Precision и recall. Как они соотносятся с порогом принятия решений?
Недавно, постигая азы Машинного Обучения и изучая классификацию, я наткнулся на precision и recall. Диаграммки, которые часто вставляют, объясняя эти концепции, мне не помогли понять отличия между ними. Но чудо, я придумал объяснение, которое понятно мне, и я надеюсь, что оно поможет кому-нибудь из вас на пути изучения ML (возможно это объяснение кто-то придумал до меня) .
Перед тем как начинать, давайте представим горку песка, но в этом песке ещё есть песчаные камни, они ведь тоже являются песком, так? Также в этом песке есть некоторый мусор. Наша задача — просеять песок. Его мы можем просеять максимально чисто, без единого мусора, но он будет не весь (комки песка не попадут), либо просеять весь песок, но мусор тоже может попасть в нашу кучу. С этим пониманием давайте двигаться дальше.

Что такое precision и recall?
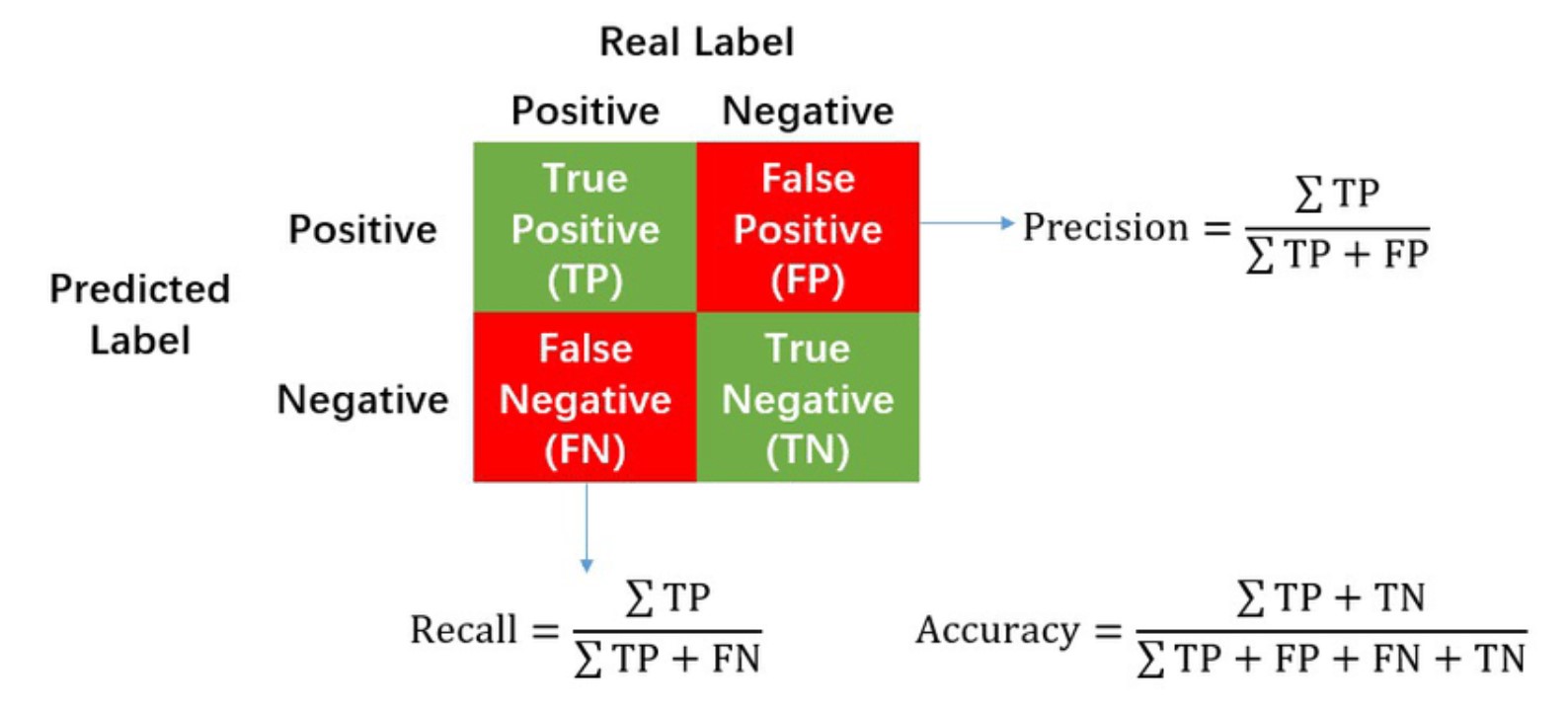
Чтобы понять, что эта диаграмма означает, в пример приводят мальчика, который сторожит овец (пусть это будет Вася) и волка, который нападает на овец ночью. Вася любит пугать жителей ночью и будит всех со словами: “Волк!”. Но также бывает, что волк на самом деле приходит ночью. Так вот, когда Вася кричит и волк на самом деле появился, то это True Positive (TP). Когда Вася кричит и волка нет, то это False Positive (FP). Когда Вася не кричит и волк пришёл, то это False Negative (FN). А когда Вася не кричит и волк не пришел, то это True Negative (TN).
