Шифровальщик (Криптограф)

Шифр — фр. chiffre — цифра; от араб. ifr — ноль. Кстати, недавно центр профориентации ПрофГид разработал точный тест на профориентацию, который сам расскажет, какие профессии вам подходят, даст заключение о вашем типе личности и интеллекте. Профессия подходит тем, кого интересует математика и информатика (см. выбор профессии по интересу к школьным предметам).
Криптография — тайнопись. от греч. Kryptos — тайный и grapho — пишу) тайнопись.
О статистическом тестировании блочных шифров Текст научной статьи по специальности «Математика»
Блочные шифры образуют один из основных классов криптографических алгоритмов. Одной из важнейших задач, возникающих в процессе разработки блочных шифров , как и любых других криптографических алгоритмов, является анализ их криптостойкости. В процессе такого анализа часто применяется статистическое тестирование блочных шифров . Обзору литературы, связанной с вопросами статистического тестирования блочных шифров , посвящена настоящая работа.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по математике , автор научной работы — Ключарёв П.Г.
Статистическое тестирование российского стандарта функции хэширования ГОСТ 34. 11-2012 («Стрибог»)
Статистический анализ поточных шифров
Метод оценки качества криптостойких генераторов псевдослучайных последовательностей
Построение псевдослучайных функций на основе обобщённых клеточных автоматов
Тесты псевдослучайных последовательностей и реализующее их программное средство
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
On Statistical Testing of Block Ciphers
Block ciphers form one of the main classes of cryptographic algorithms. One of the challenges in development of block ciphers, like any other cryptographic algorithms, is the analysis of their cryptographic security. In the course of such analysis, statistical testing of block ciphers is often used. The paper reviews literature on statistical testing of block ciphers.
Текст научной работы на тему «О статистическом тестировании блочных шифров»
Математика U Математическое
Сетевое научное издание http://mathmelpub.ru ISSN 2412-5911
УДК 004.056.55 О статистическом тестировании
Ссылка на статью:
// Математика и математическое моделирование. 2018. №5. С. 35-56.
Представлена в редакцию: 13.08.2018 © НП >
* pk.iu8@yandex.ru 1МГТУ им. Н.Э. Баумана, Москва, Россия
Блочные шифры образуют один из основных классов криптографических алгоритмов. Одной из важнейших задач, возникающих в процессе разработки блочных шифров, как и любых других криптографических алгоритмов, является анализ их криптостойкости. В процессе такого анализа часто применяется статистическое тестирование блочных шифров. Обзору текущего состояния области, связанной с таким тестированием, посвящена настоящая работа. Кратко упоминаются основные определения понятия случайной последовательности, дается обзор наборов статистических тестов. Рассматриваются методики статистического тестирования блочных шифров, в том числе, методика Ш8Т (использованная, в частности, для тестирования шифров на конкурсе ЛБ8). Делается вывод о том, что в настоящее время вопрос о построении методик статистического тестирования блочных шифров исследован недостаточно и необходима разработка новых методик такого тестирования.
Ключевые слова: статистическое тестирование; случайность; блочный шифр
Блочные шифры имеют очень широкое применение в различных задачах информационной безопасности и образуют один из основных классов криптоалгоритмов. В процессе разработки таких шифров возникает задача анализа их криптографических свойств, одним из этапов которого является статистическое тестирование. Надо сказать, что это, по-видимому, единственный этап анализа блочных шифров, который можно существенно автоматизировать. Однако для его выполнения нужна методика статистического тестирования. Причем для того, чтобы результаты такого тестирования различных шифров можно было сравнивать, желательно иметь стандартизованную методику. Обзору литературы, связанной с вопросами статистического тестирования блочных шифров, посвящена настоящая работа.
Основной метод статистического тестирования блочных шифров заключается в том, что на основе тестируемого блочного шифра создаются различные генераторы псевдослучайных последовательностей, посредством которых порождаются последовательности, которые и подвергаются статистическому тестированию. Здесь важным является то, как эти генераторы устроены и посредством каких тестов производится тестирование последовательностей.
Поэтому в данной статье кратко описываются различные наборы статистических тестов и рассматриваются различные методики статистического тестирования блочных шифров.
1. Случайные последовательности
Отметим, что в данной работе мы рассматриваем равномерно распределенные двоичные случайные (и псевдослучайные) последовательности, для краткости называя их просто случайными (соответственно, псевдослучайными) последовательностями.
Существуют разные определения понятия генератора псевдослучайных последовательностей (см., например, монографию [1]). Иногда говорят о генераторе псевдослучайных последовательностей в строгом смысле. Генератор псевдослучайных последовательностей в строгом смысле — это алгоритм, который принимая на вход ключ, генерирует двоичную последовательность, такую, что не существует полиномиального относительно длины ключа вероятностного алгоритма, отличающего ее от последовательности, сгенерированной генератором истинно случайных последовательностей, с вероятностью отличающейся от 2 более, чем на пренебрежительно малую величину.
К сожалению, не доказано существование генераторов псевдослучайных последовательностей в строгом смысле. Поэтому на практике в криптографии используется ослабленное определение генератора псевдослучайной последовательности, которым мы и будем пользоваться в настоящей работе: генератором псевдослучайной последовательности будем называть алгоритм, который принимая на вход ключ постоянной длины, генерирует такую двоичную последовательность, что лучший известный алгоритм, отличающий ее от последовательности, сгенерированной генератором истинно случайных последовательностей, имеет большую вычислительную сложность. Под большой вычислительной сложности могут пониматься разные вещи. В частности, часто (но не всегда) под ней понимается сложность перебора всех возможных ключей.
В определении генератора псевдослучайных последовательностей используется понятие генератора истинно случайных последовательностей. Однако с определением понятия случайной последовательности имеются большие сложности. Подходов к определению этого понятия известно не менее четырех: Колмогорова, Мартин-Лёфа, фон Мизеса и подход, связанных с непредсказуемостью. И все они таковы, что их нельзя использовать на практике.
В этом разделе мы кратко и неформально рассмотрим подходы к определению понятия случайной последовательности. Связанной с ними теории посвящены, в частности, монографии [2, 3, 1,4, 5]).
Колмогоровской сложностью слова над конечным алфавитом называется длина кратчайшего описания этого слова. К сожалению, колмогоровская сложность определена лишь с точностью до константы. Ситуация серьезно усугубляется тем, что колмогоровская сложность невычислима. Невычислима даже любая нетривиальная нижняя оценка колмогоров-ской сложности.
Рассматривая колмогоровскую сложность, можно ограничиться некоторым семейством языков описания. Языком описания называется множество пар (а, Ь), где слово а является описанием для слова Ь. Будем говорить, что слова г и в согласованы, если одно из них является началом другого. Язык описания называется монотонным, если он перечислим и для любых двух его элементов (а1, Ь\), (а2, Ь2), у которых слова а1 и а2 согласованы, слова Ь1 и Ь2 также являются согласованными. Длина кратчайшего описания слова х посредством языка из семейства монотонных языков описания называется монотонной колмогоровской сложностью слова х и обозначается КМ(х).
Несмотря на невычислимость колмогоровской сложности, именно на ней основан очень важный подход к определению понятия случайности. Бесконечная последовательность х\, х2, .. . символов двоичного алфавита называется случайной по Колмогорову [6] (или хаотической), если существует такая константа с, что КМ(х1, х2. хк) ^ к — с для любого к. Неформально говоря, последовательность случайна по Колмогорову, если лучшим способом ее описания является простое перечисление ее членов.
Множество случайных по Колмогорову последовательностей может быть введено и с помощью другого подхода — как множество типичных последовательностей, т.е. последовательностей, принадлежащих любому разумному большинству. Это определение принадлежит Мартин-Лёфу [7] (за строгим определением понятия «разумного большинства» отошлем заинтересованного читателя, например, к книге [5]).
Другой подход к определению понятия случайности был предложен фон Мизесом [8]. Бесконечная последовательность над алфавитом А называется случайной по фон Мизесу (или стохастической), если вероятности каждого символа в начальном отрезке Ь1, .. ., Ьк любой допустимой бесконечной подпоследовательности Ь1, Ь2. . этой последовательности стремятся к щ при к ^ то. Здесь важным является определение допустимости подпоследовательности (сам фон Мизес не дал строгого определения, но такие определения были даны Чёрчем и Колмогоровым, причем определения не эквивалентные).
Еще один подход к определению понятия случайности — непредсказуемость. Неформально говоря, последовательность является непредсказуемой, если в каком бы порядке мы не выбирали элементы этой последовательности, знание уже выбранных элементов не позволит предсказывать следующий выбираемый элемент. Строгое определение этого понятия, основанное на теории игр, предложено в работе [9].
Известен ряд теорем о том, как соотносятся между собой упомянутые подходы к определению случайности (см., например, [5]), но их подробное обсуждение выходит за рамки настоящей работы.
Вокруг каждого из этих подходов существует большая теория и множество нерешенных задач. Вместе с тем ясно, что все приведенные определения случайной последовательности являются неконструктивными в том смысле, что их невозможно напрямую применить для проверки данной последовательности на случайность. Поэтому на практике приходится ограничиваться тестированием статистических свойств последовательностей.
Тем не менее перечисленные выше подходы к определению случайности оказываются в некоторой степени полезными для практических целей. Например, несмотря на то, что нижние оценки колмогоровской сложности невычислимы, верхние ее оценки являются вычислимыми и их вполне можно использовать для оценки случайности последовательностей на практике. Например, сжатие последовательности тем или иным алгоритмом сжатия (например, Лемпеля — Зива) может рассматриваться как такая верхняя оценка — случайная последовательность не должна сжиматься. Другой пример такой верхней оценки — линейная сложность последовательности. Кроме того, подход фон Мизеса, связанный с вероятностями символов в подпоследовательностях, можно использовать, вычисляя частоты символов в тех или иных подпоследовательностях и оценивая с их помощью соответствующие распределения вероятностей.
2. Наборы статистических тестов двоичных последовательностей
Статистическое тестирование последовательности—задача, часто возникающая на практике. Особую важность эта задача имеет в области криптографии. Для ее решения на практике используют наборы статистических тестов. По-видимому, первый из таких наборов предложил Д. Кнут в 1969 г. (во втором томе известнейшей своей монографии «The Art of Computer Programming»; сошлемся здесь на современное русскоязычное издание: [10]).
Каждым статистическим тестом решается задача проверки гипотезы о случайности входной последовательности (это нулевая гипотеза; альтернативная гипотеза — то, что последовательность не является случайной). При этом задается уровень значимости а, т.е. вероятность ложноотрицательного результата. В качестве значения а часто используются значения 0.01; 0.001. Каждый статистический тест на основе данных вычисляет так называемое P-значение (P-value) — вероятность того, что идеальный генератор случайных последовательностей сгенерирует последовательность «менее случайную», чем данная, с точки зрения этого теста. Гипотеза о случайности принимается, если P-value ^ а, а в противном случае — отвергается.
При тестировании генератора псевдослучайных последовательностей тестируется большое число выработанных им последовательностей некоторой длины (например, в наборе NIST STS рекомендуемая длина последовательности составляет 1000000 битов). Если доля прошедших тест последовательностей достаточно велика и P-значения распределены равномерно, то делается вывод о том, что генератор проходит этот тест.
В настоящее время наиболее известны следующее наборы статистических тестов (реализованные в виде программного обеспечения), предназначенные для статистического тестирования двоичных последовательностей:
• DieHard [11] — набор статистических тестов, разработанный математиком из США Дж. Марсальей. Доступна также расширенная свободная реализация этих тестов DieHarder [12].
• NIST Statistical Test Suite (NIST STS) [13, 14, 15] — набор статистических тестов, разработанный в NIST.
• TestU01 [16] — набор статистических тестов, разработанный в Монреальском университете.
• RaBiGeTe [17] — набор статистических тестов, снабженный удобным GUI для Windows, разработанный в Италии.
• PractRand [18] — набор статистических тестов, разработанный программистом из США К. Доти-Хамфри.
Кроме перечисленных существует еще несколько наборов статистических тестов (например, Crypt-X, Ent и др.), которые в настоящее время по разным причинам редко используются и не поддерживаются.
Приведем здесь краткие описание принципов работы тестов, входящих в вышеупомянутые наборы.
Набор DieHard [11] состоит из следующих тестов:
• Тест промежутков между днями рождения (Birthday Spacings Test). Если случайно выбрать m дней рождений в «году» из n дней и рассмотреть список промежутков между днями рождения, то окажется, что число j элементов этого списка, встречающихся более чем один раз, асимптотически распределено по Пуассону. Тест состоит в том, что тестируемая последовательность интерпретируется как последовательность таких «дней рождения» и проверяется соответствие распределения значений j ожидаемому для случайной последовательности. Название теста связано с известным парадоксом дней рождения.
• Тест пересекающихся перестановок (Overlapping permutations). Рассматривает тестируемую последовательность как последовательность 32-разрядных чисел. Проверяет распределение всех возможных перестановок пяти последовательных чисел из этой последовательности (все 5! перестановок должны быть равновероятны).
• Тест рангов матриц (Ranks of matrices). Тестируемая последовательность трактуется как последовательность бинарных матриц (в разных вариантах теста используются матрицы разных размеров: 6 х 8, 31 х 31, 32 х 32). Вычисляются ранги этих матриц. Их распределение проверяется на соответствие ожидаемому.
• Обезьяньи тесты (Monkey Tests). Тестируемая последовательность интерпретируется как последовательность пересекающихся двоичных слов определенной длины. Последовательность этих слов делится на подпоследовательности. Для каждой из них вычисляется число слов, которые в нее не входят. Распределение этого значения проверяется на соответствие ожидаемому для случайной последовательности.
• Подсчет числа единиц в потоке байтов (The count-the-1’s test on a stream of bytes). Рассматривается последовательность весов байтов тестируемой последовательности. Из нее получается последовательность букв A, B, C, D, E, путем замены 0, 1, 2 на A, 3 на B, 4 на C, 5 на D, а 6, 7, 8 на E. Вычисляются частоты для каждого слова длины 5 (всего 55
слов). Полученные частоты проверяются на соответствие вероятностям слов ожидаемым для случайной последовательности.
• Подсчет числа единиц в некоторых байтах (The count-the-1’s test for specific bytes). Аналогичен предыдущему, однако выбирается не каждый байт последовательности, а некоторые указанные 8 бит из каждого 32-битного слова.
• Тест на парковку (Parking Lot Test) — В квадрате размера 100 х 100 случайным образом (случайные числа формируются из тестируемой последовательности) размещаются («паркуются») единичные окружности. Если очередная окружность пересекается с уже имеющейся в квадрате окружностью, то итерацию заканчивают. Всего производят 12000 таких итераций, после чего сравнивают распределение числа успешно припаркованных окружностей с ожидаемым (оно должно быть близким к нормальному).
• Тест на минимальное расстояние (Minimum Distance Test) — 8000 точек случайным образом (случайные числа формируются из тестируемой последовательности) размещаются в квадрате размера 10000 х 10000, после чего рассматриваются расстояния между каждой парой точек и выбирается минимальное среди них. Выполняется 100 таких итераций. Квадрат минимального расстояния должен иметь распределение близкое к экспоненциальному.
• Тест случайных сфер (Random Spheres Test). В кубе, ребро которого равно 1000, случайным образом выбираются 4000 точек (случайные числа формируются из тестируемой последовательности). В каждую из этих точек помещается центр сферы, радиус которой равен расстоянию до ближайшей точки. Таких итераций совершается определенное число и проверяется близость распределения объема шара, ограниченного минимальной из этих сфер, к ожидаемому для случайной последовательности.
• Тест сжатия (The Squeeze Test). Из тестируемой последовательности генерируются вещественные числа u Е [0, 1), далее находится такое минимальное i, что ti = 1, где ti+1 = \tiu], to = 231. Производится определенное число таких операций, после чего распределение величины i проверяется на соответствие ожидаемому.
• Тест пересекающихся сумм (Overlapping Sums Test). На основе тестируемой последовательности генерируется последовательность вещественных чисел u1, u2, . Е [0, 1).
Вычисляются значения si = J2 uj, i =1, 2, . Специальным образом проверяется соот-
ветствие их распределения ожидаемому.
• Тест последовательностей (Runs Test). На основе тестируемой последовательности генерируется последовательность вещественных чисел. В ней производится подсчет количества непрерывных монотонных (возрастающих и убывающих) подпоследовательностей. Проверяется соответствие распределений этих количеств ожидаемому.
• Тест игры в кости (The Craps Test) — на основе тестируемой последовательности берутся данные для игры в крэпс (craps, вид игры в кости). Для достаточно большого числа таких игр подсчитываются число побед и число бросков. Проверяется соответствие распределений этих чисел ожидаемым.
Отметим, что во многих тестах здесь и далее проверяется соответствие распределения некоторой выборки, вычисленной на основе тестируемой последовательности, распределению, которое ожидается в том случае, если тестируемая последовательность является случайной. В большинстве случаев эта проверка осуществляется либо на основе критерия X2, либо (реже) на основе критерия Колмогорова — Смирнова.
Набор тестов DieHard появился достаточно давно (в 1995 г.) и снискал большую известность, поскольку он является фактически первым широко известным набором статистических тестов, который можно было использовать для статистического тестирования криптографических алгоритмов. Однако он не свободен от недостатков — выбор входящих в него тестов довольно неоднозначный и интерпретация их результатов бывает подчас затруднительной, а программная реализация страдает ошибками.
Более новым и более широко используемым набором тестов является NIST STS [13, 14, 15]. Он состоит из 15 статистических тестов:
• Частотный побитовый тест (Frequency Monobit Test). Проверяет, что в тестируемой последовательности число единиц приблизительно равно числу нулей.
• Частотный блочный тест (Frequency Test within a Block). Делит последовательность на блоки одинаковой длины, и проверяет равномерность распределения числа единиц в этих блоках.
• Тест на последовательность одинаковых битов (Runs Test). Рассматривает отклонение числа непрерывных серий от ожидаемого для случайной последовательности (под непрерывной серией длины t понимается последовательность из t единиц, ограниченная нулями, либо последовательность из t нулей, ограниченная единицами).
• Тест на самую длинную последовательность единиц в блоке (Test for the Longest Run of Ones in a Block). Разбивает тестируемую последовательность на блоки фиксированной длины, и проверяет соответствие распределения максимальных длин непрерывных последовательностей из единиц внутри блоков ожидаемому для случайной последовательности.
• Тест рангов бинарных матриц (Binary Matrix Rank Test). Тестируемая последовательность разбивается на подпоследовательности некоторой длины, из которых составляется двоичная матрица. Тест проверяет соответствие количеств матриц максимального ранга и матриц ранга на единицу меньше максимального ожидаемым для случайной последовательности. Аналогичный тест имеется в наборе DieHard.
• Тест дискретного преобразования Фурье (спектральный тест, Discrete Fourier Transform (Spectral) Test). Биты последовательности рассматриваются как вещественные числа, при этом каждый 0 заменяется на -1. От полученной последовательности вычисляется дискретное преобразование Фурье. Проверяется близость числа спектральных компонент, амплитуда которых превышает 95% к ожидаемому для случайной последовательности.
• Тест на совпадение неперекрывающихся шаблонов (Non-overlapping Template Matching Test). Проверяется соответствие числа повторений некоторой фиксированной подпоследо-
вательности (ее называют шаблоном) в тестируемой последовательности ожидаемому. При этом для поиска шаблона длины t применяется скользящее окно: если шаблон не обнаружен, то окно сдвигается на одну позицию, а если обнаружен — на t позиций.
• Тест на совпадение перекрывающихся шаблонов (Overlapping Template Matching Test). Аналогичен тесту на совпадение неперекрывающихся шаблонов, за исключением того, что окно всегда сдвигается на одну позицию.
• Универсальный статистический тест Маурера (Maurer’s Universal Statistical Test). Вычисляет сумму логарифмов расстояний между одинаковыми шаблонами в последовательности и проверяет ее близость к ожидаемой для случайной последовательности. Фактически этот тест проверяет невозможность сжатия последовательности. Он позволяет выявлять широкий класс статистических дефектов, поэтому называется универсальным [19].
• Тест на линейную сложность (Linear Complexity Test). Линейной сложностью последовательности называется наименьшая длина регистра сдвига с линейной обратной связью, ее порождающего. Тестируемая последовательность разделяется на подпоследовательности определенной длины. Для каждой из них вычисляется линейная сложность с помощью алгоритма Берлекэмпа — Месси [20, 21]. Тест проверяет соответствие распределения линейной сложности этих подпоследовательностей ожидаемому.
• Тест на подпоследовательности (Serial Test) [22]. Определяет, соответствует ли ожидаемому количество вхождений каждого из 2* шаблонов длины t (в случайной последовательности такие шаблоны равновероятны).
• Тест приблизительной энтропии (Approximate Entropy Test) [23]. Проверяет близость соотношения числа вхождений перекрывающихся шаблонов длины t и длины t + 1 ожидаемому для случайной последовательности.
• Тест кумулятивных сумм (Cumulative Sums Test). Биты тестируемой последовательности трактуются как целые числа, причем все нули заменяются на — 1. Далее вычисляются суммы первых t членов последовательности. Тест проверяет соответствие значения максимальной по абсолютной величине суммы ожидаемому.
• Тест на произвольные отклонения (Random Excursions Test). Биты тестируемой последовательности трактуются как целые числа, причем все нули заменяются на — 1. Далее, пусть St — сумма первых t членов последовательности, t Е . Множество всех различных значений St рассматривается как множество вершин графа, а последовательность значений St — как блуждание по этому графу. Тестом оценивается соответствие распределения количества циклов в этой последовательности (под циклом в этом тесте понимается последовательность вершин, начинающаяся и заканчивающаяся нулем), в которых присутствуют определенные вершины определенное число раз, ожидаемому.
• Вариант теста на произвольные отклонения (Random Excursions Variant Test). Здесь рассматривается тот же граф, что и в предыдущем тесте, однако проверяется соответствие распределения числа проходов блуждания через каждую вершину ожидаемому.
Более подробное описание набора статистических тестов NIST STS выходит за рамки данной статьи. Заинтересованного читателя отошлем к официальной документации и работам коллектива авторов этого набора тестов: [13, 14, 15]. Ряд особенностей этого набора тестов обсуждается в работе [24].
Опишем также набор RaBiGeTe [17]. Он содержит следующие тесты:
• Тест «Улучшенная многоуровневая стратегия» (AMLS). Тестируемая последовательность разбивается на блоки. Для каждого из них применяются правила фон Неймана для «исправления» нечестной монеты (01 ^ 0; 10 ^ 1; 00 и 11 отбрасываются). Такое преобразование специальным образом производится несколько раз (образуя определенное число уровней). Распределение числа отброшенных битов в блоке сравнивается с ожидаемым.
• Тест на дискретное преобразование Фурье (DFT). Из тестируемой последовательности формируется матрица, над которой производится двухмерное дискретное преобразование Фурье. Сравнивается распределение мнимых частей полученных коэффициентов с нормальным, которое ожидается для случайной последовательности.
• Тест коротких блоков (Short blocks). Тестируемая последовательность преобразуется в последовательность блоков длины s, при этом первый блок формируется из битов 0, d, 2d, . (s — 1)d, второй блок — из битов 1, d +1, 2d + 1, . . (s — 1)d +1 и т.д., где d — некоторое число. Каждый блок рассматривается как число от 0 до 2s — 1. Распределение этих чисел сравнивается с ожидаемым (равномерным).
