Основные слои
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer=’glorot_uniform’, bias_initializer=’zeros’, kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Просто обычный плотно связанный слой NN.
Dense реализует операцию: output = activation(dot(input, kernel) + bias), где активация — это функция активации по элементам, переданная в качестве аргумента активации, кернел — это матрица весов, созданная слоем, а смещение — это вектор смещения, созданный слоем (применимо только в случае, если use_bias — True).
Замечание: если вход в слой имеет ранг больше 2, то он сглаживается перед исходным точечным продуктом с кернелом
Пример
# как первый слой в последовательной модели:
model.add(Dense(32, input_shape=(16,)))# теперь модель будет принимать в качестве входных массивов фигуры (*, 16)# и выходных массивов фигуры (*, 32)
# после первого слоя, больше не нужно указывать# размер входного сигнала:
Аргументы
- units: положительное целое число, размерность выходного пространства.
- activation: используемая функция активации (см. активации). Если ничего не указывать, активация не применяется (т.е. «линейная» активация: a(x) = x).
- use_bias: Булева, использует ли слой вектор смещения.
- kernel_initializer: Инициализатор для матрицы весов кернела (см. инициализаторы).
- bias_initializer: Инициализатор для вектора смещения (см. инициализаторы).
- kernel_regularizer: Функция регулялизатора, применяемая к матрице весов кернела (см. регуляризатор).
- bias_regularizer: Функция регуляризатора применяется к вектору смещения (см. регуляризатор).
- activity_regularized: Функция регулялизатора применяется к выходу слоя (его «активация»). (см. регуляризатор).
- kernel_constraint: Функция ограничения, применяемая к матрице весов кернела (см. ограничения).
- bias_constraint: Функция ограничения, применяемая к вектору смещения
- Переведено с помощью www.DeepL.com/Translator (бесплатная версия) (см ограничения).
Форма ввода
тензор nD с формой: (batch_size, …, input_dim). Наиболее распространенная ситуация — 2D-ввод с формой (batch_size, input_dim).
Форма вывода
тензор nD с формой: (размер партии, …, units). Например, для 2D-входа с формой (batch_size, input_dim) выход будет иметь форму (batch_size, units).
Activation
Применяет функцию активации к выводу.
Аргументы
- activation: название используемой функции активации (см.: активации), или альтернатива: Theano или TensorFlow..
Форма ввода
Произвольно. Используйте ключевой аргумент input_shape (кортеж целых чисел, не включает ось отсчета) при использовании этого слоя в качестве первого слоя в модели.
Форма вывода
Та же форма, что и при вводе.
Dropout
keras.layers.Dropout(rate, noise_shape=None, seed=None)
Применяет исключение (дропаут) на вводе.
Dropout состоит в случайной установке доли единиц ввода в 0 при каждом обновлении во время обучения, что помогает предотвратить переобучение (оверфиттинг).
Аргументы
- rate: плавает между 0 и 1. Доля входных блоков для исключения.
- noise_shape: 1D целочисленный тензор, представляющий собой форму двоичной маски выпадения, которая будет умножаться на вход. Например, если у ваших входов есть форма (batch_size, timesteps, features) и вы хотите, чтобы маска отсева была одинаковой для всех таймсестов, вы можете использовать noise_shape=(batch_size, 1, features).
- seed: Python целое число для использования в качестве случайного сида (seed).
Ссылки
- Дропаут: Простой способ предотвратить оверфиттинг нейронных сетей.
Flatten
keras.layers.Flatten(data_format=None)
Выравнивает вход. Не влияет на размер партии.
Аргументы
- data_format: Строка, одна из channel_last (по умолчанию) или channels_first. Порядок следования размеров на входах. Назначение данного аргумента — сохранить упорядочение весов при переключении модели с одного формата данных на другой. channels_last соответствует входам с формой (пакет, …, каналы), а channels_first соответствует входам с формой (пакет, каналы, …). По умолчанию значением параметра image_data_format, найденным в конфигурационном файле Keras, является ~/.keras/keras.json. Если вы никогда не устанавливали его, то это будет «channels_last».
Пример
model.add(Conv2D(64, (3, 3),
input_shape=(3, 32, 32), padding=’same’,))# теперь: model.output_shape == (None, 64, 32, 32)
model.add(Flatten())# теперь: model.output_shape == (None, 65536)
Input
Input() используется для инстанцирования тензора Keras..
Тензор Keras — это объект тензора из подложки (Theano, TensorFlow или CNTK), который мы дополняем определенными атрибутами, позволяющими построить модель Keras, просто зная входы и выходы модели.
Например, если a, b и c — тензоры Кераса, то можно сделать: model = Model(input=[a, b], output=c].
Добавлены атрибуты Кераса: Форма Кераса: Кортеж интегральной формы, распространяемый через умозаключение формы Keras-сайд. _keras_history: Из этого слоя можно рекурсивно извлечь весь граф слоя.
Аргументы
- shape: Кортеж формы (целое число), без учета размера партии. Например, shape=(32,) указывает на то, что ожидаемым входом будут партии по 32-мерным векторам.
- batch_shape: Кортеж формы (целое число), включая размер партии. Например, batch_shape=(10, 32) указывает, что ожидаемым входом будут партии с 10 32-мерными векторами. batch_shape=(None, 32) указывает, что партии с произвольным количеством 32-мерных векторов.
- name: Необязательная строка имени для слоя. Должна быть уникальной в модели (не используйте одно и то же имя дважды). Она будет автоматически сгенерирована, если не будет предоставлена.
- dtype: Тип данных, ожидаемый на входе, в виде строки (float32, float64, int32…)
- sparse: Булева, указывающая, является ли создаваемый держатель разреженным.
- tensor: Дополнительный существующий тензор для обертывания в входной слой. При установке этого параметра слой не будет создавать тензор-платформу..
Возврат
Пример
# это логистическая регрессия в Keras. #
y = Dense(16, activation=’softmax’)(x)
model = Model(x, y)
Reshape
Реформирует выход в определенную форму.
Аргументы
- target_shape: Целевая форма. Кортеж целых чисел. Не включает ось партии.
Форма ввода
Произвольно, хотя все размеры в форме входа должны быть зафиксированы. Используйте ключевой аргумент input_shape (кортеж целых чисел, не включает ось партии) при использовании этого слоя в качестве первого слоя в модели.
Форма вывода
Пример
# как первый слой в последовательной модели.
model.add(Reshape((3, 4), input_shape=(12,)))# now: model.output_shape == (None, 3, 4)# примечание: `None` — это измерение партии.
# как промежуточный слой в последовательной модели.
model.add(Reshape((6, 2)))# теперь: model.output_shape == (None, 6, 2)
# также поддерживает умозаключение формы, используя `-1` в качестве измерения.
model.add(Reshape((-1, 2, 2)))# теперь: model.output_shape == (None, 3, 2, 2)
Permute
Сохраняет размеры входного сигнала в соответствии с заданным образцом.
Полезно, например, для соединения RNN и свёртков.
Пример
model.add(Permute((2, 1), input_shape=(10, 64)))# теперь: model.output_shape == (None, 64, 10)# примечание: `None` — измерение партии
Аргументы
- dims: Кортеж целых чисел. Шаблон простановки, не включает в себя размерность образцов. Индексирование начинается с 1. Например, (2, 1) перебирает первое и второе измерение входного параметра.
Форма ввода
Произвольно. Используйте ключевой аргумент input_shape (кортеж целых чисел, не включает ось отсчета) при использовании этого слоя в качестве первого слоя в модели.
Форма вывода
То же самое, что и Форма ввода, но с измененным порядком размеров в соответствии с заданной деталью.
RepeatVector
Повторяет ввод n раз.
Пример
model.add(Dense(32, input_dim=32))# now: model.output_shape == (None, 32)# примечание: `None` — это измерение партии.
model.add(RepeatVector(3))# теперь: model.output_shape == (None, 3, 32)
Аргументы
- n: целое число, коэффициент повторения.
Форма ввода
2D тензор формы (num_samples, features).
Форма вывода
3D тензор формы (num_samples, n, features).
