[Перевод] Linux Page Cache для SRE: основные файловые операции и syscall’ы (часть 1) 21.09.2021 10:31
В этой серии постов я хотел бы поговорить о Linux Page Cache. Я считаю, что данные знания теории и инструментов жизненно необходимы и важны для каждого SRE. Общее понимание как работает Page Cache помогает и в рутинных повседневных задачах, и в экстренной отладке на продакшене. При этом Page Cache часто оставляют без внимания, а ведь его лучшее понимание. как правило, приводит к:
- более точному планированию емкости системы и лимитов сервисов и контейнеров;
- улучшенным навыкам отладки приложений, интенсивно использующих память и диски (СУБД и хранилища данных);
- созданию безопасных и предсказуемых сред выполнения специальных задач, связанных с памятью и/или вводом-выводом (например: сценарии резервного копирования и восстановления, rsync однострочники и т.д.).
Я покажу, какие утилиты вы можете использовать, когда имеете дело с задачами и проблемами, связанными с Page Cache, как правильно к ним подходить, и как понять реальное использование памяти.
Подготовка окружения
Начнём с подготовки окружения. Нам понадобиться файл для тестов:
$ dd if=/dev/random of=/var/tmp/file1.db count=128 bs=1M И утилита vmtouch . На арче (BTW, I use Arch Linux) её легко поставить из aur ‘a:
$ yay -Sy vmtouch И сбрасываем все кеши, чтобы получить чистую систему:
$ sync; echo 3 | sudo tee /proc/sys/vm/drop_cachesТеперь пришло время засучить рукава и приступить к практическим примерам.
ПРИМЕЧАНИЕ
На данный момент мы игнорируем как работает утилита vmtouch . Позже в этой статье я покажу, как написать его альтернативу с практически всеми фичами.
Чтение файлов и Page Cache
Чтение файлов используя read () syscall
Начнём с простой программы, которая считывает первые 2 байта из нашего тестового файла /var/tmp/file1.db .
with open("/var/tmp/file1.db", "br") as f: print(f.read(2))Обычно такого рода запросы транслируются в системный вызов read() . Давайте запустим скрипт под strace , для того чтобы убедиться что f.read() действительно вызывает системный вызов read() :
$ strace -s0 python3 ./read_2_bytes.pyРезультат должен выглядеть как-то так:
. openat(AT_FDCWD, "./file1.db", O_RDONLY|O_CLOEXEC) = 3 . read(3, "%B\353\276\0053\356\346Nfy2\354[&\357\300\260%D6$b?'\31\237_fXD\234". 4096) = 4096 . ПРИМЕЧАНИЕ
Из вывода видно, что системный вызов read() возвращает 4096 байт (одна страница) не смотря на то, что наш скрипт запрашивал только 2 байта. Это пример того, как python оптимизирует работу буферизованного ввода-вывода. Хотя это и выходит за рамки данного поста, но в некоторых случаях важно иметь это в виду.
Теперь давайте проверим, сколько данных закэшировало ядро. Для получения этой информации мы используем vmtouch :
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE Directories: 0 ⬇ Resident Pages: 20/32768 80K/128M 0.061% Elapsed: 0.001188 seconds
Из вывода мы видим, что вместо 2B данных, которые запрашивал python, ядро закэшировало 80 КБ или 20 страниц.
Ядро линукс в принципе не может загружать в Page Cache ничего меньше 4 КБ или одной страницы. Но почему их там оказалось на 19 страниц больше? Это отличный пример того, как ядро использует опережающее чтение (readahead) и предпочитает выполнять последовательные операции ввода-вывода, а не случайные. Основная идея состоит в том, чтобы предсказать последующие чтения и свести к минимуму количество запросов к диску. Этим поведением можно управлять с помощью системных вызовов:
posix_fadvise() ( man 2 posix_fadvise ) и
readahead() ( man 2 readahead ).
ПРИМЕЧАНИЕ
Обычно, в продакшене для систем управления базами данных и дисковых хранилищ, не имеет большого смысла в настройках параметров опережающего чтения. Если СУБД не нужны данные, которые были кэшированы при опережающем чтении, политика восстановления памяти ядра (memory reclaim) должна в конечном итоге удалить эти страницы из Page Cache. Так же, как правило, последовательный ввод-вывод не является дорогостоящим для ядра и аппаратного обеспечения. В свою очередь отключение опережающего чтения вообще — может даже навредить и привести к некоторому снижению производительности из-за увеличения числа операций ввода-вывода в дисковых очередях ядра, бÓльшего количества переключений контекста (context switches) и бÓльшего времени для подсистемы управления памятью ядра для распознавания рабочего набора данных (working set). Мы поговорим о политике восстановления памяти (memory reclaim), нагрузке на память (memory pressure) и обратной записи в кэш (writeback) позже в этой серии постов.
Теперь давайте посмотрим как использование posix_fadvise() может уведомить ядро о том, что мы читаем файл случайным образом, и поэтому не хотим иметь никакого опережающего чтения (readahead):
import os with open("/var/tmp/file1.db", "br") as f: fd = f.fileno() os.posix_fadvise(fd, 0, os.fstat(fd).st_size, os.POSIX_FADV_RANDOM) print(f.read(2))Перед запуском скрипта нам нужно сбросить все кэши:
$ echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./read_2_random.pyТеперь, если вы проверите выдачу vmtouch — вы можете увидеть, что, как и ожидалось, там находится лишь одна страница:
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE Directories: 0 ⬇ Resident Pages: 1/32768 4K/128M 0.00305% Elapsed: 0.001034 seconds
Чтение файлов с помощью системного вызова mmap ()
Для чтение данных из файла мы также можем использовать системный вызов mmap() ( man 2 mmap ). mmap() является «волшебным» инструментом и может быть использован для решения широкого круга задач. Однако для наших тестов нам понадобиться только одна его особенность, а именно, возможность отображать файл на адресное пространство процесса. Это позволяет получить доступ к файлу в виде плоского массива. Я расскажу детально о mmap() далее в этом цикле статей. Но сейчас, если вы совсем не знакомы с mmap() , его API должен быть понятным из следующего примера:
import mmap with open("/var/tmp/file1.db", "r") as f: with mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ) as mm: print(mm[:2])Данный код делает то же самое, что и системный вызов read() . Он читает первые 2 байта из файла.
Также в целях тестирования нам необходимо очистить кэш перед выполнением скрипта:
$ echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./read_2_mmap.pyТеперь давайте посмотрим на содержимое Page Cache:
$ vmtouch /var/tmp/file1.db Files: 1. LOOK HERE Directories: 0 ⬇ Resident Pages: 1024/32768 4M/128M 3.12% Elapsed: 0.000627 seconds
Как вы видите mmap() выполнил еще более агрессивный readahead, чем read() .
Давайте теперь изменим readahead при помощи системного вызва madvise() как это было сделано с fadvise() .
import mmap with open("/var/tmp/file1.db", "r") as f: with mmap.mmap(f.fileno(), 0, prot=mmap.PROT_READ) as mm: mm.madvise(mmap.MADV_RANDOM) print(mm[:2])$ echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./read_2_mmap_random.pyи содержимое Page Cache:
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE Directories: 0 ⬇ Resident Pages: 1/32768 4K/128M 0.00305% Elapsed: 0.001077 seconds
Как вы можете видеть с MADV_RANDOM нам удалось загрузить ровно одну страницу в Page Cache.
Запись в файл и Page Cache
Теперь давайте поэкспериментируем с записью.
