Полное руководство по линейной регрессии в Python
Линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между одной или несколькими предикторными переменными и переменной отклика.
В этом руководстве объясняется, как выполнить линейную регрессию в Python.
Пример: линейная регрессия в Python
Предположим, мы хотим знать, влияет ли количество часов, потраченных на учебу, и количество сданных подготовительных экзаменов на оценку, которую студент получает на определенном экзамене.
Чтобы изучить эту связь, мы можем выполнить следующие шаги в Python, чтобы провести множественную линейную регрессию.
Шаг 1: Введите данные.
Во-первых, мы создадим DataFrame pandas для хранения нашего набора данных:
import pandas as pd #create data df = pd.DataFrame() #view data df hours exams score 0 1 1 76 1 2 3 78 2 2 3 85 3 4 5 88 4 2 2 72 5 1 2 69 6 5 1 94 7 4 1 94 8 2 0 88 9 4 3 92 10 4 4 90 11 3 3 75 12 6 2 96 13 5 4 90 14 3 4 82 15 4 4 85 16 6 5 99 17 2 1 83 18 1 0 62 19 2 1 76 Шаг 2: Выполните линейную регрессию.
Далее мы будем использовать функцию OLS() из библиотеки statsmodels для выполнения обычной регрессии методом наименьших квадратов, используя «часы» и «экзамены» в качестве переменных-предикторов и «оценку» в качестве переменной ответа:
import statsmodels.api as sm #define response variable y = df['score'] #define predictor variables x = df[['hours', 'exams']] #add constant to predictor variables x = sm.add_constant(x) #fit linear regression model model = sm.OLS(y, x).fit() #view model summary print(model.summary()) OLS Regression Results ============================================================================== Dep. Variable: score R-squared: 0.734 Model: OLS Adj. R-squared: 0.703 Method: Least Squares F-statistic: 23.46 Date: Fri, 24 Jul 2020 Prob (F-statistic): 1.29e-05 Time: 13:20:31 Log-Likelihood: -60.354 No. Observations: 20 AIC: 126.7 Df Residuals: 17 BIC: 129.7 Df Model: 2 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 67.6735 2.816 24.033 0.000 61.733 73.614 hours 5.5557 0.899 6.179 0.000 3.659 7.453 exams -0.6017 0.914 -0.658 0.519 -2.531 1.327 ============================================================================== Omnibus: 0.341 Durbin-Watson: 1.506 Prob(Omnibus): 0.843 Jarque-Bera (JB): 0.196 Skew: -0.216 Prob(JB): 0.907 Kurtosis: 2.782 Cond. No. 10.8 ============================================================================== Шаг 3: Интерпретируйте результаты.
Вот как интерпретировать наиболее релевантные числа в выводе:
R-квадрат: 0,734.Это известно как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена переменными-предикторами. В этом примере 73,4% вариаций в экзаменационных баллах можно объяснить количеством часов обучения и количеством сданных подготовительных экзаменов.
F-статистика: 23,46.Это общая F-статистика для регрессионной модели.
Вероятность (F-статистика): 1,29e-05. Это p-значение, связанное с общей F-статистикой. Он говорит нам, является ли регрессионная модель в целом статистически значимой. Другими словами, он говорит нам, имеют ли объединенные две предикторные переменные статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на то, что переменные-предикторы «учебные часы» и «пройденные подготовительные экзамены» в совокупности имеют статистически значимую связь с экзаменационным баллом.
coef: коэффициенты для каждой переменной-предиктора говорят нам о среднем ожидаемом изменении переменной отклика, предполагая, что другая переменная-предиктор остается постоянной. Например, ожидается, что за каждый дополнительный час, потраченный на учебу, средний экзаменационный балл увеличится на 5,56 при условии, что количество сданных подготовительных экзаменов останется неизменным.
Вот еще один способ подумать об этом: если учащийся A и учащийся B сдают одинаковое количество подготовительных экзаменов, но учащийся A учится на один час больше, то ожидается, что учащийся A наберет на 5,56 балла больше, чем учащийся B.
Мы интерпретируем коэффициент для перехвата как означающий, что ожидаемая оценка экзамена для студента, который учится ноль часов и сдает нулевые подготовительные экзамены, составляет 67,67 .
Р>|т|. Отдельные p-значения говорят нам, является ли каждая предикторная переменная статистически значимой. Мы видим, что «часы» статистически значимы (p = 0,00), а «экзамены»(p = 0,52) не является статистически значимым при α = 0,05. Поскольку «экзамены» не являются статистически значимыми, мы можем решить исключить их из модели.
Расчетное уравнение регрессии: мы можем использовать коэффициенты из выходных данных модели, чтобы создать следующее расчетное уравнение регрессии:
экзаменационный балл = 67,67 + 5,56*(часы) – 0,60*(подготовительные экзамены)
Мы можем использовать это оценочное уравнение регрессии, чтобы рассчитать ожидаемый балл экзамена для учащегося на основе количества часов, которые он изучает, и количества подготовительных экзаменов, которые он сдает. Например, студент, который занимается три часа и сдает один подготовительный экзамен, должен получить 83,75 балла:
Имейте в виду, что, поскольку пройденные подготовительные экзамены не были статистически значимыми (p = 0,52), мы можем решить удалить их, поскольку они не улучшают общую модель. В этом случае мы могли бы выполнить простую линейную регрессию, используя только изученные часы в качестве переменной-предиктора.
