Медиана
Медиана — это значение делящее распределение пополам. Другими словами это значение ниже которого находятся 50% значений, и выше также 50% всех значений в распределении.
Например в распределении 3, 4, 5, 7, 8 Медианой будет 5 поскольку оно делит распределение пополам.
Если в распределении четное число значений, то медиана считается как среднее арифметическое между ними.
Например в распределении 3, 4, 5, 6, 7, 8 медианой будет 5.5 (пять целях пять десятых) посокльку это число будет средним арифметическим между числами 5 и 6.
Следует помнить, что при вычислении медианы данные должны быть предварительно ранжированы по возрастанию или убыванию.
Методы описательной статистики

Практически каждый исследователь сталкивается рано или поздно в своей работе с необходимостью обработки и дальнейшего предоставления статистических данных. Причем это касается самых разных отраслей науки – от технических и медицинских до социологических и культурологических.
Обусловлена такая распространенность тем, что статистические методы помогают получить и обосновать определенные суждения об объектах, субъектах, группах людей и прочем, что обладает определенной внутренней неоднородностью.
Вы можете заказать услугу срочной публикации научных статей в научных журналах. Специалисты издательства СибАК знают, как выполнить работу в сжатые сроки.
Что такое описательная статистика
Те, кто впервые в своей работе сталкивается с обработкой и описанием данных, не всегда четко представляют, в какой форме их корректно отображать и обрабатывать для того, чтобы в дальнейшем подвергнуть статистическому выводу.
Поэтому нужно четко представлять, что такое описательная статистика. Она еще носит название дескриптивной и занимается анализом и обработкой эмпирических данных с проведением необходимой систематизации. Описательная статистика – это сжатая и концентрированная характеристика изучаемого явления, представленная в виде графиков, таблиц, схем и числовых выражений.
Вот что входит в описательную статистику в качестве основных показателей:
- переменная, которая не является постоянным. Ее можно не только измерять, но и подвергать изменениям в ходе определенных манипуляций;
- экстремумы, или так называемые максимумы и минимумы значений самой переменной;
- под вариационными рядами понимают все количественные признаки, которые имеются у каждой единицы статистического наблюдения;
- среднее – представляется средним арифметическим или выборочным. Здесь есть несколько параметров, таких как гармоническое, геометрическое, арифметическое и квадратическое. Все они нужны для того, чтобы охарактеризовать центр распределения;
- мода представляет собой наиболее часто встречающееся значение в выборке. Правда, она может отражать также и среднее значение класса, обладающего наибольшей частотой;
- медиана – это среднее значение чаще всего встречающихся значений выборки;
- дисперсия – позволяет оценить отклонения в определенном числе наблюдений. Этот параметр относится к показателям рассеяния вариант.
Помимо этого, для осуществления методов описательной статистики используют еще такие показатели, как квартили, асимметрию, статистические моменты, эксцессы, гипотезы, значимости. Каждый из них играет существенную роль для корректного отображения получаемых данных.
Совокупность выше представленных показателей помогает при визуальном представлении данных осуществить:
- фиксацию их относительно осей, придав тем самым вес в числовом отражении;
- отобразить, насколько они разбросаны относительно своего центра;
- показать асимметричность распределения около центрального положения;
- вывести закон распределения данных при помощи гистограммы, таблицы частот или функции.
Как сделать описательную статистику
При выполнении определенного вида работ и решении задач придерживаются следующего порядка.
- Собирают все необходимые исходные данные. При этом учитывают размер выборки. Чтобы получить достоверные данные, минимальное число не может быть меньше 1000. Чем оно будет больше, тем точнее получится итоговый результат.
- На втором этапе строят вариационный ряд. Все полученные данные упорядочивают по возрастанию. Чтобы это было удобнее выполнить, находят минимальный и максимальный элементы, а затем относительно них переписывают его в нужной последовательности.
- В некоторых случаях для упрощения процедуры обработки допускается вычитание из каждого элемента ряда минимального значения. Таким образом, работа дальше ведется не с конкретными размерами, а только с их отклонениями.
- На следующем этапе проводят группировку данных. Для этого их разбивают на R интервалов, число которых соотносят с количеством наблюдений.
- Затем определяют частости и эмпирические плотности вероятностей (частость используется для того, чтобы заменить частоты при составлении вариационных рядов).
- После этих обработок собранной информации необходимо построить полигон. Но для этого первоначально определяют масштаб по осям.
- Когда этот этап выполнен, строят гистограмму и эмпирическую функцию распределения.
- Используя данные из гистограммы рассчитывают параметры распределения.
- И на финальном этапе оформляют результат, который сводят в таблицу, схему, гистограмму, график или прочее.
Обработку статистических параметров методом описательной статистики необходимо проводить на высшем уровне. В противном случае могут пострадать итоговые выводы и результаты научной работы.
Важность корректного представления данных
Статистическое отображение данных важно в любой научной работе. А для публикаций в журналах, индексируемых наукометрическими базами Web of Science и Scopus, нужно особо тщательно относиться к качеству подаваемого материала.
Можно самому разбираться во всех тонкостях и сложных формулах, которые нужно применять. Но, чтобы облегчить и ускорить процесс статистической обработки в исследовании, лучше обратиться к специалистам, которые доступно объяснят даже самые сложные моменты.
Описательная статистика для числовых переменных
Чтобы получить описательную статистику числовых переменных, можно щелкнуть в диалоге Frequencies на кнопке Statistics. (Статистика). Откроется диалоговое окно Frequencies: Statistics (Частоты: Статистика).
Рис. 6.2: Диалоговое окно frequencies: Statistics
В группе Percentile Values (Значения процентилей) можно выбрать следующие варианты:
- Quartiles (Квартили): Будут показаны первый, второй и третий квартили. Первый квартиль (Q1) — это точка на шкале измеренных значений, ниже (левее) которой располагаются 25% измеренных значений. Второй квартиль (Q2) — это точка, ниже которой располагаются 50% измеренных значений. Второй квартиль также называется медианой. Третий квартиль (Q3) — это точка на шкале измеренных значений, ниже которой располагаются 75% значений. Если данные имеются только в форме порядкового отношения, то качестве меры разброса используется межквартильная широта. Она определяется как
- Cut points (Точки раздела): Будут вычислены значения процентилей, разделяющие выборку на группы наблюдений, которые имеют одинаковую ширину, то есть включают одно и то же количество измеренных значений. По умолчанию предлагается количество групп 10. Если задать, к примеру, 4, то будут показаны квартили, то есть квартили соответствуют процентилям 25, 50 и 75. Видно, что число показываемых процентилей на единицу меньше заданного числа групп.
