Как спарсить любой сайт?

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
- Найдите официальное API,
- Найдите XHR запросы в консоли разработчика вашего браузера,
- Найдите сырые JSON в html странице,
- Отрендерите код страницы через автоматизацию браузера,
- Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
�� Ого? Это не очевидно ��? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте. Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
Поищите XHR запросы в консоли разработчика

Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️
Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:

- Открывайте вебстраницу, которую хотите спарсить
- Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
- Открывайте вкладку Network и кликайте на фильтр XHR запросов
- Обновляйте страницу, чтобы в логах стали появляться запросы
- Найдите запрос, который запрашивает данные, которые вам нужны
- Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. �� Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? ��♀️ Нет! ��♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! ������
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):

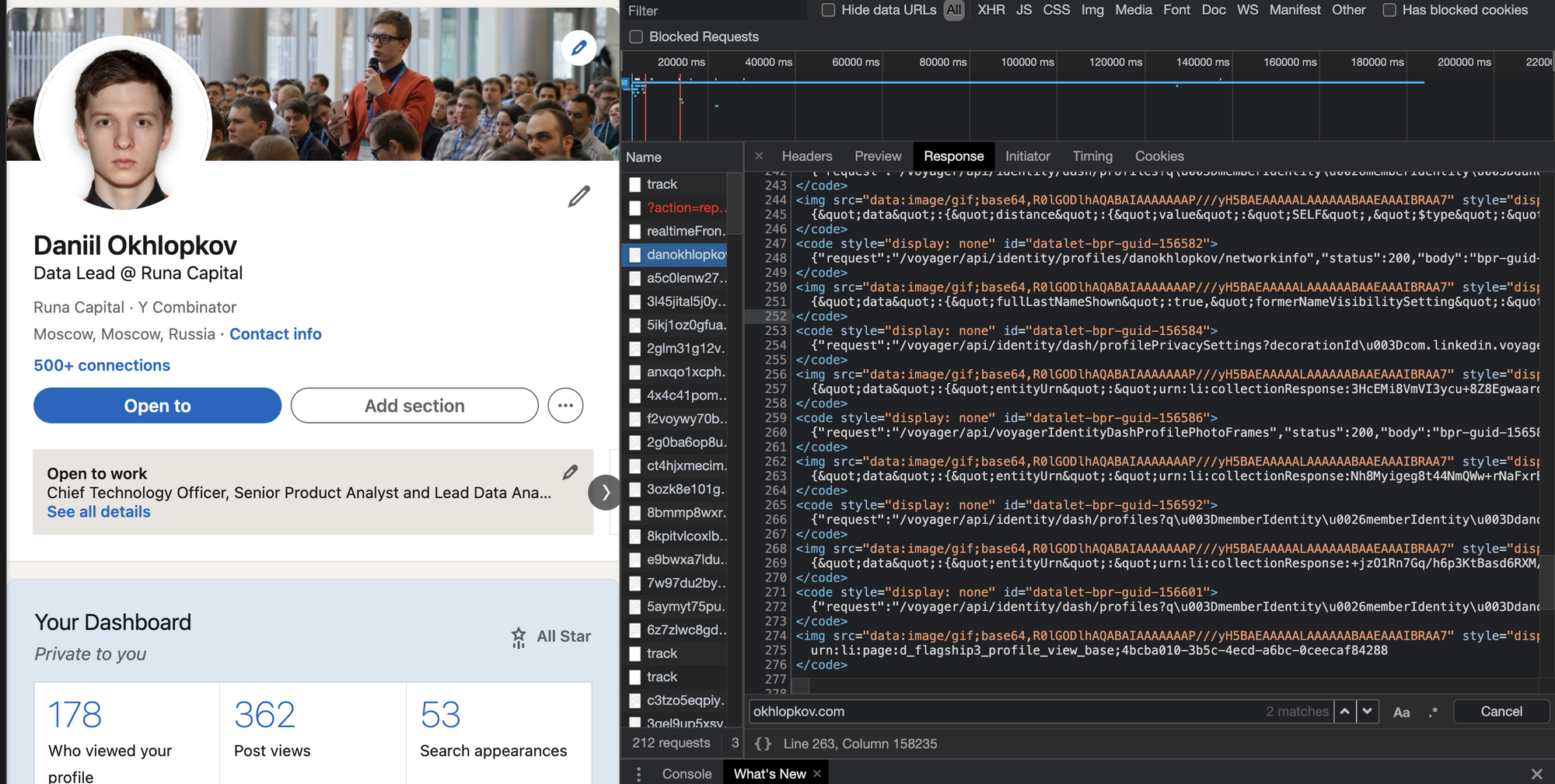
Алгоритм действий такой:
- В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
- Внизу ищите длинную длинную строчку с данными.
- Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто requests.get .
- Вырезаете JSON из HTML любыми костылямии (я использую html.find(«= <") ).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open) html = driver.page_sourceSelenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver( enable_vnc=False, browser_name="firefox" ): capabilities = < "browserName": browser_name, "version": "", "enableVNC": enable_vnc, "enableVideo": False, "screenResolution": "1280x1024x24", "sessionTimeout": "3m", # Someone used these params too, let's have them as well "goog:chromeOptions": , "prefs": < "credentials_enable_service": False, "profile.password_manager_enabled": False >, > driver = webdriver.Remote( command_executor=SELENOID_URL, desired_capabilities=capabilities, ) driver.implicitly_wait(10) # wait for the page load no matter what if enable_vnc: print(f"You can view VNC here: ") return driverЗаметьте фложок enableVNC . Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