Шаг 4: Проверьте предположения модели.
После выполнения линейной регрессии есть несколько предположений, которые вы можете проверить, чтобы убедиться, что результаты регрессионной модели надежны. Эти предположения включают:
Предположение № 1: существует линейная связь между переменными-предикторами и переменной-откликом.
- Проверьте это предположение, сгенерировавграфик остатков , который отображает подогнанные значения в сравнении с остаточными значениями для регрессионной модели.
Допущение № 2: Независимость остатков.
- Проверьте это предположение, выполнив тест Дарбина-Ватсона .
Допущение № 3: гомоскедастичность остатков.
- Проверьте это предположение, выполнив тест Бреуша-Пагана .
Допущение № 4: Нормальность остатков.
- Проверьте это предположение визуально, используя график QQ .
- Проверьте это предположение с помощью формальных тестов, таких как тест Харка-Бера или тестАндерсона-Дарлинга .
Предположение № 5: Убедитесь, что мультиколлинеарность не существует среди переменных-предикторов.
- Проверьте это предположение, рассчитав значение VIF каждой переменной-предиктора.
Если эти предположения выполняются, вы можете быть уверены, что результаты вашей модели множественной линейной регрессии надежны.
Вы можете найти полный код Python, использованный в этом руководстве , здесь .
Регрессионные модели в Python

Регрессия — это один из главных методов прогнозного моделирования и работы с data mining. Он позволяет установить связь между переменными, чтобы прогнозировать развитие какого-либо явления в будущем. Например, таким образом можно узнать, сколько товаров продаст магазин в ближайшие месяцы, как изменения цены повлияют на приток покупателей, какая доля сотрудников может уволиться из компании. Про линейную и логистическую регрессию знают даже начинающие аналитики. Остальные функции этого класса реже оказываются на слуху, но настоящему профессионалу в области Data Science обязательно нужно знать, что они из себя представляют и для чего используются. Эти знания будут полезны и frontend-программистам, веб-разработчикам и всем, кто работает с данными в Python.

Освойте профессию
«Fullstack-разработчик на Python»
Fullstack-разработчик на Python
Fullstack-разработчики могут в одиночку сделать IT-проект от архитектуры до интерфейса. Их навыки востребованы у работодателей, особенно в стартапах. Научитесь программировать на Python и JavaScript и создавайте сервисы с нуля.

Профессия / 12 месяцев
Fullstack-разработчик на Python
Создавайте веб-проекты самостоятельно
4 490 ₽/мес 7 483 ₽/мес

Сегодня мы устроим краткую экскурсию по разным видам регрессии, познакомимся с их возможностями и особенностями применения. Добавляйте эту статью в свою коллекцию шпаргалок и поехали. Инструменты для применения этих моделей в Python реализованы в библиотеках NumPy, scikit-learn, statsmodels.
Линейная регрессия
Начнем с самой простой модели, которая используется, если отношения между переменными линейны по своей природе. Например, линейная регрессия подскажет, сколько операторов колл-центра справятся с нагрузкой в горячий сезон или как пробег машины влияет на частоту ремонтов. Если у вас одна независимая переменная (дескриптор), вы имеете дело с простой линейной регрессией. Если независимых переменных две и более, то это множественная линейная регрессия. Главная особенность линейной регрессии в отсутствии выпадающих из общего тренда значений зависимой переменной и минимальном разбросе результатов. Кроме того, в этом случае между независимыми переменными нет взаимосвязи.
Читайте также Кому и для чего нужен Python?
Логистическая регрессия
Вторая по популярности модель используется в тех случаях, когда зависимая переменная бинарна по своей природе, то есть попадает в одну из двух категорий. Например, вы хотите узнать, как те или иные факторы влияют на решение пользователя закрыть сайт или остаться на странице. Или вам нужно оценить шансы на успех у нескольких участников выборов (выиграет/не выиграет). Логистическую регрессию можно также применять, если конечных вариантов больше двух. Скажем, вам нужно распределить учеников между гуманитарным, техническим и естественно-биологическим классами, используя результаты школьных экзаменов. В этом случае мы говорим о мультиномиальной, или множественной логистической регрессии.

