Что такое Redis
Простыми словами Redis (англ. Remote Dictionary Server) – это система управления базами данных в виде структур. Redis хранит данные по принципу “ключ — значение”.
Redis – вспомогательная система, которая отвечает за хранилище и кэш основной базы данных. Программа впервые появилась в 2009 года и по-прежнему регулярно обновляется.
Redis поддерживает все самые распространенные языки программирования: Python , Golang, семейство C, Java, Ruby, Perl , PHP и JavaScript.
Плюсы Redis
- Производительность. Система поддерживает хранение данных исключительно в оперативной памяти сервера. Благодаря этому снижается нагрузка на ядро, а пропускная способность увеличивается – Редис выполняет огромное количество операций каждую секунду.
- Функциональность. Работая с Redis, вы можете создать самый сложный код с меньшим количеством простых строк.
- Асинхронная репликация. Это значит, что если вы скопируйте информацию на несколько связанных серверов, это позволит распределить запросы между несколькими серверами, что важно для увеличения скорости чтения.
- Масштабируемость. В Redis есть возможность настроить кластерную архитектуру, выбрать размер кластера или нарастить его. Таким образом ваши проекты будут работать быстро и надежно.
- Гибкость. В отличие от обычных хранилищ в Redis можно работать с неструктурированными данными – они хранятся по типам: строки, списки, потоки и другие. Также вы можете добавить дополнительные типы данных.
Для каких задач подойдет Redis
Самые распространенные цели использования Redis:
- Хранение сессий пользователей. К примеру, части HTML-кода страниц или товарные позиции в корзине магазина.
- Кэширование данных основного хранилища. С помощью Redis cache можно снизить нагрузку на основное хранилище и приложение без необходимости наращивать мощности на серверах.
- Хранение промежуточных данных. Это могут быть формы, таблицы, сообщения на стене.
- Брокер сообщений. При отправке сообщений можно не тратить много времени и ресурсов.
- СУБД как для крупных проектов, так и небольших приложений. Весь трафик распределяется равномерно.
- Хранение “быстрых” данных. Например, для аналитики и других случаев, когда важна скорость и отсутствие задержек передачи.
- Машинное обучение. Скоростное хранилище, которое использует система для информации, позволяет быстро обрабатывать большие объемы данных и автоматизировать принятие решений.
Какие типы данных поддерживает Redis
По умолчанию система поддерживает следующие типы данных:
- строковые;
- потоковые;
- геоданные;
- хеш-таблицы;
- битовые массивы и поля;
- списки;
- множества, в том числе упорядоченные;
- HyperLogLog.
Основные команды Redis
Общие команды, которые можно применять для любого типа данных:
- exists — возвращает 1, если ключ существует и 0, если нет.
- del — удаляет ключ.
- type — возвращает тип значения по ключу.
- expire — удаляет ключ по прошествии указанного времени.
- ttl — возвращает число: сколько времени осталось ключу до удаления.
Полный список команд вы можете посмотреть на официальном сайте Redis.
Как запустить Redis
Самый простой способ для начала работы с системой – использовать команду:
Заключение
В этой статье мы рассмотрели, что такое и зачем нужен Redis. Нет сомнений, что это одна из самых производительных СУБД – об этом говорит время отклика сервера, которое занимает доли миллисекунд. Именно по этой причине Redis востребован в проектах, где необходимо работать с большим количеством данных: аналитика, разработка, потоковая передача, работа с геоданными и многие другие.
Кроме того, настройка Redis происходит гибко благодаря тому, что сервер хранит данные в структурах данных, а не строго в схемах.
Redis
Redis (расшифровывается как Remote Dictionary Server) – это быстрое хранилище данных типа «ключ‑значение» в памяти с открытым исходным кодом. Проект возник, когда Сальваторе Санфилиппо, первоначальный разработчик Redis, захотел улучшить масштабируемость стартапа в Италии. Он создал хранилище Redis, которое теперь используется в качестве базы данных, кэша, брокера сообщений и очереди.
Redis обеспечивает время отклика на уровне долей миллисекунды и позволяет приложениям, работающим в режиме реального времени, выполнять миллионы запросов в секунду. Такие приложения востребованы в сферах игр, рекламных технологий, финансовых сервисов, здравоохранения и IoT. Сегодня Redis – одно из наиболее популярных ядер с открытым исходным кодом, в течение пяти лет подряд называемое «самой любимой» базой данных от Stack Overflow. Благодаря быстрой производительности Redis широко применяется для кэширования, управления сеансами, разработки игр, создания таблиц лидеров, аналитики в режиме реального времени, работы с геопространственными данными, поддержки служб такси, чатов и сервисов обмена сообщениями, потоковой передачи мультимедиа и приложений с отправкой сообщений по модели «издатель – подписчик» (Pub/Sub).
AWS предлагает два полностью управляемых сервиса для запуска Redis. Amazon MemoryDB for Redis – совместимый с Redis надежный сервис базы данных в памяти, который обеспечивает сверхбыструю производительность. Amazon ElastiCache for Redis – полностью управляемый сервис кэширования, который ускоряет доступ к данным из первичных баз данных и хранилищ с микросекундной задержкой. Более того, ElastiCache также предлагает поддержку Memcached, другой популярной системы кэширования с открытым исходным кодом.
Подробную информацию об ускорении приложений с Amazon ElastiCache for Redis см. в онлайн-вебинаре Tech Talk.
Преимущества Redis
Производительность
Все данные Redis хранятся в памяти, что обеспечивает низкую задержку и высокую пропускную способность доступа к данным. В отличие от традиционных баз данных, хранилища данных в памяти не требуют перемещения на диск, что сокращает задержку ядра до микросекунд. Благодаря этому хранилища данных в памяти могут многократно увеличивать количество выполняемых операций и сокращать время отклика. В результате обеспечивается чрезвычайно высокая производительность. Операции чтения и записи в среднем занимают менее миллисекунды, скорость работы достигает миллионов операций в секунду.
