Как убрать null в sql
Чтобы убрать значения NULL из результата запроса в SQL, можно использовать функцию COALESCE() . Она возвращает первое не- NULL значение из списка переданных аргументов. Если все аргументы равны NULL , то функция вернет NULL .
Например, если у вас есть таблица users со столбцами id, name и age, и вы хотите выбрать имена пользователей и их возраст, и при этом исключить значения NULL , то запрос может выглядеть так:
SELECT name, COALESCE(age, 0) as age FROM users; В этом запросе мы выбираем столбец name из таблицы users и используем функцию COALESCE() для замены значений NULL в столбце age на 0. В результате, если значение age равно NULL , то функция COALESCE() вернет 0.
Значение NULL в SQL – неизвестное значение
Примечание:
Во всех статьях текущей категории уроков по SQL используются примеры и задачи, основанные на учебной базе данных.
Приступая к изучению данного материала, рекомендуется ознакомиться с описанием учебной БД.
Даже для небольших баз данных часто встречаются ситуации, когда значение какого-либо поля таблицы может быть неизвестно. Причины возникновения подобных ситуаций могут быть разными, начиная ошибками ПО и проектирования БД, заканчивая особенностями бизнес-процессов организации.
Если рассмотреть диаграмму таблицы сотрудников учебной БД, то можно заметить, что последний столбец диаграммы указывает возможность наличия неизвестных значение в конкретном поле, а именно:
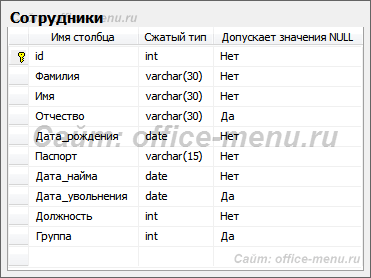
- Отчество. Вполне возможно, что сотрудником является гражданин страны, где не используется отчество.
- Дата увольнения может отсутствовать, так как увольнения еще не было.
- Группа может быть неизвестна, потому что сотрудник может быть не распределен в группу на каком-то из этапов приема на работу.
Важно понять, что неизвестные (отсутствующие) значения – это не ноль (для числовых полей) и не пустая строка (для текстовых полей). Так как ноль является вполне конкретным значением, например, 0 рублей задолженности, а пустая строка сообщает о том, что на данный момент ничего кроме строки нулевой длины в поле строки быть не должно. В примере с отчеством, приведенном выше, вместо значения NULL можно задать пустую строку и это внесло бы дополнительную ясность, что отчество сотрудника нет в принципе, а не то, что его забыли внести.
Поиск отсутствующих значений
Выше было определено, что NULL не является конкретным значением, поэтому нужно понять, как операторы сравнения с ним будут работать. Никакое значение не может быть равно (также быть больше или меньше) неизвестному значению, даже условие NULL = NULL является ложным. Чтобы определить отсутствующее значения используется специальное условие IS NULL (является неизвестным). И наоборот, если требуется найти известные значения, то задается условие IS NOT NULL.
Рассмотрим задачу.
Найти всех сотрудников, которые были когда-либо уволены.
Решение.
Если в поле «Дата_увольнения» таблицы сотрудников отсутствует значение, то сотрудники работают на данный момент. Следовательно, нужно найти строки, где значение известно. Следующий sql-запрос выведет 7 строк, удовлетворяющих решению:
USE CallCenter SELECT * FROM Сотрудники WHERE Дата_увольнения IS NOT NULL
Решим еще одну задачу.
Вывести непринятые звонки за 1 декабря 2014 года.
Решение.
Звонок считается непринятым, если в таблице «Звонки» в поле «Сотрудник» отсутствует id принявшего звонок оператора. Отфильтровав таблицу по полям «Сотрудник» и «Дата_Время», получим 184 строки, удовлетворяющих запросу:
USE CallCenter SELECT * FROM Звонки WHERE Сотрудник IS NULL AND Дата_Время >= '01/12/2014 00:00:00' AND Дата_Время < '02/12/2014 00:00:00'
Обработка неизвестных значений
Если в своих запросах, Вы будете использовать поля, которые допускают значения NULL, то обязательно обрабатывайте такие поля, чтобы избежать ошибок. Например, любые арифметические операции или объединения строк, где в качестве аргумента будет хотя бы одно значение NULL, вернут неизвестное значение.