Даниил Охлопков — Data Lead @ Runa Capital
Подписывайтесь на мой Телеграм канал, где я рассказываю свои истории из парсинга и сливаю датасеты.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход ��
Парсер
Парсер — это программа для сбора и систематизации информации, размещенной на различных сайтах. Источником данных может служить текстовое наполнение, HTML-код сайта, заголовки, пункты меню, базы данных и другие элементы. Процесс сбора информации называется парсинг (parsing).

«IT-специалист с нуля» наш лучший курс для старта в IT
Парсеры используются в интернет-маркетинге для сбора информации с сайтов-конкурентов, а также для анализа собственных веб-ресурсов. Они позволяют обрабатывать большие массивы данных в автоматическом режиме. Это ускоряет и упрощает проведение маркетинговых исследований.
Профессия / 8 месяцев
IT-специалист с нуля
Попробуйте 9 профессий за 2 месяца и выберите подходящую вам

Как работает парсер
Термин «парсинг» произошел от английского глагола to parse, означающего в переводе с английского «по частям». Процесс представляет собой синтаксический анализ любого набора связанных друг с другом данных. В общем виде парсинг выполняется в несколько этапов:
- Сканирование исходного массива информации (HTML-кода, текста, базы данных и т.д.).
- Вычленение семантически значимых единиц по заданным параметрам — например заголовков, ссылок, абзацев, выделенных жирным шрифтом фрагментов, пунктов меню.
- Конвертация полученных данных в формат, удобный для изучения, а также их систематизация в виде таблиц или отчетов для дальнейшего использования.
Объектом парсинга может быть любая грамматически структурированная система: информация, закодированная естественным языком, языком программирования, математическими выражениями и т.д. Например, если исходный массив данных представляет собой HTML-страницу, парсер может вычленить из кода информацию и перевести ее в текст, понятный для человека. Или конвертировать в JSON — формат для приложений и скриптов.
Читайте также Востребованные IT-профессии 2023 года: на кого учиться онлайн
Доступ парсера к сайту возможен:
- через протоколы HTTP, HTTPS или веб-браузер;
- с использованием бота, имеющего права администратора.
Получение данных парсером — семантический анализ исходного массива информации. Программа разбивает его на отдельные части (лексемы): слова, словосочетания и т.д. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную (синтаксическое дерево). Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:
- дерево зависимостей — такая структура состоит из компонентов, находящихся в иерархических отношениях друг к другу;
- дерево составляющих — в структуре этого типа компоненты находятся в тесной зависимости друг с другом, но без иерархических отношений.
Также результат работы парсера может представлять собой сочетание моделей. Программа действует по одному из двух алгоритмов:
- Нисходящий парсинг. Анализ осуществляется от общего к частному, а синтаксическое дерево разрастается вниз.
- Восходящий парсинг. Анализ и построение синтаксического дерева осуществляются снизу вверх.
Выбор конкретного метода парсинга зависит от конечной цели. В любом случае, парсер должен уметь вычленять из общего массива только необходимые данные, а также преобразовывать их в удобный для решения задачи формат.
Станьте веб-разработчиком и найдите стабильную работу на удаленке
Преимущества и недостатки парсеров
Применение программ-парсеров позволяет:
- автоматизировать процесс анализа и снижать нагрузку на сотрудников, перенаправлять их время и силы на решение других задач;
- ускорять анализ большого объема информации — например, нескольких сотен страниц интернет-магазина или обширную базу данных;
- выявлять ошибки на сайте или в любом другом информационном продукте, если в программе заданы настройки на их поиск.
К недостаткам парсеров можно отнести не всегда релевантный анализ данных. Однако в большинстве случаев это зависит от возможностей программы, качества ее настройки пользователем. В большинстве случаев информация, выдаваемая парсером, требует незначительной обработки для дальнейшего использования.
Применение парсеров
Парсинг применяется в любых областях, где требуется проанализировать и систематизировать большой объем данных:
- В программировании. Компьютер может воспринимать и «понимать» только машинный код — набор нулей и единиц. Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.
- В создании сайтов. Как и языки программирования, языки разметки (например HTML) непонятны компьютеру. Чтобы он смог отобразить HTML-разметку в виде визуально структурированного и понятного интерфейса сайта, парсер браузера анализирует исходный код страницы, вычленяет нужные данные, переводит их в понятный машине формат. Также парсинг позволяет выявить ошибки и недочеты в созданном сайте.
- Веб-краулинг. Это частный случай парсинга. Робот-парсер поисковика в ответ на запрос пользователя просматривает релевантные ему сайты, после чего выбирает наиболее подходящую по содержанию страницу. Особенность краулеров в том, что они не извлекают данные со страниц, как другие парсеры, а ищут в них совпадения с запросом пользователя.
- Агрегация новостей. Для упорядоченной подачи новостей сайты-агрегаторы или новостные агентства используют парсеры. Они собирают обновления со всех доступных источников, анализируют их и подают сотрудникам для конечной редактуры и публикации.
- Интернет-маркетинг. В SEO и SMM с помощью парсеров собираются и анализируются данные пользователей, товарные позиции в интернет-магазинах, метатеги (заголовки, title и description), ключевые слова и другая информация. Эти данные используются для оптимизации сайта, продвижения коммерческих групп в социальных сетях, настройки таргетированной и контекстной рекламы. Проверка размещенного на веб-ресурсе текста на плагиат также является разновидностью парсинга.
- Мониторинг цен. Парсерами можно извлечь расценки товаров на сайтах-конкурентах, чтобы проанализировать текущую ситуацию на рынке и выработать ценовую политику. Также с их помощью можно привести прайс-листы на собственном сайте в соответствие с ценами у поставщиков.
Программы-парсеры
В веб-разработке и продвижении используется большое количество бесплатных и платных программ для парсинга сайтов. К числу самых популярных относятся:

