Внедряйте статический анализ в процесс, а не ищите с его помощью баги
Написать эту статью меня сподвигло большое количество материалов о статическом анализе, всё чаще попадающихся на глаза. Во-первых, это блог PVS-studio, который активно продвигает себя на Хабре при помощи обзоров ошибок, найденных их инструментом в проектах с открытым кодом. Недавно PVS-studio реализовали поддержку Java, и, конечно, разработчики IntelliJ IDEA, чей встроенный анализатор является на сегодня, наверное, самым продвинутым для Java, не могли остаться в стороне.
При чтении таких обзоров возникает ощущение, что речь идёт про волшебный эликсир: нажми на кнопку, и вот он — список дефектов перед глазами. Кажется, что по мере совершенствования анализаторов, багов автоматически будет находиться всё больше и больше, а продукты, просканированные этими роботами, будут становиться всё лучше и лучше, без каких-либо усилий с нашей стороны.
Но волшебных эликсиров не бывает. Я хотел бы поговорить о том, о чём обычно не говорят в постах вида «вот какие штуки может найти наш робот»: чего не могут анализаторы, в чём их реальная роль и место в процессе поставки софта, и как внедрять их правильно.
Храповик (источник: википедия).
Чего никогда не смогут статические анализаторы
Что такое, с практической точки зрения, анализ исходного кода? Мы подаём на вход некоторые исходники, и на выходе за короткое время (гораздо более короткое, чем прогон тестов) получаем некоторые сведения о нашей системе. Принципиальное и математически непреодолимое ограничение состоит в том, что получить мы таким образом можем лишь довольно узкий класс сведений.
Самый знаменитый пример задачи, не решаемой при помощи статического анализа — проблема останова: это теорема, которая доказывает, что невозможно разработать общий алгоритм, который бы по исходному коду программы определял, зациклится она или завершится за конечное время. Расширением данной теоремы является теорема Райса, утверждающая, для любого нетривиального свойства вычислимых функций определение того, вычисляет ли произвольная программа функцию с таким свойством, является алгоритмически неразрешимой задачей. Например, невозможно написать анализатор, по любому исходному коду определяющий, является ли анализируемая программа имплементацией алгоритма, вычисляющего, скажем, возведение в квадрат целого числа.
Таким образом, функциональность статических анализаторов имеет непреодолимые ограничения. Статический анализатор никогда не сможет во всех случаях определить такие вещи, как, например, возникновение «null pointer exception» в языках, допускающих значение null, или во всех случаях определить возникновение «attribute not found» в языках с динамической типизацией. Всё, что может самый совершенный статический анализатор — это выделять частные случаи, число которых среди всех возможных проблем с вашим исходным кодом является, без преувеличения, каплей в море.
Статический анализ — это не поиск багов
Из вышесказанного следует вывод: статический анализ — это не средство уменьшения количества дефектов в программе. Рискну утверждать: будучи впервые применён к вашему проекту, он найдёт в коде «занятные» места, но, скорее всего, не найдёт никаких дефектов, влияющих на качество работы вашей программы.
Примеры дефектов, автоматически найденных анализаторами, впечатляют, но не следует забывать, что эти примеры найдены при помощи сканирования большого набора больших кодовых баз. По такому же принципу взломщики, имеющие возможность перебрать несколько простых паролей на большом количестве аккаунтов, в конце концов находят те аккаунты, на которых стоит простой пароль.
Значит ли это, что статический анализ не надо применять? Конечно, нет! И ровно по той же причине, по которой стоит проверять каждый новый пароль на попадание в стоп-лист «простых» паролей.
Статический анализ — это больше, чем поиск багов
На самом деле, практически решаемые анализом задачи гораздо шире. Ведь в целом статический анализ — это любая проверка исходников, осуществляемая до их запуска. Вот некоторые вещи, которые можно делать:
- Проверка стиля кодирования в широком смысле этого слова. Сюда входит как проверка форматирования, так и поиск использования пустых/лишних скобок, установка, пороговых значений на метрики вроде количества строк / цикломатической сложности метода и т. д. — всего, что потенциально затрудняет читаемость и поддерживаемость кода. В Java таким инструментом является Checkstyle, в Python — flake8. Программы такого класса обычно называются «линтеры».
- Анализу может подвергаться не только исполняемый код. Файлы ресурсов, такие как JSON, YAML, XML, .properties могут (и должны!) быть автоматически проверяемы на валидность. Ведь лучше узнать о том, что из-за каких-нибудь непарных кавычек нарушена структура JSON на раннем этапе автоматической проверки Pull Request, чем при исполнении тестов или в Run time? Соответствующие инструменты имеются: например, YAMLlint, JSONLint.
- Компиляция (или парсинг для динамических языков программирования) — это тоже вид статического анализа. Как правило, компиляторы способны выдавать предупреждения, сигнализирующие о проблемах с качеством исходного кода, и их не следует игнорировать.
- Иногда компиляция — это не только компиляция исполняемого кода. Например, если у вас документация в формате AsciiDoctor, то в момент превращения её в HTML/PDF обработчик AsciiDoctor (Maven plugin) может выдавать предупреждения, например, о нарушенных внутренних ссылках. И это — весомый повод не принять Pull Request с изменениями документации.
- Проверка правописания — тоже вид статического анализа. Утилита aspell способна проверять правописание не только в документации, но и в исходных кодах программ (комментариях и литералах) на разных языках программирования, включая C/C++, Java и Python. Ошибка правописания в пользовательском интерфейсе или документации — это тоже дефект!
- Конфигурационные тесты (о том, что это такое — см. этот и этот доклады), хотя и выполняются в среде выполнения модульных тестов типа pytest, на самом деле также являются разновидностью статического анализа, т. к. не выполняют исходные коды в процессе своего выполнения.
Какие из этих типов статического анализа следует применять в вашем проекте? Конечно, все, чем больше — тем лучше! Главное, внедрить это правильно, о чём и пойдёт речь дальше.
Конвейер поставки как многоступенчатый фильтр и статический анализ как его первый каскад
Классической метафорой непрерывной интеграции является трубопровод (pipeline), по которому протекают изменения — от изменения исходного кода до поставки в production. Стандартная последовательность этапов этого конвейера выглядит так:
- статический анализ
- компиляция
- модульные тесты
- интеграционные тесты
- UI тесты
- ручная проверка
Почему именно так, а не иначе? В той части конвейера, которая касается тестирования, тестировщики узнают широко известную пирамиду тестирования.

Тестовая пирамида. Источник: статья Мартина Фаулера.
В нижней части этой пирамиды расположены тесты, которые легче писать, которые быстрее выполняются и не имеют тенденции к ложному срабатыванию. Потому их должно быть больше, они должны покрывать больше кода и выполняться первыми. В верхней части пирамиды всё обстоит наоборот, поэтому количество интеграционных и UI тестов должно быть уменьшено до необходимого минимума. Человек в этой цепочке — самый дорогой, медленный и ненадёжный ресурс, поэтому он находится в самом конце и выполняет работу только в том случае, если предыдущие этапы не обнаружили никаких дефектов. Однако по тем же самым принципам строится конвейер и в частях, не связанных непосредственно с тестированием!
Я бы хотел предложить аналогию в виде многокаскадной системы фильтрации воды. На вход подаётся грязная вода (изменения с дефектами), на выходе мы должны получить чистую воду, все нежелательные загрязнения в которой отсеяны.

Многоступенчатый фильтр. Источник: Wikimedia Commons
Как известно, очищающие фильтры проектируются так, что каждый следующий каскад может отсеивать всё более мелкую фракцию загрязнений. При этом каскады более грубой очистки имеют бОльшую пропускную способность и меньшую стоимость. В нашей аналогии это означает, что входные quality gates имеют бОльшее быстродействие, требуют меньше усилий для запуска и сами по себе более неприхотливы в работе — и именно в такой последовательности они и выстроены. Роль статического анализа, который, как мы теперь понимаем, способен отсеять лишь самые грубые дефекты — это роль решётки-«грязевика» в самом начале каскада фильтров.
Статический анализ сам по себе не улучшает качество конечного продукта, как «грязевик» не делает воду питьевой. И тем не менее, в общей связке с другими элементами конвейера его важность очевидна. Хотя в многокаскадном фильтре выходные каскады потенциально способны уловить всё то же, что и входные — ясно, к каким последствиям приведёт попытка обойтись одними лишь каскадами тонкой очистки, без входных каскадов.
Цель «грязевика» — разгрузить последующие каскады от улавливания совсем уж грубых дефектов. Например, как минимум, человек, производящий code review, не должен отвлекаться на неправильно отформатированный код и нарушение установленных норм кодирования (вроде лишних скобок или слишком глубоко вложенных ветвлений). Баги вроде NPE должны улавливаться модульными тестами, но если ещё до теста анализатор нам указывает на то, что баг должен неминуемо произойти — это значительно ускорит его исправление.
Полагаю, теперь ясно, почему статический анализ не улучшает качество продукта, если применяется эпизодически, и должен применяться постоянно для отсеивания изменений с грубыми дефектами. Вопрос, улучшит ли применение статического анализатора качество вашего продукта, примерно эквивалентен вопросу «улучшатся ли питьевые качества воды, взятой из грязного водоёма, если её пропустить через дуршлаг?»
Внедрение в legacy-проект
Важный практический вопрос: как внедрить статический анализ в процесс непрерывной интеграции в качестве «quality gate»? В случае с автоматическими тестами всё очевидно: есть набор тестов, падение любого из них — достаточное основание считать, что сборка не прошла quality gate. Попытка таким же образом установить gate по результатам статического анализа проваливается: на legacy-коде предупреждений анализа слишком много, полностью игнорировать их не хочется, но и останавливать поставку продукта только потому, что в нём есть предупреждения анализатора, невозможно.
Будучи применён впервые, на любом проекте анализатор выдаёт огромное количество предупреждений, подавляющее большинство которых не имеют отношения к правильному функционированию продукта. Исправлять сразу все эти замечания невозможно, а многие — и не нужно. В конце концов, мы же знаем, что наш продукт в целом работает, и до внедрения статического анализа!
В итоге, многие ограничиваются эпизодическим использованием статического анализа, либо используют его лишь в режиме информирования, когда при сборке просто выдаётся отчёт анализатора. Это эквивалентно отсутствию всякого анализа, потому что если у нас уже имеется множество предупреждений, то возникновение ещё одного (сколь угодно серьёзного) при изменении кода остаётся незамеченным.
Известны следующие способы введения quality gates:
- Установка лимита общего количества предупреждений или количества предупреждений, делённого на количество строк кода. Работает это плохо, т. к. такой gate свободно пропускает изменения с новыми дефектами, пока их лимит не превышен.
