Stream API
Начиная с JDK 8 в Java появился новый API — Stream API. Его задача — упростить работу с наборами данных, в частности, упростить операции фильтрации, сортировки и другие манипуляции с данными. Вся основная функциональность данного API сосредоточена в пакете java.util.stream .
Ключевым понятием в Stream API является поток данных . Вообще сам термин «поток» довольно перегружен в программировании в целом и в Java в частности. В одной из предыдущих глав рассматривалась работа с символьными и байтовыми потоками при чтении-записи файлов. Применительно к Stream API поток представляет канал передачи данных из источника данных. Причем в качестве источника могут выступать как файлы, так и массивы и коллекции.
Одной из отличительных черт Stream API является применение лямбда-выражений, которые позволяют значительно сократить запись выполняемых действий.
При ближайшем рассмотрении мы можем найти в других технологиях программирования аналоги подобного API. В частности, в языке C# некоторым аналогом Stream API будет технология LINQ.
Рассмотрим простейший пример. Допустим, у нас есть задача: найти в массиве количество всех чисел, которые больше 0. До JDK 8 мы бы могли написать что-то наподобие следующего:
int[] numbers = ; int count=0; for(int i:numbers) < if(i >0) count++; > System.out.println(count);
Теперь применим Stream API:
import java.util.stream.*; //. long count = IntStream.of(-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5).filter(w -> w > 0).count(); System.out.println(count);
Теперь вместо цикла и кучи условных конструкций, которые мы бы использовали до JDK 8, мы можем записать цепочку методов, которые будут выполнять те же действия.
При работе со Stream API важно понимать, что все операции с потоками бывают либо терминальными (terminal) , либо промежуточными (intermediate) . Промежуточные операции возвращают трансформированный поток. Например, выше в примере метод filter принимал поток чисел и возвращал уже преобразованный поток, в котором только числа больше 0. К возвращенному потоку также можно применить ряд промежуточных операций.
Конечные или терминальные операции возвращают конкретный результат. Например, в примере выше метод count() представляет терминальную операцию и возвращает число. После этого никаких промежуточных операций естественно применять нельзя.
Все потоки производят вычисления, в том числе в промежуточных операциях, только тогда, когда к ним применяется терминальная операция. То есть в данном случае применяется отложенное выполнение.
В основе Stream API лежит интерфейс BaseStream . Его полное определение:
interface BaseStream>
Здесь параметр T означает тип данных в потоке, а S — тип потока, который наследуется от интерфейса BaseStream.
BaseStream определяет базовый функционал для работы с потоками, которые реализуется через его методы:
- void close() : закрывает поток
- boolean isParallel() : возвращает true, если поток является параллельным
- Iterator iterator() : возвращает ссылку на итератор потока
- Spliterator spliterator() : возвращает ссылку на сплитератор потока
- S parallel() : возвращает параллельный поток (параллельные потоки могут задействовать несколько ядер процессора в многоядерных архитектурах)
- S sequential() : возвращает последовательный поток
- S unordered() : возвращает неупорядоченный поток
От интерфейса BaseStream наследуется ряд интерфейсов, предназначенных для создания конкретных потоков:
- Stream : используется для потоков данных, представляющих любой ссылочный тип
- IntStream : используется для потоков с типом данных int
- DoubleStream : используется для потоков с типом данных double
- LongStream : используется для потоков с типом данных long
При работе с потоками, которые представляют определенный примитивный тип — double, int, long проще использовать интерфейсы DoubleStream, IntStream, LongStream. Но в большинстве случаев, как правило, работа происходит с более сложными данными, для которых предназначен интерфейс Stream . Рассмотрим некоторые его методы:
- boolean allMatch(Predicate predicate) : возвращает true, если все элементы потока удовлетворяют условию в предикате. Терминальная операция
- boolean anyMatch(Predicate predicate) : возвращает true, если хоть один элемент потока удовлетворяют условию в предикате. Терминальная операция
- R collect(Collector collector) : добавляет элементы в неизменяемый контейнер с типом R. T представляет тип данных из вызывающего потока, а A — тип данных в контейнере. Терминальная операция
- long count() : возвращает количество элементов в потоке. Терминальная операция.
- Stream concat(Stream a, Stream b) : объединяет два потока. Промежуточная операция
- Stream distinct() : возвращает поток, в котором имеются только уникальные данные с типом T. Промежуточная операция
- Stream dropWhile(Predicate predicate) : пропускает элементы, которые соответствуют условию в predicate, пока не попадется элемент, который не соответствует условию. Выбранные элементы возвращаются в виде потока. Промежуточная операция.
- Stream filter(Predicate predicate) : фильтрует элементы в соответствии с условием в предикате. Промежуточная операция
- Optional findFirst() : возвращает первый элемент из потока. Терминальная операция
- Optional findAny() : возвращает первый попавшийся элемент из потока. Терминальная операция
- void forEach(Consumer action) : для каждого элемента выполняется действие action. Терминальная операция
- Stream limit(long maxSize) : оставляет в потоке только maxSize элементов. Промежуточная операция
- Optional max(Comparator comparator) : возвращает максимальный элемент из потока. Для сравнения элементов применяется компаратор comparator. Терминальная операция
- Optional min(Comparator comparator) : возвращает минимальный элемент из потока. Для сравнения элементов применяется компаратор comparator. Терминальная операция
- Stream map(Function mapper) : преобразует элементы типа T в элементы типа R и возвращает поток с элементами R. Промежуточная операция
- Stream flatMap(Function> mapper) : позволяет преобразовать элемент типа T в несколько элементов типа R и возвращает поток с элементами R. Промежуточная операция
- boolean noneMatch(Predicate predicate) : возвращает true, если ни один из элементов в потоке не удовлетворяет условию в предикате. Терминальная операция
- Stream skip(long n) : возвращает поток, в котором отсутствуют первые n элементов. Промежуточная операция.
