ML: Тензоры в Numpy
Нейронная сеть является функцией $\mathbf’ = F(\mathbf)$, преобразующей один тензор $\mathbf$ в другой $\mathbf$.
Понимание природы тензоров и операций с ними лежит в основе понимания работы нейронных сетей.
Тензор — это множество упорядоченных чисел (элементов), пронумерованных при помощи d целочисленных индексов: $\mathrm[i_0,\, i_1,\. \, i_]$. Число индексов d называется размерностью тензора.
Каждый индекс меняется от 0, до $d_i-1$, где $d_i$ называется размерностью индекса.
Перечисление размерностей всех индексов: $(d_0,\,d_1. d_)$ называется формой тензора.
Существующие фреймворки машинного обучения работают с тензорами примерно одинаковым образом.
Ниже мы рассмотрим универсальную библиотеку numpy. Это не справочник по numpy, для этого см. scipy.org.
Мы сосредоточимся на понятиях размерности и формы тензора, а также на том, как они изменяются при различных операциях (что собственно и требуется при анализе нейронных сетей).
Размерность и форма тензора
В библиотеке numpy у каждого тензора t есть четыре базовых свойства (атрибута):
- t.ndim — размерность = сколько у тензора индексов;
- t.shape — форма = кортеж с размерностью каждого индекса;
- t.size — количество элементов тензора (если shape=(a,b,c), то size=a*b*c);
- t.dtype — тип тензора (float32, int32. ) одинаковый для всех элементов.
Если тензор имеет один индекс: t[i] — то это вектор (ndim=1), а если у него два индекса: t[i,j] — то это матрица (ndim=2). Индексы нумеруются начиная с нуля.
Метод np.array(lst) преобразует список lst (список чисел или список других списков) в тензор numpy:
import numpy as np # ndim: shape: size: v = np.array( [ 1, 2, 3] ) # вектор: 1 (3,) 3 m = np.array( [ [ 1, 2, 3], [ 4, 5, 6] ]) # матрица: 2 (2, 3) 6 t = np.array( [ [[ 1, 2, 3], [ 4, 5, 6]], [[ 7, 8, 9], [10,11,12]] ]) # тензор: 3 (2, 2, 3) 12
- форма одномерного тензора (вектора) это (n,) , а не (n) , т.к. для Python(n) — это число, а не кортеж.
- t = np.array( [[[1]]] ) — это тензор из одного числа, с shape=(1,1,1) и t.ndim==3, t[0,0,0]==1.
Тензоры принято изображать в табличной форме: вектор (ndim=1) — это строка чисел, матрица формы (rows,cols) — это прямоугольная таблица с rows строчками и cols колонками. Трёхмерный тензор (три индекса, ndim=3) изображают в виде стопки матриц:
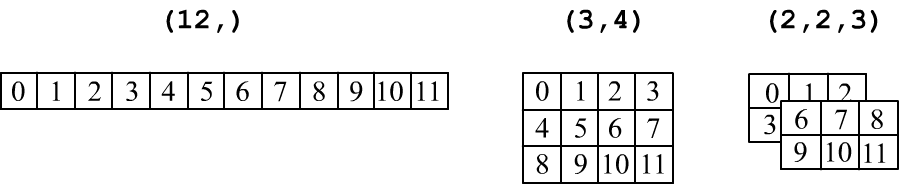
Важно не путать вектор (n,) и матрицу, состоящую из одной строки (1,n) или одной колонки (n,1):
t2 = np.array( [ 1, 2] ) # shape = (2,) t12 = np.array( [ [1,2] ] ) # shape = (1,2) t21 = np.array( [[1], # shape = (2,1) [2]]) t2[1] == t12[0,1] == t21[1,0] == 2 # True
Ниже матрицы из одной строчки или одной колонки окружены двойной линией, чтобы отличить их от вектора:
$$ \begin <|c|c|>\hline 1 & 2\\ \hline \end ~~~~~~~~~ \begin <|c|>\hline \begin <|c|c|>\hline 1 & 2\\ \hline \end \\ \hline \end ~~~~~~~~~ \begin <|c|>\hline \begin <|c|>\hline 1 \\ \hline 2\\ \hline \end \\ \hline \end $$
Последовательность элементов
Тензор формы shape = (a,b,c) состоит из size = a*b*c упорядоченных чисел (элементов).
Форму тензора можно изменить (с сохранением количества элементов size) при помощи метода reshape или прямого изменения атрибута shape:
v = np.array( [1,2,3,4,5,6] ) # shape = (6,) ndim = 6 m16 = v.reshape( (1,6) ) # shape = (1,6) ndim = 6 m32 = v m23.shape = (2,3) # shape = (2,3) ndim = 6 print(m23) # [ [1,2,3], # [4,5,6] ]
$$ \begin
При изменении формы тензора методом reshape, результат возвращается по ссылке (не создаётся новой копии множества чисел). Поэтому, если поменять значение элемента в m16, то он поменяется и в v:
m16[0,0] = 100 v # [100, 2, 3, 4, 5, 6]
Элементы в памяти идут в порядке увеличения индексов, начиная с конца. Например, для трёхмерного тензора с формой (2,1,3) это 6 чисел в следующем порядке:
t[0,0,0] t[0,0,1], t[0,0,2], t[1,0,0] t[1,0,1], t[1,0,2].
Менять форму тензора можно произвольным образом, сохраняя неизменным число элементов. Ниже метод arange создаёт вектор (одномерный тензор) из 12 целых чисел от 0 до 11. Затем получаются ссылки на матрицу и трёхмерный тензор. В последнем случае значение -1 в размерности первого индекса, просит numpy самостоятельно высчитать эту размерность (исходя из числа элементов и размерностей остальных индексов):
v = np.arange(12) # [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] m = v.reshape( (3, 4 ) ) t = m.reshape( (-1, 2, 3) ) print(v.shape, m.shape, t.shape) # (12,) (3, 4) (2, 2, 3)
Оси тензора
Индексы — это оси (axis) тензора. Первый индекс — это axis=0, второй axis=1 и т.д. У многих методов есть параметр axis. Например, суммирование по данной оси уменьшает размерность ndim на 1.
m = np.ones( (2, 3) ) # матрица 2x3 из единиц: [ [1,1,1], # [1,1,1]] print( m.sum(axis=0), # [2. 2. 2.] сумма по строчкам m.sum(axis=1), # [3. 3.] суммы по колонками m.sum() ) # 6.0 сумма всех элементов
Аналогично работают функции min, max, mean, median, var, std, argmin, argmax и т.п.
Из тензора можно вырезать подмножество его элементов. Ниже вырезается нулевая строчка и нулевая колонка, а затем квадратная матрица 2×2:
m = np.arange( 6 ).reshape((2,3)) # [[0, 1, 2], # [3, 4, 5]] v1 = m[0, :] # [0, 1, 2] v2 = m[0] # тоже самое (для 1-го индекса) v3 = m[:, 0] # [0, 3] mm = m[0:2, 0:2] # [ [0, 1], # [3, 4] ]
Подмножества элементов, находящиеся в v1, v2, v3 получаются по по ссылке, а не по значению, поэтому:
v1[0] = 100 m.reshape(-1) # [100, 1, 2, 3, 4, 5]
Менять можно не только значение одного элемента, но и всех элементов (ниже, стоящих в первой колонке):
m[:,0] = -1 # [[-1, 1, 2], print(m) # [-1, 4, 5]]
Сложение, умножение и broadcasting
При поэлементном сложении и умножении тензоров одинаковой формы результат имеет ту же форму: $$ (x+y)_:~~x_+y_,~~~~~~~~~~~~~~~~~~ (x*y)_:~~x_*y_. $$ Например (ниже np.arange(beg=0, end) — вектор целых чисел от beg до end, исключая end):
a = np.arange(3) # [0, 1, 2] b = np.arange(3,6) # [3, 4, 5] a + b # [3, 5, 7] a * b # [0, 4,10]
Аналогично работают функции от тензоров : $T’_=F(T_)$. Например: np.exp( ), np.log( ), np.sin( ), np.tanh( ), полный список см. на scipy.org.
