Что такое контроль версий?
Контроль версий, также известный как управление исходным кодом, — это практика отслеживания изменений программного кода и управления ими. Системы контроля версий — это программные инструменты, помогающие командам разработчиков управлять изменениями в исходном коде с течением времени. В свете усложнения сред разработки они помогают командам разработчиков работать быстрее и эффективнее. Системы контроля версий наиболее полезны командам DevOps, поскольку помогают сократить время разработки и увеличить количество успешных развертываний.
Программное обеспечение контроля версий отслеживает все вносимые в код изменения в специальной базе данных. При обнаружении ошибки разработчики могут вернуться назад и выполнить сравнение с более ранними версиями кода для исправления ошибок, сводя к минимуму проблемы для всех участников команды.
Практически во всех программных проектах исходный код является сокровищем: это ценный ресурс, который необходимо беречь. Для большинства команд разработчиков программного обеспечения исходный код — это репозиторий бесценных знаний и понимания проблемной области, которые они скрупулезно собирали и совершенствовали. Контроль версий защищает исходный код от катастрофических сбоев, от случайных ухудшений, вызванных человеческим фактором, а также от непредвиденных последствий.
Разработчики программного обеспечения, работающие в командах, постоянно пишут новый исходный код и изменяют существующий. Код проекта, приложения или программного компонента обычно организован в виде структуры папок или «дерева файлов». Один разработчик в команде может работать над новой возможностью, а другой в это же время изменять код для исправления несвязанной ошибки, т. е. каждый разработчик может вносить свои изменения в несколько частей дерева файлов.
Контроль версий помогает командам решать подобные проблемы путем отслеживания каждого изменения, внесенного каждым участником, и предотвращать возникновение конфликтов при параллельной работе. Изменения, внесенные в одну часть программного обеспечения, могут быть не совместимы с изменениями, внесенными другим разработчиком, работавшим параллельно. Такая проблема должна быть обнаружена и решена согласно регламенту, не создавая препятствий для работы остальной части команды. Кроме того, во время разработки программного обеспечения любое изменение может само по себе привести к появлению новых ошибок, и новому ПО нельзя доверять до тех пор, пока оно не пройдет тестирование. Вот почему процессы тестирования и разработки идут рука об руку, пока новая версия не будет готова.
Связанные материалы
Шпаргалка по Git
СМ. РЕШЕНИЕ
Изучите Git с помощью Bitbucket Cloud
Хорошее программное обеспечение для управления версиями поддерживает предпочтительный рабочий процесс разработчика, не навязывая определенный способ работы. В идеале оно также работает на любой платформе и не принуждает разработчика использовать определенную операционную систему или цепочку инструментов. Хорошие системы управления версиями обеспечивают плавный и непрерывный процесс внесения изменений в код и не прибегают к громоздкому и неудобному механизму блокировки файлов, который дает зеленый свет одному разработчику, но при этом блокирует работу других.
Группы разработчиков программного обеспечения, не использующие какую-либо форму управления версиями, часто сталкиваются с такими проблемами, как незнание об изменениях, выполненных для пользователей, или создание в двух несвязанных частях работы изменений, которые оказываются несовместимыми и которые затем приходится скрупулезно распутывать и перерабатывать. Если вы как разработчик ранее никогда не применяли управление версиями, возможно, вы указывали версии своих файлов, добавляя суффиксы типа «финальный» или «последний», а позже появлялась новая финальная версия. Возможно, вы использовали комментирование блоков кода, когда хотели отключить определенные возможности, не удаляя их, так как опасались, что этот код может понадобиться позже. Решением всех подобных проблем является управление версиями.
Программное обеспечение для управления версиями является неотъемлемой частью повседневной профессиональной практики современной команды разработчиков программного обеспечения. Отдельные разработчики ПО, привыкшие работать в команде с эффективной системой управления версиями, обычно признают невероятную пользу управления версиями даже при работе над небольшими сольными проектами. Привыкнув к мощным преимуществам систем контроля версий, многие разработчики не представляют как работать без них даже в проектах, не связанных с разработкой ПО.
Преимущества систем контроля версий
Программное обеспечение контроля версий рекомендуется для продуктивных команд разработчиков и команд DevOps. Управление версиями помогает отдельным разработчикам работать быстрее, а командам по разработке ПО — сохранять эффективность и гибкость по мере увеличения числа разработчиков.
За последние несколько десятилетий системы контроля версий (Version Control Systems, VCS) стали гораздо более совершенными, причем некоторым это удалось лучше других. Системы VCS иногда называют инструментами SCM (управления исходным кодом) или RCS (системой управления редакциями). Один из наиболее популярных на сегодняшний день инструментов VCS называется Git. Git относится к категории распределенных систем контроля версий, известных как DVCS (эта тема будет рассмотрена подробнее чуть позже). Git, как и многие другие популярные и доступные на сегодняшний день системы VCS, распространяется бесплатно и имеет открытый исходный код. Независимо от того, какую систему контроля версий вы используете и как она называется, основные ее преимущества заключаются в следующем.
1. Полная история изменений каждого файла за длительный период. Это касается всех изменений, внесенных огромным количеством людей за долгие годы. Изменением считается создание и удаление файлов, а также редактирование их содержимого. Различные инструменты VCS отличаются тем, насколько хорошо они обрабатывают операции переименования и перемещения файлов. В историю также должны входить сведения об авторе, дата и комментарий с описанием цели каждого изменения. Наличие полной истории позволяет возвращаться к предыдущим версиям, чтобы проводить анализ основных причин возникновения ошибок и устранять проблемы в старых версиях программного обеспечения. Если над программным обеспечением ведется активная работа, то «старой версией» можно считать почти весь код этого ПО.
2. Ветвление и слияние. Эти возможности полезны не только при одновременной работе участников команды: отдельные сотрудники также могут пользоваться ими, занимаясь несколькими независимыми направлениями. Создание «веток» в инструментах VCS позволяет иметь несколько независимых друг от друга направлений разработки, а также выполнять их слияние, чтобы инженеры могли проверить, что изменения, внесенные в каждую из веток, не конфликтуют друг с другом. Многие команды разработчиков ПО создают отдельные ветки для каждой функциональной возможности, для каждого релиза либо и для того, и для другого. Имея множество различных рабочих процессов, команды могут выбирать подходящий для них способ ветвления и слияния в VCS.
3. Отслеживаемость. Возможность отслеживать каждое изменение, внесенное в программное обеспечение, и связывать его с ПО для управления проектами и отслеживания багов, например Jira, а также оставлять к каждому изменению комментарий с описанием цели и назначения изменения может помочь не только при анализе основных причин возникновения ошибок, но и при других операциях по исследованию. История с комментариями во время чтения кода помогает понять, для чего этот код нужен и почему он структурирован именно так. Благодаря этому разработчики могут вносить корректные и совместимые изменения в соответствии с долгосрочным планом разработки системы. Это особенно важно для эффективной работы с унаследованным кодом, поскольку дает специалистам возможность точнее оценить объем дальнейших задач.
