Поиск палиндрома в строке
Пытаюсь решить задачу:
«Анна написала генератор красивых строк. Она считает строку красивой, если она одинаково читается как слева направо, так и справа налево. Например, rrr и anna — красивые строки, а abc и adba — нет.
Но она допустила ошибку в коде и генератор выводит не красивые строки, а строки, которые можно сделать красивыми, если из каждой удалить ровно один символ. По крайней мере, она так думает.
Она просит вас помочь определить, верно ли её предположение.
Формат входных данных
В первой строке вводится строка s состоящая из маленьких латинских букв (4≤|s|≤103, где |s| — длина строки).
Формат выходных данных
Выведите YES , если можно удалить один символ из строки так, чтобы она стала красивой; иначе — NO .»
Но у меня с массивами какая-то беда. Заполняются рандомными значениями и т.д. Помогите пожалуйста!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62
#include #include using namespace std; char* revers(char* str3) { char* left = str3; char* right = str3; while (*str3++); str3 -= 2; while (left str3) { char c = *left; *left++ = *str3; *str3-- = c; } return right; } int main() { setlocale(LC_ALL, "Russian"); int y,i,z,n=0; int len = 0; char str[1001]; gets_s(str); int x = strlen(str); if (x % 2 != 0) { int x1 = x - 1; y = x1 / 2; char *str1 = new char[y]; char *str2 = new char[y]; int y1 = strlen(str1); for (int i = 0; i y1; i++) { str1[i] = str[i]; } for (int i = 0; i y; i++) { for (int j = (y + 1); j x; j++) { str2[i] = str[j]; } } cout ; if (!strcmp(str1, revers(str2))) { cout <"YES"; } else { cout <"NO"; } } }
Поиск палиндромов в строке
помогите доделать. написал программу которая должна искать палиндромы в предложении но не учел что предложения могут заканчиваться и на 2 и на 3 строке. она может искать палиндромы только в 1 строке. как можно довести ее до ума?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64
#include #include #include int f1(char *s)//функция возвращает 1 если строка полендром или 0 если нет { int f,i,len;//len длина предложения без точки f=1;//предпологаем что полиндром len=strlen(s)-1;//определяет длину строки i=0; while (ilen/2 && f==1) { if (s[i]!=s[len-i-1])//проверяет символы равно удаленные от концов f=0; i++; } return f; } void SortStrings ( char *s[], int k[], int n )// *s[] – массив указателей ,признок того что строка поледром ,количество строк введенных { char *p;//указатель на строку int i, j,m; for ( i = 0; i n-1; i ++ ) for ( j = n-1; j > i; j -- ) if ( strcmp(s[j-1],s[j]) 0 ) { //сравнивоет фуннкция 2 строки p = s[j]; s[j] = s[j-1]; // перестановка УКАЗАТЕЛЕЙ s[j-1] = p; m=k[j];k[j]=k[j-1];k[j-1]=m;//одновременная перестановка указателей на полендром у каждого с свой к } } main() char c1[10][81]; int f,i,n,len; int k[10];//K[i] запоминаем евляется ли и- строка поледромом char *ps[10];// массив из 10 указателей на строки printf("введите кол-во строк\n"); scanf("%d",&n); while (n2
Алгоритм Манакера
Легко увидеть, что таких подстрок в худшем случае будет [math]n^2[/math] . Значит, нужно найти компактный способ хранения информации о них. Пусть [math]d_1[i][/math] — количество палиндромов нечётной длины с центром в позиции [math]i[/math] , а [math]d_2[i][/math] — аналогичная величина для палиндромов чётной длины. Далее научимся вычислять значения этих массивов.
Наивный алгоритм
Идея
Рассмотрим сначала задачу поиска палиндромов нечётной длины. Центром строки нечётной длины назовём символ под индексом [math]\left\lfloor \dfrac<|t|>\right\rfloor[/math] . Для каждой позиции в строке [math]s[/math] найдем длину наибольшего палиндрома с центром в этой позиции. Очевидно, что если строка [math]t[/math] является палиндромом, то строка полученная вычеркиванием первого и последнего символа из [math]t[/math] также является палиндромом, поэтому длину палиндрома можно искать бинарным поиском. Проверить совпадение левой и правой половины можно выполнить за [math]O(1)[/math] , используя метод хеширования.
