Как скачать таблицу из юпитер ноутбука?
Предположим, что у меня есть таблица в формате dataframe, я преобразую её в формат csv, используя to_csv, как теперь мне скачать эту таблицу?
Отслеживать
задан 15 авг 2021 в 16:57
67 1 1 серебряный знак 5 5 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Разберем на примере кода:
import pandas as pd cities = pd.DataFrame([['Sacramento', 'California'], ['Miami', 'Florida']], columns=['City', 'State']) cities.to_csv('cities.csv') В строке cities.to_csv(‘cities.csv’) вы конвертирует DataFrame-файл и записываете в файл ‘cities.csv’, также можно указать прямой путь к файлу. Далее он сохраняется в рабочем каталоге запущенного файла. Следовательно, вам не надо будет скачивать сам конвертированный файл,он будет в той же директории, где находится ваш py-файл с кодом выше(если брать пример выше).
Как конвертировать csv в excel в Jupyter Notebook
Ну что, начинаю тут вещать и собирать свои лайфхаки. Без них бы я не разобралась в том, что знаю сейчас.
В Jupyter’е есть как минимум с десяток классных функций упрощающих жизнь всем, для примера возьму импорт и экспорт датафреймов:
Импорт
pd.read_csv(filename) | Загрузить CSV file
pd.read_table(filename) | Из текстового файла с разделителями (например, TSV)
pd.read_excel(filename) | Загрузить Excel file
pd.read_sql(query, connection_object) | Загрузка из таблицы / базы данных SQL
pd.read_json(json_string) | Чтение из строки, URL или файла в формате JSON
pd.read_html(url) | Разбирает html URL, строку или файл и извлекает таблицы в список датафреймов
pd.read_clipboard() | Берет содержимое вашего буфера обмена и передает его в read_table()
pd.DataFrame(dict) | Словарь, ключи для имен столбцов, значения для данных в виде списков
Экспорт
df.to_csv(filename) | Записать в CSV file
df.to_excel(filename) | Записать в Excel file
df.to_sql(table_name, connection_object) | Записать в SQL table
df.to_json(filename) | Записать в JSON format
Сегодня расскажу немножко про боль при сохранении cvs в excel, ключевое почему не срабатывает просто сухое to_excel() — нужно сначала записать данные в эксель, а после сохранять.
Например у вас загружен в Jupyter csv с помощью pd.read_csv(filename)
Ниже будет перевод материала из вот этой статьи на медиуме, спасибо @Stephen Fordham.
У Стивена очень подробно все описано, даже с примером как в файл сохранить несколько датафреймов в разные вкладки. Я же представлю скрин того, как сохранить один датафрейм.
Опишу то что мы видим, чтобы использовать Pandas для записи объектов Dataframe в Excel, необходимо установить 2 библиотеки. Это библиотеки xlrd и openpyxl соответственно. Для удобства эти библиотеки можно установить, не выходя из Jupyter Notebook, просто добавив к команде префикс ! подписать с последующей установкой pip . Когда эта ячейка будет выполнена, вывод будет либо «Требование уже выполнено», либо установка будет выполнена автоматически.
Отвечаю на вопрос, почему у меня на скрине ! pip install openpyxl==3.0.1
При установке последней версии методом ! pip install openpyxl (ставится последняя версия 3.0.2) у меня возникает ошибка при выполнении сохранения TypeError: got invalid input value of type , expected string or Element
Собственно вопрос решается если ставить версию ниже
Далее все проще, как пишет Стивен в своей публикации — От Pandas Dataframe к Excel за 3 шага
- Чтобы начать процесс экспорта Pandas Dataframes в Excel, необходимо создать объект ExcelWriter. Это достигается с помощью метода ExcelWriter, который вызывается непосредственно из библиотеки панд. В этом методе я указываю имя файла Excel (в статье по ссылке автор выбрал Tennis_players, у меня же вы найдете games) и включаю расширение .xlsx. Этот шаг создает основную книгу экселя, в которую мы можем затем записать наши датафреймы.
- После этого я вызываю метод .to_excel на скрине выше. В методе .to_excel первым аргументом, который нужно указать, является объект ExcelWriter, за которым следует необязательный параметр имя листа. (я не использовала индекс, но в статье, на которую я ссылаюсь устанавливают аргумент index =False, по умолчанию, кстати, идет True) Проставляем аргумент ‘utf-8’ для параметра encoding для обработки любых специальных символов. Тоже самое можно повторить и для других датафреймов, единственное записывать их в разные листы, параметр sheet_name.