- Stream sorted() : возвращает отсортированный поток. Промежуточная операция.
- Stream sorted(Comparator comparator) : возвращает отсортированный в соответствии с компаратором поток. Промежуточная операция.
- Stream takeWhile(Predicate predicate) : выбирает из потока элементы, пока они соответствуют условию в predicate. Выбранные элементы возвращаются в виде потока. Промежуточная операция.
- Object[] toArray() : возвращает массив из элементов потока. Терминальная операция.
Несмотря на то, что все эти операции позволяют взаимодействовать с потоком как неким набором данных наподобие коллекции, важно понимать отличие коллекций от потоков:
- Потоки не хранят элементы. Элементы, используемые в потоках, могут храниться в коллекции, либо при необходимости могут быть напрямую сгенерированы.
- Операции с потоками не изменяют источника данных. Операции с потоками лишь возвращают новый поток с результатами этих операций.
- Для потоков характерно отложенное выполнение. То есть выполнение всех операций с потоком происходит лишь тогда, когда выполняется терминальная операция и возвращается конкретный результат, а не новый поток.
Цикл foreach против Iterable.foreach в Java 8: что лучше?
У меня есть много циклов, которые могут быть упрощены с помощью лямбд, но есть ли какие-то реальные преимущества от использования Iterator.foreach ? Улучшится ли производительность и читабельность кода?
Отслеживать
Anton Sorokin
задан 22 фев 2019 в 8:33
Anton Sorokin Anton Sorokin
6,998 6 6 золотых знаков 37 37 серебряных знаков 65 65 бронзовых знаков
ассоциация: stackoverflow.com/questions/16635398/…
22 фев 2019 в 12:40
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
С точки зрения производительности нет никаких обещанных заметных преимуществ от использования Iterable.forEach по сравнению с foreach .
Performs the given action on the contents of the Iterable, in the order elements occur when iterating, until all elements have been processed or the action throws an exception.
Т.е. понятно, что не будет никакого явного параллелизма. Добавление параллелизма будет нарушением LSP.
Про читабельность кода: вы вероятно используете Iterable.foreach только с короткими однострочными лямбдами. Если «тело» лямбды увеличится, то читабельность скорее всего будет хуже, чем в цикле.
Примечание: этот ответ работает при использовании StreamAPI . Если используется только java.util.Iterable , то этот ответ перестает работать.
У вас будет сильное преимущество при параллельной обработке большого количества данных. Если вы хотите, что бы цикл выполнялся параллельно, то вы должны использовать такую конструкцию:
list.parallelStream().forEach(e -> e.operation); Однако использование не-параллельных стримов при обработке малого количества данных будет дольше, чем foreach и циклы.
Вывод:
- Между Iterable.foreach и циклом foreach в производительности разницы нет.
- Если тело лямбды будет небольшим, то лучше использовать Iterable.foreach .
- Если вы хотите прирост в производительности, то вам лучше использовать parallelStream.foreach() .
Разница между Collection.stream().forEach() и Collection.forEach()
В большинстве случаев оба дадут одинаковые результаты, но мы рассмотрим некоторые тонкие различия.
2. Простой список
Во-первых, давайте создадим список для повторения:
ListString> list = Arrays.asList("A", "B", "C", "D"); Самый простой способ — использовать расширенный цикл for:
for(String s : list) //do something with s > Если мы хотим использовать Java в функциональном стиле, мы также можем использовать forEach() .
Мы можем сделать это непосредственно в коллекции:
ConsumerString> consumer = s -> System.out::println >; list.forEach(consumer); Или мы можем вызвать forEach() для потока коллекции:
list.stream().forEach(consumer); Обе версии будут перебирать список и печатать все элементы:
ABCD ABCD В этом простом случае не имеет значения, какую функцию forEach() мы используем.
3. Порядок исполнения
Collection.forEach() использует итератор коллекции (если он указан), поэтому определяется порядок обработки элементов. Напротив, порядок обработки Collection.stream().forEach() не определен.
В большинстве случаев не имеет значения, какой из двух мы выберем.
3.1. Параллельные потоки
Параллельные потоки позволяют нам выполнять поток в несколько потоков, и в таких ситуациях порядок выполнения не определен. Java требует только завершения всех потоков перед вызовом какой-либо терминальной операции, такой как Collectors.toList() .
Давайте рассмотрим пример, в котором мы сначала вызываем forEach() непосредственно для коллекции, а затем — для параллельного потока:
list.forEach(System.out::print); System.out.print(" "); list.parallelStream().forEach(System.out::print); Если мы запустим код несколько раз, то увидим, что list.forEach() обрабатывает элементы в порядке вставки, а list.parallelStream().forEach() выдает разные результаты при каждом запуске.