Для палиндромов чётной длины алгоритм такой же. Центр строки чётной длины — некий мнимый элемент между [math]\dfrac<|t|> — 1[/math] и [math]\dfrac<|t|>[/math] . Только требуется проверять вторую строку со сдвигом на единицу. Следует заметить, что мы не посчитаем никакой палиндром дважды из-за четности-нечетности длин палиндромов.
Псевдокод
int binarySearch(s : string, center, shift : int): //shift = 0 при поиске палиндрома нечётной длины, иначе shift = 1 int l = -1, r = min(center, s.length - center + shift), m = 0 while r - l != 1 m = l + (r - l) / 2 //reversed_hash возвращает хэш развернутой строки s if hash(s[center - m..center]) == reversed_hash(s[center + shift..center + shift + m]) l = m else r = m return r
int palindromesCount(s : string): int ans = 0 for i = 0 to s.length ans += binarySearch(s, i, 0) + binarySearch(s, i, 1) return ans
Время работы
Изначальный подсчет хешей производится за [math]O(|s|)[/math] . Каждая итерация будет выполняться за [math]O(\log(|s|))[/math] , всего итераций — [math]|s|[/math] . Итоговое время работы алгоритма [math]O(|s|+|s|\cdot \log(|s|)) = O(|s|\cdot \log(|s|))[/math] .
Избавление от коллизий
У хешей есть один недостаток — коллизии: можно подобрать входные данные так, что хеши разных строк будут совпадать. Абсолютно точно проверить две подстроки на совпадение можно с помощью суффиксного массива, но с дополнительной памятью [math]O(|s|\cdot \log(|s|))[/math] . Для этого построим суффиксный массив для строки [math]s + \# + reverse(s)[/math] , при этом сохраним промежуточные результаты классов эквивалентности [math]c[/math] . Пусть нам требуется проверить на совпадение подстроки [math]s[i \ldots i + l][/math] и [math]s[j \ldots j + l][/math] . Разобьем каждую нашу строку на две пересекающиеся подстроки длиной [math]2^k[/math] , где [math]k = \lfloor \log \rfloor[/math] . Тогда наши строки совпадают, если [math]c[k][i] = c[k][j][/math] и [math]c[k][i + l — 2^k] = c[k][j + l — 2^k][/math] .
Итоговая асимптотика алгоритма: предподсчет за построение суффиксного массива и [math]O(\log(|s|))[/math] на запрос, если предподсчитать все [math]k[/math] , то [math]O(1)[/math] .
Алгоритм Манакера
Идея
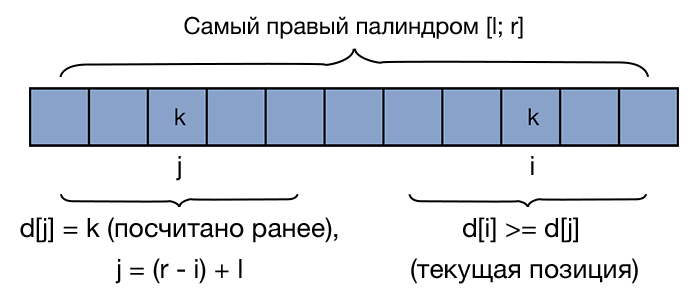
Алгоритм, который будет описан далее, отличается от наивного тем, что использует значения, посчитанные ранее. Будем поддерживать границы самого правого из найденных палиндромов — [math][l; r][/math] . Итак, пусть мы хотим вычислить [math]d_1[i][/math] — т.е. длину наибольшего палиндрома с центром в позиции [math]i[/math] . При этом все предыдущие значения в массиве [math]d[/math] уже посчитаны. Возможны два случая:
- [math]i \gt r[/math] , т.е. текущая позиция не попадает в границы самого правого из найденных палиндромов. Тогда просто запустим наивный алгоритм для позиции [math]i[/math] .