Lambda
keras.layers.Lambda(function, output_shape=None, mask=None, Arguments=None)
Обертывает произвольное выражение как объект Слоя.
Примеры
# добавить слой x -> x^2
model.add(Lambda(lambda x: x ** 2))
# добавьте слой, который возвращает конкатенцию# положительной части входа и # противоположной отрицательной части.
def antirectifier(x):
x -= K.mean(x, axis=1, keepdims=True)
x = K.l2_normalize(x, axis=1)
return K.concatenate([pos, neg], axis=1)
def antirectifier_output_shape(input_shape):
assert len(shape) == 2 # только для 2D тензоров
return tuple(shape)
# добавьте слой, возвращающий произведение Адамара# и сумму из двух входных тензоров.
def hadamard_product_sum(tensors):
out1 = tensors[0] * tensors[1]
out2 = K.sum(out1, axis=-1)
return [out1, out2]
def hadamard_product_sum_output_shape(input_shapes):
assert shape1 == shape2 # в противном случае произведение Адамара невозможно
return [tuple(shape1), tuple(shape2[:-1])]
layer = Lambda(hadamard_product_sum, hadamard_product_sum_output_shape)
x_hadamard, x_sum = layer([x1, x2])
Аргументы
- function: Функция, которая должна быть оценена. В качестве первого аргумента принимает входной тензор или список тензоров.
- output_shape: Ожидаемая форма выхода из функции. Актуально только при использовании Theano. Может быть кортежом или функцией. Если кортеж кортежа, то он указывает только первое измерение вперед; размер образца принимается либо как вход: output_shape = (input_shape[0], ) + output_shape, либо как вход None и размер образца также None: output_shape = (None, ) + output_shape Если функция, то она указывает всю фигуру как функцию формы вывода: output_shape = f(input_shape)
- mask: Либо None (указывая на отсутствие маскировки), либо Тензор, указывающий на входную маску для встраивания..
- arguments: необязательный словарь ключевых слов для передачи в функцию.
Форма ввода
Произвольно. Используйте ключевой аргумент input_shape (кортеж целых чисел, не включает ось отсчета) при использовании этого слоя в качестве первого слоя в модели.
Форма вывода
Указывается аргументом output_shape (или auto-inferred при использовании TensorFlow или CNTK).
ActivityRegularization
Слой, который применяет обновление к входной деятельности, основанной на функции затрат.
Аргументы
- l1: L1 коэффициент регуляризации (положительный флоут).
- l2: L2 коэффициент регуляризации (положительный флоут).
Форма ввода
Произвольно. Используйте ключевой аргумент input_shape (кортеж целых чисел, не включает ось отсчета) при использовании этого слоя в качестве первого слоя в модели.
Форма вывода
Та же форма, что и при вводе.
Masking
Маскирует последовательность, используя значение маски для пропуска таймфреймов.
Если все возможности для заданного временного отрезка равны значению mask_value, то временной отрезок будет замаскирован (пропущен) во всех последующих слоях (до тех пор, пока они поддерживают маскировку).
Если какой-либо последующий слой не поддерживает маскировку, но получает такую входную маску, то исключение будет поднято.
Пример
Рассмотрим массив данных Numpy x формы (образцы, временные интервалы, возможности), который будет передан в LSTM слой. Вы хотите маскировать образец #0 в timestep #3, и образец #2 в timestep #5, потому что вам не хватает возможностей для этих примеров timesteps. Вы можете это сделать:
- установить x[0, 3, :] = 0. и x[2, 5, :] = 0.
- вставьте слой Masking со значением mask_value=0. перед слоем LSTM:
model.add(Masking(mask_value=0., input_shape=(timesteps, features)))
Аргументы
- mask_value: Или None, или пропустить значение маски.
SpatialDropout1D
Пространственная 1D версия Dropout.
Эта версия выполняет ту же функцию, что и Dropout, однако вместо отдельных элементов выпадают целые карты 1D-функций. Если соседние кадры на картах объектов сильно коррелированы (как это обычно бывает в ранних слоях свертки), то регулярное отсеивание не приводит к регуляризации активаций, а в противном случае просто приводит к снижению эффективности обучения. В этом случае, SpatialDropout1D будет способствовать независимости между картами объектов и должен использоваться вместо этого..
Аргументы
- rate: флоут между 0 и 1. доля входных блоков для исключения.
Форма ввода
3D тензор с формой: (samples, timesteps, channels)
Форма вывода
То же, что и при вводе
Ссылки
- Эффективная локализация объектов с помощью свёрточных сетей
SpatialDropout2D
keras.layers.SpatialDropout2D(rate, data_format=None)
Пространственная 2D версия Dropout.
Эта версия выполняет ту же функцию, что и Dropout, однако вместо отдельных элементов выпадают целые карты 2D-функций. Если смежные пиксели на картах объектов сильно коррелированы (как это обычно бывает в ранних слоях свертки), то регулярное отсеивание не приводит к регуляризации активаций, а в противном случае просто приводит к снижению эффективности обучения. В этом случае, SpatialDropout2D будет способствовать независимости между картами объектов и должен использоваться вместо них.
Аргументы
- rate: флоут между 0 и 1. доля входных блоков для падения.
- data_format: ‘channels_first’ или ‘channels_last’. В режиме ‘channels_first’ размерность каналов (глубина) находится на индексе 1, в режиме ‘channels_last’ — на индексе 3. По умолчанию она равна значению image_data_format, найденному в вашем конфигурационном файле Keras по адресу ~/.keras/keras.json. Если вы никогда не устанавливали его, то это будет «channels_last».
Форма ввода
4D тензор с формов: (samples, channels, rows, cols) если data_format=’channels_first’ или 4D тензор с формов: (samples, rows, cols, channels) если data_format=’channels_last’.
Форма вывода
То же, что и при вводе
Ссылки
- Эффективная локализация объектов с помощью свёрточных сетей
SpatialDropout3D
keras.layers.SpatialDropout3D(rate, data_format=None)
Пространственная 3D версия Dropout.
Эта версия выполняет ту же функцию, что и Dropout, однако она удаляет целые карты 3D-функций вместо отдельных элементов. Если соседние воксели на картах объектов сильно коррелированы (как это обычно бывает в ранних слоях свертки), то регулярное отсеивание не приводит к регуляризации активаций, а в противном случае просто приводит к снижению эффективности обучения. В этом случае, SpatialDropout3D будет способствовать независимости между картами объектов и должен использоваться вместо них.
Аргументы
- rate: флоут между 0 и 1. доля входных блоков для исключения.
- data_format: ‘channels_first’ или ‘channels_last’. В режиме ‘channels_first’ размерность каналов (глубина) находится на индексе 1, в режиме ‘channels_last’ — на индексе 4. По умолчанию она равна значению image_data_format, найденному в вашем конфигурационном файле Keras по адресу ~/.keras/keras.json. Если вы никогда не устанавливали его, то это будет «channels_last».
Форма ввода
5D тензор с формой: (samples, channels, dim1, dim2, dim3) если data_format=’channels_first’ или тензор с формой: (samples, dim1, dim2, dim3, channels) если data_format=’channels_last’.
Форма вывода
То же, что и при вводе
Ссылки
- Эффективная локализация объектов с помощью свёрточных сетей
Полносвязные слои нейронных сетей в машинном обучении
В машинном обучении полносвязные (линейные) слои являются одним из важнейших компонентов нейронных сетей. Они называются «плотными» слоями (Dense layer по-английски). Этот слой обрабатывает каждый элемент предыдущего слоя, выполняя матричное перемножение этих элементов со своими весами. Полученные данные затем отправляются на следующий слой.
Нейроны полносвязного слоя соединены со всеми нейронами предыдущего слоя, что означает, что каждый нейрон полносвязного слоя может взаимодействовать с любым нейроном предыдущего слоя. Поэтому полносвязные слои очень важны для финальной части нейронных сетей, где они часто используются для классификации данных.
