Что такое Kafka

Опубликовано: 13.09.2022
программный брокер сообщений, то есть приложение, которое принимает данные от другой программы, хранит их в своей базе и отдает информацию другой программе. Kafka была разработана в LinkedIn, после исходный код был передан в Apache Software Foundation.
Область применения кафки сфокусирована в отраслях, где требуются сбор, обработка, безопасное хранение и передача больших объемов данных, например:
- Онлайн-игры.
- Социальные сети.
- Банковские системы.
- Системы геопозиционирования.
- Анализ данных (большие объемы).
- Системы с множеством датчиков, сенсоров, контроллеров и других конечных устройств (например, интернет вещей).
Архитектурно в процессе работы Kafka Apache участвуют следующие сущности:
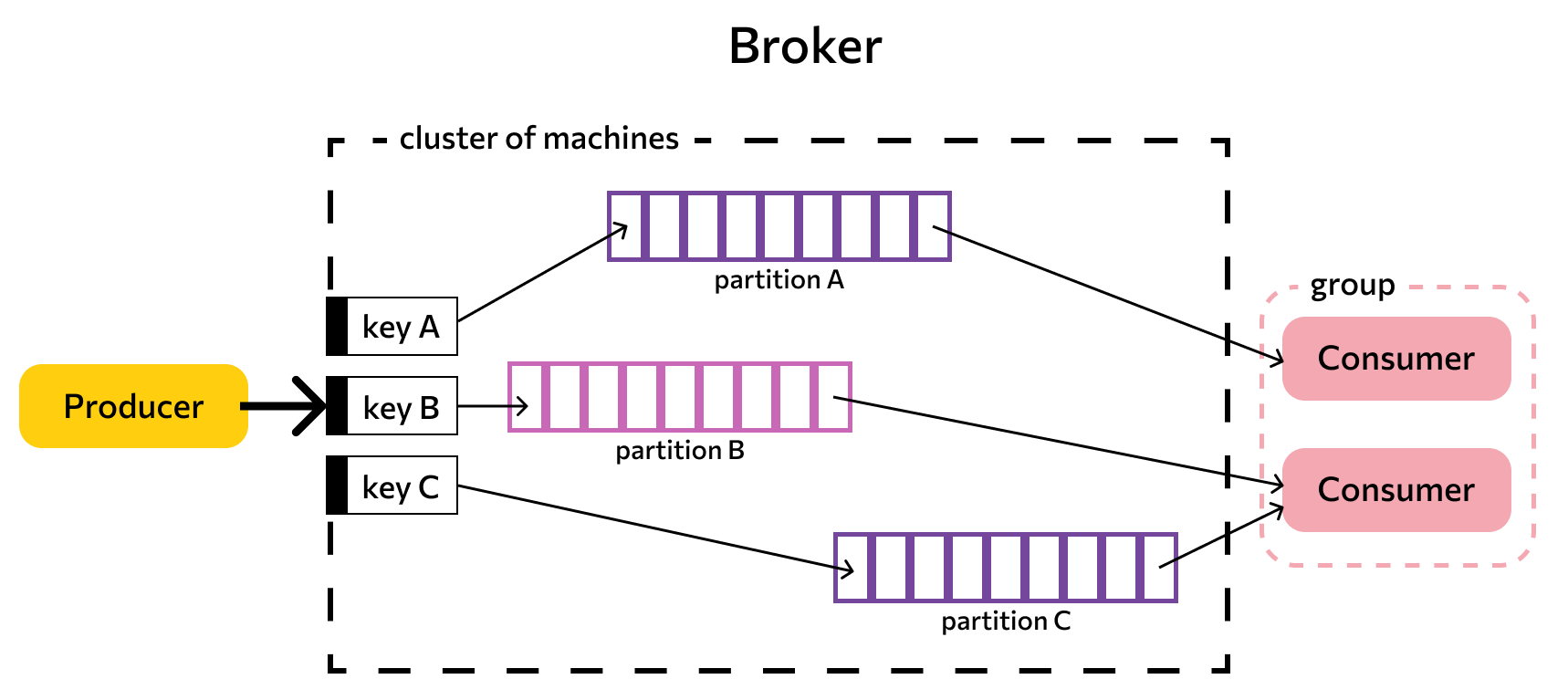
- Продюсер (producer) — то, что генерирует и посылает данные брокеру;
- Потребитель (consumer) — тот, кто принимает отправленные продюсером сообщения;
- Сообщение — данные, необходимый для совершения какой-либо операции (например, авторизации, оформления покупки или подписки);
- Брокер — узел для передачи данных от продюсера к потребителю;
- Топик (тема) — хранилище сгруппированных сообщений (по разным признакам), из которого потребитель извлекает необходимую ему информацию.
- Возможность долгого хранения данных.
