Как передать параметры в get запросе python
Параметры строки запроса представляют еще один способ передать в приложение некоторые значения в запросе типа GET. Для начала надо понимать, что такое строка запроса . Например, возьмем следующий адрес
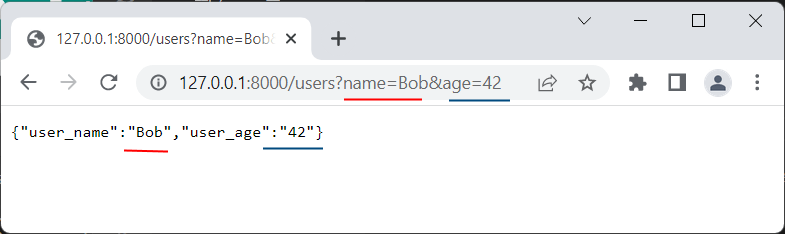
http://127.0.0.1:8000/users/add?name=Tom&age=38
Здесь та часть, которая идет после адреса сервера и порта и до вопросительного знака ?, то есть users/add , представляет путь запроса (path). А та часть, которая идет после вопросительного знака, то есть name=Tom&age=38 , представляет строку запроса (query string). В данной статье нас будет интересовать прежде всего строка запроса.
Строка запроса состоит из параметров. Каждый параметр определяется в форме
имя_параметра=значение_параметра
Если строка запроса содержит несколько параметров, то они одтеляются друг от друга знаком амперсанда &. Так, в примере в адресом http://127.0.0.1:8000/users/add?name=Tom&age=38 строка запроса состоит из двух параметров: параметр name имеет значение «Tom», а параметр age имеет значение 38.
Для получения значений параметров строки запроса мы можем в функции определить одноименные параметры:
from fastapi import FastAPI app = FastAPI() @app.get(«/users») def get_model(name, age): return
Значения по умолчанию
Вполне может быть, что при обращении к приложению пользователь не передаст значения для какого-либо параметра или даже для всех параметров строки запроса. В примере выше все параметры строки запроса являются обязательными. И если мы не передадим хотя бы один из параметров, то мы получим ошибку.
Чтобы ошибки не было, можно задать для параметров значения по умолчанию:
from fastapi import FastAPI app = FastAPI() @app.get(«/users») def get_model(name = «Undefined», age = 18): return
Параметры со значению по умолчанию должны идти после обязательных параметров.
Ограничения по типу
Также для параметров строки запроса можно задать ограничения по типу:
from fastapi import FastAPI app = FastAPI() @app.get(«/users») def get_model(name: str, age: int = 18): return
В данном случае параметр name должен представлять тип str, то есть строку, а параметр age — целое число. Если параметру age передать нечисловое значение, то мы получим ошибку.
Query
Дополнительно для работы с параметрами строки запроса фреймворк предоставляет класс Query из пакета fastapi . Класс Query позволяет прежде всего валидировать значения параметров строки запроса. В частности, через конструктор Query можно установить следующие параметры для валидации значений:
- min_length : устанавливает минимальное количество символов в значении параметра
- max_length : устанавливает максимальное количество символов в значении параметра
- regex : устанавливает регулярное выражение, которому должно соответствовать значение параметра
- lt : значение параметра должно быть меньше определенного значения
- le : значение параметра должно быть меньше или равно определенному значению
- gt : значение параметра должно быть больше определенного значения
- ge : значение параметра должно быть больше или равно определенному значению
Применим некотрые параметры:
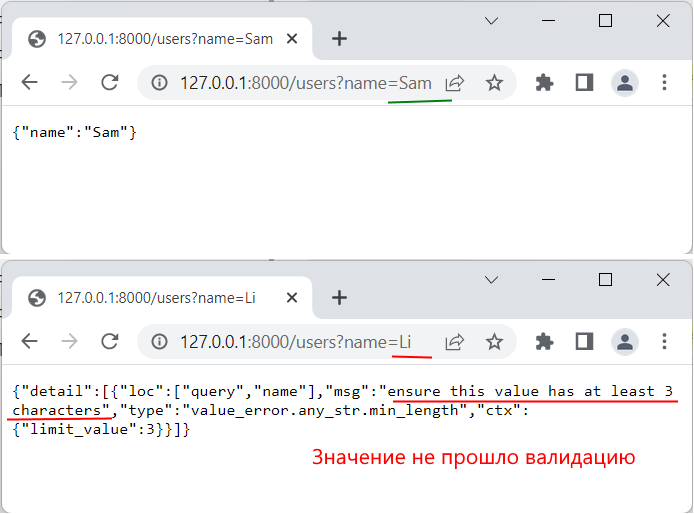
from fastapi import FastAPI, Query app = FastAPI() @app.get(«/users») def users(name:str = Query(min_length=3, max_length=20)): return
В данном случае через строку запроса получаем параметр name . Причем его значение должно иметь не меньше 3 и не больше 20 символов.