Вот один из возможных выходов:
ABCD CDBA ABCD DBCA 3.2. Пользовательские итераторы
Давайте определим список с пользовательским итератором для перебора коллекции в обратном порядке:
class ReverseList extends ArrayListString> @Override public IteratorString> iterator() int startIndex = this.size() - 1; ListString> list = this; IteratorString> it = new IteratorString>() private int currentIndex = startIndex; @Override public boolean hasNext() return currentIndex >= 0; > @Override public String next() String next = list.get(currentIndex); currentIndex--; return next; > @Override public void remove() throw new UnsupportedOperationException(); > >; return it; > > Затем мы снова пройдемся по списку с помощью forEach() непосредственно в коллекции, а затем в потоке:
ListString> myList = new ReverseList(); myList.addAll(list); myList.forEach(System.out::print); System.out.print(" "); myList.stream().forEach(System.out::print); И получаем разные результаты:
DCBA ABCD Причина разных результатов заключается в том, что forEach() , используемый непосредственно в списке, использует пользовательский итератор, а stream().forEach() просто берет элементы из списка один за другим, игнорируя итератор.
4. Модификация коллекции
Многие коллекции (например , ArrayList или HashSet ) не должны изменяться структурно при их повторении. Если элемент будет удален или добавлен во время итерации, мы получим исключение ConcurrentModification .
Кроме того, коллекции рассчитаны на быстрый сбой, а это означает, что исключение генерируется, как только происходит модификация.
Точно так же мы получим исключение ConcurrentModification при добавлении или удалении элемента во время выполнения потокового конвейера. Однако исключение будет выброшено позже.
Еще одно тонкое различие между двумя методами forEach() заключается в том, что Java явно позволяет изменять элементы с помощью итератора. Потоки, напротив, не должны мешать друг другу.
Рассмотрим удаление и изменение элементов более подробно.
4.1. Удаление элемента
Давайте определим операцию, которая удаляет последний элемент («D») нашего списка:
ConsumerString> removeElement = s -> System.out.println(s + " " + list.size()); if (s != null && s.equals("A")) list.remove("D"); > >; Когда мы перебираем список, последний элемент удаляется после того, как напечатан первый элемент («A»):
list.forEach(removeElement); Поскольку forEach() работает без сбоев, мы останавливаем итерацию и видим исключение перед обработкой следующего элемента :
A 4 Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList.forEach(ArrayList.java:1252) at ReverseList.main(ReverseList.java:1) Давайте посмотрим, что произойдет, если вместо этого мы используем stream().forEach() :
list.stream().forEach(removeElement); Здесь мы продолжаем перебирать весь список, прежде чем увидим исключение :
A 4 B 3 C 3 null 3 Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1380) at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580) at ReverseList.main(ReverseList.java:1) Однако Java не гарантирует, что исключение ConcurrentModificationException будет выброшено вообще. Это означает, что мы никогда не должны писать программу, зависящую от этого исключения.
4.2. Изменение элементов
Мы можем изменить элемент во время итерации по списку:
list.forEach(e -> list.set(3, "E"); >); Но хотя нет проблем с выполнением этого с помощью Collection.forEach() или stream().forEach() , Java требует, чтобы операция над потоком не мешала. Это означает, что элементы не должны изменяться во время выполнения потокового конвейера.
Причина этого в том, что поток должен способствовать параллельному выполнению. Здесь изменение элементов потока может привести к неожиданному поведению.
5. Вывод
В этой статье мы видели несколько примеров, которые показывают тонкие различия между Collection.forEach() и Collection.stream().forEach() .
Важно отметить, что все приведенные выше примеры тривиальны и предназначены только для сравнения двух способов перебора коллекции. Мы не должны писать код, корректность которого зависит от показанного поведения.
Если нам не нужен поток, а нужно только перебирать коллекцию, первым выбором должно быть использование forEach() непосредственно в коллекции.
Исходный код примеров из этой статьи доступен на GitHub .
- 1. Обзор
- 2. Простой список
- 3. Порядок исполнения
- 3.1. Параллельные потоки
- 3.2. Пользовательские итераторы
- 4.1. Удаление элемента
- 4.2. Изменение элементов
Глубокое погружение в Stream API Java: Понимание и Применение
В этой статье мы погрузимся в мир Stream API, узнаем, что это такое и как этим пользоваться, разберем реальные примеры и советы по лучшим практикам.
7 июля 2023 · 18 минуты на чтение

Версия Java 8 принесла множество новшеств, которые значительно упростили обработку и манипулирование данными. Одним из таких нововведений стал Stream API — эффективный инструмент для обработки коллекций в функциональном стиле.
Спонсор поста
Зачем нужен Stream API?
В прошлом, при работе с коллекциями в Java, разработчики часто прибегали к циклам и условным операторам для фильтрации, преобразования или агрегации данных. Этот подход обычно требовал большого объема кода, был трудночитаемым и подвержен ошибкам. Возьмите, например, этот код:
public void printSpecies(List seaCreatures) < SetspeciesSet = new HashSet<>(); for (SeaCreature sc : seaCreatures) < if (sc.getWeight() >= 10) speciesSet.add(sc.getSpecies()); > List sortedSpecies = new ArrayList<>(speciesSet); Collections.sort(sortedSpecies, new Comparator() < public int compare (Species a, Species b) < return Integer.compare(a.getPopulation(), b.getPopulation()); >>); for (Species s : sortedSpecies) System.out.println(s.getName()); >Он выглядит довольно громоздким, несмотря на то, что не выполняет ничего сложного. Теперь взгляните на тот же пример, но с использованием Stream API:
public void printSpecies(List seaCreatures) < seaCreatures.stream() .filter(sc ->sc.getWeight() >= 10) .map(SeaCreature::getSpecies) .distinct() .sorted(Comparator.comparing(Species::getPopulation)) .map(Species::getName) .forEach(System.out::println); >С приходом Stream API картина радикально изменилась. Stream API обеспечивает функциональный стиль работы с данными, предлагая более компактный, выразительный и читаемый код, а также облегчая параллельное выполнение операций.