В последнее время полносвязные слои также используются для решения других задач, таких как регрессия, сегментация изображений и выделение признаков. Одним из преимуществ полносвязных слоев является их простота и интуитивность: мы можем легко понять, как они работают, и оценить их эффективность, проанализировав их выходные данные.
Использование полносвязных слоев в нейронных сетях имеет множество преимуществ. Первое из них — это возможность изучения любой функции, которая может быть представлена в виде математической модели. Нейроны полносвязных слоев могут адаптироваться к любым входным данным, обучаясь выделять важные признаки и игнорировать незначительные.
Другое преимущество полносвязных слоев — это их универсальность. Они могут использоваться в различных типах нейронных сетей, включая сверточные нейронные сети, рекуррентные нейронные сети и другие.
Также следует отметить, что полносвязные слои очень просты в использовании и реализации. Они могут быть добавлены в модель с помощью нескольких строк кода.
Таким образом, полносвязный слой является необходимым инструментом в создании моделей нейронных сетей, так как он позволяет выполнять обработку всех элементов предыдущего слоя и выдавать результат в форме одного вектора, который может быть использован в дальнейшем для обучения или классификации.
Полносвязные слои имеют и некоторые недостатки. Например, если у нас есть много параметров и мало данных, они могут переобучаться. К счастью, эта проблема решается путем использования регуляризации или сверточных слоев.
Математически, полносвязный слой может быть описан следующей формулой:
y — выходные данные слоя
x — входные данные (вектор), полученные из предыдущего слоя
W — матрица весов, которая соединяет входные и выходные данные
b — вектор сдвига, который добавляется к выходным данным
activation — функция активации, которая применяется к выходным данным, чтобы добавить нелинейность.
Функция активации может быть различной в зависимости от задачи и выбора алгоритма. Наиболее распространенные функции активации являются ReLU, Sigmoid, и Tanh.
Полносвязные слои могут быть программированы в различных библиотеках машинного обучения, таких как TensorFlow, Keras, PyTorch, Theano и другие.
Следует учитывать, что способы реализации полносвязных слоев могут немного отличаться в зависимости от используемой библиотеки.
Например, в Keras полносвязный слой может быть добавлен в модель с помощью метода model.add(), который принимает аргумент Dense, указывающий на то, что это полносвязный слой. Кроме того, можно указать количество нейронов в слое и функцию активации, используемую в слое.
В TensorFlow полносвязные слои можно создать с помощью функции tf.keras.layers.Dense, которая принимает такие же аргументы, как и в Keras. Также можно использовать класс tf.layers.Dense, чтобы создать полносвязные слои непосредственно в TensorFlow.
В настоящее время использование полносвязных слоев в нейронных сетях является широко распространенным, и прогнозируется, что в будущем эта технология будет и далее улучшаться и развиваться. В настоящее время в научных кругах активно исследуются новые способы использования полносвязных слоев в нейронных сетях. В том числе повышается их точность, улучшается эффективности обучения и вычислений, а также увеличивается гибкости таких слоев для применения их в различных областях. В будущем полносвязные слои неприменно будут играть важную роль в развитии искусственного интеллекта и машинного обучения.
Tensorflow и Keras. Dense слои. Часть 1.
Давеча в «Университете искусственного интеллекта» Сергей Кузин прочитал занимателную лекцию по использованию Tensorflow и некоторому сравнению с Keras. Тема достаточно сложная, поэтому разберу её подробно для лучшего понимания, добавляя свои комментарии и ссылки на другие статьи, где разъясняются нюансы.
Keras призван максимально упростить жизнь исследователям. Писать на нем красиво и понятно. Tensorflow — подноготная Keras с более сложным синтаксисом написания кода, но максимальной гибкостью. Сложные вещи придется писать на Tensorflow, поскольку в Keras через классы-обертки Tensorflow какие-то моменты могут быть недоступны. Большинство реальных задач быстрее написать на Keras.
Изучение TensorFlow позволяет детальнее понять как работают нейронные сети. Поначалу мне было не ясно, зачем эта тема нужна студентам, которые не столько продвинуты в разработке нейронок. Но после разборок «анатомии» построения слоев нейронных сетей на Tensorflow я оценил важность изучения этого материала для более глубокого понимания сути.
TensorFlow
Я не буду глубоко касатся основ работы TensorFlow. Эти моменты прекрасно описаны в статье. Собственно, на habr много чего написано по этой теме. Исследование Tensorflow будет построено на аналогии с написанием кода на Keras как было сделано у Сергея.
Посмотрим простой код на Keras для распознавания цифр MNIST на dense слоях. Я буду использовать рисунки Сергея из лекции, дополняя какие-то моменты.
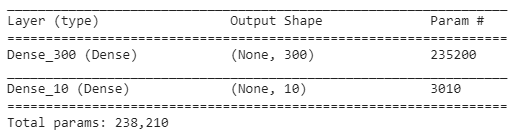
В MNIST лежат черно-белые картинки размером 28 х 28 = 784 пикселей. Для их обработки dense слоями картинки reshape-ятся в массив на 784. Между входным слоем и первым dense слоем на 300 нейронов параметры будут описываться весами. Количество весов будет 784 * 300 = 235 200 шт.
Dense слой на 300 соединен с выходным dense слоем на 10 с функцией активации softmax. Соответственно, между слоем на 300 нейронов и слоем на 10 количество весов будет 300 * 10 = 3000.
Эта нейронная сеть будет решать задачу классификации, определяя к какому из 10 классов (цифра от 0 до 9) относится поданная на вход картинка. Softmax на выходе даст вероятность того, что поданная на вход картинка относится к определенной цифре. Взяв argmax получим индекс соответствующий наибольшей вероятности — это цифра на изображении.
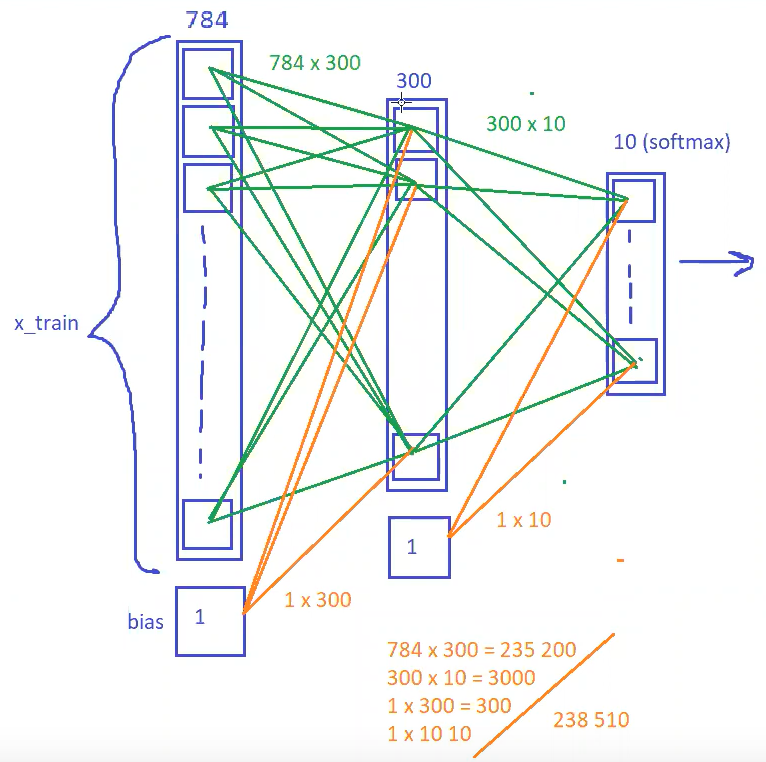
Отмечу, что «нейрон» — это некоторая абстрактная сущность. В графе сети в Tensorflow его не найти. Но есть ряд математических операций, которые условно можно обозвать нейроном:
- Есть веса которые перемножаются со значениями полученными с предыдущего слоя (MatMul).
- К результатам перемножения может добавляться (Add) смещение (bias).
- К полученым значениям применяется функция активации (например, Softmax).
Понятие «нейрон» введено скорее для облегчения понимания.
Нейрон смещения
Помимо основных нейронов Keras, по-умолчанию, добавляет нейроны смещения (bias). Рассмотрю зачем нужны эти нейроны подробнее.