- Percentile(s) (Процентили): Здесь имеются в виду значения процентилей, определяемые пользователем. Введите значение процентиля в пределах от 0 до 100 и щелкните на кнопке Add (Добавить). Повторите эти действия для всех желаемых значений процентилей. Значения в порядке возрастания будут показаны в списке. Например, если ввести значения 25, 50 и 75, то мы получим квартили. Можно задавать любые значения процентилей, например, 37 и 83. В первом случае (37) будет показано значение выбранной переменной, ниже которого лежат 37% значений, а во втором случае (83) — значение, ниже которого располагаются 83% значений.
В группе Dispersion (Разброс) можно выбрать следующие меры разброса:
- Std. deviation (Стандартное отклонение) — это мера разброса измеренных величин; оно равно квадратному корню из дисперсии. В интервале шириной, равной удвоенному стандартному отклонению, который отложен по обе стороны от среднего значения, располагается примерно 67% всех значений выборки, подчиняющейся нормальному распределению.
- Variance (Дисперсия) — это квадрат стандартного отклонения и, следовательно, эта характеристика также является мерой разброса измеренных величин. О на определяется как сумма квадратов отклонений всех измеренных значений от их среднеарифметического значения, деленная на количество измерений минус 1.
- Range (Размах) — это разница между наибольшим значением (максимумом) и наименьшим значением (минимумом).
- Minimum (Минимум) — Наименьшее значение.
- Maximum (Максимум) — Наибольшее значение.
- S.E. mean (Стандартная ошибка среднего значения) — В интервале шириной, равной удвоенной стандартной ошибке, отложенному вокруг среднего значения, располагается среднее значение генеральной совокупности с вероятностью примерно 67%. Стандартная ошибка определяется как стандартное отклонение, деленное на квадратный корень из объема выборки.
Обычно мерами разброса переменных, относящихся к интервальной шкале и подчиняющихся нормальному распределению, служат стандартное отклонение и стандартная ошибка. Как было сказано выше, стандартное отклонение позволяет задать диапазон разброса отдельных значений. По так называемому правилу кулака, в одном диапазоне стандартного отклонения (охватывающем ширину стандартного отклонения в обе стороны от среднего значения) располагается примерно 67% значений, в диапазоне удвоенного стандартного отклонения — примерно 95%, а в диапазоне утроенного стандартного отклонения — примерно 99% значений.
С другой стороны, стандартная ошибка позволяет задать доверительный интервал для среднего значения. В диапазоне удвоенной стандартной ошибки по обе стороны от среднего значения с вероятностью примерно 95% находится среднее значение генеральной совокупности. С вероятностью примерно 99% она лежит в диапазоне утроенной стандартной ошибки. Часто указывают только одну из этих двух мер разброса, обычно — стандартную ошибку, так как ее значение меньше. Во всех случаях следует точно выяснить, какая из мер разброса имеется в виду.
В группе Central Tendency (Средние) можно выбрать следующие характеристики:
- Mean (Среднее значение) — это арифметическое среднее измеренных значений; оно определяется как сумма значений, деленная на их количество. Например, если имеется 12 измеренных значений и их сумма составляет 600, то среднее значение будет х = 600 : 12 = 50.
- Median (Медиана) — это точка на шкале измеренных значений, выше и ниже которой лежит по половине всех измеренных значений. Например, если измеренные значения таковы:
то сначала они располагаются в порядке возрастания: 23344567889.
В данном случае медианой будет значение 5. Всего у нас 11 измеренных значений, следовательно, медианой является шестое значение. Выше него располагается 5 значений, и ниже — тоже 5. При нечетном количестве значений медиана всегда будет совпадать с одним из измеренных значений. При четном количестве медиана будет средним арифметическим двух соседних значений. Например, если имеются следующие измеренные значения:
то медиана в этом случае будет равна: (6 + 7) : 2 = 6,5.
- Mode (Мода) — это значение, которое наиболее часто встречается в выборке. Если одна и та же наибольшая частота встречается у нескольких значений, то выбирается наименьшее из них.
- Sum (Сумма) — сумма всех значений.
В группе Distribution (Распределение) можно выбрать следующие меры несимметричности распределения:
- Skewness (Коэффициент асимметрии) — это мера отклонения распределения частоты от симметричного распределения, то есть такого, у которого на одинаковом удалении от среднего значения по обе стороны выборки данных располагается одинаковое количество значений. Если наблюдения подчиняются нормальному распределению, то асимметрия равна нулю. Для проверки на нормальное распределение можно применять следующее правило: Если асимметрия значительно отличается от нуля, то гипотезу о том, что данные взяты из нормально распределенной генеральной совокупности, следует отвергнуть. Если вершина асимметричного распределения сдвинута к меньшим значениям, то говорят о положительной асимметрии, в противоположном случае — об отрицательной.
- Kurtosis (Коэффициент вариации или эксцесс) — указывает, является ли распределение пологим (при большом значении коэффициента) или крутым. Коэффициент вариации равен нулю, если наблюдения подчиняются нормальному распределению. Поэтому для проверки на нормальное распределение можно применять еще одно правило: Если коэффициент вариации значительно отличается от нуля, то гипотезу о том, что данные взяты из нормально распределенной генеральной совокупности, следует отвергнуть.
Как правило, для переменных, относящихся к интервальной шкале и подчиняющихся нормальному распределению, в качестве основной характеристики используют среднее значение, а в качестве меры разброса — стандартное отклонение или стандартную ошибку. Для порядковых или интервальных переменных, не подчиняющихся нормальному распределению — соответственно медиану или первый и третий квартили. Для переменных относящихся к номинальной шкале, нельзя дать других значимых характеристик кроме моды.
В диалоге есть еще один флажок:
- Values are group midpoints (Значения являются средними точками групп): Если установить этот флажок, то при вычислении медианы и остальных значений процентилей оценки этих характеристик будут определяться для концентрированных данных. Этому вопросу посвящен отдельный раздел.
Для переменной alter (возраст) мы определим следующие характеристики: среднее значение, медиану, моду, квартили, стандартное отклонение, дисперсию, размах, минимум, максимум, стандартную ошибку, асимметрию и эксцесс. Поступите следующим образом:
- Выберите в меню команды Analyze (Анализ) / Descriptive Statistics (Дескриптивные статистики) / Frequencies. (Частоты)
- В диалоге Frequencies щелкните на кнопке Reset (Сброс), чтобы отменить прежние настройки.
- Перенесите переменную alter в список выходных переменных.
- Щелкните на кнопке Statistics. (Статистика).
- В диалоге Frequencies: Statistics установите флажки желаемых характеристик. Затем щелкните на кнопке Continue (Продолжить). Вы вернетесь в диалог Frequencies.
- В диалоге Frequencies деактивируйте опцию Display frequency tables (Показывать частотные таблицы). Щелкните на кнопке ОК.