- Наконец, теперь, когда наши датафреймы поставлены в очередь для экспорта, мы вызываем метод save для объекта ExcelWriter, который мы назначили переменной my_excel_file.
Руководство для начинающих о том, как сделать Jupyter Notebook быстрее, мощнее и круче
Magic — это отличные команды, упрощающие нашу жизнь при решении определенных задач. Часто похожи на команды Unix, но реализованы на Python. Магических команд в Python великое множество!
Существует 2 типа магических команд: строчные (применяются к одной строке) и ячеечные (применимы ко всей ячейке). Строчные команды начинаются с символа % , а ячеечные — с двух %% . Просмотреть все доступные команды можно через:
%lsmagic
Установка среды
Через %env вы можете управлять переменными среды в блокноте без перезагрузки. Для вывода списка всех имеющихся переменных в среде достаточно выполнить эту команду без переменных.
Вставка кода
С помощью %load можно добавлять код из внешнего скрипта (более подробно см. ниже). Например:
%load basic_imports.py
берет файл basic_imports.py и загружает его в блокнот.
Экспорт содержимого ячейки
Это невероятно полезная опция. %%writefile позволяет экспортировать содержимое ячейки в любое время и с минимальными усилиями. Например,
%%writefile thiscode.pyЗдесь вы пишите какой-то код или функцию,
которые хотите экспортировать
и, возможно, использовать в дальнейшем!
Случалось ли вам в каждом документе импортировать одно и то же или добавлять те же самые функции? Теперь вы можете написать код один раз и пользоваться им всюду!
К примеру, можно создать файл basic_imports.py , содержащий следующий код:
%writefile basic_imports.pyimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Так вы создадите .py файл, в котором будет перечислен основной импорт.
Загрузить его можно через:
%load basic_imports.py
Выполнение данной команды заменяет содержимое ячейки загруженным файлом.
# %load imports.pyimport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Теперь можно еще раз запустить ячейку, чтобы импортировать все нужные модули и начать работу.
Сохранение и повторное использование кода через %macro
Вам, как и большинству людей, не раз приходилось прописывать одно и то же. Это могут быть и часто вычисляемые уравнения, и регулярно создаваемые строки кода. В Jupyter можно сохранять фрагменты кода в виде исполняемых макросов. Макрос — это просто код. Поэтому он может содержать переменные, которые необходимо определять до выполнения. Давайте попробуем!
name = ‘Kitten’
Для определения макроса нужен какой-то код. Мы можем сохранить почти что угодно: будь то строка, функция или что-то другое.
print(‘Hello, %s!’ % name)Hello, Kitten!
Настраивать повторно используемые макросы мы будем через магические команды %load и %macro . Названия макросов принято начинать с двойного подчеркивания — так они отличаются от других переменных.
%macro -q __hello_you 32
Магическая команда %macro принимает имя и номер ячейки (или номера). Для большей лаконичности кода мы передаем –q . %store позволяет сохранять любую переменную для использования в других сеансах. В примере выше передавалось имя созданного макроса. Таким образом, мы сможем пользоваться им в других блокнотах или при отключении ядра.
Для загрузки макроса достаточно выполнить следующую команду:
%load __hello_you
А для выполнения макроса можно просто запустить ячейку с именем макроса.
__hello_youHello, Kitten!
Давайте изменим переменную, которая использовалась в макросе.
name = ‘Muffins’
Теперь при запуске макроса берется это измененное значение.
__hello_youHello, Muffins!
Все работает, поскольку макросы выполняют сохраненный код в области ячейки. Если бы не было определено name , то мы бы увидели ошибку.
Хотите пользоваться одинаковым макросом во всех блокнотах?
Магическая команда store
%store позволяет хранить макрос и пользоваться им во всех блокнотах.
Попробуйте открыть новый блокнот и повторить пример с %store -r __hello_you .
%store -r __hello_you
name = ‘Rambo’
%load __hello_youHello, Rambo!
Магическая команда run
Команда %run выполняет код и отображает любой вывод, включая графики Matplotlib. С этой командой можно выполнять даже целые блокноты.
%run способен выполнять Python-код из .py-файлов. А еще он подходит для выполнения других блокнотов Jupyter.
Магическая команда pycat
%pycat покажет вам содержимое скрипта, если вдруг вы забыли, что в нем находится.