Рассмотрим пример.
Необходимо определить стаж работы каждого сотрудника, включая уволенных, на текущий момент. Стаж вывести в днях.
Для определения стажа необходимо найти интервал (разницу) между датой найма сотрудника и датой увольнения. Для этого можно использовать функцию DATEDIFF (ее описание можно найти в документации Microsoft). Но как быть с не уволенными сотрудниками, у которых отсутствует значение даты увольнения? Если выполнить ниже приведенный запрос, то можно убедиться, что большинство строк не покажут стаж:
USE CallCenter SELECT id, DATEDIFF(DAY, Дата_найма, Дата_увольнения) AS Стаж FROM Сотрудники
Поэтому обработаем поле «Дата_увольнения», применив функции ISNULL (если первый аргумент является NULL, то функция возвращает второй аргумент) и GETDATE (возвращает текущую системную дату и время). Следующий запрос выведет стаж в каждой строке:
USE CallCenter SELECT id, DATEDIFF(DAY, Дата_найма, ISNULL(Дата_увольнения, GETDATE())) AS Стаж FROM Сотрудники
- Объединение таблиц – UNION
- Соединение таблиц – операция JOIN и ее виды
- Тест на знание основ SQL
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
5 вопросов по SQL, которые часто задают дата-сайентистам на собеседованиях
Хотя составление SQL-запросов — это не самое интересное в работе дата-сайентистов, хорошее понимание SQL чрезвычайно важно для того, кто хочет преуспеть в любом занятии, связанном с обработкой данных. Дело тут в том, что SQL — это не только SELECT , FROM и WHERE . Чем больше SQL-конструкций знает специалист — тем легче ему будет создавать запросы на получение из баз данных всего, что ему может понадобиться.

Автор статьи, перевод которой мы сегодня публикуем, говорит, что она направлена на решение двух задач:
- Изучение механизмов, которые выходят за пределы базового знания SQL.
- Рассмотрение нескольких практических задач по работе с SQL.
Вопрос №1: второе место по зарплате
Напишите SQL-запрос для получения из таблицы со сведениями о заработной плате сотрудников ( Employee ) записи, содержащей вторую по размеру заработную плату.
Например, такой запрос, выполненный для таблицы, представленной ниже, должен вернуть 200 . Если в таблице нет значения, меньшего, чем самая высокая зарплата — запрос должен вернуть null .
+----+--------+ | Id | Salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+▍Решение А: использование IFNULL и OFFSET
Вот основные механизмы, которые будут использованы в данном варианте решения задачи:
- IFNULL(expression, alt) : эта функция возвращает свой аргумент expression в том случае, если он не равен null . В противном случае возвращается аргумент alt . Мы воспользуемся этой функцией для того чтобы возвратить null в том случае, если в таблице не окажется искомого значения.
- OFFSET : этот оператор используется с выражением ORDER BY для того чтобы отбросить первые n строк. Это нам пригодится по той причине, что нас интересует вторая строка результата (то есть — вторая по величине зарплата, данные о которой есть в таблице).
SELECT IFNULL( (SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT 1 OFFSET 1 ), null) as SecondHighestSalary FROM Employee LIMIT 1▍Решение B: использование MAX
В запросе, представленном ниже, используется функция MAX . Здесь выбирается самое большое значение заработной платы, не равное максимальной заработной плате, полученной по всей таблице. В результате мы и получаем то, что нам нужно — вторую по величине заработную плату.
SELECT MAX(salary) AS SecondHighestSalary FROM Employee WHERE salary != (SELECT MAX(salary) FROM Employee)Вопрос №2: дублирующиеся адреса электронной почты
Напишите SQL-запрос, который обнаружит в таблице Person все дублирующиеся адреса электронной почты.