Подобным образом можно использовать другие параметры валидации:
from fastapi import FastAPI, Query app = FastAPI() @app.get(«/users») def users(name:str = Query(min_length=3, max_length=20), age: int = Query(ge=18, lt=111)): return
В данном случае добавляется параметр «age», который должен представлять число в диапазоне от 18 (включительно) до 111 (не включая)
Валидация с помощью регулярного значения:
from fastapi import FastAPI, Query app = FastAPI() @app.get(«/users») def users(phone:str = Query(regex=»^\d$»)): return
Здесь параметр phone должен состоять из 11 цифр.
Query позволяет установить значение по умолчанию с помощью параметра default :
from fastapi import FastAPI, Query app = FastAPI() @app.get(«/users») def users(name: str = Query(default=»Undefined», min_length=2)): return
Здесь, если в запрошенном адресе отстуствует параметр name, то по умолчанию он будет равен строке «Undefined»
Если параметры должны быть необязательными, то параметру default передается значение None :
from fastapi import FastAPI, Query app = FastAPI() @app.get(«/users») def users(name:str | None = Query(default=None, min_length=2)): if name==None: return else: return
Получение списков значений
Использование класса Query позволяет получать через строку запроса списки. В общем случае списки значений передаются, когда в строке запроса одному параметру несколько раз передаются разные значения. Например, как в запросе по следующему адресу:
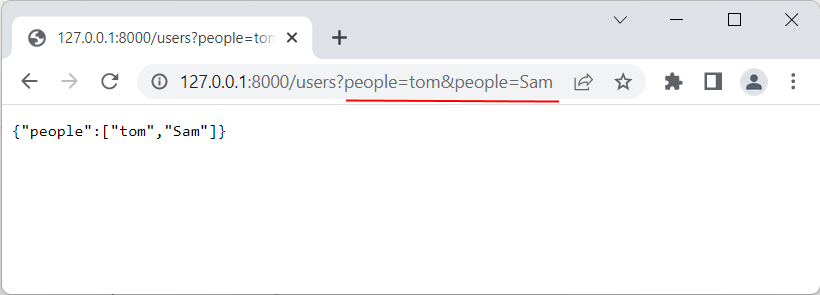
http://127.0.0.1:8000/users?people=tom&people=Sam&people=Bob
Здесь параметру people передаются три разных значения, соответственно мы ожидаем, что список people будет содержать три элемента.
Определим следующее приложение:
from fastapi import FastAPI, Query app = FastAPI() @app.get(«/users») def users(people: list[str] = Query()): return
Здесь функция users имеет один параметр — people , который должен представлять список строк — тип list[str] .
Передадим через строку запроса список значений в виде параметра people, например, с помощью запроса http://127.0.0.1:8000/users?people=tom&people=Sam :
Сочетание параметров пути и строки запроса
При необходимости можно сочетать параметры пути и строки запроса:
from fastapi import FastAPI, Path, Query app = FastAPI() @app.get(«/users/») def users(name:str = Path(min_length=3, max_length=20), age: int = Query(ge=18, lt=111)): return
GET и POST запросы c модулем requests в Python
Методы requests.get() и requests.post() модуля requests
Передача параметров в URL для HTTP GET-запросов.