- [math]i \leqslant r[/math] . Тогда попробуем воспользоваться значениями, посчитанным ранее. Отразим нашу текущую позицию внутри палиндрома [math][l;r] : j = (r — i) + l[/math] . Поскольку [math]i[/math] и [math]j[/math] — симметричные позиции, то если [math]d_1[j] = k[/math] , мы можем утверждать, что и [math]d_1[i] = k[/math] . Это объясняется тем, что палиндром симметричен относительно своей центральной позиции. Т.е. если имеем некоторый палиндром длины [math]k[/math] с центром в позиции [math]l \leqslant i \leqslant r[/math] , то в позиции [math]j[/math] , симметричной [math]i[/math] относительно отрезка [math][l; r][/math] тоже может находиться палиндром длины [math]k[/math] . Это можно лучше понять, посмотрев на рисунок. Снизу фигурными скобками обозначены равные подстроки. Однако стоит не забыть про один граничный случай: что если [math]i + d_1[j] — 1[/math] выходит за границы самого правого палиндрома? Так как информации о том, что происходит за границами этого палиндрома у нас нет (а значит мы не можем утверждать, что симметрия сохраняется), то необходимо ограничить значение [math]d_1[i][/math] следующим образом: [math]d_1[i] = \min(r — i, d_1[j])[/math] . После этого запустим наивный алгоритм, который будет увеличивать значение [math]d_1[i][/math] , пока это возможно.
После каждого шага важно не забывать обновлять значения [math][l;r][/math] .
Заметим, что массив [math]d_2[/math] считается аналогичным образом, нужно лишь немного изменить индексы.
Псевдокод
Приведем код, который вычисляет значения массива [math]d_1[/math] :
// — исходная строка int[] calculate1(string s): int l = 0 int r = -1 for i = 1 to n int k = 0 if i [math]d_1[/math][r - i + l]) while i + k + 1 and i - k - 1 > 0 and s[i + k + 1] == s[i - k - 1] k++ [i] = k if i + k > r l = i - k r = i + k return
Вычисление значений массива [math]d_2[/math] :
// — исходная строка int[] calculate2(string s): int l = 0 int r = -1 for i = 1 to n int k = 0 if i [math]d_2[/math][r - i + l + 1]) while i + k and i - k - 1 > 0 and s[i + k] == s[i - k - 1] k++ [i] = k if i + k - 1 > r l = i - k r = i + k - 1 return
Оценка сложности
Внешний цикл в приведенном алгоритме выполняется ровно [math]n[/math] раз, где [math]n[/math] — длина строки. Попытаемся понять, сколько раз будет выполнен внутренний цикл, ответственный за наивный подсчет значений. Заметим, что каждая итерация вложенного цикла приводит к увеличению [math]r[/math] на [math]1[/math] . Действительно, возможны следующие случаи:
- [math]i \gt r[/math] , т.е. сразу будет запущен наивный алгоритм и каждая его итерация будет увеличивать значение [math]r[/math] хотя бы на [math]1[/math] .
- [math]i \leqslant r[/math] . Здесь опять два случая:
- [math]i + d[j] — 1 \leqslant r[/math] , но тогда, очевидно, ни одной итерации вложенного цикла выполнено не будет.
- [math]i + d[j] — 1 \gt r[/math] , тогда каждая итерация вложенного цикла приведет к увеличению [math]r[/math] хотя бы на [math]1[/math] .
Т.к. значение [math]r[/math] не может увеличиваться более [math]n[/math] раз, то описанный выше алгоритм работает за время [math]O(n)[/math] .