Другими словами, Positive и Negative — это предсказания нашей модели (изображена ли на этой картинке кошка), а True и False- это оценка того, правильно ли определила модель наш класс (действительно ли на этой картинке кошка). Крик Васи — предсказание модели. Пришёл Волк — то, что на самом деле произошло, и относительно чего дается оценка (True или False) крику нашего Васи.
Precision (точность) — отношение TP к TP + FP. Это доля объектов, названными классификатором положительными и при этом действительно являющимися положительными. Возвращаясь к нашему объяснению про кучу песка из начала, оно измеряет, насколько чистый песок стал после просеивания (TP — просеянный песок, FP — мусор). Но стоит помнить, что песок попал не весь, потому что комки песка не смогли попасть через сетку. Или же то, насколько Вася был честным, когда кричал о нападении Волка.
Recall (Полнота) — отношение TP к TP + FN. Это то, какую долю объектов положительного класса из всех объектов положительного класса нашёл алгоритм. Оно же измеряет, насколько весь песок попал в кучу, то есть комки песка тоже должны попасть, но загвоздка в том, что мусор тоже может попасть в нашу кучу. (TP — просеянный песок, FN — непросеянный песок). Или же то, насколько внимательным был Вася и замечал нападение Волка.
В этом и есть суть этих метрик, с ростом recall уменьшается precision, и наоборот.

Как это соотносится с порогом принятия решений?
Порог принятия решений используется, когда нужно определить, к какому классу отнести наш образец. К примеру, наша модель, которая прогнозирует принадлежность картинки к коту или собаке, дала для определённого образца вероятность 75% того, что это собака. Если мы поставим порог принятия решений 60%, соответственно, алгоритм выдаст, что это собака, ведь 75 больше 60. Но если мы поставим порог принятия решений в 80%, то алгоритм причислит образец к кошке.
Порог принятия решений можно представить как линию, на одной стороне которой будет одно значение, а на другой иное.
Для выяснения того, как порог принятия решений соотносится с precision и recall, можно представить его как ширину нашей сетки. При высоком пороге сетка будет узкая, увеличится precision, то есть будет попадать только чистый песок, но уменьшится recall, то есть не весь песок будет попадать в кучу (помним, что комки слишком большие, чтобы пройти через сетку). При низком пороге сетка будет широкая, будет попадать весь песок, включая комки, но также будет попадать мусор, соответственно, recall увеличится, а precision упадёт.
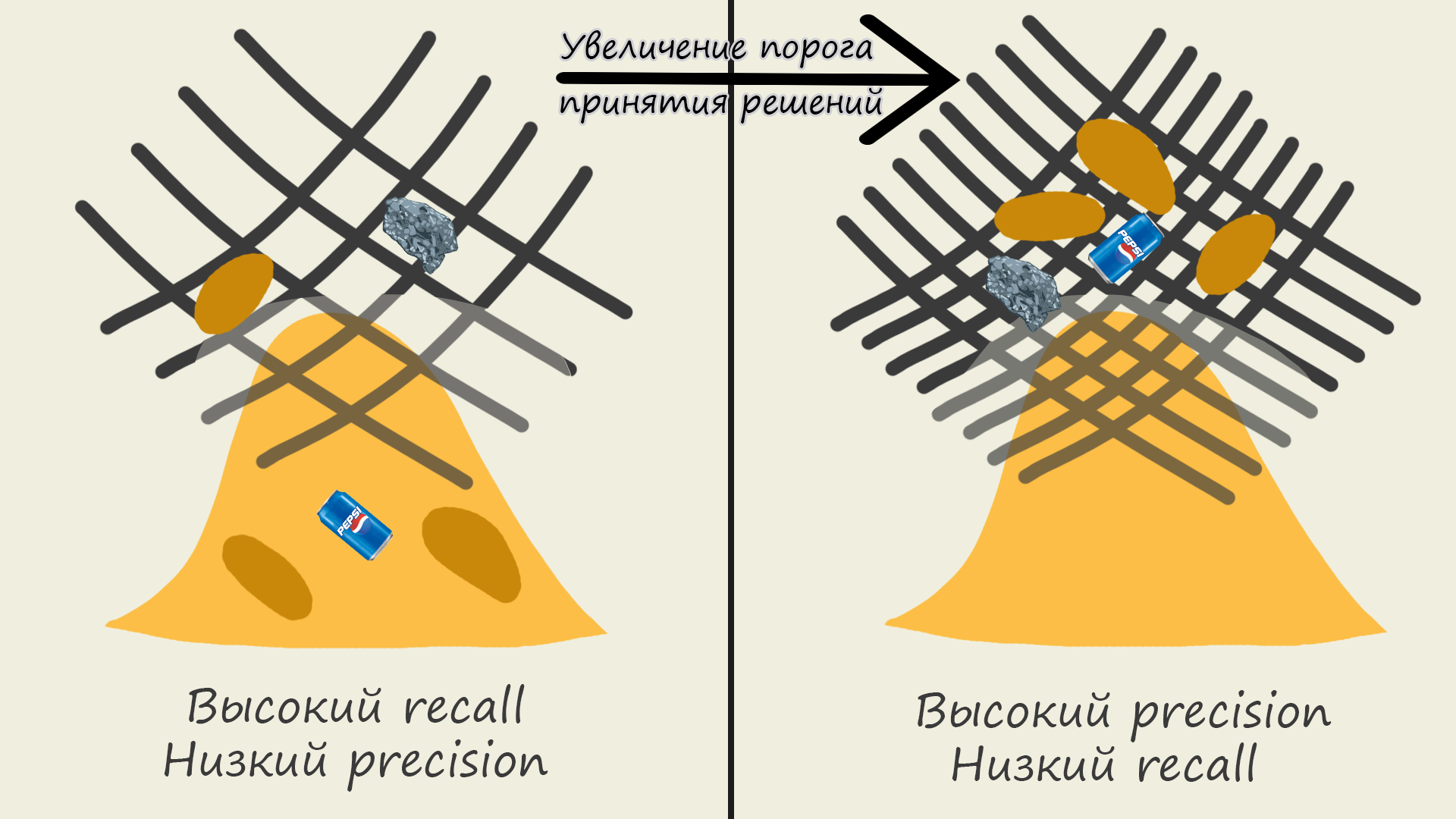
Надеюсь этой статьей я хоть немного помог приблизиться к интуитивному пониманию precision и recall. Настоятельно рекомендую прочитать другие источники и не ограничиваться только этой статьей, я не эксперт и тоже только учусь. Поэтому, если я в чем-то ошибаюсь, то буду рад если вы дадите знать это в комментариях. Это была моя первая статья, надеюсь еще скоро увидимся, cheers!
