Как и зачем мерить FLOPSы

Как известно, FLOPS – это единица измерения вычислительной мощности компьютеров в (попугаях) операциях с плавающей точкой, которой часто пользуются, чтобы померить у кого больше. Особенно важно померяться FLOPS’ами в мире Top500 суперкомпьютеров, чтобы выяснить, кто же среди них самый-самый. Однако, предмет измерения должен иметь хоть какое-нибудь применение на практике, иначе какой смысл его замерять и сравнивать. Поэтому для выяснения возможностей супер- и просто компьютеров существуют чуть более приближенные к реальным вычислительным задачам бенчмарки, например, SPEC: SPECint и SPECfp. И, тем не менее, FLOPS активно используется в оценках производительности и публикуется в отчетах. Для его измерения давно уже использовали тест Linpack, а сейчас применяют открытый стандартный бенчмарк из LAPACK. Что эти измерения дают разработчикам высокопроизводительных и научных приложений? Можно ли легко оценить производительность реализации своего алгоритма в FLOPSaх? Будут ли измерения и сравнения корректными? Обо всем этом мы поговорим ниже.
Давайте сначала немного разберемся с терминами и определениями. Итак, FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой (FP) в секунду. Здесь используется слово «вычислительных», так как микропроцессор умеет выполнять и другие инструкции с такими операндами, например, загрузку из памяти. Такие операции не несут полезной вычислительной нагрузки и поэтому не учитываются.
Значение FLOPS, опубликованное для конкретной системы, – это характеристика прежде всего самого компьютера, а не программы. Ее можно получить двумя способами – теоретическим и практическим. Теоретически мы знаем сколько микропроцессоров в системе и сколько исполняемых устройств с плавающей точкой в каждом процессоре. Все они могут работать одновременно и начинать работу над следующей инструкцией в конвеере каждый цикл. Поэтому для подсчета теоретического максимума для данной системы нам нужно только перемножить все эти величины с частотой процессора – получим количество FP операций в секунду. Все просто, но такими оценками пользуются, разве что заявляя в прессе о будущих планах по построению суперкомпьютера.
Практическое измерение заключается в запуске бенчмарка Linpack. Бенчмарк осуществляет операцию умножения матрицы на матрицу несколько десятков раз и вычисляет усредненное значение времени выполнения теста. Так как количество FP операций в имплементации алгоритма известно заранее, то разделив одно значение на другое, получим искомое FLOPS. Библиотека Intel MKL (Math Kernel Library) содержит пакет LAPAСK, — пакет библиотек для решения задач линейной алгебры. Бенчмарк построен на основе этого пакета. Cчитается, что его эффективность находится на уровне 90% от теоретически возможной, что позволяет бенчмарку считаться «эталонным измерением». Отдельно Intel Optimized LINPACK Benchmark для Windows, Linux и MacOS можно качать здесь, либо взять в директории composerxe/mkl/benchmarks, если у вас установлена Intel Parallel Studio XE.
Очевидно, что разработчики высокопроизводительных приложений хотели бы оценить эффективность имплементации своих алгоритмов, используя показатель FLOPS, но уже померянный для своего приложения. Сравнение измеренного FLOPS с «эталонным» дает представление о том, насколько далека производительность их алгоритма от идеальной и каков теоретический потенциал ее улучшения. Для этого всего-навсего нужно знать минимальное количество FP операций, требуемое для выполнения алгоритма, и точно измерить время выполнения программы (ну или ее части, выполняющей оцениваемый алгоритм). Такие результаты, наряду с измерениями характеристик шины памяти, нужны для того, чтобы понять, где реализация алгоритма упирается в возможности аппаратной системы и что является лимитирующим фактором: пропускная способность памяти, задержки передачи данных, производительность алгоритма, либо системы.

Ну а теперь давайте покопаемся в деталях, в которых, как известно, все зло. У нас есть три оценки/измерения FLOPS: теоретическая, бенчмарк и программа. Рассмотрим особенности вычисления FLOPS для каждого случая.
Теоретическая оценка FLOPS для системы
Чтобы понять, как подсчитывается количество одновременных операций в процессоре, давайте взглянем на устройство блока out-of-order в конвеере процессора Intel Sandy Bridge.

Здесь у нас 6 портов к вычислительным устройствам, при этом, за один цикл (или такт процессора) диспетчером может быть назначено на выполнение до 6 микроопераций: 3 операции с памятью и 3 вычислительные. Одновременно могут выполняться одна операция умножения ( MUL ) и одна сложения ( ADD ), как в блоках x87 FP, так и в SSE, либо AVX. С учетом ширины SIMD регистров 256 бит мы может получить следующие результаты:

8 MUL (32-bit) и 8 ADD (32-bit): 16 SP FLOP/cycle, то есть 16 операций с плавающей точкой одинарной точности за один такт.