+----+---------+ | Id | Email | +----+---------+ | 1 | a@b.com | | 2 | c@d.com | | 3 | a@b.com | +----+---------+▍Решение А: COUNT в подзапросе
Сначала мы создаём подзапрос, в котором выясняется частота появления каждого адреса в таблице. Затем результат, возвращаемый подзапросом, фильтруется с использованием инструкции WHERE count > 1 . Запрос вернёт сведения об адресах, встречающихся в исходной таблице больше одного раза.
SELECT Email FROM ( SELECT Email, count(Email) AS count FROM Person GROUP BY Email ) as email_count WHERE count > 1▍Решение B: выражение HAVING
- HAVING : это выражение, которое позволяет использовать инструкцию WHERE вместе с выражением GROUP BY .
SELECT Email FROM Person GROUP BY Email HAVING count(Email) > 1Вопрос №3: растущая температура
Напишите SQL-запрос, который находит в таблице Weather все даты (идентификаторы дат), когда температура была бы выше температуры на предшествующие им даты. То есть, нас интересуют даты, в которые «сегодняшняя» температура выше «вчерашней».
+---------+------------------+------------------+ | Id(INT) | RecordDate(DATE) | Temperature(INT) | +---------+------------------+------------------+ | 1 | 2015-01-01 | 10 | | 2 | 2015-01-02 | 25 | | 3 | 2015-01-03 | 20 | | 4 | 2015-01-04 | 30 | +---------+------------------+------------------+▍Решение: DATEDIFF
- DATEDIFF : эта функция вычисляет разницу между двумя датами. Она используется для того, чтобы обеспечить сравнение именно «сегодняшних» и «вчерашних» температур.
SELECT DISTINCT a.Id FROM Weather a, Weather b WHERE a.Temperature > b.Temperature AND DATEDIFF(a.Recorddate, b.Recorddate) = 1Вопрос №4: самая высокая зарплата в подразделении
В таблице Employee хранятся сведения о сотрудниках компании. В каждой записи этой таблицы содержатся сведения об идентификаторе ( Id ) сотрудника, о его имени ( Name ), о зарплате ( Salary ) и о подразделении компании, где он работает ( Department ).
+----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+-------+--------+--------------+ | 1 | Joe | 70000 | 1 | | 2 | Jim | 90000 | 1 | | 3 | Henry | 80000 | 2 | | 4 | Sam | 60000 | 2 | | 5 | Max | 90000 | 1 | +----+-------+--------+--------------+В таблице Department содержатся сведения о подразделениях компании.
+----+----------+ | Id | Name | +----+----------+ | 1 | IT | | 2 | Sales | +----+----------+Напишите SQL-запрос, который находит в каждом из подразделений сотрудников с максимальной заработной платой. Например, для вышеприведённых таблиц подобный запрос должен возвращать результаты, представленные следующей таблицей (при этом порядок строк в таблице значения не имеет):
+------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Jim | 90000 | | Sales | Henry | 80000 | +------------+----------+--------+▍Решение: команда IN
Команда IN позволяет задавать в инструкции WHERE условия, соответствующие использованию нескольких команд OR . Например, две следующие конструкции идентичны:
WHERE country = ‘Canada’ OR country = ‘USA’ WHERE country IN (‘Canada’, ’USA’).Здесь мы хотим получить таблицу, содержащую название подразделения ( Department ), имя сотрудника ( Employee ) и его заработную плату ( Salary ). Для этого мы формируем таблицу, в которой содержатся сведения об идентификаторе подразделения ( DepartmentID ) и о максимальной зарплате по этому подразделению. Далее мы объединяем две таблицы по условию, в соответствии с которым записи в результирующую таблицу попадают только в том случае, если DepartmentID и Salary есть в ранее сформированной таблице.
SELECT Department.name AS 'Department', Employee.name AS 'Employee', Salary FROM Employee INNER JOIN Department ON Employee.DepartmentId = Department.Id WHERE (DepartmentId , Salary) IN ( SELECT DepartmentId, MAX(Salary) FROM Employee GROUP BY DepartmentId )Вопрос №5: пересаживание учеников
Мэри — учительница в средней школе. У неё есть таблица seat , хранящая имена учеников и сведениях об их местах в классе. Значение id в этой таблице постоянно возрастает. Мэри хочет поменять местами соседних учеников.