Основы Stream API
Stream API не предлагает решения для всех возможных сценариев обработки данных. Однако, большинство задач могут быть описаны следующим общим шаблоном:
- Источник данных.
- Выполнение преобразований.
- Сохранение результата в новую структуру данных.
Если ваша задача не соответствует этому шаблону, то, возможно, использование Stream API не будет оптимальным решением.
«Стримоз» головного мозга
Это условное заболевание может возникнуть у разработчиков, которые недавно узнали о существовании Stream API. Основной симптом — необузданное желание использовать Stream API для выполнения любых операций над коллекциями.
Пример из реального мира
Представьте, что Stream API — это конвейер на рыболовецком судне. Источник — это река, полная разнообразными морскими обитателями. Мы начинаем с этой «реки» и запускаем Stream, который можно сравнить с конвейером:
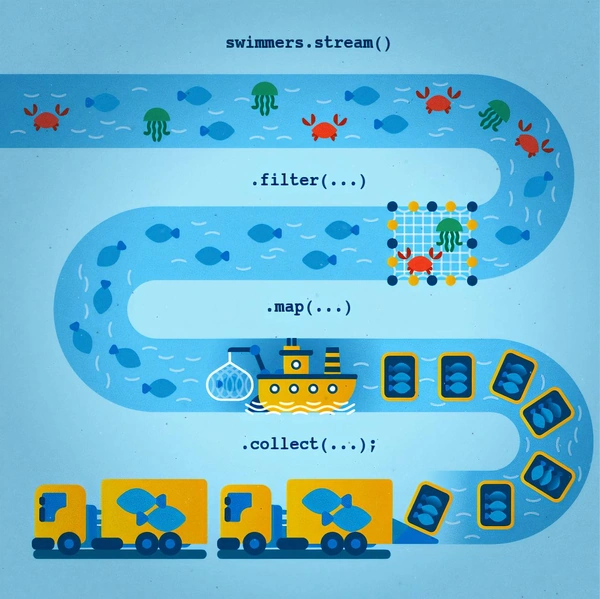
- Сначала мы используем filter() для отделения рыб от всех других морских существ. Это напоминает рыбаков, которые отбирают только нужные виды рыбы из всего множества разных созданий в реке.
- Затем, с помощью map() , мы преобразуем каждую рыбу в «упаковку с рыбой». Это подобно рыболовному сету, которое собирает рыбу и укладывает ее в контейнеры.
- В конце, с помощью collect() , мы складываем все упаковки с рыбой в «грузовик» для последующей транспортировки.
Все это происходит в рамках одного непрерывного процесса, или ‘потока’. Stream API позволяет нам обрабатывать каждый элемент коллекции эффективно и последовательно, подобно конвейеру на фабрике.
Компоненты Stream API
Stream API состоит из набора компонентов и концепций, которые работают вместе, чтобы обеспечить потоковую обработку данных.

- Источник (Source) — откуда приходят данные. Это может быть коллекция, массив, файл, генератор или любой другой источник данных.
- Операции — преобразовывают и/или обрабатывают данные.
- Поток (Stream) — последовательность элементов, подлежащих параллельной или последовательной обработке.
- Пайплайн (Pipeline) — последовательность операций в потоке, применяемых к данным.
- Терминал (Terminal) — место выхода данных из потока. Терминальная операция означает окончание обработки потока и возвращает результат.
Источники даных для потоков
Stream API способен работать с разнообразными источниками данных. Это могут быть коллекции, списки, наборы, массивы, строки, файлы или даже генераторы чисел. Все эти источники могут быть легко преобразованы в потоки для последующей обработки.
Важно отметить, что при выполнении Stream исходные данные не изменяются. В результате своей работы Stream создает новую структуру данных.

Spliterator используется в основе стримов в Java и играет важную роль при параллельной обработке данных, так как именно он отвечает за разделение данных на части для независимой обработки каждым потоком.
Методы Spliterator
Spliterator описывает 4 основных метода:
- long estimateSize() возвращает количество элементов.
- tryAdvance(Consumer) принимает функциональный интерфейс Consumer , который определяет действия, которые должны быть выполнены над текущим элементом.
- int characteristics() возвращает набор характеристик текущего сплитератора.
- Spliterator trySplit() пытается разделить текущий сплитератор на два. Если операция успешна, то возвращает новый сплитератор, и уменьшает размер исходного сплитератора. Если разделение не возможно, то возвращает null .
Характеристики Spliterator
Spliterator обладает специальными характеристиками, которые сообщают об особенностях источника данных, из которого он был создан. Эти характеристики помогают в оптимизации работы потока при выполнении терминальных операций. Например, нет смысла выполнять сортировку уже отсортированной коллекции.
- ORDERED : указывает, что элементы имеют определенный порядок.
- DISTINCT : указывает, что каждый элемент уникален. Определяется по equals() .
- SORTED : указывает, что элементы отсортированы.
- SIZED : указывает, что размер источника известен заранее.
- NONNULL : указывает, что ни один элемент не может быть null .
- IMMUTABLE : указывает, что элементы не могут быть модифицированы.
- CONCURRENT : указывает, что исходные данные могут быть модифицированы без воздействия на Spliterator .
- SUBSIZED : указывает, что размер разделенных Spliterator -ов также будет известен.