Запись в файлы с помощью системного вызова write ()
Давайте продолжим работу с нашим экспериментальным файлом и попробуем записать первые 2 байта:
with open("/var/tmp/file1.db", "br+") as f: print(f.write(b"ab"))ПРИМЕЧАНИЕ
Будьте осторожны и не открывайте файл в режиме w . Он перезапишет ваш файл и сделает его размером в 2 байта. Нам нужен режим r+ .
Удалите все из Page Cache и запустите приведенный выше скрипт:
sync; echo 3 | sudo tee /proc/sys/vm/drop_caches && python3 ./write_2_bytes.pyТеперь давайте проверим содержимое Page Cache.
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE Directories: 0 ⬇ Resident Pages: 1/32768 4K/128M 0.00305% Elapsed: 0.000674 secondsКак вы можете видеть, в Page Cache находится 1 страница данных. Это достаточно важное наблюдение, так как, если происходят записи размером меньше размера страницы, то им будут предшествовать 4 Кб чтения, для того, чтобы загрузить данные в Page Cache.
Также мы можем проверить состояние грязных (dirty) страниц, заглянув в файл статистики памяти cgroup.
Получаем текущую cgroup:
$ cat /proc/self/cgroup 0::/user.slice/user-1000.slice/session-4.scope$ grep dirty /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat file_dirty 4096Запись в файл с помощью mmap () syscall
Давайте теперь повторим наш опыт с записью, но будем использовать в этот раз mmap() :
import mmap with open("/var/tmp/file1.db", "r+b") as f: with mmap.mmap(f.fileno(), 0) as mm: mm[:2] = b"ab"Вы можете самостоятельно повторить вышеописанные команды vmtouch , cgroup и grep . В итоге вы должны получить тот же результат. Единственным исключением является опережающее чтение. По умолчанию mmap() загружает гораздо больше данных в кэш страниц даже при записи.
Грязные страницы кеша (dirty pages)
Как мы видели ранее, процесс генерирует грязные страницы путем записи в файлы через кэш.
Linux предоставляет несколько вариантов получения количества грязных (dirty) страниц. Первый и самый старый из них — это прочитать системный файл /proc/memstat :
$ cat /proc/meminfo | grep Dirty Dirty: 4 kBЧасто такую системную информацию трудно интерпретировать и использовать, поскольку мы не можем точно определить, какой процесс их сгенерировал и к какому файлу они относятся.
Поэтому, как было показано выше, лучшим вариантом для получения данной информации лучше всего использовать cgroup:
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat | grep dirt file_dirty 4096Если же ваша программа использует mmap() для записи в файлы, у вас есть еще один вариант получения статистики с детализацией по каждому процессу. В procfs есть специальный файл для каждого процесса /proc/PID/smap , где отображаются счетчики памяти с разбивкой по областям виртуальной памяти (VMA). Как мы помним, с помощью mmap() процесс отображает файл на свою память, что следовательно создает VMA с файлом и соответствующей информацией. Мы можем получить грязные страницы, найдя там:
- Private_Dirty — объем грязных данных, сгенерированных этим процессом;
- Shared_Dirty — грязные страницы других процессов. Эта метрика будет отображать данные только для страниц, на которые есть ссылки (referenced memory). Это означает, что процесс должен был обратиться к этим страницам раньше и сохранить их в своей таблице страниц (page table) (подробнее позже).
$ cat /proc/578097/smaps | grep file1.db -A 12 | grep Dirty Shared_Dirty: 0 kB Private_Dirty: 736 kBНо что, если мы хотим получить статистику наличия грязных страниц (dirty pages) для конкретного файла. Чтобы ответить на этот вопрос, ядро Linux предоставляет 2 файла в procfs : /proc/PID/pagemap и /proc/kpageflags . Я покажу, как используя эти файлы написать наш собственный инструмент позже в этом цикле статей, а сейчас мы можем использовать инструмент отладки памяти из репозитория ядра Linux чтобы получить информацию о страницах файла: page-types (https://github.com/torvalds/linux/blob/master/tools/vm/page-types.c).
$ sudo page-types -f /var/tmp/file1.db -b dirty flags page-count MB symbolic-flags long-symbolic-flags 0x0000000000000838 267 1 UDl_____M_____________________________ uptodate,dirty,lru,mmap 0x000000000000083c 20 0 RUDl_____M______________________________ referenced,uptodate,dirty,lru,mmap total 287 1
Я отфильтровал все страницы нашего файла /var/tmp/file1.db по наличию грязного ( dirty ) флага. В выводе вы можете видеть, что файл содержит 287 грязных страниц или 1 МБ грязных данных, которые в конечном итоге будут записаны обратно в хранилище. page-type объединяет страницы по флагам, поэтому в выводе вы можете увидеть 2 набора страниц. У обоих есть грязный флаг D , и разница между ними заключается в наличии флага R .
Синхронизация данных файла: fsync (), fdatasync () и msync ()
Мы уже использовали команду для синхронизации ( man 1 sync ) всех грязных страниц системы на диски перед каждым тестом, для того чтобы получить свежий Page Cache. Но что делать, если мы хотим написать систему управления базами данных, и нам нужно быть уверенными, что все записи попадут на диски до того, как произойдет отключение питания или другие аппаратные ошибки. Для таких случаев linux предоставляет несколько способов заставить ядро совершить сброс грязных страницы для конкретного файла из Page Cache на диски:
- fsync() — блокируется до тех пор, пока не будут синхронизированы все грязные страницы конкретного файла и его метаданные;
- fdatasync() — то же самое, но без метаданных;
- msync() — то же самое, что делает fsync() , но для файла, отображенного на память процесса;
- флагами открытия файла: O_SYNC или O_DSYNC сделают все записи в файл синхронными по умолчанию.
ПРИМЕЧАНИЕ
Вам все еще нужно заботиться о барьерах записи (write barriers) и понимать, как работает ваша файловая система. Обычно операции добавления в конец файла безопасны и не могут повредить данные которые были записаны до этого Другие же типы операций записи могут повредить ваши файлы (например, даже с настройками журнала по умолчанию в ext4). Поэтому все системы управления базами данных, такие как MongoDB, PostgreSQL, Etcd, Dgraph и т. д., используют журналы предварительной записи (WAL). Если вам интересно узнать более подробнее об этой теме, — можно пожалуй начать с поста в блоге Dgraph.
А вот и пример синхронизации файлов:
import os with open("/var/tmp/file1.db", "br+") as f: fd = f.fileno() os.fsync(fd)Проверяем наличие данных файла в Page Cache с помощью mincore ()
Настало время выяснить, каким же таким способом vmtouch удается показать нам, сколько страниц того или иного файла содержит Page Cache.
Секрет заключается в системном вызове mincore() ( man 2 mincore ). mincore() буквально означает «память в ядре» (memory in core). Его параметрами являются начальный адрес виртуальной памяти, длина адресного пространства и результирующий вектор. mincore() работает с памятью (а не с файлами), поэтому его можно использовать и для проверки, была ли вытеснена анонимная память в своп (swap).
man 2 mincore
mincore() returns a vector that indicates whether pages of the calling process«s virtual memory are resident in core (RAM), and so will not cause a disk access (pagefault) if referenced. The kernel returns residency information about the pages starting at the address addr, and continuing for length bytes.
Поэтому для повторения фичи vmtouch нам нужно сначала отобразить файл в виртуальную память процесса, даже если мы не собираемся выполнять ни чтение, ни запись.