В окне просмотра появятся следующие результаты:
Statistics (Статистика)
Alter
| N | Valid (Допустимые) | 106 |
| Missing (Утерянные) | 2 | |
| Mean (Среднее значение) | 22,24 | |
| Std. Error of Mean (Стандартная ошибка среднего) | 21 | |
| Median (Медиана) | 22,00 | |
| Mode (Мода) | 21 | |
| Std. Deviation (Стандартное отклонение) | 2,189 | |
| Variance (Дисперсия) | 4,791 | |
| Skewness (Асимметрия) | 0,859 | |
| Std. Error of Skewness (Стандартная ошибка асимметрии) | 0,235 | |
| Kurtosis (Коэффициент вариации / Эксцесс) | 1,042 | |
| Std. Error of Kurtosis (Стандартная ошибка эксцесса) | 0,465 | |
| Range (Размах) | 11 | |
| Minimum (Минимум) | 18 | |
| Maximum (Максимум) | 29 | |
| Percentiles (Процентили) | 25 | 21,00 |
| 50 | 22,00 | |
| 75 | 23,00 |
Респонденты опроса о психическом состоянии и социальном положении имеют средний возраст 22,24 года. Медиана составляет 22. Большинству респондентов 21 год (это мода). Самому молодому респонденту 18 лет (минимум), самому старшему — 29 лет (максимум). Самый старший респондент на 11 лет старше самого молодого (размах). Стандартное отклонение составляет 2,19. Следовательно, дисперсия — квадрат стандартного отклонения — равна (2,19) 2 = 4,79. Асимметрия и коэффициент вариации даны со соответсвующими стандартными ошибками.
Что такое медиана в описательной статистике
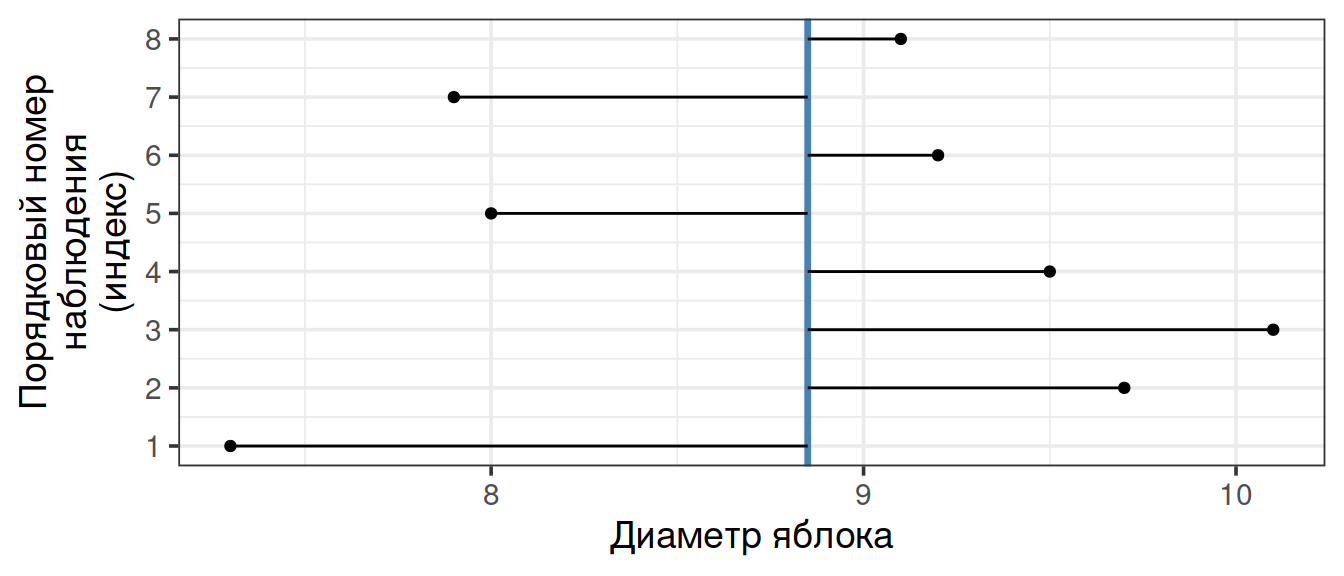
Предположим, мы занимаемся селекцией яблонь и хотим охарактеризовать урожай любимой яблони, на которую возлагаем большие надежды.
applesМедиана
Наши данные в исходном виде выглядят примерно так:
apples## [1] 7.3 9.7 10.1 9.5 8.0 9.2 7.9 9.1
Чтобы увидеть медиану, мы должны ранжировать, или отсортировать, наш вектор по возрастанию:
sort(apples)## [1] 7.3 7.9 8.0 9.1 9.2 9.5 9.7 10.1
Медиана
В ранжированном ряду медиана расположена так, что слева и справа от нее находится равное число измерений.


- Если n нечетное, то медиана = значение с индексом \(\frac\).
- Если n четное, то медиана посередине между \(\frac\) и \(\frac\) значениями.
sort(apples)
## [1] 7.3 7.9 8.0 9.1 9.2 9.5 9.7 10.1
Медиана находится в промежутке между значениями 9.1 и 9.2, т.е. 9.15

median(apples) # Проверим себя
## [1] 9.15
Медиана устойчива к выбросам
Представим, что наши измерения пострадали от неаккуратности. Допустим сотрудник, которому мы поручили измерять яблоки, измерил также арбуз и записал этот результат вместе со всеми остальными.
apples2## [1] 7.3 7.9 8.0 9.1 9.2 9.5 9.7 10.1 68.0Что станет с медианой? Сильно ли она изменится?
median(apples2)## [1] 9.2Медиана устойчива к выбросам, а среднее - нет
Давайте для сравнения посмотрим на среднее.
mean(apples)## [1] 8.85mean(apples2)## [1] 15.4Единственное наблюдение-выброс сильно повлияет на величину среднего значения.
Квантили
Квантили — это значения, которые делят ряд наблюдений на равные части.
Они называются по-разному в зависимости от числа частей.
- 2-квантиль (“два-квантиль”) — медиана
- 4-квантиль (“четыре-квантиль”)— квартиль
- 100-квантиль (“сто-квантиль”)— перцентиль
Квартили
Квартиль — частный случай квантиля.
Квартили делят распределение на четыре равные части, каждая из которых включает по 25% значений.
- I квартиль отсекает как раз 25%.
- II квартиль — 50%. Это медиана.
- III квартиль отсекает 75% значений.
Квартили можно найти при помощи функции quantile()
quantile(x = apples, probs = c(0.25, 0.5, 0.75))
## 25% 50% 75% ## 7.97 9.15 9.55
5-number summary
Функция quatile(x) без указания значений вероятностей ( probs ) покажет нам квартили, минимум и максимум.
quantile(apples)
## 0% 25% 50% 75% 100% ## 7.30 7.97 9.15 9.55 10.10
5-number summary — удобное краткое описание данных.
Персентили
Персентиль — это частный случай квантиля. Всего 99 персентилей, они делят ряд наблюдений на 100 частей.