Гибкие структуры данных
В отличие от других хранилищ на основе пар «ключ – значение», которые поддерживают ограниченный набор структур данных, Redis поддерживает огромное разнообразие структур данных, позволяющее удовлетворить потребности разнообразных приложений. Типы данных Redis включают:
- строки – текстовые или двоичные данные размером до 512 МБ;
- списки – коллекции строк, упорядоченные в порядке добавления;
- множества – неупорядоченные коллекции строк с возможностью пересечения, объединения и сравнения с другими типами множеств;
- сортированные множества – множества, упорядоченные по значению;
- хэш‑таблицы – структуры данных для хранения списков полей и значений;
- битовые массивы – тип данных, который дает возможность выполнять операции на уровне битов;
- структуры HyperLogLog – вероятностные структуры данных, служащие для оценки количества уникальных элементов в наборе данных;
- потоки – очереди сообщений со структурой журналов данных;
- пространственные данные – записи карт на основе долготы/широты, «поблизости»
- JSON – полуструктурированный объект со вложенной структурой из именованных значений с поддержкой чисел, строк, булевских значений, массивов и других объектов
Простота и удобство
Redis позволяет писать такой же сложный код с меньшим количеством простых строк. Redis позволяет писать меньше строк для хранения, использования данных и организации доступа к данным в приложениях. Разница в том, что, в отличие от языков запросов традиционных баз данных, с Redis разработчики могут использовать простую структуру команд. Например, вы можете задействовать структуру хэш-данных Redis, чтобы перемещать данные в хранилище только одной строкой кода. Решение подобной задачи с использованием хранилища данных, не поддерживающего структуры хэш‑таблиц, потребует написания серьезного объема кода для преобразования данных из одного формата в другой. Redis уже оснащен встроенными структурами данных и предоставляет множество возможностей их комбинирования и взаимодействия с данными клиента. Разработчикам под Redis доступны более ста клиентов с открытым исходным кодом. Поддерживаемые языки программирования включают Java, Python, PHP, C, C++, C#, JavaScript, Node.js, Ruby, R, Go и многие другие.
Репликация и постоянное хранение
В Redis применяется архитектура узлов «ведущий‑подчиненный» и поддерживается асинхронная репликация, при которой данные могут копироваться на несколько подчиненных серверов. Это обеспечивает как улучшенные характеристики чтения (так как запросы могут быть распределены между серверами), так и ускоренное восстановление в случае сбоя основного сервера. Для обеспечения постоянного хранения Redis поддерживает снимки состояния на момент времени (копирование наборов данных Redis на диск).
Redis не задуман как надежная и стабильная база данных. Если вам нужна надежная и совместимая с Redis база данных, рассмотрите Amazon MemoryDB for Redi s . Поскольку MemoryDB использует надежный журнал транзакций, в котором хранятся данные нескольких зон доступности (AZ), вы можете задействовать ее в качестве основной базы данных. MemoryDB специально создана для того, чтобы разработчики могли работать с API Redis, не беспокоясь об управлении отдельным кэшем, базой данных или базовой инфраструктурой.
Высокая доступность и масштабируемость
Redis предлагает архитектуру «ведущий‑подчиненный» с одним ведущим узлом или с кластерной топологией. Это позволяет создавать высокодоступные решения, обеспечивающие стабильную производительность и надежность. Если требуется настроить размер кластера, доступны различные варианты вертикального и горизонтального масштабирования. В результате можно наращивать кластер в соответствии с потребностями.
Инструменты с открытым исходным кодом
Redis – проект с открытым исходным кодом, поддерживаемый активным сообществом, включая AWS. Поскольку Redis базируется на открытых стандартах, поддерживает открытые форматы данных и имеет множество клиентов, отсутствует вероятность блокировки поставщиком или технологического тупика.
Redis
Redis — это система управления базами данных, которая хранит информацию в виде пар ключ-значение. Ключ — это название какого-то поля, а значение — его содержание.
По сути, это сервер, где хранятся структуры данных, в первую очередь так называемые словари. Это видно и в названии системы: Redis расшифровывается как Remote Dictionary Server, то есть удаленный сервер словарей.

Освойте профессию «Аналитик данных»
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.

Профессия / 12 месяцев
Аналитик данных
Находите закономерности и делайте выводы, которые помогут бизнесу

Redis Server — нереляционная СУБД. Это значит, что информацию она хранит не в виде связанных двумерных таблиц, а организует ее иначе. Поэтому Redis быстрее и удобнее стандартных баз, но не так надежен и используется в основном как вспомогательная система.
По-русски систему называют «редис» с ударением на первый слог. На сленге разработчиков — «редис» с ударением на второй слог, как овощ.
Для чего нужен Redis
СУБД нужны, чтобы управлять данными, которые хранятся в базах. Система управления помогает запрашивать данные из базы, изменять их, отправлять в хранилище, объединять и делать многое другое.
Конкретно Redis обычно применяют, чтобы:
- хранить данные сессии пользователя — например, введенный, но не отправленный текст;
- кэшировать информацию из основной СУБД, чтобы снизить на нее нагрузку;
- хранить промежуточные данные, у которых короткий «срок жизни», например результаты ответов на квиз;
- передавать сообщения — система может хранить их и пересылать получателю;
- управлять базами данных маленьких приложений и сайтов-одностраничников.
Еще Redis используют в системах, где очень критична скорость. Например, на финансовых биржах, где задержки в обновлениях курсов могут привести к денежным потерям. Там СУБД используется для хранения быстрых данных, которые как раз нужно передавать с максимальной скоростью. Но как основную базу Redis применяют редко.
Кто работает с Redis
Обычно — бэкендеры и администраторы СУБД, иногда другие специалисты, которые работают с «серверной» частью проектов. Разработчикам, которые имеют дело с этим сервером, желательно знать язык Lua: на нем системе отдают команды и запросы вместо привычного SQL.