- Screaming Frog SEO Spider. Это британская программа для комплексного анализа сайтов со множеством полезных опций. Она осуществляет поиск битых ссылок, входящих и исходящих ссылок, выявляет дубли метатегов и заголовков, ключевые слова, отдельные URL и т.д. Среди полезных дополнительных опций — генерация sitemap, сканирование сайтов, требующих оптимизации, проверка файла robots.txt. Программа имеет бесплатную версию, но функционал ограничен базовыми возможностями.
- ComparseR. Это приложение также позволяет парсить сайты, но у нее отсутствует функция поиска внутренних и внешних ссылок. В остальном оно не уступает Screaming Frog по возможностям, хотя имеются ограничения по производительности при анализе крупных сайтов — например, интернет-магазинов или больших информационных порталов. Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.

- Netpeak Spider. Одно из самых популярных приложений для парсинга, ориентированное на работу с крупными сайтами (с миллионом и более страниц). Среди преимуществ — наличие всего набора инструментов для анализа и продвижения веб-ресурсов разного типа, настраиваемые фильтры параметров, дополнительные опции наподобие генерации HTML-карты сайта, поиска ссылок nofollow, выгрузки отчетов и т.д. Единственный недостаток — полный функционал доступен по подписке, которую нужно регулярно продлевать.
- Xenu Link Sleuth. Бесплатный парсер, предназначенный для поиска битых ссылок и других ошибок на сайте. Xenu нельзя использовать для комплексного и подробного анализа веб-ресурсов. Также есть проблемы с производительностью, но с учетом доступности недостатки приемлемы.
Можно ли использовать парсеры
Распространено мнение, что парсинг сайтов как минимум неэтичен, а в некоторых случаях и незаконен. Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон. Противозаконным может стать применение данных, например:
- для спам-рассылки и звонков. Это нарушает закон о защите персональных данных;
- копирование и использование информации с сайта-конкурента на собственном ресурсе. Это может нарушать авторские права.
В целом, парсинг не нарушает нормы законодательства и этики. Автоматизированный сбор информации позволяет сделать сайт и реализуемый с его помощью продукт более удобным для клиентов.
Веб-разработчик с нуля
Веб-разработчик — мастер на все руки. Он создает программы и приложения для любых сфер и компаний: от небольшой кофейни до международных банков. Станьте специалистом, который создает востребованный продукт
Статьи по теме:
Что такое парсер и как он работает