Теперь у нас есть все необходимое для написания нашего собственного простого vmtouch , чтобы вывести информацию из Page Cache о файле. Я использую Go, потому что, к сожалению, в Python нет простого способа вызвать mincore() syscall:
package main import ( "fmt" "log" "os" "syscall" "unsafe" ) var ( pageSize = int64(syscall.Getpagesize()) mode = os.FileMode(0600) ) func main() < path := "/var/tmp/file1.db" file, err := os.OpenFile(path, os.O_RDONLY|syscall.O_NOFOLLOW|syscall.O_NOATIME, mode) if err != nil < log.Fatal(err) >defer file.Close() stat, err := os.Lstat(path) if err != nil < log.Fatal(err) >size := stat.Size() pages := size / pageSize mm, err := syscall.Mmap(int(file.Fd()), 0, int(size), syscall.PROT_READ, syscall.MAP_SHARED) defer syscall.Munmap(mm) mmPtr := uintptr(unsafe.Pointer(&mm[0])) cached := make([]byte, pages) sizePtr := uintptr(size) cachedPtr := uintptr(unsafe.Pointer(&cached[0])) ret, _, err := syscall.Syscall(syscall.SYS_MINCORE, mmPtr, sizePtr, cachedPtr) if ret != 0 < log.Fatal("syscall SYS_MINCORE failed: %v", err) >n := 0 for _, p := range cached < // the least significant bit of each byte will be set if the corresponding page // is currently resident in memory, and be clear otherwise. if p%2 == 1 < n++ >> fmt.Printf("Resident Pages: %d/%d %d/%d\n", n, pages, n*int(pageSize), size) >$ go run ./main.goResident Pages: 1024/32768 4194304/134217728И сверяем вывод с vmtouch :
$ vmtouch /var/tmp/file1.db Files: 1 LOOK HERE Directories: 0 ⬇ Resident Pages: 1024/32768 4M/128M 3.12% Elapsed: 0.000804 secondsВывод
Как видно из статьи ядро Linux предоставляет широкий набор возможностей для взаимодействия и управления Page Cache, которые на мой взгляд должен знать каждый SRE.
Habrahabr.ru прочитано 30302 раза
Page-кэш, или как связаны между собой оперативная память и файлы

Ранее мы познакомились с тем, как ядро управляет виртуальной памятью процесса, однако работу с файлами и ввод/вывод мы опустили. В этой статье рассмотрим важный и часто вызывающий заблуждения вопрос о том, какая существует связь между оперативной памятью и файловыми операциями, и как она влияет на производительность системы.
Что касается работы с файлами, тут операционная система должна решить две важные проблемы. Первая проблема – удивительно низкая скорость работы жестих дисков (особенно операций поиска) по сравнению со скоростью оперативной памяти. Вторая проблема – возможность совместного использования единожды загруженного в оперативную память файла разными программами. Взглянув на процессы с помощью Process Explorer, мы увидим, что порядка 15 МБ оперативной памяти в каждом процессе тратится на общие DLL-библиотеки. На моем компьютере в данный момент выполняется 100 процессов, и, если бы не существовала возможность совместного использования файлов в памяти, то около 1,5 ГБ памяти тратилось бы только на общие DLL-библиотеки. Это, конечно, неприемлемо. В Linux, программы тоже используют разделяемые библиотеки типа ld.so, libc и других.
К счастью, обе проблемы можно решить, как говорится, одним махом – с помощью страничного кэша (page cache). Страничный кэш используется ядром для хранения фрагментов файлов, причем каждый фрагмент имеет размер в одну страницу. Для того, чтобы лучше проиллюстрировать идею страничного кэша, я придумал программу под названием render, которая открывает файл scene.dat, читает его порциями по 512 байт и копирует их в выделенное пространство в куче. Первая операция чтения будет осуществлена так, как показано на рисунке вверху.
После того, как будут прочитаны 12 KБ, куча процесса render и имеющие отношения к делу физические страницы будут выглядеть следующим образом:

Кажется, все просто, но на деле все, много чего происходит. Во-первых, даже несмотря на то, что наша программа использует обычные вызовы read(), в результате их выполнения в страничном кэше окажется три 4-килобайтных страницы с содержимым файла scene.dat. Многие удивляются, но все стандартные операции файлового ввода / вывода работают через страничный кэш. В Linux на x86-платформе, ядро представляет файл в виде последовательности 4-килобайтных фрагментов. Если запросить прочтение всего навсего одного байта из файла, то этого приведет к тому, что 4-килобайтный фрагмент, содержащий данный байт, будет целиком прочитан с диска и помещен в страничный кэш. Вообще говоря, в этом есть смысл, потому что, во-первых, производительность при непрерывном чтении с диска (sustained disk throughput) является достаточно высокой, и, во-вторых, программы обычно читают более одного байта из некоторой области файла. Страничный кэш знает о том, какое место в файле занимает каждый скэшированный его фрагмент; это изображено на рисунке как #0, #1, и т.д. В Windows используются 256-килобайтные фрагменты (называемые “view”), которые по своему предназначению аналогичны страницам в страничном кэше Linux.
При использовании обычных операций чтения, данные сначала попадают в страничный кэш. Программисту данные доступны порционально, через буфер, и из него он копирует их (в нашем примере) в область в куче. Данный подход к делу является крайне неэффективным – не только тратятся вычислительные ресурсы процессора и оказывается негативное влияние на процессорные кэши, но также происходит напрасная трата оперативной памяти на хранение копий одних и тех же данных. Если взглянуть на предыдущий рисунок, то будет видно, что содержимое файла scene.dat хранится сразу в двух экземплярах; любой новый процесс, работающий с этим файлом, скопирует эти данные еще раз. Таким образом, вот чего мы добились – несколько уменьшили проблему задержки при чтении с диска, но в остальном потерпели полную неудачу. Однако, решение проблемы существует – это «отображение файлов в память» (memory-mapped files):

Когда программист использует отображение файлов в память, ядро мэппирует виртуальные страницы напрямую в физические страницы в страничном кэше. Это позволяет добиться значительного прироста производительности – в Windows System Programming пишут об ускорении времени выполнения программы на 30% и более по сравнению со стандартными файловыми операциями ввода/вывода. Аналогичные цифры, только теперь уже для Linux и Solaris, приводятся и в книге Advanced Programming in the Unix Environment. С помощью данного механизма можно писать программы, которые будут использовать значительно меньше оперативной памяти (хотя тут многое также зависит от особенностей самой программы).
Как всегда, главное в вопросах производительности – это измерения и наглядные результаты. Но даже и без этого, отображение файлов в память вполне себя окупает. Интерфейс программирования – достаточно приятный и позволяет читать файлы как обычные байты в памяти. Ради всех преимуществ данного механизма не придется чем-то особенным жертвовать, например, читаемость кода никак не пострадает. Как говорится, флаг вам в руки – не бойтесь экспериментировать со своим адресным пространством и вызовом mmap в Unix-подобных системах, вызовом CreateFileMapping в Windows, а также разными оберточными функциями, доступными в высокоуровневых языках программирования.
Когда создается отображение файла в память, его содержимое попадает туда не сразу, а постепенно – по мере, того, как процессор отлавливает page faults, вызванные обращением к еще незагруженным фрагментам файла. Обработчик для такого page fault отыщит нужный page-фрейм в страничном кэше и осуществит мэппирование виртуальной страницы в данный page-фрейм. Если нужные данные до этого не были скэшированы в страничном кэше, то будет инициирована операция чтения с диска.
