Обзор библиотек для машинного обучения на Python
Scikit-learn [1] — библиотека машинного обучения на языке программирования Python с открытым исходным кодом. Содержит реализации практически всех возможных преобразований, и нередко ее одной хватает для полной реализации модели. В данной библиотеки реализованы методы разбиения датасета на тестовый и обучающий, вычисление основных метрик над наборами данных, проведение Кросс-валидация [на 28.01.19 не создан] . В библиотеке также есть основные алгоритмы машинного обучения: линейной регрессии [на 28.01.19 не создан] и её модификаций Лассо, гребневой регрессии, опорных векторов [на 28.01.19 не создан] , решающих деревьев и лесов и др. Есть и реализации основных методов кластеризации. Кроме того, библиотека содержит постоянно используемые исследователями методы работы с признаками: например, понижение размерности методом главных компонент [на 28.01.19 не создан] . Частью пакета является библиотека imblearn [2] , позволяющая работать с разбалансированными выборками и генерировать новые значения.
Примеры кода
Линейная регрессия
Основная статья: Линейная регрессия [на 28.01.19 не создан]
# Add required imports import matplotlib.pyplot as plt import numpy as np from sklearn import datasets from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, r2_score
diabetes = datasets.load_diabetes() # Use only one feature diabetes_X = diabetes.data[:, np.newaxis, 2]
Разбиение датасета на тренировочный и тестовый:
# Split the data into training/testing sets x_train = diabetes_X[:-20] x_test = diabetes_X[-20:] # Split the targets into training/testing sets y_train = diabetes.target[:-20] y_test = diabetes.target[-20:]
Построение и обучение модели:
lr = LinearRegression() lr.fit(x_train, y_train) predictions = lr.predict(x_test)
# The mean squared error print("Mean squared error: %.2f" % mean_squared_error(y_test, predictions)) # Explained variance score: 1 is perfect prediction print('Variance score: %.2f' % r2_score(y_test, predictions))
> Mean squared error: 2548.07 Variance score: 0.47
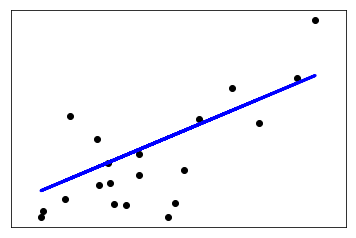
Построение графика прямой, получившейся в результате работы линейной регрессии:
plt.scatter(x_test, y_test, color='black') plt.plot(x_test, predictions, color='blue', linewidth=3) plt.xticks(()) plt.yticks(()) plt.show()
Логистическая регрессия
Основная статья: Логистическая регрессия
from sklearn.datasets import load_digits digits = load_digits()
Вывод первых трех тренировочных данных для визуализации:
import numpy as np import matplotlib.pyplot as plt plt.figure(figsize=(20,4)) for index, (image, label) in enumerate(zip(digits.data[0:3], digits.target[0:3])): plt.subplot(1, 3, index + 1) plt.imshow(np.reshape(image, (8,8)), cmap=plt.cm.gray) plt.title('Training: %i\n' % label, fontsize = 20)

Разбиение датасета на тренировочный и тестовый:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.25, random_state=0)
Построение и обучение модели:
from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(x_train, y_train) predictions = lr.predict(x_test)
score = lr.score(x_test, y_test) print("Score: %.3f" % score)
> Score: 0.953
Перцептрон
Основная статья: Нейронные сети, перцептрон
from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target
Разбиение датасета на тренировочный и тестовый:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
Построение и обучение модели:
from sklearn.neural_network import MLPClassifier mlp = MLPClassifier(hidden_layer_sizes=(10, 10, 10), max_iter=1000) mlp.fit(X_train, y_train.values.ravel()) predictions = mlp.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test,predictions)) print(classification_report(y_test,predictions))
> [[ 7 0 0] [ 0 8 1] [ 0 2 12]] precision recall f1-score support 0 1.00 1.00 1.00 7 1 0.80 0.89 0.84 9 2 0.92 0.86 0.89 14 micro avg 0.90 0.90 0.90 30 macro avg 0.91 0.92 0.91 30 weighted avg 0.90 0.90 0.90 30
Метрический классификатор и метод ближайших соседей
Основная статья: Метрический классификатор и метод ближайших соседей: пример через scikit-learn
Дерево решений и случайный лес
Основная статья: Дерево решений и случайный лес: пример через scikit-learn
Обработка естественного языка
Основная статья: Обработка естественного языка
from sklearn import fetch_20newsgroups twenty_train = fetch_20newsgroups(subset='train', shuffle=True, random_state=42)
Вывод первых трех строк первого тренивочного файла и его класса:
print("\n".join(twenty_train.data[0].split("\n")[:3])) print(twenty_train.target_names[twenty_train.target[0]])
> From: lerxst@wam.umd.edu (where's my thing) Subject: WHAT car is this!? Nntp-Posting-Host: rac3.wam.umd.edu rec.autos
Построение и обучение двух моделей. Первая на основе Байесовской классификации [на 28.01.19 не создан] , а вторая использует метод опорных векторов:
from sklearn.pipeline import Pipeline from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer from sklearn.naive_bayes import MultinomialNB text_clf1 = Pipeline([ ('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('clf', MultinomialNB()), ]) from sklearn.linear_model import SGDClassifier text_clf2 = Pipeline([ ('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('clf', SGDClassifier(loss='hinge', penalty='l2', alpha=1e-3, random_state=42, max_iter=5, tol=None)), ]) text_clf1.fit(twenty_train.data, twenty_train.target) text_clf2.fit(twenty_train.data, twenty_train.target)
twenty_test = fetch_20newsgroups(subset='test', shuffle=True, random_state=42) docs_test = twenty_test.data predicted1 = text_clf1.predict(docs_test) predicted2 = text_clf2.predict(docs_test) print("Score: %.3f" % np.mean(predicted1 == twenty_test.target)) print("Score: %.3f" % np.mean(predicted2 == twenty_test.target))
> Score for naive Bayes: 0.774 Score for SVM: 0.824
Кросс-валилация и подбор параметров
Основная статья: Кросс-валидация
Возьмем предыдущий пример с обработкой естественного языка и попробуем увеличить точность алгоритма за счет кросс-валидации и подбора параметров:
from sklearn.model_selection import GridSearchCV parameters = < 'vect__ngram_range': [(1, 1), (1, 2)], 'tfidf__use_idf': (True, False), 'clf__alpha': (1e-2, 1e-3), > gs_clf = GridSearchCV(text_clf2, parameters, cv=5, iid=False, n_jobs=-1) gs_clf = gs_clf.fit(twenty_train.data, twenty_train.target) print("Best score: %.3f" % gs_clf.best_score_) for param_name in sorted(parameters.keys()): print("%s: %r" % (param_name, gs_clf.best_params_[param_name]))
> Best score: 0.904 clf__alpha: 0.001 tfidf__use_idf: True vect__ngram_range: (1, 2)
Метод опорных векторов (SVM)
Основная статья: Метод опорных векторов (SVM) [на 28.01.19 не создан]
from sklearn import datasets iris = datasets.load_iris()
Разбиение датасета на тестовый и тренировочный:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=0)
Построение и обучение модели:
clf = svm.SVC(kernel='linear', C=1.0) clf.fit(x_train, y_train) predictions = clf.predict(x_test)
from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test,predictions)) print(classification_report(y_test,predictions))
> [[13 0 0] [ 0 15 1] [ 0 0 9]] precision recall f1-score support 0 1.00 1.00 1.00 13 1 1.00 0.94 0.97 16 2 0.90 1.00 0.95 9 micro avg 0.97 0.97 0.97 38 macro avg 0.97 0.98 0.97 38 weighted avg 0.98 0.97 0.97 38
EM-алгоритм
Основная статья: EM-алгоритм [на 28.01.19 не создан]