- Бесплатность и открытый исходный код.
- Алгоритмы работы заточены на высокую производительность.
- Механизмы защиты данных для обеспечения большей безопасности.
- Возможность установки и настройки в режиме кластера для отказоустойчивости.
- Простая масштабируемость за счет добавления узлов (горизонтальная масштабируемость).
Популярный аналог кафки — RabbitMQ. В целом, оба программных продукта позволяют реализовать очереди запросов. Но есть несколько нюансов:
- Способы доставки сообщений: Kafka использует pull (получатель сам достает сообщение), а RabbitMQ — push (брокер сам отправляет сообщение).
- Kafka хранит данные, пока не достигнет установленного администратором предела. RabbitMQ удаляет сообщение после отправки его получателю.
- При высоких нагрузках RabbitMQ обладает меньшей производительностью из-за реализованного гибкого управления.
Еще немного о Kafka на Википедии.
Встречается в статьях
Мини-инструкции:
- Как установить программный брокер Kafka на Linux и выполнить базовые команды
- Как установить и настроить NATS сервер на Linux
Что такое Apache Kafka: как устроен и работает брокер сообщений
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют это ПО.

Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют «Кафку».
Что такое брокер сообщений
Главная задача брокера — обеспечение связи и обмена информацией между приложениями или отдельными модулями в режиме реального времени.
Брокер — система, преобразующая сообщение от источника данных (продюсера) в сообщение принимающей стороны (консьюмера). Брокер выступает проводником и состоит из серверов, объединенных в кластеры.
Apache Kafka — диспетчер сообщений, разработанный LinkedIn. В 2011 году был опубликован программный код. В 2012 году Kafka попал в инкубатор Apache, дальнейшая разработка ведется в рамках Apache Software Foundation. Открытое программное обеспечение с разрешительной лицензией написано на Java и Scala.
Изначально «Кафку» создавали как систему, оптимизированную под запись, и создатель Джей Крепс выбрал такое название в честь одного из своих любимых писателей.
Шаги передачи данных
Чтобы понять, как функционирует распределенная система Apache Kafka, необходимо проследить путь данных.
Событие или сообщение — данные, которые поступают из одного сервиса, хранятся на узлах Kafka и читаются другими сервисами. Сообщение состоит из:
- Key — опциональный ключ, нужен для распределения сообщений по кластеру.
- Value — массив байт, бизнес-данные.