См. также
- Префикс-функция
- Z-функция
- Суффиксный массив
- Поиск наибольшей общей подстроки двух строк с использованием хеширования
Источники информации
- MAXimal :: algo :: Нахождение всех подпалиндромов
- Википедия — Поиск длиннейшей подстроки-палиндрома
- Алгоритмы для поиска палиндромов — Хабр
- MAXimal :: algo :: Суффиксный массив
Палиндромы
Палиндром — это фраза, которая читается одинаково слева направо и справа налево. Например:
- «was it a car or a cat I saw?»
- «а роза упала на лапу Азора»
- «abacaba» (палиндром нечётной длины)
- «abba» (палиндром чётной длины)
Для простоты, мы будем рассматривать только последовательности из строчных латинских букв.
Палиндромы — не самые часто встречающиеся в реальной жизни объекты, однако задачи на палиндромы любят давать на соревнованиях по спортивному программированию. В этой статье мы опишем эффективные способы их представления.
Алгоритм Манакера
Пусть есть строка \(s\) и мы хотим найти в ней все подпалиндромы.
Мы сразу сталкиваемся с очевидной трудностью: их в строке может быть \(O(n^2)\) , что можно видеть на примере строки \(s = aa \ldots a\) . Поэтому будем использовать следующий формат: для каждой позиции \(s_i\) найдём наибольший палиндром, центр которого совпадает с \(s_i\) (чётные и нечётные палиндромы будем рассматривать отдельно). Половину его длины, округлённую вниз, будем называть радиусом.
Наивное решение — перебрать \(s_i\) , а для него вторым циклом находить наибольшую искомую длину:
vectorint> pal_array(string s) int n = s.size(); // окружим строку спецсимволами, чтобы не рассматривать выход за границы s = "#" + s + "$"; // в этом массиве будем хранить расстояние от центра до границы палиндрома vectorint> t(n, 0); for(int i = 1; i n; i++) while (s[i - t[i - 1]] == s[i + t[i - 1]]) r[i-1]++; return r; >Тот же пример \(s = aa\dots a\) показывает, что данная реализация работает за \(O(n^2)\) .
Для оптимизации применим идею, знакомую из алгоритма z-функции: при инициализации \(t_i\) будем пользоваться уже посчитанными \(t\) . А именно, будем поддерживать \((l, r)\) — интервал, соответствующий самому правому из найденных подпалиндромов. Тогда мы можем сказать, что часть наибольшего палиндрома с центром в \(s_i\) , которая лежит внутри \(s_\) , имеет радиус хотя бы \(\min(r-i, \; t_)\) . Первая величина равна длине, дальше которой произошел бы выход за пределы \(s_\) , а вторая — значению радиуса в позиции, зеркальной относительно центра палиндрома \(s_\) .
vectorint> manacher_odd(string s) int n = (int) s.size(); vectorint> d(n, 1); int l = 0, r = 0; for (int i = 1; i n; i++) if (i r) d[i] = min(r - i + 1, d[l + r - i]); while (i - d[i] >= 0 && i + d[i] n && s[i - d[i]] == s[i + d[i]]) d[i]++; if (i + d[i] - 1 > r) l = i - d[i] + 1, r = i + d[i] - 1; > return d; >Так же, как и z-функция, алгоритм работает за линейное время: цикл while запускается только когда \(t_i = r — i\) (иначе палиндром уже во что-то упёрся), и каждая его итерация сдвигает увеличивает \(r\) на единицу. Так как \(r \leq n\) , получаем, что суммарно эти циклы сделают \(O(n)\) итераций.
Для случая чётных палиндромов меняется только индексация:
vectorint> manacher_even(string s) int n = (int) s.size(); vectorint> d(n, 0); int l = -1, r = -1; for (int i = 0; i n - 1; i++) if (i r) d[i] = min(r - i, d[l + r - i - 1]); while (i - d[i] >= 0 && i + d[i] + 1 n && s[i - d[i]] == s[i + d[i] + 1]) d[i]++; if (i + d[i] > r) l = i - d[i] + 1, r = i + d[i]; > return d; >Также можно было не писать отдельно две реализации, а воспользоваться следующим трюком — сделать замену:
\[ S = s_1 s_2 \dots s_n \to S^* = s_1 \# s_2 \# \dots \# s_n \]
Теперь нечётные палиндромы с центром в \(s_i\) соответствуют нечётным палиндромам исходной строки, а нечётные палиндромы с центром в \(\#\) — чётным.
