Fluent Generics in C#
Дженерики — мощная фича доступная во многих статически типизированных языках программирования. С их помощью можно писать код, который постоянно работает со множеством разных типов, делая упор на их общие особенности, нежели на сами типы. Они позволяют создавать гибкие и переиспользуемые компоненты без нужды в дублировании кода и жертвы безопасности типов.
Несмотря на то, что дженерики давно в C#, мне всё же удаётся найти новые интересные способы их применения. Например, в одной из моих предыдущих статей я написал об уловке, позволяющей добиться return type inference, что может облегчить работу с контейнерными union types.
Недавно, мне также довелось работать над кодом, использующим дженерики. Тогда передо мной встала нетипичная задача: было необходимо определить сигнатуру, где все типовые параметры опциональны и могут использоваться друг с другом в произвольных комбинациях. Первая попытка подступиться к решению заключалась в манипуляциях с перегрузками типов, однако такой подход оказался довольно непрактичным и не увлекательным.
После нескольких экспериментов, я нашёл способ решить проблему элегантно, используя подход схожий с паттерном проектирования fluent interface, который был применён не к объектам, а к типам. Мой подход предлагает domain-specific language, который позволяет разработчику построить нужный тип за несколько логических шагов, последовательно его «конфигурируя».
В данной статье я расскажу, что из себя представляет этот подход и как его можно использовать для того, чтобы сложные обобщённые типы писать просто.
Fluent Interfaces
Fluent interface — это популярный в ООП паттерн для построения гибких и удобных интерфейсов. Его ключевая идея лежит в построении цепочки вызовов методов для того, чтобы выразить взаимодействия через непрерывный поток человеко-читаемых инструкций.
Среди прочего, паттерн используется для упрощения операций, требующих большого количества (возможно необязательных) входных данных. Fluent interfaces дают возможность настраивать каждый отдельный аспект в отдельности друг от друга вместо ожидания всех входных параметров сразу.
В качестве примера, рассмотрим следующий код:
var result = RunCommand( "git", "/my/repository", new Dictionary < ["GIT_AUTHOR_NAME"] = "John", ["GIT_AUTHOR_EMAIL"] = "john@email.com" >, "pull" );В этом сниппете вызывается метод RunCommand , который запускает дочерний процесс и заводит блокировку до его завершения. Такие настройки, как аргументы командной строки, рабочая папка и переменные среды передаются через входные параметры.
Несмотря на выполнение поставленной задачи, такая запись не очень то и человеко-читаема. В частности, трудно сказать, за что отвечает каждый из параметров, не залезая в документацию.
Также, поскольку большинство параметров могут быть необязательными, определение метода должно это учитывать в том числе. Существуют множество способов это сделать: перегрузки, именованные параметры, значения по умолчанию и так далее. Однако по большей части все они неуклюжи, громоздки и не оптимальны.
Наш пример можно улучшить, используя паттерн fluent interface:
var result = new Command("git") .WithArguments("pull") .WithWorkingDirectory("/my/repository") .WithEnvironmentVariable("GIT_AUTHOR_NAME", "John") .WithEnvironmentVariable("GIT_AUTHOR_EMAIL", "john@email.com") .Run();Таким образом разработчик может создать объект класса Command детально контролируя его состояние. Сначала мы указываем имя исполняемого модуля, затем используя доступные методы, свободно конфигурируем другие опции согласно надобности. Результирующее выражение не только стало заметно более читабельным, но и более гибким за счёт отказа от ограничений параметров метода в пользу паттерна fluent interface.
Определение fluent type
Сейчас вам может быть любопытно, какое это вообще имеет отношение к обобщённому программированию. Всё же паттерн относится к функциям, а мы пытаемся его натянуть на систему типов.
Всё же связь есть. Ключ к её пониманию — это тот факт, что дженерики есть функции для типов. Обобщённый тип можно рассматривать, как особую конструкцию высшего порядка, которая выдаёт обычный тип данных после применения к ней требуемых типовых параметров. Это аналог взаимоотношений между функциями и значениями, где функции необходимо предоставить соответствующие аргументы, чтобы получить соответствующий результат.