Станьте аналитиком данных и получите востребованную специальность
Чем Redis отличается от реляционных СУБД
Классические системы управления базами данных вроде Oracle или MySQL — реляционные. Они хранят информацию в виде двумерных таблиц и систем отношений между ними. Разработчики обращаются к СУБД с помощью языка запросов SQL, получают или отправляют данные. Но запрос нужно сформировать, а информацию, которую вернула база, — перебрать, чтобы превратить в читаемую структуру данных на каком-то языке программирования.
Redis же напрямую хранит данные в виде структур, причем информацию он удерживает в оперативной памяти сервера, а не на жестком диске. Это дает ряд отличий от традиционных СУБД.
Быстрее проходят операции. Обращение к оперативной памяти в принципе быстрее, чем чтение или запись на жесткий диск или SSD-накопитель. Поэтому ускоряется вся система и в конечном итоге — весь продукт.
Гибче работа с базой. Двумерная реляционная таблица — довольно жесткая структура, и работать с ней надо по определенным правилам. Структуры данных в Redis более гибкие, и у разработчика больше свободы в том, как ими управлять. Это помогает реализовать больше интересных решений.
Нет языка SQL. Redis — noSQL СУБД. Это значит, что язык запросов SQL там не используется. Вместо него СУБД применяет скрипты на языке Lua, который специально спроектирован очень простым и поэтому легок в изучении.
Ниже целостность данных. В отличие от реляционных баз данных, Redis не соответствует критериям ACID, которым должна отвечать основная БД проекта. Это набор правил: атомарность, непротиворечивость, изолированность, стойкость. Проще говоря, данные не так хорошо защищены от повреждений, как в более традиционных СУБД. Поэтому Redis редко используют как основную базу.
Как устроен Redis
Давайте разберемся, что такое Redis изнутри и как он работает с информацией. Система опенсорсная и полностью бесплатная, поэтому любой может посмотреть ее исходный код или скачать, чтобы запустить со своего устройства. Но сначала стоит изучить основы.
Структуры и типы данных. Изначально Redis поддерживал только списки — структуры данных, где информация хранится в виде пар «ключ-значение». Сейчас его возможности намного шире. В нем поддерживаются:
- строки — данные в формате текста;
- множества — неупорядоченные наборы уникальных значений;
- упорядоченные множества;
- списки — упорядоченные структуры, где данные пронумерованы;
- битовые массивы — структуры, где данные хранятся в двоичном виде;
- битовые поля — структуры, которые позволяют получать доступ к отдельным битам данных;
- хеш-таблицы — специальные структуры для хранения пар «ключ-значение», обычно хешей;
- геопространственные данные — координаты каких-то точек на карте;
- HyperLogLog — вероятностная структура для хранения большого количества уникальных данных, которые занимают константный объем памяти;
- потоки — структуры данных, доступные только для добавления новой информации. Информация в потоке становится общедоступной для пользователей.
Благодаря разнообразию системой можно гибко управлять, настраивать и относительно легко работать с информацией. Кроме того, Redis поддерживает разные продвинутые функции СУБД. Рассмотрим их подробнее.
Команды. В Redis есть команды для работы со всеми перечисленными выше типами данных. Команды простые, обычно состоят из одного или двух слов, по каждой из них есть руководство в официальной документации. Например, HGET получает данные из хеш-таблицы, а EXEC выполняет все запросы в очереди.
Транзакции. Транзакция в управлении базами данных — это последовательный набор операций, который выполняется целиком или не выполняется вообще. Redis поддерживает механизм транзакций, но с оговоркой: если какая-то команда не выполнится, остальные все равно могут выполниться. Это может нарушить целостность данных — например, фамилия записалась, а имя нет, в итоге в данных остается пробел.
Подписки. Еще одна интересная возможность Redis Server — реализация механизма подписок. Один клиент может создать канал, а другой — подписаться на него и получать сообщения. Эту возможность используют, например, для оповещений о событиях или для создания чатов. У одного канала может быть много подписчиков. Механизм не гарантирует, что конкретный подписчик получит сообщение, и не может предсказать, кто именно его прочитает.
Долговременное хранение. Хотя Redis в основном хранит информацию в памяти, у него есть несколько механизмов для хранения данных на диске. Это в основном резервные копии, потому что для постоянного и надежного хранения данных в памяти Redis попросту не предназначен. Механизмов три:
- RDB — создание «снимков базы», которые описывают ее полное состояние в какой-то момент. Можно задать автоматическое создание снимка раз в определенный промежуток времени. Но если до автоматического снимка произошел сбой, можно потерять данные;
- AOF — ведение «журналов операций», куда записывается информация о каждом действии с базой. Журналы независимы друг от друга, обновляются каждую секунду и хранятся на диске;
- RDB + AOF — комбинация обоих способов считается самой надежной.
Долговременное хранение можно отключить вовсе, потому что Redis ориентирован на скорость, а не на надежность. Но так стоит делать, только если в базе хранятся данные, которые не страшно потерять, вроде кэша.
Конфигурации Redis
Redis Server существует в нескольких конфигурациях: единичный экземпляр, два узла, распределенная система или кластер. Вот в чем их особенности и чем они отличаются.
Единичный экземпляр. Самый простой вариант: есть единственная база, в которую все пишется. Подходит для простых, учебных проектов и прототипов, а еще для кэширования. Но у такой базы хуже отказоустойчивость и меньше возможностей, хотя если выдать ей достаточно мощностей, она может быть довольно производительной.
Redis HA. HA означает High Availability — высокая доступность. Это система, которая состоит из двух баз Redis: основной и зависимой. Ведущая база принимает запросы и записывает данные, а зависимая используется как резервная копия. С помощью репликации данных вся информация передается туда. В итоге, если какая-то из баз откажет, вторая сможет ее заменить — выше надежность всей системы.
Redis Sentinel. Уже более сложная структура — распределенная система. В ней существует основная база, одна или несколько подчиненных, а еще sentinel-узлы. Sentinel-узлы занимаются координацией работы базы: реагируют на сбои, проверяют доступность остальных баз, мониторят и отправляют уведомления. Они же помогают восстановить систему после сбоя и указывают новым клиентам, какой экземпляр базы сейчас ведущий.
