Varchar max это сколько
При создании таблицы для всех ее столбцов необходимо указать определенный тип данных. Тип данных определяет, какие значения могут храниться в столбце, сколько они будут занимать места в памяти.
Язык T-SQL предоставляет множество различных типов. В зависимости от характера значений все их можно разделить на группы.
Числовые типы данных
- BIT : хранит значение от 0 до 16. Может выступать аналогом булевого типа в языках программирования (в этом случае значению true соответствует 1, а значению false — 0). При значениях до 8 (включительно) занимает 1 байт, при значениях от 9 до 16 — 2 байта.
- TINYINT : хранит числа от 0 до 255. Занимает 1 байт. Хорошо подходит для хранения небольших чисел.
- SMALLINT : хранит числа от –32 768 до 32 767. Занимает 2 байта
- INT : хранит числа от –2 147 483 648 до 2 147 483 647. Занимает 4 байта. Наиболее используемый тип для хранения чисел.
- BIGINT : хранит очень большие числа от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807, которые занимают в памяти 8 байт.
- DECIMAL : хранит числа c фиксированной точностью. Занимает от 5 до 17 байт в зависимости от количества чисел после запятой. Данный тип может принимать два параметра precision и scale: DECIMAL(precision, scale) . Параметр precision представляет максимальное количество цифр, которые может хранить число. Это значение должно находиться в диапазоне от 1 до 38. По умолчанию оно равно 18. Параметр scale представляет максимальное количество цифр, которые может содержать число после запятой. Это значение должно находиться в диапазоне от 0 до значения параметра precision. По умолчанию оно равно 0.
- NUMERIC : данный тип аналогичен типу DECIMAL.
- SMALLMONEY : хранит дробные значения от -214 748.3648 до 214 748.3647. Предназначено для хранения денежных величин. Занимает 4 байта. Эквивалентен типу DECIMAL(10,4) .
- MONEY : хранит дробные значения от -922 337 203 685 477.5808 до 922 337 203 685 477.5807. Представляет денежные величины и занимает 8 байт. Эквивалентен типу DECIMAL(19,4) .
- FLOAT : хранит числа от –1.79E+308 до 1.79E+308. Занимает от 4 до 8 байт в зависимости от дробной части. Может иметь форму опредеения в виде FLOAT(n) , где n представляет число бит, которые используются для хранения десятичной части числа (мантиссы). По умолчанию n = 53.
- REAL : хранит числа от –340E+38 to 3.40E+38. Занимает 4 байта. Эквивалентен типу FLOAT(24) .
Примеры числовых столбцов:
Salary MONEY, TotalWeight DECIMAL(9,2), Age INT, Surplus FLOAT
Типы данных, представляющие дату и время
- DATE : хранит даты от 0001-01-01 (1 января 0001 года) до 9999-12-31 (31 декабря 9999 года). Занимает 3 байта.
- TIME : хранит время в диапазоне от 00:00:00.0000000 до 23:59:59.9999999. Занимает от 3 до 5 байт. Может иметь форму TIME(n) , где n представляет количество цифр от 0 до 7 в дробной части секунд.
- DATETIME : хранит даты и время от 01/01/1753 до 31/12/9999. Занимает 8 байт.
- DATETIME2 : хранит даты и время в диапазоне от 01/01/0001 00:00:00.0000000 до 31/12/9999 23:59:59.9999999. Занимает от 6 до 8 байт в зависимости от точности времени. Может иметь форму DATETIME2(n) , где n представляет количество цифр от 0 до 7 в дробной части секунд.
- SMALLDATETIME : хранит даты и время в диапазоне от 01/01/1900 до 06/06/2079, то есть ближайшие даты. Занимает от 4 байта.
- DATETIMEOFFSET : хранит даты и время в диапазоне от 0001-01-01 до 9999-12-31. Сохраняет детальную информацию о времени с точностью до 100 наносекунд. Занимает 10 байт.
Распространенные форматы дат:
- yyyy-mm-dd — 2017-07-12
- dd/mm/yyyy — 12/07/2017
- mm-dd-yy — 07-12-17 В таком формате двузначные числа от 00 до 49 воспринимаются как даты в диапазоне 2000-2049. А числа от 50 до 99 как диапазон чисел 1950 — 1999.
- Month dd, yyyy — July 12, 2017
Распространенные форматы времени:
- hh:mi — 13:21
- hh:mi am/pm — 1:21 pm
- hh:mi:ss — 1:21:34
- hh:mi:ss:mmm — 1:21:34:12
- hh:mi:ss:nnnnnnn — 1:21:34:1234567
Строковые типы данных
- CHAR : хранит строку длиной от 1 до 8 000 символов. На каждый символ выделяет по 1 байту. Не подходит для многих языков, так как хранит символы не в кодировке Unicode. Количество символов, которое может хранить столбец, передается в скобках. Например, для столбца с типом CHAR(10) будет выделено 10 байт. И если мы сохраним в столбце строку менее 10 символов, то она будет дополнена пробелами.
- VARCHAR : хранит строку. На каждый символ выделяется 1 байт. Можно указать конкретную длину для столбца — от 1 до 8 000 символов, например, VARCHAR(10) . Если строка должна иметь больше 8000 символов, то задается размер MAX, а на хранение строки может выделяться до 2 Гб: VARCHAR(MAX) . Не подходит для многих языков, так как хранит символы не в кодировке Unicode. В отличие от типа CHAR если в столбец с типом VARCHAR(10) будет сохранена строка в 5 символов, то в столце будет сохранено именно пять символов.
- NCHAR : хранит строку в кодировке Unicode длиной от 1 до 4 000 символов. На каждый символ выделяется 2 байта. Например, NCHAR(15)
- NVARCHAR : хранит строку в кодировке Unicode. На каждый символ выделяется 2 байта.Можно задать конкретный размер от 1 до 4 000 символов: . Если строка должна иметь больше 4000 символов, то задается размер MAX, а на хранение строки может выделяться до 2 Гб.
Еще два типа TEXT и NTEXT являются устаревшими и поэтому их не рекомендуется использовать. Вместо них применяются VARCHAR и NVARCHAR соответственно.
Примеры определения строковых столбцов:
Email VARCHAR(30), Comment NVARCHAR(MAX)
Бинарные типы данных
- BINARY : хранит бинарные данные в виде последовательности от 1 до 8 000 байт.
- VARBINARY : хранит бинарные данные в виде последовательности от 1 до 8 000 байт, либо до 2^31–1 байт при использовании значения MAX (VARBINARY(MAX)).
Еще один бинарный тип — тип IMAGE является устаревшим, и вместо него рекомендуется применять тип VARBINARY.
Остальные типы данных
- UNIQUEIDENTIFIER : уникальный идентификатор GUID (по сути строка с уникальным значением), который занимает 16 байт.
- TIMESTAMP : некоторое число, которое хранит номер версии строки в таблице. Занимает 8 байт.
- CURSOR : представляет набор строк.
- HIERARCHYID : представляет позицию в иерархии.
- SQL_VARIANT : может хранить данные любого другого типа данных T-SQL.
- XML : хранит документы XML или фрагменты документов XML. Занимает в памяти до 2 Гб.
- TABLE : представляет определение таблицы.
- GEOGRAPHY : хранит географические данные, такие как широта и долгота.
- GEOMETRY : хранит координаты местонахождения на плоскости.
SQL-Ex blog