Станьте Fullstack-разработчик на Python и найдите стабильную работу
на удаленке
Полиномиальная регрессия
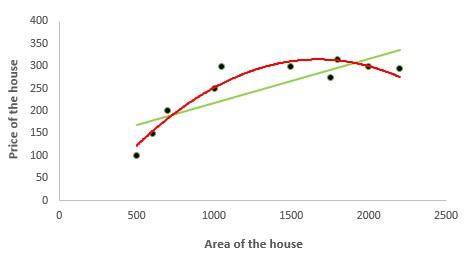
Эта техника позволяет работать с нелинейными уравнениями, используя целые рациональные (полиномиальные) функции независимых переменных. Чтобы понять разницу между полиномиальной и линейной регрессией, взгляните на график ниже. Красная кривая гораздо лучше описывает поведение зависимой переменной, поскольку ее отношения с дескриптором нелинейны. Полиномиальная регрессия помогает аналитикам и разработчикам решить проблему недообучения (underfitting), когда модель не охватывает значительную часть результатов. С другой стороны, нужно помнить, что неуместное применение этой техники или добавление ненужных, излишних характеристик создает риски переобучения (overfitting), из-за чего модель, которая показывает хорошие результаты на тренировочном сете окажется неприменима для работы с реальными данными.
Квантильная регрессия
Этот метод применяется, когда в данных присутствуют сильные искажения, часто встречаются выпадающие значения и случайные ошибки. Другими словами, если среднее значение, с которым работает линейная регрессия, неточно отражает взаимосвязь между переменными. В этих случаях квантильная регрессия позволяет ввести в расчеты целевую погрешность, или задать квантили — значения, которое результирующие переменные не будут превышать. Для применения квантильной регрессии в Python вам понадобится пакет statsmodels. С его помощью вы сможете анализировать информацию с помощью настраиваемых квантилей, получая возможность смотреть на данные под разными углами.
Лассо-регрессия / Ридж-регрессия
- L1-регуляризация — добавляет штраф к сумме абсолютных значений коэффициентов. Этот метод используется в лассо-регрессии.
- L2-регуляризация — добавляет штраф к сумме квадратов коэффициентов. Этот метод используется в ридж-регрессии.
В большинстве случаев исследователи и разработчики предпочитают L2-функцию — она эффективнее с точки зрения вычислительных функций. С другой стороны, лассо-регрессия позволяет уменьшить значения некоторых коэффициентов до 0, то есть вывести из поля исследования лишние переменные. Это полезно, если на какое-либо явление влияют тысячи факторов и рассматривать все их оказывается бессмысленно.
Оба метода регуляризации объединены в технике эластичной сети. Она оптимально подходит, когда независимые переменные сильно коррелированы между собой. В этих случаях модель сможет попеременно применять L1- и L2-функции, в зависимости от того, какая лучше подходит с учетом входных данных.
Метод главных компонент
Анализ главных компонент (Principal Components Analysis) — это еще один способ уменьшить размерность данных. Он построен на создании ключевых независимых переменных, которые оказывают наибольшее влияние на функцию. Таким образом можно построить регрессионную модель на основе сильно зашумленных данных. На первом этапе аналитик определяет среди них главные компоненты, далее применяет к ним необходимую функцию.
Важно понимать, что основные компоненты, с которыми аналитик работает в этом случае, фактически представляют собой функцию остальных характеристик. Именно поэтому мы говорим о создании ключевых переменных, а не вычленении их из общего числа. По этой причине применение PCA не подходит для объяснения фактических связей между переменными — это скорее создание имитационной модели на основе известных данных о том или ином явлении.
Регрессия наименьших частичных квадратов
В отличие от предыдущей техники, метод наименьших частичных квадратов (Partial Least Squares, PLS) принимает во внимание зависимую переменную. Это позволяет строить модели с меньшим количеством компонентов, что очень удобно в тех случаях, если количество предикторов сильно превышает количество зависимых переменных или если первые оказываются сильно коррелированы.
Технически PLS сильно напоминает PCR — сначала определяются скрытые факторы, которые объясняют взаимосвязь переменных, затем по этим данным выстраивается прогноз.
Порядковая регрессия
Этот метод позволяет изучать явления в привязке к значениям каких-либо шкал. Например, когда речь идет об отношениях пользователей к дизайну сайта — от “совсем не нравится” до “очень нравится”. Или в медицинских исследованиях таким образом можно понять, как меняются ощущения пациентов (от “очень сильной боли” до “совсем нет боли”).
Почему для этого нельзя применять линейную регрессию? Потому что она не учитывает смысловую разницу между разными разрядами шкалы. Возьмем для примера трех людей ростом в 175 см и весом в 55, 70 и 85 кг. 15 килограммов, на которые самый худой и самый тучный человек отстоят от участника со средним показателем, для линейной функции имеют одинаковое значение. А с точки зрения социологии и медицины это разница между ожирением, дистрофичностью и нормальным весом.
Регрессия Пуассона / Отрицательная биноминальная регрессия
Еще две техники, которые используются для особых ситуаций, в данном случае — когда вам нужно пересчитать некие события, которые произойдут независимо друг от друга на протяжении заданного промежутка времени. Например, спрогнозировать количество походов покупателей в магазин за каким-то конкретным продуктом. Или количество критических ошибок на корпоративных компьютерах. Такие явления происходят в соответствии с распределением Пуассона, откуда техника и получила свое название.
Недостатком этого метода является то, что при его использовании распределение зависимых переменных оказывается равным их средним значениям. В реальности аналитики нередко сталкиваются с высокой дисперсией наблюдаемых явлений, которая значительно отличается средних показателей. Для таких моделей используется отрицательная биноминальная регрессия.