- Фиксация, в определённый момент, всех старых предупреждений в коде как игнорируемых, и отказ в сборке при возникновении новых предупреждений. Такую функциональность предоставляет PVS-studio и некоторые онлайн-ресурсы, например, Codacy. Мне не довелось работать в PVS-studio, что касается моего опыта с Codacy, то основная их проблема заключается в том, что определение что есть «старая», а что «новая» ошибка — довольно сложный и не всегда правильно работающий алгоритм, особенно если файлы сильно изменяются или переименовываются. На моей памяти Codacy мог пропускать в пулл-реквесте новые предупреждения, и в то же время не пропускать pull request из-за предупреждений, не относящихся к изменениям в коде данного PR.
- На мой взгляд, наиболее эффективным решением является описанный в книге Continuous Delivery «метод храповика» («ratcheting»). Основная идея заключается в том, что свойством каждого релиза является количество предупреждений статического анализа, и допускаются лишь такие изменения, которые общее количество предупреждений не увеличивают.
Храповик
Работает это таким образом:
- На первоначальном этапе реализуется запись в метаданных о релизе количества предупреждений в коде, найденных анализаторами. Таким образом, при сборке основной ветки в ваш менеджер репозиториев записывается не просто «релиз 7.0.2», но «релиз 7.0.2, содержащий 100500 Checkstyle-предупреждений». Если вы используете продвинутый менеджер репозиториев (такой как Artifactory), сохранить такие метаданные о вашем релизе легко.
- Теперь каждый pull request при сборке сравнивает количество получающихся предупреждений с тем, какое количество имеется в текущем релизе. Если PR приводит к увеличению этого числа, то код не проходит quality gate по статическому анализу. Если количество предупреждений уменьшается или не изменяется — то проходит.
- При следующем релизе пересчитанное количество предупреждений будет вновь записано в метаданные релиза.
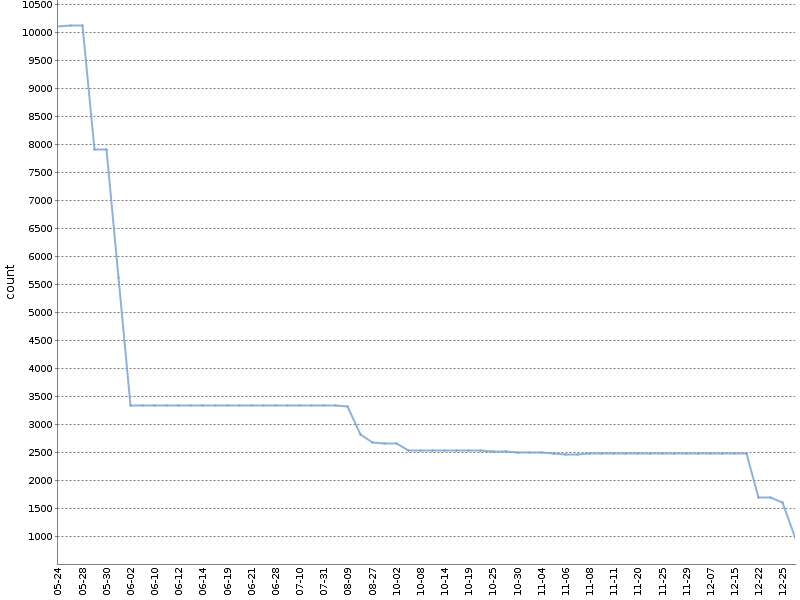
На этом графике показано общее количество Checkstyle-предупреждений за полгода работы такого «храповика» на одном из наших OpenSource проектов. Количество предупреждений уменьшилось на порядок, причём произошло это естественным образом, параллельно с разработкой продукта!
Я применяю модифицированную версию этого метода, отдельно подсчитывая предупреждения в разбивке по модулям проекта и инструментам анализа, формируемый при этом YAML-файл с метаданными о сборке выглядит примерно следующим образом:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0 В любой продвинутой CI-системе «храповик» можно реализовать для любых инструментов статического анализа, не полагаясь на плагины и сторонние инструменты. Каждый из анализаторов выдаёт свой отчёт в простом текстовом или XML формате, легко поддающемся анализу. Остаётся прописать только необходимую логику в CI-скрипте. Подсмотреть, как это реализовано в наших open source проектах на базе Jenkins и Artifactory, можно здесь или здесь. Оба примера зависят от библиотеки ratchetlib: метод countWarnings() обычным образом подсчитывает xml-тэги в файлах, формируемых Checkstyle и Spotbugs, а compareWarningMaps() реализует тот самый храповик, выбрасывая ошибку в случае, когда количество предупреждений в какой-либо из категорий повышается.
Интересный вариант реализации «храповика» возможен для анализа правописания комментариев, текстовых литералов и документации с помощью aspell. Как известно, при проверке правописания не все неизвестные стандартному словарю слова являются неправильными, они могут быть добавлены в пользовательский словарь. Если сделать пользовательский словарь частью исходного кода проекта, то quality gate по правописанию может быть сформулирован таким образом: выполнение aspell со стандартным и пользовательским словарём не должно находить никаких ошибок правописания.
О важности фиксации версии анализатора
В заключение нужно отметить следующее: каким бы образом вы бы ни внедряли анализ в ваш конвейер поставки, версия анализатора должна быть фиксирована. Если допустить самопроизвольное обновление анализатора, то при сборке очередного pull request могут «всплыть» новые дефекты, которые не связаны с изменением кода, а связаны с тем, что новый анализатор просто способен находить больше дефектов — и это поломает вам процесс приёмки pull request-ов. Апгрейд анализатора должен быть осознанным действием. Впрочем, жёсткая фиксация версии каждой компоненты сборки — это в целом необходимое требование и тема для отдельного разговора.
Выводы
- Статический анализ не найдёт вам баги и не улучшит качество вашего продукта в результате однократного применения. Положительный эффект для качества даёт лишь его постоянное применение в процессе поставки.
- Поиск багов вообще не является главной задачей анализа, подавляющее большинство полезных функций доступно в opensource инструментах.
- Внедряйте quality gates по результатам статического анализа на самом первом этапе конвейера поставки, используя «храповик» для legacy-кода.
Ссылки
- Continuous Delivery
- А. Кудрявцев: Анализ программ: как понять, что ты хороший программист доклад о разных методах анализа кода (не только статическом!)
Обзор методов статического анализа исходного кода для поиска уязвимостей
Обзор методов статического анализа исходного кода для поиска уязвимостей
Обзор методов статического анализа исходного кода для поиска уязвимостей
В связи с растущим объемом разрабатываемого ПО проблема безопасности становится все более актуальной. Одним из вариантов ее решения может стать применение безопасного цикла создания продуктов, включая планирование, проектирование, разработку, тестирование. Такой подход позволяет получать на выходе решение с продуманной системой безопасности, которое не потребуется затем многократно “латать» из-за существующих уязвимостей. В данной статье пойдет речь об одной из важных практик, применяемых на этапе тестирования, – статическом анализе кода.

Александр Миноженко
Старший исследователь департамента анализа кода
в ERPScan (дочерняя компания Digital Security)
При статическом анализе кода происходит анализ программы без ее реального исполнения, а при динамическом анализе – в процессе исполнения. В большинстве случаев под статическим анализом подразумевают анализ, осуществляемый с помощью автоматизированных инструментов исходного или исполняемого кода.
Исторически первые инструменты статического анализа (часто в их названии используется слово lint) применялись для нахождения простейших дефектов программы. Они использовали простой поиск по сигнатурам, то есть обнаруживали совпадения с имеющимися сигнатурами в базе проверок. Они применяются до сих пор и позволяют определять «подозрительные» конструкции в коде, которые могут вызвать падение программы при выполнении.
Недостатков у такого метода немало. Основным является то, что множество «подозрительных» конструкций в коде не всегда являются дефектами. В большинстве случаев такой код может быть синтаксически правильным и работать корректно. Соотношение «шума» к реальным дефектам может достигать 100:1 на больших проектах. Таким образом, разработчику приходится тратить много времени на его отсеивание от реальных дефектов, что отменяет плюсы автоматизированного поиска.
Несмотря на очевидные недостатки, такие простые утилиты для поиска уязвимостей до сих пор используются. Обычно они распространяются бесплатно, так как коммерческого применения они, по понятным причинам, не получили.
Второе поколение инструментов статического анализа в дополнение к простому поиску совпадений по шаблонам оснащено технологиями анализа, которые до этого применялись в компиляторах для оптимизации программ. Эти методы позволяли по анализу исходного кода составлять графы потока управления и потока данных, которые представляют собой модель выполнения программы и модель зависимостей одних переменных от других. Имея данные, графы можно моделировать, определяя, как будет выполняться программа (по какому пути и с какими данными).
Поскольку программа состоит из множества функций, процедур модулей, которые могут зависеть друг от друга, недостаточно анализировать каждый файл по отдельности. Для полноценного межпроцедурного анализа необходимы все файлы программы и зависимости.
Основным достоинством этого типа анализаторов является меньше количество «шума» за счет частичного моделирования выполнения программ и возможность обнаружения более сложных дефектов.
Процесс поиска уязвимостей в действии
Для иллюстрации приведем процесс поиска уязвимостей инъекции кода и SQL-инъекции (рис. 1).

Для их обнаружения находятся места в программе, откуда поступают недоверенные данные (рис. 2), например, запрос протокола HTTP.

На листинге (рис. 1) 1 на строке 5 данные получаются из HTTP запроса, который поступает от пользователей при запросе Web-страницы. Например, при запросе страницы “http://example.com/main?name =‘ or 1=‘1”. Строка or 1=‘1 попадает в переменную data из объекта request, который содержит HTTP-запрос.
Дальше на строке 10 идет вызов функции Process с аргументом data, которая обрабатывает полученную строку. На строке 12 – конкатенация полученной строки data и запроса к базе данных, уже на строке 15 происходит вызов функции запроса к базе данных c результирующим запросом. В результате данных манипуляции получается запрос к базе данных вида: select * from users where name=‘’ or ‘1’=‘1’.
Что означает выбрать из таблицы всех пользователей, а не пользователя с определенным именем. Это не является стандартным функционалом и влечет нарушение конфиденциальности, что соответственно означает уязвимость. В результате потенциальный злоумышленник может получить информацию о всех пользователях, а не только о конкретном. Также он может получить данные из других таблиц, например содержащих пароли и другие критичные данные. А в некоторых случаях – исполнить свой вредоносный код.