В зависимости от типа коллекции, из которой получен Spliterator , будут установлены разные характеристики. Например, для коллекции Collection будет установлен флаг SIZED , для Set добавится DISTINCT , а для SortedSet еще и SORTED .
Каждая операция может менять флаги характеристик. Это важно, поскольку каждый этап обработки данных будет знать об этих изменениях, что позволяет выполнить оптимальные действия. Например, операция map() сбросит флаги SORTED и DISTINCT , так как данные могут измениться, но всегда сохранит флаг SIZED , так как размер потока не изменяется при выполнении map() .
Параллельное выполнение
Stream API предоставляет возможность параллельной обработки данных, что может способствовать увеличению производительности на многоядерных процессорах. Однако необходимо учитывать, что параллельное выполнение может внести дополнительную сложность и накладные расходы, поэтому следует использовать его обдуманно.
Для выполнения потоков в параллельном режиме можно использовать методы parallelStream() или parallel() . Без явного вызова этих методов поток будет выполняться последовательно. Для разделения коллекции на части, которые могут быть обработаны отдельными потоками, Java использует метод Spliterator.trySplit() .
С точки зрения плана выполнения, параллельная обработка схожа с последовательной, за исключением одного основного отличия. Вместо одного набора связанных операций у нас будет несколько его копий, и каждый поток будет применять эти операции к своему сегменту элементов. После завершения обработки все результаты, полученные каждым потоком, объединяются в один общий результат.
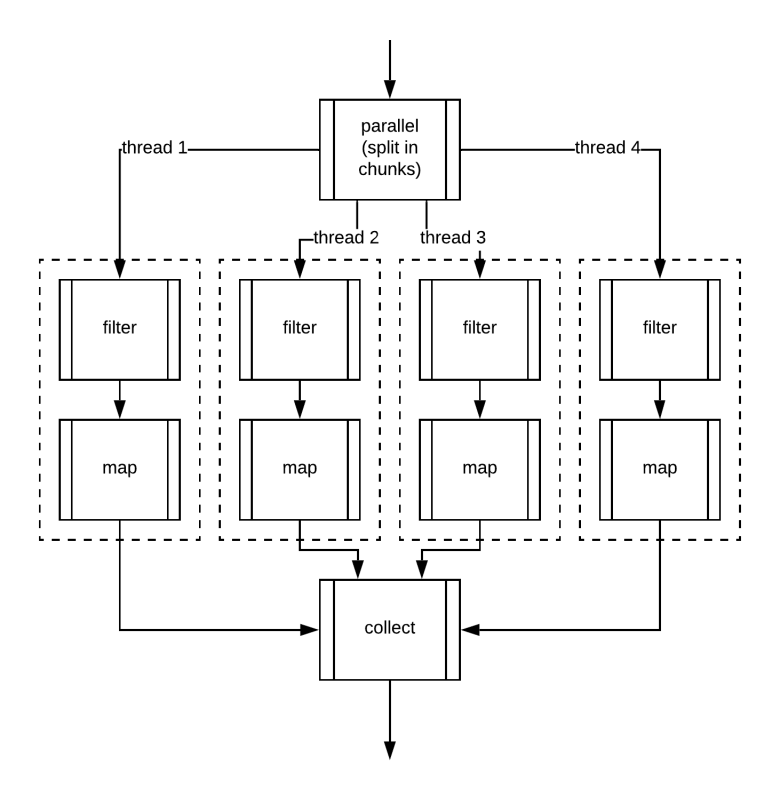
Место расположение .parallel() в Pipline
Может возникнуть вопрос, влияет ли расположение метода .parallel() в пайплайне на поведение потока?

В действительности, место, где указан .parallel() , не имеет значения, поскольку это просто устанавливает характеристику CONCURRENT . В свою очередь, sequential() удаляет эту характеристику.
Еще один важный аспект, который следует помнить о параллельных потоках, заключается в том, что Java назначает каждый фрагмент работы потоку в общем ForkJoinPool , аналогично тому, как это происходит в CompletableFuture .
Что же такое Stream?
Центральной концепцией Stream API является потоковые операции, представляющие собой ряд последовательных действий, выполняемых над данными.
Основные свойства потоков:
- Декларативность: Потоки в Java описывают, что должно быть сделано, а не конкретный способ его выполнения.
- Ленивость: Это означает, что потоки не выполняют никакой работы, пока не будет вызвана терминальная операция.
- Одноразовость: После того как терминальная операция была вызвана на потоке, этот поток больше не может быть использован. Если необходимо применить другую операцию к данным, потребуется новый поток.
- Параллельность: Несмотря на то, что потоки в Java по умолчанию выполняются последовательно, их можно легко распараллелить.
Рандомный блок
Методы Stream
Теперь, когда мы знаем, для чего нужны потоки и как они устроены изнутри, давайте рассмотрим все возможные способы работы со Stream API.
Создание Stream
Есть несколько способов создать поток с использованием Stream API. Например, вы можете создать поток из коллекции с помощью метода stream() или из массива с помощью метода of() . Как только у вас есть поток, вы можете выполнять различные операции с помощью методов, предоставляемых Stream API.
От коллекции
Вы можете создать поток из любой коллекции Java, например, списка или множества, с помощью метода stream() .
Этим способом вы будете создавать 90% своих стримов.
Collection list = new ArrayList<>(); Stream stream = list.stream();Из массива
Поток может быть создан из массива с помощью метода Arrays.stream() .
int[] numbers = ; Stream stream = Arrays.stream(numbers).boxed();Из строки
Поток может быть создан из строки с помощью метода chars() , который возвращает IntStream .