Часто в строке запроса URL-адреса, необходимо отправить какие-то данные. При составлении URL-адреса вручную, эти данные задаются в виде пар ключ/значение в конце URL-адреса после вопросительного знака, например httpbin.org/get?key=val . Модуль requests позволяет передавать эти параметры в метод requests.get() виде словаря строк, используя ключевой аргумент params . Например, если надо передать key1=value1 и key2=value2 для GET запроса к URL-адресу httpbin.org/get , то используйте следующий код:
>>> import requests # подготовка дополнительных параметров для GET запроса >>> params = 'key1': 'value1', 'key2': 'value2'> >>> resp = requests.get('https://httpbin.org/get', params=params) # смотрим, что URL-адрес был правильно закодирован >>> print(resp.url) # https://httpbin.org/get?key2=value2&key1=value1
Обратите внимание, что любой ключ словаря, значение которого равно None , не будет добавлен в строку запроса URL-адреса.
В качестве значения словаря можно передать список дополнительных элементов URL-адреса:
>>> import requests # ключ словаря 'key2' имеет список значений >>> params = 'key1': 'value1', 'key2': ['value2', 'value3']> # создаем GET запрос >>> resp = requests.get('https://httpbin.org/get', params=params) # смотрим полученный URL >>> print(resp.url) # https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Передача параметров в URL для HTTP POST-запросов.
Как правило, в POST-запросах встает необходимость отправить некоторые закодированные в форме данные. Для этого необходимо передать словарь в аргумент data метода requests.post() . Словарь с данными формы будет автоматически закодирован.
Обратите внимание, что имя аргумента для передачи параметров метода requests.post() , отличается от имени аргумента дополнительных параметров метода requests.get() .
>>> import requests # подготовка параметров для POST-запроса >>> param = 'key1': 'value1', 'key2': 'value2'> # обратите внимание, что для метода POST, аргумент для # передачи параметров в запрос отличается от метода GET >>> resp = requests.post("https://httpbin.org/post", data=param) >>> print(resp.text) # # . # "form": # "key2": "value2", # "key1": "value1" # >, # . # >
Аргумент data также может иметь несколько значений для каждого ключа. Это можно сделать, передав данные либо списком кортежей, либо словарем со списками в качестве значений. Это особенно полезно, когда форма содержит несколько элементов, использующих один и тот же ключ:
>>> import requests >>> param_tuples = [('key1', 'value1'), ('key1', 'value2')] >>> resp1 = requests.post('https://httpbin.org/post', data=payload_tuples) >>> param_dict = 'key1': ['value1', 'value2']> >>> resp2 = requests.post('https://httpbin.org/post', data=payload_dict) >>> print(resp1.text) # # . # "form": # "key1": [ # "value1", # "value2" # ] # >, # . # > >>> resp1.text == resp2.text # True
- КРАТКИЙ ОБЗОР МАТЕРИАЛА.
- GET и POST запросы c модулем requests
- Получение/отправка заголовков сервера модулем requests
- Извлечение и установка cookies с модулем requests
- Сессии/сеансы Session() модуля requests
- Объект ответа сервера Response модуля requests
- Получение и отправка данных в виде JSON с модулем requests
- Установка timeout для модуля requests
- Объект PreparedRequest модуля requests
- Загрузка файлов на сервер модулем requests
- Загрузка больших данных модулем requests
- HTTP-прокси или SOCKS-прокси с модулем requests
- Использование хуков модуля requests
- Аутентификация с модулем requests
- SSL и модуль requests
Самоучитель по запросам в Python: GET и POST для чайников

В веб-программировании на Python самое базовое знание, которое вы должны глубоко и тщательно освоить (прежде чем двигаться дальше), это техника HTTP-запросов. Несмотря на то, что в Python есть несколько популярных HTTP-библиотек, самой простой является библиотека Requests. В этом посте для начинающих мы последовательно описали все основные операции/режимы этой популярной библиотеки.