4 MUL (64-bit) и 4 ADD (64-bit): 8 DP FLOP/cycle, то есть 8 операций с плавающей точкой двойной точности за один такт.
Теоретическое пиковое значение FLOPS для доступного мне 1-сокетного Xeon E3-1275 (4 cores @ 3.574GHz) составляет:
16 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 228 GFLOPS SP
8 (FLOP/cycle)*4*3.574 (Gcycles/sec)= 114 GFLOPS DP
Запуск бенчмарка Linpack
Запускам бенчмарк из пакета Intel MKL на системе и получаем следующие результаты (порезано для удобства просмотра):
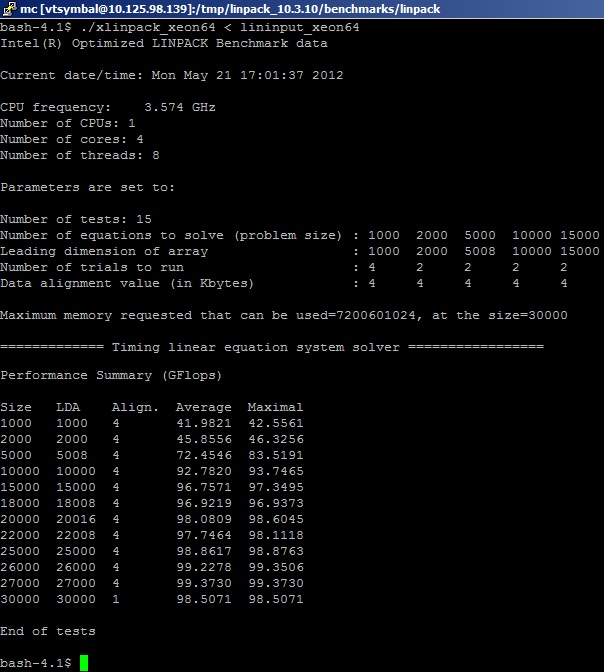
Здесь нужно сказать, как именно учитываются FP операции в бенчмарке. Как уже упоминалось, тест заранее «знает» количество операций MUL и ADD, которые необходимы для перемножения матриц. В упрощенном представлении: производится решение системы линейных уравнений Ax=b (несколько тысяч штук) путем перемножения плотных матриц действительных чисел (real8) размером MxK, а количество операций сложения и умножения, необходимых для реализации алгоритма, считается (для симметричной матрицы) Nflop = 2*(M^3)+(M^2). Вычисления производятся для чисел с двойной точностью, как и для большинства бенчмарков. Сколько операций с плавающей точкой действительно выполняется в реализации алгоритма, пользователей не волнует, хотя они догадываются, что больше. Это связано с тем, что выполняется декомпозиция матриц по блокам и преобразование (факторизация) для достижения максимальной производительности алгоритма на вычислительной платформе. То есть нам нужно запомнить, что на самом деле значение физических FLOPS занижено за счет неучитывания лишних операций преобразования и вспомогательных операций типа сдвигов.
Оценка FLOPS программы
Чтобы исследовать соизмеримые результаты, в качестве нашего высокопроизводительного приложения будем использовать пример перемножения матриц, сделанный «своими руками», то есть без помощи математических гуру из команды разработчиков MKL Performance Library. Пример реализации перемножения матриц, написанный на языке С, можно найти в директории Samples пакета Intel VTune Amplifier XE. Воспользуемся формулой Nflop=2*(M^3) для подсчета FP операций (исходя из базового алгоритма перемножения матриц) и померим время выполнения перемножения для случая алгоритма multiply3 при размере симметричных матриц M=4096. Для того, чтобы получить эффективный код, используем опции оптимизации –O3 (агрессивная оптимизация циклов) и –xavx (использовать инструкции AVX) С-компилятора Intel для того, чтобы сгенерировались векторные SIMD-инструкции для исполнительных устройств AVX. Компилятор нам поможет узнать, векторизовался ли цикл перемножения матрицы. Для этого укажем опцию –vec-report3. В результатах компиляции видим сообщения оптимизатора: «LOOP WAS VECTORIZED» напротив строки с телом внутреннего цикла в файле multiply.c.
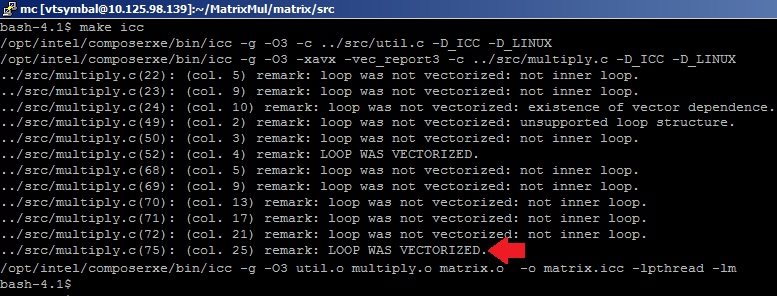
На всякий случай проверим, какие инструкции сгенерированы компилятором для цикла перемножения.
$icl –g –O3 –xavx –S
По тэгу __tag_value_multiply3 ищем нужный цикл — инструкции правильные.
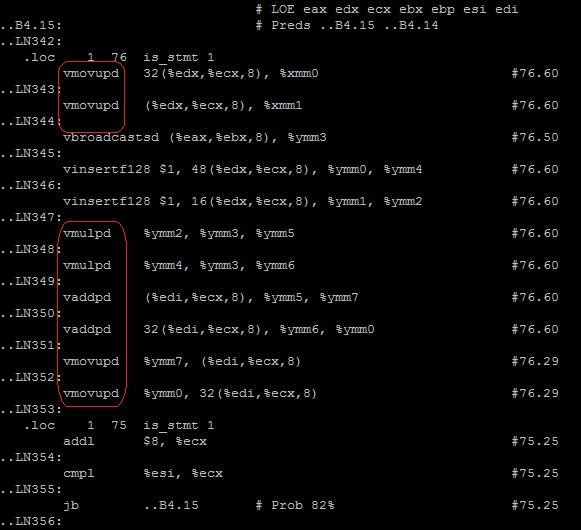
$vi muliply3.s
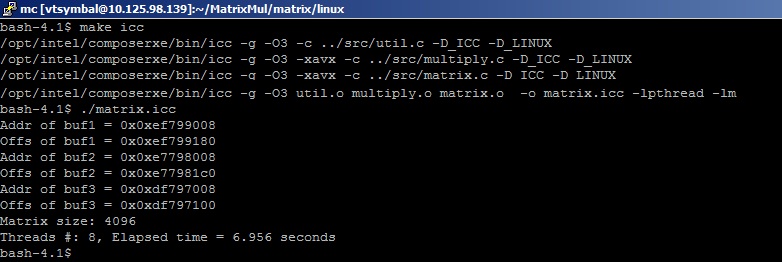
Результат выполнения программы (~7 секунд)
нам дает следующее значение FLOPS = 2*4096*4096*4096/7[s] = 19.6 GFLOPS
Результат, конечно, очень далек от того, что получается в Linpack, что объясняется исключительно квалификционной пропастью между автором статьи и разработчиками библиотеки MKL.