Дерево палиндромов
Дерево палиндромов (англ. palindromic tree, EERTREE) — структура данных, использующая другой, более мощный формат хранения информации обо всех подпалиндромах, чем размеры \(n\) палиндромов. Она была предложена Михаилом Рубинчиком на летних петрозаводских сборах в 2014-м году.
Лемма. В строке есть не более \(n\) различных подпалиндромов.
Доказательство. Пусть мы дописываем к строке по одному символу и в данный момент, записав \(r\) символов, имеем наибольший суффикс-палиндром \(s_\) . Пусть у него, в свою очередь, есть суффикс-палиндром \(s_ = t\) . Тогда он также имеет более раннее вхождение в строку как \(s_ = t\) . Таким образом, с каждым новым символом у строки появляется не более одного нового палиндрома, и если таковой есть, то это всегда наибольший суффикс-палиндром.
Этот факт позволяет сопоставить всем палиндромам строки сопоставить следующую структуру: возьмём от каждого палиндрома его правую половину (например, \(caba\) для \(abacaba\) или \(ba\) для \(abba\) ; будем рассматривать пока что только чётные палиндромы) и добавим все эти половины в префиксное дерево — получившуюся структуру и будем называть деревом палиндромов.
Наивный алгоритм построения будет в худшем случае работать за \(O(n^2)\) , но это можно делать и более эффективно.
Построение за линейное время
Будем поддерживать наибольший суффикс-палиндром. Когда мы будем дописывать очередной символ \(c\) , нужно найти наибольший суффикс этого палиндрома, который может быть дополнен символом \(c\) — это и будет новый наидлиннейший суффикс-палиндром.
Для этого поступим аналогично алгоритму Ахо-Корасик: будем поддерживать для каждого палиндрома суффиксную ссылку \(l(v)\) , ведущую из \(v\) в её наибольший суффикс-палиндром. При добавлении очередного символа, будем подниматься по суффиксным ссылкам, пока не найдём вершину, из которой можно совершить нужный переход.
Если в подходящей вершине этого перехода не существовало, то нужно создать новую вершину, и для неё тоже понадобится своя суффиксная ссылка. Чтобы найти её, будем продолжать подниматься по суффиксным ссылкам предыдущего суффикс-палиндрома, пока не найдём второе такое место, которое мы можем дополнить символом \(c\) .
const int maxn = 1e5, k = 26; int s[maxn], len[maxn], link[maxn], to[maxn][k]; int n, last, sz; void init() s[n++] = -1; link[0] = 1; len[1] = -1; sz = 2; > int get_link(int v) while (s[n-len[v]-2] != s[n-1]) v = link[v]; return v; > void add_char(int c) s[n++] = c; last = get_link(last); if (!to[last][c]) len[sz] = len[last] + 2; link[sz] = to[get_link(link[last])][c]; to[last][c] = sz++; > last = to[last][c]; >Здесь мы использовали обычный массив для хранения переходов. Как и для любых префиксных деревьев, вместо него можно использовтать бинарное дерево поиска, хэш-таблицу, односвязный список и другие структуры, позволяющие обменять время на память, немного изменив асимптотику.
Асимптотика
Покажем линейность алгоритма. Рассмотрим длину наибольшего суффикс-палиндрома строки. Каждый новый символ увеличивает её не более, чем на 2. При этом каждый переход по суффиксной ссылке уменьшает её, поэтому нахождение первого суффикс-палиндрома амортизировано работает за линейное время.
Аналогичными рассуждениями о длине второго суффикс-палиндрома (его длина увеличивается тоже не более, чем на 2) получаем, что пересчёт суффиксных ссылок при создании новых вершин тоже суммарно работает за линейное время.