда мы удаляем одного из сыновей корня, следовательно, другой сын становится новым корнем,
- у [math]gp[/math] оказалось [math]2[/math] сына, у [math]np[/math] оказалось [math]2[/math] сына. Подвесим [math]b[/math] к [math]np[/math] и удалим [math]p[/math] . Так как у [math]gp[/math] — родителя [math]p[/math] , оказалось тоже два сына, повторяем для [math]p[/math] такие же рассуждения,
- у [math]gp[/math] оказалось [math]2[/math] или [math]3[/math] сына, у [math]np[/math] оказалось [math]3[/math] сына. Просто заберем ближайшего к нам сына у [math]np[/math] и прицепим его к [math]p[/math] . Восстановим порядок в сыновьях [math]p[/math] . Теперь у [math]p[/math] оказалось снова два сына и все узлы 2-3 дерева корректны,
- у [math]gp[/math] оказалось [math]3[/math] сына, у [math]np[/math] оказалось [math]2[/math] сына. Подвесим [math]b[/math] к [math]np[/math] и удалим [math]p[/math] , а у [math]gp[/math] уменьшим количество детей. Так как у [math]np[/math] оказалось три сына, а у [math]gp[/math] все ещё больше одного сына, то все узлы 2-3 дерева корректны.
Обобщим алгоритм при удалении когда у родителя [math]t[/math] два сына:
- Если [math]np[/math] не существует, то оказывается, что мы сейчас удаляем какого-то из сыновей корня (для определенности далее левого, с правым аналогично). Тогда теперь правый сын становится корнем. На этом удаление заканчивается.
- Если [math]np[/math] существует, то удалим [math]t[/math] , а его брата ( [math]b[/math] ) перецепим к [math]np[/math] . Теперь у [math]np[/math] могло оказаться [math]4[/math] сына, поэтому повторим аналогичные действия из [math]\mathtt[/math] : вызовем [math]\mathtt(b)[/math] и [math]\mathtt(np)[/math] . Теперь рекурсивно удалим [math]p[/math] .
В результате мы получаем корректное по структуре 2-3 дерево, но у нас есть нарушение в ключах в узлах, исправим их с помощью [math]\mathtt[/math] , запустившись от [math]b[/math] .

Удаление элемента с ключом 2
Следующий и предыдущий
- [math]x[/math] — поисковый параметр,
- [math]t[/math] — текущий узел.
В силу того, что наши узлы отсортированы по максимуму в поддереве, то следующий объект — это соседний лист справа. Попасть туда можно следующим образом: будем подниматься вверх, пока у нас не появится первой возможности свернуть направо вниз. Как только мы свернули направо вниз, будем идти всегда влево. Таким образом, мы окажемся в соседнем листе. Если мы не смогли ни разу свернуть направо вниз, и пришли в корень, то следующего объекта не существует. Случай с предыдущим симметричен.
T next(T x): Node t = searchNode(x) if (t.keys[0] > x) //x не было в дереве, и мы нашли следующий сразу return t.keys[0] while (t != null) t = t.parent if (можно свернуть направо вниз) в t помещаем вершину, в которую свернули while (пока t — не лист) t = t.sons[0] return t return t.keys[0]
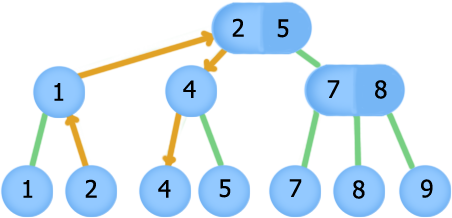
Путь при поиске следующего элемента после 2
Нахождение m следующих элементов
B+ деревья, поддерживают операцию [math]\mathtt[/math] , которая позволяет находить m следующих элементов. Наивная реализация выглядит следующим образом: будем вызывать [math]m[/math] раз поиск следующего элемента, такое решение работает за [math]O(m \log)[/math] . Но 2-3 деревья, позволяют находить m следующих элементов за [math]O(m + \log)[/math] , что значительно ускоряет поиск при больших [math]m[/math] . По построению, все листья у нас отсортированы в порядке возрастания, воспользуемся этим для нахождения m элементов. Нам необходимо связать листья, для этого модифицируем [math]\mathtt[/math] и [math]\mathtt[/math] . Добавим к узлам следующие поля:
- [math]\mathtt[/math] — указывает на правый лист,
- [math]\mathtt[/math] — указывает на левый лист.
Пусть [math]t[/math] — добавленный узел. Изменим [math]\mathtt[/math] следующим образом: в самом конце, после того как мы уже обновили все ключи, найдем [math]\mathtt[/math] и запишем ссылку на него в [math]\mathtt[/math] . Аналогично с левым.