Ну, а теперь дессерт! Собственно то, ради чего я затеял свое исследование этой, вроде бы скучной и давно избитой, темы. Новый метод измерения FLOPS.
Измерение FLOPS программы
Существуют задачи в линейной алгебре, программную имплементацию решения которых очень сложно оценить в количестве FP операций, в том смысле, что нахождение такой оценки само является нетривиальной математической задачей. И тут мы, что называется, приехали. Как считать FLOPS для программы? Есть два пути, оба экспериментальных: трудный, дающий точный результат, и легкий, но обеспечивающий приблизительную оценку. В первом случае нам придется взять некую базовую программную имплементацию решения задачи, скомпилировать ее в ассемблерные инструкции и, выполнив их на симуляторе процессора, посчитать количество FP операций. Звучит так, что резко хочется пойти легким, но недостоверным путем. Тем более, что если ветвление исполнения задачи будет зависеть от входных данных, то вся точность оценки сразу поставится под сомнение.
Идея легкого пути состоит в следующем. Почему бы не спросить сам процессор, сколько он выполнил FP инструкций. Процессорный конвеер, конечно же, об этом не ведает. Зато у нас есть счетчики производительности (PMU – вот тут про них интересно), которые умеют считать, сколько микроопераций было выполнено на том или ином вычислительном блоке. С такими счетчиками умеет работать VTune Amplifier XE.
Несмотря на то, что VTune имеет множество встроенных профилей, специального профиля для измерения FLOPS у него пока нет. Но никто не мешает нам создать наш собственный пользовательский профиль за 30 секунд. Не утруждая вас основами работы с интерфейсом VTune (их можно изучить в прилагающимся к нему Getting Started Tutorial), сразу опишу процесс создания профиля и сбора данных.
- Создаем новый проект и указываем в качестве target application наше приложение matrix.
- Выбираем профиль Lightweight Hotspots (который использует технологию сэмплирования счетчиков процессора Hadware Event-based Sampling) и копируем его для создания пользовательского профиля. Обзываем его My FLOPS Analysis.
- Редактируем профиль, добавляем туда новые процессорные счетчики событий процессора Sandy Bridge (Events). На них остановимся чуть подробнее. В их названии зашифрованы исполнительные устройства (x87, SSE, AVX) и тип данных, над которыми выполнялась операция. Каждый такт процессора счетчики складывают количество вычислительных операций, назначенных на исполнение. На всякий случай мы добавили счетчики на все возможные операции с FP:
- FP_COMP_OPS_EXE. SSE_PACKED_DOUBLE – векторы (PACKED) данных двойной точности (DOUBLE)
- FP_COMP_OPS_EXE. SSE_PACKED_SINGLE – векторы данных одинарной точности
- FP_COMP_OPS_EXE. SSE_SCALAR_DOUBLE – скалярые DP
- FP_COMP_OPS_EXE. SSE_ SCALAR _SINGLE – скалярные SP
- SIMD_FP_256.PACKED_DOUBLE – векторы AVX данных DP
- SIMD_FP_256.PACKED_SINGLE – векторы AVX данных SP
- FP_COMP_OPS_EXE.x87 – скалярые данные x87
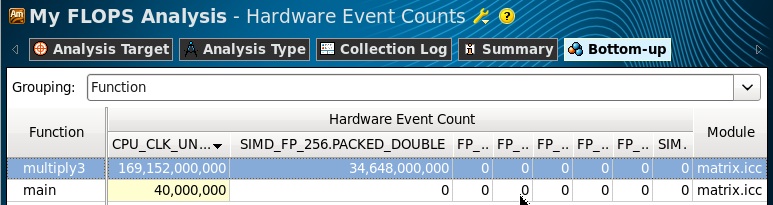
Далее мы просто подсчитываем значения FLOPS по формулам. Данные у нас были собраны для всех процессоров, поэтому умножение на их количество здесь не требуется. Операции данными двойной точности выполняются одновременно над четырмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4. Данные с одинарной точностью, соответственно, умножаем на 8. В последней формуле не умножаем количество инструкций на коэффициент, так как операции сопроцессора x87 выполняются только со скалярными величинами. Если в программе выполняется несколько разных типов FP операций, то их количество, умноженное на коэффициенты, суммируется для получения результирующего FLOPS.
FLOPS = 4 * SIMD_FP_256.PACKED_DOUBLE / Elapsed Time
FLOPS = 8 * SIMD_FP_256.PACKED_SINGLE / Elapsed Time
FLOPS = (FP_COMP_OPS_EXE.x87) / Elapsed Time
В нашей программе выполнялись только AVX инструкции, поэтому в результатах есть значение только одного счетчика SIMD_FP_256.PACKED_DOUBLE.