- precision
- recall
- classification
- machinelearning
- machine-learning
- metrics
- decisiontrashhold
- decision-trashhold
- machine
- learning
Метрики в машинном обучении: precision, recall и не только
Почему я это написал. Долгое время я был бэкэнд разработчиком. Вращался среди коллег и прекрасно их понимал. Но бэкенд нужен и людям, занимающимся машинным обучением. В какой-то момент я попал в их логово. И вот тут я поднял, что вообще не понимаю их язык. Думаю, что не только я оказывался в такой ситуации, поэтому сейчас расскажу всё понятными словами для нормальных людей.
Немного про машинное обучение
ML работает всего с несколькими вещами:
- Данные (фичи)
- Разметка этих данных
- Модель
- Предсказания модели
Приведу пример. Допустим у вас есть яблоня. Каждый год вы ломаете голову, опрыскивать ли её от долгоносика. Решили обучить модель, что она вам предсказывала нашествия долгоносика.
Данные: Допустим, вы знаете только весенние температуры в виде одного числа. (Не важно, что это, допустим, просто средняя температура.) То есть у вас есть одна фича — температура.
Разметка У вас есть журнал по годам, где отмечено, был долгоносик или нет. То есть каждой температуре вы можете сопоставить «правильный» ответ. Обратите внимание, что одной и той же температуре могут соответствовать несколько ответов, они могут быть разными (за разные годы).
Модель Пусть у нас будет модель с одним параметром: пограничной температурой. Модель будет просто говорить «да», если температура выше какой-то черты и «нет» — если ниже. Можно было бы придумать модель с двумя параметрами (она бы смотрела на интервал), или ещё сложнее, но мы сейчас возьмём самую простую, для наглядности.
Предсказания Если применить модель к температурам (фичам), то получим предсказания.
Немного кода
Чтобы было с чем играть, вот вам код. Тут есть и данные, и модель, и всё о чём мы будем говорить.
#!/usr/bin/env python # coding: U8 import numpy as np # Наши тестовые данные: набор наблюдений — пар: температура, наличие долгоносика TEST = np.array([ # 0 - нет долгоносика, 1 - есть [0, 0], [1, 1], [2, 0], [3, 0], [3, 0], [4, 0], [4, 1], [5, 1], [5, 1], [6, 1], [6, 0], [7, 0], [7, 0], [8, 0], [9, 1], ]) # Наша модель очень проста. Единственный параметр модели — threshold class Model(object): def __init__(self, threshold): self.threshold = threshold def predict(self, data): return data >= self.threshold # Получаем метрики def metrics(test_data, model): data = test_data[. 0] # входные данные (массив температур) observations = test_data[. 1] # фактические наблюдения prediction = model.predict(data) # предсказания (результат применения модели) true_positive = np.logical_and(prediction, observations) # и в прогнозе, и в реальности было "да" false_positive = np.logical_and(prediction, np.logical_not(observations)) # прогноз сказал "да", а в реальности было "нет" true_negative = np.logical_and(np.logical_not(prediction), np.logical_not(observations)) # прогноз — "нет" и он прав false_negative = np.logical_and(np.logical_not(prediction), observations) # прогноз — "нет" и ошибся tp, fp, tn, fn = (x.sum() for x in (true_positive, false_positive, true_negative, false_negative)) accuracy = (tp + tn) / (tp + fp + fn + tn) precision = tp / (tp + fp) recall = tp / (tp + fn) f1_score = 2 * (recall * precision) / (recall + precision) #dump(data, observations, prediction, true_positive, false_positive, true_negative, false_negative) return tp, fp, tn, fn, accuracy, precision, recall, f1_score def dump(temp, obs, pred, tp, fp, tn, fn): print(' <>'.format('Temp', ' '.join(map(str, temp)))) for name, v, comment in ( ('Obs', obs, '(TP+FN)'), ('Pred', pred, '(TP+FP)'), ('TP', tp, ''), ('FP', fp, ''), ('TN', tn, ''), ('FN', fn, '')): print(' <> 10>'.format(name, ' '.join([bool(x)] for x in v), sum(v), comment)) pass print(' T TP FP TN FN Accur Prec Recll F1') for model_param in range(10): m = metrics(TEST, Model(model_param)) print(' '.format(model_param, *m)) Если это запустить, то мы получим метрики для разных моделей:
T TP FP TN FN Accur Prec Recll F1 0 6 9 0 0 0.400 0.400 1.000 0.571 1 6 8 1 0 0.467 0.429 1.000 0.600 2 5 8 1 1 0.400 0.385 0.833 0.526 3 5 7 2 1 0.467 0.417 0.833 0.556 4 5 5 4 1 0.600 0.500 0.833 0.625 5 4 4 5 2 0.600 0.500 0.667 0.571 6 2 4 5 4 0.467 0.333 0.333 0.333 7 1 3 6 5 0.467 0.250 0.167 0.200 8 1 1 8 5 0.600 0.500 0.167 0.250 9 1 0 9 5 0.667 1.000 0.167 0.286 T — это параметр модели. То есть мы получили метрики, фактически, для 10 разных моделей.