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import LogNorm from sklearn import mixture n_samples = 300 # generate random sample, two components np.random.seed(0) # generate spherical data centered on (20, 20) shifted_gaussian = np.random.randn(n_samples, 2) + np.array([20, 20]) # generate zero centered stretched Gaussian data C = np.array([[0., -0.7], [3.5, .7]]) stretched_gaussian = np.dot(np.random.randn(n_samples, 2), C) # concatenate the two datasets into the final training set X_train = np.vstack([shifted_gaussian, stretched_gaussian]) # fit a Gaussian Mixture Model with two components clf = mixture.GaussianMixture(n_components=2, covariance_type='full') clf.fit(X_train) # display predicted scores by the model as a contour plot x = np.linspace(-20., 30.) y = np.linspace(-20., 40.) X, Y = np.meshgrid(x, y) XX = np.array([X.ravel(), Y.ravel()]).T Z = -clf.score_samples(XX) Z = Z.reshape(X.shape) CS = plt.contour(X, Y, Z, norm=LogNorm(vmin=1.0, vmax=1000.0), levels=np.logspace(0, 3, 10)) CB = plt.colorbar(CS, shrink=0.8, extend='both') plt.scatter(X_train[:, 0], X_train[:, 1], .8) plt.title('Negative log-likelihood predicted by a GMM') plt.axis('tight') plt.show()

Уменьшение размерности
Основная статья: Уменьшение размерности: пример через scikit-learn
Tensorflow
Описание
Tensorflow [3] — библиотека, разработанная корпорацией Google для работы с тензорами, используется для построения нейронных сетей. Поддержка вычислений на видеокартах имеет поддержку языка программирования C++. На основе данной библиотеки строятся более высокоуровневые библиотеки для работы с нейронными сетями на уровне целых слоев. Так, некоторое время назад популярная библиотека Keras стала использовать Tensorflow как основной бэкенд для вычислений вместо аналогичной библиотеки Theano. Для работы на видеокартах NVIDIA используется библиотека cuDNN. Если вы работаете с картинками (со сверточными нейросетями), скорее всего, придется использовать данную библиотеку.
Примеры кода
Сверточная нейронная сеть
Основная статья: Сверточные нейронные сети
Реализация сверточной нейронной сети для классификации цифр из датасета MNIST:
from __future__ import division, print_function, absolute_import import tensorflow as tf # Import MNIST data from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) # Training Parameters learning_rate = 0.001 num_steps = 200 batch_size = 128 display_step = 10 # Network Parameters num_input = 784 # MNIST data input (img shape: 28*28) num_classes = 10 # MNIST total classes (0-9 digits) dropout = 0.75 # Dropout, probability to keep units # tf Graph input X = tf.placeholder(tf.float32, [None, num_input]) Y = tf.placeholder(tf.float32, [None, num_classes]) keep_prob = tf.placeholder(tf.float32) # dropout (keep probability) # Create some wrappers for simplicity def conv2d(x, W, b, strides=1): # Conv2D wrapper, with bias and relu activation x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME') x = tf.nn.bias_add(x, b) return tf.nn.relu(x) def maxpool2d(x, k=2): # MaxPool2D wrapper return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1], padding='SAME') # Create model def conv_net(x, weights, biases, dropout): # MNIST data input is a 1-D vector of 784 features (28*28 pixels) # Reshape to match picture format [Height x Width x Channel] # Tensor input become 4-D: [Batch Size, Height, Width, Channel] x = tf.reshape(x, shape=[-1, 28, 28, 1]) # Convolution Layer conv1 = conv2d(x, weights['wc1'], biases['bc1']) # Max Pooling (down-sampling) conv1 = maxpool2d(conv1, k=2) # Convolution Layer conv2 = conv2d(conv1, weights['wc2'], biases['bc2']) # Max Pooling (down-sampling) conv2 = maxpool2d(conv2, k=2) # Fully connected layer # Reshape conv2 output to fit fully connected layer input fc1 = tf.reshape(conv2, [-1, weights['wd1'].get_shape().as_list()[0]]) fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1']) fc1 = tf.nn.relu(fc1) # Apply Dropout fc1 = tf.nn.dropout(fc1, dropout) # Output, class prediction out = tf.add(tf.matmul(fc1, weights['out']), biases['out']) return out # Store layers weight & bias weights = < # 5x5 conv, 1 input, 32 outputs 'wc1': tf.Variable(tf.random_normal([5, 5, 1, 32])), # 5x5 conv, 32 inputs, 64 outputs 'wc2': tf.Variable(tf.random_normal([5, 5, 32, 64])), # fully connected, 7*7*64 inputs, 1024 outputs 'wd1': tf.Variable(tf.random_normal([7*7*64, 1024])), # 1024 inputs, 10 outputs (class prediction) 'out': tf.Variable(tf.random_normal([1024, num_classes])) > biases = < 'bc1': tf.Variable(tf.random_normal([32])), 'bc2': tf.Variable(tf.random_normal([64])), 'bd1': tf.Variable(tf.random_normal([1024])), 'out': tf.Variable(tf.random_normal([num_classes])) > # Construct model logits = conv_net(X, weights, biases, keep_prob) prediction = tf.nn.softmax(logits) # Define loss and optimizer loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( logits=logits, labels=Y)) optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate) train_op = optimizer.minimize(loss_op) # Evaluate model correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # Initialize the variables (i.e. assign their default value) init = tf.global_variables_initializer() # Start training with tf.Session() as sess: # Run the initializer sess.run(init) for step in range(1, num_steps+1): batch_x, batch_y = mnist.train.next_batch(batch_size) # Run optimization op (backprop) sess.run(train_op, feed_dict=0.8>) if step % display_step == 0 or step == 1: # Calculate batch loss and accuracy loss, acc = sess.run([loss_op, accuracy], feed_dict=1.0>) print("Step " + str(step) + ", Minibatch Loss red">"".format(loss) + ", Training Accuracy red">"".format(acc)) print("Optimization Finished!") # Calculate accuracy for 256 MNIST test images print("Testing Accuracy:", \ sess.run(accuracy, feed_dict=256], Y: mnist.test.labels[:256], keep_prob: 1.0>))
> Step 1, Minibatch Loss= 41724.0586, Training Accuracy= 0.156 Step 10, Minibatch Loss= 17748.7500, Training Accuracy= 0.242 Step 20, Minibatch Loss= 8307.6162, Training Accuracy= 0.578 Step 30, Minibatch Loss= 3108.5703, Training Accuracy= 0.766 Step 40, Minibatch Loss= 3273.2749, Training Accuracy= 0.727 Step 50, Minibatch Loss= 2754.2861, Training Accuracy= 0.820 Step 60, Minibatch Loss= 2467.7925, Training Accuracy= 0.844 Step 70, Minibatch Loss= 1423.8140, Training Accuracy= 0.914 Step 80, Minibatch Loss= 1651.4656, Training Accuracy= 0.875 Step 90, Minibatch Loss= 2105.9263, Training Accuracy= 0.867 Step 100, Minibatch Loss= 1153.5090, Training Accuracy= 0.867 Step 110, Minibatch Loss= 1751.1400, Training Accuracy= 0.898 Step 120, Minibatch Loss= 1446.2119, Training Accuracy= 0.922 Step 130, Minibatch Loss= 1403.7135, Training Accuracy= 0.859 Step 140, Minibatch Loss= 1089.7897, Training Accuracy= 0.930 Step 150, Minibatch Loss= 1147.0751, Training Accuracy= 0.898 Step 160, Minibatch Loss= 1963.3733, Training Accuracy= 0.883 Step 170, Minibatch Loss= 1544.2725, Training Accuracy= 0.859 Step 180, Minibatch Loss= 977.9219, Training Accuracy= 0.914 Step 190, Minibatch Loss= 857.7977, Training Accuracy= 0.930 Step 200, Minibatch Loss= 430.4735, Training Accuracy= 0.953 Optimization Finished! Testing Accuracy: 0.94140625
Keras
Описание
Keras [4] — библиотека для построения нейронных сетей, поддерживающая основные виды слоев и структурные элементы. Поддерживает как рекуррентные, так и сверточные нейросети, имеет в своем составе реализацию известных архитектур нейросетей (например, VGG16). Некоторое время назад слои из данной библиотеки стали доступны внутри библиотеки Tensorflow. Существуют готовые функции для работы с изображениями и текстом. Интегрирована в Apache Spark с помощью дистрибутива dist-keras. Данная библиотека позволяет на более высоком уровне работать с нейронными сетями. В качестве библиотеки для бэкенда может использоваться как Tensorflow, так и Theano.