Удостоверимся, что данные события собраны для нашего цикла в функции multiply3 (переключившись в Source View):
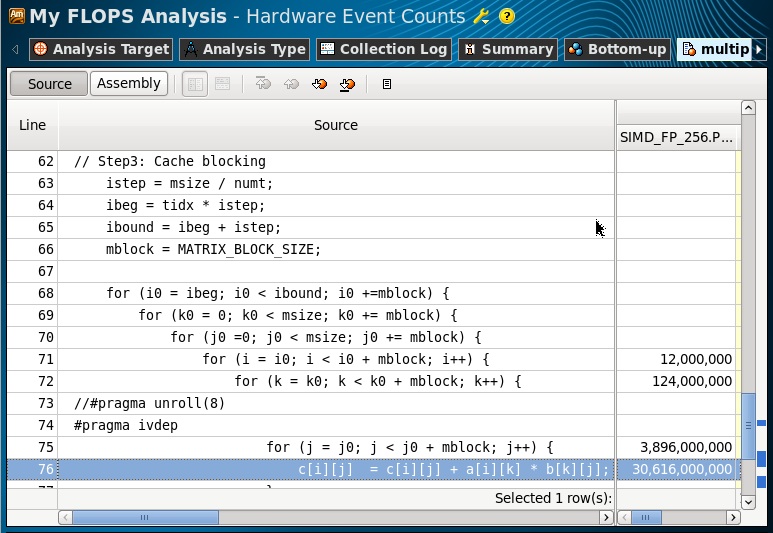
FLOPS = 4 *34.6Gops/7s = 19.7 GFlops
Значение вполне соответствует оценочному, подсчитанному в предыдущем пункте. Поэтому с достаточной долей точности можно говорить о том, что результаты оценочного метода и измерительного совпадают. Однако, существуют случаи, когда они могут не совпадать. При определенном интересе читателей, я могу заняться их исследованием и рассказать, как использовать более сложные и точные методы. А взамен очень хочется услышать о ваших случаях, когда вам требуется измерение FLOPS в программах.
Заключение
FLOPS – единица измерения производительности вычислительных систем, которая характеризует максимальную вычислительную мощность самой системы для операций с плавающей точкой. FLOPS может быть заявлена как теоретическая, для еще не существующих систем, так и измерена с помощью бенчмарков. Разработчики высокопроизводительных программ, в частности, решателей систем линейных дифференциальных уравнений, оценивают производительность реализации своих алгоритмов в том числе и по значению FLOPS программы, вычисленному с помощью теоретически/эмпирически известного количества FP операций, необходимых для выполнения алгоритма, и измеренному времени выполнения теста. Для случаев, когда сложность алгоритма не позволяет оценить количество FP операций алгоритма, их можно измерить с помощью счетчиков производительности, встроенных в микропроцессоры Intel.
- Блог компании Intel
- Программирование
- Алгоритмы
Гфлопс что это такое в смартфоне
Будь в курсе последних новостей из мира гаджетов и технологий
iGuides для смартфонов Apple

Сравнение производительности современных смартфонов и компьютеров

Егор Морозов — 5 июля 2017, 12:30

Ни для кого не секрет, что за последние 10 лет телефоны сделали качественный скачок — если тогда они воспринимались в основном как звонилки, с крайне урезанным браузером и почти без возможности проигрывать видео, то сейчас это полноценные мультимедийные устройства с нормальными браузерами и плеерами, пакетом MS Office, играми, оснащенные камерами, способными снимать 4К видео — в общем, казалось бы, это полноценный ПК в кармане.
Это же мнение активно развивают и компании-производители: Apple продвигает iPad как замену ПК, Microsoft и Samsung представили док-станции, с помощью которых можно превратить смартфон в рабочее место. И поэтому у многих может сложиться впечатление, что по производительности смартфоны уже ничуть не хуже ПК (ну или хотя бы ноутбуков). Однако, забегая вперед — это далеко не так.
Разумеется, возникает вопрос — как сравнить производительность смартфонов, построенных на ARM-процессорах, и ПК, построенных на x86? Конечно, есть кроссплатформенные тесты типа GeekBench, однако их проблема в том, что их результаты крайне сильно зависят от оптимизации бенчмарка под ту или иную архитектуру или даже процессор — к примеру, GeekBench не видит кэш L3 у процессоров Apple, а ведь он достаточно серьезно влияет на скорость вычисления. Поэтому нам нужен бенчмарк, который использует «понятные» всем процессорам команды, которые никак не зависят от системы — и на эту роль хорошо подходит Linpack, который меряет FLOPS.
Что же такое FLOPS? Это единица измерения производительности устройства, показывающая, сколько операций с плавающей запятой в секунду оно может сделать. Операции с плавающей запятой происходят «внутри» процессора и никак не зависят от системы, а только от быстродействия самого процессора. И второй плюс — в отличие от высокоуровневых бенчмарков, тестирующих отдельно процессор и отдельно видеокарту, никто не мешает вычислить производительность и того, и другого во FLOPS.