%pycat basic_imports.py
Автосохранение
Магическая команда %autosave позволяет изменять частоту автосохранения блокнота в его файл контрольных точек.
%autosave 60
Команда выше реализует автосохранение каждые 60 секунд.
Отображение графиков
%matplotlib inline
Скорее всего, вы и так знаете, что %matplotlib inline отображает графики Matplotlib в выводе ячейки. То есть вы можете добавлять графики и диаграммы Matplotlib напрямую в сами блокноты. Логичнее будет запустить эту команду в начале блокнота — в самой первой ячейке.
Управление временем
Существует две магические команды iPython для управления временем — %%time и %timeit . Они полезны тогда, когда код выполняется медленно, и вы пытаетесь отыскать причину. Обе команды имеют строковые и ячеечные режимы.
В отличие от %time , %timeit многократно запускает код и вычисляет среднее значение.
%%time дает информацию о единичном запуске кода в ячейке.
%%timeit использует Python-модуль timeit, который выполняет выражение несколько раз, а затем выдает среднее значение. Количество выполнений задается через –n , а количество повторений — через -r .
Выполнение кода из другого ядра
Вы можете выполнять ячейку на определенном языке. Существуют расширения для нескольких языков. Например:
- %%bash
- %%HTML
- %%python
- %%python2
- %%python3
- %%ruby
- %%perl
- %%capture
- %%javascript
- %%js
- %%latex
- %%markdown
- %%pypy
Например, для рендеринга HTML в блокноте выполните следующее:
%%HTML
This is really neat!
Либо воспользуйтесь напрямую LaTeX через:
%%latex
This is an equation: $E = mc²$
Магическая команда who
Команда %who без аргументов выдает перечень переменных, существующих в глобальной области видимости. При передаче параметра (например, str ) перечисляются переменные только этого типа. Так что если написать:
%who str
Магическая команда prun
%prun показывает количество времени, которое программа тратит на каждую функцию. %prun statement_name выводит упорядоченную таблицу с информацией о количестве вызовов каждой внутренней функции внутри оператора, времени каждого вызова, а также среднем времени всех запусков функции.
Магический отладчик в Python
В Jupyter есть собственный интерфейс для отладчика. С ним вы можете зайти в тело каждой функции и посмотреть, что там происходит. Активировать опцию можно через запуск %pdb в начале ячейки.
Графики в высоком разрешении
Одна простая строка магической команды iPython способна вывести график в двойном расширении для дисплеев Retina. Однако на прочих экранах ничего не отобразится.
%config InlineBackend.figure_format =’retina’
Пропуск ячейки (без выполнения)
В начале ячейки добавьте %%script false
%%script falseЗдесь может быть длинный
код, который вы пока
что не хотите выполнять
Уведомления
Это настоящий лайфхак для Python при запуске кода с длительным временем выполнения. Если вы не готовы провести весь день перед экраном компьютера, но хотите узнать о завершении выполнения кода, то можно настроить для этого звук-уведомление.
Для Linux (и Mac)
import os
duration = 1 # секунды
freq = 440 # Hz
os.system(‘play — no-show-progress — null — channels 1 synth %s sine %f’ % (duration, freq))
Для Windows
import winsound
duration = 1000 # миллисекунды
freq = 440 # Hz
winsound.Beep(freq, duration)
Для работы уведомления потребуется sox . Установить sox можно через:
brew install sox
…при условии, что у вас уже установлен менеджер пакетов Homebrew.
А теперь пора веселья!
Вы познакомились с набором полезных подсказок и советов по оптимизации Jupyter Notebook. Этой информации должно хватить на начальных этапах работы с оболочкой.
Как запустить Jupyter Notebook с GitHub
Jupyter Notebooks становятся стандартом де факто для программирования в области ИИ, машинного обучения и Data Science. Они также очень эффективны в обучении, используя принцип литературного программирования для сочетания в одном документе программного кода и его описания. В этой статье я опишу несколько способов запуска Jupyter Notebooks, как локально на вашем компьютере, так и в облаке.
Ранее, в статье про Azure Notebooks, я описывал как можно удобно запускать код онлайн и делиться кодом с помощью этого инструмента. К сожалению, этот сервис превратился в более профессиональное решение, но необходимость запускать Jupyter Notebooks осталась. Рассмотрим, как же можно запустить Jupyter Notebook.