Ничто не помешает нам узнать, например, какие значения отсекают 10% или 99% значений выборки. Подставим соответствующие аргументы:
quantile(apples, probs = c(0.1, 0.99))
## 10% 99% ## 7.72 10.07
Боксплот: 5-number summary на графике
boxplot(apples)

Отложим числа, характеризующие выборку, по оси Y:
- жирная линия — медиана,
- нижняя и верхняя границы “коробки” — это I и III квантили,
- усы — минимум и максимум.
Расстояние между I и III квартилями (высота “коробки”) называется интерквартильное расстояние
Если в выборке есть выбросы (значения, отстоящие от границ “коробки” больше чем на 1.5 интерквартильных расстояния), то они будут изображены отдельными точками.
Подготовим все, чтобы построить график в ggplot2
library(ggplot2) theme_set(theme_bw()) apple_data## diameter ## 1 7.3 ## 2 9.7 ## 3 10.1 ## 4 9.5 ## 5 8.0 ## 6 9.2Боксплот можно построить при помощи geom_boxplot()
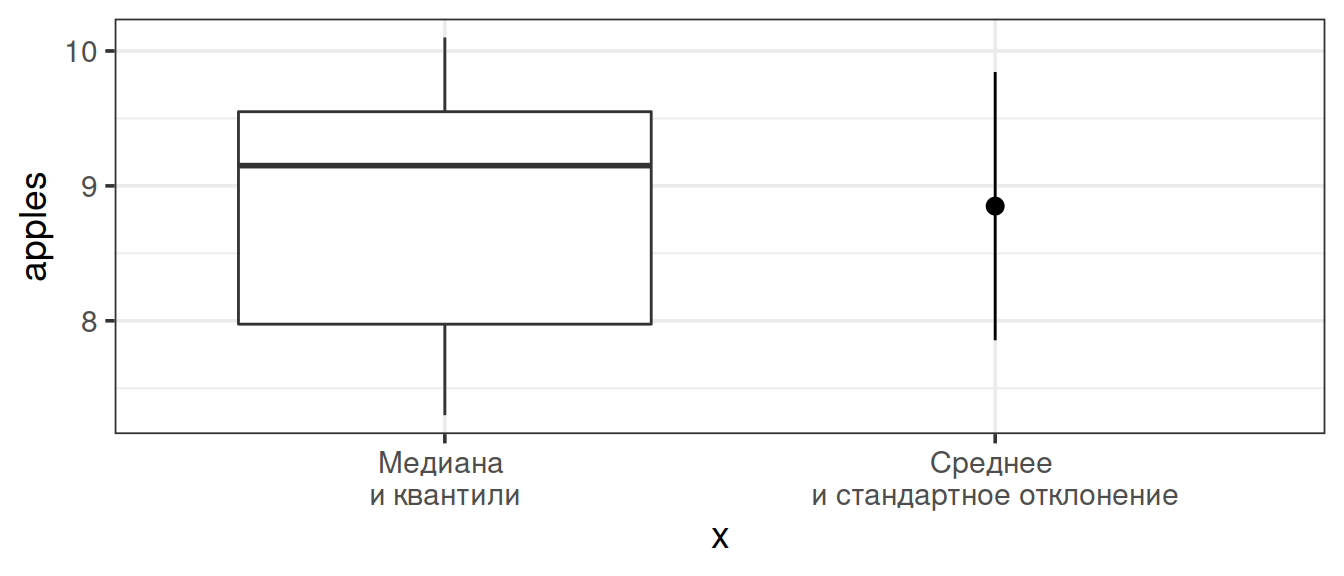
ggplot(data = apple_data) + geom_boxplot(aes(x = 'Медиана \nи квантили', y = diameter))
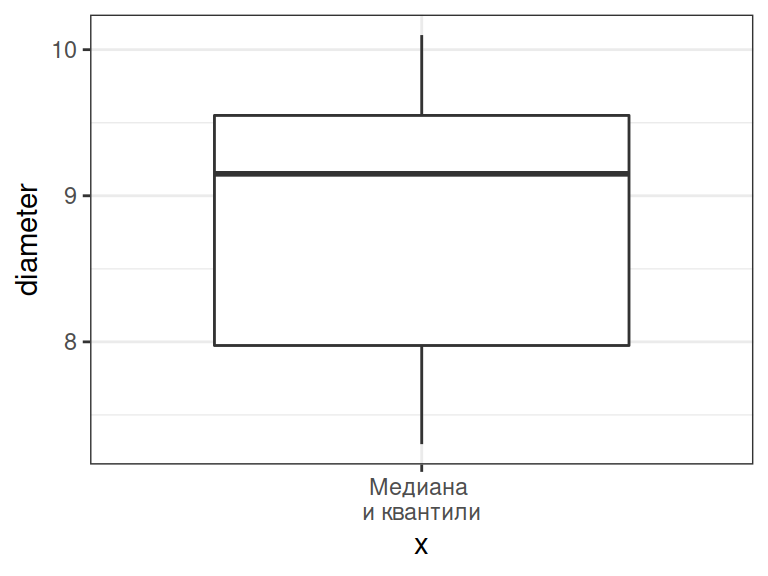
- x — категория (переменная или текстовое обозначение)
- y — зависимая переменная
Case study: диатомовые водоросли в желудках фильтраторов.
Case study: диатомовые водоросли в желудках фильтраторов. Самостоятельная работа.
В морских сообществах встречаются два вида фильтраторов, один из которых любит селиться прямо на поверхности тела другого.
Tegella armifera — это вид-хозяин. Он может жить как сам по себе, так и вместе с симбионтом.
Loxosomella nordgardi — вид-симбионт. Он практически никогда не встречается в одиночестве.
Данные: Юта Тамберг

Case study: диатомовые водоросли в желудках фильтраторов.
В файле diatome_count.csv дано количество диатомовых водорослей в желудках этих животных. Прочитаем эти данные и посмотрим на них:
diatomsВ таблице 2 переменные:
- sp — вид,
- count — число водорослей в желудке.
В переменной sp есть три варианта значений:
- “host_free” — хозяин без симбионта,
- “host_symbiont” — хозяин с симбионтом,
- “symbiont” — симбионт.
Все ли правильно открылось?
Смотрим первые несколько строк:
head(diatoms)
## sp count ## 1 host_free 10 ## 2 host_free 0 ## 3 host_free 1 ## 4 host_free 0 ## 5 host_free 2 ## 6 host_free 0
str(diatoms)
## 'data.frame': 162 obs. of 2 variables: ## $ sp : chr "host_free" "host_free" "host_free" "host_free" . ## $ count: int 10 0 1 0 2 0 1 0 8 0 .