Чтобы поддерживать информацию на своем ресурсе в актуальном состоянии, наполнять каталог товарами и структурировать контент, необходимо тратить кучу времени и сил. Но есть утилиты, которые позволяют заметно сократить затраты и автоматизировать все процедуры, связанные с поиском материалов и экспортом их в нужном формате. Эта процедура называется парсингом.
Давайте разберемся, что такое парсер и как он работает.
Что такое парсинг?
Начнем с определения. Парсинг – это метод индексирования информации с последующей конвертацией ее в иной формат или даже иной тип данных.
Парсинг позволяет взять файл в одном формате и преобразовать его данные в более удобоваримую форму, которую можно использовать в своих целях. К примеру, у вас может оказаться под рукой HTML-файл. С помощью парсинга информацию в нем можно трансформировать в «голый» текст и сделать понятной для человека. Или конвертировать в JSON и сделать понятной для приложения или скрипта.
Но в нашем случае парсингу подойдет более узкое и точное определение. Назовем этот процесс методом обработки данных на веб-страницах. Он подразумевает анализ текста, вычленение оттуда необходимых материалов и их преобразование в подходящий вид (тот, что можно использовать в соответствии с поставленными целями). Благодаря парсингу можно находить на страницах небольшие клочки полезной информации и в автоматическом режиме их оттуда извлекать, чтобы потом переиспользовать.
Ну а что такое парсер? Из названия понятно, что речь идет об инструменте, выполняющем парсинг. Кажется, этого определения достаточно.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:
- Мониторинг цен. Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
- Поиск товарных позиций. Полезная опция на тот случай, если сайт поставщика не дает возможности быстро и автоматически перенести базу данных с товарами. Можно самостоятельно «запарсить» информацию по нужным критериям и перенести ее на свой сайт. Не придется копировать данные о каждой товарной единице вручную.
- Извлечение метаданных. Специалисты по SEO-продвижению используют парсеры, чтобы скопировать у конкурентов содержимое тегов title, description и т.п. Парсинг ключевых слов – один из наиболее распространенных методов аудита чужого сайта. Он помогает быстро внести нужные изменения в SEO для ускоренного и максимально эффективного продвижения ресурса.
- Аудит ссылок. Парсеры иногда задействуют для поиска проблем на странице. Вебмастера настраивают их под поиск конкретных ошибок и запускают, чтобы в автоматическом режиме выявить все нерабочие страницы и ссылки.
Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Где найти парсер?
Добыть утилиту для поиска и преобразования информации с сайтов можно четырьмя путями.
- Использование сил своей команды разработчиков. Когда в штате есть программисты, способные создать парсер, адаптированный под задачи компании, то искать другие варианты не стоит. Этот будет оптимальным вариантом.
- Нанять команду разработчиков со стороны, чтобы те создали утилиту по вашим требованиям. В таком случае уйдет много ресурсов на создание ТЗ и оплату работы.
- Установить готовое приложение-парсер на компьютер. Да, оно тоже будет стоить денег, но зато им можно воспользоваться сразу. А настройки параметров в таких программах позволяют точно настроить схему парсинга.
- Воспользоваться веб-сервисом или браузерным плагином с аналогичной функциональностью. Встречаются бесплатные версии.
При отсутствии разработчиков в штате я бы советовал именно десктопную программу. Это идеальный баланс между эффективностью и затратами. Но если задачи стоят не слишком сложные, то может хватить и облачного сервиса.
Плюсы парсинга
У автоматического сбора информации куча преимуществ (по сравнению с ручным методом):
- Программа работает самостоятельно. Не приходится тратить время на поиск и сортировку данных. К тому же собирает она информацию куда быстрее человека. Да еще и делает это 24 на 7, если понадобится.
- Парсеру можно «скормить» столько параметров, сколько потребуется, и идеально отстроить его для поиска только необходимого контента. Без мусора, ошибок и нерелеватной информации с неподходящих страниц.
- В отличие от человека, парсер не будет допускать глупых ошибок по невнимательности. И не устанет.
- Утилита для парсинга может подавать найденные данные в удобном формате по запросу пользователя.
- Парсеры умеют грамотно распределять нагрузку на сайт. Это значит, что он случайно не «уронит» чужой ресурс, а вас не обвинят в незаконной DDoS-атаке.
Так что нет никакого смысла «парсить» руками, когда можно доверить эту операцию подходящему ПО.
Минусы парсинга
Главный недостаток парсеров заключается в том, что ими не всегда удается воспользоваться. В частности, когда владельцы чужих сайтов запрещают автоматический сбор информации со страниц. Есть сразу несколько методов блокировки доступа со стороны парсеров: и по IP-адресам, и с помощью настроек для поисковых ботов. Все они достаточно эффективно защищают от парсинга.
В минусы метода можно отнести и то, что конкуренты тоже могут использовать его. Чтобы защитить сайт от парсинга, придется прибегнуть к одной из техник:
- либо заблокировать запросы со стороны, указав соотвествующие параметры в robots.txt;
- либо настроить капчу – обучить парсер разгадыванию картинок слишком затратно, никто не будет этим заниматься.
Но все методы защиты легко обходятся, поэтому, скорее всего, придется с этим явлением мириться.
Алгоритм работы парсера
Парсер работает следующим образом: он анализирует страницу на наличие контента, соответствующего заранее заданным параметрам, а потом извлекает его, превратив в систематизированные данные.
Процесс работы с утилитой для поиска и извлечения найденной информации выглядит так:
- Сначала пользователь указывает вводные данные для парсинга на сайте.
- Затем указывает список страниц или ресурсов, на которых нужно осуществить поиск.
- После этого программа в автоматическом режиме проводит глубокий анализ найденного контента и систематизирует его.
- В итоге пользователь получает отчет в заранее выбранном формате.
Естественно, процедура парсинга через специализированное ПО описана лишь в общих чертах. Для каждой утилиты она будет выглядеть по-разному. Также на процесс работы с парсером влияют цели, преследуемые пользователем.
Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Парсинг интернет-магазина
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
- актуализация информации о цене той или иной товарной единицы,
- парсинг каталога товаров с сайтов поставщиков или конкурентов.
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Во втором случае нужно разыскать код товара и указать его в программе-парсере. Упростить задачу помогают специальные приложения. Например, Catalogloader – парсер, специально созданный для автоматического сбора данных о товарах в интернет-магазинах.
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
Обзор лучших парсеров
Далее рассмотрим наиболее популярные и востребованные приложения для сканирования сайтов и извлечения из них необходимых данных.
В виде облачных сервисов
Под облачными парсерами подразумеваются веб-сайты и приложения, в которых пользователь вводит инструкции для поиска определенной информации. Оттуда эти инструкции попадают на сервер к компаниям, предлагающим услуги парсинга. Затем на том же ресурсе отображается найденная информация.
Преимущество этого облака заключается в отсутствии необходимости устанавливать дополнительное программное обеспечение на компьютер. А еще у них зачастую есть API, позволяющее настроить поведение парсера под свои нужды. Но настроек все равно заметно меньше, чем при работе с полноценным приложением-парсером для ПК.
Наиболее популярные облачные парсеры
- Import.io – востребованный набор инструментов для поиска информации на ресурсах. Позволяет парсить неограниченное количество страниц, поддерживает все популярные форматы вывода данных и автоматически создает удобную структуру для восприятия добытой информации.
- Mozenda – сайт для сбора информации с сайтов, которому доверяют крупные компании в духе Tesla. Собирает любые типы данных и конвертирует в необходимый формат (будь то JSON или XML). Первые 30 дней можно пользоваться бесплатно.
- Octoparse – парсер, главным преимуществом которого считается простота. Чтобы его освоить, не придется изучать программирование и хоть какое-то время тратить на работу с кодом. Можно получить необходимую информацию в пару кликов.
- ParseHub – один из немногих полностью бесплатных и довольно продвинутых парсеров.
Похожих сервисов в сети много. Причем как платных, так и бесплатных. Но вышеперечисленные используются чаще остальных.
В виде компьютерных приложений
Есть и десктопные версии. Большая их часть работает только на Windows. То есть для запуска на macOS или Linux придется воспользоваться средствами виртуализации. Либо загрузить виртуальную машину с Windows (актуально в случае с операционной системой Apple), либо установить утилиту в духе Wine (актуально в случае с любым дистрибутивом Linux). Правда, из-за этого для сбора данных потребуется более мощный компьютер.
Наиболее популярные десктопные парсеры
- ParserOK – приложение, сфокусированное на различных типах парсинга данных. Есть настройки для сбора данных о стоимости товаров, настройки для автоматической компиляции каталогов с товарами, номеров, адресов электронной почты и т.п.
- Datacol – универсальный парсер, который, по словам разработчиков, может заменить решения конкурентов в 99% случаев. А еще он прост в освоении.
- Screaming Frog – мощный инструмент для SEO-cпециалистов, позволяющий собрать кучу полезных данных и провести аудит ресурса (найти сломанные ссылки, структуру данных и т.п.). Можно анализировать до 500 ссылок бесплатно.
- Netspeak Spider – еще один популярный продукт, осуществляющий автоматический парсинг сайтов и помогающий проводить SEO-аудит.
Это наиболее востребованные утилиты для парсинга. У каждого из них есть демо-версия для проверки возможностей до приобретения. Бесплатные решения заметно хуже по качеству и часто уступают даже облачным сервисам.
В виде браузерных расширений
Это самый удобный вариант, но при этом наименее функциональный. Расширения хороши тем, что позволяют начать парсинг прямо из браузера, находясь на странице, откуда надо вытащить данные. Не приходится вводить часть параметров вручную.
Но дополнения к браузерам не имеют таких возможностей, как десктопные приложения. Ввиду отсутствия тех же ресурсов, что могут использовать программы для ПК, расширения не могут собирать такие огромные объемы данных.
Но для быстрого анализа данных и экспорта небольшого количества информации в XML такие дополнения подойдут.
Наиболее популярные расширения-парсеры
- Parsers – плагин для извлечения HTML-данных с веб-страниц и импорта их в формат XML или JSON. Расширение запускается на одной странице, автоматически разыскивает похожие страницы и собирает с них аналогичные данные.
- Scraper – собирает информацию в автоматическом режиме, но ограничивает количество собираемых данных.
- Data Scraper – дополнение, в автоматическом режиме собирающее данные со страницы и экспортирующее их в Excel-таблицу. До 500 веб-страниц можно отсканировать бесплатно. За большее количество придется ежемесячно платить.
- kimono – расширение, превращающее любую страницу в структурированное API для извлечения необходимых данных.
Вместо заключения
На этом и закончим статью про парсинг и способы его реализации. Этого должно быть достаточно, чтобы начать работу с парсерами и собрать информацию, необходимую для развития вашего проекта.
Что такое парсинг и как правильно парсить