Если для примера взять простой нейрон с линейной функцией активации, то он выполняет простое преобразование, умножая значение на входе x на некоторый вес w, в результате чего на выходе y = w * x. Очевидно, что эта линейная функция может разделить объекты на два класса только в случае если они разбросаны подходящим образом, поскольку плоскость для деления всегда проходит через 0.
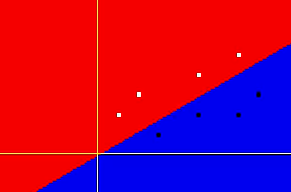
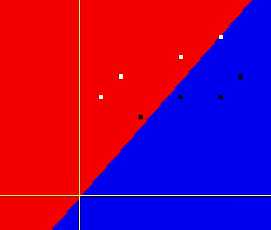
Предположим, что значения на входе сместились по оси Y вверх. В результате оптимизатор не в состоянии подобрать вес нейрона таким образом, чтобы сделать ошибку (loss) минимальной, разделив два класса линейной функцией. В таком случае нужно использовать гиперплоскость, используя несколько нейронов.
Чтобы добавить нейронке гибкости, вводят нейрон смещения. У него нет реальных входов, а значение «виртуального» входа всегда равно 1. Смещение, которое он будет задавать, равно весу связи (на картинке вес = 0,1). Фактически 1 * 0,1. Этот вес участвует в обучении нейронки и подбирается также, как и веса обычных нейронов.
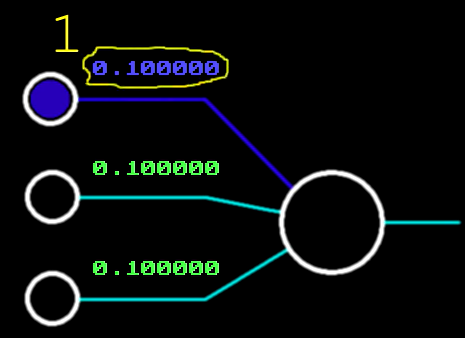
Если добавить нейрон смещения, то плоскость классификации может смещаться по оси Y и нейронка сможет подобрать параметры разделительной плоскости, используя лишь один нейрон.
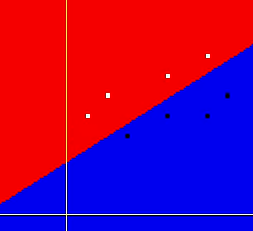
Очевидно, что если сместить все точки для классификации вправо по оси X, то за счет нейрона смещения может быть найдено оптимальное положение разделительной плоскости, которое снова сможет сделать разделение на два класса одним нейроном. Подробнее о нейроне смещения замечательно рассказывается в этом видео.
Нейрон смещения, в ряде случаев, позволяет при решении задачи обойтись меньшим количеством нейронов/связей.
Нейроны смещения могут либо присутствовать в каждом слое или отсутствовать. В выходном слое нейронов смещения быть не может, поскольку им на вход ничего не может быть подано (на картинке нейрон B3). Красным отмечены связи, которые не могут использоваться для нейронов смещения.
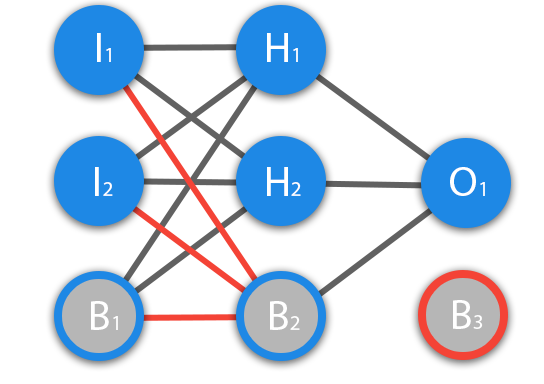
Добавление нейрона смещения для соединения с нейронами слоя на 300 нейронов добавит к нейронке ещё 1 * 300 = 300 весов. И к выходному слою на 10 нейронов добавится ещё нейрон с 1 * 10 = 10 весов. В результате получим, что эту нейронную сеть будет описывать:
- 784 * 300 = 235 200 весов
- 300 * 10 = 3000 весов
- 1 * 300 = 300 весов
- 1 * 10 = 10 весов
Итого: 238 510 весов
Хотя на картинке нейронной сети для красоты нейрон смещения изображают в предыдущем слое, логически он создается в самом слое.
В случае с нелинейными функциями активации, например, сигмойдой, веса позволяют изменять наклон сигмойды, а смещением по оси y управляет нейрон смещения.
Код распознавания MNIST на Keras
Код на Keras для описания нейронной сети очень короткий и понятный. Напишу его двумя способами.
Вариант 1
from keras.models import Sequential from keras.layers import Dense from keras.utils import plot_model model = Sequential() model.add(Dense(300, activation = "relu", use_bias = True, input_shape = (784,), name ='Dense_300')) model.add(Dense(10, activation = "softmax", use_bias = True, name ='Dense_10')) model.summary() plot_model(model, to_file='model.png')
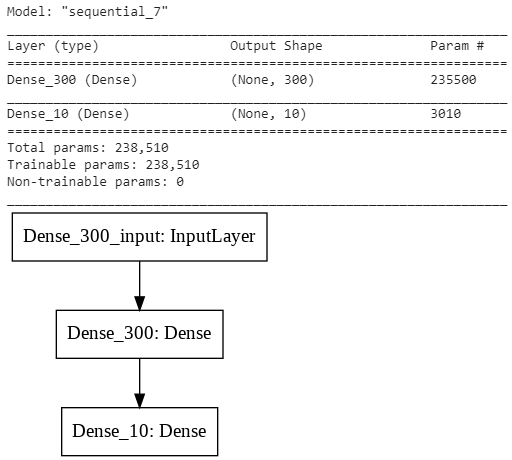
Параметр слоя use_bias = True говорит о том, что в слое надо
Вариант 2
Если использовать функциональное программирование Keras, то можно строить более сложные архитектуры нейронных сетей. В данном случае смысла в этом нет. Это лишь демонстрация возможностей Keras. По-умолчанию, use_bias для слоя установлен в True, поэтому указывать его нет необходимости.
from keras.models import Model from keras.layers import Input visible = Input(shape=(784,), name ='Input_784') hidden = Dense(300, activation = 'relu', name ='Dense_300')(visible) output = Dense(10, activation = 'softmax', name ='Dense_10')(hidden) model_1 = Model(inputs=visible, outputs=output) model_1.summary() plot_model(model_1, to_file='model_1.png')
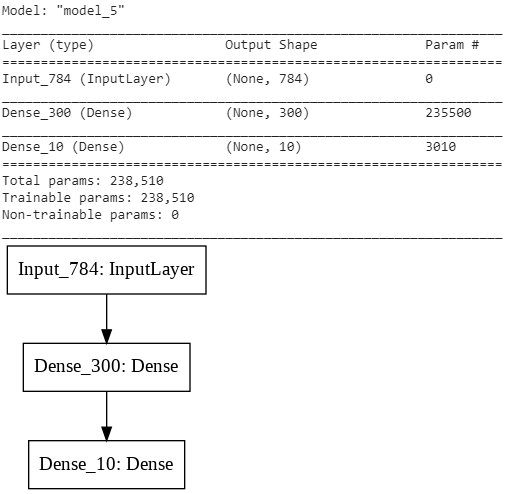
Как видно для обеих вариантов получено количество весов 238 510, как и получили ранее. Если use_bias установить в False для слоя в 300 нейронов, то количество параметров уменьшиться на 300 за счет отключения нейрона смещения.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Подгружаем данные MNIST:
from keras.datasets import mnist from keras import utils (x_train, y_train), (x_test, y_test) = mnist.load_data()
Делаем нормализацию и переводим y_train в one hot encoding (OHE) представление.
x_train = x_train.astype('float32') x_train /= 255 x_train = x_train.reshape(-1, 784) x_test = x_test.astype('float32') x_test /= 255 x_test = x_test.reshape(-1, 784) y_train_ohe = utils.to_categorical(y_train, 10) y_test_ohe = utils.to_categorical(y_test, 10) print(y_train[0], y_train_ohe[0])
5 [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
model.fit(x_train, y_train_ohe, batch_size=128, epochs=10, verbose=1, validation_split=0.2)
И получаем точность обучения на проверочной выборке:
accuracy = model.evaluate(x_test, y_test_ohe) print("Loss:", accuracy[0]) print("Accuracy:", accuracy[1])
10000/10000 [==============================] - 0s 40us/step Loss: 0.6367657449245453 Accuracy: 0.8272
Пример работы с Tensorflow
Небольшая вводная про TensorFlow в порядке шпаргалки. Тензоры — это многомерные массивы. Проще говоря, тензор — это n-мерная матрица.