Есть ли пропущенные значения?
sum(! complete.cases(diatoms))
Что это за случаи?
diatoms[! complete.cases(diatoms), ]
## sp count ## 54 host_free NA ## 159 symbiont NA ## 160 symbiont NA ## 161 symbiont NA ## 162 symbiont NA
Задание 1
## sp count ## 1 host_free 10 ## 2 host_free 0 ## 3 host_free 1 ## 4 host_free 0 ## 5 host_free 2 ## 6 host_free 0
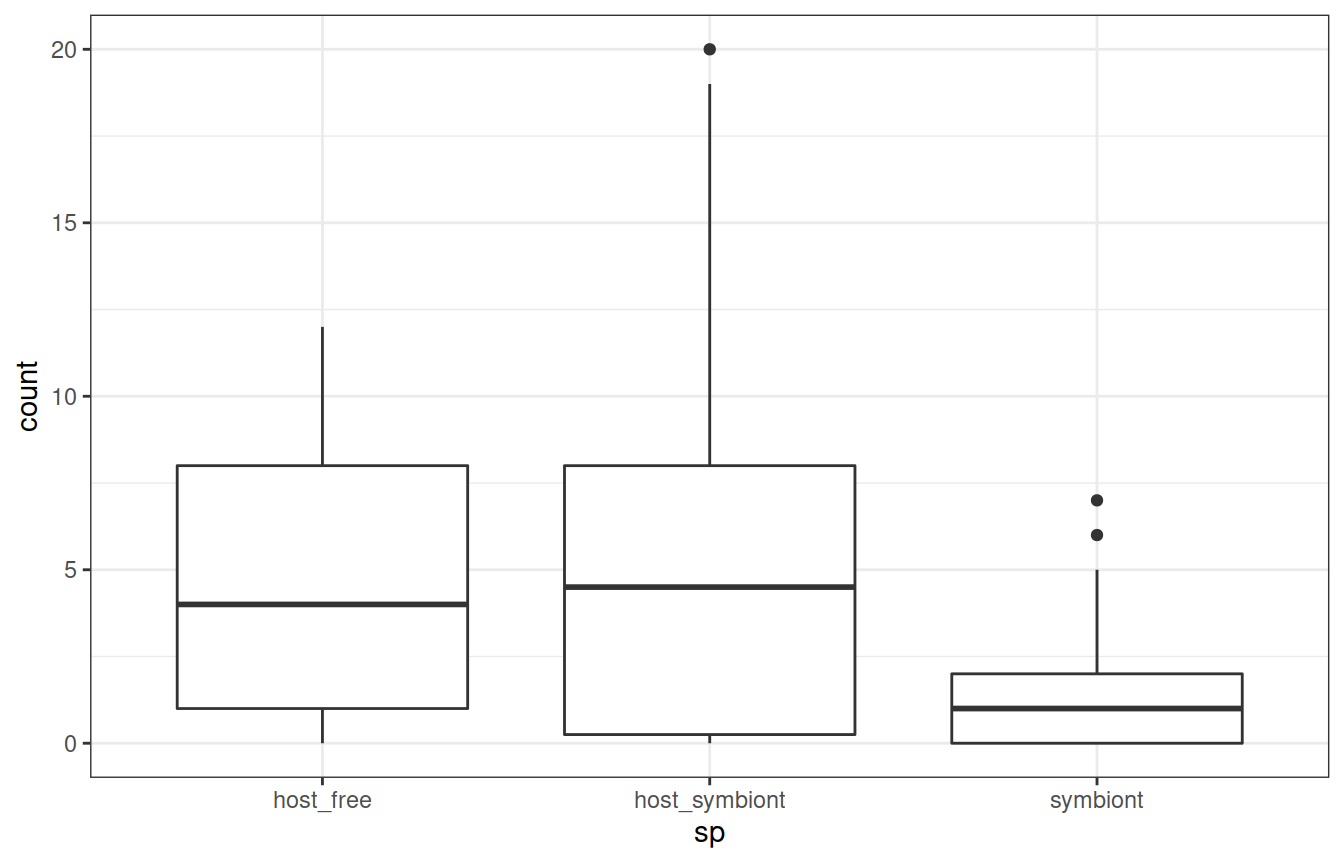
Ваша задача рассчитать 5-number summary для количества диатомовых в желудках хозяев и симбионтов (всех трех категорий).
Решение
# 5-number summary для хозяев без симбионтов host_f## 0% 25% 50% 75% 100% ## 0 1 4 8 12# Для хозяев с симбионтами host_s## 0% 25% 50% 75% 100% ## 0.00 0.25 4.50 8.00 20.00# Для одиноких симбионтов symbiont## 0% 25% 50% 75% 100% ## 0 0 1 2 7Решение (более сложный, но краткий способ)
tapply() — одна из функций семейства *pply() .
split — apply — combine
Функция tapply() берет вектор X и…
- делит (split) его на части по значениям в векторе INDEX
- применяет (apply) к каждой части функцию FUN
- соединяет (combine) результаты в одно целое в зависимости от их свойств
tapply(X = diatoms$count, INDEX = diatoms$sp, FUN = quantile, na.rm = TRUE)
## $host_free ## 0% 25% 50% 75% 100% ## 0 1 4 8 12 ## ## $host_symbiont ## 0% 25% 50% 75% 100% ## 0.00 0.25 4.50 8.00 20.00 ## ## $symbiont ## 0% 25% 50% 75% 100% ## 0 0 1 2 7
Боксплоты в ggplot2
Формат данных несколько сложен для человеческого глаза, зато очень подходит для ggplot.
ggplot(data = diatoms, aes(y = count, x = sp)) + geom_boxplot()
Медиана и квартили: непараметрические характеристики выборки
Главный плюс (но так же и минус) связки медиана + квартили это ее независимость от формы распределения.
Будь оно симметричным или с хвостом, 5-number summary опишет, а боксплот нарисует его с минимумом искажений.
Но бывают случаи, когда приходится применять более специальные, но и более информативные характеристики.