- Timestamp — текущее системное время, устанавливается отправителем или кластером во время обработки.
- Headers — пользовательские атрибуты key-value, которые прикрепляют к сообщению.
Продюсер — поставщик данных, который генерирует сообщения — например, служебные события, логи, метрики, события мониторинга.
Консьюмер — потребитель данных, который читает и использует события, пример — сервис сбора статистики.
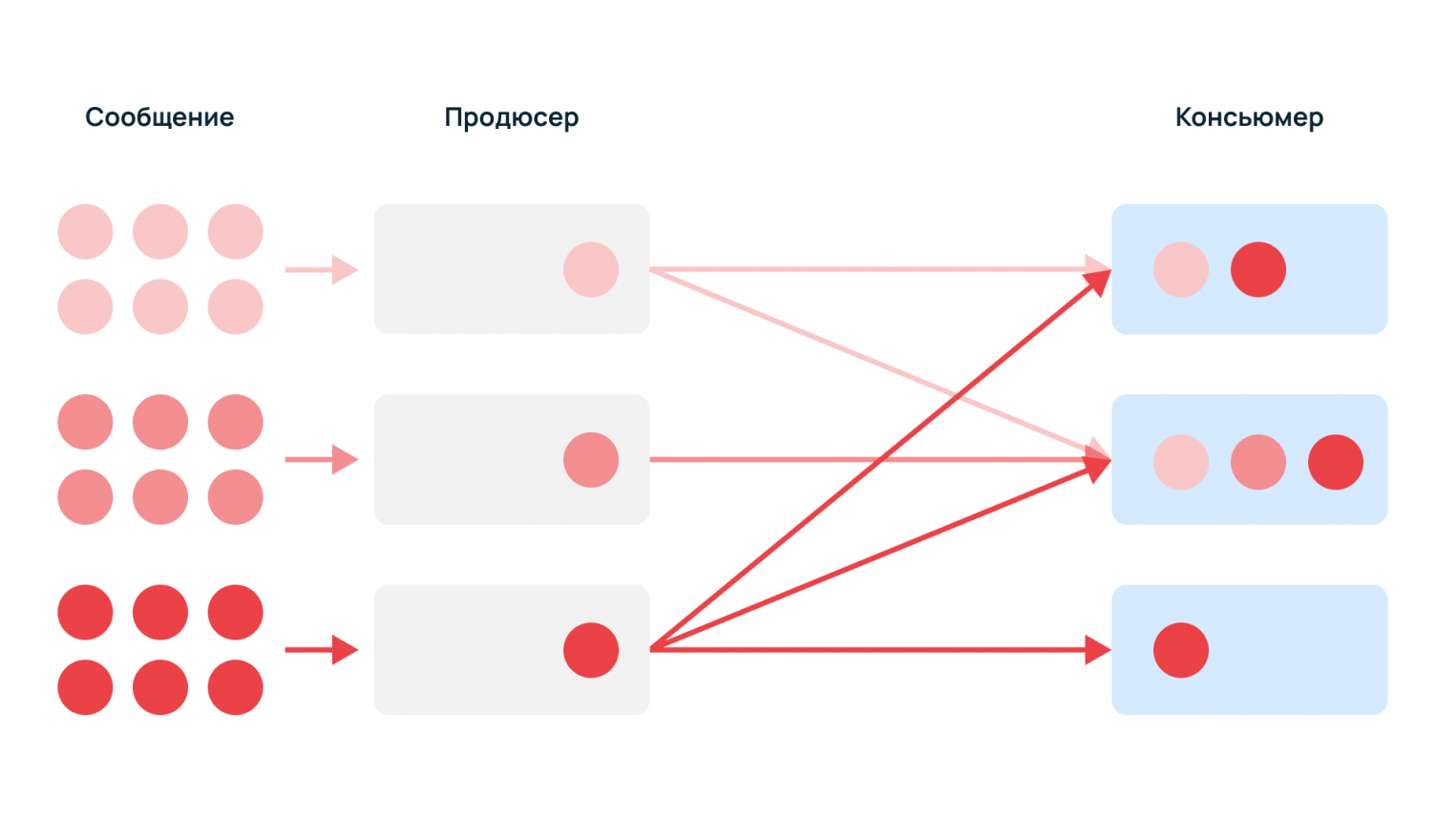
Какие сложности решает распределенная система
Сообщения могут быть однотипными или разнородными, поскольку разным потребителям нужны разные данные. Один тип событий может быть нужен всем консьюмерам, а другие — только одному.
Без брокера продюсеры должны знать получателя и резервного консьюмера, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых консьюмеров. С помощью брокера продюсеры просто отправляют информацию в единый узел.
Managed service для Apache Kafka
Сообщения хранятся на узлах-брокерах. Kafka — масштабируемый кластер со множеством взаимозаменяемых серверов, в которые добавляются новые брокеры, распределяющие задачи между собой.
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
Topic — принцип деления потока данных, базовая и основная сущность Apache Kafka. В топик складывается стрим данных, единая очередь из входящих сообщений.
Partition — для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
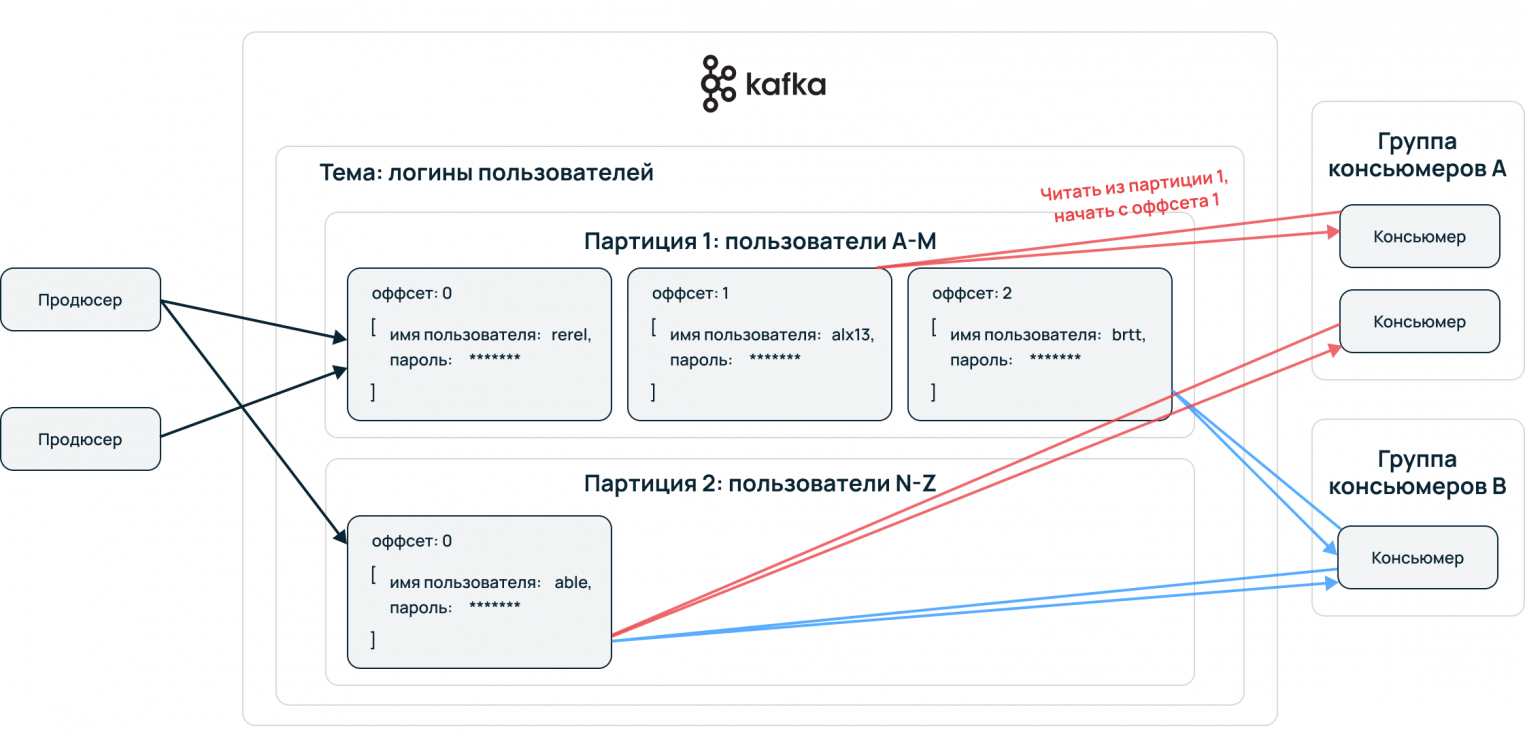
Упорядочение событий происходит на уровне партиций. Принимающая сторона потребляет данные в порядке расположения в партиции. Пример: все события одного пользователя сервисы принимают упорядоченно, обработка сохраняет последовательность пути пользователя. Выстраивается конвейер данных, алгоритмы машинного обучения могут извлекать из сырой информации необходимую для бизнеса информацию.
Преимущества Apache Kafka
Брокер распределяет информацию в широковещательном режиме. Применяющийся в Apache Kafka подход нужен для масштабирования и репликации данных.
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Офсеты
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Взаимодействие через API
Брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: продюсерам и консьюмерам необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Где применяется Apache Kafka
Отказоустойчивая система используется в бизнесе, где необходимо собирать, хранить и обрабатывать большие неструктурированные данные. Примеры — платформы, где требуется интеграция данных из большого количества источников, сервисы стриминговой аналитики, mission-critical applications.