А теперь, вопрос. Представим, что программа render завершила выполнение, и никаких ее дочерних процессов тоже не осталось. Будут ли при этом тут же высвобождены страницы в страничном кэше, хранящие фрагменты файла scene.dat? Многие думают, что да – но это было бы неэффективно. Вообще, если попытаться проанализировать ситуацию, то вот что приходит в голову: достаточно часто мы создаем файл в одной программе, она завершает свое выполнение, затем файл используется в другой программе. Страничный кэш должен предусматривать такие ситуации. И вообще, зачем ядру в принципе избавляться от содержимого страничного кэша? Мы же помним, что скорость работы жесткого диска на пять порядков медленнее оперативной памяти. И если случается так, что данные ранее уже были скэшированы, то нам крупно повезло. Именно поэтому, из страничного кэша ничего не удаляется, по крайней мере до тех пор, пока есть свободная оперативная память. Страничный кэш не зависит от какого-то конкретного процесса, наоборот – это такой ресурс, который совместно использует вся система. Неделю спустя, вновь запустим render, и если файл scene.dat все еще находится в страничном кэше — ну, что ж, нам везет! Вот почему размер страничного кэша постепенно растет, а затем его рост вдруг останавливается. Нет, не потому что операционная система – полная фигня, которая съедает всю оперативу. А потому, что так и должно быть. Неиспользуемая оперативная память – это тоже своего рода напрасно растрачиваемый ресурс. Лучше использовать как можно больше оперативной памяти под страничный кэш, чем вообще никак не использовать.
Когда программа делает вызов write(), данные просто копируются в соответствующую страницу в страничном кэше, и она помечается флагом «dirty». Запись непосредственно на сам жесткий диск не происходит сразу же, и нет смысла блокировать программу в ожидании, пока дисковая подсистема станет доступной. Есть у этого поведения и свой недостаток – если компьютер упадет в синий экран, то данные могут так и не попасть на диск. Именно поэтому критически важные файлы, как например, файлы журнала транзакций баз данных, нужно синхронизировать специальным вызовом fsync() (но вообще, есть еще кэш контроллера жесткого диска, так что и здесь нельзя быть абсолютно уверенным в успешности операции записи). Вызов read() напротив блокирует программу до тех пор, пока диск не станет доступным и данные не будут прочитаны. Для того, чтобы несколько смягчить данную проблему, операционные системы используют т.н. «метод нетерпеливой загрузки» (eager loading), и примером этого метода является «опережающее чтение» (read ahead). Когда задействуется опережающее чтение, ядро производит упреждающую загрузку определенного количества файловых фрагментов в страничный кэш, предвосхищая тем самым последуюшие запросы на чтение. Можно помочь ядру с выбором оптимальных параметров для опережающего чтения, выбрав параметр в зависимости от того, как Вы собираетесь читать файл – последовательно или в произвольном порядке (вызовы madvise(), readahead(), в Windows — cache хинты). Linux использует опережающее чтение для файлов, отраженных в память; насчет Windows я не уверен. Наконец, можно вообще не использовать страничный кэш – за это ответственны флаги O_DIRECT в Linux и NO_BUFFERING в Windows; базы данных так довольно часто и поступают.
Мэппинг файла в память может быть двух типов – или private, или shared. Эти термины обозначают только то, как система будет реагировать на изменение данных в оперативной памяти: в случае с shared-мэппингами любое изменение данных будет сбрасываться на диск или будет видимым в других процессах; в случае с private-мэппингами этого не произойдет. Для реализации private-мэппингов, ядро опирается на механизм copy-on-write, который основан на определенном использовании записей в page-таблицах. В следующем примере, наша программа render, а также программа render3d (а у меня талант на выдумывание названий программ!) создают private-мэппинг для файла scene.dat. Затем, render пишет в область виртуальной памяти, которая поставлена в соответствие файлу:
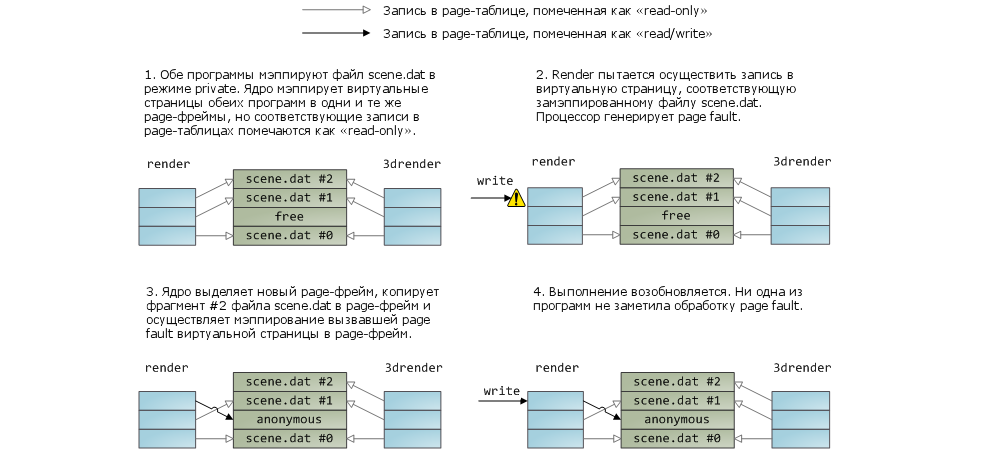
То, что записи в page-таблицах являются read-only (см. на рисунке) не должно нас смущать; и это еще не означает, что мэппинг будет доступен только на чтение. Это просто такой прием, с помощью которого ядро обеспечивает совместное использование страницы разными процессами и оттягивает необходимость создавать копию страницы до самого последнего момента. Глядя на рисунок понимаешь, что термин “private” возможно и не самый удачный, но если вспомнить, что он описывает исключительно поведение при изменении данных, то все нормально. У механизма мэппирования есть и еще одна особенность. Допустим, есть две программы, которые не связаны отношениями «родительский процесс – дочерний процесс». Программы работают с одним и тем же файлом, но мэппирют его по-разному – в одной программе это private-мэппинг, в другой – shared-мэппинг. Так вот, программа с private-мэппингом (назовем ее «первой программой») будет видеть все изменения, вносимые второй программой в некоторую страницу, до тех пор, пока первая программа сама не попытается записать что-нибудь в эту страницу (что приведет к созданию отдельной копии страницы для первой программы). Т.е. как только отработает механизм copy-on-write, изменения, вносимые другими программами, уже видны не будут. Ядро не гарантирует подобного поведения, но в случае с x86-процессорами так и происходит; и в этом есть определенный смысл, даже с точки зрения того же API.
Что же касается shared-мэппингов, то здесь дела обстоят следующим образом. На страницы выставляются права «read/write», и они просто мэппируются в страничный кэш. Таким образом, кто бы не вносил изменения в страницу, это увидят все процессы. Помимо этого, данные сбрасываются на жесткий диск. Ну и наконец, если страницы на предыдущем рисунке были бы действительно read-only, то page fault, отловленный при обращении к ним, повлек бы за собой ошибку сегментации (segmentation fault), а не отработку логики copy-on-write.
Разделяемые библиотеки также отображаются в память как и любые другие файлы. В этом нет ничего особенного — все тот же private-мэппинг, доступный программисту через вызов API. Далее приводится пример, показывающий часть адресного пространства двух экземпляров программы render, использующих механизм отображения файлов в память. Помимо этого, показаны соответствующие области физической памяти. Таким образом мы можем увязать вместе те концепций, с которыми познакомились в данной статье:
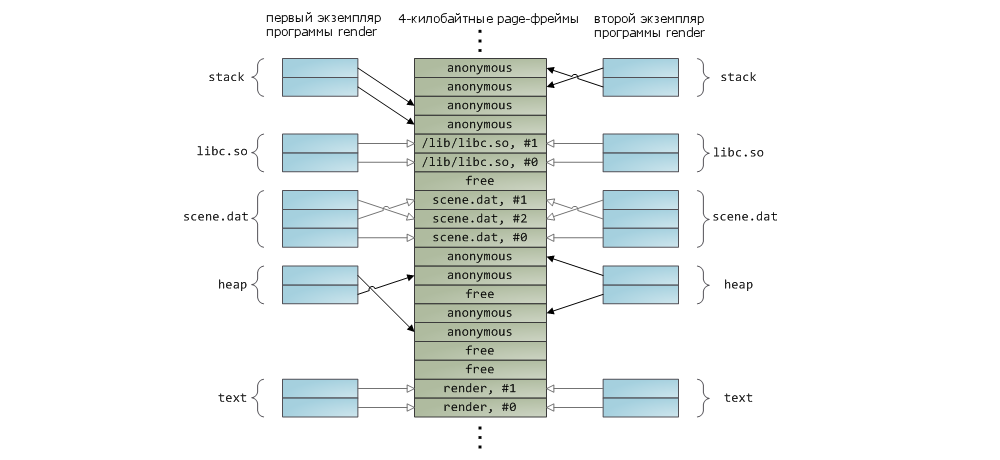
На этом завершим нашу серию из трёх статей, посвященных основам работы памяти. Надеюсь информация была для вас полезной и позволила составить общее представление по данной теме.
Ссылки на статьи серии:
- Организация памяти процесса
habrahabr.ru/company/smart_soft/blog/185226
duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory - Как ядро управляет памятью
habrahabr.ru/company/smart_soft/blog/226315
duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory - Page-кэш, или как связаны между собой оперативная память и файлы
habrahabr.ru/company/smart_soft/blog/227905
duartes.org/gustavo/blog/post/page-cache-the-affair-between-memory-and-files
Материал подготовлен сотрудниками компании Smart-Soft — smart-soft.ru.
What Are Dirty Pages in Linux
Question: What are dirty pages and what is their purpose?
Whenever application/database process needs to add virtual page into physical memory but no free physical pages are left OS must clear-out remaining old pages.
Now if old page had not been written at all then this one does not need to be saved it can be simply recovered from the the data file. But if old page has been modified already then it must be preserved somewhere so application/database can re-used later on – this is called dirty page.
OS stores such dirty pages in swap files ( so it can be removed from physical memory so another ‘new’ page can be stored in physical memory )If lots of data will be removed from page cache to dirty page area – this might cause significant IO bottleneck if actual swap device is located on local disk ( sda ) and more-over cause further issues if local disk is used as well by local root ( OS ) disk.
Page cache in Linux is just a disk cache which brings additional performance to OS which helps with intensive high read/writes on files.
As ‘sub’ product of page cache is dirty page – which was explained in above example case. Dirty pages can be also observed whenever application will write to file or create file – first write will happen in page cache area – hence creating a file which 10MB file can be really fast:
# dd if=/dev/zero of=testfile.txt bs=1M count=100 10+0 records in 10+0 records out 10485760 bytes (100 MB) copied, 0,1121043 s, 866 MB/s
Its because that file is created in memory region not actual disk – hence response time is really fast. Under the OS such thing will be noted in /proc/meminfo and more over in ‘Dirty:
Before above command will get executed – note-down the /proc/meminfo and ‘Dirty’ row:
# more /proc/meminfo | grep -i dirty Dirty: 96 kB
After command is executed:
# more /proc/meminfo | grep -i dirty Dirty: 102516 kB
Periodically OS or application/database will initiate sync which will write actual testfile.txt to disk:
# more /proc/meminfo | grep -i dirty Dirty: 76 kB
Now Oracle Database for example does not allow to do such writes into memory region as if OS will crash or if SAN LUn will fail – data will be compromised. That’s why Oracle Database requires data to be ‘in-sync’ hence all writes needs to be confirmed by backend like disk/lun before database will throw more write requests.
Normally Databases/Application periodically drop cache hence dirty pages are written to disk in small chunks. In some cases dirty pages can grow in size as maybe application/database did not configured page cache mechanism properly.
So dirty pages can write to swap files ( Swap area ) but also to special region in disk ( LUN/file-system ). If for example we create more than 100MB swap file which will be re-used later from swap file we might cause uncecessary IO issues on swap device. Enterprise systems store swap files and swap area on OS under solid state drives ( SSD ) or dedicated LUN hence local disk performance won’t be impacted ( as normally swap region is created on Local disk )
In some cases application/database might have issues internally and dirty pages will be written as swap files but will be never re-used this will cause swap area to grow and cause uncessary IOs on local disk and lead to large swap usage under OS.
To find out at what stage OS will try to dump dirty pages back to disk layer please check official kernel documentation around Virtual Memory here and look for settings like:
vm.dirty_background_ratio vm.dirty_ratio vm.swappiness
dirty_background_ratio dirty_ratio dirty_background_bytes dirty_expire_centisecs
Above settings needs to be tuned per Database/Application requirement as OS does not have any ‘best practice’ setting for them – they are tuned per DB/APP load/configuration.
Whenever application/database will demand memory pages to be free on physical memory – OS tends to keep everything in page cache – hence OS will need to re-allocate some of the pages and mark them as dirty. This process is works fine if application/database end are properly tuned and scaled – otherwise it will cause really aggressive swappiness to occur – as OS will need to write all dirty pages back to swap disk – this can be controlled via vm.swappiness setting.
If application/database will do agreessive swappiness it might cause serious IO writes on swap device and lead to serious system stalls – always make sure that application/databases are properly configured in terms of memory management.
As explained not all pages will be marked as dirty – mostly unused pages will get discarded rather than marked as dirty ( it all depends if pages which already are allocated were modified or not )
To verify which PIDs are using swap area – bellow command can be used:
for file in /proc/*/status do awk '/VmSwap|Name/END< print "">' $file done | sort -k 2 -n -r
Releasing ‘consumed’ swap space is really limited, normally if PID exits properly or simply gets shutdown swap space will be re-claimed but killing PID or if it ends-up abnormally like segfault might still leave swap space consumed. Another option is to reboot as doing swapoff and swapon command can cause serious issues or even lead to system panic state.
Some more articles you might also be interested in …
- How to extract RPM package without installing it
- How to use ipset Command in Linux
- engrampa: command not found
- Understanding RPM Versions and Naming Schemes
- rolldice: command not found
- Linux / UNIX : How to create extended partition using fdisk
- What is umask in UNIX/Linux
- cmatrix: Shows a scrolling Matrix like screen in the terminal
- ddev: Container based local development tool for PHP environments
- funzip: Print the content of the first (non-directory) member in an archive without extraction
Dirty pages linux что это
Documentation for /proc/sys/vm/* kernel version 2.6.29 (c) 1998, 1999, Rik van Riel (c) 2008 Peter W. Morreale
For general info and legal blurb, please look in README. ============================================================== This file contains the documentation for the sysctl files in /proc/sys/vm and is valid for Linux kernel version 2.6.29. The files in this directory can be used to tune the operation of the virtual memory (VM) subsystem of the Linux kernel and the writeout of dirty data to disk. Default values and initialization routines for most of these files can be found in mm/swap.c. Currently, these files are in /proc/sys/vm: — admin_reserve_kbytes — block_dump — compact_memory — compact_unevictable_allowed — dirty_background_bytes — dirty_background_ratio — dirty_bytes — dirty_expire_centisecs — dirty_ratio — dirtytime_expire_seconds — dirty_writeback_centisecs — drop_caches — extfrag_threshold — hugetlb_shm_group — laptop_mode — legacy_va_layout — lowmem_reserve_ratio — max_map_count — memory_failure_early_kill — memory_failure_recovery — min_free_kbytes — min_slab_ratio — min_unmapped_ratio — mmap_min_addr — mmap_rnd_bits — mmap_rnd_compat_bits — nr_hugepages — nr_hugepages_mempolicy — nr_overcommit_hugepages — nr_trim_pages (only if CONFIG_MMU=n) — numa_zonelist_order — oom_dump_tasks — oom_kill_allocating_task — overcommit_kbytes — overcommit_memory — overcommit_ratio — page-cluster — panic_on_oom — percpu_pagelist_fraction — stat_interval — stat_refresh — numa_stat — swappiness — unprivileged_userfaultfd — user_reserve_kbytes — vfs_cache_pressure — watermark_boost_factor — watermark_scale_factor — zone_reclaim_mode ============================================================== admin_reserve_kbytes The amount of free memory in the system that should be reserved for users with the capability cap_sys_admin. admin_reserve_kbytes defaults to min(3% of free pages, 8MB) That should provide enough for the admin to log in and kill a process, if necessary, under the default overcommit ‘guess’ mode. Systems running under overcommit ‘never’ should increase this to account for the full Virtual Memory Size of programs used to recover. Otherwise, root may not be able to log in to recover the system. How do you calculate a minimum useful reserve? sshd or login + bash (or some other shell) + top (or ps, kill, etc.) For overcommit ‘guess’, we can sum resident set sizes (RSS). On x86_64 this is about 8MB. For overcommit ‘never’, we can take the max of their virtual sizes (VSZ) and add the sum of their RSS. On x86_64 this is about 128MB. Changing this takes effect whenever an application requests memory. ============================================================== block_dump block_dump enables block I/O debugging when set to a nonzero value. More information on block I/O debugging is in Documentation/laptops/laptop-mode.txt. ============================================================== compact_memory Available only when CONFIG_COMPACTION is set. When 1 is written to the file, all zones are compacted such that free memory is available in contiguous blocks where possible. This can be important for example in the allocation of huge pages although processes will also directly compact memory as required. ============================================================== compact_unevictable_allowed Available only when CONFIG_COMPACTION is set. When set to 1, compaction is allowed to examine the unevictable lru (mlocked pages) for pages to compact. This should be used on systems where stalls for minor page faults are an acceptable trade for large contiguous free memory. Set to 0 to prevent compaction from moving pages that are unevictable. Default value is 1. ============================================================== dirty_background_bytes Contains the amount of dirty memory at which the background kernel flusher threads will start writeback. Note: dirty_background_bytes is the counterpart of dirty_background_ratio. Only one of them may be specified at a time. When one sysctl is written it is immediately taken into account to evaluate the dirty memory limits and the other appears as 0 when read. ============================================================== dirty_background_ratio Contains, as a percentage of total available memory that contains free pages and reclaimable pages, the number of pages at which the background kernel flusher threads will start writing out dirty data. The total available memory is not equal to total system memory. ============================================================== dirty_bytes Contains the amount of dirty memory at which a process generating disk writes will itself start writeback. Note: dirty_bytes is the counterpart of dirty_ratio. Only one of them may be specified at a time. When one sysctl is written it is immediately taken into account to evaluate the dirty memory limits and the other appears as 0 when read. Note: the minimum value allowed for dirty_bytes is two pages (in bytes); any value lower than this limit will be ignored and the old configuration will be retained. ============================================================== dirty_expire_centisecs This tunable is used to define when dirty data is old enough to be eligible for writeout by the kernel flusher threads. It is expressed in 100’ths of a second. Data which has been dirty in-memory for longer than this interval will be written out next time a flusher thread wakes up. ============================================================== dirty_ratio Contains, as a percentage of total available memory that contains free pages and reclaimable pages, the number of pages at which a process which is generating disk writes will itself start writing out dirty data. The total available memory is not equal to total system memory. ============================================================== dirtytime_expire_seconds When a lazytime inode is constantly having its pages dirtied, the inode with an updated timestamp will never get chance to be written out. And, if the only thing that has happened on the file system is a dirtytime inode caused by an atime update, a worker will be scheduled to make sure that inode eventually gets pushed out to disk. This tunable is used to define when dirty inode is old enough to be eligible for writeback by the kernel flusher threads. And, it is also used as the interval to wakeup dirtytime_writeback thread. ============================================================== dirty_writeback_centisecs The kernel flusher threads will periodically wake up and write `old’ data out to disk. This tunable expresses the interval between those wakeups, in 100’ths of a second. Setting this to zero disables periodic writeback altogether. ============================================================== drop_caches Writing to this will cause the kernel to drop clean caches, as well as reclaimable slab objects like dentries and inodes. Once dropped, their memory becomes free. To free pagecache: echo 1 > /proc/sys/vm/drop_caches To free reclaimable slab objects (includes dentries and inodes): echo 2 > /proc/sys/vm/drop_caches To free slab objects and pagecache: echo 3 > /proc/sys/vm/drop_caches This is a non-destructive operation and will not free any dirty objects. To increase the number of objects freed by this operation, the user may run `sync’ prior to writing to /proc/sys/vm/drop_caches. This will minimize the number of dirty objects on the system and create more candidates to be dropped. This file is not a means to control the growth of the various kernel caches (inodes, dentries, pagecache, etc. ) These objects are automatically reclaimed by the kernel when memory is needed elsewhere on the system. Use of this file can cause performance problems. Since it discards cached objects, it may cost a significant amount of I/O and CPU to recreate the dropped objects, especially if they were under heavy use. Because of this, use outside of a testing or debugging environment is not recommended. You may see informational messages in your kernel log when this file is used: cat (1234): drop_caches: 3 These are informational only. They do not mean that anything is wrong with your system. To disable them, echo 4 (bit 2) into drop_caches. ============================================================== extfrag_threshold This parameter affects whether the kernel will compact memory or direct reclaim to satisfy a high-order allocation. The extfrag/extfrag_index file in debugfs shows what the fragmentation index for each order is in each zone in the system. Values tending towards 0 imply allocations would fail due to lack of memory, values towards 1000 imply failures are due to fragmentation and -1 implies that the allocation will succeed as long as watermarks are met. The kernel will not compact memory in a zone if the fragmentation index is protection[j] = (total sums of managed_pages from zone[i+1] to zone[j] on the node) / lowmem_reserve_ratio[i]; (i = j): (should not be protected. = 0; (i > j): (not necessary, but looks 0) The default values of lowmem_reserve_ratio[i] are 256 (if zone[i] means DMA or DMA32 zone) 32 (others). As above expression, they are reciprocal number of ratio. 256 means 1/256. # of protection pages becomes about «0.39%» of total managed pages of higher zones on the node. If you would like to protect more pages, smaller values are effective. The minimum value is 1 (1/1 -> 100%). The value less than 1 completely disables protection of the pages. ============================================================== max_map_count: This file contains the maximum number of memory map areas a process may have. Memory map areas are used as a side-effect of calling malloc, directly by mmap, mprotect, and madvise, and also when loading shared libraries. While most applications need less than a thousand maps, certain programs, particularly malloc debuggers, may consume lots of them, e.g., up to one or two maps per allocation. The default value is 65536. ============================================================= memory_failure_early_kill: Control how to kill processes when uncorrected memory error (typically a 2bit error in a memory module) is detected in the background by hardware that cannot be handled by the kernel. In some cases (like the page still having a valid copy on disk) the kernel will handle the failure transparently without affecting any applications. But if there is no other uptodate copy of the data it will kill to prevent any data corruptions from propagating. 1: Kill all processes that have the corrupted and not reloadable page mapped as soon as the corruption is detected. Note this is not supported for a few types of pages, like kernel internally allocated data or the swap cache, but works for the majority of user pages. 0: Only unmap the corrupted page from all processes and only kill a process who tries to access it. The kill is done using a catchable SIGBUS with BUS_MCEERR_AO, so processes can handle this if they want to. This is only active on architectures/platforms with advanced machine check handling and depends on the hardware capabilities. Applications can override this setting individually with the PR_MCE_KILL prctl ============================================================== memory_failure_recovery Enable memory failure recovery (when supported by the platform) 1: Attempt recovery. 0: Always panic on a memory failure. ============================================================== min_free_kbytes: This is used to force the Linux VM to keep a minimum number of kilobytes free. The VM uses this number to compute a watermark[WMARK_MIN] value for each lowmem zone in the system. Each lowmem zone gets a number of reserved free pages based proportionally on its size. Some minimal amount of memory is needed to satisfy PF_MEMALLOC allocations; if you set this to lower than 1024KB, your system will become subtly broken, and prone to deadlock under high loads. Setting this too high will OOM your machine instantly. ============================================================= min_slab_ratio: This is available only on NUMA kernels. A percentage of the total pages in each zone. On Zone reclaim (fallback from the local zone occurs) slabs will be reclaimed if more than this percentage of pages in a zone are reclaimable slab pages. This insures that the slab growth stays under control even in NUMA systems that rarely perform global reclaim. The default is 5 percent. Note that slab reclaim is triggered in a per zone / node fashion. The process of reclaiming slab memory is currently not node specific and may not be fast. ============================================================= min_unmapped_ratio: This is available only on NUMA kernels. This is a percentage of the total pages in each zone. Zone reclaim will only occur if more than this percentage of pages are in a state that zone_reclaim_mode allows to be reclaimed. If zone_reclaim_mode has the value 4 OR’d, then the percentage is compared against all file-backed unmapped pages including swapcache pages and tmpfs files. Otherwise, only unmapped pages backed by normal files but not tmpfs files and similar are considered. The default is 1 percent. ============================================================== mmap_min_addr This file indicates the amount of address space which a user process will be restricted from mmapping. Since kernel null dereference bugs could accidentally operate based on the information in the first couple of pages of memory userspace processes should not be allowed to write to them. By default this value is set to 0 and no protections will be enforced by the security module. Setting this value to something like 64k will allow the vast majority of applications to work correctly and provide defense in depth against future potential kernel bugs. ============================================================== mmap_rnd_bits: This value can be used to select the number of bits to use to determine the random offset to the base address of vma regions resulting from mmap allocations on architectures which support tuning address space randomization. This value will be bounded by the architecture’s minimum and maximum supported values. This value can be changed after boot using the /proc/sys/vm/mmap_rnd_bits tunable ============================================================== mmap_rnd_compat_bits: This value can be used to select the number of bits to use to determine the random offset to the base address of vma regions resulting from mmap allocations for applications run in compatibility mode on architectures which support tuning address space randomization. This value will be bounded by the architecture’s minimum and maximum supported values. This value can be changed after boot using the /proc/sys/vm/mmap_rnd_compat_bits tunable ============================================================== nr_hugepages Change the minimum size of the hugepage pool. See Documentation/admin-guide/mm/hugetlbpage.rst ============================================================== nr_hugepages_mempolicy Change the size of the hugepage pool at run-time on a specific set of NUMA nodes. See Documentation/admin-guide/mm/hugetlbpage.rst ============================================================== nr_overcommit_hugepages Change the maximum size of the hugepage pool. The maximum is nr_hugepages + nr_overcommit_hugepages. See Documentation/admin-guide/mm/hugetlbpage.rst ============================================================== nr_trim_pages This is available only on NOMMU kernels. This value adjusts the excess page trimming behaviour of power-of-2 aligned NOMMU mmap allocations. A value of 0 disables trimming of allocations entirely, while a value of 1 trims excess pages aggressively. Any value >= 1 acts as the watermark where trimming of allocations is initiated. The default value is 1. See Documentation/nommu-mmap.txt for more information. ============================================================== numa_zonelist_order This sysctl is only for NUMA and it is deprecated. Anything but Node order will fail! ‘where the memory is allocated from’ is controlled by zonelists. (This documentation ignores ZONE_HIGHMEM/ZONE_DMA32 for simple explanation. you may be able to read ZONE_DMA as ZONE_DMA32. ) In non-NUMA case, a zonelist for GFP_KERNEL is ordered as following. ZONE_NORMAL -> ZONE_DMA This means that a memory allocation request for GFP_KERNEL will get memory from ZONE_DMA only when ZONE_NORMAL is not available. In NUMA case, you can think of following 2 types of order. Assume 2 node NUMA and below is zonelist of Node(0)’s GFP_KERNEL (A) Node(0) ZONE_NORMAL -> Node(0) ZONE_DMA -> Node(1) ZONE_NORMAL (B) Node(0) ZONE_NORMAL -> Node(1) ZONE_NORMAL -> Node(0) ZONE_DMA. Type(A) offers the best locality for processes on Node(0), but ZONE_DMA will be used before ZONE_NORMAL exhaustion. This increases possibility of out-of-memory(OOM) of ZONE_DMA because ZONE_DMA is tend to be small. Type(B) cannot offer the best locality but is more robust against OOM of the DMA zone. Type(A) is called as «Node» order. Type (B) is «Zone» order. «Node order» orders the zonelists by node, then by zone within each node. Specify «[Nn]ode» for node order «Zone Order» orders the zonelists by zone type, then by node within each zone. Specify «[Zz]one» for zone order. Specify «[Dd]efault» to request automatic configuration. On 32-bit, the Normal zone needs to be preserved for allocations accessible by the kernel, so «zone» order will be selected. On 64-bit, devices that require DMA32/DMA are relatively rare, so «node» order will be selected. Default order is recommended unless this is causing problems for your system/application. ============================================================== oom_dump_tasks Enables a system-wide task dump (excluding kernel threads) to be produced when the kernel performs an OOM-killing and includes such information as pid, uid, tgid, vm size, rss, pgtables_bytes, swapents, oom_score_adj score, and name. This is helpful to determine why the OOM killer was invoked, to identify the rogue task that caused it, and to determine why the OOM killer chose the task it did to kill. If this is set to zero, this information is suppressed. On very large systems with thousands of tasks it may not be feasible to dump the memory state information for each one. Such systems should not be forced to incur a performance penalty in OOM conditions when the information may not be desired. If this is set to non-zero, this information is shown whenever the OOM killer actually kills a memory-hogging task. The default value is 1 (enabled). ============================================================== oom_kill_allocating_task This enables or disables killing the OOM-triggering task in out-of-memory situations. If this is set to zero, the OOM killer will scan through the entire tasklist and select a task based on heuristics to kill. This normally selects a rogue memory-hogging task that frees up a large amount of memory when killed. If this is set to non-zero, the OOM killer simply kills the task that triggered the out-of-memory condition. This avoids the expensive tasklist scan. If panic_on_oom is selected, it takes precedence over whatever value is used in oom_kill_allocating_task. The default value is 0. ============================================================== overcommit_kbytes: When overcommit_memory is set to 2, the committed address space is not permitted to exceed swap plus this amount of physical RAM. See below. Note: overcommit_kbytes is the counterpart of overcommit_ratio. Only one of them may be specified at a time. Setting one disables the other (which then appears as 0 when read). ============================================================== overcommit_memory: This value contains a flag that enables memory overcommitment. When this flag is 0, the kernel attempts to estimate the amount of free memory left when userspace requests more memory. When this flag is 1, the kernel pretends there is always enough memory until it actually runs out. When this flag is 2, the kernel uses a «never overcommit» policy that attempts to prevent any overcommit of memory. Note that user_reserve_kbytes affects this policy. This feature can be very useful because there are a lot of programs that malloc() huge amounts of memory «just-in-case» and don’t use much of it. The default value is 0. See Documentation/vm/overcommit-accounting.rst and mm/util.c::__vm_enough_memory() for more information. ============================================================== overcommit_ratio: When overcommit_memory is set to 2, the committed address space is not permitted to exceed swap plus this percentage of physical RAM. See above. ============================================================== page-cluster page-cluster controls the number of pages up to which consecutive pages are read in from swap in a single attempt. This is the swap counterpart to page cache readahead. The mentioned consecutivity is not in terms of virtual/physical addresses, but consecutive on swap space — that means they were swapped out together. It is a logarithmic value — setting it to zero means «1 page», setting it to 1 means «2 pages», setting it to 2 means «4 pages», etc. Zero disables swap readahead completely. The default value is three (eight pages at a time). There may be some small benefits in tuning this to a different value if your workload is swap-intensive. Lower values mean lower latencies for initial faults, but at the same time extra faults and I/O delays for following faults if they would have been part of that consecutive pages readahead would have brought in. ============================================================= panic_on_oom This enables or disables panic on out-of-memory feature. If this is set to 0, the kernel will kill some rogue process, called oom_killer. Usually, oom_killer can kill rogue processes and system will survive. If this is set to 1, the kernel panics when out-of-memory happens. However, if a process limits using nodes by mempolicy/cpusets, and those nodes become memory exhaustion status, one process may be killed by oom-killer. No panic occurs in this case. Because other nodes’ memory may be free. This means system total status may be not fatal yet. If this is set to 2, the kernel panics compulsorily even on the above-mentioned. Even oom happens under memory cgroup, the whole system panics. The default value is 0. 1 and 2 are for failover of clustering. Please select either according to your policy of failover. panic_on_oom=2+kdump gives you very strong tool to investigate why oom happens. You can get snapshot. ============================================================= percpu_pagelist_fraction This is the fraction of pages at most (high mark pcp->high) in each zone that are allocated for each per cpu page list. The min value for this is 8. It means that we don’t allow more than 1/8th of pages in each zone to be allocated in any single per_cpu_pagelist. This entry only changes the value of hot per cpu pagelists. User can specify a number like 100 to allocate 1/100th of each zone to each per cpu page list. The batch value of each per cpu pagelist is also updated as a result. It is set to pcp->high/4. The upper limit of batch is (PAGE_SHIFT * 8) The initial value is zero. Kernel does not use this value at boot time to set the high water marks for each per cpu page list. If the user writes ‘0’ to this sysctl, it will revert to this default behavior. ============================================================== stat_interval The time interval between which vm statistics are updated. The default is 1 second. ============================================================== stat_refresh Any read or write (by root only) flushes all the per-cpu vm statistics into their global totals, for more accurate reports when testing e.g. cat /proc/sys/vm/stat_refresh /proc/meminfo As a side-effect, it also checks for negative totals (elsewhere reported as 0) and «fails» with EINVAL if any are found, with a warning in dmesg. (At time of writing, a few stats are known sometimes to be found negative, with no ill effects: errors and warnings on these stats are suppressed.) ============================================================== numa_stat This interface allows runtime configuration of numa statistics. When page allocation performance becomes a bottleneck and you can tolerate some possible tool breakage and decreased numa counter precision, you can do: echo 0 > /proc/sys/vm/numa_stat When page allocation performance is not a bottleneck and you want all tooling to work, you can do: echo 1 > /proc/sys/vm/numa_stat ============================================================== swappiness This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone. The default value is 60. ============================================================== unprivileged_userfaultfd This flag controls whether unprivileged users can use the userfaultfd system calls. Set this to 1 to allow unprivileged users to use the userfaultfd system calls, or set this to 0 to restrict userfaultfd to only privileged users (with SYS_CAP_PTRACE capability). The default value is 1. ============================================================== — user_reserve_kbytes When overcommit_memory is set to 2, «never overcommit» mode, reserve min(3% of current process size, user_reserve_kbytes) of free memory. This is intended to prevent a user from starting a single memory hogging process, such that they cannot recover (kill the hog). user_reserve_kbytes defaults to min(3% of the current process size, 128MB). If this is reduced to zero, then the user will be allowed to allocate all free memory with a single process, minus admin_reserve_kbytes. Any subsequent attempts to execute a command will result in «fork: Cannot allocate memory». Changing this takes effect whenever an application requests memory. ============================================================== vfs_cache_pressure —————— This percentage value controls the tendency of the kernel to reclaim the memory which is used for caching of directory and inode objects. At the default value of vfs_cache_pressure=100 the kernel will attempt to reclaim dentries and inodes at a «fair» rate with respect to pagecache and swapcache reclaim. Decreasing vfs_cache_pressure causes the kernel to prefer to retain dentry and inode caches. When vfs_cache_pressure=0, the kernel will never reclaim dentries and inodes due to memory pressure and this can easily lead to out-of-memory conditions. Increasing vfs_cache_pressure beyond 100 causes the kernel to prefer to reclaim dentries and inodes. Increasing vfs_cache_pressure significantly beyond 100 may have negative performance impact. Reclaim code needs to take various locks to find freeable directory and inode objects. With vfs_cache_pressure=1000, it will look for ten times more freeable objects than there are. ============================================================= watermark_boost_factor: This factor controls the level of reclaim when memory is being fragmented. It defines the percentage of the high watermark of a zone that will be reclaimed if pages of different mobility are being mixed within pageblocks. The intent is that compaction has less work to do in the future and to increase the success rate of future high-order allocations such as SLUB allocations, THP and hugetlbfs pages. To make it sensible with respect to the watermark_scale_factor parameter, the unit is in fractions of 10,000. The default value of 15,000 on !DISCONTIGMEM configurations means that up to 150% of the high watermark will be reclaimed in the event of a pageblock being mixed due to fragmentation. The level of reclaim is determined by the number of fragmentation events that occurred in the recent past. If this value is smaller than a pageblock then a pageblocks worth of pages will be reclaimed (e.g. 2MB on 64-bit x86). A boost factor of 0 will disable the feature. ============================================================= watermark_scale_factor: This factor controls the aggressiveness of kswapd. It defines the amount of memory left in a node/system before kswapd is woken up and how much memory needs to be free before kswapd goes back to sleep. The unit is in fractions of 10,000. The default value of 10 means the distances between watermarks are 0.1% of the available memory in the node/system. The maximum value is 1000, or 10% of memory. A high rate of threads entering direct reclaim (allocstall) or kswapd going to sleep prematurely (kswapd_low_wmark_hit_quickly) can indicate that the number of free pages kswapd maintains for latency reasons is too small for the allocation bursts occurring in the system. This knob can then be used to tune kswapd aggressiveness accordingly. ============================================================== zone_reclaim_mode: Zone_reclaim_mode allows someone to set more or less aggressive approaches to reclaim memory when a zone runs out of memory. If it is set to zero then no zone reclaim occurs. Allocations will be satisfied from other zones / nodes in the system. This is value ORed together of 1 = Zone reclaim on 2 = Zone reclaim writes dirty pages out 4 = Zone reclaim swaps pages zone_reclaim_mode is disabled by default. For file servers or workloads that benefit from having their data cached, zone_reclaim_mode should be left disabled as the caching effect is likely to be more important than data locality. zone_reclaim may be enabled if it’s known that the workload is partitioned such that each partition fits within a NUMA node and that accessing remote memory would cause a measurable performance reduction. The page allocator will then reclaim easily reusable pages (those page cache pages that are currently not used) before allocating off node pages. Allowing zone reclaim to write out pages stops processes that are writing large amounts of data from dirtying pages on other nodes. Zone reclaim will write out dirty pages if a zone fills up and so effectively throttle the process. This may decrease the performance of a single process since it cannot use all of system memory to buffer the outgoing writes anymore but it preserve the memory on other nodes so that the performance of other processes running on other nodes will not be affected. Allowing regular swap effectively restricts allocations to the local node unless explicitly overridden by memory policies or cpuset configurations. ============ End of Document =================================