Что такое парсинг данных должен знать каждый владелец сайта, планирующий серьёзно развиваться в бизнесе. Это явление настолько распространено, что рано или поздно с парсингом может столкнуться любой. Либо как заказчик данной операции, либо как лицо, владеющее объектом для сбора информации, то есть ресурсом в Интернете. К парсингу в российской бизнес-среде часто наблюдается негативное отношение. По принципу: если это не незаконно, то уж точно аморально. На самом деле из его грамотного и тактичного использования каждая компания может извлечь немало преимуществ.
Digital шагает семимильными шагами. Еще недавно компании и клиенты радовались первым сайтам, а сегодня загрузка страницы за 10 секунд вызывает дикое раздражение. Пройдите тест и узнайте, какие невероятные технологии уже стали реальностью, а какие пока остаются мечтой.
Что такое парсинг
Глагол “to parse” в дословном переводе не означает ничего плохого. Делать грамматический разбор или структурировать — действия полезные и нужные. На языке всех, кто работает с данными на сайтах это слово имеет свой оттенок. Парсить — собирать и систематизировать информацию, размещенную на определенных сайтах, с помощью специальных программ, автоматизирующих процесс. Если вы когда-либо задавались вопросом, что такое парсер сайта, то вот он ответ. Это программные продукты, основной функцией которых является получение необходимых данных, соответствующих заданным параметрам.
Законно ли использовать парсинг
- взлом сайта (то есть получение данных личных кабинетов пользователей и т. п.);
- DDOS-атаки (если на сайт в результате парсинга данных ложится слишком высокая нагрузка);
- заимствование авторского контента (фотографии с копирайтами, уникальные тексты, подлинность которых заверена у нотариуса и т. п. лучше оставить на их законном месте).
Парсинг законен, если он касается сбора информации, находящейся в открытом доступе. То есть всего, что можно и так собрать вручную.
Парсеры просто позволяют ускорить процесс и избежать ошибок из-за человеческого фактора. Поэтому «незаконности» в процесс они не добавляют.
Другое дело, как владелец свежесобранной базы распорядится подобной информацией. Ответственность может наступить именно за последующие действия.