Статические анализаторы работают похожим образом: помечают данные, которые поступают из недоверенного источника, отслеживаются все манипуляции с данными и пытаются определить, попадают ли данные в критичные функции. Под критичными функциями обычно подразумеваются функции, которые исполняют код, делают запросы к БД, обрабатывают XML-документы, осуществляют доступ к файлам и др., в которых изменение параметра функции может нанести ущерб конфиденциальности, целостности и доступности.
Также возможна обратная ситуация, когда из доверенного источника, например переменных окружения, критичных таблиц базы данных, критичных файлов, данные поступают в недоверенный источник, например генерируемую HTML-страницу. Это может означать потенциальную утечку критичной информации.
Одним из недостатков такого анализа является сложность определения на пути выполнения программ функций, которые осуществляют фильтрацию или валидацию значений. Поэтому большинство анализаторов включает набор стандартных системных функций фильтрации для языка и возможность задания таких функций самостоятельно.
Автоматизированный поиск уязвимостей
Достаточно сложно достоверно определить автоматизированными методами наличие закладок в ПО, поскольку необходимо понимать, какие функции выполняет определенный участок программы и являются ли они необходимыми программе, а не внедрены для обхода доступа к ресурсам системы. Но можно найти закладки по определенным признакам (рис. 3). Например, доступ к системе при помощи сравнения данных для авторизации или аутентификации с предопределенными значениями, а не использование стандартных механизмов авторизации или аутентификации. Найти данные признаки можно с помощью простого сигнатурного метода, но анализ потоков данных позволяет более точно определять предопределенные значения в программе, отслеживая, откуда поступило значение, динамически из базы данных или он было «зашито» в программе, что повышает точность анализа.

Нет общего мнения по поводу обязательного функционала третьего поколения инструментов статического анализа. Некоторые вендоры предлагают более тесную интеграцию в процесс разработки, использование SMT-решателей для точного определения пути выполнения программы в зависимости от данных.
Также есть тенденция добавления гибридного анализа, то есть совмещенных функций статического и динамического анализов. У данного подхода есть несомненные плюсы: например, можно проверять существование уязвимости, найденной с помощью статического анализа путем эксплуатации этой уязвимости. Недостатком такого подхода может быть следующая ситуация. В случае ошибочной корреляции места, где не было доказано уязвимостей с помощью динамического анализа, возможно появление ложноотрицательного результата. Другими словами, уязвимость есть, но анализатор ее не находит.
Если говорить о результатах анализа, то для оценки работы статического анализатора используется, как и в статистике, разделение результата анализа на положительный, отрицательный, ложноотрицатель-ный (дефект есть, но анализатор его не находит) и ложнопо-ложительный (дефекта нет, но анализатор его находит).
Для реализации эффективного процесса устранения дефектов важно отношение количества истинно найденных ко всем найденным дефектам. Данное отношение называют точностью. При небольшой точности получается большое соотношение истинных дефектов к ложноположительным, что так же, как и в ситуации с большим количеством шума, требует от разработчиков много времени на анализ результатов и фактически нивелирует плюсы автоматизированного анализа кода.
Для поиска уязвимостей особенно важно отношение найденных истинных уязвимостей ко всем найденным, поскольку данное отношение и принято считать полнотой. Ненайденные уязвимости опаснее ложнопо-ложительного результата, так как могут нести прямой ущерб бизнесу.
Достаточно сложно в одном решении сочетать хорошую полноту и точность анализа. Инструменты первого поколения, работающие по простому совпадению шаблонов, могут показывать хорошую полноту анализа, но при этом низкую точность из-за ограничения технологий. Благодаря тому что второе поколение анализаторов может определять зависимости и пути выполнения программы, обеспечивается более высокая точность анализа при такой же полноте.
Несмотря на то что развитие технологий происходит непрерывно, автоматизированные инструменты до сих пор не заменяют полностью ручной аудит кода. Такие категории дефектов, как логические, архитектурные уязвимости и проблемы с производительностью, могут быть обнаружены только экспертом. Однако инструменты работают быстрее, позволяют автоматизировать процесс и стоят дешевле, чем работа аудитора. При внедрении статического анализа кода можно использовать ручной аудит для первичной оценки, поскольку это позволяет обнаруживать серьезные проблемы с архитектурой. Автоматизированные же инструменты должны применяться для быстрого исправления дефектов. Например, при появлении новой версии ПО.
Существует множество решений для статического анализа исходного кода. Выбор продукта зависит от поставленных задач. Если необходимо повысить качество кода, то вполне можно использовать анализаторы первого поколения, использующие поиск по шаблонам. В случае когда нужно найти уязвимости в ходе реализации цикла безопасной разработки, логично использовать инструменты, использующие анализ потока данных. Ну а если опыт внедрения средств статического и динамического анализа уже имеется, можно попробовать средства, использующие гибридный анализ.
Статический анализ кода: что могут инструментальные средства?
Автоматизация и интернет-технологии все больше захватывают сферы бизнеса, перестают быть его конкурентным преимуществом и переходят в статус необходимых для его функционирования элементов. Резкое повышение спроса на разработку ПО, которое наблюдается в последние годы, не удовлетворяется кадровыми предложениями рынка, как следствие, весь развитый мир испытывает нехватку в опытных программистах. То есть потребности в программном обеспечении значительно опережают возможности рынка по его разработке.
При передаче кода заказчику или в эксплуатацию тестированию кода по требованиям информационной безопасности не уделяется должного внимания. При этом квалификация злоумышленников растет каждый день, киберпреступники становятся опытнее и применяют новейшие технологии атак и взломов программного обеспечения. По данным института Ponemon, ущерб от киберпреступности за 2012–2014 годы вырос на 30%. Современные системы состоят из множества компонент, между которыми очень сложные и непрозрачные связи. Эти связи достаточно трудно держать в поле зрения, если не используются специальные инструментальные средства (ИС), позволяющие визуализировать потоки данных, а также переход управления от компоненты к компоненте во время выполнения программы. Большинство популярных среди злоумышленников уязвимостей прячутся именно на стыках разных компонент.
Авторы
Екатерина Трошина В прошлом — эксперт Центра информационной безопасности компании «Инфосистемы Джет»
Теги
Другие статьи автора
Статьи по теме
Поделиться
Соответственно, анализ кода по требованиям ИБ позволяет значительно повысить качество разработки. Ни у кого не возникает вопроса, зачем выполнять регрессионное тестирование перед вводом новой функциональности системы в эксплуатацию. Анализ кода по требованиям безопасности – не менее важный этап разработки, чем комплексное тестирование ПО. По оценке исследователей Гарвардского университета, исправление ошибки, выявленной на этапе тестирования, в среднем стоит $960, а ошибки, обнаруженной на этапе эксплуатации, – $7600. Не говоря уже о том, какой ущерб может нанести злоумышленник эксплуатацией уязвимости.
В итоге приходится доверять поставщику программного обеспечения, но лучше проверять и контролировать качество того, что приобретается и вводится в эксплуатацию. Даже если не удастся немедленно отправить ПО на доработку, информация о том, какие уязвимости оно содержит, позволит защититься от них дополнительными мерами, например, настраиваемой защитой периметра.
Инструментальные средства анализа кода
Сегодня ИТ-индустрия предлагает большое разнообразие инструментальных средств, без которых разработка программного кода невозможна. Также в современном мире сложно просто эксплуатировать программные продукты, закупленные у разных производителей. Ввод в эксплуатацию требует предварительной настройки ПО, обучения персонала его использованию, а требования к обеспечению ИБ диктуют необходимость защищать среду эксплуатации программного обеспечения посредством выстраивания так называемой защиты периметра.
Для контроля качества кода с точки зрения функциональности уже давно существует много отработанных практик составления тестовых сценариев, отвечающих требованиям по полноте сценариев эксплуатации. Такие тесты разрабатываются и применяются к ПО в автоматическом и полуавтоматическом режимах.
Аналогичная ситуация имеет место и с анализом кода по требованиям ИБ. В настоящее время на рынке представлено много инструментальных средств – как коммерческих, так и свободно распространяемых. Большинство из них можно применять как в процессе разработки ПО для повышения надежности кода, так и для аудита уже готовых программных систем по требованиям информационной безопасности. Обычно такие системы используют при содействии экспертов в области ИБ, причем не в автоматическом режиме, так как задача обнаружения уязвимостей в коде очень сложна и ее качественное выполнение в других условиях невозможно.
В нашем обзоре мы рассмотрим наиболее популярные и широко востребованные ИС статического анализа кода. Обзор не претендует на полноту, однако позволяет составить представление о возможностях этих программных продуктов, их интеграции в жизненный цикл разработки и эксплуатации программного обеспечения как собственной, так и сторонней разработки. Обзор также имеет своей целью дать представление о том, что в задаче статического анализа кода можно сделать автоматически, а для чего рекомендуется привлекать экспертов в области ИБ. Стоит отметить, что наличие такого эксперта в штате не всегда необходимо, специалиста можно периодически привлекать со стороны для выполнения определенных работ, так как экспертов высокого класса сегодня на рынке не хватает.
Также следует отметить, что все ИС, представленные в обзоре, используются специалистами по анализу кода ежедневно – в повседневной работе. Мы не рассматривали определенные версии продуктов, так как они постоянно обновляются. Цель описания – показать общее направление предоставления функциональности того или иного средства статического анализа кода. Обзор основан на нашей практике эксплуатации этих ИС.
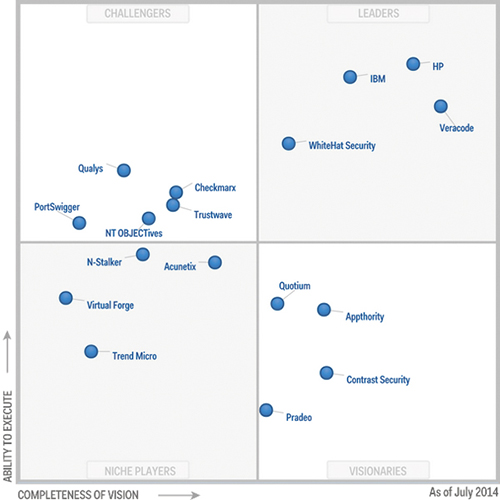
Рис. 1. Магический квадрант Гартнера – производители решений для тестирования ПО на соответствие требованиям ИБ
В целом для инструментальных средств статического анализа кода характерны:
- Ложные срабатывания (false positive) – выделение фрагмента кода как уязвимого, хотя на самом деле он уязвимости не содержит. С одной стороны, чем больше ложных срабатываний, тем более тщательный анализ выполняется, с другой – ложные срабатывания отбирают у программистов много времени на то, чтобы разобраться и понять, что выделенный фрагмент безопасен.
