Что такое ModelMapper и зачем он нужен?
ModelМapper просто использовать в начале проекта без особых знаний. Попытаюсь разобрать основные моменты работы с фреймворком.
Александр Федоров
Senior Java разработчик Usetech
- Как начать использовать ModelMapper?
- Маппинг отдельных полей
- Маппинг и наследование
- Заключение
В ходе разработки любого приложения программист сталкивается с необходимостью работать с моделями различных объектов, созданных для разных целей. И соответственно, с необходимостью конвертировать их между собой. Если ваш проект на начальном этапе развития, то можно, конечно, использовать рукописные конверторы. Но рано или поздно проект станет больше, и вы столкнётесь с необходимостью использовать уже готовое решение для конвертации моделей.
Одним из таких решений является МodelMapper. Его очень просто использовать в самом начале проекта без особых знаний. Попытаюсь разобрать основные моменты использования фреймворка.
Как начать использовать ModelMapper?
Сначала добавляем его в зависимости. Если вы используете maven, то:
org.modelmapper modelmapper 2.3.0 implementation group: ‘org.modelmapper’, name: ‘modelmapper’, version: ‘2.3.0’
Предположим, у нас простой проект с базой данных и RestAPI и нам необходимо превратить entity в dto и обратно. На этапе прототипа проекта могут полностью совпадать, и в таком простейшем примере нам вообще не нужно ничего дополнительного писать. МodelMapper всё сделает за нас.
В примере, представленном ниже, я буду использовать аннотации Lombok, чтобы было проще =)
Наши entity:
package org.example.entity; import lombok.Builder; import lombok.Data; import lombok.NoArgsConstructor; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; import javax.persistence.ManyToOne; @Data @Entity @NoArgsConstructor public class BookEntity < @Id @GeneratedValue private Long id; private String bookName; @ManyToOne private AuthorEntity author; private Integer pages; private String index; @Builder public BookEntity(Long id, String bookName, AuthorEntity author, Integer pages, String index) < this.id = id; this.bookName = bookName; this.author = author; this.pages = pages; this.index = index; >> import lombok.Builder; import lombok.Data; import lombok.NoArgsConstructor; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; @Entity @Data @NoArgsConstructor public class AuthorEntity < @Id @GeneratedValue private Long id; private String name; @Builder public AuthorEntity(Long id, String name) < this.id = id; this.name = name; >> Наша dto:
package org.example.dto; import lombok.Data; @Data public class BookDto
Для того, чтобы начать маппить entity в dto нам достаточно написать вот такой простой конвертор:
package org.example.convertor; import org.example.dto.BookDto; import org.example.entity.BookEntity; import org.modelmapper.ModelMapper; import org.springframework.stereotype.Component; @Component public class BookConvertor < private final ModelMapper modelMapper; public BookConvertor() < this.modelMapper = new ModelMapper(); >public BookDto convertToDto(BookEntity entity) < return modelMapper.map(entity,BookDto.class); >> А для наполнения базы использовать следующие entity:
AuthorEntity authorEntity1 = AuthorEntity.builder().name("Чарльз Диккенс").build(); AuthorEntity authorEntity2 = AuthorEntity.builder().name("Джейн Остин ").build(); AuthorEntity authorEntity3 = AuthorEntity.builder().name("Иоганн Вольфганг фон Гёте").build(); BookEntity bookEntity1 = BookEntity.builder() .bookName("Приключения Оливера Твиста") .author(authorEntity1) .pages(220) .index("ISBN: 978-5-91921-226-3") .build(); BookEntity bookEntity2 = BookEntity.builder() .bookName("Гордость и предубеждение") .author(authorEntity2) .pages(400) .index("ISBN: 978-5-699-52151-7") .build(); BookEntity bookEntity3 = BookEntity.builder() .bookName("Фауст") .author(authorEntity3) .pages(270) .index("ISBN: 5-699-07346-9") .build(); И наш контроллер с одним единственным методом:
package org.example.controller; import lombok.RequiredArgsConstructor; import org.example.convertor.BookConvertor; import org.example.dto.BookDto; import org.example.repositories.BookRepository; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.List; import java.util.stream.Collectors; @RestController @RequestMapping("/book") @RequiredArgsConstructor public class BookController < private final BookRepository bookRepository; private final BookConvertor bookConvertor; @GetMapping public List findAllBooks()< return bookRepository.findAll() .stream() .map(bookConvertor::convertToDto) .collect(Collectors.toList()); >> После выполнения запроса http://localhost:8080/book мы получаем следующий ответ:
МodelMapper по названию полей сам догадывается, что на что нужно маппить. Это очень удобно, если у вас есть множество моделек, которые в целом похожи друг на друга. Весь процесс можно разбить на две части: распознание и связь полей, а также перенос значений.