Вдохновляючий курс від skvot: Створення текстів.
Мистецтво слова та стилю.

Этот пост — вольный перевод на русский вот этой оригинальной статьи (с нашими дополнениями в местах, где это показалось нужным), которую написал Анирудх Рао.
В этой статье, посвященной веб-запросам в Python, я объясню все основы модуля Requests и расскажу, как можно отправлять запросы HTTP/1.1 с помощью Python. К концу этого поста вы сможете выполнять простейший веб-скрейпинг (и даже парсинг веб-страниц) с помощью Python. В посте я рассмотрю следующие темы:
- Что такое веб-запросы Python?
- Как установить модуль Requests в Python?
Цифровий курс від robotdreams: DevOps Engineer.
підходи для створення сучасних і масштабованих застосунків.
Давайте начнем наш пост в стиле «Мини-учебника по запросам» с того, что узнаем, что такое модуль запросов.
Что такое запросы в Python?
Requests — это модуль Python, который можно использовать для отправки всех видов HTTP-запросов. Это простая в использовании библиотека с множеством функций, начиная от передачи параметров в URL и заканчивая отправкой пользовательских заголовков и SSL-проверкой. В этом руководстве вы узнаете, как использовать эту библиотеку для отправки простых HTTP-запросов в Python. Но даже если у вас что-то не будет получаться, то всегда можно перенять знания у опытных специалистов, которые проводят онлайн курсы в школе наших партнеров Mate Academy.
Requests позволяет отправлять запросы протокола HTTP/1.1. Можно добавлять заголовки, данные формы, многокомпонентные файлы и параметры с помощью простых словарей Python, а также получать доступ к данным ответа таким же образом.
Как установить модуль Requests в Python?
Чтобы установить requests , просто сделайте это:
Освітній курс від laba: Delivery Manager.
Ведіть проекти до успішної доставки.
$ pip install requests
Или, если необходимо, добавьте:
$ easy_install requests
Как сделать GET-запрос?
Отправить HTTP-запрос с помощью Requests довольно просто. Для начала нужно импортировать модуль, а затем сделать запрос.
Итак, мы где-то храним информацию, верно?
Да, объект Response хранит информацию запроса.
Допустим, вам нужна кодировка веб-страницы, чтобы вы могли проверить ее или использовать где-то еще. Мы можем сделать это, используя свойство req.encoding .
Дополнительный плюс в том, что можно также извлечь многие характеристики, например, код состояния (запроса). Это можно сделать с помощью свойства req.status_code , вот так:
req.encoding # возвращает 'utf-8' req.status_code # возвращает 200
Также можно получить доступ к cookies, которые сервер отправил обратно. Это делается с помощью req.cookies , вот так все просто! Аналогично можно получить и заголовки ответа. Для этого используется req.headers .
Обратите внимание, что свойство req.headers возвращает словарь заголовков ответа без учета регистра. Что это означает?
Освітній курс від laba: Delivery Manager.
Ведіть проекти до успішної доставки.
Это означает, что req.headers[‘Content-Length’], req.headers[‘content-length’] и req.headers[‘CONTENT-LENGTH’] вернут значение только заголовка ответа ‘Content-Length’ .
Мы также можем проверить, является ли полученный ответ правильно сформированным HTTP-перенаправлением (или нет), которое могло быть обработано автоматически, используя свойство req.is_redirect . Это свойство возвращает True или False в зависимости от полученного ответа.
Также можно получить время, прошедшее с момента отправки запроса до получения ответа, используя другое свойство. Угадаете его название? Да, это свойство req.elapsed .
Помните URL, который вы изначально передали функции get() ? Так вот, он может отличаться от конечного URL ответа по многим причинам, включая перенаправления.