Маркетинг
Читайте также:
«ТенЧат»: что это за соцсеть, как она работает, как ее вести
«ТенЧат»: что это за соцсеть, как она работает, как ее вести
Для чего нужен парсинг
Что такое парсить сайт разобрались. Переходим к тому, зачем же это может понадобиться. Здесь открывается широкий простор для действий.
Основная проблема современного Интернета — избыток информации, которую человек не в состоянии систематизировать вручную.
| Для чего нужен парсинг | Польза |
| Анализа ценовой политики | Чтобы понять среднюю стоимость тех или иных товаров на рынке, удобно использовать данные по конкурентам. Однако если это сотни и тысячи позиций, собрать их вручную оперативно невозможно. |
| Отслеживания изменений | Парсинг можно осуществлять на регулярной основе, например, каждую неделю, выявляя на что повысились цены в среднем по рынку и какие новинки появились у конкурентов. |
| Наведения порядка на своём сайте | Да, так тоже можно. И даже нужно, если в интернет-магазине несколько тысяч товаров. Найти несуществующие страницы, дубли, неполное описание, отсутствие определенных характеристик или несоответствие данных по складским остаткам тому, что отображается на сайте. С парсером быстрее. |
| Наполнения карточек товаров в интернет-магазине | Если сайт новый, счёт обычно идёт даже не на сотни. Вручную на это уйдёт непозволительно количество времени. Часто используют парсинг с иностранных сайтов, переводят полученные тексты автоматизированным методом, после чего получают практически готовые описания. Иногда то же проделывают с русскоязычными сайтами, а полученные тексты изменяют с помощью синонимайзера, но за это можно получить санкции от поисковых систем. |
| Получения баз потенциальных клиентов | Существует парсинг, связанный с составлением, например, списка лиц, принимающих решения, в той или иной отрасли и городе. Для этого может применяться личный кабинет на сайтах поиска работы с доступом к актуальным и архивным резюме. Этичность дальнейшего использования подобной базы каждая компания определяет самостоятельно. |
Сквозная аналитика — это тоже своеобразный парсинг, только рекламы и продаж. Система интегрируется с площадками и CRM, а потом автоматически соединяет данные о бюджетах, кликах, сделках и подсчитывает окупаемость каждой кампании. Используйте ее, чтобы не потеряться в большом количестве информации и видеть в отчетах то, что вам действительно нужно. Отчеты Calltouch легко кастомизировать под себя и задачи команды маркетологов.
Сквозная аналитика Calltouch
- Анализируйте воронку продаж от показов до денег в кассе
- Автоматический сбор данных, удобные отчеты и бесплатные интеграции
Достоинства парсинга
Они многочисленны. По сравнению с человеком парсеры могут:
- собирать данные быстрее и в любом режиме, хоть круглосуточно;
- следовать всем заданным параметрам, даже очень тонким;
- избегать ошибок от невнимательности или усталости;
- выполнять регулярную проверку по заданному интервалу (каждую неделю и т. п.);
- представить собранные данные в любом необходимом формате без лишних усилий;
- равномерно распределять нагрузку на сайт, где проходит парсинг (обычно одна страница за 1-2 секунды), чтобы не создавать эффект DDOS-атаки.
Ограничения при парсинге
Есть несколько вариантов ограничений, которые могут затруднить работу парсера:
- По user-agent. Это запрос, в котором программа сообщает сайту о себе. Парсеры банят многие веб-ресурсы. Однако в настройках данные можно изменить на YandexBot или Googlebot и отсылать правильные запросы.
- По robots.txt, в котором прописан запрет для индексации поисковыми роботами Яндекса или Google (ими мы представились сайту выше) определенных страниц. Необходимо задать в настройках программы игнорирование robots.txt.
- По IP-адресу, если с него в течение долгого времени поступают на сайт однотипные запросы. Решение — использовать VPN.
- По капче. Если действия похожи на автоматические, выводится капча. Научить парсеры распознавать конкретные виды достаточно сложно и дорогостояще.

