Hibernate
Hibernate Framework — это фреймворк для языка Java, предназначенный для работы с базами данных. Он реализует объектно-реляционную модель — технологию, которая «соединяет» программные сущности и соответствующие записи в базе. Иногда его называют библиотекой — оба названия в принципе справедливы.

Освойте профессию «Java-разработчик»
Объектно-реляционная модель, или ORM, позволяет создать программную «виртуальную» базу данных из объектов. Объекты описываются на языках программирования с применением принципов ООП. Java Hibernate — популярное воплощение этой модели.
Hibernate построен на спецификации JPA 2.1 — наборе правил, который описывает взаимодействие программных объектов с записями в базах данных. JPA поясняет, как управлять сохранением данных из кода на Java в базу. Но сама по себе спецификация — только теоретические правила, а в «чистой» Java ее реализации нет. Hibernate — одна из самых популярных реализаций JPA на рынке.
Фреймворк бесплатный, с открытым исходным кодом, который может просмотреть любой программист. По-русски название читается как «хибернейт».
Профессия / 14 месяцев
Java-разработчик
Освойте востребованный язык

Для чего применяется Hibernate
Hibernate пользуются Java-разработчики, которые работают с базами данных или с обработкой информации для последующего переноса в базу. Фреймворк используют при создании информационных систем: приложений, крупных программ и сетей, которые работают с информацией и базами данных. Существует аббревиатура CRUD, означающая Create, Read, Update, Delete: создавать, читать, обновлять и удалять. Это четыре действия, которые должна уметь выполнять информационная система, работающая с базой. Задача Hibernate при создании такого приложения — сократить количество низкоуровневого кода и облегчить работу программиста с БД.
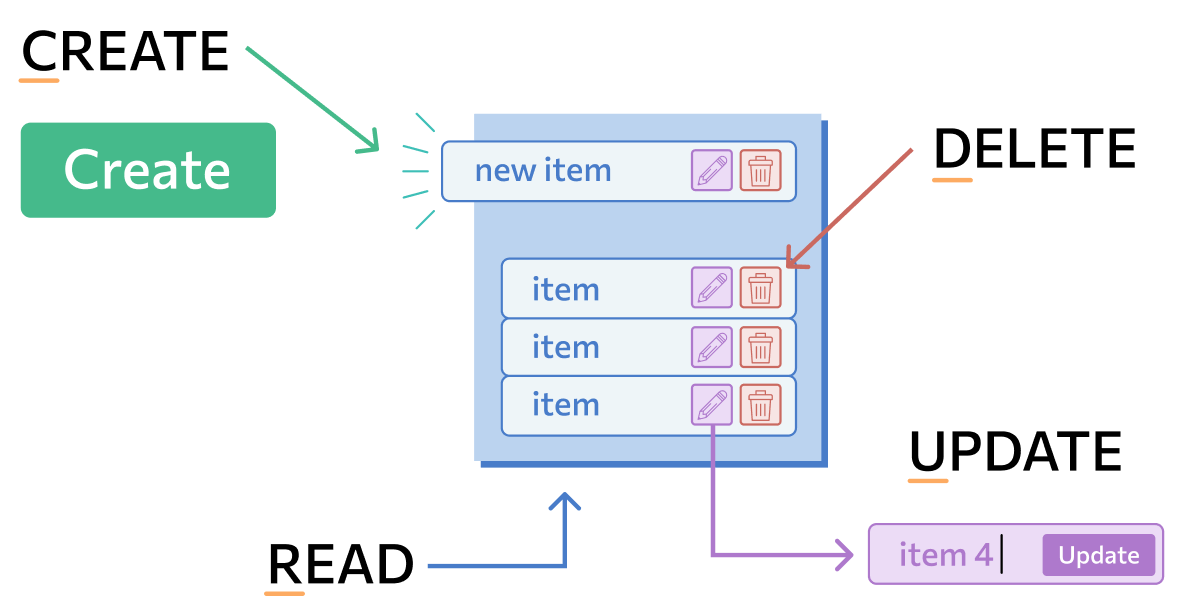
- ускоряет и облегчает написание кода;
- позволяет создать удобную модель для отображения базы данных в коде;
- дает возможность быстро и в читаемом виде записывать информацию из кода в базу.
Особенности Hibernate Framework
Идея фреймворка — создать «виртуальную» базу данных из программных объектов и работать с ней как с реальной базой. Поэтому им часто пользуются для упрощения работы. Он берет на себя взаимодействие с реляционной БД, а разработчику остается работать с кодом.
В Hibernate есть возможность, которую называют «ленивой загрузкой». Объекты в фреймворке не подгружают всю информацию из базы изначально. Вместо этого они просто «знают», как ее получить, и при первом обращении к информации загружают ее в фоне. Это нужно для оптимизации производительности.
Внутри Hibernate — собственный язык запросов Hibernate Query Language, или HQL. Это SQL-подобный язык, но полностью объектно-ориентированный и более краткий — не приходится так много работать с шаблонным кодом, как в «чистом» SQL.
Преимущества использования Hibernate
Популярность. Hibernate — популярный фреймворк, который фактически считают золотым стандартом. Это влечет за собой сразу три преимущества:
- по нему много учебников, туториалов и обсуждений на специализированных сайтах;
- большинство технологий, работающих с Java, поддерживают Hibernate. Это базы данных, фреймворки, библиотеки. Существуют плагины и для других языков или платформ, например порт на платформу .NET;
- разработчик, умеющий работать с этим фреймворком, всегда найдет работу.
Устранение лишнего кода. Повторяющийся шаблонный код, который делает программу менее читаемой, называют «спагетти». Если программа взаимодействует с базой, то в ней по определению много «спагетти»-кода, в том числе низкоуровневого. Использование Hibernate позволяет сократить количество «спагетти», соответственно, сделать программу более лаконичной и хорошо читаемой.
Возможность сосредоточиться на логике. Разработчику не приходится писать множество запросов, он избавлен от написания большого количества «технического» низкоуровневого кода. Поэтому можно сосредоточиться на логике работы программы и не отвлекаться на шаблонные задачи, поручив их фреймворку. Это облегчает и ускоряет разработку.

Станьте Java-разработчиком
и создавайте сложные сервисы
на востребованном языке
Независимость от базы данных. Hibernate может работать с любой базой и не имеет жесткой привязки к какой-то конкретной базе или СУБД. Благодаря этому он гибкий, его можно использовать в связке с другими технологиями. Язык запросов у него тоже свой, независимый от СУБД, хотя Hibernate поддерживает и «чистый» SQL.
Объектно-ориентированный подход. Hibernate реализует парадигму объектно-ориентированного программирования, которая очень распространена и хорошо знакома разработчикам. Поэтому работать с ним относительно просто, если вы уже знаете основы: не приходится постоянно отвлекаться на совершенно другую логику работы с базами данных. Можно реализовать все управление на ООП — этому способствует и наличие собственного SQL-подобного объектно-ориентированного языка запросов.
Недостатки Hibernate Framework
Сложность в освоении. Эта проблема актуальна в основном для новичков. Для работы с фреймворком нужно понимать теорию реляционных БД. Понадобится знать, что такое транзакция, по каким принципам работают базы данных, как с ними взаимодействовать и многое другое. Естественно, надо знать Java: осваивать фреймворки советуют после изучения основных принципов «чистого» языка.
Проблемы с производительностью. Несмотря на возможности, которые дает «ленивая загрузка», спецификацию JPA и в частности Hibernate часто критикуют за низкую производительность. Есть мнение, которое частично подкрепляется на практике, что такой тип взаимодействия с базой замедляет и утяжеляет код.
Непредсказуемость кода. Это еще один частый пункт критики JPA и Hibernate как ее реализации. Спецификация построена на объектно-ориентированной модели программирования, но не полностью соблюдает ее принципы. Это приводит к тому, что в коде могут появиться побочные эффекты — так называется явление, когда во время выполнения программы какие-то значения неявно изменяются. Побочные эффекты могут влиять на правильность работы программы, так что их надо избегать. А при использовании JPA избежать их сложно, и к Hibernate это тоже относится.
Сложности с кэшированием. В целом информацию в Hibernate можно кэшировать, то есть сохранять в специальном участке памяти, очень быстром и компактном. Это один из плюсов фреймворка — кэширование важно для производительности. Оно нужно для быстрого доступа к важным данным.
На практике кэширование самих сущностей JPA работает своеобразно:
- изменяемые сущности кэшировать не получится — инструментарий не дает возможности синхронизировать изменения с кэшем;
- неизменяемые сущности кэшировать можно, но не полноценно. Сущность загружается из базы через транзакцию — последовательность запросов в БД. Когда транзакция закрывается, на кэшированную сущность становится нельзя сослаться — только получить из нее данные.
Как начать пользоваться фреймворком
Что нужно. Вам понадобится загруженный и установленный Hibernate стабильной или последней версии — скачать его можно с официального сайта. Также необходима СУБД — система управления базами данных: если приложение будет работать с БД, без системы управления не обойтись. Можете выбрать любую СУБД — туториалы рекомендуют использовать PostgreSQL или MySQL, так как это бесплатные проекты с открытым исходным кодом.
Как начать. Обычно для начала работы с Hibernate рекомендуют использовать Maven — фреймворк для автоматизации сборки приложений на Java. Он создает в структуре проекта файл под названием pom.xml, где описываются все зависимости программы, все технологии, которыми она пользуется. Понадобится добавить в этот файл записи для Hibernate и для СУБД.
На официальном сайте Hibernate есть ссылки на центральный репозиторий Maven — там находятся образцы записей, которые надо добавить в файл для подключения разных версий фреймворка.
После того как все технологии подключены, можно писать код.
Java-разработчик
Java уже 20 лет в мировом топе языков программирования. На нем создают сложные финансовые сервисы, стриминги и маркетплейсы. Освойте технологии, которые нужны для backend-разработки, за 14 месяцев.

Статьи по теме:
Hibernate для начинающих
Я сталкивался (да и не только я) с проблемой развертывания Hibernate и решил попробовать осветить данную тему. Hibernate — это популярный framework, цель которого связать ООП и реляционную базу данных. Работа с Hibernate сократит время разработки проекта в сравнении с обычным jdbc.
Для новичка программирования настройка framework часто вызывает затруднения. Помощь комьюнити с освещением базовых проблем поможет начинающим осваивать языки программирования быстрее. Статья предназначена только для начинающих в Java, которые впервые развертывают hibernate. Я развертывал hibernate на базе лицензионной IDEA.
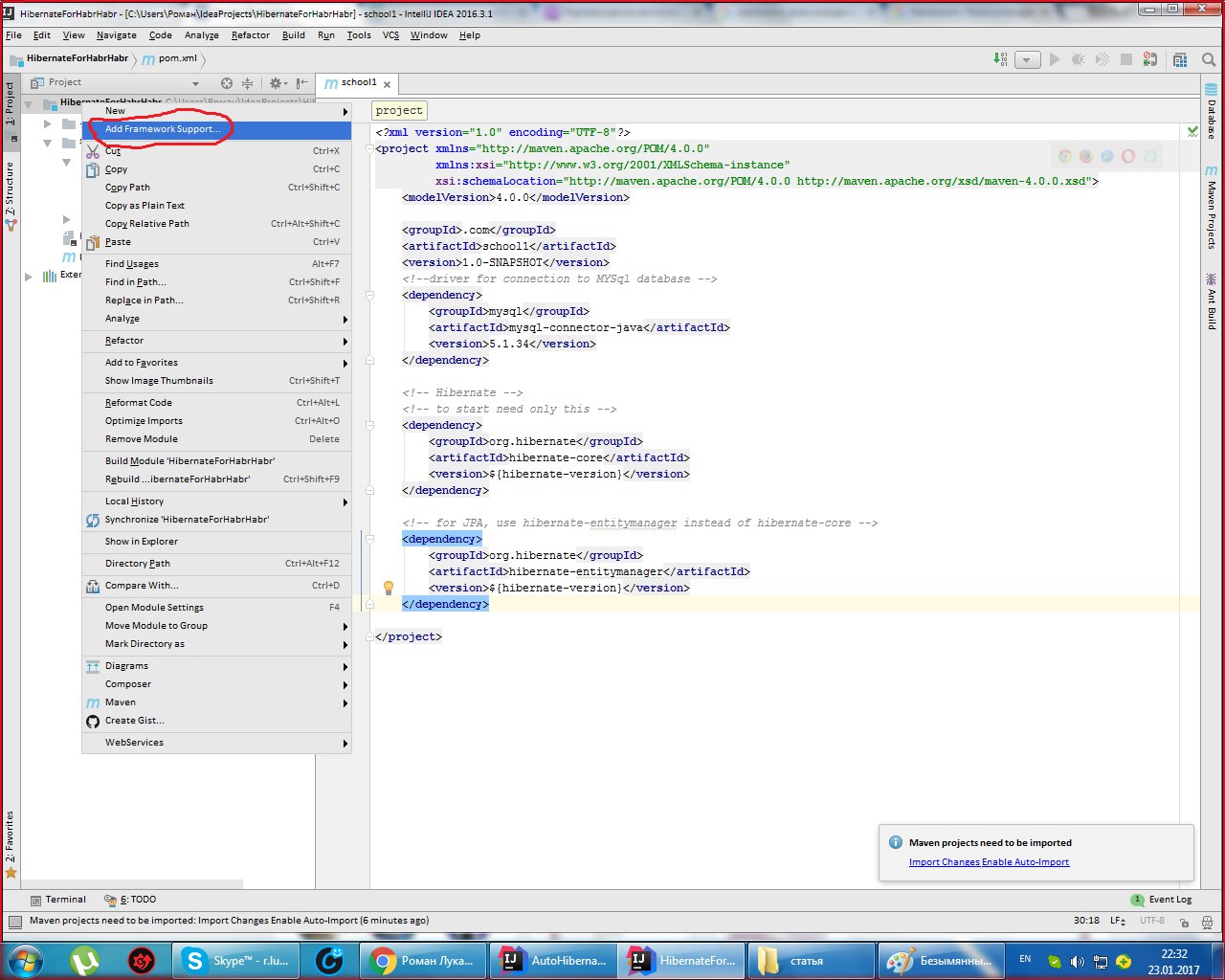
Maven framework для автоматизации сборки проекта на основе POM, позволяющая подключать из интернета зависимости, не скачивая библиотеки в проект. POM (project object model) -декларативное описание проекта. Копируем название библиотек в xml формате с сайта mvnrepository.com.
Для начала создаёте структуру проекта maven:
Потом в pom.xml вставляем. Нам понадобятся две зависимости: hibernate-core и mysql-connector, но если вы хотите больше функционала — вы должны подключить больше зависимостей.
Существуют стандартные рекомендации подключать зависимости по отдельности, но я так не делаю.
5.0.1.Final mysql mysql-connector-java 5.1.34 org.hibernate hibernate-core $ org.hibernate hibernate-entitymanager $ И щелкаем на Import Changes Enable Auto-Import, автоматически импортируя изменения.
Подключаемся к базе данных, которая развернута на локальном компьютере, выбираем поставщика баз данных MySQL.
Вводим имя базы данных, имя пользователя и пароль. Протестируйте соединение.
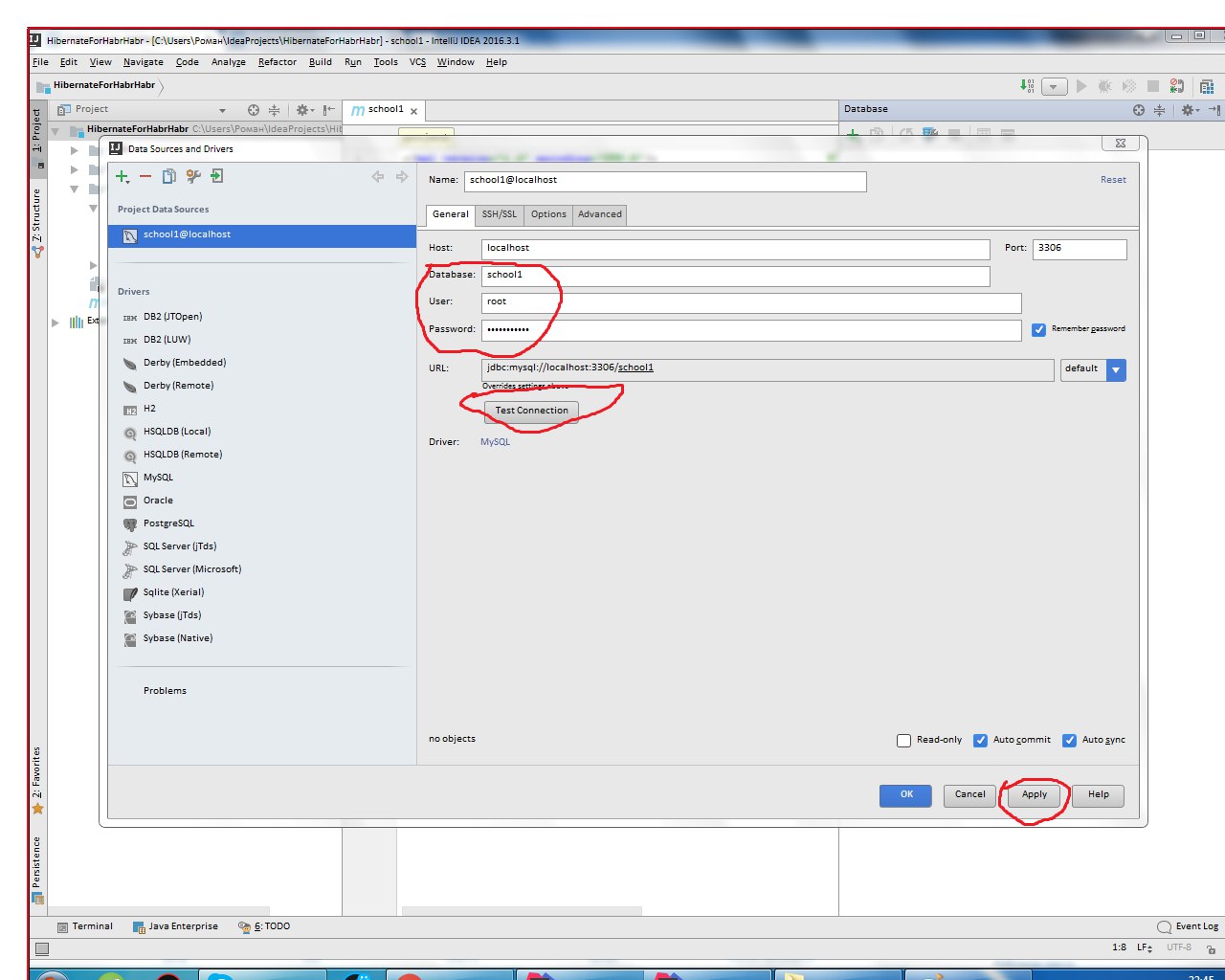
Выбираем проект и через framework support просим у хибернейта создать за нас Entity файлы и классы с Getter и Setter.
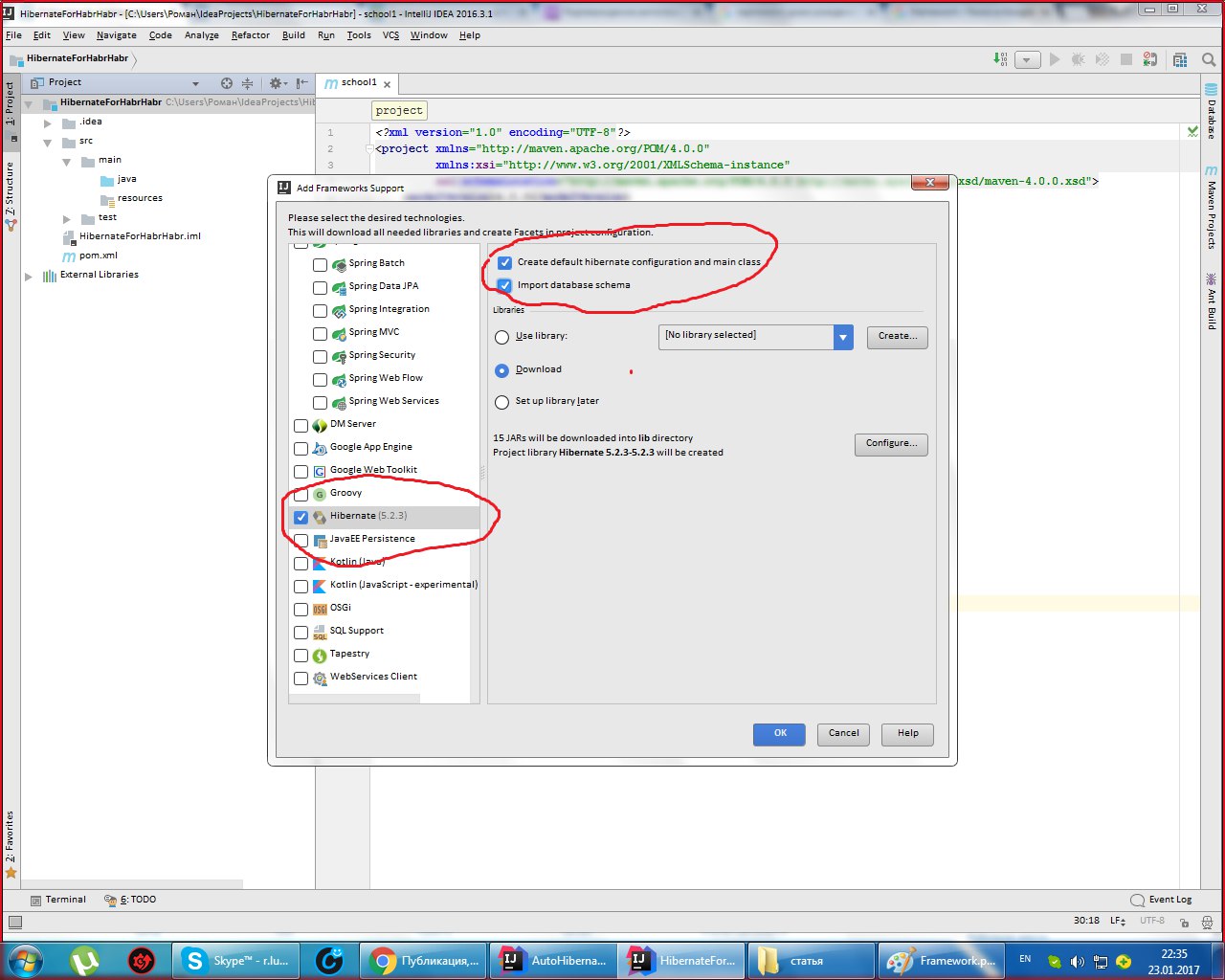
Выбираем Generate Persistence Mapping через кладку Persistence, выбираем jenerate Persistance Mapping, а в появившемся окне прописываем схему базы данных, выбираем prefix и
sufix к автоматически сгенерированным названиям. Будут сгенерированы названия xml файлов и классов с аннотациями:
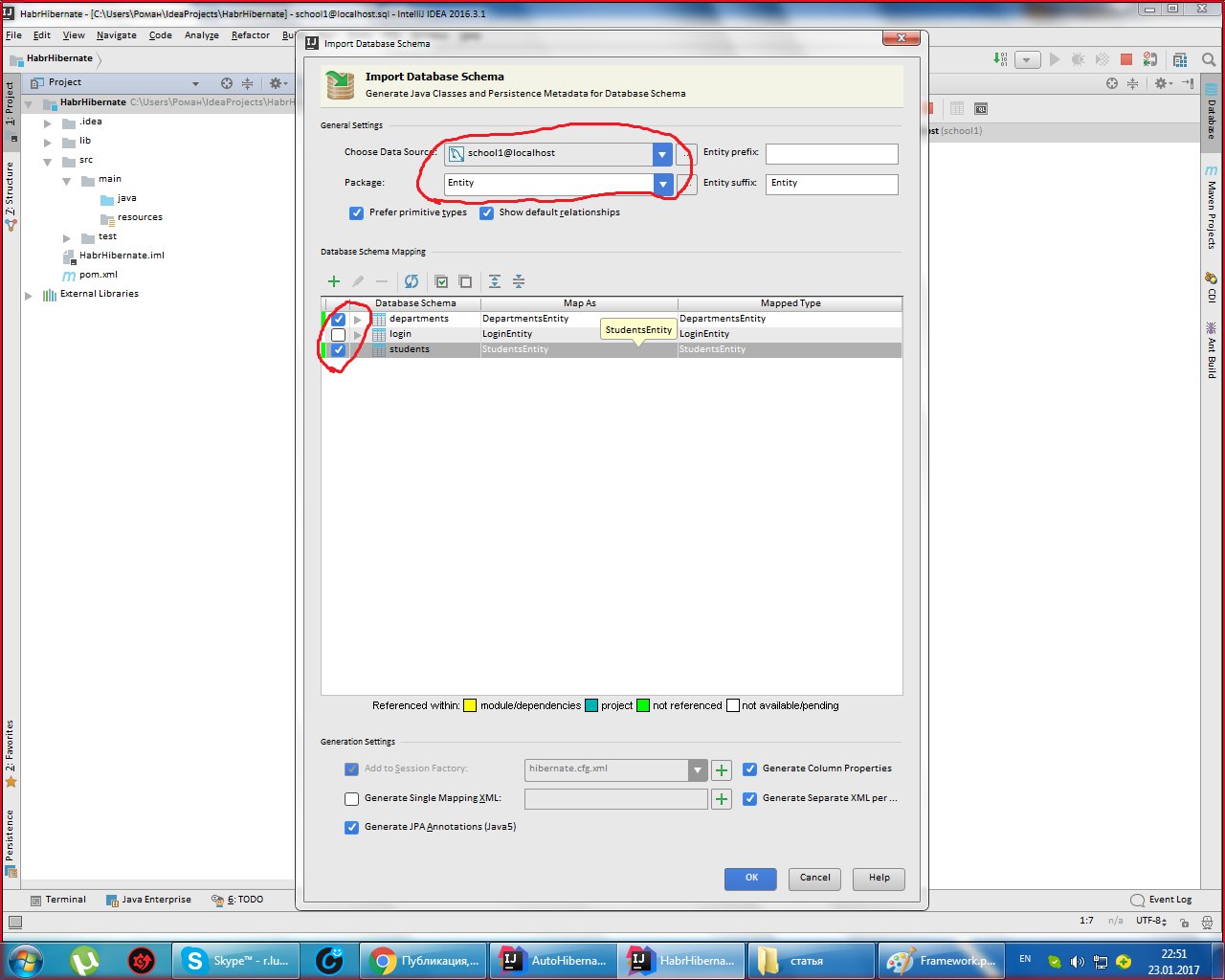
Раскидайте файлы в таком порядке: .xml-файлы должны находится в папке с ресурсами, а сущности в папке java.
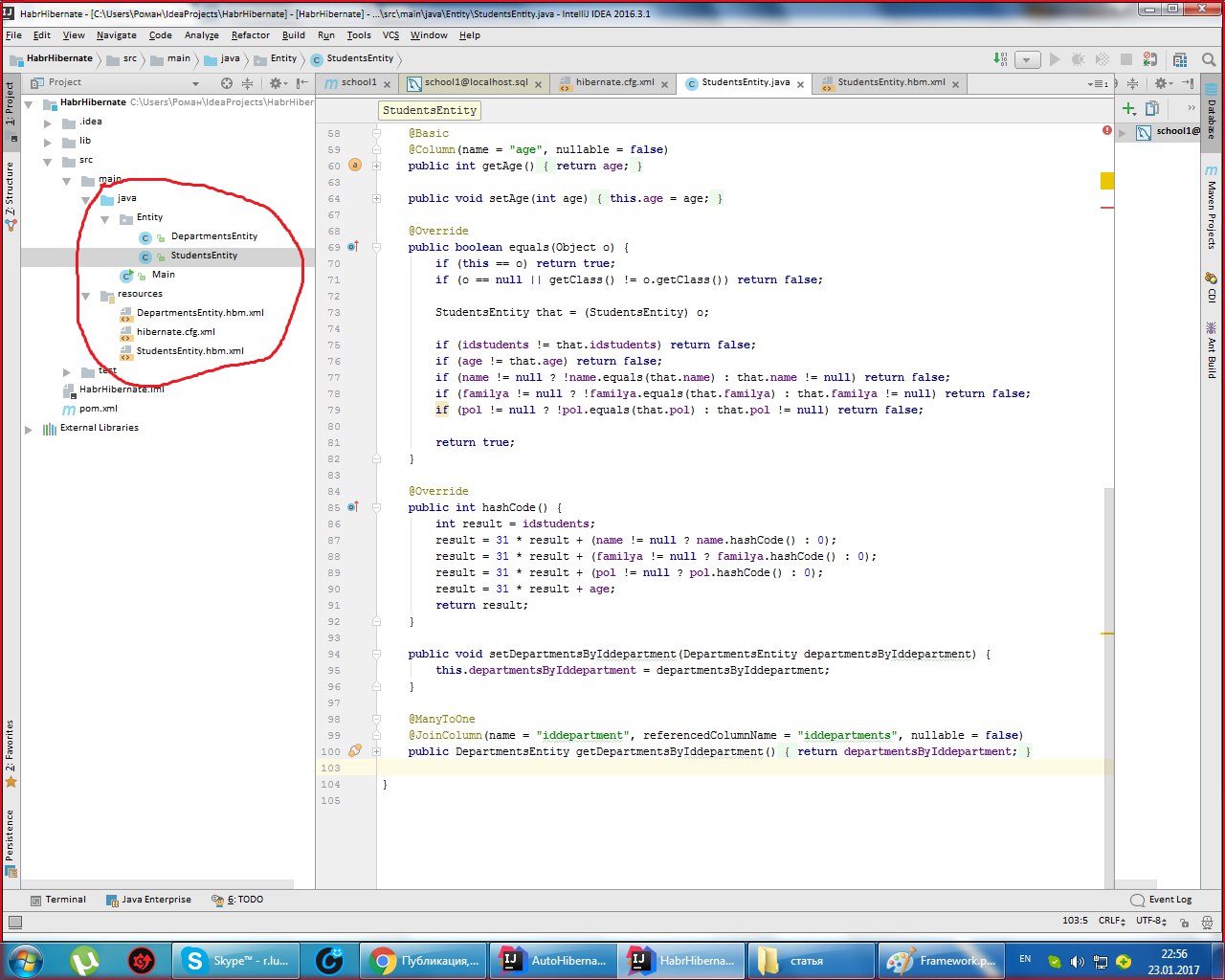
Дописываем в hibernate.cfg username и password (звёзды поставил я, а так пишите обычным шрифтом).
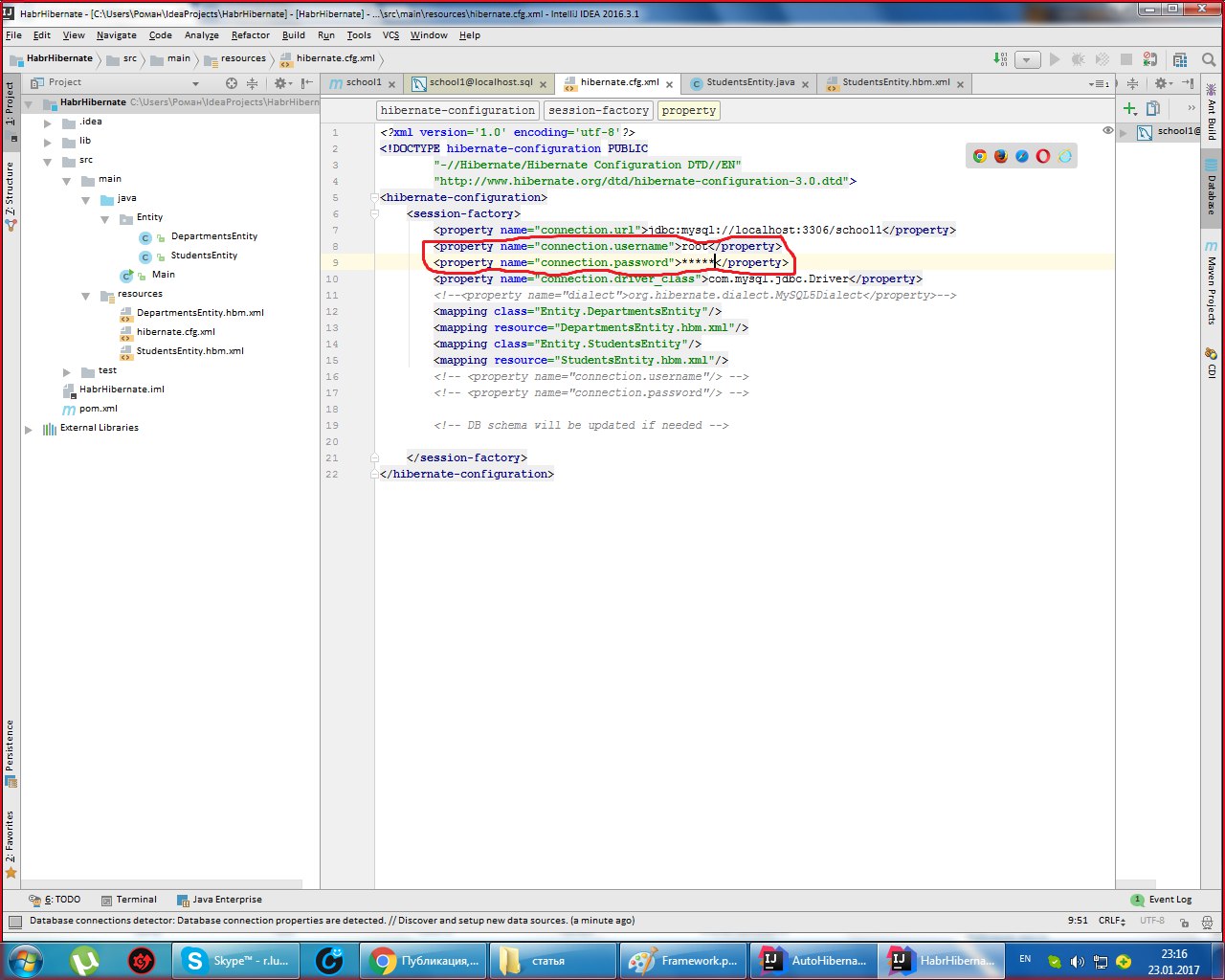
Вот и все! Дальше через класс main запускаем проект.
Это моя первая статья. Рассчитываю на здравую критику.
Hibernate в вопросах и ответах
Hibernate — это библиотека с открытым исходным кодом (open source) для Java, предназначенная для решения задач ORM (object-relational mapping, объектно-реляционного отображения). Она представляет собой свободное программное обеспечение, распространяемое на условиях GNU Lesser General Public License. Hibernate Framework имеет легкий в использовании каркас для отображения объектно-ориентированной модели данных в традиционные реляционные базы данных и предоставляет стандартные средства JPA.
2. Преимущества использования Hibernate Framework?
Библиотека Hibernate является одним из самых востребованных ORM фреймворков для Java, поскольку :
- позволяет разработчику сосредоточиться на бизнес логике, не отвлекаясь на управление ресурсами;
- предоставляет собственный язык запросов (HQL), внешне похожий на SQL. Необходимо отметить, что HQL полностью объектно-ориентирован и понимает такие принципы, как наследование, полиморфизм и ассоциации (связи);
- может использовать также чистый SQL, а, следовательно, поддерживает возможность оптимизации запросов и работы с любым сторонним провайдером БД;
- поддерживает JPA аннотации, что позволяет сделать реализацию кода независимой;
- поддерживает разные уровни cache, а следовательно может повысить производительность;
- поддерживает ленивую инициализацию используя proxy объекты и выполняя запросы к базе данных только по необходимости;
- интегрируется с другими Java EE фреймворками; например, Spring Framework поддерживает встроенную интеграцию с Hibernate;
- является широко распространенным open source продуктом. Благодаря этому доступны тысячи открытых статей, примеров, а также документация по использованию фреймворка.
3. Объекты Hibernate SessionFactory, Session и Transaction
| SessionFactory | Экземпляр SessionFactory создается методом buildSessionFactory (ServiceRegistry) объекта org.hibernate.Configuration и предназначен для получения объекта Session. Инициализируется SessionFactory один раз. Внутреннее состояние SessionFactory неизменно (immutable), т.е. он является потокобезопасным. Internal state (внутреннее состояние) включает в себя все метаданные об Object Relational Mapping, определяемые при создании SessionFactory. SessionFactory также предоставляет методы для получения метаданных класса и статистики, типа данных о втором уровне кэша, выполняемых запросах и т.д. |
| Session | Однопоточный объект, устанавливающий связь между объектами/сущностями приложения и базой данных. Сессия создается при необходимости работы с БД и ее необходимо закрыть сразу же после использования. Экземпляр Session является интерфейсом между кодом в java приложении и hibernate framework, предоставляя методы для операций CRUD. |
| Transaction | Однопоточный объект, используемый для атомарных операций. Это абстракция приложения от основных JDBC или JTA транзакций. org.hibernate.Session может занимать несколько org.hibernate.Transaction в определенных случаях. |
Пример использования объектов SessionFactory, Session, Transaction.
4. Конфигурационный файл Hibernate
Файл конфигурации hibernate.cfg.xml содержит информацию о базе данных (драйвер, пул подключений, диалект) и параметрах подключения к серверу БД (url, login, password). В качестве параметров подключения можно использовать как JDBC, так и JNDI. В файле конфигурации также определяются дополнительные параметры, которые будут использованы при работе с сервером БД, Так, здесь необходимо определить маппинги сущностей/классов.
Чтобы отобразить в консоли SQL-скрипты, генерируемые Hibernate, необходимо в hibernate.cfg.xml определить истиное значение свойства «show_sql». Помните, что это необходимо использовать только на уровне разработки и тестирования. В финальной версии свойство «show_sql» должно быть отключено.
Пример файла конфигурации связанных сущностей.
5. Файл mapping
Файл отображения (mapping file) используется для связи entity бинов с таблицами базы данных. Содержимое файла имеет формат XML. Файл mapping можно использовать вместо аннотаций JPA. Особенно он становится необходимым при использовании сторонних библиотек.
6. Важные аннотации для отображения в Hibernate
Наиболее употребительные аннотации Hibernate из пакета javax.persistence представлены в следующей таблице :
| @Entity | Определение класса как сущность entity bean |
| @Table, @Column | Определение таблицы в БД и наименования колонки в таблице |
| @Id | Поле Primary Key в сущности entity bean |
| @GeneratedValue | Определение стратегии создания основных ключей |
| @SequenceGenerator | Определение генератора последовательности |
| @OneToMany, @ManyToOne, @ManyToMany | Определение связи между сущностными бинами |
Подробнее об аннотациях в сущностных бинах.
7. Отличие методов openSession и getCurrentSession
Методы openSession и getCurrentSession объекта SessionFactory возвращают сессию Session.
Метод getCurrentSession объекта SessionFactory возвращает сессию, связанную с контекстом. Но для того, чтобы метод вернул не NULL, необходимо настроить параметр current_session_context_class в конфигурационном файле hibernate. Поскольку полученный объект Session связан с контекстом hibernate, то отпадает необходимость в его закрытии; он закрывается вместе с закрытием SessionFactory.
thread
Метод openSession объекта SessionFactory всегда создает новую сессию. В этом случае необходимо обязательно контролировать закрытие объекта сессии по завершению всех операций с базой данных. Для многопоточной среды необходимо создавать новый объект Session для каждого запроса.
При загрузке больших объемов данных без удержания большого количества информации в кэше можно использовать метод openStatelessSession(), который возвращает Session без поддержки состояния. Полученный объект не реализует первый уровень кэширования и не взаимодействует со вторым уровнем. Сюда же можно отнести игнорирование коллекций и некоторых обработчиков событий.
8. Отличие методов get и load объекта Session
Для загрузки информации из базы данных в виде набора/коллекции сущностей объект Session имеет несколько методов. Наиболее часто используемые методы get и load. Метод get загружает данные сразу же при вызове, в то время как load использует прокси объект и загружает данные только тогда, когда это требуется на самом деле (при обращении к данным). В этом плане load имеет преимущество в плане ленивой загрузки данных.
Метод load вызывает исключение, если данные не найдены. Поэтому load нужно использовать только при уверенности в существовании данных. Если необходимо удостовериться в наличии данных в БД, то нужно использовать метод get.
9. Различные состояния Entity Bean
Сущность Entity Bean может находиться в одном из трех состояний :
| transient | Состояние сущности, при котором она не была связана с какой-либо сессией и не является persistent. Сущность может перейти в состояние persistent при вызове метода save(), persist() или saveOrUpdate() объекта сессии. |
| persistent | Экземпляр сущности, полученный методами get() или load() объекта сессии, находится в состоянии persistent, т.е. связан с сессией. Из состояния persistent сущность можно перевести в transient после вызова метода delete() сессии. |
| detached | Если объект находился в сотоянии persistent, но перестал быть связанным с какой-либо сессией, то он переходит в состояние detached. Такой объект можно сделать персистентным, используя методы update(), saveOrUpdate(), lock() или replicate(). |
Из состояний transient и detached объект можно перевести в состояние persistent в виде нового объекта после вызова метода merge().
10. Отличия методов save, saveOrUpdate и persist
Метод save используется для сохранения сущности в базе данных. Этот метод возвращает сгенерированный идентификатор. Возникаемые проблемы с использованием save связаны с тем, что метод может быть вызван без транзакции. А следовательно если имеется отображение нескольких связанных объектов, то только первичный объект будет сохранен, т.е. можно получить несогласованные данные.
Метод hibernate persist аналогичен save, но выполняется с транзакцией. Метод persist не возвращает сгенерированный идентификатор сразу.
Метод saveOrUpdate используется для вставки или обновления сущности. Если объект уже присутствуют в базе данных, то будет выполнен запрос обновления. Метод saveOrUpdate можно применять без транзакции, но это может привести к аналогичным проблемам, как и в случае с методом save.
11. Использование метода сессии merge
Метод Hibernate merge объекта сессии может быть использован для обновления существующих значений. Необходимо помнить, что данный метод создает и возвращает копию из переданного объекта сущности. Возвращаемый объект является частью контекста персистентности с отслеживанием любых изменений, а переданный объект не отслеживается.
12. Отсутствие в Entity Bean конструктора без параметров
Hibernate использует рефлексию для создания экземпляров Entity бинов при вызове методов get или load. Для этого используется метод Class.newInstance, который требует наличия конструктора без параметров. Поэтому, в случае его отсутствия, будет вызвано исключение HibernateException.
13. Entity Bean не должна быть final
Hibernate использует прокси классы для ленивой (lazy) загрузки данных (т.е. не сразу, а по необходимости). Это достигается с помощью расширения Entity Bean. Отсюда следует, что если бы он был final, то это было бы невозможно.
Ленивая загрузка данных во многих случаях повышает производительность, а следовательно важна и от нее не следует отказываться.
14. Сортировка данных в Hibernate
При использовании алгоритмов сортировки из Collection API используется сортированный список (sorted list). Для маленьких коллекций это не приводит к излишнему расходу ресурсов. Однако на больших коллекциях это может привести к потере производительности и ошибкам OutOfMemory.
Entity Bean’ы для работы с сортированными коллекциями должны реализовывать интерфейс Comparable/Comparator. При использовании фреймворка Hibernate для загрузки данных можно применить Collection API и команду order by для получения сортированного списка (ordered list). Ordered list является лучшим способом получения sorted list, т.к. используется сортировка на уровне базы данных, работающая быстрее и не приводящая к утечке памяти. Пример запроса к БД для получения ordered list :
List list = session.createCriteria(Employee.class) .addOrder(Order.desc("id")).list();
Hibernate использует следующие типы коллекций : Bag, Set, List, Array, Map.
15. Использование Query Cache в Hibernate
Hibernate реализует область кэша для запросов ResultSet, который тесно взаимодействует с кэшем второго уровня Hibernate. Для подключения этой дополнительной функции необходимо определить истинное значение свойства hibernate.cache.use_query_cache в файле конфигурации hibernate.cfg.xml и в коде при обращении к БД использовать метод setCacheable(true). Кэшированные запросы полезны только при их частом исполнении с повторяющимися параметрами.
Определение свойства в файле конфигурации Hibernate :
true
Формирование запроса с использованием метода setCacheable (true) :
Query query = session.createQuery("from Employee"); query.setCacheable(true); query.setCacheRegion("ALL_EMP");
16. Язык запросов HQL
Hibernate включает мощный язык запросов HQL (Hibernate Query Language), который очень похож на родной SQL. В сравнении с SQL, HQL полностью объектно-ориентирован и использует понятия наследования, полиформизма и связывания.
HQL использует имя класса взамен имени таблицы, а также имя свойства вместо имени колонки. Пример HQL :
Query query = session.createQuery("from ContactEntity where firstName = :paramName"); query.setParameter("paramName", "Nick"); List list = query.list();
17. Нативный SQL-запрос в Hibernate
Для выполнения нативного запроса необходимо использовать SQLQuery, который может выполнять чистый SQL-запрос. Но необходимо учитывать, что в этом случае можно потерять все преимущества HQL (ассоциации, кэширование). Пример нативного SQL-запроса :
String sql ; Query query; sql = «select id, name, salary from employees»; query = session.createSQLQuery(sql).addEntity(Employee.class); List list = query.list(); for (Iterator it = users.iterator(); it.hasNext();)
Обратите внимание, что при формировании Query был добавлен класс Employee.class, в результате чего метод list() объекта Query вернул коллекцию сотрудников List.
В следующем коде при формировании Query нет привязки к конкретному классу. В результате метод list() возвращает коллекцию объектов List
query = session.createSQLQuery(sql); List
18. Преимущества поддержки нативного SQL-запроса
Использование нативного SQL может быть необходимо при выполнении некоторых запросов к базам данных, которые могут не поддерживаться в Hibernate. Т.е. включение в запросы специфичных для БД «фишек».
19. Именованный запрос, Named SQL Query
Hibernate поддерживает использование именованных запросов, которые можно определить в одном месте и использовать в любом месте в коде. Именованные запросы поддерживают как HQL, так и Native SQL. Для создания Named SQL Query можно использовать JPA аннотации @NamedQuery, @NamedNativeQuery или конфигурационный файл отображения (mapping files). Пример описания и использования Named SQL Query.
// Определение Named SQL Query @NamedQuery( name = "getContacts", query = "select ce from ContactEntity ce where ce.id >=:id" ) // Сущность @Entity @Table(name="contact", schema = "", catalog = "javastudy") public class ContactEntity < >. . . // использование Named SQL Query Query query = session.getNamedQuery("getContacts") .setString("id", "10");
20. Преимущества именованных запросов Named SQL Query
Named Query имеют глобальный характер, т.е. заданные в одном месте, доступны в любом месте кода. Синтаксис Named Query проверяется при создании SessionFactory, что позволяет заметить ошибку на раннем этапе, а не при запущенном приложении и выполнении запроса.
Одним из основных недостатков именованного запроса является то, что его сложнее отлаживать. Сложности могут быть связаны с поиском места определения запроса. Поэтому не разбрасывайтесь описанием запросов в различных участках. Можно все связанные с сущностью запросы описать непосредственно в классе, используя аннотацию @NamedQueries, как это показано в следующем коде :
@Entity @Table(name=»student») @NamedQueries(< @NamedQuery(name="selectStudents", query="select st from Student st"), @NamedQuery(name="updateStudentRecord", query="update Student st set st.sname =: name where st.id =:id") >) public class Student
21. Использование org.hibernate.Criteria
Hibernate Criteria API представляет альтернативный подход HQL и позволяет выполнять запросы в БД без написания SQL кода. Для создания экземпляров Criteria используется класс Session. Пример Criteria с необязательным обрамлением в транзакцию :
session.beginTransaction(); List users users = session.createCriteria(User.class) .setMaxResults(10).list(); session.getTransaction().commit();
Приведенный выше запрос вернет первые 10 записей из таблицы сущности User. Метод setMaxResults представляет собой аналог команды LIMIT в SQL-запросе. Чтобы прочитать определенное количество записей с с определенной позиции (LIMIT 2, 15) необходимо дополнительно использовать метод setFirstResult :
List users users = session.createCriteria(User.class) .setFirstResult(2) .setMaxResults(15).list();
Подробнее о org.hibernate.Criteria можно прочитать здесь.
22. Hibernate proxy и ленивая загрузка (lazy load)
Hibernate может использовать прокси для поддержки отложенной загрузки. При соответствующем атрибут fetch аннотации связи (fetch определяет стратегию загрузки дочерних объектов) из базы данных не загружаются связанные объекты. При первом обращении к дочернему объекту с помощью метода get, если связанная сущность отсутствует в кэше сессии, то прокси код перейдет к базе данных для загрузки связанной сущности. Для этого используется javassist, чтобы эффективно и динамически создавать реализации подклассов Entity Bean объектов.
Подробнее об атрибуте загрузки связанных объектов fetch.
23. Каскадные связи
При наличии зависимостей (связей) между сущностями необходимо определить влияние различных операций одной сущности на связанные. Это можно реализовать с помощью аннотации каскадных связей @Cascade. Пример использования @Cascade :
import org.hibernate.annotations.Cascade; @Entity @Table(name = «EMPLOYEE») public class Employee
Помните, что имеются некоторые различия между enum CascadeType в Hibernate и в JPA. Поэтому обращайте внимание на импортируемый пакет при использовании аннотации и константы типа. Наиболее часто используемые CascadeType перечисления описаны ниже :
- None : без каскадирования, т.е. никакая операция для родителя не будет иметь эффекта для ребенка;
- ALL : все операции родителя будут отражены на ребенке (save, delete, update, evict, lock, replicate, merge, persist);
- SAVE_UPDATE : операции save и update, доступно только для hibernate;
- DELETE : в Hibernate передается действие native DELETE;
- DETATCH, MERGE, PERSIST, REFRESH, REMOVE – для простых операций;
- LOCK : передает в Hibernate native LOCK действие;
- REPLICATE : передает в Hibernate native REPLICATE действие.
24. Управление транзакциями
Hibernate не допускает большинство операций без использования транзакций. Для начала транзакции необходимо выполнить метод beginTransaction объекта сессии Session, возвращающий ссылку, которую можно использовать для подтверждения или отката транзакции.
Любое вызываемое в Hibernate исключение автоматически вызывает rollback.
Использование JNDI DataSource в Hibernate
При использовании Hibernate в WEB-приложении и определении соответствующих настроек в контейнере сервлетов, касающихся подключения Datasource, можно использовать JNDI. Для этого необходимо в файле конфигурации hibernate.cfg.xml определить свойство hibernate.connection.datasource :
java:comp/env/jdbc/MyLocalDB
Hibernate для чайников. Обзор книги «Java Persistence API и Hibernate»

Не секрет, что большинство технической литературы в мире написано на английском языке. И Java-разработка здесь не исключение — значительная часть материалов или вообще недоступна на русском, или переведена так, что лучше учить с помощью гугл-транслейта. Тем радостнее для всего русскоязычного Java-сообщества будет то, что самая известная книга на эту тему «Java Persistence API with Hibernate» — примерно полгода назад была переведена на русский язык.

- Если вы не знаете, что такое реляционные базы данных, не можете создать таблицу или написать даже простой SELECT-запрос и т.д. — лучше все-таки начать именно с этого. Это, кстати, будет полезно для тех, кто планирует участвовать в стажировке JavaRush. Начинайте с SQL’a, Hibernate потом. Благо, по SQL написан отличный Head-First (на мой вкус, один из лучших HeadFirst’ов во всей серии).
- JDBC. Технология далеко не новая, но многие опытные разработчики по ряду до сих пор предпочитают ее хибернейту.
- После этого, неплохо было бы прочитать (хотя бы поверхностно) про то, что такое ORM и зачем она нужна. Ведь Hibernate — это прежде всего ORM, то есть штука, которая превращает Java-объекты в записи базы данных (и наоборот). К примеру, у вас есть класс User, есть класс Auto, и у каждого User’a есть список его машин List<Auto> autos. Как записать все это в базу данных, чтобы еще и связи между юзерами и их машинами сохранились? Ведь юзер один, а машин у него может быть много:/ А как автоматически удалить из базы данных все машины юзера, если мы удалили его самого (то есть запретить БД хранить «бесхозные» машины)? Вот Hibernate как раз и знает как:)
- Кроме того, в Java есть и собственная реализация ORM-модели — Java Persistence API, или просто JPA. В книге она также рассматривается, но лучше предварительно бегло пробежаться и по ней. Не нужно читать тонны литературы на тему: если вы будете знать, что такое POJO, Entity, и какие требования предъявляются к Entity — будет уже неплохо.
- Если вы не знакомы с форматом XML — самое время познакомиться с ним перед прочтением книги. Очень часто конфиг-файлы Hibernate (как и Spring), пишутся в XML-формате, и если он ввергает вас в ужас — читать книгу будет сложнее.
- Если вы знакомы с паттернами проектирования (хотя бы по задачам JavaRush), то можно почитать про паттерн DAO и зачем он нужен. DAO очень легко реализуется при помощи Hibernate. Участники стажировки, кстати, будут создавать «даошки» при написании тестового задания (и на самом проекте тоже). Да и в реальной работе их создание — рутинная задача, поэтому лишним это не будет.
- Вполне хороший перевод с английского. Про важность этого пункта, думаю, писать отдельно не стоит. Конечно, оригинал всегда будет лучше, и если вы знаете английский на достаточном уровне — лучше читать именно его. Однако, для тех, кто с английским пока не в ладах, а останавливать из-за этого учебу не хочет — вариант отличный.
- Очень широкое покрытие тем. Рассказано почти обо всех «внутренностях» библиотеки. О чем-то очень подробно, о чем-то более скупо. Но в целом, охват получился весьма приличный.
- Простой и понятный язык.
Комментарии (15)
ЧТОБЫ ПОСМОТРЕТЬ ВСЕ КОММЕНТАРИИ ИЛИ ОСТАВИТЬ КОММЕНТАРИЙ,
ПЕРЕЙДИТЕ В ПОЛНУЮ ВЕРСИЮ
18 июля 2022
Сорян за некропостинг, но увидел случайно и припекло. «Стоит ли покупать книгу? Однозначно да.» Однозначно — нет. За некоторым исключением. Да, как справочник она хороша и иметь ее в личной библиотеке — правильно. Но она совершенно не подойдет как первый источник знаний по гибернейту и категорически противопоказана джунам. Эту книгу тяжело читать даже более опытному разработчику, который уже щупал гибернейт и что-то знает про JPA, знает как писать запросы и их оптимизировать, как работать с сессией и т.п. Это примерно как учить яву по официальной документации. Она написана махровым техническим слогом, в сравнении с которым даже Шилдт покажется бульварным чтивом. Java Persistance with Hibernate, это Hibernate in Action на стероидах — та же книга, но раздутая до 600+ (изначально — менее 400 крупным шрифтом) страниц из которых полезной нагрузки, если вы не конструируете БД под серьезный энтерпрайз, будет ~20%. А даже если и будет, то часть информации безбожно устарела и в таком виде вы ее найдете мало где. Если хочется именно книгу, то лучше начинать с Beginning Hibernate: Java Persistence from Beginner to Pro, сейчас (2022) это 6 издание, но 5 найти проще. Также, отличным вариантом для начинающего будет Just Hibernate. И, конечно, Spring Persistence With Hibernate. Оно все на английском. И уже потом, можно попробовать читать Java Persistance with Hibernate, но вряд ли оно уже будет нужно.
Kunonuk Уровень 17
27 декабря 2021
Введение в заблуждение в третьем пункте. К примеру, у вас есть класс User, есть класс Auto, и у каждого User’a есть список его машин List<Auto> autos. Как записать все это в базу данных, чтобы еще и связи между юзерами и их машинами сохранились? Ведь юзер один, а машин у него может быть много:/ А как автоматически удалить из базы данных все машины юзера, если мы удалили его самого (то есть запретить БД хранить «бесхозные» машины)? Вот Hibernate как раз и знает как:) Это и база данных знает как сделать.. Точнее все кроется во внешних ключах. FOREIGN KEY (auto_id) REFERENCES Auto(id) ON DELETE CASCADE FOREIGN KEY (user_id) REFERENCES User(id) ON DELETE CASCADE и при удалении машины или юзера , база данных автоматически удаляет запись.. работает на большинстве диалектов — mysql, postgresql и тд
Константин Иванов Уровень 22
5 ноября 2018
200 экземпляров всего было выпущено в 2017 году. Видимо, успех, т.к. в 2018-м вышло переиздание. Для сравнения, издание 2017 года https://www.ozon.ru/context/detail/id/141415731/ и 2018-го https://www.ozon.ru/context/detail/id/147137095/ Это разные издания — по ISBN (уникальный для всей планеты идентификатор книги)
Евгений Уровень 16
28 сентября 2018
Можно купить здесь — https://www.manning.com/books/java-persistence-with-hibernate-second-edition Конкретно я нашел промокод и купил книжку за те же 24$, что она продается в ритейле, ну на английском и только электронный вариант (меня больше устраивает с собой устройства таскать, чем довольно толстую книжку)
Fonzy Уровень 40
19 июля 2018
Стоит ли покупать книгу? Однозначно да. Тем более, что ее бумажный тираж — всего 200 экземпляров:) Я надеюсь все-таки 200 тыс экземпляров?)
Andrew Shtramak Уровень 40
18 апреля 2018
Кроме того, в Java есть и собственная реализация ORM-модели — Java Persistence API, или просто JPA. Так совсем неправильно писать. JPA — это спецификации JEE, а Hibernate — одна из ее реализаций, хотя, если точнее быть, то JPA писалось с Hibernate. Главное такое на собесе не ляпнуть
Виктор Уровень 30
15 апреля 2018
С примерами действительно беда, ни фига не понятно что и как компилировать.
Максим Уровень 40 Expert
19 февраля 2018
Спасибо за ссылки. Надо будет ознакомиться. Хотя, пожалуй, самое сложное в обучении это как раз таки объемы нового материала. Столько всего надо изучить, прям не знаешь за что хвататься. Голова кругом идет.
Anonymous #1193138 Уровень 40
19 февраля 2018
А где скачать то можно?
Стас Пасинков Уровень 26 Master
19 февраля 2018
а что делать если я неплохо знаком с XML, но он все-равно ввергает меня в ужас?))) абзац про то, что примеры надо ручками набирать и потом еще самому себе задачку придумать аналогичную — поддерживаю всеми руками и ногами!))