Примеры кода
Сверточная нейронная сеть
Основная статья: Сверточные нейронные сети
Реализация сверточной нейронной сети для классификации текста:
from __future__ import print_function from keras.preprocessing import sequence from keras.models import Sequential from keras.layers import Dense, Dropout, Activation from keras.layers import Embedding from keras.layers import Conv1D, GlobalMaxPooling1D from keras.datasets import imdb # set parameters: max_features = 5000 maxlen = 400 batch_size = 32 embedding_dims = 50 filters = 250 kernel_size = 3 hidden_dims = 250 epochs = 2 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features) print(len(x_train), 'train sequences') print(len(x_test), 'test sequences')
> 25000 train sequences 25000 test sequences
print('Pad sequences (samples x time)') x_train = sequence.pad_sequences(x_train, maxlen=maxlen) x_test = sequence.pad_sequences(x_test, maxlen=maxlen) print('x_train shape:', x_train.shape) print('x_test shape:', x_test.shape)
> Pad sequences (samples x time) x_train shape: (25000, 400) x_test shape: (25000, 400)
model = Sequential() model.add(Embedding(max_features, embedding_dims, input_length=maxlen)) model.add(Dropout(0.2)) model.add(Conv1D(filters, kernel_size, padding='valid', activation='relu', strides=1)) model.add(GlobalMaxPooling1D()) model.add(Dense(hidden_dims)) model.add(Dropout(0.2)) model.add(Activation('relu')) model.add(Dense(1)) model.add(Activation('sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test))
> Train on 25000 samples, validate on 25000 samples Epoch 1/2 25000/25000 [==============================] - 136s 5ms/step - loss: 0.4107 - acc: 0.7923 - val_loss: 0.2926 - val_acc: 0.8746 Epoch 2/2 25000/25000 [==============================] - 136s 5ms/step - loss: 0.2294 - acc: 0.9082 - val_loss: 0.3200 - val_acc: 0.8652
Другие библиотеки для машинного обучения на Python
Вспомогательные библиотеки
- NumPy [5] — библиотека, добавляющая поддержку больших многомерных массивов и матриц вместе с большой библиотекой высокоуровневых математических функций для операций с этими массивами. Данная библиотека предоставляет реализации вычислительных алгоритмов (в виде функций и операторов), оптимизированные для работы с многомерными массивами. В результате любой алгоритм, который может быть выражен в виде последовательности операций над массивами (матрицами) и реализованный с использованием NumPy, работает так же быстро, как эквивалентный код, выполняемый в MATLAB [6] ;
- SciPy [7] — открытая библиотека высококачественных научных инструментов для языка программирования Python. SciPy содержит модули для оптимизации, интегрирования, специальных функций, обработки сигналов, обработки изображений, генетических алгоритмов, решения обыкновенных дифференциальных уравнений и других задач, обычно решаемых в науке и при инженерной разработке;
- Pandas [8] — библиотека Python, которая является мощным инструментом для анализа данных. Пакет дает возможность строить сводные таблицы, выполнять группировки, предоставляет удобный доступ к табличным данным и позволяет строить графики на полученных наборах данных при помощи библиотеки Matplotlib;
- Matplotlib [9] — библиотека Python для построения качественных двумерных графиков. Matplotlib является гибким, легко конфигурируемым пакетом, который вместе с NumPy, SciPy и IPython [10] предоставляет возможности, подобные MATLAB.
- Autograd — Библиотека автодифференциирования функций на numpy. ПОзволяет делать простые нейросети и оптимизацию научных расчётов. Для тяжёлого лучше использовать GPU-библиотеки.
- JAX — улучшенный autograd.
- Tensor shape annotation lib — позволяет назначить измерениям тензора человекочитаемые метки
Библиотеки для глубокого обучения
- Tenzorflow [11] — открытая программная библиотека для машинного обучения, разработанная компанией Google для решения задач построения и тренировки нейронной сети с целью автоматического нахождения и классификации образов, достигая качества человеческого восприятия. Широко применяется в бизнес-приложениях.
- PyTorch [12] — библиотека для глубокого обучения, созданная на базе Torch [13] и развиваемая компанией Facebook. Две ключевые функциональности данной библиотеки — тензорные вычисления с развитой поддержкой ускорения на GPU (OpenCL) и глубокие нейронные сети на базе системы autodiff;
- Theano [14] — расширение языка программирования Python, позволяющее эффективно вычислять математические выражения, содержащие многомерные массивы. Библиотека предоставляет базовый набор инструментов для конфигурации нейронных сетей и их обучения. Наибольшее признание данная библиотека получила в задачах машинного обучения при решении задач оптимизации. Она позволяет использовать возможности GPU без изменения кода программы, что делает ее незаменимой при выполнении ресурсоемких задач;
- Caffe [15] — фреймворк для обучения нейронных сетей, созданный университетом Беркли. Как и Tensorflow, использует cuDNN для работы с видеокартами NVIDIA;
- Microsoft Cognitive Toolkit (CNTK) [16] — фреймворк от корпорации Microsoft, предоставляющий реализации архитектур различных нейронных сетей.
- plaidml — ещё одна библиотека на OpenCL, умеющая компилировать граф в оптимизированные кастомные ядра OpenCL.
Библиотеки для обработки естественного языка
- NLTK [17] — пакет библиотек и программ для символьной и статистической обработки естественного языка, написанных на языке программирования Python;
- Gensim [18] — инструмент для автоматической обработки языка, основанный на машинном обучении. В Gensim реализованы алгоритмы дистрибутивной семантики word2vec и doc2vec, он позволяет решать задачи тематического моделирования и выделять основные темы текста или документа.