Если раскомментировать dump() то будет видна детальная информация.
Сейчас мы со всем разберёмся.
TP, TN, FP, FN и друге буквы
Когда люди начинают жонглировать этими буквами, с непривычки, можно очень легко запутаться и потерять нить. Чтобы всё встало на свои места, нам понадобится ещё несколько букв и пара полезных соотношений.
Давайте посмотрим на входные данные (разметку, фактические наблюдения). Введём две буквы:
- P (positive) — сколько у нас положительных ответов (результатов наблюдений)
- N (negative) — сколько отрицательных ответов
Теперь посмотрим на прогнозы модели. Здесь тоже есть positive и negative, но их сразу же делят на четыре группы:
- все positive-ответы (модель сказала «да») делят на:
- TP (true positive) — модель ответил «да» и угадала
- FP (false positive) — модель ответила «да» и ошиблась
- TN (true negative) — модель ответил «нет» и это было правильно
- FN (false negative) — «нет» и это ошибка
Тут важно проникнуться простыми соотношениями:
P = TP + FN N = TN + FPОстановитесь тут и подумайте минуту.
Ну и, конечно, ясно что такое TP+FP (это все ответы «да», полученные от модели) и NT+FN (все ответы «нет»).
Ценность метрик
У нас появились первые метрики. Давайте посмотрим, на сколько они полезны.
Метрики нужны, чтобы понять, какая модель лучше. Выше мы видели все метрики для всех моделей. Поглядите на колонки TP , TN , FP , FN .
Видно, что ни одна из этих метрик не позволяет нам выбрать лучшую модель. Например, модель, которая всегда говорит только «да», показывает лучший TP . Это и понятно: везде, где в наблюдениях было «да», наша модель сказала «да». Однако, ясно, что это глупейшая модель.
Аналогично не работают и другие три метрики. Нужно что-то получше.
Accuracy
Первое, что приходит в голову: давайте поделим все правильные ответы на все вообще ответы.
TP + TN TP + TN Accuracy = ───────── = ─────────────────── P + N TP + FN + TN + FPТакая метрика уже лучше, чем ничего, но всё же, она очень плоха. Даже в моём примере (хотя я не подгонял специально числа) видно, что, с одной стороны, разумные модели имеют высокую точность, однако, побеждает по точности просто самая пессимистичная модель.
Вы можете поиграться с данными и посмотреть, как это происходит. Но понять смысл очень просто на другом примере. Допустим вы хотите предсказывать землетрясения (какое-то очень редкое явление). Ясно, что по этой метрике всегда будет побеждать модель, которая даже не пытается ничего предсказывать, а просто говорит всегда «нет». Те же модели, которые будут пытаться говорить когда-то «да», будут иногда ошибаться в позитивных прогнозах и сразу же терять очки.
Поэтому, про эту метрику вы, скорее всего, даже не услышите никогда. Я тут её упомянул только чтобы показать её неэффективность при, кажущейся, логичности.
Precision, recall и их друзья
Лично я чаще всего сталкивался именно с этими словами. При том, что, как мне кажется, это самые неудачные варианты. Я буду приводить альтернативные называния, которые, как мне кажется, на много лучше отражают суть.
Recall aka sensitivity, hit rate, or true positive rate (TPR)
Мне кажется, hit rate и TPR лучше всего отражают суть. В этой метрике мы рассматриваем только P-случаи: когда в реальных наблюдениях было «да». И считаем, какую долю из этих случаев модель предсказала правильно.
Все случаи «нет» мы отбрасываем.
TP TP TPR (recall, hit rate) = ──── = ───────── P TP + FNRecall сам по себе довольно бесполезен. Взгляните на результаты для нашей модели: модель, которая всегда тупо говорить «да» — безусловно побеждает. Фактически, recall пропорционален TP , если P — константа (напомню, что это просто количество ответов «да» в наших фактических данных).
У recall есть брат-близнец:
Specificity, selectivity or true negative rate (TNR)
TN TN TNR = ──── = ───────── N TN + FPЗдесь верны все те же самые оговорки. Специфичность, фактически, пропорциональна TN .
Важно, так же, заметить, что если T и P сильно отличаются (как в примере с землетрясениями), то сравнивать recall и специфичность надо очень осторожно.