Вычисления в Tensorflow описываются графами. Граф — абстрактный математический объект, представляющий собой множество вершин графа и набор рёбер, то есть соединений между парами вершин (взято отсюда). Подробнее по использованию Tensorflow здесь.
Например, последовательность математических операций совершаемых над входными данными можно отобразить в виде графа:

Пустой граф создается функцией tf.Graph(). Граф по-умолчанию создаётся при подключении библиотеки и если явно не указывать граф, то будет использоваться именно он.
Передача данных и выполнение операций происходят в сессиях. Для запуска сессии вызывается tf.Session. Чтобы её закрыть нужно вызвать метод close() созданного объекта сессии.
Можно использовать конструкцию with, которая принудительно закроет сессию при выходе из неё. Это более красивый и технологичный способ.
Например, в этом примере создается граф по-умолчанию и выполняется в сесии sess:
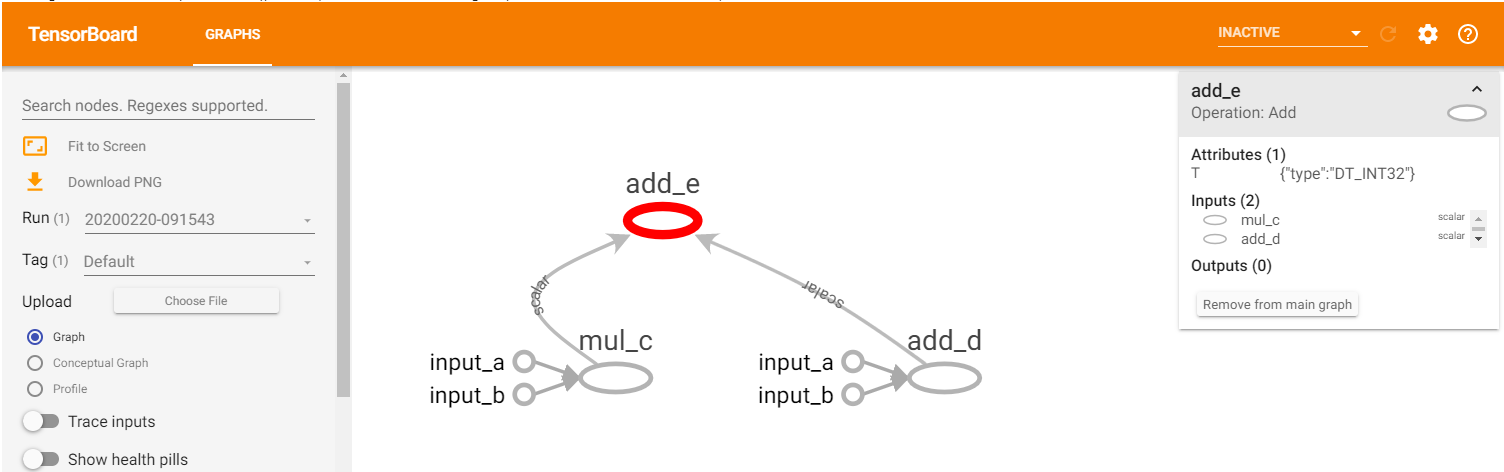
import tensorflow as tf #sess = tf.Session() with tf.compat.v1.Session() as sess: a = tf.constant(9, name = "input_a") b = tf.constant(5, name = "input_b") c = tf.multiply(a,b, name = "mul_c") d = tf.add(a,b, name = "add_d") e = tf.add(c,d, name = "add_e") print(sess.run(e)) #sess.close() >>59
Можно создать новый граф «second_graph» и затем выполнить его в новой сессии:
# создаём пустой граф second_graph = tf.Graph() with second_graph.as_default() : a = tf.constant(9, name = "input_a") b = tf.constant(5, name = "input_b") c = tf.multiply(a,b, name = "mul_c") d = tf.add(a,b, name = "add_d") e = tf.add(c,d, name = "add_e") #sess = tf.Session() #Запустим созданный граф в новой сессии with tf.Session(graph=second_graph) as sess: print(sess.run(e)) >>59
В Tensorflow помимо constants есть ещё variables и placeholders:
- Placeholder — это узел, через который в модель будут передаваться данные. Например, обучающие массивы x и y.
- Переменная (Variable) — это узел, который может изменяться по ходу выполнения графа. Переменные используются для хранения весов обычных нейронов (weights) и нейронов смещения (bias). Переменная должна быть проинициализирована вызовом tf.global_variables_initializer().run().
Например, в коде ниже через placeholder передаются начальные значения для a и b:
with tf.compat.v1.Session() as sess: a = tf.placeholder(tf.int32, shape = (None), name = "input_a") b = tf.placeholder(tf.int32, shape = (None), name = "input_b") f = tf.constant(9, name = "input_a") c = tf.multiply(a,b, name = "mul_c") d = tf.add(a,b, name = "add_d") e = tf.add(c,d, name = "add_e") #print(sess.run(e, feed_dict=)) result_a, result_b, result_c, result_d, result_e = sess.run([a, b, c, d, e], feed_dict=) print("result_a:", result_a, "\r\nresult_b:", result_b, "\r\nresult_c:", result_c, "\r\nresult_d:", result_d, "\r\nresult_e:", result_e) result_a: 5 result_b: 9 result_c: 45 result_d: 14 result_e: 59
Если визуализировать с помощью TensorBoard:
import os import datetime # Clear any logs from previous runs !rm -rf ./logs/ logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S")) writer = tf.summary.FileWriter(logdir, sess.graph) # Запуск TensorBoard %load_ext tensorboard %tensorboard --logdir logs
На скриншоте граф визуализируется в понятной форме. Если кликнуть на узел (node), то отображается информация о имени узла, входах, типе и пр.
Код распознавания MNIST на TensorFlow
Посмотрим, как код на Keras выглядит в TensorFlow. Это важно, чтобы понять как работает Keras внутри.
import tensorflow as tf import datetime, os from tensorflow.examples.tutorials.mnist import input_data import tensorflow_hub as hub import numpy as np import os import pandas as pd import re import seaborn as sns
Объявляем placeholder-ами вход и выход нейронной сети. При запуске сессии в placeholders x будет передаваться вектор с размерностью 784 с картинками, а на выход — OHE.