Разрабатывать программное обеспечение можно и без управления версиями, но такой подход подвергает проект огромному риску, и ни одна профессиональная команда не порекомендует применять его. Таким образом, вопрос заключается не в том, использовать ли управление версиями, а в том, какую систему управления версиями выбрать.
Среди множества существующих систем управления версиями мы сосредоточимся на одной: системе Git. Подробнее о других типах программного обеспечения для контроля версий.
1.1 Введение — О системе контроля версий
Эта глава о том, как начать работу с Git. Вначале изучим основы систем контроля версий, затем перейдём к тому, как запустить Git на вашей ОС и окончательно настроить для работы. В конце главы вы уже будете знать, что такое Git и почему им следует пользоваться, а также получите окончательно настроенную для работы систему.
О системе контроля версий
Что такое «система контроля версий» и почему это важно? Система контроля версий — это система, записывающая изменения в файл или набор файлов в течение времени и позволяющая вернуться позже к определённой версии. Для контроля версий файлов в этой книге в качестве примера будет использоваться исходный код программного обеспечения, хотя на самом деле вы можете использовать контроль версий практически для любых типов файлов.
Если вы графический или web-дизайнер и хотите сохранить каждую версию изображения или макета (скорее всего, захотите), система контроля версий (далее VCS) — как раз то, что нужно. Она позволяет вернуть файлы к состоянию, в котором они были до изменений, вернуть проект к исходному состоянию, увидеть изменения, увидеть, кто последний менял что-то и вызвал проблему, кто поставил задачу и когда и многое другое. Использование VCS также значит в целом, что, если вы сломали что-то или потеряли файлы, вы спокойно можете всё исправить. В дополнение ко всему вы получите всё это без каких-либо дополнительных усилий.
Локальные системы контроля версий
Многие люди в качестве метода контроля версий применяют копирование файлов в отдельный каталог (возможно даже, каталог с отметкой по времени, если они достаточно сообразительны). Данный подход очень распространён из-за его простоты, однако он невероятно сильно подвержен появлению ошибок. Можно легко забыть в каком каталоге вы находитесь и случайно изменить не тот файл или скопировать не те файлы, которые вы хотели.
Для того, чтобы решить эту проблему, программисты давным-давно разработали локальные VCS с простой базой данных, которая хранит записи о всех изменениях в файлах, осуществляя тем самым контроль ревизий.
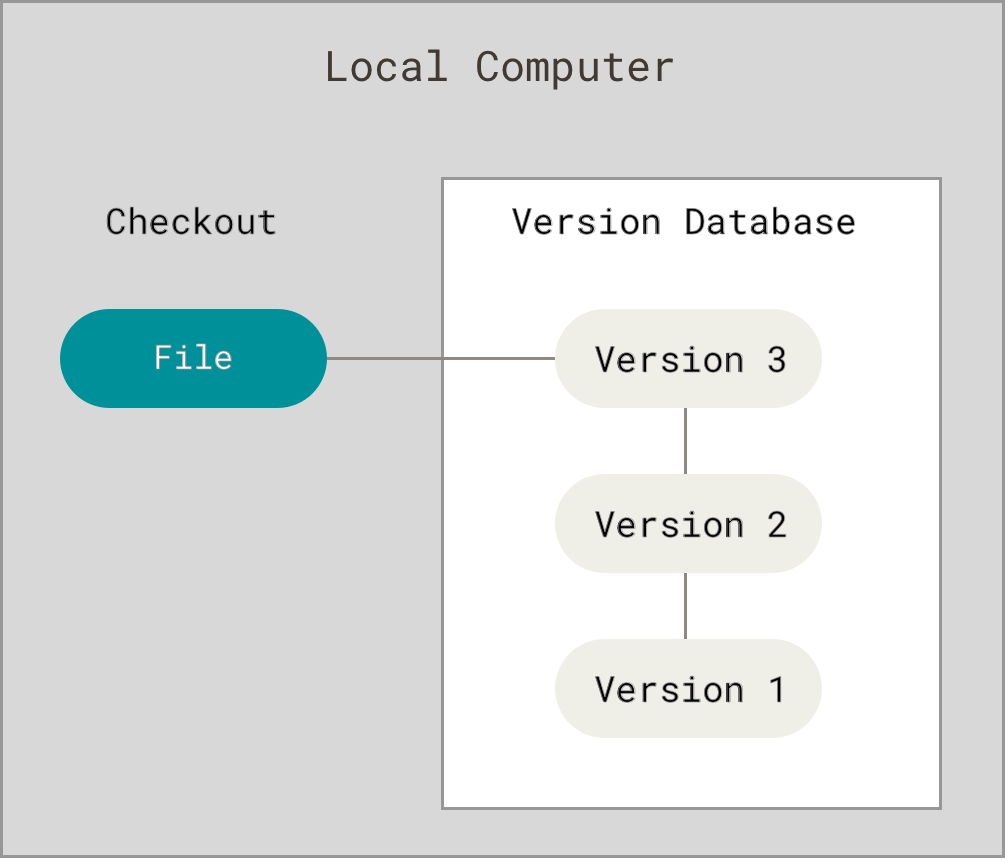
Рисунок 1. Локальный контроль версий
Одной из популярных VCS была система RCS, которая и сегодня распространяется со многими компьютерами. RCS хранит на диске наборы патчей (различий между файлами) в специальном формате, применяя которые она может воссоздавать состояние каждого файла в заданный момент времени.
Централизованные системы контроля версий
Следующая серьёзная проблема, с которой сталкиваются люди, — это необходимость взаимодействовать с другими разработчиками. Для того, чтобы разобраться с ней, были разработаны централизованные системы контроля версий (Centralized Version Control System, далее CVCS). Такие системы, как CVS, Subversion и Perforce, используют единственный сервер, содержащий все версии файлов, и некоторое количество клиентов, которые получают файлы из этого централизованного хранилища. Применение CVCS являлось стандартом на протяжении многих лет.
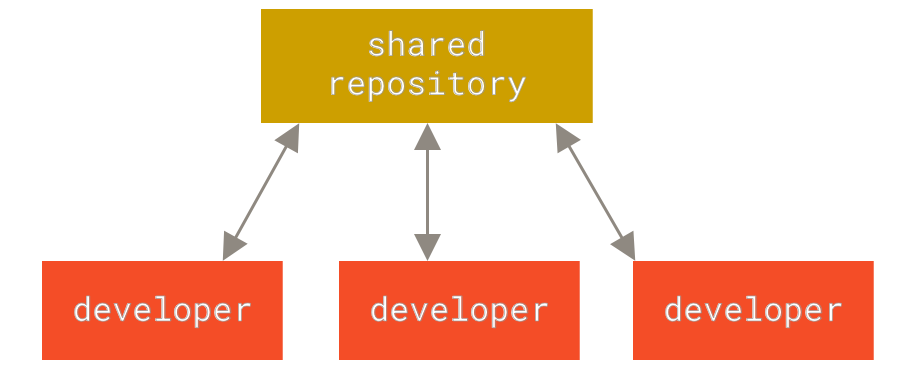
Рисунок 2. Централизованный контроль версий
Такой подход имеет множество преимуществ, особенно перед локальными VCS. Например, все разработчики проекта в определённой степени знают, чем занимается каждый из них. Администраторы имеют полный контроль над тем, кто и что может делать, и гораздо проще администрировать CVCS, чем оперировать локальными базами данных на каждом клиенте.
Несмотря на это, данный подход тоже имеет серьёзные минусы. Самый очевидный минус — это единая точка отказа, представленная централизованным сервером. Если этот сервер выйдет из строя на час, то в течение этого времени никто не сможет использовать контроль версий для сохранения изменений, над которыми работает, а также никто не сможет обмениваться этими изменениями с другими разработчиками. Если жёсткий диск, на котором хранится центральная БД, повреждён, а своевременные бэкапы отсутствуют, вы потеряете всё — всю историю проекта, не считая единичных снимков репозитория, которые сохранились на локальных машинах разработчиков. Локальные VCS страдают от той же самой проблемы: когда вся история проекта хранится в одном месте, вы рискуете потерять всё.
Распределённые системы контроля версий
Здесь в игру вступают распределённые системы контроля версий (Distributed Version Control System, далее DVCS). В DVCS (таких как Git, Mercurial, Bazaar или Darcs) клиенты не просто скачивают снимок всех файлов (состояние файлов на определённый момент времени) — они полностью копируют репозиторий. В этом случае, если один из серверов, через который разработчики обменивались данными, умрёт, любой клиентский репозиторий может быть скопирован на другой сервер для продолжения работы. Каждая копия репозитория является полным бэкапом всех данных.
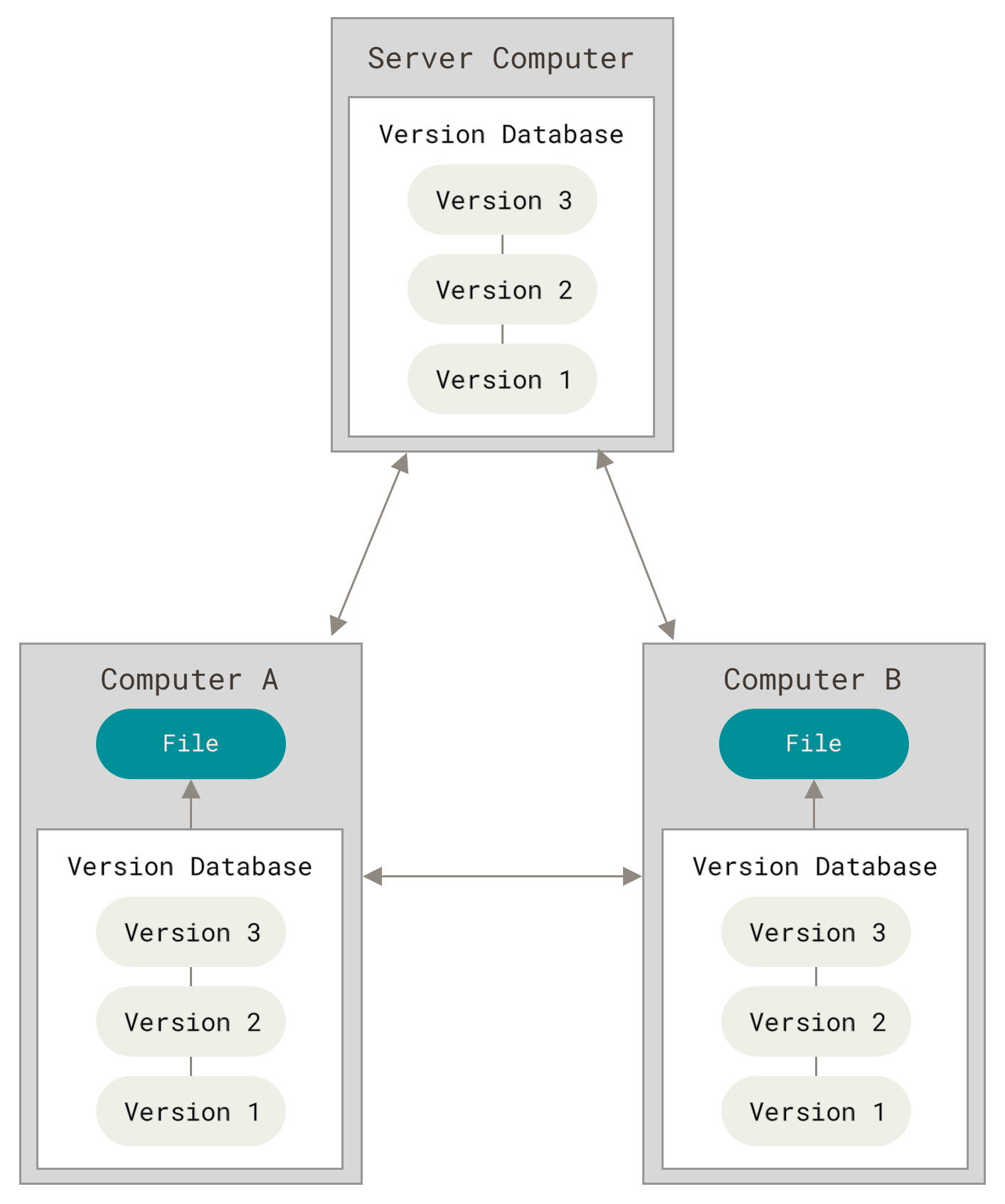
Рисунок 3. Распределённый контроль версий
Более того, многие DVCS могут одновременно взаимодействовать с несколькими удалёнными репозиториями, благодаря этому вы можете работать с различными группами людей, применяя различные подходы единовременно в рамках одного проекта. Это позволяет применять сразу несколько подходов в разработке, например, иерархические модели, что совершенно невозможно в централизованных системах.
Что такое VCS (система контроля версий)
Система контроля версий (от англ. Version Control System, VCS) — это место хранения кода. Как dropbox, только для разработчиков!
Она заточена именно на разработку продуктов. То есть на хранение кода, синхронизацию работы нескольких человек, создание релизов (бранчей). Но давайте я лучше расскажу на примере, чем она лучше дропбокса. Всё как всегда, история с кучей картиночек для наглядности ))
А потом я подробнее расскажу, как VCS работает — что значит «создать репозиторий», «закоммитить и смерджить изменения», и другие страшные слова. В конце мы пощупаем одну из систем VCS руками, скачаем код из открытого репозитория.
- Что это такое и зачем она нужна
- Как VCS работает
- Подготовительная работа
- Создать репозиторий
- Скачать проект из репозитория
- Ежедневная работа
- Обновить проект, забрать последнюю версию из репозитория
- Внести изменения в репозиторий
- Разрешить конфликты (merge)
- Создать бранч (ветку)
- Через консоль
- Через IDEA
- Через TortoiseGit
Что это такое и зачем она нужна
Допустим, что мы делаем калькулятор на Java (язык программирования). У нас есть несколько разработчиков — Вася, Петя и Иван. Через неделю нужно показывать результат заказчику, так что распределяем работу:
- Вася делает сложение;
- Петя — вычитание;
- Иван — начинает умножение, но оно сложное, поэтому переедет в следующий релиз.
Исходный код калькулятора хранится в обычной папке на сетевом диске, к которому все трое имеют доступ. Разработчик копирует этот код к себе на машину, вносит изменения и проверяет. Если всё хорошо — кладет обратно. Так что код в общей папке всегда рабочий!
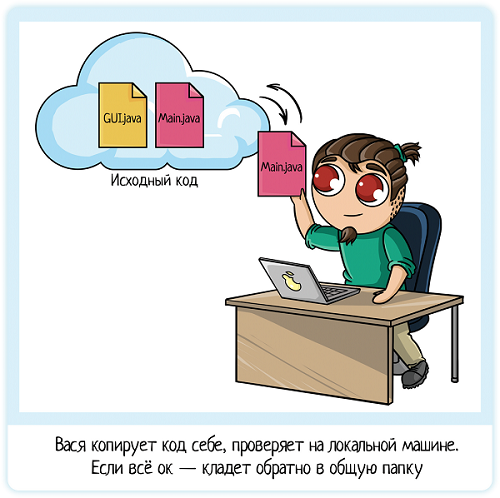
Итак, все забрали себе файлы из общей папки. Пока их немного:
- Main.java — общая логика
- GUI.java — графический интерфейс программы
С ними каждый и будет работать!
Вася закончил работу первым, проверил на своей машине — все работает, отлично! Удовлетворенно вздохнув, он выкладывает свой код в общую папку. Вася сделал отдельный класс на сложение (Sum.java), добавил кнопку в графический интерфейс (внес изменения в GUI.java) и прописал работу кнопки в Main.java.