Redis Cluster. Самая сложная из всех конфигураций — кластер. Это горизонтальная сеть, где участвует множество клиентов и пар «ведущий-зависимый узлы». Кроме репликации, тут используется шардирование: равномерное распределение данных по всем узлам, которое помогает снижать нагрузку на серверы. Подходит, если базу, например, нужно разделить на несколько устройств. Для мониторинга используется отдельный протокол gossip.
Преимущества Redis
- Высокая скорость — главная причина популярности СУБД среди разработчиков.
- Производительность — может обрабатывать миллионы запросов за секунду.
- Поддержка репликации и шардирования — можно создавать распределенные системы и масштабировать их.
- Работа с разными структурами данных — это дает больше гибкости при разработке.
- Возможность делать «снимки» базы и обеспечивать персистентность, то есть фактически контроль версий.
- Реализация паттерна проектирования «издатель-подписчик» благодаря механизму подписок.
- Многообразие конфигураций — можно запустить и для маленького приложения, и для большой системы.
Недостатки Redis
- Проблемы с долгосрочной записью на диск — в основном Redis хранит информацию в памяти, а при создании «снимка» базы может «потерять» часть сведений.
- Необходимость выбирать между скоростью и надежностью — можно включить персистентность данных, чтобы информация не терялась но это снижает производительность.
- Дороговизна хранения — хранить данные в оперативной памяти более дорого и ресурсоемко, чем на диске. К тому же есть технические ограничения на размер такого хранилища.
Как начать пользоваться Redis
Самый простой способ — развернуть единичный экземпляр базы в Docker-контейнере. Там можно будет открыть консоль Redis и потренироваться отправлять запросы, редактировать и обрабатывать базу данных. Чтобы это сделать, нужно иметь минимальное представление, как работают контейнеры и развертывание программ в них — основы изучить несложно.
Разбираемся с Redis
Этот материал представляет собой глубокое исследование всего, что связано с Redis. В частности — речь пойдёт о различных способах организации хранилищ Redis, о постоянном хранении данных, о форках процессов.

Что такое Redis?
Redis (Remote Dictionary Service) — это опенсорсный сервер баз данных типа ключ-значение.
Точнее всего описать Redis можно, сказав, что это — сервер структур данных. Уникальные особенности сервера Redis стали основной причиной его популярности и того, что он применяется во множестве реальных проектов.
Вместо того чтобы работать со строками базы данных, перебирать, сортировать, упорядочивать их, что если информация с самого начала будет находиться в структурах данных, которые нужны программисту? Первое время Redis использовали практически так же, как Memcached. Но, по мере развития Redis, эта система управления базами данных (СУБД) нашла применение и во многих других ситуациях. В частности — в реализациях механизма издатель/подписчик, в задачах потоковой обработки данных, в системах, где нужно работать с очередями.
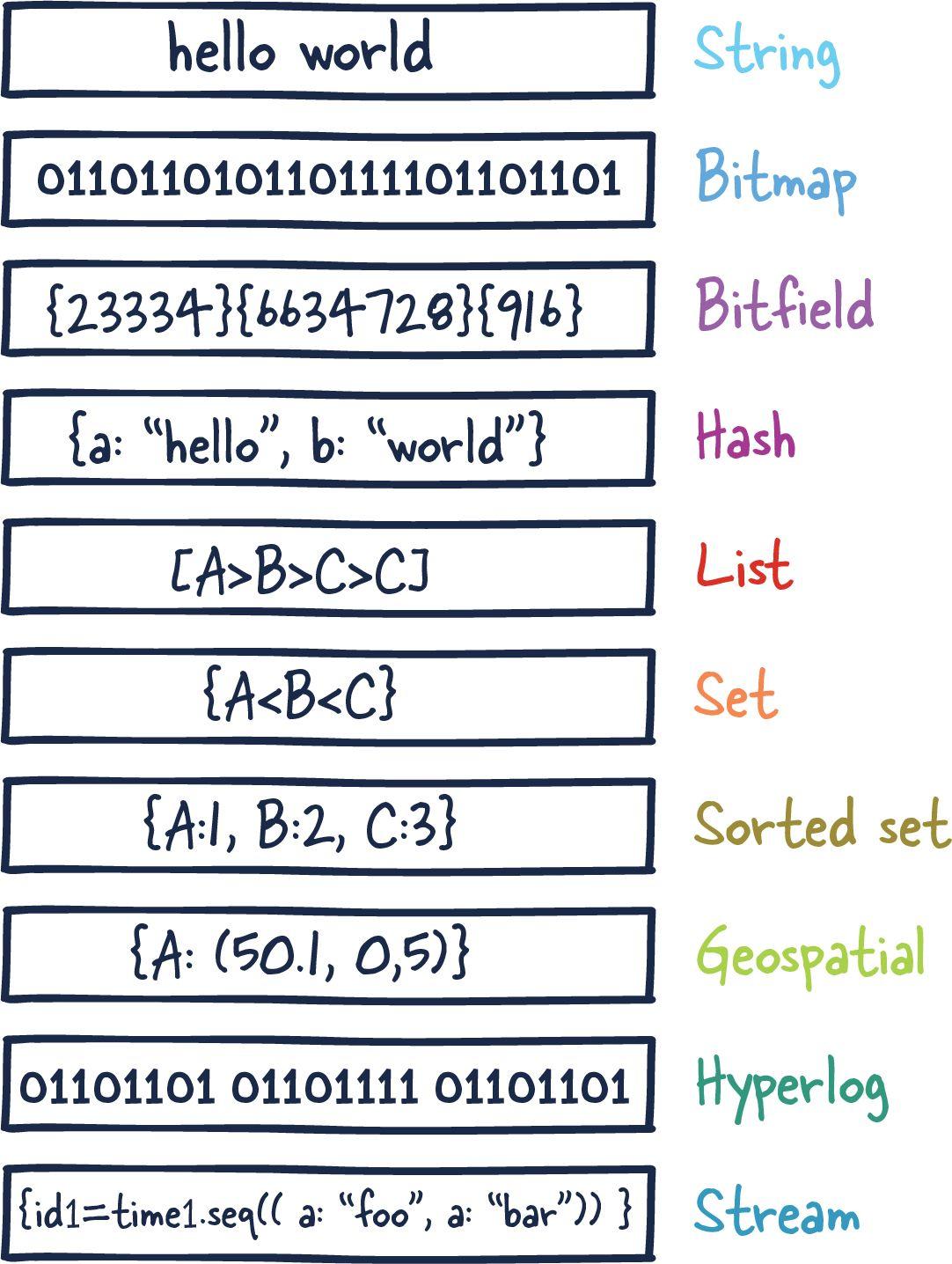
Вот какие типы данных поддерживает Redis:
- Строка (String)
- Битовый массив (Bitmap)
- Битовое поле (Bitfield)
- Хеш-таблица (Hash)
- Список (List)
- Множество (Set)
- Упорядоченное множество (Sorted set)
- Геопространственные данные (Geospatial)
- Структура HyperLogLog (HyperLogLog)
- Поток (Stream)
Redis — это база данных, размещаемая в памяти, которая используется, в основном, в роли кеша, находящегося перед другой, «настоящей» базой данных, вроде MySQL или PostgreSQL. Кеш, основанный на Redis, помогает улучшить производительность приложений. Он эффективно использует скорость работы с данными, характерную для памяти, и смягчает нагрузку центральной базы данных приложения, связанную с обработкой следующих данных:
- Данные, которые редко меняются, к которым часто обращается приложение.