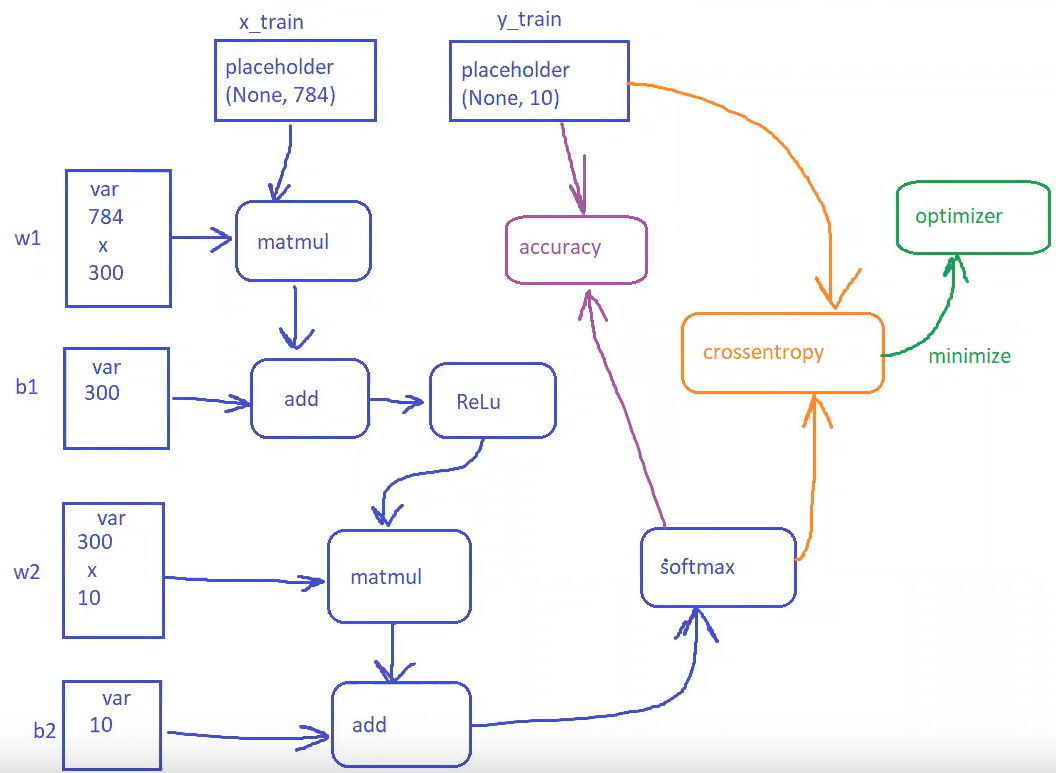
# Параметры оптимизации learningRate = 0.5 epochs = 10 batchSize = 100 # Объявляем placeholders для тренировочного набора # Размерность x = 28 x 28 пикселей = 784 x = tf.placeholder(tf.float32, [None, 784]) # None пока неизвестное количество скрытых слоев # Количество объектов на вход является переменной типа placeholder # Объявляем выход placeholder, т.е. 10 цифр y = tf.placeholder(tf.float32, [None, 10])
По аналогии с Keras нужно создать слои. Если в Keras для каждого слоя одна строка, то в Tensorflow посложнее. Слой описывается весами. В модели есть веса описывающие связь:
- Между входным слоем на 784 и внутренним слоем на 300.
- Между слоем на 300 и выходным слоем на 10.
- Нейрон смещения для слоя в 300 нейронов.
- Нейрон смещения для слоя в 10 нейронов
Для задания весов используются Variables Tensorflow. Как и в Keras веса изначально заполняются случайными значениями с нормальным распределением. Начальные значения важны, поскольку оптимизатор будет искать локальный оптимум, исходя из начальных значений весов модели. Локальных оптимумов может быть много.
Если веса модели инициализировать не случайными значениями, а подгрузив веса после обучения, то можно продолжить обучение нейронной сети с предыдущего состояния (checkpoint).
# Объявляем веса, связанные со скрытым слоем W1 = tf.Variable(tf.random_normal([784, 300], stddev=0.03), name='W1') #300 размер скрытого слоя, инциализириуем значения # Используя нормальное распределение со средним ноль и статистическим отклонением 0.03, определяем веса для нейрона смещения bias (Аналогичная есть у numpy) b1 = tf.Variable(tf.random_normal([300], stddev=0.03), name='b1') # То же делаем для весов и нейрона смещения (bias) от скрытого к выходному W2 = tf.Variable(tf.random_normal([300, 10], stddev=0.03), name='W2') b2 = tf.Variable(tf.random_normal([10]), name='b2')
Далее нужно перемножить входные значения x полученные из placeholder-а с весами tf.matmul(x, W1) и добавить веса нейрона смещения tf.add(tf.matmul(x, W1), b1), т.е. реализуем операцию: W1*x + b1.
Далее к полученным после этой операции данным нужно применить активационную функцию. В данном случае relu. Активационных функций придумано немало.
# Выход скрытого слоя hiddenOut = tf.add(tf.matmul(x, W1), b1) # запускаем перемножение матрицы весов и входного вектора, прибавляем (отклонение)bias hiddenOut = tf.nn.relu(hiddenOut) # применяем функцию активации relu
Выход hiddenOut с выхода первого слоя на 300 нейронов перемножается на веса W2 и опять-же добавляются веса нейрона смещения b2: W2*hiddenOut + b2.
# Считаем выход скрытого слоя y_ = tf.nn.softmax(tf.add(tf.matmul(hiddenOut, W2), b2)) # снова перемножаем веса уже с выходом скрытого слоя и добавляем bias b2. # здесь на выходе softmax
Функция потерь (loss)
Для оптимизации весов нейронной сети нужен критерий по которому оптимизатор будет менять значения для поиска локального оптимума.
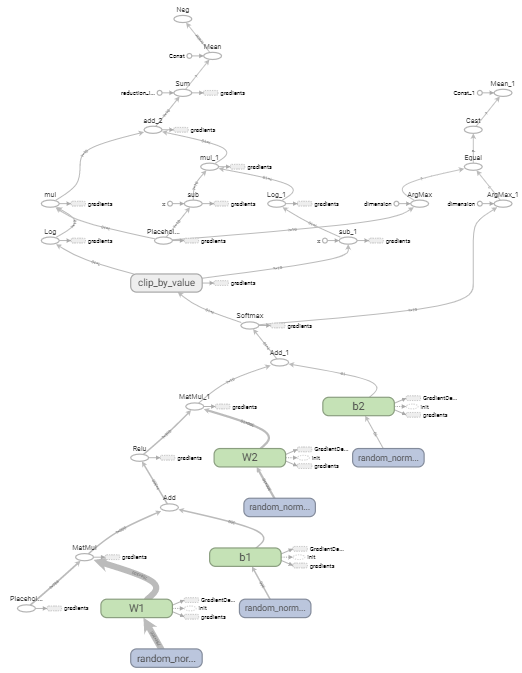
Для устранения ошибок приводящих к появлению бесконечных значений (например, 1/0 или log(0)) используется функция Tensorflow clip_by_value. Она заменяет все значения меньше clip_value_min на clip_value_min . Все значения больше clip_value_max заменяются на clip_value_max.
y_clipped = tf.clip_by_value(y_, 1e-10, 0.9999999) # конвертируем содержимое выхода y_ в формат 1e-10 to 0.999999 - гарантия того, # что не будет log(0). Иначе Nan и ошибка
В качестве функции потерь (loss) при классификаци используется cross entropy. Энтропия — мера неопределенности некоторой системы. Если неопределенность отсутствует (близкая к 100% уверенность в результате), то энтропия стремится к 0. Если процесс непредсказуем (случайный), то энтропия стремится к бесконечности.
В случае с кроссэнтропией сравниваются вероятности появления некоторого события по обучающей выборке и предсказание сделанное нейронной сетью.
Например, нейронной сети нужно распознать по картинке из MNIST, какая цифра изображена. Для простоты возьмем, что картинок всего 4. Если представить номера на картинках их в виде OHE:
- Единица = 1 0 0 0
- Двойка = 0 1 0 0
- Тройка = 0 0 1 0
- Четверка = 0 0 0 1
По-сути, первый OHE говорит о том, что вероятность того, что на картинке единица — 100%. Второй, что вероятность двойки — 100% и т.д.
Предположим, что картинку подали на нейронную сеть и получили некоторые вероятности того, что на ней изображена та или иная цифра. Например, на изображении в обучающей выборке была цифра один = [1 0 0 0]. Нейронка сделала предсказание Q1=[0.4 0.3 0.1 0.1], т.е. она считает, что лишь с вероятностью 40% на картинке изображена цифра один. С вероятностью 30% — два, а вероятность, что на картинке тройка или четверка составляют 10%. У нейронки нет уверенности в предсказании определенной категории.