Специфика этих регрессий обуславливает определенные требования к зависимым переменным: они должны выражаться целыми, положительными числами.
Регрессия Кокса
Последняя в нашей подборке модель используется для оценки времени до определенного события. Какова вероятность, что сотрудник проработает в компании 10 лет? Сколько гудков готов ждать клиент, прежде чем положит трубку? Когда у пациента наступит следующий кризис?
Модель работает на основе двух параметров: один отражает течение времени, второй, бинарный показатель определяет, случилось событие или нет. Это напоминает механику логистической регрессии, однако та техника не использует время. Основополагающие предположения для регрессии Кокса состоят в том, что между независимыми переменными нет корреляции и все они линейно влияют на ожидаемое событие. Кроме того, в любой отрезок времени вероятность наступления события для любых двух объектов должна быть пропорциональна.
Это не полный список регрессий, которые доступны разработчикам и аналитикам в Python. Однако даже этот перечень дает представление о том, какие возможности для изучения самых разных данных открывает этот язык.
Простая линейная регрессия
Для простой линейной регрессии, давайте рассмотрим только влияние телевизионной рекламы на продажи. Прежде чем перейти непосредственно к моделированию, давайте посмотрим, как выглядят данные.
Мы используем matplotlib , популярная библиотека для построения графиков на Python
plt.figure(figsize=(16, 8))
plt.scatter(
data['TV'],
data['sales'],
c='black'
)
plt.xlabel("Money spent on TV ads ($)")
plt.ylabel("Sales ($)")
plt.show()
Запустите эту ячейку кода, и вы должны увидеть этот график:

Как видите, существует четкая взаимосвязь между суммой, потраченной на телевизионную рекламу, и продажами.
Давайте посмотрим, как мы можем сгенерировать линейное приближение этих данных.
X = data['TV'].values.reshape(-1,1)
y = data['sales'].values.reshape(-1,1)reg = LinearRegression()
reg.fit(X, y)print("The linear model is: Y = + X".format(reg.intercept_[0], reg.coef_[0][0]))
Да! Это так просто, чтобы подогнать прямую линию к набору данных и увидеть параметры уравнения. В этом случае мы имеем

Давайте представим, как линия соответствует данным.
predictions = reg.predict(X)plt.figure(figsize=(16, 8))
plt.scatter(
data['TV'],
data['sales'],
c='black'
)
plt.plot(
data['TV'],
predictions,
c='blue',
linewidth=2
)
plt.xlabel("Money spent on TV ads ($)")
plt.ylabel("Sales ($)")
plt.show()
И теперь вы видите:

Из приведенного выше графика видно, что простая линейная регрессия может объяснить общее влияние суммы, потраченной на телевизионную рекламу и продажи.
Оценка актуальности модели
Теперь, если вы помните из этого после, чтобы увидеть, является ли модель хорошей, нам нужно посмотреть на значение R² ир-значениеот каждого коэффициента.
Вот как мы это делаем:
X = data['TV']
y = data['sales']X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
Что дает вам этот прекрасный вывод:

Глядя на оба коэффициента, мы имеемр-значениеэто очень мало (хотя, вероятно, это не совсем 0). Это означает, что существует сильная корреляция между этими коэффициентами и целью (продажи).
Затем, глядя на значение R², мы получаем 0,612. Следовательно,около 60% изменчивости продаж объясняется суммой, потраченной на телевизионную рекламу, Это нормально, но точно не лучшее, что мы можем точно предсказать продажи. Конечно, расходы на рекламу в газетах и на радио должны оказывать определенное влияние на продажи.
Посмотрим, будет ли лучше работать множественная линейная регрессия.
Множественная линейная регрессия
моделирование
Как и для простой линейной регрессии, мы определим наши функции и целевую переменную и используемscikit учитьсябиблиотека для выполнения линейной регрессии.
Xs = data.drop(['sales', 'Unnamed: 0'], axis=1)
y = data['sales'].reshape(-1,1)reg = LinearRegression()
reg.fit(Xs, y)print("The linear model is: Y = + *TV + *radio + *newspaper".format(reg.intercept_[0], reg.coef_[0][0], reg.coef_[0][1], reg.coef_[0][2]))
Больше ничего! Из этой ячейки кода мы получаем следующее уравнение:

Конечно, мы не можем визуализировать влияние всех трех сред на продажи, так как оно имеет четыре измерения.
Обратите внимание, что коэффициент для газеты является отрицательным, но также довольно небольшим. Это относится к нашей модели? Давайте посмотрим, рассчитав F-статистику, значение R² ир-значениеза каждый коэффициент.
Оценка актуальности модели
Как и следовало ожидать, процедура здесь очень похожа на то, что мы делали в простой линейной регрессии.
X = np.column_stack((data['TV'], data['radio'], data['newspaper']))
y = data['sales']X2 = sm.add_constant(X)
est = sm.OLS(y, X2)
est2 = est.fit()
print(est2.summary())
И вы получите следующее:

Как вы можете видеть, R² намного выше, чем у простой линейной регрессии, со значением0,897!