- Данные, не относящиеся к критически важным, которые часто меняются.
Примеры таких данных могут включать в себя сессионные кеши или кеши данных, а так же содержимое панелей управления — вроде списков лидеров и отчётов, включающих в себя данные, агрегированные из разных источников.
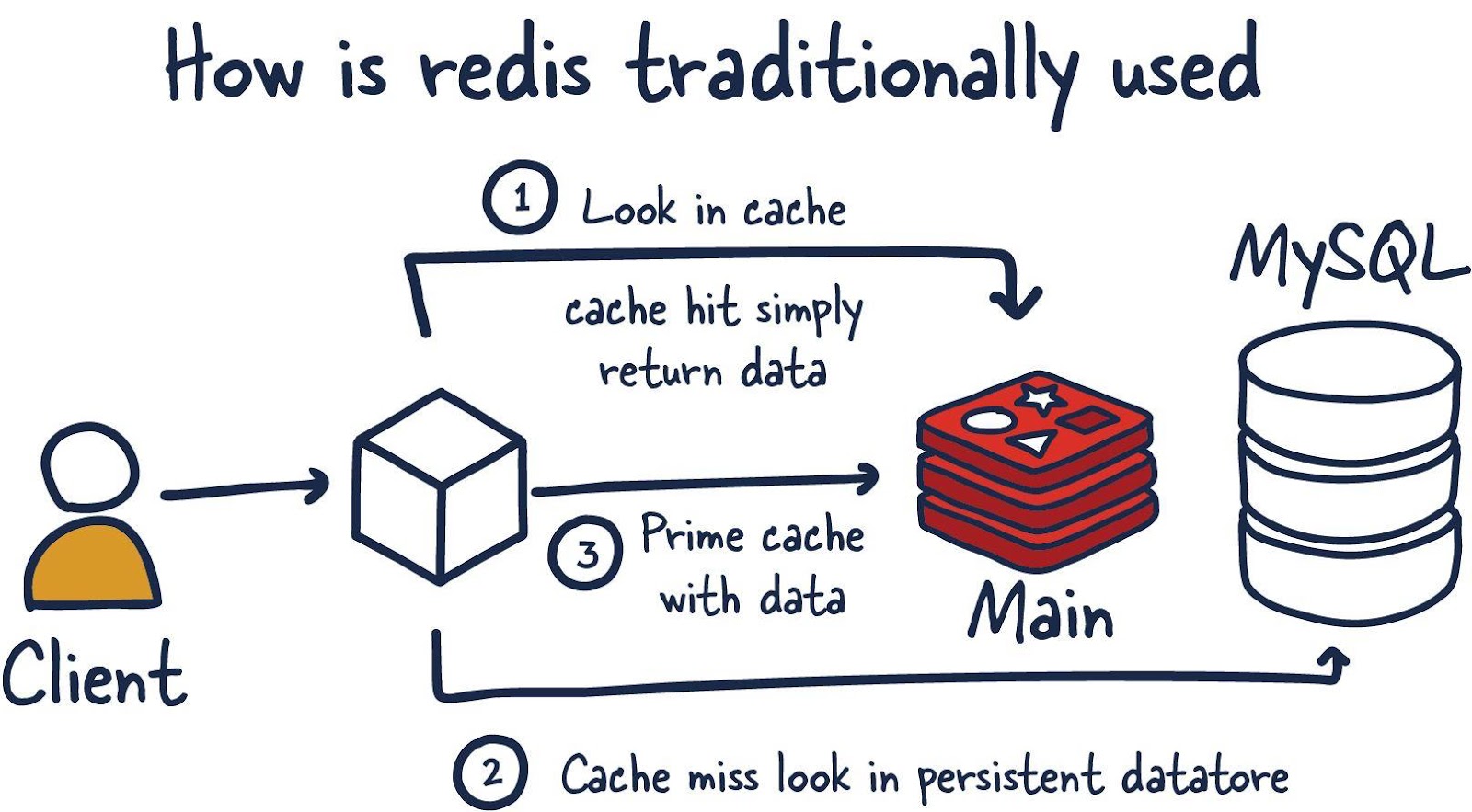
Но во многих случаях Redis гарантирует достаточно высокий уровень сохранности данных, что позволяет использовать эту СУБД в роли настоящей основной базы данных. А добавление в систему плагинов Redis и различных конфигураций высокой доступности (High Availability, HA) делает базу данных Redis крайне интересной для определённых сценариев использования и рабочих нагрузок.