Петя химичил-химичил, ускорял работу, оптимизировал. Но вот и он удовлетворенно вздохнул — готово! Перепроверил ещё раз — работает! Он копирует файлы со своей машины в общую директорию. Он тоже сделал отдельный класс для новой функции (вычитание — Minus.java), внес изменения в Main.java и добавил кнопку в GUI.java.

Ваня пока химичит на своей машине, но ему некуда торопиться, его изменения попадут только в следующий цикл.
Все довольны, Вася с Петей обсуждают планы на следующий релиз. Но тут с показа продукта возвращается расстроенная Катя, менеджер продукта.
— Катя, что случилось??
— Вы же сказали, что всё сделали! А в графическом интерфейсе есть только вычитание. Сложения нет!
— Как это нет? Я же добавлял!
Стали разбираться. Оказалось, что Петин файл затер изменения Васи в файлах, которые меняли оба: Main.java и GUI.java. Ведь ребята одновременно взяли исходные файлы к себе на компьютеры — у обоих была версия БЕЗ новых функций.

Вася первым закончил работу и обновил все нужные файлы в общей папке. Да, на тот момент всё работало. Но ведь Петя работал в файле, в котором ещё не было Васиных правок.

Поэтому, когда он положил документы в хранилище, Васины правки были стерты. Остался только новый файл Sum.java, ведь его Петя не трогал.

Хорошо хоть логика распределена! Если бы всё лежало в одном классе, было бы намного сложнее совместить правки Васи и Пети. А так достаточно было немного подправить файлы Main.java и GUI.java, вернув туда обработку кнопки. Ребята быстро справились с этим, а потом убедились, что в общем папке теперь лежит правильная версия кода.
Собрали митинг (жаргон — собрание, чтобы обсудить что-то):
— Как нам не допустить таких косяков в дальнейшем?
— Давайте перед тем, как сохранять файлы в хранилище, забирать оттуда последние версии! А ещё можно брать свежую версию с утра. Например, в 9 часов. А перед сохранением проверять дату изменения. Если она позже 9 утра, значит, нужно забрать измененный файл.
— Да, давайте попробуем!

Вася с Петей были довольны, ведь решение проблемы найдено! И только Иван грустит. Ведь он целую неделю работал с кодом, а теперь ему надо было синхронизировать версии. То есть объединять свои правки с изменениями коллег.

Доделав задачу по умножению, Иван синхронизировал свои файлы с файлами из хранилища. Это заняло половину рабочего дня, но зато он наконец-то закончил работу! Довольный, Иван выключил компьютер и ушел домой.
Когда он пришел с утра, в офисе был переполох. Вася бегал по офису и причитал:
— Мои изменения пропали. А я их не сохранил!
Увидев Ваню, он подскочил к нему и затряс за грудки:
— Зачем ты стер мой код??

Стали разбираться. Оказалось что Вася вчера закончил свой кусок работы, проверил, что обновлений файлов не было, и просто переместил файлы со своего компьютера в общую папку. Не скопировал, а переместил. Копий никаких не осталось.
После этого изменения вносил Иван. Да, он внимательно вычитывал файлы с кодом и старался учесть и свои правки, и чужие. Но изменений слишком много, часть Васиных правок он потерял.
— Код теперь не работает! Ты вообще проверял приложение, закончив синхронизацию?
— Нет, я только свою часть посмотрел.

Вася покачал головой:
— Но ведь при сохранении на общий диск можно допустить ошибку! По самым разным причинам:
- Разработчик начинающий, чаще допускает ошибки.
- Случайно что-то пропустил — если нужно «объединить» много файлов, что-то обязательно пропустишь.
- Посчитал, что этот код не нужен — что он устарел или что твоя новая логика делает то же самое, а на самом деле не совсем.
И тогда приложение вообще перестанет работать. Как у нас сейчас.
— Хм. Да, пожалуй, ты прав. Нужно тестировать итоговый вариант!
— И сохранять версии. Может, перенесем наш код в Dropbox, чтобы не терять изменения?