- Пропущенные ошибки (false negative) – уязвимости в программном коде, которые не были найдены при анализе.
Свободно распространяемые инструментальные средства статического анализа кода, как правило, представляют собой только основу для проведения статического анализа, их ценностью является библиотека правил, по которым выявляются уязвимости. Над разработкой библиотек трудятся огромные команды специалистов в области ИБ. Правила должны быть не только полными, чтобы не пропускать уязвимости и тем самым минимизировать наличие false positive, но и точными, чтобы количество ложных срабатываний стремилось к минимуму.
Помимо этого, инструментальные средства анализа кода должны анализировать программный код по внутреннему представлению, позволяющему учитывать особенности выполнения программы. Уязвимости, в отличие от недокументированных возможностей (НДВ), являются побочными эффектами выполнения кода, отвечающего за реализацию функционала системы. 90% современных уязвимостей, которые успешно эксплуатируются злоумышленниками, не идентифицируются посредством анализа только текста программы. Однако следует отметить, что обнаружение НДВ возможно посредством анализа только исходных текстов программы с применением библиотеки шаблонов, основанной на регулярных выражениях.
К инструментальным средствам статического анализа кода, целью которых является выявление уязвимостей, предъявляются следующие требования:
- Качественные технологии и алгоритмы для глубокого анализа кода и выявления всех уязвимостей
- Регулярно обновляемая база правил с возможностями гибкой настройки и расширения
- Предоставление исчерпывающих обоснований наличия уязвимости и подробных рекомендаций по её устранению
- Сопоставление результатов анализа при повторном сканировании отредактированного кода (выделение исправленных, неисправленных, вновь появившихся уязвимостей)
- Поддержка большого числа языков программирования
- Интеграция со средами разработки, системами контроля версий и системами отслеживания ошибок
- Функционал, обеспечивающий связь между командами разработчиков и экспертов, отвечающих за безопасность
- Минимальное количество ложных срабатываний
- Представление результатов анализа в удобном для восприятия (в том числе непрофессионалами) виде
- Наличие средств автоматического составления отчётов
- Возможность проводить анализ кода удалённо
ИС статического анализа кода, полностью соответствующие изложенным требованиям, точнее диагностируют проблемы анализируемого кода и позволяют тратить меньше ресурсов на локализацию и устранение ошибок.
Пользовательский интерфейс также крайне важен: без качественной визуализации, обобщения и компактного представления информации никакой, даже самый полный, анализ не будет приносить должного результата. Люди – аналитики, разработчики, контролеры качества разработки кода – просто не смогут воспринять полученную информацию.
HP Fortify
Компания HP предлагает несколько продуктов для тестирования ПО на соответствие требованиям ИБ:
- HP Fortify Static Code Analyzer (SCA) – инструмент для статического анализа кода. Определяет причины уязвимостей, приоритизирует результаты и даёт подробные рекомендации по исправлению кода. Статический анализ предоставляется для 21 языка программирования.
- HP Web Inspect – инструмент для динамического анализа кода. Он проводит тестирование приложений, имитирующее реальные атаки. Обладает средствами управления историей тестирования.
- HP WebInspect Real-Time – имитирует атаку средствами HP WebInspect, предоставляя пользователю возможность наблюдать за работой приложения на уровне кода. Полученные сведения используются в качестве основы для динамического анализа.
- HP WebInspect Enterprise – платформа по управлению веб-приложениями, позволяющая проводить распределённое оценивание безопасности приложений и руководить процессом тестирования.
- HP Fortify Runtime Analyzer – инструмент для централизованного управления угрозами безопасности на уровне компании. Защищает уже выпущенные приложения от попыток несанкционированного доступа. Регистрирует записи о событиях в Fortify Software Security Center (SSC).
- HP Fortify SSC – веб-инструмент для централизованного управления безопасностью приложения. Поддерживает единую базу данных об уязвимостях. Позволяет эффективно организовать совместную работу разработчиков и специалистов по безопасности.
HP Fortify SCA дает хорошее качество сканирования. На наш взгляд, это лучшее сканирование по сочетанию «время работы/количество ложных срабатываний и пропущенных ошибок». В общей сложности это инструментальное средство было протестировано более чем на 15 тыс. CLOC (Count Lines of Code) различного кода, реализованного на разных языках. Количество пропущенных ошибок приближается к нулю, те же, которые есть, в настоящее время просто нельзя идентифицировать автоматически. Для повышения точности сканирования, то есть уменьшения количества ложных срабатываний, можно модифицировать набор предоставляемых правил. Сделать это просто, так как интерфейс ИС удобен, а язык правил доступен.
IBM AppScan
Линейка решений от компании IBM для аудита ПО на соответствие требованиям информационной безопасности состоит из следующих продуктов:
- IBM AppScan Standard – инструмент для динамического анализа кода («чёрный ящик»). Предназначен для поиска уязвимостей в работающем ПО, применяется на последних этапах разработки и после выпуска приложения. Относительно несложен в установке и настройке. Позволяет отправлять сообщения о найденных уязвимостях в систему отслеживания ошибок. При помощи расширения JavaScript Security Analyzer может проводить гибридный анализ JavaScript-кода.
- IBM AppScan Source – инструмент для статического анализа кода («белый ящик»). Он предназначен для специалистов по информационной безопасности, требует высокой квалификации, зато формирует более полную картину уязвимостей с привязкой к исходному коду. Обеспечивает взаимодействие между сотрудниками, ответственными за безопасность приложений, и разработчиками. Обладает средствами интеграции с распространёнными средами разработки, что позволяет отслеживать уязвимости на ранних стадиях. Работает только в качестве дополнения к IBM AppScan Enterprise. Статический анализ поддерживает 21 язык программирования.
- IBM AppScan Enterprise – веб-инструмент для централизованного динамического тестирования приложений, учёта и наглядного представления степени риска, которому они подвергаются. Позволяет вычислять метрики и осуществлять быстрое сканирование. Предназначен, в том числе, для неспециалистов, позволяет составлять наглядные отчёты по результатам сканирования. При наличии AppScan Source может проводить тестирование по методу «прозрачного ящика» (Glass Box), сопоставляя результаты динамического и статического анализов. Обладает средствами интеграции с системой мониторинга безопасности QRadar.
В состав AppScan Source входят инструменты для поиска и анализа уязвимостей в исходном коде (Source for Analysis), автоматизации процесса разработки (Source for Automation) и интеграции со средами разработки, такими как Visual Studio и Eclipse (Source for Development). Также в решение входит база знаний об уязвимостях и способах их устранения (Source Security Knowledgebase) и средство для централизованного обмена информацией об уязвимостях (Source Enterprise Server). Подробно рассмотрим AppScan Source for Analysis, а также перечислим основные понятия, используемые при анализе кода в рамках AppScan.
Данные, которые использует AppScan, организованы следующим образом:
- Приложение (application) содержит один или несколько проектов и соответствующие им атрибуты.
- Проект состоит из множества файлов (в том числе с исходным кодом), а также содержит сопутствующую информацию (например, параметры конфигурации).
- Атрибуты – характеристики приложения, позволяющие наглядно представить результаты сканирования. Пользователь может самостоятельно определять атрибуты.
Выявленные уязвимости могут быть классифицированы по следующим признакам:
- уровень риска (высокий, средний или низкий);
- тип уязвимости (например, внедрение SQL-кода или переполнение буфера);
- файл, где уязвимость была обнаружена;
- интерфейс приложения (выделяются подозрительный вызов API-функции и переданные ей аргументы);
- метод (функция или метод, откуда был сделан подозрительный вызов);
- положение (номера строки и столбца в файле с исходным кодом, где содержится подозрительный вызов);
- классификация (уязвимость или исключение).
Не все результаты поиска являются уязвимостями. AppScan предлагает следующий метод их классификации:
- Уязвимость – участок исходного кода, содержащий ошибки, позволяющие злоумышленнику заставить приложение осуществлять незапланированные действия, что приводит к несанкционированному доступу к данным, повреждению системы и т.д.
- Исключение типа I – подозрительный участок исходного кода, скорее всего, являющийся уязвимостью, при этом для отнесения его к этому классу не хватает информации. Например, степень подверженности атаке может зависеть от параметров использования динамических элементов или вызова библиотечных функций, о которых у AppScan недостаточно сведений.
- Исключение типа II – подозрительный участок исходного кода, для которого невозможно оценить вероятность подверженности атаке.
С целью обеспечения полной безопасности приложения нужно проводить дополнительные исследования для отнесения исключений либо к уязвимостям, либо к ложным срабатываниям, причём для обработки исключений типа II, как правило, требуется больше усилий. В дальнейшем для краткости мы будем называть результаты сканирования AppScan «уязвимостями», понимая под этим собственно уязвимости и исключения I и II типов.
Статический анализ IBM AppScan дает нормальное качество, однако складывается впечатление, что база правил здесь несколько более скудная, нежели у HP Fortify. Некоторые уязвимости ищутся по «старым» шаблонам. По соотношению «скорость сканирования/количество ложных срабатываний и пропущенных ошибок» ИС сильно уступает HP Fortify: количество ложных срабатываний меньше, но больше пропущенных уязвимостей. Как мы уже отмечали выше, ложные срабатывания при отсутствии пропусков ошибок лучше, нежели пропущенные ошибки с минимальным количеством ложных срабатываний.
Positive Technologies Application Inspector
Инструментальное средство использует методы динамического и статического анализа для поиска уязвимостей. За счет этого, как говорят разработчики продукта, минимизируется количество ложных срабатываний. Application Inspector может анализировать приложения, созданные на разных языках программирования и платформах (Java, .NET, PHP, JavaScript, мобильные платформы и т.п.).
Так как на момент написания статьи нам не удалось получить продукт для пробной эксплуатации в промышленной среде, представленное описание основано на демонстрационных показах производителя, а также на документации, доступной в открытом доступе.
Важной особенностью средства является возможность генерации эксплоитов – возможных атак с использованием данной уязвимости, что упрощает процесс её анализа.
ИС позиционируется как средство в помощь команде контроля качества разработки и информационной безопасности, а не разработчиков. Возможность интеграции со средами разработки и другими системами управления проектом отсутствует. Помимо этого, в настоящее время Application Inspector предоставляет статический анализ только для интерпретируемых языков, однако производитель говорит о том, что поддержка компилируемых языков также будет присутствовать.