Чтобы увидеть фактический URL-адрес ответа, можно использовать свойство req.url .
import requests req = requests.get('http://www.edureka.co/') req.encoding # returns 'utf-8' req.status_code # returns 200 req.elapsed # returns datetime.timedelta(0, 1, 666890) req.url # returns 'https://edureka.co/' req.history req.headers['Content-Type'] # returns 'text/html; charset=utf-8'
Согласны, что получать всю эту служебную информацию о веб-странице — очень интересная возможность? Но вы, скорее всего, хотите чего-то большего — получить доступ к реальному содержимому страницы, верно?
Если содержимое, к которому вы обращаетесь, является текстом, вы всегда можете использовать свойство req.text для доступа к нему. Обратите внимание, что содержимое будет разобрано только как юникод. Вы можете передать кодировку, с помощью которой можно декодировать текст, используя свойство req.encoding , как мы обсуждали ранее.
В случае нетекстовых ответов к ним получить доступ также очень просто. Фактически это делается в двоичном формате, когда используется req.content . Этот модуль автоматически декодирует для нас передаваемые кодировки gzip и deflate . Это может быть очень полезно, когда вы имеете дело непосредственно с медиафайлами. Кроме того, можно получить доступ к JSON-кодированному содержимому ответа, если оно существует, используя функцию req.json() .
Довольно просто и очень гибко
Кроме того, при необходимости можно получить необработанный raw-ответ от сервера, просто используя req.raw . Имейте в виду, что вам придется передать stream=True в запросе, чтобы получить необработанный ответ в соответствии с вашими потребностями.
Но некоторые файлы, которые вы загружаете из интернета с помощью модуля Requests , могут иметь огромный размер, верно? В таких случаях не стоит сразу загружать весь ответ или файл в память сервера. При правильном подходе рекомендуется загружать такой файл по частям или кусками, используя метод iter_content(chunk_size = 1, decode_unicode = False) .
Итак, этот метод итерирует данные ответа в количестве байт chunk_size за один раз. А когда stream=True в запросе, этот метод позволит избежать чтения всего файла в память за один раз только для реально больших ответов.
Обратите внимание, что параметр chunk_size может быть как целым числом, так и None . Если параметр chunk_size имеет целочисленное значение, то он определяет количество байт, которые должны быть считаны в память за один раз.
Когда chunk_size установлен в None , а stream установлен в True , данные будут считываться по мере их поступления в виде кусков любого размера. Но если chunk_size установлен в None , а stream установлен в False , все данные будут возвращаться только как один кусок данных.
Далее в этом посте «Мини-учебника по запросам» мы рассмотрим, как можно загрузить изображение с помощью модуля Requests . Давайте попробуем применить всю эту теорию к чему-то из реального мира.
Загрузка изображения с помощью модуля Requests
Итак, давайте загрузим следующее изображение леса с помощью модуля Requests , о котором мы узнали. Вот фактическое изображение для тестирования:

Вот код, который вам понадобится для загрузки изображения:
import requests req = requests.get('path/to/forest.jpg', stream=True) req.raise_for_status() with open('Forest.jpg', 'wb') as fd: for chunk in req.iter_content(chunk_size=50000): print('Received a Chunk') fd.write(chunk)
Обратите внимание, что ‘path/to/forest.jpg’ — это фактический URL изображения. Вы можете подставить сюда URL highload.today, либо любого другого хоста-источника, чтобы загрузить что-то еще. Это просто пример, размер данного файла изображения составляет около 185 Кб, а размер chunk_size установлен на 50 000 байт.
Это означает, что при тестировании загрузки сообщение «Received a Chunk» должно быть выведено в терминале четыре раза. Размер последнего чанка будет равен 39 350 байт, потому что часть файла, которую осталось получить после первых трех итераций, равна 39 350 байт. Если вы посчитали все так же, как и мы, значит, понимаете все правильно.