Big Data
Первоначально LinkedIn разработали «Кафку» для своих целей: обмена данными между службами, репликации баз данных, потоковой передачи информации о деятельности и операционных показателях приложений.
Для IBM Apache Kafka работает как средство обмена сообщениями между микросервисами. В аналитических системах американской корпорации Apache Kafka обрабатывает потоковые и событийные данные.
Uber, Twitter, Netflix и AirBnb с помощью хорошо развитых пайплайнов обработки данных передают миллиарды сообщений в день. «Кафка» решает проблемы перемещения Big data из одного источника в другой.
Издание The New York Times использует Apache Kafka для хранения и распространения опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей в режиме реального времени.
Internet of Things
IoT-платформы используют архитектуру с большим количеством конечных устройств: контроллеров, датчиков, сенсоров и smart-гаджетов. ПО интернета вещей с помощью алгоритмов ML составляет графики профилактического ремонта оборудования, анализируя данные, поступающие с устройств.
ML-системы работают с онлайн-потоками, когда приборы, приложения и пользователи постоянно посылают данные, а сервисы обрабатывают их в реальном времени. Apache Kafka выступает центральным звеном в этом процессе.
Отрасли
Kafka используют организации практически в любой отрасли: разработка ПО, финансовые услуги, здравоохранение, государственное управление, транспорт, телеком, геймдев.
Сегодня Kafka пользуются тысячи компаний, более 60% входят в список Fortune 100. На официальном сайте представлен полный список корпораций и учреждений, которые используют брокера Apache.
Конкуренты
Чаще всего Kafka сравнивают с RabbitMQ. Обе системы — брокеры сообщений. Главное отличие в модели доставки: Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика; брокер RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
«Кролик» удаляет событие после доставки, «Кафка» хранит до запланированной очистки журнала. Таким образом, брокер Apache используется как источник истории изменений.
Разработчики RabbitMQ создали системы управления потоком сообщений: мониторинг получения, маршрутизация и шаблоны доставки. Подобное гибкое управление подойдет для высокоскоростного обмена сообщениями между несколькими сервисами. Минус такого подхода в снижении производительности при высокой нагрузке.
Главный вывод — для сбора и агрегации событий из большого количества источников, логов и метрик больше подойдет Apache Kafka.