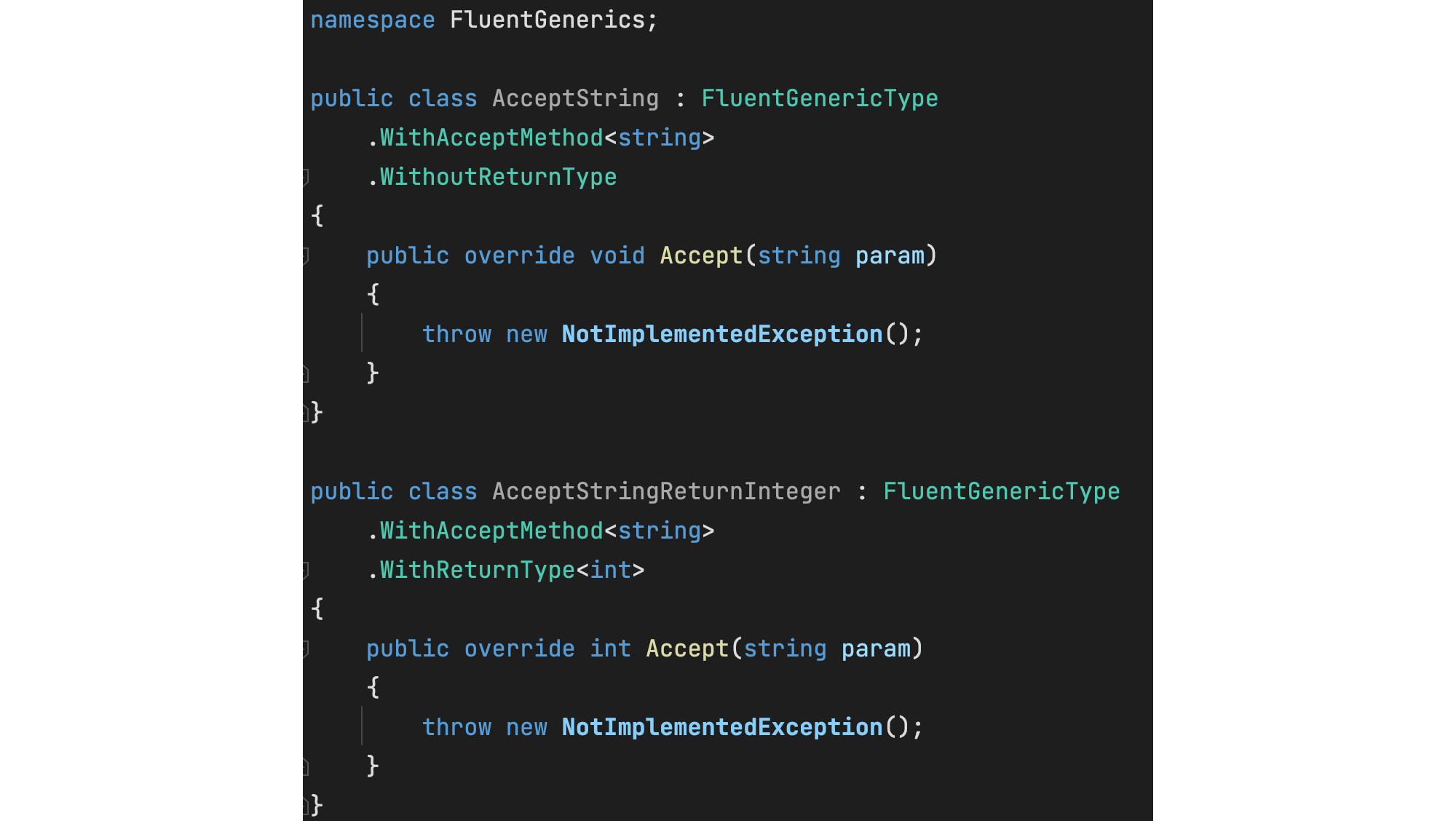
Иногда обобщённые типы могут страдать теми же недостатками проектирования, что и функции, по причине их схожести. Для демонстрации давайте представим, что мы разрабатываем веб фреймворк и хотим определить такой контракт Endpoint , который был бы ответственен за сопоставление десериализованных запросов с соответствующими объектами ответов.
Такой тип данных мог бы быть смоделирован следующим образом:
public abstract class Endpoint : EndpointBase < public abstract Task> ExecuteAsync( TReq request, CancellationToken token = default ); >Получили базовый обобщённый класс, который принимает типовой параметр соответствующий запросу, который должен быть отправлен, и другой типовой параметр, который соответствует ожидаемому ответу. Класс также определяет метод ExecuteAsync , который должен быть переопределён согласно логике конкретного эндпоинта.
Его можно использовать как фундамент для построения обработчиков разных маршрутов таким образом:
public class SignInRequest < public string Username < get; init; >public string Password < get; init; >> public class SignInResponse < public string Token < get; init; >> public class SignInEndpoint : Endpoint < [HttpPost("auth/signin")] public override async Task> ExecuteAsync( SignInRequest request, CancellationToken token = default) < var user = await Database.GetUserAsync(request.Username); if (!user.CheckPassword(request.Password)) < return Unauthorized(); >return Ok(new SignInResponse < Token = user.GenerateToken() >); > >Компилятор автоматически выводит корректную сигнатуру целевого метода при наследовании типа Endpoint . Очень удобно, когда тебе помогают избегать ошибок и делать структуру приложения более согласованной.
Несмотря на то, что класс SignInEndpoint идеально вписывается в архитектуру, не все эндпоинты обязательно имеют запрос и ответ. Например, можно придумать класс SignUpEndpoint , который не возвращает тело ответа, и класс SignOutEndpoint , не требующий каких-то данных в запросе.
Чтобы приспособить архитектуру к такого рода эндпоинтам, мы можем расширить описание типов, добавив несколько дополнительных обобщённых перегрузок:
public abstract class Endpoint : EndpointBase < public abstract Task> ExecuteAsync( TReq request, CancellationToken cancellationToken = default ); > public abstract class Endpoint : EndpointBase < public abstract TaskExecuteAsync( TReq request, CancellationToken cancellationToken = default ); > public abstract class Endpoint : EndpointBase < public abstract Task> ExecuteAsync( CancellationToken cancellationToken = default ); > public abstract class Endpoint : EndpointBase < public abstract TaskExecuteAsync( CancellationToken cancellationToken = default ); >Поначалу может показаться, что решение проблемы найдено. Однако, код, приведённый выше, не скомпилируется. Причина тому неоднозначность между Endpoint и Endpoint , поскольку нет возможности определить означает типовой параметр запрос или ответ.
Ровно как и с методом RunCommand ранее в статье существует несколько прямолинейных способов исправить ошибку, но не очень элегантных. Например, простейшим решением будет переименование типов таким образом, чтобы обозначить их предназначение и избежать коллизий:
public abstract class Endpoint : EndpointBase < public abstract Task> ExecuteAsync( TReq request, CancellationToken cancellationToken = default ); > public abstract class EndpointWithoutResponse : EndpointBase < public abstract TaskExecuteAsync( TReq request, CancellationToken cancellationToken = default ); > public abstract class EndpointWithoutRequest : EndpointBase < public abstract Task> ExecuteAsync( CancellationToken cancellationToken = default ); > public abstract class Endpoint : EndpointBase < public abstract TaskExecuteAsync( CancellationToken cancellationToken = default ); >Ошибка компиляции устранена, но мы получили уродливый дизайн. Из-за разного именования половины типов пользователю библиотеки придётся тратить много времени в поисках нужного. Более того, если мы представим расширение функционала библиотеки (например, добавление не асинхронных обработчиков), то станет очевидно, что такая архитектура плохо масштабируется.
Конечно, озвученные выше проблемы могут казаться надуманными и можно вообще не пытаться их решать. Однако, лично я думаю, что одна из главных целей библиотек — упростить жизнь разработчику.