String str = "Hello"; IntStream stream = str.chars();Из файла
Поток может быть создан из строк файла с помощью метода Files.lines() .
Path path = Paths.get("file.txt"); Stream stream = Files.lines(path);Stream из Iterator-а
Многие источники данных хорошо делятся на части, что позволяет использовать преимущества параллельной обработки. Однако такие источники, как Files.lines() , Files.find() , Files.walk() , Files.list() , BufferedReader().lines() , Pattern.splitAsStream() , создают вначале Iterator , который затем трансформируется в Spliterator .
Проблема в том, что Iterator не содержит информации о размере исходного набора данных. Тем временем, для эффективной работы, Spliterator предполагает наличие информации о размере. Без этой информации Spliterator не может эффективно разбивать данные на части, что может привести к снижению эффективности параллелизма или даже к его полному отсутствию.
Генерирование
Поток может быть создан с помощью метода Stream.generate(Supplier) . Supplier должен возвращать новое значение при каждом вызове.
Stream stream = Stream.generate(() -> new Random().nextInt());Билдер
Поток может быть создан с помощью Stream.Builder .
Stream.Builder builder = Stream.builder(); builder.add(1); builder.add(2); builder.add(3); Stream stream = builder.build();Промежуточные методы
Мы разобрались с большинством методов создания стрима. Теперь давайте рассмотрим методы для обработки элементов.
filter(Predicate)
Этот метод используется для создания нового потока, включающего только элементы, которые удовлетворяют определенному условию. В качестве аргумента метод принимает функциональный интерфейс Predicate , задающий условие фильтрации.
Вот пример использования метода filter() для создания нового потока, который включает только четные числа из списка целых чисел.
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); Stream evenNumbersStream = numbers.stream() .filter(n -> n % 2 == 0); evenNumbersStream.forEach(System.out::println); // prints 2, 4, 6, 8, 10ORDERED : обычно сохраняется.
DISTINCT , SORTED , NONNULL , IMMUTABLE , CONCURRENT : сохраняются, если были в исходном Spliterator .
SIZED , SUBSIZED : теряются, поскольку количество элементов после фильтрации неизвестно.map(Function)
Метод map() принимает в качестве аргумента функциональный интерфейс Function , задающий преобразование, применяемое к каждому элементу. Возвращаемый поток содержит преобразованные элементы.
Метод map() возвращает новый поток. Он не изменяет исходный поток и коллекцию. Обычно он используется для выполнения операций, таких как преобразование элементов из одного типа в другой.
List words = Arrays.asList("apple", "banana", "orange", "peach"); Stream lengthsStream = words.stream() .map(String::length); lengthsStream.forEach(System.out::println); // prints 5, 6, 6, 5В данном примере мы с помощью map() преобразовали строку в количество символов в строке, используя короткую запись лямбды ( String::length ), так называемую ссылку на метод.
ORDERED : обычно сохраняется.
DISTINCT , SORTED : могут быть потеряны.
SIZED , SUBSIZED : обычно сохраняются.
NONNULL : может быть потеряно.
IMMUTABLE , CONCURRENT : сохраняются.flatMap()
Метод flatMap() используется для создания одного потока из множества потоков. Он принимает функцию в качестве аргумента, которая применяется к каждому элементу исходного потока. Эта функция принимает элемент исходного потока и возвращает новый поток.
List> listOfLists = Arrays.asList( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9) ); Stream flattenedStream = listOfLists.stream() .flatMap(Collection::stream); flattenedStream.forEach(System.out::println); // prints 1, 2, 3, 4, 5, 6, 7, 8, 9В данном примере мы начинаем со списка списков целых чисел и создаем поток с помощью метода stream() . Затем мы используем метод flatMap() для создания нового потока, включающего все целые числа из вложенных списков, путем применения метода stream() к каждому из вложенных списков. Наконец, мы используем метод forEach() для вывода каждого элемента нового потока.
Влияние на характеристики:
ORDERED : обычно сохраняется.
DISTINCT , SORTED : обычно теряются.
SIZED , SUBSIZED : теряются.
NONNULL : может быть потеряно.
IMMUTABLE , CONCURRENT : сохраняются.Разница между map() и flatMap()
Функция map() преобразует элемент исходного потока из одного типа в другой. В отличие от этого, функция flatMap() позволяет получить новый поток из элементов коллекций, которые были внутри элементов первого потока.
distinct()
Метод distinct() возвращает новый поток, содержащий только уникальные элементы исходного потока. Дубликаты определяются на основе их естественного порядка или с использованием переданного компаратора.
Вот пример, в котором функция distinct() используется для удаления дубликатов из потока целых чисел:
List numbers = Arrays.asList(1, 2, 3, 2, 1, 4, 5, 3, 5); List uniqueNumbers = numbers.stream() .distinct() .collect(Collectors.toList()); System.out.println(uniqueNumbers); // prints [1, 2, 3, 4, 5]ORDERED : обычно сохраняется.
DISTINCT : всегда устанавливается после операции.
SORTED : сохраняется, если исходный Spliterator был SORTED.
SIZED , SUBSIZED : теряются, поскольку количество уникальных элементов неизвестно.
NONNULL , IMMUTABLE , CONCURRENT : сохраняются.limit(n)
Метод limit(n) возвращает новый поток, содержащий не более n элементов исходного потока. Если исходный поток содержит меньше n элементов, новый поток будет содержать все элементы исходного потока.