При добавлении к матрице (n, m) вектора (n,) или матрицы, состоящей из одной строки (1,n), у последней дублируются строки и затем происходит сложение (или умножение) матриц одинаковой формы. При добавлении к матрице (n, m) матрицы, состоящей из одной колонки (m,1), у последней дублируются колонки: $$ \begin <|c|c|>\hline 0 & 1 \\ \hline 2 & 3 \\ \hline \end ~+~ \begin <|c|c|>\hline \mathbf & \mathbf \\ \hline \end ~=~ \begin <|c|c|>\hline 0 & 1 \\ \hline 2 & 3 \\ \hline \end ~+~ \begin <|c|c|>\hline \mathbf & \mathbf \\ \hline \mathbf & \mathbf \\ \hline \end, ~~~~~~~~~~~~~~~~ \begin <|c|c|>\hline 0 & 1 \\ \hline 2 & 3 \\ \hline \end ~+~ \begin <|c|>\hline \begin <|c|>\hline \mathbf \\ \hline \mathbf \\ \hline \end \\ \hline \end ~=~ \begin <|c|c|>\hline 0 & 1 \\ \hline 2 & 3 \\ \hline \end ~+~ \begin <|c|c|>\hline \mathbf & \mathbf \\ \hline \mathbf & \mathbf \\ \hline \end $$
m = np.array([ [0, 1], [2, 3]]) v = np.array( [4, 5] ) print(m+v) # [[4, 6], # [6, 8]]
- выравнивается число индексов (ndim), добавляя к меньшему в shapeспереди единицы;
- размерности индексов считаются сравнимыми если они равны или один из них 1;
- размерность единичного индекса увеличиваем до большего, дублируя значения по этой оси:
(3, 1, 4, 1) + (7, 1, 5) = (3, 1, 4, 1) + (1, 7, 1, 5) = (3, 7, 4, 5)
Например, сложим матрицу из одной колонки и вектора $(3,1) + (2,) = (3,1) + (\underline<1,>2) = (3,2)$: $$ \begin <|c|>\hline \begin <|c|>\hline 1\\ \hline 2\\ \hline 3\\ \hline \end \\ \hline \end ~+~ \begin <|c|c|>\hline 4 & 5 \\ \hline \end ~~ = ~~ \begin <|c|>\hline \begin <|c|>\hline 1\\ \hline 2\\ \hline 3\\ \hline \end \\ \hline \end ~+~ \begin <|c|>\hline \begin <|c|c|>\hline 4 & 5 \\ \hline \end \\ \hline \end ~~ = ~~ \begin <|c|c|>\hline 1 & 1 \\ \hline 2 & 2 \\ \hline 3 & 3 \\ \hline \end ~+~ \begin <|c|c|>\hline 4 & 5 \\ \hline 4 & 5 \\ \hline 4 & 5 \\ \hline \end ~=~ \begin <|c|c|>\hline 5 & 6 \\ \hline 6 & 7 \\ \hline 7 & 8 \\ \hline \end $$
Свёртка векторов и матриц
Важными операциями являются скалярное произведение векторов и умножение матриц со свёрткой: $$ \mathbf
В numpy обе операции выполняются при помощи метода dot. Так, для векторов:
u = np.array( [1,2,3] ) v = np.array( [3,2,1] ) print( np.dot(u,v) ) # 10 = 1*3 + 2*2 + 3*1 print( u.dot(v) ) # 10 - тот же результат print( np.sum(u*v) ) # 10 - тот же результат
P = np.arange( 6).reshape( (2,3) ) Q = np.arange(12).reshape( (3,4) ) np.dot(P, Q) P.dot(Q) # то-же самое
Представим последнее умножение в табличном виде:
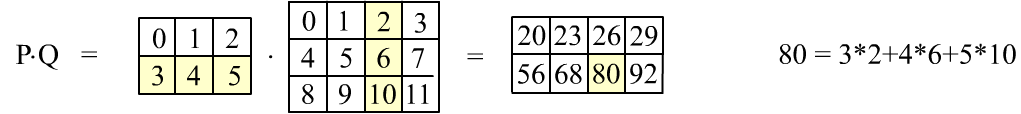
При матричном умножении сворачиваются строки первой матрицы со столбцами второй.
На рисунке выше приведено вычисление элемента $80$, закрашенного желтым цветом.
Чтобы получить все элементы, сначала первая строка первой матрицы должна 4 раза свернуться с 4-я колонками второй матрицы. Это даёт первую строку результирующей матрицы. Затем то-же делает вторая строка, что приводит ко второй строке результата.
Свёртка матриц возможна только, когда число колонок первой матрицы равно числу строк второй.
Выполняется следующая важная формула для форм исходных матрицы и результата свёртки:
$$ (n,\, \underline) \cdot (\underline, m) ~=~ (n,\,m) $$
Если первая матрица состоит из одной строчки, а вторая из одного столбика, то их произведение будет по-прежнему матрицей, но с одним элементом $(1,\,\underline)\cdot(\underline,\,1)=(1,\,1)$:
$$ \begin <|c|>\hline \begin <|c|c|>\hline 1 & 2\\ \hline \end \\ \hline \end ~ \cdot ~ \begin <|c|>\hline \begin <|c|>\hline 3\\ \hline 4\\ \hline \end \\ \hline \end ~ = ~ \begin <|c|>\hline \begin <|c|>\hline 11 \\ \hline \end \\ \hline \end $$
Свёртка по единственному индексу: $(2,\,\underline) \cdot (\underline,\,2) = (2,\,2)$ равна попарному перемножению элементов (по тому же правилу «строка на столбец»): $$ \begin <|c|>\hline \begin <|c|>\hline 1\\ \hline 2\\ \hline \end \\ \hline \end ~ \cdot ~ \begin <|c|>\hline \begin <|c|c|>\hline 3 & 4\\ \hline \end \\ \hline \end ~ = ~ \begin <|c|c|>\hline 3 & 4 \\ \hline 6 & 8 \\ \hline \end = c_r_ $$
Транспонирование матриц
Операция транспонирования переставляет элементы таким образом, что столбцы и строчки меняются местами. Если форма исходной матрицы была $(n,\,m)$, то у транспонированной она будет $(m,\,n)$:
$$ t^T_ = t_,~~~~~~~~~~~~~~~~~~~ \mathrm~~ \begin <|c|c|c|>\hline 0 & 1 & 2 \\ \hline 3 & 4 & 5 \\ \hline \end ~ = ~ \begin <|c|c|c|>\hline 0 & 3 \\ \hline 1 & 4 \\ \hline 2 & 5 \\ \hline \end $$
В numpy транспонирование осуществляется методом transpose() или при помощи атрибута .T:
a = np.arange(6).reshape(2,3) b = a.T b.shape # (3, 2)
Подчеркнём что транспонирование и перестановка размерностей при помощи reshape приводят к различному порядку элементов:
v = np.arange(6) m = v.reshape(3,2) m1 = m.reshape(2,3) # m1 = [[0 1 2] m2 = [[0 2 4] m2 = m.T # [3 4 5]] [1 3 5]]
Транспонирование не создаёт новой матрицы (возвращается ссылка, а не значения). Поэтому:
m2[0,0]=100 m # [ [100, 1, 2], # [ 3, 4, 5]]
Не квадратную матрицу можно умножить саму на себя, только предварительно транспонировав её (иначе не выполнится правило совпадение числа колонок и числа строк):
a = np.arange(6).reshape(2,3) np.dot(a, a.T) # [ [ 5, 14], [14, 50] ] (2,3)(3,2)=(2,2) np.dot(a.T, a) # [ [ 9, 12, 15], [12, 17, 22], [15, 22, 29]] (3,2)(2,3)=(3,3)
Для тензоров произвольной размерности операция транспонирования переставляет все индексы в противоположном порядке $t^T_=t_<. kji>$:
x = np.empty( (4,3,2,7) ) # массив с "мусорными" значениями элементов print(x.T.shape) # (7,2,3,4)
Как и в случае с матриц, такая перестановка индексов приводит иному порядку элементов, чем просто изменение атрибута shape.