• SOB (Sparse Occupancy Bitstream). Представляет собой вариант обезьяньих тестов из DieHard.
• Оконный тест автокорреляции (Windowed autocorrelation). Тестируемая последовательность рассматривается как последовательность блоков 6Ь b2, .. ., bN. Распределение расстояний Хемминга между блоками Ь и bi+d, 0 ^ i < N — d, сравнивается с ожидаемым.
• Тест перестановок (Permutation). Тестируемая последовательность делится на блоки длиной от 2 до 12 двоичных разрядов каждый. Каждые t последовательных блоков группируются. Рассматриваются только те из этих групп, в которых нет совпадающих элементов. Элементы в группе могут быть различным образом упорядочены. Например, пусть группа состоит из блоков щ, . ut. Они могут быть упорядочены: щ < u2 < . < ut, u2 < щ < щ < . < ut и т.д. (всего n! различных порядков). Для каждого порядка подсчи-тывается число групп. Распределение полученных величин сравнивается с ожидаемым.
• Тест собирателя купонов (Coupon collector test). Тестируемая последовательность делится на блоки длины s. Последовательность блоков сканируется и подсчитываются величины r — сколько блоков надо просканировать, чтобы нашлись все 2s различных блоков. Проверяется соответствие распределения величин r ожидаемому.
• Тест Маурера (Maurer). Повторяет аналогичный тест NIST.
• Тест на наибольший общий делитель (GCD). На основе тестируемой последовательности генерируются пары целых чисел. Вычисляется наибольший общий делитель каждой
пары. Проверяются соответствие распределений значения наибольшего общего делителя и числа шагов алгоритма Евклида ожидаемым.
• Тест Blocks’n’gaps. Подсчитывает число подпоследовательностей различной длины, состоящих из одних единиц, либо одних нулей. Распределение этих величин сравнивается с ожидаемым.
• Частотный блочный тест (Long blocks). Повторяет аналогичный тест NIST.
• Тест на последовательность одинаковых битов (Runs). Повторяет аналогичный тест NIST.
• Тест кумулятивных сумм (Cumulative sum). Повторяет аналогичный тест NIST.
• Тест на подпоследовательности (Serial). Повторяет аналогичный тест NIST.
• Тест на совпадение неперекрывающихся шаблонов (Non overlapping template match-ings). Повторяет аналогичный тест NIST.
• Тесты рангов матриц. Повторяют аналогичные тесты Diehard.
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
• Тест промежутков между днями рождения (Tough birthday spacings). Повторяют аналогичный тест Diehard.
RaBiGeTe обладает рядом преимуществ — снабжен удобным графическим интерфейсом пользователя, обладает многопоточной версией. В то же время, некоторые входящие в него тесты разработаны его автором (например, AMLS, DFT, Short blocks и др.) и ранее в таком виде не применялись. По ним отсутствуют какие-либо значимые независимые исследования. Ожидаемое распределение для некоторых тестов получено их автором эмпирически. Кроме того, некоторые тесты, взятые из других наборов, могут иметь отличающиеся параметры. Все это усугубляет трудности интерпретации результатов и без того присущие наборам статистических тестов и делает их не слишком надежными. Это ограничивает применимость данного набора тестов.
Еще один набор тестов PractRand, к сожалению, снабжен не слишком подробной документацией, в которой описаны лишь некоторые из входящих в него тестов, причем описаны очень скупо. В связи с этим, его рассмотрение невозможно.
Все перечисленные тесты направлены на проверку тех или иных свойств, характерных для случайной последовательности. Ряд тестов (например, частотный побитовый тест, частотный блочный тест, тест на последовательность одинаковых битов, тесты на совпадение перекрывающихся и неперекрывающихся шаблонов и др.) фактически можно трактовать, как использующие подходы, в чем-то аналогичного подходу фон Мизеса. Некоторые тесты (в частности, универсальный тест Маурера [19] и тест на линейную сложность) можно рассматривать как вычисление верхних оценок коломогоровской сложности.
Из рассмотренных здесь наборов статистических тестов наиболее исследованным и апробированным является NIST STS. Он разработан в серьезной правительственной организации (NIST), за ним стоит целая команда разработчиков — профессионалов в области математической статистики. Кроме того, он использовался для тестирования криптографических
алгоритмов на государственном уровне — в том числе для тестирования блочных шифров, представленных на конкурс AES. В него входят тесты, которые либо достаточно очевидны (как например, частотные тесты), либо имеют хорошее теоретическое обоснование (как, например, тест Маурера или тест на линейную сложность). Поэтому результаты, полученные с помощью этого набора, гораздо легче интерпретировать, по сравнению с результатами, полученными с помощью других наборов статистических тестов.
3. Режимы работы блочных шифров
Как известно, блочные шифры могут быть использованы различными способами, которые называются режимами работы блочных шифров или режимами шифрования. Таких режимов известно достаточно много. Описание классических режимов шифрования приведено, например, в монографии [25]. В нашей стране режимы работы блочных шифров регламентируются ГОСТ Р 34.13-2015 [26]. Здесь мы приведем краткие сведения лишь о некоторых режимах шифрования, которые могут использоваться в процессе статистического тестирования блочных шифров.
Самый простой режим работы, состоящий в том, что открытый текст делится на блоки, каждый из которых зашифровывается отдельно на одном и том же ключе, называется ECB (Electronic Code Book, режим электронной кодовой книги, в русскоязычной традиции — режим простой замены). Он используется редко, так как во многих случаях не является безопасным за счет того, что сохраняет структуру открытого текста (поскольку результат зашифрования одного и того же блока в разных частях текста одинаков). Чаще используются другие режимы работы. Нас будут интересовать режимы OFB и CTR, фактически превращающие блочных шифр в поточный, реализуя на основе блочного шифра генератор псевдослучайных последовательностей.
В режимах OFB и CTR генерируется последовательность блоков Yi, Y2. . Шифрование заключается в наложении этой последовательности на открытый текст с помощью побитового сложения по модулю 2. Пусть e(key,x) — функция зашифрования блочного шифра (key — ключ, x — блок открытого текста). Режим OFB (Output feedback, режим обратной связи по выходу) реализуется следующим образом: jl = e(key, IV); y% = e(key, Yi-l), i > 2. Здесь IV — вектор инициализации. Режим CTR (Counter mode, режим счетчика) реализуется следующим образом: Yi = e(key, ci), где значения ci формируются по некоторому правилу, например ci = L||ti; ti+l = (ti + 1) mod 2s; (L||to) = IV. Здесь s — длина to, а || означает конкатенацию.
Также в дальнейшем будет упоминаться режим CBC (Cipher Block Chaining), в котором происходит зашифрование на ключе key последовательности блоков открытого текста xl, x2, . .. в последовательность блоков шифртекста yl, y2, . следующим образом: yi = e(key, xi 0 IV); yi = e(key, xi 0 yi-i), i > 2.
4. Статистическое тестирование блочных шифров
Наиболее распространенный метод статистического тестирования блочных шифров заключается в генерации с помощью блочного шифра псевдослучайных последовательностей, которые подвергаются тестированию с помощью какого-либо набора статистических тестов. При этом для генерации этих последовательностей обычно используются следующие подходы:
• Создание генератора псевдослучайных последовательностей из блочного шифра посредством использования того или иного поточного режима шифрования (например, OFB, CTR). С помощью этого генератора и происходит генерация последовательностей.
• Шифрование (в том или ином режиме) некоторой заранее заданной последовательности.
• Шифрование последовательности, состоящей из пар блоков, таких, что расстояния Хемминга между блоками каждой пары мало (например, равно 1) с побитовым сложением по модулю 2 шифртекстов каждой пары. Статистическое тестирование полученной последовательности фактически проверяет выполнение строгого лавинного критерия. Напомним, что говорят, что функция f : n ^ m удовлетворяет строгому лавинному критерию (Strict avalanche criteria, SAC), если изменение одного бита входа приводит к тому, что каждый бит выхода меняется с вероятностью 1/2.
При этом распространенной практикой является исследование блочных шифров с уменьшенным числом раундов с целью определения номера раунда, начиная с которого функция зашифрования успешно проходит все статистические тесты набора.
Наиболее известной методикой статистического тестирования блочных шифров является разработанная NIST методика, которая описана в работах [27, 28], посвященных тестированию блочных шифров, представленных на конкурс AES. Приведем ее здесь.
Мы будем обозначать функцию зашифрования блочного шифра через e(key, x), где key — ключ, а x — блок открытого текста. Напомним, что в конкурсе AES участвовали блочные шифры, у которых длина блока составляла 128 двоичных разрядов, а длина ключа могла принимать значения 128, 192, 256 двоичных разрядов. Обозначим через bit(j) блок веса 1, единица у которого находится в разряде j.
Методика, посредством которой тестировали финалистов конкурса AES (в работе [28], в которой исследовано 5 криптоалгоритмов, вышедших в финал конкурса AES: Rijndael, Serpent, Twofish, RC6 и MARS), состоит в том, что восемью различными способами генерировались по 300 двоичных последовательностей. Все они тестировались набором статистических тестов NIST STS. Если последовательности не могли успешно пройти тесты, делался вывод о недостаточном качестве данного блочного шифра.
Перечислим способы генерации последовательностей для статистического тестирования, используемые в этой методике:
1. Для тестирования лавинного эффекта по открытому тексту. Проверяется чувствительность к изменениям открытого текста. Выбирается ключ key, состоящий из всех нулей.
Генерируется 19200 случайных 128-разрядных блоков открытого текста. Для каждого такого блока xi вычисляются выходные блоки yi,j = e(key, xi) ф e(key, xi ф bit(j)), j = 0, . 127. Далее все полученные блоки конкатенируются: y10 || . || y1,127 || y2,0 || . || y2,127 || . . || y19200,0 || . || y19200,127. Эта последовательность представляет собой двоичную последовательность длиной 314572800 двоичных разрядов. Она трактуется как 300 двоичных последовательностей длиной по 1048576 разрядов каждая.
2. Для тестирования лавинного эффекта по ключу. Здесь используется блок открытого текста x, состоящий из всех нулей. Генерируется 19200 случайных ключей (длиной либо 192, либо 256 двоичных разрядов). Для каждого такого ключа keyi вычисляются выходные блоки yi,j = e(keyi,x) ф e(keyi ф bit(j),x), j = 0, . 127. Далее все полученные блоки конкатенируются: y1,0 || . || yM27 || y2,0 || . || y2,127 || . || y19200,0 || . || y19200,127. Полученная последовательность трактуется как 300 двоичных последовательностей, длиной по 1048576 разрядов каждая.
3. Для тестирования корреляции между открытым текстом и шифртекстом. Выбирается случайный ключ key и 8192 случайных блоков открытого текста x1, . . x8192. Для каждого из них вычисляется выходной блок yi = e(key, xi) ф xi. Эти блоки конкатенируются и получается последовательность y1 || y2 || . || y81g2, которая трактуется как двоичная последовательность длиной в 1048576 двоичных разрядов. Всего генерируется 300 таких последовательностей (каждый раз выбирается новый случайный ключ key).
4. Для тестирования работы шифра в режиме сцепления блоков. Выбирается случайный ключ key и вектор инициализации IV, длиной в 128 двоичных разрядов, состоящий из нулей. Далее формируется выходная последовательность, состоящая из 8192 блоков y1, .. ., y8192 (по 128 двоичных разрядов в каждом блоке). Первый выходной блок вычисляется как y1 = e(key, IV). Остальные выходные блоки вычисляются как yi+1 = e(key, yi). Выходная последовательность трактуется как двоичная последовательность длиной 1048576 двоичных разрядов. Всего генерируется 300 таких последовательностей (каждый раз вырабатывается новый случайный ключ key).
5. Для тестирования работы шифра в случае низкой плотности открытого текста. Выбирается случайный ключ key и формируется 8257 блоков открытого текста: один блок веса 0; 128 различных блоков веса 1 и 8128 блоков веса 2. Все эти блоки зашифровываются на ключе key. Полученная последовательность блоков шифртекста трактуется как двоичная последовательность длиной 1056896 двоичных разрядов. Всего генерируется 300 таких последовательностей (каждый раз выбирается новый случайный ключ key).
6. Для тестирования работы шифра в случае ключей низкой плотности. Выбирается случайный блок открытого текста x и формируется 8257 ключей: один ключ веса 0, 128 различных ключей веса 1, в каждом из которых единица содержится в одном из первых 128 разрядов, и 8128 различных ключей веса 2, в каждом из которых обе единицы содержатся среди первых 128 разрядов. На каждом из этих ключей зашифровывается блок x. Полученная последовательность блоков шифртекста трактуется как двоичная последовательность