Ещё одна важная особенность Redis заключается в том, что эта СУБД размывает границы между кешем и хранилищем данных. Тут важно понять то, что чтение данных из памяти и работа с данными, находящимися в памяти, гораздо быстрее чем те же операции, выполняемые традиционными СУБД, использующими обычные жёсткие диски (HDD) или твердотельные накопители (SSD).
Изначально Redis чаще всего сравнивали с Memcached, с системой, в которой тогда не было и намёка на долговременное хранение данных.
Хранилище Memcached создал в 2003 году Брэд Фицпатрик. Оно появилось на 6 лет раньше Redis. Сначала это был Perl-проект, а позже его переписали на C. В своё время Memcached был стандартным инструментом кеширования. Главные различия между ним и Redis заключаются в том, что в Memcached имеется меньше типов данных, и в ограничениях, связанных с политикой вытеснения ключей. Memcached поддерживает лишь политику LRU (Least Recently Used), когда первыми вытесняются данные, которые не использовались дольше всех.
Ещё одно отличие этих хранилищ заключается в том, что Redis — это однопоточная система, а Memcached — многопоточная. Memcached может показывать отличные результаты производительности в ограниченных окружениях кеширования. А при использовании этой системы в распределённом кластере нужны дополнительные настройки. Redis же поддерживает подобные сценарии работы сразу после установки.
В следующей таблице приведены сведения об актуальных в наши дни различиях между Memcached и Redis.
Характеристика
Memcached
Redis
Задержки менее миллисекунды
Простота использования для разработчиков
Поддержка широкого набора языков программирования
Продвинутые структуры данных
Поддержка модели «издатель/подписчик»
Поддержка геопространственных данных
В наши дни Redis поддерживает настройку того, как именно данные сохраняются на диск. А в самом начале эта система использовала снепшоты, когда асинхронные копии данных, находящихся в памяти, отправляли на диск для долговременного хранения. К сожалению, у этого механизма имеется недостаток, выражающийся в возможной потере данных, изменённых или добавленных в хранилище на временных интервалах между снепшотами.
Хранилище Redis, с момента его появления в 2009 году, серьёзно развилось. Мы рассмотрим большую часть архитектурных и топологических решений, характерных для Redis, что позволит вам, изучив эту систему, включить её в состав своего арсенала систем хранения данных.
Архитектура Redis
Прежде чем мы начнём разговор о внутренних механизмах Redis — рассмотрим различные варианты развёртывания этого хранилища и обсудим компромиссы, на которые приходится идти тем, кто выбирает тот или иной вариант.
Мы, в основном, уделим внимание следующим конфигурациям:
- Единственный экземпляр Redis.
- Redis HA.
- Redis Sentinel.
- Redis Cluster.
Вы можете выбрать ту или иную конфигурацию в зависимости от особенностей вашего проекта и его масштабов.
Единственный экземпляр Redis

Самый простой вариант развёртывания Redis — это использование одного экземпляра системы. При таком подходе в распоряжении пользователя оказывается небольшое хранилище, которое поможет проекту расти и развиваться и ускорит сервисы этого проекта. Но у такого способа использования Redis есть и недостатки. Например, если используемый в проекте экземпляр Redis даст сбой или окажется недоступным — все обращения клиентов к Redis окажутся неудачными, в результате упадёт общая производительность и скорость работы системы.
Если дать экземпляру Redis достаточно памяти и серверных ресурсов, этот экземпляр может оказаться довольно-таки мощной сущностью. Такой подход, в основном, используется для кеширования, позволяет, потратив минимум сил и времени на настройку системы, получить серьёзный рост производительности проекта. При наличии достаточных серверных ресурсов развернуть подобный сервис Redis можно на той же машине, на которой работает основное приложение.
Для обеспечения успешной работы с Redis важно понимать некоторые концепции этой системы, связанные с управлением данными. Запросы, поступающие к базе данных Redis, обрабатываются путём работы с данными, хранящимися в памяти. Если используемый экземпляр Redis предусматривает применение постоянного хранения данных, в системе будет форк процесса. Он использует RDB (Redis Database, база данных Redis) для организации постоянного хранения снепшотов (снимков) данных. Это — весьма компактное представление данных Redis на определённый момент времени. Вместо RDB могут использоваться файлы, предназначенные только для добавления данных (Append-Only File, AOF).
Эти два механизма позволяют Redis иметь долговременное хранилище данных, поддерживать различные стратегии репликации, помогают реализовывать на базе Redis более сложные топологии. Если сервер Redis не настроен на постоянное хранение данных, то, при перезагрузке или сбое системы, данные теряются. Если же постоянное хранение включено, то при перезагрузке системы осуществляется загрузка в память данных из снепшота RDB или из AOF. После этого экземпляр Redis сможет обрабатывать запросы клиентов.
Учитывая вышесказанное — рассмотрим конфигурации Redis, которые характеризуются, так сказать, большей распределённостью, чем рассмотренная.
Redis HA
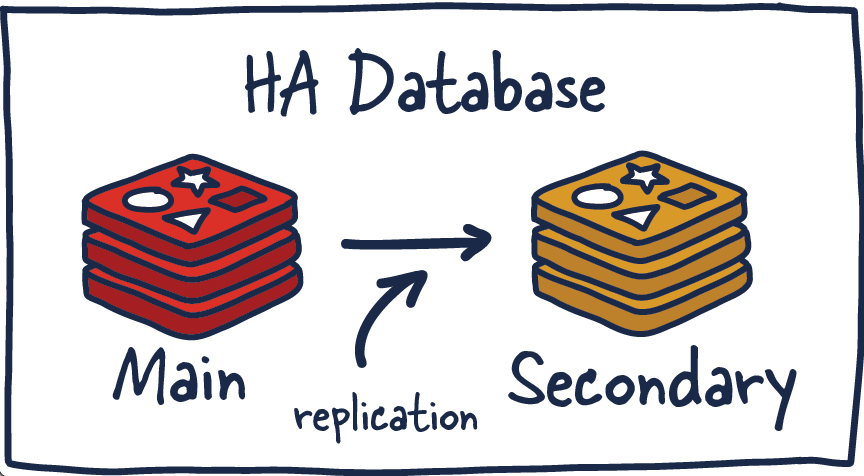
Ещё одна популярная конфигурация Redis представляет собой систему, состоящую из ведущего и подчинённого узлов, состояние которых синхронизируется посредством репликации. По мере того, как данные записываются в ведущем экземпляре Redis, копии соответствующих команд отправляются в выходной буфер для подчинённых узлов, что обеспечивает выполнение репликации данных. В состав подчинённых узлов может входить один или большее количество экземпляров Redis. Эти экземпляры способны помочь в масштабировании операций чтения данных или обеспечить отказоустойчивость системы при потере связи с ведущим узлом.