Перемножение тензоров со свёрткой
Для произвольных тензоров операция свёртки dot работает по принципу последний индекс с предпоследним: $$ (\mathbf\,.\mathbf)_ = \sum_\alpha a_
При этом выполняется правило для форм: $$ (n_1,\,n_2,\,\underline
Произведение вектора $\mathbf$ и тензора $\mathbf$, независимо от ndim последнего, интерпретируется следующим образом.
У тензора берутся последние два индекса и делаются такие свёртки (второй случай — по принципу «последний с предпоследним»):
Если у тензора ndim=2 (матрица), то вектор справа превращается в столбик, а слева — в строчку:
$$ \begin <|c|c|>\hline 1 & 1 \\ \hline \end \cdot \begin <|c|c|c|>\hline 1 & 1 & 1\\ \hline 1 & 1 & 1\\ \hline \end \cdot \begin <|c|c|c|>\hline 1 \\ \hline 1 \\ \hline 1 \\ \hline \end ~=~ 6 $$ В этом случае для форм имеем: $\underline\,. (3,) = (3,)\,. (3,) = $ скаляр или $(2,)\,. \underline = (2,)\,. (2,) = $ тот же скаляр.
Другие операции свёртки
Существует ещё один метод свёртки matmul (и @ — операция для него). Для ndim = 2 результат такой свёртки не отличается от свёртки dot. Различия начинаются при ndim > 2.
В этом случае тензоры интерпретируются как стопки 2D матриц по последним двум индексам.
Эти 2D матрицы перемножаются независимо в каждой «плоскости стопки».
Последние два индекса тензоров фиксируются, а по остальным тензоры расширяются (broadcasting).
Для векторов индекс добавляется, а потом убирается. $$ (\overline\, 2, 3) ~@~ (\overline \,3, 5) ~~~\Rightarrow~~~ (\overline\, 2, 3) ~@~ (\overline\,3, 5) ~~~\Rightarrow~~~ (3, 2, 2, \underline) ~@~ (3, 2, \underline, 5) ~~~\Rightarrow~~~ (3, 2, 2, 5) $$ Перемножить $(\mathbf,~2,~3)~ @ ~(\mathbf,~3,~5)$ нельзя, т.к. они нерасширяемы по «жирным» индексам (по последним двум индексам должно быть матричное умножение и их не трогаем). Как и в dot, размерность последнего индекса первого тензора и предпоследнего второго должны совпадать.
Универсальная свёртка np.tensordot(A, B, axes = (axes_A, axes_B)) проводит свёртку вдоль указанных индексов тензоров A и B:
A = np.empty( (3,4,5) ) B = np.empty( (1,3,4,2) ) C = np.tensordot(A,B, axes=([0,1], [1,2])) # 0-й с 1-м и 1-й со 2-м C.shape # (5, 1, 2)
Если axes = 1, то это стандартное dot — произведение. Если axes = 0, то это прямое произведение $A\otimes B$.
Инициализация элементов
Инициализация элементов тензора может быть самой разнообразной. Для следующих методов элементы будут иметь тип float64:
y = np.empty( (2,3) ) # 2 строки и 3 столбца без инициализации x = np.zeros( (2,3) ) # 2 строки и 3 столбца из нулей x = np.ones ( (2,3) ) # 2 строки и 3 столбца из единиц x = np.eye(3) # единичная матрица 3x3 x = np.linspace(0, 1, 3) # [0. , 0.5, 1. ] (x=beg, x Следующие функции приводят к целочисленным элементам int32:x = np.arange(3) # [0, 1, 2] от 0 до end - 1 x = np.arange(1,3) # [1, 2] от beg до end - 1 x = np.arange(10, 30, 5) # [10, 15, 20, 25] (i=beg, i < end, i+=step)Тип элементов этих тензоров зависит от аргументов методов инициализации:
x = np.empty_like(y) # той-же формы, что и y, но с "мусором" x = np.zeros_like(y) # из нулей такой же формы как у тензора y x = np.full((2,3), 5) # 2x3 пятёрок (если 5 то int32; для 5. float64) x = np.tile(y, (2, 2)) # замостить тензором y матрицу 2x2Тип элементов можно менять в процессе инициализации:
x = np.ones ((4,), dtype=np.int64) x = np.arange(3, dtype=np.float32)Случайные тензоры
Случайные одиночные числа:
x = np.random.seed(1) # фиксирование сида генератора x = np.random.randint(0,10) # одно целое равномерно распр. из [0. 10) int32 x = np.random.uniform(0,10) # одно равномерно распр. число из [0. 10) float64 x = np.random.normal (0, 1) # одно гауссово сл.чисел aver=0, sigma=1 float64Случайные тензоры типа float64:
x = np.random.random ( (2,3) ) # 2x3 равномерно распр. случайных чисел [0. 1) x = np.random.normal (0, 1, (10,) ) # 10 гауссовых сл.чисел aver=0, sigma=1Случайные тензоры типа int32:
x = np.random.randint(0, 4, (10,) ) # 10 целых сл. чисел [0. 3] x = np.random.permutation(5) # перемешанная последовательность 0,1. 4Генерация целых чисел от 0 до len(prob)-1 с вероятностями prob:
prob=[0.1, 0.1, 0.3, 0.25, 0.25] np.random.choice(len(prob), 3, p=prob)# [2, 2, 4] : 3 случайных числа с вероятностями probРазные полезности
Пусть надо отобрать элементы, удовлетворяющие условию:
a = np.array([0,2,4,6,8]) idx = a > 2 # [False, False, True, True, True] b = a[idx] # [4, 6, 8]Ещё одна возможность: numpy.where(condition, x[, y]) - из x или y:
a = np.arange(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] np.where(a < 5, a, 10*a) # [0, 1, 2, 3, 4, 50,60,70,80,90]Пусть есть два массива, элементы которых нужно синхронно перемешать:
a = np.array([0,2,4,6,8]) b = np.array([1,3,5,7,9]) idx = np.random.permutation(a.shape[0]) # целые индексы в случайном порядке a = a[idx] # [0 8 4 6 2] b = b[idx] # [1 9 5 7 3]Для добавления (типа append) массивов друг к другу, необходимо для начального пустого массива определить форму с нулевым первым индексом (для одномерных - не обязательно)
ar1 = np.array([], dtype=np.float32).reshape(0,2) # (0,2) ar1 = np.vstack([ar1, np.zeros((1,2))]) # (1,2) ar1 = np.vstack([ar1, np.ones ((3,2))]) # (4,2) .Если финальный размер известен, лучше сразу его выделить и менять значения.
Число значащих цифр и другие свойства вывода тензоров на печать задаются методом:
np.set_printoptions(precision=3, suppress=True) # 3 цифры после точки в printТензоризируем глубинные нейронные сети
Статья «Tensorizing Neural Networks», подготовленная в группе Байесовских методов под руководством доцента факультета компьютерных наук ВШЭ Дмитрия Ветрова, принята на конференцию NIPS — крупнейший мировой форум по когнитивным исследованиям, искусственному интеллекту и машинному обучению, имеющий высший ранг А* по международному рейтингу CORE. В этом году она состоится 7-12 декабря в Монреале. В рубрике «Взгляд ученого» Дмитрий Ветров рассказывает о представленном исследовании и о том, чем статьи для конференций лучше публикаций в научных журналах.