длиной 1О5б89б двоичных разрядов. Всего генерируется ЗОО таких последовательностей (каждый раз выбирается новый случайный блок x).
7. Для тестирования работы шифра в случае высокой плотности открытого текста. Выбирается случайный ключ key и формируются S257 блоков открытого текста: один блок веса 12S, 12S различных блоков веса 127 и S12S различных блока веса 12б. Все эти блоки зашифровываются на ключе key. Полученная последовательность блоков шифртекста трактуется как двоичная последовательность длиной 1О5б89б двоичных разрядов. Всего генерируется ЗОО таких последовательностей (каждый раз выбирался новый случайный ключ key).
8. Для тестирования работы шифра в случае ключей высокой плотности. Выбирается случайный блок открытого текста x и формируется S257 ключей: один ключ веса m, 12S различных ключей веса m — 1, в каждом из которых О содержится в одном из первых 12S разрядов, и S12S различных ключей веса m — 2, в каждом из которых оба нуля содержатся среди первых 12S разрядов (здесь m — длина ключа). На каждом из этих ключей шифруется блок x. Полученная последовательность блоков шифртекста трактуется как двоичная последовательность длиной 1О5б89б двоичных разрядов. Всего генерируется ЗОО таких последовательностей (каждый раз выбирался новый случайный блок x).
В более ранней работе [27] авторов набора NIST STS тестировались также последовательности, сгенерированные путем шифрования случайных блоков на случайных ключах (в этой работе протестировано 15 криптоалгоритмов, представленных на конкурс AES: CAST-25б, CRYPTON, DEAL, DFC, E2, FROG, HPC, LOKI97, MAGENTA, MARS, RC6, Rijndael, SAFER+, Serpent и Twofish). Но, как было замечено в работе [29], на результат такого теста существенное влияние оказывают статистические свойства генератора этих случайных блоков и случайных ключей, поэтому такое тестирование ненадежно. Вообще, в работе [29] ряд аспектов методики тестирования блочных шифров NIST подвергнут критике. В частности, указывается на то, что в документации недостаточно четко определены нулевые и альтернативные гипотезы, длины входных данных и уровни значимости недостаточно обоснованы, а ряд тестов не инвариантны по отношению к криптографически незначимым преобразованиям данных.
В статье [30] проведено статистическое тестирование блочных шифров Мухомор, Лабиринт, Калина и ADE, представленных на украинский конкурс по выбору претендента на национальный стандарт блочного симметричного шифрования. При этом использовалась значительно более простая методика, состоящая в статистическом тестировании с помощью набора тестов NIST STS результата зашифрования некоторого файла, размером более 1О Мб, в режиме CBC (о том, как этот файл был получен, в статье не сказано).
Существуют также другие подходы к статистическому тестированию блочных шифров, не получившие широкого распространения. Tак, в работе [31] предлагалось использовать два теста, один из которых основан на проверке распределения свободных членов алгебраических нормальных форм, описывающих функции зашифрования и расшифрования тестируемого блочного шифра, а другой основан на проверке распределения количества мономов
данной степени в этих алгебраических нормальных формах. В работе [32] предложен способ тестирования, заключающийся в том, что для случайного блока открытого текста x0 длины n (как правило, n = 128) формируется n различных блоков xi, . . xn, таких что lxi ф xo| = 1, i = 1, . n, где |x| — вес x. Из них формируются блоки yi = e(key,xi) ф e(key,x0), i = 1, . n. Далее из блоков yi формируется двоичная матрица A размера n x n, в строках которой записываются в двоичном виде блоки yi, i = 1, . n. Тест состоит в проверке соответствия соотношения частоты нулей в произведении двух различных таких матриц (полученных для различных x0 и/или различных ключей key) и частоты нулей в самих этих матрицах тому, которое ожидается для идеального блочного шифра. В работе [33] предложено просто тестировать шифртекст набором статистических тестов DieHard, причем о том, как формировать открытый текст, в этой работе почти ничего не говорится.
Несмотря на высокую степень актуальности методик автоматизированного тестирования криптографического качества блочных шифров, в настоящее время фактически единственной достаточно хорошо исследованной и проработанной, а также апробированной на практике методикой статистического тестирования блочных шифров является описанная выше методика, использованная NIST для тестирования криптоалгоритмов на конкурсе AES (где с ее помощью было протестировано 15 различных блочных шифров). Вместе с тем, к этой методике существует ряд нареканий [29]. Другие существующие методики не являются общепринятыми и недостаточно хорошо проработаны. Все это приводит к необходимости разработки новых методик статистического тестирования блочных шифров, свободных от замеченных недостатков. Кроме того, возникает задача разработки методик статистического тестирования других классов криптографических алгоритмов, в частности, криптографических хэш-функций.
Работа выполнена при финансовой поддержке РФФИ в рамках научного проекта № 1607-00542.
1. Vadhan S.P. Pseudorandomness. Boston: NowPubl., 2012. 338 p.
2. Downey R.G., Hirschfeldt D.R. Algorithmic randomness and complexity. N.Y.: Springer, 2010. 855 p.
3. Ming Li, Vitanyi P. An introduction to Kolmogorov complexity and its applications. N.Y.: Springer, 2014. 550 p.
4. Nies A. Computability and randomness. Oxf.; N.Y.: Oxf. Univ. Press, 2009. 433 p.
5. Верещагин Н.К., Успенский В.А., Шень А. Колмогоровская сложность и вычислительная случайность. М.: МЦНМО, 2013. 575 p.
6. Колмогоров А.Н. Три подхода к определению понятия «количество информации» // Проблемы передачи информации. 1965. Т. 1, № 1. С. 3-11.
7. Martin-Lof P. The definition of random sequences // Information and control. 1966. Vol.9, no. 6. Pp. 602-619. DOI: 10.1016/S0019-9958(66)80018-9
8. Mises R.v. Grundlagen der wahrscheinlichkeitsrechnung//Mathematische Zeitschrift. 1919. Vol. 5, no. 1-2. Pp. 52-99. DOI: 10.1007/BF01203155
9. Muchnik A.A., Semenov A.L., Uspensky V.A. Mathematical metaphysics of randomness // Theoretical Computer Science. 1998. Vol.207, no.2. Pp. 263-317. DOI: 10.1016/S0304-3975(98)00069-3
10. Кнут Д.Э. Искусство программирования: пер с англ. 3-е изд. Т. 2: Получисленные алгоритмы. М.: Вильямс, 2000. 828 с. [Knuth D.E. The art of computer programming. In 3 vol. 3rd ed. Reading: Addison-Wesley Publ. Co., 1997].
11. Marsaglia G. The Marsaglia random number CDROM including the DIEHARD battery of tests of randomness. Режим доступа: http://ftpmirror.your.org/pub/misc/diehard (дата обращения 22.11.2018).
12. Brown R.G.,EddelbuettelD., Bauer D. Dieharder: A random number test suite. Version 3.31.1. Режим доступа: http://webhome.phy.duke.edu/ rgb/General/dieharder.php (дата обращения 22.11.2018).
13. Rukhin A., Soto J., Nechvatal J., Smid M., Barker E., Leigh S., Levenson M., Vangel M., Banks D., Heckert A., Dray J., Vo S. A statistical test suite for random and pseudorandom number generators for cryptographic applications//NIST Spec. Publ. 2001. 800-22 revision 1a. Режим доступа: http://csrc.nist.gov/groups/ST/toolkit/rng/documents/SPS00-22b.pdf (дата обращения 22.11.2018).
14. Bassham L.E., Rukhin A.L., Soto J., Nechvatal J.R., Smid M.E., Leigh S.D., Levenson M., Vangel M., Heckert N.A., Banks D.L. A statistical test suite for random and pseudorandom number generators for cryptographic applications // NIST Spec. Publ. 2010. 800-22 revision 1a. Режим доступа: https://www.nist.gov/publication/statistical-test-suite-random-and-pseudorandom-number-generators-cryptographic (дата обращения 26.11.2018).
15. Soto J. Statistical testing of random number generators // 22nd National information systems security conf.: NISSC’1999 (Arlington, Virginia, USA, October 18-21, 1999): Proc. Vol. 10. 1999. 12 p. Режим доступа: https://csrc.nist.gov/csrc/media/publication/conference-paper/ 1999/10/21/proceedings-of-the-22nd-nisc-1999-documents/papers/p24.pdf (дата обращения 26.11.2018).
16. L’Ecuyer P., Simard R. TestU01: A C library for empirical testing of random number generators // ACM Trans. on Mathematical Software. 2007. Vol. 33, no. 4. Article 22. DOI: 10.1145/1268776.1268777
17. RaBiGeTe MT. Режим доступа: http://cristianopi.altervista.org/RaBiGeTe_MT/ (дата обращения 26.11.2018).
18. PractRand Documentation. Режим доступа: http://pracrand.sourceforge.net/ (дата обращения 26.11.2018).
19. Maurer U.M. A universal statistical test for random bit generators // J. of Cryptology. 1992. Vol. 5, no. 2. Pp. 89-105. DOI: 10.1007/BF00193563
20. Massey J. Shift-register synthesis and BCH decoding // IEEE Trans. on Information Theory. 1969. Vol. 15, no. 1. Pp. 122-127. DOI: 10.1109/TIT. 1969.1054260
21. Atti N.B., Diaz-Toca G.M., Lombardi H. The Berlekamp-Massey algorithm revisited // Applicable Algebra in Engineering, Communication and Computing. 2006. Vol. 17, no. 1. Pp. 75-82. DOI: 10.1007/s00200-005-0190-z
22. Good I.J. The serial test for sampling numbers and other tests for randomness // Math. Proc. of the Cambridge Philosophical Soc. 1953. Vol.49, no. 02. P. 276-284. DOI: 10.1017/S030500410002836X
23. Rukhin A.L. Approximate entropy for testing randomness // J. of Applied Probability. 2000. Vol. 37, no. 1. Pp. 88-100. DOI: 10.1239/jap/1014842270
24. Rukhin A.L. Statistical testing of randomness: New and old procedures//Randomness through computation: Some answers, more questions / Ed. by H. Zenil. Ch. 3. Singapore: World Scientific, 2011. Pp. 33-51. DOI: 10.1142/9789814327756,0003
25. Шнайер Б. Прикладная криптография: Протоколы, алгоритмы, исходные тексты на языке Си: пер. с англ. М.: Триумф, 2002. 815 с. [Schneier B. Applied cryptography: Protocols, algorithms and source code in C. 2nd ed. N.Y.: Wiley, 1996. 784 p.].
26. ГОСТ Р 34.13-2015. Информационная технология (ИТ). Криптографическая защита информации. Режимы работы блочных шифров. Введ. 2016-01-01. М.: Стандартинформ, 2016.
27. Soto J. Randomness tеsting of the advanced encryption standard candidate algorithms. U.S. Dep. of Commerce. Technology Administration. Nat. Inst. of Standards and Technology. 1999. Режим доступа: https://pdfs.semanticscholar.org/65e1/ccfe7d0e3b68c2bb2acdbc35 eb7b046f6430.pdf (дата обращения 26.11.2018).
28. Soto J., Bassham L. Randomness testing of the advanced encryption standard finalist candidates. U.S. Dep. of Commerce. Technology Administration. Nat. Inst. of Standards and Technology. 2000. Режим доступа: https://ws680.nist.gov/publication/get-pdf.cfm?pub-id= 151216 (дата обращения 26.11.2018).
29. Murphy S. The power of NIST’s statistical testing of AES candidates. 2000. Режим доступа: http://www.isg.rhbnc.ac.uk/~sean/StatsRev.pdf (дата обращения 26.11.2018).
30. Долгов В.И., Настенко А.А. Большие шифры — случайные подстановки. проверка статистических свойств шифров, представленных на украинский конкурс с помощью набора тестов nist sts // Системи обробки шформацп. 2012. № 7(105). С. 2-16.
31. Filiol E. A new statistical testing for symmetric ciphers and hash functions // Information and communications security: ICICS 2002: Intern. conf. on information and communications security. B.; Hdbl.: Springer, 2002. Pp. 342-353. DOI: 10.1007/ DOI: 3-540-36159-6-29
32. Katos V. A randomness test for block ciphers // Applied mathematics and computation. 2005. Vol. 162, no. 1. Pp. 29-35. DOI: 10.1016/j.amc.2003.12.122
33. Alani M.M. Testing randomness in ciphertext of block-ciphers using diehard tests // Intern. J. of Computer Science and Network Security. 2010. Vol. 10, no. 4. Pp. 53-57.
Mathematics and Mathematical Modeling, 2018, no. 5, pp. 35-56.
http://mathmelpub.ru ISSN 2412-5911
On statistical testing of block ciphers
Klyucharev P. G.1’* *pk.iu8@yandex.ru
1Bauman Moscow State Technical University, Russia
Keywords: statistical testing; randomness; block cipher
Block ciphers form one of the main classes of cryptographic algorithms. One of the challenges in development of block ciphers, like any other cryptographic algorithms, is the analysis of their cryptographic security. In the course of such analysis, statistical testing of block ciphers is often used. The paper reviews literature on statistical testing of block ciphers.
The first section of the paper briefly and informally discusses approaches to the definition of the concept of a random sequence, including the Kolmogorov, von Mises, and Martin-L?f approaches and the unpredictability-related approach. However, all these approaches to the definition of randomness are not directly applicable in practice.
The second section describes statistical tests of binary sequences. It provides brief descriptions of the tests included in the DieHard, NIST STS, RaBiGeTe statistical test suites.