Вот таблица исходного размещения учеников:
+---------+---------+ | id | student | +---------+---------+ | 1 | Abbot | | 2 | Doris | | 3 | Emerson | | 4 | Green | | 5 | Jeames | +---------+---------+Вот что должно получиться после пересаживания соседних учеников:
+---------+---------+ | id | student | +---------+---------+ | 1 | Doris | | 2 | Abbot | | 3 | Green | | 4 | Emerson | | 5 | Jeames | +---------+---------+Напишите запрос, который позволит учительнице решить вышеописанную задачу.
Обратите внимание на то, что если количество учеников является нечётным — последнего ученика никуда пересаживать не надо.
▍Решение: использование оператора WHEN
SQL-конструкцию CASE WHEN THEN можно рассматривать как оператор if в программировании.
В нашем случае первый оператор WHEN используется для проверки того, назначен ли последней строке в таблице нечётный идентификатор. Если это так — строка не подвергается изменениям. Второй оператор WHEN отвечает за добавление 1 к каждому нечётному идентификатору (например — 1, 3, 5 превращается в 2, 4, 6) и за вычитание 1 из каждого чётного идентификатора (2, 4, 6 превращаются в 1, 3, 5).
SELECT CASE WHEN((SELECT MAX(id) FROM seat)%2 = 1) AND MAX(id) FROM seat) THEN id WHEN id%2 = 1 THEN id + 1 ELSE id - 1 END AS id, student FROM seat ORDER BY idИтоги
Мы разобрали несколько задач по SQL, попутно обсудив некоторые продвинутые средства, которые можно использовать при составлении SQL-запросов. Надеемся, то, что вы сегодня узнали, пригодится вам при прохождении собеседований по SQL и окажется полезным в повседневной работе.
P.S. В нашем маркетплейсе есть Docker-образ с SQL Server Express, который устанавливается в один клик. Вы можете проверить работу контейнеров на VPS. Всем новым клиентам бесплатно предоставляются 3 дня для тестирования.
Уважаемые читатели! Что вы можете посоветовать тем, кто хочет освоить искусство создания SQL-запросов?

- Блог компании RUVDS.com
- Занимательные задачки
- SQL
- Карьера в IT-индустрии
7 распространенных ошибок в SQL-запросах, которые делал каждый (почти)
Сегодня SQL используют уже буквально все на свете: и аналитики, и программисты, и тестировщики, и т.д. Отчасти это связано с тем, что базовые возможности этого языка легко освоить.
Однако работая с большим количеством junior-ов, мы раз от раза находим в их решениях одни и те же ошибки. Реально — иногда просто создается ощущение, что они копируют друг у друга код.
Кстати, иногда такая же участь постигает и специалистов более высокого полета.
Сегодня мы решили собрать 7 таких ошибок в одном месте, чтобы как можно меньше людей их совершали.
Примечание: Ошибки будут 2 видов — реальные ошибки и своего рода best practices, которым часто не следуют.
Но, обо всем по порядку 🙂

1. Преобразование типов
Мы привыкли, что в математике мы всегда можем разделить одно число на другое и получить ответ. Если нацело не получается, то в виде дроби.
В SQL это не всегда так работает. Например, в PostgreSQL деление двух целых чисел друг на друга даст целочисленный ответ. Это можно проверить как для целочисленных столбцов, так и для чисел.
SELECT a/b FROM demo # столбец целых чисел SELECT 1 / 2 # 0Аналогичные запросы, например, в MySQL дадут дробное число, как и положено.
Если Вы точно не уверены или хотите подстраховаться, то лучше всегда явно делать преобразование типов. Например:
SELECT a::NUMERIC/b FROM demo SELECT a*1.0/b FROM demo SELECT CAST(1 AS FLOAT)/2 FROM demoВсе перечисленные примеры дадут нужный ответ.