К счастью, существует лучшее решение. Проводя параллели между функциями и обобщёнными типами, можно избавиться от перегрузок и заместить их подобным fluent определением:
public static class Endpoint < public static class WithRequest < public abstract class WithResponse< public abstract Task ExecuteAsync( TReq request, CancellationToken cancellationToken = default ); > public abstract class WithoutResponse < public abstract TaskExecuteAsync( TReq request, CancellationToken cancellationToken = default ); > > public static class WithoutRequest < public abstract class WithResponse< public abstract Task ExecuteAsync( CancellationToken cancellationToken = default ); > public abstract class WithoutResponse < public abstract TaskExecuteAsync( CancellationToken cancellationToken = default ); > > >Дизайн выше сохраняет исходные четыре типа, организуя их иерархически, нежели плоским способом. Такое возможно благодаря возможности C# объявлять вложенные типы, даже если они обобщённые.
В частности, типы содержащиеся внутри дженериков имеют доступ к типовым параметрам объявленным снаружи. Это позволяет расположить WithResponse внутри WithRequest и использовать оба типа: и TReq , и TRes .
Функционально, оба подхода идентичны. Как бы то ни было, необычная структура, которая здесь применена, полностью устранила проблемы обнаружимости типов, предлагая при этом высокий уровень гибкости.
Теперь, если пользователь хочет реализовать эндпоинт, он может сделать это следующим образом:
public class MyEndpoint : Endpoint.WithRequest.WithResponse < /* . */ >public class MyEndpointWithoutResponse : Endpoint.WithRequest.WithoutResponse < /* . */ >public class MyEndpointWithoutRequest : Endpoint.WithoutRequest.WithResponse < /* . */ >public class MyEndpointWithoutNeither : Endpoint.WithoutRequest.WithoutResponse < /* . */ >Вот как выглядит новая версия SignInEndpoint :
public class SignInEndpoint : Endpoint .WithRequest .WithResponse < [HttpPost("auth/signin")] public override async Task ExecuteAsync( SignInRequest request, CancellationToken cancellationToken = default) < // . >> Как видно, такой подход ведёт к использованию достаточно выразительной и ясной сигнатуры. Разработчик всегда начнёт с класса Endpoint , комбинируя гибким и человеко-читаемым образом необходимые возможности, независимо от того, какой эндпоинт требуется реализовать.
Кроме того, такая структура фактически представляет из себя конечный автомат. Поэтому она обезопасит разработчика от случайного неправильного использования. Например, следующие попытки неправильно создать эндпоинт приведут к ошибкам компиляции:
// Incomplete signature // Error: Class Endpoint is sealed public class MyEndpoint : Endpoint < /* . */ >// Incomplete signature // Error: Class Endpoint.WithRequest is sealed public class MyEndpoint : Endpoint.WithRequest < /* . */ >// Invalid signature // Error: Class Endpoint.WithoutRequest.WithRequest does not exist public class MyEndpoint : Endpoint.WithoutRequest.WithRequest < /* . */ >Вывод
Несмотря на неоспоримую пользу дженериков их косная природа может усложнить использование обобщённых типов в некоторых случаях. В частности, при необходимости определить сигнатуры, инкапсулирующие большое количество различных комбинаций типовых параметров, можно обратиться к перегрузкам, что влечёт за собой определённые ограничения.
В качестве альтернативного решения, можно вкладывать дженерики друг в друга, создавая иерархическую структуру, которая позволит разработчикам комбинировать их в гибкой манере. Это позволяет совместить в процессе разработки очень тонкую настройку с наилучшим удобством использования.
Ещё я веду telegram канал StepOne, где оставляю небольшие заметки про разработку и мир IT.
Кто такие дженерики?
Узнал недавно о существовании в дотнете и джвм такого понятия как Generic
Лучшие ответы ( 2 )
94731 / 64177 / 26122
Регистрация: 12.04.2006
Сообщений: 116,782
Ответы с готовыми решениями:
Кто такие хакеры?
Приветствую всех форумчан!Я вот сотни раз слышал хакер хакер вот в моём понимание хакер это человек.
TP-LINK — кто такие?
Ребят, а чего за зверь такой TP-LINK? Давно на рынке? В частности присматриваюсь к TD-W8950ND.
Кто такие программисты ..
наверняка уже кто-то публиковал похожее, но вот фантазия выдала =Ъ . Немногие знают кем на.
Кто такие русские?
Присмотритесь к заставке: http://livvve.ru/pro-kino/nerealnaya-istoriya.html.
1123 / 794 / 219
Регистрация: 15.08.2010
Сообщений: 2,185
![]() Сообщение от Николянус
Сообщение от Николянус 
Это типо улучшенные массивы?
это лишь пример их использования
![]() Сообщение от Николянус
Сообщение от Николянус
Можно пожалуйста объяснить на каком-нибудь примере типо «вот так без дженериков», а «вот так с ними».
попробую не примером, а простой задачкой. Думаю попробовав ее решить вы приблизитесь к пониманию:
напишите метод, который принимает аргумент любого типа, что-то делает с ним (например выводит в консоль его через ToString()) и возвращает этот же самый аргумент того же типа
т.е. вызываться он будет так:
int a = 10; int b = Foo(a);
2063 / 1542 / 168
Регистрация: 14.12.2014
Сообщений: 13,399
Николянус, Это типа шаблонов только ничего толком не умеют. В общем урезанное средство обобщенного программирования. Суть — аргументом дженерика являются типы. Они потом используются в коде самого дженерика вместо реальных типов. А фактический тип задается при инстанционировании экземпляра. Позволяет не переписывать алгоритмы для разных типов. Ну к примеру алгоритм сортировки массива не зависит от типа элементов. Зависит только от функции сравнения элементов. Поэтому функцию сортировки можно представить в обобщенном виде для абстрактного типа T. а при вызове так или иначе сообщить компилятору фактический тип чтобы он путем подстановки его в этот код функции вместо абстрактного автоматически сгенерировал функцию именно для этого типа.
Собственно это кое как и обеспечивают дженерики.