Последние несколько лет часто называют эпохой больших данных (big data). Отчасти это справедливо. Впервые в истории рост объемов данных, пригодных для анализа, начал обгонять рост вычислительных мощностей, которые, собственно, и призваны их анализировать. В таких условиях экспериментально было установлено два интересных факта. Во-первых, классические методы обработки данных (в частности, машинного обучения) не масштабируются на такие объемы информации, т.е. их применение ко всей совокупности данных на современных компьютерах займет месяцы и годы. Во-вторых, в выборке из триллиона объектов содержится гораздо больше полезной информации, чем в выборке из миллиона объектов. Последний факт весьма нетривиален и означает, что мы не можем ограничиться обработкой подвыборки сравнительно небольшого объема по сравнению с объемом исходных данных без потери важной информации. Установить его удалось благодаря появлению глубинных нейронных сетей (deep neural networks) и масштабируемых методов их обучения на больших данных в конце нулевых годов.
Масштабируемые методы оптимизации (так называемая стохастическая оптимизация) творят чудеса, позволяя, например, оптимизировать функцию, зависящую от миллионов параметров за время меньшее, чем нужно, чтобы вычислить значение этой функции в одной (sic!) точке. Современные нейронные сети обучаются с помощью методов стохастической оптимизации и на многих задачах (распознавание речи, классификация изображений и др.) уже превзошли возможности человеческого интеллекта. Эксперименты показали, что чем больше слоев в нейронной сети и чем они шире, тем выше точность сети, поэтому нейросетевые архитектуры последнего поколения занимают всю доступную оперативную память компьютера. Это означает, что мы достигли границ экстенсивного расширения ширины и глубины нейронных сетей. Что же делать?
Процедуры, разработанные коллективом группы Байесовских методов, позволили уменьшить объем памяти, необходимый для хранения одного слоя нейронной сети, в 700 тысяч раз без потери качества работы самой сети, которую уместно назвать тензорнетом
На помощь приходят современные методы тензорных разложений из мультилинейной алгебры. Тензор — это просто многомерный массив. Любой вектор или матрицу можно преобразовать в тензор (так называемая операция reshape). Тензоры могут содержать огромное число элементов (например, в 200-мерном тензоре, по каждому измерению, имеющему длину 2, содержится больше элементов, чем атомов в нашей Вселенной). Технологии тензорных разложений позволяют, в определенных условиях, преобразовывать тензор в более компактный формат, устраняя избыточность в данных, — примерно так же, как мы уменьшаем размер файла, архивируя его.
Такое представление может требовать на многие порядки меньше памяти, чем хранение самого тензора. Оказывается, что ряд алгебраических операций, которые нужно выполнять над весами нейронной сети, при ее обучении, могут быть выполнены непосредственно над компактным представлением тензора. Но это означает, что можно веса нейронной сети (десятки и сотни миллионов параметров) представить в виде тензора, который, в свою очередь, перевести в компактное представление и обучать не веса, а их тензорное представление.
Необходимые для этого процедуры были разработаны коллективом группы Байесовских методов и позволили уменьшить объем памяти, необходимый для хранения одного слоя нейронной сети в 700 тысяч раз без потери качества работы самой сети, которую уместно назвать тензорнетом.
Эти результаты открывают новые возможности. Прежде всего, для хранения глубинных нейронных сетей на мобильных устройствах, что позволит обрабатывать данные (например, распознавать речь) «на месте», без передачи сигнала на нейронную сеть сервера и обратно, как происходит сейчас. А кроме того, новинка дает возможность разрабатывать новые архитектуры нейронных сетей, имеющих на несколько порядков большую ширину при том же объеме оперативной памяти.
Результаты нашей работы были приняты на одну из ведущих конференций по машинному обучению Neural Information Processing Systems (NIPS), имеющую ранг А* по международному рейтингу CORE.
Зачем нужны рейтинги конференций
Область компьютерных наук в настоящее время переживает взрывное развитие. Получаемые результаты устаревают уже через 3-5 лет. Поэтому крайне важно оперативно знакомить сообщество с полученными результатами, что, в свою очередь, дополнительно подстегивает темп развития области.
Традиционная система публикации научных результатов через уважаемые научные журналы тут не очень подходит, поскольку процесс публикования в хорошем научном журнале занимает в среднем 1,5-2 года с момента первой подачи рукописи в редакцию. Это связано как с ограниченностью объема журнала, так и с консерватизмом издательств, не желающих оптимизировать свою работу с целью сокращения времени ожидания статьи. Кроме того, многие издательства распространяют свои журналы платным образом, что, очевидно, сужает круг читателей и препятствует научному развитию. Следует отметить, что ссылки на необходимость поддержания научной экспертизы здесь неуместны, так как рецензенты журналов за свою работу денег не получают.
Сообщество ученых в области компьютерных наук нашло, как справиться с диктатом научных издательств, существенно подняв планку требований к публикации на профильных конференциях. Это позволило добиться сразу нескольких целей. Во-первых, труды конференций по компьютерным наукам, как правило, находятся в свободном доступе (в любом случае авторы имеют право опубликовать их в архиве препринтов arxiv.org и/или домашних страницах). Во-вторых, срок рассмотрения работы занимает 2-3 месяца, а всего с момента подготовки текста статьи до момента ее опубликования проходит не больше полугода. В-третьих, рецензирование осуществляется анонимно ведущими учеными в области, причем статьи распределяет компьютер по специальному алгоритму, позволяющему избежать конфликта интересов. Это делает ненужным громоздкий и неповоротливый аппарат журнальных издательств.
Научные журналы безнадежно проигрывают в этой гонке и, как правило, публикуют просто развернутые версии докладов с опозданием на пару лет
Конференции в области компьютерных наук, как и научные журналы, бывают разные. Для того, чтобы понимать, какие являются ведущими, а какие имеют ограниченное значение, были введены различные системы рейтингования, например, рейтинг CORE, делящий известные международные научные конференции на 4 категории: А* (ведущие), А (отличные), В (хорошие), С (неплохие). Единственная российская конференция, попавшая в рейтинг CORE, это Computer Science in Russia (CSR), имеющая рейтинг С. Конференций рейтинга А*, таких как FOCS, NIPS, ICML, и другие, не более 30. Именно на них представляются результаты, которые определяют развитие соответствующих разделов компьютерных наук на несколько лет вперед.
Научные журналы безнадежно проигрывают в этой гонке и, как правило, публикуют просто развернутые версии докладов с опозданием на пару лет. Разумеется, за право пробиться на такие конференции идет жесткая борьба. Число мест ограничено, а желающих много. В среднем конкурс составляет 4-15 работ на одну принятую.
Для аспиранта доклад на такой конференции — это гарантия продолжения научной карьеры в сильной научной группе в качестве постдока. Для постдока такой доклад — почти гарантированный грант на продолжение исследований. Для профессора — это дополнительное финансирование научной группы и приток сильных аспирантов и постдоков.
Процесс отбора статей занимает 2-3 месяца и идет очень тщательно. Особое внимание уделяется научной этике. Авторы статьи не знают, кто рецензирует их, рецензенты не знают, чью работу они рецензируют. Каждую работу рецензируют 3-5 рецензентов, а в случае, если их мнения расходятся (что бывает довольно редко), вопрос выносится на отдельное групповое рассмотрение. За нарушение анонимности, работы беспощадно исключаются из рассмотрения.
Такой процесс приводит к тому, что даже крупные ученые с мировым именем время от времени получают плохие рецензии и отказы от принятия работ. Это никого не расстраивает, а, наоборот, заставляет доработать свою статью с учетом замечаний рецензентов и подать на следующую конференцию того же ранга или, не сильно утруждая себя доработкой, подать ее на конференцию на ступеньку ниже в рейтинге. Такая система получила название double blind. Она способствует росту качества статей на конференциях и препятствует злоупотреблению научным авторитетом, чем нередко грешат конференции и журналы, не применяющие анонимного рецензирования статей.