- По умолчанию ModelMapper ищет поля, помеченные как public, и использует JavaBeans Naming Convention, чтобы определить какие проперти соответствуют друг другу. Каждый шаг распознавания поля и связи с полем модели назначения можно настроить;
- AccessLevel — имеет следующие значения PUBLIC, PROTECTED, PACKAGE_PRIVATE, PRIVATE;
- NamingConvention — имеет следующие значения JAVABEANS_ACCESSOR, JAVABEANS_MUTATOR, NONE JAVABEANS_ACCESSOR ищет гетторы а JAVABEANS_MUTATOR ищет сеттеры, так-же можно создать свой NamingConvention dspdfd NamingConvention.builder();
- NameTokenizers — имеет следующие значения CAMEL_CASE, UNDERSCORE эта опция используется для глубокого маппинга, пример маппинга имени автора выше;
- MatchingStrategies — может быть STANDARD, LOOSE, STRICT по умолчанию стоит STANDARD.
Если описать работу маппера простыми словами, то: он сканирует поля в соответствии с AccessLevel, парсит их и бьёт на токены, сравнивая эти токены он пытается понять подходит ли поле для маппинга. Стратегии настраивают степень точности:
- STRICT — все токены должны быть в одном порядке, а также все токены модели источника должны совпадать с токенами модели получателя;
- STANDARD — порядок токенов может не совпадать, все токены цели должны совпадать и только один токен источника должен совпадать.;
- LOOSE — порядок токенов может не совпадать, только один токен модели источника и получателя должен совпадать.
Пример настройки значений для ModelMapper:
public BookConvertor()
Это далеко не все настройки МodelMapper, больше настроек можно посмотреть в классе InheritingConfiguration.
Маппинг отдельных полей
Для начинающего специалиста, показанного выше, вполне достаточно. Но для серьёзного приложения нужен больший контроль над маппингом определённых полей. Также было бы удобно маппить вложенные сущности. В этом разделе мы рассмотрим, как нам с этим поможет МodelMapper.
Давайте немного усложним наш маппинг. Предположим, что нам в нашем поле index не нужна подстрока ISBN:. Как нам изменить условия маппинга, чтобы для одного поля мы удаляли эту подстроку?
Можно использовать Converter :
package org.example.convertor; import org.example.dto.BookDto; import org.example.entity.BookEntity; import org.modelmapper.Converter; import org.modelmapper.ModelMapper; import org.springframework.stereotype.Component; @Component public class BookConvertor < private final ModelMapper modelMapper; private ConverterisbnRemover = (src) -> src.getSource().replaceAll("ISBN: ", ""); public BookConvertor() < this.modelMapper = new ModelMapper(); modelMapper.createTypeMap(BookEntity.class, BookDto.class) .addMappings(mapper ->mapper.using(isbnRemover).map(BookEntity::getIndex, BookDto::setIndex)); > public BookDto convertToDto(BookEntity entity) < return modelMapper.map(entity, BookDto.class); >> В данном примере мы создали TypeMap для двух наших объектов и указали поле, для которого мы хотим использовать этот конвертер.
Теперь наш запрос возвращает следующее:
Также конвертер можно добавить и для всего МodelMapper, если написать modelMapper.addConverter(isbnRemover); . Тогда он будет применён для всех конвертаций String->String.
А также можно создать конвертер на весь TypeMap: modelMapper.createTypeMap(BookEntity.class, BookDto.class).setConverter(ctx->BookDto.builder().build()); , но тогда будет возвращён пустой объект BookDto.