Библиотеки для градиентного бустинга
- Xgboost [на 28.01.19 не создан] [19] — библиотека с реализацией градиентного бустинга, которая для выбора разбиения использует сортировку и модели, основанные на анализе гистограмм;
- LightGBM [20] — фреймворк с реализацией градиентного бустинга от корпорации Microsoft. Является частью проекта Microsoft DMTK, посвященного реализации подходов машинного обучения для .Net;
- CatBoost[21] — библиотека с градиентным бустингом от компании Яндекс, в которой реализуется особый подход к обработке категориальных признаков, основанный на подмене категориальных признаков статистиками на основе предсказываемого значения.
См. также
- Примеры кода на Scala
- Примеры кода на R [на 28.01.19 не создан]
- Примеры кода на Java
sklearn.discriminant_analysis .LinearDiscriminantAnalysis¶
class sklearn.discriminant_analysis. LinearDiscriminantAnalysis ( solver = ‘svd’ , shrinkage = None , priors = None , n_components = None , store_covariance = False , tol = 0.0001 , covariance_estimator = None ) [source] ¶
Linear Discriminant Analysis.
A classifier with a linear decision boundary, generated by fitting class conditional densities to the data and using Bayes’ rule.
The model fits a Gaussian density to each class, assuming that all classes share the same covariance matrix.
The fitted model can also be used to reduce the dimensionality of the input by projecting it to the most discriminative directions, using the transform method.
New in version 0.17: LinearDiscriminantAnalysis.
Read more in the User Guide .
- ‘svd’: Singular value decomposition (default). Does not compute the covariance matrix, therefore this solver is recommended for data with a large number of features.
- ‘lsqr’: Least squares solution. Can be combined with shrinkage or custom covariance estimator.
- ‘eigen’: Eigenvalue decomposition. Can be combined with shrinkage or custom covariance estimator.
Changed in version 1.2: solver=»svd» now has experimental Array API support. See the Array API User Guide for more details.
- None: no shrinkage (default).
- ‘auto’: automatic shrinkage using the Ledoit-Wolf lemma.
- float between 0 and 1: fixed shrinkage parameter.
This should be left to None if covariance_estimator is used. Note that shrinkage works only with ‘lsqr’ and ‘eigen’ solvers.
priors array-like of shape (n_classes,), default=None
The class prior probabilities. By default, the class proportions are inferred from the training data.
n_components int, default=None
store_covariance bool, default=False
If True, explicitly compute the weighted within-class covariance matrix when solver is ‘svd’. The matrix is always computed and stored for the other solvers.
New in version 0.17.
tol float, default=1.0e-4
Absolute threshold for a singular value of X to be considered significant, used to estimate the rank of X. Dimensions whose singular values are non-significant are discarded. Only used if solver is ‘svd’.
New in version 0.17.
covariance_estimator covariance estimator, default=None
If not None, covariance_estimator is used to estimate the covariance matrices instead of relying on the empirical covariance estimator (with potential shrinkage). The object should have a fit method and a covariance_ attribute like the estimators in sklearn.covariance . if None the shrinkage parameter drives the estimate.
This should be left to None if shrinkage is used. Note that covariance_estimator works only with ‘lsqr’ and ‘eigen’ solvers.
New in version 0.24.
Attributes : coef_ ndarray of shape (n_features,) or (n_classes, n_features)
intercept_ ndarray of shape (n_classes,)
covariance_ array-like of shape (n_features, n_features)
Weighted within-class covariance matrix. It corresponds to sum_k prior_k * C_k where C_k is the covariance matrix of the samples in class k . The C_k are estimated using the (potentially shrunk) biased estimator of covariance. If solver is ‘svd’, only exists when store_covariance is True.
explained_variance_ratio_ ndarray of shape (n_components,)
Percentage of variance explained by each of the selected components. If n_components is not set then all components are stored and the sum of explained variances is equal to 1.0. Only available when eigen or svd solver is used.
means_ array-like of shape (n_classes, n_features)
priors_ array-like of shape (n_classes,)
Class priors (sum to 1).
scalings_ array-like of shape (rank, n_classes — 1)
Scaling of the features in the space spanned by the class centroids. Only available for ‘svd’ and ‘eigen’ solvers.
xbar_ array-like of shape (n_features,)
Overall mean. Only present if solver is ‘svd’.
classes_ array-like of shape (n_classes,)
Unique class labels.
n_features_in_ int
Number of features seen during fit .
New in version 0.24.
feature_names_in_ ndarray of shape ( n_features_in_ ,)
Names of features seen during fit . Defined only when X has feature names that are all strings.
New in version 1.0.
Quadratic Discriminant Analysis.
>>> import numpy as np >>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = LinearDiscriminantAnalysis() >>> clf.fit(X, y) LinearDiscriminantAnalysis() >>> print(clf.predict([[-0.8, -1]])) [1]
Apply decision function to an array of samples.
Fit the Linear Discriminant Analysis model.
Fit to data, then transform it.
Get output feature names for transformation.
Get metadata routing of this object.
Get parameters for this estimator.
Predict class labels for samples in X.
Estimate log probability.
score (X, y[, sample_weight])
Return the mean accuracy on the given test data and labels.
Set output container.
Set the parameters of this estimator.
Request metadata passed to the score method.
Project data to maximize class separation.
Apply decision function to an array of samples.
The decision function is equal (up to a constant factor) to the log-posterior of the model, i.e. log p(y = k | x) . In a binary classification setting this instead corresponds to the difference log p(y = 1 | x) — log p(y = 0 | x) . See Mathematical formulation of the LDA and QDA classifiers .
Parameters : X array-like of shape (n_samples, n_features)
Array of samples (test vectors).
Returns : C ndarray of shape (n_samples,) or (n_samples, n_classes)
Decision function values related to each class, per sample. In the two-class case, the shape is (n_samples,), giving the log likelihood ratio of the positive class.
Fit the Linear Discriminant Analysis model.
Changed in version 0.19: store_covariance has been moved to main constructor.
Changed in version 0.19: tol has been moved to main constructor.
Parameters : X array-like of shape (n_samples, n_features)
y array-like of shape (n_samples,)
Returns : self object
Fit to data, then transform it.
Fits transformer to X and y with optional parameters fit_params and returns a transformed version of X .
Parameters : X array-like of shape (n_samples, n_features)
y array-like of shape (n_samples,) or (n_samples, n_outputs), default=None
Target values (None for unsupervised transformations).
**fit_params dict
Additional fit parameters.
Returns : X_new ndarray array of shape (n_samples, n_features_new)
get_feature_names_out ( input_features = None ) [source] ¶
Get output feature names for transformation.
The feature names out will prefixed by the lowercased class name. For example, if the transformer outputs 3 features, then the feature names out are: [«class_name0», «class_name1», «class_name2»] .
Parameters : input_features array-like of str or None, default=None
Only used to validate feature names with the names seen in fit .
Returns : feature_names_out ndarray of str objects
Transformed feature names.
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
Returns : routing MetadataRequest
A MetadataRequest encapsulating routing information.
Get parameters for this estimator.
Parameters : deep bool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
Returns : params dict
Parameter names mapped to their values.
Predict class labels for samples in X.
Parameters : X of shape (n_samples, n_features)
The data matrix for which we want to get the predictions.
Returns : y_pred ndarray of shape (n_samples,)
Vector containing the class labels for each sample.
Estimate log probability.
Parameters : X array-like of shape (n_samples, n_features)
Returns : C ndarray of shape (n_samples, n_classes)
Estimated log probabilities.
Parameters : X array-like of shape (n_samples, n_features)
Returns : C ndarray of shape (n_samples, n_classes)
Return the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
Parameters : X array-like of shape (n_samples, n_features)
y array-like of shape (n_samples,) or (n_samples, n_outputs)
True labels for X .
sample_weight array-like of shape (n_samples,), default=None
Returns : score float
Mean accuracy of self.predict(X) w.r.t. y .