Запросы также позволяют передавать параметры в URL. Это особенно полезно, когда вы ищете веб-страницу по каким-то результатам, например, учебник или конкретное изображение. Это работает и с поиском в Google. Можно передать эти строки запроса в виде словаря строк, используя ключевое слово params в запросе GET. Посмотрите этот простой пример:
import requests query = req = requests.get('https://pixabay.com/en/photos/', params=query) req.url # returns 'https://pixabay.com/en/photos/?order=popular_height=600&q=Forest&min_width=800'
Все готово, далее в этом руководстве мы рассмотрим, как сделать свой первый POST-запрос!
Как сделать POST-запрос?
Выполнить POST-запрос так же просто, как и GET-запрос. Просто используйте функцию post() вместо get() .
Это может быть полезно при автоматической отправке форм. Например, следующий код загрузит всю страницу Википедии о нанотехнологиях и сохранит ее на вашем компьютере.
import requests req = requests.post('https://en.wikipedia.org/w/index.php', data = ) req.raise_for_status() with open('Nanotechnology.html', 'wb') as fd: for chunk in req.iter_content(chunk_size=50000): fd.write(chunk)
Если вы хотите стать экспертом в языке программирования python, то обратите внимание на курсы наших партнеров Mate Academy и Powercode. Их выпускники работают в крупных компаниях по всему миру.
Как вставить заголовки и Cookies в такой запрос?
Как уже упоминалось ранее, вы можете получить доступ к кукам и заголовкам, которые сервер отправляет вам обратно, используя req.cookies и req.headers . Запросы также позволяют вам отправлять собственные пользовательские куки и заголовки вместе с запросом. Это может быть полезно, когда вы хотите, например, установить определенный пользовательский агент для вашего запроса.
Чтобы добавить HTTP-заголовки в запрос, вы можете просто передать их в виде dict в параметр headers . Аналогичным образом вы можете отправить на сервер свои собственные cookies, используя dict , переданный в параметре cookies.
import requests url = 'http://some-domain.com/set/cookies/headers' headers = cookies = req = requests.get(url, headers=headers, cookies=cookies)
Cookie jar также могут хранить файлы cookie. Они предоставляют более полный интерфейс, позволяющий использовать эти куки по нескольким путям.
Посмотрите на этот обзорный пример ниже:
import requests jar = requests.cookies.RequestsCookieJar() jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies') jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra') jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies') url = 'http://httpbin.org/cookies' req = requests.get(url, cookies=jar) req.text # returns '< "cookies": < "first_cookie": "first", "third_cookie": "third" >>'
Что такое сессионные объекты?
Иногда полезно сохранять определенные параметры при нескольких запросах. Объект Session делает именно это. Например, он сохраняет данные cookie во всех запросах, сделанных с помощью одной и той же сессии.
Объект Session в Python использует пул соединений urllib3 . Это означает, что базовое TCP-соединение будет повторно использоваться для всех запросов, сделанных к одному и тому же хосту.
Это может значительно повысить производительность. Также можно использовать методы объекта Requests с объектом Session .
Сессии также полезны, когда вы хотите отправлять одни и те же данные во всех запросах. Например, если вы решили отправлять cookie или заголовок user-agent при всех запросах к определенному домену, можно использовать объекты Session .
import requests ssn = requests.Session() ssn.cookies.update() reqOne = ssn.get('http://httpbin.org/cookies') print(reqOne.text) # prints information about "visit-month" cookie reqTwo = ssn.get('http://httpbin.org/cookies', cookies=) print(reqTwo.text) # prints information about "visit-month" and "visit-year" cookie reqThree = ssn.get('http://httpbin.org/cookies') print(reqThree.text) # prints information about "visit-month" cookie
Как можете видеть, сессионный файл cookie «visit-month» отправляется со всеми тремя запросами. Однако cookie «visit-year» отправляется только во время второго запроса. В третьем запросе также нет упоминания о cookie «visit-year» . Это подтверждает тот факт, что файлы cookie или другие данные, установленные в отдельных запросах, не будут отправлены с другими сессионными запросами.