Кроме того, F-статистика570,3, Это намного больше, чем 1, и поскольку наш набор данных достаточно мал (всего 200 точек),демонстрирует тесную связь между расходами на рекламу и продажами,
Наконец, поскольку у нас есть только три предиктора, мы можем рассмотреть ихр-значениеопределить, имеют ли они отношение к модели или нет. Конечно, вы заметили, что третий коэффициент (для газеты) имеет большойр-значение, Поэтому рекламные расходы на газетуне является статистически значимым, Удаление этого предиктора немного уменьшит значение R², но мы могли бы сделать более точные прогнозы.
Вы качаетесь ��. Поздравляю с завершением, теперь вы мастер линейной регрессии!
Как упоминалось выше, это может быть не самый эффективный алгоритм, но он важен для понимания линейной регрессии, поскольку он формирует основу более сложных статистических подходов к обучению.
Я надеюсь, что вы когда-нибудь вернетесь к этой статье.
Python, корреляция и регрессия: часть 2
Хотя, возможно, и полезно знать, что две переменные коррелируют, мы не можем использовать лишь одну эту информацию для предсказания веса олимпийских пловцов при наличии данных об их росте или наоборот. При установлении корреляции мы измерили силу и знак связи, но не наклон, т.е. угловой коэффициент. Для генерирования предсказания необходимо знать ожидаемый темп изменения одной переменной при заданном единичном изменении в другой.
Мы хотели бы вывести уравнение, связывающее конкретную величину одной переменной, так называемой независимой переменной, с ожидаемым значением другой, зависимой переменной. Например, если наше линейное уравнение предсказывает вес при заданном росте, то рост является нашей независимой переменной, а вес — зависимой.
Описываемые этими уравнениями линии называются линиями регрессии . Этот Термин был введен британским эрудитом 19-ого века сэром Фрэнсисом Гэлтоном. Он и его студент Карл Пирсон, который вывел коэффициент корреляции, в 19-ом веке разработали большое количество методов, применяемых для изучения линейных связей, которые коллективно стали известны как методы регрессионного анализа.
Вспомним, что из корреляции не следует причинная обусловленность, причем термины «зависимый» и «независимый» не означают никакой неявной причинной обусловленности. Они представляют собой всего лишь имена для входных и выходных математических значений. Классическим примером является крайне положительная корреляция между числом отправленных на тушение пожара пожарных машин и нанесенным пожаром ущербом. Безусловно, отправка пожарных машин на тушение пожара сама по себе не наносит ущерб. Никто не будет советовать сократить число машин, отправляемых на тушение пожара, как способ уменьшения ущерба. В подобных ситуациях мы должны искать дополнительную переменную, которая была бы связана с другими переменными причинной связью и объясняла корреляцию между ними. В данном примере это может быть размер пожара. Такие скрытые причины называются спутывающими переменными, потому что они искажают нашу возможность определять связь между зависимыми переменными.
Линейные уравнения
Две переменные, которые мы можем обозначить как x и y, могут быть связаны друг с другом строго или нестрого. Самая простая связь между независимой переменной x и зависимой переменной y является прямолинейной, которая выражается следующей формулой:
Здесь значения параметров a и b определяют соответственно точную высоту и крутизну прямой. Параметр a называется пересечением с вертикальной осью или константой, а b — градиентом, наклоном линии или угловым коэффициентом. Например, в соотнесенности между температурными шкалами по Цельсию и по Фаренгейту a = 32 и b = 1.8. Подставив в наше уравнение значения a и b, получим:
Для вычисления 10°С по Фаренгейту мы вместо x подставляем 10:
Таким образом, наше уравнение сообщает, что 10°С равно 50°F, и это действительно так. Используя Python и возможности визуализации pandas, мы можем легко написать функцию, которая переводит градусы из Цельсия в градусы Фаренгейта и выводит результат на график:
'''Функция перевода из градусов Цельсия в градусы Фаренгейта''' celsius_to_fahrenheit = lambda x: 32 + (x * 1.8) def ex_3_11(): '''График линейной зависимости температурных шкал''' s = pd.Series(range(-10,40)) df = pd.DataFrame() df.plot('C', 'F', legend=False, grid=True) plt.xlabel('Градусы Цельсия') plt.ylabel('Градусы Фаренгейта') plt.show()Этот пример сгенерирует следующий ниже линейный график:
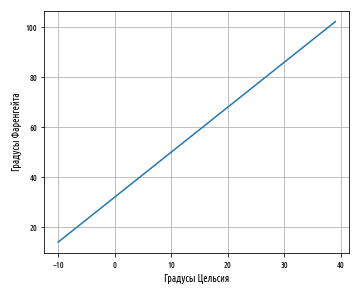
Обратите внимание, как синяя линия пересекает 0 на шкале Цельсия при величине 32 на шкале Фаренгейта. Пересечение a — это значение y, при котором значение x равно 0.