Николянус, товарищ Fulcrum_013 просто очень любит похоливарить, рекомендую воспринимать ту часть, где его личное мнение очень осторожно
| Меню пользователя @ КОП |
@ Fulcrum_013
КОП, ну надеюсь тот факт что неумение дженериков определить наличие оператора/метода у фактического аргумента в компайл-тайме всю малину с утиной типизацией ломают и делают их абсолютно непригодными для определения алгебры над сущностями предметной области и запихивания высокоуровневых абстракций на самый низ оспаривать не будете?
| Меню пользователя @ Fulcrum_013 |
Fulcrum_013, ну так на то он и факт, что оспаривать нечего. формулировку закрутили конечно. Вот мнения — другое дело, но этим я в этом разделе заниматься не буду)
| Меню пользователя @ КОП |
@ Fulcrum_013
КОП, ну дак холивары и начинаются когда начитавшись сказок для девочек рекламных проспектов начинают факты пытаться оспорить
| Меню пользователя @ Fulcrum_013 |
![]() Сообщение от Fulcrum_013
Сообщение от Fulcrum_013
Это типа шаблонов только ничего толком не умеют
Начинается.
| Меню пользователя @ IamRain |
@ Fulcrum_013
![]() Сообщение от IamRain
Сообщение от IamRain
Начинается.
дык вот то что дженерики не умеют большую часть того, для чего обобщенное программирование нужно и есть факт. Именно потому что с утиной типизацией не дружат в компайлтайме.
| Меню пользователя @ Fulcrum_013 |
![]() Сообщение от Fulcrum_013
Сообщение от Fulcrum_013
ну дак холивары и начинаются когда
или когда пытаются требования (внутренние идеалы) к одному языку перенести на другой, взяв только выгодные для определенного языка метрики
как там было «лучшее — враг хорошего», а информацию из фактов еще правильно интерпретировать надо
| Меню пользователя @ КОП |
@ Fulcrum_013
![]() Сообщение от КОП
Сообщение от КОП
или когда пытаются требования (внутренние идеалы) к одному языку перенести на другой
Язык это инструмент решения задач. От того что это другой язык цели и задачи к примеру обобщенного программирования никак не меняются. А требования к инструменту определяют именно задачи а не что то еще.
| Меню пользователя @ Fulcrum_013 |
![]() Сообщение от Fulcrum_013
Сообщение от Fulcrum_013
От того что это другой язык цели и задачи к примеру обобщенного программирования никак не меняются.
ну вот выберите инструмент, где обобщенное программирование оптимизировали лучше чем кроссплатформенность или быстродействие или скорость разработки или кривая обучения или наличие базы готовых либ или что еще там есть.
а я пока посплю. всем бобра
| Меню пользователя @ КОП |
@ Fulcrum_013
![]() Сообщение от КОП
Сообщение от КОП
ну вот выберите инструмент, где обобщенное программирование оптимизировали лучше чем кроссплатформенность или быстродействие или скорость разработки
Дык я его давно выбрал. Чего и остальным желаю. Потому что он реально помогает решать проблемы, а не создает их на ровном месте как урезанные новомодные языки.
| Меню пользователя @ Fulcrum_013 |
Singleberry
Регистрация: 10.12.2017
Сообщений: 107
1 2 3 4 5
int Foo(Object q) { Console.WriteLine(q.ToString()); return q; }
2063 / 1542 / 168
Регистрация: 14.12.2014
Сообщений: 13,399
Николянус, При такой реализации тип должен быть потомком Object и деспитчеризация функции осуществляться может только в рантайме. Что для «легких» функций имеет очень высокие накладные расходы на вызов относительно выполняемой полезной работы. Т.е. ни int не пролезет ни скорости не будет.
Эту проблему и решает обобщенное программирование и утиная типизация.
1 2 3 4 5
T FooT>(T q) { Console.WriteLine(q.ToString()); return q; }
А вот так пролезет все что угодно. Компилятор сгенерирует код для нужного типа при вызове функции. Т.е. в общем дает полиморфизм только в компайл-тайме, т.е. для тех случаев когда фактический тип определяем в компайл-тайме.
1148 / 740 / 483
Регистрация: 21.01.2014
Сообщений: 1,903
![]() Сообщение от Fulcrum_013
Сообщение от Fulcrum_013
Т.е. ни int не пролезет ни скорости не будет.
Пролезет, только упакуется перед этим. А скорости не будет, да.
Регистрация: 24.01.2014
Сообщений: 92
дженерики это передаваемый тип в объект и их лучше понимать вместе с наследованием.
Типичный дженерик это List где у нас все объекты какого-то определённого типа, в данном примере они унаследованы от интерфейса I.
Кликните здесь для просмотра всего текста
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
using System; using System.Collections.Generic; using System.Linq; public class Test { interface I { char Name { get; } } class A : I { public char Name { get; set; } public A() { Name = 'A'; } } class B : I { public char Name { get; set; } public B() { Name = 'B'; } } public static void Main() { var list = new ListI>(); list.Add(new A()); list.Add(new B()); list.ForEach(x => Console.WriteLine(x.Name)); } }
Так же дженерики используются в Tuple, когда надо из функции передать какие-то данные, но так лучше не делать, но тоже можно
162 / 21 / 13
Регистрация: 02.02.2014
Сообщений: 323

Сообщение было отмечено Николянус как решение
Решение
int Foo(Object q)
Console.WriteLine(q.ToString());
return q;
>
В целом ты прав — большую часть мест, где они используются можно заменить object’ами. Кстати, до появления дженериков, на заре C#, так и было Но у object-ов, есть две проблемы. Если простыми словами, то object жрёт больше ресурсов (в некоторых ситуациях гораздо больше) — памяти, процессора и т.п; и второе — в object преобразовать несложно, это происходит автоматически, а вот обратно — надо вручную, и тебе каждый раз придется это делать. Например, список:
1 2 3 4 5
var myNumbers = new Listint>(); myNumber.Add(5); var number = myNumbers[0]; //number - это int, потому что List
а без generic’ов это было бы
1 2 3 4 5 6
var myNumbers = new List(); myNumber.Add(5); var number = myNumbers[0]; //number - это object var n = (int)number; //И так везде и каждый раз.
что неэффективно, медленно, прожорливо и неудобно.