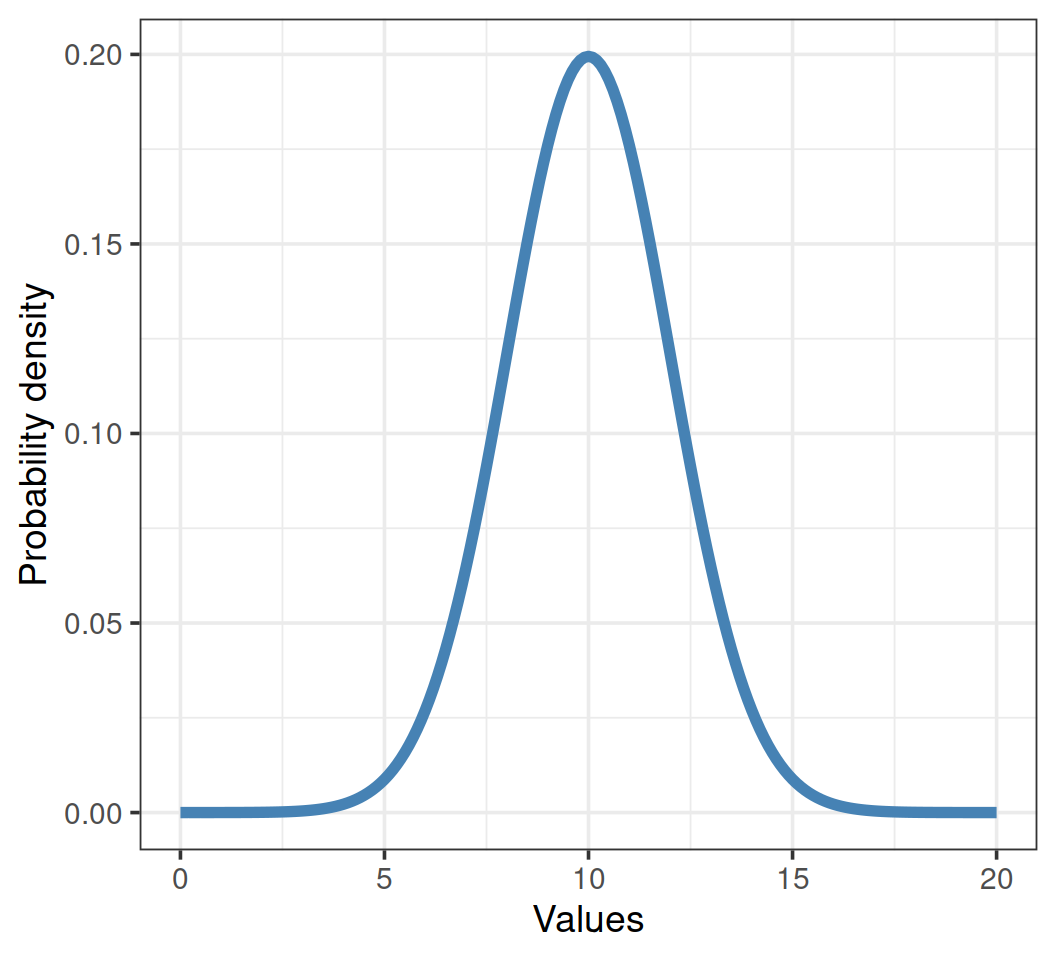
ЧАСТЬ 2. Нормальное распределение - первое знакомство
Все распределения равны, но некоторые равнее
Это непрерывное распределение, получаемое из мерных данных. Однако, многие распределения других типов тоже могут приближаться к нормальному.
Относительная частота и плотность вероятности
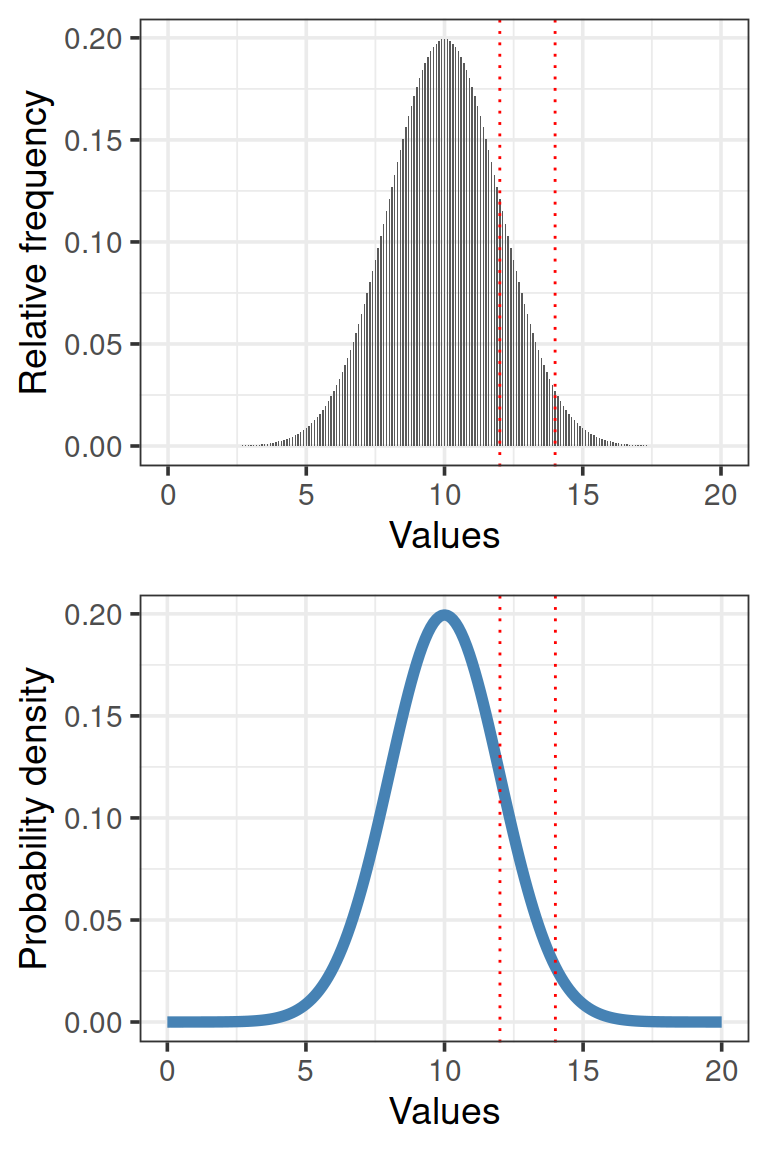
На оси Y может быть отложена относительная частота значений Х в эмпирическом распределении, или вероятность из теоретического распределения.
На оси Х отложены значения Х в интервале от 0 до 20, в действительности же кривая простирается от \(-\infty\) до \(+\infty\)
Площадь под кривой = 1. Интегрируя кривую на промежутке \((k. l)\), можно узнать вероятность встречи значений в этом промежутке \((x_k. x_l)\).
Но нельзя рассчитать вероятность одного значения \(X = x_k\), так как это точка, и под ней нет площади.
Приятные особенности нормального распределения
Нормальных кривых бесконечно много, и их описывает формула с параметрами \(\mu\) и \(\sigma\).
- \(\mu\) — среднее,
- \(\sigma\) — стандартное отклонение.
Достаточно знать значения этих двух параметов, чтобы восстановить или смоделировать любое нормальное распределение. И наоборот, если данные в выборке распределены нормально, то мы можем оценить параметры этого распределения.
ЧАСТЬ 3. Среднее и стандартное отклонение
Центральная тенденция
Среднее арифметическое
Рассчитаем вручную и проверим:
sum(apples) / length(apples)
## [1] 8.85
mean(apples)
## [1] 8.85
Как оценить разброс значений?