Если посчитать cross entropy для такого случая:
- H(Q1,P1)= — Sum(P1i * log(Q1i)
- H(Q1,P1)= — (1*log(0.4)+0*log(0.3)+0*log(0.1+0*log(0.1))
- H(Q1,P1)=1.3
Перекрестная энтропия получилась довольно высокой. В случае уверенного предсказания она должна стремится к 0. Оптимизатор будет подбирать такую комбинацию весов нейронки и нейрона смещения при которых сумма cross entropy по каждому изображению MNIST будет принимать минимальное значение.
#Вычисление cross entropy crossEntropy = -tf.reduce_mean(tf.reduce_sum(y * tf.log(y_clipped) + (1 - y) * tf.log(1 - y_clipped), axis=1)) #reduce_sum - берет сумму опеределенной оси выбранного тензора, в случае cross entropy - вторая ось или столбец #reduce_mean - среднее любого выбранного тензора # Аналог этой же формулы из документации tensorflow #crossEntropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_clipped, labels=y))
Минимизацией функции потерь занимается оптимизатор. В коде ниже оптимизатор просят минимизировать величину crossEntropy. При тренировке оптимизатор найдет в графе TensorFlow Variables описывающие веса нейронки и нейрона смещения и будет менять их таким образом, чтобы результирующая перекрестная энтропия стала минимальной.
# Градиентный спуск. Инициализируем через learning rate и говорим, что хотим, чтобы он делал. # Здесь - минимизация cross_entropy # Функция реализует градиентный спуск и обратное распространение ошибки сразу. optimizer = tf.train.GradientDescentOptimizer(learning_rate=learningRate) optimizer.minimize(crossEntropy) #optimizer = tf.train.AdamOptimizer(learning_rate=1e-5).minimize(crossEntropy)
Для определения точности предсказания нужно добавить ещё функцию accuracy. По ней можно определять точность предсказания, например, используя проверочную выборку, т.е. значения, которые нейронная сеть не «видела» при обучении.
# Инициализируем все переменные разом initOp = tf.global_variables_initializer() # Определим функцию accuracy, чтобы измерять точность предсказания correctPrediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # Возвращает тензор mx1 True/False в зависимости от правильности предсказания accuracy = tf.reduce_mean(tf.cast(correctPrediction, tf.float32)) # для нахождения среднего значения преобразуем Boolean в объект TensorFlow # cast - преобразование в TensorFlow float
Все предсказанные значения сравниваются с правильным вариантом. Затем True значения конверируются во float и получаются 1-цы и считается среднее арифметическое, т.е. фактически, процент верно угаданных ответов.
Запуск сесии
Полученный граф нужно запустить на обучение. Нужно подгрузить данные MNIST-а.
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # Здесь one_hot=True каждая метка для цифры автоматически
Проинициализируем переменные графа.
# Начать сессию sess = tf.Session() # операция, которая инициализирует все переменные # Запустить инициализацию sess.run(initOp)
Добавлю объект saver, чтобы можно было сохранять и восстанавливать веса сети для дообучения. В результате, если в TensorBoard посмотреть граф модели, то там добавится узел Saver.
#Create a saver object which will save all the variables saver = tf.train.Saver() saver.restore(sess, './tensorflow_mnist_model')
Для обучения на граф обучающая выборка подается порциями (batch-ами). Соотвественно, задается размер batchSize и вычисляется сколько запусков нужно сделать, чтобы перебрать все экземпляры изображений в обучающей выборке:
totalBatch = int(len(mnist.train.labels) / batchSize) # Количество batch
Для тренировки нейронки обучающая выборка будет подана на нейронку несколько раз. Количество повторов называется эпохами (epochs).
- Берется порция данных размером batchSize: batchX, batchY.
- Прогоняется обучение вызовом: _, c = sess.run([optimizer, crossEntropy], feed_dict=)
- Значение crossEntropy полученное после прогонки очередного batch делится на
- Вышеуказанная последовательность повторяется нужное количество epochs.
for epoch in range(epochs): avgLoss = 0 # сюда будет добавлять среднее значение функции потерь for i in range(totalBatch): # Для каждого batch batchX, batchY = mnist.train.next_batch(batch_size=batchSize) _, c = sess.run([optimizer, crossEntropy], # т.к. нам не нужно для каждой итерации запоминать вычисления непосредственно самого оптимизатора, то _ # для функции потерь - присваеваем переменную c feed_dict=) # feed_dict сначала строим граф, под который резервируем место и только потом уже "скармливаем" ему данные avgLoss += c / batchSize # отношение функции потери ошибки к размеру batch будет давать среднюю ошибку на элемент выборки print("Epoch:", (epoch + 1), "Loss =", "".format(avgLoss))
После тренировки модели можно посчитать точность. Веса модели уже подобраны и передача в сессии в качестве аргумента проверочной выборки вернет точность предсказания нейронкой (accuracy).
# Предсказание нашей модели print("Точность:",sess.run(accuracy, feed_dict=)*100,"%") #Save the graph saver.save(sess, 'tensorflow_mnist_model')
Граф в TensorBoard выглядит довольно сложно. Я убрал узел Saver, чтобы немного упростить граф, но все равно много объектов и плохо читаемо на картинке.
Пространство имен (name_scope) в Tensorflow
Чтобы упростить визуализацию графа объединим узлы относящиеся к одной сущности (например, слою) в пространства имен (name_scope). Очистим граф по-умолчанию (reset_default_graph).
# Объединим слой в пространство имен. Берем раннее определенные переменные и слои # и объединяем под tf.name_scope("название") tf.reset_default_graph() #
Входы x и y можно объединить под именем «inputs», но тогда граф модели станет менее читаемым. Поэтому не будем минимизировать количество блоков до такой степени и оставим placeholder-ы без изменений.
# Создаем пространство имен входных данных #with tf.name_scope("inputs"): # x = tf.placeholder(tf.float32, [None, 784]) # placeholder для данных # y = tf.placeholder(tf.float32, [None, 10]) # placeholder для меток x = tf.placeholder(tf.float32, [None, 784], name ="x_placeholder") # placeholder для данных y = tf.placeholder(tf.float32, [None, 10], name ="y_placeholder") # placeholder для меток
Каждый слой состоит из основных весов, весов нейрона смещения и активационной функции. В Keras при создании слоя эти объекты создаются автоматически. Параметры передаются в аргументе метода для создания слоя. Для первого слоя «layer1» сгруппируем соотвествующие узлы графа:
# Создаем пространство имен первого слоя with tf.name_scope("layer1"): W1 = tf.Variable(tf.random_normal([784, 300], stddev=0.03), name='W1') # Объявляем веса, связанные со скрытым слоем # Используя нормальное распределение со средним ноль # и статистическим отклонением 0.03, определяем bias(Аналогичная есть у numpy) b1 = tf.Variable(tf.random_normal([300]), name='b1') hiddenOut = tf.add(tf.matmul(x, W1), b1) # вычисляем скрытый слой hiddenOut = tf.nn.relu(hiddenOut) # функция активации для скрытого слоя relu
Аналогично сгруппируем все узлы относящиеся ко второму слою «layer2».
# Создаем пространство имен второго слоя with tf.name_scope("layer2"): # Подобно первому слою задаем веса и отклонения для второго слоя W2 = tf.Variable(tf.random_normal([300, 10], stddev=0.03), name='W2') # 300 - число весов скрытого слоя, 10 - выходного b2 = tf.Variable(tf.random_normal([10]), name='b2') y_ = tf.nn.softmax(tf.add(tf.matmul(hiddenOut, W2), b2)) # задаем выходной слой и применяем к нему функцию активации softmax
При вычислении accuracy сначала вычисляется количество совпадений предсказния и эталона и затем считается точность вычислением среднего арифметического. Все эти операции объединим в пространство имен «accuracy».
# Создаем пространство имен точности with tf.name_scope("accuracy"): correctPrediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # Возвращает тензор mx1 True/False в зависимости от правильности предсказания accuracy = tf.reduce_mean(tf.cast(correctPrediction, tf.float32)) # для нахождения среднего значения преобразуем Boolean в объект TensorFlow # cast - преобразование в TensorFlow float
При расчете перекрестной энтропии сначала граничные значения в исходных данных замещаются на минимальные и максимальные (отличные от 0 и 1), а затем вычисляется cross entropy. Сгруппируем эти операции под именем «Loss».