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); List limitedNumbers = numbers.stream() .limit(5) .collect(Collectors.toList()); System.out.println(limitedNumbers); // prints [1, 2, 3, 4, 5]ORDERED : сохраняется, если исходный Spliterator был упорядочен.
DISTINCT , SORTED , NONNULL , IMMUTABLE , CONCURRENT : сохраняются, если были в исходном Spliterator .
SIZED , SUBSIZED : могут быть установлены, если размер исходного стрима был известен и больше значения limit() , иначе могут быть потеряны.skip(n)
Метод skip(n) возвращает новый поток, который содержит все элементы исходного потока, исключая первые n элементов. Если исходный поток содержит меньше n элементов, новый поток будет пустым.
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); List skippedNumbers = numbers.stream() .skip(5) .collect(Collectors.toList()); System.out.println(skippedNumbers); // prints [6, 7, 8, 9, 10]ORDERED : сохраняется, если исходный Spliterator был упорядочен.
DISTINCT , SORTED , NONNULL , IMMUTABLE , CONCURRENT : сохраняются, если были в исходном Spliterator .
SIZED , SUBSIZED : могут быть потеряны, если количество пропускаемых элементов неизвестно или исходный Spliterator не был SIZED или SUBSIZED . Если размер исходного стрима известен и больше значения skip, эти характеристики сохраняются.sorted()
Метод sorted() создает новый поток, содержащий элементы исходного потока, отсортированные в порядке возрастания.
При вызове метода sorted() возвращается новый поток, содержащий те же элементы, что и исходный поток, но в отсортированном порядке.
List names = Arrays.asList("Alice", "Bob", "Charlie", "David"); List sortedNames = names.stream() .sorted() .collect(Collectors.toList()); System.out.println(sortedNames); // prints ["Alice", "Bob", "Charlie", "David"]Если элементы исходного потока не реализуют интерфейс Comparable , может возникнуть исключение ClassCastException . Чтобы избежать этого, можно предоставить собственный компаратор в качестве аргумента метода sorted() .
ORDERED : всегда устанавливается после операции sorted() , так как элементы теперь упорядочены в соответствии с естественным порядком или порядком, определенным компаратором.
DISTINCT : сохраняется, если был в исходном Spliterator .
SORTED : всегда устанавливается.
SIZED , SUBSIZED : сохраняются, если были в исходном Spliterator .
NONNULL : сохраняется, если был в исходном Spliterator .
IMMUTABLE , CONCURRENT : сохраняются, если были в исходном Spliterator .takeWhile(Predicate)
Метод takeWhile() создает новый поток, содержащий элементы исходного потока до тех пор, пока они удовлетворяют указанному условию. Если первый элемент потока не соответствует предикату, новый поток будет пустым.
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); List takenNumbers = numbers.stream() .takeWhile(n -> n < 5) .collect(Collectors.toList()); System.out.println(takenNumbers); // prints [1, 2, 3, 4]ORDERED : сохраняется, если исходный Spliterator был упорядочен.
DISTINCT , SORTED , NONNULL , IMMUTABLE , CONCURRENT : сохраняются, если были в исходном Spliterator.
SIZED , SUBSIZED : могут быть потеряны, поскольку количество элементов после takeWhile() неизвестно.dropWhile(Predicate)
Метод dropWhile() возвращает новый поток, который включает все элементы исходного потока, начиная с первого элемента, не удовлетворяющего указанному условию. В момент, когда предикат возвращает false , все последующие элементы из исходного потока включаются в новый поток.
List numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10); List droppedNumbers = numbers.stream() .dropWhile(n -> n < 5) .collect(Collectors.toList()); System.out.println(droppedNumbers); // prints [5, 6, 7, 8, 9, 10]ORDERED : сохраняется, если исходный Spliterator был упорядочен.
DISTINCT , SORTED , NONNULL , IMMUTABLE , CONCURRENT : сохраняются, если были в исходном Spliterator.
SIZED , SUBSIZED : могут быть потеряны, поскольку количество элементов после takeWhile() неизвестно.peek(Consumer)
Метод peek() создает новый поток, идентичный исходному, но с дополнительной операцией, применяемой к каждому элементу при его прохождении по конвейеру потока.
List numbers = Arrays.asList(1, 2, 3, 4, 5); numbers.stream() .peek(System.out::println) .collect(Collectors.toList());В данном примере, метод peek() применяется к потоку чисел. Consumer , переданный в метод peek() , выводит каждый элемент на консоль. В процессе этого, каждый элемент, проходя по конвейеру потока, отображается на консоли, но сам поток остается неизменным.
Метод peek() удобен, когда необходимо выполнить дополнительные операции с элементами потока, например, для целей логирования, отладки или профилирования, не меняя при этом сами элементы. Но важно быть осторожным с его использованием, так как неправильное применение метода peek() может привести к нежелательным последствиям.
Поскольку peek() – это промежуточная операция, которая не предназначена для изменения элементов потока, непреднамеренные изменения могут вызвать непредсказуемые результаты при параллельном выполнении потока.
В общем случае, рекомендуется использовать peek() редко и, преимущественно, для отладки, а не как средство модификации элементов потока. Если требуется изменить элементы потока, предпочтительнее использовать метод map() .
На моей практике был всего 1 случай, когда реализовать по другому было невозможно и пришлось использовать peek() .