2. HAVING вместо WHERE
Часто встречается ошибка — оператор HAVING используется вместо WHERE в запросах с агрегацией. Это неверно!
WHERE производит фильтрацию строк в исходном наборе данных, отсеивая неподходящие. После этого GROUP BY формирует группы и оператор HAVING производит фильтрацию уже целых групп (будто группа — одно запись).
SELECT date, COUNT(*) FROM transactions t WHERE date >= '2019-01-01' GROUP BY date HAVING COUNT(*) = 2 Здесь мы сначала отсеиваем строки, в которых хранятся записи до 2019 года. После этого формируем группы и оставляем только те, в которых ровно две записи.
Некоторые же пишут так:
SELECT date, COUNT(*) FROM transactions t GROUP BY date HAVING COUNT(*) = 2 AND date >= '2019-01-01'Так делать не нужно 🙂
Кстати, для закрепления этой темы мы специально делали задачку «Отфильтрованные продажи» у себя на платформе. Если интересно порешать и другие задачки по SQL - welcome 🙂
3. Алиасы и план запроса
Если «проговаривать SQL-запрос» словами, то получится что-то такое:
В таблице есть старая цена, а есть новая цена. Их разность я назову diff. Я хочу отобрать только те строки, где значение diff больше 100.
Звучит вполне логично. Но в SQL прям так реализовать не получится - и многие попадаются в эту ловушку.
Вот неправильный запрос:
SELECT old_price - new_price AS diff FROM goods WHERE diff > 100Ошибка его заключается в том, что мы используем алиас столбца diff внутри оператора WHERE.
Да, это выглядит вполне логичным, но мы не можем так сделать из-за порядка выполнения операторов в SQL-запросе. Дело в том, что фильтр WHERE выполняется сильно раньше оператора SELECT (а значит и AS). Соответственно, в момент выполнения столбца diff просто не существует. Об этом, кстати, и говорит ошибка:
ERROR: column "diff" does not existПравильно будет использовать подзапрос или переписать запрос следующим образом:
SELECT old_price - new_price AS diff FROM goods WHERE old_price - new_price > 100Важно: Внутри ORDER BY вы можете указывать алиас - этот оператор выполняется уже после SELECT.
Кстати, мы тут делали карточку, где наглядно показывается последовательность выполнения операторов. Возможно, это вам пригодится.
4. Не использовать COALESCE
Пришло время неочевидных пунктов. Но сейчас мы поясним свои чаяния.
COALESCE - это оператор, который принимает N значений и возвращает первое, которое не NULL. Если все NULL, то вернется NULL.
Нужен этот оператор для того, чтобы в расчеты случайно не попадали пропуски. Такие пропуски всегда сложно заметить, потому что при расчете среднего на основании ста тысяч строк вы вряд ли заметите подвох, даже если 1000 просто будет отсутствовать. Обычно такие численные пропуски заполняют средними значениями/минимальными/максимальными/медианными/средними или с помощью какой-то интерполяции — зависит от задачи.
Мы же рассмотрим нечисловой пример, а вполне себе бизнесовый. Например, есть таблица клиентов Clients. В поле name заносится имя пользователя.
Отдел маркетинга решил сделать email-рассылку, которая начинается с фразы:
Очевидно, что если name is NULL, то это превратится в тыкву:
Вот в таких случаях и помогает COALESCE:
SELECT COALESCE(name, 'Дорогой друг') FROM ClientsСовет: Лучше всегда перестраховываться. Особенно это касается вычислений и агрегирований - там вы не найдете ошибку примерно никогда, так что лучше подложить соломку.
5. Игнорирование CASE
Если вы используете CASE, то иногда вы можете сократить свои запросы в несколько раз.
Вот, например, была задача — вывести поле sum со знаком «-», если type=1 и со знаком «+», если type=0.
Пользователь предложил такое решение:
SELECT id, sum FROM transactions t WHERE type = 0 UNION ALL SELECT id, -sum FROM transactions t WHERE type = 1В целом, не так плохо. Но это всего лишь промежуточный запрос, задача была намного масштабней и таких конструкций в итоге было наворочено очень много.