Set output container.
See Introducing the set_output API for an example on how to use the API.
Parameters : transform , default=None
Configure output of transform and fit_transform .
- «default» : Default output format of a transformer
- «pandas» : DataFrame output
- None : Transform configuration is unchanged
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as Pipeline ). The latter have parameters of the form __ so that it’s possible to update each component of a nested object.
Parameters : **params dict
Returns : self estimator instance
Request metadata passed to the score method.
Note that this method is only relevant if enable_metadata_routing=True (see sklearn.set_config ). Please see User Guide on how the routing mechanism works.
The options for each parameter are:
- True : metadata is requested, and passed to score if provided. The request is ignored if metadata is not provided.
- False : metadata is not requested and the meta-estimator will not pass it to score .
- None : metadata is not requested, and the meta-estimator will raise an error if the user provides it.
- str : metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default ( sklearn.utils.metadata_routing.UNCHANGED ) retains the existing request. This allows you to change the request for some parameters and not others.
New in version 1.3.
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a Pipeline . Otherwise it has no effect.
Parameters : sample_weight str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for sample_weight parameter in score .
Returns : self object
The updated object.
Project data to maximize class separation.
Parameters : X array-like of shape (n_samples, n_features)
Returns : X_new ndarray of shape (n_samples, n_components) or (n_samples, min(rank, n_components))
Transformed data. In the case of the ‘svd’ solver, the shape is (n_samples, min(rank, n_components)).
How does sklearn.svm.svc’s function predict_proba() work internally?
I am using sklearn.svm.svc from scikit-learn to do binary classification. I am using its predict_proba() function to get probability estimates. Can anyone tell me how predict_proba() internally calculates the probability?
651 1 1 gold badge 15 15 silver badges 24 24 bronze badges
asked Feb 27, 2013 at 11:50
user2115183 user2115183
851 2 2 gold badges 9 9 silver badges 13 13 bronze badges
2 Answers 2
Scikit-learn uses LibSVM internally, and this in turn uses Platt scaling, as detailed in this note by the LibSVM authors, to calibrate the SVM to produce probabilities in addition to class predictions.
Platt scaling requires first training the SVM as usual, then optimizing parameter vectors A and B such that
P(y|X) = 1 / (1 + exp(A * f(X) + B)) where f(X) is the signed distance of a sample from the hyperplane (scikit-learn’s decision_function method). You may recognize the logistic sigmoid in this definition, the same function that logistic regression and neural nets use for turning decision functions into probability estimates.
Mind you: the B parameter, the «intercept» or «bias» or whatever you like to call it, can cause predictions based on probability estimates from this model to be inconsistent with the ones you get from the SVM decision function f . E.g. suppose that f(X) = 10 , then the prediction for X is positive; but if B = -9.9 and A = 1 , then P(y|X) = .475 . I’m pulling these numbers out of thin air, but you’ve noticed that this can occur in practice.
Effectively, Platt scaling trains a probability model on top of the SVM’s outputs under a cross-entropy loss function. To prevent this model from overfitting, it uses an internal five-fold cross validation, meaning that training SVMs with probability=True can be quite a lot more expensive than a vanilla, non-probabilistic SVM.
1.10. Деревья решений ¶
Деревья решений (DT) — это непараметрический контролируемый метод обучения, используемый для классификации и регрессии . Цель состоит в том, чтобы создать модель, которая предсказывает значение целевой переменной, изучая простые правила принятия решений, выведенные из характеристик данных. Дерево можно рассматривать как кусочно-постоянное приближение.
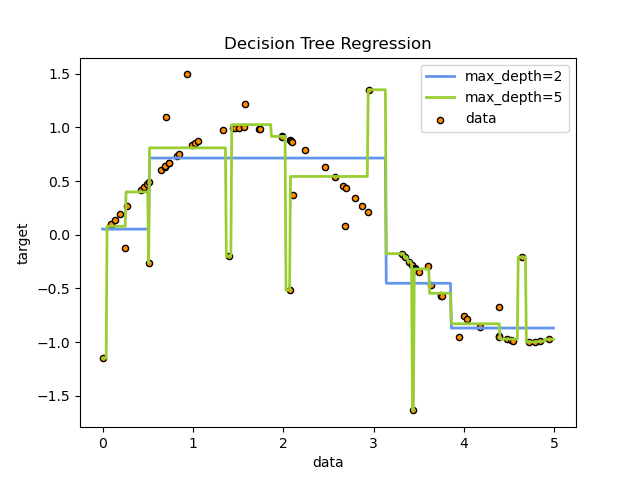
Например, в приведенном ниже примере деревья решений обучаются на основе данных, чтобы аппроксимировать синусоидальную кривую с набором правил принятия решений «если-то-еще». Чем глубже дерево, тем сложнее правила принятия решений и тем лучше модель.
Некоторые преимущества деревьев решений:
- Просто понять и интерпретировать. Деревья можно визуализировать.
- Требуется небольшая подготовка данных. Другие методы часто требуют нормализации данных, создания фиктивных переменных и удаления пустых значений. Однако обратите внимание, что этот модуль не поддерживает отсутствующие значения.
- Стоимость использования дерева (т. Е. Прогнозирования данных) является логарифмической по количеству точек данных, используемых для обучения дерева.
- Может обрабатывать как числовые, так и категориальные данные. Однако реализация scikit-learn пока не поддерживает категориальные переменные. Другие методы обычно специализируются на анализе наборов данных, содержащих только один тип переменных. См. Алгоритмы для получения дополнительной информации.
- Способен обрабатывать проблемы с несколькими выходами.
- Использует модель белого ящика. Если данная ситуация наблюдаема в модели, объяснение условия легко объяснить с помощью булевой логики. Напротив, в модели черного ящика (например, в искусственной нейронной сети) результаты могут быть труднее интерпретировать.
- Возможна проверка модели с помощью статистических тестов. Это позволяет учитывать надежность модели.
- Работает хорошо, даже если его предположения несколько нарушаются истинной моделью, на основе которой были сгенерированы данные.
К недостаткам деревьев решений можно отнести:
- Обучающиеся дереву решений могут создавать слишком сложные деревья, которые плохо обобщают данные. Это называется переобучением. Чтобы избежать этой проблемы, необходимы такие механизмы, как обрезка, установка минимального количества выборок, необходимых для конечного узла, или установка максимальной глубины дерева.
- Деревья решений могут быть нестабильными, поскольку небольшие изменения в данных могут привести к созданию совершенно другого дерева. Эта проблема смягчается за счет использования деревьев решений в ансамбле.
- Как видно из рисунка выше, предсказания деревьев решений не являются ни гладкими, ни непрерывными, а являются кусочно-постоянными приближениями. Следовательно, они не годятся для экстраполяции.
- Известно, что проблема обучения оптимальному дереву решений является NP-полной с точки зрения нескольких аспектов оптимальности и даже для простых концепций. Следовательно, практические алгоритмы обучения дереву решений основаны на эвристических алгоритмах, таких как жадный алгоритм, в котором локально оптимальные решения принимаются в каждом узле. Такие алгоритмы не могут гарантировать возврат глобального оптимального дерева решений. Это можно смягчить путем обучения нескольких деревьев в учащемся ансамбля, где функции и образцы выбираются случайным образом с заменой.