Мы научились модифицировать правила конвертации отдельных полей и целых объектов. С этим уже можно полноценно работать. Но бывают случаи, когда нам не нужно модифицировать значение, а необходимо просто связать два названных по-разному поля.
Добавим в наши объекты поля: comment в BookEntity и review в BookDto и модифицируем наш BookConverter:
package org.example.convertor; import org.example.dto.BookDto; import org.example.entity.BookEntity; import org.modelmapper.Converter; import org.modelmapper.ModelMapper; import org.springframework.stereotype.Component; @Component public class BookConvertor < private final ModelMapper modelMapper; private ConverterisbnRemover = (src) -> src.getSource().replaceAll("ISBN: ", ""); public BookConvertor() < this.modelMapper = new ModelMapper(); modelMapper.createTypeMap(BookEntity.class, BookDto.class) .addMapping(BookEntity::getComment,BookDto::setReview) .addMappings(mapper ->mapper.using(isbnRemover).map(BookEntity::getIndex, BookDto::setIndex)); > public BookDto convertToDto(BookEntity entity) < return modelMapper.map(entity, BookDto.class); >> И тогда запрос будет выглядеть вот так:
Теперь при маппинге отдельных полей у нас будет меньше мороки.
А что, если нам нужно маппить ещё и вложенную сущность? Для этого мы снова модифицируем BookDto и добавляем туда поле author вместо authorName. А также создаём класс AuthorDto, содержащий только поле name.
И наш BookConverter теперь будет выглядеть следующим образом:
package org.example.convertor; import org.example.dto.AuthorDto; import org.example.dto.BookDto; import org.example.entity.AuthorEntity; import org.example.entity.BookEntity; import org.modelmapper.Converter; import org.modelmapper.ModelMapper; import org.springframework.stereotype.Component; @Component public class BookConvertor < private final ModelMapper modelMapper; private ConverterisbnRemover = (src) -> src.getSource().replaceAll("ISBN: ", ""); public BookConvertor() < this.modelMapper = new ModelMapper(); modelMapper.createTypeMap(BookEntity.class, BookDto.class) .addMapping(BookEntity::getComment, BookDto::setReview) .addMappings(mapper ->mapper.using(isbnRemover).map(BookEntity::getIndex, BookDto::setIndex)); modelMapper.createTypeMap(AuthorEntity.class, AuthorDto.class); > public BookDto convertToDto(BookEntity entity) < return modelMapper.map(entity, BookDto.class); >> А в ответе на запрос книг получаем:
Маппинг и наследование
Самое просто мы разобрали ранее. Теперь давайте посмотрим, как же ModelМapper работает с наследованием. Для этого мы изменим модель наших данных, добавив наследников для книг.
Теперь наша модель будет выглядеть так:
@Data @Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @NoArgsConstructor public class BookEntity < @Id @GeneratedValue private Long id; private String bookName; @ManyToOne private AuthorEntity author; private String index; private String comment; public BookEntity(Long id, String bookName, AuthorEntity author, String index, String comment) < this.id = id; this.bookName = bookName; this.author = author; this.index = index; this.comment = comment; >> @Entity @Data @NoArgsConstructor public class HardCoverBookEntity extends BookEntity < private Integer pages; @Builder public HardCoverBookEntity(Long id, String bookName, AuthorEntity author, String index, String comment, Integer pages) < super(id, bookName, author, index, comment); this.pages = pages; >> @Entity @Data @NoArgsConstructor public class AudioBookEntity extends BookEntity < private Integer playLength; private String reader; @Builder() public AudioBookEntity(Long id, String bookName, AuthorEntity author, String index, String comment, Integer playLength, String reader) < super(id, bookName, author, index, comment); this.playLength = playLength; this.reader = reader; >> А наши начальные данные так:
BookEntity bookEntity1 = HardCoverBookEntity.builder() .bookName("Приключения Оливера Твиста") .author(authorEntity1) .pages(220) .comment("Отличный приключенчиский роман") .index("ISBN: 978-5-91921-226-3") .build(); BookEntity bookEntity2 = HardCoverBookEntity.builder() .bookName("Гордость и предубеждение") .author(authorEntity2) .pages(400) .comment("Занудная история про богатеев в Америке") .index("ISBN: 978-5-699-52151-7") .build(); BookEntity bookEntity3 = AudioBookEntity.builder() .bookName("Фауст") .author(authorEntity3) .playLength(873) .comment("Пища для ума") .index("ISBN: 5-699-07346-9") .reader("Илья Прудовский") .build(); И вот так мы поменяем наш конвертор:
@Component public class BookConvertor < private final ModelMapper modelMapper; private final MaptypeMap = Map.of( HardCoverBookEntity.class, HardCoverBookDto.class, AudioBookEntity.class, AudioBookDto.class); private Converter isbnRemover = (src) -> src.getSource().replaceAll("ISBN: ", ""); private Converter playTimeConverter = (src) -> src.getSource() + " минут"; public BookConvertor() < this.modelMapper = new ModelMapper(); TypeMapbaseTypeMap = modelMapper.createTypeMap(BookEntity.class, BookDto.class); modelMapper.createTypeMap(AuthorEntity.class, AuthorDto.class); baseTypeMap .addMapping(BookEntity::getComment, BookDto::setReview) .addMappings(mapper -> mapper.using(isbnRemover).map(BookEntity::getIndex, BookDto::setIndex)); baseTypeMap .include(AudioBookEntity.class, AudioBookDto.class) .include(HardCoverBookEntity.class, HardCoverBookDto.class); modelMapper.typeMap(AudioBookEntity.class, AudioBookDto.class) .addMappings(mapper -> mapper.using(playTimeConverter).map(AudioBookEntity::getPlayLength, AudioBookDto::setPlayTime)) .addMapping(AudioBookEntity::getReader, AudioBookDto::setReader); modelMapper.typeMap(HardCoverBookEntity.class, HardCoverBookDto.class) .addMapping(HardCoverBookEntity::getPages, HardCoverBookDto::setPages); > public BookDto convertToDto(BookEntity entity) < return modelMapper.map(entity, typeMap.get(entity.getClass())); >> Для того, чтобы ModelМapper понял, что AudioBookEntity и HardCoverBookEntity — это наследники BookEntity, мы должны к TypeMap вызвать include и добавить маппинги. Но, к сожалению, для внутренних маппингов нам надо будет указывать вручную маппинг всех полей, как показано в примере. Эта особенность может стать проблемой если у вас на проекте примитивные базовые классы и развитая иерархия наследования классов.
В ответе на запрос теперь мы получаем:
[ < "bookName": "Приключения Оливера Твиста", "index": "978-5-91921-226-3", "review": "Отличный приключенчиский роман", "author": < "name": "Чарльз Диккенс" >, "pages": 220 >, < "bookName": "Гордость и предубеждение", "index": "978-5-699-52151-7", "review": "Занудная история про богатеев в Америке", "author": < "name": "Джейн Остин" >, "pages": 400 >, < "bookName": "Фауст", "index": "5-699-07346-9", "review": "Пища для ума", "author": < "name": "Иоганн Вольфганг фон Гёте" >, "playTime": "873 минут", "reader": "Илья Прудовский" > ] Заключение
ModelМapper — это удобный фреймворк, который можно использовать как на старте вашего проекта, так и на более поздних этапах. Но у него, как и у любого инструмента, есть свои слабые стороны и ограничения, о которых стоит знать и которые стоит учитывать.

Следите за новыми постами по любимым темам
Подпишитесь на интересующие вас теги, чтобы следить за новыми постами и быть в курсе событий.
Как переводится на русский слово «mapper»?
A semantic mapper processes on a list of data elements in the source namespace.
- open_in_new Ссылка на источник
- warning Запрос проверить
Information is then fed back to mappers, who use it to draw detailed maps.
- open_in_new Ссылка на источник
- warning Запрос проверить
A first-of-its-kind lightning mapper, meanwhile, will take 500 snapshots a second.
- open_in_new Ссылка на источник
- warning Запрос проверить
The ordnance survey mappers of the 1850s recorded even modest farm buildings on their plans.
- open_in_new Ссылка на источник
- warning Запрос проверить
The semantic mapper will successively translate the data elements from the source namespace to the destination namespace.