Наклон линии с неким угловым коэффициентом определяется параметром b; в этом уравнении его значение близко к 2. Как видно, диапазон шкалы Фаренгейта почти вдвое шире диапазона шкалы Цельсия. Другими словами, прямая устремляется вверх по вертикали почти вдвое быстрее, чем по горизонтали.
Остатки
К сожалению, немногие связи столь же чистые, как перевод между градусами Цельсия и Фаренгейта. Прямолинейное уравнение редко позволяет нам определять y строго в терминах x. Как правило, будет иметься ошибка, и, таким образом, уравнение примет следующий вид:
Здесь, ε — это ошибка или остаточный член, обозначающий расхождение между значением, вычисленным параметрами a и b для данного значения x и фактическим значением y. Если предсказанное значение y — это ŷ, то ошибка — это разность между обоими:
Такая ошибка называется остатком. Остаток может возникать из-за случайных факторов, таких как погрешность измерения, либо неслучайных факторов, которые неизвестны. Например, если мы пытаемся предсказать вес как функцию роста, то неизвестные факторы могут состоять из диеты, уровня физической подготовки и типа телосложения (либо просто эффекта округления до самого близкого килограмма).
Если для a и b мы выберем неидеальные параметры, то остаток для каждого x будет больше, чем нужно. Из этого следует, что параметры, которые мы бы хотели найти, должны минимизировать остатки во всех значениях x и y.
Обычные наименьшие квадраты
Для того, чтобы оптимизировать параметры линейной модели, мы бы хотели создать функцию стоимости, так называемую функцией потери, которая количественно выражает то, насколько близко наши предсказания укладывается в данные. Мы не можем просто взять и просуммировать положительные и отрицательные остатки, потому что даже самые большие остатки обнулят друг друга, если их знаки противоположны.
Прежде, чем вычислить сумму, мы можем возвести значения в квадрат, чтобы положительные и отрицательные остатки учитывались в стоимости. Возведение в квадрат также создает эффект наложения большего штрафа на большие ошибки, чем на меньшие ошибки, но не настолько много, чтобы самый большой остаток всегда доминировал.
Выражаясь в терминах задачи оптимизации, мы стремимся выявить коэффициенты, которые минимизируют сумму квадратов остатков. Этот метод называется обычными наименьшими квадратами, от англ. Ordinary Least Squares (OLS), и формула для вычисления наклона линии регрессии по указанному методу выглядит так:

Хотя она выглядит сложнее предыдущих уравнений, на самом деле, эта формула представляет собой всего лишь сумму квадратов остатков, деленную на сумму квадратов отклонений от среднего значения. В данном уравнении используется несколько членов из других уравнений, которые уже рассматривались, и мы можем его упростить, приведя к следующему виду:
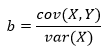
Пересечение (a) — это член, позволяющий прямой с заданным наклоном проходить через среднее значение X и Y:
Значения a и b — это коэффициенты, получаемые в результате оценки методом обычных наименьших квадратов.
Наклон и пересечение
Мы уже рассматривали функции covariance , variance и mean , которые нужны для вычисления наклона прямой и точки пересечения для данных роста и веса пловцов. Поэтому вычисление наклона и пересечения имеют тривиальный вид:
def slope(xs, ys): '''Вычисление наклона линии (углового коэффициента)''' return xs.cov(ys) / xs.var() def intercept(xs, ys): '''Вычисление точки пересечения (с осью Y)''' return ys.mean() - (xs.mean() * slope(xs, ys)) def ex_3_12(): '''Вычисление пересечения и наклона (углового коэффициента) на примере данных роста и веса''' df = swimmer_data() X = df['Рост, см'] y = df['Вес'].apply(np.log) a = intercept(X, y) b = slope(X, y) print('Пересечение: %f, наклон: %f' % (a,b))Пересечение: 1.691033, наклон: 0.014296В результате будет получен наклон приблизительно 0.0143 и пересечение приблизительно 1.6910.
Интерпретация
Величина пересечения — это значение зависимой переменной (логарифмический вес), когда независимая переменная (рост) равна нулю. Для получения этого значения в килограммах мы можем воспользоваться функцией np.exp , обратной для функции np.log . Наша модель дает основания предполагать, что вероятнее всего вес олимпийского пловца с нулевым ростом будет 5.42 кг. Разумеется, такое предположение лишено всякого смысла, к тому же экстраполяция за пределы границ тренировочных данных является не самым разумным решением.
Величина наклона показывает, насколько y изменяется для каждой единицы изменения в x. Модель исходит из того, что каждый дополнительный сантиметр роста прибавляет в среднем 1.014 кг. веса олимпийских пловцов. Поскольку наша модель основывается на данных о всех олимпийских пловцах, она представляет собой усредненный эффект от увеличения в росте на единицу без учета любого другого фактора, такого как возраст, пол или тип телосложения.
Визуализация
Результат линейного уравнения можно визуализировать при помощи имплементированной ранее функции regression_line и простой функции от x, которая вычисляет ŷ на основе коэффициентов a и b.