Просто посмотреть
Если вы просто хотите посмотреть на код в ноутбуке, не запуская его — это очень просто! Если код расположен в репозитории GitHub — просто откройте файл .ipynb , и его содержимое будет показано прямо в браузере.
Можно также использовать nbviewer для просмотра ноутбуков. Для этого нужно будет ввести онлайн имя/репозиторий на GitHub, либо любую URL, доступную через интернет. Вот пример того, как выглядит репозиторий GitHub при открытии в nbviewer.
Ещё одной хорошей опцией будет использовать Visual Studio Code, в которой возможность просмотра ноутбуков встроена “из коробки”. Если Visual Studio Code не установлена — можно использовать онлайн-версию vscode.dev, или github.dev.
GitHub.dev — это отличный способ открыть любой репозиторий в режиме Visual Studio Code для простого редактирования файлов. Для этого достаточно в адресе репозитория заменить github.com на github.dev . Заодно становится доступным просмотр ноутбуков.
Запуск локально или в облаке
В большинстве случае вам захочется не только посмотреть, но и запустить Jupyter notebooks, изменить код и посмотреть, как он работает. В этом случае — читайте дальше!
- Установить всё необходимое окружение у себя на компьютере
- Использовать облачные сервисы
В первом случае у вас есть полный контроль над окружением, файлами и вычислительными ресурсами, но придётся потратить некоторое время на установку. Во втором случае, вы будете использовать чьи-то вычислительные ресурсы, и скорее всего количество бесплатных ресурсов, доступных вам, будет ограничено. Зато не потребуется установка ПО, и вы сможете начать работать за считанные минуты.
Локальная установка
Если вы работаете в области ИИ, машинного обучения или Data Science, у вас уже скорее всего установлена среда Python. Иметь Python на своём компьютере — это в любом случае хорошая идея, поскольку велика вероятность, что она вам рано или поздно понадобится.
Проще всего установить Python с помощью дистрибутива Miniconda. Хотя большинство обычно рекомендует ставить Anaconda, которая включает в себя большое количество библиотек, я всегда рекомендую начинать с “голой” установки Python, а все библиотеки устанавливать по мере необходимости. У Miniconda размер первоначального установщика всего 50 Mb, в противовес почти 500 Mb у Anaconda.
Установив Miniconda, будет необходимо установить Jupyter:
conda install -c conda-forge notebook pip install notebook После установки, перейдите в папку с вашими ноутбуками, и запустите Jupyter:
jupyter notebook Откроется окно браузера, и можно начинать работать!
В некоторых репозиториях GitHub есть файл requirements.txt , содержащий сведения о необходимых для работы проекта библиотеках. В этом случае рекомендуется перед запуском ноутбука установить эти библиотеки командой
pip install -r requirements.txt Возможно, вместо классического Jupyter, вы захотите установить JupyterLab, его более продвинутую версию.
pip install juputerlab jupyter-lab 
JupyterLab больше напоминает полноценную среду разработки, позволяя вам, помимо ноутбуков, редактировать скрипты Python, текстовые файлы и многое другое.
Поддержка языков .NET
Jupyter поддерживает много различных языков программирования в дополнение к Python. Если вы хотите использовать C# или F#, вы можете установить .NET Interactive. Установка поддержки .NET для Jupyter описана здесь
Используем Visual Studio Code
Редактировать и исполнять ноутбуки в браузере — не лучшая идея. Намного больше возможностей доступно при использовании Visual Studio Code, в которой есть отличная поддержка Jupyter Notebooks, с возможностью просмотра значений переменных, отладки и т.д. Для выполнения ноутбуков, вам нужно будет установить расширение Python (или расширение .NET, для C#/F#). Вам также понадобится установленное на вашем компьютере Python-окружение, описанное в предыдущем разделе.
Вот ещё немного документации по использованию Jupyter в VS Code.
Установка Python на ваш компьютер — хорошее решение в долгосрочной перспективе, но если вы хотите запустить ноутбук по-быстрому — имеет смысл использовать облачное окружение. Вам не придётся ничего устанавливать на свой компьютер, и вы сможете наслаждаться работой уже через несколько минут. Иногда имеет смысл использовать облачные окружения даже тогда, когда у вас есть Python — например, чтобы избежать конфликта библиотек и запустить ноутбук в “чистом” окружении.