Precision aka positive predictive value (PPV)
Какая часть наших предсказаний «да» действительно сбылась:
TP PPV = ───────── TP + FPНедостатки этой метрики аналогичны: она вообще никак не учитывает предсказания «нет». Из наших результатов видно, что побеждает модель, которая почти всегда говорить «нет». Она как бы снижает риск проиграть, выводя большую часть своих ответ за рамки рассмотрения.
У этой метрики есть аналогичный близнец
Negative predictive value (NPV)
TN NPV = ───────── TN + FNКакая часть «нет»-предсказаний сбылась.
И ещё немного метрик
Перечислю кратко и другие метрики. Это далеко не все существующие, а просто аналоги вышеперечисленных, только относительно отрицательных прогнозов.
Miss rate aka false negative rate (FNR)
FN FN FNT = ──── = ───────── P TP + FNFall-out aka false positive rate (FPR)
FP FP FPR = ──── = ───────── N TN + FPFalse discovery rate (FDR)
FP FDR = ───────── FP + TPFalse omission rate (FOR)
FN FOR = ───────── FN + TNИ что же со всем этим делать
Как вы уже видели, каждая из этих метрик рассматривает только какое-то подмножество предсказаний. Поэтому их эффективность очень сомнительна.
Однако, их очень часто используют для двух вещей:
- Во-первых, по ним можно судить о характере модели: какая часть предсказаний ей даётся лучше, а в чём она слаба.
- Во-вторых, из этих метрик можно собирать что-то полезное.
На втором я хотел бы остановиться в некотором философском ключе.
Давайте задумаемся, а что значит «одна модель лучше другой»? Единого ответа тут нет.
В нашем примере с долгоносиком всё зависит от наших приоритетов.
Если мы хотим ни в коем случае не потерять урожай, то нам надо максимизировать TP любой ценой. Фактически, в предельном случае, мы можем выкинуть любые модели и просто опрыскивать дерево химикатами всегда.
Если мы хотим минимизировать применение ядов, то нам надо максимизировать TN . В предельном случае, нам просто надо никогда не опрыскивать дерево: потеря урожая для нас не так страшна, как безосновательное применение ядохимикатов.
В реальной же жизни, мы ищем некоторый компромисс. Во многих случаях он может быть совершенно чётко сформулирован, с учётом цен на химикаты, стоимости урожая, репутационных потерь и прочего.
Не редко, люди придумывают собственные метрики. Но есть и готовые, пригодные во многих случаях.
F1-score
Это комбинация recall и precision:
recall * precision F1 = 2 * ─────────────────── recall + precisionНо мне кажется, поведение этой функции становится гораздо понятней, если записать её так:
2 F1 = ───────────────────── 1 1 ───────── + ───────── recall precisionТо есть, это гармоническое среднее.
Максимальный F1-score мы получим, если и recall, и precision достаточно далеки от нуля. Он позволяет найти некое компромиссное решение, фактически, между максимизацией TP по разным шкалам.
Это не единственная возможная метрика. И у неё, как вы видите, тоже есть чёткий фокус, а значит и недостатки. Однако, даже её достаточно, чтобы среди наших моделей выиграла та, у которой пограничная температура равна 4. Давайте ещё раз взглянем на сравнение всех моделей:
T TP FP TN FN Accur Prec Recll F1 0 6 9 0 0 0.400 0.400 1.000 0.571 1 6 8 1 0 0.467 0.429 1.000 0.600 2 5 8 1 1 0.400 0.385 0.833 0.526 3 5 7 2 1 0.467 0.417 0.833 0.556 4 5 5 4 1 0.600 0.500 0.833 0.625И вот детализация по этой конкретной модели (с T=4):
Temp 0 1 2 3 3 4 4 5 5 6 6 7 7 8 9 Obs . T . . . . T T T T . . . . T 6 (TP+FN) Pred . . . . . T T T T T T T T T T 10 (TP+FP) TP . . . . . . T T T T . . . . T 5 FP . . . . . T . . . . T T T T . 5 TN T . T T T . . . . . . . . . . 4 FN . T . . . . . . . . . . . . . 1Вы можете взять мой код, раскомментировать функцию dump() и посмотреть детализацию по всем моделям.
Видно, что ответ разумный, но выработан с фокусом на TP . То есть на то, чтобы больше перебдеть. Возможно, это как раз то, что нужно. А может и нет. Поэтому и существует ещё множество других метрик, но основа у них одинаковая.
Надеюсь, я пролил некоторый свет на вопрос.
Перевод "precision" на русский
Еще одна приятная деталь, которая позволяет вам оценить ту замечательную механическую точность, о которой я упоминал ранее.
However, all of three criteria lack precision.
Тем не менее, всем трем критериям не хватает точности.
You cannot possibly lose precision beyond 100 yards.
Возможно, вы не можете потерять точность более 100 ярдов.
Speed is as important as precision.
Скорость очень важна, равно как и точность.Microrobots or macroscale robots which can move with nanoscale precision can also be considered nanorobots.
Для этой точки зрения макромасштабированные роботы или микророботы, которые могут перемещаться с точностью до наномасштаб, также могут считаться нанороботами.
Marketing science is boosting the precision of real-time operating decisions.
Научные методы маркетинга помогают значительно повысить точность операционных решений в режиме реального времени.
