Парсинг JavaScript сайтов
Инструкция содержит всё необходимое для организации и поддержания краулинга динамических сайтов в целях аудита или парсинга данных. Для создания самих правил под Web Scraping перейдите по ссылке внизу этой страницы.
Основные требования к JavaScript сайтам и web-приложениям
LinksTamed обрабатывает страницы прямо в браузере, уже по умолчанию выполняя JavaScript и ожидая подгружаемый контент. Однако сайт должен соответствовать требованиям, которые предъявляются для браузерного бота googlebot. Вкратце, отдельным документом считается контент, который имеет уникальный URL-адрес, а ссылки в этом документе сгенерированы в ссылки a href , что критически важно при краулинге SPA и PWA.
SPA и PWA -сайты — это одностраничные JavaScript web-приложения, которые обновляют контент без перезагрузки страницы, чаще всего используя технологию взаимодействия с сервером AJAX , которая поставляет данные для частичной замены объектов на странице. Страницы таких гибридов сайта и приложения не нуждаются в уникальном адресе web-страницы, но для успешной индексации в поисковых системах на них должны присутствовать HTML-ссылки a href , клик по которым должен перехватываться. Правильное сканирование с помощью LinksTamed и браузерными ботами возможно, если сайт имеет статическую версию или динамически загруженный по клику контент будет доступен потом при переходе по ссылке. Таким образом парсинг в LinksTamed достаточно точно отражает способность сайта быть проиндексированным поисковыми системами.
- Использование таких популярных JavaScript-фреймворков (программных сред для работы) как React, Angular и Vue не гарантирует, что события обновления контента являются «SEO-friendly» : продублированы ссылкой a href , изменяют адресную строку и метаданные. LinksTamed поможет обнаружить такие проблемы;
- При выборе в настройках googlebot или yandexbot генерация контента в LinksTamed происходит одинаковым образом, хотя на практике роботам Яндекса требуются статические копии страниц с ?_escaped_fragment_= , а более ресурсоёмкий метод Google (и Bing) является пока что только экспериментальным;
- Учитываются только ссылки a href : у события есть ссылка, а подгружаемый контент доступен при переходе на сайт через адресную строку по этой ссылке;
- Фрагмент URL-адреса после # (Sha-bang (шебанг), он же hashbang (хешбанг)) обрабатывается не как якорь только в сочетании c идущим далее восклицательным знаком ( #! );
- Парсер не прокручивает страницы, это значит, что идет взаимодействие с первым видовым экраном — скрипт сайта подгрузит контент в том объеме, который посчитали нужным разработчики при первичном показе страницы, например, на странице категории с бесконечной прокруткой;
- Значение таймера Ожидание JS или refresh редиректов, AJAX и асинхронных скриптов на странице настроек должно быть не менее 1020 мс при старте парсинга.
Выставляем оптимальные таймауты для парсинга
Специфическая проблема парсинга сайтов с подгружаемыми ресурсами — увеличенное время обхода из-за простоев в режиме бездействия, так как без этих задержек краулер не может узнать, будет ли вообще асинхронный AJAX-запрос или загрузка файла JavaScript, а если они есть — стоит ли ожидать очередной ответ после запроса или это была отправка некой статистики.
Для ботов поисковых систем время простоя страниц после события onload составляет не менее 5 секунд. Для нас это очень большое время простоя вкладки в состоянии бездействия, особенно когда на странице вообще нет динамически генерируемого контента. С другой стороны ваше устройство может быть загружено сторонними процессами и 5 секунд может оказаться недостаточно.
Таймер Прервать ожидание AJAX-запросов, асинхронных скриптов и refresh редиректов после события onload, при продолжительном отсутствии запросов со значением по умолчанию 1020 мс — время простоя от последнего асинхронного JS или AJAX-запроса (XMLHttpRequest), после которого краулер решает, что больше запросов не будет. Отсчет времени начинается после события onload. Потери времени частично компенсируются большим количеством параллельных потоков, которое выбирается парсером при первичной установке исходя из количества ядер процессора на вашем устройстве. Для некоторых сайтов можно выставить значение ниже планки по умолчанию, но перед парсингом незнакомых сайтов следует выставлять таймауты не ниже 1020 мс по умолчанию.
С таймаутами по умолчанию можно парсить большинство сайтов вообще без проблем, особенно на мощных ПК, а в случае поздних асинхронных запросов LinksTamed предупредит через уведомление, что надо увеличивать таймауты. Обратите внимание, что таймауты (кроме Мин. таймаут между запросами к серверу… ) действуют только на страницы индексируемого типа. Страницы с HTTP-кодами, контент которых не индексируется, в целях предотвращения проблем с парсингом, обрабатываются по внутренним таймерам в автоматическом режиме.
Секция проверки достаточности таймаутов

Для проверки достаточности времени простоя страниц в ожидании асинхронно подгружаемых ресурсов используйте секцию Проверка достаточности таймаутов для загрузки динамических сайтов (на иллюстрации), которая расположена на главной странице LinksTamed в разделе Этапы работы парсера .
-
Самый поздний script или AJAX запрос после события onload — если значение близко к значению (или больше) метрики под названием При этом максимальное время их ожидания (меняется на странице с настройками), существует риск, что часть асинхронных запросов могла быть не сделана скриптом страницы. В этом случае необходимо начать краулинг заново с новыми таймаутами, если это не отправка статистических и других не важных данных, что можно будет уточнить в Монитор сетевых запросов , который описывается ниже на этой странице.
Максимальная задержка между ними, если их несколько — если значение близко к значению Завершение ожидания, если нет их повторных запросов (на странице с настройками), есть вероятность того, что парсер мог не дождаться очередного запроса скриптом страницы и необходимо повторить парсинг. Иными словами краулер ждет после загрузки страницы или прошлого запроса установленное время и если задержки слишком большие, LinksTmaed может просто не узнать о таком запросе, начав и закончив анализ страницы до этого запроса. Промежутки более 2000 мс могут означать, что сервер не справляется с большим количеством параллельных потоков.
- 15% — становится оранжевым ;
- 5% (или больше максимального таймера) — становится красным . В этом случае также приходит уведомление о недостаточности таймаутов.
- Прервать ожидание AJAX-запросов… свыше 19000 мс,
- Макс. время ожидания AJAX-запросов… свыше 8000 мс
и после запуска краулинга заняться ресурсоёмкой деятельностью, а после парсинга 50-100 страниц снизить таймауты с запасом в 15-20% от максимальных значений в секции (или выставить минимальные, если запросов нет). Поскольку интенсивность нагрузки на сеть и ядра процессора вырастут после снижения задержек, могут вырасти и таймауты, поэтому в первый раз таймауты стоит снизить с запасом в 25-30% и через 50-100 страниц до значений с запасом в 15-20%. Двухэтапное снижение настоятельно рекомендуется если сайт использует последовательный протокол передачи данных HTTP/1.1 (будет отображено в аудите в секции HTTP header после парсинга первой страницы), так как сайт может начать не справляться с большим количеством параллельных потоков. 50-100 страниц для тестирования — это рациональный минимум, но правильнее просканировать количество страниц, равное количеству ссылок на главной странице.
Монитор сетевых запросов на страницах
Инструмент позволяет увидеть запрошенные страницей сетевые ресурсы (если они есть), а именно: тип запроса, сколько прошло после события onload на момент запроса, через сколько мс получен код ответа, ошибки загрузки, заголовок HTTP-ответа и прочее.
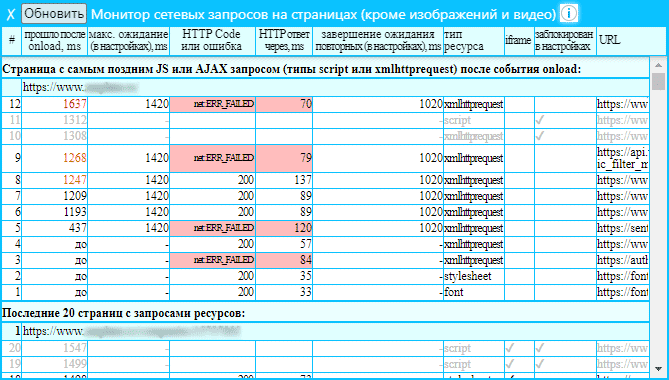
- Помимо просмотра списка сетевых запросов JavaScript-файлов (отображается как script ) и AJAX-запросов (отображается как XMLHttpRequest ) можно отслеживать сетевые запросы пользовательских шрифтов ( font ) и стилей ( stylesheet );
- Изображения, <object> , <embed> , а также очевидные форматы видео и аудио не отображаются в Монитор… , однако в случае проблем с их загрузкой, они попадут в аудит, как и все остальные виды ресурсов с ошибками загрузки;
- Что означают значения в ms с цифрами оранжевого и красного цвета описано в предыдущем разделе.
Где находится: значок в секции Проверка достаточности таймаутов… на главной странице LinksTamed.
- Страница с самым поздним JS или AJAX запросом после события onload ;
- Последние 20 страниц с запросами ресурсов ;
- Самая первая страница с запросом ресурса .
- Увеличить размеры секции можно за счёт скрытия секции Основные события парсинга и обработки данных: расположенной выше;
- Если в ссылке этого или любого другого ненужного сетевого запроса типа script или XMLHttpRequest в Монитор… имеется уникальный фрагмент, который не встречается в других запросах, мы можем добавить его в список Блокировать запросы JS файлов и вызовы AJAX (XMLHttpRequest) к URL-адресам, которые содержат фрагменты из списка на странице настроек, который будет действовать для всех веб-сайтов. В ином случае, остается подогнать таймеры так, чтобы были на 15-20% больше самого позднего значимого сетевого запроса типа script или XMLHttpRequest ;
- Если ресурс в списке является запросом к другому сайту или вызов был сделан из фрейма ( iframe ), высоковероятно, что парсер может без него обойтись. Это можно проверить, сделав пробный парсинг с ним или без него;
- Если возникают проблемы при загрузке контента, возможно заблокирован какой-то скрипт, что можно проверить в Монитор… в столбце заблокирован в настройках . Если никакие важные ресурсы не блокируются, таймауты достаточны и даже включена загрузка изображений на странице настроек, необходимо опробовать активизацию видимости для событий о которой рассказывается ниже;
- С помощью значений в столбце HTTP ответ через, ms можно оценить наиболее проблемные по времени загрузки не медиа ресурсы, однако чтобы снизить влияние других вкладок, следует производить парсинг в один поток (настраивается на странице Настройки).
Активизация видимости страницы
Иногда могут возникать проблемы с доступом или страницы с динамически подгружаемым контентом могут загржаться без части контента, при этом все таймеры выставлены с запасом. В этом случае, возможно, скрипт на странице сайта проверяет видимость окна браузера на экране пользователя.
Чаще всего на сайтах используются такие JavaScript-события проверки видимости как visibilitychange , focusin , focus , pageshow и webglcontextrestored . Они могут циклически переназначаться и быть завязаны на таймеры, которые должны отработать несколько сотен миллисекунд, поэтому эмуляция событий активизации видимости не всегда даёт ожидаемые результаты. Чтобы надежно решать задачи краулер LinksTamed просто фокусирует вкладку на переднем экране на указанное количество мс.
Важные моменты для SEO и индексации страниц с динамическим JavaSript контентом в поисках системах:
Поскольку вечнозеленый рендирующий googlebot использует headless сборку браузера Chrome, на момент написания инструкции он не мог активизировать никакие события видимости. Если Вами будет обнаружено, что проблема парсинга была связанна именно с этим, то этот контент, загружаемый за счет проверки видимости вкладки, не может быть обработан ботами поисковых систем. Таким образом, данный режим предназначен для проверки теорий или парсинга данных (web scraping).
Чтобы включить режим показа вкладки, установите таймер Мин. время показа каждой вкладки на странице настроек выше нуля. Время показа последней вкладки будет отображаться также в секции Проверка достаточности таймаутов для загрузки динамических сайтов , которая расположена на главной странице LinksTamed в разделе Этапы работы парсера .
- Поскольку может быть показана только одна вкладка за раз, другие потоки будут вынуждены ждать своей очереди. Так как каждая вкладка проходит свои этапы загрузки и анализа, есть некоторое количество мс, которые не будут оказывать существенного влияния на время парсинга. Это минимальное время указано возле таймера на странице настроек.
- Если скрипт страницы проверяет активизацию при каждом асинхронном запросе ресурса (что проверяется двумя пробными парсингами страницы), время показа вкладки следует увеличить вплоть до значений Макс. время ожидания AJAX-запросов, асинхронных скриптов и META Refresh редиректов .
- Для надежной работы механизма активизации видимости необходимо присутствие окна браузера в видимой части экрана вашего устройства. Это может быть всего один пиксель именно, как ни странно, окна браузера (на момент написания статьи), а не вкладки. Если режим показа вкладки включен (таймер имеет значение отличное от нуля), будет проверяться видимость вкладки и если окно было вами скрыто, LinksTamed поставит краулинг сайта на паузу и известит о данной проблеме. После возобновления парсинга страницы без активизации будут проверены повторно;
- К четко выверенному таймеру Мин. время показа каждой вкладки рекомендуется прибавить ещё 30—100 мс из-за того, что ядро процессора с которым работает вкладка, может занять другой процесс на вашем устройстве (не касается процессора Apple M1).
ЯДРО-СЕРВИС 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023…
ВСЕ ПРАВА ЗАЩИЩЕНЫ.
Страница сгенерирована за 0.003617 сек.
Как парсить через requests/bs4,сайт генерируемый через JS?
Добрый день.
Хотел спарсить сайт через использование requests/bs4. Но сайт генерируется на JS, и результаты парсинга через requests/bs4, не выдает 🙁 (хотя Content-Type: text/html).
Если парсить через selenium, то все ОК, нужную информацию получаю.
Собственно вопрос, можно ли сайты на js, парсить через requests/bs4, а не через selenium? Если да, то как?
- Вопрос задан более трёх лет назад
- 844 просмотра
Комментировать
Решения вопроса 1
Дмитрий Свиридов @dimuska139
Backend developer
Нет, нельзя, потому что requests просто получает контент страницы (без выполнения js, естественно), а bs4 разбирает html. Selenium можно заменить разве что PhantomJS.
Как парсить страницы сайтов с автоподгрузкой на примере Instagram
Статья обновлена 19 января 2020 в связи с изменениями структуры JS необходимой для извлечения query_hash в парсере по тэгам. Механика автоподгрузки на страницах сайтов осуществляется с помощью Javascript. Поэтому, для того, чтобы определить на какой URL нам нужно обращаться и какие параметры использовать, нам нужно либо досконально изучить JS код который работает на странице, либо, и что предпочтительней, изучить запросы, которые делает браузер при прокрутке страницы вниз. Изучить запросы мы можем с помощью Инструментов для разработчика, которые встроены во все современные браузеры. В нашей статье мы будем использовать Google Chrome, но вы можете использовать любой другой браузер, приняв во внимание, что инструменты разработчика могут выглядеть по разному в разных браузерах.
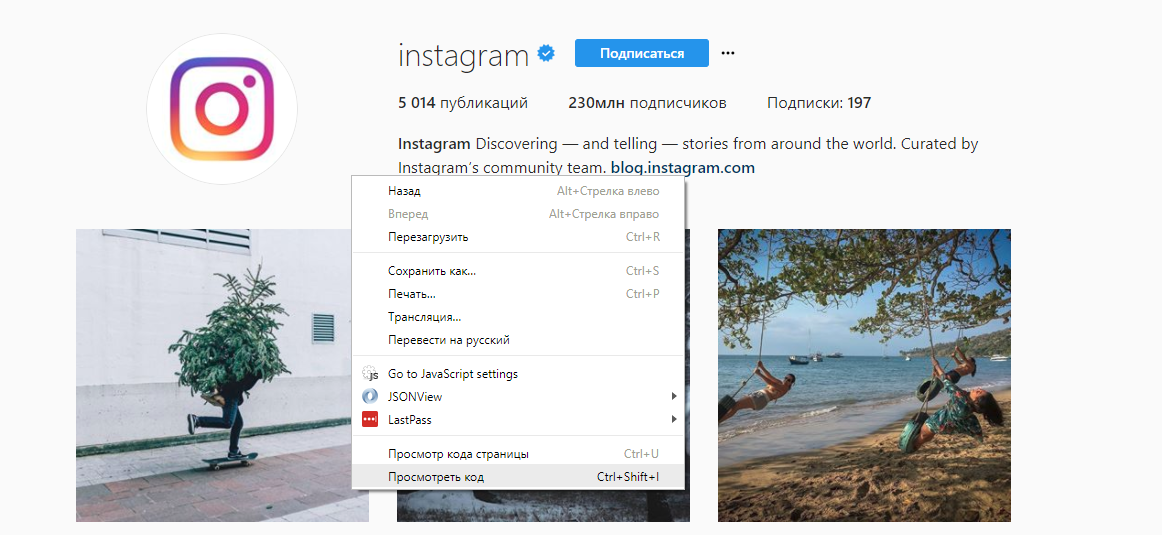
Изучать нашу задачу мы будем на примере Instagram, а именно, используя официальный канал Instagram. Откроем эту страницу в браузере, и запустим Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Просмотреть код» или нажмите «Ctrl+Shift+I»:
У нас откроется окно инструментов, где мы перейдем во вкладку Network и в фильтрах выберем показ только XHR запросов. Мы это делаем для того, чтобы отфильтровать ненужные нам запросы. После этого перезагрузим страницу в браузере с помощью кнопки Reload в интерфейсе браузера или клавиши «F5» на клавиатуре.
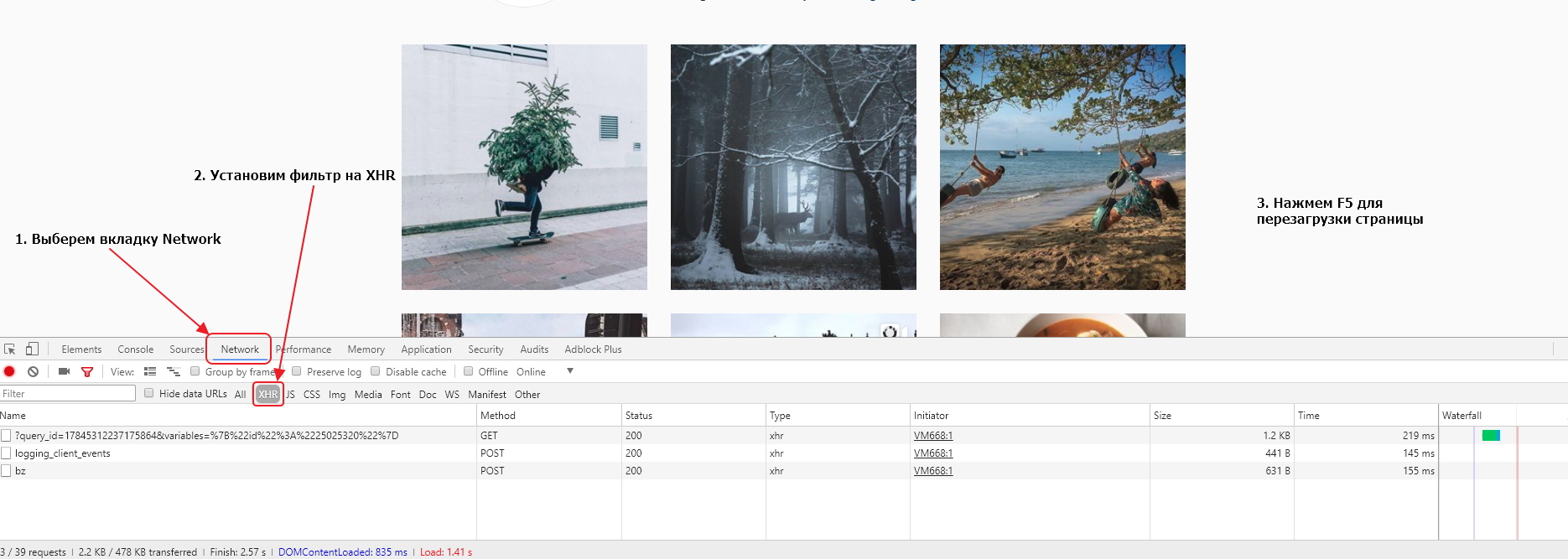
Давайте теперь прокрутим страницу вниз несколько раз с помощью колесика мышки, что вызовет подгрузку контента. Каждый раз, когда при прокручивании мы будем достигать нижней части страницы, JS будет делать XHR запрос на сервер, получать данные и добавлять их на страницу. В результате, у нас в списке окажется несколько запросов, которые выглядят почти одинаково. Скорее всего они нам и нужны.

Чтобы удостовериться в этом, мы должны выбрать один из запросов и в открывшемся окне перейти во вкладку Preview. Там мы сможем увидеть отформатированное содержимое, которое сервер прислал в браузер по этому запросу. Доберемся до одного из конечных элементов и удостоверимся, что там находятся данные об изображениях, которые есть у нас на странице.
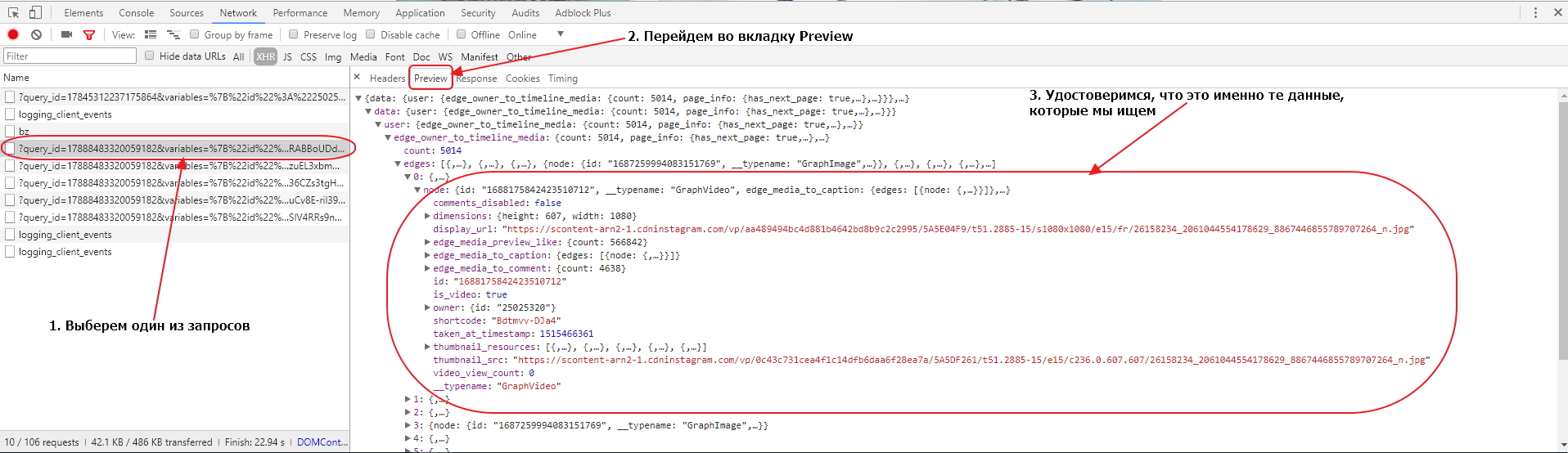
Убедившись, что это нужные нам запросы, рассмотрим один из них более внимательно. Для этого перейдем во вкладку Headers. Там мы можем найти информацию о том, на какой именно URL производится запрос, какой тип запроса (POST или GET) используется, а также какие параметры передаются с запросом.

Параметры запроса лучше изучать в секции Query String Parameters, прокрутив рабочее окно в панели инструментов вниз до конца:

Результатом нашего анализа станут следующие факты:
URL запроса: https://www.instagram.com/graphql/query/
Тип запроса: GET
Передаваемые параметры: query_hash и variables
Очевидно, что в query_hash передается статичный id, который генерируется, скорее всего, когда вы заходите на страницу. В variables же передаются некие параметры в JSON формате, влияющие на выборку данных.
Давайте проведем небольшой эксперимент, возьмем URL с параметрами, который использовался для загрузки данных:
Если бы до последнего апдейта API мы бы взяли и вставили его в адресную строку браузера и нажали Enter, то мы бы увидели как загрузится страница в JSON формате:
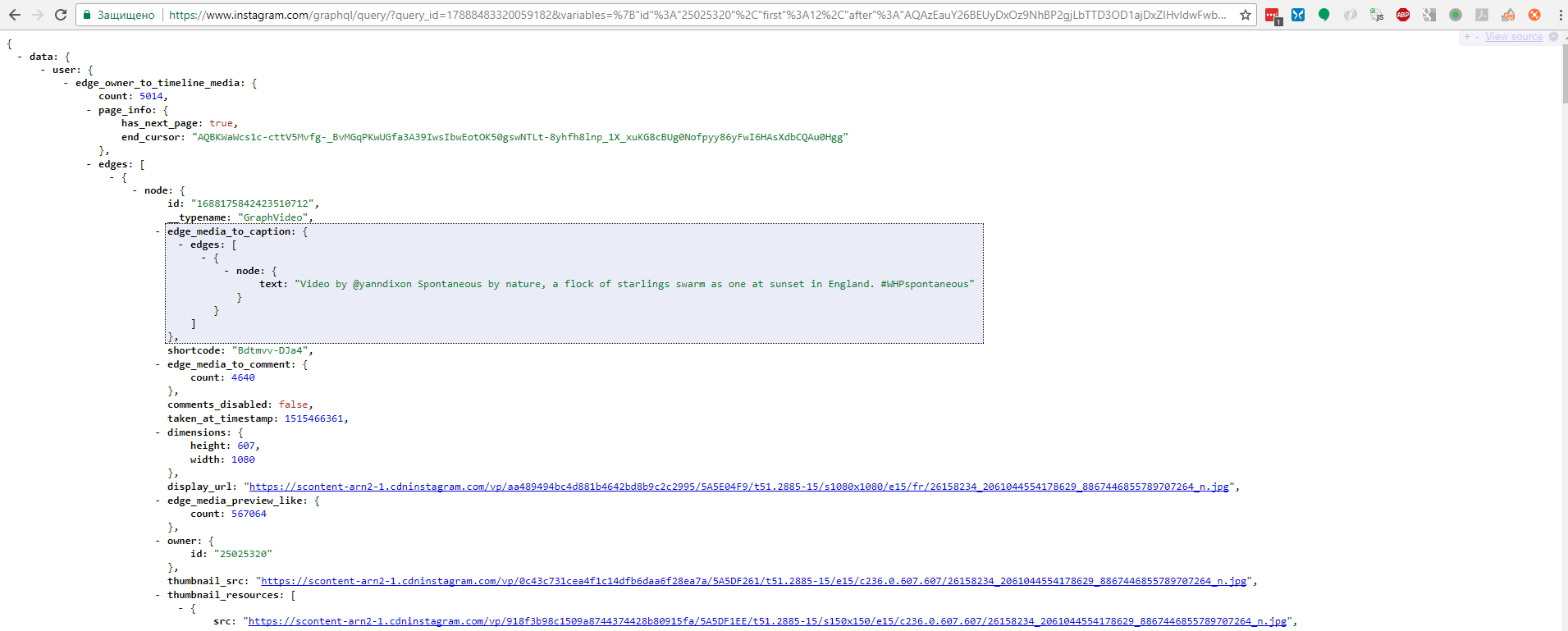
Однако, теперь просто так API Инстаграма не отдает данные, для этого необходимо рассчитать подпись для запроса и передать ее в заголовке запроса. Этот вопрос более подробно рассматривается ниже. Без корректного заголовка все что мы получим сейчас — это ошибку 403.
Теперь нам нужно понять, откуда берется query_hash. Если мы перейдем во вкладку Elements и попытаемся найти (CTRL+F) наш query_hash f2405b236d85e8296cf30347c9f08c2a, то мы узнаем что на самой странице его нет, а значит он подгружается или генерируется где-то в коде Javascript. Поэтому, перейдем опять во вкладку Network и поставим фильтр на JS. Таким образом мы увидим только запросы на JS файлы. Последовательно перебирая запрос за запросом, будем искать наш id в загруженных файлах: просто выбираем запрос, затем открываем в открывшейся панели вкладку Response чтобы увидеть содержимое JS и делаем поиск нашего id (CTRL+F). После нескольких неудачных попыток, мы обнаружим, что наш id находится в следующем JS файле:
а фрагмент кода, который обрамляет id, выглядит так:
s.pagination>,queryId:"f2405b236d85e8296cf30347c9f08c2a" Соответственно, для получения query_hash нам надо найти на первой странице URL на ProfilePageContainer.js файл, извлечь этот URL, забрать JS файл по этому URL, распарсить место с нужным нам id и записать его в переменную для дальнейшего использования.
Теперь давайте посмотрим, что за переменные передаются в variables:
Если мы проанализируем все XHR запросы с догружаемыми данными, что мы обнаружим, что меняется только параметр after. Поэтому id скорее всего есть id канала, который мы парсим, first — количество записей, которые сервер должен отдать по запросу, а after — очевидно id последней показанной записи.
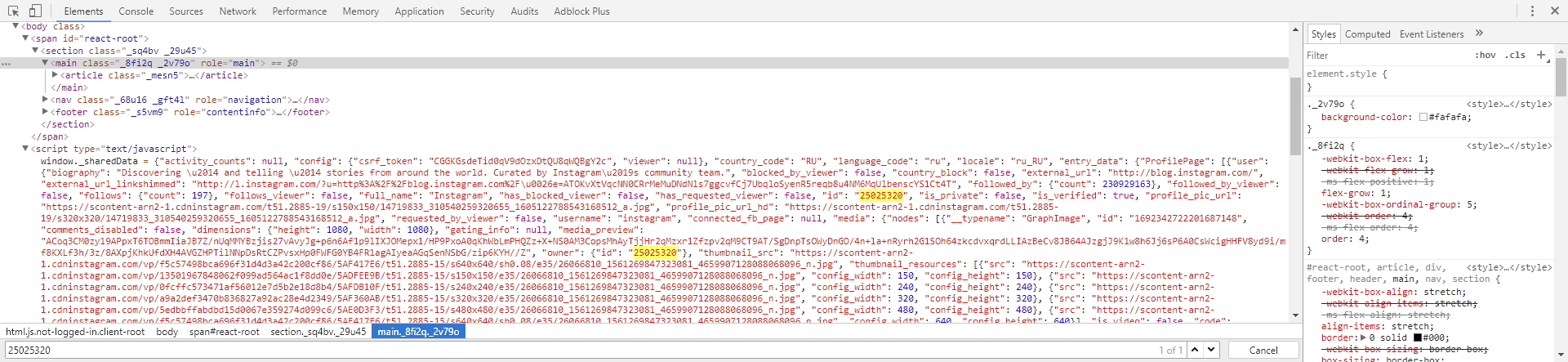
Нам нужно найти место, из которого мы можем извлечь id канала, для этого первым делом мы поищем текст 25025320 в исходном коде начальной страницы. Перейдем во вкладку Elements и сделаем поиск (CTRL+F) нашего id. Мы обнаружим, что он есть в JSON структуре на самой странице, именно оттуда мы и можем его извлечь:
Вроде все понятно, но где нам брать этот самый after для каждой последующей подгрузки? Все очень просто. Если мы загрузим в браузере следующий URL:
мы увидим, что там есть следующая структура:
data: < user: < edge_owner_to_timeline_media: < count: 5014, page_info: < has_next_page: true, end_cursor: "AQCCoEpYvQtj0-NgbaQUg9g4ffOJf8drV2RieFJw1RA3E9lDoc8euxXjeuwlUEtXB6CRS9Zs2ZGJcNKseKF9f6b0cN0VC3ck8rnTfOw5q8nlJw" >> > > То есть, в нашей логике мы сможем использовать значение поля has_next_page чтобы знать переходить ли на следующую страницу или нет и end_cursor как значение параметра after.
Сейчас мы напишем заготовку нашего парсера, загрузим первую страницу и попытаемся загрузить JS файл с query_id. Создайте диггер в вашем аккаунте Diggernaut и добавьте в него следующую конфигурацию:
--- config: agent: Firefox debug: 2 do: # Загружаем начальную страницу - walk: to: https://www.instagram.com/instagram/ do: # Ищем элементы script которые подгружают JS - find: path: script[type="text/javascript"] do: # Парсим значение атрибута src - parse: attr: src # Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js - if: match: ProfilePageContainer\.js do: # Переходим по URL скрипта - walk: to: value do:Установите диггер в режим Отладка. Теперь нам нужно запустить наш парсер и после того как он отработает посмотреть лог. В конце лога мы увидим как диггернаут работает с JS файлами. Он преобразовывает их в следующую структуру:
А значит селектор для забора всего JS будет script. Давайте допишем функцию парсинга query_id из JS:
--- config: agent: Firefox debug: 2 do: # Загружаем начальную страницу - walk: to: https://www.instagram.com/instagram/ do: # Ищем элементы script которые подгружают JS - find: path: script[type="text/javascript"] do: # Парсим значение атрибута src - parse: attr: src # Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js - if: match: ProfilePageContainer\.js do: # Переходим по URL скрипта - walk: to: value do: # Ищем элемент, содержащий искомый JS - find: path: script do: # Парсим контент элемента, используя фильтр с регулярным выражением - parse: filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\; # Сохраняем полученное значение в переменной - variable_set: queryidСохраним наш парсер и снова запустим. Подождем когда он закончит работу и посмотрим в лог. В логе мы увидим следующую строчку:
Set variable queryid to register value: 42323d64886122307be10013ad2dcc44
Это значит, что query_hash был успешно извлечен и записан в переменную с именем queryid.
Теперь мы извлечем id канала. Как вы помните, он есть в JSON объекте на самой странице. Поэтому нам нужно взять содержимое определенного элемента script, вытащить оттуда JSON, конвертировать его в XML и забрать нужное нам значение, используя CSS селектор.
--- config: agent: Firefox debug: 2 do: # Загружаем начальную страницу - walk: to: https://www.instagram.com/instagram/ do: # Ищем элементы script которые подгружают JS - find: path: script[type="text/javascript"] do: # Парсим значение атрибута src - parse: attr: src # Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js - if: match: ProfilePageContainer\.js do: # Переходим по URL скрипта - walk: to: value do: # Ищем элемент, содержащий искомый JS - find: path: script do: # Парсим контент элемента, используя фильтр с регулярным выражением - parse: filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\; # Сохраняем полученное значение в переменной - variable_set: queryid # находим элемент script, который содержит текст window._sharedData - find: path: script:contains("window._sharedData") do: - parse - space_dedupe - trim # извлекаем JSON - filter: args: window\._sharedData\s+\=\s+(.+)\s*;\s*$ # конвертим JSON в XML - normalize: routine: json2xml # превращаем XML строку в DOM блок - to_block - find: path: body_safe do: # Находим элемент в котором хранится id канала - find: path: entry_data > profilepage > graphql > user > id do: # Парсим содержимое элемента - parse # Сохраняем полученное значение в переменной - variable_set: chidЕсли вы внимательно посмотрите в лог, то увидите, что JSON структура трансформируется в DOM следующим образом:
qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz US 1.5 480 360 profilePage_25025320 Discovering — and telling — stories from around the world. Curated by Instagram’s community team. false false http://blog.instagram.com/ http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M 230937095 false 197 false Instagram false false 25025320 false true 5014 GraphVideo false 607 1080 https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg 573448 Video by @yanndixon Spontaneous by nature, a flock of starlings swarm as one at sunset in England. #WHPspontaneous 4709 1688175842423510712 true 25025320 Bdtmvv-DJa4 1515466361 150 150 https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 240 240 https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 320 320 https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 480 480 https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 640 640 https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 2516274 . AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ true 45ca3dc3d5fd true Это поможет нам построить CSS селекторы для забора первых 12 записей и маркера последней записи, который нужен нам для забора следующих 12 записей. Напишем логику для извлечения данных, а также начем формировать пул (pool) линков со ссылками на фиды (feeds) с подгружаемыми данными. Далее начнем итерацию по пулу линков и посмотрим как преобразует Diggernaut полученный JSON, так, чтобы мы смогли построить корректные CSS селекторы для логики парсера.
Совсем недавно Instagram сделал изменения в публичном API, теперь для авторизация делается не по CSRF токену, а по специальной сигнатуре, которая рассчитывается используя новый параметр rhx_gis, передаваемый в sharedData странице канала и передаваемые в запросе переменные. Алгоритм можно узнать при разборе JS. Этот алгоритм мы используем и будем автоматически подписывать запросы. Для этого нам нужно извлечь rhx_gis параметр.
--- config: agent: Firefox debug: 2 do: # Загружаем начальную страницу - walk: to: https://www.instagram.com/instagram/ do: # Ищем элементы script которые подгружают JS - find: path: script[type="text/javascript"] do: # Парсим значение атрибута src - parse: attr: src # Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js - if: match: ProfilePageContainer\.js do: # Переходим по URL скрипта - walk: to: value do: # Ищем элемент, содержащий искомый JS - find: path: script do: # Парсим контент элемента, используя фильтр с регулярным выражением - parse: filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\; # Сохраняем полученное значение в переменной - variable_set: queryid # находим элемент script, который содержит текст window._sharedData - find: path: script:contains("window._sharedData") do: - parse - space_dedupe - trim # извлекаем JSON - filter: args: window\._sharedData\s+\=\s+(.+)\s*;\s*$ # конвертим JSON в XML - normalize: routine: json2xml # превращаем XML строку в DOM блок - to_block - find: path: body_safe do: # Находим элемент в котором хранится id канала - find: path: entry_data > profilepage > graphql > user > id do: # Парсим содержимое элемента - parse # Сохраняем полученное значение в переменной - variable_set: chid # Находим элемент в котором хранится rhx_gis - find: path: rhx_gis do: # Парсим содержимое элемента - parse # Сохраняем полученное значение в переменной - variable_set: rhxgis # Находим элементы записей и итерируем по ним - find: path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node do: # Создаем новый объект с именем item - object_new: item # Находим элемент с URL изображения - find: path: display_url do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: url # Находим элемент с описанием записи - find: path: edge_media_to_caption > edges > node > text do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: caption # Находим элемент с флагом видео это или нет - find: path: is_video do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: video # Находим элемент с количеством комментариев - find: path: edge_media_to_comment > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: comments # Находим элемент с количеством лайков - find: path: edge_media_preview_like > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: likes # записываем объект в базу - object_save: name: item # Находим элемент, в котором хранятся данные для подгрузки - find: path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info do: # Находим элемент, в котором хранятся данные о наличии следующей страницы - find: path: has_next_page do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: hnp # Читаем содержимое переменной в регистр - variable_get: hnp # Проверяем равно ли значение 'true' - if: match: 'true' do: # Если да, то находим элемент с курсором - find: path: end_cursor do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: cursor # URL-энкодим параметр - eval: routine: js body: '(function () ")>)();' # Сохраняем значение в переменную - variable_set: cursor_encoded # Формируем пул линков и добавляем в него URL на первую подгрузку - link_add: url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D # Формируем подпись и записываем ее в переменную signature - register_set: ':<"id":"","first":12,"after":"">' - normalize: routine: md5 - variable_set: signature # Устанавливаем счетчик подгрузок в 0 - counter_set: name: pages value: 0 # Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса - walk: to: links headers: x-instagram-gis: x-requested-with: XMLHttpRequest do:После запуска в логе мы можем увидеть вот такую структуру, с которой нам нужно работать:
qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz US 1.5 480 360 profilePage_25025320 Discovering — and telling — stories from around the world. Curated by Instagram’s community team. false false http://blog.instagram.com/ http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M 230937095 false 197 false Instagram false false 25025320 false true 5014 GraphVideo false 607 1080 https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg 573448 Video by @yanndixon Spontaneous by nature, a flock of starlings swarm as one at sunset in England. #WHPspontaneous 4709 1688175842423510712 true 25025320 Bdtmvv-DJa4 1515466361 150 150 https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 240 240 https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 320 320 https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 480 480 https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 640 640 https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg 2516274 . AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ true 45ca3dc3d5fd true Мы намеренно укоротили исходный код, убрав повторяющиеся элементы. Теперь мы можем описать логику парсинга всех нужных нам полей, а также добавить ограничитель на количество подгрузок, скажем, 10. Также мы добавим паузу, для менее агрессивного парсинга. В результате мы получим финальную версию нашего парсера Instagram.
--- config: agent: Firefox debug: 2 do: # Загружаем начальную страницу - walk: to: https://www.instagram.com/instagram/ do: # Ищем элементы script которые подгружают JS - find: path: script[type="text/javascript"] do: # Парсим значение атрибута src - parse: attr: src # Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js - if: match: ProfilePageContainer\.js do: # Переходим по URL скрипта - walk: to: value do: # Ищем элемент, содержащий искомый JS - find: path: script do: # Парсим контент элемента, используя фильтр с регулярным выражением - parse: filter: profilePosts\.byUserId\.get[^,]+,queryId\:\&\s*quot\;([^&]+)\&\s*quot\; # Сохраняем полученное значение в переменной - variable_set: queryid # находим элемент script, который содержит текст window._sharedData - find: path: script:contains("window._sharedData") do: - parse - space_dedupe - trim # извлекаем JSON - filter: args: window\._sharedData\s+\=\s+(.+)\s*;\s*$ # конвертим JSON в XML - normalize: routine: json2xml # превращаем XML строку в DOM блок - to_block - find: path: body_safe do: # Находим элемент в котором хранится id канала - find: path: entry_data > profilepage > graphql > user > id do: # Парсим содержимое элемента - parse # Сохраняем полученное значение в переменной - variable_set: chid # Находим элемент в котором хранится rhx_gis - find: path: rhx_gis do: # Парсим содержимое элемента - parse # Сохраняем полученное значение в переменной - variable_set: rhxgis # Находим элементы записей и итерируем по ним - find: path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node do: # Создаем новый объект с именем item - object_new: item # Находим элемент с URL изображения - find: path: display_url do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: url # Находим элемент с описанием записи - find: path: edge_media_to_caption > edges > node > text do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: caption # Находим элемент с флагом видео это или нет - find: path: is_video do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: video # Находим элемент с количеством комментариев - find: path: edge_media_to_comment > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: comments # Находим элемент с количеством лайков - find: path: edge_media_preview_like > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: likes # записываем объект в базу - object_save: name: item # Находим элемент, в котором хранятся данные для подгрузки - find: path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info do: # Находим элемент, в котором хранятся данные о наличии следующей страницы - find: path: has_next_page do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: hnp # Читаем содержимое переменной в регистр - variable_get: hnp # Проверяем равно ли значение 'true' - if: match: 'true' do: # Если да, то находим элемент с курсором - find: path: end_cursor do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: cursor # URL-энкодим параметр - eval: routine: js body: '(function () ")>)();' # Сохраняем значение в переменную - variable_set: cursor_encoded # Формируем пул линков и добавляем в него URL на первую подгрузку - link_add: url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D # Формируем подпись и записываем ее в переменную signature - register_set: ':<"id":"","first":12,"after":"">' - normalize: routine: md5 - variable_set: signature # Устанавливаем счетчик подгрузок в 0 - counter_set: name: pages value: 0 # Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса - walk: to: links headers: x-instagram-gis: x-requested-with: XMLHttpRequest do: - sleep: 3 # Находим элемент, в котором хранятся данные для подгрузки - find: path: edge_owner_to_timeline_media > page_info do: # Находим элемент, в котором хранятся данные о наличии следующей страницы - find: path: has_next_page do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: hnp # Читаем содержимое переменной в регистр - variable_get: hnp # Проверяем равно ли значение 'true' - if: match: 'true' do: # Если да, то проверяем счетчик подгрузок, больше ли он 10 - counter_get: pages - if: type: int gt: 10 else: # Если нет, то находим элемент с курсором - find: path: end_cursor do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: cursor # URL-энкодим параметр - eval: routine: js body: '(function () ")>)();' # Сохраняем значение в переменную - variable_set: cursor_encoded # Формируем пул линков и добавляем в него URL следующей подгрузки - link_add: url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22id%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D # Формируем подпись и записываем ее в переменную signature - register_set: ':<"id":"","first":12,"after":"">' - normalize: routine: md5 - variable_set: signature # Находим элементы записей и итерируем по ним - find: path: edge_owner_to_timeline_media > edges > node do: # Создаем новый объект с именем item - object_new: item # Находим элемент с URL изображения - find: path: display_url do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: url # Находим элемент с описанием записи - find: path: edge_media_to_caption > edges > node > text do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: caption # Находим элемент с флагом видео это или нет - find: path: is_video do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: video # Находим элемент с количеством комментариев - find: path: edge_media_to_comment > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: comments # Находим элемент с количеством лайков - find: path: edge_media_preview_like > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: likes # записываем объект в базу - object_save: name: item # Увеличим счетчик подгрузок на 1 - counter_increment: name: pages by: 1Теперь мы пожем перевести наш диггер в Активный режим и запустить его. Как результат в вашем наборе данных будут подобные записи.
Надеемся что данная статья поможет вам в изучении мета-языка и теперь вы сможете решать задачи по парсингу страниц с подгрузкой без затруднений. В качестве домашнего задания, попробуйте разобраться с тем как работает версия парсера для поиска по хэштегам. Ниже приведим код парсера:
--- config: agent: Firefox debug: 2 do: # Инициальзируем переменную в которую записываем hashtag - variable_set: field: tag value: beard # Загружаем начальную страницу - walk: to: https://www.instagram.com/explore/tags/ do: # Ищем элементы script которые подгружают JS - find: path: script[type="text/javascript"] do: # Парсим значение атрибута src - parse: attr: src # Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка Consumer.js - if: match: Consumer\.js do: # Переходим по URL скрипта - walk: to: value do: # Ищем элемент, содержащий искомый JS - find: path: script do: # Парсим контент элемента, используя фильтр с регулярным выражением - parse: filter: T\.pagination\>,queryId\:\&\s*quot\;([^&]+)\&\s*quot\; # Сохраняем полученное значение в переменной - variable_set: queryid # находим элемент script, который содержит текст window._sharedData - find: path: script:contains("window._sharedData") do: - parse - space_dedupe - trim # извлекаем JSON - filter: args: window\._sharedData\s+\=\s+(.+)\s*;\s*$ # конвертим JSON в XML - normalize: routine: json2xml # превращаем XML строку в DOM блок - to_block - find: path: body_safe do: # Находим элемент в котором хранится rhx_gis - find: path: rhx_gis do: # Парсим содержимое элемента - parse # Сохраняем полученное значение в переменной - variable_set: rhxgis # Находим элементы записей и итерируем по ним - find: path: entry_data > tagpage > graphql > hashtag > edge_hashtag_to_media > edges > node do: # Создаем новый объект с именем item - object_new: item # Находим элемент с URL изображения - find: path: display_url do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: url # Находим элемент с описанием записи - find: path: edge_media_to_caption > edges > node > text do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: caption # Находим элемент с флагом видео это или нет - find: path: is_video do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: video # Находим элемент с количеством комментариев - find: path: edge_media_to_comment > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: comments # Находим элемент с количеством лайков - find: path: edge_media_preview_like > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: likes # записываем объект в базу - object_save: name: item # Находим элемент, в котором хранятся данные для подгрузки - find: path: entry_data > tagpage > graphql > hashtag > edge_hashtag_to_media > page_info do: # Находим элемент, в котором хранятся данные о наличии следующей страницы - find: path: has_next_page do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: hnp # Читаем содержимое переменной в регистр - variable_get: hnp # Проверяем равно ли значение 'true' - if: match: 'true' do: # Если да, то находим элемент с курсором - find: path: end_cursor do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: cursor # URL-энкодим параметр - eval: routine: js body: '(function () ")>)();' # Сохраняем значение в переменную - variable_set: cursor_encoded # Формируем пул линков и добавляем в него URL на первую подгрузку - link_add: url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22tag_name%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D # Формируем подпись и записываем ее в переменную signature - register_set: ':<"tag_name":"","first":12,"after":"">' - normalize: routine: md5 - variable_set: signature # Устанавливаем счетчик подгрузок в 0 - counter_set: name: pages value: 0 # Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса - walk: to: links headers: x-instagram-gis: x-requested-with: XMLHttpRequest do: - sleep: 3 # Находим элемент, в котором хранятся данные для подгрузки - find: path: edge_hashtag_to_media > page_info do: # Находим элемент, в котором хранятся данные о наличии следующей страницы - find: path: has_next_page do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: hnp # Читаем содержимое переменной в регистр - variable_get: hnp # Проверяем равно ли значение 'true' - if: match: 'true' do: # Если да, то проверяем счетчик подгрузок, больше ли он 10 - counter_get: pages - if: type: int gt: 10 else: # Если нет, то находим элемент с курсором - find: path: end_cursor do: # Парсим содержимое элемента - parse # Сохраняем значение в переменную - variable_set: cursor # URL-энкодим параметр - eval: routine: js body: '(function () ")>)();' # Сохраняем значение в переменную - variable_set: cursor_encoded # Формируем пул линков и добавляем в него URL следующей подгрузки - link_add: url: https://www.instagram.com/graphql/query/?query_hash=&variables=%7B%22tag_name%22%3A%22%22%2C%22first%22%3A12%2C%22after%22%3A%22%22%7D # Формируем подпись и записываем ее в переменную signature - register_set: ':<"tag_name":"","first":12,"after":"">' - normalize: routine: md5 - variable_set: signature # Находим элементы записей и итерируем по ним - find: path: edge_hashtag_to_media > edges > node do: # Создаем новый объект с именем item - object_new: item # Находим элемент с URL изображения - find: path: display_url do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: url # Находим элемент с описанием записи - find: path: edge_media_to_caption > edges > node > text do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: caption # Находим элемент с флагом видео это или нет - find: path: is_video do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: video # Находим элемент с количеством комментариев - find: path: edge_media_to_comment > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: comments # Находим элемент с количеством лайков - find: path: edge_media_preview_like > count do: # Парсим содержимое элемента - parse # Записываем значение в поле объекта item - object_field_set: object: item field: likes # записываем объект в базу - object_save: name: item # Увеличим счетчик подгрузок на 1 - counter_increment: name: pages by: 1Получить содержимое страницы генерируемое js

Получить содержимое html страницы
В общем, у мя есть адрес html страницы, нужно получить ее содержимое в текстовую переменную.
Получить содержимое страницы
Здравствуйте Нужно получить содержимое страницы.
Получить содержимое страницы
Доброго времени суток, подскажите плз как получить содержимое страницы, на которой контент.
Получить содержимое страницы
Пытаюсь получить html код с сайта rghost.ru unit Unit1; interface uses Windows, .
2740 / 2339 / 620
Регистрация: 19.03.2012
Сообщений: 8,830
Сообщение было отмечено Фархад93 как решение
Решение
Ты уже вроде спрашивал об этом, ну да не суть. Чтобы получить данные готорые генерит js, тебе нужен браузер, то есть то, что будет интрепретировать js.
Тебе нужено использовать или pyqt с его QWebView или selenium.
Регистрация: 20.11.2015
Сообщений: 42
Доброго времени суток. Селениум не оправдал надежд. Много всплывающих окон и переходов на другие ресурсы при тестах. Может кто нибудь подскажет как питоном парсить ajax запросы. Заранее спасибо!
2740 / 2339 / 620
Регистрация: 19.03.2012
Сообщений: 8,830
![]() Сообщение от Фархад93
Сообщение от Фархад93 
Может кто нибудь подскажет как питоном парсить ajax запросы
Ты хочешь написать свой браузер интерпретирующий странички?
Ты понял, чего спросил?
87844 / 49110 / 22898
Регистрация: 17.06.2006
Сообщений: 92,604
Помогаю со студенческими работами здесь
Необходимо получить содержимое страницы
Добрый день! Мне необходимо получить html-код страницы: http://kidsco.md/ Выполняю cURL запрос.
Получить содержимое веб-страницы
Всем привет, как с помощью HTTP-запросов вывести содержимое веб-страницы в listbox? При условии.
Получить содержимое из html страницы
Всем привет! Помогите пожалуйста разобраться, с такой задачкой столкнулась впервые, можно сказать.
Получить содержимое главной страницы
Всем привет! Редиректит со страниц сайта на левый домен. Как-то можно получить все-таки код.
Получить содержимое страницы на PHP
всем доброе время суток. подскажите пожалуйста, как написать парсинг курсов валют с сайта втб .
Получить содержимое HTML-страницы
Добрый день, уважаемые участники сообщества! Есть HTML-код нескольких страниц. Мне не нужна.