- Существуют концепции, которые трудно изучить, поскольку деревья решений не выражают их легко, например проблемы XOR, четности или мультиплексора.
- Ученики дерева решений создают предвзятые деревья, если некоторые классы доминируют. Поэтому рекомендуется сбалансировать набор данных перед подгонкой к дереву решений.
1.10.1. Классификация
DecisionTreeClassifier — это класс, способный выполнять мультиклассовую классификацию набора данных.
Как и в случае с другими классификаторами, DecisionTreeClassifier принимает в качестве входных данных два массива: массив X, разреженный или плотный, формы (n_samples, n_features), содержащий обучающие образцы, и массив Y целочисленных значений, формы (n_samples,), содержащий метки классов для обучающих образцов:
>>> from sklearn import tree >>> X = [[0, 0], [1, 1]] >>> Y = [0, 1] >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
После подбора модель можно использовать для прогнозирования класса образцов:
>>> clf.predict([[2., 2.]]) array([1])
В случае, если существует несколько классов с одинаковой и самой высокой вероятностью, классификатор предскажет класс с самым низким индексом среди этих классов.
В качестве альтернативы выводу определенного класса можно предсказать вероятность каждого класса, которая представляет собой долю обучающих выборок класса в листе:
>>> clf.predict_proba([[2., 2.]]) array([[0., 1.]])
DecisionTreeClassifier поддерживает как двоичную (где метки — [-1, 1]), так и мультиклассовую (где метки — [0,…, K-1]) классификацию.
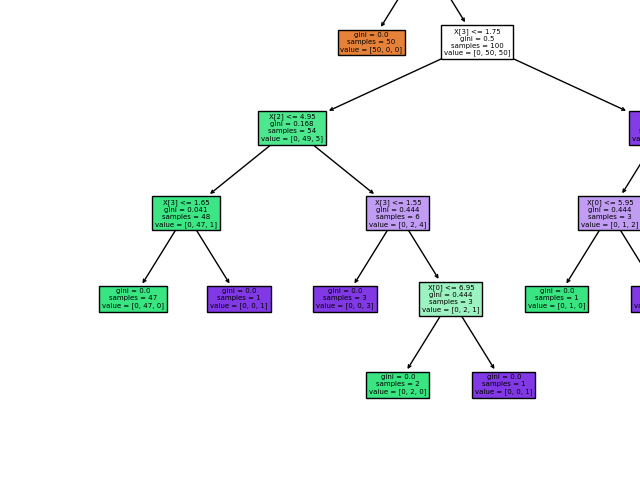
Используя набор данных Iris, мы можем построить дерево следующим образом:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> iris = load_iris() >>> X, y = iris.data, iris.target >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, y)
После обучения вы можете построить дерево с помощью plot_tree функции:
>>> tree.plot_tree(clf)
Мы также можем экспортировать дерево в формат Graphviz с помощью export_graphviz экспортера. Если вы используете Conda менеджер пакетов, то Graphviz бинарные файлы и пакет питон может быть установлен conda install python-graphviz .
В качестве альтернативы двоичные файлы для graphviz можно загрузить с домашней страницы проекта graphviz, а оболочку Python установить из pypi с помощью pip install graphviz .
Ниже приведен пример экспорта graphviz вышеуказанного дерева, обученного на всем наборе данных радужной оболочки глаза; результаты сохраняются в выходном файле iris.pdf :
>>> import graphviz >>> dot_data = tree.export_graphviz(clf, out_file=None) >>> graph = graphviz.Source(dot_data) >>> graph.render("iris")
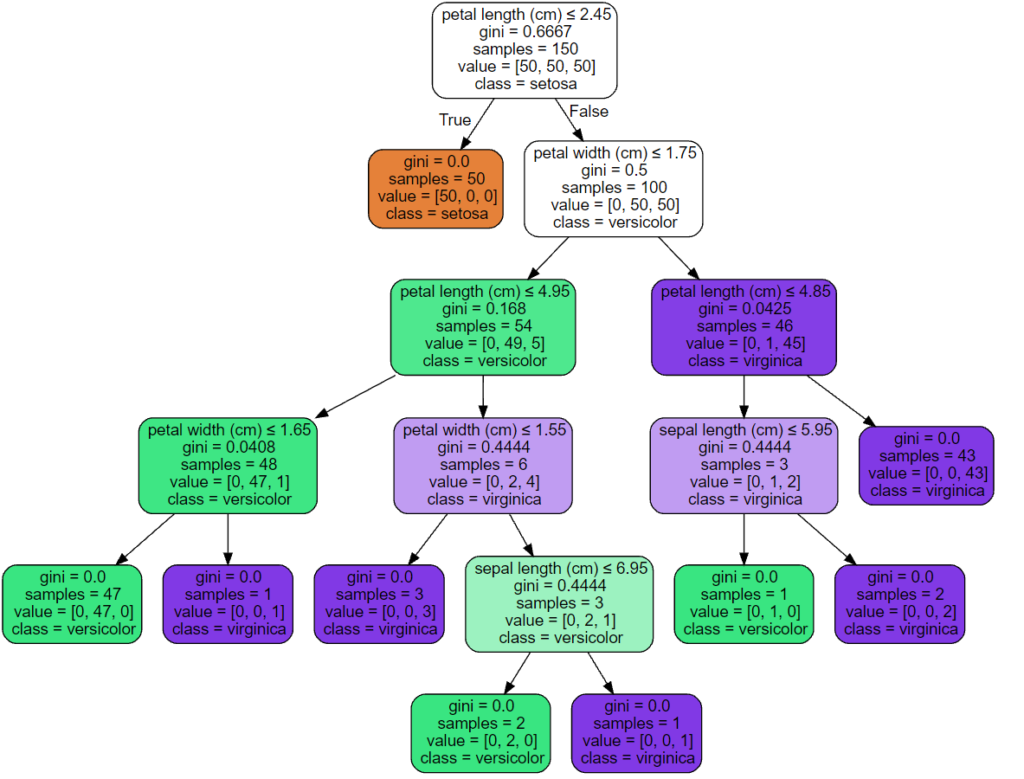
Экспортер export_graphviz также поддерживает множество эстетических вариантов, в том числе окраски узлов их класс (или значение регрессии) и используя явные имена переменных и классов , если это необходимо. Блокноты Jupyter также автоматически отображают эти графики встроенными:
>>> dot_data = tree.export_graphviz(clf, out_file=None, . feature_names=iris.feature_names, . class_names=iris.target_names, . filled=True, rounded=True, . special_characters=True) >>> graph = graphviz.Source(dot_data) >>> graph
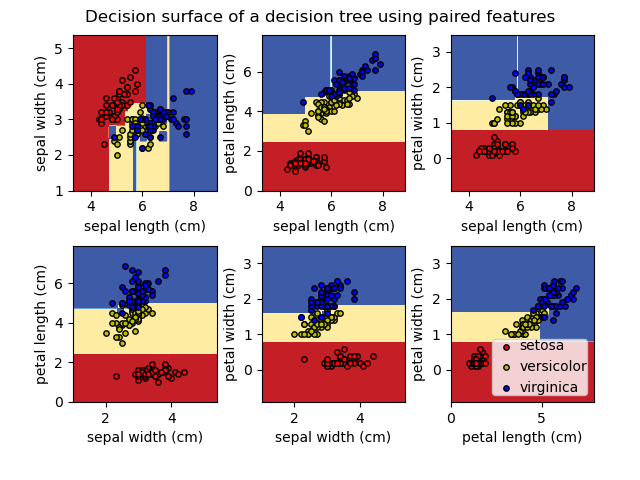
В качестве альтернативы дерево можно также экспортировать в текстовый формат с помощью функции export_text . Этот метод не требует установки внешних библиотек и более компактен:
>>> from sklearn.datasets import load_iris >>> from sklearn.tree import DecisionTreeClassifier >>> from sklearn.tree import export_text >>> iris = load_iris() >>> decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2) >>> decision_tree = decision_tree.fit(iris.data, iris.target) >>> r = export_text(decision_tree, feature_names=iris['feature_names']) >>> print(r) |--- petal width (cm) 0.80 | |--- petal width (cm) 1.75 | | |--- class: 2
- Постройте поверхность принятия решений дерева решений на наборе данных радужной оболочки глаза
- Понимание структуры дерева решений
1.10.2. Регрессия
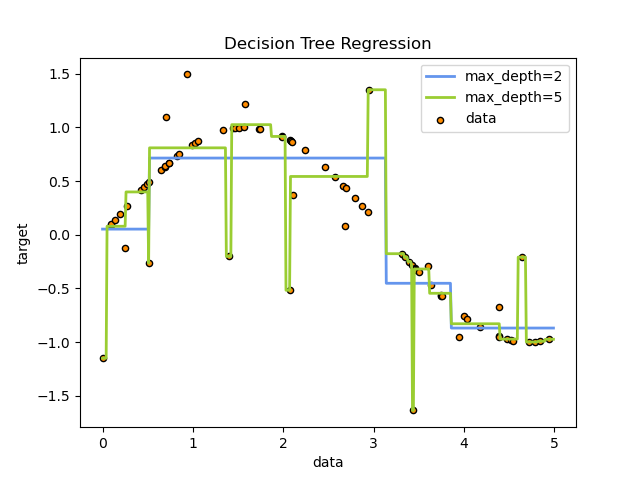
Деревья решений также могут применяться к задачам регрессии с помощью класса DecisionTreeRegressor .