Публикация на одной из ведущих конференций требует колоссального объема работы и подтверждает, среди прочего, то, что авторы трудятся на очень высоком уровне, а ведущие ученые планеты проявляют интерес к результатами их труда. Именно поэтому, учитывая специфику компьютерных наук, Высшая школа экономики (впервые в практике отечественных вузов) решила приравнять статьи на конференциях А* к статьям в ведущих научных журналах.
TensorFlow туториал. Часть 1: тензоры и векторы
TensorFlow — это ML-framework от Google, который предназначен для проектирования, создания и изучения моделей глубокого обучения. Глубокое обучение — это область машинного обучения, алгоритмы в которой были вдохновлены структурой и работой мозга. Вы можете использовать TensorFlow, чтобы производить численные вычисления. Само по себе это не кажется специфичным, однако эти вычисления производятся с помощью data-flow графов. В этих графах вершины представляют собой математические операции, в то время как ребра представляют собой данные, которые обычно представляются в виде многомерных массивов или тензоров, которые сообщаются между этими ребрами.
Поняли? Название «Tensor Flow» происходит от вычислений, которые нейросеть производит с многомерными данными и тензорами! Буквально — поток тензоров. На данный момент это все, что нужно знать о тензорах, но мы вернемся к ним чуть позже.
TensorFlow туториал познакомит вас с глубоким обучением в интерактивной форме:


- Сначала вы узнаете больше о тензорах;
- Затем, туторил плавно расскажет о там, как установить TensorFlow;
- Далее вы узнаете об основах Tesorflow: как произвести свои первые простейшие вычисления;
- Следующий этап — настоящая задача на реальных данных: данные по Бельгийскому дорожным знаком и обработка с помощью статистики;
- Научитесь размечать данные таким образом, чтобы “скормить” эти данные нейросети;
- Наконец, разработаете свою модель нейронной сети — слой за слоем;
- Как только архитектура будет готова, вы сможете тренировать сеть интерактивно, а также производить оценку эффективности, использую тестовую выборку;
- Последнее — вы получите указания, как можно улучшить свою модель и как можно дальше работать с TensorFlow.
Введение в тензоры
Чтобы хорошо понять тензоры, следует иметь хорошие знания в линейной алгебре и уметь производить вычисления с векторами. Вы уже прочитали, что тензоры реализованы в TensorFlow как многомерные массивы данных, но давайте немного освежим в памяти, что такое тензоры и какова их роль в машинном обучении.
Плоские векторы
Перед тем, как мы перейдем к плоским векторам, неплохо бы вспомнить о том, что такое вектор. Вектор — это особый вид матрицы, прямоугольный массив с числами. Так как векторы — это упорядоченный набор чисел, то они часто представляются в виде столбцов матриц. Другими словами, вектор — скалярная величина, которой дали направление.
Пример скаляра — “5 метров” или “60 м/с”, тогда как вектор — “5 метров на север” или “60 м/с на восток”.
Разница между ними очевидна: вектор имеет направление. Тем не менее, примеры могут быть очень далеки от тех векторов, с которыми вы столкнетесь, занимаясь машинными обучением.
Длина математического вектора — величина абсолютная, в то время как направление — относительная. Длина измеряется относительно направления, а в качестве единиц выступают градусы или радианы. Обычно считается, что направление положительно и отсчитывается против часовой стрелки относительно начальной точки отсчета.
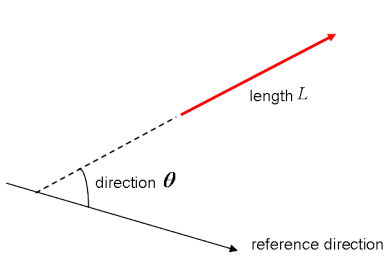
Визуально, конечно, векторы представляют собой стрелки, как на картинке выше. Это означает, что вы можете рассматривать векторы, как стрелки определенной длины и направления.
Так что же с плоскими векторами?
Плоский вектор — это простейший тензор. Они очень похожи на обычные векторы, такие как вы видели выше, с тем небольшим отличием, что они могут сами определять себя в векторном пространстве.
Чтобы понять, что это значит, рассмотрим пример: пусть есть вектор 2 X 1. Это означает, что вектор принадлежит множеству действительных чисел, которые объединены в пары. Или, иначе говоря, элемент двумерного пространства. В таких случаях вы можете задавать вектор на координатной плоскости, как стрелки или лучи.
Работая на координатной плоскости, вы можете узнать х координату конца луча с началом в (0, 0), посмотрев на первую строчку вектора, а у координату — на вторую.
Замечание: если вы рассматриваете вектор размера 3 X 1, то вы работаете трехмерном пространстве. Здесь вы можете представить вектор как стрелку в трехмерном пространстве, которая обычно задается тремя осями х, у и z.
Замечательно иметь данные вектора и их представление на координатной плоскости, но в сущности важно лишь то, какие вы можете производить над ними операции. В этом вам поможет выражение данных векторов через базисные или единичные вектора.
Единичные векторы — векторы длины 1. Двумерные или трехмерные вектора хорошо раскладываются в сумму ортогональных единичных векторов, таких как оси координат.
Тензоры
Плоский вектор — это частный случай тензора. Помните, вектор определялся в прошлом разделе как скаляр, которому задали направление. Тензор же — это математическое представление физической сущности, которая может быть задана величиной и несколькими направлениями.
И так же как вы представляли скаляр одним числом, а трехмерный вектор как тройку чисел, тензор представляется в виде массива 3R чисел в трехмерном пространстве.
R в этой записи отвечает за ранг тензора: в трехмерном пространстве тензор ранга 2 может быть представлен девятью числами. В N-мерном скаляр требует только одного числа, векторы требуют N чисел, а тензоры требуют N^R чисел. Этим объясняется, почему скаляры часто называют тензорами размера 0: у них нет направления, и они могут быть представлены только одним числом.
Видео про тензоры на примере обычных объектов (на английском языке, можно включить перевод на русский в субтитрах):
Интересные статьи:
- Как создать собственную нейронную сеть с нуля на языке Python
- Как создать собственный датасет из картинок Google
- Обзор Tensorflow.JS: машинное обучение на JavaScript
Знакомимся с инструментом для создания нейронных сетей. Встречайте - PyTorch
Как нейронные сети получили свое название, из каких компонентов они состоят, как они обучаются и главное - являются ли они полноценным искусственным интеллектом, способным заменить человека?
Статья рассказывает читателю о методе, на котором основано обучение абсолютно всех нейронных сетей ‒ методе градиентного спуска.
В статье рассказывается о принципе работы сверточных нейронных сетей
В статье рассказывается о принципе работы GAN-моделей и методах их обучения.
Рассмотрим основы фреймворка PyTorch, на примерах научимся создавать тензоры, обращаться к ним по индексам, делать срезы, работать с осями, считать разные метрики и находить ошибку. Все это позволит нам написать свою нейронную сеть в следующем уроке.
В предыдущих статьях мы с вами узнали о принципах работы полносвязных, сверточных и генеративно-состязательных нейронных сетей, методах их обучения и областях применения. В этой статье мы погрузимся глубже в устройство нейронных сетей и начнем знакомиться с тем, как их пишут на практике. Но для начала мы научимся работать с базовыми функциями фреймворка PyTorch , а также освоим среду Google Colab . С этой среды и начнем.
Google Colab
Для начала разберемся с новыми понятиям.
- IPython (англ. Interactive Python ) - это интерактивная оболочка языка Python. Часто используется специалистами по машинному обучению, как более удобная (за счет своей интерактивности).
- Jupiter notebook - это IDE для исполнения IPython кода. Запускается у вас на компьютере.
- Google Colab - это бесплатный облачный сервис Google, основанный на Jupiter Notebook . Отличие в том, что вычислительные мощности вам предоставляет сам Google.
- Ноутбук - это IPython-файл , в котором хранится код. Помимо кода в ноутбуке может быть форматированный текст (поддерживается markdown разметка) и картинки. Файл ноутбука имеет расширение .ipynb и является некоторым аналогом файла .py для обычного Python.