The third section provides the appropriate information to present further the operation modes of block ciphers.
The fourth section deals with techniques for statistical testing of block ciphers. Usually such techniques lie in the fact that based on the block cipher under test, various generators of the pseudorandom sequences are built, with their output sequences being tested using any suite of statistical tests. The approaches to the construction of such generators are given.
The paper describes the most known statistical test technique for block ciphers among the submitted for the AES competition. It is a technique the NIST uses for statistical testing of ciphers. In addition, there are other techniques mentioned in the literature.
In conclusion the paper states that there is a need to develop new techniques for statistical testing of block ciphers.
The paper support was provided from the Russian Foundation for Basic Research in the framework of the research project No. 16-07-00542 supported
1. Vadhan S.P. Pseudorandomness. Boston: Now Publ., 2012. 338 p.
2. Downey R.G., Hirschfeldt D.R. Algorithmic randomness and complexity. N.Y.: Springer, 2010. 855 p.
3. Ming Li, Vitanyi P. An introduction to Kolmogorov complexity and its applications. N.Y.: Springer, 2014. 550 p.
4. Nies A. Computability and randomness. Oxf.; N.Y.: Oxf. Univ. Press, 2009. 433 p.
5. Vereshchagin N.K., Uspenskij V. A., Shen’ A. Kolmogorovskaia slozhnost’ i algoritmicheskaia sluchajnost’ [Kolmogorov complexity and algorithmic randomness]. Moscow: MTSNMO Publ., 2013. 575 p. (in Russian).
6. Kolmogorov A.N. Three approaches to the definition of «quantity of information». Problemy peredachi informatsii [Problems of Information Transmission], 1965, vol. 1, no. 1, pp. 3-11 (in Russian).
7. Martin-Lof P. The definition of random sequences. Information and control, 1966, vol. 9, no. 6, pp. 602-619. DOI: 10.1016/S0019-9958(66)80018-9
8. Mises R.v. Grundlagen der wahrscheinlichkeitsrechnung. Mathematische Zeitschrift, 1919, vol. 5, no. 1-2, pp. 52-99. DOI: 10.1007/BF01203155
9. Muchnik A.A., Semenov A.L., Uspensky V.A. Mathematical metaphysics of randomness. Theoretical Computer Science, 1998, vol.207, no.2, pp. 263-317. DOI: 10.1016/S0304-3975(98)00069-3
10. Knuth D.E. The art of computer programming. In 3 vol. 3rd ed. Reading: Addison-Wesley Publ. Co., 1997.
Reading: Addison-Wesley Publ. Co., 1997. (Russ. ed.: Knuth D.E. Iskusstvo program-mirovaniia. 3-e izd. Tom 2: Poluchislennye algoritmy. Moscow: Vil’iams Publ., 2000. 828 p.).
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
11. Marsaglia G. The Marsaglia random number CDROM including the DIEHARD battery of tests of randomness. Available at: http://ftpmirror.your.org/pub/misc/diehard, accessed 22.11.2018.
12. Brown R.G.,EddelbuettelD., Bauer D. Dieharder: A random number test suite. Version 3.31.1. Available at: http://webhome.phy.duke.edu/ rgb/General/dieharder.php, accessed 22.11.2018.
13. Rukhin A., Soto J., Nechvatal J., Smid M., Barker E., Leigh S., Levenson M., Vangel M., Banks D., Heckert A., Dray J., Vo S. A statistical test suite for random and pseudorandom number generatorsfor cryptographic applications. NIST Spec. Publ., 2001, 800-22 revision 1a. Available at: http://csrc.nist.gov/groups/ST/toolkit/rng/documents/SPS00-22b.pdf, accessed 22.11.2018.
14. Bassham L.E., Rukhin A.L., Soto J., Nechvatal J.R., Smid M.E., Leigh S.D., Levenson M., Vangel M., Heckert N.A., Banks D.L. A statistical test suite for random and pseudorandom number generators for cryptographic applications. NIST Spec. Publ., 2010,
800-22 revision 1a. Available at: https://www.nist.gov/publication/statistical-test-suite-random-and-pseudorandom-number-generators-cryptographic, accessed 26.11.2018.
15. Soto J. Statistical testing of random number generators. 22nd National information systems security conf.: NISSC’1999 (Arlington, Virginia, USA, October 18-21, 1999): Proc. Vol. 10. 1999. 12 p. Available at: https://csrc.nist.gov/csrc/media/publication/conference-paper/1999/ 10/21/proceedings-of-the-22nd-nisc-1999-documents/papers/p24.pdf accessed 26.11.2018.
16. L’Ecuyer P., Simard R. TestU01: A C library for empirical testing of random number generators. ACM Trans. on Mathematical Software, 2007, vol. 33, no. 4, article 22. DOI: 10.1145/1268776.1268777
17. RaBiGeTe MT. Available at: http://cristianopi.altervista.org/RaBiGeTe_MT/, accessed 26.11.2018.
18. PractRand Documentation. Available at: http://pracrand.sourceforge.net/, accessed 26.11.2018.
19. Maurer U.M. A universal statistical test for random bit generators. J. of Cryptology, 1992, Vol. 5, no. 2, pp. 89-105. DOI: 10.1007/BF00193563
20. Massey J. Shift-register synthesis and BCH decoding. IEEE Trans. on Information Theory, 1969, vol. 15, no. 1, pp. 122-127. DOI: 10.1109/TIT.1969.1054260
21. Atti N.B., Diaz-Toca G.M., Lombardi H. The Berlekamp-Massey algorithm revisited. Applicable Algebra in Engineering, Communication and Computing. 2006, vol. 17, no. 1, pp. 75-82. DOI: 10.1007/s00200-005-0190-z
22. Good I.J. The serial test for sampling numbers and other tests for randomness. Math. Proc. of the Cambridge Philosophical Soc., 1953, vol.49, no. 02, pp. 276-284. DOI: 10.1017/S030500410002836X
23. Rukhin A.L. Approximate entropy for testing randomness. J. of Applied Probability, 2000, vol. 37, no. 1, pp. 88-100. DOI: 10.1239/jap/1014842270
24. Rukhin A.L. Statistical testing of randomness: New and old procedures. Randomness through computation: Some answers, more questions / Ed. by H. Zenil. Ch. 3. Singapore: World Scientific, 2011. Pp. 33-51. DOI: 10.1142/9789814327756.0003
25. Schneier B. Applied cryptography: Protocols, algorithms and source code in C. 2nd ed. N.Y.: Wiley, 1996. 784 p. (Russ. ed.: Schneier B. Prikladnaia kriptografiia: Protokoly, algoritmy, iskhodhye teksty na iazyke SI. Moscow: Triumf Publ., 2002. 815 p.).
26. GOSTR 34.13-2015. Informatsionnaia tekhnologiia. Kriptograficheskaia zashchita informat-sii. Rezhimy raboty blochnykh shifrov [State Standard R 34.13-2015. Information technology. Cryptographic data security. Block ciphers operation modes]. Moscow: Standartinform Publ., 2016 (in Russian).
27. Soto J. Randomness testing of the advanced encryption standard candidate algorithms. U.S. Dep. of Commerce. Technology Administration. Nat. Inst. of Standards and Technol-
ogy. 1999. Available at: https://pdfs.semanticscholar.org/65e1/ccfe7d0e3b68c2bb2acdbc35 eb7b046f6430.pdf, accessed 26.11.2018.
28. Soto J., Bassham L. Randomness testing of the advanced encryption standard finalist candidates. U.S. Dep. of Commerce. Technology Administration. Nat. Inst. of Standards and Technology. 2000. Available at: https://ws680.nist.gov/publication/get-pdf.cfm?pub-id= 151216, accessed 26.11.2018.
29. Murphy S. The power of NIST’s statistical testing of AES candidates. 2000. Available at: http://www.isg.rhbnc.ac.uk/~sean/StatsRev.pdf, accessed 26.11.2018.
30. Dolgov V.I., Nastenko A.A. Large ciphers — random permutations. Verification of statistical properties ciphers submitted for ukranian contest with a test suite NIST STS. Sistemi obrobki informatsii [Information Processing Systems], 2012, no. 7(105), pp. 2-16 (in Russian).
31. Filiol E. A new statistical testing for symmetric ciphers and hash functions. Information and communications security: ICICS 2002: Intern. conf. on information and communications security. B.; Hdbl.: Springer, 2002. Pp. 342-353. DOI: 10.1007/DOI: 3-540-36159-6,29
32. Katos V. A randomness test for block ciphers. Applied mathematics and computation, 2005, vol. 162, no. 1, pp. 29-35. DOI: 10.1016/j.amc.2003.12.122
33. Alani M.M. Testing randomness in ciphertext of block-ciphers using diehard tests. Intern. J. of Computer Science and Network Security, 2010, Vol. 10, no. 4, pp. 53-57.
Симметричное шифрование
Симметричное шифрование — это способ шифрования данных, при котором один и тот же ключ используется и для кодирования, и для восстановления информации. До 1970-х годов, когда появились первые асимметричные шифры, оно было единственным криптографическим методом.
Принцип работы симметричных алгоритмов
В целом симметричным считается любой шифр, использующий один и тот же секретный ключ для шифрования и расшифровки.
Например, если алгоритм предполагает замену букв числами, то и у отправителя сообщения, и у его получателя должна быть одна и та же таблица соответствия букв и чисел: первый с ее помощью шифрует сообщения, а второй — расшифровывает.
Однако такие простейшие шифры легко взломать — например, зная частотность разных букв в языке, можно соотносить самые часто встречающиеся буквы с самыми многочисленными числами или символами в коде, пока не удастся получить осмысленные слова. С использованием компьютерных технологий такая задача стала занимать настолько мало времени, что использование подобных алгоритмов утратило всякий смысл.
Поэтому современные симметричные алгоритмы считаются надежными, если отвечают следующим требованиям:
- Выходные данные не должны содержать статистических паттернов исходных данных (как в примере выше: наиболее частотные символы осмысленного текста не должны соответствовать наиболее частотным символам шифра).
- Шифр должен быть нелинейным (то есть в шифрованных данных не должно быть закономерностей, которые можно отследить, имея на руках несколько открытых текстов и шифров к ним).
Большинство актуальных симметричных шифров для достижения результатов, соответствующих этим требованиям, используют комбинацию операций подстановки (замена фрагментов исходного сообщения, например букв, на другие данные, например цифры, по определенному правилу или с помощью таблицы соответствий) и перестановки (перемешивание частей исходного сообщения по определенному правилу), поочередно повторяя их. Один круг шифрования, состоящий из этих операций, называется раундом.
Виды алгоритмов симметричного шифрования
В зависимости от принципа работы алгоритмы симметричного шифрования делятся на два типа:
Блочные алгоритмы шифруют данные блоками фиксированной длины (64, 128 или другое количество бит в зависимости от алгоритма). Если все сообщение или его финальная часть меньше размера блока, система дополняет его предусмотренными алгоритмом символами, которые так и называются дополнением.
К актуальным блочным алгоритмам относятся:
Потоковое шифрование данных предполагает обработку каждого бита информации с использованием гаммирования, то есть изменения этого бита с помощью соответствующего ему бита псевдослучайной секретной последовательности чисел, которая формируется на основе ключа и имеет ту же длину, что и шифруемое сообщение. Как правило, биты исходных данных сравниваются с битами секретной последовательности с помощью логической операции XOR (исключающее ИЛИ, на выходе дающее 0, если значения битов совпадают, и 1, если они различаются).
Потоковое шифрование в настоящее время используют следующие алгоритмы:
Достоинства и недостатки симметричного шифрования
Симметричные алгоритмы требуют меньше ресурсов и демонстрируют большую скорость шифрования, чем асимметричные алгоритмы. Большинство симметричных шифров предположительно устойчиво к атакам с помощью квантовых компьютеров, которые в теории представляют угрозу для асимметричных алгоритмов.
Слабое место симметричного шифрования — обмен ключом. Поскольку для работы алгоритма ключ должен быть и у отправителя, и у получателя сообщения, его необходимо передать; однако при передаче по незащищенным каналам его могут перехватить и использовать посторонние. На практике во многих системах эта проблема решается шифрованием ключа с помощью асимметричного алгоритма.
Область применения симметричного шифрования
Симметричное шифрование используется для обмена данными во многих современных сервисах, часто в сочетании с асимметричным шифрованием. Например, мессенджеры защищают с помощью таких шифров переписку (при этом ключ для симметричного шифрования обычно доставляется в асимметрично зашифрованном виде), а сервисы для видеосвязи — потоки аудио и видео. В защищенном транспортном протоколе TLS симметричное шифрование используется для обеспечения конфиденциальности передаваемых данных.
Симметричные алгоритмы не могут применяться для формирования цифровых подписей и сертификатов, потому что секретный ключ при использовании этого метода должен быть известен всем, кто работает с шифром, что противоречит самой идее электронной подписи (возможности проверки ее подлинности без обращения к владельцу).
Публикации на схожие темы
- Правильное хранение паролей — основа безопасности
- Как выглядит будущее без паролей?
- Сквозное шифрование: что это и зачем оно нужно вам
- Luna и Black Basta — новые шифровальщики для Windows, Linux и ESXi
- ToddyCat: неизвестная APT-группа, нацеленная на организации Европы и Азии
- ISaPWN – исследование безопасности ISaGRAF Runtime
На страже информации. Криптография