Как и в настройке классификации, метод fit будет принимать в качестве аргументов массивы X и y, только в этом случае ожидается, что y будет иметь значения с плавающей запятой вместо целочисленных значений:
>>> from sklearn import tree >>> X = [[0, 0], [2, 2]] >>> y = [0.5, 2.5] >>> clf = tree.DecisionTreeRegressor() >>> clf = clf.fit(X, y) >>> clf.predict([[1, 1]]) array([0.5])
1.10.3. Проблемы с несколькими выходами
Задача с несколькими выходами — это проблема контролируемого обучения с несколькими выходами для прогнозирования, то есть когда Y — это 2-й массив формы (n_samples, n_outputs) .
Когда нет корреляции между выходами, очень простой способ решить эту проблему — построить n независимых моделей, то есть по одной для каждого выхода, а затем использовать эти модели для независимого прогнозирования каждого из n выходов. Однако, поскольку вполне вероятно, что выходные значения, относящиеся к одному и тому же входу, сами коррелированы, часто лучшим способом является построение единой модели, способной прогнозировать одновременно все n выходов. Во-первых, это требует меньшего времени на обучение, поскольку строится только один оценщик. Во-вторых, часто можно повысить точность обобщения итоговой оценки.
Что касается деревьев решений, эту стратегию можно легко использовать для поддержки задач с несколькими выходами. Для этого требуются следующие изменения:
- Сохранять n выходных значений в листьях вместо 1;
- Используйте критерии разделения, которые вычисляют среднее сокращение для всех n выходов.
Этот модуль предлагает поддержку для задач с несколькими выходами, реализуя эту стратегию как в, так DecisionTreeClassifier и в DecisionTreeRegressor . Если дерево решений соответствует выходному массиву Y формы (n_samples, n_outputs), то итоговая оценка будет:
- Вывести значения n_output при predict ;
- Выведите список массивов n_output вероятностей классов на predict_proba .
Использование деревьев с несколькими выходами для регрессии продемонстрировано в разделе «Регрессия дерева решений с несколькими выходами» . В этом примере вход X — это одно действительное значение, а выходы Y — синус и косинус X.
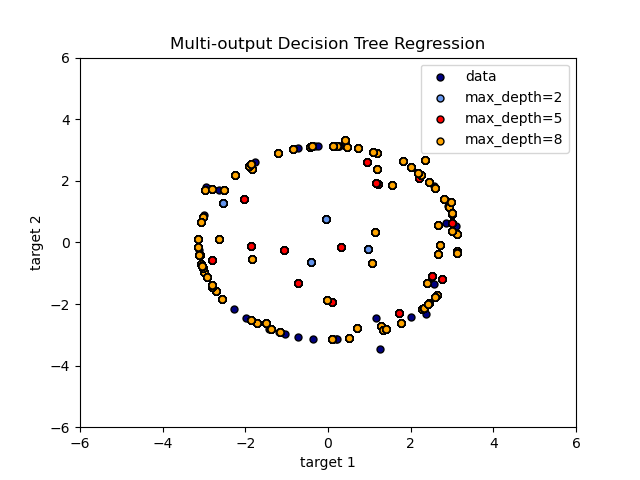
Использование деревьев с несколькими выходами для классификации демонстрируется в разделе «Завершение лица с оценками с несколькими выходами» . В этом примере входы X — это пиксели верхней половины граней, а выходы Y — пиксели нижней половины этих граней.

- Регрессия дерева решений с несколькими выходами
- Завершение лица с помощью многовыходных оценщиков
- М. Дюмон и др., Быстрая мультиклассовая аннотация изображений со случайными подокнами и множественными выходными рандомизированными деревьями , Международная конференция по теории и приложениям компьютерного зрения, 2009 г.
1.10.4. Сложность
В общем, время выполнения для построения сбалансированного двоичного дерева составляет $O(n_n_\log(n_))$ и время запроса $O(\log(n_))$. Хотя алгоритм построения дерева пытается генерировать сбалансированные деревья, они не всегда будут сбалансированными. Предполагая, что поддеревья остаются примерно сбалансированными, стоимость на каждом узле состоит из перебора $O(n_)$ найти функцию, обеспечивающую наибольшее снижение энтропии. Это стоит $O(n_n_\log(n_))$ на каждом узле, что приводит к общей стоимости по всем деревьям (суммируя стоимость на каждом узле) $O(n_n_^\log(n_))$
1.10.5. Советы по практическому использованию
- Деревья решений имеют тенденцию чрезмерно соответствовать данным с большим количеством функций. Получение правильного соотношения образцов к количеству функций важно, поскольку дерево с небольшим количеством образцов в многомерном пространстве, скорее всего, переоборудуется.
- Предварительно рассмотрите возможность уменьшения размерности (PCA, ICA, или Feature selection), чтобы дать вашему дереву больше шансов найти отличительные признаки.
- Понимание структуры дерева решений поможет лучше понять, как дерево решений делает прогнозы, что важно для понимания важных функций данных.
- Визуализируйте свое дерево во время тренировки с помощью export функции. Используйте max_depth=3 в качестве начальной глубины дерева, чтобы понять, насколько дерево соответствует вашим данным, а затем увеличьте глубину.
- Помните, что количество образцов, необходимых для заполнения дерева, удваивается для каждого дополнительного уровня, до которого дерево растет. Используйте max_depth для управления размером дерева во избежание переобучения.