- Колаб абсолютно бесплатен. Да, вы можете купить себе премиум-доступ (если вы живете в США или Канаде), который позволит вам получать бóльшие вычислительные мощности, но в 99% случаев можно обойтись и без этого.
- Большинство библиотек (в т. ч. PyTorch ) уже установлены, так что вам не придется тратить время на их установку.
- Google предоставляет вам от 12 Гигабайт оперативной памяти, и по вашему требованию – видеокарту от 8 Гигабайт. Это довольно большие вычислительные мощности, учитывая, что за них не нужно платить. Более того, не каждый компьютер может похвастаться таким набором, поэтому как правило обучение нейросетей на колабе проходит быстрее, чем локально.
- Linux. Колаб работает на ядре Linux, что несомненно является преимуществом, поскольку Linux требует меньше ресурсов, а также «Сделана программистами для программистов».
- Онлайн-доступ. Чтобы загрузить какой-либо датасет, вам не обязательно скачивать как правило огромный архив данных к себе на компьютер. Вы можете загрузить его на колаб с помощью стандартных утилит Linux. Это позволит вам работать, даже если на жестком диске вашего компьютера осталось мало места.
- Заведите аккаунт Google, если у вас его нет.
- Затем переходите на сайт Google Colab : https://colab.research.google.com
- Готово! Вам откроется приветственный блокнот с описанием возможностей колаба.
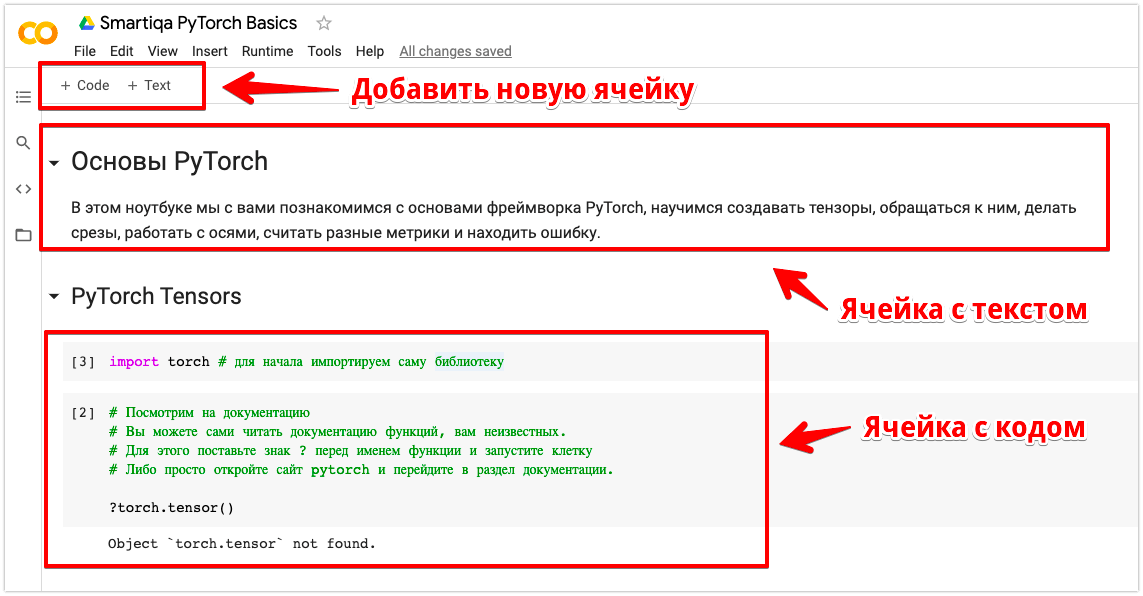
Google Colab: Ячейки с текстом и кодом
3. Чтобы выполнить код в конкретной ячейке, нажмите на кнопку Run Cell (черный треугольник на белом фоне) у соответствующей ячейки. Кроме этого, вы можете установить курсор в соответствующую ячейку и нажать Shift+Enter .
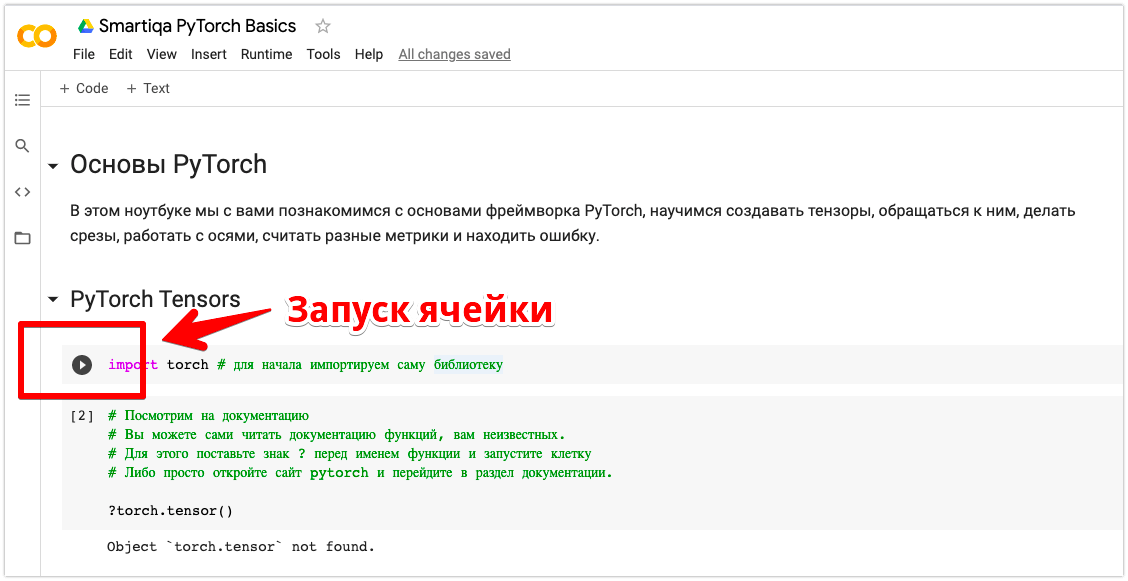
Google Colab: Запуск ячейки
4. Несколько ячеек можно запускать разом. Но выполняться они будут последовательно. Сначала выполнится первая запущенная ячейка, после нее вторая, затем третья и так далее.
5. В ячейках с кодом можно запускать команды терминала Linux, только начать их надо с ! . Например: !ls
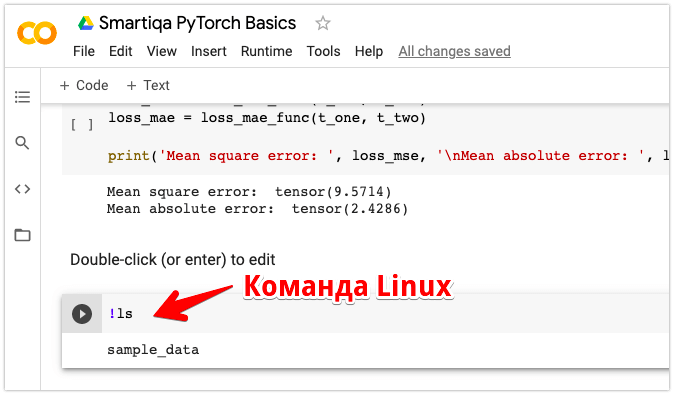
Google Colab: Выполнение команды Linux
В принципе, ничего сложного в этом нет. Вам нужно научиться делить свой код по ячейкам так, чтобы он не потерял читаемость. В любом случае, сейчас мы рассмотрим все вышесказанное на примере.
Читайте также
[ Нейросети Часть 3 ] Откуда нейросеть знает, что на картинке котик? Все, что вы хотели знать о сверточных нейросетях
В статье рассказывается о принципе работы сверточных нейронных сетей
PyTorch
PyTorch – невероятно мощный фреймворк для работы с данными. Он включает в себя все инструменты для написания нейросетей, а также целый "зоопарк" предобученных моделей.