На сегодняшний день набор применяемых правил для поиска уязвимостей достаточно беден, однако ведется непрерывная работа по наращиванию базы правил, при этом используется богатый опыт разработчика по предоставлению сервисов по анализу кода. По нашему мнению, разработка ИС идет по правильному сценарию, с использованием верных технологий, что позволяет верить в успешность проекта и выход этого продукта в лидеры рынка в ближайшем будущем.
Veracode
Это еще одно инструментальное средство статического анализа кода. Но здесь статический анализ доступен только как услуга. Тот код, который необходимо проверить, нужно загрузить на сервер Veracode, эксперты выполнят сканирование и вышлют отчет. Это не всегда приемлемо и удобно, особенно для банковской сферы, где к коду предъявляются повышенные требования. Загрузка кода на сторонние серверы, тем более находящиеся не в России, сильно ограничивает возможности эксплуатации продукта.
В то же время производитель анонсирует возможность выполнения статического анализа бинарного кода. Но при его загрузке на сервер необходимо предоставить информацию для отладки в виде так называемой Debug-сборки и со всеми сторонними библиотеками, которые подключаются к проекту на этапе динамической сборки. На практике же сторонний разработчик предоставляет систему в виде Release-, а не Debug-сборки: во-первых, декомпиляция приложения по Debug-версии значительно проще, чем по Release-версии, во-вторых, Debug-версия занимает значительно больше места и имеет сравнительно низкую производительность. К тому же если можно собрать сборку в виде Debug-версии, то исходные коды обычно тоже доступны.
На наш взгляд, возможность выполнения бинарного анализа при таком ограничении следует рассматривать как маркетинговое заявление, а не как особенность продукта, которая выгодно отличает его от других. Также следует отметить, что выполнение статического анализа кода удаленно предоставляет и компания HP.
Checkmarx
Еще одно инструментальное средство анализа кода, которое пытается завоевать рынок. Продукт показывает достойные результаты сканирования, однако складывается впечатление, что его база уязвимостей менее полная, чем у конкурентов, в частности, у HP Fortify. Мы проводили сравнение Checkmarx с HP Fortify SCA в 5 независимых проектах. Время работы средств было сопоставимым, однако количество выявленных действительных уязвимостей у HP Fortify оказалось значительно больше. Это свидетельствует о том, что Checkmarx пропускает уязвимости, которые можно идентифицировать автоматически.
Также следует отметить, что даже представители производителя при демонстрации системы тратят некоторое время на ее развертывание, тогда как HP Fortify не требует никакой специальной подготовки для инсталляции.
Несмотря на указанные выше особенности, при выборе инструментального средства статического анализа кода следует рассматривать все продукты, представленные в нашем небольшом обзоре. Каждая компания уникальна, а у специалистов по ИБ могут быть свои предпочтения в отношении работы системы.
InfoWatch APPERCUT
Отдельно стоит отметить еще одно ИС, которое позиционируется как инструментальное средство в помощь разработчикам и специалистам в области ИБ, – InfoWatch APPERCUT. Мы намеренно не называем его инструментальным средством статического анализа кода. Обычно под этим подразумевают ИС, которые анализируют особенности выполнения программы, моделируют преобразование данных в процессе ее работы. Именно на основании информации о преобразовании данных в процессе выполнения программы строятся заключения о наличии или отсутствии альтернативных сценариев эксплуатации ПО, которые могут использовать злоумышленники.
ИС APPERCUT выполняет анализ по текстовому представлению программы, при этом никакого анализа преобразования данных в процессе выполнения программы нет. Анализ строится на применении набора шаблонов языковых конструкций, которые потенциально неправильно использовать при кодировании.
Внешний вид правил, обзор метода работы сканера и комментарии производителя по поводу того, «как работает сканер», позволяют сказать, что он функционирует по принципу «лексического анализатора». Вся анализируемая программа разбивается на поток лексем, к которым применяется набор правил. Такой метод неэффективен для большей части широко известных уязвимостей, так как просто невозможно без анализа потока данных выявить ошибки работы с памятью, переполнение, неправильное составление запросов и т.д. Невозможно описать правила обнаружения большинства уязвимостей, используя шаблон текста программы. В настоящее время широко используются анализ потока данных, семантический анализ, анализ потока управления для поиска уязвимостей. Анализаторы, применяющие названные методы, значительно более эффективны с точки зрения полноты обработки программ: они находят меньше «ложных» уязвимостей, а полнота ошибок, которые они обнаруживают, удовлетворительна.
Производитель заявляет, что у него большая библиотека шаблонов, и они позволяют находить большое количество уязвимостей и недокументированных возможностей. Следует отметить, что большинство ошибок и уязвимостей, которые можно идентифицировать посредством применения к программе лексического анализатора, выявляются средами разработки, так как при компиляции и трансляции в bite-code выполняется лексический анализ. Разработчики добавляют правила для поиска уязвимостей и ошибок на этапе компиляции и трансляции в bite-code. Выполнять более полную проверку на этой стадии среда разработки не может, так как это занимает много времени.
Эксперименты показали, что все уязвимости, которые находит инструмент APPERCUT для программ C/C++, обнаруживаются MVS (Microsoft Visual Studio) 2012 при включении опции полной проверки. Все уязвимости, которые находит APPERCUT для Java-программ, выявляет среда разработки Eclipse c плагином Find Bugs. Eclipse и Find Bugs – это свободно распространяемое программное обеспечение.
Возможно, данное ИС можно использовать в качестве продвинутого анализатора исходного кода с целью поиска недокументированных возможностей, закладок и проверки соблюдения определенных стандартов программирования, которые могут быть приняты в ИТ-компаниях. Однако можно с уверенностью сказать, что аналогичный функционал имеет любое инструментальное средство статического анализа кода, которое предоставляет интерфейс самостоятельного редактирования правил
Экспертная проверка кода по требованиям ИБ
При правильном анализе кода программной системы отчет, который выдается компании, должен содержать следующую информацию:
- действительные уязвимости (true positive), которые ранжированы по степени риска;
- для каждой уязвимости необходимо:
-
- описать ущерб, который может быть нанесен в результате ее успешной эксплуатации злоумышленником;
- представить возможный сценарий/сценарии ее эксплуатации, описать уровень квалификации злоумышленника, позволяющий ему проэксплуатировать уязвимость;
- представить рекомендации по устранению уязвимостей с оценкой трудоемкости.
Тогда компания будет иметь полную информацию о том коде, который собирается эксплуатировать, следовательно, она сможет принять правильное решение о том, как управлять ситуацией.
Несмотря на то, что современные инструментальные средства статического анализа кода предоставляют много информации о выявленных уязвимостях в удобном для восприятия формате, все они должны эксплуатироваться соответствующими специалистами. Дополнительная обработка экспертом результатов сканирования крайне необходима для получения точного представления о дефектах анализируемого кода. Специалист всегда знает об анализируемом программном продукте значительно больше, нежели инструментальное средство, выполняющее анализ.
Помимо выявления уязвимостей, задачей эксперта по анализу кода является обнаружение недекларированных возможностей программного приложения. Она может быть качественно выполнена только в полуавтоматическом режиме при сочетании следующих факторов:
- Хорошее ИС, позволяющее разрабатывать собственные правила для анализа кода. Язык для составления правил должен быть удобным, а интерфейс их загрузки в систему – интуитивно понятным.
- Наличие грамотного специалиста, который владеет большим набором шаблонных ситуаций внедрения недекларированных возможностей в код. Помимо этого, эксперт должен уметь формализовывать такие шаблоны и описывать их на языке правил инструментального средства, которое будет использоваться для поиска НДВ по всему коду программного приложения.
- Наличие специалиста по анализу кода, умеющего быстро и качественно работать с ним в полуавтоматическом режиме, так как в противном случае стоимость анализа будет сопоставима со стоимостью разработки кода (значит, стоимость разработки возрастет в два раза).
Понимание компанией итогов выполнения экспертного аудита кода зависит от представления этого результата в виде отчетов. Требования к отчетам разные:
- руководство за неимением времени желает получать сжатые отчеты, которые содержат информацию по существу;
- технические специалисты, которые должны понимать причину проблемы и искать путь ее решения, должны получать развернутые отчеты;
- специалисты по информационной безопасности должны получать отчеты, содержащие информацию о рисках, которым подвергается бизнес при эксплуатации программного обеспечения, в котором содержатся выявленные уязвимости.
Эксплуатация ПО в настоящее время должна выполняться под контролем службы информационной безопасности, для того чтобы бизнес мог управлять рисками. Аудирование ПО должны осуществлять исключительно ИБ-специалисты, так как найденные ошибки, которые на самом деле не являются критичными для эксплуатации, будут отвлекать программистов. Цена даже одной пропущенной ошибки в коде, которая будет успешно использована злоумышленником, может быть очень высокой.