MyBinder
MyBinder.org позволяет вам создать виртуализированное (точнее, контейнеризованное) окружение Jupyter из любого GitHub-репозитория. Вы просто вводите GitHub URL, а Binder создаст контейнер и запустит среду Jupyter. Многие репозитории с ноутбуками даже содержат кнопку Launch Binder, позволяющую вам открыть проект в Binder автоматически.
Binder попытается создать окружение, наилучшим образом подходящее для вашего проекта. Например, если в репозитории есть файл requirements.txt с описанием необходимых библиотек, они будут автоматически установлены. Более тонко можно настраивать конфигурацию с помощью файлов в директории binder — вплоть до описания Docker-контейнера, который необходимо собрать для запуска.
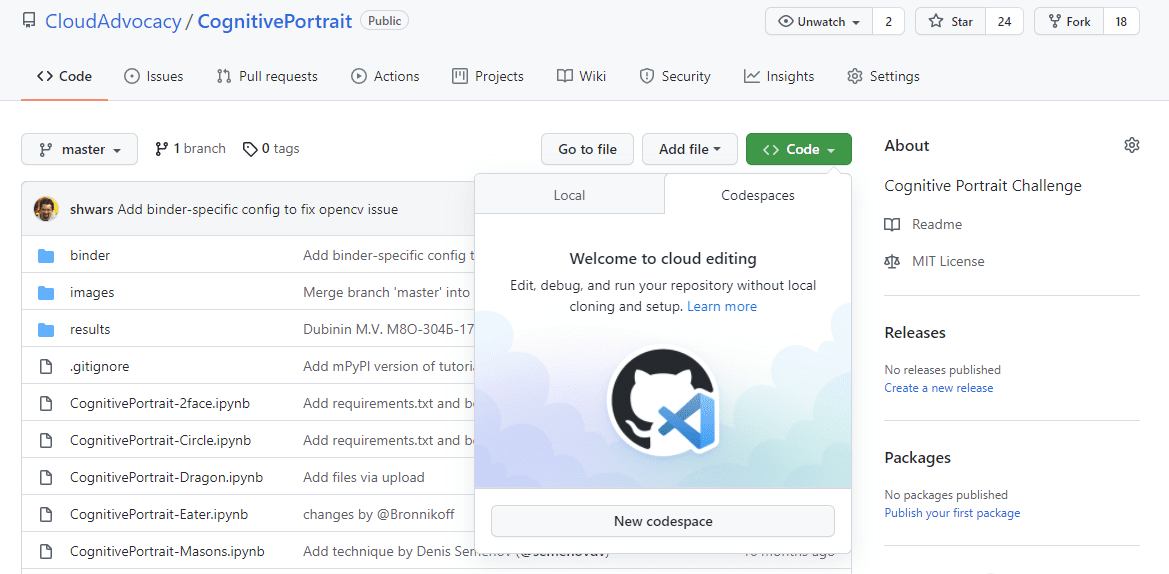
GitHub Codespaces
GitHub Codespaces — это новая встроенная в GitHub возможность открывать любой репозиторий в виртуализированном облачном окружении, доступном через среду VS Code в браузере или настольной версии. В настоящий момент Codespaces функционируют в режиме бета-тестирования, предоставляя индивидуальным пользователям некоторый объем бесплатных вычислительных ресурсов.
Datalore, CoCalc и др.
- JetBrains Datalore предоставляет некоторый объем бесплатных вычислительных ресурсов (в настоящий момент — 120 часов в месяц), а также некоторое количество GPU. Вам придётся предварительно загрузить ваши ноутбуки в рабочую область Datalore.
- CoCalc — это полноценное окружение для специалистов по Data Science, поддерживающее несколько популярных языков, таких как R, Julia и Sage, систему символьной компьютерной алгебры. Вы также можете запускать ограниченный набор GUI-приложений Linux и редактировать тексты в LaTeX. Я ранее писал про CoCalc в моей заметке про использование систем символьной алгебры для школьников.
- Про Google Colab вы скорее всего и так уже знаете, поэтому я не буду здесь его подробно описывать.
Заключение
- Установить Python-окружение на ваш компьютер, и использоват интерфейс Jupyter/JupyterLab в браузере, или Visual Studio Code
- Запустить в облачной среде онлайн, используя Binder, или одну из описанных выше опций.
У обоих подходов есть свои позитивные и негативные стороны, и я надеюсь, что после прочтения этой заметки вы сможете легко выбрать для себя оптимальный способ запуска Jupyter Notebooks.
Dmitri Soshnikov 2021-09-08 EDUCATION
jupyter notebooks