Терминальные методы
Как упоминалось ранее, терминальный метод запускает обработку всего потока. Рассмотрим основные из таких методов.
forEach(Consumer)
Этот метод не рекомендуется использовать в продакшене, так как он не возвращает результат. Это означает, что у него может быть только побочный эффект. Например, если мы начинаем собирать данные с помощью метода forEach() , а затем кто-то применяет параллельное выполнение к стриму, мы тут же столкнемся со всеми проблемами синхронизации.

Класс Collectors содержит набор статических методов-коллекторов, которые упрощают выполнение общих операций, таких как преобразование элементов в списки, множества и другие структуры данных.
Вот некоторые наиболее популярные методы класса Collectors :
- toList() : Этот метод возвращает коллектор, который накапливает входные элементы в новый List .
- toSet() : Этот метод возвращает коллектор, который накапливает входные элементы в новый Set .
- joining() : Возвращает коллектор, который объединяет элементы потока в единую строку.
- counting() : Возвращает коллектор, который подсчитывает количество элементов в потоке.
Вы можете быстро реализовать метод collect(Collector collector) для сбора элементов в какую-то конкретную структуру.
Stream stream; List list = stream.collect(Collectors.toList()); //Коллектор выше аналогичен данному коду list = stream.collect( () -> new ArrayList<>(), // определяем структуру (list, t) -> list.add(t), // определяем, как добавлять элементы (l1, l2) -> l1.addAll(l2) // и как объединять две структуры в одну );reduce()
Метод reduce() применяется для комбинирования элементов потока в одно значение. Он отличается от метода collect() тем, что использует ассоциативную функцию, принимающую два значения и объединяющую их в одно. Например, метод reduce() можно использовать для суммирования чисел или для нахождения максимального или минимального числа.
Optional findAny()
Метод findAny() может оказаться полезным в ситуациях, когда вам нужно получить любой элемент из потока без конкретного предпочтения.
В отличие от findFirst() , который всегда возвращает первый найденный элемент потока, findAny() , при параллельном выполнении потока, может возвращать любой элемент, поскольку выбор элемента зависит от того, какой поток обработает его первым.
boolean anyMatch(Predicate)
Метод anyMatch(Predicate) используется для проверки, соответствует ли хотя бы один элемент потока указанному предикату.
boolean allMatch(Predicate)
Возвращает true , если все элементы потока удовлетворяют предикату.
Short-circuiting
Рассмотрим так называемые операции "короткого замыкания", которые прекращают обработку, как только находят нужный результат. Это значительно повышает производительность, особенно при работе с большими потоками данных. Примерами операций короткого замыкания могут служить методы anyMatch() , allMatch() , noneMatch() , findFirst() , findAny() .
Важно отметить, что поведение операций короткого замыкания может изменяться в зависимости от того, является ли поток параллельным или последовательным. Например, в параллельном потоке метод findAny() может вернуть любой элемент, удовлетворяющий условию, вместо первого попавшегося, как это происходит в последовательном потоке.
Продвинутые советы и использование
В этом разделе будут собраны различные продвинутые подходы для работы со Stream API.
Возвращать Stream вместо коллекций
Это позволит защитить вашу коллекцию внутри сущности, не позволяя ее модифицировать извне.
Так же потребитель вашего API сможет сам выбрать, какая коллекция ему нужна.

Группировка элементов
Чтобы сгруппировать данные по какому-нибудь признаку, нам надо использовать метод collect() и метод Collectors.groupingBy() .
Этот раздел "честно" позаимствован из этой статьи на хабре, чтобы сохранить эту шпаргалку у себя, если автор скроет статью или что-то случится с хабром.
Группировка списка рабочих по их должности (деление на списки)
Map> map1 = workers.stream() .collect(Collectors.groupingBy(Worker::getPosition));Группировка списка рабочих по их должности (деление на множества)
Map> map2 = workers.stream() .collect( Collectors.groupingBy( Worker::getPosition, Collectors.toSet() ) );Подсчет количества рабочих, занимаемых конкретную должность
Map map3 = workers.stream() .collect( Collectors.groupingBy( Worker::getPosition, Collectors.counting() ) );Группировка списка рабочих по их должности, при этом нас интересуют только имена
Map> map4 = workers.stream() .collect( Collectors.groupingBy( Worker::getPosition, Collectors.mapping( Worker::getName, Collectors.toSet() ) ) );Расчет средней зарплаты для данной должности
Map map5 = workers.stream() .collect( Collectors.groupingBy( Worker::getPosition, Collectors.averagingInt(Worker::getSalary) ) );Группировка списка рабочих по их должности, рабочие представлены только именами единой строкой
Map map6 = workers.stream() .collect( Collectors.groupingBy( Worker::getPosition, Collectors.mapping( Worker::getName, Collectors.joining(", ", "") ) ) );Группировка списка рабочих по их должности и по возрасту.
Map>> collect = workers.stream() .collect( Collectors.groupingBy( Worker::getPosition, Collectors.groupingBy(Worker::getAge) ) );Заключение
В целом, Stream API в Java — это мощный инструмент для обработки данных, который может кардинально изменить ваш подход к программированию. Он позволяет организовывать код в читаемые и компактные последовательности операций, что делает его идеальным для работы с большими объемами данных.
Вместе с тем, важно помнить, что он не подходит для всех задач. Если ваша задача не соответствует шаблону "источник-преобразование-сбор", возможно, стоит обратиться к другим инструментам Java.
В любом случае, понимание и умение использовать Stream API является важным навыком для каждого разработчика на Java, и безусловно, этот инструмент заслуживает времени, уделенного на его изучение.