Читайте также
это уже не магазин ;Татьяна Вандышева;https://www.jetinfo.ru/autor/tatiana-vanfysheva/;https://www.jetinfo.ru/laboratoriya-stoit-15-mln-rublej-i-ne-prinosit-siyuminutnoj-pribyli-no-dlya-kompanii-eto-shans-vyjti-na-ustojchivoe-razvitie/;;|Когда-то топ-менеджмент уделял инновациям 3% своего времени, а теперь 20-30% ;Василий Тарасевич;https://www.jetinfo.ru/speakers/vasilij-tarasevich/;https://www.jetinfo.ru/interviews/pyatiletnie-strategii-menyayutsya-na-ne-provalitsya-zdes-i-sejchas/;;|Решили самостоятельно внедрять iiot? не удивляйтесь, но вас могут посадить.;Сергей Андронов;https://www.jetinfo.ru/autor/sergej-andronov/;https://www.jetinfo.ru/interviews/reshili-samostoyatelno-vnedryat-iiot-ne-udivlyajtes-no-vas-mogut-posadit/;;| 11 млн запросов в час поступало на сайт «утконос» в марте 2020 г.;Антон Тарабрин;https://www.jetinfo.ru/speakers/anton-tarabrin/;https://www.jetinfo.ru/interviews/konkurencziya-drajvit-e-com-rynok/;;| 4 часа потребовалось «делимобиль», чтобы перейти на удаленную работу в марте 2020 г.;Дмитрий Рязанов;https://www.jetinfo.ru/speakers/dmitrij-ryazanov/;https://www.jetinfo.ru/interviews/karshering-eto-didzhital-produkt/;;| 150-200 млн руб может сэкономить за 5 лет крупный ритейлер благодаря омниканальным решениям;Александр Воронцов;https://www.jetinfo.ru/autor/aleksandr-voronczov/;https://www.jetinfo.ru/idealnyj-omniritejler-kakoj-on/;;|Мошенники могут монетизировать похищенные баллы программ лояльности и получить от 30 до 50% их номинальной стоимости.;Алексей Сизов;https://www.jetinfo.ru/autor/aleksei_sizov/;https://www.jetinfo.ru/moshennichestvo-v-programmah-loyalnosti/;;| Более 10% годового дохода инвестирует в исследования Huawei ;Алексей Емельянов;https://www.jetinfo.ru/speakers/aleksej-emelyanov/;https://www.jetinfo.ru/interviews/nelzya-prosto-vzyat-i-dokupit-ibp-no-esli-modulnyj-to-mozhno/;;| 57 видов личных данных будут храниться в «Цифровом профиле» клиента банка.;Денис Кузнецов;https://www.jetinfo.ru/speakers/denis-kuzneczov/;https://www.jetinfo.ru/interviews/skb-bank/;;| Людей можно мотивировать не только деньгами , но и задачами. Иначе войну рублями можно вести бесконечно ;Александр Сабуров;https://www.jetinfo.ru/speakers/aleksandr-saburov/;https://www.jetinfo.ru/interviews/data-sajentistov-u-kotoryh-est-dostup-k-ozeru-my-znaem-v-liczo/;;| Задача катастрофоустойчивости не решена ни в одной финансовой организации Казахстана, поэтому наш проект уникален ;Сергей Караханов;https://www.jetinfo.ru/speakers/sergej-karahanov/;https://www.jetinfo.ru/interviews/novye-servisy-my-vnedryaem-tolko-v-kontejnerah-kak-ustroena-it-infrastruktura-sberbanka-v-kazahstane/;;| Вместо «информационных систем» у нас появляется все больше «ИТ-сервисов» и «микросервисов» ;Сергей Караханов;https://www.jetinfo.ru/speakers/sergej-karahanov/;https://www.jetinfo.ru/interviews/novye-servisy-my-vnedryaem-tolko-v-kontejnerah-kak-ustroena-it-infrastruktura-sberbanka-v-kazahstane/;;| Сейчас инструменты DG легче «приземлить» на реальный бизнес, поэтому их используют в телекоме, логистике, на производстве ;Роман Шемпель;https://www.jetinfo.ru/speakers/roman-shempel/;https://www.jetinfo.ru/interviews/vnedryat-data-governance-pora-kogda-top-menedzhery-perestayut-doveryat-otchetam/;;| А что если ваш конкурент прямо сейчас заказывает сервер в облаке, пока вы обсуждаете, где взять ресурсы для проекта? ;Вячеслав Медведев;https://www.jetinfo.ru/autor/viacheslav-medvedev/;https://www.jetinfo.ru/kak-perejti-v-oblako-i-ne-oblazhatsya/;;| Все чаще в кабинете CIO дашборд «Количество дней без аварий» меняется на «Количество релизов за день» ;Илья Воронин;https://www.jetinfo.ru/autor/ilya_voronin/;https://www.jetinfo.ru/bolshoj-infrastrukturnyj-perehod/;;| 4 из 10 российских компаний хотя бы раз подвергались атакам программ-вымогателей;Роман Харыбин;https://www.jetinfo.ru/autor/roman-harybin/;https://www.jetinfo.ru/kak-nastroit-infrastrukturu-chtoby-zashhititsya-ot-virusov-shifrovalshhikov/;;| Более 400 млн руб. за три года выделила ОМК на научные разработки;Александр Мунтин;https://www.jetinfo.ru/speakers/aleksandr-muntin/;https://www.jetinfo.ru/interviews/samoe-vazhnoe-umenie-prizemlit-razrabotki-na-realnoe-proizvodstvo/;;| У 93% компаний есть выделенные эксперты для проактивного поиска угроз;Александр Ахремчик, Алла Крджоян;https://www.jetinfo.ru/autor/aleksandr-ahremcnik/;https://www.jetinfo.ru/kak-organizovat-threat-hunting/;Алла Крджоян;https://www.jetinfo.ru/autor/alla-krdzhoyan/| Чтобы эффективно реагировать на угрозы, нужно быть проактивным — этот принцип лежит в основе Threat Hunting. ;Александр Ахремчик;https://www.jetinfo.ru/autor/aleksandr-ahremcnik/;https://www.jetinfo.ru/kak-organizovat-threat-hunting/;Алла Крджоян;https://www.jetinfo.ru/autor/alla-krdzhoyan/| 53% сотрудников российских компаний считают биометрию удобнее других методов идентификации. ;Алексей Кузьмин;https://www.jetinfo.ru/autor/aleksej-kuzmin/;https://www.jetinfo.ru/kak-sotrudniki-kompanij-otnosyatsya-k-biometrii-issledovanie-infosistemy-dzhet/;;| 38% сотрудников российских компаний не готовы ни под каким предлогом предоставить работодателям свою биометрию. ;Алексей Кузьмин;https://www.jetinfo.ru/autor/aleksej-kuzmin/;https://www.jetinfo.ru/kak-sotrudniki-kompanij-otnosyatsya-k-biometrii-issledovanie-infosistemy-dzhet/;;|В 250 раз выросло количество противоправных действий в сфере высоких технологий за последние 10 лет. ;Алексей Сизов;https://www.jetinfo.ru/autor/aleksei_sizov/;https://www.jetinfo.ru/o-bankovskom-moshennichestve-v-czelom-i-mnogoobrazii-vnutrennego-v-chastnosti/;;|Всего 40% выданных прав доступа в среднем использует линейный сотрудник банка. ;Алексей Сизов;https://www.jetinfo.ru/autor/aleksei_sizov/;https://www.jetinfo.ru/o-bankovskom-moshennichestve-v-czelom-i-mnogoobrazii-vnutrennego-v-chastnosti/;;| Jet Detective агрегирует сотни тысяч операций в минуту из множества источников — от сетевых каналов до бизнес-систем — и оперативно проводит анализ каждого события. ;Алексей Сизов;https://www.jetinfo.ru/autor/aleksei_sizov/;https://www.jetinfo.ru/o-bankovskom-moshennichestve-v-czelom-i-mnogoobrazii-vnutrennego-v-chastnosti/;;|В 2,5 раза выросло количество атак на e-comm и сферу развлечений весной 2022 г. по сравнению с 2021-м. ;Александр Морковчин;https://www.jetinfo.ru/autor/aleksandr-morkovchin/;https://www.jetinfo.ru/ne-preryvaemsya-10-shagov-k-nepreryvnosti-biznesa/;Алексей Джураев;https://www.jetinfo.ru/autor/aleksej-dzhuraev/| В ближайшем будущем мы увидим реализацию ИБ-атак, подготовка к которым началась после 24 февраля. Вполне возможно, самое страшное уже позади, а самое сложное — впереди. ;Алексей Мальнев;https://www.jetinfo.ru/autor/aleksei-malnev/;https://www.jetinfo.ru/samoe-strashnoe-uzhe-pozadi-a-samoe-slozhnoe-vperedi-ugrozy-2022-glazami-jet-csirt/;;| Порядка 90% значимых ИБ-инцидентов сегодня приходится на социальную инженерию и атаки внешнего периметра компаний. ;Алексей Мальнев;https://www.jetinfo.ru/autor/aleksei-malnev/;https://www.jetinfo.ru/samoe-strashnoe-uzhe-pozadi-a-samoe-slozhnoe-vperedi-ugrozy-2022-glazami-jet-csirt/;;| На 50% дороже в среднем стоят сотрудники, которые умеют работать с открытым кодом.;Евгений Вызулин;https://www.jetinfo.ru/autor/evgenij-vyzulin/;https://www.jetinfo.ru/open-source-v-soc/;;| В SIEM-системе компании, где работают около 1000 сотрудников , в среднем регистрируется до 10 000 событий в секунду. Только за день в таком потоке будет выплывать более 100 подозрительных активностей. ;Гурген Цовян;https://www.jetinfo.ru/autor/gurgen-czovyan/;https://www.jetinfo.ru/para-slov-ob-xdr/; Ринат Сагиров;https://www.jetinfo.ru/autor/rinat-sagirov/| Внедрение DLP — это не разовый проект, а процесс , который нужно легализовать, поддерживать и модифицировать вместе с развитием компании ;Екатерина Краснова;https://www.jetinfo.ru/autor/ekaterina-krasnova/;https://www.jetinfo.ru/dlp-otnosheniya-ot-rabochej-rutiny-do-sudebnyh-proczessov/;;| Лучший ответ, который ИБ может дать на вопрос о приоритетах в защите, — это «мы не знаем и не можем знать». Приоритеты может расставить только руководство компании. ;Андрей Янкин;https://www.jetinfo.ru/autor/andrej-yankin/;https://www.jetinfo.ru/horoshaya-bezopasnost-rabotaet-s-lyudmi/;;|SOC можно запустить за 30 рабочих дней. ;Ринат Сагиров;https://www.jetinfo.ru/autor/rinat-sagirov/;https://www.jetinfo.ru/soc-za-chetyre-nedeli-a-chto-tak-mozhno-bylo/;;| «Меня это не касается» — очень распространенное заблуждение. Если вы еще не сталкивались с угрозой, это не значит, что от нее не нужно защищаться. ;Никита Ступак;https://www.jetinfo.ru/autor/nikita-stupak/;https://www.jetinfo.ru/zashhishhaemsya-ot-ddos-kejsy-i-sovety-infosistemy-dzhet/;;| Уже есть кейсы, когда российские компании заявляли о вредительских действиях зарубежным регуляторам и регистраторам, на что им приходил ответ: «Мы не рассматриваем заявления из России». ;Сергей Гук;https://www.jetinfo.ru/speakers/sergej-guk/;https://www.jetinfo.ru/interviews/sezon-ohoty-na-russkie-informsistemy/;;| С острой фазой кризиса ИБ-отрасль уже справилась. Но сможем ли мы добиться отмены сезона охоты на русские информсистемы? ;Сергей Гук;https://www.jetinfo.ru/speakers/sergej-guk/;https://www.jetinfo.ru/interviews/sezon-ohoty-na-russkie-informsistemy/;;| Российский ИБ-рынок гораздо более зрелый, чем рынок ИТ-продуктов. Да, не все средства защиты эффективны настолько, насколько бы хотелось, но они есть, и с этим можно работать. ;Сергей Барбашин;https://www.jetinfo.ru/speakers/sergej-barbashin/;https://www.jetinfo.ru/interviews/effekt-zarubezhnogo-banka-rosbank-v-novoj-ib-realnosti/;;|Не существует более или менее опасных атак — все угрозы равноценны. ;Сергей Барбашин;https://www.jetinfo.ru/speakers/sergej-barbashin/;https://www.jetinfo.ru/interviews/effekt-zarubezhnogo-banka-rosbank-v-novoj-ib-realnosti/;;|Главный вызов — развеять миф о том, что ИБ-угрозы как микробы: не вижу, значит, их нет. ;Дмитрий Балдин;https://www.jetinfo.ru/speakers/dmitrij-baldin/;https://www.jetinfo.ru/interviews/bez-pilotirovaniya-my-nichego-ne-vnedryaem-eto-vnutrennee-tabu-informaczionnaya-bezopasnost-v-rusgidro/;;| Российское ПО прошло уровень «сырых продуктов» — в основном это достаточно хорошие коробочные решения.;Дмитрий Балдин;https://www.jetinfo.ru/speakers/dmitrij-baldin/;https://www.jetinfo.ru/interviews/bez-pilotirovaniya-my-nichego-ne-vnedryaem-eto-vnutrennee-tabu-informaczionnaya-bezopasnost-v-rusgidro/;;| Мы допускаем, что злоумышленник сможет проникнуть в нашу инфраструктуру, но возможность развития атаки мы должны исключить. ;Дмитрий Балдин;https://www.jetinfo.ru/speakers/dmitrij-baldin/;https://www.jetinfo.ru/interviews/bez-pilotirovaniya-my-nichego-ne-vnedryaem-eto-vnutrennee-tabu-informaczionnaya-bezopasnost-v-rusgidro/;;| Злоумышленники не спят — они стучатся из разных часовых поясов, поэтому нам приходится круглосуточно отслеживать угрозы. ;Александр Данченков;https://www.jetinfo.ru/speakers/aleksandr-danchenkov/;https://www.jetinfo.ru/interviews/my-vozvrashhaemsya-no-v-parallelnoe-ruslo-informaczionnaya-bezopasnost-v-rusagro/;;’ data-object-img=’https://www.jetinfo.ru/wp-content/uploads/2021/06/l-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-2-3.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-2-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-2-1.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-3-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-3-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-3-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-4-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-4-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-4-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-5-3.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-5-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-5-1.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-6-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-6-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-6-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/08/l-7-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/08/l-7-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-6-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/08/l-8-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/06/l-6-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/06/l-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/08/l-9-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/08/l-9-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-10-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-10-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-10-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-11-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-11-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-11-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-11-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-12-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-12-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-13-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-13-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-13-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-10-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-14-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-14-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-15-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-15-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-15-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-15-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-16-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-16-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2021/11/l-17-1.