Заключение
Благодаря высокой пропускной способности и согласованности данных Apache Kafka обрабатывает огромные массивы данных в реальном времени. Системы горизонтального масштабирования и офсеты гарантируют надежность. Kafka — удачное решение для проекта с очень большими нагрузками на обработку данных. Установить это ПО можно на серверы Ubuntu, Windows, CentOS и других популярных операционных систем.
Что такое Apache Kafka и как он работает
Apache Kafka — это распределенное хранилище данных, которое оптимально подходит для приема и обработки потоковых сообщений в режиме реального времени. Платформа может последовательно и поэтапно справляться с информацией, поступающей из тысяч источников. В статье расскажем, как это работает и кому может быть полезным.
Что такое Apache Kafka
Данная платформа применяется для создания конвейеров потоковой передачи данных в реальном времени и приложений, которые адаптируются к потокам данных. В ней объединены обмен сообщениями, хранение и потоковая обработка информации. Благодаря этому можно хранить и анализировать как старые данные, так и те, что поступают в реальном времени.
Kafka даёт пользователям три основные функции:
- Публиковать и подписываться на потоки записей
- Эффективно хранить потоки записей в порядке их создания
- Обрабатывать потоки записей в режиме реального времени
Как работает Kafka?
В Kafka сочетаются две модели обмена сообщениями: очередь и публикация-подписка. Таким образом потребителям получают преимущества обеих. Благодаря очереди обработка данных распределяется по множеству потребителей, а это ведёт к высокой масштабируемости. Но в отличие от традиционных очередей (не многоабонентским), модель «публикация-подписка» позволяет работать с множеством подписчиков.
Метод «публикация-подписка» предусматривает несколько подписчиков, но так как сообщение отправляется каждому подписчику, он не подходит для организации работы между разными рабочими процессами. В Kafka применяется модель поделенного на секции журнала, благодаря чему можно объединить оба решения.
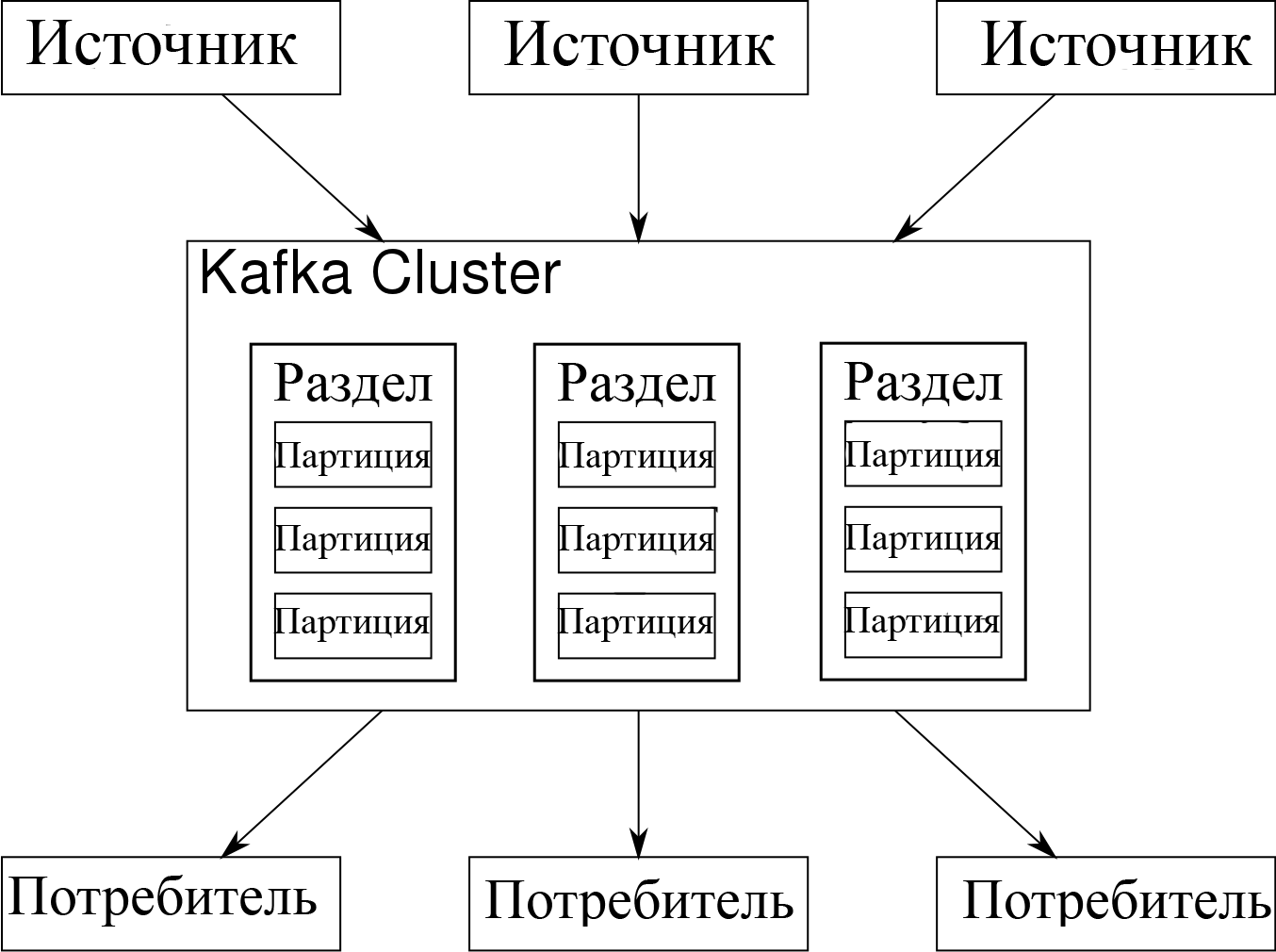
Журнал – это упорядоченная последовательность записей. Сам журнал разбит на сегменты или разделы, которые соответствуют разным подписчикам. То есть на одну и ту же тему может быть несколько подписчиков, и каждому назначается раздел, что даёт возможности для масштабируемости.