Когда использовать CHAR, VARCHAR или VARCHAR(MAX)
Добавил Sergey Moiseenko on Четверг, 21 июля. 2022
В каждой базе данных имеются различные виды данных, которые нужно хранить. Некоторые данные строго числовые, в то время как другие данные состоят только из букв или комбинации букв, чисел и даже специальных символов. Даже при простом хранении данных в памяти или на диске требуется, чтобы каждая часть данных имела тип. Выбор правильного типа зависит от характеристик сохраняемых данных. В этой статье объясняется разница между CHAR, VARCHAR и VARCHAR(MAX).
При выборе типа данных столбца необходимо подумать о характеристиках данных, чтобы назначить правильный тип данных. Будет ли каждое значение иметь одну и ту же длину, или размер будет сильно различаться от значения к значению? Как часто будут меняться данные? Будет ли длина столбца меняться со временем? Могут быть и другие факторы, подобные эффективному использованию пространства и производительности, которые могут привести вас к принятию того или иного типа данных.
Типы данных CHAR, VARCHAR и VARCHAR(MAX) могут хранить символьные данные. В этой статье будут обсуждаться и сравниваться эти три различных типа символьных данных. Приведенная информация призвана помочь вам выбрать подходящий среди этих трех типов данных.
Символьный тип данных фиксированной длины CHAR
Тип данных CHAR является типом данных фиксированной длины. Он может хранить буквы, числа и специальные символы в строках размером до 8000 байт. Тип данных CHAR наилучшим образом используется для хранения данных, которые имеют сопоставимую длину. Например, двухсимвольные коды штатов США, односимвольные коды половой принадлежности, номера телефонов, почтовые коды и т.п. Столбец CHAR является не лучшим выбором для хранения данных, у которых существенно варьируется длина. Столбцы, хранящие данные типа адресов или мемо-полей не подходят для столбцов с типом данных CHAR.
Это не означает, что столбец CHAR не может содержать значения, которые варьируются по размеру. Когда в столбец CHAR заносятся строки, которые короче, чем длина столбца, справа будут добавляться пробелы. Число этих пробелов определяется разностью между размером столбца и длиной сохраняемых символов. Поскольку столбцы CHAR при необходимости полностью добиваются пробелами, каждый столбец занимает одно и то же пространство на диске или в памяти. Концевые пробелы также играют роль при поиске в столбцах типа CHAR. Подробнее об этом несколько позже.
Символьный тип данных переменной длины VARCHAR
Столбцы VARCHAR, как подразумевает название, хранят данные переменной длины. Они могут хранить буквы, числа и специальные символы, как и столбец CHAR, и поддерживают строки размером до 8000 байт. Столбец переменной длины занимает только то место, которое требуется для хранения строки символов, и не дополняются никакими пробелами. По этой причине столбцы VARCHAR отлично подходят для хранения строк, которые сильно варьируются по размеру.
Для поддержки столбцов переменной длины необходимо, помимо самих данных, хранить их длину. Поскольку длина необходима для вычислений и используется ядром базы данных при чтении и сохранении столбцов переменной длины, считается, что они несколько менее производительны по сравнению со столбцами CHAR. Однако, если учесть, что они используют только то пространство, которое им необходимо, экономия места на диске сама по себе может компенсировать потери производительности при использовании типа VARCHAR.
Различия типов данных CHAR и VARCHAR
Фундаментально отличие CHAR от VARCHAR состоит в том, что тип данных CHAR имеет фиксированную длину, в то время как тип данных VARCHAR поддерживает столбцы данных переменной длины. Но он и похожи. Оба предназначены для хранения алфавитно-цифровых данных. Для лучшего понимания разницы между этими двумя типами, посмотрите таблицу 1, где сделан обзор их подобия и отличий.

Таблица 1: сравнение типов CHAR и VARCHAR
Что означает «N» в CHAR(N) или VARCHAR(N)
«N» означает не максимальное число символов, которое может храниться в столбце CHAR или VARCHAR, а максимальное число байтов, которое займет тип данных. SQL Server имеет различные коллации для хранения символов. Некоторые наборы символов, подобные Latin, хранят каждый символ и одном байте пространства. В то время как другие наборы символов, например, японский, требуют нескольких байтов на символ.
Столбцы CHAR и VARCHAR могут хранить до 8000 байтов. Если используется односимвольный набор, то столбец CHAR или VARCHAR может хранить до 8000 символов. Если используется мультибайтовая коллация, максимальное число символов, которое может хранить CHAR или VARCHAR, будет меньше 8000. Обсуждение коллации выходит за рамки этой статьи, но если вы хотите больше узнать об однобайтовом и многобайтовыми наборами символов, обратитесь к документации.
Ошибка усечения
Если столбец определен как CHAR(N) или VARCHAR(N), «N» представляет число байтов, которое может храниться в столбце. При заполнении столбца CHAR(N) или VARCHAR(N) символьной строкой может возникнуть подобная ошибка усечения, показанная на рисунке 1.
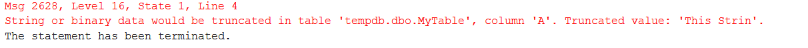
Рис.1 Ошибка усечения
Эта ошибка возникает при попытке сохранить строку, размер которой превышает максимальную длину столбца
CHAR или VARCHAR. Когда возникает подобная ошибка усечения, код TSQL прерывается, и последующий код не выполняется. Это можно продемонстрировать следующим кодом в листинге 1.
Листинг 1: код, приводящий к ошибке усечения
USE tempdb;
GO
CREATE TABLE MyTable (A VARCHAR(10));
INSERT INTO MyTable VALUES ('This String');
-- Продолжение
SELECT COUNT(*) FROM MyTable;
GO
Код в листинге 1 вызывает ошибку, показанную на рисунке 1, при выполнении оператора INSERT. Оператор SELECT, следующий за оператором INSERT, не был выполнен из-за ошибки усечения. Ошибка усечения и прерывание выполнения скрипта могут давать вам желаемую функциональность, но иногда вы не хотите получать ошибку усечения, прерывающую ваш код.
Предположим, что необходимо перенести данные из старой системы в новую. В старой системе есть таблица MyOldData, которая содержит данные, созданные с помощью скрипта в листинге 2.
Листинг 2: таблица в старой системе
USE tempdb;
GO
CREATE TABLE MyOldData (Name VARCHAR(20), ItemDesc VARCHAR(45));
INSERT INTO MyOldData
VALUES ('Widget', 'This item does everything you would ever want'),
('Thing A Ma Jig', 'A thing that dances the jig');
GO
Планируется перенести данные из таблицы MyOldData в таблицу MyNewTable, которая имеет меньший размер столбца ItemDesc. Код в листинге 3 используется для создания новой таблицы и переноса данных.
Листинг 3: перенос данных в новую таблицу
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
INSERT INTO MyNewData SELECT * FROM MyOldData;
SELECT * FROM MyNewData;
GO
При выполнении кода в листинге 3 вы получите ошибку усечения, подобную ошибке на рис.1, и никакие данные перенесены не будут.
Для успешного переноса данных необходимо определиться с тем, что делать с усечением, чтобы гарантировать перенос всех строк. Одним из методов является усечение описания элемента (ItemDesc) с помощью функции SUBSTRING при выполнении кода в листинге 4.
Листинг 4: Устранение ошибки усечения с помощью SUBSTRING
DROP Table MyNewData
GO
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
INSERT INTO MyNewData SELECT Name, substring(ItemDesc,1,40)
FROM MyOldData;
SELECT * FROM MyNewData;
GO
При выполнении кода в листинге 4 все записи переносятся. При этом ItemDesc превышающая 40 будет усекаться с помощью функции SUBSTRING, но есть и другой способ.
Если вы хотите избежать ошибки усечения без написания специального кода усечения столбцов, длина которых слишком велика, можно выключить параметр ANSI_WARNINGS, как показано в листнге 5.
Листинг 5: устранение ошибки усечения при выключении ANSI_WARNINGS.
DROP Table MyNewData
GO
USE tempdb;
GO
CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40));
SET ANSI_WARNINGS OFF;
INSERT INTO MyNewData SELECT * FROM MyOldData;
SET ANSI_WARNINGS ON;
SELECT * FROM MyNewData;
GO
При выключении параметра ANSI_WARNINGS ядро SQL Server не следует стандарту ISO для некоторых состояний ошибок, одним из которых является состояние ошибки усечения. При отключении этого параметра SQL Server автоматически усекает исходный столбец для соответствия его целевым столбцам без возвращения ошибки. Следует осторожно использовать выключение параметра ANSI_WARNINGS, поскольку при этом могут также остаться незамеченными другие ошибки. Поэтому изменение параметра ANSI_WARNINGS следует использовать ситуативно.
VARCHAR(MAX)
Тип данных VARCHAR(MAX) подобен типу данных VARCHAR в том, что он поддерживает символьные данные переменной длины. VARCHAR(MAX) отличается от VARCHAR тем, что он поддерживает строки символов длиной вплоть до 2 Гб (2,147,483,647 байтов). Вам следует рассмотреть использование VARCHAR(MAX) только тогда, когда каждая строка, сохраняемая в этом типе данных существенно варьируется по длине, и значение может превышать 8000 байтов.
Вы можете спросить себя, почему бы не использовать VARCHAR(MAX) везде вместо использования VARCHAR(N)? Вы можете, но имеется несколько причин, почему этого делать не стоит:
столбцы VARCHAR(MAX) не могут быть включены в ключевые столбцы индекса;
столбцы VARCHAR(MAX) не позволяют ограничить длину столбца;
для хранения больших строк столбцы VARCHAR(MAX) используют единицы распределения LOB_DATA. Хранилище LOB_DATA существенней медленней, чем использование единиц распределения хранилища IN_ROW_DATA;
хранилище LOB_DATA не поддерживает сжатие страниц и строк.
Можно подумать, что столбцы VARCHAR(MAX) будут устранять ошибку усечения, которую мы наблюдали ранее. Это частично верно при условии, что вы не пытаетесь сохранить строку со значением длинее, чем 2,147,483,647 байтов. Если вы попытаетесь записать строку, размер которой превышает 2,147,483,647 байтов, вы получите ошибку, показанную на рисунке 2.