- Используйте min_samples_split или, min_samples_leaf чтобы гарантировать, что несколько выборок информируют каждое решение в дереве, контролируя, какие разделения будут учитываться. Очень маленькое число обычно означает, что дерево переоборудуется, тогда как большое число не позволяет дереву изучать данные. Попробуйте min_samples_leaf=5 в качестве начального значения. Если размер выборки сильно различается, в этих двух параметрах можно использовать число с плавающей запятой в процентах. В то время как min_samples_split может создавать произвольно маленькие листья, min_samples_leaf гарантирует, что каждый лист имеет минимальный размер, избегая малодисперсных, чрезмерно подходящих листовых узлов в задачах регрессии. Для классификации с несколькими классами min_samples_leaf=1 это часто лучший выбор.
1.10.6. Алгоритмы дерева: ID3, C4.5, C5.0 и CART
Что представляют собой различные алгоритмы дерева решений и чем они отличаются друг от друга? Какой из них реализован в scikit-learn?
ID3 (Iterative Dichotomiser 3) был разработан Россом Куинланом в 1986 году. Алгоритм создает многостороннее дерево, находя для каждого узла (т. Е. Жадным образом) категориальный признак, который даст наибольший информационный выигрыш для категориальных целей. Деревья вырастают до максимального размера, а затем обычно применяется этап обрезки, чтобы улучшить способность дерева обобщать невидимые данные.
C4.5 является преемником ID3 и снял ограничение, что функции должны быть категориальными, путем динамического определения дискретного атрибута (на основе числовых переменных), который разбивает непрерывное значение атрибута на дискретный набор интервалов. C4.5 преобразует обученные деревья (т. Е. Результат алгоритма ID3) в наборы правил «если-то». Затем оценивается точность каждого правила, чтобы определить порядок, в котором они должны применяться. Удаление выполняется путем удаления предусловия правила, если без него точность правила улучшается.
C5.0 — это последняя версия Quinlan под частной лицензией. Он использует меньше памяти и создает меньшие наборы правил, чем C4.5, но при этом является более точным.
CART (Classification and Regression Trees — деревья классификации и регрессии) очень похож на C4.5, но отличается тем, что поддерживает числовые целевые переменные (регрессию) и не вычисляет наборы правил. CART строит двоичные деревья, используя функцию и порог, которые дают наибольший прирост информации в каждом узле.
scikit-learn использует оптимизированную версию алгоритма CART; однако реализация scikit-learn пока не поддерживает категориальные переменные.
1.10.7. Математическая постановка
Данные обучающие векторы $x_i \in R^n$, i = 1,…, l и вектор-метка $y \in R^l$ дерево решений рекурсивно разбивает пространство признаков таким образом, что образцы с одинаковыми метками или аналогичными целевыми значениями группируются вместе.
Пусть данные в узле m быть представлен $Q_m$ с участием $N_m$ образцы. Для каждого раскола кандидатов $\theta = (j, t_m)$ состоящий из функции $j$ и порог $t_m$, разделите данные на $Q_m^(\theta)$ а также $Q_m^(\theta)$ подмножества
$$Q_m^(\theta) = <(x, y) | x_j <= t_m>$$
$$Q_m^(\theta) = Q_m \setminus Q_m^(\theta)$$
Качество кандидата разделения узла $m$ затем вычисляется с использованием функции примеси или функции потерь $H()$, выбор которых зависит от решаемой задачи (классификация или регрессия)
$$G(Q_m, \theta) = \frac> H(Q_m^(\theta)) + \frac> H(Q_m^(\theta))$$
Выберите параметры, которые минимизируют примеси
$$\theta^* = \operatorname_\theta G(Q_m, \theta)$$
Рекурсия для подмножеств $Q_m^(\theta^*)$ а также $Q_m^(\theta^*)$ пока не будет достигнута максимально допустимая глубина, $N_m < \min_$ или же $N_m = 1$.
1.10.7.1. Критерии классификации
Если целью является результат классификации, принимающий значения 0,1,…, K-1, для узла m, позволять
$$p_ = 1/ N_m \sum_ I(y = k)$$
быть пропорцией наблюдений класса k в узле m. Еслиmявляется конечным узлом, predict_proba для этого региона установлено значение $p_$. Общие меры примеси следующие.
Энтропия:
$$H(Q_m) = — \sum_k p_ \log(p_)$$
Неверная классификация:
$$H(Q_m) = 1 — \max(p_)$$
1.10.7.2. Критерии регрессии
Если целью является непрерывное значение, то для узла m, общими критериями, которые необходимо минимизировать для определения местоположений будущих разделений, являются среднеквадратичная ошибка (ошибка MSE или L2), отклонение Пуассона, а также средняя абсолютная ошибка (ошибка MAE или L1). MSE и отклонение Пуассона устанавливают прогнозируемое значение терминальных узлов равным изученному среднему значению $\bar_m$ узла, тогда как MAE устанавливает прогнозируемое значение терминальных узлов равным медиане $median(y)_m$.
Половинное отклонение Пуассона:
$$H(Q_m) = \frac \sum_ (y \log\frac<\bar_m> — y + \bar_m)$$
Настройка criterion=»poisson» может быть хорошим выбором, если ваша цель — счетчик или частота (количество на какую-то единицу). В любом случае, y>=0 является необходимым условием для использования этого критерия. Обратите внимание, что он подходит намного медленнее, чем критерий MSE.
Обратите внимание, что он подходит намного медленнее, чем критерий MSE.
1.10.8. Обрезка с минимальными затратами и сложностью
Сокращение с минимальными затратами и сложностью — это алгоритм, используемый для сокращения дерева во избежание чрезмерной подгонки, описанный в главе 3 [BRE] . Этот алгоритм параметризован $\alpha\ge0$ известный как параметр сложности. Параметр сложности используется для определения меры затрат и сложности, $R_\alpha(T)$ данного дерева $T$:
$$R_\alpha(T) = R(T) + \alpha|\widetilde|$$
где $|\widetilde|$ количество конечных узлов в $T$ а также $R(T)$ традиционно определяется как общий коэффициент ошибочной классификации конечных узлов. В качестве альтернативы scikit-learn использует взвешенную общую примесь конечных узлов для $R(T)$. Как показано выше, примесь узла зависит от критерия. Обрезка с минимальными затратами и сложностью находит поддеревоT что сводит к минимуму $R_\alpha(T)$.
Оценка сложности стоимости одного узла составляет $R_\alpha(t)=R(t)+\alpha$. Ответвление $T_t$, определяется как дерево, в котором узел $t$ это его корень. В общем, примесь узла больше, чем сумма примесей его конечных узлов, $R(T_t)(t)=\frac<|T|-1>$. Нетерминальный узел с наименьшим значением $\alpha_$ является самым слабым звеном и будет удалено. Этот процесс останавливается, когда обрезанное дерево минимально $\alpha_$ больше ccp_alpha параметра.
- BRE Л. Брейман, Дж. Фридман, Р. Олшен и К. Стоун. Деревья классификации и регрессии. Уодсворт, Белмонт, Калифорния, 1984.
- https://en.wikipedia.org/wiki/Decision_tree_learning
- https://en.wikipedia.org/wiki/Predictive_analytics
- JR Quinlan. C4. 5: программы для машинного обучения. Морган Кауфманн, 1993.
- Т. Хасти, Р. Тибширани и Дж. Фридман. Элементы статистического обучения, Springer, 2009.
Если вы хотите помочь проекту с переводом, то можно обращаться по следующему адресу support@scikit-learn.ru
© 2007 — 2020, scikit-learn developers (BSD License).