На том и порешили. Остаток дня все трое работали над тем, чтобы приложение снова заработало. После чего бережно перенесли код в дропбокс. Теперь по крайней мере сохранялись старые версии. И, если разработчик криво синхронизировал файлы или просто залил свои, затерев чужие изменения, можно было найти старую версию и восстановить ее.
Через пару дней ребята снова собрали митинг:
— Ну как вам в дропбоксе?
— Уже лучше. По крайней мере, не потеряем правки!
Петя расстроенно пожимает плечами:
— Да, только мы с Васей одновременно вносили изменения в Main.java, создалась конфликтующая версия. И пришлось вручную их объединять. А класс то уже подрос! И глазками сравнивать 100 строк очень невесело. Всегда есть шанс допустить ошибку.
— Ну, можно же подойти к тому, кто создал конфликт и уточнить у него, что он менял.
— Хорошая идея, давайте попробуем!

Попробовали. Через несколько дней снова митинг:
— Да всё зашибись, работаем!
— А почему код из дропбокса не работает?
— Как не работает. Мы вчера с Васей синхронизировались!
— А ты попробуй его запустить.
Посмотрели все вместе — и правда не работает. Какая-то ошибка в Main.java. Стали разбираться:
— Так, тут не хватает обработки исключения.
— Ой, подождите, я же её добавлял!
— Но ты мне не говорил о ней, когда мы объединяли правки.
— Да? Наверное, забыл.
— Может, еще что забыл? Ну уж давай лучше проверим глазами.

Посидели, выверили конфликтные версии. Потратили час времени всей команды из-за пустяка. Обидно!
— Слушайте, может, это можно как-то попроще делать, а? Чтобы человека не спрашивать «что ты менял»?
— Можно использовать программу сравнения файлов. Я вроде слышал о таких. AraxisMerge, например!
— Ой, точно! В IDEA же можно сравнивать твой код с клипбордом (сохраненным в Ctrl + C значении). Давайте использовать его!
Начали сравнивать файлы через программу — жизнь пошла веселее. Но через пару дней Иван снова собрал митинг:
— Ребята, тут такая тема! Оказывается, есть специальные программы для хранения кода! Они хранят все версии и показывают разницу между ними. Только делает это сама программа, а не человек!
— Да? И что за программы?
— Системы контроля версий называются. Вот SVN, например. Давайте попробуем его?

Попробовали. Работает! Еще и часть правок сама синхронизирует, даже если Вася с Петей снова не поделили один файл. Как она это делает? Давайте разбираться!
Как VCS работает
Подготовительная работа
Это те действия, которые нужно сделать один раз.
1. Создать репозиторий
Исходно нужно создать место, где будет лежать код. Оно называется репозиторий. Создается один раз администратором.
Ребята готовы переехать из дропбокса в SVN. Сначала они проверяют, что в дропбоксе хранится актуальная версия кода, ни у кого не осталось несохраненных исправлений на своей машине. Потом ребята проверяют, что «итоговый» код работает.
А потом Вася берет код из дропбокса, и кладет его в VCS специальной командой. В разных системах контроля версии разные названия у команды, но суть одна — создать репозиторий, в котором будет храниться код.
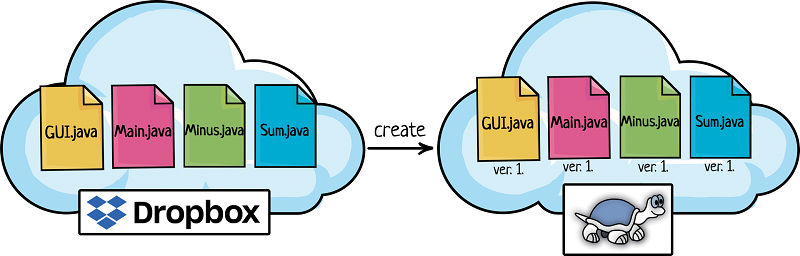
Всё! Теперь у нас есть общее хранилище данных! С ним дальше и будем работать.
2. Скачать проект из репозитория
Теперь команде нужно получить проект из репозитория. Можно, конечно, и из дропбокса скачать, пока там актуальная версия, но давайте уже жить по-правильному!
Поэтому Петя, Вася и Иван удаляют то, что было у них было на локальных компьютерах. И забирают данные из репозитория, клонируя его. В Mercurial (один из вариантов VCS) эта команда так и называется — clone. В других системах она зовется иначе, но смысл всё тот же — клонировать (копировать) то, что лежит в репозитории, к себе на компьютер!

Забрать код таким образом нужно ровно один раз, если у тебя его ещё не было. Дальше будут использоваться другие команды для передачи данных туда-сюда.
А когда на работу придет новый сотрудник, он сделает то же самое — скачает из репозитория актуальную версию кода.

Ежедневная работа
А это те действия, которые вы будете использовать часто.
1. Обновить проект, забрать последнюю версию из репозитория
Приходя утром на работу, нужно обновить проект на своем компьютере. Вдруг после твоего ухода кто-то вносил изменения?
Так, Вася обновил проект утром и увидел, что Ваня изменил файлы Main.java и GUI.java. Отлично, теперь у Васи актуальная версия на машине. Можно приступать к работе!

В SVN команда обновления называется «update», в Mercurial — «pull». Она сверяет код на твоем компьютере с кодом в репозитории. Если в репозитории появились новые файлы, она их скачает. Если какие-то файлы были удалены — удалит и с твоей машины тоже. А если что-то менялось, обновит код на локальном компьютере.

Тут может возникнуть вопрос — в чем отличие от clone? Можно же просто клонировать проект каждый раз, да и всё! Зачем отдельная команда?
Клонирование репозитория производится с нуля. А когда разработчики работают с кодом, у них обычно есть какие-то локальные изменения. Когда начал работу, но ещё не закончил. Но при этом хочешь обновить проект, чтобы конфликтов было меньше.
Если бы использовалось клонирование, то пришлось бы переносить все свои изменения в «новый» репозиторий вручную. А это совсем не то, что нам нужно. Обновление не затронет новые файлы, которые есть только у вас на компьютере.
А еще обновление — это быстрее. Обновиться могли 5 файликов из 1000, зачем выкачивать всё?
2. Внести изменения в репозиторий
Вася работает над улучшением сложения. Он придумал, как ускорить его работу. А заодно, раз уж взялся за рефакторинг (жаргон — улучшение системы, от англ. refactor), обновил и основной класс Main.java.
Перед началом работы он обновил проект на локальном (своём) компьютере, забрав из репозитория актуальные версии. А теперь готов сохранить в репозиторий свои изменения. Это делается одной или двумя командами — зависит от той VCS, которую вы используете в работе.
1 команда — commit
Пример системы — SVN.
Сделав изменения, Вася коммитит их. Вводит команду «commit» — и все изменения улетают на сервер. Всё просто и удобно.

2 команды — commit + push
Примеры системы — Mercurial, Git.
Сделав изменения, Вася коммитит их. Вводит команду «commit» — изменения сохранены как коммит. Но на сервер они НЕ уходят!

Чтобы изменения пошли на сервер, их надо «запушить». То есть ввести команду «push».
Это удобно, потому что можно сделать несколько разных коммитов, но не отправлять их в репозиторий. Например, потому что уже code freeze и тестировщики занимаются регрессией. Или если задача большая и может много всего сломать. Поэтому её надо сначала довести до ума, а потом уже пушить в общий репозиторий, иначе у всей команды развалится сборка!
При этом держать изменения локально тоже не слишком удобно. Поэтому можно спокойно делать коммиты, а потом уже пушить, когда готов. Или когда интернет появился =) Для коммитов он не нужен.
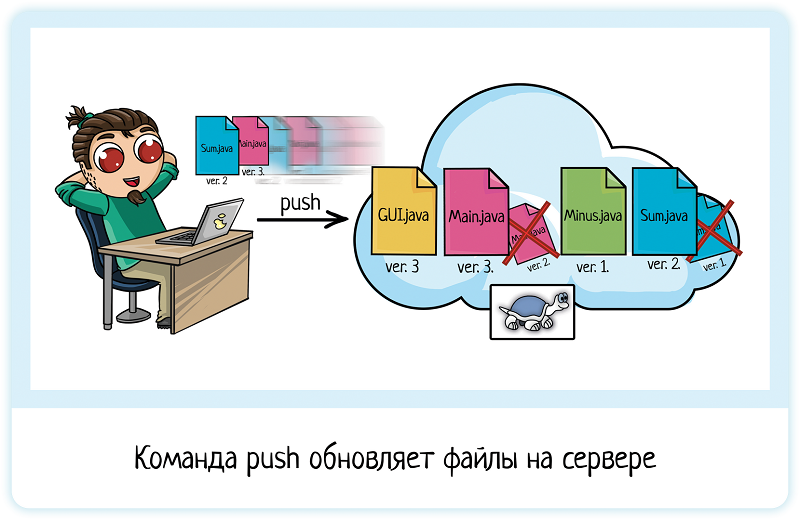
Итого
Когда разработчик сохраняет код в общем хранилище, он говорит:
Смотря в какой системе он работает. После этих слов вы уверены — код изменен, можно обновить его на своей машине и тестировать!
3. Разрешить конфликты (merge)
Вася добавил вычисление процентов, а Петя — деление. Перед работой они обновили свои локальные сборки, получив с сервера версию 3 файлов Main.java и Gui.java.
Для простоты восприятия нарисуем в репозитории только эти файлы и Minus.java, чтобы показать тот код, который ребята трогать не будут.