Бесплатно Электронная книга
23 действующих способа сделать свой маркетинг круче, быстрее, эффективнее, чем сейчас Получить бесплатно
Какую информацию можно парсить
Спарсить можно всё, что есть на сайте в открытом доступе. Чаще всего требуются:
- наименования и категории товаров;
- основные характеристики;
- цена;
- информация об акциях и новинках;
- тексты описания товаров для их последующего переделывания «под себя» и т. п.
Изображения с сайтов технически спарсить тоже можно, но, как уже упоминалось выше, если они защищены авторским правом, лучше не нужно. Нельзя собирать с чужих сайтов личные данные их пользователей, которые те вводили в личных кабинетах.
Парсинг часто используется в индустрии e-commerce. Оценить влияние парсинга и его результатов можно в сквозной аналитике для интернет-магазинов. Вам доступны отчеты по любым временным срезам, метрикам и товарам. С помощью этих данных вы узнаете, из каких источников вы получаете добавления в корзины и продажи, и сможете оптимизировать рекламу с опорой на эти данные.
Аналитика для интернет-магазина
- Отслеживайте корзины, звонки, заявки и продажи с них с привязкой к источнику
- Постройте воронку продаж и оптимизируйте маркетинг
Алгоритм работы парсинга
Принцип действия программы зависит от целей. Но схематично он выглядит так:
- Парсер ищет на указанных сайтах или по всему Интернету данные, соответствующие параметрам.
- Информация собирается и производится первоначальная систематизация (её глубина также определяется при настройке);
- Из данных формируется отчёт в формате, соответствующем требуемым критериям. Большинство современных парсеров мультиформатны и могут успешно работать хоть с PDF, хоть с архивами RAR, хоть с TXT.
Способы применения
Основных способов применения парсинга существует два:
- анализировать свой сайт, внося в него необходимые улучшения;
- анализировать сайты конкурентов, заимствуя оттуда основные тенденции и конкретные характеристики товаров.
Обычно оба варианта работают в тесной связке друг с другом. Например, анализ ценовых позиций у конкурентов отталкивается от имеющегося диапазона на собственном сайте, а обнаруженные новинки сопоставляются с собственной товарной базой и т. п.
Предложения от наших партнеров
Online CRM для автосервиса
До 3-х месяцев CRM-системы для автосервисов

Бесплатная часовая сессия с ведущим маркетологом
Хостинг-провайдер и аккредитованный регистратор доменных имён
Скидка до 80% на пакет услуг «Быстрый старт» для создания сайта