Механика дженериков следующая: пишешь себе класс или структуру
1 2 3 4 5 6 7
public class MyClassT> { public int Number; public T Value; public void MyFunc(T argument, string text) { . } public T MyFuncReturn() { . } }
это как-бы говорит шарпу: «вот класс, у него внутри всякие методы и свойства, некоторые могут иметь не конкретный какой-то тип вроде int или string, а некий такой тип T, я потом скажу что это за тип такой T, главное что методы и свойства такие-то с именами такими-то, ок?»
И дальше в нужном месте, когда ты напишешь MyClass или MyClass, C# автоматом перезаменяет все места, где ты написал T, на нужный тип — int, Button и т.п. И все нужные методы и свойства будут того типа, который нужен, без необходимости преобразований руками.
На деле C# при компиляции для каждого случая генерирует отдельный вариант твоего класса с каждым типом, который ты использовал. И преобразований object->тип->object по этому не выполняется. Собственно, поэтому оно и быстрое, и оптимально использует память. Хотя, конечно, никто не мешает использовать object, или на каждый случай писать отдельно заново класс, отличающийся только типами некоторых членов класса.
6213 / 2462 / 722
Регистрация: 11.04.2015
Сообщений: 3,977
Записей в блоге: 43
Сообщение было отмечено Николянус как решение
Решение
Николянус, для лучшего понимания вопроса «кто они такие», наверно было бы правильно объяснить, какие проблемы они решают и почему другие средства справляются с этим хуже. Зайду издалека. ))
В языках программирования типизация бывает статической или динамической (там где она вообще присутствует, разумеется). Очень много написано о преимуществах и недостатках той и другой, но если в двух словах, то:
В динамически типизированных языках типы определяются исполнительной средой во время исполнения программы, также при необходимости выполняются необходимые приведения типов, что в конечном итоге избавляет разработчика от лишних телодвижений, связанных с «ручной» работой с типами. Осваиваются они обычно проще, код компактнее и там еще есть ряд ништяков. Однако все эти ништяки не даются бесплатно. Главными проблемами такого программирования являются плохая производительность и отсутствие контроля за правильностью кода со стороны средств разработки, что в конечном итоге приводит к ошибкам времени исполнения, порой трудноотслеживаемым, иногда к дополнительным тормозам из-за того, что вовремя не выполнены необходимые преобразования, а порой и просто программа вроде работает, а выдает не то что нужно, хотя с виду в порядке. Но это в двух словах.
В статически типизированных языках типы ограничиваются, в результате в функцию ты не сможешь передать что-то, что она не умеет обрабатывать, переменной по запарке не передашь объект не того типа, а проверять типы во время исполнения нет необходимости, поскольку все уже проверено перед компиляцией. Просто сказка, но есть нюанс. Если ограничивать типы исключительно до конкретных значений, то фактически мы лишимся возможности писать универсальный код. Например, есть у нас некий алгоритм, способный работать или с любыми типами или с некоторым набором типов, отвечающих некоторым критериям и получается, что если нам нужно, чтобы данный алгоритм обрабатывал несколько разных типов, то нам придется для каждого из них описывать отдельную функцию с абсолютно одинаковым алгоритмом, в коде которого только типы и будут отличаться. Недостатки такого подхода вполне очевидны: лишняя работа, сложность модификации такого кода(поскольку придется вносить изменения во все версии копипасты), ну и невозможность перечислить все возможные типы, включая пользовательские, о которых в момент написания функции ничего не известно.
Почему я начал повествование с типизации? Ну потому, что в динамических языках таких проблем нет, а стало быть в статических их тоже надо как-то решать. Решением данной проблемы в статически типизированных языках является полиморфизм. Если сформулировать в двух словах что это такое, то это механизм, позволяющий вводить такие ограничения типов, которые не сводятся к одному конкретному типу, а вместо этого, скажем так, задают некоторые критерии, которым требуемый тип должен соответствовать.
Первый тип полиморфизма, это полиморфизм, основанный на подтипах, хорошо известен во всех (ну почти) объектно-ориентированных языках. Он подразумевает, что в тех местах, где необходим некий конкретный тип (например тип параметра фукнции) можно использовать не только экземпляры указанного типа, но и экземпляры любых типов-наследников в любом поколении. Если это тип интерфейса, то используются любые реализаторы этого интерфейса или любые их потомки в любом поколении.
Такой полиморфизм безусловно расширяет возможности статически типизированных языков в плане написания более универсального кода, но к сожалению он оказывается бессильным в решении некоторых достаточно типичных задач и предоставляет в лучшем случае половинчатые решения. В качестве примера рассмотрим гипотетическую функцию Concat, которая принимает два массива и возвращает новый массив, содержащий все элементы входящих массивов. Если мы зададимся вопросом ограничения типов элементов массивов, то несложно заметить, что для реализации алгоритма вообще не имеет значения что это за типы, поскольку единственная операция, которая с ними будет производиться — это копирование их из одного массива в другой и никакого взаимодействия с их свойствами или методами.
Единственная возможность сделать код более менее универсальным, которую предоставляет здесь полиморфизм подтипов — это использовать в качестве типа элементов корневой тип иерархии(object), который можно заменить чем угодно. К сожалению этот вариант несет в себе ряд проблем. Во-первых, при дальнейшей обработке полученного массива мы заранее не знаем какого типа элементы и таким образом в коде, работающем с этим массивом придется это как-то проверять и приводить к нужному типу. Таким образом мы сразу лишаемся преимуществ статической типизации, а преимуществ динамической не приобретаем, поскольку все проверки и приведения, выполняемые в динамический языках автоматически, придется выполнять вручную. Во-вторых, если мы хотим объединить два массива int[], то вероятно хотим получить массив int[]. Но тут возникает вопрос, что нам помешает передать такой функции два разнотипных массива? Полиморфизм подтипов не предоставляет ровным счетом никаких средств объяснить компилятору, что хоть функция и может принимать массивы любых типов, но между собой эти типы все-таки должны совпадать. И уж тем более что одна и та же функция может возвращать объекты разных типов, в зависимости от того, объекты каких типов были получены как аргументы. Но зато со всеми этими задачами прекрасно справляется параметрический полиморфизм, который как раз и представлен джинериками.