«Высокая доступность» (HA, High Availability) — это характеристика системы, которая нацелена на обеспечение согласованного уровня показателей её деятельности (обычно — времени безотказной работы системы) на временных интервалах, превышающих средние.
В системах высокой доступности важно отсутствие единой точки отказа. Это позволяет им корректно и быстро восстанавливать нормальную работу после сбоев. Конфигурации высокой доступности предусматривают наличие надёжных линий связи, что исключает потерю данных при их передаче от ведущего узла к подчинённому. Кроме того, в таких системах осуществляется автоматическое обнаружение сбоев и восстановление после них.
Так как теперь мы перешли к распределённым системам, с которыми связано множество заблуждений, нам нужно ознакомиться с несколькими новыми понятиями. То, что раньше было простым и ясным, теперь становится сложнее.
Репликация данных в Redis
Каждый ведущий узел Redis имеет идентификатор (ID) и смещение репликации. Эти два показателя чрезвычайно важны для того, чтобы выяснить момент времени, когда подчинённый узел может продолжать процесс репликации, или чтобы определить, что необходимо выполнить полную синхронизацию данных. Смещение инкрементируется при выполнении любого действия, которое происходит в ведущем узле Redis.
Replication ID, offsetЕсли описать это более конкретно, то окажется, что когда подчинённый узел Redis отстаёт лишь на несколько шагов смещения от ведущего узла, он получает оставшиеся необработанными команды от ведущего узла, эти команды применяются к данным, так происходит до момента синхронизации узлов. Если два экземпляра не могут договориться об ID репликации, или ведущий узел не имеет сведений о смещении, подчинённый узел запрашивает полную синхронизацию данных. Сюда входит создание ведущим узлом нового снепшота RDB и отправка его подчинённому узлу. В процессе передачи этих данных ведущий узел буферизует промежуточные обновления данных, произошедшие между моментом создания снепшота и текущим моментом. Эти обновления будут отправлены подчинённому узлу после того, как он синхронизируется со снепшотом. После завершения этого процесса репликация может продолжаться в обычном режиме.
Если у разных экземпляров Redis имеются одинаковые ID и смещение, это значит, что они хранят в точности одни и те же данные. Тут может появиться вопрос о том, почему в Redis используется ID репликации. Дело в том, что когда уровень экземпляра Redis повышается до ведущего узла, или если экземпляр сразу запускается как ведущий, ему назначается новый ID репликации. Он используется для выяснения того, какой экземпляр Redis был до этого ведущим. А именно, выясняется то, из какого экземпляра раньше копировал данные узел, уровень которого был только что повышен. Это даёт возможность выполнения частичной синхронизации (с другими подчинёнными узлами), так как новый ведущий узел помнит свой старый ID репликации.
Например, два экземпляра Redis, ведущий и подчинённый, имеют один и тот же ID репликации, а их смещения отличаются на несколько сотен команд. То есть — если на «отстающем» экземпляре воспроизвести соответствующие команды, в распоряжении обоих экземпляров будет идентичный набор данных. Предположим, что ID репликации экземпляров различаются и нам неизвестен предыдущий ID (у экземпляров нет общего предка) узла, уровень которого недавно понижен до подчинённого (он подключён к ведущему узлу). В такой ситуации нужно выполнить ресурсозатратную операцию полной синхронизации данных.
С другой стороны, если предыдущий ID репликации известен — мы можем подумать о том, как синхронизировать данные двух узлов. Так как нам известен общий предок узлов, это значит, что они хранят общие данные, а значит, воспользовавшись смещением, мы можем провести частичную синхронизацию данных.