Новиков, Д. А. На страже информации. Криптография / Д. А. Новиков, С. А. Харченко. — Текст : непосредственный // Юный ученый. — 2022. — № 3 (55). — С. 52-60. — URL: https://moluch.ru/young/archive/55/2825/ (дата обращения: 29.10.2023).
В статье автор доказывает возможность защиты информации с помощью криптографии. Он осуществляет шифрование открытого сообщения двумя разными алгоритмами, используя шифровальные устройства. Один алгоритм — известный, другой алгоритм — самостоятельно разработанный.
Ключевые слова: криптография, шифрование.
Моя работа посвящена защите информации. Это очень актуально в наше время, было актуально в прошлом и будет актуально всегда. «Кто владеет информацией, тот владеет и миром» — это известное высказывание Натана Ротшильда очень точно описывает важность информации и ее место в развитии человечества.
Успех предпринимателей, надежная работа банков, политическая деятельность, развитие науки, исходы военных конфликтов, электронные услуги — всё это и многое другое зависит от безопасной передачи информации. Ведь крайне важно, чтобы информация доходила от отправителя к получателю таким образом, чтобы никто посторонний не мог её заполучить и использовать с плохими намерениями. Но в то же время важно, чтобы информацию смог получить в целостности и понять адресат. Этим и занимается криптография.
Проблема
– информация может быть похищена и использована злоумышленниками
Гипотеза
– информацию можно защитить
Цель проекта
– доказать, что с помощью криптографии можно защитить информацию
Задачи проекта:
– изучить алгоритмы шифрования прошлого;
– произвести шифрование открытого текста известным алгоритмом шифрования с помощью шифровального инструмента;
– самостоятельно разработать алгоритм шифрования и собрать макет шифровального устройства для данного алгоритма;
– произвести шифрование открытого текста по разработанному алгоритму с помощью собранного устройства;
– проанализировать полученные результаты и сделать выводы о возможности защиты информации с помощью криптографии.
Понятия и принципы
Дословно термин «криптография» означает «тайнопись». Смысл этого термина выражает основное предназначение криптографии — защитить и сохранить в тайне необходимую информацию [4]. Криптография не «прячет» передаваемое сообщение, а преобразует его в форму, недоступную для понимания постороннего. Процесс такого обратимого преобразования открытой информации, при котором доступ к ней может быть только у определенных лиц — получателей информации — называется «шифрованием». Зашифрованная информация называется «шифрограмма, шифротекст». Процесс преобразования шифрограммы в открытый текст называется «расшифровка».
Таким образом процесс криптографической защиты (рис.1) состоит из:
– шифрования исходного сообщения с использованием ключа, то есть получение шифрограммы;
– расшифровка полученной шифрограммы с использованием ключа.
![Структура криптографической защиты. [6]](https://moluch.ru/young/blmcbn/2825/2825.001.png)
Рис. 1. Структура криптографической защиты. [6]
Ключ шифрования передается адресату или одновременно с самим сообщением или заранее. Также заранее адресату передается информация о выбранном шифре, то есть об алгоритме преобразования исходного сообщения.
Важно четко понимать значения понятий «шифр» и «ключ шифрования». Простым языком их можно выразить следующим образом:
Шифр — это какой-либо алгоритм преобразования исходного сообщения в шифрованное, то есть определенная последовательность действий для всех символов или слов.
Ключ шифрования — это изменяемый параметр в алгоритме, который позволяет получить разные результаты без изменения самого алгоритма, он является важным элементом защиты, обеспечивающем дополнительную стойкость шифра к взлому.
Быстрый взлом шифра возможен только при условии, что известен и сам алгоритм, и ключ шифрования. Например, в шифре Цезаря, который появился в период около 100 лет до н. э., алгоритмом является сдвиг алфавита на определенную величину. [1] А вот эта самая величина сдвига и есть ключ шифрования — в данном случае 3. (рис.2)
![Алгоритм шифра Цезаря. [7]](https://moluch.ru/young/blmcbn/2825/2825.002.png)
Рис. 2. Алгоритм шифра Цезаря. [7]
Взлом шифра — успешная попытка раскрытия шифрованного сообщения без знания алгоритма и ключа.
Шифрование, в котором используется один ключ для шифрования и расшифровки, называются симметричным, а сам ключ называется общим.
В асимметричном шифровании данные шифруются одним ключом, а расшифровываются другим. Первый ключ можно держать у всех на виду, а вот второй нужно прятать.
Ассиметричное шифрование более сложное и обычно осуществляется с применением компьютеров. В данной работе будет рассмотрено только симметричное шифрование.
История шифрования
Шифр Цезаря не был первым шифром в истории. История шифрования берет свое начало намного раньше. Нам известен папирус с измененными иероглифами времен фараона Аменемхета II (рис. 3), а это примерно 4000 тыс лет до н. э. В Древней Спарте использовалась скитала (рис.4). Также мы знаем о диске Энея (рис.5). А кардинал Ришелье использовал для шифрования решетку Кардано (рис.6). Пустые поля текста заполнялись другим текстом для маскировки сообщений под обычные послания — таким образом, применение решётки является одной из форм стеганографии. [2]
![Древнеегипетский папирус с измененными иероглифами [8]](https://moluch.ru/young/blmcbn/2825/2825.003.jpg)
Рис. 3. Древнеегипетский папирус с измененными иероглифами [8]
![Скитала [9]](https://moluch.ru/young/blmcbn/2825/2825.004.png)
Рис. 4. Скитала [9]
![Диск Энея [10]](https://moluch.ru/young/blmcbn/2825/2825.005.png)
Рис. 5. Диск Энея [10]
![Решетка Кардана [11]](https://moluch.ru/young/blmcbn/2825/2825.006.png)
Рис. 6. Решетка Кардана [11]
Промышленная революция не обошла вниманием и криптографию. Около 1790 года один из отцов — основателей США Томас Джефферсон создал дисковый шифр, прозванный позже цилиндром Джефферсона (рис.7). Этот прибор, основанный на роторной системе, позволил автоматизировать процесс шифрования и стал первым криптоустройством Нового времени. [3]
![Цилиндр Джефферсона. [12]](https://moluch.ru/young/blmcbn/2825/2825.007.png)
Рис. 7. Цилиндр Джефферсона. [12]
Говоря о шифровальных машинах, нельзя не упомянуть об Энигме (рис.8).
![Шифровальная машина «Энигма». [13]](https://moluch.ru/young/blmcbn/2825/2825.008.jpg)
Рис. 8. Шифровальная машина «Энигма». [13]
Взлом шифра этой немецкой шифровальной машины способствовал победе над фашистской Германией.
Исследование: шифрование и дешифровка открытого сообщения.
Чтобы проверить, сможет ли криптографическая защита сделать открытую информацию недоступной для посторонних, я буду шифровать исходное сообщение «Знания — сила», используя один известный шифр и один, разработанный мной самостоятельно. Из этого исходного сообщения мы уберём пробелы и знаки препинания. Регистр букв не имеет значения при шифровании. Таким образом, исходным сообщением во всех шифрах будет «ЗНАНИЯСИЛА».
Шифры, которые мы будем использовать, следующие:
– шифр упорядоченного смешения
После шифрования я проверю полученные шифрограммы на стойкость к взлому и сделаю вывод о надежности криптографической защиты информации.
Шифр Виженера
Зашифруем исходное сообщение «Знания — сила» с использованием ключевого слова «лицей» с помощью шифра Виженера.
Впервые этот метод описал Джовани Баттиста Белласо (итал. Giovan Battista Bellaso) в книге в 1553 году, однако в XIX веке шифр получил имя Блеза Виженера, французского дипломата. Несмотря на то, что метод прост для понимания и реализации, он является недоступным для простых методов криптоанализа, то есть является трудным для расшифровки. На протяжении трех столетий он противостоял всем попыткам его взломать, чем и заработал имя «неразгаданный шифр». [5]
Для шифрования и расшифровки используется таблица Виженера, известная также под названием tabula recta (лат.). (Приложение 1). Для работы с таблицей Виженера сначала необходимо преобразовать ключ. Для этого записываем ключ циклически до тех пор, пока его длина не будет соответствовать длине исходного текста, при этом ключ не обязательно должен быть записано полностью. Таким образом получаем преобразованный ключ «ЛИЦЕЙЛИЦЕЙ». Каждому символу исходного сообщения соответствует символ преобразованного ключа с тем же порядковым номером.