Девиата (отклонение)
— это разность между значением вариаты (измерения) и средним:
raw_deviates## [1] -1.55 0.85 1.25 0.65 -0.85 0.35 -0.95 0.25
Меры разброса
Девиаты не годятся как мера разброса
К сожалению мы не можем просто сложить все значения девиат и поделить их на объем выборки. Сумма девиат всегда будет равна нулю.
round(sum(raw_deviates))\[\begin \sum<(x_i - \bar
)> &= \sum x_i - \sum \bar x = \\ &= \sum x_i - n \bar x = \\ &= \sum x_i - n \cfrac = 0 \end\] Меры разброса
Сумма квадратов = SS, Sum of Squares
Избавиться от знака девиаты можно, возведя значение в квадрат.
sum(raw_deviates^2)Но на что разделить \(SS\), чтобы получить меру усредненного отклонения значений от среднего?
Меры разброса
Как усреднить отклонения от среднего значения?
Мы не можем делить на \(n\), поскольку отклонения от среднего \(x_i - \bar x\) не будут независимы.
Что это значит? Сумма отклонений всегда равна нулю \(\sum<(x_i - \bar
)> = 0\).
Поэтому, если мы знаем \(\bar x\) и \(n - 1\) отклонений, то всегда сможем точно вычислить последнее отклонение.\(n - 1\) — это число независимых значений (число степеней свободы — degrees of freedom).
Меры разброса
Дисперсия = MS, Mean Square, Variance
Если мы теперь поделим сумму квадратов на объем выборки минус 1, то получим дисперсию по этой выборке.
sum(raw_deviates^2) / (length(apples) - 1) var(apples)Дисперсию не получится нарисовать на графике, т.к. там используются не отклонения, а их квадраты
Меры разброса
Среднеквадратичное/стандартное отклонение = Standard Deviation
Квадратный корень из дисперсии позволит вернуться к исходным единицам измерения
Стандартное отклонение — это средняя величина отклонения, и ее уже можно изобразить на графике.
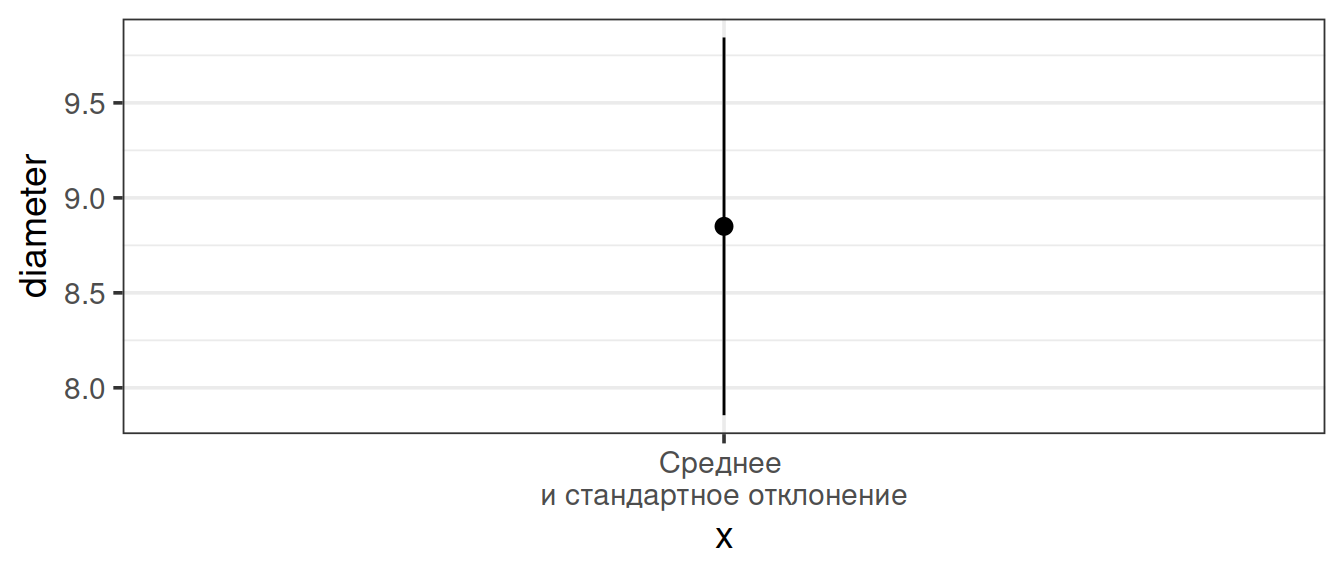
sqrt(sum(raw_deviates^2) / (length(apples) - 1)) sd(apples)Среднее и стандартное отклонение при помощи stat_summary()
ggplot(data = apple_data) + stat_summary(geom = 'pointrange', fun.data = mean_sdl, fun.args = list(mult = 1), aes(x = 'Среднее \nи стандартное отклонение', y = diameter))
stat_summary() использует geom_pointrange()
точка — среднее, усы изображают \(\pm\) стандартное отклонениеmean_sdl() рассчитывает координаты точки и усов, ее аргумент mult = 1 показывает, сколько стандартных отклонений отложить
Особенности применения связки
- только вместе,
- чувствительны к выбросам,
- плохо работают с несимметричными распределениями.