Пусть [math]t[/math] — удаляемый узел. Изменим [math]\mathtt[/math] следующим образом: в самом начале, до удаления [math]t[/math] , найдем следующий [math]\mathtt[/math] и запишем в [math]\mathtt[/math] правый лист относительно [math]t[/math] . С левым поступим аналогично.
В итоге, мы имеем двусвязный список в листьях, и чтобы нам вывести [math]m[/math] элементов, нам достаточно один раз найти нужный элемент и пробежаться вправо на [math]m[/math] элементов.
10. Понятие дерева. Классификация деревьев. Способы представления дерева.

Древовидная структура характеризуется множеством узлов (nodes), происходящих от единственного начального узла, называемого корнем (root). На Рис. 3 корнем является узел А. В терминах генеалогического дерева узел можно считать родителем (parent), указывающим на 0, 1 или более узлов, называемых сыновьями (children). Например, узел В является родителем сыновей E и F. Родитель узла H — узел D. Дерево может представлять несколько поколений семьи. Сыновья узла и сыновья их сыновей называются потомками (descendants), а родители и прародители – предками (ancestors) этого узла. Корень дерева — это единственный узел, нe имеющий непосредственного предка. Например, узлы E, F, I, J – потомки узла B. Каждый некорневой узел имеет только одного родителя, и каждый родитель имеет 0 или более сыновей. Узел, не имеющий детей (E, G, H, I, J), называется листом (leaf). При представлении в памяти компьютера элементы дерева (узлы) связывают между собой таким образом, чтобы каждый узел был связан со своим непосредственным предком и/или своими непосредственными потомками. Наиболее распространенными способами представления дерева являются следующие три (или их комбинации). При первом способе каждый узел (кроме корня) содержит указатель на узел, являющийся его непосредственным предком, т. е. на элемент, находящийся на более высоком уровне иерархии. Для корня дерева соответствующий указатель будет пустым. При таком способе представления, имея информацию о местоположении некоторого узла, можно, отслеживая указатели, подниматься на более высокие уровни иерархии. К сожалению, этот способ представления непригоден, если требуется не только подниматься вверх по дереву, но и спускаться вниз, и при этом нет возможности получать независимо ссылки на узлы дерева. Тем не менее такое представление дерева иногда используется в алгоритмах, где прохождение узлов всегда осуществляется в восходящем порядке. Преимуществом этого способа представления дерева является то, что в нем используется минимальное количество памяти, причем практически вся она эффективно используется для представления связей. Второй способ представления применяют, если каждый узел дерева имеет не более двух (в общем случае не более К) непосредственных потомка. Тогда можно включить в представление узла указатели на этих потомков. В этом случае дерево называют двоичным (бинарным), а два поддерева каждого узла называют соответственно левым и правым поддеревьями этого узла. Разумеется, узел может иметь и только одно — левое или правое — поддерево (эти две ситуации в бинарных деревьях обычно считаются различными) или может вообще не иметь поддеревьев (и в этом случае узел называется концевым или терминальным узлом или листом дерева). При этом способе представления достаточно иметь ссылку на корень дерева, чтобы получить доступ к любому узлу дерева, спускаясь по указателям, однако, память при таком способе представления используется не столь эффективно— часть зарезервированной памяти будет содержать пустые указатели. template class T> class Tree < // Определение класса для узла дерева struct Node < Т item; // содержимое узла Node *left; // указатель на левое поддерево Node *right; // указатель на правое поддерево // Конструктор узлов дерева: Node(const T & item, Node *left = NULL, Node *right = NULL) < Node::item = item; Node::left = left; Node::right = right; >>; Третий способ представления дерева состоит в том, что каждый узел списка содержит список своих поддеревьев. При этом можно задать такой список, непосредственно используя шаблон классов List, так что описание структуры узла дерева в контексте описания шаблона для самого дерева могло бы выглядеть следующим образом: struct Node < Т item; // содержание узла List*> subtrees; // список поддеревьев >; Самые простые из деревьев считаются бинарные деревья. Бинарное