Порядок шифрования следующий:
- Используя таблицу Виженера определяем символы зашифрованного сообщения. Для этого:
- Ищем в таблице Виженера строку, соответствующую символу преобразованного ключа.
- Ищем столбец, соответствующий символу исходного сообщения с тем же порядковым номером.
- Символ, находящийся на пересечении этих строки и столбца, является зашифрованным символом.
Ищем в таблице Виженера строку, соответствующую первой букве преобразованного ключа («Л») и столбец, соответствующий первой букве исходного сообщения («З»). На пересечении этих строки и столбца находится символ «У». Это первый символ зашифрованного сообщения.
Ищем строку для символа «И» и столбец для символа «Н». На пересечении находится второй зашифрованный символ — «Ц».
Таким образом получается вот такое шифрованное сообщение:
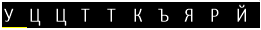
Расшифровка производится следующим образом:
- Составляется преобразованный ключ тем же способом, как и при шифровании — путем циклической записи ключа под шифрованным сообщением.
- Определяются символы исходного сообщения:
- В таблице Виженера находится строка, соответствующая символу преобразованного ключа;
- В данной строке находится символ зашифрованного текста с тем же порядковым номером.
- Столбец, в котором находится данный символ, соответствует соответствующему символу исходного сообщения.
Алгоритм шифра Виженера можно эффективно реализовать с помощью простого в использовании и изготовлении механического шифровального инструмента, который называется линейка Сен-Сира. [3] Образец данного устройства мы изготовили специально для моего исследования. (рис.9)