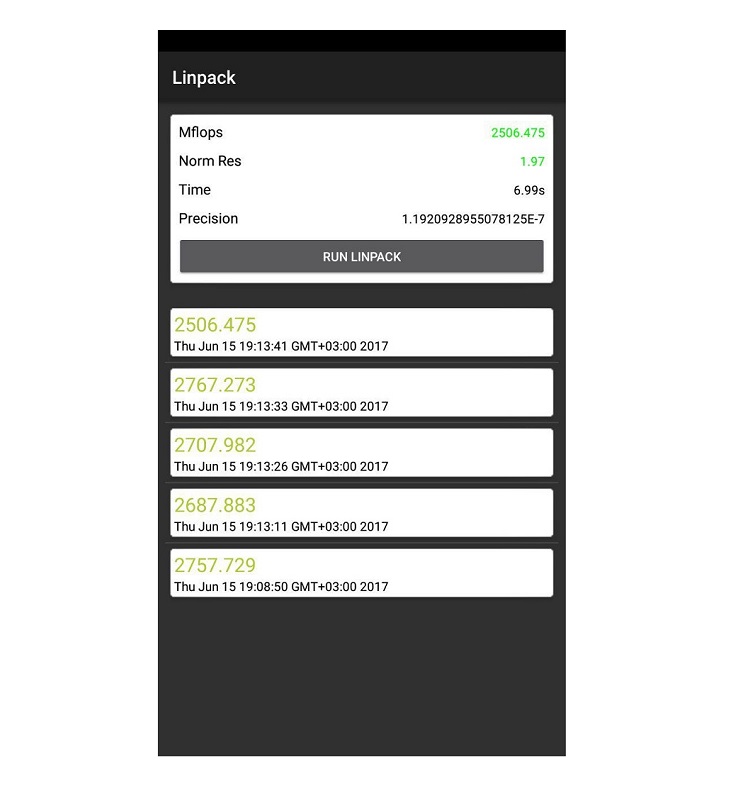
Увы, нормального Linpack под iOS я не нашел (есть один, но он не поддерживает х64-вычисления, что, разумеется, скажется на производительности). А вот под Android он есть, и поддерживает х64 — можно его бесплатно скачать в Google Play. Для тестов был взят практически топовый по современным меркам Snapdragon 820, и его результат — порядка 2.7 GFLOPS:
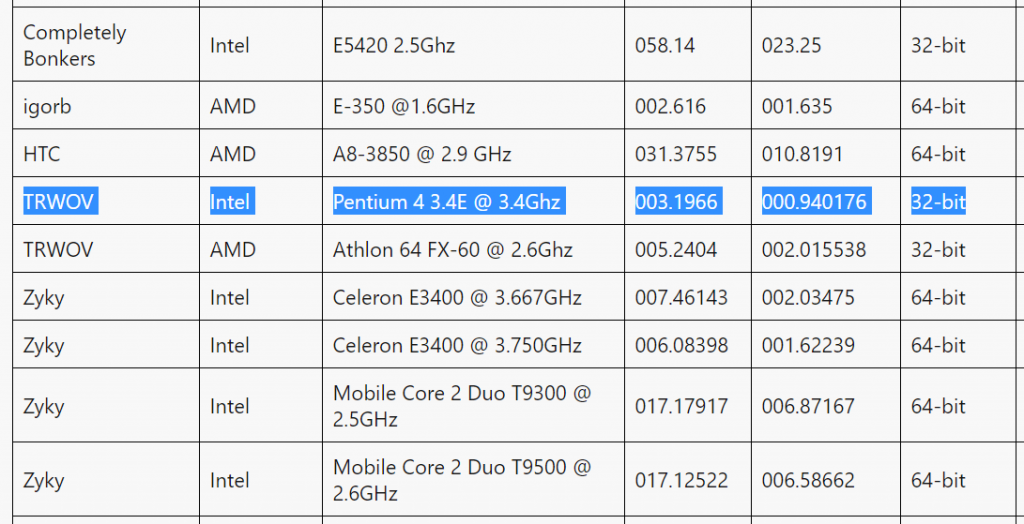
Тут, разумеется, возникает вопрос — это много или мало? Увы — это мало: к примеру, Intel Core i3-7100U, низковольтный современный процессор от Intel, набирает порядка 40 GFLOPS. Сравнимый с Snapdragon 820 результат (3.2 GFLOPS) набрал Pentium 4 на 3.4 ГГц:
То есть топовые смартфоны имеют тот же уровень производительности, что и топовые ПК 2004-2005 годов. Отсюда опять же возникает вопрос: почему на таком слабом по современным меркам процессоре Android работает вполне себе шустро? Тут все просто — Android изначально оптимизировали под слабые устройства, и поэтому никаких проблем с быстродействием нет. Ровно также на Pentium 4 летала Windows XP — эта ОС могла работать на процессорах с частотой в 300 МГц, то есть на порядок ниже. Это же касается и мобильных браузеров — они работают в масштабе 1:2, а то и 1:3 — то есть реальное разрешение в браузере будет не 1920х1080, а 640х360 — поэтому опять же нет никаких тормозов.
Теперь давайте на минутку представим, что в телефоне действительно стоит Pentium 4 (вообще говоря — предположение вполне себе верное: если программа под ПК требует процессор определенной производительности, то оптимизированная под мобильные ОС версия программы с тем же функционалом вряд ли будет иметь меньшие системные требования). Что из современного софта мы сможем запустить?
- Microsoft Office 2016 — требуется 1 ГГц процессор и 1 ГБ ОЗУ. У нас же 3 ГГц и 3-6 ГБ ОЗУ, так что проблем с запуском нет, более того — офисный пакет от MS уже был несколько лет назад как портирован.
Второй миф, который запустила Nvidia больше 5 лет назад на презентации своего процессора Tegra 2 — это игры «консольного уровня». Что самое забавное — с тех пор каждый производитель счел своим долгом на презентациях говорить, что вот сейчас мы точно достигли уровня консолей. Только вот вопрос — каких?