# Создаем пространство имен функции ошибки with tf.name_scope("Loss"): y_clipped = tf.clip_by_value(y_, 1e-10, 0.9999999) # конвертируем содержимое выхода y_ в формат 1e-10 to 0.999999 - гарантия того, # что не будет log(0). Иначе Nan и ошибка crossEntropy = -tf.reduce_mean(tf.reduce_sum(y * tf.log(y_clipped) # вычисление функции ошибки с помощью формулы, представленной выше + (1 - y) * tf.log(1 - y_clipped), axis=1))
Для оптимизатора зададим имя «optimizer».
# Создаем пространство имен оптимизатора with tf.name_scope("optimizer"): # Градиентный спуск. Инициализируем через learning rate и говорим, что хотим, чтобы он делал. # Здесь - минимизация cross_entropy # Функция реализует градиентный спуск и обратное распространение ошибки сразу. optimizer = tf.train.GradientDescentOptimizer(learning_rate=learningRate).minimize(crossEntropy)
При визуализации в TensorBoard графа после объединения узлов под новыми именами визуализация и добавление в модель saver-а для сохранения весов сети:
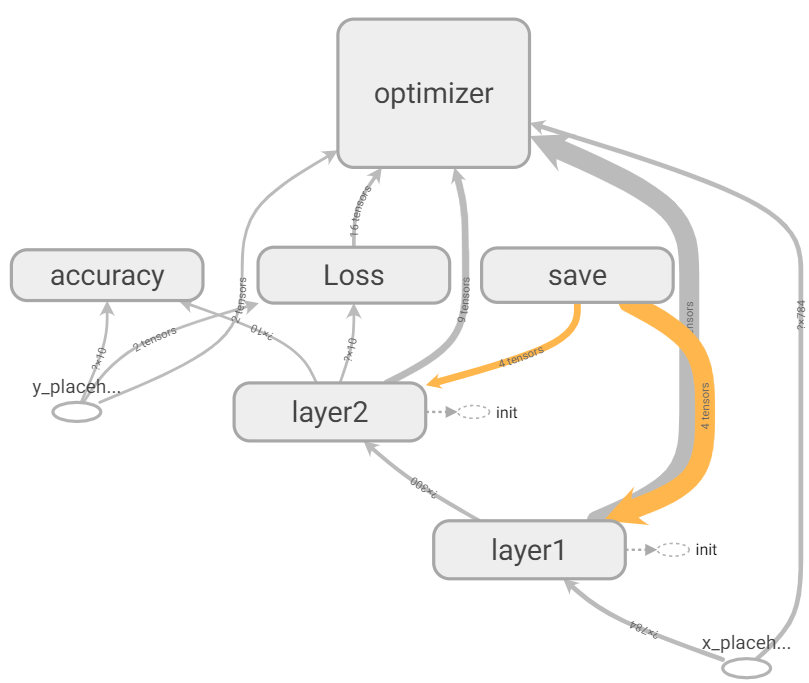
При КАЖДОМ вызове saver = tf.train.Saver() добавляется узел save. Вызывать эту строчку для графа нужно только один раз.
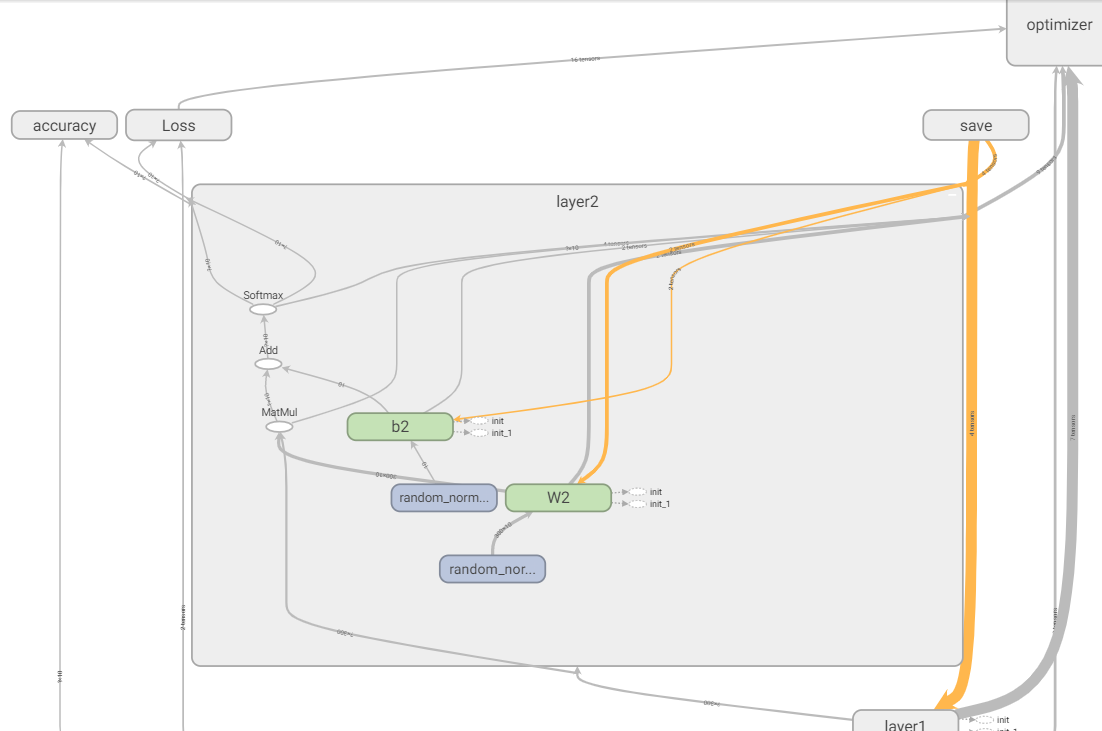
Если развернуть в TensorBoard содержимое layer2, то в нем присутствуют все нужные узлы слоя: веса W2, b2 и преобразования MatMul, Add и Softmax.
Обращаю внимание на то, что узел Save соединяется только с TensorFlow Variables для сохранения весов слоя.
Optimizer встраивается в узлы модели и может управлять весами слоя, меняя их для минимизации Loss. При этом Optimizer получает данные с MatMul, Softmax и Loss.
Посмотрев на код одной и той-же архитектуры нейронки написанный на Keras и Tensorflow становится очевидно, что код на Keras получается гораздо компактнее и читабельнее.
Полезные ссылки
- Colab с кодом к примеру.
- Как работает нейронная сеть: алгоритмы, обучение, функции активации и потери.
- Видео про нейрон смещения.
- Как использовать функциональный API Keras для глубокого обучения
- https://blog.bitsrc.io/learn-tensorflow-fundamentals-in-20-minutes-cdef2dec331a
- A Gentle Introduction to Cross-Entropy for Machine Learning
- Do you want to learn AI, learn Cross-Entropy First?
- A quick complete tutorial to save and restore Tensorflow models
- Variables: Creation, Initialization, Saving, and Loading
Dense layer: перевод, синонимы, произношение, примеры предложений, антонимы, транскрипция
![]()
- Теория
- Грамматика
- Лексика
- Аудио уроки
- Диалоги
- Разговорники
- Статьи
- Онлайн
- Тесты
- Переводчик
- Орфография
- Радио
- Игры
- Телевидение
- Специалистам
- Английский для медиков
- Английский для моряков
- Английский для математиков
- Английский для официантов
- Английский для полиции
- Английский для IT-специалистов
- О проекте
- Реклама на сайте
- Обратная связь
- — Partners
- OpenTran
- Словари
- Испанский
- Голландский
- Итальянский
- Португальский
- Немецкий
- Французский
- Хинди
- Содержание
- Перевод
- Синонимы
- Антонимы
- Произношение
- Определение
- Примеры
- Транскрипция
Copyright © 2009-2023. All Rights Reserved.
Все права на сервисы и материалы, находящиеся на сайте EnglishLib.org, защищены. Использование материалов возможно только с письменного разрешения владельца и при указании прямой активной ссылки на EnglishLib.org.