Вся работа с PyTorch сходится к работе с тензорами.
Тензор – это объект линейной алгебры, линейно преобразующий одно пространство в другое. Частными случаями тензора являются скаляры (тензоры нулевого ранга), векторы (тензоры первого ранга), матрицы (тензоры третьего ранга) и т. д.
Не переживайте, если вы плохо знакомы с линейной алгеброй. Ее знание конечно упростит вам понимание некоторых вещей, но не более.
Перед началом работы нам нужно импортировать сам PyTorch . Устанавливать его не надо, если вы работаете в колабе, но если локально – придется установить. Подробная инструкция по установке есть на официальном сайте.
Более того, для вас мы подготовили готовый ноутбук в колабе. Вы можете скопировать его к себе на диск (кнопка в верхнем меню справа), либо, если вам так удобнее, – скачать к себе на компьютер и выполнять в Jupiter Notebook .
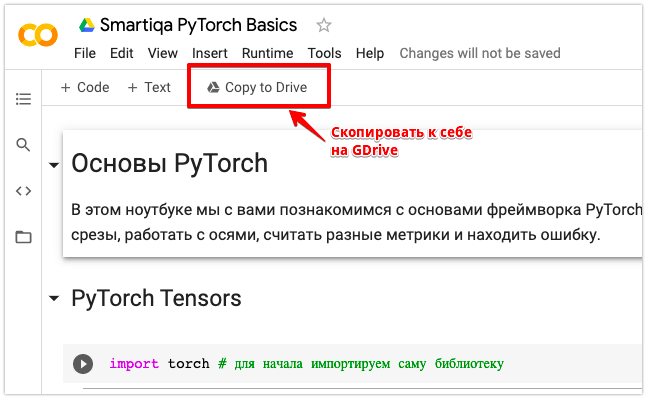
Google Colab: Копирование ноутбука на свой GDrive
Итак, импортируем PyTorch :
Python - Colab Cell
import torch # для начала импортируем саму библиотеку
Теперь почитаем документацию о тензорах. В колабе можно читать документацию функций, добавив знак ? перед самой функцией.
Python - Colab Cell
?torch.tensor()
Результат: Google Colab Help
Docstring: tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False) -> Tensor Constructs a tensor with :attr:`data`. .. warning:: :func:`torch.tensor` always copies :attr:`data`. If you have a Tensor ``data`` and want to avoid a copy, use :func:`torch.Tensor.requires_grad_` or :func:`torch.Tensor.detach`. If you have a NumPy ``ndarray`` and want to avoid a copy, use :func:`torch.as_tensor`. .
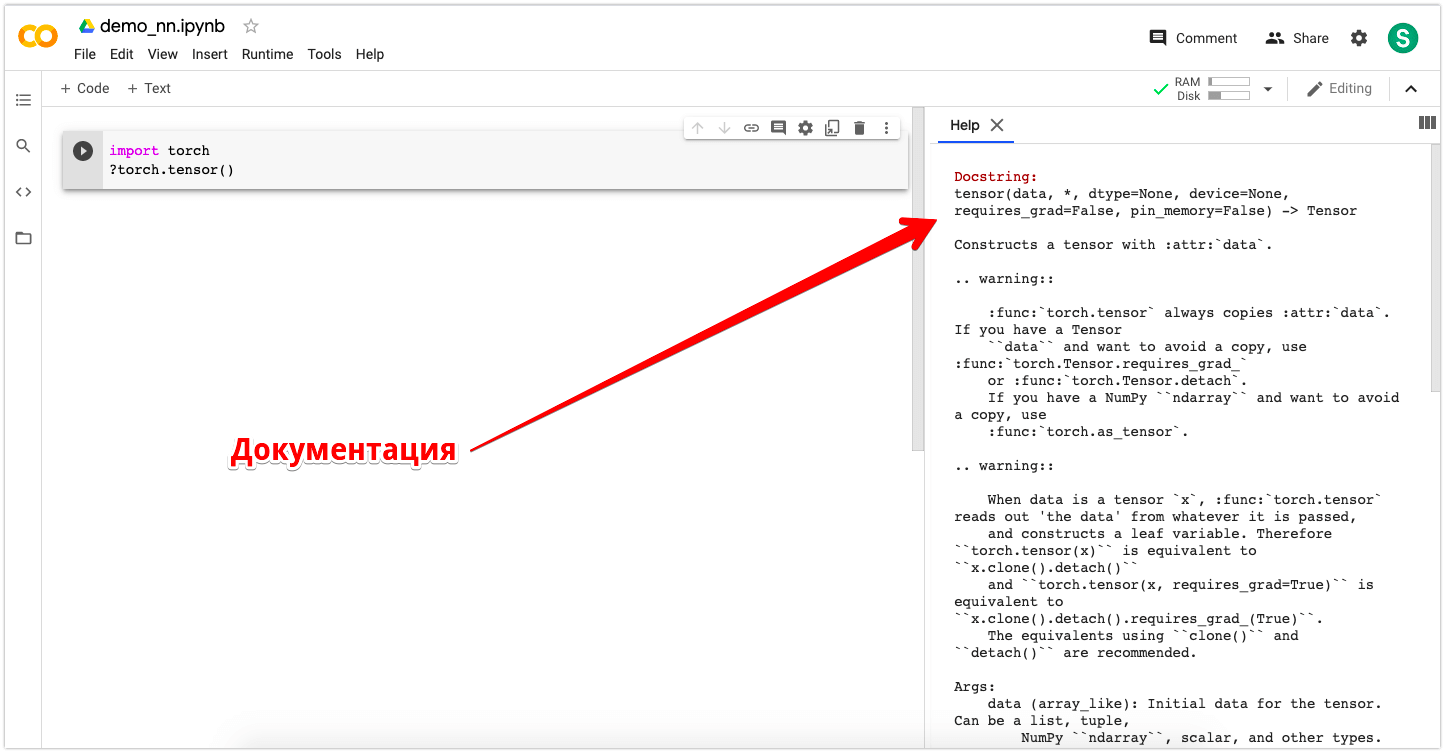
Google Colab: Документация для torch.tensor()
Читайте также
[ Нейросети Часть 2 ] Все о градиентном спуске или как учится нейронная сеть
Статья рассказывает читателю о методе, на котором основано обучение абсолютно всех нейронных сетей ‒ методе градиентного спуска.