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-17-2.png,https://www.jetinfo.ru/wp-content/uploads/2021/11/l-17-3.png;200,0,30;200,0,30|https://www.jetinfo.ru/wp-content/uploads/2023/01/1-1-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/1-2-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/1-3-3.png;200,,30;200,,30|https://www.jetinfo.ru/wp-content/uploads/2023/01/2-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/2-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/27-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/3-1-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/3-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/3-3-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/4-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/4-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/4-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/5-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/5-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/5-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/6-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/6-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/6-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/7-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/7-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/7-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/8-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/8-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/8-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/9-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/9-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/9-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/10-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/10-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/10-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/11-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/11-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/11-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/12-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/12-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/12-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/13-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/13-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/13-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/14-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/14-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/14-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/15-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/15-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/15-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/16-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/16-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/16-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/18-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/18-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/18-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/19-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/19-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/19-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/20-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/20-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/20-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/22-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/22-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/22-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/23-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/23-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/23-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/24-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/24-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/24-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/25-1.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/25-2.png,https://www.jetinfo.ru/wp-content/uploads/2023/01/25-3.png;200,,60;200,,60|https://www.jetinfo.ru/wp-content/uploads/2023/01/26-1.png;200;200’>
Самое популярное

Внедрение DLP — это не разовый проект, а процесс , который нужно легализовать, поддерживать и модифицировать вместе с развитием компании
О статическом анализе начистоту
Последнее время все чаще говорят о статическом анализе как одном из важных средств обеспечения качества разрабатываемых программных продуктов, особенно с точки зрения безопасности. Статический анализ позволяет находить уязвимости и другие ошибки, его можно использовать в процессе разработки, интегрируя в настроенные процессы. Однако в связи с его применением возникает много вопросов. Чем отличаются платные и бесплатные инструменты? Почему недостаточно использовать линтер? В конце концов, при чем тут статистика? Попробуем разобраться.

Сразу ответим на последний вопрос – статистика ни при чем, хотя статический анализ часто по ошибке называют статистическим. Анализ статический, так как при сканировании не происходит запуск приложения.
Для начала разберемся, что мы хотим искать в программном коде. Статический анализ чаще всего применяют для поиска уязвимостей – участков кода, наличие которых может привести к нарушению конфиденциальности, целостности или доступности информационной системы. Однако те же технологии можно применять для поиска и других ошибок или особенностей кода.
Оговоримся, что в общем виде задача статического анализа алгоритмически неразрешима (например, по теореме Райса). Поэтому приходится либо ограничивать условия задачи, либо допускать неточность в результатах (пропускать уязвимости, давать ложные срабатывания). Оказывается, что на реальных программах рабочим оказывается второй вариант.
Существует множество платных и бесплатных инструментов, которые заявляют поиск уязвимостей в приложениях, написанных на разных языках программирования. Рассмотрим, как обычно устроен статический анализатор. Дальше речь пойдет именно о ядре анализатора, об алгоритмах. Конечно, инструменты могут отличаться по дружелюбности интерфейса, по набору функциональности, по набору плагинов к разным системам и удобству использования API. Наверное, это тема для отдельной статьи.
Промежуточное представление
В схеме работы статического анализатора можно выделить три основных шага.
- Построение промежуточного представления (промежуточное представление также называют внутренним представлением или моделью кода).
- Применение алгоритмов статического анализа, в результате работы которых модель кода дополняется новой информацией.
- Применение правил поиска уязвимостей к дополненной модели кода.

Аналогично компиляторам, лексический и синтаксический анализ применяются для построения внутреннего представления, чаще всего — дерева разбора (AST, Abstract Syntax Tree). Лексический анализ разбивает текст программы на минимальные смысловые элементы, на выходе получая поток лексем. Синтаксический анализ проверяет, что поток лексем соответствует грамматике языка программирования, то есть полученный поток лексем является верным с точки зрения языка. В результате синтаксического анализа происходит построение дерева разбора – структуры, которая моделирует исходный текст программы. Далее применяется семантический анализ, он проверяет выполнение более сложных условий, например, соответствие типов данных в инструкциях присваивания.
Дерево разбора можно использовать как внутреннее представление. Также из дерева разбора можно получить другие модели. Например, можно перевести его в трехадресный код, по которому, в свою очередь, строится граф потока управления (CFG). Обычно CFG является основной моделью для алгоритмов статического анализа.

При бинарном анализе (статическом анализе двоичного или исполняемого кода) также строится модель, но здесь уже используются практики обратной разработки: декомпиляции, деобфускации, обратной трансляции. В результате можно получить те же модели, что и из исходного кода, в том числе и исходный код (с помощью полной декомпиляции). Иногда сам бинарный код может служить промежуточным представлением.
Теоретически, чем ближе модель к исходному коду, тем хуже будет качество анализа. На самом исходном коде можно делать разве что поиск по регулярным выражениям, что не позволит найти хоть сколько-нибудь сложную уязвимость.
Анализ потока данных
Одним из основных алгоритмов статического анализа является анализ потока данных. Задача такого анализа — определить в каждой точке программы некоторую информацию о данных, которыми оперирует код. Информация может быть разная, например, тип данных или значение. В зависимости от того, какую информацию нужно определить, можно сформулировать задачу анализа потока данных.

Например, если необходимо определить, является ли выражение константой, а также значение этой константы, то решается задача распространения констант (constant propagation). Если необходимо определить тип переменной, то можно говорить о задаче распространения типов (type propagation). Если необходимо понять, какие переменные могут указывать на определенную область памяти (хранить одни и те же данные), то речь идет о задаче анализа синонимов (alias analysis). Существует множество других задач анализа потока данных, которые могут использоваться в статическом анализаторе. Как и этапы построения модели кода, данные задачи также используются в компиляторах.
В теории построения компиляторов описаны решения задачи внутрипроцедурного анализа потока данных (отследить данные необходимо в рамках одной процедуры/функции/метода). Решения опираются на теорию алгебраических решеток и другие элементы математических теорий. Решить задачу анализа потока данных можно за полиномиальное время, то есть за приемлемое для вычислительных машин время, если условия задачи удовлетворяют условиям теоремы о разрешимости, что на практике происходит далеко не всегда.
Расскажем подробнее про решение задачи внутрипроцедурного анализа потока данных. Для постановки конкретной задачи, помимо определения искомой информации, нужно определить правила изменения этой информации при прохождении данных по инструкциям в CFG. Напомним, что узлами в CFG являются базовые блоки – наборы инструкций, выполнение которых происходит всегда последовательно, а дугами обозначается возможная передача управления между базовыми блоками.
Для каждой инструкции определяются множества:
- (информация, порождаемая инструкцией ),
- (информация, уничтожаемая инструкцией ),
- (информация в точке перед инструкцией ),
- (информация в точке после инструкции ).
Второе соотношение формулирует правила, по которым информация «объединяется» в точках слияния дуг CFG ( – предшественники в CFG). Может использоваться операция объединения, пересечения и некоторые другие.
Искомая информация (множество значений введенных выше функций) формализуется как алгебраическая решетка. Функции и рассматриваются как монотонные отображения на решётках (функции потока). Для уравнений потока данных решением является неподвижная точка этих отображений.
Алгоритмы решения задач анализа потока данных ищут максимальные неподвижные точки. Существует несколько подходов к решению: итеративные алгоритмы, анализ сильно связных компонент, T1-T2 анализ, интервальный анализ, структурный анализ и так далее. Существуют теоремы о корректности указанных алгоритмов, они определяют область их применимости на реальных задачах. Повторюсь, условия теорем могут не выполняться, что приводит к усложнению алгоритмов и неточности результатов.
Межпроцедурный анализ
На практике необходимо решать задачи межпроцедурного анализа потока данных, так как редко уязвимость будет полностью локализовываться в одной функции. Существует несколько общих алгоритмов.
Встраивание (inline) функций. В точке вызова функции мы осуществляем встраивание вызываемой функции, тем самым сводим задачу межпроцедурного анализа к задаче внутрипроцедурного анализа. Такой метод легко реализуем, однако на практике при его применении быстро достигается комбинаторный взрыв.