Рассмотрим сигнатуры конката для нескольких типов
1 2 3
int[] Concat(int[] x, int[] y) { } string[] Concat(string[] x, string[] y) { } double[] Concat(double[] x, double[] y) { }
Несложно заметить, что выглядят они одинаково, только тип в одних и тех же местах меняется. Джинерик-версия предлагает один вариант, где конкретный тип заменен параметром, который будет заменен конкретным типом, когда будет надо.
T[] ConcatT>(T[] x, T[] y) { }
С классами та же история. Класс содержит кучу свойств, полей разных типов, методов с разными сигнатурами и т. д. и если нужно сделать его более универсальным, то можно не ограничивать некоторые из них конкретными типами, но при этом увязать их между собой, ну например связать тип параметра конструктора с полем, в которое будет сохраняться переданный через него объект.
Кроме того, уж коль скоро выше я упоминал, что полиморфизм подразумевает предъявление некоторых критериев к типам, то у джинериков также есть возможность внести ограничения и таким образом помимо определения взаимосвязей между типами описать еще дополнительные требования, предъявляемые к ним. Хотя, как уже было справедливо замечено, языку C# в этом смысле кое чего не достает.
Добавлено через 1 минуту
![]() Сообщение от VBDUnit
Сообщение от VBDUnit
На деле C# при компиляции для каждого случая генерирует отдельный вариант твоего класса с каждым типом, который ты использовал.
Что такое дженерики какие проблемы они решают c
Кроме обычных типов фреймворк .NET также поддерживает обобщенные типы (generics), а также создание обобщенных методов. Чтобы разобраться в особенности данного явления, сначала посмотрим на проблему, которая могла возникнуть до появления обобщенных типов. Посмотрим на примере. Допустим, мы определяем класс для хранения данных пользователя:
class Person < public int Id < get;>public string Name < get;>public Person(int id, string name) < Name = name; >>
Класс Person определяет два свойства: Id — уникальный идентификатор пользователя и Name — имя пользователя.
Здесь идентификатор пользователя задан как числовое значение, то есть это будут значения 1, 2, 3, 4 и так далее.
Однако также нередко для идентификатора используются и строковые значения. И у числовых, и у строковых значений есть свои плюсы и минусы. И на момент написания класса мы можем точно не знать, что лучше выбрать для хранения идентификатора — строки или числа. Либо, возможно, этот класс будет использоваться другими разработчиками, которые могут иметь свое мнение по данной проблеме, например, они могут для представления идентификатора создать специальный класс.
И на первый взгляд, чтобы выйти из подобной ситуации, мы можем определить свойство Id как свойство типа object. Так как тип object является универсальным типом, от которого наследуется все типы, соответственно в свойствах подобного типа мы можем сохранить и строки, и числа:
class Person < public object Id < get;>public string Name < get;>public Person(object id, string name) < Name = name; >>
Затем этот класс можно было использовать для создания пользователей в программе:
Person tom = new Person(546, "Tom"); Person bob = new Person("abc123", "Bob"); int tomId = (int)tom.Id; string bobId = (string) bob.Id; Console.WriteLine(tomId); // 546 Console.WriteLine(bobId); // abc123
Все вроде замечательно работает, но такое решение является не очень оптимальным. Дело в том, что в данном случае мы сталкиваемся с такими явлениями как упаковка (boxing) и распаковка (unboxing) .
Так, при передаче в конструктор значения типа int, происходит упаковка этого значения в тип Object:
Person tom = new Person(546, "Tom"); // упаковка в значения int в тип Object
Чтобы обратно получить данные в переменную типов int, необходимо выполнить распаковку:
int tomId = (int)tom.Id; // Распаковка в тип int
Упаковка (boxing) предполагает преобразование объекта значимого типа (например, типа int) к типу object. При упаковке общеязыковая среда CLR обертывает значение в объект типа System.Object и сохраняет его в управляемой куче (хипе). Распаковка (unboxing), наоборот, предполагает преобразование объекта типа object к значимому типу. Упаковка и распаковка ведут к снижению производительности, так как системе надо осуществить необходимые преобразования.
Кроме того, существует другая проблема — проблема безопасности типов. Так, мы получим ошибку во время выполнения программы, если напишем следующим образом:
Person tom = new Person(546, "Tom"); string tomId = (string)tom.Id; // !Ошибка - Исключение InvalidCastException Console.WriteLine(tomId); // 546
Мы можем не знать, какой именно объект представляет Id, и при попытке получить число в данном случае мы столкнемся с исключением InvalidCastException. Причем с исключением мы столкнемся на этапе выполнения программы.
Для решения этих проблем в язык C# была добавлена поддержка обобщенных типов (также часто называют универсальными типами). Обобщенные типы позволяют указать конкретный тип, который будет использоваться. Поэтому определим класс Person как обощенный:
class Person < public T Id < get; set; >public string Name < get; set; >public Person(T id, string name) < Name = name; >>
Угловые скобки в описании class Person указывают, что класс является обобщенным, а тип T, заключенный в угловые скобки, будет использоваться этим классом. Необязательно использовать именно букву T, это может быть и любая другая буква или набор символов. Причем сейчас на этапе написания кода нам неизвестно, что это будет за тип, это может быть любой тип. Поэтому параметр T в угловых скобках еще называется универсальным параметром , так как вместо него можно подставить любой тип.
Например, вместо параметра T можно использовать объект int, то есть число, представляющее номер пользователя. Это также может быть объект string, либо или любой другой класс или структура:
Person tom = new Person(546, "Tom"); // упаковка не нужна Person bob = new Person("abc123", "Bob"); int tomId = tom.Id; // распаковка не нужна string bobId = bob.Id; // преобразование типов не нужно Console.WriteLine(tomId); // 546 Console.WriteLine(bobId); // abc123
Поскольку класс Person является обобщенным, то при определении переменной после названия типа в угловых скобках необходимо указать тот тип, который будет использоваться вместо универсального параметра T. В данном случае объекты Person типизируются типами int и string :
Person tom = new Person(546, "Tom"); // упаковка не нужна Person bob = new Person("abc123", "Bob");
Поэтому у первого объекта tom свойство Id будет иметь тип int, а у объекта bob — тип string. И в случае с типом int упаковки происходить не будет.