See also the warning about float precision.
Смотрите более подробно: предупреждение о точности чисел с плавающей точкой.
Real space in his works passed almost illusory precision, the colors muted.Реальное пространство в его работах передавалось почти с иллюзорной точностью, цветовая характеристика сдержанна, краски приглушены.
Full-service precision plastic injection modular molding company.
Полное обслуживание точности литья пластмасс под модульное литье компании.
Fixed bug causing excessive displayed precision.
Исправлена ошибка, приводившая к чрезмерной отображается точность.
Repeat positioning control precision can reach 0.5 pulse.
З. повторить управления точность позиционирования может достигать 0,5 пульс.
As if calculating their eventual collapse. with mathematical precision.
Как если бы мы рассчитывали их конечное разрушение. с математической точностью.
The blows fall with surgical precision.
Но эти удары были нанесены с хирургической точностью.
The difference between having powers and having precision.
Разница между тем, чтобы иметь способности и владеть точностью.
Because precision matters in everything we do.
Потому что точность имеет значение во всем, что мы делаем.
Currently, the term healthspan lacks clarity and precision especially in animals.В настоящее время термин продолжительность здоровой жизни не имеет четкости и точности, в особенности в отношении человека.
Certain written assurances reveal very broad provisions which lack legal precision.
Некоторые письменные заверения содержат слишком широкие положения, которым не хватает юридической точности.
Discipline is inextricably associated with spontaneity, precision with freedom.
Дисциплина находится в прямой зависимости от спонтанности, а точность от свободы.
No other technique allows for such precision.
Ни один другой метод не позволяет добиться такой точности.
Возможно неприемлемое содержаниеПримеры предназначены только для помощи в переводе искомых слов и выражений в различных контекстах. Мы не выбираем и не утверждаем примеры, и они могут содержать неприемлемые слова или идеи. Пожалуйста, сообщайте нам о примерах, которые, на Ваш взгляд, необходимо исправить или удалить. Грубые или разговорные переводы обычно отмечены красным или оранжевым цветом.
Общие понятия
Здесь про TP, TN, FP, FN и понятия, через них выражающиеся, мы говорим в рамках одного класса бинарной классификации. То есть, в такой системе подразумевается, что реальное число объектов класса 0 (для бинарного случая 0/1) может выражаться как [math]\text[/math]
Confusion matrix (матрица ошибок / несоответствий / потерь, CM)
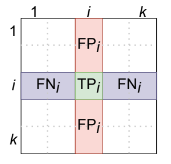
Вычисление TP, FP, FN по CM
— квадратная матрица размера k × k, где [math]\text_[/math] — число объектов класса [math]t[/math] , которые были квалифицированны как класс [math]c[/math] , а [math]k[/math] — число классов. Значения ячеек CM могут быть вычислены по формуле: [math]\text(y, \hat)_ = \displaystyle\sum_^[(y_i = t) ∧ (\hat = c)][/math] , где [math]y_i[/math] — реальный класс объекта, а [math]\hat[/math] — предсказанный.
Для бинарного случая:
Принадлежит классу (P) Не принадлежит классу (N) Предсказана принадлежность классу TP FP Предсказано отсутствие принадлежности к классу FN TN Для многоклассовой классификации матрица несоответствий строится по тому же принципу:
Предсказанный класс Класс 1 (C₁) Класс 2 (C₂) Класс 3 (C₃) 1 (P₁) T₁ F₁₂ F₁₃ 2 (P₂) F₂₁ T₂ F₂₃ 3 (P₃) F₃₁ F₃₂ T₃ В этом случае TP, TN, FP и FN считаются относительно некоторого класса [math](i)[/math] следующим образом:
[math]\text_i = T_i[/math] [math]\text_i = \sum\limits_> \text_[/math] [math]\text_i = \sum\limits_> \text_[/math] [math]\text_i = \text_i - \text_i - \text_i[/math]
Простые оценки
- Accuracy — (точность) показывает долю правильных классификаций. Несмотря на очевидность и простоту, является одной из самых малоинформативных оценок классификаторов.
- Recall — (полнота, sensitivity, TPR (true positive rate)) показывает отношение верно классифицированных объектов класса к общему числу элементов этого класса.
- Precision — (точность, перевод совпадает с accuracy)показывает долю верно классифицированных объектов среди всех объектов, которые к этому классу отнес классификатор.
- Specificity — показывает отношение верных срабатываний классификатора к общему числу объектов за пределами класса. Иначе говоря, то, насколько часто классификатор правильно не относит объекты к классу.
- Fall-out — (FPR (false positive rate)) показывает долю неверных срабатываний классификатора к общему числу объектов за пределами класса. Иначе говоря то, насколько часто классификатор ошибается при отнесении того или иного объекта к классу.
Ввиду того, что такие оценки никак не учитывают изначальное распределение классов в выборке (что может существенно влиять на полученное значение), также существуют взвешенные варианты этих оценок (в терминах многоклассовой классификации):
Различные виды агрегации Precision и Recall
Примеры и картинки взяты из лекций курса «Введение в машинное обучение» [1] К.В. Воронцова
Арифметическое среднее:
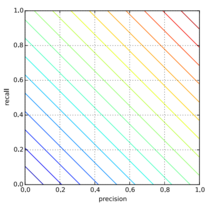
Линии уровня для среднего арифметического
- Если precision = 0.05, recall = 1, то A = 0.525
- Если precision = 0.525, recall = 0.525, то A = 0.525.