А вот то же самое с CASE:
SELECT id, CASE WHEN type = 0 THEN sum ELSE -sum END FROM transactions t Так более того, CASE можно использовать еще много для чего. Например, чтобы сделать из «длинной» таблицы «широкую».
А еще, кстати, COALESCE, который мы обсуждали выше — это просто «синтаксический сахар» и обертка вокруг CASE. Если интересно — мы подробно это описали в статье.
6. Лишние подзапросы
Из-за того, что многие пишут SQL-запросы также, как это «звучит» в их голове, получается нагромождение подзапросов.
Это проходит с опытом — начинаешь буквально «мыслить на SQL» и все становится ок. Но первое время появляются такие штуки:
SELECT id, LAG(neg) OVER(ORDER BY id) AS lg FROM ( SELECT id, sm, -sm AS neg FROM ( SELECT id, sum AS sm FROM transactions t ) t ) t1И это еще не все — можно и побольше накрутить. Но зачем так, если можно так:
SELECT id, LAG(-sum) OVER(ORDER BY id) FROM transactions t Совет: Если пока сложно, не надо сразу бросаться писать оптимизированными конструкциями. Напишите сначала, как сможете, а потом пытайтесь сократить.
Как говорил дядюшка Кнут:
Преждевременная оптимизация — корень всех зол
7. Неправильное использование оконных функций
Вообще говоря, оконные функции — довольно продвинутый инструмент. Считается, что им владеют специалисты уровня Middle и выше. Но по факту, их нужно знать всем — сейчас без них уже сложно жить (это чистое имхо).
И если базовые вещи по оконным функциям можно освоить довольно быстро, то всякая экзотика и нестандартное поведение осваивается, как правило, только на собственных шишках.
Одна из таких вещей — поведение оконной функции LAST_VALUE и прочих.
Например, когда мы пишем запрос:
WITH cte AS ( SELECT 'Marketing' AS department, 50 AS employees, 2018 AS year UNION SELECT 'Marketing' AS department, 10 AS employees, 2019 AS year union SELECT 'Sales' AS department, 35 AS employees, 2018 AS year UNION SELECT 'Sales' AS department, 25 AS employees, 2019 AS year ) SELECT c.*, LAST_VALUE(employees) OVER (PARTITION BY department ORDER BY year) AS emp FROM cte cМы ожидаем увидеть 2 раза по 10 для департамента Маркетинг и 2 раза по 25 для Продаж. Однако такой запрос дает иную картину:

Получается, что запрос тупо продублировал значения из столбца employees. Как так?
Лезем в документацию PostgreSQL и видим:
Заметьте, что функции first_value, last_value и nth_value рассматривают только строки в «рамке окна», которая по умолчанию содержит строки от начала раздела до последней родственной строки для текущей.
Ага, вот и ответ. То есть каждый раз у нас окно — это не весь набор строк, а только до текущей строки.
Получается, есть два способа вылечить такое поведение:
- Убрать ORDER BY
- Добавить определение рамки
Вот, например, второй вариант:
WITH cte AS ( SELECT 'Marketing' AS department, 50 AS employees, 2018 AS year UNION SELECT 'Marketing' AS department, 10 AS employees, 2019 AS year union SELECT 'Sales' AS department, 35 AS employees, 2018 AS year UNION SELECT 'Sales' AS department, 25 AS employees, 2019 AS year ) SELECT c.*, LAST_VALUE(employees) OVER ( PARTITION BY department ORDER BY year ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS emp FROM cte cКстати, такую тему подняла наша подписчица в Телеграме под постом «7 самых важных оконных функций». Спасибо ей!
А вас рады будем видеть в числе подписчиков 🙂
Эпилог
Эти 7 ошибок — не единственные, которые часто встречаются среди новичков и даже профессионалов. У нас есть еще одна пачка тезисов по этому поводу — но это уже тема другой статьи.
Если вам есть что добавить — будем рады продолжить обсуждение в комментариях. Возможно, чей-то код станет лучше и чище в результате нашей беседы 🙂