При попытке передать для параметра id значение другого типа мы получим ошибку компиляции:
Person tom = new Person("546", "Tom"); // ошибка компиляции
А при получении значения из Id нам больше не потребуется операция приведения типов и распаковка тоже применяться не будет:
int tomId = tom.Id; // распаковка не нужна
Тем самым мы избежим проблем с типобезопасностью. Таким образом, используя обобщенный вариант класса, мы снижаем время на выполнение и количество потенциальных ошибок.
При этом универсальный параметр также может представлять обобщенный тип:
// класс компании class Company < public P CEO < get; set; >// президент компании public Company(P ceo) < CEO = ceo; >> class Person < public T Id < get;>public string Name < get;>public Person(T id, string name) < Name = name; >>
Здесь класс компании определяет свойство CEO, которое хранит президента компании. И мы можем передать для этого свойства значение типа Person, типизированного каким-нибудь типом:
Person tom = new Person(546, "Tom"); Companymicrosoft = new Company (tom); Console.WriteLine(microsoft.CEO.Id); // 546 Console.WriteLine(microsoft.CEO.Name); // Tom
Статические поля обобщенных классов
При типизации обобщенного класса определенным типом будет создаваться свой набор статических членов. Например, в классе Person определено следующее статическое поле:
class Person < public static T? code; public T Id < get; set; >public string Name < get; set; >public Person(T id, string name) < Name = name; >>
Теперь типизируем класс двумя типами int и string:
Person tom = new Person(546, "Tom"); Person.code = 1234; Person bob = new Person("abc", "Bob"); Person.code = "meta"; Console.WriteLine(Person.code); // 1234 Console.WriteLine(Person.code); // meta
В итоге для Person и для Person будет создана своя переменная code.
Использование нескольких универсальных параметров
Обобщения могут использовать несколько универсальных параметров одновременно, которые могут представлять одинаковые или различные типы:
class Person < public T Id < get;>public K Password < get; set; >public string Name < get;>public Person(T id, K password, string name) < Name = name; Password = password; >>
Здесь класс Person использует два универсальных параметра: один параметр для идентификатора, другой параметр — для свойства-пароля. Применим данный класс:
Person tom = new Person(546, "qwerty", "Tom"); Console.WriteLine(tom.Id); // 546 Console.WriteLine(tom.Password);// qwerty
Здесь объект Person типизируется типами int и string. То есть в качестве универсального параметра T используется тип int , а для параметра K — тип string .
Обобщенные методы
Кроме обобщенных классов можно также создавать обобщенные методы, которые точно также будут использовать универсальные параметры. Например:
int x = 7; int y = 25; Swap(ref x, ref y); // или так Swap(ref x, ref y); Console.WriteLine($»x= y=»); // x=25 y=7 string s1 = «hello»; string s2 = «bye»; Swap(ref s1, ref s2); // или так Swap(ref s1, ref s2); Console.WriteLine($»s1= s2=»); // s1=bye s2=hello void Swap(ref T x, ref T y)
Здесь определен обощенный метод Swap, который принимает параметры по ссылке и меняет их значения. При этом в данном случае не важно, какой тип представляют эти параметры.
При вызове метода Swap типизируем его определенным типом и передаем ему соответствующие этому типу значения.
- Вопросы для самопроверки
- Упражнения
Generics
Дженерики (generics) в языке программирования Java — это сущности, которые могут хранить в себе данные только определенного типа. Например, список элементов, в котором могут быть одни числа. Но не только: дженерик — обобщенный термин для разных структур.

Освойте профессию «Java-разработчик»
Можно представить дженерик как папку для бумаг, куда нельзя положить ничего, кроме документов определенного формата. Это удобно: помогает разделить разные данные и не допустить ситуаций, когда в сущность передается что-то не то.
Дженерик-сущности еще иногда называют параметризованными, общими или обобщенными. Такая сущность создается со специальным параметром. Параметр позволяет указать, с каким типом данных она будет работать. Отсюда и название.
В разных источниках можно услышать про «тип-дженерик», «класс-дженерик» или «метод-дженерик». Это нормально, ведь обобщение и параметризация касаются всех этих сущностей, а generics — общий термин.
Для чего нужны дженерики
С дженериками работают программисты на Java. Без этой возможности писать код, который работает только с определенным видом данных, было сложнее. Существовало два способа, и оба неоптимальные:
- указывать проверку типа вкоде. Например, получать данные — и сразу проверять, а если они не те, выдавать ошибку. Это помогло бы отсеять ненужные элементы. Но если бы класс понадобилось сделать более гибким, например, создать его вариацию для другого типа, его пришлось бы переписывать или копировать. Не получилось бы просто передать другой специальный параметр, чтобы тот же класс смог работать еще с каким-то типом;
- полагаться на разработчиков. Например, оставлять в коде комментарий «Этот класс работает только с числами». Слишком велик риск, что кто-то не заметит комментарий и передаст в объект класса не те данные. И хорошо, если ошибка будет заметна сразу, а не уже на этапе тестирования.
Поэтому появились дженерики: они решают эту проблему, делают написание кода проще, а защиту от ошибок надежнее.
Профессия / 14 месяцев
Java-разработчик
Освойте востребованный язык

Как работают дженерики
Чтобы вернее понять принцип работы, нужно представлять, как устроены сущности в Java. Есть классы — это как бы «чертежи» будущих сущностей, описывающие, что они делают. И есть объекты — экземпляры классов, непосредственно существующие и работающие. Класс — как схема машины, объект — как машина.
Когда разработчик создает дженерик-класс, он приписывает к нему параметр в треугольных скобках — метку. К примеру, так:
Теперь при создании объекта этого класса нужно будет указать на месте T название типа, с которым будет работать объект. Например, myClass для целых чисел или myClass для строк. Сам класс остается универсальным, то есть общим. А вот каждый его объект специфичен для своего типа.
С помощью дженериков можно создать один класс, а потом на основе него — несколько объектов этого класса для разных типов. Не понадобится дублировать код и усложнять программу. Поэтому дженерики лучше и удобнее, чем проверка типа прямо в коде — тогда для каждого типа данных понадобился бы свой класс.