Бесплатный тестовый доступ к облаку на 30 днейПолучить
Преимущества Apache Kafka
- Масштабируемость. Модель разделенного журнала Kafka позволяет распределять данные по нескольким серверам, что делает их масштабируемыми, в отличие от модели размещения на одном сервере.
- Скорость. Kafka разделяет потоки данных, поэтому задержки минимальны.
- Надёжность. Разделы распределяются и реплицируются на множество серверов, а все данные записываются на диск. Это помогает защититься от сбоев сервера, позволяя добиться высокой надёжности и отказоустойчивости.
Зачем использовать Apache Kafka
Данная система отлично подходит для задач, в рамках которых требуется собирать, хранить и обрабатывать большие неструктурированные данные. Например, это могут быть платформы, аккумулирующие данные из множества источников, сервисы, которые занимаются стриминговой аналитикой.
Изначально Apache Kafka была разработана под собственные цели LinkedIn, а именно, обмена данными между службами, создания бэкапов, потоковой передачи информации о деятельности приложений. Для других организаций она может стать средством обмена сообщениями между микросервисами, обрабатывать потоковые данные, перемещать Big data из одного источника в другой.
В сфере Интернета вещей, Kafka также может быть незаменима. Платформы IoT собирают огромное количество данных с разных устройств, и северы получают возможность обрабатывать их в реальном времени.
Таким образом Apache Kafka может оказаться полезной практически в любой отрасли от транспортной сферы до разработки программного обеспечения.
Kafka Apache
Kafka Apache — распределенная система обмена сообщениями между серверными приложениями в режиме реального времени. Благодаря высокой пропускной способности, масштабируемости и надежности применяется в компаниях, работающих с большими объемами данных. Написана на языках Java и Scala.

Освойте профессию
«Fullstack-разработчик на Python»
Kafka разработана компанией LinkedIn. В 2011 году разработчик опубликовал исходный код системы. С тех пор платформа развивается и поддерживается как открытый проект в рамках фонда Apache Software Foundation. Apache Kafka используют многие крупные компании, такие как LinkedIn, Microsoft, The New York Times, Netflix и другие.
Профессия / 12 месяцев
Fullstack-разработчик на Python
Создавайте веб-проекты самостоятельно

Применение Kafka Apache
Kafka Apache — эффективный инструмент для организации работы серверных проектов любого уровня. Благодаря гибкости, масштабируемости и отказоустойчивости используется в различных направлениях IT-индустрии, от сервисов потоковых видео до аналитики Big Data.
- Для связи микросервисов. Kafka — связующее звено между отдельными функциональными модулями большой системы. Например, с ее помощью можно подписать микросервис на другие компоненты для регулярного получения обновлений.
- Потоковая передача данных. Высокая пропускная способность системы позволяет поддерживать непрерывные потоки информации. За счет грамотной маршрутизации «Кафка» не только надежно передает данные, но и позволяет производить с ними различные операции.
- Ведение журнала событий. Kafka сохраняет данные в строго организованную структуру, в которой всегда можно отследить, когда произошло то или иное событие. Информация хранится в течение заданного промежутка времени, что можно использовать для разгрузки базы данных или медленно работающих систем логирования.
Читайте также Как выбрать IT-специальность в новых реалиях?
Как устроена и работает Kafka Apache
Кратко архитектуру системы сообщений можно охарактеризовать следующим образом:
- распределенность — отдельные узлы системы располагаются на нескольких аппаратных платформах (кластерах). Это обеспечивает ей высокую отказоустойчивость;
- масштабируемость — систему можно наращивать за счет простого добавления новых узлов (брокеров сообщений).