Технический аудит вашего сайта за 50 рублей
Агенство по разработке сайтов
Бесплатная помощь в формировании концепции вашего сайта
Сервис мониторинга и оптимизации интернет-рекламы
Три дня бесплатного пользования сервисом
Как парсить данные
Для парсинга данных можно выбрать один из двух форматов:
- воспользоваться специальными программами, которых на рынке существует немало;
- написать их самостоятельно. Для этого может применяться практически любой язык программирования, например, PHP, C++, Python/
Если требуется не вся информация по странице, а только что-то определенное (наименования товаров, характеристики, цена), используется XPath.
XPath – это язык, на котором формируются запросы к XML-документам и их отдельным элементам.
С помощью его команд необходимо определить границы будущего парсинга, то есть задать как парсить данные с сайта — полностью или выборочно.
Чтобы определить XPath конкретного элемента необходимо:
- Перейти на страницу любого товара на анализируемом сайте.
- Выделить цену и щелкнуть по выделению правой кнопкой мыши.
- В открывшемся окне выбрать пункт «Посмотреть код».
- После появления с правой стороны экрана кода, нажать на три точки с левой стороны от выделенной строки.
- В меню выбрать пункт “Copy”, затем “Copy XPath”.
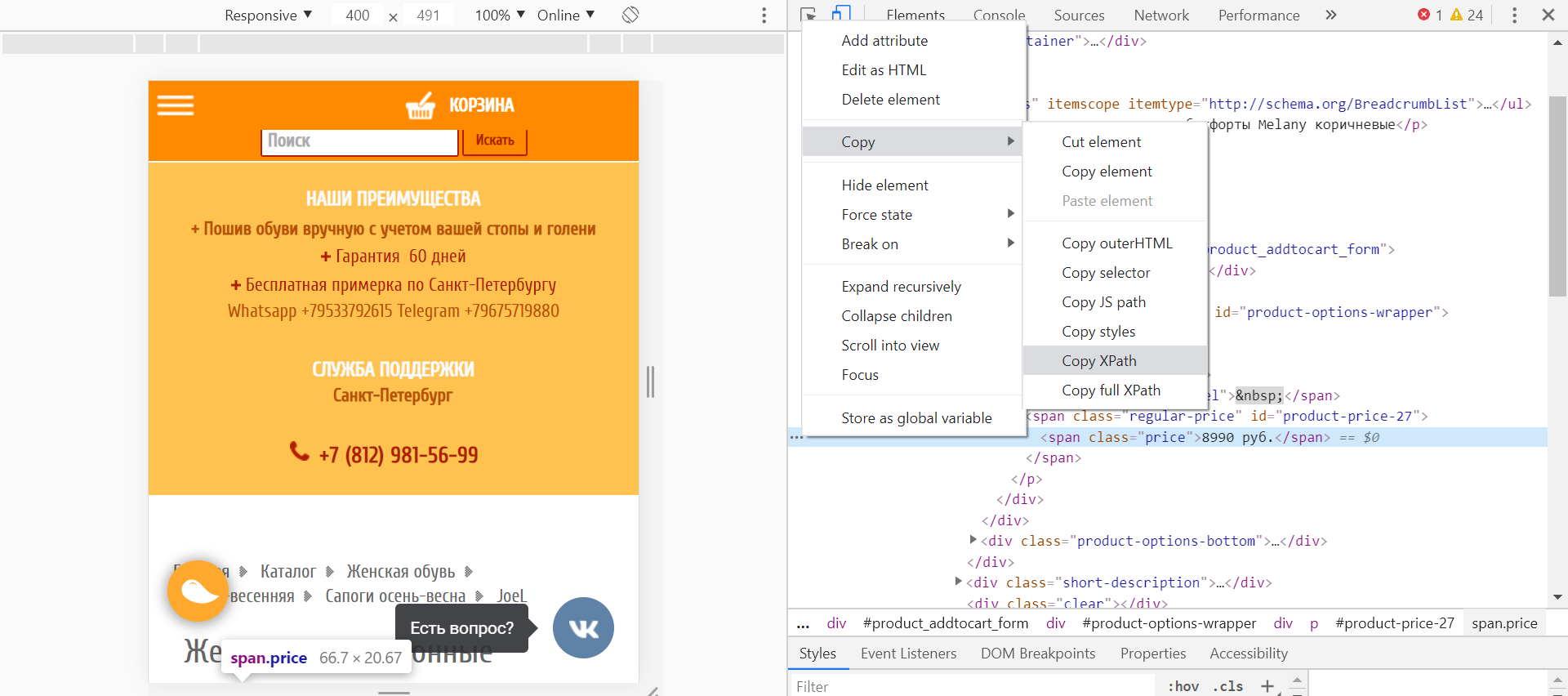
Пример определения XPath элемента на сайте интернет-магазина обуви Holtz
Как спарсить цену
Задаваясь вопросом «Парсинг товаров — что это?», многие подразумевают именно возможность провести ценовую разведку на сайтах конкурентов. Цены парсят чаще всего и действовать необходимо следующим образом. Скопированный в примере выше код ввести в программу-парсер, которая подтянет остальные данные на сайте, соответствующие ему.
Чтобы парсер не ходил по всем страницам и не пытался найти цены в статьях блога, лучше задать диапазон страниц. Для этого необходимо открыть карту XML (добавить “/sitemap.xml ” в адресную строку сайта после названия). Здесь можно найти отсылки к разделам с ценами — обычно это товары ( products) и категории (categories), хотя называться они могут и по-другому.
Маркетинг
Читайте также:
Что такое продакт-плейсмент и эффективно ли его использовать
Что такое продакт-плейсмент и эффективно ли его использовать
Как спарсить характеристики товаров
Здесь всё достаточно просто. Определяются коды XPath для каждого элемента, после чего они вносятся в программу. Так как технические характеристики у одинаковых товаров будут совпадать, можно настроить автозаполнение своего сайта на основе полученной информации.
Как парсить отзывы (с рендерингом)
Процесс сбора отзывов на других сайтах с целью переноса их к себе вначале выглядит похожим образом. Необходимо определить XPath для элемента. Однако далее возникают сложности. Часто дизайн выполнен так, что отзывы появляются на странице именно в тот момент, когда пользователь прокручивает её до нужного места.
В этом случае необходимо изменить настройки программы в пункте Rendering и выбрать JavaScript. Так парсер будет полностью воспроизводить сценарий движения по странице обычного пользователя, а отзывы получит путём выполнения скриншота.
Как парсить структуру сайта
Парсинг структуры — полезное занятие, поскольку помогает узнать, как устроен сайт конкурентов. Для этого необходимо проанализировать хлебные крошки (breadcrumbs):
- Навести курсор на любой элемент breadcrumbs;
- Нажать правую кнопку мыши и повторить действия по копированию XPath.
Далее действие необходимо выполнить для других элементов структуры.
Заключение
Парсинг сайтов — что это? Зло для владельцев сайтов или полезный инструмент для бизнеса. Скорее второе, ведь без кропотливого сбора данных не обходится ни один глубокий анализ конкурентов. Парсинг помогает ускорить процесс, снять с человека нагрузку бесконечной рутинной работы и избежать ошибок, вызванных переутомлением.
Использовать парсинг — абсолютно законно, особенно если знать все сопутствующие нюансы. А возможности этого инструмента практически безграничны. Спарсить можно почти всё — нужно только знать как.