- Первый классификатор — константный, не имеет смысла.
- Второй классификатор показывает неплохое качество.
Таким образом, взятие среднего арифметического не является показательным.
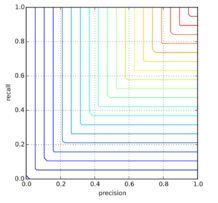
Линии уровня для минимума
- Если precision = 0.05, recall = 1, то M = 0.05
- Если precision = 0.525, recall = 0.525, то M = 0.525.
То есть, довольно неплохо отражает качество классификатора, не завышая его.
- Если precision = 0.2, recall = 1, то M = 0.2.
- Если precision = 0.2, recall = 0.3, то M = 0.2.
Но не отличает классификаторы с разными неминимальными показателями.
Гармоническое среднее, или F-мера:
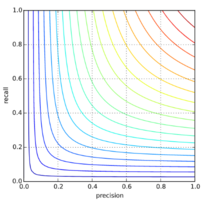
Линии уровня для F-меры
- Если precision = 0.05, recall = 1, то F = 0.1.
- Если precision = 0.525, recall = 0.525, то F = 0.525.
- Если precision = 0.2, recall = 1, то F = 0.33.
- Если precision = 0.2, recall = 0.3, то F = 0.24.
Является наиболее точным усреднением, учитывает оба показателя.
Геометрическое среднее, или Индекс Фоулкса–Мэллова (Fowlkes–Mallows index)
Менее строгая мера.
F-мера
Для общей оценки качества классификатора часто используют F₁-меру. Оригинально она вычисляется для позитивного класса случая бинарной классификации, обобщается с помощью приниципа «один против всех» (описан подробнее ниже, для многоклассовой классификации). F₁-мера — среднее гармоническое между precision и recall:
[math]\text_1 = \left ( \dfrac^ + \text^> \right )^ = 2 \cdot \dfrac \cdot \text>>[/math]
Среднее гармоническое взвешенное Fβ (F1-мера — частный случай Fβ-меры для β = 1). Fβ измеряет эффективность классификатора учитывая recall в β раз более важным чем precision:
[math]\text_β = (1 + β^2) \dfrac \cdot \text>>[/math]
F-мера для многоклассовой классификации. Три вида усреднения
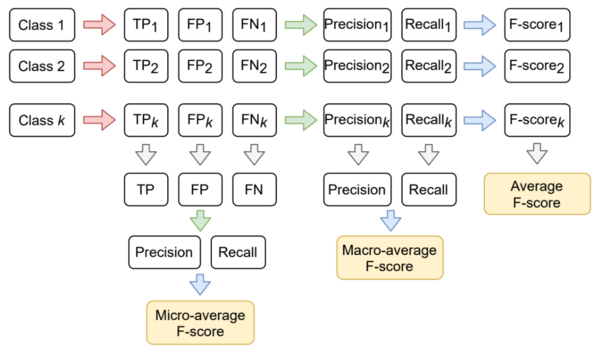
Принцип усреднения различных F-мер для нескольких классов
Вычисление TP, FP, FN для многоклассовой классификации
Для вычисления F-меры (и других) метрик в рамках многоклассовой классификации используется подход «один против всех»: каждый класс ровно один раз становится «положительным», а остальные — отрицательным (пример вычисления изображён на матрице).
Таким образом, в зависимости от этапа вычисления, на котором производится усреднение, можно вычислить micro-average, macro-average и average F-меры (логика вычисления изображена на схеме справа). Микро- и макро-:
[math]\text = 2 \cdot \dfrac \cdot \text>>[/math] ,
где для micro-average precision и recall вычислены из усреднённых TP, FP, FN;
для macro-average precision и recall вычислены из усреднённых precisioni, recalli;
[math]\text = \dfrac \displaystyle\sum_^ <\text_1score_i>[/math] ,
где [math]i[/math] — индекс класса, а [math]k[/math] — число классов.
ROC-кривая
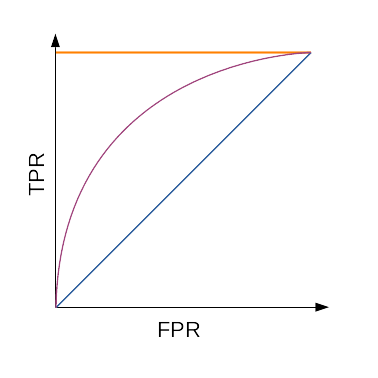
ROC-кривая; оранжевым показан идеальный алгоритм, фиолетовым — типичный, а синим — худший
Для наглядной оценки качества алгоритма применяется ROC-кривая. Кривая строится на плоскости, определённой TPR (по оси ординат) и FPR (по оси абсцисс).
Для построении графика используется мягкая классификация: вместо того, чтобы чётко отнести объект к классу, классификатор возвращает вероятности принадлежности объекта к различным классам. Эта уверенность сравнивается с порогом (какой уверенности «достаточно», чтобы отнести объект к положительному классу). В зависимости от значения этого порога меняются значения TPR и FPR.