Redis Sentinel
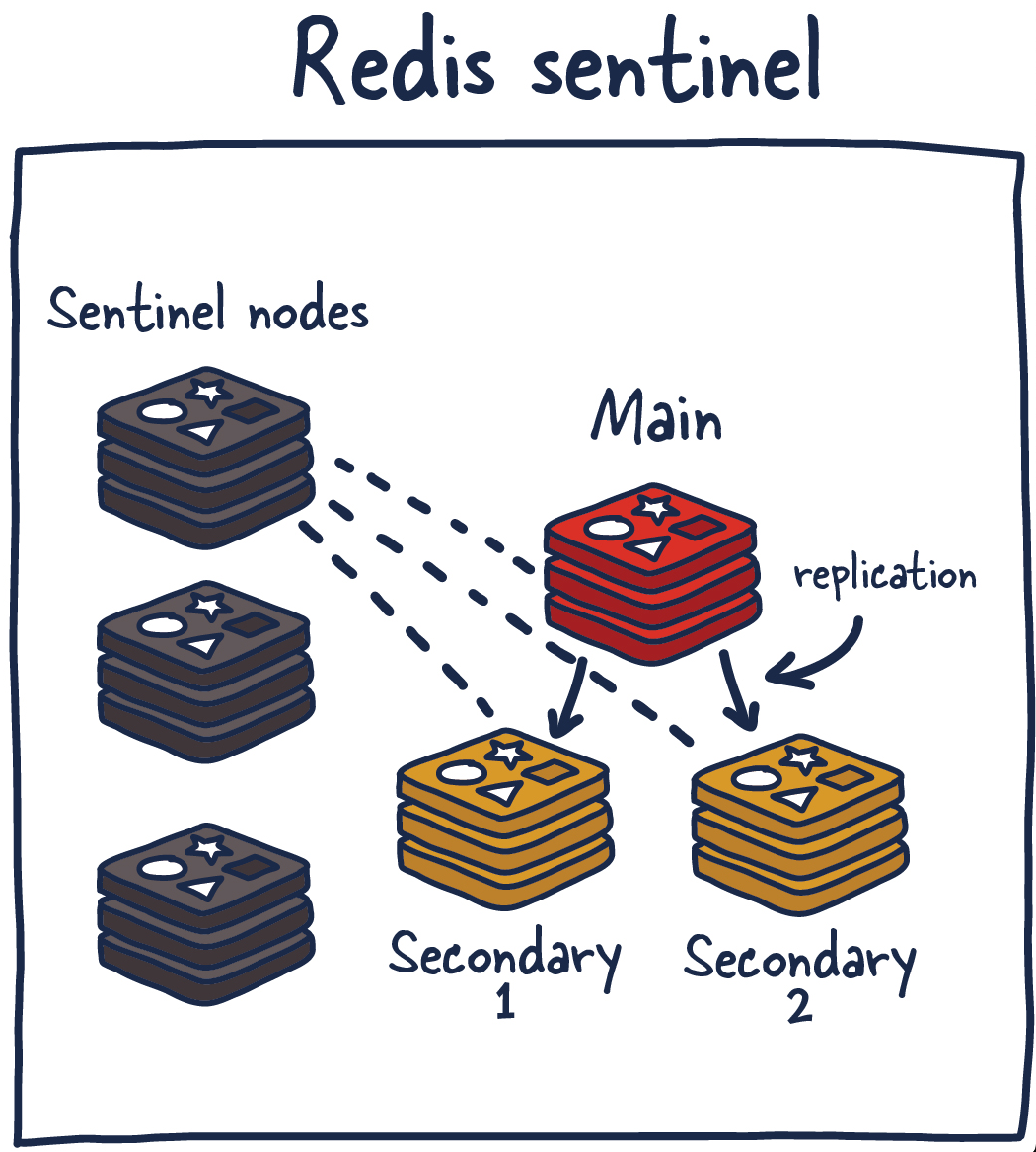
Redis Sentinel — это сервис, обеспечивающий создание распределённых систем. И, как и в случае со всеми распределёнными системами, у Sentinel имеются и сильные, и слабые стороны. В основе Sentinel лежит кластер Sentinel-процессов, работающих совместно. Они координируют состояние системы, реализуя конфигурацию высокой доступности Redis. Sentinel — это сервис, защищающий хранилище Redis от сбоев. Поэтому логично то, чтобы этот сервис не имел бы единой точки отказа.
Сервис Sentinel решает несколько задач. Во-первых — он обеспечивает работоспособность и доступность текущих ведущих и подчинённых узлов. Благодаря этому текущий Sentinel-процесс (вместе с другими подобными процессами) может отреагировать на ситуацию, когда теряется связь с ведущими и/или подчинёнными узлами. Во-вторых — он играет определённую роль в деле обнаружения сервисов. Похожим образом в других системах работают Zookeeper и Consul. То есть — когда новый клиент пытается что-то записать в хранилище Redis, Sentinel сообщит клиенту о том, какой экземпляр Redis в этот момент является ведущим.
Получается, что узлы Sentinel постоянно мониторят доступность экземпляров Redis и отправляют сведения о них клиентам, что позволяет клиентам предпринимать определённые действия в тех случаях, когда хранилище даёт сбой.
Вот какие функции выполняют узлы Sentinel:
- Мониторинг. Обеспечение того, что ведущие и подчинённые узлы работают так, как ожидается.
- Отправка уведомлений администраторам. Система отправляет администраторам уведомления о происшествиях в экземплярах Redis.
- Управление восстановлением системы после отказа. Узлы Sentinel могут запустить процесс восстановления системы после сбоя в том случае, если ведущий экземпляр Redis недоступен и достаточное количество (кворум) узлов согласно с тем, что это так.
- Управление конфигурацией. Узлы Sentinel, кроме того, играют роль системы, позволяющей обнаруживать текущий ведущий экземпляр Redis.
Использование Redis Sentinel для решения вышеописанных задач позволяет обнаруживать сбои Redis. Процедура обнаружения сбоя включает в себя получение согласия нескольких узлов Sentinel с тем, что текущий ведущий экземпляр Redis недоступен. Процесс получения такого согласия называют кворумом (quorum). Это позволяет повысить надёжность системы, защититься от ситуаций, когда один из процессов ведёт себя неправильно и не может подключиться к ведущему узлу Redis.
Кворум — это минимальное число голосов, которое нужно получить распределённой системе для того, чтобы ей было бы позволено выполнять определённые операции, наподобие восстановления после сбоя. Это число поддаётся настройке, но оно должно отражать количество узлов в рассматриваемой распределённой системе. Размеры большинства распределённых систем равняются трём или пяти узлам, в них, соответственно, кворум равен двум или трём голосам. Нечётные количества узлов предпочтительны в случаях, когда системе необходимо разрешать неоднозначности.
У Redis Sentinel есть и недостатки. Поэтому мы рассмотрим несколько рекомендаций и практических советов, касающихся этого сервиса.
Redis Sentinel можно развернуть несколькими способами. Честно говоря, чтобы дать какие-то адекватные рекомендации, мне нужны подробности о той системе, в составе которой планируется использовать Redis Sentinel. В качестве общего правила я посоветовал бы запускать узел Sentinel вместе с каждым из серверов приложения (если это возможно). Это позволит не обращать внимания на различия, связанные с сетевыми подключениями узлов Sentinel и клиентов, которые используют Redis.
Sentinel можно запустить и на тех же машинах, на которых работают экземпляры Redis, или даже в виде независимых узлов, но это, в различных формах, усложняет ситуацию. Рекомендую применять как минимум три узла с кворумом, как минимум, из двух. Вот простая таблица, в которой описано количество серверов в кластере, даны сведения о кворуме и о количестве допустимых отказов.
Количество серверов
Кворум
Количество допустимых отказов