дерево-это конечное множество элементов, которое либо пусто, либо содержит один элемент, называемый корнем дерева, а остальные элементы множества делятся на два непересекающихся подмножества, каждое из которых само является бинарным деревом. Эти подмножества называются левым и правым поддеревьями исходного дерева. Сильноветвящиеся деревья могут содержать в своих узлах более, чем один ключ. Разрешим тройные и четверные узлы, которые могут содержать два или три ключа соответственно. У тройного узла есть 3 выходящие из него ветви, одна ветвь для всех записей ключи которых меньше чем оба его ключа, одна для всех записей, которые больше либо равны первому ключу, но меньше второго , и одна для всех записей, которые больше его ключей или равны второму ключу. Аналогично, 4-ной узел имеет 4 ветви выходящие из него; по одной для каждого интервала определенного его 3 ключами. (Узлы в обычном бинарном дереве можно таким образом называть двойными узлами: один ключ, две ветви.) Сильноветвящееся дерево можно представить с использованием связных списков для запоминания указателей сыновей каждой вершины. Рассмотрим другую задачу. Пусть требуется ввести некоторую последовательность символов, заканчивающуюся точкой, и напечатать ее в обратном порядке (т.е. если на входе будет «ABcEr-1.» то на выходе должно быть «1-rEcBA»). Представленная ниже программа сначала вводит все символы последовательности, записывая их в стек, а затем содержимое стека печатается в обратном порядке. Это основная особенность стека — чем позже элемент занесен в стек, тем раньше он будет извлечен из стека. Реализация стека выполнена в связанном хранении при помощи указателей p и q на тип, именованный именем STACK. #include typedef struct st /* объявление типа STACK */ < char ch; struct st *ps; >STACK; main() < STACK *p,*q; char a; p=NULL; do /* заполнение стека */ < a=getch(); q=malloc(sizeof(STR1)); q->ps=p; p=q; q->ch=a; > while(a!=’.’); do /* печать стека */ < p=q->ps;free(q);q=p; printf(«%c»,p->ch); > while(p->ps!=NULL); > Node2 *prev;//указатель на предыдующий элемент Node2 *next;//указатель на следующий элемент> typedef Node2* PNode2;
07.02.2016 526.76 Кб 4 SavageArcanum.pdf
20.08.2019 73.22 Кб 0 Seminar-ЗЕД турфірми.doc
07.02.2016 965.63 Кб 33 SerdAntOPUVdlyaRP.doc
26.08.2019 535.04 Кб 1 Sh_chast.doc
07.02.2016 779.26 Кб 15 Sistemny_analiz_2012.doc
28.10.2018 209.92 Кб 0 Skripnik.doc
07.02.2016 162.82 Кб 5 Slovnik.doc
07.02.2016 1.73 Mб 65 sm_rgr_1d.pdf
07.02.2016 564.72 Кб 4 sm_rgr_1z.pdf
07.02.2016 727.5 Кб 4 sm_rgr_2d.pdf
07.02.2016 496.17 Кб 4 sm_rgr_2z.pdf
Ограничение
Для продолжения скачивания необходимо пройти капчу:
Методы программирования
Задание состоит из трех частей, первая и третья обязательны для выполнения, вторая выполняется по желанию студента. Срок сдачи задания — 17 октября.
Теория
Двоичное дерево задается следующей структурой:
typedef struct _t int data; /* данные в узле */
struct _t *left, *right; /* указатели на левого и правого сыновей */
> t;
t *root; /* корень дерева */
Таким образом, каждый элемент дерева содержит некоторые данные и два указателя на потомков (на левого сына и на правого). Сам узел будем называть отцом этих двух потомков. Определение дерева требует, чтобы у каждого узла, кроме корня, был ровно один отец. Указатель на корень дерева хранится в переменной root , она равна нулю, если дерево пусто.
Левым и правым поддеревьями узла t ( t != 0 ) будем называть деревья (возможно, пустые), корнями которых являются соответственно t->left и t->right .
Основные операции на деревьях: поиск элемента, добавление элемента, удаление элемента. Для поиска элемента в произвольном бинарном дереве необходимо обойти все элементы этого дерева. Существует два основных способа обхода дерева: в глубину и в ширину.
Обход дерева в глубину
Обход в глубину производится рекурсивно либо с использованием стека. В обоих случаях можно обходить узлы дерева в различной последовательности. Обход начинается от корня. Выделяют три наиболее важных порядка обхода в глубину:
- префиксный (прямой) обход — сначала обрабатывается текущий узел, затем левое и правое поддеревья;
- инфиксный (симметричный) обход — сначала обрабатывается левое поддерево текущего узла, затем корень, затем правое поддерево;
- постфиксный (обратный) обход — сначала обрабатываются левое и правое поддеревья текущего узла, затем сам узел.