В одном из самых мощных смартфонов современности, Apple iPhone 6s, стоит видеочип PowerVR GT 7600, производительность которого, если судить по сайту AnandTech, составляет 115 GFLOPS:
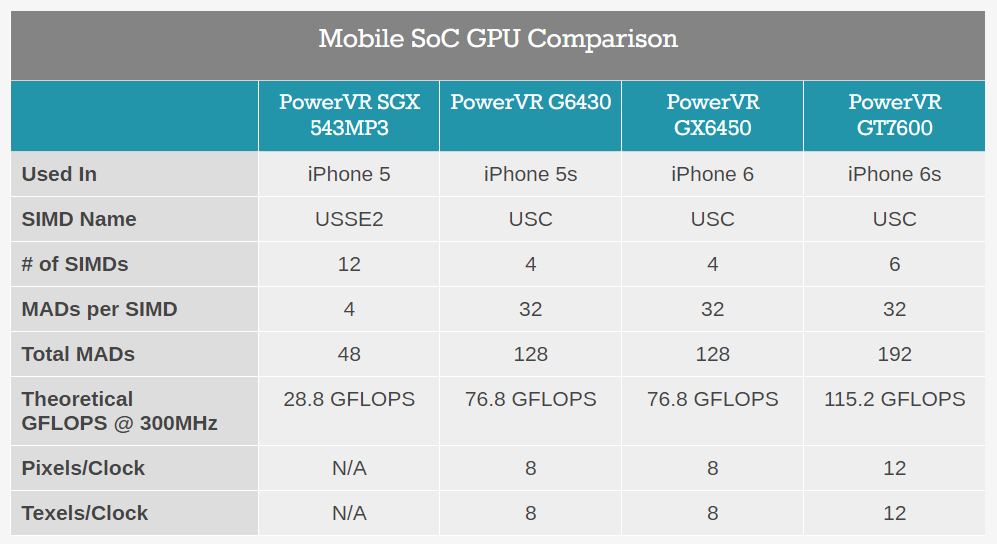
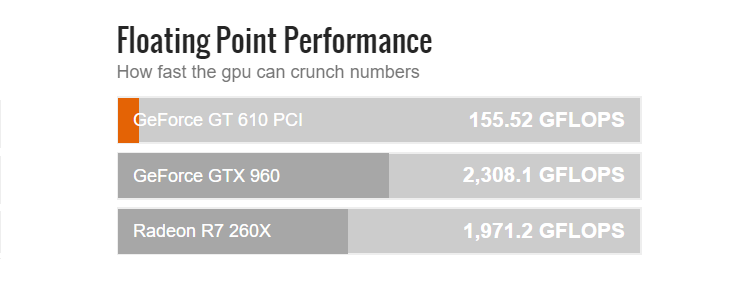
В iPhone 7 стоит чип GT 7600 PLUS, который является разогнанной версией 7600, то есть его производительность составляет 130-140 GFLOPS. Ближайшая из относительно современных видеокарт с такой же производительностью — Nvidia GT 610:
Чтобы было понятнее — это видеокарта-затычка пятилетней давности, охлаждаемая пассивно и стоящая на данные момент меньше 2 тысяч рублей. От середнячка предыдущего поколения видеокарт Nvidia — GTX 960 — она отстает в 15 раз, а производительность в современных играх аховая: GTA 5 идет в 800х600 на минимальных настройках с 25-30 fps, Witcher 3 в 1024х768 опять же на минимальной графике выдает 7-10 fps. Консоли предыдущего поколения, PlayStation 3 и Xbox 360, выдают порядка 220-250 GFLOPS, то есть они вдвое мощнее графического процессора в iPhone 7! В итоге получается, что топовые мобильные видеочипы имеют производительность между PlayStation 2 и 3, то есть уровень видеокарт 2004-2005 года. Поэтому предел мечтаний — игры того времени, что мы и видим: под мобильные ОС с хорошей графикой были портированы GTA вплоть до San Andreas (2004), Half-Life 2 (2004), Titan Quest (2006).
Что же в итоге? А в итоге топовые смартфоны и планшеты имеют уровень производительности компьютеров 2004-2005 года, поэтому говорить о полноценной работе и играх на них просто смешно: их предел это мультимедиа и серфинг в интернете, а все рассказы производителей о том, что планшеты и смартфоны заменят ПК — увы, просто байки.
Консольная графика на телефонах – почему не стоит ждать
Мобильные процессоры уже имеют столько же транзисторов, что и настольные игровые приставки. Сравнивая исключительно количество транзисторов, производители говорят, что можно ожидать на смартфоне графику уровня консолей. Но кто угодно, запустив одинаковые игры на разных девайсах, может убедиться, что это не так. Попробуем разобраться, почему маркетинговые заявления расходятся с практикой.

Чипсет Apple A10, который используется в iPhone 7, имеет 3,3 млрд транзисторов. Видеокарта Nvidia GTX 1050 Ti имеет столько же.
Сравнивать видеокарту с чипсетом не совсем честно, ведь чипсет дополнительно имеет еще процессор. Именно такое решение под названием APU от AMD использовано в консоли Xbox One. Оригинальная игровая приставка имела 5 млрд транзисторов в своем APU. Свежие мобильные чипы AMD Ryzen немного меньше, но все равно у них 4,5 млрд транзисторов.
Последний Apple A11 Bionic насчитывает 4,3 млрд транзисторов. У мощного мобильного чипсета Qualcomm Snapdragon 835 3 млрд транзисторов. Система Huawei Kirin 970 является одной из крупнейших по количеству транзисторов мобильных решений – 5,5 млрд штук.