В архитектуре Kafka Apache ключевыми являются концепции:
- продюсер (producer) — приложение или процесс, генерирующий и посылающий данные (публикующий сообщение);
- потребитель (consumer)— приложение или процесс, который принимает сгенерированное продюсером сообщение;
- сообщение — пакет данных, необходимый для совершения какой-либо операции (например, авторизации, оформления покупки или подписки);
- брокер — узел (диспетчер) передачи сообщения от процесса-продюсера приложению-потребителю;
- топик (тема)— виртуальное хранилище сообщений (журнал записей) одинакового или похожего содержания, из которого приложение-потребитель извлекает необходимую ему информацию.
В упрощенном виде работа Kafka Apache выглядит следующим образом:
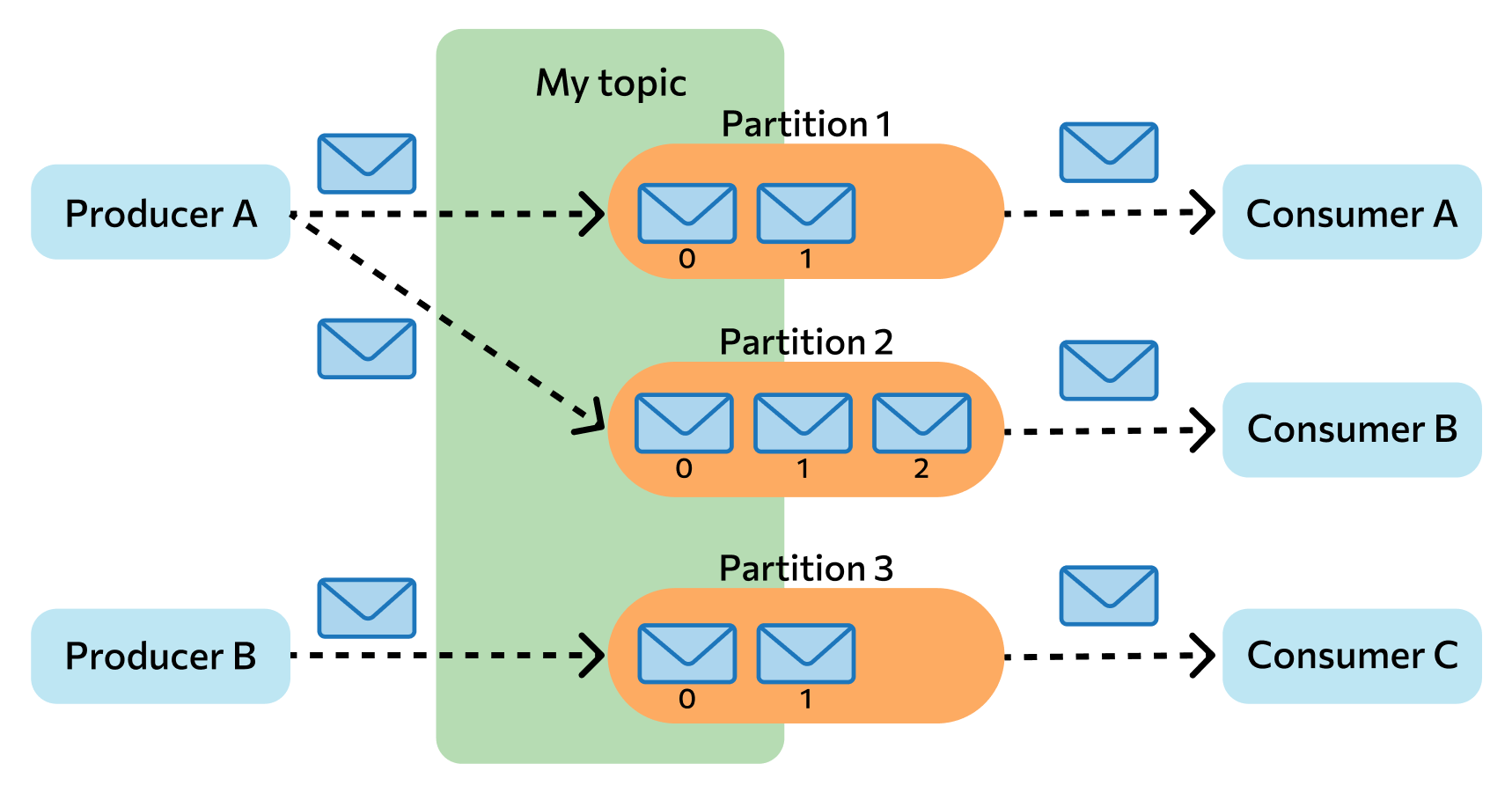
- Приложение-продюсер создает сообщение и отправляет его на узел Kafka.