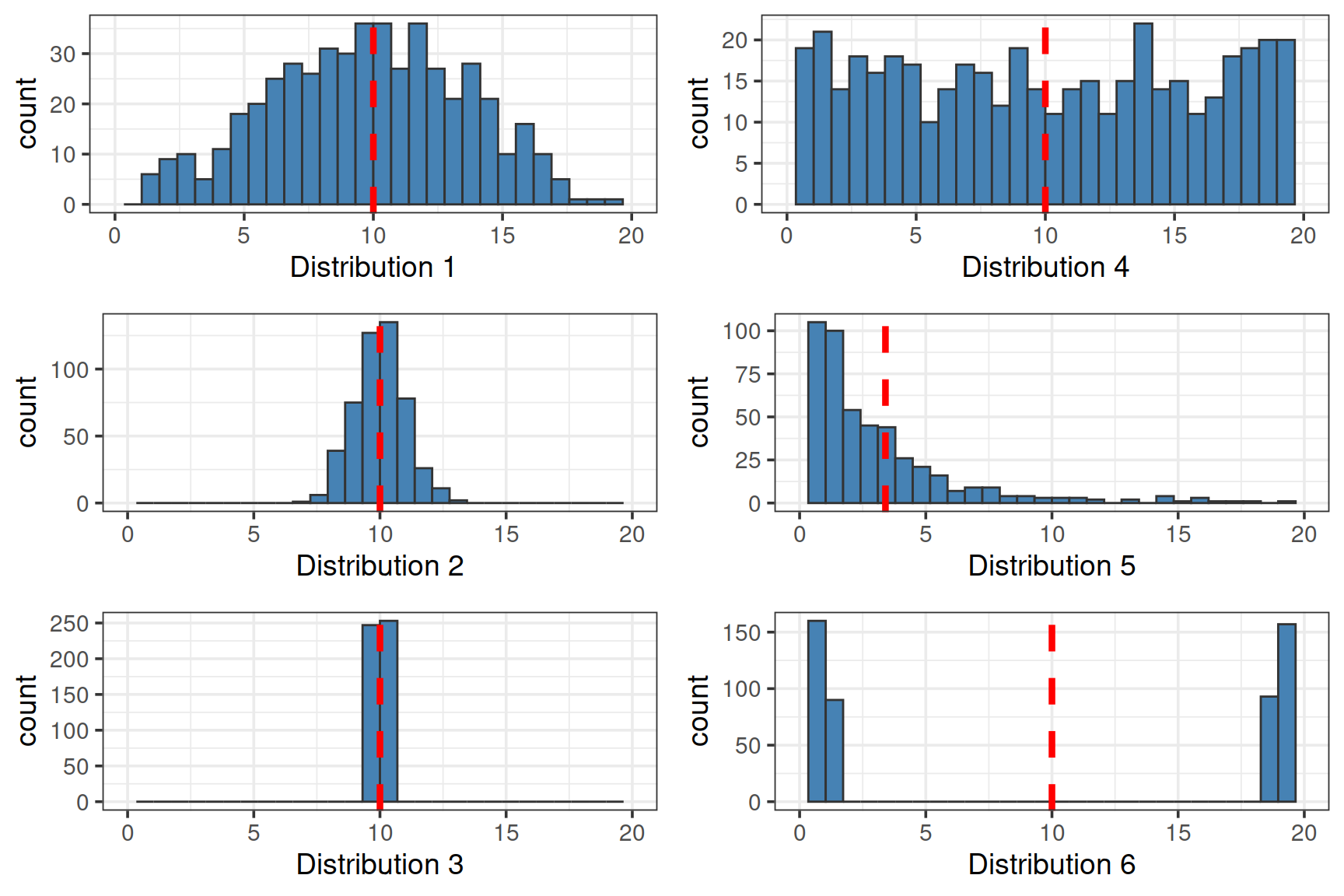
Сравните разброс (стандартное отклонение) в выборках
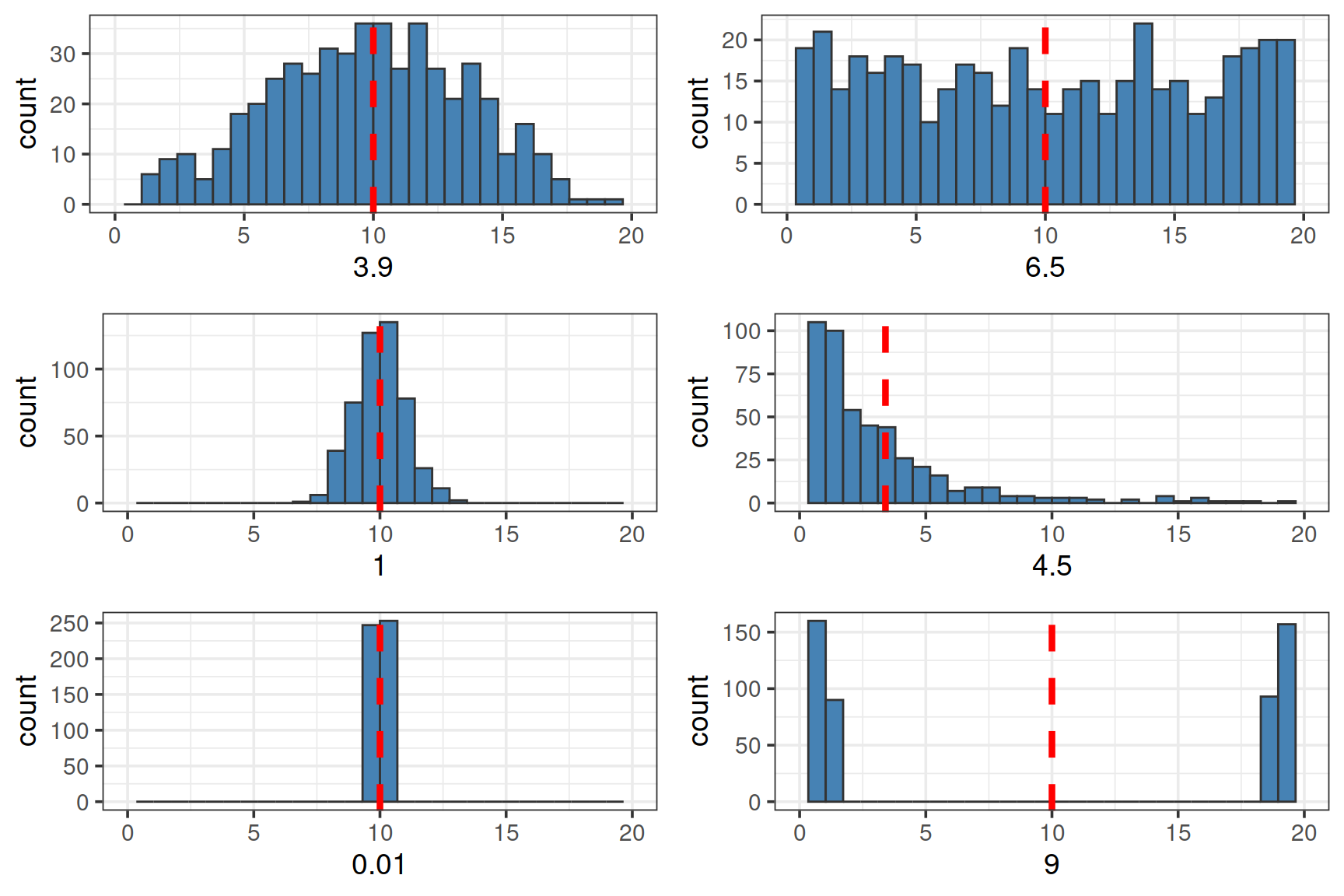
Проверим себя
Задание 2
Из 5 положительных чисел создайте выборку со средним = 10 и медианой = 7
Решение
В выборке с медианой = 7 и n = 5, мы точно знаем: (а) одно из значений должно быть равно 7, (б) два значения должны быть меньше, и два — больше 7.
Создадим вектор, в котором одно значение задано, а три других просто придумаем:
exampleСреднее это сумма всех значений выборки, поделенная на ее объем. Умножив среднее на 5 получим сумму всех значений.
Определим недостающее и проверим себя:
10 * 5 - sum(example)## [1] 26example## [1] 10Как соотносятся способы оценки центра и размаха в выборке?
ggplot(data = apple_data) + geom_boxplot(aes(x = 'Медиана \nи квантили', y = apples)) + stat_summary(geom = 'pointrange', fun.data = mean_sdl, fun.args = list(mult = 1), aes(x = 'Среднее \nи стандартное отклонение', y = diameter))
Медиана и среднее дают сходные результаты, если выборка не содержит выбросов (сильно отличающихся от других наблюдений).
Take-home messages
- Описательные статистики ходят только в связке.
- Выбирая между медианой и средним, учитывайте природу данных.