Хотя по количеству транзисторов мобильные и консольные чипсеты похожи, они имеют очень разную производительность. Приставка Xbox One выдавала 1 310 гигафлопс (это единица измерения количества расчетов за секунду). Видеоядро Mali-G72 MP12 в Kirin способно лишь на 347 гигафлопс. Видеоядро Adreno 540 в Snapdragon 835 обещает 567 гигафлопс. Apple не разглашает производительность своего видеоядра, но для A10 оно примерно равное 250 гигафлопс. Компания также сказала, что графика в A11 Bionic на 30% быстрее предшественника, то есть выдает 325 гигафлопс – почти так же, как и видео в Kirin.
Все цифры являются приблизительными, однако они показывают, что мобильные решения имеют лишь от четверти до половины производительности чипа настольной игровой приставки.
Одной из причин, почему на мобильных гаджетах не стоит в ближайшее время ждать графики консольного уровня, является физика, а именно – тепловыделение. У настольных игровых приставок есть вентиляторы для принудительного охлаждения. Телефоны же охлаждаются исключительно пассивно. У некоторых из них есть теплопроводные трубки, но это устройство предназначено лишь для передачи тепла.
Производители мобильных чипсетов не называют их уровень энергопотребления. По приблизительным подсчетам, чтобы сделать телефон невыносимо горячим, чип должен выделять 2-3 Вт тепла. Новейшие чипы AMD Ryzen для ноутбуков предлагают похожую на Xbox One производительность и имеют энергопотребление на уровне 9-25 Вт.
По материалам: GSMArena
Как выбрать смартфон с хорошим процессором? Учимся читать характеристики
SoC (чипсет) состоит из процессора (CPU), видеоядра (GPU), контроллера памяти RAM, модема и прочих элементов. В отличие от компьютеров и ноутбуков, когда можно приобрести две абсолютно идентичные системы с отличием лишь в процессорах (Intel или AMD), с мобильниками такой фокус не прокатит. почти. Объясняем больше — ниже.
Компания Samsung выпускает свои смартфоны как на фирменных чипах Exynos, так и на Snapdragon для американского рынка. Последние больше пользуются спросом из-за большей стабильности, хотя в синтетических тестах показатели обоих чипсетов практически не различаются. В чем дело? Есть такое волшебное слово, как оптимизация. Именно оптимизированное программное обеспечение может дать лучший пользовательский опыт, нежели увеличенная тактовая частота или больший объем оперативной памяти.

Как тогда выбрать смартфон, чтобы у него был хороший чипсет? На что стоит обращать внимание, важны ли показатели синтетических бенчмарков и что вообще значат цифры в AnTuTu и GeekBench?
SoC в смартфонах — основные категории и чем они отличаются
Мобильные аппараты можно грубо поделить на три категории: флагманы, средний сегмент и устройства начального уровня. В зависимости от того, в какой ценовой категории находится мобильник, пользователь получает чипсет с топовой, средней или базовой мощностью. Флагманские решения — это ультимативные разработки с использованием передовых технологий для идеальной работы во всех задачах.
- Топовых SoC существует всего несколько, точнее три — они обновляются каждый год. В 2020 году актуальными чипами флагманского уровня являются Snapdragon 865 и 865+, Kirin 990 и Exynos 990. Есть еще свежий Mediatek Dimensity 1000+, но его уровень производительности сравним с флагманами Snapdragon, Kirin и Exynos 2019 года. То есть Mediatek отстает от конкурентов на одно поколение (на 1 год). Apple A Bionic и вовсе не берем в расчет, поскольку это совсем другая вселенная. При этом чипы Apple мощнее любого решения, производимого для Android-гаджетов.
Среднебюджетные SoC позволяют как поиграть в тяжелые игрушки на оптимальных настройках графики, так и предоставить комфорт пользователю в повседневных задачах. Чипы начального уровня дают возможность смартфону комфортно «переваривать» базовые утилиты и даже поиграть на низких настройках графики.
- С чипсетами среднего и начального уровня существенно сложнее, поскольку их намного больше, они разнообразнее и не всегда новые модели лучше предшественников. Именно для этих целей и существуют такие программы, как AnTuTu и GeekBench (есть и другие, но эти самые популярные). С помощью бенчмарков определяется, скажем так, теоретическая мощность чипсета. Поэтому полностью полагаться на синтетику не стоит, важно еще и реальное быстродействие SoC и смартфона в целом.
Повторимся, это очень грубое представление той многогранности выбора, предоставляемого производителями мобильных чипов и смартфонов. Если углубиться в детали, чего делать на самом деле не стоит, рассказывать можно очень долго.
Samsung Galaxy S20 FE – стильный флагманский смартфон для ваших увлечений по доступной цене. Узнайте больше о девайсе, в котором сочетаются все самые важные функции: от большого экрана 120 ГЦ и камеры с искусственным интеллектом до влагозащиты IP68 и надежного аккумулятора на 4500 мАч.

На что стоит обращать внимание при выборе SoC
В первую очередь на само мобильное устройство. Одним чипсетом сыт не будешь: важны дизайн, эргономика, камеры, экран, — в общем все. SoC — это лишь одна из важных составляющих мобильника, но не главенствующая.
Технологический процесс
Характеристика масштаба технологии, определяющая размер используемых полупроводников. Чем меньше значение (измеряется в нанометрах), тем лучше. Нынешний предел — это 5 нм (Apple A14 Bionic, Kirin 9000 и готовящийся к выпуску Snapdragon 875). Маленький техпроцесс позволяет при одних и тех же размерах кристалла разместить на нем больше транзисторов, тем самым увеличив мощность и снизив потребление энергии. Для 2020 минимально допустимым является техпроцесс 14 нм.