Построение общего графа потока управления программы, в котором вызовы функций заменены на переходы по адресу начала вызываемой функции, а инструкции возврата заменены на переходы на все инструкции, следующие после всех инструкций вызова данной функции. Такой подход добавляет большое количество нереализуемых путей выполнения, что сильно уменьшает точность анализа.
Алгоритм, аналогичный предыдущему, но при переходе на функцию происходит сохранение контекста – например, стекового фрейма. Таким образом решается проблема создания нереализуемых путей. Однако алгоритм применим при ограниченной глубине вызовов.
Построение информации о функциях (function summary). Наиболее применимый алгоритм межпроцедурного анализа. Он основан на построении summary для каждой функции: правил, по которым преобразуется информация о данных при применении данной функции в зависимости от различных значений входных аргументов. Готовые summary используются при внутрипроцедурном анализе функций. Отдельной сложностью здесь является определение порядка обхода функций, так как при внутрипроцедурном анализе для всех вызываемых функций уже должны быть построены summary. Обычно создаются специальные итеративные алгоритмы обхода графа вызовов (call graph).
Межпроцедурный анализ потока данных является экспоненциальной по сложности задачей, из-за чего анализатору необходимо проводить ряд оптимизаций и допущений (невозможно найти точное решение за адекватное для вычислительных мощностей время). Обычно при разработке анализатора необходимо искать компромисс между объемом потребляемых ресурсов, временем анализа, количеством ложных срабатываний и найденных уязвимостей. Поэтому статический анализатор может долго работать, потреблять много ресурсов и давать ложные срабатывания. Однако без этого невозможно находить важнейшие уязвимости.
Именно в этом моменте серьезные статические анализаторы отличаются от множества открытых инструментов, которые, в том числе, могут себя позиционировать в поиске уязвимостей. Быстрые проверки за линейное время хороши, когда результат нужно получить оперативно, например, в процессе компиляции. Однако таким подходом нельзя найти наиболее критичные уязвимости – например, связанные с внедрением данных.
Taint-анализ
Отдельно стоит остановиться на одной из задач анализа потока данных — taint-анализе. Taint-анализ позволяет распространить по программе флаги. Данная задача является ключевой для информационной безопасности, так как именно с помощью нее обнаруживаются уязвимости, связанные с внедрением данных (внедрения в SQL, межсайтовый скриптинг, открытые перенаправления, подделка файлового пути и так далее), а также с утечкой конфиденциальных данных (запись пароля в журналы событий, небезопасная передача данных).
Попробуем смоделировать задачу. Пусть мы хотим отследить n флагов – . Множеством информации здесь будет множество подмножеств , так как для каждой переменной в каждой точке программы мы хотим определить ее флаги.
Далее мы должны определить функции потока. В данном случае функции потока могут определяться следующими соображениями.
- Задано множество правил, в которых определены конструкции, приводящие к появлению или изменению набора флагов.
- Операция присваивания перебрасывает флаги из правой части в левую.
- Любая неизвестная для множеств правил операция объединяет флаги со всех операндов и итоговое множество флагов добавляется к результатам операции.
Наконец, нужно определить правила слияния информации в точках соединения дуг CFG. Слияние определяется по правилу объединения, то есть если из разных базовых блоков пришли разные наборы флагов для одной переменной, то при слиянии они объединяются. В том числе отсюда появляются ложные срабатывания: алгоритм не гарантирует, что путь в CFG, на котором появился флаг, может быть исполнен.
Например, необходимо обнаруживать уязвимости типа «Внедрение в SQL» (SQL Injection). Такая уязвимость возникает, когда непроверенные данные от пользователя попадают в методы работы с базой данных. Необходимо определить, что данные поступили от пользователя, и добавить таким данным флаг taint. Обычно в базе правил анализатора задаются правила постановки флага taint. Например, поставить флаг возвращаемому значению метода getParameter() класса Request.
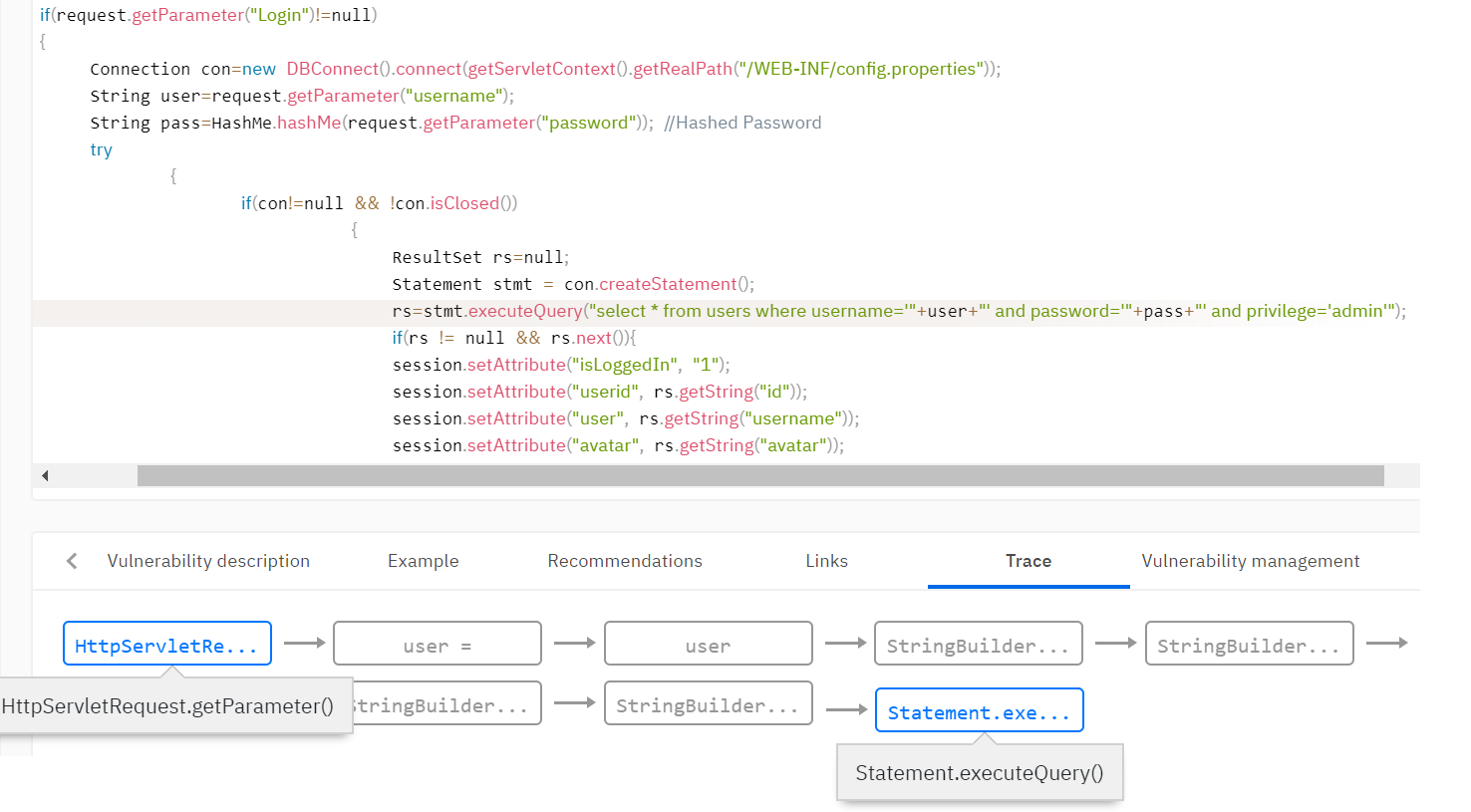
Далее необходимо распространить флаг по всей анализируемой программе с помощью taint-анализа, учитывая, что данные могут быть валидированы и флаг может исчезнуть на одном из путей исполнения. В анализаторе задается множество функций, которые снимают флаги. Например, функция валидации данных от html-тегов может снимать флаг для уязвимости типа «Межсайтовый скриптинг» (XSS). Или функция привязки переменной к SQL-выражению снимает флаг о внедрении в SQL.
Правила поиска уязвимостей
В результате применения указанных выше алгоритмов промежуточное представление дополняется информацией, необходимой для поиска уязвимостей. Например, в модели кода появляется информация о том, каким переменным принадлежат определенные флаги, какие данные являются константными. Правила поиска уязвимостей формулируются в терминах модели кода. Правила описывают, какие признаки в итоговом промежуточном представлении могут говорить о наличии уязвимости.
Например, можно применить правило поиска уязвимости, которое будет определять вызов метода с параметром, у которого есть флаг taint. Возвращаясь к примеру SQL-инъекции, мы проверим, что переменные с флагом taint не попадают в функции запроса к базе данных.
Получается, важной частью статического анализатора, помимо качества алгоритмов, является конфигурация и база правил: описание, какие конструкции в коде порождают флаги или другую информацию, какие конструкции валидируют такие данные, и для каких конструкций критично использование таких данных.
Другие подходы
Помимо анализа потока данных существуют и другие подходы. Одним из известных является символьное выполнение или абстрактная интерпретация. В этих подходах происходит выполнение программы на абстрактных доменах, вычисление и распространение ограничений по данным в программе. С помощью такого подхода можно не просто находить уязвимость, но и вычислить условия на входные данные, при которых уязвимость является эксплуатируемой. Однако у такого подхода есть и серьезные минусы – при стандартных решениях на реальных программах алгоритмы экспоненциально взрываются, а оптимизации приводят к серьезным потерям в качестве анализа.
Выводы
Под конец, думаю, стоит подвести итог, сказав о плюсах и минусах статического анализа. Логично, что сравнивать будем с динамическим анализом, в котором поиск уязвимостей происходит при выполнении программы.

Безусловным преимуществом статического анализа является полное покрытие анализируемого кода. Также к плюсам статического анализа можно отнести то, что для его запуска нет необходимости выполнять приложение в боевой среде. Статический анализ можно внедрять на самых ранних стадиях разработки, минимизируя стоимость найденных уязвимостей.
Минусами статического анализа является неизбежное наличие ложных срабатываний, потребление ресурсов и длительное время сканирований на больших объемах кода. Однако, эти минусы неизбежны, исходя из специфики алгоритмов. Как мы увидели, быстрый анализатор никогда не найдет реальную уязвимость типа SQL-инъекции и подобных.
Об остальных сложностях использования инструментов статического анализа, которые, как оказывается, вполне можно преодолевать, мы писали в другой статье.
- sast
- статический анализ кода
- поиск уязвимостей
- анализ потока данных
- Блог компании Ростелеком-Солар
- Информационная безопасность
- Тестирование IT-систем
- Совершенный код
- Тестирование мобильных приложений