'''Функция линии регрессии''' regression_line = lambda a, b: lambda x: a + (b * x) # вызовы fn(a,b)(x) def ex_3_13(): '''Визуализация линейного уравнения на примере данных роста и веса''' df = swimmer_data() X = df['Рост, см'].apply( jitter(0.5) ) y = df['Вес'].apply(np.log) a, b = intercept(X, y), slope(X, y) ax = pd.DataFrame(np.array([X, y]).T).plot.scatter(0, 1, s=7) s = pd.Series(range(150,210)) df = pd.DataFrame( ) df.plot(0, 1, legend=False, grid=True, ax=ax) plt.xlabel('Рост, см.') plt.ylabel('Логарифмический вес') plt.show()Функция regression_line возвращает функцию от x, которая вычисляет a + bx.
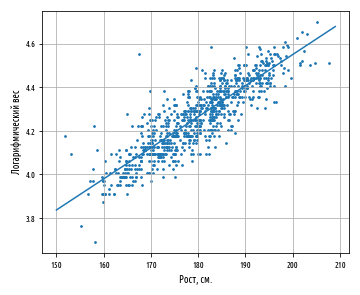
Указанная функция может также использоваться для вычисления каждого остатка, показывая степень, с которой наша оценка ŷ отклоняется от каждого измеренного значения y.
def residuals(a, b, xs, ys): '''Вычисление остатков''' estimate = regression_line(a, b) # частичное применение return pd.Series( map(lambda x, y: y - estimate(x), xs, ys) ) constantly = lambda x: 0 def ex_3_14(): '''Построение графика остатков на примере данных роста и веса''' df = swimmer_data() X = df['Рост, см'].apply( jitter(0.5) ) y = df['Вес'].apply(np.log) a, b = intercept(X, y), slope(X, y) y = residuals(a, b, X, y) ax = pd.DataFrame(np.array([X, y]).T).plot.scatter(0, 1, s=12) s = pd.Series(range(150,210)) df = pd.DataFrame( ) df.plot(0, 1, legend=False, grid=True, ax=ax) plt.xlabel('Рост, см.') plt.ylabel('Остатки') plt.show()График остатков — это график, который показывает остатки на оси Y и независимую переменную на оси X. Если точки на графике остатков разбросаны произвольно по обе стороны от горизонтальной оси, то линейная модель хорошо подогнана к нашим данным:
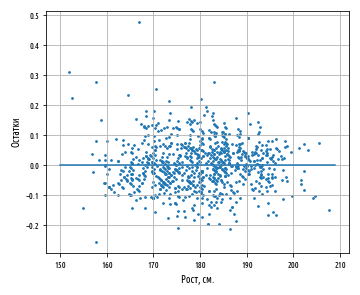
За исключением нескольких выбросов на левой стороне графика, график остатков, по-видимому, показывает, что линейная модель хорошо подогнана к данным. Построение графика остатков имеет важное значение для получения подтверждения, что линейная модель применима. В линейной модели используются некоторые допущения относительно данных, которые при их нарушении делают не валидными модели, которые вы строите.
Допущения
Первостепенное допущение линейной регрессии состоит в том, что, безусловно, существует линейная зависимость между зависимой и независимой переменной. Кроме того, остатки не должны коррелировать друг с другом либо с независимой переменной. Другими словами, мы ожидаем, что ошибки будут иметь нулевое среднее и постоянную дисперсию по отношению к зависимой и независимой переменной. График остатков позволяет быстро устанавливать, является ли это действительно так.
Левая сторона нашего графика имеет более крупные значения остатков, чем правая сторона. Это соответствует большей дисперсии веса среди более низкорослых спортсменов. Когда дисперсия одной переменной изменяется относительно другой, говорят, что переменные гетероскедастичны, т.е. их дисперсия неоднородна. Этот факт представляет в регрессионном анализе проблему, потому что делает не валидным допущение в том, что модельные ошибки не коррелируют и нормально распределены, и что их дисперсии не варьируются вместе с моделируемыми эффектами.
Гетероскедастичность остатков здесь довольно мала и особо не должна повлиять на качество нашей модели. Если дисперсия на левой стороне графика была бы более выраженной, то она привела бы к неправильной оценке дисперсии методом наименьших квадратов, что в свою очередь повлияло бы на выводы, которые мы делаем, основываясь на стандартной ошибке.
Качество подгонки и R-квадрат
Хотя из графика остатков видно, что линейная модель хорошо вписывается в данные, т.е. хорошо к ним подогнана, было бы желательно количественно измерить качество этой подгонки. Коэффициент детерминации R 2 , или R-квадрат, варьируется в интервале между 0 и 1 и обозначает объяснительную мощность линейной регрессионной модели. Он вычисляет объясненную долю изменчивости в зависимой переменной.