Создание тензора
Теперь рассмотрим, как создавать тензоры, и что можно с ними сделать. Тензоры можно создавать несколькими способами:
- Из обычного списка Python
- Заполняя их нормальным распределением
- Заполняя их целыми случайными числами
Python - Colab Cell
# Тензоры можно создавать несколькими способами: # Из списка print('Из списка\n', torch.tensor([1, 2, 3, 4, 5]), '\n---------\n\n') # Заполняя их нормально распределенными случайными числами. # Такая функция принимает размер тензора на вход print('Нормальное распределение\n', torch.randn((5,)), '\n') # Здесь мы создаем вектор длины 5 print(torch.randn((2, 2)), '\n---------\n\n') # А здесь матрицу 2 на 2 # Заполняя их целыми случайными числами # Такая функция принимает на вход размер тензора # и верхнюю границу интервала, из которого будут # выбираться случайные числа. print('Целые случайные числа\n', torch.randint(high=10, size=(5,)), '\n') # Здесь мы создаем вектор длины 5 print(torch.randint(high=10, size=(2, 2)), '\n---------\n\n') # А здесь матрицу 2 на 2
Результат выполнения
Из списка tensor([1, 2, 3, 4, 5]) --------- Нормальное распределение tensor([2.2068, 2.0775, 2.5762, 1.4185, 1.6751]) tensor([[ 1.3320, -0.2528], [-0.4859, 0.9697]]) --------- Целые случайные числа tensor([5, 5, 4, 4, 2]) tensor([[2, 3], [8, 2]])
Индексация
Обращение по индексам к тензорам происходит так же, как и к обычным спискам в Python. Но все же разберем его на примере:
Python - Colab Cell
# Создадим целочисленный тензор 3-го ранга и обратимся к нему по индексам our_tensor = torch.randint(high=10, size=(2, 3, 4)) print('А вот и наш тензор:\n', our_tensor) # Теперь обратимся к какому-то его элементу # Обращаемся к нулевому элементу. # Нулевой элемент -- это в данном случае матрица 3 на 4 print('\nНулевой элемент:\n', our_tensor[0]) # Обращаемся к нулевой строке нулевого элемента. print('\nНулевая строка нулевого элемент:\n', our_tensor[0][0]) # Обращаемся к элементу с индексом 1, 2, 3 # То есть первая матрица, вторая строка, третий элемент print('\nПервая матрица, вторая строка, третий элемент:\n', our_tensor[1][2][3]) # Кроме того, индексы можно писать через запятую: print('\nПишем индексы через запятую:\n', our_tensor[1, 2, 3])
Результат выполнения
А вот и наш тензор: tensor([[[9, 8, 2, 9], [0, 5, 3, 9], [2, 1, 2, 8]], [[2, 7, 5, 9], [5, 9, 8, 5], [6, 8, 0, 2]]]) Нулевой элемент: tensor([[9, 8, 2, 9], [0, 5, 3, 9], [2, 1, 2, 8]]) Нулевая строка нулевого элемент: tensor([9, 8, 2, 9]) Первая матрица, вторая строка, третий элемент: tensor(2) Пишем индексы через запятую: tensor(2)
PyTorch также поддерживает срезы тензоров. Но чтобы понять, как работают срезы, нужно узнать, что такое оси( axis ). С их помощью вы можете брать любые срезы сколько-угодно-мерных тензоров. Давайте разберемся с ними.
Оси и срезы тензоров
В общем случае ось – это номер измерения тензора. Например, у вектора всего одно измерение – поэтому у него всего одна ось, равная 0 (оси нумеруются с 0 ). У матрицы уже два измерения – у нее есть столбцы и строки. Так вот для матрицы ось 0 – это ось столбцов, а ось 1 – ось строк. Все станет понятнее с иллюстрацией:
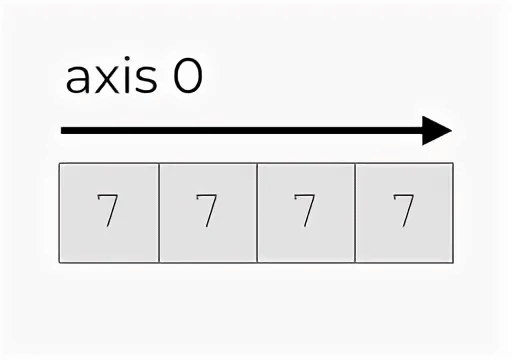
У вектора всего одна ось.
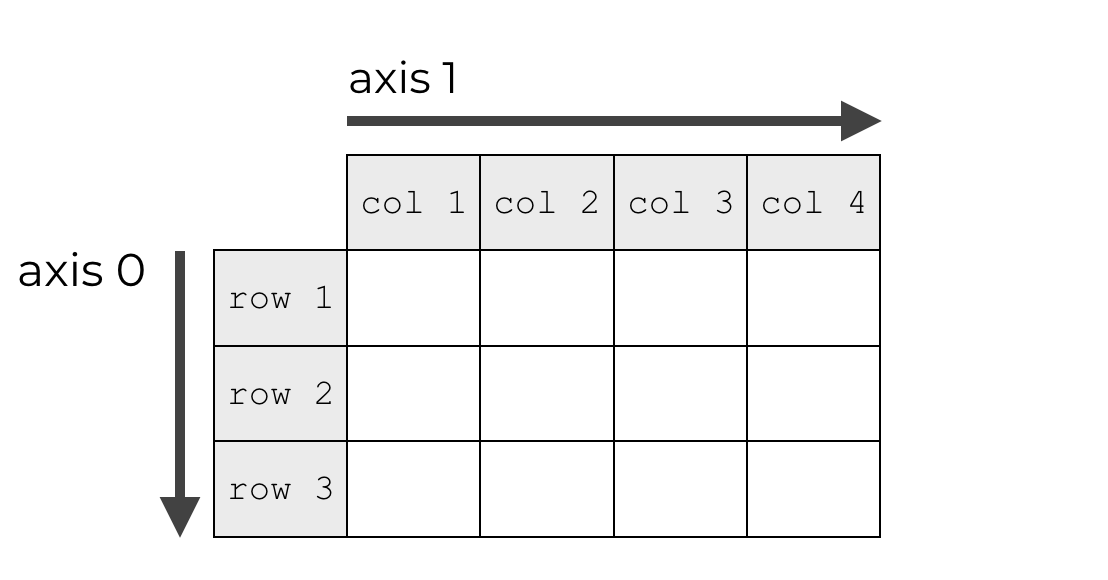
А у матрицы уже два измерения. Поэтому и оси две.
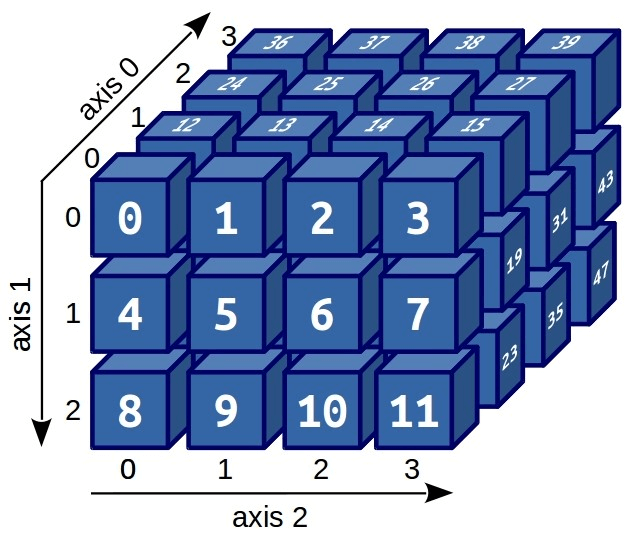
А вот тензор третьего ранга. Он большой и страшный, но не пугайтесь его. У него есть три измерения, поэтому и оси три.
Кстати, если вы знакомы с numpy, то могли заметить оси в torch – то же самое, что и в numpy .
Индексация тензора тоже происходит по осям, когда вы пишете our_tezor[2, 3, 1] , вы говорите, что ищете элемент, который имеет индекс 2 по нулевой оси, индекс 3 – по второй, и индекс 1 – по третьей.
Благодаря этому, оси можно использовать, чтобы делать срезы тензоров. Если вы хотите выбрать все элементы по данной оси, просто укажите : , например our_tezor[2, :, 1] выбирает второй элемент по нулевой оси, все элементы по второй и первый элемент по третьей. Кроме того оси передаются, как параметр в некоторую функцию, но это мы рассмотрим позднее.
Если вы что-то недопоняли, то не переживайте. Переходим от теории к практике, чтобы у вас не осталось сомнений. Выведем весь тензор, используя срезы:
Python - Colab Cell
# Воспользуемся нашим тензором из предыдущей клетки print('Все тот же наш тензор:\n', our_tensor) # Возьмем срез всех строк, всех столбцов всех матриц, # то есть просто выведем весь тензор, используя знания о срезах print('\nСрез всего тензора:\n', our_tensor[:, :, :])
Результат выполнения
Все тот же наш тензор: tensor([[[6, 7, 6, 6], [0, 3, 2, 6], [0, 3, 9, 2]], [[9, 9, 6, 2], [5, 5, 8, 1], [2, 6, 0, 9]]]) Срез всего тензора: tensor([[[6, 7, 6, 6], [0, 3, 2, 6], [0, 3, 9, 2]], [[9, 9, 6, 2], [5, 5, 8, 1], [2, 6, 0, 9]]])