Рис.2: ошибка, когда размер строки превышает 2 Гб
Столбцы VARCHAR(MAX) следует использовать только тогда, когда вы знаете, что некоторые сохраняемые данные будут ожидаемо превосходить 8000-байтовый предел для столбца VARCHAR(N), и все данные будут короче предела 2 Гб для типа данных VARCHAR(MAX).
Проблемы конкатенации со столбцами CHAR
Когда столбец CHAR не полностью заполнен строкой символов, неиспользованные символы замещаются пробелами. Когда столбец CHAR дополняется пробелами, это может вызвать некоторые проблемы при конкатенации столбцов CHAR. Для лучшего понимания рассматрим несколько примеров, которые используют таблицу, созданную в листинге 6.
Листинг 6: таблица для примеров Sample
USE tempdb;
GO
CREATE TABLE Sample (
ID int identity,
FirstNameChar CHAR(20),
LastNameChar CHAR(20),
FirstNameVarChar VARCHAR(20),
LastNameVarChar VARCHAR(20));
INSERT INTO Sample VALUES ('Greg', 'Larsen', 'Greg', 'Larsen');
Таблица Sample, созданная в листинге 6, содержит 4 столбца. Первые два определены как CHAR(20), а вторые два — VARCHAR(20). Эти столбцы будут использоваться для хранения моего имени и фамилии.
Для демонстрации проблем конкатенации, связанной с дополняемыми столбцами CHAR, выполните код в листинге 7.
Листинг 7: демонстрация проблемы конкатенации
SELECT FirstNameChar + LastNameChar AS FullNameChar,
FirstNameVarChar + LastNameVarChar AS FullNameVarChar FROM Sample;

Результат выполнения кода в листнге 7
Здесь столбец FirstNameCHAR содержит несколько пробелов между именем и фамилией. Эти пробелы являются пробелами, дополненными в столбце FirstNameCHAR при сохранении имени в столбце типа CHAR. Столбец FullNameVARCHAR не содержит пробелов между именем и фамилией. Если длина записываемого значения меньше длины столбца VARCHAR, пробелы не добавляются.
При конкатенации столбцов CHAR вам может понадобиться удалить концевые пробелы, чтобы получить желаемый результат. Вы можете использовать функцию RTRIM для удаления пробелов, как показано в листинге 8.
Листинг 8: удаление концевых пробелов с помощью функции RTRIM
SELECT RTRIM(FirstNameChar) + RTRIM(LastNameChar) AS FullNameChar,
FirstNameVarChar + LastNameVarChar AS FullNameVarchar
FROM Sample;
Результат выполнения скрипта показан на рисунке ниже.
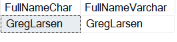
Пр использовани функции RTRIM все дополнительные пробелы, добавленные к столбцам FirstNameCHAR и LastNameCHAR удаляются перед выполнением конкатенации.
Проблемы с поиском пробелов в столбцах CHAR
Поскольку столбцы CHAR могут дополняться пробелами, поиск пробела может стать проблемой.
Предположим, что имеется таблица, содержащая фразы, подобные создаваемым в листинге 9.
Листинг 9: создание таблицы Phrase
USE tempdb;
GO
CREATE TABLE Phrase (PhraseChar CHAR(100));
INSERT INTO Phrase VALUES ('Worry Less'),
('Oops'),
('Think Twice'),
('Smile');
Некоторые фразы в таблице Phrase состоят из одного слова, а другие содержать два. Для поиска в таблице Phrase всех фраз, которые содержат два слова, воспользуемся кодом в листинге 10.
Листинг 10: попытка найти фразы из двух слов
SELECT PhraseChar FROM Phrase WHERE PhraseChar like '% %';
Результат выполнения скрипта показан ниже.

Почему были возвращены все фразы из таблицы Phrase, хотя имеется только две строки, состоящие из двух слов? Поисковая строка % % также находит пробелы, которые были добавлены в конце значения столбца. И опять, функция RTRIM может использоваться, чтобы гарантировать, что дополненные пробелы не будут включены в результаты поиска при выполнении кода в листинге 11.
Листинг 11: удаление концевых пробелов
SELECT PhraseChar FROM Phrase
WHERE RTRIM(PhraseChar) like '% %';
Вы можете сами проверить, что будут возвращены только фразы из двух слов.
Сравнение производительности VARCHAR и CHAR
Количество работы, которое выполняет движок базы данных при сохранении и извлечения столбцов VARCHAR, больше, чем для столбца CHAR. При каждом извлечении информации из столбца VARCHAR движок базы данных должен использовать информацию о длине, хранящуюся вместе с данными в столбце VARCHAR.
Использование информации о длине вызывает лишние циклы работы ЦП. В то же время фиксированная длина столбца CHAR позволяет SQL Server более легко выполнять навигацию по записям столбца CHAR, благодаря его фиксированной длине.
При работе со столбцами CHAR и VARCHAR проблемой может стать дисковое пространство. Поскольку столбец типа CHAR имеет фиксированную длину, он всегда будут занимать одинаковое пространство диска. Столбцы VARCHAR изменяются по размеру, поэтому необходимое пространство основывается на размере хранимых строк, а не на размере в определении столбца. Когда подавляющее большинство значений, хранимых в столбце CHAR, меньше заданного размера, то использование столбца VARCHAR может использовать меньше дискового пространства. Когда используется меньше дискового пространства, требуется меньше операций ввода/вывода при работе с данными столбца, что означает улучшение производительности. Эти два соображения определяют выбор между CHAR и VARCHAR.
CHAR, VARCHAR и VARCHAR(MAX)
Столбцы CHAR фиксированы по размеру, в то время как столбцы VARCHAR и VARCHAR(MAX) поддерживают данные переменной длины. Столбцы CHAR следует использовать для столбцов, длина которых меняется незначительно. Строковые значения, которые значительно варьируются по длине и не превышают 8000 байтов, следует хранить в столбце VARCHAR. Если у вас огромные строки (свыше 8000 байтов), то следует использовать VARCHAR(MAX). При использовании столбцов VARCHAR вместе с данными хранится информация о длине строки. Вычисление и хранение значения длины для столбца VARCHAR означает, что SQL Server должен выполнить немного больше работы для записи и извлечения столбцов VARCHAR по сравнению типом данных CHAR.
Когда вам предстоит решить, должен ли новый столбец иметь тип CHAR, VARCHAR или VARCHAR(MAX), задайте себе несколько вопросов, чтобы выбрать подходящий тип. Все ли сохраняемые строковые значения близки по размеру? Если да, то следует выбрать CHAR. Если сохраняемые строки значительно варьируются по размеру, и их размер не превышает 8000, используйте VARCHAR. В противном случае следует использовать VARCHAR(MAX).
varchar(max)-varchar(max) и в продакшн
Недавно поучаствовал в дискуссии на тему влияния на производительность указания длины в столбцах с типом nvarchar. Доводы были разумны у обеих сторон и поскольку у меня было свободное время, решил немного потестировать. Результатом стал этот пост.
Спойлер – не всё так однозначно.
Все тесты проводились на SQL Server 2014 Developer Edition, примерно такие же результаты были получены и на SQL Server 2016 (с небольшими отличиями). Описанное ниже должно быть актуально для SQL Server 2005-2016 (а в 2017/2019 требуется тестирование, поскольку там появились Adaptive Memory Grants, которые могут несколько исправить положение).
Нам понадобятся – хранимая процедура от Erik Darling sp_pressure_detector, которая позволяет получить множество информации о текущем состоянии системы и SQL Query Stress – очень крутая open-source утилита Adam Machanic/Erik Ejlskov Jensen для нагрузочного тестирования MS SQL Server.
О чём вообще речь
Вопрос, на который я стараюсь ответить – влияет ли на производительность выбор длины поля (n)varchar (далее везде просто varchar, хотя всё актуально и для nvarchar), или можно использовать varchar(max) и не париться, поскольку если длина строки < 8000 (4000 для nvarchar) символов, то varchar(max) и varchar(N) хранятся IN-ROW.
Готовим стенд
create table ##v10 (i int, d datetime, v varchar(10)); create table ##v100 (i int, d datetime, v varchar(100)); create table ##vmax (i int, d datetime, v varchar(max));Создаём 3 таблицы из трёх полей, разница только в длине varchar: 10/100/max. И заполним их одинаковыми данными:
;with x as (select 1 x union all select 1) , xx as (select 1 x from x x1, x x2) , xxx as (select 1 x from xx x1, xx x2, xx x3) , xxxx as ( select row_number() over(order by (select null)) i , dateadd(second, row_number() over(order by (select null)), '20200101') d , cast (row_number() over(order by (select null)) as varchar(10)) v from xxx x1, xxx x2, xxx x3 ) --262144 строк insert into ##v10 --varchar(10) select i, d, v from xxxx; insert into ##v100 --varchar(100) select i, d, v from ##v10; insert into ##vmax --varchar(max) select i, d, v from ##v10; В итоге каждая таблица будет содержать 262144 строк. Столбец I (integer) содержит неповторяющиеся числа от 1 до 262145; d (datetime) уникальные даты и v (varchar) – cast (I as varchar(10)). Чтобы это было чуть больше похоже на реальную жизнь, создаём уникальный кластерный индекс по i:
create unique clustered index #cidx10 on ##v10(i); create unique clustered index #cidx100 on ##v100(i); create unique clustered index #cidxmax on ##vmax(i);Поехали
Сначала посмотрим планы выполнения разных запросов.
Во-первых, проверим, что отбор по полю varchar не зависит от его длины (если там хранится < 8000 символов). Включаем действительный план выполнения и смотрим:
select * from ##v10 where v = '123'; select * from ##v100 where v = '123'; select * from ##vmax where v = '123';
Как ни странно, разница, хоть и небольшая, но есть. План запроса с varchar(max) сначала выбирает все строки, а потом их отфильтровывает, а varchar(10) и varchar(100) проверяют совпадения при сканировании кластерного индекса. Из-за этого, сканирование занимает практически в 3 раза больше времени – 0,068 секунд против 0.022 у varchar(10).
Теперь посмотрим, что будет, если просто выводить varchar-колонку, а отбирать данные по ключу кластерного индекса:
select * from ##v10 where i between 200000 and 201000; select * from ##v100 where i between 200000 and 201000; select * from ##vmax where i between 200000 and 201000; 
Тут всё понятно – для таких запросов никакой разницы нет.
Теперь интересная часть. Предыдущим запросом мы получили всего-то 1001 строку, а теперь хотим отсортировать их по неиндексированной колонке. Пробуем:
select * from ##v10 where i between 200000 and 201000 order by d; select * from ##v100 where i between 200000 and 201000 order by d; select * from ##vmax where i between 200000 and 201000 order by d;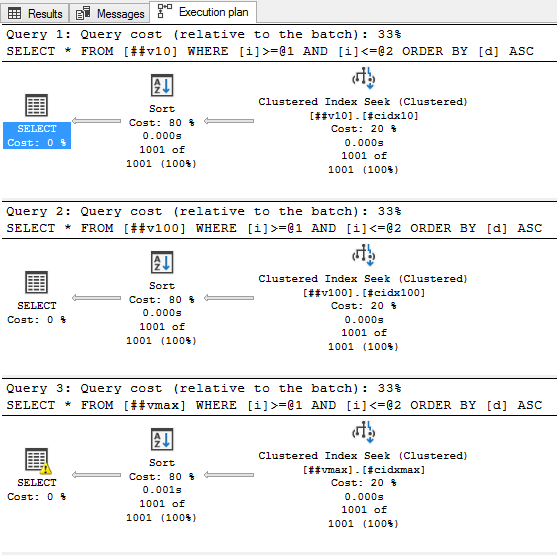
Ой, а что там такое жёлтенькое?
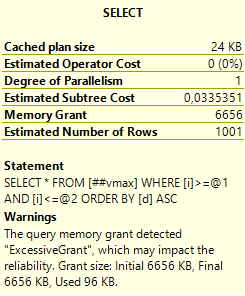
Забавно, т.е. запрос запросил и получил 6,5 мегабайт оперативной памяти для сортировки, а использовал только 96 килобайт. А насколько будет хуже, если строк будет побольше. Ну, пусть будет не 1000, а 100000:
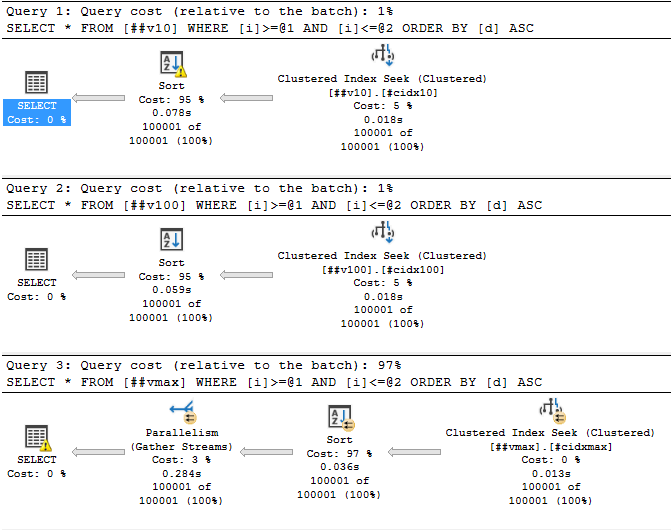
А вот тут уже посерьёзнее. Причём первый запрос, который работает с самым маленьким varchar(10) тоже чем-то недоволен:
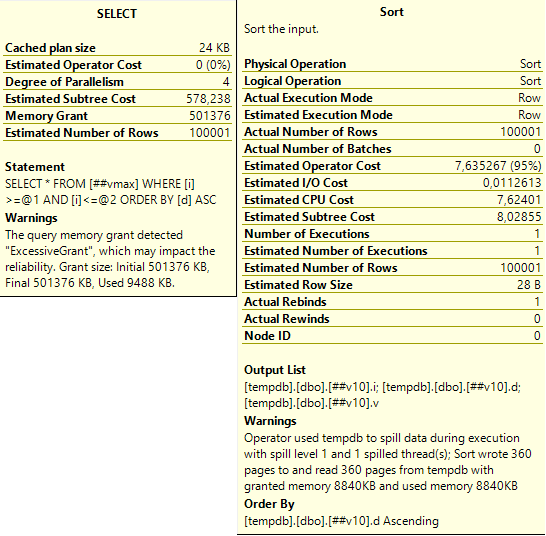
Слева тут предупреждение последнего запроса: запрошено 500 мегабайт, а использовано всего 9,5 мегабайт. А справа – предупреждение сортировки: запрошено было 8840 килобайт, но их не хватило и ещё 360 страниц (по 8 кб) было записано и прочитано из tempdb.
И тут напрашивается вопрос: WTF?
Ответ – так работает оптимизатор запросов SQL Server. Чтобы что-то отсортировать, это что-то нужно сначала поместить в память. Как понять сколько памяти нужно? Вообще, нам известно сколько какой тип данных занимает места. А что же со строками переменной длины? А вот с ними интереснее. При выделении памяти для сортировок/hash join, SQL Server считает, что в среднем они заполнены наполовину. И выделяет под них память как (размер / 2) * ожидаемое количество строк. Но varchar(max) может хранить аж 2Гб – сколько же выделять? SQL Server считает, что там будет половина от varchar(8000) – т.е. примерно 4 кб на строку.
Что интересно – такое выделение памяти приводит к проблемам не только с varchar(max) – если размер ваших varchar’ов любовно подобран так, что большая часть из них заполнена наполовину и больше – это тоже ведёт к проблемам. Проблемам иного плана, но не менее серьёзным. На рисунке выше есть описание – SQL Server не смог корректно выделить память для сортировки маленького varchar’а и использовал tempdb для хранения промежуточных результатов. Если tempdb лежит на медленных дисках, или активно используется другими запросами – это может стать очень узким местом.
SQL Query Stress
Теперь посмотрим, что происходит при массовом выполнении запросов. Запустим SQL Query Stress, подключим его к нашему серверу, и скажем выполнить все эти запросы по 10 раз в 50 потоках.
Результаты выполнения первого запроса:
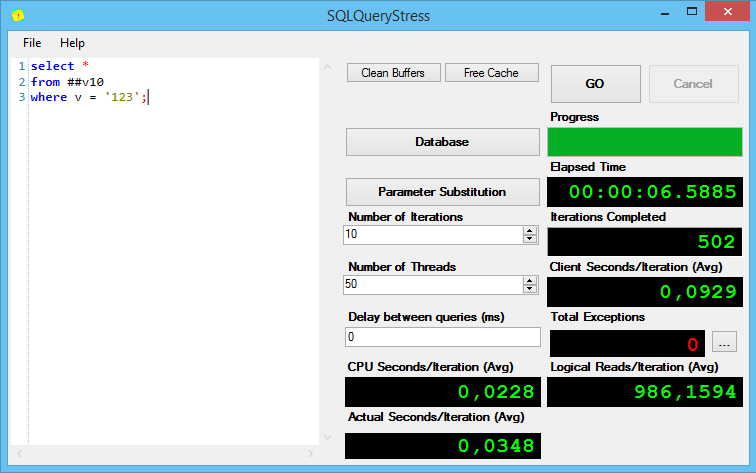
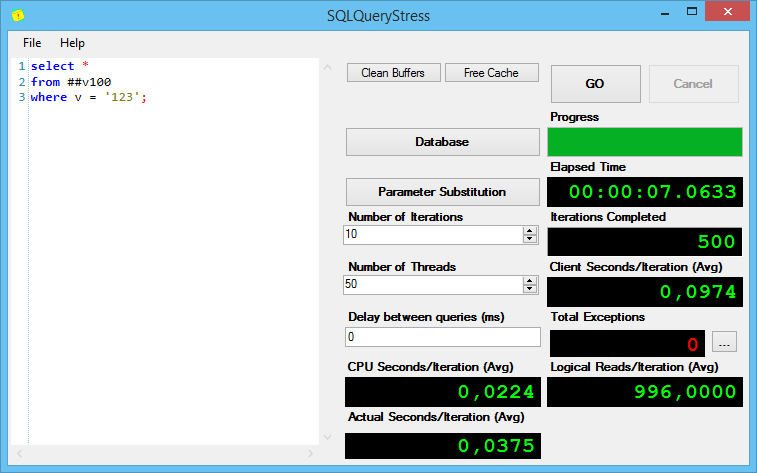
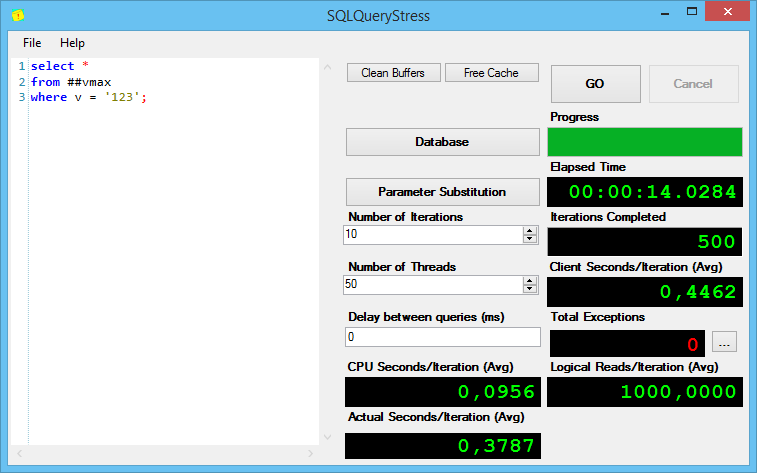
Интересно, но без индексов, при поиске varchar(max) показывает себя хуже всех, причём солидно так хуже по процессорному времени на итерацию и общему времени выполнения.
sp_pressure_detector не показывает тут ничего интересного, поэтому её вывод не привожу.
Результаты выполнения второго запроса:
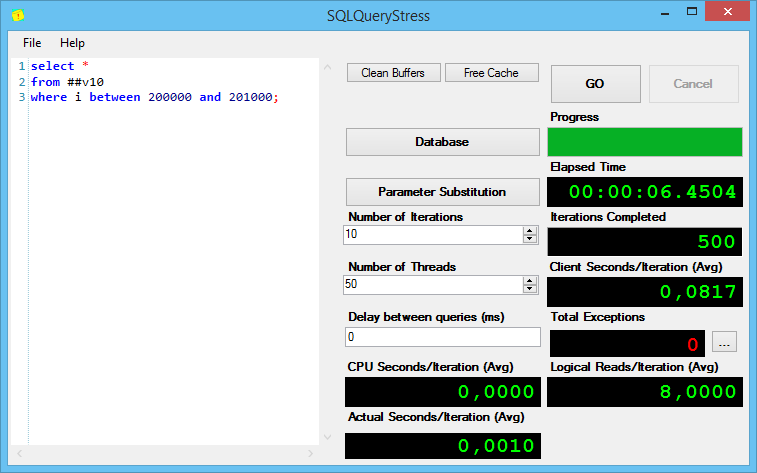
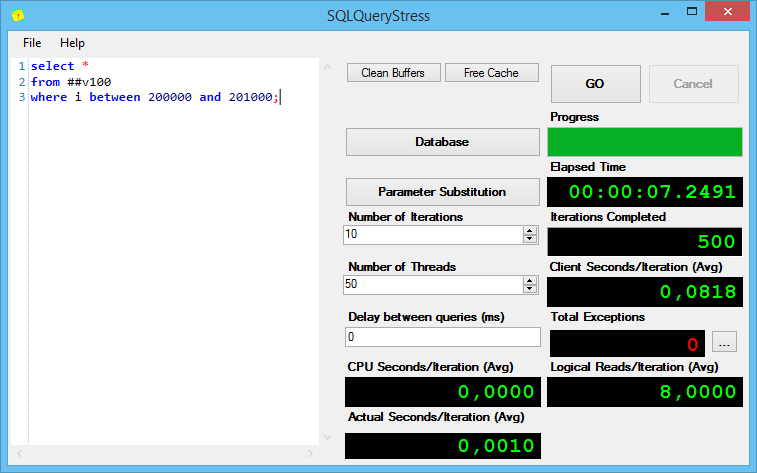

Тут всё ожидаемо – одинаково хорошо.
Теперь интересная часть. Запрос с сортировкой полученной тысячи строк:

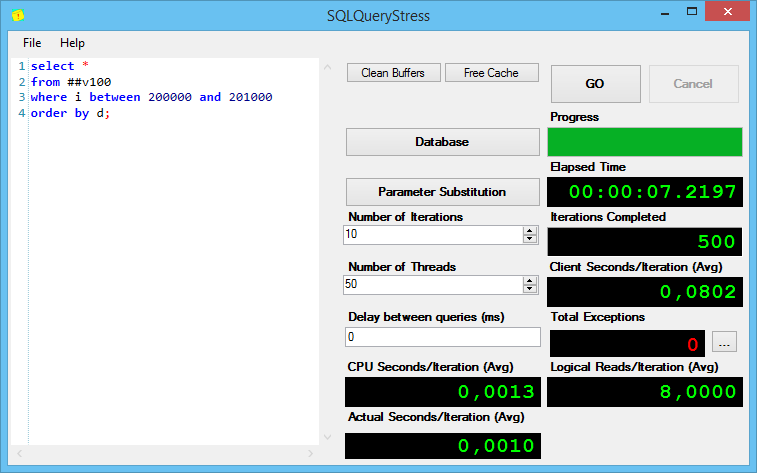
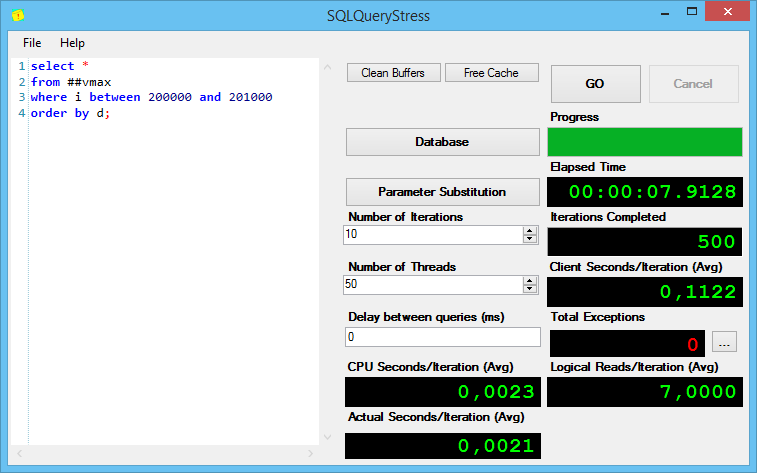
Тут всё оказалось точно также, как и с предыдущим запросом – строк не много, сортировка проблем не вызывает.
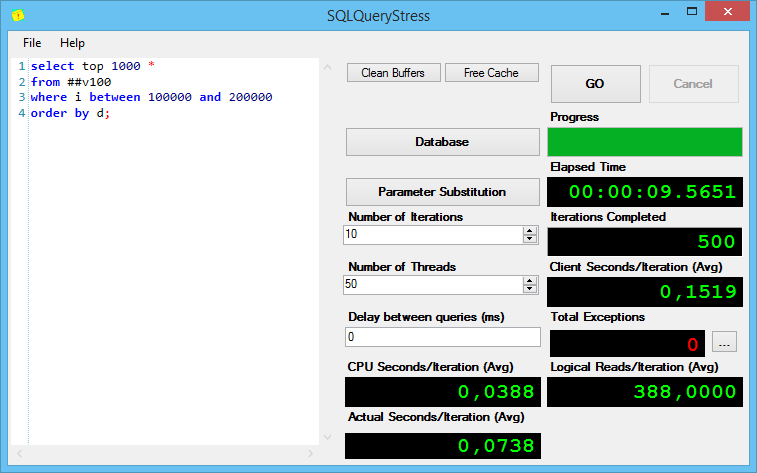
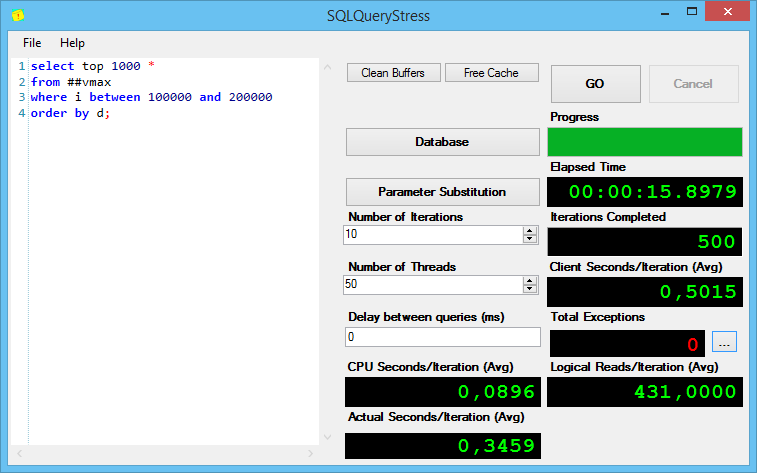
Теперь последний запрос, который сортирует неоправданно много строк (я добавил в него top 1000, чтобы не тянуть весь сортированный список):

И вот тут привожу вывод sp_pressure_detector:

Что он нам говорит? Все сессии запрашивают по 489 МБ (на сортировку), но только на 22 из них SQL Server’у хватило памяти, даже учитывая, что используют все эти 22 сессии всего по 9 МБ!
Всего доступно 11 Гб памяти, 22 сессиям было выделено по 489.625 и у SQL Server’a осталось всего-то 258 доступных мегабайт, а новые сессии тоже хотят получить по 489. Что делать? Ждать, пока освободится память – они и ждут, даже не начиная выполняться. Что будут делать пользователи, если в их сессиях выполняются такие запросы? Тоже ждать.
Кстати, обратите внимание на рисунок с varchar(10) – запросы с varchar(10) выполнялись дольше, чем запросы с varchar(100) – и это при том, что у меня tempdb на очень быстром диске. Чем хуже диск под tempdb – тем медленнее будет выполняться запрос.
Отдельное примечание для SQL Server 2012/2014
В SQL Server 2012/2014 есть ещё одна забавная шутка с sort spills. Даже если вы используете тип char/nchar – это не гарантирует отсутствие spill’ов в tempdb. MS признала проблему в оптимизаторе, когда он выделял слишком мало памяти для сортировки, даже если количество строк было оценено верно.
create table ##c6 (i int, d datetime, v char(6)); insert into ##c6 (i, d, v) select i, d, v from ##v10 select * from ##c6 where i between 100000 and 200000 order by d;
Включаем документированный флаг трассировки (НЕ ДЕЛАЙТЕ ЭТОГО НА ПРОДЕ БЕЗ НЕОБХОДИМОСТИ):
DBCC TRACEON (7470, -1);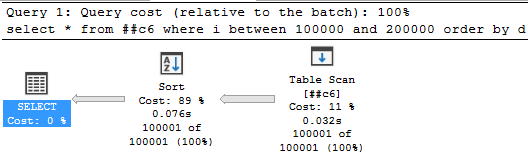
Восклицательный знак у сортировки пропал, spill’а больше нет.
Выводы
С осторожностью используйте сортировку в своих запросах, там где у вас есть колонки (n)varchar. Если сортировка всё же нужна, крайне желательно, чтобы по колонке сортировки был индекс.
Учтите, что чтобы получить сортировку совсем необязательно явно использовать order by – её появление возможно и при merge join’ах, например. Та же проблема с выделением памяти возможна и при hash join’ах, например, вот с varchar(max):
select top 100 * from ##vmax v1 inner hash join ##v10 v2 on v1.i = v2.i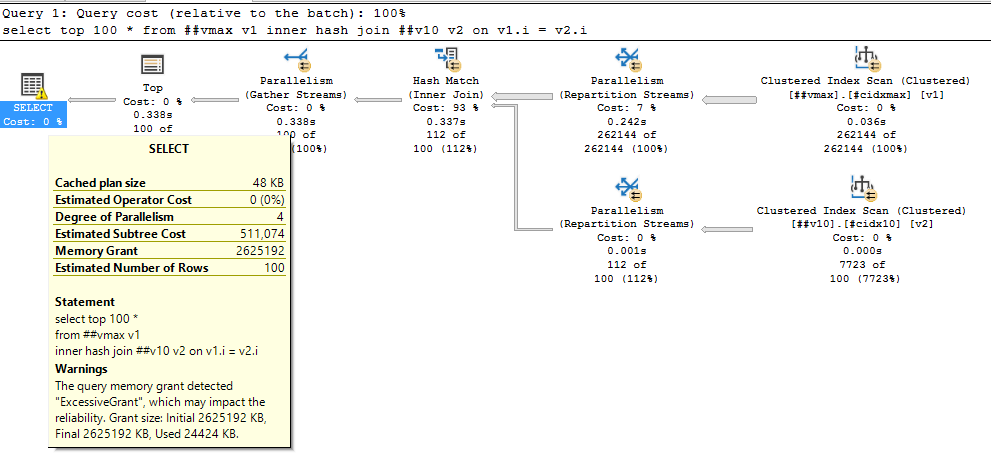
Выделено 2.5 ГИГАБАЙТА памяти, используется 25 мегабайт!
Главный для меня вывод: размер колонки (n)varchar – ВАЖЕН! Если размер слишком маленький – возможны spill’ы в tempdb, если слишком большой – возможны слишком большие запросы памяти. При наличии сортировок разумным будет объявлять длину varchar как средняя длина записи * 2, а в случае SQL Server 2012/2014 — даже больше.
Неожиданный для меня вывод: varchar(max), содержащий меньше 8000 символов, реально работает медленнее, при фильтрах по нему. Пока не знаю как это объяснить — буду копать ещё.
Бонусный вывод для меня: уже почти нажав «опубликовать» я подумал, что ведь и с varchar(max) можно испытать проблему «маленького varchar’a». И правда, при хранении в varchar(max) больше чем 4000 символов (2000 для nvarchar) — сортировки могут стать проблемой.
insert into ##vmax(i, d, v) select i, d, replicate('a', 4000) v from ##v10; select * from ##vmax where i between 200000 and 201000 order by d; 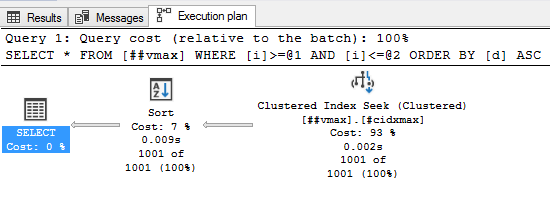
truncate table ##vmax; insert into ##vmax(i, d, v) select i, d, replicate('a', 4100) v from ##v10; select * from ##vmax where i between 200000 and 201000 order by d;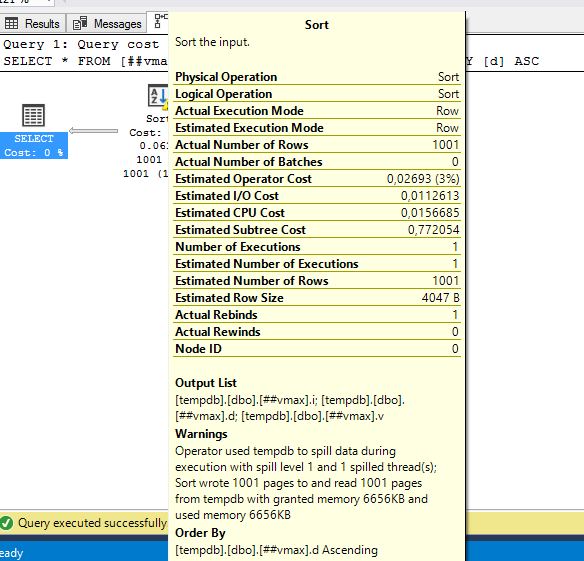
Почему в самом начале я написал, что не всё так однозначно? Потому что, например, на моём домашнем ноуте с полумёртвым диском, spill’ы в tempdb при сортировке «маленьких» varchar приводили к тому, что такие запросы выполнялись на ПОРЯДКИ медленнее, чем аналогичные запросы с varchar(max). Если у вас хорошее железо, возможно, они не станут такой проблемой, но забывать о них не стоит.
Что было бы ещё интересно — посмотреть есть ли какие-то проблемы из-за слишком больших/маленьких размеров varchar’ов в других СУБД. Если у вас есть возможность проверить — буду рад, если поделитесь.
Маленький бонус
Отловить такие проблемы с помощью кэша планов запросов, к сожалению, не получится. Вот примеры планов из кэша: никаких предупреждений в них, увы, нет.
SQL-Ex blog
Типы данных varchar в SQL Server, Oracle и PostgreSQL
Добавил Sergey Moiseenko on Суббота, 23 июля. 2022
Здесь мы рассмотрим как сохранить максимальное число символов в столбце переменной длины и различия между тремя системами баз данных. В частности, будут рассмотрены различные процедуры, используемые для хранения больших строк в столбце с целью обработки большого текста или структурированных данных типа JSON (будет отдельная статья).
Как обычно, будем использовать свободно распространяемую тестовую базу Chinook, доступную в форматах многих реляционных СУБД. Эта база данных имитирует магазин цифровых медиа с образцовыми данными, так что все, что вам требуется, это загрузить необходимую копию, и вы получите скрипты создания структур данных и операторы вставки данных.
SQL Server
В SQL Server имеются следующие строковые типы данных: VARCHAR(n), VARCHAR(MAX) и NVARCHAR(n), NVARCHAR(MAX); имеется также тип TEXT, но поскольку он является устаревшим, его не следует больше использовать.
В типах данных VARCHAR n означает максимальное число хранимых байтов; это не число символов, и их может быть максимум 8000. Если же вы используете MAX, то максимально возможный размер достигает 2 Гб (размер хранилища) для символьного типа данных, не являющегося Unicode.
Аналогично в типах данных NVARCHAR n означает число пар байтов, поэтому предельное значение составляет 4000 (максимальная длина), а MAX означает максимальное количество в 2 Гб (максимальное хранилище) для символов Юникод.
Очевидно, что число байтов или пар байтов для латинских наборов символов эквивалентно числу символов, но для других наборов это не справедливо!
Давайте установим пример T-SQL, создающий новую таблицу, в которой мы будем хранить сообщения в клиентскую службу для магазина цифрового медиа.
CREATE TABLE CustomerMessages(
MessageId int not null,
CustomerId int NOT NULL,
InsertDate smalldatetime NOT NULL,
UpdateDate smalldatetime NULL,
MessageContent varchar(5000)
CONSTRAINT PK_Message PRIMARY KEY CLUSTERED
(
MessageId ASC
) ON [PRIMARY]
) ON [PRIMARY];
ALTER TABLE CustomerMessages ADD CONSTRAINT [FK_CustomerMessages_Customer] FOREIGN KEY(CustomerId)
REFERENCES Customer (CustomerId)
Как можно увидеть, мы создали новую таблицу, добавив внешний ключ для связи с CustomerID и проверки, что клиент существует, а также первичный ключ на MessageId. В этом случае мы получаем максимум 5000 байтов (в нашем случае, поскольку мы имеем набор латиницы, это 5000 символов) в столбце MessageContent.
Теперь предположим, что мы увидели, что 5000 символов недостаточно в некоторых случаях, а также заметили, что текст, в Messages сильно варьируется от нескольких слов до длинных параграфов, поэтому мы хотим изменить его на varchar(max). Это может быть сделано следующим образом.
ALTER TABLE CustomerMessages ALTER COLUMN MessageContent varchar(max)
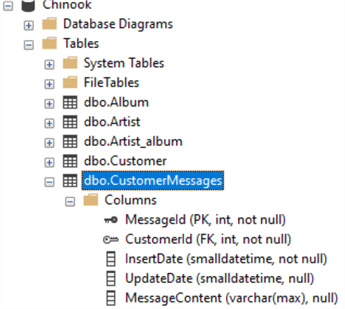
Как видно, в SQL Server изменить тип очень просто!
Oracle
В Oracle строковые типы используются аналогично, но мы имеем другие предельные значения. Во-первых, есть VARCHAR2 и NVARCHAR2, которые имеют предел 4000 байтов, если параметр MAX_STRING_SIZE установлен в значение STANDARD (об этом ниже). Они более или менее похожи на строки переменной длины VARCHAR и NVARCHAR в SQL Server.
Два других типа, используемых для хранения большого текста, это CLOB и NCLOB. LOB — это сокращение для Large Objects (большие объекты), C здесь означает символы (characters), а N, как и N в NVARCHAR, обозначает National Character (национальные символы) для данных Юникод. Эти типы данных довольно удобны для хранения большого количества данных и ограничены размером в 4 Гб. Они могут быть очень сложными и, вообще говоря, не очень хороши с точки зрения производительности, т.к. хранятся в отдельных табличных пространствах, а также требуют специальной обработки на стороне приложения.
Давайте добавим ту же таблицу, что и для SQL Server.
CREATE TABLE CHINOOK.CUSTOMERMESSAGES
(MESSAGEID NUMBER NOT NULL ENABLE,
CUSTOMERID NUMBER NOT NULL ENABLE,
INSERTDATE date NOT NULL ENABLE,
UPDATEDATE date,
MESSAGECONTENT varchar2(4000),
CONSTRAINT PK_MESSAGE PRIMARY KEY (MESSAGEID));
ALTER TABLE CHINOOK.CUSTOMERMESSAGES add CONSTRAINT FK_CUSTOMERID FOREIGN KEY (CUSTOMERID)
REFERENCES CHINOOK.CUSTOMER (CUSTOMERID) ENABLE;
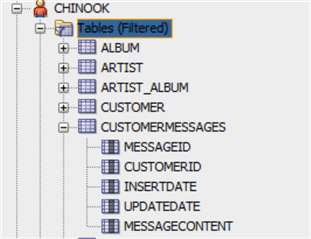
Структура и типы данных таблицы аналогичны использованным в SQL Server, но обратите внимание, что столбец MESSAGECONTENT имеет ограничение 4000 байтов (символов в нашем случае). Теперь давайте попытаемся изменить на 5000, как в SQL Server.
ALTER TABLE CHINOOK.CUSTOMERMESSAGES MODIFY (MESSAGECONTENT VARCHAR2(5000 BYTE));
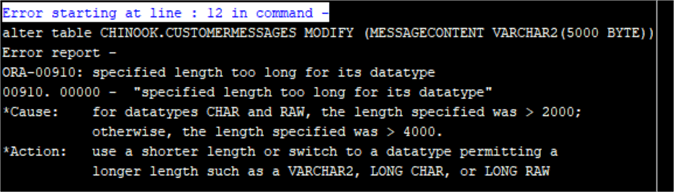
Как видно, мы достигли предела, но, начиная с версии Oracle 12c, имеется решение, о котором я намекал ранее, которое позволяет увеличить предел типов данных VARCHAR2 и NVARCHAR2 до 32767 байтов.
Сначала давайте проверим упомянутый выше параметр MAX_STRING_SIZE.
SHOW PARAMETER MAX_STRING_SIZE
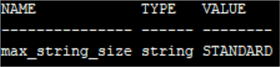
Как ожидалось, параметр установлен в значение по умолчанию STANDARD. Для увеличения предела VARCHAR2 и NVARCHAR2 до 32767 байтов нам нужно установить этот инициализационный параметр в значение EXTENDED.
Прежде чем начинать процедуру изменения инициализационного параметра, нужно проверить параметр COMPATIBLE, который должен быть установлен в 12.0.0.0 или выше, чтобы выполнить эту процедуру.
SELECT name, value, description FROM v$parameter WHERE name = 'compatible';

Теперь, когда мы уверены, продолжим, но должны держать в уме, что эта процедура потребует, по крайней мере, пару перезапусков базы данных, и должна быть выполнена пара внешних скриптов преобразования.
Я покажу эти шаги для изменения параметра на единственной PDB.
Первый шаг — это остановить PDB и снова открыть её в режиме UPGRADE (или миграции), что может быть сделано подключением к хосту в ssh, а затем подключением к Container DB или CDB с помощью sqlplus и выполнением команды:

Теперь мы можем выполнить команду для её открытия в режиме миграции:

Мы теперь можем подключиться к PDB и изменить параметр инициализации: 


Сейчас мы можем выполнить эти два скрипта для преобразования и перекомпиляции объектов в нашей базе данных:

и 
Теперь мы готовы перезапустить базу данных (PDB):

И снова проверим параметр:

Теперь мы можем снова попытаться изменить столбец MESSAGECONTENT на 5000 байтов:
ALTER TABLE CHINOOK.CUSTOMERMESSAGES MODIFY (MESSAGECONTENT VARCHAR2(5000 BYTE));

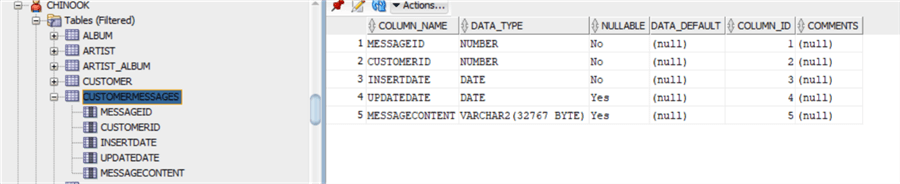
Проверяя таблицу в Oracle Developer, мы видим, что теперь размер столбца равен 5000 байтов:

Помните, что предельное значение составляет 32767 байтов, поэтому VARCHAR2(32767) — это максимум, который мы можем задать.
ALTER TABLE CHINOOK.CUSTOMERMESSAGES MODIFY (MESSAGECONTENT VARCHAR2(32767 BYTE) );

PostgresSQL
В PostgreSQL у нас есть два типа данных, которые используются для хранения больших текстов: VARCHAR(N) и TEXT.
Имеется пара отличий от SQL Server и Oracle: первое, N является числом символов, а не байтов, более того, мы можем опустить это число, и тогда это будет эквивалентно VARCHAR(MAX) в SQL Server и типу данных TEXT. В этом случае предельное значение числа символов не указывается в официальной документации PostgreSQL, хотя имеется такая информация: «В любом случае максимальная строка символов, которая может быть сохранена, имеет длину около 1 Гб».
Теперь мы можем попробовать создать таблицу, аналогичную двум другим СУБД:
CREATE TABLE IF NOT EXISTS public."CustomerMessages"
(
"MessageId" integer not null,
"CustomerId" integer NOT NULL,
"InsertDate" timestamp without time zone NOT NULL,
"UpdateDate" timestamp without time zone,
"MessageContent" varchar(5000),
CONSTRAINT "PK_Message" PRIMARY KEY ("MessageId")
)
ALTER TABLE public."CustomerMessages"
ADD CONSTRAINT "FK_CustomerMessages_Customer" FOREIGN KEY("CustomerId")
REFERENCES public."Customer" ("CustomerId") MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION;
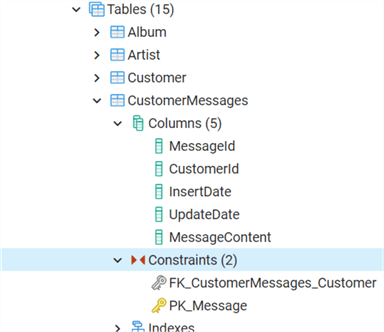
Обратите внимание на предложение IF NOT EXISTS в CREATE TABLE, это очень удобно!
Поскольку мы увидели, что 5000 символов недостаточно, модифицируем столбец, выходя за предел, чтобы мы могли хранить максимальное символов:
ALTER TABLE "CustomerMessages" ALTER COLUMN "MessageContent" type varchar

Вот и все для PostgreSQL!
Заключение
Здесь мы рассмотрели типы данных, которые обычно используются для хранения больших строк в SQL Server, Oracle и PostgreSQL. Мы увидели различные предельные значения синтаксис, а также модификацию инициализационных параметров базы данных для увеличения предельного значения в Oracle.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись