Что такое тестовые данные
При рассмотрении задачи проектирования теста были описаны два важных артефакта: тестовые сценарии и тестовые наборы. В отсутствие данных для тестов эти два артефакта реализовать невозможно. Они являются описаниями условий, сценариев и путей, но не предусматривают конкретных значений для реализации. Тестовые данные сами по себе не являются артефактом, но заметно влияют на успех или неудачу теста. Тестирование не может быть выполнено без данных для тестов. Они требуются для следующего:
- входные данные для создания условия
- выходные данные для оценки требования
- вспомогательные данные (как предварительное условие для теста)
Поэтому определение значений — это важная часть работы при создании тестовых наборов, см. Рабочий продукт: тестовый набор и Рекомендация: тестовый набор.
При определении фактических данных для тестов следует учитывать четыре параметра:
- объем данных — количество тестовых данных
- полнота — степень вариации тестовых данных
- охват — применимость данных для цели тестирования
- архитектура — физическая структура тестовых данных
Эти параметры подробно описываются в следующих разделах:
Объем
Объем — это количество данных для тестирования. Объем данных — это важный параметр; если данных слишком мало, они могут не отразить все возможные ситуации, если же слишком много — то с ними будет трудно работать. Лучше всего, если тестирование начинается с небольшого объема данных, пригодного для критически важных (и, как правило, позитивных) тестовых наборов. По мере того как достоверность тестирования будет увеличиваться, объем данных должен расширяться, пока не охватит все существенные случаи развертывания в среде (в разумных пределах).
Полнота
Полнота данных означает степень изменения данных для тестирования. Ее можно увеличивать, создавая больше записей. Часто этого достаточно, но фактически нам требуется видеть изменения данных, с которыми можно встретиться в реальной ситуации. Без этого в тестировании можно упустить из виду какие-либо ошибки, да и не все ограничиваются получением строго $50.00 из банкомата. Поэтому в тесте нужно учесть вариацию данных в реальной среде, например, получение $10.00 или $120.00. Кроме того, данные должны учитывать возможные вариации фактических данных, например:
- Имена могут включать звания, числа, пунктуацию и суффиксы:
- Проф. Иванов, г-жа А. Сизова, Ж. Рони-старший
- James Johnson III, Steven Wilshire 3rd, Charles James Ellsworth, Esq.
- Бонч-Бруевич, Владимир Дмитриевич
- 6500 Broadway Street
Suite 175 - 1550 Broadway
Floor 17
Mailstop 75A
- Lexington, MA, USA + 01 781 676 2400
- Kista, Sweden +46 8 56 62 82 00
- Paris, France +33 1 30 12 09 50
Значения тестовых данных могут содержать выбору физических или статистических данных на основе реальных данных. Оба метода имеют свою ценность и рекомендуются к использованию.
Для того чтобы создать данные для тестирования на основе физических данных, определите допустимый диапазон значений для каждого элемента и убедитесь в том, что для каждого такого элемента в тестовых данных содержится хотя бы одна запись с допустимыми значениями.
© 0829 0000 0000 по
0829 9999 9999(X) 0799 0000 0000 по
0799 9999 9999Эта таблица содержит минимальное число записей, которые могли бы представлять допустимые значения данных. Для каждого из трех диапазонов номеров счетов присутствует одна запись, все PIN-коды входят в допустимый диапазон, есть несколько вариантов остатка на счете, включая и отрицательный, и записи охватывают все три типа счета. Эта таблица содержит минимальное число данных, и ее можно улучшить, добавив значения на границе каждого из диапазонов и внутри диапазона — см. Рекомендация: тестовый набор.
Преимущество физического представления состоит в том, что данные тестов ограничены по объему, ими легко управлять, и они содержат допустимые значения. Недостаток заключается в том, что не отражены статистические тенденции реальных данных. Реальные данные обычно статистически неоднородны, и их тенденции могут влиять на производительность. Это фактор не будет учитываться при работе с физическим представлением.
Статистический подход к созданию данных для тестирования отражает особенности данных, с которыми работает реальная система. Например, можно проанализировать базу данных рабочей системы и выявить следующее:
- Общее число записей: 294031
- Общее число счетов типа S: 141135 (48%)
- Общее число счетов типа C: 144075 (49%)
- Общее число счетов типа X: 8821 (3%)
- Номера счетов и PIN-коды распределены равномерно
с учетом этой статистики тестовые данные могли бы включать 294 записи (а не 4, как раньше):
Данные для тестирования (0,1% от общего числа) Число записей Процент Общее число записей 294 100 Номер счета
(S) 0812 0000 0000 по
0812 9999 9999141 48 Номер счета
© 0829 0000 0000 по
0829 9999 9999144 49 Номер счета
(X) 0799 0000 0000 по
0799 9999 99999 3 Эта таблица отражает только типы счетов. При статистическом подходе к созданию данных для тестирования следует включить значимые элементы данных. В этом примере это могло бы означать учет фактических остатков на счете.
Недостатком статистического подхода будет то, что данные могут не отражать весь диапазон допустимых значений.
Обычно применяется сочетание обоих методов, и тестовые данные включают значения, отражающие как аспект производительности, так и аспект полноты.
Понятие полноты тестовых данных относится и к тестовым данным, которые применяются как входные данные для теста, и тем, которые применяются как вспомогательные к уже имеющимся данным.
Охват
Охват — это применимость тестовых данных для цели теста. Она связана с объемом и полнотой данных. Большое число данных не означает, что среди них обязательно есть нужные данные. Как и в том, что касается полноты тестовых данных, мы должны убедиться, что данные отвечают цели теста, то есть приведет ли выполнение теста к ответу на поставленные вопросы.
Например, в следующей таблице первые четыре записи содержат допустимые значения для каждого элемента данных. Однако для счетов типа C и X нет записей с отрицательным остатком. Поэтому, хотя эти тестовые данные и включают запись с отрицательным остатком (приемлемая полнота), но их было бы недостаточно для тестирования отрицательных остатков для всех типов счета (недостаточный охват). Это упущение преодолевается тем, что в данные добавляются записи, содержащие отрицательный остаток для двух других типов счетов.
© 0829 0000 0000 по
0829 9999 9999(X) 0799 0000 0000 по
0799 9999 9999Понятие охвата тестовых данных относится и к тестовым данным, которые применяются как входные данные для теста, и тем, которые применяются как вспомогательные к уже имеющимся данным.
Архитектура
Понятие физической структуры тестовых данных относится только к тестовым данным, которые применяются как вспомогательные к уже имеющимся данным, например, в базе данных или таблице правил.
Тестирование — это не процесс, который происходит только один раз. Тестирование повторяется и в итерациях, и между ними. Для того чтобы тестирование было точным, достоверным и эффективным, тестовые данные следует вернуть в исходное состояние перед выполнением теста. Это особенно важно для автоматизированных тестов.
Точность, достоверность и эффективность тестирования достигаются тогда, когда тестовые данные не зависят от внешних факторов, и их состояние известно до, во время и после выполнения теста. Для достижения этой цели необходимо решить две проблемы:
- неустойчивость / изоляция — устранение внешних влияний на данные
- начальное состояние — точное знание начального состояния данных и воспроизводимость этого состояния
Все эти вопросы влияют на работу с базой данных для тестирования, проектирование модели тестирования и взаимодействие с другими объектами.
Неустойчивость / изоляция
Неустойчивость тестовых данных может возникнуть по следующим причинам:
- внешние воздействия. не относящиеся к тесту, изменяют данные
- участники тестирования не знают о том, какие данные применяются другими участниками
Для того чтобы тестирование было достоверным и полным, тестовые данные должны быт полностью изолированы от таких воздействий. Для этого применяются следующие способы:
- отдельная среда тестирования — участники тестирования работают в полностью изолированной среде, физически отделенной от остальных. Они имеют свой собственный объект тестирования и данные. Это достигается, например, тем, что каждый участник тестирования работает на своем компьютере.
- отдельные базовые экземпляры тестовых данных. Участники тестирования работают со своим экземпляром данных, изолированным от прочих влияний. Физическая среда, и, возможно, сам целевой объект тестирования могут быть общими, но каждый участник работает со своим экземпляром данных, который в таком случае оказывается не подверженным постороннему воздействию.
- Разделение тестовых данных в базе данных. Все участники работают с общей базой данных и знают о том, какие данные используют другие участники (и не используют их). Например, один участник работает с записями 0 — 99, другой — с записями 100 — 199, или один работает с клиентами, фамилии которых начинаются с букв А-М, а другой — с Н-Я.
Начальное состояние
Важным вопросом в архитектуре тестовых данных является состояние данных в начале теста. Это особенно важно при автоматизации тестирования. И сам объект тестирования, и тестовые данные должны быть в нужном, контролируемом состоянии. При этом возникает возможность достичь повторяемости результатов тестирования и уверенности в достоверности тестов.
Для решения этого вопроса обычно применяются четыре стратегии:
- обновление данных
- повторная инициализация данных
- сброс данных
- опора на текущие данные
Подробнее все они описаны далее.
Фактический метод будет зависеть от разных факторов, включая физические особенности базы данных, техническую компетентность участников тестирования, доступность внешних ролей (не относящихся к тесту), и сам целевой объект тестирования.
Обновление данных
Предпочтительный способ возвращения данных в исходное состояние — это обновление данных. При этом создается копия базовых данных в их исходном состоянии. По завершении выполнения теста (или перед его началом) копия тестовых данных помещается в среду тестирования. Таким образом обеспечивается тождественность тестовых данных перед началом теста.
В этом методе данные можно сохранить для разных начальных состояний. Например, тестовые данные могут включать архивы для состояния в конце дня, конце недели, конце месяца и пр. При этом участник тестирования может быстро восстановить состояние любого теста, например, теста варианта использования, отвечающего концу месяца.
Повторная инициализация данных
Если данные нельзя обновить, то следующим способом может быть восстановление исходного состояния данных с помощью какой-либо программы. Повторно инициализировать данные можно для каких-либо вариантов использования с помощью инструментов, восстанавливающих начальное значение тестовых данных.
При этом нужно особенно внимательно следить за тем, чтобы в данные, их отношения и ключевые значения не вкрались никакие ошибки.
Одним из преимуществ этого метода может быть тестирование с недопустимыми значениями из базы данных. В обычных условиях база данных не содержит недопустимых значений, потому что их не разрешается туда вводить (например, это запрещает правило проверки в клиенте). Однако данные могут быть изменены другим способом (например, при обновлении из другой системы). При тестировании необходимо убедиться, что недопустимые данные будут распознаваться и обрабатываться правильно, независимо от того, как они возникли.
Сброс данных
Простым методом восстановления исходного состояния данных может быть «обращение изменений», вносимых в данные в ходе тестирования. Этот метод опирается на возможность целевого объекта отменять изменения, то есть добавлять удаленные данные и восстанавливать значения измененных данных.
Этот метод содержит и соответствующие риски, а именно:
- необходимо обратить все действия без исключения
- он опирается на вариант использования целевого объекта. Необходимо удостовериться в том, что он работает правильно и может применяться для сброса данных.
- не всегда возможно восстановить значения ключей, указателей и индексов в базе данных
Если этот метод единственно доступен в вашей среде, то не применяйте ключи, индексы и указатели в базе данных как средства проверки. Так, для определения того, был ли пациент записан в базу данных, используйте его имя, а не ИД пациента, генерируемый системой.
Опора на текущие данные
Этот способ наименее приемлем для восстановления начального состояния тестовых данных. Фактически он не решает этот вопрос. Вместо этого состояние данных по завершении выполнения какого-либо теста становится начальным состоянием тестовых данных для другого теста. Обычно при этом требуется внести изменения в входные данные для теста и/или в варианты использования и тестовые данные, применяемые для анализа результатов.
В некоторых случаях такой подход является необходимым, например, в конце месяца. Если архив данных на конец месяца отсутствует, то тестовые данные и тестовые сценарии для каждого дня месяца необходимо «прокрутить вперед», чтобы привести данные в состояние, пригодное для теста в конце месяца.
С этим методом связаны следующие риски:
- не всегда возможно восстановить значения ключей, указателей и индексов в базе данных
- данные постоянно изменяются
- достоверность результатов требует дополнительной проверки
© Copyright IBM Corp. 1987, 2006. Все права защищены..
Создайте свои тестовые данные
Всем известно, что тестирование — это процесс, который производит и потребляет большие объемы данных. Данные, используемые в тестировании, описывают начальные условия для теста и представляют среду, посредством которой тестер влияет на программное обеспечение. Это важная часть большинства функциональных испытаний . Но что на самом деле является тестовыми данными? Почему это используется? Возможно, вы задаетесь вопросом: «Разработка тестовых случаев достаточно сложна, тогда зачем беспокоиться о чем-то таком тривиальном, как тестовые данные» Цель этого руководства — познакомить вас с тестовыми данными, их важностью и дать практические советы и рекомендации для быстрой генерации тестовых данных. , Итак, начнем!
Что такое тестовые данные? Почему это важно?
Тестовые данные на самом деле являются входными данными для программы. Он представляет данные, которые влияют или зависят от выполнения определенного модуля. Некоторые данные могут использоваться для положительного тестирования, как правило, для проверки того, что данный набор входных данных для данной функции дает ожидаемый результат. Другие данные могут использоваться для отрицательного тестирования, чтобы проверить способность программы обрабатывать необычный, экстремальный, исключительный или неожиданный ввод. Плохо спроектированные данные тестирования могут не проверять все возможные сценарии тестирования, которые будут ухудшать качество программного обеспечения.

Что такое генерация тестовых данных? Почему тестовые данные должны быть созданы до выполнения теста?
В зависимости от среды тестирования вам может потребоваться СОЗДАТЬ тестовые данные (в большинстве случаев) или, по крайней мере, определить подходящие тестовые данные для ваших тестовых случаев (если тестовые данные уже созданы).
Обычно тестовые данные создаются синхронно с тестовым набором, для которого они предназначены.
Тестовые данные могут быть сгенерированы —
- Вручную
- Массовое копирование данных из производства в среду тестирования
- Массовое копирование тестовых данных из устаревших клиентских систем
- Инструменты автоматического создания тестовых данных
Как правило, образцы данных должны быть сгенерированы перед началом выполнения теста, поскольку в противном случае сложно обработать управление данными теста. Поскольку во многих средах тестирования создание тестовых данных требует много предварительных шагов или конфигураций среды тестирования, что занимает очень много времени . Кроме того, если генерация тестовых данных выполнена, когда вы находитесь в фазе выполнения теста, вы можете превысить срок тестирования.
Ниже описаны несколько типов тестирования, а также некоторые предложения относительно их потребностей в данных тестирования.
Тестовые данные для тестирования белого ящика
В White Box Testing управление данными тестирования выводится из непосредственного изучения кода, подлежащего тестированию. Тестовые данные могут быть выбраны с учетом следующих вещей:
- Желательно охватить как можно больше веток; данные тестирования могут быть сгенерированы таким образом, что все ветви в исходном коде программы проверяются хотя бы один раз
- Тестирование пути: все пути в исходном коде программы проверяются как минимум один раз — можно подготовить тестовые данные, чтобы охватить как можно больше случаев.
- Отрицательное API-тестирование :
- Данные тестирования могут содержать недопустимые типы параметров, используемые для вызова различных методов.
- Данные тестирования могут состоять из недопустимых комбинаций аргументов, которые используются для вызова методов программы
Тестовые данные для тестирования производительности
Тестирование производительности — это тип тестирования, который выполняется для определения того, насколько быстро система реагирует на конкретную рабочую нагрузку. Целью этого типа тестирования является не поиск ошибок, а устранение узких мест. Важным аспектом тестирования производительности является то, что набор используемых образцов данных должен быть очень близок к «реальным» или «живым» данным, которые используются в производстве. Возникает следующий вопрос: «Хорошо, хорошо проверять реальные данные, но как мне получить эти данные?» Ответ довольно прост: от людей, которые знают лучше всего — от клиентов . Они могут предоставить некоторые данные, которые у них уже есть, или, если у них нет существующего набора данных, они могут помочь вам, предоставив обратную связь относительно того, как могут выглядеть реальные данные.Если вы находитесь в Проект технического обслуживания вы можете скопировать данные из производственной среды в испытательный стенд. Хорошей практикой является анонимизация (шифрование) конфиденциальных данных клиента, таких как номер социального страхования, номера кредитных карт, банковские реквизиты и т. Д., Пока выполняется копия.
Тестовые данные для тестирования безопасности
Тестирование безопасности — это процесс, который определяет, защищает ли информационная система данные от злонамеренных действий. Набор данных, который необходимо спроектировать для полного тестирования безопасности программного обеспечения, должен охватывать следующие темы:
- Конфиденциальность. Вся информация, предоставляемая клиентами, хранится в строжайшем секрете и не передается третьим лицам. В качестве короткого примера, если приложение использует SSL, вы можете создать набор тестовых данных, который проверяет, что шифрование выполнено правильно.
- Целостность: определите, что информация, предоставленная системой, верна. Для разработки подходящих тестовых данных вы можете начать с тщательного изучения дизайна, кода, баз данных и файловых структур.
- Аутентификация: представляет процесс установления личности пользователя. Данные тестирования могут быть спроектированы как различные сочетания имен пользователей и паролей, и их целью является проверка того, что только уполномоченные лица могут получить доступ к программной системе.
- Авторизация: сообщает, какие права принадлежат конкретному пользователю. Данные тестирования могут содержать различную комбинацию пользователей, ролей и операций , чтобы проверить, что только пользователи с достаточными привилегиями могут выполнять определенную операцию.
Тестовые данные для тестирования черного ящика
В Black Box Testing код не виден тестеру. Ваши функциональные тесты могут иметь тестовые данные, соответствующие следующим критериям:
- Нет данных : проверка ответа системы при отсутствии данных
- Допустимые данные : проверьте ответ системы при отправке действительных тестовых данных.
- Неверные данные : проверьте ответ системы при отправке тестовых данных InValid
- Недопустимый формат данных : проверьте ответ системы, когда данные теста имеют недопустимый формат.
- Набор данных граничных условий: данные испытаний, соответствующие граничным условиям
- Набор данных эквивалентных разделов: тестовые данные, квалифицирующие ваши эквивалентные разделы.
- Набор данных таблицы решений: тестовые данные, отвечающие вашей стратегии тестирования таблиц решений
- Набор тестовых данных перехода состояний: тестовые данные соответствуют вашей стратегии тестирования перехода состояний
- Use Case Test Data : данные теста синхронизированы с вашими вариантами использования.
Примечание . В зависимости от того, какое приложение тестируется, вы можете использовать некоторые или все вышеперечисленные методы создания тестовых данных.
Инструменты автоматического создания тестовых данных
Чтобы генерировать различные наборы данных, вы можете использовать гамму инструментов автоматического создания тестовых данных. Ниже приведены некоторые примеры таких инструментов:
1) Генератор тестовых данных GSApps можно использовать для создания интеллектуальных данных практически в любой базе данных или текстовом файле. Это позволяет пользователям:
- Завершите тестирование приложения, накачав базу данных значимыми данными
- Создание отраслевых данных, которые можно использовать для демонстрации
- Защита конфиденциальности данных путем создания клона существующих данных и маскирования конфиденциальных значений
- Ускорьте цикл разработки за счет упрощения тестирования и создания прототипов.
2) Генератор тестовых данных DTM — это полностью настраиваемая утилита, которая генерирует данные, таблицы (представления, процедуры и т. Д.) Для тестирования базы данных (тестирование производительности, тестирование качества, нагрузочное тестирование или тестирование удобства использования).
Datatect является генератором данных SQL от Banner Software, генерирует различные реалистичные тестовые данные в плоских файлах ASCII или напрямую генерирует тестовые данные для СУБД, включая Oracle, Sybase, SQL Server и Informix.Вывод
В заключение, хорошо разработанные данные тестирования позволяют выявлять и исправлять серьезные недостатки в функциональности. Выбор выбранных тестовых данных должен быть переоценен на каждом этапе многофазного цикла разработки продукта. Поэтому всегда следите за этим.
Правильные тестовые данные или почему Вася Пупкин лучший друг тестировщиков?
Будучи молодым QA-инженером, я тестировал модуль регистрации пользователя одного десктопного приложения. Набирать сочетания случайных букв в качестве тестовых имени и фамилии мне изначально не нравилось, а использование личных данных считалось некорректным, поэтому я начал использовать имена и фамилии существующих политиков.
Барак Обама, Джордж Буш и другие регистрировались в сервисе кастинга голосовых актеров, проводили сессии голосовых записей, исправно платили по счетам и выполняли прочие бизнес-действия. Через некоторое время об этом узнал наш ПМ, который попросил отказаться от практики привлечения политиков в ряды наших тестовых пользователей, т.к. правила компании предполагают использование нейтральных тестовых данных. Передо мной встал выбор: пользоваться случайным набором букв или придумать некий шаблон, который я буду использовать в своих кейсах. Я выбрал второй вариант.
С тех пор персонаж Василий Пупкин стал моим лучшим другом. Теперь почти всегда, когда при тестировании нужно было вводить данные персоны, на помощь мне приходил Василий. Предположу, что у вас также есть шаблон, которым вы пользуетесь при быстром тестировании. Это своего рода Alter Ego тестеровщика.
Эта история заставила меня задуматься над критериями тестовых данных и быть более осмотрительным при их подборе, хотя здесь речь шла об этичности данных, которые никак не влияют на качество продукта. Будучи уже лидом, я часто наблюдаю картину, когда тестировщик не особо беспокоится о том, какие тестовые данные использовать в процессе ad-hoc тестирования, что кажется не особо удачной практикой. В этой статье предлагаю немного поразмышлять над качеством тестовых данных.
Статья состоит из двух больших блоков:
Первая — Идеальные данные – какие они? Уникальные, целостные и эквивалентные боевым — с постановкой проблемы. Здесь я говорю о том, как важно иметь данные с боя, рассказываю об опасности рутины и ищу виноватых.
Вторая — «Источники правильных тестовых данных» — с предложением решения. Здесь я рассказываю на примере поля регистрации, на что обращать внимание при самостоятельной генерации данных и о том, какие есть источники для того, чтобы облегчить себе работу, а также расскажу о своем генераторе данных, который помогает с локализацией и привожу текст README, чтобы облегчить генерацию тестовых данных.
Идеальные данные – какие они? Уникальные, целостные и эквивалентные боевым
Постановка проблемы
Многие скажут: спасибо Кэп, мы и так это все знали. К сожалению, знание хороших принципов не приводит к хорошим практикам.
При проверке продукта методом черного ящика правильные входные данные являются залогом успешного тестирования. И в данном случае речь не о граничных значениях или классах эквивалентности, хотя в каком-то смысле данная статья затрагивает эквивалентность, а о семантике данных. Об их непосредственном содержании.
Лучшими данными будут те, которые эквиваленты боевым. Но для тестирования использование боевых данных возможно в очень редких случаях. Законы о персональных данных и требование безопасности – все это накладывает ограничения, которые можно обойти, но риски будут несопоставимо выше профитов.
Например, если вы проверяете эквайринг, то вряд ли будете использовать данные своей личной карты и уже тем более данные чужой карты. Какие же данные использовать? Можно пойти путем простого подбора, при котором номер кредитной карты будет состоять из случайных цифр. Но если ваш продукт сделан качественно, то валидация по алгоритму Луна должна будет отбить ваш номер карты. При этом ваш кейс из позитивного тут же превратится в негативный, что тоже неплохо, но как же быть с позитивным кейсом? Где взять валидный номер карты, кроме своей зарплатной?
В этом то и суть проблемы: получение фейковых данных, эквивалентных боевым, – это нетривиальный процесс, требующий усилий и разумного подхода. В какой-то момент этот процесс становится рутинным и к нему прикладывают все меньше усилий.
В чем опасность рутины?
При тестировании формы регистрации первые разы вы заполняете все поля валидными эквивалентными данными. Но со временем, когда подобную операцию нужно выполнить третий раз в день или сотый раз в неделю, мы все меньше прикладываем усилий к этому «творческому» процессу. Как и в любых рутинных процессах происходит неизбежная деградация. Если вначале наш мозг мог выдать с десяток уникальных ФИО, то постепенно мы зацикливаемся на Василии Пупкине или, что ещё хуже, начинаем вписывать случайные сочетания букв.
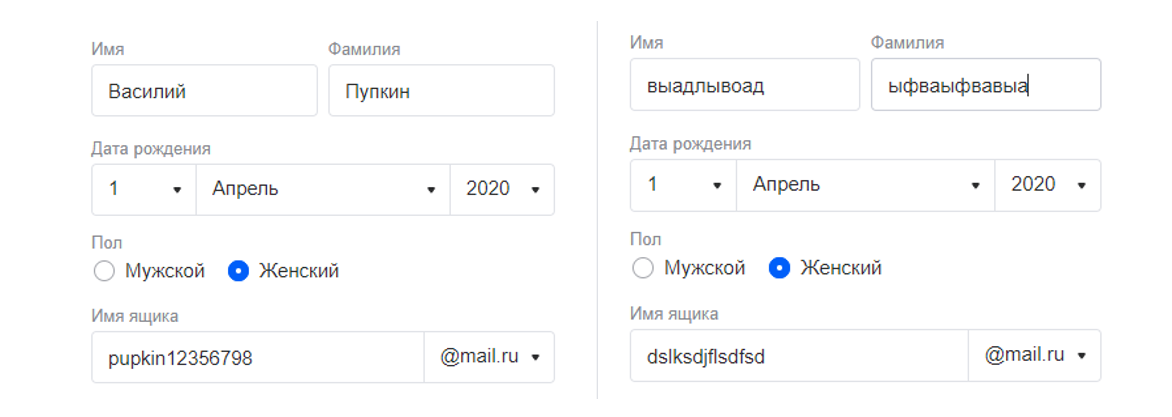
Что плохого в таком подходе? Деградация тестовых данных неизбежно приведет к деградации качества тестирования.
Почему это так? Что плохого в «Фывапр Йцукенг Павловна», если рассматривать это как тестовые данные?
Банальные примеры:
- Если после регистрации на экране отображается уведомление об успешном прохождении процесса или после успешной авторизации в шапке выводятся полностью ФИО, то как понять, что строка со значениями ФИО не была обрезана внутри нашего «черного ящика»?
- Если существует требование о четком порядке ФИО (во многих государственных АИС это жесткое правило), то как обнаружить ошибку, если разработчик сделает неправильный порядок? «Фывапр Йцукенг» и «Йцукенг Фывапр» с точки человеческого восприятия одинаковы, но с точки зрения выходных данных – это баг, который невозможно интуитивно обнаружить.
Таким образом, используя в качестве ФИО рандомные строки, вы сами стреляете себе в ногу.
Пример посерьезнее:
- Если при тестировании бухгалтерских систем выбирать слишком маленькие финансовые значения, можно не обнаружить не только ошибки верстки, когда строка будет выходить за зону видимости, но и переполнение памяти, если речь идет о тестировании квартального или годового отчета. Поэтому нужно озаботится адекватными (близкими к боевым) суммами при тестировании, чтобы не обнаружить проблему до начала эксплуатации.
Можно придумать множество других примеров, когда входные данные адекватно не отражают сущности предметной области, что может привести к пропускам более серьезных ошибок, но мне лень. Додумайте сами.
Кроме того, деградация тестовых данных заключается и в их однообразности с точки зрения класса эквивалентности. В какой-то момент Василий Пупкин попадет под действие «эффекта пестицида» и баги, живущие в вашей системе, постепенно «адаптируются» к нему. Тогда Вася Пупкин станет не лучшим другом, а злейшим врагом.
Кто же виноват?
Что же мешает каждый раз идти путем создания новых качественных данных? Ответ прост – лень. Как известно из исследований по нейробиологии, мы с трудом заставляем себя думать, когда речь идет о рутинных процессах. Подробнее об этом эффекте интересно написано в книге «Думай медленно… решай быстро» Даниэля Канемана. Автор так описывает закономерность умственной работы в любой сфере:
«По мере того как вы приобретаете новый навык, он требует все меньше энергии. Исследования показывают, что со временем при исполнении действия активизируется все меньше участков мозга. Сходное действие и у таланта. Люди с высоким интеллектом тратят меньше сил на решение заданий, на что указывает и размер зрачков, и активность головного мозга. И к физическим, и к умственным усилиям применяется один и тот же «закон наименьшего напряжения». Согласно ему, из нескольких вариантов достижения одной цели люди в конечном итоге всегда склоняются к наименее затратному. В экономике действия усилие – это затраты, а получение навыков уравновешивает соотношение затрат и выгод. Лень – неотъемлемая часть нашей натуры»
Наш мозг, как источник тестовых данных, с одной стороны является нашим союзником на короткие дистанции, а с другой — нашим врагом на длинные.
Оказывается, что придумывать новые данные гораздо сложнее, чем использовать какие-то существующие шаблоны. Наш мозг привык идти по пути наименьшего сопротивления, потому-то мы обречены циклически обходить наши шаблоны и использовать их в качестве тестовых данных, что само по себе может привести к «эффекту пестицида».
Кто-то может сказать, что несложно нагенерировать в своем сознании сотню уникальных ФИО. И с этим действительно вряд ли будут проблемы. Но что если нужно сгенерировать более сложные сущности, состоящие из десятка атрибутов, которые имеют строгие логические и семантические связи? Готов поспорить, что вы быстро деградируете в этом процессе на длинной дистанции, если только ваш лид не будет стоять за спиной, стимулируя вашу мозговую деятельность.
Итак, нам нужны хорошие тестовые данные, которые будут эквиваленты боевым. Генерация таких данных – процесс нетривиальный и во многом рутинный. Если с вопросом «кто виноват?» уже примерно разобрались, то нужно задаться следующим вопросом: «что делать?».
Источники правильных тестовых данных
Что такое «правильные» тестовые данные?
Любая АИС является представлением реального мира, и в ней мы взаимодействуем с его информационными моделями реального мира. Чем ближе эта модель к реальному прототипу, тем выше шансы найти важный дефект. Так, например, при регистрации пользователя мы не просто заполняем поля формы, но создаем некую сущность, которая должна отражать реальность.
Лучшим подходом будет рассматривать данные регистрации как некую целостную сущность, которая отражает часть реального мира, т.е. некую персону. У персоны есть пол, дата рождения и ФИО. Все эти данные логически и семантически связаны друг с другом.
Вряд ли, отправляясь в ЗАГС для получения свидетельства для своей новорожденной дочери, вы выберите ей имя «Фывапр Йцукенг Павловна». Вряд ли вы назовете свою дочь мужским именем.
Вряд ли дата рождения персоны может быть более 100-110 лет.При таком подходе информационная модель данных далека от реальности, а сами атрибуты имеют слабые логические и семантические связи. Наилучшим подходом будет сущность, имеющая явно выраженные логические связи между атрибутами, которая адекватная реальности.
Речь идет о том, что ФИО должны соответствовать полу персоны, а год рождения должен быть в некоем адекватном диапазоне. Если копнуть еще глубже, то можно выявить корреляцию между датами рождения и неким множеством имен, которые были популярны в эти годы. Подобными статистическими закономерностями можно пренебречь, т.к. их отсутствие критически не уменьшит логическую связь.
Чем могут помочь открытые источники данных?
Как вы поняли, наш мозг — хороший источник тестовых данных, но обладает рядом недостатков.
Любые рутинные процессы с четким алгоритмом должны быть автоматизированы. Процесс генерации тестовых данных — не исключение. Давайте посмотрим, какие источники тестовых данных сегодня есть.
- Нейросети. Только ленивый уже не писал про ИИ для ИТ-сферы. Возможности тестовых ИИ и вправду поражают. По запросу они могут создавать или преобразовывать целые массивы специфицированных данных. Проблема в том, что эти данные нуждаются в проверке и не могут быть приняты как корректные по умолчанию.
- Биржи данных. Это площадки, где можно легально пробрести данные из различных предметных областей. Данные, как правильно, деперсонифицированы, но при этом наиболее близки к боевым. По своей сути такие данные являются целостной моделью реальных сущностей. Это их главный плюс. А минусы в том, что нужно платить за это, и они неизбежно будут устаревать. Такие данные можно использовать как при ручном тестировании, так и в автоматизированном. Например, наполнять ими заглушки, тестовые БД или использовать для генерации данных.
- Сервисы данных. По своей сути это веб-сайты, на которых можно сгенерировать данные нужного вам типа. Вот несколько примеров:
- https://generatedata.com/
- https://www.random1.ru/
- https://www.vccgenerator.org/
Это отличный вариант при использовании в ручном тестировании. Благо, что существуют множество вариантов с данными, которые локализованы под российские проекты. Но проблема в том, что многие тестовые стенды находятся в закрытых контурах и перенос данных туда будет затруднен. Не говоря о том, что машиночитаемый формат будет опосредован, что затруднит использование при автотестировании.
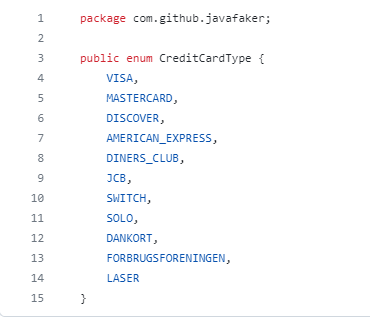
- Библиотеки генерации Это программные модули, которые можно подключить к существующему проекту, и получать их данные для использования в юнит-, автотестах или наполнения заглушек. Например, JavaFaker. Эта библиотека с открытым кодом, которая имеет достаточно обширный набор предметных областей, для которых можно генерировать данные. Недостаток в том, что нет данных валидных для российских проектов. Например, в списке типов кредитных карт нет платежной системы МИР, да и вряд ли когда-нибудь будет.
- Персоны
- Паспортные данные
- СНИЛС
- Расчетный счет банка
- Банковские данные
- ИНН для ФЛ
- ИНН для ЮЛ
- ОГРН для ЮЛ
- Номер мобильного телефона
- Номер городского телефона
- Адрес электронной почты
- Автомобильные гос. номера
- Реквизиты банковских карт
В таком случае, мы сами можем допиливать эту библиотеку под свои нужды. Но это немногие захотят делать!
Есть другой вариант – написание свой библиотеки, которая будет иметь локализацию для российский проектов. Задавшись такой целью, я создал свою библиотеку, которая в общем и целом закрывает вышеописанные проблемы.
Свой велосипед для данных!
Это библиотека с открытым кодом, цель которой – генерировать данные, эквивалентные боевым, подходящие под нужды автоматизаторов и тестировщиков, работающих на российских проектах.
Поскольку, по чистой случайности, автор статьи и автор библиотеки один тот же человек, то расскажу про нее чуть подробнее.
Есть множество библиотек для Java, но все они выполняют узкие задачи или не выдают данные, подходящие для российских проектов. Но для нужд тестирования эти данные очень нужны.
Библиотека реализует все принципы, описанные выше, все данные генерируются семантически верными и проходящими формальную валидацию.
Например, все номера банковских карт проходят валидацию по алгоритму Луна или имеют БИН реального банка, кроме случаев, когда у банка отсутствует подходящий тип карты.
С другой стороны, библиотека выдает несуществующие почтовые адреса, которые вряд ли пройдут валидацию по ГАР. Однако если вы используете вместо адресного сервиса заглушку для валидации адресов, то библиотека поможет вам наполнить ее семантически верными данными.
Ниже описание самой библиотеки:
Ниже текст из README самой библиотеки, в котором описан ее функционал.
DATAGENERATOR
Данная библиотека предназначена для генерации случайных данных, специфицированных под русскоязычные проекты. Данные аналогичны реальным, боевым данным.
Библиотека не использует чьих-то персональных данных. Все данные являются случайно сгенерированными (кроме случаев кастомной генерации) и любые совпадения с реальными персональными данными являются вероятностным совпадением.
Все реальные данные взяты из открытых источников и не нарушают права третьих лиц.
Методы генерации не являются идемпотентными, т.е. каждый последующий вызов метода будет возвращать уникальные данные. В качестве тезауруса используются списки, хранящиеся в тестовых файлах в папке resource/dictionary. Классы генераторов получают данные о расположении файлов из dagen.properties по соответствующим ключам.
Генерация данных происходит по алгоритму случайных выборок из тезауруса и комбинирования данных для создания сущности. Класс DataGenerator
–является точкой входа и содержит статические методы, для получения данных из соответствующих генераторов.Библиотека генерирует следующие данные:
Примеры использования:
//Персоны, отличные от Васи Пупкина FakePerson fakePerson = DataGenerator.persons().get(); FakePerson malePerson = DataGenerator.persons().get(Gender.MALE); //Паспортные данные FakeRussianPassport fakeRussianPassport = DataGenerator.documents().passport(); //Банковский счет FakeAccount accountNumber = DataGenerator.accountDetails().account( PersoneType.PERSON, Currency.RUB, ProfileType.COMMERCIAL, DataGenerator.accountDetails().bank() ); //Почтовый адрес FakeAddress fakeAddress = DataGenerator.address().address(); //Банковская карта FakeCard fakeCard = DataGenerator.bankCard().card( Banks.SBER, CardType.MIR, //Имя держателя карты. При генерации будет транслитерировано в латинские буквы "Василий Пупкин" ); //Автомобильные гос. номера FakeCarStateNumber fakeCarStateNumber = DataGenerator.cars().stateNumber(); //Контакты FakePhoneNumber fakePhoneNumber = DataGenerator.contacts().mobile(); FakePhoneNumber fakePhoneNumber = DataGenerator.contacts().cityPhone(); String email = DataGenerator.contacts().email("test.ru");Как подключить библиотеку?
Добавить в pom.xml вашего проекта, как зависимость:
pro.dagen datagenerator 1.2.0 Несмотря на то, что библиотека новая, ее код уже многие годы используется на реальном проекте. Не исключаю, что она может содержать некоторые проблемы и ошибки, которые еще не были найдены. Буду очень благодарен, если дадите конструктивную обратную связь или заведете тикет на улучшение в https://github.com/upaul23/DataGenerator.
Вместо заключения
В итоге, каким бы способом генерации данных вы не пользовались, важно использовать данные, близкие к «боевым». Следуя этому принципу, вы уменьшите риск пропуска багов в продакшен и, конечно же, сможете повысить качество продукта. Неважно, каким способом вы тестируете — ручным или автоматизированным. В обоих подходах главное — придерживаться критериев уникальности, целостности и эквивалентности боевым данным. К счастью, сегодня есть множество инструментов, которые могут с этим помочь. Часть таких решений была представлена в данной статье. Хочется надеется, что после ее прочтения вы задумаетесь над вопросом подбора тестовых данных, а помимо Васи Пупкина, у вас появятся еще больше тестовых «друзей».
- Тестирование IT-систем
- Java
- Тестирование веб-сервисов
Тестовые данные в тестировании ПО
При тестировании программного обеспечения большое значение имеют тестовые данные, которые вы вводите в систему. Если они будут непродуманными или некачественными, это может сказаться на результатах тестирования. В этой статье мы рассмотрим, что такое тестовые данные, какими они бывают и как их готовить.
Тестовые данные и их значение
Тестовые данные – это данные, которые будут использоваться для тестирования определенной части программного обеспечения. В то время как одни данные используются для получения подтверждающих результатов, другие могут быть использованы для проверки возможностей ПО.
Существует несколько способов получения тестовых данных. Они могут быть созданы как силами самого тестировщика, так и с помощью специальных программ.
Например, команда тестировщиков проверяет, выдает ли программное обеспечение желаемый результат. Тестировщик вводит данные в систему и выполняет в ней определенные шаги. Анализ ответа системы на действия тестировщика покажет, был ли получен ожидаемый результат. Программа должна выдавать ожидаемые результаты без каких-либо заминок, ведь для этого ее и создали.
Но также тестируемое ПО не должно выдавать неожиданные, необычные или экстремальные результаты в случае передачи ему нестандартных (неправильных) входных данных. Для проверки всех негативных сценариев также должно быть достаточное количество тестовых данных. Это необходимо для бесперебойной работы программного обеспечения даже в том случае, если конечный пользователь случайно введет неверную информацию или сделает это намеренно, чтобы поиграть с системой.
Вопрос о том, следует ли использовать для тестирования реальные или синтетические данные, вызывает разногласия у экспертов. Например, в случае узконаправленных тестов или в автоматизированном тестировании синтетические данные не имеют себе равных. Однако реальные тестовые данные подойдут куда лучше в ситуациях, когда тестируемая система должна показать свои возможности в условиях, максимально приближенных к реальным.
Какие бывают типы тестовых данных?
Для разных тестов данные тоже должны быть разными. Давайте посмотрим, какими они могут быть.
Граничные тестовые данные
Этот тип данных помогает устранить дефекты, связанные с обработкой граничных значений. Тестовые данные этого типа представляют собой комбинацию граничных значений, которых достаточно для работы приложения. И если тестировщик выходит за эти пределы, то это может привести к поломке приложения.
Валидные тестовые данные
Эти типы данных валидны, то есть поддерживаются приложением. Они помогают проверить функции системы и получить ожидаемый результат при подаче входных данных.
Невалидные тестовые данные
Эти типы данных включают неподдерживаемые приложением форматы данных. При работе с недопустимыми значениями приложение должно показать соответствующее сообщение об ошибке и уведомить пользователя, что данные не подходят для работы.
Пустые данные
Пустые данные относятся к файлам, которые не содержат никаких данных. Использование пустых данных помогает проверить, как приложение реагирует, когда в программу вводятся пустые или отсутствующие данные.
Как подготовить тестовые данные
Тестовые данные можно создать вручную
Этот метод создания тестовых данных является самым простым. Вручную можно создать самые разные данные: валидные и невалидные, пустые, стандартные синтаксические данные или данные для нагрузочного тестирования.
Преимущество этого способа в том, что он не требует дополнительных инструментов, тестировщики будут применять собственные навыки и идеи. Однако это занимает больше времени и дает меньшую производительность. Если тестировщик не обладает необходимыми знаниями в данной области, то этот метод может привести к получению некачественных данных.
Внедрение внутренних данных
В этом методе используются внутренние серверы с большими базами данных. При этом пропадает необходимость в идеях команды тестировщиков. Также не придется вводить данные через внешний интерфейс, что сильно ускоряет процесс тестирования.
Из недостатков можно отметить более сложную реализацию метода, которая несет определенные риски для базы данных и приложения.
Тестовые данные можно сгенерировать автоматически
При автоматизированной генерации тестовые данные получаются путем обработки большого объема информации из различных источников. Чаще всего для этого используются такие инструменты, как Web Services API и Selenium.
Генерация данных позволяет регулировать объем и структуру получаемых данных, благодаря чему мы можем тестировать работу системы при разных условиях.
Помимо высокой эффективности метод исключает необходимость кропотливой работы нескольких ручных тестировщиков, что в разы увеличивает скорость получения результатов. Но генерировать тестовые данные автоматизированным способом дорого, к тому же вам понадобится талантливый специалист, который будет это реализовывать.
Проблемы поиска источников тестовых данных
- Если тестировщики запрашивают тестовые данные у разработчиков, а те, по причине загруженности, долго не отвечают, тестирование затягивается.
- В большинстве случаев команды тестирования не имеют доступа к инструментам получения источников данных.
- Существуют тестовые сценарии, когда может потребоваться больший объем данных за короткий период времени. При недостатке инструментов это может стать проблемой.
- Если дефекты в данных не будут выявлены на ранней стадии, это может оказать огромное влияние на программное обеспечение на последующих этапах разработки.
- Управление тестовыми данными требует от команды тестирования знаний об альтернативных вариантах генерации данных, что может быть неосуществимо в некоторых компаниях.
Заключение
Таким образом, тестовые данные, используемые для проверки любой системы, оказывают большое влияние на работу готового программного продукта. Именно они определяют, работает ли система в соответствии с ожиданиями. Поэтому каждая команда тестирования должна серьезно относиться к этому фактору.
Похожие записи:
- Что такое чек-лист (Check-list) в тестировании?
- Основы тестирования
- Большой учебник по тестированию
- Как тестировать умнее?