В качестве примера рассмотрим следующее дерево:
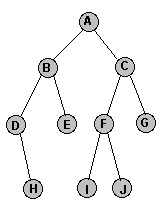
- префиксный обход: A, B, D, H, E, C, F, I, J, G
- инфиксный обход: D, H, B, E, A, I, F, J, C, G
- постфиксный обход: H, D, E, B, I, J, F, G, C, A
Запишем в качестве примера рекурсивную процедуру, выводящую на экран узлы дерева в порядке префиксного обхода.
void prefix(t *curr)
if (!curr)
return;
printf(«%d «, curr->data);
prefix(curr->left);
prefix(curr->right);
>
Обход дерева в ширину
Обход в ширину производится с помощью очереди. Первоначально в очередь помещается корень, затем, пока очередь не пуста, выполняются следующие действия:
- Из очереди выталкивается очередной узел;
- Этот узел обрабатывается;
- В очередь добавляются оба сына этого узла.
Узлы дерева на рисунке перечисляются в порядке обхода в ширину следующим образом: A, B, C, D, E, F, G, H, I, J. Заметим, что перечисление узлов происходит в порядке удаления от корня, что делает поиск в ширину удобным, например, для поиска узла дерева со значением k , наиболее близкого к корню, и т.д.
Приведем пример процедуры, которая выводит на экран узлы дерева в порядке обхода в ширину. Считаем, что определены три функции:
void add(t *elem); /* добавляет в конец очереди элемент elem */
t *del(); /* удаляет из очереди первый элемент и возвращает указатель на него */
int empty(); /* возвращает 1, если очередь пуста, и 0 в противном случае */
Тогда процедура обхода будет иметь следующий вид:
void width(t *root)
if (!root)
return;
add(root);
while (!empty()) t *curr = del();
printf(«%d «, curr->data);
if (curr->left)
add(curr->left);
if (curr->right)
add(curr->right);
>
>
Двоичные деревья поиска
Для поиска узла в таком дереве можно использовать как рекурсивную функцию, так и простой цикл. Ниже приведен пример функции, которая ищет узел со значением k в двоичном дереве поиска с корнем root . Этот код весьма напоминает обычный бинарный поиск:
t *search(t *root, int k)
t *curr = root;
while (curr) if (k == curr->data)
return (curr);
if (k < curr->data)
curr = curr->left;
else
curr = curr->right;
>
return (0);
>
Добавление узла в двоичное дерево поиска напоминает добавление элемента в середину связанного списка: выполняется проход по дереву с запоминанием указателя на узел, предшествующий текущему, и добавление узла к предыдущему, как только текущий указатель станет равным нулю. Необходимо отдельно обработать случай пустого дерева.
Удаление узла из двоичного дерева поиска является менее тривиальной операцией: необходимо поддерживать выполнение условия расположения элементов («слева меньше, справа больше»). Одним из возможных способов является следующий:
- если у удаляемого узла нет сыновей, его удаление не представляет проблемы (освобождаем память и зануляем указатель на нее у его отца);
- если у удаляемого узла есть ровно один сын, удаляем узел, а указатель на него у отца заменяем указателем на этого сына;
- если у удаляемого узла есть оба сына, ищем в правом поддереве узел с минимальным значением (у него по определению будет отсутствовать левый сын) и ставим этот узел на место удаляемого, аккуратно поменяв все необходимые указатели.
Сбалансированные деревья
При работе с двоичными деревьями поиска возможен случай, когда дерево по сути примет вид линейного связанного списка (например, если элементы подавались на вход в порядке возрастания). В таком случае поиск элемента в дереве будет занимать линейное время. Одним из способов предотвращения подобной ситуации является балансировка дерева по мере добавления элементов.
Сбалансированным деревом (AVL-деревом) называется двоичное дерево поиска, удовлетворяющее следующему условию: для любого узла глубина левого поддерева отличается от глубины правого поддерева не более чем на 1. В сбалансированном дереве поиск элемента выполняется за время O(log2N), где N — количество узлов (Адельсон-Вельский, Ландис, 1962). Алгоритм построения сбалансированных деревьев можно найти в сети и в литературе (Вирт, Кнут, . ), поэтому подробное описание его здесь не приводится.
Формулировка задания
а. Реализация простых двоичных деревьев поиска
Во входном файле input.txt в первой строке находится количество записей N , в следующих N строках находятся записи вида имя значение , причем имена могут повторяться. В файл output.txt выдать итоговые значения всех переменных в алфавитном порядке. Хранение записей организовать в виде двоичного дерева поиска.
Примеры
| Ввод: input.txt 5 a 10 b 20 a 15 c 25 b 11 |
Вывод: output.txt a 15 c 25 b 11 |
b. ** Реализация сбалансированных деревьев
Задание аналогично предыдущему, но требуется поддерживать дерево сбалансированным. Задание не является обязательным.
c. Реализация префиксного, инфиксного и постфиксного обходов двоичного дерева
Необходимо реализовать функции обхода дерева в порядке префиксного, инфиксного и постфиксного обходов. Дерево задается произвольным образом.