- Брокер сохраняет сообщение в топике, на который подписаны приложения-потребители.
- Потребитель при необходимости делает запрос в топик и получает из него нужные данные.
Сообщения хранятся в Kafka в виде журнала коммитов — записей, размещенных в строгой последовательности. Их можно только добавлять. Удалять или корректировать нельзя. Сообщения хранятся в той последовательности, в которой поступили, их считывание ведется слева направо, а отслеживание — по изменению порядкового номера. Брокеры Kafka не обрабатывают записи — только помещают их в тему на кластере. Хранение может длиться в течение определенного периода или до достижения заданного порога.

Станьте Fullstack-разработчик на Python и найдите стабильную работу
на удаленке
Если тема слишком разрастается, для упрощения и ускорения процесса она разделяется на секции. Каждая секция содержит сообщения, сгруппированные по объединяющему признаку. Например, массив пользовательских запросов можно сгруппировать по первой букве имени пользователей. Так приложению-потребителю не придется просматривать весь топик — только нужную тему, что ускоряет процесс обмена сообщениями.
Преимущества Kafka
Отказоустойчивость
Kafka — распределенная система обмена сообщениями, узлы которой содержатся на нескольких кластерах. Принимая сообщение от продюсера, она реплицирует (копирует) его, а копии сохраняет на разных узлах. При этом один из брокеров назначается ведомым в секции, через него потребители будут обращаться к записям. Другие брокеры остаются ведомыми, их главная задача — обеспечить сохранность сообщения (его копий) даже при выходе одного или нескольких узлов из строя. Распределенный характер и механизм репликации записей обеспечивают системе высокую устойчивость. Надежность повышает интеграция с Apache ZooKeeper, которая обеспечивает координацию компонентов друг с другом.
Масштабируемость
Apache Kafka поддерживает «горячее» расширение, то есть ее можно увеличивать с помощью простого добавления новых машин в кластеры, не отключая всю систему. Так исключаются простои, связанные с переоборудованием серверных мощностей. Принцип удобнее горизонтального масштабирования, при котором на одну серверную машину «навешиваются» дополнительные ресурсы: жесткие диски, CPU, RAM и т.д. При необходимости систему можно легко сократить, исключив лишние машины из кластера.
Производительность
В Kafka процессы генерирования/отправки и считывания сообщений организованы независимо друг от друга. Тысячи приложений, процессов могут одновременно и параллельно играть роль генераторов и потребителей сообщений. В сочетании с распределенным характером и масштабируемостью это позволяет применять «Кафка» как в небольших, так и в масштабных проектах с большими объемами данных.
Открытый исходный код
Kafka распространяется по свободной лицензии фонда Apache Software Foundation. Благодаря этому Kafka Apache имеет ряд преимуществ:
- большой объем подробной справочной информации от официальных разработчиков, а также различных мануалов, лайфхаков, инструкций и обзоров от большого числа энтузиастов-любителей и профессионалов;
- большое количество дополнительных программных пакетов, патчей от сторонних разработчиков, расширяющих и улучшающих базовый функционал системы;
- возможность самостоятельно адаптировать систему под специфику проекта за счет гибкости настроек.
Безопасность
В Kafka есть инструменты, обеспечивающие безопасную работу и достоверность данных. Например, настроив уровень изоляции для транзакций, можно исключить чтение незавершенных или отмененных сообщений. Кроме того, благодаря сохранению данных в топиках пользователь может в любой момент отследить изменения в системе. А принцип последовательной записи позволяет быстро находить нужные сообщения.
Долговечность
Данные в Kafka сохраняются в долговременные виртуальные хранилища в течение заданного периода времени (дней, недель, месяцев). За счет распределенного хранения информации она не потеряется при сбое одного или нескольких узлов, и потребитель сможет в любой момент обратиться к нужному сообщению в топике, отследив его смещение.
Интегрируемость
Благодаря собственному протоколу на базе TCP «Кафка Апач» взаимодействует с другими протоколами передачи данных (REST, HTTP, XMPP, STOMP, AMQP, MQTT). Встроенный фреймворк Kafka Connect позволяет Kafka подключаться к базам данных, файловым и облачным хранилищам.
Единственный заметный недостаток системы — ориентированность на обработку больших объемов данных. Из-за этого функционал маршрутизации потоков ограничен по сравнению с другими аналогичными платформами. По мере развития Kafka это различие становится менее заметным, а сама система — более гибкой и универсальной.
Fullstack-разработчик на Python
Fullstack-разработчики могут в одиночку сделать IT-проект от архитектуры до интерфейса. Их навыки востребованы у работодателей, особенно в стартапах. Научитесь программировать на Python и JavaScript и создавайте сервисы с нуля.