Алгоритм построения кривой:
- Запустить классификатор на тестовой выборке
- Отсортировать результаты по уверенности классификатора в принадлежности объекта к классу
- Пока не кончились элементы:
- Взять объект с максимальной уверенностью
- Сравнить метку с реальной
- Пересчитать TPR и FPR на взятых объектах
- Поставить точку, если обе характеристики не NaN / ±∞
Таким образом: число точек не превосходит число объектов идеальному алгоритму соответствует ROC-кривая, проходящая через точку [math](0;1)[/math] худшему алгоритму (например, монетке) соответствует прямая TPR = FPR.
Для численной оценки алгоритма по ROC-кривой используется значение площади под ней (AUC, area under curve). Идеальный алгоритм имеет AUC, равный 1, худший — 0,5.
С другой стороны, для построения ROC-кривой не обязательно пересчитывать TPR и FPR.
Существует альтернативный алгоритм построения ROC-кривой.
- сортируем объекты по уверенности классификатора в их принадлежности к положительному классу
- начинаем в точке (0, 0)
- последовательно продолжаем кривую вверх:
- для каждого «отрицательного» объекта вверх
- для каждого «положительного» — вправо.
Корректность алгоритма обосновывается тем, что с изменением предсказания для одного объекта в зависимости от его класса меняется либо TPR, либо FPR (значение второго параметра остаётся прежним). Ниже описана другая логика, подводящая к алгоритму выше.
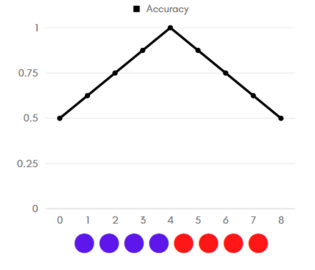
График Accuracy для идеальной классификации
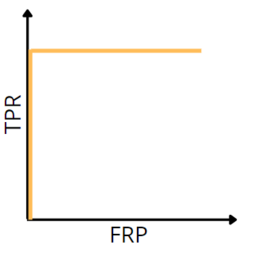
ROC-кривая для идеальной классификации
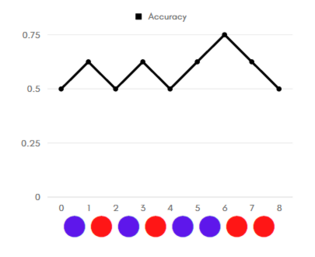
График Accuracy для неидеальной классификации
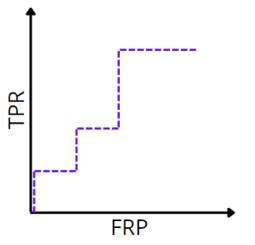
ROC-кривая для неидеальной классификации
Напомним, что мы работаем с мягкой классификацией.
Рассмотрим примеры (графики accuracy, цветом указан реальный класс объекта: красный — положительный, синий — отрицательный). Отсортируем наши объекты по возрастанию уверенности классификатора в принадлежности объекта к положительному классу. Допустим, что объекты находятся на равном (единичном) расстоянии друг от друга.
Начнём перебирать «границу раздела»: если граница в нуле — мы решаем относить все объекты к положительному классу, тогда accuracy = 1/2. Последовательно сдвигаем границу по единичке вправо:
- если реальный класс объекта, оказавшегося теперь по другую сторону границы — отрицательный, то accuracy увеличивается, так как мы «угадали» класс объекта, решив относить объекты левее границы к отрицательному классу;
- если же реальный класс объекта — положительный, accuracy уменьшается (по той же логике)
Таким образом, на графиках слева, видно, что:
- на графике идеальной классификации точность в 100% достигается, неидеальной — нет;
- площадь под графиком accuracy идеального классификатора больше, чем аналогичная площадь для неидеального.
Заметим, что, повернув график на 45 градусов, мы получим ROC-кривые для соответствующих классификаторов (графикам accuracy слева соответствуют ROC-кривые справа). Так объясняется альтернативный алгоритм построения ROC-кривой.
Precision-Recall кривая
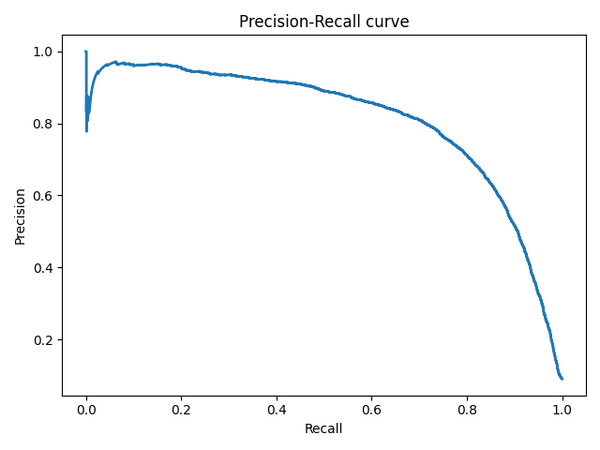
Обоснование: Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм [math]a(x)[/math] , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь «плохой» алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма. Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм [math]b(x)[/math] , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая.
Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
Источники
- Coursera: https://www.coursera.org/learn/vvedenie-mashinnoe-obuchenie
- Оценка качества в задачах классификации и регрессии
- Лекции А. Забашта
- Лекции Е. А. Соколова
- Оценка классификатора (точность, полнота, F-мера)