Что такое raw types
В Java есть понятие raw types. Так называют дженерик-классы, из которых удалили параметр. То есть изначально класс описали как дженерик, но при создании объекта этого класса тип ему не передали. То есть что-то вроде myClass<> — тип не указан.
Дословно это название переводится как «сырые типы». Пользоваться ими сейчас в коммерческой разработке — чаще всего плохая практика. Но в мире все еще много старого кода, который написали до появления дженериков. Если такой код еще не успели переписать, в нем может быть очень много «сырых типов». Это надо учитывать, чтобы не возникало проблем с совместимостью.
Дженерики-классы и дженерики-методы
Выше мы говорили, что дженериками могут быть разные сущности. Разберемся подробнее:
- дженерик-классы (generic classes)— это классы, «схемы» объектов с параметром. При создании объекта ему передается тип, с которым он будет работать;
- дженерик-методы (generics methods)— это методы, работающие по такому же принципу. Метод — это функция внутри объекта, то, что он может делать. Методу тип передается при вызове, сразу перед аргументами. Так можно создавать более универсальные функции и применять одну и ту же логику к данным разного типа.
Кстати, дженериками могут быть и встроенные классы или методы, и те, которые разработчик пишет самостоятельно. Например, встроенный ArrayList — список-массив — работает как дженерик.

Станьте Java-разработчиком
и создавайте сложные сервисы
на востребованном языке
Что будет, если передать дженерику не тот тип
Если объекту класса-дженерика передать не тот тип, который указали при его объявлении, он выдаст ошибку. Например, если в ходе работы экземпляра myClass в нем попытаются сохранить дробное число или даже строку, программа не скомпилируется. Вместо этого разработчик увидит ошибку: неверный тип.
Эта ошибка отличается от тех, которые возникнут, если не пользоваться дженериками. По ней сразу ясно, из-за чего она возникла и как можно ее исправить. Кроме того, она появляется сразу. Поэтому код становится легче отлаживать.
А если отправить «не тот» тип объекту без дженерика, действия с ним выполнятся с ошибкой. Но по этой ошибке не всегда очевидно, чем она вызвана. Худший вариант — код успешно запустится, но сработает неправильно: так ошибку будет найти еще сложнее.
Особенности дженериков
У дженериков есть несколько особенностей, о которых стоит знать при работе с ними. Если не учитывать эти детали, программировать будет как минимум менее удобно. А как максимум можно допустить ошибку и не понять, куда она закралась.
Выведение типа. Эта особенность касается объявления экземпляра класса, то есть создания объекта. Полная запись создания будет выглядеть так:
myClass objectForIntegers = new myClass();
objectForIntegers — это название объекта, оно может быть любым. То, что находится после знака «равно», — непосредственно команда «создать новый экземпляр класса».
Но полная запись очень громоздкая. Поэтому современные компиляторы Java способны на выведение типа — автоматическую его подстановку в записи после первого упоминания. То есть конструкцию myClass понадобится написать только один раз.
Запись, в которой программист пользуется возможностью выведения типа, будет выглядеть так:
myClass objectForIntegers = new myClass<>();
Повторное упоминание типа опускается. Запись становится короче. Кажется, что это мелочь, но таких конструкций в коде могут быть десятки и писать полную запись всегда было бы не очень удобно.
Стирание типов. Важная деталь, которая касается работы дженериков, — они существуют только на этапе компиляции. В этом их суть: «не пропускать» данные ненужного типа в объект, а такие вещи определяет компилятор.
После компиляции код на Java превращается в байт-код. И на этом уровне никаких дженериков нет. myClass и myClass в байт-коде будут идентичны, просто с разными данными внутри.
Это называется стиранием типов. Суть в том, что внутри дженерик-класса нет информации о его параметре и после компиляции эти сведения просто исчезают. Так сделали, потому что дженерики появились в Java не сразу. Если бы информацию о параметре добавили в байт-код, это сломало бы совместимость с более старыми версиями.
О стирании типов важно помнить. Для запущенной программы в байт-коде дженериков не существует, и это может вызвать ошибки. Например, при сравнении myClass и myClass программа скажет, что они одинаковые. А иногда в объект в запущенном коде и вовсе получается передать данные другого типа.
«Дикие карты». Еще одна интересная и полезная особенность дженериков — так называемые wildcards, или «дикие карты». Это термин из спорта, означающий особое приглашение спортсмена на соревнование в обход правил. А в карточных играх так называют карты, которые можно играть вместо других, например джокера.
В основе wildcards в Java лежит такая же идея: изменить предустановленное поведение и сделать что-то в обход установленных рамок. Когда объявляется «дикая карта», в треугольных скобках вместо названия типа ставится вопросительный знак. Это означает, что сюда можно подставить любой тип.
Подставить wildcard можно не везде. Например, при создании класса это сделать не получится, а при объявлении объекта этого класса — получится. Чаще всего «дикую карту» используют при работе с переменными и с коллекциями.
Ограниченные «дикие карты». Кроме стандартной wildcard, существует еще несколько типов — ограниченные «дикие карты». С их помощью можно передать в объект данные не только конкретного типа, но и унаследованных от него — «потомков». Или же «предков» — типов, от которых был унаследован упомянутый.
Ограниченный wildcard описывается как вопросительный знак, за которым следует правило.
Есть два вида ограничений:
- upper bounding — ограничение сверху. За вопросительным знаком следует слово extends и название типа. В такой дженерик можно передавать названный тип и его потомков;
- lower bounding — ограничение снизу. Ситуация наоборот: за вопросительным знаком слово super и тип, а подставлять можно элементы этого типа и его предков.
Скорее всего, впервые столкнуться с дженериками придется еще в начале изучения Java, просто новичку не сразу понятно, что это такое. Со временем появляется понимание, как работает эта конструкция, и становится легче решать более сложные задачи.
Java-разработчик
Java уже 20 лет в мировом топе языков программирования. На нем создают сложные финансовые сервисы, стриминги и маркетплейсы. Освойте технологии, которые нужны для backend-разработки, за 14 месяцев.

Статьи по теме: