Заметки по языку R | Часть 2: Используем синтаксический сахар и приёмы Python в R
Заметки по языку R — это серия статей, в которых я собираю наиболее интересные публикации канала R4marketing из рубрики «#заметки_по_R» .
В прошлый раз мы говорили о нетипичных визуализациях, сегодняшняя подборка состоит из описания приёмов, которые свойственны и горячо любимы пользователям Python, но большинство пользователей R о них не знают.
Для пользователей Python эта статья будет полезна тем, что они найдут реализацию своих любимых приёмов в другом языке, для пользователей R статья будет полезна тем, что они откроют для себя изящные приёмы Python, и смогут перенести их в свои R проекты.

Если вы интересуетесь анализом данных возможно вам будут полезны мои telegram и youtube каналы. Большая часть контента которых посвящены языку R.
- Декораторы
- Множественное присваивание
- Списковые включения
- Индексирование с нуля
- Обработка исключений (try — except)
- Классическое ООП в R
- Логирование (logging)
- Работа с табличными данными
- Заключение
Декораторы в R
На самом деле декораторы широко применяются в Python и горячо любимы пользователям этого языка, а в R они пока не получили широкого распространения. Тем не менее в R тоже можно реализовывать декорирование функций.
Немного теории:
Декораторы — это, по сути, «обёртки», которые дают нам возможность изменить поведение функции, не изменяя её код.
Визуально изображение ниже помогает понять смысл декораторов.

Первоначальная функция — автомобиль. Декоратор добавляет к машине антенну и крыло, но основной функционал машины (перевозка людей) остается неизменным.
Реализация декораторов в R
Базовый скелет декораторов выглядит следующим образом:
deco res return(res) > return(wrapper) >Ниже представлен пример декоратора, который выводит время начала и завершения выполнения задекорированной функции:
timer return(wrapper) >Теперь задекорируем функцию cos() из базового R и используем её задекорированную версию.
# декорируем cos() cos_timed Пакет tinsel
Мы привели пример декоратора в R, но выглядят приведённые примеры в R всё ещё не так привлекательно как в Python:
# Пример декоратора в Python @decorator def f(args): #
Добавить синтаксического сахара в реализацию декораторов в R поможет пакет tinsel . Он позволяет применять декораторы с помощь специального синтаксиса комментариев. Например, что бы задекорировать функцию написанным ранее декоратором timer , достаточно использовать комментарий #. timer .
#. timer say_hi
Эта заметка является неполным передом статьи "Decorators in R".
Множественное присваивание
Множественное присваивание, так же как и декораторы, горячо любимо пользователями Python. Этот приём даёт возможность присвоить одновременно значения сразу нескольким объектам. Множественное присваивание в Python используется например для обмена значений между двумя переменными, не используя при этом третью, временную переменную. Также его удобно использовать в случаях, когда функция возвращает набор значений в виде списка, например summary() . Тогда вы можете распаковать её результат сразу в несколько переменных, поэтому множественное присваивание также иногда называют распаковочным, параллельным или деструктурирующим.
В базовом R аналога этой операции нет, но как мы помним, в R на любой чих есть готовый паке. Для множественного присваивания можно использовать оператор %
Ниже несколько примеров его использования:
# распаковываем список или вектор c(lat, lng) % c(lat, lng) %Ссылка на заметку.
Списковые включения
Списковое включение – это некий синтаксический сахар, позволяющий упростить генерацию последовательностей. Этот приём, аналогично рассмотренным выше, очень распространён в Python, но в R о нём знают не многие, а используют ещё меньше.
Списковые включения, или как их ещё называют - генераторы списков, в Python выглядят следующим образом: a = [i for i in range(1,15)] .
В результате вы получите следующий список (не путайте со списками в R, в Python список наиболее похож на вектор из R): [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] .
Пример не самый выразительный, но он демонстрирует в простейшем виде синтаксис списковых включений в Python. (Конкретно этот пример в R можно заменить на a
Аналог списковых включений в R
В базовом R пока нет аналога генераторов списков, но они реализованы в пакете comprehenr .
Пакет включает три основные функции:
- to_list() - генерация списков;
- to_vec() - генерация векторов;
- alter() - приводит преобразование над объектом, и возвращает объект того же типа, что и входящий, но уже с преобразованными значениями (из приведённых примеров кода, понять смысл этого определения будет проще).
Примеры:
library(comprehenr) to_vec(for(i in 1:10) if(i %% 2==0) i*i) to_list(for (x in 1:20) for (y in x:20) for (z in y:20) if (x^2 + y^2 == z^2) c(x, y, z)) colours = c("red", "green", "yellow", "blue") things = c("house", "car", "tree") to_vec(for(x in colours) for(y in things) paste(x, y)) # преобразование фактора в текстовый тип res = alter(for(i in iris) if(is.factor(i)) as.character(i)) # удаление столбцов - факторов res = alter(for(i in iris) if(is.factor(i)) exclude())Индексирование с нуля
Значимой разницей в R и Python является индексирование. По умолчанию в Python индексация элементов объектов начинается с нуля, а в R с единицы.
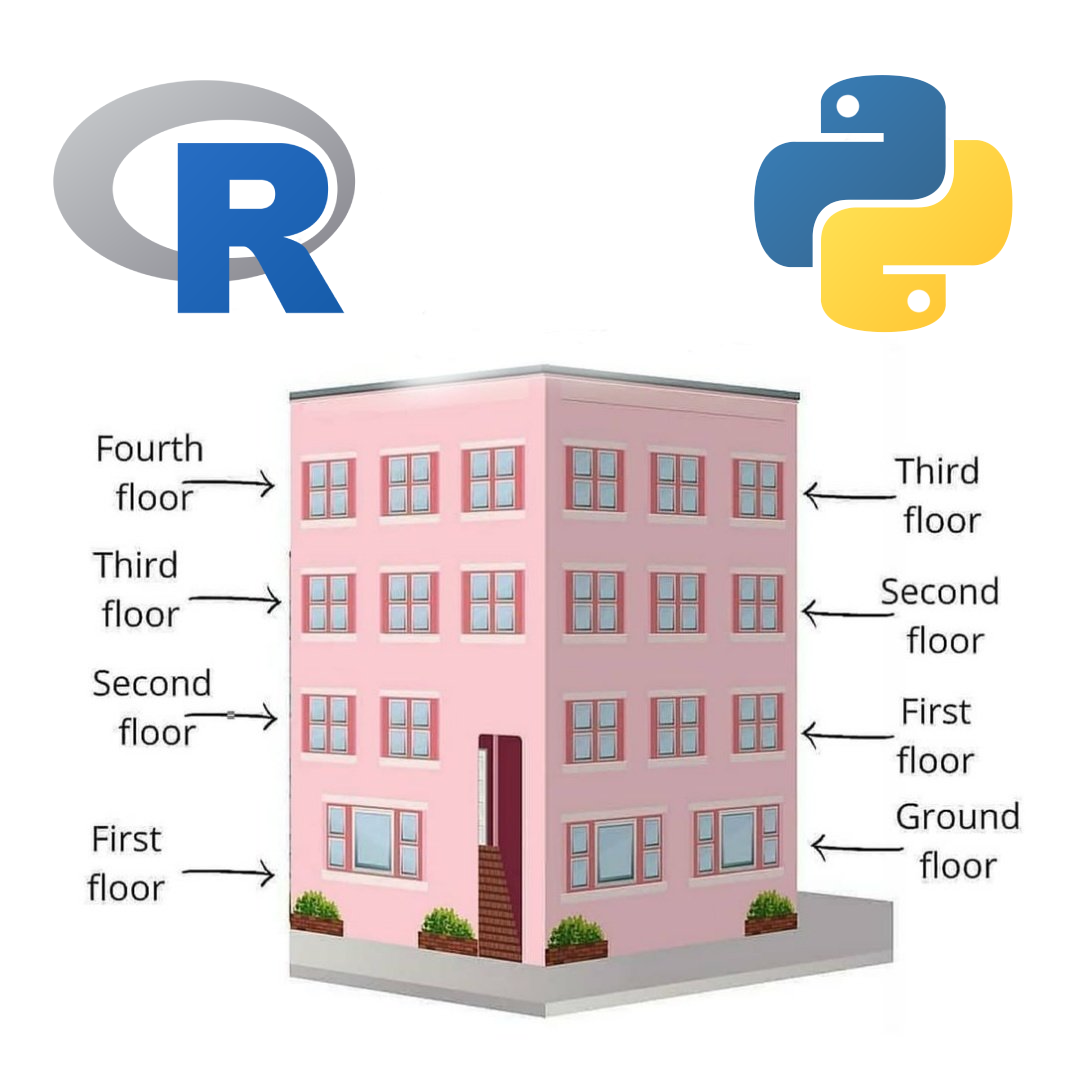
Если вы привыкли к индексации в Python, использовать её в R позволяет пакет index0 .
library(index0) letters0 [1] "a" #> indexed from 0 numbers0[0] #> [1] 2 #> indexed from 0 letters0[c(1, 2, 4)] #> [1] "b" "c" "e" #> indexed from 0 numbers0[c(1, 3)] [1] 2 NA 4 NA 6 #> indexed from 0Заметка родилась из статьи "Indexing from zero in R".
Обработка исключений (try - except)
В базовом Python обработка исключений зачастую реализуется конструкцией try-except , которая имеет следующий синтаксис:
try: ~ Тут код который будет выполняться ~ except Exception: ~ Код который будет выполняться в случае возникновения ошибки в блоке try ~ finally: ~ Код который будет выполняться в любом случае, не зависимо от того закончилось выражение try ошибкой или нет ~т ~ Аналогом этой операции в R является конструкция tryCatch() , которая имеет следующий синтаксис:
tryCatch(expr = < ~ Тут код который будет выполняться ~ >, error = function(err) < ~ Код который будет выполняться в случае возникновения ошибки в блоке expr ~ >, finally = < ~ Код который будет выполняться в любом случае, не зависимо от того закончилось выражение expr ошибкой или нет ~ >)Более подробно изучить конструкцию tryCatch() можно посмотрев следующее видео:
Классическое объектно ориентированное программирование
Ключевая разница между R и Python заключаются в том, что эти языки используют разные парадигмы программирования:
- R - функциональный язык программирования;
- Python - объектно ориентированный язык программирования.
По умолчанию в базовом R ООП реализовано на S3 классах и обобщённых функциях. Подробнее об этом можно узнать из статьи "ООП в языке R (часть 1): S3 классы".
Но, так же в R вам доступно и классическое ООП, которое в этом языке реализовано в отдельном пакете - R6 .
Ниже приведён пример кода, построения класса Cat , включающий в себя несколько свойств и методов.
library(R6) # создаём класс Cat Cat , add_year = function(ages = 1) < self$age ) ) # инициализируем объект класса Cat tom Более подробно про классическое объектно ориентирование программирование в R можно узнать из статьи "ООП в языке R (часть 2): R6 классы".
Логирование (logging)
Модуль logging поставляется с базовой комплектацией Python, в базовом R подобный функционал мне не известен, но он реализован в пакете lgr .
Пример создания простейшего логгера в R, с помощью пакета lgr :
# создаём обычный логгер lg Подробно узнать о работе с пакетом lgr можно из статьи "Логирование выполнения скриптов на языке R, пакет lgr" или следующего видео:
Работа с табличными данными
В Python вся работа с табличными данными зачастую реализуется средствами библиотеки pandas . Уэс Мак-Кинни начал разработку pandas под вдохновением от работы с данными на языке R.
В R есть несколько средств манипуляции данными:
- Базовый синтаксис data.frame
- Пакеты dplyr и tidyr
- Пакет data.table
Тема манипуляции табличными данными очень обширная, и не поместиться в раздел одной статьи, поэтому я более подробно описал примеры манипуляции данных на R и Python в статье "Какой язык выбрать для работы с данными — R или Python? Оба! Мигрируем с pandas на tidyverse и data.table и обратно".
Заключение
В этой статье я продемонстрировал несколько приёмов в R, которые довольно популярны среди пользователей Python, но знакомы далеко не всем пользователям R.
На самом деле я искрене надеюсь, что статья будет полезна как пользователям R, так и пользователям Python, которые планируют ознакомится с возможностями R.
Буду рад видеть вас в рядах подписчиков моего telegram и youtube каналов.
Делитесь в комментариях другими интересными приёмами, которые мигрировали из одного языка в другой.
Синтаксический сахар: определение, происхождение и примеры


В информатике, синтаксический сахар является лингвистикой в языке программирования. Он предназначен, для того чтобы сделать код легче, более читабельным и выразительным. Данный сахар делает язык «более сладким» для использования человеком. То есть вещи могут быть выражены четко, кратко или в альтернативном стиле, который некоторые могут предпочесть.
Синтаксический сахар: что это такое?

Многие языки программирования предоставляют специальный отдел грамматики для обновления элементов. Абстрактно, ссылка на данный объект — это процедура двух аргументов: массива и нижнего индекса, который может быть выражен как get_array(Array, vector(i, j)) . Вместо этого, многие языки предоставляют синтаксис, такой как Array [i, j] . Точно так же обновление элемента массива, например, set_array(Array, vector(i, j), value) , представляет собой процедуру из трех аргументов, но многие профессионалы предоставляют такой код, как Array[i, j] = value .
Конструкция в языке называется «синтаксическим сахаром», если она может быть удалена из программы без какого-либо влияния на функциональность и выразительность.
Различные процессоры, в том числе компиляторы и статические анализаторы, часто расширяют подслащенные конструкции до более фундаментальных устройств перед обработкой. Такой процесс называется «десагеринг».
Происхождение
Термин «синтаксический сахар» был введен Питером Дж. Ландином в 1964 году для описания поверхностного отдела грамматики простого ALGOL, языка программирования, который был определен семантически в терминах аппликативных выражений лямбда-исчисления, сосредоточенных на лексической замене λ с «где».
Более поздние языки программирования, такие как CLU, ML и Scheme, расширили термин для обозначения производной в языке, которая может быть определена как синтаксический сахар c точки зрения ядра основных конструкций. Удобные функции более высокого уровня могут быть «дезагрегированы» и разложены на подмножество. Это, на самом деле, обычная математическая практика построения из примитивов.
Опираясь на различие Ландина между основными языковыми конструкциями и свойствами синтаксического сахара, в 1991 году Матиас Феллайзен предложил кодификацию «выразительной силы», чтобы соответствовать широко распространенным убеждениям в литературе. Он определил это как «более многозначительный», чтобы обозначить, что без рассматриваемых языковых конструкций программа должна быть полностью реорганизована.
Известные примеры синтаксического сахара

В языке COBOL многие из промежуточных ключевых слов являются «сладкими», то есть при желании могут быть опущены. Например, предложение MOVE A B. и MOVE A TO B. выполняют точно одну и ту же функцию, но второе делает действие, которое должно быть выполнено, более четким.
Расширенные операторы составного присваивания: например, a += b эквивалентно a = a + b в C и аналогичных языках, предполагают, что a не имеет побочных эффектов, например, a является регулярной переменной if.
В Perl, unless (condition) <. >является синтаксически if (not condition) <. >. Кроме того, за любым оператором может следовать условие, что statement if condition эквивалентно if (condition) , но первый более естественно отформатирован в одной строке.
В языке «Си» указатели на начало элемента памяти могут записываться без применения специальных синтаксисов: *(a + i) . Хотя в этом языке существует и специальный синтаксис для этого процесса: a[i]. Аналогично, a->x , запись является синтаксическим сахаром для доступа к членам с помощью оператора разыменования (*a). x .
Using
Заявление в C # гарантирует, что некоторые объекты утилизированы правильно. Компилятор расширяет оператор в блок try-finally.
Язык C # позволяет объявлять переменные как var x = expr , что разрешает компилятору выводить тип x из выражения expr , вместо того чтобы требовать явного объявления.
Списки также содержат синтаксический сахар Python (например, [x*x for x in range (10)] для списка квадратов) и декораторы ( @staticmethod ).
В Haskell строка, обозначенная кавычками, семантически эквивалентна числу символов.
В пакете rvest встречается обозначение %>%, и говорит о том, что данные (или выход функции), предшествующие ему, будут служить в качестве первого аргумента следующего инструмента. Это обеспечивает более линейный поток и дизайн манипулирования данными. Tidyverse написано для размещения значений.
Критика

Некоторые программисты считают, что эти возможности использования синтаксиса либо не важны, либо просто несерьезны. Примечательно, что специальные лингвистические формы делают язык менее однообразным, а его спецификацию — более сложной, и могут вызывать проблемы по мере того, как программы становятся большими. Это представление особенно широко распространено в сообществе Lisp, так как оно имеет очень простой, регулярный и поверхностный синтаксис, который может быть легко изменен.
Производные термины

Синтаксическая соль. Метафора была расширена за счет введения этого термина, который обозначает функцию, разработанную, чтобы затруднить написание плохого кода. В частности, синтаксическая соль — это обруч, через который программисты должны перепрыгнуть, чтобы доказать, что они знают, что происходит, а не выражать действие программы. Например, в Java и Pascal присвоение значения с плавающей точкой переменной, объявленной как int, без дополнительного синтаксиса, явно заявляющего, что намерение приведет к ошибке компиляции, в то время как C и C ++ автоматически усекают все числа с плавающей точкой, назначенные int. Однако это не синтаксис, а семантика.
В C # при сокрытии унаследованного члена класса выдается предупреждение компилятора, если только ключевое слово не используется для указания того, что скрытие является преднамеренным. Это нужно для того, чтобы избежать возможных ошибок вследствие схожести переключателя заявления синтаксиса с тем, что из C или C ++, C # требует break для каждой непустой case метки switch, даже если он не допускает неявное падение.
Синтаксическая соль может нарушить свое назначение, сделав код нечитабельным и, таким образом, ухудшив его качество. В крайних случаях основная часть может быть короче, чем накладные расходы, введенные для удовлетворения требований языка.
Альтернативой данного понятия является генерация предупреждений компилятора, когда существует высокая вероятность того, что код представляется результатом ошибки практика, распространенная в современных компиляторах C / C ++.
Синтаксический сахарин

Другим расширением также является сироп. Он так же, как и сахарин означает беспричинный синтаксис, который не облегчает программирование.
Может показаться странным называть язык «сладким», но если работать в Rubyist, то это будет оправдано. В данной программе больше синтаксического сахара, чем во множестве языков, потому что он делает акцент на человеческом понимании, а не на компьютерном. Создатель Ruby, Юкихиро Мацумото, хотел сделать язык не только эффективным, но и увлекательным. Компиляторам и интерпретаторам может понравиться такой высоко структурированный, однозначный отдел грамматики, но людям может быть трудно его понять. Вот тут-то и появляется синтаксический сахар — он делает язык «слаще» и в письме, и в чтении.
Написание кода

Необходимо помнить, что «синтаксический сахар» — это не технический термин, а конструкция, предназначенная для того, чтобы помочь описать способ выражения языка. Проще говоря, данный термин подразумевает оптимизированный код для людей. Цель состоит в том, чтобы упростить синтаксис, чтобы его было легко читать, даже если это уменьшает некоторую техническую ясность. Конечно, написание сладкого кода не означает, что можно пропустить важный этап понимания.
Как и в реальной жизни, знание того, сколько сахара используется, важно для общего состояния здоровья. Sugar делает код простым и выразительным, но также вызывает неоднозначность. Связано это обычно с тем, что не каждый знает и применяет такое понятие при программировании.

Рукопожатие является основной концепцией протокола Websocket. Ключевыми моментами веб-сокетов являются истинный параллелизм и оптимизация производительности, что приводит к более отзывчивым и насыщенным веб-приложениям.

Паттерны проектирования обеспечивают надежный и простой способ следовать проверенным принципам проектирования и писать хорошо структурированный и поддерживаемый код. Одним из популярных и часто используемых шаблонов в объектно-ориентированной .

Что такое RSS-лента и зачем она нужна? Является ли технология пережитком прошлого или она все еще актуальна? Как создать и настроить RSS-ленту на веб-ресурсе, каков принцип ее работы и при помощи каких программ можно ее читать - расскажем в статье.

Delphi был чрезвычайно продвинутым языком с момента своего создания - конца 1990-х. Ко времени, когда популярность достигла своего апогея, его сообщество предоставило пользователям множество высококачественного бесплатного программного продукта с .

В разработке программного обеспечения, процесс наследования дает возможность создавать класс на основе других. Наследование методов классов — важнейший механизм ООП. Интерфейсы, абстрактные классы - это все удобные инструменты для воплощения задачи .
GNOME, KDE и Xfce - популярнейшие настольные среды для Linux. Большинство людей применяют рабочую оболочку, поставляемую с Linux. Но опытные пользователи предпочитают выбирать ее по соображениям удобства, производительности, дизайна или настройки.

Бинарный поиск - это алгоритм нахождения элемента массива последовательным делением массива пополам и сравниванием исходного числа с числом из середины массива. Первый алгоритм двоичного поиска был опубликован в 1946 году. Двоичным поиском следует пользоваться, если нужна быстрая работа программы.

Искусственная нейронная сеть - вычислительная модель, основанная на структуре и функциях биологических нейронных сетей. Информация, которая проходит через цепь, влияет на структуру и изменяется на входе и выходе. Такая схема считается инструментом нелинейных данных, в которых моделируются сложные взаимосвязи между входами и выходами и обнаруживаются закономерности.

Известная традиция всех, кто обучается программированию: в качестве первой простейшей программы писать вывод фразы Hello, World! ("Привет, Мир!"). В данной статье рассмотрим, как написать свою первую программу на одном из самых популярных языков программирования Python.

Canvas (холст) является элементом HTML 5, который позволяет создавать графику и анимацию на веб-странице. Графика реализуется программированием, обычно это Javascript Canvas. После создания графического изображения пользователь программирует действия работы с объектами, например, запуск анимации или изменения элементов рисунка.
19 советов для улучшения вашего синтаксиса в Python
Как упоминалось в "The Zen of Python": “красивое лучше, чем уродливое”. Хороший язык программирования, такой как Python, всегда предоставит соответствующий синтаксический сахар, который поможет разработчикам легко писать элегантный код.
В этой статье освещаются 19 важнейших синтаксических ошибок в Python. Путь к мастерству предполагает их понимание и умелое использование.
1. Операторы Объединения: Самый Элегантный Способ Объединения словарей Python
В Python существует множество подходов к объединению нескольких словарей, но ни один из них нельзя было назвать элегантным до тех пор, пока не был выпущен Python 3.9.
Например, как мы могли объединить следующие три словаря до Python 3.9?
Одним из методов является использование циклов for:
Что такое синтаксический сахар
Иногда на форумах и в комментариях опытных коллег-программистов можно услышать что-то вроде «Это просто синтаксический сахар, не обращай внимания». Давайте разберёмся, что это такое, зачем оно нужно и откуда такое название.
Что такое синтаксический сахар
Синтаксический сахар — это способ написания кода, чтобы сделать его более понятным для программиста. Иногда сахар нужен для того, чтобы сделать код короче, оставив ту же самую логику. При этом на работу программы такое оформление вообще не влияет — при запуске компьютер упрощает код, выбрасывает сахар и исполняет суть программы.
Можно сделать код короче
Проще всего синтаксический сахар показать на примерах. Допустим, у нас значение одной переменной зависит от другой:
// исходная переменная var st = "true"; // если она истинна if (st == "true") < // то присваиваем второй переменной 'Y' var hasName = 'Y'; >else < // иначе присваиваем второй переменной 'N' var hasName = 'N'; >;Этот же самый фрагмент можно записать короче, используя синтаксический сахар — тернарный оператор, который обрабатывает сразу три параметра:
hasName = name ? 'Y' : 'N';
Этот код делает всё то же самое:
- Проверяет, в name — истина или ложь.
- Если истина — присваивает переменной hasName значение 'Y'.
- Иначе присваивает ей значение 'N'.
Логика работы и действия остались точно такими же, но второй код получился компактнее, чем второй, хотя для новичка он выглядит гораздо сложнее.
Сделать код проще
Есть сахар, который, наоборот, делает код проще. Например, вот классический способ организовать цикл, чтобы вывести все его элементы на экран:
// объявляем простой цикл, чтобы вывести все элементы массива for (let i = 0; i
А вот то же самое, но с синтаксическим сахаром:
for (const element of massiv)
Здесь сразу понятно, что мы перебираем все значения массива massiv, кладём их в переменную element и выводим её на экран.
Ещё примеры синтаксического сахара
В большинстве случаев мы даже не задумываемся над тем, что используем синтаксический сахар в своём коде. Но часто с ним удобнее, чем без него:
Например, вот классический способ сделать объект в JavaScript:
var obj = new Object();
А вот более короткий вариант с сахаром:
Первая строчка — классический способ завести пустой массив, вторая — более привычный сахарный способ:
var arr = new Array();
var arr = [];
Если в JavaScript нужно проверить что-то с помощью регулярных выражений, переменную с этим выражением можно задать двумя способами: традиционным и с сахаром. Сделают они одно и то же, просто вторая будет короче:
var regex = new RegExp('something');
var regex = /something/;
А вот пример чистого сахара. Мы объявляем анонимную функцию, и тут же её выполняем:
В каких языках есть синтаксический сахар
Почти во всех языках программирования есть сахар, причём чем высокоуровневее язык, тем больше сахара можно в нём встретить. Меньше всего сахара в Ассемблерах и в странных языках типа Brainfuck.
Обязательно ли использовать сахар в коде
Использовать синтаксический сахар необязательно, на то он и сахар. Программа с ним и без него будет работать одинаково. Другое дело — как потом эту программу будут поддерживать и обновлять, но и тут есть нюанс. Программа с сахаром может выглядеть читаемее, а может, и менее читаемо — зависит от того, какие именно конструкции вы используете.
Когда код пишут начинающие разработчики, они чаще используют код без сахара, чтобы дисциплинировать себя и сделать код максимально читаемым для себя же. Со временем, начитавшись StackOverflow и набравшись опыта, они нахватаются разных оформительских и структурных привычек и будут использовать тот сахар, который им будет казаться самым полезным. А следующие за ними новички будут смотреть на их код и ничего не понимать.