Mapper — наш, или еще одна технология электронно-много-лучевой литографии
Коротко описанная в предыдущей статье технология от IMS обладает недостаточной производительностью, чтобы конкурировать на рынке массового производства микросхем. Она хороша для производства фотошаблонов, а также прототипов и малый партий, т.к. исключат такое дорогостоящее звено как фотошаблоны (маски).
Однако, примерно в то же самое время, когда в Австрии на IMS конструировали свою установку, в Нидерландах тоже решили попробовать силы в этом направлении.
Причем, поставили себе задачу достичь производительности не меньше 10 шт./час для пластин 300 мм.
MAPPER — акроним расшифровывается, как Multiple Aperture Pixel by Pixel Enhancement of Resolution, т. е. многоапертурное попиксельное улучшение разрешения. Название технологии почти никак не связанное с ее сущностью.

Начало было положено в 1998 году Питером Круитом (Pieter Kruit) из Делфтского технического университета в Нидерландах (Technische Universiteit Delft, TU Delft). Чуть позже к нему присоединились Берт Ян Камфербек (Bert Jan Kampherbeek) и Марко Виланд (Marco Wieland). Для коммерциализации технологии в 2000 был создан маленький стартап Mapper Lithography. Одним из акционеров стал университет.
В 2001 году одним из первых инвесторов стал Артур дель Прадо (Arthur del Prado), основатель компаний ASM и ASML.
В 2008 году построено два лабораторных прототипа аппаратов.
С 2010 года началось финансирование разработки по Европейской программе MAGIC (MAskless lithoGraphy for IC manufacturing), были выделены 11,75 млн. евро на поддержку компаний MAPPER и IMS Nanofabrication.
В 2012 году инвестировано 40 млн. евро в создание производства в Нидерландах, в этом же году начинается сотрудничество с корпорацией «Роснано», выделившей еще 40 млн. евро (1 млрд. рублей) на создания производства МЭМС электронно‑оптических элементов (ключевое звено в технологии), причем одним из условий было размещение предприятия в России. 2014 году запуск производства в России.
В 2015 собран первый образец промышленного литографа (FLX-1200), способный записывать 1шт/час пластин 300мм при технологической норме 28нм.
9 сентября 2016 года — худший день в истории компании Mapper. В этот день умер главный инвестор Артур дель Прадо. Это человек‑легенда в мире микроэлектронной литографии. Человек обладавшей редкой способностью видеть будущее. Можно сказать отец‑основатель
европейской микроэлектроники, сделавший свою компанию ASML важнейшим звеном во всей мировой микроэлектронной промышленности.



Но вернемся к компании Mapper.
С 2017 года литограф FLX-1200 доступен, как демонстрационный образец.
В 2018 году собран 2-й образец, но инвестиции в компанию были остановлены и в декабре этого же года было объявлено о банкротстве компании.
В январе 2019 года компания AMSL, как самая заинтересованная, выиграла аукцион по продаже Mapper Lithography.
Вся интеллектуальная собственность перешла к ASML. Хотя AMSL не анонсирует, каких либо новостей о работах над технологией, не связанные с AMSL структуры в КНР, предположительно, ведут работы над технологией.

Расходящийся из электронного источника (Electron source) поток электронов, пройдя через коллиматорную макро‑линзу (Collimator lens) в виде параллельного потока падает на массив апертурных отверстий (Apertute array). Отверстия формирует пучок из >13000 лучей. Каждый луч с помощью массива конденсорных микро‑линз (Condensor lens array) фокусируется в центры отверстий гасящего лучи массива (Beam blanker array).
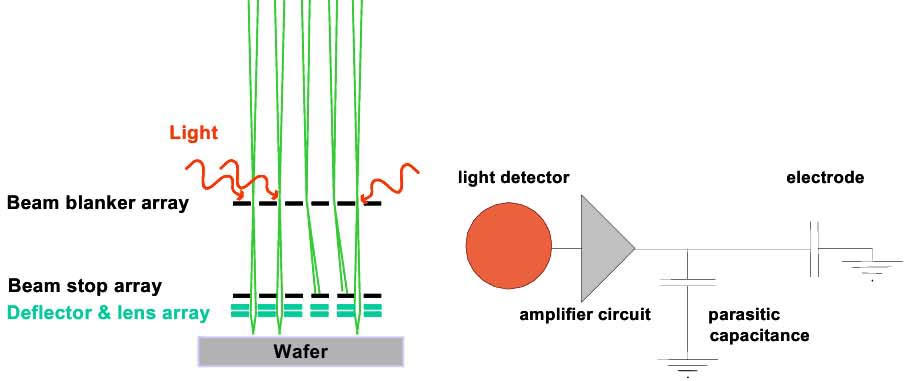
Этот массив, сделанный по технологии КМОП и МЭМС, включал в себя фотодиодные элементы принимающими управляющий свет (Light) от лазерной системы. Такое решение объясняется скоростью потока данных (7.6 Гбит/с на микроколону). Гасимые лучи отбрасываются на останавливающий лучи массив (Beam stop array). Лучи, которые не были отброшены, проходят останавливающий лучи массив (Beam stop array) и попадают в массив микро‑колон, состоящих из массива дефлекторов и линз (Deflector & lens array). Каждая микро‑линза в массиве фокусирует отдельный луч на пластине и отклоняет в диапазоне 2 мкм с частотой 6 МГц и точностью 1 нм. Лучи отклоняются одновременно во всех микро‑линзах.
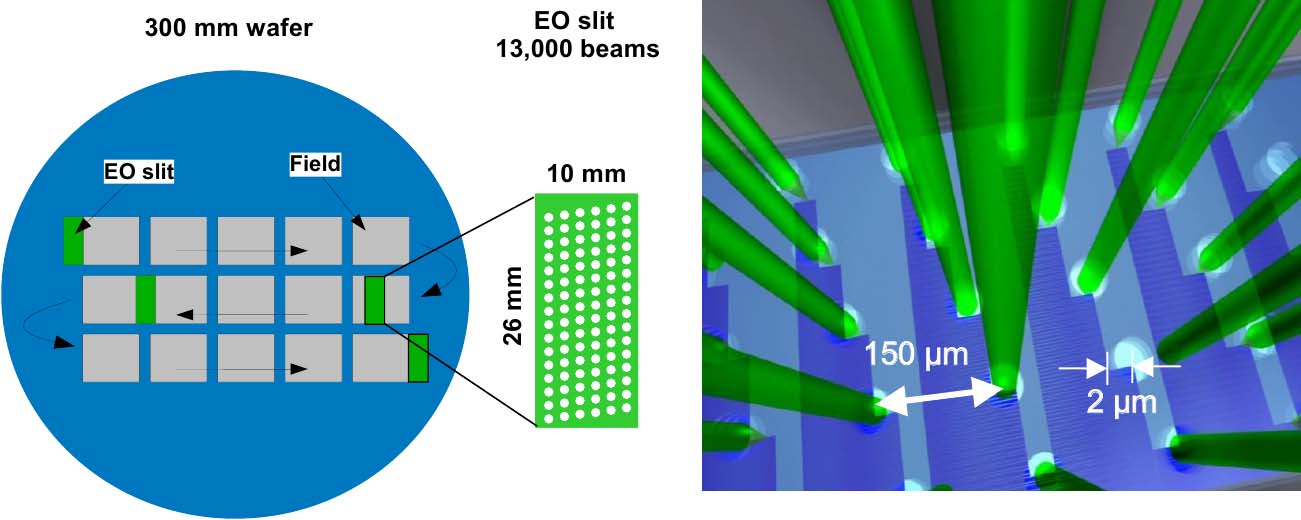
В первых аппаратах Mapper массив лучей формировался из 13050 лучей (174×75) лучей в прямоугольнике 26,1×11,25 мм. Это позволяло засвечивать прямоугольник, который примерно соответствует «стандартному» полю 26×33 мм в проекционный литографии, засвечиваемому за один шаг степпера (с маской 104×132 мм при 4х кратном уменьшении).
В направлении 26 мм шаг лучей 150 мкм, в направлении 10 мм шаг между рядами также 150 мкм и каждый последующий ряд смещен относительно предыдущего на 2 мкм. Запись идет в направлении перпендикулярном широкой стороне (26 мм).

1 — источник, 3 — коллиматорная электростатическая макро‑линза, 4 — апертурная пластина, 5 — система электростатических фокусирующих микро‑линз (МЭМС пластина), 6 — апертурная пластина, формирующая суб‑лучи (группы 7×7), 7 — управляющая система (blanker), массив МЭМС дефлекторов‑электродов, отклоняющих суб‑лучи, 8 — гасящая МЭМС пластина, массив апертурных отверстий, через которые проходят суб‑лучи не отклоненные управляющей пластиной, 9 — дефлекторная МЭМС пластина, сканирующая лучами, для засветки промежутков 2 мкм, между лучами, 10 — фокусирующая система, производящая финальную фокусировку на поверхность мишени (МЭМС пластина), 11 — мишень (кремниевая пластина), 16 — координатный стол, 20 — расходящийся поток электронов, 21 — коллимированый поток электронов, 22 — главные электронные лучи (1352 шт.), 23 — суб‑лучи (66248 шт., группами по 49 шт.), 24 — редуцированные лучи, формирующие финальный рисунок, 140 — система управления.
В дальнейшем, в демонстрационно‑промышленном образце FLX-1200 количество лучей было увеличено до 66248 шт., разделенных на группы по 49 (7×7) лучей. Сначала общий коллимированный поток электронов разделялся на 1352 «толстых» луча, потом каждый «толстый» луч разбивался на 49 суб‑лучей. Причем конфигурация матрицы лучей была изменена — между полями суб‑лучей были выделены «проходы» для лазерных лучей, управляющих матрицей. Каждый лазерный луч управлял группой суб‑лучей. Лазерные лучи излучались с концов оптоволокон и фокусировались на приемники расположенные между рядами. Вся система управлялась через 888 оптоволокна.
Заявленная технологией цель 10 шт/час пластин 300 мм требовала общего тока на поверхности пластины порядка 150 мкА. Если использовать ускоряющее напряжение 100 кВ, тогда на пластине будет выделяться 15 Вт — это недопустимо, поэтому ускоряющее напряжение снижено до 5 кВ, что дает на пластине 0,75 Вт при токе 150 мкА.
Однако ток 150 мкА на пластине для электронного источника, используемого на колоне MAPPER, с яркостью порядка 10^6 А/(см2*ср*В), с учетом потерь на апертурной пластине, пропускающей лишь небольшую долю от общего потока, фактически недостижим.
Так на демонстрационном промышленном образце был подтвержден ток отдельного луча в микро‑колоне 0.26 нА, таким образом, при количестве лучей 66248шт. общий ток, падающий на пластину, составил ~17 мкА.
При этом производительность достигла только 1 шт/час пластин 300 мм при технологической норме 28 нм. Хотя это довольно высокая производительность, но составляет лишь 1/10 от целевой.
В дальнейшем, для повышения производительности, планировалась использовать источник с меньшей яркостью (dispenser cathode), но большим током. Для многолучевой литографии с пятном 20 нм это вполне приемлемо. Хотя, в этом случае, сам катод становился бы дополнительным источником загрязнения в оптической системе. Так же придется позаботиться об охлаждении первой апертурной пластины и коллиматорной линзы — деталях воспринимающих бОльшую часть излучения.
Довольно сложная в техническом плане концепция разделения лучей по микро‑колонам была выбрана для устранения сил Кулоновсого отталкивания одноименно заряженных частиц. Т.к. для целевой производительности требуется довольно большой ток, то становиться невозможно, использовать кроссовер (место схождения всех лучей) используемый в электронно‑лучевой оптике для фокусировки луча и уменьшения размера пятна. Управление же тысячами микро‑колон требует довольно сложной электронной части и прецизионного изготовления самих микро‑колон. Для этого при финансировании «Роснано» было создано собственное производство в Москве (ООО «Маппер», mapperllc.ru). Хотя единицы оборудование ООО «Маппер» является стандартным для отросли, но его конфигурация необычна, для компании занимающейся МЭМС. Это вызвано строгими требованиями по производству микро‑линзовой электронной оптики.
Но, проблемы неустойчивой работы источника электронов на больших токах, так и в управлении микро‑колонами, позволили достичь лишь 1/10 целевой производительности.
Видимо, с уходом из жизни главного инвестора — Артура дель Прадо, уверенность оставшихся растаяла, а терпение закончилось.


Это 2-я статья из цикла.