Рис. 9. Линейка Сен-Сира
Одну часть линейки — короткую, с нанесенным на ней алфавитом, называют неподвижной шкалой. Вторую часть линейки, представляющую из себя перемещающуюся длинную полосу с нанесенными на ней двумя алфавитами друг за другом — называют подвижной шкалой.
При работе с линейкой символы неподвижной шкалы не должны выходить за границы символов подвижной шкалы.
Для начала работы с линейкой необходимо получить преобразованный ключ, как мы это уже делали ранее:

Порядок шифрования следующий (рис.10):
- Длинной частью линейки выставляется символ ключа напротив символа А короткой части.
- Ищем зашифрованный символ, он тоже находится тоже на длинной части. Он расположен под исходным символом на короткой части.
- Проделываем данную замену для каждого символа исходного сообщения. В шаге 1 нужный символ преобразованного ключа всегда располагается напротив символа А неподвижной шкалы. В результате получается шифрованное сообщение, равное по длине и исходному сообщению и преобразованному ключу.

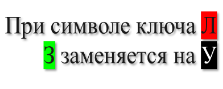

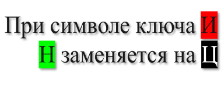
Рис. 10. Порядок шифрования линейкой Сен-Сира.
В результате также получаем шифрограмму:
Порядок расшифровки следующий:
- Длинной частью линейки выставляется символ ключа напротив символа А короткой части.
- Ищем на длинной части символ шифрограммы. Над ним, на короткой части, расположен символ исходного сообщения.
- Проделываем данную замену для каждого символа шифрограммы.
Шифр упорядоченного смешения
Я придумал этот шифр, изучив много других шифров и принципы их действия. Он основывается на перемешивании между собой строк и столбцов с исходным текстом в определенном порядке, определяемым ключом, а именно, упорядочивании по алфавиту символов слов ключа, которые являются заголовками строк и столбцов таблицы с вписанным в неё зашифрованным текстом. Алгоритм моего шифра следующий:
- Исходное сообщение дополняется некоторым количеством дополнительных символов в алфавитном порядке, так чтобы получившуюся фразу можно было полностью вписать в таблицу. Дополнительные символы нужны для увеличения сложности шифра. Вписывать надо по строкам .
В моем случае я добавил 10 символов алфавита к исходному сообщению ЗНАНИЯСИЛА и получил следующую таблицу (рис.11):

Рис. 11. Исходное сообщение, дополненное символами алфавита

-
Устанавливается ключ шифрования. Ключ состоит из двух слов, длина каждого слова соответствует размеру таблицы. Первое слово — высота таблицы, т. е. количество строк; второе слово — ширина таблицы, т. е. количество столбцов. Важно, чтобы в каждом из слов не повторялись буквы . После этого ключи добавляются к таблице слева вертикально и сверху горизонтально, образую заголовки строк и столбцов. В моем случае я выбрал ключ

Получается следующая таблица (рис.12):
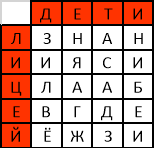
Рис. 12. Исходное сообщение, дополненное ключом
- Переставляем строки таблицы вместе с заголовками таким образом, чтобы символы первого слова ключа выстроились по алфавиту (рис.13):
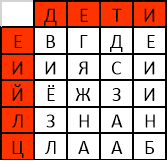
Рис. 13. Упорядочивание строк по алфавиту
- Переставляем столбцы таблицы вместе с заголовками таким образом, чтобы символы второго слова ключа выстроились по алфавиту(рис.14):
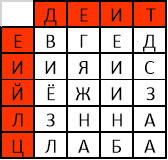
Рис. 14. Упорядочивание столбцов по алфавиту
Из получившейся таблицы выписываем символы по столбцам , не включая заголовки (измененные ключи). Эти символы и будут шифрограммой. В моем случае это ВИЁЗЛГЯЖНАЕИИНБДСЗАА.
Получатель, зная шифрограмму и ключ, может приступить к расшифровке. Делается это в следующем порядке:
-
Зная ключ

, получатель строит таблицу размером 5 строк х 4 столбца.
- В таблицу по столбцам вписывается шифрограмма ВИЁЗЛГЯЖНАЕИИНБДСЗАА.
- К таблице добавляются слева вертикально и сверху горизонтально заголовки, представляющие из себя слова ключа в алфавитном порядке —

Оставшиеся символы являются исходным сообщением — ЗНАНИЯСИЛА.
При разработке моего алгоритма целью было не только осуществление шифрования, но и возможность реализации алгоритма на несложном шифровальном устройстве. Устройство должно иметь следующие возможности:
– составление таблицы с произвольным набором символов (возможность замены букв);
– свободное перемещение столбцов и строк этой таблицы.
Я придумал такое устройство, которое удовлетворяет данным требованиям, а папа помог мне его изготовить. (рис.15–17).


Рис. 15. Изготовление кубиков

Рис. 16. Нанесение символов на сменные стикеры

Рис. 17. Мое шифровальное устройство
Оно состоит из кубиков, в каждом из которых проделаны сквозные перпендикулярные отверстия, короба для них и длинных палочек. Если кубики сложить в виде таблицы в короб, то, благодаря отверстиям, возможно палочками перемещать как строки таблицы, так и столбцы. Клеящееся сменные стикеры с нарисованными буквами позволяют использовать данное приспособление для разных фраз и ключей. Шифрование длинных сообщений требует увеличения самой таблицы или изготовление других таких же наборов.
Используя два разных алгоритма шифрования, я получил следующие варианты зашифрованного исходного сообщения: «Знания — сила»:
После получения шифрограмм я решил проверить их на стойкость к взлому — я попросил нескольких людей разгадать две эти шифрограммы, не раскрывая им алгоритм и ключи шифрования. За несколько дней, которые я отвел на испытание, шифры не были разгаданы. Более того, расшифровка не удалась даже после того, как я раскрыл ключи. Получение двух шифрограмм двумя способами не заняло у меня много времени, а вот их расшифровка без знания алгоритма, с помощью которого они получены, а также без знания ключей шифрования, представляет из себя трудоемкий процесс и может занять длительное время.
Заключение
Проведя исследование, я получил следующие результаты:
– я понял, как строится криптографическая защита;
– я разработал шифр и собрал шифровальное устройство, реализующее алгоритм данного шифра;
– я самостоятельно зашифровал исходное сообщение с использованием двух разных шифров с помощью шифровальных устройств.
А после испытание шифрограмм на устойчивость к взлому я сделал вывод от том, что криптография позволяет защитить информации.
Развитие компьютерных технологий революционно изменило принципы построения криптосистем. Криптография ушла далеко вперед от примитивных шифров к сложным алгоритмам шифрования, но будет развиваться и дальше, становясь все более совершенным инструментом на страже информации.
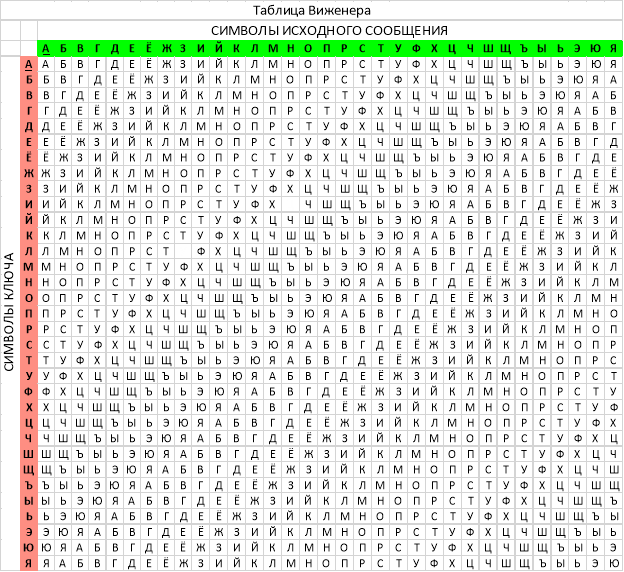
- Роман Душкин: Математика и криптография. Тайны шифров и логическое мышление. 2017г., Издательство АСТ, г. Москва, 190 стр.
- Ирина Русецкая: История криптографии в Западной Европе в раннее Новое время. 2014г, Центр гуманитарных инициатив, Университетская книга — СПб, 144 стр.
- Шифры из прошлого: тайнопись и загадки докомпьютерной эпохи [Электронный ресурс]: 3D News. — Режим доступа: https://3dnews.ru/916293/shifri-iz-proshlogo-taynopis-i-zagadki-dokompyuternoy-epohi (дата обращения: 12.12.2021)
- Криптография и защищённая связь: история первых шифров [Электронный ресурс]: Хабр. — Режим доступа: https://habr.com/ru/post/321338/ (дата обращения: 12.12.2021)
- Шифр Виженера [Электронный ресурс]: Википедия. — Режим доступа: https://ru.wikipedia.org/wiki/ %D0 %A8 %D0 %B8 %D1 %84 %D1 %80_ %D0 %92 %D0 %B8 %D0 %B6 %D0 %B5 %D0 %BD %D0 %B5 %D1 %80 %D0 %B0 (дата обращения: 12.12.2021).
- Структура криптографической защиты https://cdn.otus.ru/media/public/f6/7d/symmetric_encryption_graphic_ru-20219-f67d82.png
- Шифр Цезаря https://ru.wikipedia.org/wiki/ %D0 %A8 %D0 %B8 %D1 %84 %D1 %80_ %D0 %A6 %D0 %B5 %D0 %B7 %D0 %B0 %D1 %80 %D1 %8F#/media/ %D0 %A4 %D0 %B0 %D0 %B9 %D0 %BB:Caesar3.svg
- Древнеегипетский папирус с измененными иероглифами https://rostec.ru/upload/medialibrary/018/0187e7c1d1c5fa5f548a9bf432eea4a0.jpg
- Скитала https://3dnews.ru/assets/external/illustrations/2015/06/27/916293/2.png
- Диск Энея https://avatars.mds.yandex.net/get-zen_doc/4395091/pub_60d1e1225fc3481f3f417d9a_60d1ebe6d4596758d59a3b09/scale_1200
- Решетка Кардано https://3dnews.ru/assets/external/illustrations/2015/06/27/916293/13.png
- Цилиндр Джефферсона. https://spy-museum.s3.amazonaws.com/files/callouts/classic-lrg-jefferson-cipher-3.jpg
- Энигма http://vichivisam.ru/wp-content/uploads/2019/02/d96c00eab0f265cdfe882f8edb07f183–1068×712.jpg