Вася закончил первым. Проверив свой код, он отправил изменения на сервер. Он:
- Добавил новый файл Percent.java
- Обновил Main.java (версию 3)
- Обновил Gui.java (версию 3)
При отправке на сервер были созданы версии:

- Percent.java — версия 1
- Main.java — версия 4
- Gui.java — версия 4
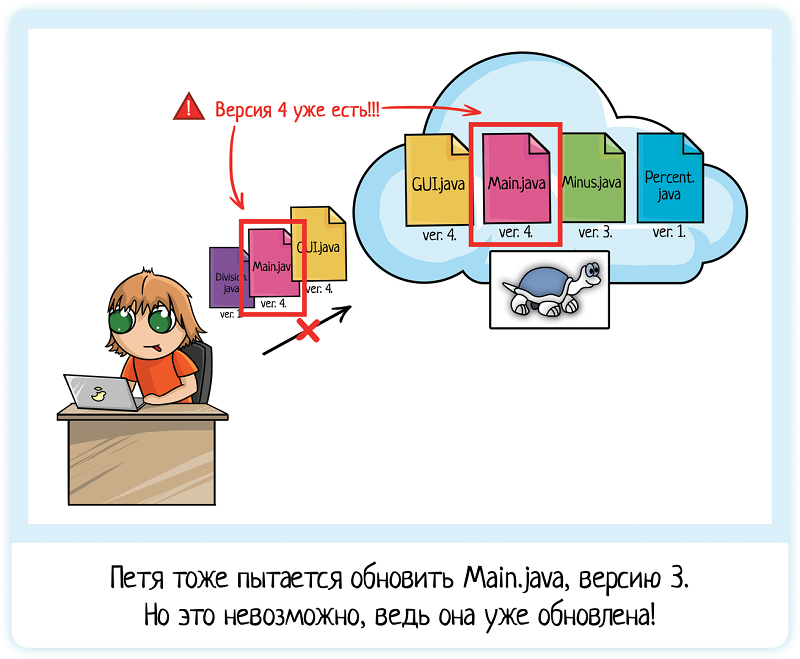
Петя закончил чуть позже. Он:
- Добавил новый файл Division.java
- Обновил Main.java (версию 3, ведь они с Васей скачивали файлы одновременно)
- Обновил Gui.java (версию 3)
Готово, можно коммитить! При отправке на сервер были созданы версии:
- Division.java — версия 1
- Main.java — версия 4
- Gui.java — версия 4
Но стойте, Петя обновляет файлы, которые были изменены с момента обновления кода на локальной машине! Конфликт!
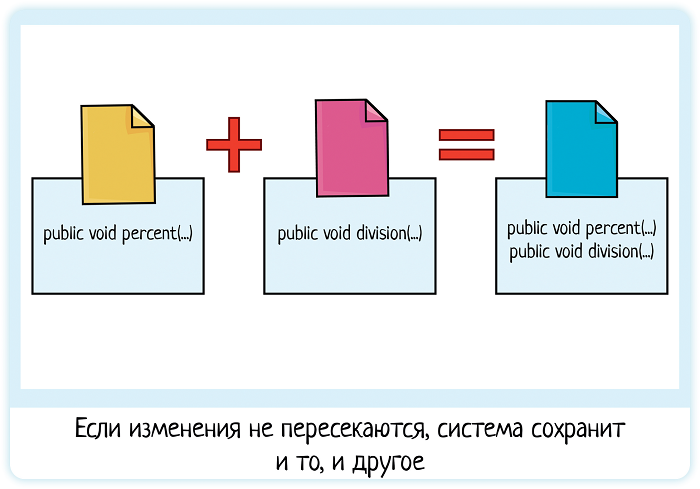
Часть конфликтов система может решить сама, ей достаточно лишь сказать «merge». И в данном случае этого будет достаточно, ведь ребята писали совершенно разный код, а в Main.java и Gui.java добавляли новые строчки, не трогая старые. Они никак не пересекаются по своим правкам. Поэтому система «сливает» изменения — добавляет в версию 4 Петины строчки.
Но что делать, если они изменяли один и тот же код? Такой конфликт может решить только человек. Система контроля версий подсвечивает Пете Васины правки и он должен принять решение, что делать дальше. Система предлагает несколько вариантов:
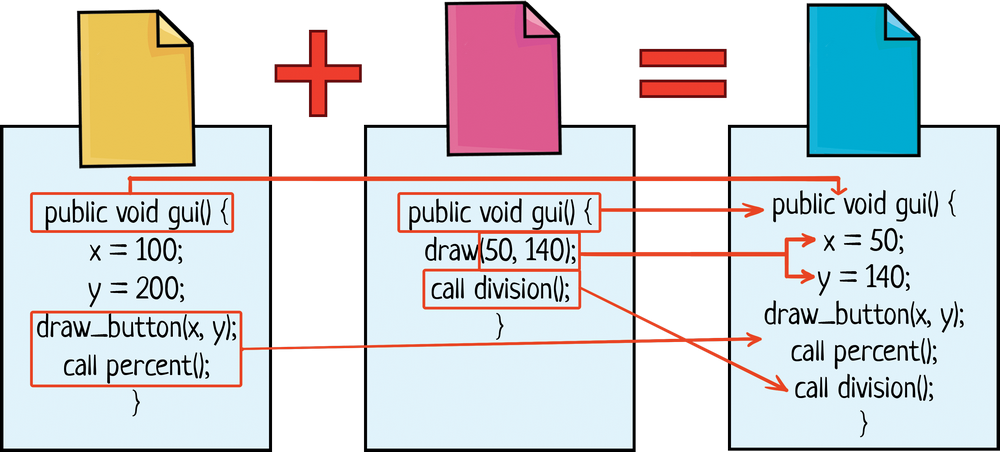
- Оставить Васин код, затерев Петины правки — если Петя посмотрит Васины изменения и поймет, что те лучше
- Затереть Васины правки, взяв версию Петра — если он посчитает, что сам все учел
- Самому разобраться — в таком случае в файл кода добавляются обе версии и надо вручную слепить из них итоговый кусок кода
Разрешение конфликтов — самая сложная часть управления кодом. Разработчики стараются не допускать их, обновляя код перед тем, как трогать файл. Также помогают небольшие коммиты после каждого завершенного действия — так другие разработчики могут обновиться и получить эти изменения.
Но, разумеется, конфликты все равно бывают. Разработчики делают сложные задачи, на которые уходит день-два. Они затрагивают одни и те же файлы. В итоге, вливая свои изменения в репозиторий, они получают кучу конфликтов, и нужно просмотреть каждый — правильно ли система объединила файлы? Не нужно ли ручное вмешательство?
Особая боль — глобальный рефакторинг, когда затрагивается МНОГО файлов. Обновление версии библиотеки, переезд с ant на gradle, или просто выкашивание легаси кода. Нельзя коммитить его по кусочкам, иначе у всей команды развалится сборка.
Поэтому разработчик сначала несколько дней занимается своей задачей, а потом у него 200 локальных изменений, среди которых явно будут конфликты.

А что делать? Обновляет проект и решает конфликты. Иногда в работе над большой задачей разработчик каждый день обновляется и мерджит изменения, а иногда только через несколько дней.
Тестировщик будет сильно реже попадать в конфликтные ситуации, просто потому, что пишет меньше кода. Иногда вообще не пишет, иногда пополняет автотесты. Но с разработкой при этом почти не пересекается. Однако выучить merge все равно придется, пригодится!
4. Создать бранч (ветку)
На следующей неделе нужно показывать проект заказчику. Сейчас он отлично работает, но разработчики уже работают над новыми изменениями. Как быть? Ребята собираются на митинг:
— Что делать будем? Не коммитить до показа?
— У меня уже готовы новые изменения. Давайте закоммичу, я точно ничего не сломал.
Катя хватается за голову:
— Ой, давайте без этого, а? Мне потом опять краснеть перед заказчиками!
Тут вмешивается Иван:
— А давайте бранчеваться!

Все оглянулись на него:
Иван стал рисовать на доске:
— Бранч — это отдельная ветка в коде. Вот смотрите, мы сейчас работаем в trunk-е, основной ветке.

Когда мы только-только добавили наш код на сервер, у нас появилась «точка возврата» — сохраненная версия кода, к которой мы можем обратиться в любой момент.

Потом Вася закоммитил изменения по улучшению классов — появилась версия 1 кода.

Потом он добавил проценты — появилась версия кода 2.

При этом в самой VCS сохранены все версии, и мы всегда можем:

- Посмотреть изменения в версии 1
- Сравнить файлы из версии 1 и версии 2 — система наглядно покажет, где они совпадают, а где отличаются
- Откатиться на прошлую версию, если версия 2 была ошибкой.
Потом Петя добавил деление — появилась версия 3.

И так далее — сколько сделаем коммитов, столько версий кода в репозитории и будет лежать. А если мы хотим сделать бранч, то система копирует актуальный код и кладет отдельно. На нашем стволе появляется новая ветка (branch по англ. — ветка). А основной ствол обычно зовут trunk-ом.

Теперь, если я захочу закоммитить изменения, они по-прежнему пойдут в основную ветку. Бранч при этом трогать НЕ будут (изменения идут в ту ветку, в которой я сейчас нахожусь. В этом примере мы создали branch, но работать продолжаем с trunk, основной веткой)
Так что мы можем смело коммитить новый код в trunk. А для показа использовать branch, который будет оставаться стабильным даже тогда, когда в основной ветке всё падает из-за кучи ошибок.
С бранчами мы всегда будем иметь работающий код!

— Подожди, подожди! А зачем эти сложности? Мы ведь всегда может просто откатиться на нужную версию! Например, на версию 2. И никаких бранчей делать не надо!
— Это верно. Но тогда тебе нужно будет всегда помнить, в какой точке у тебя «всё работает и тут есть все нужные функции». А если делать говорящие названия бранчей, обратиться к ним намного проще. К тому же иногда надо вносить изменения именно в тот код, который на продакшене (то есть у заказчика).
Вот смотри, допустим, мы выпустили сборку 3, идеально работающую. Спустя неделю Заказчик ее установил, а спустя месяц нашел баг. У нас за эти недели уже 30 новых коммитов есть и куча изменений.
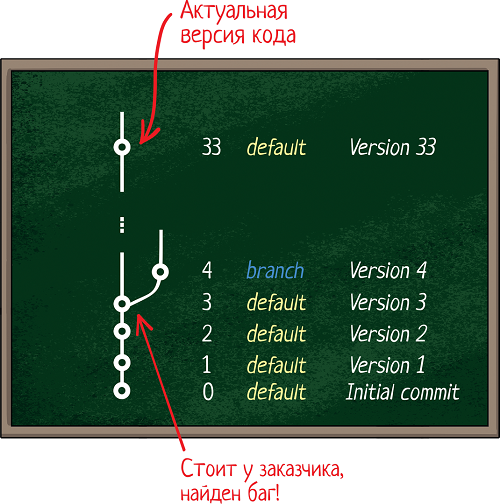
Заказчику нужно исправление ошибки, но он не готов ставить новую версию — ведь ее надо тестировать, а цикл тестирования занимает неделю. А баг то нужно исправить здесь и сейчас! Получается, нам надо:
- Обновиться на версию 3
- Исправить баг локально (на своей машине, а не в репозитории)
- Никуда это не коммитить = потерять эти исправления
- Собрать сборку локально и отдать заказчику
- Не забыть скопипастить эти исправления в актуальную версию кода 33 и закоммитить (сохранить)
Что-то не очень весело. А если нужно будет снова дорабатывать код? Искать разработчика, у которого на компьютере сохранены изменения? Или скопировать их и выложить на дропбокс? А зачем тогда использовать систему контроля версий?

Именно для этого мы и бранчуемся! Чтобы всегда иметь возможность не просто вернуться к какому-то коду, но и вносить в него изменения. Вот смотрите, когда Заказчик нашел баг, мы исправили его в бранче, а потом смерджили в транк.
Смерджили — так называют слияние веток. Это когда мы внесли изменения в branch и хотим продублировать их в основной ветке кода (trunk). Мы ведь объединяем разные версии кода, там наверняка есть конфликты, а разрешение конфликтов это merge, отсюда и название!

Если Заказчик захочет добавить новую кнопочку или как-то еще изменить свою версию кода — без проблем. Снова вносим изменения в нужный бранч + в основную ветку.
Веток может быть много. И обычно чем старше продукт, тем больше веток — релиз 1, релиз 2. релиз 52.
Есть программы, которые позволяют взглянуть на дерево изменений, отрисовывая все ветки, номера коммитов и их описание. Именно в таком стиле, как показано выше =) В реальности дерево будет выглядеть примерно вот так (картинка из интернета):

А иногда и ещё сложнее!
— А как посмотреть, в какой ветке ты находишься?
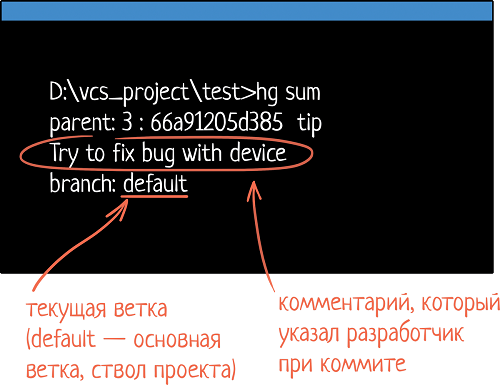
— О, для этого есть специальная команда. Например, в Mercurial это «hg sum»: она показывает информацию о том, где ты находишься. Вот пример ее вызова:
D:\vcs_project\test>hg sum parent: 3:66a91205d385 tip Try to fix bug with device branch: defaultВ данном примере «parent» — это номер коммита. Мы ведь можем вернуться на любой коммит в коде. Вдруг мы сейчас не на последнем, не на актуальном? Можно проверить. Тут мы находимся на версии 3. После двоеточия идет уникальный номер ревизии, ID кода.

Потом мы видим сообщение, с которым был сделан коммит. В данном случае разработчик написал «Try to fix bug with device».
И, наконец, параметр «branch»! Если там значение default — мы находимся в основной ветке. То есть мы сейчас в trunk-е. Если бы были не в нём, тут было бы название бранча. При создании бранча разработчик даёт ему имя. Оно и отображается в этом пункте.
— Круто! Давайте тогда делать ветку!
Для Git создали интерактивную «игрушку», чтобы посмотреть на то, как происходит ветвление — https://learngitbranching.js.org
Отдельно хочу заметить, что бранчевание на релиз — не единственный вариант работы с VCS. Есть и другой подход к разработке — когда транк поддерживают в актуальном и готовом к поставкам состоянии, а все задачи делают в отдельных ветках. Но его мы в этой статье рассматривать не будем.
Итого
Система контроля версий (от англ. Version Control System, VCS) — это dropbox для кода.
Популярные VCS и отличия между ними
Наиболее популярные — это:
- SVN — простая, но там очень сложно мерджиться
- Mercurial (он же HG), Git — намного больше возможностей (эти системы похожи по функционалу)
SVN — очень простая система, одна из первых. Сделал — закоммитил. Всё! Для небольшого проекта её вполне достаточно. Вы можете делать разные ветки и мерджить хоть туда, хоть сюда. Но у неё так себе работает автоматический мердж, на моей практике приходилось каждый файлик брать и копипастить изменения в основную ветку, это было проще, чем смерджить.
@lizardus в комментариях добавил о преимуществах системы:
Главные трудности в svn — всегда нужна сеть, и он может быть очень мммееееддддленный. Ну и с ветками работать не так удобно, в svn это просто директории. Хотя для новичков «папки» svn обычно интуитивнее.
А в целом, svn просто другая система (он работает просто как файловая система) со своими преимуществами и недостатками. Его легко поставить на windows (не тянет за собой треть линукса), он безопасен (все что закоммичено — сохранено навеки, удалить нельзя ничего, никакого rebase), легко сделать checkout одной маленькой части проекта и работать только с ней (а это позволяет модный монорепо без костылей), можно мешать ревизии отдельных файлов в папке проекта и мерджить отдельные файлы произвольным образом. Права доступа к отдельным частям проекта — легко. svn работает с бинарными данными и даже (теоретически) как-то мерджит. Легко аутентификацию по сертификату. Встроенный WebDAV с минимальными усилиями: можно смонтировать как диск в Windows для тех, кому нужен доступ только для чтения, или просто бросить ссылку для браузера (какие-нибудь дизайнеры так могут любоваться картинками из svn или скрипт может получать последние бинарные данные для управления коллайдером).
Mercurial и Git — распределенная система контроля версий. Внесение изменений двухступенчатое — сначала коммит, потом push. Это удобно, если вы работаете без интернета, или делаете мелкие коммиты, но не хотите ломать основной код пока не доделаете большую задачу. Тут есть и автоматическое слияние разных бранчей. Больше возможностей дают системы.
У любой системы контроля версий есть «консольный интерфейс». То есть общаться с ними можно напрямую через консоль, вводя туда команды. Склонировать репозиторий, обновить его, добавить новый файл, удалить старый, смерджить изменения, создать бранч. Всё это делается с помощью команд.
Но есть и графический интерфейс. Устанавливаете отдельную программу и выполняете действия мышкой. Обычно в моей практике это делается через «черепашку» — программа называется Tortoise. TortoiseSVN, TortoiseHG, TortoiseGit. Часть команд можно сделать через среду разработки — IDEA, Eclipse, etc. Плюс есть еще куча других инструментов, часть из них можно найти в комментариях =)
Но любой графический интерфейс как работает? Вы потыкали мышкой, а система Tortoise составила консольную команду из вашего «тык-тык», её и применила.
См также:
Что такое API — подробнее о том, что скрывается за интерфейсом.
Вот некоторые базовые команды и форма их записи в разных VCS:
Действие
Основы VCS на примере Git
https://git-scm.com/ – тут крутые entry видео, документация и прочее.
VCS
Version Control System (VCS) – система контроля версий.
Из названия следует основной кейс применения таких систем – контроль версий систем. VCS сохраняет изменения, которые произошли от одной версии файла к другой. В качестве систем могут быть файлы с кодом программ, скриптов или конфигурационные файлы (например, файлы конфигурации DHCP, файлы зон DNS, настроек iptables или apache).
VCS позволяют не только сохранять историю кода, но и конфигов, template да и в целом любых текстовых файлов. Это нельзя забывать никогда - пригодится по жизни во многих местах.
Помимо возможности просмотра предыдущих версий файлов (не только текстовых) VCS позволяют:
- track changes (what, when, who, why)
- rollbacks
- pull requests – очень крутая штука
Если более детально:
- посмотреть когда файл был изменен
- посмотреть кто внес изменения в какой файл
- посмотреть что поменялось
- посмотреть комменты к изменениям (commit)
- можно вносить изменения в несколько файлов как одно изменение (commit changeset)
- позволяет легко откатить изменения (rollback)
- позволяет одновременную работу нескольких кодеров над одним проектом
Исходя из плюсов можно определенно сказать, что VCS имеет смысл использовать даже если ты единственный программист.
Git
- Для удобства работы в git с подсветкой статусов в командной строке можно использовать скрипт. Процесс установки прост – копируем репозиторий в домашнюю папку, в bashrc добавляем строку со ссылкой на скрипт из репозитория и перезапускаем bash для принятия изменений. Процесс расписан тут:
https://pyneng.github.io/docs/git-basics/ cd ~ git clone https://github.com/magicmonty/bash-git-prompt.git .bash-git-prompt --depth=1 GIT_PROMPT_ONLY_IN_REPO=1 source ~/.bash-git-prompt/gitprompt.sh exec bash
Самый популярный VCS – Git.
Помимо git есть Mercurial, Subversion, Team Foundation Server (TFS) но они хуже по многим аспектам – бесплатность, коворкинг, скорость, открытость, децентрализация, офф-лайн режим, порог входа (особенно из-за крутого графического интерфейса, легкого для установки/настройки сервера на любую платформу, понятной истории), отслеживания содержимого (а не просто файлов), указание объектов для коммита.
Git является бесплатным open source VCS. Может быть установлен на Unix-based, Windows, OSX. Git был создан Linus Torvalds, создателем Linux, изначально как VCS для кода ядра Linux. На сайте https://git.kernel.org/ можно посмотреть как он используется при программировании ядра. А тут можно посмотреть коммиты самого Torvalds.
У Git, в отличии от многих других VCS, децентрализованная архитектура, т.е. он очень гибок:
- нет необходимости работы клиента с каким то единым сервером
- копия кода репозитория (клон), над которой производится работа, всегда находится локально на машине
- можно установить Git на одном ПК, даже без интернет подключения этого ПК
- ничто не мешает установить Git на сервере, а остальными цепляться к этому серверу как клиентами для получения актуальных данных репозитория, отправки туда изменений (обычно так и происходит)
- в git config можно указать даже pgp/gpg ключ для подписи коммитов
- взаимодействие между Git клиентами и серверами может быть на основе HTTP, SSH или специального протокола Git.
Файлы в Git могут находиться в стадиях:
- неотслеживаемые (untracked) – не добавленные в репозиторий (git add) или удаленные файлы, по умолчанию все новые файлы в этом состоянии
- немодифицированные (unmodified) – отслеживаемые, файлы после commit
- модификация (modified) – это новый файл или сделаны изменения в старом, но он еще не закоммичен (не применен commit)
- подготовленные (staged) – файлы, поставленные на commit (добавленные в следующий commit)
- подтвержденные (commited) – срез (snapshot) файла сохранен в базе
Каждый Git проект имеет три секции:
- Рабочее дерево (working tree) – тут проводятся модификации над файлами, тут обычно находятся последние версии файлов (modified files)
- Область подготовки (staging area/index) – тут сохраняются подготовленные файлы (staged files)
Директория Git (Git directory) – по сути база твоего проекта. Тут сохраняются все snapshot проекта. Git в результате commit сохраняет в Git директории не просто разницу между предыдущим состоянием и текущим (diff), а полностью файлы. (commited files)
Commit представляет собой по сути snapshot файлов, которые были поставлены на commit. В комментариях к commit нужно указывать нужную информацию о причинах commit, например номера тикетов или ссылок на документы, rfc, переписки и прочее. Если коммит длинный – то комментарий к commit не нужно указывать непосредственно в cli, а просто ввести commit. Тогда откроется текстовый редактор, в нем первой строкой краткое описание, а далее подробный текст изменения. Есть даже сайт посвященный стилю commit https://commit.style/.
When you commit a snapshot to your repository, Git is doing which of the following?
Recording the entire contents of every file that you've changed and is part of the commitCommit идентифицируется ID в виде HASH, расчитанного по алгоритму SHA1. Hash сделан чтобы можно было сравнивать что данные которые ты внес соответствуют данным, которые сохранены т.к. любое изменение данных приводит к изменению hash этих данных. Git ругнеться если hash от данных не будет соответсвовать hash commit. Изменение может быть безобидным – сетевая проблема, проблема с диском, но и намеренным внедрением (mitm). При использовании в командах можно указывать только первые символы hash, а не весь hash, git найдет нужный commit по вхождению в hash (обычно достаточно всего первых 4 символов).
HEAD – индикатор текущего commit для текущего branch в репозитории (по сути за ним скрывается ID текущего commit), что-то типо закладки для отслеживания местоположения (используется в командах git reset, diff, branch, status).
Github
Github – бесплатный web-based сервер репозиториев на основе git. Предоставляет доп. плюшки в виде wiki, bug tracking, task management. Бесплатен только если проект (репозиторий) публичен, если нужен приватный репозиторий – заплати денег, хотя и не много. GitHub является крупнейшим веб-сервисом для хостинга IT-проектов и их совместной разработки. Основан на системе контроля версий Git и разработан на Ruby on Rails и Erlang. Проекты можно выгружать через git clone или даже в zip. Есть аналоги – BitBucket, Gitlab. Github куплен microsoft.
GIT LFS
- Описание использования команд
- git lfs fetch
- git lfs fetch –all
- git lfs pull
Github начал использовать LFS (Git Large File Storage) для хранения в репозиториях больших файлов – по сути в репозитории теперь хранится ссылка/pointer на файл, а не сам файл.
An open source Git extension for versioning large files Git Large File Storage (LFS) replaces large files such as audio samples, videos, datasets, and graphics with text pointers inside Git, while storing the file contents on a remote server like GitHub.com or GitHub Enterprise.
Загрузка из LFS хранилища всех LFS файлов для текущего репозитория. В данном случае не сработала из-за жадности github ��
git clone sudo apt-get install git-lfs # Download Git LFS objects at the given refs from the specified remote. git lfs fetch
fetch: Fetching reference refs/heads/main batch response: This repository is over its data quota. Account responsible for LFS bandwidth should purchase more data packs to restore access. error: failed to fetch some objects from 'https://github.com/julienatry/VMware-ESXi-6.7.0-RTL8111.git/info/lfs'