Обычно, чем ближе R 2 к 1, тем лучше линия регрессии подогнана к точкам данных и больше изменчивости в Y объясняется независимой переменной X. R 2 можно вычислить с помощью следующей ниже формулы:
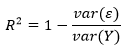
Здесь var(ε) — это дисперсия остатков и var(Y) — дисперсия в Y. В целях понимания смысла этой формулы допустим, что вы пытаетесь угадать чей-то вес. Если вам больше ничего неизвестно об испытуемых, то наилучшей стратегией будет угадывать среднее значение весовых данных внутри популяции в целом. Таким путем средневзвешенная квадратичная ошибка вашей догадки в сравнении с истинным весом будет var(Y), т.е. дисперсией данных веса в популяции.
Но если бы я сообщил вам их рост, то в соответствии с регрессионной моделью вы бы предположили, что a + bx. В этом случае вашей средневзвешенной квадратичной ошибкой было бы или дисперсия остатков модели.
Компонент формулы var(ε)/var(Y) — это соотношение средневзвешенной квадратичной ошибки с объяснительной переменной и без нее, т. е. доля изменчивости, оставленная моделью без объяснения. Дополнение R 2 до единицы — это доля изменчивости, объясненная моделью.
Как и в случае с r , низкий R 2 не означает, что две переменные не коррелированы. Просто может оказаться, что их связь не является линейной.
Значение R 2 описывает качество подгонки линии регрессии к данным. Оптимально подогнанная линия — это линия, которая минимизирует значение R 2 . По мере удаления либо приближения от своих оптимальных значений R 2 всегда будет расти.
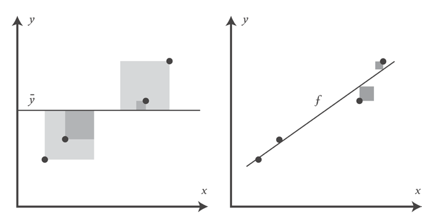
Левый график показывает дисперсию модели, которая всегда угадывает среднее значение для , правый же показывает меньшие по размеру квадраты, связанные с остатками, которые остались необъясненными моделью f. С чисто геометрической точки зрения можно увидеть, как модель объяснила большинство дисперсии в y. Приведенный ниже пример вычисляет R 2 путем деления дисперсии остатков на дисперсию значений y:
def r_squared(a, b, xs, ys): '''Рассчитать коэффициент детерминации (R-квадрат)''' r_var = residuals(a, b, xs, ys).var() y_var = ys.var() return 1 - (r_var / y_var) def ex_3_15(): '''Рассчитать коэффициент R-квадрат на примере данных роста и веса''' df = swimmer_data() X = df['Рост, см'].apply( jitter(0.5) ) y = df['Вес'].apply(np.log) a, b = intercept(X, y), slope(X, y) return r_squared(a, b, X, y)0.75268223613272323В результате получим значение 0.753. Другими словами, более 75% дисперсии веса пловцов, выступавших на Олимпийских играх 2012 г., можно объяснить ростом.
В случае простой регрессионной модели (с одной независимой переменной), связь между коэффициентом детерминации R 2 и коэффициентом корреляции r является прямолинейной:
Коэффициент корреляции r может означать, что половина изменчивости в переменной Y объясняется переменной X, но фактически R 2 составит 0.5 2 , т.е. 0.25.
Множественная линейная регрессия
Пока что в этой серии постов мы видели, как строится линия регрессии с одной независимой переменной. Однако, нередко желательно построить модель с несколькими независимыми переменными. Такая модель называется множественной линейной регрессией.
Каждой независимой переменной потребуется свой собственный коэффициент. Вместо того, чтобы для каждой из них пытаться подобрать букву в алфавите, зададим новую переменную β (бета), которая будет содержать все наши коэффициенты:
Такая модель эквивалентна двухфакторной линейно-регрессионной модели, где β1 = a и β2 = b при условии, что x1 всегда гарантированно равен 1, вследствие чего β1 — это всегда константная составляющая, которая представляет наше пересечение, при этом x1 называется (постоянным) смещением уравнения регрессии, или членом смещения.
Обобщив линейное уравнение в терминах β, его легко расширить на столько коэффициентов, насколько нам нужно:
Каждое значение от x1 до xn соответствует независимой переменной, которая могла бы объяснить значение y. Каждое значение от β1 до βn соответствует коэффициенту, который устанавливает относительный вклад независимой переменной.
Простая линейная регрессия преследовала цель объяснить вес исключительно с точки зрения роста, однако объяснить вес людей помогает много других факторов: их возраст, пол, питание, тип телосложения. Мы располагаем сведениями о возрасте олимпийских пловцов, поэтому мы смогли бы построить модель, которая учитывает и эти дополнительные данные.
До настоящего момента мы предоставляли независимую переменную в виде одной последовательности значений, однако при наличии двух и более параметров нам нужно предоставлять несколько значений для каждого x. Мы можем воспользоваться функциональностью библиотеки pandas, чтобы выбрать два и более столбцов и управлять каждым как списком, но есть способ получше: матрицы.
Примеры исходного кода для этого поста находятся в моем репо на Github. Все исходные данные взяты в репозитории автора книги.
Темой следующего поста, поста №3, будут матричные операции, нормальное уравнение и коллинеарность.
- python
- программирование
- учебный процесс
- статистика
- регрессионный анализ