Подведение итогов
В качестве закрепления, еще раз тезисно пробежим по самому главному из того, что мы узнали выше. HTTP — это набор протоколов, предназначенных для обеспечения связи между клиентами и серверами. Он работает как протокол «запрос-ответ» между клиентом и сервером.
В качестве клиента может выступать веб-браузер, а в качестве сервера — приложение на компьютере, на котором размещен веб-сайт.
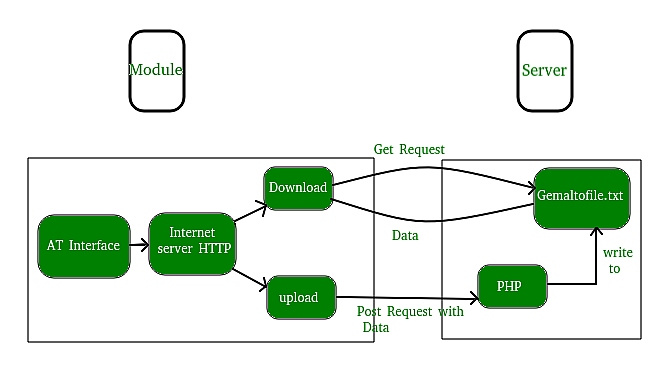
Таким образом, чтобы запросить ответ от сервера, существует два стандартных метода в рамках HTTP/1.1:
- GET: запрос данных с сервера.
- POST: отправка данных для обработки на сервер.
Вот простая диаграмма, которая объясняет основную концепцию методов GET и POST:
Теперь, чтобы выполнять HTTP-запросы в Python, мы можем использовать несколько популярных в Python HTTP-библиотек, таких как:
Самой элегантной и простой из перечисленных выше библиотек является библиотека Requests . В этом посте выше мы последовательно описали все основные операции из самой популярной Python-библиотеки Requests .
Как работать с библиотекой requests в Python
Погрузитесь в мир Python с нашей статьей о работе с библиотекой requests: отправка запросов, обработка данных и устранение ошибок — все это здесь!
Алексей Кодов
Автор статьи
10 июля 2023 в 17:48
Библиотека requests в Python — это мощный инструмент для работы с HTTP-запросами. В этой статье мы разберемся, как использовать эту библиотеку для отправки GET, POST, PUT, DELETE и других запросов, а также как обрабатывать полученные данные.
Установка библиотеки requests
Для начала установим библиотеку requests с помощью pip:
pip install requests
Теперь мы готовы начать работу с библиотекой!
Отправка GET-запроса
Для отправки GET-запроса используется функция get() :
import requests response = requests.get('https://api.example.com/data')
Полученный ответ можно обработать следующим образом:
print(response.status_code) # Выводит статус-код ответа (например, 200) print(response.text) # Выводит текст ответа
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Отправка POST-запроса
Для отправки POST-запроса используется функция post() . В качестве примера отправим данные в формате JSON:
import requests import json data = headers = response = requests.post('https://api.example.com/data', data=json.dumps(data), headers=headers)
Обработка ответа аналогична GET-запросу:
print(response.status_code) print(response.text)
Работа с параметрами запроса
Иногда нужно передать параметры в запросе. Для этого используется аргумент params :
import requests params = response = requests.get('https://api.example.com/data', params=params)
�� В результате, будет отправлен GET-запрос на URL https://api.example.com/data?key=value&key2=value2 .
Обработка ошибок
Для обработки ошибок при отправке запроса можно использовать блок try-except :
import requests from requests.exceptions import RequestException try: response = requests.get('https://api.example.com/data') except RequestException as e: print(f"Ошибка: ")
Заключение
В этой статье мы разобрали основы работы с библиотекой requests в Python. Теперь вы знаете, как отправлять различные типы запросов, передавать параметры и обрабатывать ошибки.
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Не забывайте практиковаться и изучать дополнительные возможности requests, чтобы стать еще более опытным разработчиком на Python!