Базовая работа и команды
git --version
Указание username и почты (чтобы размечать тебя в commit в публичных репозиториях). В git config можно указать даже pgp/gpg ключ для подписи коммитов.
git config --global user.name "Petr Redkin"
git config --global user.email "petr@redkin.net"
git config --global core.editor vimgit config -l
Инициализация нового проекта (создает автоматически директорию, эмулируя mkdir “myproject”, папку не обязательно указывать – тогда это будет .git в текущей)
git init |myproject|
Переходим в директорию с проектом (тут будут файлы самого проекта и файлы, которые хранят изменения в файлах проекта)
cd myproject
Добавляем элемент или всю папку в hold на commit (переводим модифицированный файл в commit, добавляем новый файл в tracked и переводим его в commit – проставляем на файлы staged статус)
git add |-p| index.html git add * git add .
Убираем элемент или всю папку из staging area
git reset HEAD|commit_hash_id sw
Можно удалять и перемещать файлы в репозитории – говорим Git не отслеживать файл, удаляем/перемещаем его из Git directory. Файл уходит в staged, поэтому нужно сделать commit для завершения удаления/перемещения.
git rm sw
git mv sw new_dir/GITIGNORE
Через файл .gitignore мы говорим Git не отслеживать определенные файлы. Полезно если коммит делается через *. Есть рекомендации что включать в этот файл.
vi .gitignore
*.exe # ignore compiled files
*.rar # ignore archive filesПолезно часто просто игнорировать все файлы кроме python-скриптов (или исполняемых файлов другого языка, который нужен).
https://stackoverflow.com/questions/987142/make-gitignore-ignore-everything-except-a-few-files # Ignore everything * # But not these files. !.gitignore !*.py
COMMIT
Делаем commit – создаем snapshot с данными.
-m – добавляем коммент прямо из консоли. По style так писать нежелательно, но в целом так делают даже в кратком review на сайте Git �� Как по мне если изменение минорное – очень полезная вещь.
-a – автоматически добавляет все файлы, которые отслеживаются (находяться в репозитории Git) на commit (нет необходимости делать git add, если только это не новый файл)git commit |-a| |-m "Imporing all the code"|
Перезаписть последний commit новым (удаление старого commit, все что в текущий момент в staging area будет закоммичено). Можно использовать не только когда сменились данные, но и когда нужно только поправить комментарий. Время commit будет равно времени изначального commit, а не времени amend, все остальные данные будут перезаписаны (коммент, id). Крайне нежелательно использовать для публичных commit, вместо этого нужно использовать revert.
git commit --amend
Восстановить или откатить
Чтобы восстановить конкретный файл из последнего commit, новый файл еще не в staging area (после изменения или удаления ДО применения add/rm на новую версию файла)
git checkout -- deleted_file.rb
Чтобы восстановить конкретный файл из последнего commit, новый файл уже в staging area (после изменения или удаления И применения add/rm на новую версию файла)
git reset HEAD|commit_hash_id deleted_file.rb
git checkout -- deleted_file.rbОткат текущего состояния на определенный commit делается через checkout.
git checkout `commit-id`
Откат изменений, внесенных определенным commit делается через revert. Revert делает новый коммит, который отменяет все изменения, сделанные в указанном коммите (HEAD – в последнем коммите или commit_hash_id, можно указать не полностью) – т.е. если строка была добавлена, то в результате revert эта строка будет удалена. Таким образом можно посмотреть что было не так в “плохом” commit после отката.
git revert HEAD|commit_hash_id
Сравнение и Логи
Статус файлов, в каком состоянии они находятся
git status
Логи
git log
Опции:
-p – показать что поменялось в файлах между текущим и предыдущим commit,
-2 – показать только два последних commit,git log -2
–decorate – добавление информации о branch, в какой branch сейчас смотрит HEAD или проще говоря для какого branch в логах показаны commit
–stat – просмотр какие файлы поменялись
origin/master – можно указать удаленный repo и branch, для которого будут показаны логиgit log |--graph --decorate --abbrev-commit --all --pretty=oneline|
Сравниваем текущие данные (в staging area) с данными определенного commit с помощью git diff.
git diff dc3009ec74733
Сравниваем данные разных commit между собой.
git diff e15f6fe92b0c dc3009ec7473
BRANCHING AND MERGING
Branch – указатель на определенный commit. Каждый branch указывает на отдельную линию разработки в проекте. Master – branch по умолчанию, создаваемый при инициализации Git. Принято его считать и использовать как основную, production или known-good, ветку проекта. При изменениях проекта, например добавления новой фичи делается еще один branch, на основе которого происходит работа, без необходимости изменения production ветки. Branch’и позволяют очень легко экспериментировать с новыми идеями в проекте и используются повседневно. Основной профит branch состоит в том, что они не хранят и не копируют данные, они просто указывают на определенный commit.
Показать все branch в репозитории, звездой помечается в каком ты сейчас находишься
git branch
Создаем branch на основе текущего branch (не обязательно master)
git branch branch_name
Для переключения между branch’ами нужно использовать checkout, в результате команды 1) working tree изменяется с предыдущего branch на последний новый, т.е. меняются файлы в соответствии с branch 2) HEAD указывает на последний commit в новом branch, а не в старом 3) меняется commit history т.к. она ведется для branch
git checkout branch_name
Можно создать branch и сразу переключиться в него через checkout
git checkout -b branch_name
Удаление branch (ругнеться если есть неза’commit’енные в master изменения в удаляемом branch)
git branch -d branch_name
Соединяем данные и history log branch с текущим branch. Git использует два алгоритма для merge:
- fast-forward – когда branch, из которого взяты обновления, имеет все commit текущего branch (история commit между branch не отличается, один просто имеет свежие данные). В таком случае git просто переносит указатель HEAD на основе merging branch (накатывает все commit из нового branch в текущий) и по сути нет никакого merging.
- three-way-merge – когда branch, из которого взяты обновления, не имеет все commit текущего branch. т.е. в текущем branch были изменения после того как сделана копия данных (если говорить о master branch). В таком случае Git найдет самый последний commit, который совпадает между branch и будет делать merge различающихся commit’ов branch’ей после этого шага. В случае конфликтов (изменение одного региона одного файла), это называется merge conflict, Git об этом скажет. В таком случае можно использовать git status для просмотра конфликтных файлов и далее открыть сами конфликтные файлы, чтобы увидеть какие данные являются конфликтными. После разрешения конфликта (изменения необходимых строк в файле) нужно использовать git add на этот файл и сделать commit – все, конфликт разрешен.
git merge branch_name
Сбросить процедуру merge, если конфликты слишком сложные, чтобы их быстро разрешить. Данные в working tree будут восстановлены на основе текущего branch, не включая конфликты. При использовании –hard все незакомиченные изменения в текущем branch будут сброшены!
git reset --hard
КОЛЛАБОРАЦИЯ
- git push – отправить на сервер изменения в локальном репозитории после commit. Git push делается после локального коммита. Настроенные remote (настраиваются автоматически при использовании git clone) позволяют это делать одной командой.
- git merge – соединение твоей копии репозитория с основной на сервере.
git checkout master
git commit -a -m "my new logo"
git pushОбычный пользователь, ответственный за какую то ветку (branch)
git checkout -b dana
git commit -a -m "my new code"
git push origin danaАдмин после этого собирает к себе на комп (git pull) и объединяет изменения последних коммитов в репозитории (git merge), с вопросами какие изменения сохранить в случае наличия конфликтов и прочим
git pull git merge dana
УДАЛЕННЫЕ РЕПОЗИТОРИИ (github)
- На github удобно diff смотреть – есть режим просмотра unified (последовательно origin – версия до изменения и change – версия после изменения) и split (на одной стороне экрана origin, на второй change – как по мне, удобнее классической) .
Крайне удобно комментировать код – можно выбрать конкретные строки, отписать коммент и уведомить автора что что-то не так или наоборот так.
git clone – копируем удаленный репозиторий для локального использования (используется вместо git init, остальные команды все аналогичные, до тех пор пока не понадобится обновить удаленный репозиторий – там нужно добавить в обычной последовательности действий push). Репозиторий будет скопирован и будет иметь имя по умолчанию origin.-
- Git clone возможен по ssh или https. В первом случае можно аутентифицироваться по ключу (и паролю), во втором по логину и паролю.
- Git clone можно сделать для последней версии repo, а можно с указанием конкретной определенной версии (по tag и/или branch) репозитория. Альтернативный путь получить код не последней версии – загрузить последнюю и делать checkout на нужную версию.
Вместо создания клона можно создать связь с удаленным репозиторием. Можно использовать HTTP (обычно только RO доступ к repo), HTTPS, SSH, Git. Связь автоматически создается при использовании git clone.
git remote add origin https://github.com/paulboone/ticgit
Просмотреть все связи с удаленными репозиториями (-v показывает URL и какой будет использовать для fetch from repo и push to repo, обычно один и тот же)
git remote |-v|
git remote rename origin new-origin
git remote rm origin
git pull – получаем изменения из repo. Обновление данных локального репозитория на основе удаленного. Git автоматически это не делает. Например, когда на работу пришел и нужно получить изменения, запушенные в репозиторий из дома. Команда которая делает одновременно fetch из remote repo (url shortcut) и merge на основе удаленного repo. По умолчанию branch определяется на основе текущего branch, но можно поменять. Перед git pull можно посмотреть что изменилось в repo с помощью команды git diff HEAD..origin
git pull origin |master|
git push – Обновляем удаленный репозиторий изменениями (всеми snapshot после всех commit), которые мы сделали. Нужно указать и repo (url shortcut) и branch. Git сервер скорей всего спросит username/password перед апдейтом. При использовании -all будут переданы все branch текущего репозитория. В случае конфликтов Git скажет что нужно сначала получить актуальный репозиторий через git pull, сделать merge локально (автоматически вызывается при использовании pull), а потом загружать.
git push origin master
get push --all origingit checkout – для перехода в другую ветку git. Ветка по умолчанию (основная) называется обычно master. Git checkout master – переход в master.
git fetch – получаем данные из удаленного репозитория в локальный как remote branch. Для получения конкретной ветки можно указать эту ветку. git branch -r смотрим такие ветки в нашем репозитории. Такие branch можно только просмотривать, не изменять.
git fetch origin |master|
git branch -rgit merge – обновляем данные нашего репозитория на основе данных удаленного.
git merge origin/master
Fork для изменения без прав + pull request для запроса на редактирование основной ветки
Posted on January 28, 2018 October 14, 2023 Author weril Categories Coding
Leave a Reply Cancel reply
You must be logged in to post a comment.
- Подготовительная работа