Тактовая частота
Показатель, измеряемый в ГГц, отображающий сколько вычислений может произвести процессор и графический ускоритель в единицу времени. В 2020 году флагманские чипсеты предлагают CPU с частотой до 3 ГГц, среднебюджетные решения имеют CPU с частотой до 2,5 ГГц, а бюджетники CPU до 2,2 ГГц. Чем выше этот показатель, тем лучше, но прямой зависимости между тактовой частотой и производительностью нет. Эффект от повышения этого параметра наблюдается только когда один и тот же вид ядер, допустим Cortex-A76, разгоняют до более высоких значений.
Тип и компоновка ядер CPU
В современных чипсетах применяется система кластеризации big.LITTLE. Кластер big отвечает за высокую производительность и в нем применяются тип ядер Cortex-A75, Cortex-A76, Cortex-A77 и т.д. (чем выше число, тем лучше). Кластер LITTLE необходим для выполнения несложных задач, таких как звонки, СМС, социальные сети и т.п. Он использует ядра Cortex-A53 и Cortex-A55 — другие не используются! В итоге получается сбалансированная система с оптимальным энергопотреблением и высокой производительностью.
Однако некоторые производители чипсетов любят поэкспериментировать. Так, Qualcomm использует в Snapdragon ядра Kryo, а Samsung — Mongoose. И первое и второе является кастомизированным решением ядер Cortex-A 50-й и 70-й серий. Также компании отступают и от классической компоновки ядер 4x big + 4x LITTLE, применяя схемы 1 + 3 + 4, 2 + 6 или 2 + 2 + 4.

Что из этого стоит усвоить? Если процессор включает в себя только ядра класса Cortex-A53/A55, то это чип начального уровня. Если имеется минимум 2 ядра Cortex-A 70-й серии, то это чип среднего класса. Остальное — флагманы.
Графический ускоритель (GPU)
В 2020 году актуальными являются видеоподсистемы Adreno и Mali. Adreno используется только в решениях Qualcomm (Snapdragon), а Mali применяется в Exynos, Kirin и Mediatek.
Что предпочтительнее? В последнее время видеоускорители Mali существенно подросли, но до Adreno им все еще далеко. Сказываются не только лучшие инженерные решения, разработанные Qualcomm, но и оптимизация игр, поэтому геймеры предпочитают девайсы на Snapdragon.
Оперативная и пользовательская память
Эти характеристики хоть и имеют прямое отношение к чипсетам, но тип используемой памяти необходимо смотреть непосредственно в параметрах смартфона. Дело в том, что условный Snapdragon 765G поддерживает как медленную память типа eMMC 5.1, так и быструю UFS 3.0. Производители смартфонов ради низкой цены могут экспериментировать с этими параметрами, используя память помедленнее. Для 2020 года актуальными стандартами являются LPDDR4 и выше для ОЗУ, а также UFS 2.0 и выше для ПЗУ.
Баллы в синтетических бенчмарках — что нужно знать
Бенчмарки, если что, это специальный софт, в котором можно посмотреть оценку конкретного процессора на основе множества параметров. И сравнивать его с другими. Здесь работает принцип «чем больше — тем лучше». Но не все так просто, как может показаться, — сейчас объясним.
- Если речь идет о топовых процессорах, то вообще нет никакой разницы, какие баллы они демонстрируют. Грубо говоря, работают флагманские чипсеты одного уровня, выпущенные в один и тот же год, почти одинаково
- Сравнивая чипсеты среднего и бюджетного классов разных производителей, в первую очередь стоит обращать внимание на результаты тестирования CPU и GPU. Показатели именно этих подсистем демонстрируют, насколько мощны сами смартфоны, как шустро они работают в повседневных задачах и тяжелых играх
- Данные раздела MEM показывают быстродействие памяти. Больше баллов — быстрее запускаются приложения
- Показатель UX (удобство использования) — это общий балл поведения смартфона. Здесь оцениваются ощущения от использования девайса, оптимизация установленного ПО под имеющееся «железо»
GeekBench в плане информативности менее эффективен, так как оценивает только производительность процессорной части. С другой стороны, это кроссплатформенный бенчмарк и позволяет сравнить мощность процессора в телефоне с производительностью CPU на компьютере. Зачем это необходимо, не совсем понятно, но факт остается фактом.
Что в итоге?
Возникает вопрос, а что тогда выбрать, чтобы девайс работал быстро и плавно? Отвечаем числами из AnTuTu:
- Для повседневной работы годится любой смартфон, набирающий от 100 000. Это уровень примерно Snapdragon 625. Можно взять и аппарат на Helio A22 с его 80 000 баллами, но запаса на будущее у него нет
- Для баланса цена/производительность подойдет решение, выдающее от 200 000 баллов. Это примерно уровень Helio G80, Snapdragon 710, Exynos 9611
- Для бюджетного гейминга сгодятся чипы, набирающие от 280 000+. Это Snapdragon 732G, Helio G90T, Kirin 810, Exynos 9810
- Чипы, набирающие свыше 350 000 баллов — это флагманы 2018, 2019 и 2020 годов. Этим ребятам «все по зубам».
Это тоже интересно:
- Сам себе режиссер. Топ 5 бесплатных видео приложений на смартфоне
- Cмартфон, заменивший фотоаппарат. Как снимает лучшая мобильная камера
- Обзор iPhone 12: пожалуй, лучший смартфон Apple «для всех»